
At the beginning of every year, I make predictions. At the end of every year, I score them (this year I’m very late). Here are 2014, 2015, 2016, 2017, and 2018.
And here are the predictions I made for 2019. Strikethrough’d are false. Intact are true. Italicized are getting thrown out because I can’t decide if they’re true or not. All of these judgments were as of December 31 2019, not as of now.
Please don’t complain that 50% predictions don’t mean anything; I know this is true but there are some things I’m genuinely 50-50 unsure of. Some predictions are redacted because they involve my private life or the lives of people close to me. A few that started off redacted stopped being secret; I’ve put those in [brackets].
US
1. Donald Trump remains President: 90%
2. Donald Trump is impeached by the House: 40%
3. Kamala Harris leads the Democratic field: 20%
4. Bernie Sanders leads the Democratic field: 20%
5. Joe Biden leads the Democratic field: 20%
6. Beto O’Rourke leads the Democratic field: 20%
7. Trump is still leading in prediction markets to be Republican nominee: 70%
8. Polls show more people support the leading Democrat than the leading Republican: 80%
9. Trump’s approval rating below 50: 90%
10. Trump’s approval rating below 40: 50%
11. Current government shutdown ends before Feb 1: 40%
12. Current government shutdown ends before Mar 1: 80%
13. Current government shutdown ends before Apr 1: 95%
14. Trump gets at least half the wall funding he wants from current shutdown: 20%
15. Ginsberg still alive: 50%
ECON AND TECH
16. Bitcoin above 1000: 90%
17. Bitcoin above 3000: 50%
18. Bitcoin above 5000: 20%
19. Bitcoin above Ethereum: 95%
20. Dow above current value of 25000: 80%
21. SpaceX successfully launches and returns crewed spacecraft: 90%
22. SpaceX Starship reaches orbit: 10%
23. No city where a member of the general public can ride self-driving car without attendant: 90%
24. I can buy an Impossible Burger at a grocery store within a 30 minute walk from my house: 70%
25. Pregabalin successfully goes generic and costs less than $100/month on GoodRx.com: 50%
26. No further CRISPR-edited babies born: 80%
WORLD
27. Britain out of EU: 60%
28. Britain holds second Brexit referendum: 20%
29. No other EU country announces plan to leave: 80%
30. China does not manage to avert economic crisis (subjective): 50%
31. Xi still in power: 95%
32. MbS still in power: 95%
33. May still in power: 70%
34. Nothing more embarassing than Vigano memo happens to Pope Francis: 80%
SURVEY
35. …finds birth order effect is significantly affected by age gap: 40%
36. …finds fluoxetine has significantly less discontinuation issues than average: 60%
37. …finds STEM jobs do not have significantly more perceived gender bias than non-STEM: 60%
38. …finds gender-essentialism vs. food-essentialism correlation greater than 0.075: 30%
PERSONAL – INTERNET
39. SSC gets fewer hits than last year: 70%
40. I finish and post [New Atheism: The Godlessness That Failed]: 90%
41. I finish and post [Structures Of Paranoia]: 50%
42. I finish and post [a sequence based on Secret Of Our Success]: 50%
43. [New Atheism] post gets at least 40,000 hits: 40%
44. [The Proverbial Murder Mystery] post gets at least 40,000 hits: 20%
45. New co-blogger with more than 3 posts: 20%
46. Repeat adversarial collaboration contest with at least 5 entries: 60%
47. [Culture War thread successfully removed from subreddit]: 90%
48. [Culture War new version getting at least 500 comments per week]: 70%
49. I start using Twitter again (5+ tweets in any month): 60%
50. I start using Facebook again (following at least 5 people): 30%
PERSONAL – HEALTH
51. I get the blood tests I should be getting this year: 90%
52. I try one biohacking project per month x at least 10 months: 30%
53. I continue taking sceletium regularly: 70%
54. I switch from [Zembrin to Tristill] for at least 3 months: 20%
55. I find at least one new supplement I take or expect to take regularly x 3 months: 20%
56. Minoxidil use produces obvious progress: 50%
57. I restart [redacted]: 20%
58. I spend one month at least substantially more vegetarian than my current compromise: 20%
59. I spend one month at least substantially less vegetarian than my current compromise: 30%
60. I weigh more than 195 lbs at year end: 80%
61. I meditate at least 30 minutes/day more than half of days this year: 30%
62. I use marijuana at least once this year: 20%
PERSONAL – PROJECTS
63. I finish at least 10% more of [redacted]: 20%
64. I completely finish [redacted]: 10%
65. I finish and post [redacted]: 5%
66. I write at least ten pages of something I intend to turn into a full-length book this year: 20%
67. I practice calligraphy at least seven days in the last quarter of 2019: 40%
68. I finish at least one page of the [redacted] calligraphy project this year: 30%
69. I finish the entire [redacted] calligraphy project this year: 10%
70. I finish some other at-least-one-page calligraphy project this year: 80%
PERSONAL – PROFESSIONAL
71. I attend the APA Meeting: 80%
72. [redacted]: 50%
73. [redacted]: 40%
74. I still work in SF with no plans to leave it: 60%
75. I still only do telepsychiatry one day with no plans to increase it: 60%
76. I still work the current number of hours per week: 60%
77. I have not started (= formally see first patient) my own practice: 80%
78. I lease another version of the same car I have now: 90%
PERSONAL – HOUSE
79. I still live in my current house with no specific plans to leave: 80%
80. I set up a decent home library: 60%
81. We got a second trash can: 90%
82. The gate is fixed with no problems at all: 50%
83. The ugly paint spot on my wall gets fixed: 30%
84. There is some kind of nice garden: 60%
85. …and I am at least half responsible: 20%
86. I get my own washing machine: 20%
87. There is another baby in my house: 60%
88. No other non-baby resident (expected 6+ month) in my house who doesn’t live there now: 70%
89. No existing resident moves away (except the one I already know about): 80%
90. No other long-term (expected 6+ month) resident of my subunit who doesn’t live there now: 80%
91. [Decision Tree House] is widely considered a success: 70%
92. …with plans (vague okay) to create a second one: 20%
PERSONAL – ROMANCE
93. I find a primary partner: 30%
94. I go on at least one date with someone who doesn’t already have a primary partner: 90%
95. I remake an account on OKCupid: 80%
96. [redacted]: 10%
97. [redacted]: 20%
98. [redacted]: 20%
99. [redacted]: 20%
100. [redacted]: 20%
101. [redacted]: 30%
102. [redacted]: 10%
103. [redacted]: 30%
104. [I go on at least three dates with someone I have not yet met]: 50%
105. [redacted]: 10%
106. [redacted]: 50%
PERSONAL – FRIENDS
107. I am still playing D&D: 60%
108. I go on a trip to Guatemala: 90%
109. I go on at least one other international trip: 30%
110. I go to at least one Solstice outside the Bay: 40%
111. I go to at least one city just for an SSC meetup: 30%
112. [redacted] is in a relationship: 40%
113. [redacted] still has their current partner: 50%
114. [redacted] is at their current job: 20%
115. [redacted] is still at their current job: 80%
116. I hang out with [redacted] at least once: 60%
117. I hang out with [redacted] at least once: 60%
118. I am in [redacted] Discord server: 80%
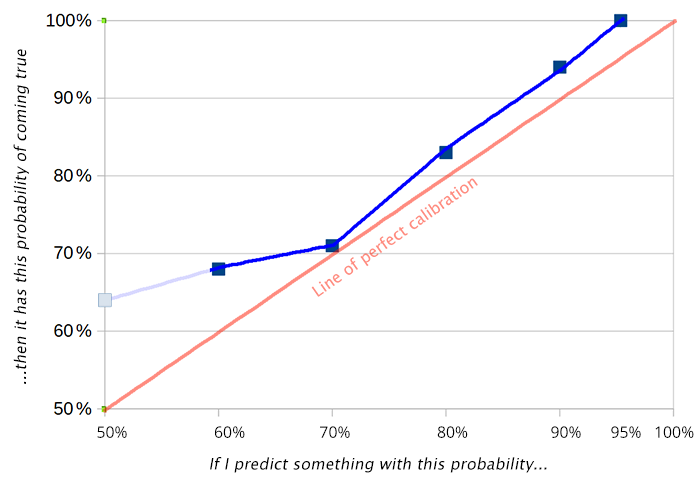
Calibration chart. The red line represents perfect calibration, the blue my predictions. The closer they are, the better I am doing.
Of 11 predictions at 50%, I got 4 wrong and 7 right, for an average of 64%
Of 22 predictions at 60%, I got 7 wrong and 15 right, for an average of 68%
Of 17 predictions at 70%, I got 5 wrong and 12 right, for an average of 71%
Of 37 predictions at 80%, I got 6 wrong and 31 right, for an average of 83%
Of 17 predictions at 90%, I got 1 wrong and 16 right, for an average of 94%
Of 5 predictions at 95%, I got 0 wrong and 5 right, for an average of 100%
50% predictions are technically meaningless since I could have written them either way. I’ve lightened them on the chart to indicate they can be ignored.
It was another good year for me. Unlike past years, where I erred about evenly in both directions, this year I was about 4% underconfident across the board. I’m not sure how much I should adjust and become more confident. In past years I’ve been burned by major black swan events that affect multiple predictions and made me look overconfident. In 2019 I tried to leave a cushion for that, but nothing too unexpected happened and I ended up playing it too safe. My worst failures were underestimating Bitcoin (but who didn’t?) and overestimating SpaceX’s ability to launch their crew on schedule. I didn’t check formally, but there doesn’t seem to be much difference in my calibration about world affairs vs. my personal life.
I forgot to make predictions for 2020 until now, which in retrospect was the best prediction I’ve ever made. I’ll probably come up with some later this month.
















22. SpaceX Starship reaches orbit: 10%
This is marked as true, but I don’t think it is… You will never err if you predict delays to Musk’s timelines.
ETA:
Same for 28. Britain holds second Brexit referendum: 20%
You’re right, thanks, fixed. I think I graded myself on those correctly, but kept forgetting whether I was strike-outing for “thing did not come true” or “my prediction was bad”.
Actually, still needs fixing. The UK has left the EU but it finds itself in a transition period where it still applies all of the EU rules, can still trade with the EU as ‘member’ etc. https://www.theguardian.com/politics/2020/jan/31/britain-has-left-the-eu-what-happens-now-guide-negotiations#maincontent
The UK was still in the EU as of December 31 2019, so the prediction is struck out as it should be.
Brexit happened end of January, the predictions were for end of December.
Calibration chart: red line is perfect, no?
I still don’t get how to be this well calibrated. I guess I’m going to practice some more…
Lets say you are planning to predict whether X happens or not.
You flip a coin:
If it is heads then you say: “X will happen – 50%”
If it is tails then you say: “X will not happen. – 50%”
This algorithm will achieve close to perfect calibration for your 50% predictions.
Sure, but what if you’re not doing that?
Then it’s great! Problem is people can’t tell whether someone done that or not from their reporting, so it would require us to trust Scott that he did not do this which I do, but I have been criticised as being too naive before, so idk. I’m just reporting the reason I’ve seen 50% predictions being criticised.
Trusting Scott is the only real option when several predictions are redacted.
Depends what you think the point of the exercise is, I suppose. From my perspective, Scott would only be cheating himself.
If you are looking to “cheat” in order to claim perfect calibration at all levels, you can do this to other probabilities, too: take near-certain events, invert 30% of them, claim that each of the resulting set of events has a 70% chance. Boom, 70% of them will be correct.
OTOH if there is some asymmetry between the statements you make and their negations (e.g. you always predict that X will remain in power, rather than that X is ousted, then you can’t cheat this way, even at 50% probability, and thus the calibration is definitely meaningful.
What Scott does is probably somewhere between the two: he probably doesn’t “cheat”, and there might be some regularity as to which side of each prediction is usually made, but there is no clear rule.
Notice you say “take near certain events”, so yes you can do this with other probabilities provided you know the exact true probabilities ie you are perfectly calibrated anyway. Otherwise you cant make your 70% predictions perfect with an algorithm.
EDIT: After rereading, I think I might have misunderstood you. If you meant that you can inflate other categories’ accuracy by deliberately miscategorizing near-certain things that’s true, but upon reporting we would surely notice it.
One way to work around this would be to have a pre-set list of things that numerous people must predict, and then some measure of correctness that rewards, say, a 90% prediction of something that turns out to happen more than an 80% prediction.
For example, if the people doing the predicting assign a number in the [0,1] range for each event, and then you give everyone a “score” that is sum((A_i – P_i)^2), where each P_i is the probability for the ith event happening and A_i is 0 or 1 depending on whether it happened. Low score is better.
The best possible performance is to give 100% or 0% for everything and always be right. But if a bunch of events are true coin flips, it’s best to give 50% for each; if there are 10 such coin flips, and you randomly assign 100% or 0% to each, you’re likely to get a total score on those events of 5; but if you do 50% for each, you’ll get 2.5.
You are right. E.g. the game of thrones prediction challenge on reddit worked precisely the same way.
And in the second paragraph you reinvented Brier-score 😀
You can do the same with any probability, and cheat across all buckets.
Is
based solely on this, or also on something else?
Example of a meaningful 50% prediction: “there is 50% chance that laptop that I ordered will be delivered within 4 days”.
Example of set of meaningless 20% predictions:
20% Sun will explode within 2 hours
20% Sun will not explode within 2 hours
20% Sun will not explode within 2 hours
20% Sun will not explode within 2 hours
20% Sun will not explode within 2 hours
No, you can’t do this trick with any predicted probability. The trick rests on that P(X happens)*0.5+(1-P(X happens))*0.5=0.5 whatever P(X happens) is and on that people can’t tell whether you’ve negated the prediction or not (which is admittedly not always the case).
Contrast this with negating with a 70% probability: P(X happens)*0.3+(1-P(X happens))*0.7 is not equal 0.3 except when P(X happens) happens to be exactly 1.
For example: “UK will exit EU.” and “UK will remain in the EU.” are negations of each other, yet you can’t tell which one was the “original” if I only publish one of them. Your example sentence’s negation is harder to phrase in a natural way, but maybe: “There is a 50% chance that the laptop I ordered will be late, ie delivered later than the projected 4 days.” If I post this people might not be able to decide whether I’ve randomly negated it or not.
I’m not sure what your point is with the Sun example: Everyone knows that Sun exploding in 2 hr has ~0% probability, so I’m not sure who you could trick with it.
I’m sorry, but I have to point out that that was a very poorly calibrated set of predictions: 80% of your 20% predictions came true.
I agree. Every number is valid provided it’s attached to a specific claim. If you make 100 50% claims and 90% of them come true, you’re poorly calibrated. If 10% of them are correct, you’re poorly calibrated. Some events are only accurately predicted at 50%, like coin flips. I don’t see an argument against 50% predictions having meaning…
ETA: Taleuntum beat me to it.
90% of 50% claims coming true would be extremely weird, since their “True” or “False” status depend on how you formulated each question. “Brexit will happen” would be false, but “Brexit won’t happen” would be true. If you’re right 90% of the time, it means that you somehow knew that e.g. Brexit wouldn’t happen, and then made sure to formulate the prediction so that it would end up as “True” rather than “False”. I guess it could happen subconsciously, but again, really weird.
In the case of 50% predictions, the person in charge of phrasing the questions is doing 100% of the work. Therefore the predicter’s calibration cannot be graded, you’d really be grading the question-phraser.
Suppose there are 10 events that can either have an outcome of “yes” or “no,” and you want to predict them. I am giving you a calibration survey, and I have the option to phrase each of the ten questions either in the positive “Will this return yes?” or in the negative “Will this return no?” Suppose that you believe they all have 50/50 probability, so predict that all of my questions will come true with 50% probability. Notice that your answer to the survey shouldn’t depend in any way upon my decision, since you will give an answer of 50% to both the positive and the negative questions.
By choosing whether to ask in the positive or negative phrasing, I can totally determine your score. If the first 3 events return yes and the rest return no, then I can phrase the first three questions in the positive and the rest in the negative and it looks like all of your predictions came true so you are underconfident. If I phrase the final two questions in the negative and the rest in the positive, then exactly half of your predictions will come true and you seem perfectly calibrated.
This issue only comes up with the 50/50 predictions. If you estimate something at 60% probability and I reverse the phrasing, you will likewise change your answer.
I see a problem with the “X leads the Democratic field” predictions: they’re not independent. They’re mutually exclusive. (This is actually the same problem as with 50% predictions, but in a subtler form.)
What that means is that, as long as you get the total probability mass of all the contenders you predict for correct, the numbers you assign to individual contenders don’t need to be correct. And Scott has actually maximized this problem by assigning the four candidates equal probability to each other.
Suppose there’s a 65% chance Kamala Harris leads the field, and Sanders, Biden, and O’Rourke have a 5% chance each. You predict a 20% chance for each of them. You are terribly calibrated. Except that one of those four will lead the field 80% of the time, making you look like a perfectly-calibrated genius.
u/ScottAlexander How’s your garden coming along? I, for one, would love to read some garden blogging.
I just bought wildflower seeds and threw them in the dirt and did nothing else, and after the rainy season I got lots of beautiful flowers. 10/10 would recommend.
The Virgin Gardener:
* Painstakingly researches what plants to grow
* Obsesses about when to start the seeds
* Heating mats, expensive lamps, hydroponic set-ups
* Plans the garden on his computer, still comes out crappy
The Chad Scott Alexander Sower:
* Wild flowers
* Lets nature take its course
* Effortless
* Probably gets better results
You do need to be a bit careful, “wildflowers” can also count as “weeds” if they start growing more profusely/in areas you don’t want 🙂
My brother mowed the grass recently once the weather got dry and fine enough, and now the lawn is all buttercups and daisies. I don’t mind (and neither does he), that counts as wildflowers as far as I’m concerned, but dedicated gardeners who want the velvet smooth unblemished sea of green would be tearing their hair out!
(The nettles and thistles that also tend to pop up are not wildflowers, even though I like thistle flowers; those can get the chop).
Similarly, I’d love a post about your home library.
If you want to increase your telework, and have at least one patient in your private practice, I’d be happy to retain you for a weekly session.
I was wondering– one 50/50 prediction might be meaningless, but if you make a bunch of them and half of them come true, wouldn’t that be good calibration?
Um, wasn’t this wrong? In a few suburbs of Phoenix, AZ, download the Waymo app, call a car, you might get an unattended one. Or at least, I’m pretty sure that was true on 12/31/19 – they’ve since put the program on hold for COVID.
Article from November: https://techcrunch.com/2019/11/01/hailing-a-driverless-ride-in-a-waymo/
This is my understanding as well.
Wait. They decided to put the program on hold when other human beings became potential carriers of plague???
Yeah, it seems somewhat questionable to call this prediction correct. I suppose one source of ambiguity is whether this is really available to the “general public”, since you apparently get on a waitlist when you sign up for the app. It sounds like some people do get off the waitlist, but the process seems somewhat opaque as far as I can tell from the linked article.
I’m in Mesa, and opted in / got into the waitlist, but never did get my driverless ride. Bit of luck to it, and I don’t rideshare enough.
I’m in Mesa, and opted in / got into the waitlist, but never did get my driverless ride. Bit of luck to it, and I don’t rideshare enough.
I guess it depends on how you define “general public” (in a given city/area).
> Early rider program members are people who are selected based on what ZIP code they live in and are required to sign NDAs.
You still have to apply, get in a waitlist, and then be selected. It seems reasonable to me that Scott’s bar was closer to “anyone in this geographical area can use it”.
I would sat that requiring NDA alone is making it “not general public”.
If I believed the claims in that article (and some implied ones), then I might count it. But I believe that the region that it can handle is secret. Even if it were published, the NDA prevents us from verifying what they do. Worst, the policy of not always giving unattended rides allows them to disguise what the policy actually is. They might not actually be capable of all rides in that territory, but only easy routes (eg, some judgement of which left turns are easy).
My understanding is that Waymo One usage is not generally subject to an NDA, just the early rider program (but both programs are sometimes fully driverless).
This says otherwise. I’ll believe it when a journalist writes an article interviewing riders not under NDA.
Added: I agree with other commenters that it being under NDA means that it’s not “general public,” but I was saying something additional: that it prevents us from finding out what’s going on. Without such coverage, I wouldn’t believe Waymo’s direct statements, if I could find them. They have made false statements in the past. Maybe not deceitful, but things have ramped up much more slowly then they had claimed.
Without such coverage, I wouldn’t believe Waymo’s direct statements, if I could find them.
Not a bad general rule of thumb to have. Take any company’s press releases (and a lot of journalism on such topics is nothing but puffery, with the reporter rewriting whatever the marketing/PR guy handed out) with a grain of salt, especially when they’re trying to push new technology (because that will never have all the bugs worked out) and most particularly when they’re trying to beat their competitors to getting themselves established in the public mind as “if you want X, we’re the Best And Only Way To Go!”
From other articles I gathered that they have reliable extra-precise maps of just a few areas, not the whole metropolitan region. A person randomly calling a car won’t always be wanting to go only in the areas they have mapped but might want to go somewhere else. In order for the app to be useful given that context, the software assigns a driverless car if the route requested is appropriate for that and calls a regular driver if not.
In thinking about this a little bit, something occurred to me that strikes me as a bit of a flaw in the reasoning behind the idea of the calibration chart.
It strikes me that I can get a way better calibration than Scott if I approach this right. I just have to make a bunch of predictions that I’m really sure of, invert a bunch of them, and then give them varying probabilities in the right numbers so as to get the right curve.
In other words, have a bunch of predictions like “Wisconsin will be a state in 1 year”, “Elon Musk will not turn out to be two kids in a trenchcoat”, “I will cure Coronavirus”, “San Francisco will elect Karl Malone as its mayor in a write-in campaign over the loud objections of Karl Malone”, etc. Make 60 such predictions, with 45 being right and 15 wrong; and then give 10 predictions a 50% chance (5 right 5 wrong), give 10 predictions a 60% chance (6 right 4 wrong), etc.
The above are obvious, and I think Scott’s a little less so; but there might be times when someone is subtly (even unintentionally) doing something like this. I would give, as an (I assume unintentional) example, Scott listing 4 predictions that various Dems will lead the polls, each with a 20% confidence level; flipped into negatives for purposes of the chart, this is 4 statements that “X will not lead the polls” with 80% confidence. Either 3 or 4 out of 4 of these statements will be true, either 75% or 100% for things listed as 80% confidence. No matter what it was going to be reasonably close.
Same, potentially, with Scott’s various personal predictions of “some low chance I dedicate a bunch of time to this thing”, when historically there might be like 2 or 3 such things that he dedicates a bunch of time to in a year. Of course I don’t know enough about Scott’s personal activities to say whether this is what’s going on.
This is why it’s important to track both calibration (do your probabilities mean what you say they mean?) and skill (how much entropy is there in your prediction?).
For example, if you have 10 predictions that you’re pretty sure at least 9 of which will be right, why not predict them with 90% confidence? You’ll get basically the same calibration as the version where you deliberately flip some and lower the probability, but will have higher skill (you assigned less uniform probabilities to things and were right).
At the risk of raising ire similar to the above, are multiple predictions that are linked but mutually exclusive in outcome, like the following, not ‘cheating’ slightly?
Isn’t the above, mathematically, just: 3. Either KH, BS, JB, or BO’R leads the DF: 80%? More than one cannot simultaneously lead the field, so giving them equal probability in separate predictions just gives you extra-well calibrated-ness for the same prediction, doesn’t it?
(For instance, suppose you listed predictions for every single candidate running and gave them all equal probability of leading the field equal to 100% divided by the number of candidates. Then, when whichever one of them leads the field at the end of the year, that huge set of predictions is perfectly calibrated, regardless of who leads the field. All you’ve really done is predicted that there won’t be some utterly unforeseen circumstance preventing any of the candidates from running or something, and given this prediction ~100% likelihood.)
I think that’s cheating in terms of calibrated-ness, but not in terms of accuracy. Eg, if there’s a 70% chance it’s Biden, and a 3.3% chance it’s each of the other 3, you are more accurate to give those probabilities than 20% across the board. So there’s still meaningful information conveyed, though it’s not captured by Scott’s metric of only calibration
I gather that Brier score is the standard measure used to capture both of these, but don’t know much of the details
Generally, the way this would be handled is by making it one question and computing the brier score for the question. So, the question would be:
Then you spread your 100% probability mass across the questions however you’d like. Scott went with a uniform forecast (maximum entropy). When it comes to scoring, you’d generally use a brier score, which maps all maximum entropy forecasts to 0.5, all perfect forecasts to 0, and all perfectly bad forecasts to 2 (in case it wasn’t obvious: high scores are bad).
So, for this question, Scott gets a Brier score of 0.5. Not great, but I think his point was “Who knows?” Maybe someone better at forecasting got closer, but a year ago it was pretty uncertain who was going to do well so I don’t really fault him for this one.
No no no, 50% predictions are not meaningless. They are, in fact, very much like any other percentage.
There is a property of predictions separate from probability and truth value, which you may call impressiveness. It’s possible to have perfect calibration in expectation at the cost of reducing impressiveness to zero:
A coin I throw comes up heads – 50%
A die I throw comes up 4 – 16.67%
No difference, see?
The part where 50% is unique is that there is a simple way to do this: make any number of 50% predictions, randomly select half of them, flip those around, and you have perfect calibration in expectation regardless of your prior accuracy. This is harder to do with non-50% predictions because making it so that, say, 4 out of 5 predictions come true is nontrivial. But it can still be approximately done. Just take a bunch of statements to which prediction markets assign 80%. Randomly flip every fifth of them. Now (if the prediction market baseline is correct) you have perfect calibration on expectation, again with zero “impressiveness”.
But in neither case is it an inherent feature of predictions. Just imagine someone makes predictions like this:
Tesla stock is between 543 and 545 at EoY – 50%
Trump resigns on 2020/03/25 – 50%
The first time I can buy an impossible burger in a store in my city is between 2019/11/23 and 2019/11/28 – 50%
etc.
It would be incredibly impressive if 50% of those predictions came true!
Each prediction divides the future state space into two parts. You should always phrase a 50% prediction such that the positive part is the one that seems intuitively smaller, as in the example above. Same with any other percentage. That way, calibration becomes meaningful across the board.
(And as others have pointed out, you can cheat even more effectively with dependent predictions. In that case, you can achieve guaranteed perfect calibration rather than just perfect calibration in expectation. This also works at any percentage point: divide the future state space into n parts, then assign each part 1/n probability.
In this case, if you added “None of the above leads the Democratic field – 20%,” you’d have done this at the 20% mark.)
>The part where 50% is unique is that there is a simple way to do this: make any number of 50% predictions, randomly select half of them, flip those around, and you have perfect calibration in expectation regardless of your prior accuracy. This is harder to do with non-50% predictions because making it so that, say, 4 out of 5 predictions come true is nontrivial. But it can still be approximately done. Just take a bunch of statements to which prediction markets assign 80%. Randomly flip every fifth of them. Now (if the prediction market baseline is correct) you have perfect calibration on expectation, again with zero “impressiveness”.
But note that to make it work for the non-50% predictions, you need to have some correct baseline to start off with.
The 50% ones you can do with no baseline at all.
The place to punish 50% predictions is in discrimination, not calibration.
Yes, that’s exactly right. More specifically, you can push any baseline closer to 50% by flipping some of the predictions. You can push it all the way to 50% by flipping each one with 50% chance. So if you don’t know the baseline, 50% is all you can do. That’s the only way that 50% is special.
There were so many contenders for the Dems that having a punt on each of them wasn’t a bad idea, but agreed that it didn’t make for good predicitive rigour.
Particularly as the dogs in the street knew it would come down to Biden, anyway (sorry Bernie supporters, not this lifetime) 🙂
Whats the “Decision Tree House”? Google doesn’t bring up anything seemingly relevant
I think it’s this?
I had the same question and found “Decision Treehouse” as well but wasn’t too sure if that was the referent.
I was thinking it would be some sort of rationalist group house thing, because that seems to fit better with the idea of “making a second one”. Not sure what that would mean for a coaching/consultation service.
lil-ego is right about it being a rationalist group house – most of those are not Google-able. I don’t know the details very well, but Decision Tree was an experiment, with a goal something along the lines of providing free/cheap housing and mentorship to promising people who need help getting their feet under them. As Scott indicates in his predictions, it’s ambiguous whether it should be successful, but in any case, the original experiment has been ended. Hope that clears things up 🙂
Nothing more embarassing than Vigano memo happens to Pope Francis: 80%
Define “embarrassing”, this is omitting the entire Pachamama debacle. I saw a lot of online fury from not just the Usual Suspects, and though I am committed in filial obedience to the Pope even I did a bit of wincing. No, I don’t think it’s “we told you so, there’s an ongoing strain of such conferences which are nothing but smuggling full-blown paganism into the Church, this so-called Amazon Synod is only the most blatant to date!”, yes I realise about melding long-standing local cultural practices and that this has been going on a long time and it’s a delicate and complex balance, yes I recognise the ongoing strand of modernism (the small “m” variety) that Francis, as opposed to Benedict, champions (he is a Jesuit after all) and which at its worst is the much-excoriated “Spirit of Vatican II” and finally, South American emphases, y’all.
Still was a bit of an own-goal.
I think the next flashpoint would have been women deacons (I’m not a huge fan of the movement towards this – as against the re-introduction of deaconesses – because yes it will be used by some as a wedge to push for women’s ordination which I do not support), but the coronavirus stuff has put everything on hold.
One thing that always blew my mind about Catholic officialdom is that the Pope is theoretically infallible, but as a matter of practice he needs to invoke that authority specifically and almost never does it. Not much point in being the Holy See if you spend your whole life in CYA mode anyway.
I suppose the obvious question is:
Which of Scott’s most important works should be written in which script?
Unsong: Insular. Give it the full Book of Kells treatment. Gold leaf and stuff.
Meditations on Moloch: Schwabacher Gothic?
The Control group is out of control: Italic
*: more than you wanted to know: Humanist
The categories were made for man… : Uncial and Carolingian?
To put it another way from everyone else – a prediction of X having probability 50% is also a prediction of not-X with probability 50%. You really are making both predictions.
So exactly half of anyone’s the 50% predictions on binary questions must come true.
There’s a fight over 50% predictions every year and I guess the “50% is meaningless” side has finally managed to convince Scott. I’ve said before and will repeat that we shouldn’t notice a problem with 50% predictions, decide to ignore them, and then pretend everything else must be fine – it points to some deeper issue. e.g. if 50% predictions are meaningless, what, quantitatively, does that say about how to think about 50.01% predictions vs 60% predictions vs 99% predictions? It’s a bit of an indictment of the “rationalist community” that after several years no one has thought this through carefully, written it up, and managed to convince everyone of the right way to think about it.
I just assume he’s trolling the comments at this point.
Excellent work.
However, I didn’t see how you did on the prediction for:
“Catastrophic novel virus discovered by 12/31/2019.”
In general, the really historic events are hard to even dream up ahead of time.
By the way, I’m looking forward to reading “41. I finish and post [Structures Of Paranoia]: 50%”
The one elderly man I’ve known with severe paranoia had an interesting cognitive mechanism behind his paranoia. He could form positive as well as negative short term (current day) memories, so each day was fairly pleasant for him. But all his positive short term memories vanished overnight, so as soon as he woke up the next day, when he looked back on the day before, it seemed like a nightmare of negative memories unrelieved by positive memories.
Oddly, this problem became less severe for him in extreme old age. This change for the better may have had to do with taking fewer heart medications as he got very old.
Actually 50% predictions are the only valid ones, all other probabilities are meaningless (since any event either happens or it doesn’t, so 50/50).
You’re joking this time right?
I totally agree with you: for me the question behind Scott’s predictions is not “is X going to be true or not” but “what is the best estimation for the probability of X”, and in this case 50/50 questions are not special at all.
Also I’m super impressed with the quality of Scott’s predictions, It is almost a perfect match, which is really amazing!
It’s a bit sad that the predictions in the project and romance categories were correctly predicted as unlikely, as opposed for example to those in the professional or home categories. Maybe Scott needs deadlines or some group interactions to get things done!
So Scott broke up with his previous partner?
She unexpectedly left him. She left him in the year where he predicted that there was a 70% chance of an engagement.
I believe you meant to write 80% instead of 50% there.
So I know it’s already April, but I think it would still be worthwhile to make some predictions.
What will the trajectory of the coronavirus look like? Do you think you will get sick? Who will win the elections? I’d love to see your predictions.
Here are mine:
My over/under for the number of fatalities from the virus is 500,000.
I think my probability of getting it are about 20%, but very likely only in a mild form.
Trump will win the election: 80%. I just feel that his starting point is better now than 4 years ago.
When measuring forecasting ability, usually people use what are called “proper scoring rules.” These are ways of assessing the quality of predictions that ensure that giving anything other than your true belief results in a worse score than just predicting what you genuinely believe to be true. One example of this is the Brier Score, which is essentially the squared error of the prediction. If you normalize the brier score so that the worst score you can get is a 2 and a perfect score is 0 (this is fairly standard), then giving a 50/50 forecast will always result in a brier score of 0.5. These scores are mostly useful when comparing different people on the same set of questions. A score of 0.5 is always going to be quite bad, since it corresponds to the prediction “sometimes things happen”. Good forecasters on hard problems (such as the ones Tetlock studies), will get brier scores of 0.2-0.3. Good forecasters on easy problems will get scores near 0 (because they just tell you what will happen). If Scott posts a .csv or excel file with the data and the outcomes, I’d be happy to compute his brier score and post it here. Then others who forecasted on the same questions as Scott can compare their forecasting ability with his.
The main takeaway is that while calibration is great, it tells you very little about what you’re really after: How well are you forecasting the future with precision? Calibration is still a great tool for assessing how you might be erring in your forecasting ability (especially if you’re doing it on yourself and you can be confident in your own honesty), so it makes a lot of sense for a blogger self-reporting his own forecasts, since it allows him to make statements like these:
I did some analysis of how well calibrated Scott is last year. Brier scores were included. (He’s pretty good!)
Two typos: “The blue line represents perfect calibration, the red my predictions.” -> switch blue and red
and “Of 37 predictions at 50%” -> 80%
Just thought of a better way to test calibration. You as the estimator don’t get to select the events you predict. Other people decide the events and you make your estimate. As both the estimator and the event selector, it’s too easy to cherry pick stuff you are very familiar with. Therefore, your calibration is limited to your experience and can’t be generalized to other knowledge.
A lot of these predictions were about events in your personal life that you have some control over. I wouldn’t say that it’s trivial to be able to accurately predict one’s own behavior over the time span of a year, but I’m not sure you can count it towards being generally well-calibrated on predicting external events.
I will go further and say that any probability assigned to a prediction of a unique, one time, “either or” event is meaningless or at the very least non-scientific. There is no way to verify the correctness of that specific numerical value. And I also argue that what the person making the prediction is really expressing in not the probability of the event occurring but rather their confidence in their prediction.
Isn’t that the same thing?
No, they are not the same thing. Suppose I’m not feeling well. I see my doctor and she examines me and runs some tests. I call her the next day and she says
“I’m sorry, I have bad news. You have a 50% chance of having cancer.”
Now, while I’m speaking to her, I either have cancer or I don’t. My doctor is expressing the amount of confidence she has in her diagnosis which is an entirely different thing than the state of my health.
… and that’s what a Bayesian probability is, or so I understand it.
I mean, if you personally don’t believe in Bayesianism, then so be it. But that’s what Scott and most of the people commenting here mean when they talk about a probability.
Harry Maurice Johnston :
Again, my claim is that one’s confidence in a prediction that an event will happen is very different thing from a statement about the probability of an event happening. If there is a problem with the Bayesian approach it is that it encourages us to confuse the two because a Bayesian prior contains elements of both level of confidence and (frequentist) probability of occurrence.
Consider a hat full of 50 red cards and 50 green cards. My Bayesian prior for drawing a red card is 50%. That prior is a concatenation of two distinct things. It is an expression of both a high degree of knowledge (confidence) about the event and the actual nature of the event which results in a red card 50% of time. Now suppose the hat has an unknown proportion of red and green cards. What is my Bayesian prior for pulling a red card? Still 50%? Would this 50% Bayesian prior really be expressing the “same thing” as that expressed in the “50% chance of red” prediction where the proportion of red and green cards is equal?
If Scott’s probabilities are truly expressions only of his confidence in his predictions then he did a great job of misleading us with a graph that plots probability of prediction vs. probability of event happening and saying a “perfect score” would be for all points to lie on a 45 degree line.
In principle, an outside observer could predict in advance whether you were going to pull out a red card or a green card, so saying that the actual nature of the event in that scenario results in a 50% probability seems wrong to me.
Regardless, my original comment was prompted by the possibility that you just weren’t aware of what a Bayesian probability is, or that I had misunderstood something. Sounds like you know at least as much on the subject as I do, and just have some sort of philosophical objection to it. So please consider my comments withdrawn.
Harry Maurice Johnston – thanks for engaging.
If you round your predictions to 10% to create neat little bins, you can’t be precise enough to be much more accurate.
One of the most important things I’ve learned about statistics is that they’re often unintuitive, and easy to use to infer the wrong thing. I of course know very little about statistics formally which is why the most important thing I know is a heuristic about how they’re difficult, so my question for those who are more familiar: is the calibration chart method actually the best way to determine the accuracy of someone’s predictions as a whole? It just looks like something to me which, as the simple and intuitive approach, won’t give you the right answer, but possibly it just is that simple!
I guess my basic idea of how to make it complicated would be that you’re creating a bayesian model of how accurate you believe a person to be, and you have to work out the probability that the probability of each event was the same as the prediction, conditioned on the actual observed outcomes, then update your model of the person based on each event. Of course, it’s possible that when you do the math, something like that just reduces down to the calibration chart method. I don’t have any evidence it’s wrong, just a feeling that it should be harder.
Calibration charts are fine, and there’s a discussion above about Brier scores, which are one of many ways to more directly evaluate calibration.
One issue with Scott’s evaluation of his predictions is the implicit assumption that each prediction is independent. They’re not.
There are plenty of other issues depending on how far into the weeds you’d want to get, but the main takeaway should be that ‘It’s good to document your predictions, it’s good to look back on your predictions and see how you did, and it’s good to attempt to calibrate your predictions accordingly.” These are the more important things. 🙂
Do you play D&D only or RPGs in general and D&D is a stand-in so your readers know what you are talking about?
If you like RPGs but haven’t tried much outside of D&D, I’d be happy to recommend other games, mainstream and indie, which deliver interesting, likely quite different, experiences.
As others have pointed out, making 50/50 predictions doesn’t tell you anything about your calibration ability because a) you can achieve perfect calibration by randomly negating half of your 50/50 prediction statements, and b) if an Evil Tester is writing your prediction statements for you, they could choose statements which they know are all false but which they know you would give a 50/50 chance to. They could thus ensure that 0% of your 50/50 predictions actually come true (or any other percentage for that matter).
However, 50/50 predictions can be used to test whether you are obeying the laws of probability. Specifically the axiom of unit measure, which is the one that says all your probabilities for all possible outcomes need to add up to 100%.
Suppose you are given a list of prediction statements, and you negate half of them in case they were written by the Evil Tester. However, after you’ve assigned your probabilities, you still find that 0% of your 50/50 predictions came true. What’s gone wrong? One explanation is that it’s a statistical fluke. The other explanation is that there are some prediction statements which you assigned a 50% probability to, but which you wouldn’t have assigned a 50% probability to their negation.
Concretely, maybe you like to encourage positive thinking, so you only assign 40% to statements on which you have zero knowledge when they are expressed in the negative form. Conversely, you do assign 50% to statements on which you have zero knowledge when they are expressed in the positive form. This way the Evil Tester can still give you questions on which you have zero knowledge but which are all false. All the statements which you negate you will give a 40% probability to (and they will all be true). All the statements which you don’t negate, you will give a 50% probability to (and they will all be false). Hence, all your 50/50 predictions will be wrong.
The moral is that your 50/50 predictions are meaningful in that you can use them to check that you’re not breaking the laws of probability. By extension, this can also check whether you are being Von Neumann-Morgenstern rational, and whether you are open to Dutch books.
This is marked as true, but I don’t think it is… You will never err if you predict delays to Musk’s https://sky-writer.com/papersowl-review/
Can someone explain what is meant by “food essentialism”, or point to somewhere that explains it?
See here #10. The question was:
Unless you weren’t counting the third subject from the original CRISPR baby experiment, I think #26 might actually be false: https://futurism.com/neoscope/china-confirms-birth-third-gene-edited-baby