
At the beginning of every year, I make predictions. At the end of every year, I score them. Here are 2014, 2015, 2016, and 2017.
And here are the predictions I made for 2018. Strikethrough’d are false. Intact are true. Italicized are getting thrown out because I can’t decide if they’re true or not. Please don’t complain that 50% predictions don’t mean anything; I know this is true but there are some things I’m genuinely 50-50 unsure of.
US:
1. Donald Trump remains president at end of year: 95%
2. Democrats take control of the House in midterms: 80%
3. Democrats take control of the Senate in midterms: 50%
4. Mueller’s investigation gets cancelled (eg Trump fires him): 50%
5. Mueller does not indict Trump: 70%
6. PredictIt shows Bernie Sanders having highest chance to be Dem nominee at end of year: 60%
7. PredictIt shows Donald Trump having highest chance to be GOP nominee at end of year: 95%
8. [This was missing in original]
9. Some sort of major immigration reform legislation gets passed: 70%
10. No major health-care reform legislation gets passed: 95%
11. No large-scale deportation of Dreamers: 90%
12. US government shuts down again sometime in 2018: 50%
13. Trump’s approval rating lower than 50% at end of year: 90%
14. …lower than 40%: 50%
15. GLAAD poll suggesting that LGBQ acceptance is down will mostly not be borne out by further research: 80%
ECONOMICS AND TECHNOLOGY:
16. Dow does not fall more than 10% from max at any point in 2018: 50%
17. Bitcoin is higher than $5,000 at end of year: 95%
18. Bitcoin is higher than $10,000 at end of year: 80%
19. Bitcoin is lower than $20,000 at end of year: 70%
20. Ethereum is lower than Bitcoin at end of year: 95%
21. Luna has a functioning product by end of year: 90%
22. Falcon Heavy first launch not successful: 70%
23. Falcon Heavy eventually launched successfully in 2018: 80%
24. SpaceX does not attempt its lunar tourism mission by end of year: 95%
25. Sci-Hub is still relatively easily accessible from within US at end of year (even typing in IP directly is relatively easy): 95%
26. Nothing particularly bad (beyond the level of an funny/weird news story) happens because of ability to edit videos this year: 90%
27. A member of the general public can ride-share a self-driving car without a human backup driver in at least one US city by the end of the year: 80%
CULTURE WARS:
28. Reddit does not ban r/the_donald by the end of the year: 90%
29. None of his enemies manage to find a good way to shut up/discredit Jordan Peterson: 70%
COMMUNITIES:
30. SSC gets more hits in 2018 than in 2017: 80%
31. SSC gets mentioned in the New York Times (by someone other than Ross Douthat): 60%
32. At least one post this year gets at least 100,000 hits: 70%
33. A 2019 SSC Survey gets posted by the end of the year: 90%
34. No co-bloggers make 3 or more SSC posts this year: 80%
35. Patreon income less than double current amount at end of year: 90%
36. A scientific paper based on an SSC post is accepted for publication in real journal by end of year: 60%
37. I do an adversarial collaboration with somebody interesting by the end of the year: 50%
38. I successfully do some general project to encourage and post more adversarial collaborations by other people: 70%
39. New SSC meetups system/database thing gets launched successfully: 60%
40. LesserWrong remains active and successful (average at least one halfway-decent post per day) at the end of the year: 50%
41. LesserWrong is declared official and merged with LessWrong.com: 80%
42. I make fewer than five posts on LessWrong (posts copied over from SSC don’t count): 70%
43. CFAR buys a venue this year: 50%
44. AI Impacts has at least three employees working half-time or more sometime this year: 50%
45. Rationalists get at least one more group house on Ward Street: 50%
46. No improvement in the status of reciprocity.io (either transfer to a new team or at least one new feature added): 70%
PERSONAL:
47. I fail at my New Years’ resolution to waste less time on the Internet throughout most of 2018: 80%
48. I fail at my other New Years’ resolution to try one biohacking project per month throughout 2018: 80%
49. I don’t attend the APA National Meeting: 80%
50. I don’t attend the New York Solstice: 80%
51. I travel outside the US in 2018: 90%
52. I get some sort of financial planning sorted out by end of year: 95%
53. I get at least one article published on a major site like Vox or New Statesman or something: 50%
54. I get a tax refund: 50%
55. I weigh more than 195 lb at year end: 60%
56. I complete the currently visible Duolingo course in Spanish: 90%
57. I don’t get around to editing Unsong (complete at least half the editing by my own estimate) this year: 95%
58. No new housemate for at least one month this year: 90%
59. I won’t [meditate at least one-third of days this year]: 90%
60. I won’t [do my exercise routine at least one third of days this year]: 80%
61. I still live in the same house at the end of 2018: 60%
62. I will not have bought a house by the end of 2018: 90%
63. Katja’s paper gets published: 90%
64. Some other paper of Katja’s gets published: 50%
SECRET: (mostly speculating on the personal lives of friends who read this blog; I don’t necessarily want them to know how successful I expect their financial and romantic endeavors to be. I’ve declassified the ones that now seem harmless to admit.)
65. My partner and I come to a decision about whether to have children: 80%
66. My partner and I are engaged by the end of the year: 70%
67. My partner and I do not break up by the end of the year: 70%
68. [Secret prediction]: 60%
69. [Secret prediction]: 70%
70. [Secret prediction]: 60%
71. [Secret prediction]: 50%
72. [Secret prediction]: 50%
73. [Secret prediction]: 50%
74. [Secret prediction]: 90%
75. [Secret prediction]: 90%
76. [Secret prediction]: 60%
77. [Secret prediction]: 70%
78. [Secret prediction]: 60%
79. [Secret prediction]: 50%
80. [Secret prediction]: 60%
81. I lose my bet against Duncan about Dragon Army Barracks: 80%
82. Dragon Army Barracks is still together at the end of the year: 70%
83. I will visit Greece: 50%
84. I will visit Germany: 70%
85. [Secret prediction]: 70%
86. [Secret prediction]: 70%
87. [Secret prediction]: 60%
88. [Secret prediction]: 50%
89. [Secret prediction]: 50%
90. [Secret prediction]: 70%
91. [Secret prediction]: 90%
92. [Secret prediction]: 50%
93. Still working at my current job at the end of 2018: 90%
94. Working 30 hours/week or less at the end of 2018: 50%
95. Have switched to practicing entirely in the East Bay: 60%
96. [Secret prediction]: 60%
97. Will not finish first section of a difficult calligraphy project: 60%
98. Will not finish all sections of difficult calligraphy project: 95%
99. I will not do work for AI Impacts by the end of the year: 70%
100. I will not finish more than 25% of a new novel: 70%
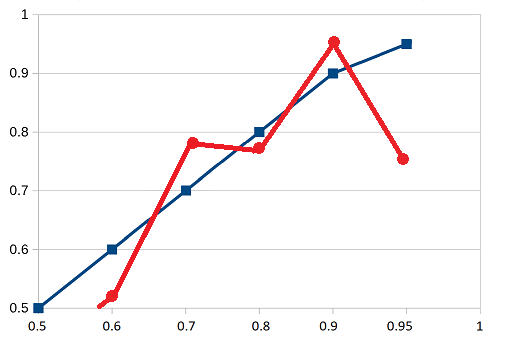
Calibration chart. The blue line represents perfect calibration, the red line represents my predictions. The closer they are, the better I am doing.
Of 50% predictions, I got 6 right and 16 wrong, for a score of 27%
Of 60% predictions, I got 8 right and 7 wrong, for a score of 53%
Of 70% predictions, I got 14 right and 4 wrong, for a score of 78%
Of 80% predictions, I got 10 right and 3 wrong, for a score of 77%
Of 90% predictions, I got 17 right and 1 wrong, for a score of 94%
Of 95% predictions, I got 6 right and 2 wrong, for a score of 75%
50% predictions are technically meaningless since I could have written them either way – which makes it surprising I managed to get such an imbalance between right and wrong. I think I’m more wrong than should be statistically possible. I’m not sure what to think about that.
After that, things go okay until the 95% level, where I get a very poorly calibrated 75%. This is partly the fault of not having very many 95% predictions this year, but even so I should have done better than this.
Two things happened that screwed with a lot of my predictions. First, cryptocurrency crashed (remember, I made last year’s prediction during the height of the boom, when Bitcoin was around $15,000). I expected it would go down, but not this much. Since I made a lot of predictions about cryptocurrency and all of them were correlated, this went badly. I can hear the ghostly sound of Nassim Nicholas Taleb laughing at me.
The other thing that happened was that my partner unexpectedly broke up with me, changing all of my life plans and precipitating a move to a different house. Again, this was a black swan that affected a lot of correlated predictions. In this case, my move took a lot of money, which meant I didn’t have enough money to be worth investing, which means I didn’t bother doing any fancy financial planning like I had been dead set on doing in January 2018. I’m usually pretty good at following through on important things, so I was 95% sure I would get the financial planning done, but black swan = spend savings = no point in financial planning was something I hadn’t considered.
I’m not sure how to deal with those sorts of correlations here except to not make too many correlated predictions.
I’ll post my 2019 predictions later this week. If you’ve made some of your own, post a link in the comments and I’ll link them along with mine. And while you’re waiting, I also made some predictions last February for the next five years.
















“50% predictions are technically meaningless since I could have written them either way – which makes it surprising I managed to get such an imbalance between right and wrong. I think I’m more wrong than should be statistically possible. I’m not sure what to think about that.”
Isn’t the obvious conclusion that you’re bad at accurately deciding a prediction should be a 50% one?
(Which is not too surprising, since “50%” is a semi-unconscious fallback for “I don’t know the probability”, but the underlying probability is not likely to actually be 50%?)
The solution for enterprising readers, should this trend continue, is to bet Scott per his policy at 30% odds for all his 50% bets until he wises up to the plot and recalibrates.
(The fact that you can do this is what makes 50% predictions not meaningless – you have to be confident in other people not having reliably better information than you about the subject.)
This is especially useful because Scott seems to be systematically underconfident (if his repost of 16 right and 5 wrong is correct) or overconfident (if his 24% is right) — you can definitely make money. He was underconfident last year as well though on a small sample size.
I disagree with Scott’s assertion (I think reacting to criticism from readers past) that 50% is meaningless, it’s a perfectly reasonable prediction for odds of something, and you can measure your calibration against it. It’s not meaningless to predict that a coin flip will be heads 50% of the time, and in fact any other prediction is wrong assuming a fair coin.
But it is meaningless to say “I bet the coin will come up heads with 50% confidence” because that is a prediction it will come up tails at exactly the same confidence.
I don’t think ‘meaningless’ is quite the right word, here. “I bet the coin will come up heads with 50% confidence” is interchangeable with “I bet the coin will come up tails with 50% confidence”, but both are committing him to the meta-prediction that this event belongs to a set (50% predictions) that should come out the way he ‘predicted’ about half of the time. If that doesn’t hold up, it makes sense to look for an explanation — something that would bias him toward writing his 50% predictions in the way that is in fact more/less likely to come out correct.
With a literal coin flip it’s hard to think of a good reason, but for his actual 50% predictions, a possible explanation is that he tends to write them in the form ‘X will happen’ rather than ‘X won’t happen’, and that singling out an event in that way makes it feel more likely than it should. (This seems plausible to me if the ‘X will happen’ predictions tend to represent departures from the status quo. It’s hard to test this because a lot of the 50% predictions were redacted.)
edit: not sure how my suggested explanation squares with the other results, though. You’d think he would be overconfident in general, or at least for his 60% predictions, if it were true.
It’s not the prediction that’s meaningless, but only the calibration record that results from such predictions. And they are not totally meaningless, they say something about how the way in which Scott chooses to phrase his 50% predictions is biased towards stating the false prediction.
think I’m repeating what melolontha said but, predicting the coin will come up heads with 50% confidence means you put the right amount of confidence; if Scott has a big imbalance on his 50% confidences, that means he’s miscalibrated, right? So in the aggregate these do maybe matter, although not in the way a lot of his predictions do (and not in a way that makes him look good hehe)
That people can make money betting against you doesn’t mean you are miscalibrated; it merely indicates that other people have superior information.
He could defeat you by randomly flipping his 50% predictions, though.
This suggests that these predictions are correlated in some way and randomizing them would be destroying information. Maybe, if Scott is that uncertain, it’s better to bet that the thing will not happen?
A simple solution for Scott would be to randomize all your 50% predictions. If you want to say “50% chance of X happening,” then you flip a coin and on heads you say “50% chance of X happening” and on tails you say “50% chance of X not happening.”
Of course, that would obscure the reality that Scott is bad at predicting events like that, which is something to learn from.
Yeah, but that’s not a full explanation — there must (assuming there’s a real effect here rather than just noise) be some reason why he is systematically erring in one direction.
I vote for “more wrong than should be statistically possible” to be the new blog strapline!
Hi Scott,
Are you doing any *non* fancy financial planning? i.e. contributing to an IRA, a 401k, have some emergency savings set aside etc. ? Curious what your definition of fancy is.
I’m just acquiring savings now, and once I have enough for it to be worth it I’ll do the stuff where I get stocks or funds or something. I did the math and a 401K didn’t seem to make sense.
If you did the math and a tax advantaged savings vehicle didn’t seem to make sense, you probably did the math wrong. That stuff is free money. <== this is not financial advice
Might still be paying off debt?
Doctors have a particularly weird financial profile in that they spend a decade+ with no money and another decade+ paying off school loans. Then they wake up one day in their late 30s or 40s with no debt and a top 1% income. Unsurprisingly, a lot of them go on to make some really bad financial decisions.
If you can afford $5 a month, you can set up auto-investing with Stash. They let you pick what you invest in, with a whole bunch of different profiles. Or, you can let the Stash account grow, then do a single-time investment of a bunch of money.
*note, I’ve only just started investing using this service. I am not a financial advisor, and not affiliated with the company. This is a suggestion, not an endorsement. Please remember to do your research.
“19. Bitcoin is lower than $20,000 at end of year: 70%”
Was this conditional on the previous predictions being correct? Otherwise, it shouldn’t be struck through.
Failed Bitcoin prediction is IMHO great illustration how financial bubbles happen and why they are dangerous.
Bitcoin crashed because every news outlet predicted it would. (chain effect: everyone thinks it will crash, therefore people stop using it, therefore it crashes)
People treated it like a stock instead of a currency, is the biggest problem. It was treated like an “investment”. It wasn’t supposed to be an investment. It was supposed to be a currency.
Sooner or later bubbles burst whether or not the news predict it. Once there are no more people willing to take the gamble, the price stops growing. After it’s flat for a while, speculators who bought it to profit from the rising price start to cash out. Then others panic and cash out too, and the price crashes.
Where did SSC get mentioned in the New York Times?
Here. Here is how to find it.
Ah, good point adding “scott alexander” to the search — I did a quick search for “slate star codex” and didn’t see anything.
I guess David Brooks is the next obvious source after Douthat.
By my count, you got 8 50%ers right and 15 of them wrong, which means you were 35% right on those. You’re claiming 16 right and 5 wrong for 24% (which should be 76%), as “more wrong than should be statistically possible”.
You’re right, I miscounted.
I think this correction makes it quite plausible that there’s no real effect to be explained here, right? If I’m doing this correctly, random chance would give you a 10.5% chance of correctly picking <= 8 coinflips out of 23, which means a 21% chance of getting a result this extreme in one direction or the other.
(And your previous years' results do not suggest any ongoing bias toward getting 50% predictions wrong.)
Scott, I would be fascinated to hear more about the monthly biohacking projects you mention in 48. If there’s anything you’re willing to share, please do!
Several were public I think, like more plants indoors and the medication sampler kit. If there were other public ones I’m not remembering them and would also be very curious.
#67 is the saddest short story of the year.
Though not as sad as it could be given it is explicitly addressed later.
You were mentioned by Ross Douthat just today, in fact: https://www.nytimes.com/2019/01/22/opinion/covington-catholic-march-for-life.html
Thanks for the link that was a fun read.
I really enjoyed that article. But reading the comments was amazing to see almost every person walk right into the scissor, sometimes even in the context of agreeing with Douthat’s use of the scissor idea. I’ll remind myself as always that commentariats are heavily self-selected for this sort of thing.
One thing you can do is chunk them together conditioned on some parent prediction. So then you can say, “no radical change in my personal life that will cause massive disruption: 90%”, and every other personal prediction is conditional on that one. For BTC, you could say “market doesn’t move more than 80% in either direction” and have your other bets condition on that one. Etc.
If you’re predicting a distribution (Scott’s implied BTC distribution was 5% less than $5k, 15% $5-10k, 50% $10-20k, 30% more than $20k) as a series of binary predictions, then you have one event that shows up ~4 times in your reckoning of calibration, and in a way that’s sort of weird (especially if you flip all events <50% to be greater than 50%). It's not clear that making them conditional is all that useful, and makes them much harder to read off. ("Conditional on BTC being worth at least $5k, there's a 84.2% chance it will be worth more than $10k. Conditional on BTC being worth at least $10k, there's a 62.5% chance it'll be worth less than $20k.")
Yeah, when you wrote “Since I made a lot of predictions about cryptocurrency and all of them were correlated, this went badly.”, you didn’t give yourself sufficient credit. So hopefully you’re still barely safe from a twitter tirade by Nassim Taleb…
1) Where is this outside-published piece (#53) that we can read?
2) Do you need/want some help in financial planning? I don’t have any certifications, but consider myself an “amateur expert,” (though I do have an economics degree, and have other qualifications I can discuss privately) and would be happy to help. I’d bet there are some credentialed CFPs on your blog too who would be willing to offer their services too.
1. I should have strikethroughd that one, it doesn’t exist.
2. No, I just need to have money that I can financially plan with, and last year I sunk it all into a house. Thanks though.
Sorry about the breakup :/
Yeah, that sucks.
I’m also sorry for the break up.
That’s rough.
Me too. Here’s to a fresh start in 2019.
Vox also recently made a list of predictions with probability estimates. It would be so great if this trend takes off! If you have to have a history of well-calibrated predictions to be a serious pundit, we’d have smarter news, smarter politics, and a better world.
Self-driving car nonsense in that Vox article.
“Waymo announced in the fall of 2018 that it would have fully autonomous self-driving cars — cars that don’t need a human driver or guide at all — offering rides, like Uber and Lyft, on the streets in Arizona by the end of the year. It made that target (though there were still humans in the cars for nearly all rides)”
They made their target for fully autonomous self-driving cars, even though humans are still in the driver seat for all rides? Here’s the one report I’ve seen from an actual user of the service.
I was really ambitious and I tried to take it to Costco on the weekend during the holiday season,” he said. “And basically we essentially got kind of stuck outside of the entrance.” After several minutes of failing to find a gap through the number of pedestrians streaming in and out of the store, Metz said the vehicle “timed out” and the safety driver had to call Waymo’s remote support center for re-routing help… Inclement weather, and rain specifically, poses another problem. Metz said he hailed a Waymo vehicle during a recent rainstorm, and when he got in, discovered that the company’s human monitor was driving the car manually… Pickups and drop-offs with Waymo are fairly seamless, he said, though there was one incident when the minivan dropped him off on the wrong side of the street. “The driver put it in manual mode just because our trip already ended, to take us across the street,” he said.
Can’t get any more fully autonomous than that, I guess.
There’s a difference between “all rides” and “nearly all rides”. Since it’s “nearly all”, presumably there was at least one paid ride completed without a human driver? If so, that’s one for the record books.
But aside from that technicality. I agree that it’s rather disappointing.
“Nearly all” is more than 1.
I intentionally wrote “all” because my understanding is that all rides have drivers. At least, that is the policy and I have yet to see any evidence to the contrary. Considering the nature of the discussion, where “fully autonomous” means having a safety driver behind the wheel, this seems reasonable to assume that “nearly all” is just more sloppy writing.
80% chance that U.S. homicide rate will go down seems amazingly overconfident given that it’s been trending up since 2014.
The recession predictions strike me as very bad.
1. I think 2019 is much more likely than a typical year to see the start of a recession in the US, not only a little more likely.
2. The probability of a recession (as opposed to a slowdown in growth) in India is approaching 0. The probability that official Chinese GDP figures show a recession is also close to 0. The probability of a recession really happening in China is significant, but the chance that we could confidently say that it had – certainly at the time, and perhaps ever, is close to zero.
My predictions in this area:
No US recession: 65%
No Indian recession: 99%
No Chinese recession per official data: 99%
No Chinese recession in reality: 85% (but it may well be some time before we can check this, if ever)
I believe we are reasonably close to a major global downturn, which would involve certainly a US and probably a Chinese (real) recession, but I think the likeliest year for it to hit is 2020.
I don’t see what you’re getting at with the black swan correlated predictions thing. Your two errors on 95% predictions you explain with different black swan events. Wouldn’t an explanation for poor predictive accuracy in terms of black swans correlating prediction errors need to have a black swan event that links your two 95% prediction failures? The explanation given looks like an attempt at explaining poor calibration for your less confident predictions, even though you were well-calibrated on those, so you don’t need to explain poor calibration on them.
I think ‘Black Swan’ is being confused with ‘multiple highly correlated predictions’. A black swan event can expose highly correlated predictions, and perhaps we only notice black swan events under such a scenario; but I believe it is itself a different thing.
To reiterate what you are saying above, ‘Black Swan’ events shouldn’t really occur twice in one year. Every time multiple correlated predictions turn out false, it does not help improve your calibration to throw up your hands and say ‘black swan’
It seems to me that the error about financial planning could somewhat reasonably be considered a black swan: Scott attempted a prediction about his personal willpower and discipline, which was invalidated by a surprising change in circumstances unrelated to his willpower and discipline. He probably had a good model of his own psychological makeup, but either he had a poor model of the likelihood of big changes in life circumstances or (more likely) he failed to even consider the possibility of factors beyond his control when making the prediction.
A crypto-crash just isn’t a black swan at all. A prediction about the future price of a volatile asset class that doesn’t consider the possibility of a major crash is foolish, to the point where I have no doubt that Scott considered it when making his prediction, and simply believed it was less likely than it (presumably) was.
He put a 30% probability on a breakup with his partner [which partner? I thought he had multiple]. An event you put a 30% probability on beforehand is not a black swan. It sounds like he just didn’t consider the effects of other events (besides his own willpower), not even of the events he explicitly considered in separate predictions.
I think describing “obvious bubble bursts” as a black swan even is quite generous.
Yeah. That and the self-driving car prediction show a deficiency with regard to technology. These (still) are bubbles.
Great line in recent article summarizing self-driving car progress in 2018:
“Waymo One, the fully autonomous commercial taxi service with humans in the driver seats”
I’m using “Black Swan” to mean a single event which causes many different things to go wrong, which I think is an aspect of (even if it doesn’t perfectly correspond to) the original.
Suggestion: For next year’s 50% predictions, flip a coin each time to chose which way to phrase them. If the chosen direction seems wrong, you’ve caught yourself predicting something other than 50% and adjust accordingly.
The real trick is remembering to do this when you make predictions outside of the context of the yearly prediction ritual.
Also, you might make everything more accurate if you use the coin-flip trick for every question: first commit to prediction A with credence p, and then flip a coin to decide uniformly between reporting (A, p) and (not A, 1-p).
I think you’ve badly misunderstood the purpose and mindset behind this. Scott’s not trying to make his predictions come true, he’s just testing his ability to make accurate predictions. Aside from being an interesting intellectual exercise, this kind of self-knowledge can be useful for making better judgments, and therefore better decisions, in the future.
The idea that Scott would stay in a bad relationship in order to prove himself right must be based on a very low pre-existing opinion of his sanity.
(I understand some discomfort around the personal predictions, especially regarding other people’s lives, but ‘borderline sociopathic’ seems way way way over the top. And again, I see no indication that Scott would ever hope to be proven correct rather than see his friends happy — let alone that he would villainously intervene to make it so.)
The same incentives that push Scott to making his predictions more like reality, push him to makes his life more like his predictions.
You may believe that Scott is far more resistant to the latter, but that doesn’t change that the incentives exist.
My main point is that, even if such ‘incentives’ technically exist, they will (I believe, unless Scott’s psychology differs greatly from what I expect) be swamped by other considerations and can probably be ignored when anything vaguely important is at stake.
(Though they might have an effect when deliberately used like a public commitment mechanism, e.g. making a confident prediction that he will do something he intends to do.)
If we’re being really literal and ignoring context, of course you can defend the line ‘you have an incentive’ in the original comment; but the rest of the comment makes clear that bengraham2 was making a much bigger claim than that such an incentive is technically >0.
(Even in defending the tiny claim, I think you’re making some assumptions, and I don’t think the sentence I quoted is obviously true. Is it so hard to believe that Scott’s motivation for trying to make good predictions is the desire to accurately test his calibration? If we (safely) assume that he also likes being/looking right, then sure, technically some of the same incentives apply.* But not all of them, and not necessarily any of the important ones.)
*Though they might be canceled out by a stronger desire not to let one’s predictions affect one’s behaviour. I know that if something bad happened to a friend, and I could possibly have had some influence over the outcome, I would feel worse for having accurately predicted it. Hard to say how this would apply to cases only involving myself, and cases where the outcome is not unambiguously bad.
Rather than list them at 50% confidence, you should list them at 51% confidence. This expresses the idea that you think that X is more likely than ~X, but have very little confidence in that fact. I think that gets at what you’re going for in the 50% predictions.
2020 predictions:
1. The SSC comment section argues about whether 50% predictions make sense: 100%
Anyway, I also have a non-joke comment:
I think correlated predictions are a really big problem for this kind of prediction/calibration. For example, let’s assume there are two coins that are flipped twice a year: coin A and coin B. A is a fair coin (50/50 chance of heads and tails) and B is an unfair coin (100/0).
Let’s say you make the following predictions:
1. coin A lands on tails at least once: 75%
2. coin B lands on tails the first roll: 50%
3. coin B lands on tails the second roll: 50%
4. coin B lands on tails at least once: 75%
You would get most of the predictions wrong and would seem not to be well calibrated. But the fact is that, while you’re not perfect, you’re not as terribly calibrated as the data would make it seem. You just have an incorrect model of one of the two coins. How well calibrated you are depends less on how accurate your model of the world is and more on how many predictions you make about coin A vs. coin B.
This is a good example. These are all really highly correlated. If you get all these predictions wrong (or right) it doesn’t say that much about calibration in general since they’re all about the same thing (coin B).
I did predictions again this year over at socratic-form-microscopy.com. Here’s the 2019 predictions and here’s my 2018 calibration.
Are you thinking of a luna product other than the one found here? Because it would be a real stretch to call that a functioning product. As far as I can tell from Luna’s FAQ, there isn’t another, more complete/working option, and it mentions there will be a demo out at the end of January (relevant FAQ). So it seems like that prediction is incorrectly scored unless I’m missing something.
The head of Luna told me he believed his existing demo should count. While I guess he could have a bias to make his team look more productive, I thought that was a fairer way of making the decision than anything else.
Fair enough. Asking you to QA the app before making a decision does seem like it would be unreasonable. I would like to point out though that the one currently implemented use for their distinctive feature is still broken many (about 6?) months after I originally informed them of the issue.
If somebody is popular enough that they hit their first message limit for the day you have the option to pay stars to bypass that limit. But if you actually try clicking the message button on a popular profile (Aella’s profile has usually worked for me to reproduce the issue) then the next screen shows you a different profile and gives you the option to pay in order to message that one.* (example).
Maybe it could be called a (borderline) functional product if they were making just a dating app, but their product is supposed to be a dating app that uses LSTR to solve attention imbalance problems, and they don’t seem to have that at the moment. So this sounds to me like the head of Luna is not just biased but lying through his teeth.
*Full disclosure, I haven’t tried buying stars to actually send the message, so I can’t be 100% sure it wouldn’t go to the intended recipient instead of the one it says you’re paying to message.
If I understand your process correctly, you first write out all of the statements, then assign probabilities, then if the probabilities are below 50%, you flip the wording and the probability (e.g. 40% it happens -> 60% it doesn’t happen).
So it is possible you were overconfident in the statements you predicted at 50%. Some of them “should” have been flipped and given 60% or 70% probability, e.g. “Democrats do NOT take control of the Senate in midterms: 60%”.
It seems like most of the 50% statements were “positive” (i.e. X will happen) as opposed to “negative” (i.e. X will NOT happen), so you were overconfident in these things happening (underconfident in them not happening).
Seems to me that your definition of a “Black Swan” is off. Which is good, because I don’t think you should be so referential to NNT.
First, you thought Bitcoin would be down, it went down, just more than you thought. This is not all that shocking. Also something happened in your personal life. This can be shocking in the existential sense, but it really shouldn’t be from a statistical sense, and, to me, just shows that maybe its not great to assign probabilities to the realm of personal conflict.
Personally I think your other 95% predictions are ones that would only be interrupted by a unexpected and catastrophic event, aside from this one:
This prediction strikes me as “correct” as in 95% confidence is correct, but I don’t think it deserves nearly the confidence levels of ones such as:
#1 seems in hindsight and foresight to be much more likely than #20. So maybe you need just more granularity.
I am sure I missed an endless thread on this, but are 50% predictions really meaningless? Here, I’ll answer: They are not, and I am fighting Aumann to determine how confident I should be. Predictions should be measured against the field, not against 50%, right? A 50-50 prediction can be very bold indeed.
If I predict a 99% chance that the moon landing will not be proven to be faked in 2019, that’s an underconfident prediction.
If I predict a 50% chance of France leaving NATO, and France leaves NATO, you should increase your trust in my predictions of this type if that hits. (I am not predicting that.) If you think there is a 50% chance that the Baltimore Orioles win the World Series, you can bet on this and win a lot of money. Also, you’re really bad at this and I recommend avoiding sports betting entirely.
For the calibration charts, of course, scoring 50%ers is problematic unless you have a field baseline. But there’s a massive difference in predicting a 50% chance that Bitcoin will be over $12K than a 50% chance of it being over $125K. One of those is less wrong than the other, and a very bold 50% prediction is fundamentally interesting.
If I make a bunch of 50% predictions and they’re all bold and I am 50-50 on them, I’m pretty great at predicting. If I hit 80%, I’m really awesome at predicting but maybe not so great at avoiding underconfidence and I need to calibrate better.
Is my explanation clear? Have we covered this before?
It depends on whether you’re doing calibration or bayes factors.
For the calibration approach to ranking predictors, 50% predictions aren’t much use, but I think that’s an weakness of the calibration approach instead.
But an alternative way of ranking predictors would be to compare the product of the probabilities they assigned to correct outcomes on the same observations. And for that approach, 50% predictions are just as useful to tell who is better at assessing probabilities accurately as any others.
Every year since Scott started doing this.
You were 100% confident that if you were still with your partner you would be engaged?
Or he thought “become engaged and then break up” was just as likely as “stay together but don’t become engaged”.
I guess, if you interpret “are engaged” as “were engaged at some point during the year”.
Planned to make a proposal, which is in his control, and figured that was no chance of the relationship surviving a rejected proposal?
I’m surprised that I’m the first to point out that the chance of <=6 successes out of 8 for a binomial distribution with probability .95…. is about .057
In other words, if you take "Scott is perfectly calibrated" as your null hypothesis, there isn't really enough evidence to discard it by usual frequentist standards. There are at least half a dozen comparisons being made, a full dozen if you think two-tailed tests are more justifiable, so I'd say a cutoff of p=.05 is actually pretty generous. Verdict: not enough data for a meaningful answer.
I'll let someone else work out the Bayesian posterior for his actual 95%-bin success rate assuming a uniform prior or something…
To build somewhat on what arabaga said, saying that you’re 50% confident something will happen isn’t exactly the same as saying you’re 50% confident the opposite will happen.
First of all, if we ignore the confidence levels entirely and just focus on the prediction, what was predicted either came to pass or it didn’t. The choice to make a prediction at all (and prediction success rate) is, therefore, significant in and of itself.
Bringing confidence levels back into account, we get two measures of accuracy to look at:
1. Was the prediction itself accurate?
2. Where the chances of the prediction being accurate correctly estimated? (Confidence level.)
I believe we can test and illustrate this by means of the following, simple model: turning confidence levels into betting odds. If, for example, you say that you’re 95% confident something will happen, it is equivalent to saying you’ll give 19:1 odds on it happening. If you’re only 50% confident, you’d only give 1:1 odds, and so forth.
With confidence levels given as percentages, imagine the following betting game: for each prediction you got wrong, you pay an amount equal to your confidence level in dollars ($95 @ 95%, $80 @ 80%, etc.) For each prediction you got right, you get 100 – your confidence level dollars ($5 @ 95%, $20 @ 80%, etc.) Safe bets (high confidence) are low payout/high loss, whilst riskier bets have higher payouts/smaller losses. If I’m not mistaken (corrections welcome), a game like this both preserves the odds within individual confidence levels, and allows us to make comparisons between confidence levels.
In short, if you have correctly assigned confidence levels to your predictions, your payout over a long series of iterations should tend towards zero. For example, a long series of predictions made at a correctly estimated 50% confidence should result in you getting around half of them right @ $50 ea. and half of them wrong @ $-50 ea. – aggregate payout $0, because each correct prediction is cancelled out by a wrong prediction; you would need ten correct 95% confident predictions (@ $5) to cancel out one incorrect 50% confident prediction (@ $-50), etc.
If your payout is positive, you are better at predicting things than you give yourself credit for (you are underconfident). If your payout is negative, you are overconfident in your predictions.
It would be fun to examine all predictions individually, but I don’t really have time for this now, so let’s just look at the aggregate numbers:
– 50% confidence: 6 * $50 = $300; 16 * $-50 = $-800; result: $-500
– 60% confidence: 8 * $40 = $320; 7 * $-60 = $-420; result: $-100
– 70% confidence: 14 * $30 = $420; 4 * $-70 = $-280; result: $140
– 80% confidence: 10 * $20 = $200; 3 * $-80 = $-240; result: $-40
– 90% confidence: 17 * $10 = $170; 1 * $-90 = $-90; result: $80
– 95% confidence: 6 * $5 = $30; 2 * $-95 = $-190; result: $-160
Overall result: $-550.
The way you deal with correlated errors making several of your predictions go wrong at once is that you make lots of predictions, and you average over all of them.
Nate Silver made this point several times in relation to the 2018 mid-terms. The 538 model looks pretty absurdly underconfident if you only take into account the 2018 mid-terms, but that’s because before the election, the confidence has to take into account things like ‘maybe all the polls are off by 2% in the same direction’, and then when something like that doesn’t happen, it looks like you weren’t being confident enough.
Roughly the same thing is going on here – your confidence for each individual prediction should take into account your estimate of the probability that, say, the State of California will secede from the Union. In an average year, that probably won’t happen, and you’ll look a little underconfident, and then maybe very occasionally it will, and you’ll look wildly overconfident.
Quickly looking through past posts, I think you’re 35:3 on 95% predictions overall, which is really pretty good.
https://fivethirtyeight.com/features/how-fivethirtyeights-2018-midterm-forecasts-did/
I am really surprised and uncomfortable with the idea that 50% predictions are worthless.
50% that Thing will happen and 50% that Thing *won’t* happen are the same thing, sure.
But so are 70% that Thing will and 30% that it won’t.
The relevant thing is that a 50% prediction is distinct from a 70% prediction.
A 50% prediction that my sister will get a dog this year is reasonable, and distinct from a 5% or 95% or any other prediction.
A 50% prediction that scientists will prove the world is flat is, well, bold at the very least.
Put it this way: if you challenged me to write down a list of 10 predictions for 2019 *exactly* half of which would come true, would you be surprised if I proved it possible to fail?
50% means it could happen or not in equal measure – and for many, many things that is worth saying.
I’d be very interested in hearing where I am going wrong here. This may be close to a stop-reading-SSC level disconnect for me. If this basic truth I feel exists is not taken as true here, it makes me nervous that many other conclusions have hidden, understood dependencies that contradict my basic world perspective.
In all fairness, what we have here isn’t Scott saying, for example: “there’s a 50% chance that the Democrats will take control of the Senate in midterms”, but rather something along the lines of: “I predict that there’s a 100% chance that the Democrats will take control of the Senate in midterms, and I’m 50% sure that my prediction is correct”. It looks kinda the same, but isn’t.
When Scott says he could’ve written the 50% predictions either way, we can understand it that there exists a possible alternate world in which Scott wrote the opposite predictions and got them right. That’s true, but it isn’t this world.
You’re absolutely right that there is a difference between “I’m 50% sure that scientists will prove the earth is flat” and “I’m 50% sure my sister will be whistled at” – it’s most easily explained by assuming that the predictor does a poor job of assigning cofidence to their predictions.
What does the transformation of “get a job” to “be whistled at” here tell us about the effects of culture war on reading comprehension?
@Watchman:
Given that I read “dog” as “wolf whistle” and you as “job”, you tell me… 😀
“I am 50% confident” is often a statement about the distribution, not just the average; if you have 30 predictions made at a confidence of 50%, and in most possible worlds they’re either all correct or all incorrect, the score averaged over all possible worlds is 50%, but the distribution does not have a peak at 50%.
It’s rather easy to get an expected 50% accuracy on binary predictions. Just flip a coin to decide which side to take.
Getting exactly half of them right at better than the normal rate is going to require making more accurate predictions and then being intentionally wrong about half of them- the kind of calibration-hacking that makes the measurement of your confidence calibration useless.
Sure, but that would apply to most buckets. If I’m 95% sure of something of 2 statements, then I could just throw 7 coins for another 7 statements, and voilà my 60% prediction. Maybe 4 and 5 for the 70%. Etc etc.
The fact is that choosing statements is in itself not so random. If I go to a conspiracy website, pick a few of the things they say will happen in 2019, and then make coin tosses on them, I will fail miserably on my 50-50.
The conspiracies are right roughly 0% of the time.
You flip a coin, 50% of the time you predict the conspiracy theories are incorrect.
Therefore, you’re right 50% of the time, and you’ve still successfully predicted something with 50% confidence.
Oops, you are right, I totally slipped there.
Still, the first argument applies to the rest of the buckets. You choose a few correct statements of which you are very sure (“this conspiracy theory will not be proved right”), and then add in some coin tosses. So yes, one can be dishonest making the 50-50 predictions, but not much more than with the rest.
It being easy to cheat doesnt make it a meaningless exercise approached honestly. With a bucket of water and access to the server racks I could kick alpphago’s ass, but that wouldn’t tell you a lot about my playing ability
Examining a number of issues and coming back with the prediction that they are 50/50 is a totally different exercise from sneakily substituting the known probabilities of a serires of coin flips.
Anyway, with Scott’s 50% performance being so much worse than everything else, what I’m guessing happened is the category acted as a mental stop for predictions which were on reflection improbable but somehow appealing/satisfying so they got put in the lowest available category instead of being appropriately inverted and the sorted higher.
To me a 50% prediction could indicate a couple of things:
1.) Scott has a lack of information on which to base his prediction.
2.) The prediction really is something that can’t be nailed down further and does hinge on actions that amount to a coin flip.
In the first case this can be useful.
If 1, then possibly deeper research is needed.
If 2, well, ¯\_(ツ)_/¯
And after a comment my other half made, I wonder if you failed to do enough “if this goal fails, what’s the most likely way it fails” or “is this goal actually saying what I’m thinking”. I’m guessing you were thinking about the chance of you getting round to doing better organised savings and didn’t stop to think enough what else might prevent that happening. You’re still much better than me at this sort of thing, but if you don’t already, maybe a pass over the predictions of “explicitly list most likely ways this could fail” would bring to light insufficiently considered effects?
The “black swan” problem (no semantic discussion here) could be avoided by stacking conditionals. Say, this list
> Printer ink barrel more than 1000 BatCoins: 90%
> Printer ink barrel more than 2000 BatCoins: 70%
> Printer ink barrel more than 3000 BatCoins: 35%
is the same statement as
> Printer ink barrel more than 1000 BatCoins: 90%
>> Conditional on that, more than 2000 RatCoins: 80%
>>> Conditional on that, more than 3000 RatCoins: 50%
But amount of correct information does not equal amount of correct statements. By not using conditionals, we are counting information twice (Bayesian sin!) for the calibration curve. This is bad when there are “evil black swans”, but also helps inflate correct guesses (anyone else feels it would be natural to label outcomes with good/evil and lawful/chaotic?). For the sake of the argument, let’s take it a bit too far, and imagine that some Straw Man gave his guesses as
> Printer ink barrel more than 2000 BatCoins: 95%
> Printer ink barrel more than 2001 BatCoins: 95%
> Printer ink barrel more than 2002 BatCoins: 95%
…
> Printer ink barrel more than 2090 BatCoins: 95%
plus another 10 guesses @95% confidence that are actually 50-50. The barrel is at 500 BatCoins and no market analyst even considers that it may go above 1000. Then some random market stuff happens, and it turns out Straw Man got it right abut the Printer Ink barrels, and they go to 2500. Well, he nailed 95% of his correct guesses @95%, with N=100. Not one lucky guess, but a hundred! We should really trust him when he says he’s pretty sure of something!
[Hand is raised in the back of the room.] If the tests were reproduced infinity times because we are in a frequentist world, our Straw Man would be right in block and fail in block, eventually evening out and giving his actual prediction ability! Yes, but we cannot wait infinity years to update our priors because we are not in a frequentist world, and in the meantime it just confuses our perception of the subject’s prediction ability.
Also, I want to give another vote to the “50-50 is non-trivial information” crowd. Somebody choosing to put “2019 will see the rise of Atlantis” in the 50% bucket is making a decision not to put it in the 99% bucket (well, or its negation). This is probably better explained in many other comments.
But I’d say even when using a calibration curve. Empirically, we have seen that someone can miss the 50-50 point. If Straw Man really didn’t want to think about certain consequences of Brexit, pre-referendum, he may have subconsciously increased the likelihood of “the value of the pound will rise during the negotiations” to 50-50, because then it does not sound that bad. So true, one could make an easy set of 50-50 predictions by flipping coins, but we’re assuming a bit of honesty.
Out of curiosity, where did the “50-50 is meaningless” thing come from?
EDIT: Plus, somebody getting 50-50 right on the calibration curve maybe conveys no information (maybe he’s good, maybe he threw coins). But getting it wrong does (axolotl correctly points out that it is not quite the case here). And anyway, the same kind of hacking could be applied to other levels. If I have a few predictions of which I’m really sure, I can mix them with the right proportion of coin tosses to fill in the 60%, 70% and 80% buckets. By that reasoning, assuming such manipulation on the side of the person making the predictions, the whole exercise is pointless!
50/50 predictions are obviously legitimate. It’s just that you need to run the experiment many times over to see if your prediction of 50% is correct. The prediction becomes about the probability than about the specific event happening or not.
If you keep saying X will happen at 50%, Y will happen at 50%, ect, you could be wrong in that X or Y happens 95% of the time. There’s a way to avoid this though. Whenever you are about to predict that X will happen at 50%, flip a coin. If it’s heads, make the prediction. If it’s tails, say that X will not happen at 50%. Do this consistently, and you will average 50% accuracy, no matter the prior probability of X happening. Either X or not X must happen, and if you pick randomly, you will pick the correct answer 50% of the time.
However, I still think 50% predictions are useful. If you are giving 50% chances to things other people are giving 95% or 5% chances to, they will notice.
the coin flip is the perfect example of a 50-50 prediction. if a guy says he is 99% sure the coin will land on heads, and he’s correct the first time, his 50-50 prediction was still wrong. but those are different types of predictions than the predictions Scott is making. the probability of 50% in a coin flip is inherent to the coin flip and can be derived from first principles. any probability other than 50% is incorrect or suggests a coin that was tampered with.
the way I read Scott’s predictions of 50% is simply that based on his observations the probability of something happening or not is equal. it does convey information, so it’s not a useless statement.
The point is that every forecast of the form P(X) = p is actually *two* forecasts: P(X) = p, and P(~X) = 1-p. When p=0.5 exactly half of your predictions will be correct, by construction.
This would be more clear if Scott also included the implied predictions. Thus he would extend the graph to show his 40% predictions (the mirror image of his 60% predictions), and so on. In this case, the line would necessarily pass through 50%.
I think the 50/50 is actually simpler than described. I think it’s also not as rigorous in practice as it intends.
If I were to do a 50% prediction, I would think of it as “I think this will happen, but I don’t have a solid basis for assigning a positive probability.” It’s the equivalent of a gut feeling that something will happen, without sufficient evidence to support it.
What Scott seems to be doing is along the lines of “I am aware of the possibility of [thing happening], and would like to track whether it occurs or not. I have no solid basis for determining probability, so I will assign 50%.”
I think a lot of folks here are misunderstanding what calibration is, and it’s causing all sorts of confusion.
It’s not a ‘high score’, but a diagnostic test.
Comparing calibration tests is meaningless. What is meaningful is the fact that the test gives you a direction in which to adjust your biases.
It doesn’t tell you your accuracy, but the direction in which to adjust you predictions, in order to improve your accuracy.
Why not? If I had to give someone some money to bet on a load of questions like these, I’d probably favour the best calibrated contender.
All else equal, calibration is a good thing.
But it fundementally measures something different from ‘ability to bet well’.
For example: from the point of view of calibration, there’s no difference between predicting a 16% chance that a d6 will land on a 5, and a 16% chance that a given Fortune 500 company will go bankrupt within the next quarter.
Being able to do the latter will earn you a lot more money than the former.
And you only need to be better than everyone else at making one bet. Better to be a savant of rhodium futures than a jack of all trades.
(this isn’t an explanation of the differences, but just a couple of illustrations to prove that there are fundamental differences.)
Sure, if the only information you had was calibration, you might as well pick someone who is well-calibrated. But in general, accuracy matters more than calibration.
Indeed, becoming well-calibrated is not that hard — you just need to get good at translating your knowledge of a thing into a probability. (Or just say 50% for everything!) Acquiring useful knowledge and utilizing it to successfully predict the future is what’s hard.
Really what I’m trying to say here is that the 50% problem is fundamentally invalid.
‘Do you get any points for being calibrated at 50%?’ is part of the ‘high score’ paradigm which people naively shoehorn this kind of calibration exercise into.
But calibration does not really work according to that paradigm, so the answers people get out are hopelessly confused and inconsistent (in the mathematical sense of the word).
Do 50% predictions matter? Mu
I think we can say that Scott is pretty well calibrated. But accuracy is what really matters.
It’s easy enough to score Scott’s forecasts (I like logarithmic scoring personally). The problem is that we can’t really say how well he did without knowing how difficult the underlying questions were. For that we need some baseline probabilities to compare him to.
Obvious ideas are for other commenters to make their own forecasts when Scott does, and to compare his predictions to betting markets on the same questions.
I made some predictions, inspired by Scott’s post last year, though for most the dates of scoring aren’t the same:
https://alexanderturok.wordpress.com/predictions/
Someone should make a website where people can make probabilistic predictions for others to make their own estimates against, with the prediction’s originator able to set a time limit on how long others can make predictions.(If it’s about conditions on Jan 1, 2024, you don’t want people to be able to swoop in the day before.)
Have you looked at metaculus?
If Scott’s up to it, an obvious idea is to put the predictions in a poll (like the survey) that users can fill out with their own forecasts (including their handle). Then he can provide the spreadsheet next year, and we can see how everyone stacks up.
https://www.gjopen.com/
Not as user-definable as you would like, but a lot I think you’d be interested in.
Hey, stupid question:
Are there any prediction market websites for things other than politics? For instance, if you wanted to wager on something like whether SpaceX will successfully test their new Hopper?
Yeah:
http://longbets.org/
Ok so as someone with some knowledge of risk management I might as well weigh in:
50% predictions are not really meaningless, and the probably we are assigning is based on how much information you assign to an event.
So lets say we don’t know anything about a system, only that it has 2 outcomes, A or B. We again know nothing about the system in question, or what A or B stand for. Without any prior knowledge, we would assign a 50% probably to each event.
That signifies that we have no information. Lets take an opposite example. Say we have a coin and we want to flip it, heads or tails. We know quite a bit about this coin, it is evenly weighted, 2 sides, and we know quite a bit about the system. What we know is that the system is so utterly chaotic and impossible to predict that the probability of either side is 50%.
So what’s the difference? In the latter case, you had as much information as you could have possibly wanted before engaging in total chaos, and in the former, you knew nothing. So in a deterministic world, there is information you don’t know but someone else might or is possible to collect, and there is information no one can possibly get. I am assuming you assigned a 50% probability because you don’t have the former information, not that you had it and decided that the true probability was 50%.
So there is a “true” probability of an event occurring, that is, formally, the probability an event occurs with the maximum amount of information one can possibly gain before the system becomes so chaotic that it is impossible to quantify anything. But there is another probability in which we don’t know so we guess a prior probability and then update as more information should become available.
Of the probabilities you assigned 50:50, you did that because you didn’t have any useful information. So going back to the first example, say we did a test and it seemed that A showed up roughly 27% of the time. Now, this holds even though A and B could be anything and we could switch A and B at will. Then it seems that one can say, hey, if I don’t know whats going to happen, it will happen at 27%.
Of course that sounds sketchy as hell, so lets justify that with the examples you gave.
“Muller investigation canceled” “US government shuts down” “Dems take the senate” “AI impacts has at least 3 employees,” “Trump approval rating lower than 40%”, (and of course a bunch of things you kept hidden)
Aha. In each and every one of those things, to answer in the affirmative means the status quo will change, or something would happen that deviates from whats happening now. You we given a bunch of questions, “Is the status quo going to change”, yes or no, and you assumed that, given no other information, there is a 50-50 chance of it changing. And I would wager that in the hidden things you assumed something would change in the framing of the question.
What the data is telling you is that, assume no information and you are unsure about the facts. Then there is a 25% a thing will happen. That should be your prior probability something big will happen. In the way you designed these questions, most of them require a shift from status quo, and while that can be very likely (dems take house is a staus quo shift that was extremely likely) without any information or other knowledge, the background prior probability is around 27%. So when you are unsure about something changing, set that as your prior. In the way you designed your questions, A and B are not truly random. A is that something will happen, B is that it won’t, and things don’t tend to change 50% of the time.
Or you can better randomize the questions such that for them to be true, the status quo could remain the same.
@Aladin, I think you’re underestimating the difficulty of the problem. When an experiment is repeatable as in your coin flip example there is no problem assigning outcomes a 50% probability. But the real problem is when there’s no comparability between outcomes of different experiments. Instead of having to choose between A and B some number of times, we have to choose between A and B, between C and D, between E and F, and so on, with no way to compare A to C or D. There are 2^N possible combinations for predictions and no obvious way to differentiate them. The distribution of correctness of each combination is a
Even your proposal at the end is an attempt to put categories of “change the status quo” and “not” on the choices to recreate the idea of a repeatable experiment with labeled repeated outcomes. This is not possible in general.
Well what I am trying to do is find similarities among the different scenarios.
If there was no similarity at all, it should be 50%, as the choice is completely random. To explain the 27% as found, the only way I can see is to categorize as I have.
Pretend you didn’t know anything about the choices. Pretend you were just randomly guessing. It would be 50% because you didn’t know, right? I am not quite sure what you are getting at with the 2^N choices.
If I asked you “will the dems take the senate in 2030” well you don’t know, so you assign a 50% value, they either will or they won’t. I ask a completely different question “will I wear a suit next week” well you don’t know, so you assign a 50% value.
It doesn’t matter if the choices are not comparable. In fact that is the entire point. With your lack of information things will bear out 50% of the time. And the less you know about each event and the less they are related to each other, the closer the result should be to 50%.
Flip a thousand coins and guess a truth value for each of those coins. You should be right half the time. OK fine, but we know the probability of each coin, (50%). So flip a thousand differently weighted coins (i.e more likely heads or tails), each randomly differently weighted. You will still be right about 50% of the time, PRECISELY BECAUSE each and every coin is completely different from one another, and precisely because you don’t have the information on the weighing of each coin.
So the fact that only 27% of the choices bore out is weird right? And that is probably because each event, while completely different, is framed towards a certain bias, that, given no information about an event except that it is different from what is currently taking place, the event will happen or not happen about 50% of the time.
If I were to say, will event A happen? Event B? Event C? Event D? and I haven’t told you what they are, in fact I don’t know what A, B, C, D is, and you say 50%, you assume that if you were to pick an event out of a hat on average it would happen about 50% of the time.
And this is in fact true, unless there is information encoded that you are forgetting. And that information is that I am referring to “events” that “happen.” If every event is a shift from the status quo, on average the events do not take place because the status quo does not change that often.
So basically what I am doing is saying, suppose these events are completely and utterly unrelated and you know nothing about said events. What is the prior probability that any event I pick out of a hat happens? If you had absolutely no information, and there was, again, no relationship between events, you would be right about 50% of the time.
But the events are related. They are all events that represent a shift from the status quo. If I were asked, here is a random machine from a random factory from a random country, what is the probability that it will be broken next year? There is information there. Machines don’t break very often, and it is unrealistic to suggest that half will be broken next year so I can assign a prior probability, given no other information aside from, machine is broken. Say I have absolutely no idea what that prior probability is. So then you ask me a different question, what is the probability that a random thing hits a random thing at a random time” and I don’t know anything about things and times and I would say, 50%.
So then while 50% is the wrong answer to the first question, if I ask 100 different questions, it would average around 50%. If I don’t know anything about anything, 50% is probably correct in the aggregate, and the more abstract and the less connected everything is the more 50% is the right answer. But in any individual case where things are connected, 50% would be wrong.
In this case the events are all connected, even if very abstractly, so it doesn’t average at 50%. But if I added a bunch of things that don’t represent shifts from the status quo, and you still don’t know anything about those events? Well then it would look more like 50%. Deviations simply mean that the events are not as random as they seem to be. Or its just random chance. I’m just hypothesizing here.
Here’s my take on whether or not Scott is “well-calibrated”. (I don’t address the issue of correlation, which is pretty important here, but I think Scott covered it adequately.)
From a classical statistical point of view, there’s not adequate data to conclude that he’s mis-calibrated. Also, this year he was a over-confident while in past years he was under-confident. This is consistent with the hypothesis that Scott was consciously adjusting for being under-confident in the past. (Or it could be random noise. I didn’t have time for a multi-year look, but that could be interesting, too!)
I’m also struck by a sense of Déjà vu on the 50% question. Didn’t this get discussed last year? Didn’t we agree that “It’s useful to know when an event is a toss-up as well as how accurately you can identify toss-ups”? Perhaps we discussed but didn’t reach agreement? Is this a weird non-culture-war scissor where it’s bafflingly obvious to some that 50% predictions are useful, nay vital, while to others its equally obvious that they’re pointless?
It gets discussed every year. Seems to be one of those scissor things, if a relatively benign one.
Sorry to hear about your breakup, man. That really sucks 🙁
If you come to Greece this year, I will be thrilled to shake your hand.
Unsong is one of the best things I ‘ve read in my life.
I noticed you had trouble controlling Internet time-wasters. One strategy that worked for me is to take a microscope to how I personalize my tech interfaces. Doing so led me to delete all my bookmarks, so that I’m required to type in “reddit.com” to visit it, thus slowing me down enough to consider not going there. Furthermore, I unsubscribed from all subbreddits, so that I have to take the extra step of navigating to a specific subreddit. I do, however, have bookmarks to Gmail and Facebook, but my link to Facebook is a direct link to Messenger.
The interesting Elon Musk – related predictions are:
Elon Musk will be reassigned from CEO in 2019: 40%
Tesla will file for Chapter 11 in 2019: 20%
Space X will file for Chapter 11 in 2019: 25%
OK, I won’t complain about your decisions if you present them as decisions. But that’s not what you did. If you do make up bullshit excuses, I’m not going to believe them. I’m going to complain about them.
Maybe there are things that you’re genuinely 50-50 unsure of, but there are other things that you’re genuinely 65-35 unsure of, yet you’re able to bucket them as either 70-30 or 60-40. So you could force items out of 50-50 just as well.
If you want to do something meaningful with the 50% results, find some non-random way to select which way you ask them, ideally one that tracks some concern about your decision-making you’d like to check.
E.G. if you want to check for irrational pessimism or optimism, always choose the option you’d prefer to happen as the ‘confirmed’ case.
I think generally tracking which predictions are preferred is a good idea, not just for 50%.
See whether there’s a systematic bias going on.