
Last year in January I made some predictions for 2014 and gave my calibration level for each. Time to see how I did. Ones in black were successes, ones in red were failures.
1. Obamacare will survive the year mostly intact: 80%
2. US does not get involved in any new major war with death toll of > 100 US soldiers: 90%
3. Syria’s civil war will not end this year (unstable cease-fire doesn’t count as “end”): 60%
4. Bitcoin will end the year higher than $1000: 70%
5. US official unemployment rate will be < 7% in Dec 2014: 80%
6. Republicans will keep the House in US midterm elections: 80%
7. Democrats will keep the Senate in US midterm elections: 60%
8. North Korea’s government will survive the year without large civil war/revolt: 80%
9. Iraq’s government will survive the year without large civil war/revolt: 60%
10. China’s government will survive the year without large civil war/revolt: 99%
11. US government will survive the year without large civil war/revolt: 99%
12. Egypt’s government will survive the year without large civil war/revolt: 60%
13. Israel-Palestine negotiations remain blocked, no obvious plan for Palestinian independence: 99%
14. Israel does not get in a large-scale war (ie >100 Israeli deaths) with any Arab state: 95%
15. Sochi Olympics will not be obvious disaster (ie spectacular violence, protests that utterly overshadow events, or have to be stopped early): 90%
16. Putin will remain President of Russia at end of 2014: 95%
17. Obama will remain President of USA at end of 2014: 95%
18. No nuclear weapon used in anger in 2014: 99%
19. No terrorist attack in USA killing > 100 people: 90%
20. No mass shooting in USA killing > 10 people: 50%
21. Republic of Shireroth will not officially disband or obviously die before end of 2014: 90%
22. Republic of Shireroth will remain in Bastion Union: 80%
23. Active population of Shireroth on last 2014 census will be between 10 and 20: 70%
24. Slate Star Codex will remain active until end of 2014: 70%
25. Slate Star Codex will get more hits in 2014 than in 2013: 60%
26. At least one 2014 Slate Star Codex post will get > 10,000 hits total: 80%
27. No 2014 Slate Star Codex post will get > 100,000 hits total: 90%
28. 2014 Less Wrong Survey will show higher population than 2013 Survey conditional on similar methodology: 80%
29. 2014 Less Wrong Survey will show population < 2000 C.O.S.M.: 70%
30. 2014 Less Wrong Survey will have > % female than 2013 Less Wrong Survey: 70%
31. 2014 Less Wrong Survey will have < 20% female: 90%
32. HPMoR will conclude in 2014: 80%
33. At least 1 LW post > 100 karma in 2014: 50%
34. No LW post > 100 karma by me: 80%
35. CFAR will continue operating in end of 2014: 90%
36. MIRI will continue operating in end of 2014: 99%
37. MetaMed will continue operating in end of 2014: 80%
38. None of Eliezer, Luke, Anna, or Julia will quit their respective organizations: 60%
39. No one in LW community will become world-famous (let’s say >= Peter Thiel) for anything they accomplish this year: 80%
40. MIRI will not announce it is actively working on coding a Friendly AI (not just a few bits and pieces thereof) before the end of 2014: 99%
41. I will remain at my same job through the end of 2014: 95%
42. I will get a score at >95th percentile for my year on PRITE: 70%
43. I will be involved in at least one published/accepted-to-publish research paper by the end of 2014: 20%
44. I will not break up with any of my current girlfriends through the end of 2014: 50%
45. I will not get any new girlfriends in 2014: 50%
46. I will not be engaged by the end of 2014: 80%
47. I will be living with Ozy by the end of 2014: 80%
48. I will take nootropics on average at least once/week through the second half of 2014: 50%
49. I will not manage to meditate at least 100 days in 2014: 80%
50. I will attend NYC Solstice ritual: 60%
51. I will arrange some kind of Michigan Solstice Ritual: 50%
52. I will not publicly identify as religious (> atheist) by the end of 2014: 95%
53. I will not publicly identify as neoreactionary or conservative (> liberal or libertarian) by the end of 2014: 70%
54. I will not publicly identify as leftist or communist (> liberal or libertarian) by the end of 2014: 80%
55. I will get a Tumblr in 2014: 50%
56. I will not delete/abandon either my Facebook or Twitter accounts: 60%
57. I will have less than 1000 Twitter followers by the end of 2014: 60%
58. When Eliezer sends me a copy of “Perfect Health Diet”, I will not be convinced that it is more correct or useful than the best mainstream nutrition advice (eg Stephen Guyenet’s blog): 70%
59. I will end up being underconfident on these predictions: 50%
Of predictions at the 50% level, 4/8 (50%) were correct
Of predictions at the 60% level, 7/9 (77%) were correct
Of predictions at the 70% level, 6/8 (75%) were correct
Of predictions at the 80% level, 12/15 (80%) were correct
Of predictions at the 90% level, 7-0 (100%) were correct
Of predictions at the 95% level, 5-0 (100%) were correct
Of predictions at the 99% level, 6-0 (100%) were correct
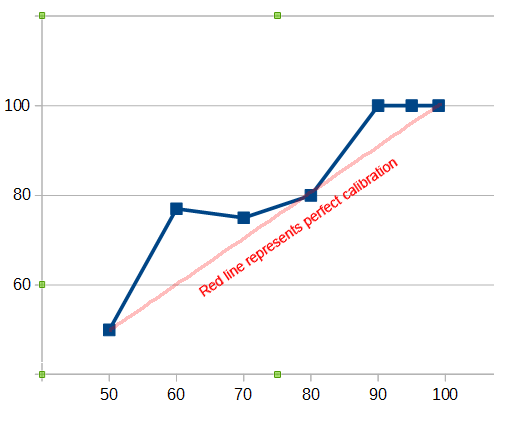
I declare myself to be impressively well-calibrated. You should all trust me about everything.
2015 predictions coming soon.
















Predictions are not useful if they do not have some pay-off metric. ie Expectation NOT yes/no answers. Therefore half of this is legitimate and the other half is illegitimate, but because if you are wrong multiplied by the payoff matrix (expectation) you could either be extremely incorrect or not.
Pushing this even further it is the expectation part that undergoes the majority of ‘variance’.
Furthermore
Happy 2015 however.
The heck? Could you maybe elaborate on any of that?
But asking people to explain things is Socratic bullshit! If you claim to not understand something, it can’t possibly be that the other person didn’t explain it properly, you must just be trolling.
I think he means that unless there is a penalty for false predictions and a reward for correct ones, then a plain yes/no isn’t much good? e.g. if you bet on a horse race, you are predicting that you have confidence My Punt will win or place. The more confident you are the more money you’ll bet on a plain ‘win’ bet; the less confident you are, you’ll go for an each-way bet.
And if you lose your shirt, then your prediction was “extremely incorrect”, while if your horse finishes second or third and you were each-way, then you were incorrect but still salvaged something from the incorrect prediction.
He is just poorly channeling Taleb.
He’s right that you need a payoff, but if the payoff is binary – and it sometimes is – then a probability is exactly what you need.
A better criticism would be to say that most interesting payoffs in life aren’t binary at all, and require taking an expectation over a potentially fat-tailed distribution. This is much harder than assessing binary probabilities, if not impossible.
The general point Taleb makes is that you are better off controlling the shape of the payoff function than trying to estimate tail probabilities.
I got “Antifragility” by Taleb as a Christmas present.
I’m just about to hit the half way line, but so far I’d say your last paragraph is worth at least 100 of his pages.
Concise, he is not 🙂
“Fooled by randomness”
Selection effects, and psychological biases means we often find spurious patterns in noise.
“The Black Swan”:
Unless you have strong prior information, you can’t meaningfully estimate tail probabilities much lower than one in number-of-datapoints.
Some people says ‘Antifragile’ could be more short, but I think he making the same point on different topics. However, he make a lot controversial claims, specially about economics and the accuracy of predictions.
More poseur nonsense.
Something like “If this goes tits-up, how badly am I likely to be burned?”
How much can I afford to lose if this doesn’t work/how much am I willing to risk for the chance this will pay-off?
Lol. How cute. I learned a lot from Taleb. But I learned most of my intuitive ‘calibration’ from sports gambling and poker. Any one who does not see why merely saying something is “well calibrated” merely because of hitting superficial contingencies never learned the probability they fake.
@gwern ???? This one is a home run
Good summary as well as those below. Thanks. I’ve promoted Taleb’s books a few places in my queue as a result.
@gwern I don’t know. You are otherwise a severely well informed individual, yet you cannot realize why merely calibrating superficial contingencies of frequencies cannot be considered ‘calibration’. Without considering, uh I don’t know EVERYTHING? Kurtosis, variance, volatility. Why are Bayesians obsessed with frequencies?
Stochastic convergence* makes it difficult to do merely “Oh look, I was right!”. I can’t believe I have to even explain this. Forget the payoff part.
@Arthur B/the idiot in the suit expectation is some beginner level stuff. No one compares percentages without considering the ontological content contained inside first. ie multiplied by the price.
* In general not necessarily for this example. I see this error everywhere.
Chill, bro.
Just take the logs of the probabilities assigned to the actual outcomes, and sum them up.
That doesn’t address SanguineEmpiricist’s complaint (though I don’t understand that in any case), but it _is_ a good way to measure overall accuracy. The number [(-1/n) sum_i log_2 p_i], where p_i is the probability you assigned to the actual outcome of the ith question, is called the KL divergence of the empirical outcome distribution versus your predictive distribution. It has two nice properties: (1) it properly incentivizes you to report your actual uncertainty, unlike some intuitive accuracy measures that reward reporting more certainty than you have; and (2) the “true value” (viewing the questions you answered as a random sample from a larger class of questions) can be estimated from a smaller number of data points, so you don’t have to do what you’ve done, binning the questions into a small number of predictive probabilities and estimating a separate accuracy for each one. The mysterious information-theoretic interpretation for binary outcomes is “I’d need on average this many bits to describe the true outcome if you told me your predictive distribution,” so 0 is the best and 1 is what you get for the baseline strategy of saying everything has a 50% chance.
The calibration curve isn’t a bad thing to do, either, though.
Well, the payoff matrix is that I look smart and feel good if I’m right, and I look dumb and feel bad if I’m wrong. That’s the same no matter which direction I’m wrong in.
How does one count with the fifty percentagers? If you give something 20%, you use the complementer with 80% certainity, but with the fifties, you can take whatever you want for success, or failure, as wanted, can’t you?
20. No mass shooting in USA killing > 10 people: 50% could as well be taken for giving 50% for mass shootings, which would be a failed prediction. As such, you could give yourself anything from 0 to 100%. Manipulating those to be 50 would be like saying whenever I say it could go either way, it would be reasonable to take my word for it, but it does’nt matter who says it! Maybe it would be best to discard ‘I don’t have a clue’ predictions?
I suppose if you found out that you got those 50% predictions at, say, 80%, you were underconfident about your certainty on the prediction and so could make such predictions with a higher confidence in the future. As it stands, it looks like Scott genuinely didn’t have a clue about those 8 predictions.
“50% chance” doesn’t mean “doesn’t have a clue”.
If experts say that there’s a 50% chance that the Earth will be consumed in a storm of nuclear hellfire tomorrow morning, they have access to some very serious, very troubling information.
Sure, but that’s because we have a strong prior re: nuclear war: the previous 23,351 days have contained no nuclear war, which if we don’t have any particular model in mind suggests a commensurately small probability for nuclear war tomorrow.
If we’re in a situation where we don’t have any comparable information, our priors are whatever we choose them to be, and 50/50 is not an unreasonable choice. Though the question of what to do when you don’t even know what reference class to put something in is kind of an interesting one, and it’s one that Bayesian inference doesn’t by itself give you an answer to. Unless you want to forego reference classes entirely and start talking about inference over world-states, but the likes of you and I don’t have the juice for that.
As long as you pick a particular outcome to represent “success” before the actual outcome is determined, then an even mix of “successes” and “failures” would indicate a good calibration, since it demonstrates the correct level of uncertainty about the events in question.
Though, if the outcomes are not evenly balanced, there doesn’t seem to be any meaningful difference between putting the data point above the “perfect calibration” line or below it.
I suppose, by that logic, the calibration curve should be rotationally symmetric about the point (.5,.5)
You’re right that it’s irrelevant whether I list it in black or red here. But on the broader scale, 50% means I expect to get 50% of the ones in that category right, and 50% of them wrong.
So if I get 100% of my 50%s right, I was wrong to assign them 50%, but if I get 50% of my 50% ones right, then I was accurately assessing that I was equal either way on those.
Note that this is not the same as saying “No information”. The claim “50% chance the stock market will stand at exactly 22165 on January 1 2020” is making a very strong claim of knowledge. So when I say 50%, that’s the result of an assessment of how much information I have.
That is indeed impressively well calibrated.
I do find it hilarious that you assigned > 20% to HPMoR concluding in 2014.
Really? It was 80% done at the beginning of the year, I figured Eliezer would just have to quickly finish it off.
Note that he now intends to have it finished by March, so I wasn’t far off.
ISIS is essentially a rebranded Sunni revolt, so that one’s ambiguous.
Happy new year!
Is it ambiguous whether the United State government survived 1861? Or the Confederate government, for that matter?
In 1861, it survived, but it didn’t “survive the year without large civil war/revolt”
Good catch, I missed that. And yes, anything that involves an armed force pushing the government out of one of the country’s largest cities ought to count as a “large civil war/revolt”.
That’s a good point. It may be worth noting that counting it as a failed prediction would have improved Scott’s calibration score.
This is not ambiguous!
http://en.wikipedia.org/wiki/Template:Iraq_war_detailed_map
http://commons.wikimedia.org/wiki/File:Iraq_war_map.png
Huh, Iraqi Kurdistan seems to have made some gains since the last time I looked at that map.
Hey, never commented here before, but I just want to say:
I work in investment research (“buy this, sell that”) and I have always felt that analysts should have something like this included in their performance analysis. Make a prediction, include some kind of subjective likelihood, and then see how you did at the end of the year over all your predictions.
As it stands right now, a great analyst is one who is right (in a binary sense) 60% of the time instead of 50-50 as chance would dictate. You can imagine that it’s very hard to separate the signal from the noise that way.
You are very rational and well-calibrated and I salute you.
Now, any tips for the 3:30 at Sandown on Saturday? 🙂
Iraq is not experiencing a large civil war?
Exactly my thoughts, Daniel. On the other hand, Scott’s predictions become even more well-calibrated.
Yeah, I thought about that, but what I was thinking when I wrote that was that the government would stay stable. So far it has.
Well, Maliki’s no longer prime minister, so even by the metric of stability it wasn’t very stable. Also, I’m a textualist, not an originalist.
Also, what’s with the “Go away, everybody”?
He regrets writing “Untitled”.
Impressive. Best wishes for the new year, in your predictions and beyond them.
Breaking news and off-topic, but I’m so furiously angry I have to rant.
Steven Gerrard will be leaving Liverpool FC at the end of this season.
I realise that means nothing to any of you, but [swearing swearing furious swearing more swearing] the manner of his departure is not good news and I am simultaneously heart-broken and incandescent with fury.
Wonderful way to kick off 2015, Liverpool! Just in time for the tenth anniversary of Istanbul, no less!
Thank you for your patience.
Go not to the well-calibrated for counsel, for they will say both no and yes.
Have the survey results been released yet, or are you just teasing us?
43. I will be involved in at least one published/accepted-to-publish research paper by the end of 2014: 20%
I find predictions of X (less than 50%) to be confusing, instead of -X (greater than 50%). Does this prediction in black font mean you were involved in a published paper or not? If yes, shouldn’t this count against your calibration skills?
I don’t know what red/black means for that item, but he counted only 15 predictions of 80%, so I think he forgot to include that item in the score.
Also, that one does not appear to have been included in the final tally.
Yeah, I screwed that one up.
Didn’t publish a paper yet, but hopeful for next year.
I’m always dubious when I see a plot with some data without error bands, and a supposed fit line, and then some words saying “see it fits great.” You can’t say something fits great unless you understand the uncertainties on your measurements and understand how much variation you expected.
The right thing to do here (well, a reasonable thing anyway; there are always lots of variants) is probably compute the chi-squared* of your fit. In other words, assuming you sampled from data that was perfectly calibrated, see what standard deviation you expect in the number of successes at each probability. So for example, at probability 0.6, Scott has 9 data points. If they’re really 0.6, you’d expect to see 9*0.6=5.4 successes, with standard deviation sqrt(9*0.6*0.4)=1.5. Scott observed 7 successes, which is 1.1 standard devs high. So you can see how many standard devs off the observed is from the fit at each data point. That (the 1.1 in the example) is called the chi value. Then those chi values should form a distribution whose exact nature is complicated, but should have mean 0 (because you expect the expected number) and variance 1 (this is true but not super obvious — if wikipedia were remotely good at explaining math, I would suggest you look here . But umm, I dunno.). People usually use the sum of the squares instead of the variance, because the mean should have been 0 anyway.
Doing this, I see that the chi’s have average 0.4 and mean chi-squared 0.3. So we conclude two things:
1. Scott’s observed rates are systematically a little high, which is obvious from the plot, but by only half a standard deviation, so that’s well within the noise.
2. Scott’s mean chi-sqaured is less than 1. That means that even if Scott were perfectly calibrated, and all those probabilities he made up were exactly right, then you’d expect the observed values to differ from the expected by about twice as much as they actually do (because sqrt(0.3)~0.5). That is probably just a symptom of low sample size, although if the effect stayed as the sample size grew (i.e. the chi-squared did not go toward 1), one might begin to suspect some sort of systematic bias.
So, yeah, congratulations Scott, you are indeed well calibrated. But you should still always include error bands in your plots :)!
*Technically that’s not quite what I’m doing because chi-squared is the name for it when you have a gaussian distribution, not a binomial distribution.
Despite the small sample size, Scott’s data rejects the null hypothesis that he is as overconfident as the typical person. (Perhaps a better way of putting it is that Scott fails to reject the hypothesis that he is calibrated, while most people with the same amount of data succeed in rejecting it.)
I fail to see how there could be some sort of systematic bias forgoing time travel…
You could get systematic bias in a predictions game like this by going back and editing the post where you estimated confidence levels. Or, more hilariously, by acting so as to make your predictions come out a certain way (“Too many of my 50% predictions are turning out true! We must break up.”) I do not think Scott has done either of these things.
That’s pretty impressive. I’m confused by your method of counting results though. If I understand correctly, the credence level is your probability that the event will happen. So 20% credence in something means you’d bet 4:1 against it. Should not 43. count as a failed at 80% prediction, then? In other words, if you gave less than even odds that something would happen and it nonetheless happened, that’s a failed (complementary) prediction is it not? I’m somewhat confident that the proper way to count this is to convert all the predictions with probabilities less than 50% to their negations and then count how that panned out. Or to use a proper scoring rule.
gwern, if you see this, could you please share your take on this? I trust your expertise in statistics far more than mine.
Yeah, I totally screwed up on 43
Do you think that a part of your success was that you were able to select the questions you wanted to make predictions about? If someone else asked you to make predictions about things they were interested about, would results have been different?
I’m not sure. I feel like selection of questions should benefit accuracy, but not necessarily calibration, except in the degenerate case where I select things I’m sure about and say 100%.
If I chose easy questions, all my calibration estimates should be higher, but calibration is still a hard problem.
Scoring time! Using the log scoring rule (higher is better) you get -0.6 on average. Impressive.
For comparison, the good people of predictionbook get scored like this for an average of -0.83. And Gwern gets scored like this for an average of -0.78.
Please please change your tagline to “officially better at predictions than gwen”.
It’s a tad odd to make that claim, because he had essentially infinite discretion when it comes to what he was predicting (where the prediction markets typically have pre-specified questions). So, for instance, I could seem extremely well calibrated by having 40,000 predictions that are “This coin, when flipped, will land heads with 50% certainty.” But that doesn’t mean I’m better than gwern at anything, really.
To be fair, Gwen has the same discretion about what he bets on at predictionbook. But of course, I was being tongue in cheek.
“4. Bitcoin will end the year higher than $1000: 70%”
That was a bad bet, even if you were very bullish on Bitcoin. The price reflects an expectation, but the distribution is extremely skewed.
You did well enough, but you suffer from Nate Silver disease; your individual predictions were right but you were significantly underconfident.
Significantly underconfidant?! Compared to who?
Compared to his own reported confidence ratings. Look at the scatter plot: every single prediction is at or above “perfect calibration”. That’s not actually more accurate than if everything were to a similar degree at or below confidence.
He is not statistically significantly underconfident.
1. What are you using “statistically significant” to mean here, precisely? That is a very slippery phrase.
2. Yes, by any reasonable definition of that term, he was. There is a strong and noticeable bias toward being less confident than his success rate warrants, and the bias is unidirectional.
Name 2 “reasonable definitions” of “statistically significant.”
Well, you could at very least specify a p value.
a parameterized definition is not slippery.
anyhow,
α=0.05 is always assumed. physicists think it’s stupid, but they use other words to indicate other values.See David’s comment about chi-squared above. Scott is off by less than we would expect him to randomly be off if he were predicting the results of flipping weighted coins whose weighting he knew.
You included here some stats for the Less Wrong Survey prediction. I am curious – did you ever post an analysis of the corresponding SSC survey somewhere? I *think* I’ve been reading everything you’ve written here since the SSC survey was posted, but I would probably have missed it if the stuff ended up on tumblr or something. A link, anyone?
Not yet. Now that I’ve posted the LW survey, that’s what I should work on next.
The original predictions are here, from 28 January. I wanted to know the date for the bitcoin prediction, because early January was a volatile time. (though not as volatile as the preceding month).
And, as a silly gotcha, I would date the ISIS revolt becoming “major” to Fallujah in early January, well before the predictions. I don’t think much has changed since then, though it may have been hard to tell that it was major until the government tried and failed to retake it.
Is the less wrong 2014 survey published yet? You reference it in this pair but I haven’t seen its results on the main site.
> 9. Iraq’s government will survive the year without large civil war/revolt: 60%
So losing 1/3 of the country to ISIL doesn’t count?
Odd: Livejournal seems to have stopped syndicating this blog, somehow.
When I look at http://slatestarcodex.livejournal.com/, I see the most recent post is “7:17am, 28th December 2014: Links 12/14: Auld Link Syne”.
I wonder if it’s a new year thing somehow?
“9. Iraq’s government will survive the year without large civil war/revolt: 60%”
That should be red
The romantic calibration of Scott is not so good.
This is, I find, and important point. That is to say, there are different domains, and even if you are generally good (or bad) at predictions, you can still suck at specific domains (or excell).
To say you’re generally good (or bad) at predicting might make you over- ( or under-) estimate how good you are at preditions in a specific domain.
Impressive indeed.
How about a prediction for whether or not someone alive today will still be alive 1000 years from now? (via cryonics or some other means)
I don’t think I’ve ever read your opinion of cryonics.
http://lesswrong.com/lw/jjd/rationalists_are_less_credulous_but_better_at/
Sorry, but the comments were locked on ‘UNTITLED’, and I had to say this: Thank you. It is simply the best essay I have ever read on the subject. I glanced at it when I was about to go to sleep, and it (and Radicalizing The Romanceless) kept me awake and reading for another hour. Also, specific thanks need to be given for making me aware of ‘Motte & Bailey’. I have needed a term for this for I don’t know how long. Thank you, thank you, thank you. I look forward to reading the fuck out of the rest of your blog.
Sorry, I’m a bit new to this community, but this list seems to indicate that you have multiple girlfriends.
Yep! Here is a relevant post.
Huh, neat.
So, you’re like autistic or something?
Did you by any chance find your way here from Instapundit?
I’d like to see error bars. If you get 8/10 of 75%-predictions correct, that’s well calibrated; if you get 800/1000 of 75%-predictions correct, that may be cause for recalibration.
You thought bitcoin would end the year at over $1000?
Why?
Do you actually believe in bitcoin as a form of currency or did you just think the bubble would last the year?
To me it seems almost beyond obvious that bitcoin is essentially structurally unsound, and that the marketing effort around it was somewhat a pyramid scheme. I was saying this right from the moment I first became aware of the bitcoin rise.
The reason that bitcoin is unsound is that it isn’t backed by any organization capable of exercising force. You know that goldbug argument that currency isn’t sound unless backed by gold or something tangible? Well, that’s not really a valid argument. It’s sufficient for a currency to be backed by a government with strong police forces who can credibly enforce the claim of “legal tender for all debts.” But bitcoin has neither the backing of the legal system nor any underlying tangible asset. All it has is artificial scarcity, a scarcity that is undermined by the ability of people to invent cryptocurrencies of their own.
“bitcoin has neither the backing of the legal system nor any underlying tangible asset. All it has is artificial scarcity, a scarcity that is undermined by the ability of people to invent cryptocurrencies of their own.”
That was exactly my thought when I first learned about bitcoin (well before the bubble), and why I didn’t buy any of it. Could someone explain to me why many intelligent people believe otherwise? Even if you are bullish on the idea of crypotocurrencies, why should bitcoin succeed rather than some hypothetical bitcoin 2.0?
You’re putting too much stock in the idea of a tangible asset. Now, you mentioned gold, so let’s take that as an example. Sure, you can do some interesting stuff with it — it’s a good conductor, it doesn’t corrode under normal circumstances, and it has some handy properties for metalworking. And it has a certain amount of intrinsic value in that way. But most of its value comes not from its physical properties but from the fact that people, due to a series of historical and physical coincidences, have implicitly agreed to use it as a store of value.
This actually undermines the goldbug argument — it means that gold is perfectly capable of crashing or becoming a vector for all sorts of other economic misbehavior, including a lot of government-driven misbehavior, as anyone who’s studied its history already knows. But it makes it a pretty good analogy to cryptocurrency, which has some interesting mathematical properties but which gets its actual value mostly by consensus.
What keeps Bitcoin’s value from being undermined by whatever altcoins someone decides to spin up? Roughly the thing that keeps gold’s value from dropping if someone decides to mint coins out of indium. It’s fundamentally just a Schelling point, with a dash of first-mover advantage.
(That being said, I didn’t buy a lot of Bitcoin.)
” 9. Iraq’s government will survive the year without large civil war/revolt: 60%”
Sorry, as with others above I’m pretty sure ISIS counts as the disproof of this one