
[Epistemic status: so, so, so speculative. I do not necessarily endorse taking any of the substances mentioned in this post.]
There’s been recent interest in “smart drugs” said to enhance learning and memory. For example, from the Washington Post:
When aficionados talk about nootropics, they usually refer to substances that have supposedly few side effects and low toxicity. Most often they mean piracetam, which Giurgea first synthesized in 1964 and which is approved for therapeutic use in dozens of countries for use in adults and the elderly. Not so in the United States, however, where officially it can be sold only for research purposes. Piracetam is well studied and is credited by its users with boosting their memory, sharpening their focus, heightening their immune system, even bettering their personalities.
Along with piracetam, a few other substances have been credited with these kinds of benefits, including some old friends:
“To my knowledge, nicotine is the most reliable cognitive enhancer that we currently have, bizarrely,” said Jennifer Rusted, professor of experimental psychology at Sussex University in Britain when we spoke. “The cognitive-enhancing effects of nicotine in a normal population are more robust than you get with any other agent. With Provigil, for instance, the evidence for cognitive benefits is nowhere near as strong as it is for nicotine.”
But why should there be smart drugs? Popular metaphors speak of drugs fitting into receptors like “a key into a lock” to “flip a switch”. But why should there be a locked switch in the brain to shift from THINK WORSE to THINK BETTER? Why not just always stay on the THINK BETTER side? Wouldn’t we expect some kind of tradeoff?
Piracetam and nicotine have something in common: both activate the brain’s acetylcholine system. So do three of the most successful Alzheimers drugs: donepezil, rivastigmine, and galantamine. What is acetylcholine and why does activating it improve memory and cognition?
Acetylcholine is many things to many people. If you’re a doctor, you might use neostigmine, an acetylcholinesterase inhibitor, to treat the muscle disease myasthenia gravis. If you’re a terrorist, you might use sarin nerve gas, a more dramatic acetylcholinesterase inhibitor, to bomb subways. If you’re an Amazonian tribesman, you might use curare, an acetylcholine receptor antagonist, on your blowdarts. If you’re a plastic surgeon, you might use Botox, an acetylcholine release preventer, to clear up wrinkles. If you’re a spider, you might use latrotoxin, another acetylcholine release preventer, to kill your victims – and then be killed in turn by neonictinoid insecticides, which are acetylcholine agonists. Truly this molecule has something for everybody – though gruesomely killing things remains its comparative advantage.
But to a computational neuroscientist, acetylcholine is:
…a neuromodulator [that] encodes changes in the precision of (certainty about) prediction errors in sensory cortical hierarchies. Each level of a processing hierarchy sends predictions to the level below, which reciprocate bottom-up signals. These signals are prediction errors that report discrepancies between top-down predictions and representations at each level. This recurrent message passing continues until prediction errors are minimised throughout the hierarchy. The ensuing Bayes optimal perception rests on optimising precision at each level of the hierarchy that is commensurate with the environmental statistics they represent. Put simply, to infer the causes of sensory input, the brain has to recognise when sensory information is noisy or uncertain and down-weight it suitably in relation to top-down predictions.
…is it too late to opt for the gruesome death? It is? Fine. God help us, let’s try to understand Friston again.
In the predictive coding model, perception (maybe also everything else?) is a balance between top-down processes that determine what you should be expecting to see, and bottom-up processes that determine what you’re actually seeing. This is faster than just determining what you’re actually seeing without reference to top-down processes, because sensation is noisy and if you don’t have some boxes to categorize things in then it takes forever to figure out what’s actually going on. In this model, acetylcholine is a neuromodulator that indicates increased sensory precision – ie a bias towards expecting sensation to be signal rather than noise – ie a bias towards trusting bottom-up evidence rather than top-down expectations.
In the study linked above, Friston and collaborators connect their experimental subjects to EEG monitors and ask them to listen to music. The “music” is the same note repeated again and again at regular intervals in a perfectly predictable way. Then at some random point, it unexpectedly shifts to a different note. The point is to get their top-down systems confidently predicting a certain stimulus (the original note repeated again for the umpteenth time) and then surprise them with a different stimulus, and measure the EEG readings to see how their brain reacts. Then they do this again and again to see how the subjects eventually learn. Half the subjects have just taken galantamine, a drug that increases acetylcholine levels; the other half get placebo.
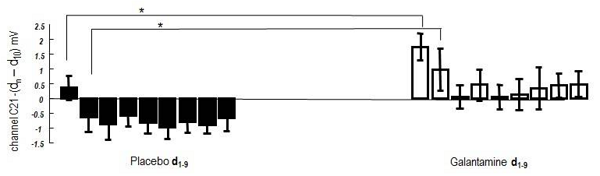
I don’t understand a lot of the figures in this paper, but I think I understand this one. It’s saying that on the first surprising note, placebo subjects’ brains got a bit more electrical activity [than on the predictable notes], but galantamine subjects’ brains got much more electrical activity. This fits the prediction of the theory. The placebo subjects have low sensory precision – they’re in their usual state of ambivalence about whether sensation is signal or noise. Hearing an unexpected stimulus is a little bit surprising, but not completely surprising – it might just be a mistake, or it might just not matter. The galantamine subjects’ brains are on alert to expect sensation to be very accurate and very important. When they hear the surprising note, their brains are very surprised and immediately reevaluate the whole paradigm.
One might expect that the very high activity on the first discordant note would be matched with lower activity on subsequent notes; the brain has now fully internalized the new prediction (ie is expecting the new note) and can’t be surprised by it anymore. As best I can tell, this study doesn’t really show that. A very similar study by some of the same researchers does. In this one, subjects on either galantamine or a placebo have to look at a dot as quickly as possible after it appears. There are some arrows that might or might not point in the direction where the dot will appear; over the course of the experiment, the accuracy of these arrows changes. The researchers measured how quickly, when the meaning of the arrows changed, the subjects shifted from the old paradigm to the new paradigm. Galantamine enhanced the speed of this change a little, though it was all very noisy. Lower-weight subjects had a more dramatic change, suggesting an effective dose-dependent response (ie the more you weigh, the less effect a constant-weight dose of galantamine will have on your body). They conclude:
This interpretation of cholinergic action in the brain is also in accord with the assumption of previous theoretical notions posing that ACh controls the speed of the memory update (i.e., the learning rate)
“Learning rate” is a technical term often used in machine learning, and I got a friend who is studying the field to explain it to me (all mistakes here are mine, not hers). Suppose that you have a neural net trying to classify cats vs. dogs. It’s already pretty well-trained, but it still makes some mistakes. Maybe it’s never seen a Chihuahua before and doesn’t know dogs can get that small, so it thinks “cat”. A good neural network will learn from that mistake, but the amount it learns will depend on a parameter called learning rate:
If learning rate is 0, it will learn nothing. The weights won’t change, and the next time it sees a Chihuahua it will make the exact same mistake.
If learning rate is very high, it will overfit. It will change everything to maximize the likelihood of getting that one picture of a Chihuahua right the next time, even if this requires erasing everything it has learned before, or dropping all “common sense” notions of dog and cat. It is now a “that one picture of a Chihuahua vs. everything else” classifier.
If learning rate is a little on the low side, the model will be very slow to learn, though it will eventually converge on a good understanding of its topic.
If learning rate is a little on the high side, the model will learn very quickly, but “jump around” between different understandings heavily weighted toward what best fits the last case it has worked on.
On many problems, it’s a good idea to start with a high learning rate in order to get a basic idea what’s going on first, then gradually lower it so you can make smaller jumps through the area near the right answer without overshooting.
Learning rates are sort of like sensory precision and bottom-up vs. top-down weights, in that as a high learning rate says to discount prior probabilities and weight the evidence of the current case more strongly. A higher learning rate would be appropriate in a signal-rich environment, and a lower rate appropriate in a noise-rich environment.
If acetylcholine helps set the learning rate in the brain, would it make sense that cholinergic substances are cognitive enhancers / “study drugs”?
You would need to cross a sort of metaphorical divide between a very mechanical and simple sense of “learning” and the kind of learning you do where you study for your final exam on US History. What would it mean to be telling your brain that your US History textbook is “a signal-rich environment” or that it should be weighting its bottom-up evidence of what the textbook says higher than its top-down priors?
Going way beyond the research into total speculation, we could imagine the brain having some high-level intuitive holistic sense of US history. Each new piece of data you receive could either be accepted as a relevant change to that, or rejected as “noise” in the sense of not worth updating upon. If you hear that the Battle of Cedar Creek took place on October 19, 1864 and was a significant event in the Shenandoah Valley theater of the Civil War, then – if you’re like most people – it will have no impact at all on anything beyond (maybe, if you’re lucky) being able to parrot back that exact statement. If you learn that the battle took place in 2011 and was part of a Finnish invasion of the US, that changes a lot and is pretty surprising and would radically alter your holistic intuitive sense of what history is like.
Thinking of it this way, I can imagine these study drugs helping the exact date of the Battle of Cedar Creek seem a little bit more like signal, and so have it make a little bit more of a dent in your understanding of history. I’m still not sure how significant this is, because the exact date of the battle isn’t surprising to me in any way, and I don’t know what I would update based on hearing it. But then again, these drugs have really subtle effects, so maybe not being able to give a great account of how they work is natural.
And what about the tradeoff? Is there one?
One possibility is no. The idea of signal-rich vs. signal-poor environments is useful if you’re trying to distinguish whether a certain pattern of blotches is a camoflauged tiger. Maybe it’s not so useful for studying US History. Thinking of Civil War factoids as anything less than maximally-signal-bearing might just be a mismatch of evolution to the modern environment, the same way as liking sweets more than vegetables.
Another possibility is that if you take study drugs in order to learn the date of the Battle of Cedar Creek, you are subtly altering your holistic intuitive knowledge of American history in a disruptive way. You’re shifting everything a little bit more towards a paradigm where the Battle of Cedar Creek was unusually important. Maybe the people who took piracetam to help them study ten years ago are the same people who go around now talking about how the Civil War explains every part of modern American politics, and the 2016 election was just the Confederacy getting revenge on the Union, and how the latest budget bill is just a replay of the Missouri Compromise.
And another possibility is that you’re learning things in a rote, robotic way. You can faithfully recite that the Battle of Cedar Creek took place on October 19, 1864, but you’re less good at getting it to hang together with anything else into a coherent picture of what the Civil War was really like. I’m not sure if this makes sense in the context of the learning rate metaphor we’re using, but it fits the anecdotal reports of some of the people who use Adderall – which has some cholinergic effects in addition to its more traditional catecholaminergic ones.
Or it might be weirder than this. Remember the aberrant salience model of psychosis, and schizophrenic Peter Chadwick talking about how one day he saw the street “New King Road” and decided that it meant Armageddon was approaching, since Jesus was the new king coming to replace the old powers of the earth? Is it too much of a stretch to say this is what happens when your learning rate is much too high, kind of like the neural network that changes everything to explain one photo of a Chihuahua? Is this why nicotine has weird effects on schizophrenia? Maybe higher learning rates can promote psychotic thinking – not necessarily dramatically, just make things get a little weird.
Having ventured this far into Speculation-Land, let’s retreat a little. Noradrenergic and Cholinergic Moduation of Belief Updating does some more studies and fails to find any evidence that scopolamine, a cholinergic drug, alters learning rate (but why would they use scopolamine, which acts on muscarinic acetylcholine receptors, when every drug suspected to improve memory act on nicotinic ones?). Also, nicotine seems to help schizophrenia, not worsen it, which is the opposite of the last point above. Also, everything above about acetylcholine sounds kind of like my impression of where dopamine fits in this model, especially in terms of it standing for the precision of incoming data. This suggests I don’t understand the model well enough for everything not to just blend together to me. All that my usual sources will tell me is that the acetylcholine system modulates the dopamine system.
(remember, neuroscience madlibs is “________ modulates __________”, and no matter what words you use the sentence is always true.)
















This seems highly plausible to me. Sitting down and learning something from a book is not at all like anything that happened in the ancestral environment. It’s surprising that it’s possible at all. I’m going to guess that since the invention of writing there’s been strong evolutionary pressure for literacy, but even so I doubt that our brains are anywhere close to optimal for absorbing information from text.
This seems to come up whenever a learning technique is shown to be effective: somebody will suggest that it is facilitating a shallow form of learning. I’m skeptical, because this never seems to be cashed out empirically and my own experience suggests that a detailed knowledge of the underlying facts is very helpful to gaining a deep understanding of a topic.
I don’t think reading is totally alien to a hunter-gatherer’s brain, since they learn from their elders telling them things. I think our difficulties with reading come from earlier ancestors who didn’t talk. I also don’t think there’s been recent evolution for literacy; if there were, I’d expect people of Middle Eastern descent to be better at it than, for example, northern Europeans.
Yeah, reading produces an (inner) voice that tells you a story, which I imagine is how we spent a huge portion of the ancestral lives around the campfires.
Not everyone has an inner voice (the same way not everyone has a “mind’s eye”), and lacking it doesn’t prevent them from reading.
See Guessing the Teacher’s Password, and contrast with Truly Part Of You.
I think the real distinction between history books and the ancestral environment is the reliability of the data. When you encounter a new piece of information you typically don’t 100% believe it and update all of your models under the assumption that this is the word of God, you take it into account and assimilate it with other information and beliefs that you already had. Too high of a learning rate means someone is gullible and believes everything they hear. There are false statements purporting themselves as facts all the time, so a skeptical mind is adaptive even in the modern environment. The new thing is that there are certain books which we can verify are abnormally trustworthy, but perhaps our brains aren’t wired to internalize them in proportion to how much they ought to be trusted.
I’m just speculating here though, and I know a lot less about this than actual neuroscientists would. Are there any experiments that tests whether people oncognitive enhancers are more gullible or more likely to internalize false statements? If you give them a history book filled with false or biased statements, will they “learn” wrong things from it and have it totally screw them up long-term worse than it would a person on placebo? That second question is probably incredibly unethical to test, but you could do a simple test involving unimportant facts like the details of a scene.
So, kind-of like simulated annealing?
Precisely. That exact term has been used by researchers who dealt with Artificial Neural Networks for decades.
With simulated annealing the *overall* learning rate does gradually lower over time, but that’s true of other simpler heuristics. The distinguishing characteristic of simulated annealing is that the learning rate doesn’t decrease monotonically, but sometimes kicks up at random (according to a pre-selected probability distribution).
Thinking in metaphorical terms of hill-climbing, a problem with a monotonically decreasing learning rate is that at some point the rate gets low enough that the climber will never hike far enough to leave her current hill and find a taller one. She might reach the top of her current hill and then clime part way down, but when she starts walking on the next try she’ll turn around and head up the same hill. With simulated annealing she will occasionally walk farther, and very occasionally walk significantly farther, which could lead her to a more promising hill.
> Going way beyond the research into total speculation, we could imagine the brain having some high-level intuitive holistic sense of US history. Each new piece of data you receive could either be accepted as a relevant change to that, or rejected as “noise” in the sense of not worth updating upon.
Often our measures for the performance of smart drugs focus entirely on the details (e.g. memorizing strings of random numbers). Are there any tests for how the ‘holistic sense’ progresses? In my experience, much of academics valued careful attention to details, and would plausibly be significantly improved by a higher learning rate. Some practical jobs rely a lot on intuition and a holistic view, so those might not be improved by acetylcholine enhancers. However, it’s not totally clear to me that such drugs would really skew or bias the holistic picture away from truth enough to be detrimental.
Yes, there is a prominent model of learning which proposes that changes in acetylcholine drive changes in the relative strength of “encoding” and “retrieval” in the hippocampus. It is thought that the alternation between the “encode” mode (externally biased) and “retrieve” mode (internally biased) is critical for integrating new information with our brain’s internal models.
The process of switching between internal and external modes also occurs more generally throughout the cerebral cortex on very fast timescales (less than a second) up to rather slow timescales (hours). This widespread switching may also drive learning, and is regulated by acetylcholine, among other control signals.
Finally, for those who are interested in hierarchical predictive coding models, there is evidence that acetylcholine supports visual sequence learning in the early visual cortical pathway . It seems that a local cortical circuit (a patch of V1) can become sensitive to the regularity in which visual items A, B, C, D follow in sequence. This process is acetylcholine-dependent. But the changes in neuronal responses over the course of learning are not consistent with predictive coding models.
Can you elaborate on that last sentence?
From the article: “Our findings are consistent with the hierarchical predictive coding hypothesis derived from studies in humans, which posits that the architecture of the cortex implements a prediction algorithm that anticipates incoming sensory stimuli, although they diverge from predictive coding models that assume NMDA receptor–mediated plasticity and predict that novel stimuli will drive larger responses than anticipated familiar stimuli.”
Gavornik & Bear found that the visual stimulus sequence produced a larger response after learning than before learning. The response to the learned sequence is also larger than the response to the same stimuli presented in a random, unpredictable order. This effect is the opposite of what should happen if error signals (deviations from what is predicted / expected) are the primary message that is sent from V1 to higher visual regions.
The response I’ve seen from the PP side to findings like this is that correct prediction reduces early cortical activity, but attention increases it, so whenever you see elevated early cortical response to more predictable stimuli it’s because the stimulus source (right or left hemifield, in the linked study) is attended to more closely, because it’s assumed to be more reliable/task-relevant. And it’s intuitive that in some cases you’ll pay more attention to stimuli you’re more familiar with, because you can make more sense of them — for example, you’ll pay more attention to an overheard English conversation than a conversation in an unfamiliar language. But yeah, this attention-as-precision-weighting component of PP allows for both possibilities and I’m not sure if there is anything like a principled account of when to expect the effects of prediction or attention to prevail.
There is an extensive and growing literature on the destructive cognitive effects of both prescription and OTC drugs that have anticholinergic effects in the elderly, even when those effects aren’t the primary purpose of the drug. See https://www.ncbi.nlm.nih.gov/pubmed/8369593 for an overview. I suppose nerve agents would be at the other end of the continuum of cholinergic tweaking, and some of the drugs that have mild acetylcholinesterase activities, like Physostigmine.
I quit smoking in 1979 at the request of my mother who was being treated for breast cancer. I was a substance abuse therapist at the time and every one of my clients was a smoker. I would find myself watching the smoke from the cigarettes drift toward the ceiling and realize I hadn’t heard anything in some time of what they were saying. While I recovered some of my attentional focus over the six weeks after cessation, my attention has never been what it was while I was smoking. So I can vouch for the nicotinic effects.
You probably meant learning rate as 1. A learning rate of infinity would turn all the weights into plus or minus infinity, ending up with a person half brain-dead at the same time they are having the mother of all seizures.
I also feel like the learning rate of NNs might not be the best hyperparameter for the analogy. It doesn’t really control how fast a network learns (even though higher values usually accelerate learning). A less misleading name is step-size, as it controls how far you move in the direction of the gradient. A learning rate of 1 would only maximise the chance of classifying your chihuahua correctly if the gradient is constant in that direction (as in the case where the loss surface is a plane).
We have to remember that gradient descent is — ironically — a hill climbing algorithm. We can only see the shape of the surface immediately around us. The learning rate is kept low because the bottom of the valley is almost surely not where it looks like from where you currently are. So it is not about the signal to noise ratio, but how smooth the loss surface is.
Learning rate can be bigger than one, though you are correct that “learning rate is infinity” is a little extreme. A better way of putting it would be “as the learning rate approaches infinity”.
When using simple gradient descent, weight updates follow the formula:
new_weights = old_weights – learning_rate * gradient
So while nothing physically stops you from using numbers bigger than one, I have never come across a case where that was done. The learning rate is usually set to very low values, as higher numbers (but still less than 1) almost certainly cause instability issues and impede convergence.
When using infinite learning rate (is there any difference between saying “infinite” and “as it approaches infinity”?) the new weights will depend only the sign of the old ones, and take arbitrarily large values (positive and negative). This would lead to the case where neurons would either be completely inert or firing like crazy regardless of input, leading to my epileptic zombie.
If Scott wanted a super overfit classifier he would need to use a small enough learning rate to achieve convergence, but do many successive updates on minimising the error of classifying that example. So the important part is not the magnitude of the LR but how many iterations are done.
Came down to the comments wanting to make this point. Learning rate is about how large the changes in weights are, not how well the current inputs get memorized.
I do think Izaak is correct that (in simple gradient descent) there’s nothing special about a learning rate of 1, though. Suppose the loss function is L(θ) = C · (θ – θ*)², where θ is the current weights and θ* is the optimum. Then you can derive that the optimal learning rate (that will get you to θ* in one update) is 1/(2C). So to construct a scenario where you want a learning rate of 100, just set C = 0.005 🙂
I’m not an expert in these things, but I’d guess learning rate = 1 means recent observations are weighed the same amount as earlier ones (i.e. observing A and then B results in the same posterior as observing B and then A — i.e. what would be correct Bayesian updating if you were sure all the relevant underlying mechanisms aren’t changing with time).
You typically use the same LR for all samples (or batches), so in that sense, every observation counts the same. You could imagine an LR that decreases as 1/i for sample i, but I don’t think it is the right intuition.
NN learning is gradient descent in a landscape with complex curvature, so learning isn’t symmetric. If you are on the top of a hill and A makes you take a step to the left, the gradient in your new position would be different, so the step caused by observation B will be in a different direction than if the steps were taken in the opposite order.
I used to work with a QA engineer who once worked at a company where many of the workers were using speed. This had some weird consequences. Workers on speed can really crank it out, but sometimes they go off on some weird tangent but don’t realize what they are cranking out is dogshit.
I suggested that perhaps the way to deal with this would be to have small groups of workers on speed with a supervisor who is not on it, which means they could tell when their subordinates get loopy and punch the reset button.
But no one ever listens to my brilliant ideas. 🙁
1: Bad news johan, your work has declined greatly in quality, this means punishment.
JL: You don’t mean? NOOOOO!
1: That’s right, we are promoting you to manager.
JL: You can’t do that to me! Papa needs his medicine!
This is very similar to the concept of ‘focus’ in A Deepness in the sky. ‘Focused’ workers can get stuck in a loop, or lost in a tangent and need to be monitored and ‘adjusted’ by supervisors. (Great book)
I know taking nicotine is generally a terrible idea, but this analysis does give a whole new meaning to a “three pipe problem.” Maybe Sherlock did the right thing to help him pay attention to clues that may otherwise seem like noise? Doesn’t explain the cocaine though…
Time to plow additional research dollars into the ever popular “Is vaping safe?” debate!
Is nicotine gum safe?
Holmes used the cocaine when he was _bored_, not when he was on a case.
How do you “know taking nicotine is generally a terrible idea”?
Using tobacco is a terrible idea. So insofar as nicotine addicts one to tobacco use, nicotine is pretty destructive to health. But this isn’t 1990 anymore. There are now plenty of ways to consume nicotine without tobacco consumption, including patches, gums, and vaping.
So, what about nicotine itself? It might have some negative cardiovascular effects in people who already have cardiovascular disease, but it might not. It might have some tumor-promoting effects, it might not. The known benefits to weight loss (suppressing appetite, raising metabolism) might very well make it a net benefit to health in the general population even if it does have the suspected cardiovascular and tumor-promoting effects.
So nicotine boosts cognitive abilities
Smoking rates climbed in the 20th century
IQ climbed in the 20th century
Smoking has been in decline
IQ gains have slowed or started reversing
This also suggests that the new fangled vaping thing is young people going “Nicotine helps me be competitive, but tobacco will kill me.” I doubt they’re quite so intentional about it, but positive reinforcement is a powerful motivator.
I was quite so intentional about it. I started vaping because Gwern’s blog said so
Yes, but I figure people on here and otherwise involved in the rationalism community are probably a standard deviation outside the norm.
Point of order: I’ve never recommended nor used vaping. I think the establishment has been extremely hysterical about it and manufactured a lot of cruddy excuses & studies to justify a moral panic for regulating it as identical to tobacco, but I am still somewhat doubtful of how safe it is and think that patches/gum are probably more instrumentally useful anyway.
It’s at least plausible. Nicotine has two main problems — the delivery system has all sorts of side effects, and it’s addictive as hell. We’ve mostly licked the former (vaping and/or patches), but that addiction issue still makes it a poor nootropic; I don’t want to become a slave to a drug for a few IQ points.
Except it’s been proven that Nicotine is not as addicting as cigarette smoking. So most thought about nicotine addiction is actually incorrect.
But has it really? I’m not trying to be confrontational here, I’m genuinely curious. This is not the first time I have seen people claiming this, but googling it just gives me results about nicotine actually being highly addictive.
Now it might be because I’m failing at getting results that are about nicotine isolated from tobacco, but I don’t have the energy to go too much further and I’ll just be lazy and rely on my priors for now.
A largish set of people seem to have taken up vaping. It would be interesting to ask them whether they’ve found it hard to stop.
I will say: I don’t find nicotine to be addictive. The physical habits associated with smoking are far more addictive (for me) than the nicotine itself. (My evidence for this claim is that I’ve done 0 nicotine vaping for long periods with no noticeable decrease in the amount of vaping)
@woah77 – the situational aspect of almost addiction tends to be much stronger than so-called “physical” effects. So far as I know this is just as true for heroin as it is for smoking as it is for gambling.
@Enkidum – Do you mean by this that the act of vaping is a more strong addiction than the chemical dependency?
woah – basically yes, and this is true of addiction in general.
Longer answer: it’s not necessarily the “act of vaping” alone so much as the entire context surrounding it, the small rituals you go through when you take your vape out of the drawer where you keep it, the friends you do it with, the way you check your phone with your right hand while you vape with your left – the whole process from thinking “I need a vape” to coming back inside after having done it. Whatever is constant about the multiple experiences of doing the drug (or whatever you’re addicted to) is one of the strongest components of any addiction.
Scott’s written a bit about this in the past (something something rat hotel) although I think he was a bit more skeptical about it. Also I am not a medical doctor and not an addiction specialist, so take everything I’m saying with a very large grain of salt.
“Not as addicting” ≠”not addicting”.
I recently tried nicotine patches (NicoDerm), as a nootropic. Hadn’t noticed any benefit after several weeks, so I stopped. Didn’t notice any withdrawal effects either. I suppose it’s possible I just didn’t use a high enough dose—I’ve never smoked, so I limited myself to 7mg per day.
I once chewed nicotine gum after having never been a smoker and I felt so sick after I wanted to die.
Part of that very well could be because you aren’t supposed to chew it, except briefly. Chew for a few seconds, then you lip it between your gum and lower lip like dip and let it sit there. Chewing constantly is going to release a lot of nicotine faster than intended (and you’ll swallow it rather than it entering your bloodstream through the gums).
Most likely the dose was too high. Even the lowest “level” (the one you are supposed to take just before quitting) is far more than a never-smoker should be taking.
Indeed, this seems so obvious that I’d expect some researcher in the area to have checked on it already, e.g. by trying to look at IQ data for known-all-smoker or known-all-nonsmoker populations over time (though of course mix shifts with changes in smoking rate would create confounding effects there). Anyone know whether it’s been done, and if not, why not?
It’s nonsense and I would guess Baconbits9 is at least a little bit tongue in cheek.
The Flynn effect shows in little children. Not many smokers there.
Nicotine doesn’t raise IQ, it just helps with focus. Same with other nootropics, afaik.
In adults (for example conscript data) the Flynn effect parallels height increase and brain size increase. It would be weird if the causes weren’t mostly the same.
The peak in smoking was decades earlier than the IQ peak.
In an interesting coincidence, this study was published today: Faster, but not smarter: An experimental analysis of the relationship between mental speed and mental abilities
Faster is just because smokers need to get outside for a cigarette.
Perhaps dopamine encodes relevance, acetylcholine encode reliability? Learning rate is something like the product of both?
I know that in reinforcement learning in complex environments (such as RTS games, Doda, etc.), encoding ‘attention’ is an area of study. Basically, which raw pixels do you pass into the neural net for more complex and computationally intensive processing? Dopamine could be analogous to that. But only more complex models need / benefit from such a term. Whereas every learning system must have a learning rate. Would be interesting if dopamine were only found in more complex animals but acetylcholine were present even in proto brain, jellyfish CNS type structures.
Why shouldn’t there be smart drugs? Some people are smarter than others. People are smarter at some times than others.
Presumably this is based in physical changes. It might be surprising that drugs can make those physical changes, but it doesn’t seem extremely surprising.
Caffeine and intelligence— I’m not sure whether they tested the effect of caffeine on people who were short on sleep.
My understanding of the argument is essentially:
Humans have an evolutionary pressure towards being smarter. (and have for a long time)
Evolution is good at doing small changes to increase fitness.
Therefore there is no small change that will increase intelligence.
It’s like, there might be plenty of small changes that would affect the brain in ways we might consider positive from a certain point of view, but they’d need to have tradeoffs that are bad from the point of view of evolution tinkering with the DNA of Stone Age hunter-gatherers in the ancestral environment.
So if we’re talking about just boosting the amounts of a chemical in the blood that (and this is important) we already have in there, or increasing the sensitivity of a receptor we already have, or doing something more complicated like blocking the production of a different chemical that acts as an antagonists to the chemical in question…
If it’s going to provide us with benefits, there would have to be something we could recognize as a tradeoff. Say, increased risk of having a stroke. Or it enhances one aspect of cognition while making us bad at others- the stereotypical tradeoff being, say, increased overall learning ability but decreased social intelligence; that would be a pretty good way to ensure your genes don’t get passed on.
This argument proves too much.
Humans have an evolutionary pressure towards resisting infections, and have for a long time.
Evolution is good at doing small changes to increase fitness.
Therefore there is no small change that will increase resistance to infections. (Hence, neither vaccines nor antibiotics can exist.)
Vaccines activate the defences we have evolved, by introducing us to pathogens we haven’t previously met. I don’t think there is an easy evolutionary pathway towards searching out new pathogens and making sure you get a measured inoculation.
Antibiotics are a better example, but the case can be made that if we started secreting penicillin, it wouldn’t be many human generations before pathogens adapted. What if we only secreted it in vulnerable parts of the body so as not to encourage bacterial immunity? Well, as I understand it, there *are* in fact anti-microbial compounds in tears. Maybe the body risks the odd face infection to avoid eye infections…
Our bodies have tons of antibacterial defenses all over the place[1]. Anything living that can’t resist passing bacteria gets turned into a giant microbial all-you-can-eat buffet. But we still can benefit from borrowing antibacterials from other organisms, or making our own. This is true, even though resisting bacterial infections is something we’ve been selected for more-or-less forever.
Similarly, vaccines let us expose ourselves to dangerous pathogens without getting sick, and then develop an immunity to them. If we could do something as helpful for thinking as vaccines are for avoiding getting sick, that would be a huge win.
These both contradict the idea that we can’t possibly develop medicines that improve on something (resistance to infection, intelligence) that has been selected for.
[1] Notably, there’s complement and PRRs on various immune system cells–both evolved to react to patterns that commonly occur on the outside of bacteria and kill them ASAP.
My point was more related to the idea that serious trade-offs are to be expected in most cases of trying to improve the working body (or mind). Vaccines may be a counterexample, and so are writing and other data storage technologies. But these are things that aren’t close to our local evolution-driven genetic maxima.
Of course it is indeed conceivable that there are drugs or other treatments for which the same applies.
> This argument proves too much.
Humans have an evolutionary pressure to become physically stronger and faster, for a long time.
Therefore there is no drugs that enhance speed or strength.
So I agree the reductio-ad-evolutionem doesn’t quite hold water when it comes to IQ either.
Therefore, there are no drugs that enhance speed or strength that don’t also carry disadvantageous/risky side-effects.
I suspect the real answer is more like there are no drugs that make you faster/stronger/smarter whose effects evolution could reach. That is:
a. Maybe it’s something evolution couldn’t do, like look through millions of organisms to find their antibacterial mechanisms, and then start synthesizing antibacterial molecules based on the most effective of those mechanisms.
b. Maybe it’s a tradeoff that makes sense now, but didn’t back then–for example, making you bigger and stronger also makes you need to eat more. That’s not a problem here and now, but it would have been a big problem for most of our ancestors. (The tradeoffs we care about now are pretty different–there probably wasn’t a lot of selection removing things that elevated your prostate cancer risk in your 60s, given how many people died earlier than that.)
c. Maybe it’s a place where evolution got stuck at a local maximum and couldn’t find a way out, but we can.
My guess is that this is sort of what it is.
I think the issue most people have with say, studying for a history exam, is that they really just don’t care about the material. They don’t see it as interesting, important, or noteworthy in any particular way. They care about it only to the extent that it helps them pass this course, knowing full well that they will never need (or even want) to recall the information again after the exam. I imagine this places a significant mental barrier towards effective learning.
As such, I think the brain sees these sort of factoids as essentially noise, with someone deliberately having to make great conscious efforts (perhaps by writing facts down on note cards, reviewing them, etc.) to try and temporarily treat it as signal.
But if a drug can help you treat any new information as signal, that might be useful in a situation like this. It’s not that the drug is actually improving your memory, it’s just, say, altering your perspective such that new information simply feels more interesting/significant/important. Perhaps the drug helps you block out the unconscious part of your brain that is constantly telling you “This is stupid and unimportant and I don’t really want to be doing it” and instead treat the information as genuinely worth knowing.
So the drug is, in effect, a form of artificial canned conscientiousness, as opposed to artificial canned intelligence-enhancement?
I wonder if we could find a way to measure conscientiousness before and after taking some of these drugs.
I don’t know if conscientiousness is quite how I’d put it, but I think that’s generally what I’m saying, yeah.
That what the drug does is make you more open to the possibility that new information is signal and not noise. And the rest is all basically “on your own.”
I’ve never struggled to learn information that I was intrinsically motivated to learn about because I genuinely wanted to know it. I suspect that even in a low-IQ crowd, that individuals have an easier time learning about things that interest them than they do learning about things that don’t interest them. A drug that makes everything you encounter seem more interesting would therefore also enhance learning ability. There might be drawbacks to that as well, depending on the time and manner of use (sometimes, noise really is noise, and you’re better off ignoring it).
I wonder how this relates to hallucinogens whose effects seem also to radically increase the salience of a wider range of things. LSD et al are serotonergic and glutaminergic, right? An interesting question about what kind of learning hallucinogens enable — definitely some kind of big model updating, but not in the conventional learning sense.
Regarding a way to measure conscientiousness: In one of his lectures on personality psychology, JB Peterson talks about how he and his lab have tried for a long time to come up with some sort of behavioural/lab test that reliably measures conscientiousness, without success. Doesn’t seem to be easy.
On a scale of 1 to 10, how painful do you find this series of images?
Interesting! Makes me wonder which other big-5 personality trait modifying drugs exist? MDMA to increase Openness? Cannabis for Agreeableness? Valium to reduce neuroticism?
Psilocybin famously has the potential to increase openness over significant timeframes. IIRC, it was (one of) the first times major (long-term) changes in any Big 5 trait was observed in adults.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3537171/
Though I’m not sure how helpful it is to frame temporary drug-induced changes in behaviour related to big 5 traits as “modifying” these traits. Would you say someone is suddenly lower in trait neuroticism if she happens to feel calm, optimistic and confident today, e.g. because of some positive reinforcement experiences earlier, or just randomly?
A curiousity enhancer
Along with learning, this raises interesting questions on how we process and react to music — e.g. the expected tone vs. the unexpected tone.
I also wonder how the chemical reactions discussed here might relate to time of day — I feel sharp and receptive at certain times and duller or more mechanical at others. Learning rate might peak for different people at different times
The nicotine thing shouldn’t be surprising, but back when I used to smoke a few cigarettes a day it was to help clear my mind rather than focus it.
What’s the difference? Less noise = (relatively) more signal, right?
Good point — though while clearing out the noise I was also studiously avoiding any new signals, for the moment at least.
I wonder how this noise-vs.-signal processing might relate to various meditation techniques. (Which I know nothing about although I’m an expert daydreamer)
I have to agree that while I’m consuming nicotine, I’m also typically trying to avoid lots of stimulus. It’s like putting a factory reset or a local calibration on what I’m experiencing.
Do you think this might be incidental? Did you have to get up and go outside/elsewhere to smoke? In that case, or similar ones, it would be a good excuse/opportunity to do the equivalent of pausing work or whatever you’re doing and just taking some deep breaths for a couple of minutes, independent from any other neuropharmacological effects of nicotine.
(Though as nicotine reinforces pretty much everything you’re doing at the time, that “taking a break” habit would be strengthened by the smoking)
Sounds like we may need a battery of distinct nootropics for different phases of the learning and/or creative process. Optimize for high “learning rate” early on, then ramp down and perhaps deliberately suppress in the final stages, on the theory that the neurotypical baseline is optimized for the midgame and needs tweaking at both ends?
But, notwithstanding the occasional successes in medicalizing weapons, I think the IRB will cause no end of headaches when we try to figure out where Sarin and VX fit into this spectrum. And for once, “You know who else experimented with nerve gas on human subjects?” will be absolutely correct and appropriate.
Still, I can easily imagine Sherlock Holmes 2050 noting a particularly difficult problem and self-diagnosing three nicotine patches, one-half dram of the seven percent solution, and ten micrograms of Novichok, in the proper order and schedule. Non-fictional superior intellects might want to find safer alternatives.
Wikipedia informs me we’ve already done tests using Sarin. It doesn’t seem like a promising nootropic
As someone who works on very, very related stuff, and who collaborates with people who specifically work on nicotinic receptors in learning studies, I’d just like to say that everything in this article up to the history metaphor part is a very good and concise layman’s explanation of some of what’s going on in the field. You’re doing a service here, Scott.
Also, I don’t mean to diss the metaphor, I just haven’t had enough drugs this morning and I haven’t finished thinking about how much it fits my understanding of the issues. There’s some hand-wavy problems I had when I read it but I don’t have the energy to work them out in detail at the moment.
Learning rate works very much as Scott described – you could think of it as a parameter determining how much you would allow evidence to alter your beliefs. When learning rate is high, you can radically re-alter your understanding of the world at the drop of a hat. When it’s low, it takes a hell of a lot to alter anything in the system.
In many (most?) computational studies, learning rate is a constant – you set it at the start of the training period, the model learns some stuff, and then at some point you define learning as finished, and you have a final model. However there is work being done on models that flexibly update their learning rate in response to their history, and I think these are the models that will really have the most to say about how humans (and other animals) actually learn. So you don’t have a “training period” and a “testing period” – you just have a model that continually changes, but it can alter the amount it’s willing to change at any time.
(Caveat: I am not a computational guy, and kind of not really a neuroscientist either but it’s complicated)
That may be true for machine learning studies, but if so it seems like a curious oversight. When using e.g. simulated annealing for single-problem optimization, it is both standard and necessary to dial down the rate as you converge on a solution.
>That may be true for machine learning studies
I don’t think so. Working in the industry, tweaking the learning rate is what they teach you in Machine Learning 101, it’s one of the most standard hyperparameters to tune. It’d be extremely surprising if they wouldn’t do it in studies.
Tuning the learning rate based on repeated partial training runs is distinct from adjusting the rate within a run. It is in fact fairly common at the contemporary “101” (in, say, the more recent Ng Coursera courses) to choose a learning rate based on trails and assessing performance on the tuning data and then using a single learning rate for the whole run.
The two main potential advantages of an adjusted learning rate are 1) fewer computations and 2) escaping/staying near local maxima (either can be goal). Simulated annealing is popular among data scientists because (to simplify) it provides a happy medium between staying and escaping across a variety of problems, and usually doesn’t much interfere even when it doesn’t provide a benefit.
Machine learning is often focused on applications of parameter sets *after* tuning, so more training cycles isn’t necessarily a big deal. And there is a sense that the (not quite concrete) multi-dimensional spaces explored in the training are either a) on the smooth side or b) don’t wind up working well with or without heuristics like annealing. That translates into less interest in such heuristics.
Another thing to keep in mind is that the data scientists using simulated annealing are often trying to find a numerical solution relative to the specific data set in front of them. That’s not how machine learning works — if you approach the problem that way you wind up over-training.
I guess it depends on the definition of “machine learning studies”.
Certainly it’s “101 level” practice in the industry to adapt the learning rate during training. This is mostly done heuristically (say, dividing it by 10 every K epochs or after convergence) but more sophisticated approaches are used, too.
Would you consider an academic study recommending letting the learning rate cyclically vary between reasonable boundary values to be “machine learning studies”?
B_Epstein: Are you replying to me or to Elton?
I didn’t say that the learning rate is never adjusted during a training period, I said that it is common not to. And I tried to explain why a certain heuristic popular in other data science contexts is not commonly used.
(And “101 level” typically designates educational contexts rather than industry contexts. Elton was presumably referring to how machine learning is currently taught.)
@ skef
I guess I was trying to understand the terms of the discussion, more than anything.
I wanted to point out that the division between industry and education contexts is not clear.
In particular, a large fraction of industry training, especially in DL, is done based on sources such as Ng’s course that you’ve mentioned, or the famous CS231.
@skef
All I was trying to say is that the idea of changing learning rate (both between and within training cycles) is very familiar even to me, despite the fact that I’m a novice and only ever dealt with applying well-known techniques to practical problems, never with any kind of a research or study. So it’s very unlikely that people who actually do research in the area are not familiar with it, as John have suggested and Enkidum implied.
The specific example of 101 I was referring to is O’Reilly’s “Hands-On
Machine Learning”, though I’m sure I’ve seen the concept in other places too.
Basil – see my replies below. I certainly didn’t mean to suggest that any researchers don’t know about the possibility of changing learning rates during a run, just that in practice, most computational neuroscientists don’t, for a variety of reasons. I know relatively little about ML or computation in general outside the realm of neuroscience, though probably more than your average layperson.
I have a strong suspicion Enkidum’s “computational” is referring to studies in e.g. computational neuroscience, not machine learning or CS stuff in general. I.e., studies trying to build models that represent or approximate how these things actually work in humans/animals, not to build a learning algorithm optimized for performance on given (sets of) problems. This is not saying that using a constant learning rate is not an oversight, but as he says, there is work being done on models updating the rate. But computational neuroscience researchers necessarily have more constraints on, and different priorities for, their models.
Some clues this is what he meant:
– talks about what models have to say about human/animal learning as an important factor
– says he’s “not a computational guy”, followed by “not really a neuroscientist either”; => computational neuroscientist
– I can confirm that loads of comp. neuro. models use constant learning rates, long after ML started doing all kinds of parameter shenanigans with NNs.
(Caveat on the latter: I’m not an ML guy, more a cognitive (neuro)science guy interested in learning, and through that peripheral interest in ML)
Yes, sorry, this is all exactly right. I work in a neuroscience lab that does a lot of computational work. And I was referring to computational neuroscience.
Ah, that makes more since. Thanks to both of you for the elaboration.
As Chris P says in response to you, I was specifically referring to computational neuroscience studies. Sorry for not making that clear.
It’s kind of weird, actually, but in the cognitive sciences in general, there is a surprising dearth of studies on learning as opposed to learned behaviours. I.e. where the focus of the study is the transition from ignorance to knowledge of some kind. This is partly because studying learned behaviours is just easier, in terms of designing studies, but also I think because there’s still a bias to treat brains as fixed.
(Of course there are literally thousands of studies on learning, but vastly more on the outcomes of learning rather than the process itself.)
I am clearly biased in that I work on learning (just starting out – begun my PhD this year so don’t really have anything of my own to show yet), but to me it did seem reasonably clear. The main post is how things work in humans, your comment was about how it works in humans, simply referencing learning rate the same way Scott did, as a term common in machine learning that happens to (not unexpectedly) also be useful when constructing theoretical models of how brains learn things.
I suppose there’s a lot of CS/ML people here, or those interested in/having some functional knowledge of the fields, so it’s an overall reasonable assumption for them to assume a pure CS context when hearing “computational” and “learning rate” – whether their own learning rate is high or low, previous data likely supported their classification systems getting tuned to classifying input containing these words as relating to CS topics 🙂
Enkidum, could you tell me what kind of research you/your lab/your nicotinic-receptors-collaborators are doing?
Edit: Read your comment below on you valueing your pseudonimity, which I very much understand, sending an email instead.
Replied to your email. Cheers!
I’m interested in what your background is given your comment here. I like your framing of this: “you could think of [learning rate] as a parameter determining how much you would allow evidence to alter your beliefs.”
To my (non-neuroscientist) mind, learning is a different thing than memorization (say of historical facts), though I get that memory is involved. I would describe learning similarly to you, as something like “developing a new model and continuously improving the model based on new evidence.” Being able to flexibly move one’s attention at will between levels seems key.
What does the experience of people with ADHD and the role of dopamine and norepinephrine in the prefrontal cortex have to tell us about all this? My experience of people with ADHD is that they can be exceptionally quick learners when it comes to things they are interested in — that salience essentially eradicates the attention problem in those defined areas. I find this fascinating because it doesn’t seem to be a gradual thing — it seems like people with ADHD are fully “on” with all their intellectual faculties when it comes to things they are interested in, and “off” when they aren’t. I feel like that ought to tell us something about the role of salience in learning.
I was really good at school but history was the one subject I struggled with — it was a procession of factoids that I couldn’t ever find a model for, and so the factoids just fell out of my head. For me, salience in any subject came almost entirely from having a model, a sense of building something larger that either was useful or made internal sense. My son is exceptionally good at history and what he says is that history is a huge story that makes sense to him; the narrative arc is his model that gives it salience. I don’t see any narrative arc; it looks to me just like shit that happened (I assume this is a lack of imagination on my part). I feel like I have ADHD level impairment when it comes to history. I wonder what it would take to get someone like me to learn history.
Another angle on this is that conscientiousness and openness to experience are both correlated in big five personality trait research with good outcomes for people across the lifespan. Those two traits would seem to enhance both capacity to control attention and flexibility to update models based on new information. Are the good outcomes in people high in those personality traits essentially because they are quick learners? Some of the quickest learners I know do indeed score very high in those traits — is that a tautology basically?
And then, because anxiety is my main interest, I also wonder what it has to tell us about how learning works or doesn’t — anxiety clearly runs at cross purposes to cognitive functioning, and yet we see lots of anxiety among very smart people. If we think about a certain level of anxiety simply as “alertness” or “activation” (glutamate?) then you could see how it might enhance focus and so improve learning rates. But beyond some point (and that point may be sooner than we think) anxiety distorts what’s signal and what’s noise, undermines focus, and makes a whole bunch of other input salient in a way that wrecks flexibility for model-updating. I don’t know enough about how neurotransmitters interact to know if there’s something relevant there. As more and more people self-prescribe CBD to deal with their anxiety, I’m wondering how GABA agonists affect learning.
(I know just enough to get myself into trouble obviously)
Are we basically a bunch of fluctuating neurotransmitters that aren’t all that well optimized by evolution or will we come to see that idea as ridiculous as the Oedipal complex in another fifty or a hundred years?
It is likely that for ADHD users that learn faster when they can relate the new learning to something is that they are learning in expert mode .. they are taking their top down knowledge and relating it to the new information. Because executive and or working memory is impaired new data not related to a current broad heirarchy… Or hard to relate to the current model is thus much harder to learn. However…. Since this the top down system is consistently used to learn for ADHD users they are better at this expert mode learning than the non-adhd user
This jives with my experience. If I have–or can build–a model, then I kick ass. If I can’t, the knowledge falls right out. So, with apologies to Lord Rutherford, when what I’m learning is physics, I’m great. When what I’m learning is stamp collecting, not so much.
In my experience, ADHD people can only function as mappers, as opposed to normal people who can be mappers or packers, or switch between modes. If you’ve never heard of mappers vs. packers, this is a decent summary: http://reciprocality.wikia.com/wiki/The_Mapper-Packer_Divide
This is not to say that all ADHD people are mappers, just that successful ones are.
This matches my personal experience with my ADHD, which I will admit made college a real burden, but makes analysis a lot more fun. I do lots of mapping style behaviors and can’t see the value in packer style behavior (at least for myself).
My background: not sure how much detail you want (and I’m semi-protective of my pseudonymity, but you could probably search my comments on this and other sites and with some clever googling figure out exactly who I am). But I’m currently a researcher in a neuroscience lab (not the PI), and for the past decade+ I’ve been primarily focussed on studying human cognition and attention.
I’d say that your ADHD comments equivocate between different meanings of attention and salience. To me, salience means stuff that commands attention in a bottom-up manner, essentially without requiring frontal cortex to get involved. High contrast in any sensory modality, basically (loud noises in a quiet setting, bright lights in a dark room, etc). When ADHD folks get super invested in the way you describe, that sounds, to the contrary, like hyperactive frontal activity to me. So most of the time they’re at the mercy of even mild salience, and get distracted by everything around them, because the top-down attentional circuits are sleeping on the job. But then those circuits get activated and BOOM they zero in on whatever it is they care about and the rest of the world just gets filtered out completely.
Caveat: I know basically nothing about ADHD, I am not a medical doctor, my neuroscience is shoddy at best and I’m really just going off your description.
I think of history much like your son, and have always found it easy for that reason. If you haven’t read it, you might be interested in the essay “Such, Such Were the Joys” by Orwell, where he describes how history was taught to the upper middle class in England before WWI, it sounds very much like your impression of the field. Perhaps you just had some crummy teachers?
This is kind of how I see it, save that it’s more that the society we have designed for ourselves is extremely bad for our brains. I’m a political idealist of sorts, and think we could have a society we’re optimal for, we just need the will. I’m pessimistic that this will ever happen, however.
Thanks for this. Yes, I was just interested in your general field of work, not so much that it would risk your anonymity here.
I appreciate your thoughts about attention and salience and it makes me sort of sad I don’t have people around me right now who like to talk and think with that kind of precision. As a clinician, once you leave graduate school, the clinical work is really rich, but a lot of the opportunities for continuing education have seemed pretty dumb.
And yes about bad history teachers and Orwell. This rings true: “I recall positive orgies of dates, with the keener boys leaping up and down in their places in their eagerness to shout out the right answers, and at the same time not feeling the faintest interest in the meaning of the mysterious events they were naming.”
I agree with you about much of society being bad for our brains. It also feels to me like we’ve only just begun to recognize needs for mental well-being as a legitimate thing to weigh as a priority against other priorities. So the good news is there’s a lot of room for improvement, at both the individual and societal level. We expect people by age 18 to be able to perform all kinds of complex cognitive and physical exercises, but we don’t teach them the most basic emotional regulation and communication skills. It’s weird.
I just want to say thank you; this is the sort of posts I come to SSC to read, but have nothing useful to say about.
Same here.
+1
+1
Thanks for letting me know!
May I register a gentle objection to the use of “ epistemic status” prolegomena? They ought to be superfluous, since any clear writer (and Scott is certainly that) will be making clear his degree of certainty in the course of his discussion. If I’m engaging in a highly speculative discussion about something then something is seriously wrong if the reader can’t tell that that is the case without a sticker on the front of it saying “SPECULATIVE!” And this essay is a perfect example. If you chopped off the “epistemic status” field there is no danger at all that the reader would mistake this for a highly confident set ofconclusions. The text says that we are in “Speculation-Land,” and explicitly suggests that the author does not “understand the model well enough” to come to confident conclusions. We’re all set! Which leaves the final question whether anything is gained by affixing a description of the degree of certainty out of place at the very beginning of the discussion, before the reader even knows what’s going on. I confess that I don’t see the value to it. It seems clunky and pointless to me. Granted this may be partly a function of the novelty of this usage, but that just suggests that creating a new convention like this probably places the burden of showing utility on the community adopting it.
People will get on your case for being “sloppy” if you say ANYTHING without slathering caveats everywhere. IMO, there’s a place for creative speculation, and it’s on a blog; if you knew for sure, you’d write a book or a journal article or something. But there are people who will talk shit even so, and a little bit of defensive labeling is all you can do.
I agree that any reasonable, well-intentioned reader could figure out my epistemic status by reading between the lines.
Unfortunately, on the Internet you have to write defensively, so that when the stupidest troll deliberately misinterprets you to spread viral outrage, you can point to the exact sentence where you say “I’m not making that claim”.
Like TV ads that have to include the subtitle, “Closed Race Course. Professional Driver. Do Not Attempt”
…even if all the car is doing is tooling around curves at a reasonable speed on a well-paved road.
Personally, I consider the “epistemic status” thing part of the style, much like your part dividers (I., II., …). I just like ’em.
I would like to (gently) strenuously object to the gentle objection – I love your epistemic statuses. I think forcing yourself to be explicit about this is really, really worthwhile, both for your readers and for yourself.
I like it for its precision. Sure, I can infer epistemic status from the text itself, but it’s convenient to have the author explicitly summarize it.
Also, when I need to update on an issue discussed in an archived entry it helps me decide whether to read the entry again (if Scott’s certainty is high) or whether I’m better off getting new sources and making do with my memory of what the entry was (if his certainty is low).
So there are times when you have an excuse to read an older post of Scott’s and you decide, rationally, to skip it rather than read it anyway – and you actually do that?
I guess I should be jealous. Can’t recall considering re-reading a post and then simply… doing something else with my time.
I’m personally a big fan of these… my reasons overlap with other peoples’, but I’ll list them anyway:
1. Clarity/concisenessof the main text It reduces the requirement of adding caveats and qualifiers and “OTOH, it might be totally different” to any possibly contentious claim elsewhere in the article, making it more readable. I dislike it when authors (feel like they) need to pad their texts with too much of these, but if they don’t, and don’t include any disclaimer like that, it quickly sounds like batshit fringe nuttery when the content is uncertain theorizing.
2. This is the internet, it’s hard to overestimate how uncharitable/superficial/inattentive the readers on the extreme end of the relevant distributions can get.
3. It’s a convenient way to classify/set expectations for posts before reading them. Some posts are rather long (not a criticism), and it can be nice to know these things without reading the entire thing.
I wish this was a widespread convention.
In addition to the reasons others have given, I like epistemic statuses, even when they’re a bit superfluous given the rest of the text, because:
1. Some of the audience didn’t read the whole thing. There are title readers, first paragraph readers, skimmers, and full readers. (Less Wrong post by Stuart Armstrong about this.) Hopefully, the epistemic status reaches almost everyone who reads beyond the title.
2. It helps writers publish speculative things that they’d otherwise not feel comfortable sharing. Devon Zuegel wrote about this recently.
3. It sets the example of using epistemic statuses, hopefully spreading it to other writers, and draws attention to the under-appreciated concept of epistemology.
Another vote for the pro-epistemic-status faction here. (If we had upvotes here I could register this in a more lightweight way without having to type words.)
I find it’s common for people who have an idea they want to share to get really excited about that idea – which is good, it probably leads to those ideas being generated & shared a lot more often! – but excitement can sound a lot like certainty, and it might even feel a lot like certainty from the inside, even if when prompted to take a step back the author recognizes that their idea is actually pretty speculative and they haven’t yet thoroughly tested it and it very well could be wrong. Slapping a “speculative and uncertain” epistemic status at the top of a very confident-sounding piece of writing is… not necessarily enough and can sometimes come across as insincere, but I think it’s better than nothing.
(Or: we get valuable new ideas from people with high learning rates, which is good, but those high learning rates are likely to generate a lot of ideas that are incomplete or wrong, and it’s good for those people to keep that in mind on the meta-level even as they eagerly jump into their many new ideas.)
Yeah but why does it kill you gruesomely?
It’s basically the neurotransmitter for muscles. If you do something to it peripherally, all your muscles either stop working, or work much too much.
Weird coincidence, I was just teaching about the autonomic nervous system last week. Acetylcholine isn’t just a signalling molecule in the central nervous system, it’s also a major signalling molecule in the peripheral nervous system. In particular, it’s a molecule that is released from axons to trigger muscle contraction (one function among other things). Acetylcholine esterase is an enzyme that breaks down acetylcholine and is located on the surface of cells that are receiving an acetylcholine signal. Releasing acetylcholine into the synaptic cleft turns the “contract” signal on, and the destruction of acetycholine by acetylcholine esterase turns the signal off.
If you inhibit acetycholine esterase with something like an insecticide or nerve gas…congratulations, now your muscles are contracting out of control. That includes muscles like the ones in your lungs that allow you to breath. Good times.
Edit: Obviously I need to click refresh more often. Pwned at 9:39.
For extra fun, if you inhibit acetycholine esterase with nerve gas, the standard treatment is a prompt injection of (mostly) atropine. Which has been used since antiquity as an assassin’s poison on account of its tendency to make your muscles not contract at all.
Do try not to take the antidote if you haven’t actually been exposed to the equal and opposite poison.
It seems like it would be optimal for humans learning rate to natural decline as they get older — they know more about the world as a whole so they should update less from a given experience. Alzheimer’s could be this adaptation gone too far — the learning rate is zero and people can only know/remember things that they learned before. That would explain why effective Alzheimer’s drugs are ones that activate a system that increases the learning rate.
Algernons law is a pretty solid argument, but there’s gotta be some wiggle room, right? For example, if you could achieve higher mental throughput for more calories, that might be a simple “THINK BETTER” switch that evolution didn’t want to press. Or, if the switch creates a small risk of doing something that could kill you in nature (for example, becoming overtaken with curiosity for a pattern in the stars), that might be ok in our relatively less sharp-edged world.
It’s a good thing there was an evolutionary advantage to running faster, having higher endurance, recovering from injuries faster, and building muscle mass faster. Because otherwise, there would be some possible way to make performance-enhancing drugs, and can you imagine how much trouble that would cause in the sports world?
Well, yes–but the trade-off point seems to be pretty well optimized. I mean, you CAN enhance performance–but you’ll either kick aggression through the roof and get everyone killed in fights, screw with blood flow to the point that people die in their sleep because their blood stops circulating, or screw up blood clotting.
As best I can tell, nearly all professional and Olympic athletes, and a large fraction of top-tier college athletes, have been juicing one way or another for the last few decades. And yet, we don’t actually see huge numbers of these athletes dropping dead at 60, or dying in their sleep from their blood ceasing to circulate. We don’t even see that in sports like cycling, where it’s an open secret that everyone’s been juicing for years.
Are there downsides to juicing? Sure. It’s probably not great for your longevity, and sometimes it messes with your personality or something. But most professional and olympic athletes seem to go on functioning pretty well despite the juicing.
We have a worked set of examples here that contradict the Algernon argument–this is all stuff humans have definitely been selected for, and yet, drugs can seriously improve performance–enough so that in many sports, you basically can’t compete at the top level without using them.
Drugs that fight off infection (antibiotics, antiparasitics, vaccines) are another example. Humans have been heavily selected for ability to fight off or survive various infections (think of sickle-cell!). And yet, fairly simple stuff like vaccines based on killed or weakened virus strains can make us a lot less likely to get sick.
Or consider glasses. Surely we can all agree that humans evolved to have good vision, so we could see both close-in and far-away stuff. There are huge survival benefits to both. And yet, glasses bring about a huge improvement in how well people function. Glasses are pretty old technology, and yet they’re enough to substantially improve vision. (Among other things, this lets older people keep doing close-in work!)
Medicine improves on stuff humans evolved for *all the time*.
It is very unclear to me whether there was selection pressure for higher testosterone. In many population the pressure seems to go in the opposite direction, for example selection against height. The qualities of professional athletes are not “stuff humans have definitely been selected for”.
Glasses are only necessary because we are not in our ancestral environment. Glasses rectify deficits we only have because of our current lifestyle.
Nonetheless, I think that it is possible to create nootropics that actually work. You could compare iodine to glasses for example.
Say you have a population which has some skill that has a normal distribution of performance.
You randomly assign half the population to take a performance enhancing drug which improves their performance by a relatively small amount.
Then you select from the whole populations those who are a great many standard deviations above average performance. You’ll find that your sampling contains mostly juicers even though the benefit was small. This happens due to the slope of the normal curve as you have an increasingly far from the median cut-off.
The effect is even stronger for small changes in the variance. So, you could have a treatment that on average has no change but increases variance (or even on average makes people worse) and find that when you select the best of the best you still end up full of juicers.
So I do not believe your observation that competition at the highest levels benefits from performance enhancement actually implies the existence of really substantial performance enhancing substances. Though not my expertise, what I’ve seen in physical performance enhancement, with few exceptions, just isn’t that impressive either. [E.g. some of the strongest results are for steroid use, and there you see things like deadlift going from 269kg to 257kg ( https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0105330 ) … the muscles get significant larger, but the performance change struggles to be statistically significant in that study.]
What differences remain to the efficacy of cognitive enhancement can probably by chalked up to increased speed of development due how much easier it is to measure things like strength/speed/endurance compared to cognitive performance.
We were already producing testosterone, so evolution could easily tune the amount up or down. Probably selection was responding to some kind of tradeoffs–bigger stronger more aggressive people are useful but also costly in terms of food and order in the community, so find the local optimum based on your conditions. And our conditions now are so different that very different optima are available.
But overall, selection would have favored faster, stronger people who recovered from injuries faster. The knob wasn’t tuned 100% in that direction because there were tradeoffs, but if doubling your testosterone level doubled your strength and speed at no other cost, presumably we’d all be at that level.
[ETA]
Being able to see things far away is extremely useful for hunting, fighting with missile weapons, hiding from enemies, spotting dangers far away, etc. There’s no way this wasn’t advantageous in the environment of our ancestors. A substantial number of people have lousy far-away vision. Glasses correct this pretty easily.
Being able to see close-in and do close-in work is extremely useful for sewing, weaving, puling out splinters, smithing, knapping flint, etc. Once again, lots of people (almost everyone over 40 or so) has trouble with this without glasses.
Another way of saying this: If glasses are only necessary because we’re in a new environment now, this implies that there was no advantage in having good distance and close-up vision in the ancestral environment. I’d love to see you make that case. For example, how do you suppose distance vision affects your success as a hunter with spears, slings, or bow-and-arrow?
Your speculation leads me to one of my own:
We have a highly selective education system. A lot of this selection operates on the ability of people to memorize large amounts of specific information and closely analyze details of information. Comparatively little of this selection is for big-picture/top-down ability.
Does this lead to a skew in the kind of people we promote in our society towards people lacking big-picture reasoning ability?
By the way, my guess is that any such selection is very much secondary to selection on IQ and conscientiousness (and maybe some sort of sociability). Which reminds me (again) to be surprised at how much variation there seems to be in those (seemingly purely adaptive) traits.
I think we also have to consider the possibility that our brains, which are calibrated to a pre-modern HG/agricultural society, might just be pretty miscalibrated for a modern (post)-industrial society. So maybe it’s not all that surprising that there are ways to modify our brain chemistry, easily reachable by evolution, that are nevertheless highly net-positive (under our utility function).
I’ve previously mentioned that we might be very much miscalibrated on risk-taking, for example (since the past was much more dangerous). And when food was scarce there was probably a much higher cost to any energy expenditure, making people naturally “lazy”.
I think this makes a lot of sense. A lot of what the human brain does is really efficient pattern-matching heuristics. If you’re walking through the forest, your brain is constantly evaluating the environment trying to figure out whether anything in the leaves is “predator”, and basically discarding everything else as “irrelevant.” Which is good, because leaves don’t kill you, but tigers do.
Likewise, a doctor can look at a printout of your bloodwork and compare them to the patterns they’ve been trained over years/decades to recognize, and immediately see which things are abnormal and what those numbers mean. Whereas I, as an engineer, just see a list of numbers as I have no reference for what they “should” be. Their job has given them the pattern matching skills that are important to them to accomplish what they need.
Reading about the Battle of Cedar Creek, which occurred ~150 years ago, also isn’t going to kill you. So your brain’s natural inclination is that if it doesn’t fit a pattern to which you’re already attuned, to ignore that fact as noise. And most learning of this type doesn’t fit a pattern unless you’re a Civil War buff, and not taking an American History class because it’s required for your degree.
If the mechanism of these drugs is to increase your brain’s propensity to believe the world is more signal-rich than noise-rich, it would seem that it improves memory perhaps by blocking that natural “pattern match” filtering heuristic a little bit. I.e. your brain is trying to remember the forest, not looking for the tiger.
In the modern world, in a “learning” environment, like the workplace or school, that might be an advantage. In the wilderness, where you life depends on the near-immediate recognition of “tiger vs. leaves”, it is not.
So it wouldn’t make sense that our brains are wired for “THINK WORSE” over “THINK BETTER”, but more that our brains are more wired for pattern matching than they are for new information acquisition, and we call this “THINK WORSE” when it comes to rote memorization tasks.
“Likewise, a doctor can look at a printout of your bloodwork and compare them to the patterns they’ve been trained over years/decades to recognize, and immediately see which things are abnormal and what those numbers mean. Whereas I, as an engineer, just see a list of numbers as I have no reference for what they should be. Their job has given them the pattern matching skills that are important to them to accomplish what they need.”
That’s what we want you to think. Actually, it’s because the lab puts the important results in bold.
Fair enough. I’ve also seen the ones where they actually put the normal bounds of each value right next to the measured value so you can easily see which ones are abnormal.
Still, as an engineer I can’t decipher what something being abnormal means, whereas a doctor is trained to do so. If three certain markers are elevated, there might be a correlation where they all point to a certain affliction that any single one of them doesn’t, and that’s the sort of pattern that a well-trained doctor will see almost immediately whereas most who haven’t developed that experience would miss it.
Maybe a better analogy is chess? A good player can look at a board and immediately recognize patterns that reveal strengths and weaknesses of each player’s position. For a novice, (i.e. me) it’s a long and tedious sequence of if-this-then-that. For a non-player, it’s just a random jumble of pieces on a checkers board.
Chess is an excellent example. I’d need to do some digging to find the specific citation, but for a dramatic example I remember a study that mixed up the standard how-well-can-grandmasters-memorize-boardstates experiments (extraordinarily well, to noone’s surprise) by including a number of boardstates that could not be reached in typical play. In such cases the chessmasters’ recall dropped into the merely-very-good range, while someone unfamiliar with the game might not be able to distinguish what even separated the scenarios.
There’s a big problem with your analogy: high learning rates don’t cause overfitting. In fact, they tend to make overfitting impossible. Think about it this way: if your learning rate is sufficiently high, you jump around all over the place with each new sample you see, never able to settle down on any strong theory for what’s going on. You’ll have a woefully underfit model, never able to make progress since every jump in the right direction overshoots or is immediately countered by a jump in the wrong direction.
Low learning rates, on the other hand, allow for overfitting, but don’t necessarily result in overfitting. What they really do is let you converge more surely towards a locally optimal state. For every learning rate of step size S, you’ll eventually find yourself within a distance-proportional-to-S away from a local optimum. It determines the size of valleys you can get stuck in in the landscape, and equivalently the size of valleys you’ll tend to skip over.
He meant overfitting to a single example, not to the whole dataset.
If learning rate is very high, it will overfit.
This is a bit of a misunderstanding of what causes overfit, at least in the context of a supervised learning deep neural net, such as would be used to classify dog and cat pictures.
A learning rate that is too high will just fail to work its way down into the local minima of the n-dimensional parameter space. Basically you get an inaccurate classifier. That’s approximately the opposite of overfit, which happens when you keep iterating with your training examples until you work your way so far down into the local minima that you have trained the system to recognize only your training examples. It’s too accurate rather than not accurate enough.
FWIW, this is why you keep training and validation sets separate. You train to the point where your accuracy in classifying both sets stays roughly similar. If you go further and your accuracy at classifying the training set gets higher than your accuracy at classifying the validation set, you know you’re overfitting.
Simple piece of anecdata which might be related. I have some friends who take Modafinil in spurts when they have major exams coming up (especially professional exams with lots of content like the CFA). I’m not sure if Modafinil works through similar pathways to discussed here, but…
They commonly say that when taking Modafinil while studying, it’s difficult to remember things you learnt in the same study session while you weren’t on Modafinil. Almost as if the signal from the Modafinil-supported session is stronger, but ‘drowns-out’ the signal from other study sessions.
I read a study about how long term antipsychotic use shrunk the brains of monkeys by 10% in a year. So I’m a little freaked and I’ve been reading about smart drugs in the hopes that they could maybe balance it out. Or something.
I have read that a number of inventors found that starving the brain of oxygen (e.g. simple apnea in a pool) helped them in generating new ideas/inventions. I’m not sure how the propensity to generate ideas correlates with an increase in noticing noise as signal as in the article. However, I wonder if there is any way that starving the brain of oxygen might increase the natural secretion of acetylcholine and act as a temporary booster for significance of noise signals (or increase the learning rate) in the brain. Does the body interpret apnea as a panic situation and therefore ramp up the release of acetylcholine as a “focusing agent” similar to adrenaline? Could holding one’s breath improve one’s ability to retain historical facts?
Is there any way to study learning rate change over time? I imagine children have higher learning rates than adults, and I certainly feel like when I was in high school every idea was DEEP AND PROFOUND, but now I have to kind of work myself into that mental space where ideas seem DEEP AND PROFOUND.
I wonder how teachable older adults are all the time. How do 50 year olds learn? Does a 50 year old have a harder time comprehending a foreign philosophy than a 25 year old? In the workplace most adults seem very bad at learning new systems or processes, but kids seem prepared to about-face in all sorts of surprising ways.
Does piracetam really do anything?
My memory from information here sometime back is that there is evidence that it slows age related cognitive decline.
This seems more intuitive on the “going too slow vs. overshooting” interpretation of learning rate, as opposed to the “noisy environment vs. signal-rich environment” interpretation. These two interpretations actually refer to two different tradeoffs: one is about how noisy you think the observations are, and one is about your capacity to model the environment even in the absence of noise.
Generally your best model of some phenomenon is going to make some prediction errors, not (just) due to observation noise, but because reality is more complicated than your model can possibly be. Once your model is about as good as it can be, you want to stop changing it when it makes prediction errors. This is especially important because the “changes” in an ML model (or, presumably, nervous system) are not perfect Bayesian updates that jump straight to the optimally changed state, they’re crude approximate steps that try to take you in the right general direction. When there is no right direction to go in, because you already have the least error-prone model that can fit in your brain (or whatever), you don’t want to keep taking steps even though you’re still making errors.
It makes some sense that studying, or other tasks where people would expect “cognitive enhancers” to help, demand more and bigger “steps” than are usually sensible. In most of my existence, I experience unexpected stimuli all the time — weather changes, other people going about their business, etc. — which arise from systems I can’t possibly understand in full, so my brain isn’t constantly and desperately reconfiguring itself to explain why it just heard a car alarm or something. But when you’re studying something, you want to push a bunch of new changes into your brain, in a way that wouldn’t be otherwise reasonable. (Memorizing something apparently very random, like the weather, is generally useless, so the brain doesn’t do it; it has to be forced when the apparently random thing is a set of academic facts.) Or, say, when you’re trying to understand a pre-existing concept or even solve an intellectual problem, there’s a much higher expectation that you can decrease your error rate by updating than usual. You expect to eventually “get it,” in a way that you will never “get” the weather, or indeed most things.
That’s all spitballing on the assumption that ACh really controls something like a learning rate. I continue to be generally skeptical of Friston’s ideas, and although I don’t fully understand the two papers cited for “previous theoretical notions posing that ACh controls the speed of the memory update (i.e., the learning rate),” they looked really speculative at best.
Another possible slider is focus. I seem to have ridiculous tunnel vision, in every sense of the term, from not noticing things in my peripheral vision to not realizing related concepts have anything to do with each other. This is great for focusing on particular things and not getting distracted, but bad for taking in all possibly relevant information, and is generally very OCD-inducing. The opposite side would be a complete inability to focus but noticing everything in the environment, probably involving a lot of ADD. Obviously there are benefits to the slider being all along the line depending on circumstances, but if your job is vice president of staring at spreadsheets the hyperfocus is probably strongly preferable at work.
I come back to my favorite theory of The Biggest Question We Never Talk About:
Why did civilization go into overdrive these last few centuries?
I like to think progress went viral when COFFEE spread across the world, and people started to Get Shit Done.
https://en.wikipedia.org/wiki/History_of_coffee
Unrelated to this hypothesis, I recommend having a look at the 1674 pamphlet “Women’s Petition Against Coffee” which is cited unironically and without much context in the section about the history of coffee in England, merely as an example that the “new commodity proved controversial among some subjects”…
It is basically a rant complaining that, thanks to “the Excessive Use of that Newfangled, Abominable, Heathenish Liquor called COFFEE”, certain “shit” is most decidedly not getting done. A sample:
“They come from it with nothing moist but their snotty Noses, nothing stiffe but their Joints, nor standing but their Ears: They pretend ’twill keep them Waking, but we find by scurvy Experience, they sleep quietly enough after it.”
https://web.archive.org/web/20060810201646/http://staff-www.uni-marburg.de/~gloning/wom-pet.htm
People have made similar observations before re the importance of caffeine; at one point in the L. Neil Smith novel The Nagasaki Vector the protagonist notes how it may not be a coincidence that the Industrial Revolution got going in the nation where everything stops every afternoon for a nice cup of tea.
Michael Vassar is what happens when your learning rate is too high…
>But why should there be smart drugs? Popular metaphors speak of drugs fitting into receptors like “a key into a lock” to “flip a switch”. But why should there be a locked switch in the brain to shift from THINK WORSE to THINK BETTER? Why not just always stay on the THINK BETTER side? Wouldn’t we expect some kind of tradeoff?
Not necessarily. Evolutionary pressure on mental activity might be similar to the pressure on physical activity: when active, the organism’s performance should be as good as possible, but the organism should try to minimize activity to conserve resources. Continuing the analogy, perhaps there is a dial in the brain that determines how aversive thinking is. All the way to the left, the dial makes thinking so aversive that any kind of abstract thought requires intense effort. All the way to the right, and thinking feels effortless – it becomes easy to concentrate on a problem for hours on end.
Under this model, some nootropics might operate by making it easier to maintain cognitive exertion over a prolonged period, rather than by enhancing cognitive abilities.
The examples of learning environments the post cites involve a pair of extremes: one of standard school learning, in which the cognitively-enhanced student is learning true information about the Civil War, and one of psychosis, in which the sight of a street sign with a weird name is taken to be a capital-R Revelation.
I would argue that today’s world offers a number of learning environments that might be termed as a middle ground between those extremes, in which alarming assertions which contradict conventional wisdom are made with sophisticated arguments and/or clever sophistry, and in which it’s not really reasonable to expect a person to be able to intuit the truth of falsehood of all of the assertions made. Examples might include cryptocurrency pitches, strident political op-eds, twitter, or the results of a youtube search for “feminism”. One might hypothesize that a milder quantity of psychotic thinking – “things getting a little weird” – would not be enough for a street sign to augur the apocalypse, but would be enough for a slickly produced video to convince someone to believe a Big Lie.
Why is it so absurd that there could be a drug that makes you smarter?
1) If it takes more energy to be smarter, then we may not be evolved to be as smart as possible at all times. Why waste energy memorizing dates from the Civil War?
I spend a lot of effort convincing my body to waste energy on muscles I don’t need, and it still isn’t really getting the message.
2) Maybe intelligence/stupidity is like clearness/blurriness of vision. It’s obviously worse to have blurry vision than clear vision, and no one is surprised we have ways of making blurry vision clear with almost no side effects. Sure, you can’t do much for people with 20-20 vision, but most people are worse than that anyway.
If it takes more energy to be smarter, to a metabolically significant degree, then we would expect the relevant “smart drugs” to have already been discovered as “miracle fat-busting diet drugs”, with a side order of noticing that the dieters are a bit smarter or more focused.
This sort of happened with amphetamines and tobacco/nicotine, but nothing else that I can think of. That suggests there isn’t much else that really works by shifting the “conserve energy think harder” slide to the right, or at least nothing that is likely to have come up with small-molecule searches or to have evolved in nature.
Wait, doesn’t the existence of amphetamines and nicotine support my argument? It isn’t surprising that it’s hard to trick your body into wasting energy (if you run out, you die!), but the fact that we already have some imperfect ways of doing this supports the idea that intelligence can be increased at the expense of energy, a trade-off most of us are happy to make in an age of plentiful food.
Nice article. Thank you.