
[Content warning: suicide. Thanks to someone on Twitter I forget for alerting me to this question]
Among US states, there’s a clear relationship between gun ownership rates and suicide rates, but not between gun ownership rates and homicide rates:
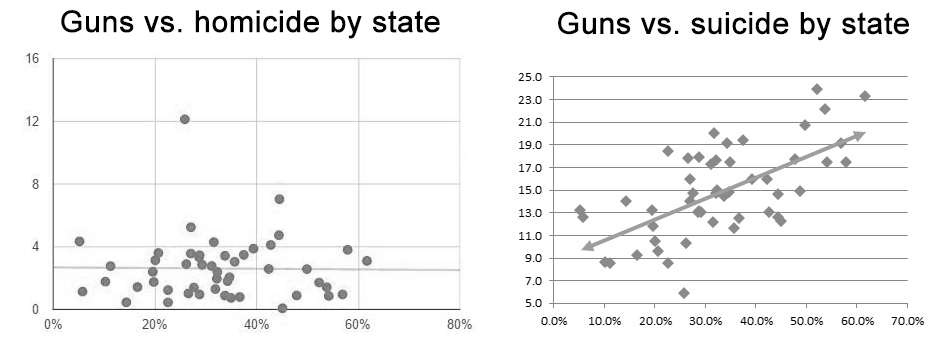
You might conclude guns increase suicides but not homicides. Then you might predict that the gun-loving US would be an international outlier in suicides but not homicides. In fact, it’s the opposite:
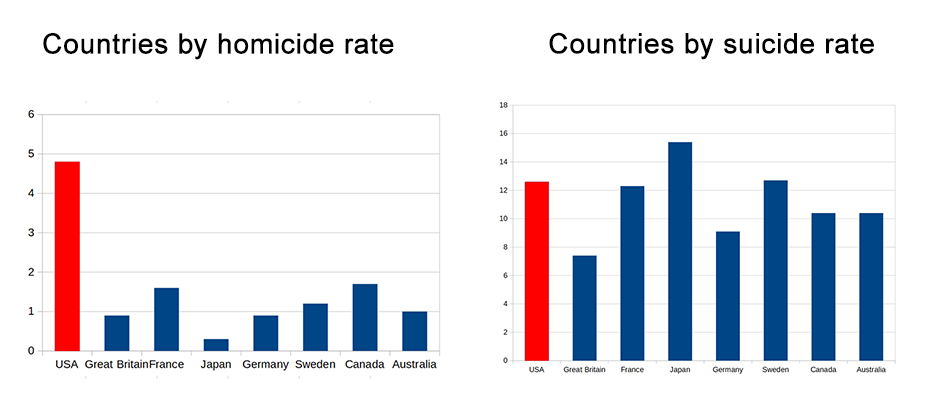
Why should this be?
We’ve already discussed why US homicide rates are so high. But why isn’t the suicide rate elevated?
One possibility: suicide methods are fungible. If guns are easily available, you might use a gun; if not, you might overdose, hang yourself, or jump off a bridge. So getting rid of one suicide method or another doesn’t do much.
This sounds plausible, but it’s the opposite of scientific consensus on the subject. See for example Controlling Access To Suicide Means, which says that “restrictions of access to common means of suicide has lead to lower overall suicide rates, particularly regarding suicide by firearms in USA, detoxification of domestic and motor vehicle gas in England and other countries, toxic pesticides in rural areas, barriers at jumping sites and hanging…” This is particularly brought up in the context of US gun control – see eg Suicide, Guns, and Public Policy, which describes “strong empirical evidence that restriction of access to firearms reduces suicides”.
The state-level data from above support this view – taking guns away from a state does decrease its suicide rate. And then there’s this graph, from Armed With Reason:
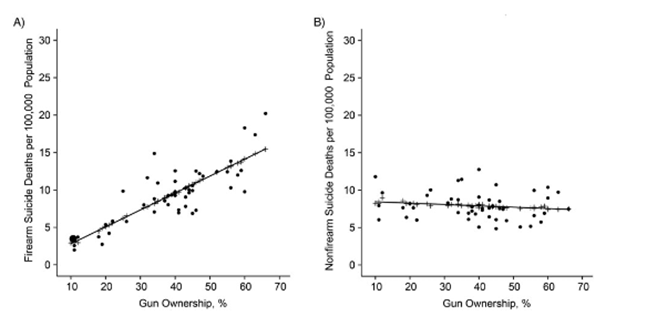
…which shows that adding more guns to a state does not decrease its nonfirearm suicide rate.
But if suicide methods aren’t fungible, then why doesn’t the US have higher suicide rates? Here’s another way of asking this question:
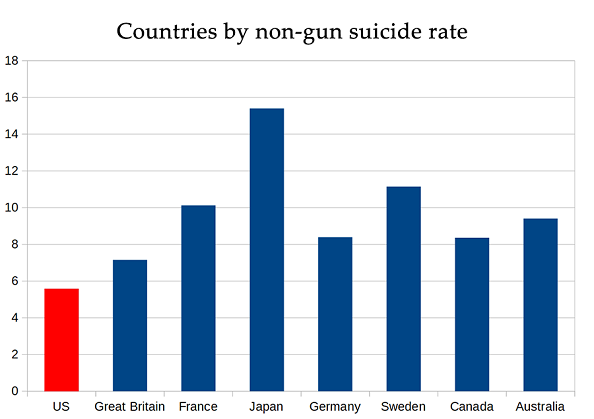
The US has fewer nongun suicides than anywhere else. The seemingly obvious explanation is that guns are so common that everyone who wants to commit suicide is using guns, decreasing the non-gun rate. But that contradicts all the nonfungibility evidence above. So the other possibility is that the US ought to have an very low suicide rate, and it’s just all our guns that are bringing us back up to average.
Of all US states, Massachusetts, New Jersey, and Hawaii have the fewest guns. Unsurprisingly, suicides in these states are less likely than average to be committed with firearms. In MA, the rate is 22%; in NJ 24%; in HI, 20%. Their suicide rates are 8.8, 7.2, and 12.1, respectively. Hawaii has an unusual ethnic composition – 40% Asian and 20% Native Hawaiian, both groups with high suicide rates (see eg the suicide rate for Japan above). So it might be worth taking Massachusetts and New Jersey as examples to look at in more detail.
Either state, if it were independent, would be among the lowest-suicide-rate developed nations. And both still have more guns than our comparison countries. If we did a really simple linear extrapolation from New Jersey-level gun control to imagine a state where firearms were as restricted as in Britain, we would expect it to have a suicide rate of around 5 or 6 – which is around the current level of non-gun US suicides. This is much lower than any of the large comparison countries in the graph above, but there are two developed countries currently around this level – Italy and Israel. I think it makes sense to suppose that the US might have a low Italy/Israel-style base rate of suicides.
For one thing, it’s unusually religious for a developed country. Religion is one of the strongest protective factors against suicide. This also seems like a good explanation for Italy and Israel.
For another, it’s culturally similar to Britain, which also has a low suicide rate somewhere in the 7s. Other British colonies don’t seem to have kept this effect – Australia and Canada are both higher – but maybe the US did.
And for another, it’s unusually ethnically diverse. Blacks and Hispanics have only about half the suicide rate of whites; which means you would expect the US to be less suicidal than Europe. I previously believed this was because whites had more guns, but this doesn’t seem to be true: Riddell et al find that whites have higher non-firearm suicide rates too. So this could be an additional factor driving US rates down.
(another conclusion from the graphs above: US whites – who have most of the guns – do have an anomalously high suicide rate compared to other countries)
A confounding factor – the US has lots of different cultures, and Massachusetts and New Jersey represent only one of them. But if anything I would expect Southern and Midwestern culture, which are more religious, to have a lower base suicide rate; the South also has a lower percent white, another reason to expect their rate to be lower. And there is no evidence of these states having a higher non-firearm suicide rate, which we might expect if they were unusually suicidal.
So I think the simplest explanation is true. A gun-free US would have one of the lowest suicide rates in the developed world, maybe 5 or 6 people per hundred thousand. The US’ average-seeming suicide rate is an artifact caused by combining the low base with the distorting effects of high gun availability. The lack of a relative suicide crisis in the US doesn’t indicate that easy firearm access isn’t causing thousands of preventable suicides per year.
This is maybe not the most pressing question we’re facing right now, but I take it as a warning against gotcha-style debating. A simple bar graph comparing national suicide and homicide rates would be a compelling, elegant, and easily-digested argument that guns increased homicides but not suicides. It would also be totally wrong.
[EDIT: Commenters point out this paper by Alex Tabarrok on how there is some, but less-than-perfect, substitutability of suicide methods.]
















Is the sort of person who’s likely to commit suicide also the sort of person who’s likely to be the victim of a homicide? Maybe the US has a bunch of people who otherwise would have committed suicide eventually, but got murdered first.
Edit: or maybe it’s something similar to “suicide by cop”, where you go provoke your local gangster into killing you, and this just happens to be easier to do in the US?
Surely the base rates of either are too low for that to be a significant factor.
Compare the prevalence criminal records of suicide and homicide victims. My prediction is that homicide victims often have criminal records because homicides often happen in a gangs or drugs related way or just generally disputes between violent people. Suicide victims will rarely have criminal records, as they tend to be too depressed to do things that are out of the norm.
The US has by far the highest rate of opiate usage in the developed world – 1.6% of Americans have used opiates in the past year, compared to 0.1% of Japanese, 0.4% of French people, etc. The US also has extremely high rates of marijuana use (16%), cocaine use (2%), and so on compared to other countries listed above.
Could it be that in the US, if you feel like absolute shit, you can smoke a joint or take some vicodin, sleep for a while, and then feel better – but with those options much harder to get (or much less socially acceptable), people in Japan or elsewhere turn to suicide?
Interesting thought. My inclination, though, is to think that alcohol is the dominant recreational drug for suicide victims, and I doubt the US sits atop that statistic.
It doesn’t. Eastern Europeans especially drink like fish, but American alcohol consumption, while above much of Asia and the developing world, is below almost all of Europe and the rest of the Anglosphere — #48 per capita per Wikipedia, where Canada is #40, the UK is #25, and France is #18. Probably a cultural legacy of Prohibition and the temperance movements that led to it. We have relatively low rates of tobacco use too, though that’s more geographically mixed — some European countries smoke less, and developed Asian countries tend to smoke a lot more.
Oddly, our rates of chronic obstructive pulmonary disease — closely linked to smoking — are very high. Maybe the statistics looked different forty years ago, and all the pack-a-day smokers from the Sixties are just now dying of it.
How much above Asia? I’ve been on a business trip to China; very limited experience, but neither the travelers nor the natives needed much prompting to go out drinking each night.
China is way down at #89. Japan is #71. South Korea is #17, but it’s the only Asian country anywhere near that high.
I’m guessing there are big class and region differences in China especially, but another factor might be that drinking seems much more gendered in Asia than it is in the States.
Would be interesting if South Korea’s position is largely a result of being more urban middle class than China – so equivAlent chinese/SK individuals would drink at around the same rate.
Alcohol is a depressant, so perhaps alcohol is not a good treatment for depression, but it actually causes suicides.
Perhaps we should legalize weed and ban alcohol.
The “ban alcohol” part has been tried, and did not work out well.
I know, it wasn’t a very serious suggestion.
@Aapje
Many Thanks!
Well, we’re not just looking at drug use in general, we’re looking at drug use as a way of self-medicating to suppress acute suicidal impulses.
The typical alcohol (ab?)user experiences long periods of going around with impaired judgment and poor impulse control, but still physically able to move about and, say, jump off a bridge or otherwise fall upon their metaphorical swords. Alcohol might be ineffective at suppressing impulsive suicides, compared to other drugs that knock you out faster or make it less likely you’ll try to act while intoxicated.
[This is in addition to the others’ point that using addictive drugs to self-medicate for suicidal impulses is likely to eventually lead to death by drug overdoes]
Or you kill yourself with opiates and get recorded as an accidental overdose rather than a suicide.
My thoughts exactly; alcohol is a similar possibility.
This reminds me of the story where the guy was going to commit suicide. But before going through with it, he decided to have one last week, and went to Mexico to spend the rest of his money partying. After seven days drinking tequila, snorting mountains of coke and having orgies with hookers, he realized that life was actually pretty beautiful and worth living.
That guy was never going to kill himself anyway.
Alcohol is available everywhere, and while doctors say it makes depression worse, in my experience it cheers me up, with the combination of uplifting music even after 22 years of relatively hard drinking, that even if I was suicidial instead of just normally depressed, I would postpone it indefinitely every time after getting semi-drunk and rocking out.
And even if it doesn’t? What will a typical drinker do if five beers hadn’t lifted him up? Drink another three. And that will most likely result in going to sleep much rather than harming themselves.
What little I know about Japan is that getting shitfaced in the evening is curiously not against the social norms, and while shitfaced all those rather strict social norms get relaxed. No. I think the suicide people are those who cannot even be lifted by an evening of getting sloshed and playing pachinko.
Alternatively… Well, not everyone is a cheerful drunk.
When you say that black and hispanics have lower suicide rates, it’s also relevant that they have higher levels of religiosity. In other words, it could be that religiosity entirely explains the differences in suicide rates among the countries you cite. Though, “religiosity” might not be right. It might be better to say “ideology.” Christianity frowns on suicide, but not all religions do. I’d imagine a lot of the difference in rates of non-gun suicides is due to cultural attitudes towards suicide.
Last I remember, the American white suicide rate was three times higher than the American black suicide rate. Are American blacks that much more religious than American whites?
To my knowledge, yes.
White people in America include coastal hippies who will reject religion as a tool for controlling the masses and Southern Bible thumping Christians. Making white americans a uselessly broad category. I’m thinking back to Albion’s Seed here.
Church attendance leads to a feeling of community, which tends to prevent someone from being suicidal.
Except if you’re gay.
What do you think monasteries are for?
Protestants don’t have those, though, and Christians in the US are mostly protestant.
I daresay part of it means going to a church relatively well matched with your views; churches with varying levels of acceptance of gay people exist, all the way up to allowing same sex marriage in the UK at least.
I think this is likely right. (Note I am an ardent supporter of gun rights and a gun owner.)
For the purposes of cost-benefit analysis, has anyone ever tried to quantify the value of human lives conditioningon whether they’ve tried to commit suicide? It’s possible that (again, using a CBA approach) this explanation would actually work against gun control.
If you mean something like “people who commit suicide seem pretty miserable, so maybe it’s best to let them get the oblivion they seem to prefer, I argue (somewhat) against this at https://slatestarcodex.com/2013/04/25/in-defense-of-psych-treatment-for-attempted-suicide/
Yeah, I thought about this post of yours. It nudges in that direction, for sure. I still think it leaves a lot of room between $0 and, say, $6 million (something close to what people usually use as the average value of a human life), though, when thinking about this in CBA terms.
There’s a fairly firm principle in health economics against conditioning the value of a statistical life too closely on the exact characteristics of the persons saved, other than age and expected future health-related quality of life (HRQOL).
We don’t, for example, value female lives saved more highly on the basis of longer expected lifespans.
What you’re suggesting would be to bring suicidal feelings and/or the state of the world responsible for causing them under the umbrella of HRQOL, either by categorising it as a poor health state or by appealing directly to the victim’s revealed preference evaluation.
Typically, HRQOL is evaluated (on a scale where 0 is equivalent in utility to death and 1 is equivalent to full health and negative evaluations are admitted) on the basis of the patient’s description of their health state but society’s evaluation of its utility based on the description (typically encoded using some sort of summary descriptor).
So, if I’m trying to squeeze your suggestion into the way things are done rather than defend it in philosophical terms, we summarise the mental (but not material) state of a suicide victim and present members of society with that information and evidence on their future prognosis/the typical timepath taken by the mental condition from which they suffer (and probably also physical or mental comorbidities in a lot of cases) and ask them to sort of integrate under the HRQOL curve (expected value of six months at HRQOL -0.1 and 60 years at HRQOL 0.7, just for example) to produce a weighting for “suicidal lives saved”.
I’m definitely not signing off on that approach, and you might favour something much more radical which takes into account material as well as medical detriments the victim suffers and/or is likely to suffer, but that’s how it would look in a fairly conventional framework for healthcare CBA.
Thanks. That was pretty informative.
For full disclosure of a potential source of large bias in my beliefs, I’ll say I have a strong distaste for some non-trivial fraction of people who commit suicide by gun. I know someone whose father did this, and family members who discovered the body don’t exactly have the nicest parting image. Basically, if you leave a mess for your family to find, I think you’re kind of an inconsiderate dick to begin with.
This argument may work better from the other side.
We have a population of people who would currently commit suicide. We know that reducing access to firearms will prevent some of the suicides, but that still leaves a population of people who are in such a miserable condition that the only thing preventing their suicide is lack of access to a firearm.
There are other known ways to prevent suicides. Psychiatric counseling, drug rehab, increased economic opportunities, etc. If we use these methods it actually improves the lives of these people, and then they don’t commit suicide even if they continue to have access to firearms.
So which method of preventing the suicides should we prefer?
Scott, You left out one factor. Prescibed psychiatric drugs, especially SSRI drugs, which can cause suicide, homicide, and have been a factor in all school shootings (the pharmaceutical companies have been quick to cover this one up). Psychiatric drugging, especially if used long-term, creates dependency on the drugs. Long-term drugging creates the illusion that the drugs are actually needed and the false notion that there was a chemical imbalance to begin with, when really, the drugs create the imbalances. These drugs cause violence and erratic behavior, including suicide and homicide. The pharmaceutical companies and the psychiatric industry do not want to admit this, as the industry is making billions by fooling people. Who loses out? Those that are duped into taking the drugs and society in general.
Current evidence suggests that SSRIs probably do not increase suicidal behavior and may decrease it. See here and here.
The claim that all school shooters were on antidepressants seems transparently false; for example, the perpetrator of the most recent school shooting in Santa Fe wasn’t.
juliemadblogger’s steelmanned argument is that withdrawal from prescribed psychiatric drugs (especially but not limited to SSRI’s) is a factor in school shootings, and this connection has received little MSM attention.
The Santa Fe shooter was diagnosed with ADHD and has a nurse for a mother, so it seems likely that he was prescribed an ADHD medication such as Ritalin.
There is something weird about so many people having the prior of assuming it is the meds that made the shooters do it instead of the mental conditions themselves they got the meds prescribed for. But a reasonable middle ground may be that rarer and more complex mental illnesses may have been misdiagnosed (anger outbursts? male depression!) and mistreated with SSRIs instead of, say, antipsychotics.
Simpler story: the drugs don’t work well enough for many people, their violent and erratic behavior isn’t sufficiently suppressed by it and they commit some heinous act *despite* the medication, so the problem is actually *too little* medication.
It isn’t the drugs that get you, it is the withdrawal symptoms.
(But… no, the drugs really do have severe negative effects on some people, and both the drugs and the withdrawal can make people, using the word in it’s colloquial sense, psychotic.)
Look. As my psych said, literally everybody who is diagnosed with ADHD as an adult also has depression because they had enough shit to deal with to get it. And one thing adult ADHD does, med or no med, is to forget things. So if I don’t want to pay through the nose for my Venlafaxin, I have to go to the doctor right in the middle of my two week dose to get another two weeks dose prescribed and the cost approved by some (European) government agency so I pay €5 for it and not €100. This regimen is something they would surely change if forgetting to do this would result in psychosis. Instead, forgetting to do this mainly means some headache.
This is anecdotal, but both me and a friend of mine became homicidal on SSRI’s. In my case i started having intrusive thoughts about murdering my own family, freaked the fuck out, and flushed the pills down the toilet. In my friend’s case she was on them twice and became so unhinged she had to be involuntarily committed both times. The second time around she actually tried to murder a police officer with a rock when they came to escort her to the psych ward, giving him a nasty forehead wound.
Fortunately since she was already legally committed, she could not be held legally responsible for it, so no charges were pressed. In fact she was eventually able to prove in court that her psychoticness was caused by the medicine and got her gun rights back, as otherwise an involuntary commitment would bar her from owning any. This means somewhere out there is at least one sealed court case were the judge finds that SSRI’s can make you crazy.
So as far as i can tell, this is a real side effect, just one that is not much discussed because it’s rare, and when it does occurs it’s easily attributed to other factors.
… oooookay.
You mean an “artifact”, not an “illusion”, right? The extra dead folks are real-dead, not illusion-dead. But they don’t have the statistical implications some might expect.
Just to preface this: I’ve more than my fair share of experience with suicide. Several family members and friends killed themselves, others merely tried, and I made my own attempt in high school (if I’d had access to a gun, I definitely wouldn’t still be alive).
Still, I think you’re making an assumption that we should WANT to prevent these suicides. I’m not saying you’re wrong, but I want to push back on that for just a second.
First, a very high rate of those who fail in their suicide attempt will simply try again (and are usually successful the second time around). Around 1/25 people will try again, successfully, inside of five years.
In my family, this sort of thing has often increased the suffering of everyone involved, not least the person in question. To what degree should we make it difficult for someone to make their own choice regarding what to do with their own life? I’m not just talking about the pain of the attempts themselves. I’m talking about an unhappy person who doesn’t want to be alive making the people around them unhappy, as well.
In other words, you seem to have completely ruled out the prospect that suicide can be a rational, compassionate choice, even when more “acceptable” alternatives are considered. I can understand the need to maintain this mindset as a psychologist, but, perhaps, not everyone can/should be “saved” from suicide. People should try like hell, of course, but at a certain point, maybe everyone should be allowed to make their own decision.
Finally, many suicide “attempts” are cries for help. They’re DANGEROUS cries for help, but the person in question didn’t really want to die. I don’t have stats for a country-wide population, but my family members (and friends) who survived their attempts ALL had access to a gun, but chose other methods instead. In other words, maybe the people who are using guns are often the most certain about their decision.
In fact, I have no idea what I would’ve done if I’d had access to a gun when I made my own attempt. Perhaps I would’ve still tried to overdose. Maybe I would’ve shot myself. Or maybe I wouldn’t have done ANY of it because I wasn’t quite certain I wanted to die, and a gun is a near-certainty. So maybe guns are actually preventing people from making “safer” attempts that still might kill them.
People seem to start from the standpoint of “every suicide should be prevented.” Some have, of course, started to come around on physician-assisted suicide, but never regarding any kind of mental illness. This displays, to me, a fundamental misunderstanding about how painful, incurable, and all-consuming mental illness can be. I’m surprised at the lack of conversation about compassionate care which might include, as a last resort, ending a person’s suffering.
David Foster Wallace wrote that, “The so-called ‘psychotically depressed’ person […] will kill herself the same way a trapped person will eventually jump from the window of a burning high-rise. [Her] terror of falling from a great height is still just as great as it would be for you or me standing speculatively at the same window just checking out the view; i.e. the fear of falling remains a constant. The variable here is the other terror, the fire’s flames: when the flames get close enough, falling to death becomes the slightly less terrible of two terrors. It’s not desiring the fall; it’s terror of the flames. And yet nobody down on the sidewalk, looking up and yelling ‘Don’t!’ and ‘Hang on!’, can understand the jump. Not really. You’d have to have personally been trapped and felt flames to really understand a terror way beyond falling.”
In other words, to some degree, this kind of post makes me feel like people are trying to make every option for the suicidal feel like burning to death. Like people want to rule out every kind of death available to a suicidal person besides the most painful and difficult ones. Sure, you want a deterrent to suicide. But is making suicide EVEN MORE painful really the best action to take? Aren’t these people in enough pain? Surely you could, say, try to make a person’s life better instead of making their death more painful?
I recognize that I’m waaaaay oversimplifying in one direction here. But it drives me batty that people think the answer is just “drive the numbers of suicide down” regardless of the cost in actual human suffering.
EDIT: I just saw your link to the post IN DEFENSE OF PSYCH TREATMENT FOR ATTEMPTED SUICIDE above. Glad to see you’ve considered this, Scott.
You’re mistaking me for a much better person who wants to improve the world. My real motivation for writing this was “Huh, these two ways of looking at the data give contradictory conclusions, what’s up with that?”
Haha, fair enough.
To expand on a small point I made that might still be relevant, I think it’s possible that a gun can be a deterrent to less-fatal (but still possibly fatal) suicide attempts. Perhaps a person has enough resolve to OD on medication, but not nearly enough to use their gun. But, because they have access to a gun, they don’t really consider ODing.
(I also think it’s possible that familiarity might make some methods easier for some people than others. For example, a doctor might more easily poison herself with medication. A hunter might more easily shoot himself. A mechanic might more easily hook up a hose to the tailpipe. Etc. So with the amount of guns in the US, maybe this is just a matter of “go with the thing I’m familiar with.”)
You might also have people who want to lower the odds of just injuring themselves. Since guns are pretty easily available, it might just be a case of “why risk some other method? I’ll just wait until I have a gun.”
And, as others have pointed out, you’ve likely got a bunch of “acceptable” ways to kill yourself if you’re unhappy. Eat or smoke yourself into an early grave, for example. Plenty of depressed people aren’t “consciously” killing themselves, but might as well be with excessive food, drugs, etc. In other words, if you expanded the terms a bit to a fatal lack of self-care, I think the US would perform much higher.
You don’t have to be a good person who wants to improve the world to help people who do want to improve the world.
That is a fair motivation, but when you write things like “The lack of a relative suicide crisis in the US doesn’t indicate that easy firearm access isn’t causing thousands of preventable suicides per year” and call religious bias a “protective factor”, people will predictably interpret this as advocacy.
After all, you wrote this entire post without even giving lip-service to the consent principle.
My problem with the medical profession is that you don’t see yourselves as service providers offering consensual good-faith service to willing customers. Many representatives of your profession communicate as though the rest of society were patients whether they actually individually consent or not.
I have zero interest in nonconsensual suicide prevention. I do have an interest in actual options. I want my end-of-life choice set to be open. I want to be able to walk into a drug store, buy a deadly dose of pentobarbital with my own money and take it without violating the rights of others and without asking others for permission. Instead, we get prohibitionism, derogatory language, subtle and not-so-subtle propaganda attacks and unwanted paternalism. To me, this is enemy action.
I don’t need my enemies to understand why they are my enemies, or to consent to being my enemies. If you harm my interests, you are an enemy whether you like it or not, no matter how much moralistic or euphemistic framing you use.
Don’t attack this liberty, explicitly or implicitly.
P.S.: Religion may prevent suicide, but why? Because people believe in an incorrect cost-reward-ratio? To call that “protective” may be technically correct in medical jargon, but it still harms people.
Yes, we we should want to prevent these suicides. Consider this as the flip-side of euthanasia.
If someone is unbearably physically ill with no hope of relief, they are able to make a competent decision to end their life.
If someone is unbearably mentally ill, they are, by definition, incompetent to make such a decision.
Hence we should (with appropriate checks and balances) allow and enable the first. We should not allow or enable the second.
What is your stance on people who are unbearably mentally ill with no chance of relief? Your statement about the ‘unbearably mentally ill’ was unqualified, so I presume they are included within its scope. If so, how do you defend that? (Saying that they are by definition incompetent to make the decision isn’t enough; it just pushes the question back a step.)
edit: I don’t want this to be taken as a drive-by attack or a gotcha or anything like that, so I’ll elaborate a bit. I can understand why one might argue that allowing/assisting the suicides of people who aren’t physically ill would cause more harm than good if adopted as a general policy: maybe too many people whose mental pain would have been relatively short-lived, and who would have come to be glad of their survival, would give in to despair at their lowest point; maybe the suffering inflicted on loved ones and dependents would be worse than the suffering averted; maybe breaking another taboo around euthanasia would move us toward a dangerous slippery-slope. Those arguments would be interesting to discuss and hard to settle. But your statement seems a bit more absolute than that — I may be misinterpreting you, but it seems like you would claim that the assisted/permitted suicide of a person who is mentally and not physically ill could never be appropriate. And unless you believe that everyone gets better, I don’t understand that. (Unless you’re simply putting a huge amount of weight on the concept of ‘competence to decide’, in which case my question is how you defend that.)
How do you determine when there is no chance of relief from a mental illness? With physical illness, assisted suicide is usually conditioned on expert assessment that the disease will kill the patient within some time horizon (i.e. sooner than one could expect an effective novel treatment to be developed). With mental illness, there is no such horizon (as long as the patient can be kept from suicide or accidental death) and it’s much, much harder to establish that no existing or developing treatment could help.
Given the degree of ambiguity, where should the line be drawn for “no chance of relief” and who should judge where the patient lies with respect to it? Not the patient, because even brief periods of suicidality can feel absolute and interminable.
Maybe the question is easier if someone experiences major depression for, say, ten years straight and tries every legal medication and therapeutic technique with no response. But then what if psilocybin is approved for clinical use two years later or a novel chemical is developed and one of those would have made their life totally livable? Is the doctor (or anyone else who could have a responsibility to prevent the patient’s suicide) in the clear just because the case was really hard and the patient (whose judgment is compromised by the illness they’re trying to escape) really consistently wanted to die for a long time?
I’m not saying it’s categorically impossible to find a situation in which the decision could be made ethically, but I do think the path to it is so narrow and thorny that it’s not unreasonable to just rule it out and not bother trying to develop a formula by which it could be enacted. It’s not that everyone always gets better, but that it’s so much harder to be certain compared to physical illness that the condition may be impossible to satisfy in practice.
What appropriate checks and balances might those be (particularly interested in the second case)?
I ask because my probably overly-simplistic view on a lot of mental illness cases, so-called, is that it’s “well this patient has all the trappings of a good life but his mental life is terrible, which means he’s mentally ill”. Which is kinda funny, because that does not work cross-culturally in many cases.
1/25 is not a “very high rate”. In fact it seems to me almost unbelievably low. If that is the true number you don’t need to look any further for the best reason for why preventing suicide is a good idea.
Interesting numbers here. Very few attempting suicide actually end up killing themselves – one out of ten men, and only 2% of the women. So even if 1 in 25 seems like a low number, repeated attempters still constitute a large fraction of total successful suicides.
I’m always sceptical about what ‘attempted suicide’ means here and if it includes cases that are actually cries for help etc.
E.g. I’ve seen it argued that more women attempt suicide than men and the lower rate of suicide is just that they use less violent methods. But I’d have thought that someone shouting themself in the head can more clearly be judged as attempting suicide than someone who takes an overdose and tells someone (I have personally and through friends known several of the latter)
Since the set is of “first lifetime attempts reaching medical attention”, does it exclude people who died immediately on the attempt?
It seems that it did not, since it [on checking the full study] required entry of a diagnosis code, which I don’t … think? they do for dead-on-scene or dead-on-arrival?
That complicates the result for your purposes, if it’s how that works.
Agreed. It’s mind blowing to me it would be that low and I see that as a strong argument for prevention.
Is a 4% successful recidivism rate really “very high”?
I’d say 1 in 25 is pretty low, if we start with “seriously wants to die” as the baseline.
(I do think your point about choice of method makes sense; serious suicides would certainly seem likely to pick “gun” or “hanging” or something basically certain to work.
The old “cry for help” group would seem likely to pick remediable or uncertain modes, like “handful of pills”.
Equally I don’t have the domain expertise to say how real that categorization actually is in terms of observed data on real suicide attempts, statistically.)
You’re correct that 4% isn’t “very high,” at least not on its face. But I think there are understandable reasons why it appears that low.
The vast majority are treatable and capable of getting better, at least to some degree. It was never my intent to argue against that. A very large majority who attempt suicide seem to get better with help. I’m simply trying to articulate the fact that there ARE people who can’t be cured. Of course, I don’t know that it makes sense to create some kind of legal path to suicide for these people (I tend to agree with antpocalypse; I can’t conceive of a way for the system to implement it). But I think it’s worth remembering in these conversations.
I think that 4% is high because I have a somewhat unorthodox view on repeat attempts. Namely, that they are exponentially more difficult than a first attempt. Reasons for this include:
1) Person has seen first-hand what an attempt does to loved ones.
2) Loved ones are more watchful/aware.
3) Deadly tools are more difficult to reach/have been removed.
4) Injury or pain from first attempt causes increased fear.
5) Stigmatization and judgment from others after first attempt causes embarrassment about how others will view them after a second attempt.
6) Knowledge of potential failure makes person more cautious, more likely to “make certain”.
7) Attempts to be treated result in suicide feeling more like a personal failure (additional/changed relationships with doctors, family, friends, etc. increase the number of people who will be culpable in your failure.)
8) Financial/familial entanglements tend to increase as one ages, which also increases the impact of suicide on those left behind, beyond grief.
9) Awareness of resources and options have increased choices/doubts for moments of crisis.
Etc.
In other words, I’m pretty stunned that so many people would make another, successful attempt inside such a short time frame.
If we believe The American Foundation for Suicide Prevention’s statistics, there are somewhere around 45,000 successful suicides each year. And if 4% of the nearly 1.1 million attempts each year try again successfully, that means that around 45,000 of those who failed the first time will kill themselves within the next five years.
So around 20% of successful suicides in the United States each year are from a repeat attempt within five years of a previous attempt. That does strike me as high.
This is still a fairly surface-level analysis based on correlation. What has happened over time to suicide rates in states that have more or fewer guns than in the past?
Another confounder: overdose deaths that look accidental, but are actually suicides. The opioid overdose death rate seems about right to explain the difference. You could test for this by seeing if accidental-looking overdose deaths spike after high-profile celebrity suicides.
There might be something here. My experience has been that coronial services require fairly clear evidence to rule that a death was intentional: the default presumption is unintentional unless proven otherwise. That suggests that, where the preferred means of suicide can also be seen as accidental (drowning, for example, or “suicide by cop”, to borrow an example upthread) suicides will be undercounted, whereas, in areas where suicide is typically attempted in ways which can’t be misread as accidents the count will be more accurate. Does this apply to guns? I have no idea, but my uninformed speculation is that an accidental gun death looks obviously different from a deliberate one, sufficiently so that the coroner is unlikely to fudge in favour of accidental death the way they might for, say, an overdose.
I’m not sure there’s always a clear line between the two. I can imagine an addict thinking “I feel really shitty, I’ll take a large dose”, and the “suicidal ideations” module in his brain going “yeah, that’s right, take an EXTRA large dose!”
There’s also the problem of, with the modern “fentanyl in everything” mode of opiate abuse (compare with the old “which kind of heroin is it anyway?” mode), that junkies can easily OD without any intention at all.
Cut heroin with fentanyl (or replace it with poorly-diluted same) and junkies are going to OD a lot more purely by accident.
I agree. Maybe it’s only a definition quibble, but I wouldn’t take suicide to include subconscious motivations. It doesn’t matter how daring a BASE jump you attempt, if you consciously intend/hope/want to make it then you haven’t committed suicide if you don’t.
This makes me think of the other case of accidents that may actually be suicides: car crashes. It’s been speculated that, especially among men, a lot of single car accidents are actually suicides. Suddenly driving straight into a tree on the side on an empty road and such. It makes some sense if you don’t want your family to know that you killed yourself. Americans drive a lot.
The opposite is also possible: maybe countries with higher reported suicide rates class some accidental drug overdoses as suicides.
When I read “missing US suicides,” my first thought was that this was going to be about suicides that are recorded as something else. I think this may be an important factor that you could be neglecting.
In the US, gun suicides outnumber accidental gun deaths by about 2 orders of magnitude, suggesting that coroners are pretty good at distinguishing accidental gun deaths from suicides. Hanging is also unmistakable in the overwhelming majority of cases.
But when you look at other methods, things aren’t so clear cut. According to the CDC, in 2015 there were 47,478 unintentional poisoning deaths and 6,818 poisoning suicides, a 7:1 ratio. There were also 33,381 unintentional fall deaths, more than 9 times as many as the number of suicides that did not involve either firearms, strangulation, or poisoning. I can’t find nationwide statistics on fatal single-vehicle car accidents, but in Pennsylvania about half of fatal car accidents involve only one vehicle, and a majority of those involve a single vehicle hitting a fixed object.
So I think we should consider the possibility that would-be gun suicides tend to be substituted for methods that are less likely to be recorded as suicides. In international comparisons, there is also the question of whether there are cultural/institutional differences in the likelihood of classifying certain causes of death as suicide or accidental in ambiguous cases.
Data that might shed light on this question: What percent of gun suicides leave notes or other explicit statements of intent compared to other methods? Are gun suicides negatively correlated with accidental poisoning deaths, accidental falling deaths, and/or single vehicle single occupant car crashes?
I’d really like to know more about what those unintentional poisonings involved before I drew any strong conclusions about how likely they were to be suicides. Fall deaths too: are we talking about someone falling off a ladder and breaking their neck, or are we talking about someone falling from a balcony on the fiftieth floor of the Sketchy Investment Products Building in Manhattan on September 16, 2008?
More than 90% of accidental poisoning deaths are drug overdoses, where it seems like it would be very difficult to distinguish between an accident and a suicide that didn’t leave a note.
As for falls, according to this article, about 42% of fatal falls involve a ladder. Other sources indicate that a large portion of the rest may be made up of old people who trip and hit their head on something hard. The best category to look for accidental fatal falls that might be misclassified suicides would probably be “falls from a large height by people who weren’t working at a job where that is a common workplace hazard,” but unfortunately I can’t find a breakdown that specific.
I like this theory. But as you said, it requires that the OTHER countries that Scott is comparing the rates against to be recording these same kinds of deaths differently. In other words, are Sweden, Canada, and GB all approaching these kinds of deaths (poisonings, single car accidents, etc.) in the same way? Why would the US be approaching them as accidental? Why would other countries be more inclined to call them suicides?
Americans drive more, and are more likely to have a car that other nationalities, so I would expect more suicides by single car accident. My impression is that over-dosable drugs are also more easily available in America.
For instance, large bottles of paracetamol (acetaminophen) are not available in the UK, and may not be available in other places in Europe. Over-the-counter and supermarket sales of it are restricted to blister packs, IIRC of no more than 16 pills (8 grams), and the number of packs you can buy at a time without a prescription is also limited.
EDIT: On looking it up, the limit is 16 pills in a supermarket, 32 over-the-counter in a pharmacy.
Do you know why paracetamol purchases are limited in the UK? Is it an anti-overdose measure, or is there some illicit use of paracetamol that they’re trying to control, kinda like the way the US restricts pseudoephedrine because it can be used as a precursor to methamphetamine?
I’ve heard that supposedly part of the explanation for Japan’s high suicide rate is that any unexplained death is recorded as such, with the implication that yakuza-related killings end up swept under the rug.
There are two claims there. One is that because the official suicide rate is so high, it’s easy to hide murders in them. That’s probably true, since there aren’t that many murders to hide. But why is it high? Your other claim was that lots of deaths are misclassified as suicide. But then what were they, really? Surely not enough murders to drive the suicide rate. Accidents? Could be, depending on what the method is. But a full 60% of (officially recognized) Japanese suicides are by hanging. I don’t think that those are misclassified accidents.
I don’t doubt that the suicide rate is legitimately very high, and by its nature the claim is very hard to prove.
There was a point — this was decades ago and it may very well not still be true — where if a husband killed his whole family and himself, in Japan, all the deaths were considered suicides, where in the US this would be considered murder/suicide.
But I doubt that was ever that big a statistical factor.
“cultural/institutional differences”
Bingo.
We all acknowledge that comparing rates of different crimes across countries is often extremely challenging. Why not suicides?
It’s worth remembering that within living memory, the Catholic Church refused to bury or provide funerals for suicides. It effectively brought immense shame upon the family. In Japan, traditionally suicide had the opposite effect, sometimes the only means of restoring honor to the family. Now, the cultural differences may not be quite so stark today, but do we not think this could have a non-trivial effect on the reported suicide rate across countries? Families may be able to pressure the authorities into reclassifying, and in places where suicide is immensely shameful, there may even be a tradition of tolerating this, an unspoken rule that people will pretend deaths are not suicides unless the evidence is absolutely undeniable.
Heck, nevermind social pressure, think about the cold hard financial incentives created by life insurance. In a country where unusually many people are insured, medical professionals might rule a death as accidental in order to charitably give the family their insurance payout.
That’s an outdated rule. In the US, life insurance does pay out in case of suicide (subject to a waiting period, but past that period courts and regulators have ruled that insurance companies must pay).
Even in the last few years, a friend killed himself, and his death was always referred to as an ‘accident’ until the inquest was completed and returned a verdict of suicide (by which time his Catholic funeral had already happened).
Note though that the same confounder, lack of clarity about whether intent was present in many forms of accidental death/suicide, applies to every other country as well. It might be a factor explaining different reported rates, say if Japan culturally expects suicide so reports all potential cases as such, whilst countries with high religiosity of a type that opposes suicide may choose to interpret the same event as accidental to avoid social implications. Would be a fairly major job of research to prove this though. I don’t think we can use this argument about US statistics only though, as UK coroners are not, to the best of my knowledge, any more able to speak to the dead and ascertain their intent than their transatlantic equivalents.
I’ll post this again, since I hadn’t read this comment and it’s obviously relevant:
My experience has been that coronial services require fairly clear evidence to rule that a death was intentional: the default presumption is unintentional unless proven otherwise. That suggests that, where the preferred means of suicide can also be seen as accidental (drowning, for example, or “suicide by cop”, to borrow an example upthread) suicides will be undercounted, whereas, in areas where suicide is typically attempted in ways which can’t be misread as accidents the count will be more accurate. Does this apply to guns? I have no idea, but my uninformed speculation is that an accidental gun death looks obviously different from a deliberate one, sufficiently so that the coroner is unlikely to fudge in favour of accidental death the way they might for, say, an overdose.
There are only a couple hundred recorded accidental gun deaths every year, compared to 20,000+ gun suicides (see page 41 of this report), so it isn’t possible that a large number of gun suicides are being classified as accidents. My understanding is that, due to powder residue and muzzle flash burns and so on, gunshot wounds where the barrel was very close to or touching the skin look different from wounds where the barrel was even one foot away. Which, for obvious reasons, makes it possible to distinguish between accidental gun deaths and gun suicides with a pretty high degree of confidence.
That’s helpful and seems to close off the avenue I was considering, so thanks
One huge issue then is that you are basically assuming that the US has a large amount of missing suicides from drug overdoses or car crashes getting characterized but that other countries don’t have these issues. I have not checked the veracity of this site, but if correct you have 3x the likelyhood of an alcohol related death in Denmark as you do in the US, or 5.25 more deaths per 100,000. For Germany its an 80% increase for about 1.75 more deaths per 100, if we classified those as suicides that drops more than half the difference between the German and US suicide rates.
Are we actually going through and figuring out all of the regional differences, or are we just looking at headline grabbing or familiar explanations? Does ODing on pills count and slowly drinking yourself to death not? Do we really have a black and white situation outside of “puts gun to head or noose around neck, or leaves note”?
Typo or subtle grammar observation experiment?
All my typos are subtle grammar observation experiments until proven otherwise. Mistakes in my twitter feed are likewise attempts to own the libs when they point them out and then look elitist.
I’m going to go with the scientific consensus being just plain wrong on this one. Or at least overstated or misstated. Sarchiapone et al make a strong case supported by many references that reducing access to common means of suicide results in fewer suicides by that method, but for a reduction in the overall suicide, and particularly for a long-term rather than transitory reduction, the evidence is much weaker. In Sarchiapone, and in my recollection of my own dive into the subject many years ago.
At the societal level, I believe the various high-lethality suicide methods are largely fungible, and strong individual preferences that would deny substitution are themselves the result of known or expected availability of the favored method. Take away Bob’s gun, or make him move from a tall building to a one-story house, and he may not think of another way to kill himself when he’s resigned to being a failure and a burden on his family. Thinking takes effort, and Bob’s really depressed. But take away all of the guns, or tear down all of the tall buildings, and Bob Jr. just grows up with a mental model of “I’d drive my car into a bridge abutment if…”, rather than “I’d eat a bullet/take a leap if…”, and then it takes no effort at all to put it into action.
And I’ve hidden a possible explanation of America’s anomalous suicide pattern in there as well. Because I’m pretty sure one of the major drivers for high-lethality suicide attempts (i.e. NOT drug overdoses), is the perception that one is an irredeemable economic failure, burden on one’s family, etc. And two things that make that seem particularly worth killing one’s self over, are the Protestant(ish) work ethic, and Honor Culture. Which in the United States intersect most strongly among rural, incidentally gun-owning, white males.
This seems very dubious on its face.
From a psychological perspective it’s reasonable to predict that suicide methods would be fungible given roughly equivalent expected degrees of suffering, where “expected” includes the chance of getting the method wrong. It’s very counter-intuitive to predict fungiblity regardless of suffering.
With a gun you do run the risk of not hitting enough of the right parts of the brain, but otherwise the suffering profile hits a sweet spot. Most of the time jumping from a bridge probably amounts to drowning with broken legs. Dropping from a great height onto pavement is more certain, but there are reports of groaning victims, and who knows what the drop time will feel like? Walking in front of a train eliminates the journey (and accordingly seems to be generally preferable) but not all of the risks. Hanging is supposedly lower-suffering when done correctly but that’s hard to pull off on one’s own.
A nitrogen or helium exit bag is probably better than a gun on these fronts (unless just the duration itself is bothersome) but requires equipment not likely to be around for other reasons. Massive doses of seditives are similar except in their effectiveness, and this is probably one reason (besides the “cry for help” factor) they are such a common method.
Regardless, “the evidence is weaker” + a pile of motivated reasoning != wrong.
And yet people keep doing it. In Hong Kong, almost half of all suicides are by jumping from great heights, I would assume onto pavement. Possibly they haven’t read the same reports you have. And how many people understand the actual cause of death in jumping from bridges into water? It factors into approximately 0% of mainstream media and pop-culture discussions of the phenomenon.
The default presumption for any hypothesis is that it is wrong until proven otherwise. If the evidence isn’t strong enough, the presumption stands.
And accusations of motivated reasoning, presented without evidence, are a clear indication that you have departed the path of wisdom and descended into the realm of insult.
But, I’ll stick to evidence.
A dissertation in which ten high-risk suicide survivors in Australia were subject to detailed interviews including choice of method. Ten out of ten explicitly considered multiple methods of suicide in the months leading up to the event; only 4/10 indicated a clear preference for one method over others. 2/10 made actual preparations for one method and then switched to a different method.
Or a study of suicides in Taiwan, indicating that 37% of people who attempted suicide with a highly lethal method (i.e. not drug overdose or wrist-slitting) and subsequently reattempted, used a different method on the later attempt. The most common methods of suicide in Taiwan are hanging and charcoal burning, so this probably isn’t a matter of a preferred method becoming unavailable.
And then there’s the extreme variability in preferred suicide methods. In Hong Kong, as noted, 46% of suicides are by jumping. Across the border in mainland China, jumping is <10% of the total but pesticides account for 62%. In the Baltic states, 70-80% of suicides are by hanging, but just north in Scandinavia that drops to 30-40%. In El Salvador, 86% of suicides are by pesticide ingestion, down to 5% in Mexico. Charcoal burning is big across a swath of Asia, but not elsewhere. And these differences are much greater than the absolute difference in suicide rates between the nations in question.
If suicide rates are non-fungible, if a person denied their preferred method of self-termination probably won't bother to kill themselves at all, then isn't it strangely convenient that such preferences so neatly align with what is locally available, that the integral of (preference for jumping) * (availability of tall buildings) gives highly urbanized Hong Kong almost exactly the same suicide rate that (preference for poisining) * (availability of pesticides) delivers in still-mostly-rural Mainland China?
People, en masse, adopt whatever highly lethal methods of suicide are available in their communities. There are always highly lethal methods available, and the inconvenience or discomfort of e.g. hanging is clearly no deterrent if the local culture decides that hanging is the way to go. And even individuals tend to be flexible if their first choice doesn't pan out.
Per the actual evidence, at least.
I considered it self-evident, and still do. Why would anyone come to this strange conclusion unless to justify something else?
From that study:
You continue;
Can you think of a reason that someone who attempted suicide using one method and failed might use a different method on a second try? Isn’t 37%, if anything, surprisingly low?
And how does variability between societies support the thesis “At the societal level, I believe the various high-lethality suicide methods are largely fungible”?
You claimed that high-lethality methods of suicide were fungible on the societal level. I argued that this was nuts — people have strong preferences for dying one way or another for obvious reasons. Now you’re asking about rates, which either changes the subject or restates the original claim inaccurately. Stable rates are compatible with my claim as long as methods with similar enough suffering profiles are available. It’s also compatible with a reduction in rates without similarity, which would help explain the graphs in the OP above. (And note that I portrayed jumping onto pavement as relatively low-suffering.)
[FWIW, the lack of charcoal burning deaths in the U.S. (and maybe Europe, I don’t know about grilling infrastructure there) is probably due to a lack of knowledge on the subject. The auto tailpipe method has been dropping as emissions standards rise, but was once common, and 60 years ago the head-in-the-oven method was also common enough to be a cliche. Both of those methods (the latter in virtue of coal gas prior to the switch to methane) were, as charcoal burning is, primarily carbon monoxide-based, which is supposed to be a peaceful and painless way to go.]
I have no dog in this particular race, but I have to insist that your assertion here is quite uncharitable.
Regardless of whether you agree with John Schilling’s conclusions, he has nevertheless provided plenty of evidence and reasoning, so you have no basis for asserting that motivated reasoning is self-evident here.
Motivated reasoning is reasoning, not (for example) arriving at a position on faith. And epistemic charity does not require reading every argument (or actually, in the case of the first post, assertion, name-dropping and citation of a past “dive” in place of argument), however bad, as good.
Accuse me of condescending psychoanalysis all you want. When I do it here (in this rather abstruse rhetorical environment we call “SSC”) it’s in a spirit of mirroring, which I take to have an overall positive effect over time. Still, I know the feelings it is likely to provoke and how it makes me look and I go ahead with it anyway.
Sorry, but you’re in the wrong on this one. First, a past dive is indeed evidence when coming from someone who you know has good epistemic standards. Let’s say that you’re having a conversation with Scott Alexander about something, and he says that he looked into it fairly seriously a long time ago, and came to a certain conclusion. It’s not as much evidence as him pulling up a “much more than you wanted to know” post on his phone and handing it to you, but it’s a lot more than zero. John absolutely qualifies to be trusted in that manner, and it’s an isolated demand for rigor to react the way you did to it. Asking for more evidence is fine, but it’s not a strike against him to not trot out a full post on this stuff in the first place. Second, describing anything in his first post as name-dropping is insulting and completely wrong. Sarchiapone was the lead author on the paper, and citing works in that manner is completely normal. He looked at the paper Scott cited and disagreed with Scott’s interpretation.
It’s possible that he’s wrong. I don’t care enough about the issue to try to figure it out. But accusing someone of motivated reasoning when he does a pretty decent job of laying out his case and doesn’t indulge in bad epistemic behaviors is entirely out of line with the discussion norms here.
Referring to a past dive can be evidence, but it counts as argument in at most a degenerate sense.
I am aware that Schilling makes frequent and high quality contributions here in more than one area of expertise, but that puts me under no obligation to generalize that quality to his other various culture-war-y interests. Indeed, that’s not a safe generalization in … general.
In this case my first comment elicited a response that people can judge on the merits and update their sense of his reliability accordingly. I found it both underwhelming and an attempt to mischaracterize the original claim (unless the difference is just due to sloppy language).
You think you’re making a general claim about discussion norms here, but you’re more likely protecting an Anointed Regular. Deiseach trampled (tramples?) over supposed norms every which way and was generally either not commented on at all or defended as an endearing scamp. Anyway, a primary premise of rationalism is that errors such as motivated reasoning are easy to fall into. It’s not inconsistent to point out instances of it when they arise. It’s an entirely ordinary topic of conversation here.
[Maybe you think I’m using the term in another sense. I don’t mean to suggest a conscious rhetorical strategy, but in the way described by the wikipedia article.]
Extraordinary claims call for extraordinary evidence. The claim that people don’t really have preferences about how to kill themselves beyond their knowledge of the lethality of different methods is extraordinary. I mean, I’m happy that John has had such a consistently good life and all but some sanity-checking with people who have thought about this more would have been helpful. Or he could have read the Australian paper he cited more carefully.
Sorry, but no. If you can accuse him of motivated reasoning, I can accuse you of bulverism, and with rather better grounds. Calling people out on their biases in an attempt to win a debate is a bad thing, certainly in this sphere. It moves the focus away from the facts. And to quote Jesus, “he who is without sin, let him cast the first stone”. If you were a good enough rationalist to be without sin on this, you’d not stoop to bulverism.
That’s not his claim. His claim is that people’s choices of suicide method are not inherently fixed, and will change to work around removed options, but not fast enough to show up on most studies. If you’ve grown up thinking that the only way a Real Man commits suicide is with a gun, then not having access to guns is going to stop you committing suicide. But culture isn’t static, and your son is likely to believe that a Real Man can jump from a building or crash his car instead. I think he makes a good point, with a caveat that some methods aren’t perfectly fungible, which is why there was a real drop in suicides after the various CO methods were removed in the west, probably because they were non-disfiguring. (Charcoal-burning seems like something that should be kept out of the public consciousness as much as possible.)
That is not the claim that is being made. That is obviously not the claim that is being made.
The claim that is being made, is that preferences regarding the method of suicide are subordinate to the preference for suicide. That the ranking of preferences, for most suicidal people, is,
1. Suicide by first-choice method
2. Suicide by second-choice method
…
N. Don’t bother with suicide at all
N+1. Suicide by Nth-choice method
rather than
1. Suicide by first-choice method
2. Don’t bother with suicide at all
3. Suicide by second-choice method
…
I do not believe that this claim is extraordinary. It is the alternate claim that is extraordinary, particularly in the strong form required for Scott’s hypothesis, in that it requires that a very large fraction of otherwise-likely suicides, over the long term, “don’t bother with suicide at all” ranks exactly between their first- and second-choice suicide methods.
There is very little evidence for that very precise ranking, and I have I think presented more than adequate evidence against it.
Does epistemic charity now extend to reinterpreting the meaning of fairly ordinary words? I missed that memo.
Anyway, with respect to this specific point:
I don’t see as much relevance to this dichotomy as you seem to. It’s only explanatory against Scott’s point in a world where the impetus to actually attempt suicide is somewhat stable over time, which the evidence presented doesn’t support and which goes against the common (but certainly not universal) “crisis” model. If someone vaguely considering suicide without planning is then “pushed over the edge”, it matters quite a bit what methods are at hand at that time. Someone might face several of these crises without ever actively planning. (And someone else might plan from the start, or plan after not being willing to act the first time.)
So unless the phrase “over the long term” is implicitly narrowing the cases in a way that begs the question, there is no unrealistic “strong form” needed to support Scott’s hypothesis.
Fine, accuse me of Bulverism. I’ll say that that particular charge doesn’t seem to fit given that my reference to “motivated reasoning” was an aside after a couple of paragraphs of explanation, and then people can judge for themselves.
Good lord. PEOPLE GENERALLY PREFER LESS PAINFUL METHODS OF SUICIDE. Not everyone, but most people. The preference has been restated many times in other comments on this page. CO has the additional benefit of a lack of a hard “action cliff” (e.g. pulling a trigger, jumping).
[Disfigurement is admittedly another factor for many people, perhaps depending most on how much the person in question hates their parents in the moment … ]
skef:
… fungibility is the property of a good or a commodity whose individual units are essentially interchangeable.
Does epistemic charity now extend to reinterpreting the meaning of fairly ordinary words?
—
Unfortunately, many people in the community here use “fungible” in a way that is not in accord with its usual usage. Even more ridiculously, they make it into a verb, “funge”, whose relationship to the usual meaning of “fungible” is distant at best. As we can see, this may not be the best communication strategy…
If I understand the claim correctly, it is not that getting rid of all guns today would not prevent some suicides. Not just preventing them tomorrow, many of the people who were going to kill themselves tomorrow would not kill themselves some other day. The claim is that if all the guns were gone, the culture would shift so that most people’s #1 method of choice for suicide was no longer a gun. At which point the gun removal would stop influencing the suicide rate. The influence on the suicide rate would be temporary.
You don’t seem to be interacting with that claim. So it looks like you attacked a claim you did not understand. Which looks uncharitable. Especially when mixed with what could be interpreted as personal attacks on various people.
The first couple sentences here are a little word-salady and the last two are ambiguous. You could mean that the rate would decrease for a while and then stop decreasing, or you could mean that the rate would drop temporarily and then return to its previous level.
The first interpretation would (ironically?) not be epistemically charitable, given this statement:
So we’ll go with the second, which aligns well.
[However, note that I took issue in my original response with the passage I quoted. It’s not clear to me why I necessarily need to address this claim given that that’s not what it said. But: fine.]
My original point was that methods are only interchangeable within similar degrees of suffering (if that). I’ve added that it’s also relevant what is and is not readily available. Guns in particular can be used in a low-suffering way and are (in the U.S. ) often readily available. I don’t see many options with the same profile, and I certainly don’t see such options that wouldn’t be further regulated if people started using them widely to attempt suicide. I would anticipate that availability of helium and nitrogen, for example, would be more restricted if physically healthy people started using them to attempt suicide far more widely. Do you think pulling charcoal off the shelves (or changing the formulation) here is outside of the realm of possibility? I don’t.
Anyway, here is another way to think about the question: Suppose that most drug stores started carrying an over the counter drug-based product that very reliably effected a quick and painless death. Is the proposal that perhaps after a brief increase, the suicide rate would settle back down to exactly what it was before? This is what I find very dubious.
skef:
Are there historical examples where we’ve seen appealing suicide methods removed from a society, and then the suicide rate dipped and either went back to where it started, or didn’t?
My intuition (which I admit up front is not well-informed) is that the “activation energy” of a suicide method probably matters a lot. A fully functional intelligent person can probably come up with like a dozen ways to reliably kill themselves if they decide to; a person in an acute mental-health crisis or personal crisis that wants to end it all is probably not thinking so clearly, and maybe some complicated 8-step plan for suicide will just be too hard for them to work out. For that, a loaded gun or potent easily-reached poison are way more of a risk than something that would require an hour of consistent action toward the goal of death. And one of the things that lowers the “activation energy” of a suicide method is the culture–what are the common ways people commit suicide in your society, that you’ve always heard of people doing and maybe know some people who’ve done?
albatross11:
There are in fact historical examples. The most famous is the UK’s switch from coal gas (which contains lots of CO) to natural gas. Here’s the relevant journal article. Other suicide methods increased (especially in females), but not nearly enough to maintain the same rate of suicides. It reminds me a lot of LeChatlier’s Principle from chemistry: the system attempts to counteract the stimulus, but never succeeds fully.
I wondered if what was going on was that guns are high-lethality, and if guns are not present, if there is regional or cultural or whatever variation in the alternate method of suicide that people choose, and there is a difference in lethality of those alternate methods.
My understanding is it’s pretty easy to kill yourself with a gun or by jumping off a bridge or in front of a train, and pretty hard to kill yourself via poisoning or car accident.
This is kind of similar to the homicide debate, like, if guns lead to a higher homicide rate, is that just because they’re more lethal than knives or fists or cricket bats? Or do people attempt murder more in the US than the UK (I understand the answer to that being that yes, people in the US attempt murder more than in the UK, they aren’t just more successful).
Fatal car accidents are very easy to arrange presuming you have access to a car in good working order. Put the petal to the metal, steer for a bridge abutment or large tree or the like, and don’t stop. Airbags and crumple zones are not magic; this is asymptotically close to 100% fatal in basically any car ever made.
Fatal poisonings are also very easy to arrange, but fatal painless poisonings depend strongly on local resources. Agricultural communities in the developing world still have lots of organophosphate insecticides that are basically low-grade nerve gas and quite effective for suicide; modern western suburbs mostly just have barbituates and tranquilizers that mostly provide painless nonfatal Drama. Carbon monoxide is also harder to come by than it used to be.
I have no doubt that it is possible for a sufficiently competent person to drive a car in such a way that they are almost certain to die. But I don’t think that it turns out that way all that often for actual suicide attempters.
Johan_larson’s link below suggests that this is true, putting car accident and poisoning down in the 70’s in efficacy, though I have no idea how reliable those numbers are.
I suspect it’s a failure of nerve rather than competence. It must take some serious willpower to keep the car pointed at the immovable object with the pedal to the metal, all the way up to impact. You wouldn’t need much time to turn that into a possibly-nonfatal (but probably still quite bad) collision by turning the wheel and/or braking.
Shotgun to the head is the way to go.
http://lostallhope.com/suicide-methods/statistics-most-lethal-methods
I think there might be a useful distinction between short-term fungibility and long-term fungibility, and that most of the research is capturing short-term fungibility.
Consider a depressed person who goes through a long stretch of suicidal ideation. He endlessly fantasizes that he’s going to jump off that stupid bridge he drives across every day to his soul-crushing job. One day, he finally snaps, and on complete impulse, he jumps out of his car, rushes to the edge of the bridge, and discovers a large anti-suicide barrier preventing him from dropping off. He collapses in a heap, picks up the crisis phone helpfully placed at the edge of the bridge, and ends up psychiatrically committed. The suicide barrier did its job. But what if this person already knew about anti-jumping barriers? What if jumping off of a bridge never occurred to him as an option?
The same thing probably happens with guns. If you ban, regulate, or restrict gun ownership, transfer, or sale, people can’t impulsively shoot themselves as easily. But if you’re in a country like Britain where nobody has guns in the first place, your suicidal depressive doesn’t ideate about shooting himself any more than someone who lived in a small town without any bridges or subway trains would ideate about jumping off a bridge or in front of a subway train.
If you look at Sarchiapone, a lot of what they found does seem to suggest this. For instance, suicide barriers at prominent suicide spots did reduce suicide from that spot, but had no impact on overall jumping deaths in the city in question. They did make a good case for why CO poisoning might well have been less fungible than other methods (painless, accessible, certain, and non-disfiguring) but if you’re willing to throw out the last criteria, then I expect substitution to happen when what methods people expect to use changes.
Or maybe what happens is that suicide methods are socially-determined leading to delayed fungibility. So in the US people who kill themselves tend to shoot themselves. So if you’re thinking of killing yourself, the availability heuristic kicks in and you think of using a gun. If no gun is available, you’re probably not in your best problem-solving mind and so you’re likely to just not kill yourself.
But let’s say gun ownership goes away. Some people will still kill themselves using other means. So over time, a new suicide meme blossoms. People who think “I should kill myself” no-longer think “I should use a gun. I don’t have a gun. I give up.” Instead, they immediately turn to another method. So the lack of gun ownership is not an obstacle to their suicide.
An experimental test would be if the suicide rate rebounds after a while when you remove a suicide method. (It wouldn’t rebound completely since the new methods might be less effective. But I would expect it to rebound a bit.)
This is the thing I’ve always wondered about when this discussion comes up. I recall the common example that’s made when talking about how getting rid of a method “permanently” reduces the suicide rate is the change from town gas in the UK resulted in a marked decrease in overall suicides in the 60s (?) or something. Well, then how do they have a higher rate now?
So what about other high gun ownership societies?
Serbia has the second highest per capita gun ownership in the world by some estimates. Their crude suicide rate is comparable with Western Europe. Cyprus has the highest gun ownership rate in the EU and one of the lowest suicide rates.
Rounding out the top 5 we have Yemen and Saudi Arabia. I am not exactly sure who makes a good comparison for Yemen if I use Sudan (another poor country with a Muslim majority and a recent history of war in the area) they are much lower and likewise for Eritrea. For Oman they are higher. Saudi Arabia is pretty close to other Muslim states in the region: identical to Jordan, just lower than Kuwait, and just above Syria, Lebanon and Egypt.
What about countries at the bottom of the firearms per capita ranks?
Absolute bottom is Tunisia at .1 firearms per 100. Their suicide rate is higher than the US, Morocco, and Algeria and pretty close to Libya.
The rest of the bottom five for firearms per capita are East Timor, the Solomon Islands, Ghana and Ethiopia. East Timor and the Solomon Islands are above a lot of other island states for suicide (e.g. Vanuatu, Samoa, and Mauritius), but below Micronesia. Ethiopia is high suicide country (much higher than South Sudan or Kenya) but on par with Uganda (which is also pretty low on guns). Only Ghana shows a pretty large drop in suicide rate, but I have no idea who is a good comparator – Burkina Faso is terribly different on culture, Ivory Coast has had a couple of civil wars recently, and Togo had a major refugee crisis while Ghana is one of the best run African countries by many metrics.
Looking at low gun toting nations seems like it should be more informative – after all the US is really weird about a lot of things (e.g. super power status). Likewise we can see some much larger differentials in firearm ownership rates (e.g. the US to Canada is only a ratio of 3:1 while Ethiopia to Kenya is 1:16). Spitballing sure seems to show a messy protective effect on international suicide rates if one exists, but I just glanced at the relevant Wikipedia tables. Is there actually a correlation between suicide and firearms per capita?
I mean I could buy that one country is an outlier, but Jordan and Saudi Arabia share ethnicity, monarchy, a border, and religion but a three fold difference in firearm ownership amounts to a big fat zero difference in suicide rate.
Thanks, this is a good point I should look into more.
I think the main factor is that other countries have so much lower per capita gun ownership than the US that they don’t have that many firearm suicides relative to total amount. In Belgrade (best data I could get on Serbia), firearm suicides seem to be only about 5% of suicides (probably more in rural Serbia, but no US state is that low). Same in Saudi Arabia. I don’t know why some countries with so many guns have such low firearm suicide rates. Culture, maybe?
Looking at https://en.wikipedia.org/wiki/List_of_countries_by_firearm-related_death_rate , we find that Serbia has about 2.5 firearm suicides per 100K, vs. the US’ 7.1. Most countries near Serbia have about as many guns as it does, but Serbia having +2.5/100K extra suicides above its base rate seems plausible,
I’m actually kind of suspicious of all of this because I see other data saying Serbia has some of the world’s highest suicide rates, and other data saying other Balkan countries have firearm suicide rates 3x that of Serbia with fewer guns, so it’s pretty confusing and I don’t know if I trust any of those countries to have good data.
Is gun availability really that much lower though? Focusing on guns per capita has always struck me as odd for homicide and it seems downright terrible for suicides.
It is my understanding that firearms in the US are heavily skewed in their distribution with “collectors” owning a sizeable fraction of the total arsenal. After all the median American has zero guns in their home. Mother Jones (via Google previews) tells me that the average gun owner has 8.
With about one-third of Americans owning guns is that all that much different from places like Yemen or Serbia? After all Americans who like things tend to own a lot more of them than other societies (e.g. shoes, cars, and private airplanes). Is there really that much difference between having one gun in the home (my overwhelming experience in the military overseas) and >four (my overwhelming experience among US gun owners)?
I could be wrong, but given that the US has only about three to four times the number of guns per capita of a lot of societies I would strongly guess that we are looking at no more than a factor of two difference in the number of households with easy access to guns between the US and a lot of other places (e.g. Canada, France, Norway, Finland, Switzerland, Yemen, Cyprus, Serbia).
Ultimately I am not sure why suicide rates would rise with firearms only for developed nations as opposed to everyone. Whatever magic sauce links firearms and suicide in the developed, secular, or whatever world should also apply to places like Yemen or Saudi Arabia. It seems awfully hard that they all just have lower natural suicide rates than their peers.
Likewise, we should be seeing some very low suicide rates in some of the very low gun ownership countries (after all the UK has 60 times more guns per capita than Tunisia while the US has about 16 times more guns the UK). We have 180 countries in the world, so where are the ones that married low innate suicide rates with low gun access to get idiotically low suicide rates? Indonesia is the only place in the bottom 10 for gun ownership and for suicide rate, but they are still below Brunei and Pakistan.
Maybe it is a threshold model. Maybe it is deeply intertwined with culture, but I just do not see all that many prima facie countries with a suicide dose dependent response to guns when compared to regional/cultural peers.
Here is a website that claims to report %households with guns, by country. But the numbers vary a lot from year to year, so they might not be very accurate. It puts America at 40% in the most recent year and France at 16%. But the number is going down in France and, maybe, going up in America. The most recent year for France was 2005, when America was only at 33%.
If you restrict to handguns, there is a big discrepancy of 20% vs 4%.
Guns per household doesn’t take into account that many households own more than one gun. I’m not sure as many households or individuals would tend to own more than one handgun. Percent of households that own guns (one or more) might lead us to a different statistic entirely.
(first attempt got eaten, sorry if this shows up as a duplicate)
I submit that relying on official government statistics from places like Tunisia, Ethiopia, and East Timor is not a good idea.
In particular, East Timor has had a decades-long civil war that required the presence of U.N. peacekeeping troops as recently as 2012. That doesn’t sound to me like a society that’s likely to have a low rate of firearms ownership.
Imagine doing a telephone survey and asking the respondents whether they have any heroin, crack cocaine, or crystal meth in the house.
How close do you suppose the reported number would be to the actual number?
Hint: not very close.
Addendum:
> Mother Jones (via Google previews) tells me that the average gun owner has 8.
Mother Jones is a lying communist magazine run by lying communists who lie.
If memory serves it is actually part of the reason they have such a low firearms ownership rate in East Timor. East Timor is one of the few places that has a full ban on civilian ownership of guns and has pretty hefty penalties for violating that.
I do know that one of the major precipitating events in said civil war was distribution of firearms to the populace. Unless things have changed recently, they have maintained a pretty severe crackdown on private gun ownership.
And it is not like this is an isolated thing. Pretty much all the very low gun possessing states have average or higher suicide rates for their locality. Indonesia is the only state in the bottom 10 for both suicides and firearms ownership.
Again I can buy that there is something special about America. I can buy that plenty of countries fiddle with the statistics. I just have trouble buying that all of the fiddling results in the same outcome. If guns are a major contributor to suicide rate, then we should expect to see some massive decrements for states with ultra-low gun ownership relative to their peers.
There may be a suicide prevention effect from restricting access to guns, but it sure is not obvious when looking at the countries of the world.
Switzerland is usually regarded as pretty high for gun-ownership, but there aren’t a lot of handguns there and suicide with a rifle is pretty hard.
No, it really isn’t, as e.g. Kurt Cobain and Ernest Hemingway have demonstrated. Hemingway, at least, almost certainly had handguns immediately available, but the shotgun was his personal favorite and that’s what he used.
Its plausible that people like Hemingway and Cobain took a more difficult route than was necessary due to their underlying personalities though.
I was not aware that Kurt Cobain had a reputation for doing needlessly difficult things for, what, the sense of accomplishment?
And no, it is not plausible. It is not plausible because committing suicide with a rifle or shotgun IS NOT DIFFICULT. It simply isn’t. Seriously. Is there a polite way for me to suggest you go try for yourself, without actually killing yourself or violating the core rules of gun safety?
“Swallowing a shotgun” has been used as a jocular term for suicide for as long as I can remember.
Suicide by shotgun might not be particularly hard, but a common failure mode sucks — shooting your face off without hitting anything vital. Not recommended.
I have never put a shotgun in my mouth, or a handgun to my head, but I can imagine that one of those is more visually disturbing. I have, however, held a blade against my wrists with enough pressure to allow blood to escape and can say with high confidence that the visual and initial pain of the actions can significantly change the course of your actions for at least some people.
The fact that mechanically it is possible and perhaps even as easy to use a rifle as a handgun doesn’t come close to covering all of the possible aspects that would prevent some from not trying one of the options. In the same way that you shouldn’t start from the assumption that a person who calls 911 before they swallow the pills is just a better organized version of someone who calls 911 after, you probably don’t want to assume that the mechanical aspects of pulling the trigger are the primary determinant in a psychological decision.
@baconbits: I’m having trouble parsing your post as anything but, essentially, “It’s complicated, you don’t know everything, so shut up”. If there was more to it than that, well, I’m probably not going to shut up but I am willing to listen.
As always, raw guns/capita numbers hide a lot of relevant differences. Are they hunting rifles or pistols? Are they required to be locked up securely? Is ammo restricted? Imperatrix also has a good point about guns/person vs. proportion of households with a gun.
ISTM that the relevant question is “What fraction of the population can fairly quickly (say, <1 hour) put a loaded gun in their hands?" Any adult who keeps guns and ammo around, and probably any teenager in a home with guns and ammo, can probably manage this.
The reason I think this is the relevant question is that if someone's trying to kill himself and he's able and willing to spend a whole day of concentrated effort on the project, I don't think there's any policy other than involuntarily committing him that's going to stop that suicide. There are just too many ways to die. So I'd expect having a loaded handgun in your desk drawer to be relevant to how likely you were to suicide, whereas having the ability to go to the store tomorrow and buy a gun and some ammo is probably not nearly so relevant.
As someone who can say “Burkina Faso is terribly different in culture” from Ghana, do you happen to have a newsletter I can subscribe to?
I could tell you, but then I’d have to kill you..
I seem to remember an early theory mentioned in a sociology class about suicide and homicide having an inverse trend and being correlated with economic stagnancy and upheaval respectively. It was possibly related with Émile Durkheim’s “Le Suicide”, but it doesn’t seem to support this theory.
Of course if such a component would exist, gun availability would have to be an unrelated factor independently increasing suicide rates.
Altitude seems to be a factor in suicides for reasons.
http://theconversation.com/the-curious-relationship-between-altitude-and-suicide-85716
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3114154/
https://journals.lww.com/hrpjournal/Abstract/2018/03000/Living_High_and_Feeling_Low___Altitude,_Suicide,.1.aspx
When the link between guns and suicide is pointed out in America I wonder how much of the correlation is driven by western states having guns and altitude.
Scott wrote about altitude and cited that second link but then rejected it and put it on his mistakes page. I think that the conclusion was that altitude was just a proxy for population density.
It was kind of a weak rejection, since he was mostly focused on the correlation between suicide and happiness:
He says that it strengthens the case that high-altitude states have more suicide, but weakens the case that high altitude directly causes suicide, so I’m not sure what that means overall. The study is paywalled so I can’t read it myself.
New Jersey gun owner here. We have really restrictive gun laws. To purchase and transport a firearm, you need to jump through a bunch of hoops and wait 2-12 months (depending on your town) to get an NJ Firearms Purchaser ID card.
And because gun ownership is so difficult, gun ranges that rent guns have to put some strong policies in place to prevent people from going to the range, renting a gun, and killing themselves. They require that renters either:
1) Have a gun with them already
2) Show up with a friend, and share the gun/port with them
The theory is that if they already have a gun, they already have access to the means, and have no need to come to the range to kill themselves. If they show up with a friend, they are much, much less likely to kill themselves in front of someone they know.
That being said, every range that rents has had a suicide.
Myself, I don’t see why one would choose firearms over pills to kill yourself. And I love firearms. It’s just that such a thing is really messy, and trying to kill yourself with a pistol round in particular has mixed success rates — you could just wind up in a coma or persistent vegetative state instead. (Never mind I’m a Catholic that believes in Hell, but that’s besides the point.)
Pills have a low completion rate and can take forever. Tylenol, for instance, can result in lingering for days. Very few drugs are able to be: quick, irreversible, and mostly painless. Guns have very high completion rates because people think they will be painless and it is frightfully easy to exsanguinate from a large hole in the head even if it misses the instant kill stuff.
If I chose to go, I’d go for an overdose, of some drug people accidentally kill themselves using.
Some people die chasing the dragon? Great! That sounds like the way to go; it is so subjectively great people risk death to do it.
(There is a fully general recommendation here. I mean, if you are going to kill yourself anyways, you might as well do something fun. And hey, maybe you’ll find something you prefer to death. See if you can hit the LD50 of LSD or something. Or maybe not that, that might be terrible.)
My SO working in mental health talks about how one of the questions they’re supposed to ask to help distinguish seriously suicidal people from people who are less at risk is “do you have a plan”
And it occurred to me that if I was ever asked that and answered honestly I’d be thrown in the high risk group. While I have no suicide intentions of course I have a plan, several. How could I not? Along with some reasonably plausible plans for how I’d take over a plane if I ever had to and plans for how to get away with a murder if I needed to and how I’d induce maximum terror on a countries population if I was a terrorist with a budget of $X. Among my geeky friends that seems close to the norm but apparently normies don’t automatically come up with plans for things they have no intention of pulling off.
So, that being said, nitrogen suffocation. No panic, just sleep. Ideally after putting up copious warning signs to avoid anyone else from getting caught in it.
Yeah… I’d just not answer “do you have a plan” questions honestly. I plan tons of unlikely scenarios, because working through certain kinds of logistical problems is fun.
I think long-lasting SHTF scenarios that a lot of preppers talk about are *really* unlikely, but honestly, gaming it out in your head is kinda fun. And it intersects with my hobbies. I’m into guns (obvious applications), ham radio (same), blacksmithing (ability to make stuff out of scrap), and brewing beer (can manufacture high-value commodity for barter).
And as a plus, having solar and 3-6 month’s supply of food and water, it means that things like major hurricanes and stuff that’s actually likely to inconvenience large numbers of people have minimal effect on my family.
@Cecil
Totally get what you mean. Sometimes mitigation for unlikely threats also work as mitigation for unlikely ones.
If you ever need to defend that, just claim it’s in case of a Con Air situation where the plane has already been taken over by terrorists and you’re trying to regain control before they can fly you into something.
And yes, I definitely have plans for similar things that I have no intention or expectation of ever enacting. I bet, these days, a ton of otherwise normal people have a zombie outbreak plan, for example.
having a zombie outbreak plan is just good policy in general.
https://www.cdc.gov/phpr/zombie/index.htm
One possible reason why Australia and Canada would have much higher suicide rates than the mother country: each has a significant aboriginal minority with a grotesquely high suicide rate (3% of Australia’s Population and 5% of Canada’s versus 1% of the US)
The Australian aboriginal suicide rate is 2x the general rate. That’s grotesque, but it doesn’t have much effect on the total. It just makes it 3% higher. It’s doesn’t explain the difference from the UK.
The Inuit suicide rate apparently is ten times the Canadian average.
Yes, the Canadian example is more extreme than the Australian. But there are hardly any Inuit; the 5% is mainly First Nations, with a rate 5x the national average. So that bumps up the figure by 25%, which is getting somewhere, but not most of the difference.
I’m not sure you can ascribe suicide rates to ethnicity though. Are the suicide rates for aboriginal minorities actually higher than those for other economically and socially bypassed communities in those countries? And do the rates remain as high for members of the ethnic group who have integrated into mainstream society? Only with comparative information can we be sure that ethnicity is a cause of suicide.
Ethnicity may be a factor.
In EU, Hungary has one of the biggest suicide rates (19), Romania is just average (11).
http://ec.europa.eu/eurostat/web/products-eurostat-news/-/DDN-20170517-1
In Romania, there are two counties with majority Hungarian populations: Harghita (85% Hungarians, suicide rate 25) and Covasna (74% Hungarians, suicide rate 24):
https://ziarulunirea.ro/wp-content/uploads/2015/06/sinucideri-2.jpg
The 2 counties also have mountains on much of their surface – but Hungary is mostly plain.
And civilians can’t have guns in Romania, except the hunters.
I wouldn’t claim that Aboriginals in Canada commit more suicides because they’re aboriginal, there’s ample reason to believe that the reasons are almost entirely social- the results of generations of ethnocide followed by generations of bad government policies trying to ‘help’ them. I’m just observing that the existence of these communities might skew the statistics when observed on a national scale.
In the comparison of suicide rates between ethinicities, I’ve always assumed that community cohesion has played a large stabilizing role. Many minority groups often have really strong identities that give them a sense of belonging, which acts as a protective factor against suicide. White identity doesn’t have this sense of belonging and so the protective factor is completely lacking.
Interestingly, black suicides have been increasing over the last 5-10 years, and I’m wondering if that’s a sign that the sense of belonging to the black community is starting to fray.
Then why do some minorities have very high suicide rates?
And why do white minorities (like Afrikaners) have a high suicide rate?
Answer: Because it’s in large parts genetic. Like everything.
Not sure why that is stronger than if you switched ‘genetic’ for ‘cultural’.
There are genetic variants linked to suicide risk but they only explain a small fraction of the observed suicides.
Is there adoption study data on this?
The obvious intuition here is that there would be genetic predisposition for some mental illnesses (depression, bipolar disorder, schizophrenia, alcoholism) that then often lead to suicide. But data is always better than speculation.
There’s some meta analysis
https://www.biologicalpsychiatryjournal.com/article/S0006-3223(02)01748-1/abstract
Also some twin studies comparing monozygotic twins vs dizygotic but are mostly small.
Scott should have first decided ahead of time what his hypothesis is, what statistics he would look up, and what results he would consider to confirm or disconfirm the hypothesis, then looked at the statistics and figured out whether they confirm or disconfirm it by his standards. Otherwise it’s just p-hacking, and whatever answer he gets is not a conclusion, it’s something that itself needs to be confirmed.
You can’t modify your hypothesis to fit the data and then use the data as proof of the hypothesis.
And it’s unlikely that he thought up the hypothesis “The US’ average-seeming suicide rate is an artifact caused by combining the low base with the distorting effects of high gun availability” ahead of time. (And he can try to confirm it by, as someone else suggested, checking the suicide rates before and after gun laws are passed.)
Hmm.
I think part of the explanation here is cultural mediation of suicide reporting.
I could find a lot of studies on suicide risk and protective factors, but not so much on reporting factors even though we anecdotally know them to have a strong influence on whether a given death is reported as accident or suicide. In the old days, a young woman with child out of wedlock might kill herself rather than bear the shame, and such a suicide, while known to be such by her family, community and the police, would be reported as an accident.
For example, I’m not sold thst Japan necessarily has much higher rates of people deliberately killing themselves than other developed countries; I suspect that a big part of their apparently higher rate is that they have a culture where suicide is not as taboo as in those countries heavily influenced by Christianity. A person killing themself in Japan is engaging in, frankly, a traditional activity. They are less likely to hide it, and it is less likely to be misreported since it is seen as less shameful. Conversely, a Catholic from a Catholic family is more likely to try to make their suicide seem like an accident, and a Catholic community with a Catholic dominated coroner’s department is more likely to want to accept that the death was something other than a mortal sin and report it accordingly. In this way, overall reported suicide rates are probably attenuated by cultural factors.
CDC stats suggest this may play a part. Part of my job is investigating motor vehicle accidents; many, many fatal single vehicle accidents may or may not be suicide, but almost none are ever reported as suicide. 44,000 suicides are reported in those stats, of which 22,000 are reported to be by firearm; 37,000 deaths by motor vehicle accident are reported, but only 429 accidental deaths by firearm are reported. Suicide by motor vehicle, despite being apparently reasonably common, is not reported. If you plot suicide rates vs vehicle accident death rates, you even get a neat correlation where as people stop dying in vehicle accidents, more seem to start dying by suicide – almost as though as cars become safer, and so harder to kill yourself with in a way that gets written off as an accident, more people start killing themselves in ways that aren’t written off as accidental. This provides some support to the general idea above, but also suggests that some means of death seem far more likely to be chalked up as suocide than others, either because of some bureaucratic policy that makes it hard to rule something like a single vehicle accident a suicide, or because we’re culturally primed to associate certain means of death with suicide more than accident.
Basically, I think there’s more here.
That wasn’t a great link on vehicles vs suicides, but the stats follow the same trend for groups other than 10-14 year olds as well. https://www.cdc.gov/media/releases/2013/p0502-suicide-rates.html
In societies where life insurance can refuse to pay out on suicides I would imagine that more suicides would be by “deniable” means.
actually makes me wonder whether there were sudden dropoffs in road deaths and uptick in recorded suicides in places where laws changed to prevent insurance companies refusing to pay after suicide.
Also, in the other direction I’ve seen some speculation on how many teen suicides are actually something like auto-erotic asphyxiation where the people who found the body put some pants on their loved one to make it look like a “normal” suicide.
And speculation that in japan, since suicide rate is high and murder rate low… if you actually commit murder you just have to make it look vaguely plausibly like a suicide to get it written off without much question.
And having watched The Heathers, I wonder how easy it would be to murder a teenager and make it look like suicide.
In order to make this work, you need two separate and somewhat extraordinary hypotheses to nearly cancel out. First, you need some force that causes the United States to have a suicide rate maybe half that of the rest of the developed world, modulo a few small outliers like Israel. Second, you need some force that makes guns specifically likely to incite suicide in a way that things like coal gas and tall buildings don’t. Because availability of coal gas, tall buildings, etc, are subject to substantial regional variation and in the case of coal gas to having the societally-preferred suicide method banned across nations over a modest period of time, yet the effect on suicide rate of those variations is much smaller than the twofold or greater impact you posit for guns. Jumping off a convenient bridge or balcony is no harder than loading and shooting a gun, nor is blowing out a pilot light and turning on an oven; all three (and many more) are widely believed to be painless and highly effective means of suicide, but it’s specifically and only guns that can drive massive increases in suicide rate.
Which effect turns out to be just as strong as it needs to be to cancel out the “missing US suicides” and put the US solidly in the normal range for developed nations – right where it would be if there were neither a mysterious suicide depressant that operates between the 49th parallel and the Rio Grande nor mysterious gun rays that incite people to suicide.
Occam’s Razor suggests that for the slope in figure 2, look for a non-causal correlation between whatever drives suicide in the developed world, and whatever drives gun ownership in the United States.
One of the graphs you link to shows that the Asian/Pacific Islander group has low suicide rates.
Others here have sort of danced around this point, but, with the exception of Japan, the graph seems to indicate Suicide is roughly proportional to the extent of the social safety net, especially for mental health.
My (probably unfair.) hypothesis is that the US suicide pool falls off the social cliff into the underclass more readily, and dies of something else long before suicide (alcoholism, drugs, disease, crime.) In other countries, these people receive help, and we’re seeing the failures of a robust social intervention.
Doesn’t sound very plausible to me, to put it mildly.
Just because you’re holding back doesn’t mean the diluted version is worth saying. If you want to write, “what are you, an idiot?”, but instead write, “nuh uh”, you’re still not making a positive contribution.
edit: seeing as a similiar-appearing response has been presumably-crossposted, I want to make it clear that I don’t mean this as a ‘reprimand’ or negative social feedback, just literally that this is something to watch out for. (which I have found myself confusing before)
Thank you for your much more valuable contribution.
Of course I engaged Michael’s hypothesis, no ad hominem involved. You just policed me. For microsnark or something.
See what that did to the atmosphere?
No, in fact, you didn’t engage at all.
All you said was that you disagreed, and that you were holding back by restricting yourself to this contentless nuh-uh, the obvious implication being that you were inclined to excoriate him for his foolishness.
It’s the equivalent of lamenting “give me strength” before you address someone’s argument, minus that last part.
I assumed this was an honest error, arising from a moment of temper. It seems that I was wrong.
It’s traditional here to make arguments based on reasoning and/or evidence rather than plausibility.
There are cultural factors (like performance pressure), environmental factors (like hours of sunlight), genetic factors (depression has a heritability of >0.30) that all differ between populations and are more likely explanations for observed differences in suicide rates.
There is no robust correlation between socio-economic status and suicide (in fact many studies find a negative correlation), the pool of people who depend on welfare is relatively small.
And even if that were all not the case, it would still be wildly implausible that more welfare just leads to more people surviving until they commit suicide.
Scott, since you’re already ankle-deep in suicide statistics, could you spare a word about the “Look at the male suicide rates, men are obviously doing terrible compared to women!” argument used by MRAs and their sympathizers? I feel this is a pretty cheap argument, seeing how many factors influence the decision to attempt suicide (with more or less serious intent), and how many of them are plausibly influenced by the inevitable sexual dimorphism.
As a matter of fact, you mention lots of factors like religiosity, culture/ ethnicity, gun availability… but nothing like a “general level of misery” that would cause people to commit suicide. Does such a measure exist? And how much of a role does it play in suicide rates?
Socio-economic status at least doesn’t seem to be much of a factor. Often it is even found to be inversely correlated with suicide rates, though I can easily see that being confounded by ethnicity.
You could look at happiness research, but that always seemed to me methodologically problematic.
Do you mean that they conclude suicide rates prove men have it worse as a whole? If so that’s clearly absurd. But I’ve mostly seen it as an example of a specific male public health problem, sometimes with the (I think fair) addition that if the stats were the other way round people would be automatially asking how this was caused by oppression/patriarchy/men
The higher successful suicide rate for men and the higher suicide attempts rate for women may reflect that women are more likely to get a positive response to a cry for help, while men may be more likely to end up in a situation where they are truly without hope.
However, it can also merely reflect male stoicism.
Indeed. In general, issues that (are perceived as) mainly hurting women tend to be seen as women’s issues, while issues that mainly hurt men tend to be seen as issues effecting everyone.
With regard to your last paragraph, I think the important thing there is that for issues perceived as harming women, men get little to no support (or additional harm, as in the case of domestic violence), whereas with issues primarily affecting men, men get, at best, an equal allocation of support resources (and in practice, usually less even so, since a woman suffering get a more attention and social support).
@Aapje:
I think that it just reflects that men and women choose different suicide methods: men probably tend to prefer more bloody, tough and certain ones, like guns, women probably prefer less violent methods like pills overdose (and those can be reversed if they are discovered in time).
What is fascinating is that most MRAs, pointing at happiness surveys, seem to think men are getting better off, not worse, except for specific problems.
Likewise, women are getting worse off, as measured by happiness surveys. (Work sucks. I don’t know if the rush to join men was more “Noble joining in a miserable enterprise” or “Naive pursuit of an idealized version of what women thought work would be like”, but it doesn’t really matter.)
The problem is more complex than “Men have it worse, as proven by suicide” – rather, the MRA position seems to be “Men have specific and sometimes quite terrible problems, one of which is a lack of the kind of social support that helps reduce suicide rates”.
But certainly suicide rates are decent evidence that things aren’t as great for men as seems to be the default mode of thinking for some people
@Thegnskald
I think that the usual claim is more that women are becoming worse off or worse off faster than men, not that men are becoming better off.
Mostly it’s used in the sense you describe, yes, but the example I was thinking of was a recent video by Sargon of Akkad, where he said “in a society, I would think you can probably judge who has it worse by who commits suicide the most.”
“Cheap”?
What? Like, they’re trying to trick you into caring about men?
It’s cheap in the same sense that feminists throwing out “77 cents to the dollar” are making a cheap argument. It may be a “true” statement if you read all the fine print, but it doesn’t make the point they think it makes on its own, and the more detailed analysis might or might not support the point.
In the same way, “more men than women committing suicide” could be a public health problem that could be fixed with appropriate policy if only someone cared, or it could be pretty much a (terrible, but hard-to-change) biological constant (like men’s higher rates of violent crime), or it could be a (terrible, and still hard-to-change) cultural artifact, or it could be an indicator of men suffering from terrible oppression of some sort. I’m all in favor of finding out which one it is (and fixing it if possible), but just throwing out some number or ratio is not doing the work.
I’d be careful about explaining away the ratio without first considering whether it is measuring the relevant thing. It seems pretty likely to me that:
1. lacking financial and often physical security might engender a stronger survival instinct, -a habit of considering how one can avoid going under, -which by default pressuposes that this is desirable.
2. That “miserable/disinvested enough to destroy their lives” is (or at least could be) a more relevant measure than “miserable/disinvested enough to destroy their lives *instantly*”. Certainly a life of crime is much shittier and more reprehensible than killing yourself, but is it so totally non-suicidal to not even consider in a comparison? -If three times as many whites kill themselves, and three times as many blacks are in jail, then clearly whites see less reason to hold onto hope?
Meta:
I would like to lobby for a mandatory propaedeutic class for everybody seeking a college degree, not just those going on to study an empirical science.
1. Analyse the way data is collected for biases. This means that the data collection process has to be described and documented. Be sceptical of sources who don’t do that.
2. Analyse if the collected data is appropriate for the question at hand. In this case we have data that depends on thousands and thousands of different variables that we don’t control, many that we don’t even know about.
2′. Specifically don’t trust univariate analyses.
3. Separate representations of data like statistics (in the mathematical sense, a form of aggregation determined by a mathematical algorithm), from drawing conclusions. Analyse if the conclusions are actually supported by the data.
3′. Specifically: correlation is not causation.
3”. Please at least put descriptions on your diagrams that explain what they are showing, like e.g. units on the x- and y-coordinates. Like, the x-axes of the first two diagrams show percentages. Of what?
Happy to see that comment threads have already picked up 1 and 2.
In order to compensate for my smugness (sorry!), here is an ample source of on-topic gotcha-lines:
1. Switzerland is a rich and happy country with stable economics, politics and social welfare net.
2. Switzerland has a really high suicide rate.
3. Switzerland has a really low homicide rate.
4. Switzerland has a very high rate of gun ownership.
5. Actually 4) means that many men are drafted into the army and have to take care of their own equipment, including weapons, that’s why.
6. Switzerland supports assisted suicide, like with an application form you can fill out at a hospital. There is an optional field for the reason on this form.
7. Switzerland’s national origin story shares the US trope of taking up weapons and killing the tyrant, thus liberating the village and depicting solving conflicts through violence as a virtue.
8. Celebration of violence as heroism and a path to freedom is actually no important part of Swiss public culture.
There’s also the male/female split.
The apparently accepted american scientific consensus on the subject appears to be that men have more guns and use guns more…. hence the 4-1 suicide. But that seems to fall apart the moment you look at any non US country.
I spent an afternoon a while back searching for suicide stats by method for many countries and it seems kinda devastating for the hypothesis that methods aren’t fungible or that suicide rates are a result of mens methods being more likely to succeed. In some countries men and women use the same methods and you mostly see a similar split between 1/3 and 1/5 female/male. (China claims a lower male than female suicide rate but I kinda wonder if china is messing with their stats)
My vague guess is that men are just more inclined to suicide in general since it seems like a thing pretty much across all continents but when I’ve mentioned it on forums the immdiate response is for people to declare that the scientific consensus is that it’s men+guns+”toxic masculinity” = suicide and that there is no question/debate. which kinda makes me think that the “consensus” in this case is a tad motivated.
Just a bit.
And as you say similar correlations outside the US (in UK men still use more violent methods but I suspect this partially means women are more likely to do things that get classified as suicide attempts but aren’t.
Counting only successful suicides. Some countries I found hanging or poison were used almost identically by both men and women so even when the methods used are the same the high male to female ratio remains.
I’m not disputing the motivated reasoning, but how do you distinguish between “men are just more inclined to suicide in general” and “it’s toxic masculinity”?
Well, if “toxic masculinity” is a real cultural phenomenon and not just a snarl term, then we should be able to talk about cultures of masculinity in different places that’re more or less toxic. And it’s supposed to be responsible for a whole constellation of cultural woes, so it’d predict that other cultures showing those would be more toxic than average, and therefore likelier to have high male:female suicide ratios.
I’d bet a stack of money as high as my arm that no such correlation exists, though.
https://en.wikipedia.org/wiki/Gender_differences_in_suicide#/media/File:Male-Female_suicide_ratios_2015.png
http://thedailyviz.com/2016/06/22/alcohol-consumption-by-country-gender-chart/
I would say that the very specific piece of toxic masculinity that drives this difference is the meme-plex that “real men drink” – the top offenders all have extremely gendered alcohol consumption levels, and suicide and alcohol have a solid link, so there you go.
A toxic masculinity trait that is not equally present everywhere, and which is very plausibly driving some of this.
Visually that seems mostly driven by russia and it doesn’t marry up very well for most other places.
I mentioned that i don’t really believe china’s claims of lower male suicide vs female and I still don’t very much but from a quick google:
“55.6% of men and 15.0% of women were current drinkers”
If china’s claim of 5:4 female male is true then that would fly massively in the face of it being about gendered alcohol consumptions.
Of course it is driven by Russia and a couple of other nations. I was demonstrating that toxic masculinity does decompose into a number of specific cultural ideas about manhood, and that some of the things it decomposes into have obvious effects on suicide rates.
I neither claim nor expect alcohol to be the universal causal agent of suicide or gender difference in suicide, just that it sometimes is, thus refuting Nornagest by existence proof.
Heck, even for Russia, there are more causes for the difference than just alcohol.. but the rest are mostly *also* examples of toxic masculinity, like the hazing culture in the russian army.
You haven’t actually shown a correlation, you know.
Also, decomposing “toxic masculinity” into uncorrelated ideas about manhood (some of which, yes, might affect suicide rates) is exactly what you’d expect to be able to do if it was basically a bogus concept. Correlations between a couple things you think of as “toxic” could be there by pure happenstance; for the term to carry much predictive value, everything under it needs to be fairly strongly correlated. Which is precisely the point I was trying to make in the ancestor, but I guess going for the lazy “refutation” is easier.
To illustrate, let us define a metric “bleem” which decomposes into blood pH, hair color, frequency of erotic fantasies about ferrets, and miles driven per month. Are car crashes caused by bleem? Well, sure, there’s gonna be a correlation. Does that tell us much? No.
@Thomas
You’re sorta missing the point. You seem to be keen to define the concept nebulously enough that you can pull something out of the hat no matter what observation you actually get. You make any attributions to it unfalsifiable and thus useless as a concept.
hormonal differences?
X-linked genetic causes?
You could look at hormone levels or genetics and determine whether there was a correlation between that and suicide rate. With hormones you could potentially look at the effects of altering them, or of intersex conditions (admittedly, confounded by the social effects of violating gender norms for the more extreme changes). Compare these things in a culture with high “toxic masculinity” and low “toxic masculinity”. Though, maybe that itself is downstream of these things …
How confident are we that different countries code the same things as suicide? More religious places may also be more likely to treat a case with no note but that looks deliberate s accidental for the sake of the family etc.
I realize that this may sound like a Sphinx argument, but I think it’s important to be mindful that attempts and deaths under similar circumstances can be classified as accident or suicide depending on demographic and familial relations. Especially when previous methods that could show intention could now look plausibly like an accident though this has often been the case with cars and/or drugs I realize some people brought this up already in several disparate responses, but thought it would be important to at least have some quantifiable measure of it.
In addition, I know a bunch of posters on this thread also have explained a potential for inflated male suicide statistics on this thread, and Fluffy Buffalo mentioned about trying to include a “general level of misery”. At the very least, to try and quantify/assess what ‘general misery’ might be, we could say general clinical depression, and see if it’s a predictor, but based on suicide statistics and depression rates it seems they are only weakly correlated, mainly in Russia and probably Northern Africa. The gender ratio graph for suicides seems to be more telling: In places where depression levels are high, a gender imbalance in male to female suicide rates takes hold.
Perhaps the statistics are not collected well.
I have a vague memory of watching a frontline on how bad Coronors are in most states. I remember coming away thinking that the u.s does not count its suicides properly.
https://www.pbs.org/video/frontline-post-mortem/
It’s interesting that suicide rates are higher for groups that are doing better economically, with Asians over whites over blacks/Hispanics. Maybe the higher rates in Canada and Australia is due to those countries having a larger percentage Asian population? I wonder why that correlation could be—maybe more neurotic and demanding cultures drive people to work harder and earn more money but also push some to suicide?
I think the Christianity point covers this. I think Christians put a lot more stigma on suicide than other religions (or at least more stigma than non-Abrahamic religions), and Black & Hispanic Americans are more Christian than White Americans, who are more Christian than Asian Americans.
My impression is that old traditional Catholicism stigmatized suicide more than most Protestant denominations, and African Americans aren’t particularly Catholic. In any case, traditional Christianity generally prohibits sex out of wedlock and drug abuse, and even more emphatically prohibits theft, assault, and murder. I don’t know why Black and Hispanic Christians would be specifically obedient to their faith’s rules about suicide.
The belief that suicide automatically guarantees Hell is still widespread in the laity, despite being considered incorrect by most modern theologians. That might play some part.
Could difference in access and quality of medical care explain some of the difference in rates of suicide by method? If we have a higher chance of saving the person who attempts suicide with non-firearms than other countries, but not for saving people who attempt by firearms, then our non firearm suicide rate would look low by comparison to those countries, and the firearm suicide rate might look high if our citizens tend to have more firearms. In that case, when we take people’s firearms away, the suicide rate would go down because now people are less likely to actually die from their suicide attempts, but where these people are not able to access medical care as likely to save them from non firearm attempts, the suicide rate might not be significantly influenced by removing firearms,because when they use other methods, it’s similarly fatal.
I don’t know well enough whether countries differ in medical care to the extent that the above scenario would be likely.
Be careful about the term “access to medical care”. If you get found by somebody while you’re in the process of committing suicide, you’re going to get as good care in the US as anywhere. You’re just going to have a large bill to pay afterwards. The ambulance company and hospital won’t stop to check insurance until you’re stable.
Unless you’re referring to the fact that the US is more rural, so there might be less “access to medical care” due to distance, but even there once the ambulance arrives they can probably keep you stable on the ride to the hospital for most non-lethal measures, so I’d be surprised if that was a major driver of suicide rate.
Sorry my wording was unclear. I was referring to the ability to obtain quality medical care that would be likely to save one’s life with non-firearms suicides. (Not necessarily denying people care, primarily the speed and efficacy of the care).
For example, in the US, it’s becoming increasingly more common for people to carry naloxone – if a person was found having attempted suicide by opiate OD, they might be saved by a friend or family member, definitely by the emergency services. However if the person was found having shot themself, depending where they made the wound, they might not be saved whether or not the ambulance makes it in time. In places where ambulances or emergency services are lower quality, this may make a larger comparable difference in the non-firearms attempts, and a smaller comparable difference in the firearms attempts. (Though certainly I would expect rurality to affect whether someone receives medical attention in time – if one attempts suicide in some remote, empty area, like a deserted cornfield, I think it would take a lot longer for someone to find them than someone who attempts in the city, even in an empty street, someone is more likely to walk by and see the person.)
The point I’m making is that the US might just be better at saving people who make non-firearm suicide attempts, but equally good as other nations at saving people from attempts with firearms, and so if we have a lot more firearms, it would put the suicide rate up. If we removed the firearms, we might have an extremely low rate because of a possible higher rate of saving people from attempts without firearms.
Dorothy Parker seems to have thought that some suicides can be deterred by the lack of an acceptable method :
Razors pain you,
Rivers are damp,
Acids stain you,
And drugs cause cramp.
Guns aren’t lawful,
Nooses give,
Gas smells awful.
You might as well live.
Massachusetts and New Jersey may not be all that religious overall, but they are also pretty Catholic states. Catholicism is very anti-suicide, more so than Protestantism on the whole.
My memory is that suicide rates by state tend to be highest in the less religious parts of the country, such as the northwestern quarter of the states. A combination of not much faith and a lot of hunting rifles probably leads to more suicide.
It would be useful to look at the numbers without suicides by the terminally ill. My feeling is that preventing suicides by the non-terminally ill should be a higher priority of policy, while suicides by dying old men in a lot of pain would be a lower priority.
Two more-or-less random thoughts:
a. I kind-of wonder how sensitive this analysis is to choosing other representative states.
b. I wonder how much of this is cultural contagion. Like, are there instances where suicide rapidly either “catches on” in a society or “goes out of fashion” in a society?
As a related aside, I think there are common media guidelines about reporting on suicides in the US. I’m not sure how well they’re followed, or how effective they are, but my understanding is that there’s some evidence that some kinds of reporting on/depiction of suicides in media can lead to copycat suicides. (The version of this we keep doing in the US is doing saturation coverage of mass-shootings, which I think does lead to copycats.) This might also be something different between the US and other societies–I don’t know.
No discussion of this subject can be complete absent this important contribution.
Thanks for an amazing blog!
Not sure why you’re looking at #guns v. #suicides (or #homicides). The question is if there is a correlation between how easy it is to get a gun when you want one, and suicides/homicides. The number of guns may be higher in some states than in others for cultural or economic reasons, but it might be equally easy to buy a gun in both states if you want to kill yourself/someone else. Given the 2nd amendments I guess it’s reasonably easy to find a gun in every state so you wouldn’t expect variance in suicide/homicide rates due to this factor.
Your supposition regarding the constitution is not really accurate; in the United States various states regulate gun purchases according to their own policies and politics. In some states, such as Massachusett, one must apply to the local police department for permission to purchase a firearm, and such permission is usually denied. So far, the fact that it is *sometimes* *not* denied has passed muster in the courts as being an adequate compliance with the country’s constitition. Therefore the number of guns possessed serves as a first order proxy for the policies in effect at the state level. If you suspect that it is not a *good* proxy for policies, you could look up rankings of state policies (these are scored subjectively by various pro- and anti- gun lobbying organizations) and use that instead of ownership rates to redo the analysis.
That’s only really the case for handguns. Massachusetts is one of the few states that requires a quasi-license to purchase a rifle or shotgun, but even there it is non-discretionary, the police have to issue it unless there is a specific, statutory, reason not to.
On the other hand, pretty much anyone who isn’t a convicted criminal (or e.g. already known by their doctor to be suicidal) can obtain a shotgun certificate in the United Kingdom. This allows only non-repeating (e.g. classic double-barreled) shotguns, and only birdshot ammunition, but as has been discussed above this is quite adequate for an easy and very reliable suicide.
Approximately 2.5% of UK households keep at least a shotgun, and approximately 2.8% of UK suicides are by firearm. Suggests that nobody bothers to buy a gun for the specific purpose of committing suicide, but if a suicide happens to have a gun at hand they’ll probably use it. But you’d want to also look at the distinction between US jurisdictions where same-day long gun purchase are allowed, and those where laws impose a delay, to see if there’s a discernable difference there.
Hi,
It seems you are not taking into account another possible reason – biases/noise in the data.
For example, in Israel, (Jewish) suicides are buried outside of the cemetery. There is a very strong preference to not call something a suicide, even if it is, for the family.
A man that walks into a truck would be a “traffic fatality”, a man who shoots himself while in the army will be “Played with guns”, or “Fell in the line of duty”. Many suicides are not written as such.
What is the source of the data for the first two graphs in the article?
One demographic factor that I didn’t see mentioned in the post or the comments is the number of veterans. The US has a high portion of the population that has been on military deployments and veterans are at an elevated risk of suicide. They are also more likely to own firearms.
The percentage of army veterans in Israel is much higher while the rate of suicides is much lower than in the US.
Could suicide methods be semi-fungible?
If I grew up around guns, my conception of “suicide” might be “putting a gun to my head and pulling the trigger”. If guns aren’t available, I’m less likely to commit suicide.
Whereas if I grew up where access to guns is highly constrained, my concept of “suicide” might be “jumping off a bridge” (or whatever) in which case the availability of guns would be irrelevant to my odds of committing suicide?
I’m grateful to never have been there. But if I were in such emotionally pain that suicide was an option, I don’t think it would a calm rational search for the ideal method. In times of crisis, we fall back on embedded patterns. If I’m in crisis and hurting so bad I want to end myself, that might well map to “Get gun, shoot myself!” or “Go to high bridge, jump!” If that default method isn’t available, I might find another way, but I there’s a decent chance I might not.
I suspect much of the answer is the high minority population of the US. Blacks commit homicide at about 7-8 times the rate of whites, according to Justice Department statistics and research by Darrell Steffensmeier (Hispanics are slightly elevated). Minorities also commit suicide at far lower rates.
Surely not the whole explanation, but quite possibly a large part of it.