
I.
It is a well known fact that the gods hate prophets.
False prophets they punish only with ridicule. It’s the true prophets who have to watch out. The gods find some way to make their words come true in the most ironic way possible, the one where knowing the future just makes things worse. The Oracle of Delphi told Croesus he would destroy a great empire, but when he rode out to battle, the empire he destroyed was his own. Zechariah predicted the Israelites would rebel against God; they did so by killing His prophet Zechariah. Jocasta heard a prediction that she would marry her infant son Oedipus, so she left him to die on a mountainside – ensuring neither of them recognized each other when he came of age.
Unfortunately for him, Oxford philosopher Toby Ord is a true prophet. He spent years writing his magnum opus The Precipice, warning that humankind was unprepared for various global disasters like pandemics and economic collapses. You can guess what happened next. His book came out March 3, 2020, in the middle of a global pandemic and economic collapse. He couldn’t go on tour to promote it, on account of the pandemic. Nobody was buying books anyway, on account of the economic collapse. All the newspapers and journals and so on that would usually cover an exciting new book were busy covering the pandemic and economic collapse instead. The score is still gods one zillion, prophets zero. So Ord’s PR person asked me to help spread the word, and here we are.
Imagine you were sent back in time to inhabit the body of Adam, primordial ancestor of mankind. It turns out the Garden of Eden has motorcycles, and Eve challenges you to a race. You know motorcycles can be dangerous, but you’re an adrenaline junkie, naturally unafraid of death. And it would help take your mind off that ever-so-tempting Tree of Knowledge. Do you go?
Before you do, consider that you’re not just risking your own life. A fatal injury to either of you would snuff out the entire future of humanity. Every song ever composed, every picture ever painted, every book ever written by all the greatest authors of the millennia would die stillborn. Millions of people would never meet their true loves, or get to raise their children. All of the triumphs and tragedies of humanity, from the conquests of Alexander to the moon landings, would come to nothing if you hit a rock and cracked your skull.
So maybe you shouldn’t motorcycle race. Maybe you shouldn’t even go outside. Maybe you and Eve should hide, panicked, in the safest-looking cave you can find.
Ord argues that 21st century humanity is in much the same situation as Adam. The potential future of the human race is vast. We have another five billion years until the sun goes out, and 10^100 until the universe becomes uninhabitable. Even with conservative assumptions, the galaxy could support quintillions of humans. Between Eden and today, the population would have multiplied five billion times; between today and our galactic future, it could easily multiply another five billion. However awed Adam and Eve would have been when they considered the sheer size of the future that depended on them, we should be equally awed.
So maybe we should do the equivalent of not motorcycling. And that would mean taking existential risks (“x-risks”) – disasters that might completely destroy humanity or permanently ruin its potential – very seriously. Even more seriously than we would take them just based on the fact that we don’t want to die. Maybe we should consider all counterbalancing considerations – “sure, global warming might be bad, but we also need to keep the economy strong!” – to be overwhelmed by the crushing weight of the future.
This is my metaphor, not Ord’s. He uses a different one – the Cuban Missile Crisis. We all remember the Cuban Missile Crisis as a week where humanity teetered on the precipice of destruction, then recovered into a more stable not-immediately-going-to-destroy-itself state. Ord speculates that far-future historians will remember the entire 1900s and 2000s as a sort of centuries-long Cuban Missile Crisis, a crunch time when the world was unusually vulnerable and everyone had to take exactly the right actions to make it through. Or as the namesake precipice, a place where the road to the Glorious Future crosses a narrow rock ledge hanging over a deep abyss.
Ord has other metaphors too, and other arguments. The first sixty pages of Precipice are a series of arguments and thought experiments intended to drive home the idea that everyone dying would be really bad. Some of them were new to me and quite interesting – for example, an argument that we should keep the Earth safe for future generations as a way of “paying it forward” to our ancestors, who kept it safe for us. At times, all these arguments against allowing the destruction of the human race felt kind of excessive – isn’t there widespread agreement on this point? Even when there is disagreement, Ord doesn’t address it here, banishing counterarguments to various appendices – one arguing against time discounting the value of the future, another arguing against ethical theories that deem future lives irrelevant. This part of the book isn’t trying to get into the intellectual weeds. It’s just saying, again and again, that it would be really bad if we all died.
It’s tempting to psychoanalyze Ord here, with help from passages like this one:
I have not always been focused on protecting our longterm future, coming to the topic only reluctantly. I am a philosopher at Oxford University, specialising in ethics. My earlier work was rooted in the more tangible concerns of global health and global poverty – in how we could best help the worst off. When coming to grips with these issues I felt the need to take my work in ethics beyond the ivory tower. I began advising the World Health Organization, World Bank, and UK government on the ethics of global health. And finding that my own money could do hundreds of times as much good for those in poverty as it could do for me, I made a lifelong pledge to donate at least a tenth of all I earn to help them. I founded a society, Giving What We Can, for those who wanted to join me, and was heartened to see thousands of people come together to pledge more than one billion pounds over our lifetimes to the most effective charities we know of, working on the most important causes. Together, we’ve already been able to transform the lives of thousands of people. And because there are many other ways beyond our donations in which we can help fashion a better world, I helped start a wider movement, known as “effective altruism”, in which people aspire to use prudence and reason to do as much good as possible.
We’re in the Garden of Eden, so we should stop worrying about motorcycling and start worrying about protecting our future. But Ord’s equivalent of “motorcycling” was advising governments and NGOs on how best to fight global poverty. I’m familiar with his past work in this area, and he was amazing at it. He stopped because he decided that protecting the long-term future was more important. What must he think of the rest of us, who aren’t stopping our ordinary, non-saving-thousands-of-people-from-poverty day jobs?
In writing about Ord’s colleagues in the effective altruist movement, I quoted Larissa MacFarquahar on Derek Parfit:
When I was interviewing him for the first time, for instance, we were in the middle of a conversation and suddenly he burst into tears. It was completely unexpected, because we were not talking about anything emotional or personal, as I would define those things. I was quite startled, and as he cried I sat there rewinding our conversation in my head, trying to figure out what had upset him. Later, I asked him about it. It turned out that what had made him cry was the idea of suffering. We had been talking about suffering in the abstract. I found that very striking.
Toby Ord was Derek Parfit’s grad student, and I get sort of the same vibe from him – someone whose reason and emotions are unusually closely aligned. Stalin’s maxim that “one death is a tragedy, a million deaths is a statistic” accurately describes how most of us think. I am not sure it describes Toby Ord. I can’t say confidently that Toby Ord feels exactly a million times more intense emotions when he considers a million deaths than when he considers one death, but the scaling factor is definitely up there. When he considers ten billion deaths, or the deaths of the trillions of people who might inhabit our galactic future, he – well, he’s reduced to writing sixty pages of arguments and metaphors trying to cram into our heads exactly how bad this would be.
II.
The second part of the book is an analysis of specific risks, how concerned we should be about each, and what we can do to prevent them. Ord stays focused on existential risks here. He is not very interested in an asteroid that will wipe out half of earth’s population; the other half of humanity will survive to realize our potential. He’s not completely uninterested – wiping out half of earth’s population could cause some chaos that makes it harder to prepare for other catastrophes. But his main focus is on things that would kill everybody – or at least leave too few survivors to effectively repopulate the planet.
I expected Ord to be alarmist here. He is writing a book about existential risks, whose thesis is that we should take them extremely seriously. Any other human being alive would use this as an opportunity to play up how dangerous these risks are. Ord is too virtuous. Again and again, he knocks down bad arguments for worrying too much, points out that killing every single human being on earth, including the ones in Antarctic research stations, is actually quite hard, and ends up convincing me to downgrade my risk estimate.
So for example, we can rule out a high risk of destruction by any natural disaster – asteroid, supervolcano, etc – simply because these things haven’t happened before in our species’ 100,000 year-odd history. Dino-killer sized asteroids seem to strike the Earth about once every few hundred million years, bounding the risk per century around the one-in-a-million level. But also, scientists are tracking almost all the large asteroids in the solar system, and when you account for their trajectories, the chance that one slips through and hits us in the next century goes down to less than one in a hundred fifty million. Large supervolcanoes seem to go off about once every 80,000 years, so the risk per century is 1/800. There are similar arguments around nearby supernovae, gamma ray bursts, and a bunch of other things.
I usually give any statistics I read a large penalty for “or maybe you’re a moron”. For example, lots of smart people said in 2016 that the chance of Trump winning was only 1%, or 0.1%, or 0.00001%, or whatever. But also, they were morons. They were using models, and their models were egregiously wrong. If you hear a person say that their model’s estimate of something is 0.00001%, very likely your estimate of the thing should be much higher than that, because maybe they’re a moron. I explain this in more detail here.
Ord is one of a tiny handful of people who doesn’t need this penalty. He explains this entire dynamic to his readers, agrees it is important, and adjusts several of his models appropriately. He is always careful to add a term for unknown unknowns – sometimes he is able to use clever methods to bound this term, other times he just takes his best guess. And he tries to use empirically-based methods that don’t have this problem, list his assumptions explicitly, and justify each assumption, so that you rarely have to rely on arguments shakier than “asteroids will continue to hit our planet at the same rate they did in the past”. I am really impressed with the care he puts into every argument in the book, and happy to accept his statistics at face value. People with no interest in x-risk may enjoy reading this book purely as an example of statistical reasoning done with beautiful lucidity.
When you accept very low numbers at face value, it can have strange implications. For example, should we study how to deflect asteroids? Ord isn’t sure. The base rate of asteroid strikes is so low that it’s outweighed by almost any change in the base rate. If we successfully learn how to deflect asteroids, that not only lets good guys deflect asteroids away from Earth, but also lets bad guys deflect asteroids towards Earth. The chance that an dino-killer asteroid approaches Earth and needs to be deflected away is 1/150 million per century, with small error bars. The chance that malicious actors deflect an asteroid towards Earth is much harder to figure out, but it has wide error bars, and there are a lot of numbers higher than 1/150 million. So probably most of our worry about asteroids over the next century should involve somebody using one as a weapon, and studying asteroid deflection probably makes that worse and not better.
Ord uses similar arguments again and again. Humanity has survived 100,000 years, so its chance of death by natural disaster per century is probably less than 1 / 1,000 (for complicated statistical reasons, he puts it at between 1/10,000 and 1/100,000). But humanity has only had technology (eg nuclear weapons, genetically engineered bioweapons) for a few decades, so there are no such guarantees of its safety. Ord thinks the overwhelming majority of existential risk comes from this source, and singles out four particular technological risks as most concerning.
First, nuclear war. This was one of the places where Ord’s work is cause for optimism. You’ve probably heard that there are enough nuclear weapons to “destroy the world ten times over” or something like that. There aren’t. There are enough nuclear weapons to destroy lots of majors city, kill the majority of people, and cause a very bad nuclear winter for the rest. But there aren’t enough to literally kill every single human being. And because of the way the Earth’s climate works, the negative effects of nuclear winter would probably be concentrated in temperate and inland regions. Tropical islands and a few other distant locales (Ord suggests Australia and New Zealand) would have a good chance of making it through even a large nuclear apocalypse with enough survivors to repopulate the Earth. A lot of things would have to go wrong at once, and a lot of models be flawed in ways they don’t seem to be flawed, for a nuclear war to literally kill everyone. Ord gives the per-century risk of extinction from this cause at 1 in 1,000.
Second, global warming. The current scientific consensus is that global warming will be really bad but not literally kill every single human. Even for implausibly high amounts of global warming, survivors can always flee to a pleasantly balmy Greenland. The main concern from an x-risk point of view is “runaway global warming” based on strong feedback loops. For example, global warming causes permafrost to melt, which releases previously trapped carbon, causing more global warming, causing more permafrost to melt, etc. Or global warming causes the oceans to warm, which makes them release more methane, which causes more global warming, causing the oceans to get warmer, etc. In theory, this could get really bad – something similar seems to have happened on Venus, which now has an average temperature of 900 degrees Fahrenheit. But Ord thinks it probably won’t happen here. His worst-case scenario estimates 13 – 20 degrees C of warming by 2300. This is really bad – summer temperatures in San Francisco would occasionally pass 140F – but still well short of Venus, and compatible with the move-to-Greenland scenario. Also, global temperatures jumped 5 degree C (to 14 degrees above current levels) fifty million years ago, and this didn’t seem to cause Venus-style runaway warming. This isn’t a perfect analogy for the current situation, since the current temperature increase is happening faster than the ancient one did, but it’s still a reason for hope. This is another one that could easily be an apocalyptic tragedy unparalleled in human history but probably not an existential risk; Ord estimates the x-risk per century as 1/1,000.
The same is true for other environmental disasters, of which Ord discusses a long list. Overpopulation? No, fertility rates have crashed and the population is barely expanding anymore (also, it’s hard for overpopulation to cause human extinction). Resource depletion? New discovery seems to be faster than depletion for now, and society could route around most plausible resources shortages. Honeybee collapse? Despite what you’ve heard, losing all pollinators would only cause a 3 – 8% decrease in global crop production. He gives all of these combined plus environmental unknown unknowns an additional 1/1,000, just in case.
Third, pandemics. Even though pathogens are natural, Ord classifies pandemics as technological disasters for two reasons. First, natural pandemics are probably getting worse because our technology is making cities denser, linking countries closer together, and bringing humans into more contact with the animal vectors of zoonotic disease (in one of the book’s more prophetic passages, Ord mentions the risk of a disease crossing from bats to humans). But second, bioengineered pandemics may be especially bad. These could be either accidental (surprisingly many biologists alter diseases to make them worse as part of apparently legitimate scientific research) or deliberate (bioweapons). There are enough unknown unknowns here that Ord is uncomfortable assigning relatively precise and low risk levels like he did in earlier categories, and this section generally feels kind of rushed, but he estimates the per-century x-risk from natural pandemics as 1/10,000 and from engineered pandemics as 1/30.
The fourth major technological risk is AI. You’ve all read about this one by now, so I won’t go into the details, but it fits the profile of a genuinely dangerous risk. It’s related to technological advance, so our long and illustrious history of not dying from it thus far offers no consolation. And because it could be actively trying to eliminate humanity, isolated populations on islands or in Antarctica or wherever offer less consolation than usual. Using the same arguments and sources we’ve seen every other time this topic gets brought up, Ord assigns this a 1/10 risk per century, the highest of any of the scenarios he examines, writing:
In my view, the greatest risk to humanity’s potential in the next hundred years comes from unaligned artificial intelligence, which I put at 1 in 10. One might be surprised to see such a high number for such a speculative risk, so it warrants some explanation.
A common approach to estimating the chance of an unprecedented event with earth-shaking consequences is to take a sceptical stance: to start with an extremely small probability and only raise it from there when a large amount of hard evidence is presented. But I disagree. Instead, I think that the right method is to start with a probability that reflects our overall impressions, then adjust this in light of the scientific evidence. When there is a lot of evidence, these approaches converge. But when there isn’t, the starting point can matter.
In the case of artificial intelligence, everyone agrees the evidence and arguments are far from watertight, but the question is where does this leave us? Very roughly, my approach is to start with the overall view of the expert community that there is something like a 1 in 2 chance that AI agents capable of outperforming humans in almost every task will be developed in the coming century. And conditional on that happening, we shouldn’t be shocked if these agents that outperform us across the board were to inherit our future.
The book also addresses a few more complicated situations. There are ways humankind could fail to realize its potential even without being destroyed. For example, if it got trapped in some kind of dystopia that it was impossible to escape. Or if it lost so many of its values that we no longer recognized it as human. Ord doesn’t have too much to say about these situations besides acknowledging that they would be bad and need further research. Or a series of disasters could each precipitate one another, or a minor disaster could leave people unprepared for a major disaster, or something along those lines.
Here, too, Ord is more optimistic than some other sources I have read. For example, some people say that if civilization ever collapses, it will never be able to rebuild, because we’ve already used up all easily-accessible sources of eg fossil fuels, and an infant civilization won’t be able to skip straight from waterwheels to nuclear. Ord is more sanguine:
Even if civilization did collapse, it is likely that it could be re-established. As we have seen, civilization has already been independently established at least seven times by isolated peoples. While one might think resources depletion could make this harder, it is more likely that it has become substantially easier. Most dissasters short of human extinction would leave our domesticated animals and plants, as well as copious material resources in the ruins of our cities – it is much easier to re-forge iron from old railings than to smelt it from ore. Even expendable resources such as coal would be much easier to access, via abandoned reserves and mines, than they ever were in the eighteenth century. Moreover, evidence that civilisation is possible, and the tools and knowledge to help rebuild, would be scattered across the world.
III.
Still, these risks are real, and humanity will under-respond to them for predictable reasons.
First, free-rider problems. If some people invest resources into fighting these risks and others don’t, both sets of people will benefit equally. So all else being equal everyone would prefer that someone else do it. We’ve already seen this play out with international treaties on climate change.
Second, scope insensitivity. A million deaths, a billion deaths, and complete destruction of humanity all sound like such unimaginable catastrophes that they’re hardly worth differentiating. But plausibly we should put 1000x more resources into preventing a billion deaths than a million, and some further very large scaling factor into preventing human extinction. People probably won’t think that way, which will further degrade our existential risk readiness.
Third, availability bias. Existential risks have never happened before. Even their weaker non-omnicidal counterparts have mostly faded into legend – the Black Death, the Tunguska Event. The current pandemic is a perfect example. Big pandemics happen once every few decades – the Spanish flu of 1918 and the Hong Kong Flu of 1968 are the most salient recent examples. Most countries put some effort into preparing for the next one. But the preparation wasn’t very impressive. After this year, I bet we’ll put impressive effort into preparing for respiratory pandemics the next decade or two, while continuing to ignore other risks like solar flares or megadroughts that are equally predictable. People feel weird putting a lot of energy into preparing for something that has never happened before, and their value of “never” is usually “in a generation or two”. Getting them to care about things that have literally never happened before, like climate change, nuclear winter, or AI risk, is an even taller order.
And even when people seem to care about distant risks, it can feel like a half-hearted effort. During a Berkeley meeting of the Manhattan Project, Edward Teller brought up the basic idea behind the hydrogen bomb. You would use a nuclear bomb to ignite a self-sustaining fusion reaction in some other substance, which would produce a bigger explosion than the nuke itself. The scientists got to work figuring out what substances could support such reactions, and found that they couldn’t rule out nitrogen-14. The air is 79% nitrogen-14. If a nuclear bomb produced nitrogen-14 fusion, it would ignite the atmosphere and turn the Earth into a miniature sun, killing everyone. They hurriedly convened a task force to work on the problem, and it reported back that neither nitrogen-14 nor a second candidate isotope, lithium-7, could support a self-sustaining fusion reaction.
They seem to have been moderately confident in these calculations. But there was enough uncertainty that, when the Trinity test produced a brighter fireball than expected, Manhattan Project administrator James Conant was “overcome with dread”, believing that atmospheric ignition had happened after all and the Earth had only seconds left. And later, the US detonated a bomb whose fuel was contaminated with lithium-7, the explosion was much bigger than expected, and some bystanders were killed. It turned out atomic bombs could initiate lithium-7 fusion after all! As Ord puts it, “of the two major thermonuclear calculations made that summer at Berkeley, they got one right and one wrong”. This doesn’t really seem like the kind of crazy anecdote you could tell in a civilization that was taking existential risk seriously enough.
So what should we do? That depends who you mean by “we”.
Ordinary people should follow the standard advice of effective altruism. If they feel like their talents are suited for a career in this area, they should check out 80,000 Hours and similar resources and try to pursue it. Relevant careers include science (developing helpful technologies to eg capture carbon or understand AI), politics and policy (helping push countries to take risk-minimizing actions), and general thinkers and influencers (philosophers to remind us of our ethical duties, journalists to help keep important issues fresh in people’s minds). But also, anything else that generally strengthens and stabilizes the world. Diplomats who help bring countries closer together, since international peace reduces the risk of nuclear war and bioweapons and makes cooperation against other threats more likely. Economists who help keep the market stable, since a prosperous country is more likely to have resources to devote to the future. Even teachers are helping train the next generation of people who can help in the effort, although Ord warns against going too meta – most people willing to help with this will still be best off working on causes that affect existential risk directly. If they don’t feel like their talents lie in any of these areas, they can keep earning money at ordinary jobs and donate some of it (traditionally 10%) to x-risk related charities.
Rich people, charitable foundations, and governments should fund anti-x-risk work more than they’re already doing. Did you know that the Biological Weapons Convention, a key international agreement banning biological warfare, has a budget lower than the average McDonald’s restaurant (not total McDonald corporate profits, a single restaurant)? Or that total world spending on preventing x-risk is less than total world spending on ice cream? Ord suggests a target of between 0.1% and 1% of gross world product for anti-x-risk efforts.
And finally, Ord has a laundry list of requests for sympathetic policy-makers (Appendix F). Most of them are to put more research and funding into things, but the actionable specific ones are: restart various nuclear disarmament treaties, take ICBMs off “hair-trigger alert”, have the US rejoin the Paris Agreement on climate change, fund the Biological Weapons Convention better, and mandate that DNA synthesis companies screen consumer requests for dangerous sequences so that terrorists can’t order a batch of smallpox virus (80% of companies currently do this screening, but 20% don’t). The actual appendix is six pages long, there are a lot of requests to put more research and funding into things.
In the last section, Ord explains that all of this is just the first step. After we’ve conquered existential risk (and all our other problems), we’ll have another task: to contemplate how we want to guide the future. Before we spread out into the galaxy, we might want to take a few centuries to sit back and think about what our obligations are to each other, the universe, and the trillions of people who may one day exist. We cannot take infinite time for this; the universe is expanding, and for each year we spend not doing interstellar colonization, three galaxies cross the cosmological event horizon and become forever unreachable, and all the potential human civilizations that might have flourished there come to nothing. Ord expects us to be concerned about this, and tries to reassure us that it will be okay (the relative loss each year is only one five-billionth of the universe). So he thinks taking a few centuries to reflect before beginning our interstellar colonization is worthwhile on net. But for now, he thinks this process should take a back seat to safeguarding the world from x-risk. Deal with the Cuban Missile Crisis we’re perpetually in the middle of, and then we’ll have time for normal philosophy.
IV.
In the spirit of highly-uncertain-estimates being better than no estimates at all, Ord offers this as a draft of where the existential risk community is right now (“they are not in any way the final word, but are a concise summary of all I know about the risk landscape”):
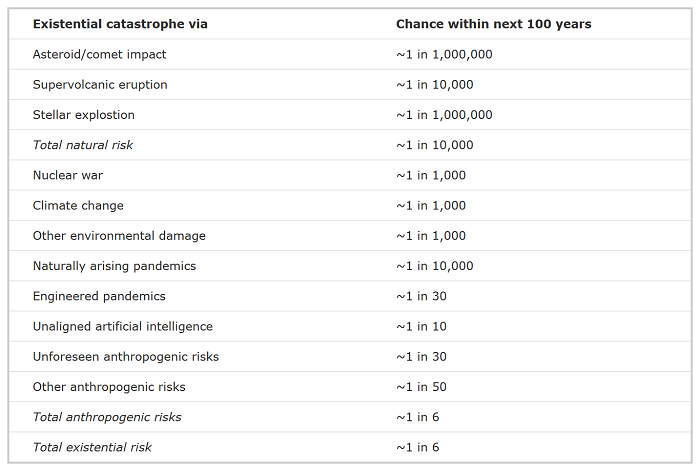
Again, the most interesting thing for me is how low most of the numbers are. It’s a strange sight in a book whose thesis could be summarized as “we need to care more about existential risk”. I think most people paying attention will be delighted to learn there’s a 5 in 6 chance the human race will survive until 2120.
This is where I turn to my psychoanalysis of Toby Ord again. I think he, God help him, sees a number like that and responds appropriately. He multiplies 1/6th by 10 billion deaths and gets 1.6 billion deaths. Then he multiplies 1/6th by the hundreds of trillions of people it will prevent from ever existing, and gets tens of trillions of people. Then he considers that the centuries just keep adding up, until by 2X00 the risk is arbitrarily high. At that point, the difference between a 1/6 chance of humanity dying per century vs. a 5/6 chance of humanity dying may have psychological impact. But the overall takeaway from both is “Holy @!#$, we better put a lot of work into dealing with this.”
There’s an old joke about a science lecture. The professor says that the sun will explode in five billion years, and sees a student visibly freaking out. She asks the student what’s so scary about the sun exploding in five billion years. The student sighs with relief: “Oh, thank God! I thought you’d said five million years!”
We can imagine the opposite joke. A professor says the sun will explode in five minutes, sees a student visibly freaking out, and repeats her claim. The student, visibly relieved: “Oh, thank God! I thought you’d said five seconds.”
When read carefully, The Precipice is the book-length version of the second joke. Things may not be quite as disastrous as you expected. But relief may not quite be the appropriate emotion, and there’s still a lot of work to be done.
















We can’t. Not if we want to reach all those billions of stars one day. You can’t even see the stars from a cave.
My opinions on AI risk are probably getting tiresome by now, but still: I still don’t get how this calculation works:
So, we know for a fact that asteroid impacts can happen. We know how often (roughly speaking) they happen, and we know the consequences (in the extreme cases, planet-wide extinction of all dinosaurs). Based on our knowledge, the probability of the next asteroid impact is 1 in 1,000,000.
We know very little about GAI. We have some vague hints that it might be possible in some way, but currently no one knows how to make one (and not for lack of trying, mind you). There has never been any kind of an AI (as far as we know, modulo the Simulation Argument), so we can’t just count up the AI events and divide by time elapsed. Based on this nearly-total lack of knowledge, the probability of AI risk is 1 in 10, 100,000 times larger than asteroid impacts. Therefore, we should stop worrying about asteroids, and start worrying about AI.
How does this make sense ? As I’ve said before, we have never seen demonic incursions, and in fact we have good evidence to suggest they might be impossible; does this mean that the probability of a demonic incursion is 1 in 2, and we should start collecting Sentinel Power Batteries ? How does lack of knowledge about a proposition make that proposition more likely ?
Also, I get the whole “quintillions of humans” thing. However, if we stop worrying about anything except for total existential risks, we will probably never get to that step. Sure, losing 50% of humanity won’t wipe us out completely, but it would sure set back our prospects of galactic expansions by quite a few years. Maybe even by 10,000 years or so, at which point the next asteroid impact / pandemic / whatever will come along and reset the clock. I’m deliberately ignoring all the other massive issues with this argument, but even if you focus purely on non-existential risk as a threat to (otherwise guaranteed) galactic expansion, it makes little sense.
Ord agrees that we have to work on developing technology and advancing in order to reach the future, he just wants us to do it very carefully. His recommendations aren’t much more radical than “have better nuclear disarmament treaties” and “fund bioweapons watchdogs”. Maybe I’ll take out the passage about the cave.
He also has a passage that I think directly addresses your AI objection:
“In my view, the greatest risk to humanity’s potential in the next hundred years comes from unaligned artificial intelligence, which I put at 1 in 10. One might be surprised to see such a high number for such a speculative risk, so it warrants some explanation.
A common approach to estimating the chance of an unprecedented event with earth-shaking consequences is to take a sceptical stance: to start with an extremely small probability and only raise it from there when a large amount of hard evidence is presented. But I disagree. Instead, I think that the right method is to start with a probability that reflects our overall impressions, then adjust this in light of the scientific evidence. When there is a lot of evidence, these approaches converge. But when there isn’t, the starting point can matter.
In the case of artificial intelligence, everyone agrees the evidence and arguments are far from watertight, but the question is where does this leave us? Very roughly, my approach is to start with the overall view of the expert community that there is something like a 1 in 2 chance that AI agents capable of outperforming humans in almost every task will be developed in the coming century. And conditional on that happening, we shouldn’t be shocked if these agents that outperform us across the board were to inherit our future.”
This is basically just describing Bayesian reasoning, but it’s an unusually eloquent description, so I might add it into the main post.
I don’t like using expert opinion for estimating AI risk, and I’m surprised that so many reasonable people keep doing it. AI experts are disproportionately people who believe AI will be a big deal, otherwise they wouldn’t have gone into the field; and furthermore they’re incentivized to claim that AI will be a big deal, because it keeps their field sexy and prosperous. I don’t know how badly these factors skew their estimates, but my guess would be a lot.
In fairness, I don’t have a better way to get a canonical probability of AGI. Maybe you could try to count all the times in history that a long-shot but physically plausible technology was pursued, and check the ratio of successes to total attempts. But what technologies would belong in that bucket? Alchemy? Moon landing?
EDIT: I’m interested to know the best historical analogues for AGI research, but having thought it over I probably wouldn’t accept a probability estimate based on them. Over time we should expect it to become harder and harder to achieve speculative technological goals, due to the low-hanging fruit effect.
> I don’t like using expert opinion for estimating AI risk, and I’m surprised that so many reasonable people keep doing it…
I’m kind-of one of those people, so I’ll try to defend it two ways. First, I agree with you that we don’t have a better method. That seems like a good argument- but I think we can do even better. It’s often pointed out that experts have mis-predicted previous breakthroughs, such as flight – but the way in which they did so seems amenable to analysis. (That is, it seems likely that despite the fact that experts are wrong, they are wrong in a way that gives information.) But more critically, there are lots of places where they got it basically right,
For example, when it was unclear how long it would take to solve all of the challenges to create a nuclear bomb, in the 1930s, there was still clear agreement that it was at least potentially possible, and that there were challenges. By the time the US was close, there seemed to have been agreement for quite a while that a couple specific breakthroughs were needed. (The Germans realized the same – they just were missing a few specific peices of information that let the allies succeed.) Did anyone predict exactly when we’d get there, years in advance? Not really, but it didn’t matter because we had clear evidence of progress, and experts did see that.
Another example is computers. It was unclear when a general purpose computer would first be built, but analog computers were build before the start of the 20th century, and there were clear indications of progress towards more general electro-mechanical computers. By WWII, governments in the US, England, and Germany (see: Zuse) all thought it was promising enough to devote resources towards it as a priority during the war. That means they thought it was at least plausibly pretty close. Predictions might not have been great, and timelines were unclear, but it got clearer as time went on.
It seems very unclear when we will make AGI, but there is agreement that it’s possible, and most disagreement is on which specific breakthroughs are needed. And that seems to parallel the above two cases much better than it does the case of flight.
And resources to run necessary factories. A-bomb turned out to be quite resource expensive.
http://blog.nuclearsecrecy.com/2013/05/17/the-price-of-the-manhattan-project/
My understanding of the big reason Germany didn’t devote the resources to developing the bomb was because it was both speculative and would require lots of resources to achieve. (Speculative in the sense that nobody knew when it would happen, and there was still some doubt about whether it was possible.) In contrast, RADAR wasn’t speculative, and the fruits were available for use during the war, so lots of research funding on both sides went to that effort.
The reason the US was successful at building a bomb was because it stayed out of the war for so long and had oceans for borders so that invasion wasn’t a major threat. Therefore, it could devote lots of resources to speculative research ventures. Meanwhile, the other allies were hard at work perfecting conventional bombing so far as to develop fire bombing, which was starting to approach the destructiveness of nuclear weapons anyway. The difference between the two approaches to research is that one gets you results you can use in battle next month, or at least next year. If you’re in the middle of a defined conflict, you’re forced to think in that strategic direction, which is why the other countries’ nuclear programs were so far behind that of the US.
In defense of the Nazis (really? how’d I get to this point?) their calculation proved accurate, because the bomb wasn’t ready for the US to use until the conflict had pretty much been decided. Had the Germans put in a similar effort the bomb almost certainly wouldn’t have been ready in time for them to make use of it. So focusing on RADAR instead of the bomb was the right strategic call.
As late as 1939, Fermi himself was skeptical that nuclear chain reactions were possible. Months laters he changed his mind and less than four years later his team activated the first man-made nuclear reactor.
“I think there is a world market for maybe five computers.” – Thomas Watson, president of IBM, 1943.
“I think there is a world market for maybe five computers.” – Der Spiegel, 1965, probably making it up on the spot.
“The IBM archives of Frequently Asked Questions[38] notes an inquiry about whether he said in the 1950s that he foresaw a market potential for only five electronic computers. The document says no, but quotes his son and then IBM President Thomas J. Watson, Jr., at the annual IBM stockholders meeting, April 28, 1953, as speaking about the IBM 701 Electronic Data Processing Machine, which it identifies as “the company’s first production computer designed for scientific calculations”. He said that “IBM had developed a paper plan for such a machine and took this paper plan across the country to some 20 concerns that we thought could use such a machine. I would like to tell you that the machine rents for between $12,000 and $18,000 a month, so it was not the type of thing that could be sold from place to place. But, as a result of our trip, on which we expected to get orders for five machines, we came home with orders for 18.” Watson, Jr., later gave a slightly different version of the story in his autobiography, where he said the initial market sampling indicated 11 firm takers and 10 more prospective orders.”
So apparently it was a different person, it happened 10 years later and he was talking about a specific model, not computers in general. Damn journalists!
The basic reactions for atomic bombs were known going in the 30s. A lot of technical problems remained.
The basic mechanisms for AGI are not known right now.
Big difference.
I read this and immediately thought of the field of microscopy. Have you ever heard of superresolution microscopy? I had a conversation once with a physicist friend about it and he balked at the idea of light microscopy below the diffraction limit – yet here we are.
To be fair, I share your skepticism about the projections people make in the realm of AGI. But I also know sometimes we make huge strides in a field we thought we’d mined dry. Suddenly the low-hanging fruit effect is reversed for a time due to unexpected engineering solutions.
If it helps, I’m not very incentivized to claim AI will be a big deal (I’m a self-funded independent AI researcher) after a few years of mostly independent reading and learning, my view is “holy shit this is gonna be big”.
(I don’t agree with the common view that the alignment problem will be super difficult to solve however. That’s not to say paranoia is unjustified–I’m just saying my mainline outlook is optimistic.)
All these why-didn’t-Germany-have-the-bomb totally miss the point… they DID have nerve gas, in huge quantities, when no one else had it. And they could have both burned down cities with combination fire and gas raids, AND collected all other nations’ tanks and artillery, all by with night bombing against which there was no effective defense.
But their intelligence services just could not imagine that the Allies were too dumb to have noticed nerve gas… even though it was invented in 1902, and the Germans were embarrassed that they had missed it then. (They SHOULD have know by noticing that the Allies were still dragging mustard gas around as a deterrent in 1943, and we took mustard gas casualties from a ship the Germans sunk in an Italian harbor in 1943…)
Maybe nobody actually said it, but in a sense, they were right. Those computers being even larger and more complex than the floor-sized monsters envisioned, and called Google Compute Engine, Microsoft Azure, and Amazon AWS.
Both Ord’s approach and the “start with an extremely small probability and only raise it from there when a large amount of hard evidence is presented” approach feel off to me.
Why must we be able to come up with semi-defensible probability estimates in situations where we’re largely ignorant? Don’t we also have the option of deciding probabilistic reasoning isn’t a tool that can tell us how we should act in every possible situation?
This is a good question. My understanding goes like this:
We have to do some reasoning about it, because we need to either act or not act. Not acting is implicitly saying there’s a low probability, since if there was a very high probability, we would want to act. Even actions as banal as going to the doctor because you have a cough involve implicit probability estimates about whether the cough is serious or whether the doctor will be able to help.
We don’t have to express our reasoning in numerical probabilities. We could just say things like “AI seems unlikely to be a risk now” or “With this new development, it seems almost certain that AI is a risk”.
One very weak defense of numerical probabilities is that they’re just a way of being a little more precise. We can imagine a language that only had two terms, “certainly true” and “certainly false”, and it would be hard to reason very well in this language. Another might have three terms, “certainly true”, “certainly false”, and “maybe”. Another might have a higher gradation of terms, from “probably true” to “somewhat likely to be false”. Using numerical probabilities is just taking this to the limit and having an infinite number of very precise terms.
It’s also acknowledging that you can do precise math with probabilities. If I had to use terms like “pretty likely”, I might have to make arguments like “It’s very likely that Biden will win the primary, pretty likely that Trump would defeat Biden in a head-to-head contest, and somewhat likely that Trump would pass more tax cuts in a second term”, and then I wouldn’t have a good sense of whether those tax cuts were overall likely or unlikely. But if I say “90% chance Biden wins the primary, 70% chance Trump beats Biden, 50% chance Trump enacts more tax cuts”, then I can easily multiply out to say there’s a 32% chance of all three things happening in a row. Obviously this estimate is only as good as the numbers we put into it, but see https://slatestarcodex.com/2013/05/02/if-its-worth-doing-its-worth-doing-with-made-up-statistics/ for why this might still be helpful.
I think you might be strawmanning Chris Smith’s position a little bit (though I could be wrong). He is not saying, “numerical probabilities are generally a poor reasoning technique”; he’s saying “numerical probabilities a poor reasoning technique in cases of insufficient data”.
Hey, thanks for the reply Scott!
I agree that trying to be precise with numerical probability estimates can often be helpful.
I think you’re making a jump here. I agree that in domains that we have some understanding/experience with, there’s a sense in which the decisions we make come along with implicit probability estimates (i.e., I’ve had coughs before, I know people who’ve had coughs, and I have a vague idea of why people cough –> my choice of whether to go to a doctor involves implicit reasoning about the probability that my cough is a sign of a serious health problem).
I take issue with the idea that this is always the case when people make decisions. Imagine you were the first ancient human who accidentally discovered fire. Even if you magically knew of probability theory and Bayesian statistics, I don’t think you could meaningfully assess things like:
-Probability starting another fire could burn the whole world
-Probability fire could cook things
-Probability fire would unleash evil demons
-Probability fire could be used to manufacture awesome new materials
-Probability fire could be used to make disastrous new weapons
—
At some point, some ancient human who discovered fire for the first time must have decided to make a second fire. IMO, it’s much more reasonable to say that person acted despite their ignorance than to say they acted according to (something like) probabilistic reasoning.
I think the insistence that we can (or should) hash out all of our ignorance in the form of probability estimates causes big problems in how the EA community prioritizes among causes. If it’s of interest to you, I discussed this topic in more detail elsewhere.
Chris Smith: Thanks a lot for writing that article and linking it here! I’ve yet to read it, but it seems to be tremendously interesting, relevant, and important to me!
I think there’s an implicit assumption Scott is making in the post he linked to from 2013. He’s not just saying, “it’s worth doing with made up statistics”, he’s implicitly adding the qualifier “for which you have a 95% confidence interval”. Let’s take the example above, but plug in a few CIs. Say those are narrow:
Biden wins primary – 90% +/-3%
Trump beats Biden – 70% +/-3%
Trump cuts taxes – 50% +/- 3%
I’m not going to pretend to do this right, but let’s just take Scott’s original estimate of a 32% probability of tax cuts. Our confidence that this 32% estimate represents reality is high enough that we can start reasoning based on this 1 in 3 chance. Meanwhile, if our CI is wide:
Biden wins primary – 90% +/-30%
Trump beats Biden – 70% +/-30%
Trump cuts taxes – 50% +/- 30%
Our confidence that tax cuts will happen stretches from 0% to 100%, which is about as meaningful as “either it will or it won’t”. This is the underlying subtext of the contention between Scott and Chris Smith. Scott is likely assuming a CI small enough to at least provide meaningful information about AGI, whereas Chris Smith thinks the CI for the estimates is too great to provide meaningful information.
If Scott is right, he got some information out of assigning probabilities. If Chris Smith is right, Scott’s use of probabilistic reasoning is giving a false sense of having learned something.
So I do think it’s useful to define whether applying numbers to a situation is helpful. In this case, maybe we could even use numbers to determine whether numerical analysis is useful. Of course, if we’re making up numbers all the way down, without any solid foundation, well you get out of an algorithm what you put into it.
Thank you, sclmlw. That concretizes my vague feelings on this matter. I’d love to hear a response from Scott on this reasoning. I think this nicely tags the feeling I’ve had for a long time that there was something fishy about this “making numbers up” business. The implied error bars may be wider than 5%, but I agree that they seem unlikely to be as wide as 30%.
@sclmlw
I think that by assigning “confidence intervals” to probabilities, you’re making the mistake that EY rails against in Probability is in the Mind. When we estimate the probability of e.g. Biden winning the nomination–let’s say we call it 90%–we’re not saying that we think he’s going to win 90% of the nomination, or that if we re-ran the election 100 times he would win 90 of them. Either he wins or he loses–one outcome will happen, the other will not. The 90% is describing our state of uncertainty about the outcome. If I’m less confident that he will be nominated, that should be described not by “error bars” on the probability, but by a probability that’s closer to 50%.
So, saying that “a 32% estimate of tax cuts represents reality” is meaningless. In reality, either the tax cuts happen or they don’t. You could ask whether the 32% estimate was well-calibrated–that is, whether among predictions you made with ~30% confidence, about 3/10 of them came true. And if you just want to consider this probability in isolation, you can ask whether it truly represents a logical synthesis of the information you had available or whether it resulted from a miscalculation or you made it up without thinking. But the probability never represents reality–it represents your mind.
@VoiceOfTheVoid
I know Scott does something like that with his annual prediction – giving percentages for each and calibrating the previous year’s accuracy. In those, he only reports predictions at/above 50%, because like you said either it will or won’t happen.
But I don’t get the sense that’s what Scott is doing here. If he were, he’d be making the point that once you combine three probabilities like he did here you don’t get much more out of putting numbers to paper than you do just going with your gut feeling – exactly the point Chris Smith is making that his confidence is too low for a numerical analysis. Instead, he’s making the opposite point – that he can glean useful information out of this prediction of an either/or situation that he says “there’s a 32% chance of”. That feels different than what you’re describing, because the way he presents it sounds like he’s claiming both that there’s a 1/3 chance the tax cuts will happen and a 2/3 chance they won’t happen.
Does he have grounds for that kind of confidence? I don’t think so. I think he has grounds to say, “I have less than 50% confidence in the outcome, which is as useful as a non-numerical estimate.”
The article you linked to is abusing probability, I think. It’s committing the same fallacy as anyone who refuses to switch their guess in the classic “Let’s Make a Deal” situation. You have to update probabilities when you’re given new information, which the author of the linked article does not do when projecting wrong predictions for ‘frequentists’.
That option certainly exists, but I think you’d be hard pressed to argue convincingly in favor of choosing it.
If you’re interested, I tried to make that argument here.
@Chris Smith:
It’s a great article, thanks for posting it. I really enjoyed the dry yet brutal style.
@Chris Smith-
I appreciate the article. It sounds like the EA movement doesn’t understand probability modeling very well. The recommendations you make at the end are all quite simple and tractable. The “Optimizer’s Curse” has simple solutions if one takes the time to think and look at past results.
Could you possibly elaborate a bit on “Wrong Way Reductions”? I’m not sure I quite understood what you were getting at. Is this just people claiming “To solve this [moderately challenging problem] is easy once you have [solved this much more challenging problem]!” and then failing to provide a good solution to the second problem?
@Bugmaster –
Thank you, really appreciate that!
@matthewravery –
Thanks! I’d clarify that I don’t so much think the EA community doesn’t understand probability modeling as I think the community is wrong about the boundaries of where probability modeling is useful (for situations where probability modeling is appropriate, I think there are a lot of people in the community that are way more skilled with the math & reasoning than I am).
In my view, probability modeling is sometimes super useful for handling uncertainty, sometimes kind of useful, and sometimes useless. There seems to be an idea in parts of the EA/rationalist community that probability modeling must always be useful for handling uncertainty.
On wrong-way reductions, I think you understand most of the idea. People often solve hard problems by reducing them to easier problems. A wrong-way reduction comes up when people take a hard problem and reduce it to something that looks like an easy problem but isn’t.
Hardcore utilitarianism is a good example. Figuring out how to handle ethics is hard. Utilitarianism is appealing because it can turn ethics into an easy math problem if we assign utilities to everything. Strict utilitarianism ends up as a wrong-way reduction because it turns out that assigning utilities to everything in a satisfying way is super hard (or impossible).
While utilitarianism has the appeal of initially looking simple, we know it’s really not since philosophers have had to come up with a hundred different flavors of utilitarianism, none of which are entirely satisfying.
I’d strongly recommend David Chapman’s article where he coined the term.
Phil Tetlock’s forecasting research showed that the best forecasters tended to be probabilistic thinkers. He randomly gave probability training to some and saw their forecasting ability improve. To illustrate, here’s a quote from his book on Bayes:
I’m not aware of any research where discouraging participants to think probabilistically produced an improvement in forecasting ability.
I agree with your suggestions at the end though. BTW, I’m very sympathetic to Nassim Nicholas Taleb style critiques of overcomplex models that have fancy math just for the sake of fancy math.
@Reasoner
It can both be true that probabilistic thinking increasing prediction ability, but also increases overconfidence. Did Tetlock look at overconfidence separate from prediction ability?
Sorry, I’m not sure I understand. It sounds to me like Ord is saying in this passage (*), in Bayesian terms, is that our prior for AI risk should be extremely high. I say “extremely”, because I struggle to imagine any other catastrophic global event with a 50% chance over 100 years (which is the prior he’s starting with). I understand that he’s basing this on consensus in the expert community, but I don’t think his estimate is accurate (we can talk about that later, if you’d like, and Briefling offers a similar opinion above). I could also point out that AI researchers have been consistently wrong about the progress of their research, ever since the 60s.
But even given this extremely high prior, are we warranted in updating it down from 0.5 to 0.1 given the scant evidence ? This is a 5x reduction, which sounds significant — but it looks to me like most (if not all) of the other items on the list received a much higher reduction. Should we not take this into account when we try to essentially patch up holes in our predictions with guesswork ? What about all the evidence contrary to the claim; does it not also play a role ?
Broadly speaking, I agree that if you set your Bayesian prior high enough, you can arrive at whatever conclusion you want; but this IMO is a weakness in Bayesian reasoning (and one reason why we still have Creationism), not its strength.
(*) Just to clarify, this is my own [mis]understanding of his passage, I’m not trying to strawman him.
I think you’re misunderstanding Ord’s argument. 50% is the likelihood that general AI is developed within the next century, not that it is an existential risk. This is the information he includes to come up with the 10% x-risk number. From my perspective, this is still a gigantic flaw, as 1/10 suggests that conditional on AGI being developed, the chance that AGI is an x-risk is 1 in 5. It’s unfortunate that so often, people who write about x-risk have a favorite. A 1/5 prior that AGI is an x-risk is laughable, given the broad range of possible technologies we might call AGI. I think something like 1/100 is more believable.
See here:
The 1 in 2 is referring to AGI existing in the next century in general, not any of the various doomsday scenarios contingent on its existence (which would have a 1 in 2 multiplied by the chances that one of those scenarios occurred, assuming AGI existence)
@bholly, Purplehermann:
I stand corrected, but I’m with bholly when he says,
However, I personally don’t believe that even the probability of AGI arising at all is anywhere near 50%; although that depends on “the broad range of possible technologies we might call AGI”. If you define AGI broadly enough, then of course you can increase the probability of it happening. But if you define it as something like, “a machine that can solve any conceivable problem when it is stated in conversational English”, I’d say that the chances of that happening are a lot lower than 50%. Oh, and the chances of it taking over/eating/destroying the world are a lot lower than 1/100, as well.
Again, I would argue that assigning high priors to hitherto unseen events is a poor strategy, since it compels you to waste resources on pursuing pretty much every weird scenario that comes along.
@Bugmaster
I don’t know what the referenced experts considered 1 in 2, or why they use those numbers.
I’d prefer to hear from experts in the field rather than conjecture possibilities, I feel like I could make a plausible (to myself and other people who don’t understand the field) case for a very wide range of probabilities for various definitions of AGI, which translates to “I have no idea and am very suspicious of any estimates that aren’t using appeals to authority, and think everyone else should think similarly “.
Do you have good reason for those priors?
In regards to high priors and unseen events, how would you set your priors?
A portion of the risk of AI taking over is that humanity itself just gives up because it can’t measure up.
Given that humans typically don’t give up even when demonstrably shown multiple times that they can’t measure up to other humans I see this as an unlikely event.
What??
A common trope in science fiction is the species (sometimes human, sometimes not) that just sort of withers away and dies when confronted with an obviously-superior competitor.
But there are no experts on AGI. If the object of your study has never existed, and if you have no clue how you might create that object, then you’re not an expert.
There are experts on machine learning etc., but the state of the art is a far cry from AGI, and machine learning experts have no clue how to build an AGI or how an AGI would behave. Besides, the entire field of AI has a 64-year long tradition of not having a clue about when and how to achieve anything close to AGI.
Together with what Briefling said regarding AI researcher bias, you should take everything that field says about AGI with a huge grain of salt.
Full Bayesian always starts with 50%
Two hundred years ago, the idea of UFAI or nuclear weapons was inconceivable. We have received little Bayesian evidence about them since. If the mean time between UFAIs is now around 1000 years, the odds are that we will be destroyed by something novel and currently inconceivable before then, since the current base rate of notable new anthropgenic existential risks per century is about 1.
The idea of an artificial being going rougue actually existed since at least the 19th century: Frankenstein was published in 1818, and the narratives about the Golem of Prague, set in the 16th century apparently also originated in the 19th century.
Perhaps it represents the adult fear of being repudiated by one’s own children in an era of fast social transformation.
In the scheme of galactic expansion, a pause of 10,000 years is a complete triviality as would be even thousands of such pauses. If things are ‘reset’ and over again but so that something intelligent can survive/re-evolve and then escapes doom on one future cycle that’s as perhaps as good as if we ourselves do so. But since we can’t be confident that intelligence can re-evolve here or anywhere other than being based on humanity, we need to act now with all diligence to keep humanity from going extinct – with far far greater precedence than any resisting any mere reset.
The most important difference between asteroid impacts and AI is not even that asteroid impacts have happened before, and AI hasn’t. It’s that we are not going to do anything that would increase the risk of asteroid impacts (except perhaps the remote possibility of using one as a weapon), while we are actively working on making AIs.
If we were actively working on producing demons, perhaps small demons at first and then try for bigger ones, for some definition of demon that might be at least physically possible, then it would be reasonable to worry about demonic invasions. If we are not doing anything to increase the chance of demonic invasions, and no demonic invasions of serious consequences have happened in the past hundreds of millions of years, then we can upper bound the risk of demonic invasions by 1 in hundreds of millions per year, and worry about them even less than asteroid impacts.
I think you might be begging the question; this is probably partly my fault, since I used the term “AI”, as opposed to the more specific “uFAGI”, thus leading to equivocation. Anyway, the claim here is something like, “our current experiments in AI research will inevitably lead to a superintelligent, nigh-omnipotent, and effectively hostile technological Singularity”. Currently, we’re making pitifully simple AIs (as compared to us humans, at least). I agree that this leads some credence to the Singularity claim. However, such an AGI would not merely be quantitatively different than our current AIs, but qualitatively different. Thus, we wouldn’t be justified in updating our probability all that much, based on this evidence alone.
To put it another way, the Singularity is such an unknown unknown, that I don’t think it makes sense to say “we are increasing the probability of the Singularity by doing X” for any given X — at least, not in any kind of a rigorous, quantifiable way.
That, or maybe you’re a moron. In more friendly terms, the chance that your intuition that general AI is qualitatively different from our current AIs is wrong is orders of magnitude higher than the chance of catastrophic asteroid impacts or demonic invasions. (I don’t share that intuition. Visual recognition, something AIs manage to a large extent, feels about as intractable to me as conscious thought, and it also takes comparable brain power in an order of magnitude sense. From this, my uninformed intuition is that we are at least 20% of the way towards general AI, possibly half way.)
How so ? Can you point to any modern AI that can solve any conceivable problem ? On the flip side, can you get AGI just by hooking up a bunch of data centers all running visual object-classification software ? I would argue that if you take a program that can distinguish dogs from cats, and multiply its computing power a thousandfold, you’d get a system that can distinguish dogs from cats super-fast — and not AGI.
Obviously, I could be wrong, but I just don’t see what you’re basing this “orders of magnitude higher” assertion on.
On a purely personal/subjective note, all of the recent advances in computer vision had given me the opposite impression than the one you got. It’s not that computers had become super-smart; it’s that vision turned out a lot easier to solve (or rather, approximate) than people thought. Granted, winning a race against a snail is still super-impressive if you’ve got to first invent locomotion from first principles, but, at the end of the day, you’re still outracing a snail.
@Bugmaster When I said that general AI is not a qualitative advance, I didn’t mean that you could (say) take a current visual recognition AI technology, build a network with more neurons, and it would be a general AI. I meant that if we go down the current path, with the current pace, for a few decades, we arrive at general AI. Technically this would require qualitative advances. But, since you implied that if a general AI requires qualitative advances, our current progress shouldn’t be considered significant evidence about the chance of achieving it, I assumed that you used “qualitative” more narrowly, and “quantitative” more broadly than that.
As an analogy, Moore’s law held up for quite a few decades, until we nearly hit physical limits. At various points, new inventions in the manufacturing process were needed to keep up the progress. These inventions were qualitative (in a broad sense): they were not just bigger, stronger or smaller versions of the previous processes. Nevertheless, one would have been right to predict that, with a decent chance, these inventions would come at the steady pace necessary to hold up Moore’s law. Your argument would imply that, after 20–30 years of Moore’s law, one shouldn’t have updated in the direction that the law would hold up, beyond the point where a qualitative improvement would be needed. IMO one should have. Similarly, the fact that we managed to solve problems as complex as visual recognition should make us update in the direction that we will solve cognition too.
visual recognition is done by practically everything with eyes, conscious thought is pretty obviously less common.
High quality abstract thought and general problem solving skills used together seem to be restricted to a relatively small portion of humanity.
(Yes I would claim that typical people with an IQ below 100 have a lower quality of thought)
the super AGI talked about seems much much harder than visual recognition
The problem is that progress toward AGI (or any other technology) is not linear. The last 10% of the way could take 500 years, or we might go from 30% to 100% in a few months. This is why Nick Bostrom classifies AI scenarios, in part, on how quickly people get from where we are to AGI.
@Bugmaster – possibly unintentional by you, but the fragment of 10240’s sentence you chose to quote seriously strawmans what he said. Do you realize this?
The wider context (bold mine):
Or put it this way – 1/1000 per century for example should be some orders of magnitude larger than the risk for catastrophic asteroids, at the scale of catastrophe that we’re talking about here.
So the question becomes: are you more than 999/1000 confident about general AI? Suppose you were to try to make a thousand separate pronouncements about what should or should not be possible in a wide range of fields of technology, engineering, and scientific research or about the degree and difficulty of breakthrough required to achieve various results, (lets say, in each case you also magically get to build up about a similar level of personal expertise and knowledge in each field as you do in this case). Would you actually expect to be correct so often that you’d usually get at most 1 wrong, with a decent chance literally 1000/1000 predictions correct?
For some definitions of the above (language is fuzzy), personally I’d expect to be able to do this vastly better than chance if allowed each time to become an expert in the relevant field, but getting literally 999 or 1000 out of 1000 right would be absurd.
I’m guessing that’s what a less straw-manned reading of 10240’s claim in that sentence might be.
@lightvector:
My apologies, I was just trying to save space. My bad.
Yes.
I would not expect to be correct 999/1000 times if I made predictions about some aspects of future cars: their shape, flight capabilities, fuel economy, etc. However, I can confidently predict that they won’t fly faster than light; I can further predict that they won’t be powered by Argent Energy which will destroy us all due to its demonic content.
From my perspective, claims about AGI risk largely fall into three categories:
1). Things that are probably physically impossible (e.g. molecular nanotechnology, verbal mind control, infinitely scaling infrastructure with no diminishing returns).
2). Poorly-defined concepts that sound cool, but have no clear definition (primarily, “superintelligence”) — basically, handwaving.
3). Vast overestimation of current technology; underappreciation of the problems involved (e.g. equating image recognition with fully conscious thought); unwarranted exponential extrapolation of trends — basically, math errors.
Another interesting thing about the “FTL cars” analogy is that breaking the speed of light is (sadly) not a matter of making some clever breakthrough. The more we learn about the world, the likelier it looks that FTL travel is simply impossible. A massive breakthrough will likely make us more certain that it’s impossible, not less. Now, obviously AGI is possible in principle — after all, we are implementing it in our meat-based heads right now ! — but I’m increasingly coming to believe that an “AI FOOM” Singularity scenario couldn’t work without breaking the rules of physics (though I am not entirely certain about this).
And that’s precisely the huge difference from FTL cars or Argent Energy.
Moreover, we also have proof-by-example that at least some of the things the brain does are possible with much less computing power than would be required to faithfully simulate the relevant part of the brain: the visual cortex is a non-negligible fraction of the brain. Also through image recognition, we have an example of a task for which we couldn’t devise anything like an exact algorithm, but we could solve (part of) it through artificial neural networks. The two requisites of general AI are having sufficient computing power, and actually developing the AI for that computing power. Not only it is not physically impossible, we have no reason to think it’s definitely impossible with near-term technology—though we have no reason to think it’s definitely possible either.
Nitpick alert:
Bugmaster:
“I would argue that if you take a program that can distinguish dogs from cats, and multiply its computing power a thousandfold, you’d get a system that can distinguish dogs from cats super-fast — and not AGI.”
I agree that it wouldn’t be AGI, but it might be able to identify breeds of cats and dogs, maybe even some of the easier crossbreeds.
@Nancy Lebovitz:
No, it would not. At least, not if you just fed it more computing power. It would only be able to distinguish cats from dogs at lightning speed. If you wanted to distinguish crossbreeds and such, you’d need significantly more training data, and likely a different network architecture.
@10240:
Just to clarify, I have no doubt that AGI of some sort is possible, in the same way that colonizing Alpha Centauri is possible. However, that doesn’t mean we’ll be on Alpha Centauri anytime soon, and it also doesn’t mean that you could travel there from Earth in an hour. You say,
This is technically true, but almost completely meaningless, since no one currently knows how to even begin doing the second part. The first part is fine if you want to talk about a garden-variety AGI. However, if you’re talking about a nigh-omnipotent superintelligence, then it’s very likely you’re getting into “Earth to Alpha Centauri in an hour” territory.
I know you didn’t do it on purpose, but this equivocation between “An AI that is sort of as versatile as a human” to “Superintelligent gray goo converts the Earth into computronium in a blink of an eye” is very much a motte-and-bailey situation for the AI risk movement.
@Bugmaster Now we are back to what we have already discussed in both this and another thread: it’s “we are working hard towards it, it’s physically possible, and we have no idea whether or not it’s practically possible on the short-to-medium term”, which yields a much bigger and much more uncertain probability estimate than “we are not doing anything to make it more likely, so we can use the fact that it happens less than once in 100M years to conclude that the risk is less than 1M per century”.
This drives me so crazy! Sometimes I think we should start calling AI-risk proponents “Demon Summoners”, since the model of AI development they seem to assume is roughly equivalent to “anyone might summon an omnipotent demon in their basement one day, so we should figure out the proper magic words to use in the summoning ritual so the demon will grant our wishes instead of taking over the world evily and then teach The Magic Words to all the would-be demon summoners out there just in case”, which has approximately nothing in common with any real or plausibly extrapolated AI developments.
In real life, version 1.1.13 is not going to be noticably better than 1.1.12, and if and when GAI ever happens, noone will notice or care, any more than we care about increasingly powerful image recognition or translation systems. People won’t even be sure when the threshold was reached, since there’s no bright dividing line.
@10240:
I think you might have missed the point of my previous comment. Yes, AGI is theoretically possible. Yes, we are sort of working toward it right now, in the same way that discovering fire is an advancement toward titanium alloys. But “AGI” is not synonymous with “unstoppable night-instantaneous Singularity” ! You appear to be equating the two terms, perhaps subconsciously, but in order for the Singularity to happen many other low-probability events would all have to occur, at the same time; and, like I keep saying, I’m not even convinced that all of them are physically possible and/or coherent concepts.
Creating something like a self-driving car is not the penultimate step on the road to the Singularity. It’s not even the first step. It’s more like a tentative glimpse through fog at something that may or may not even be there.
IMO to the extent that “the Singularity” will happen, it is already happening, and it started at least 50 years ago, possibly centuries ago. Which is of course equally uninteresting from a Will We Have Rapture For Rationalists? perspective.
@Loriot We’ve already discussed in another thread that this is not what they/we (mainly) assume, and
when the problems may start and how we may notice a fast takeoff only when it’s too late even if it’s not immediately after the first human-level AI, so
maybe snark or ridicule are not a substitute for (counter)arguments.
@Bugmaster As you’ve probably seen the argument many times, once we have human-level AI, that may lead to dangerous superintelligence through recursive self-improvement. Is it 100% certain? No. Is there a way more than 0% chance that it’s possible? IMO yes, though you probably disagree. Do we have an upper bound of 1 in a million, on the basis that it hasn’t happened before? No, because we are actively affecting relevant aspects of the world (by trying to develop AIs). Is it possible that your intuition that it’s implausible is wrong? Yes, and way more likely than demonic invasions or catastrophic asteroid impacts.
Alternatively, let’s assume that a human-level AI definitely doesn’t lead to fast take-off. We don’t even notice it. So the path is not
nothing —-> image recognition —-> ??? —-> human-level AI -> recursive self-improvement,
but
nothing —-> image recognition —-> ??? —-> human-level AI —-> ??? —-> recursive self-improvement.
My point still stands: we are working in its direction, we will probably try to reach it (that it, once we reach human-level AI, we will probably work further to get to the point of recursive self-improvement because of the potential benefits, at least if we ignore the dangers), so there is a chance that we actually realize it. And since we are working towards it (not directly at this point, but in its direction, and we will probably try to get closer and closer), we don’t have the sort of upper bounds on its probability as on meteors or demons.
@10240:
As I have mentioned before, there are several problems with this chain of reasoning:
1). Unbounded (or functionally unbounded) recursive self-improvement is likely impossible.
2). “Superintelligence” is not a coherent concept.
3). Being able to think really fast does not automatically grant you superpowers; in fact, most superpowers are physically impossible.
You keep referring to “my intuition” being wrong, but I’m not just basing these claims on intuition; we already have evidence for most of them. For example, the combination of the speed of light and the square/cube law means that you can’t just keep chaining together multiple CPUs to get a linear improvement in speed; adding more nodes to a neural network does not automatically make it better; building (or destroying !) things in the real world takes real, measurable time; and so on. Obviously, we could sidestep some (not all) of these problems by positing e.g. some kind of magical nanotechnology that can do anything; but sadly it looks like the activation energies involved would make it impossible to implement in reality.
Is there more than a 0% chance that I could be wrong ? Well, yes, obviously. However, when you start multiplying all of these small numbers together, you get an even smaller number, you know ?
Another issue is that Foomism also ignores basically everything we know about computational complexity.
I feel like most people who make these arguments have probably never tried to actually do any CS research. (This is of course not true of everyone. For example, I first learned about Lob’s Theorem from some MIRI-like post, so clearly a few people in the field know what they’re talking about).
Remember one person’s modus ponens is another’s modus tolens? That happens all over the field of computational complexity. If you say problem A is hard, but we could solve it if we could solve problem B, the reaction isn’t “great, that’s progress towards A”, it’s “well I guess B must be hopeless then as well”.
There seems to be a huge blindspot among Foomists that you can solve a hard problem by deferring it to an even harder problem. Like, we have no idea to do X, so we’ll just invent an AI and tell it do X instead. But when you actually try to do the math, you’re not allowed to cheat like that.
In real life, solving a more general problem is at least as hard as solving the simpler problems that it subsumes. For example, remember all the hype about SAT solvers, like how they are fast in practice and make P=NP in practice? Anyone who says stuff like that has clearly never actually tried to use a SAT solver for anything difficult, let alone studied the known hardness results about unification proofs.
SAT solvers aren’t specifically good at anything. For any specific task, they could be beaten by a more dedicated algorithm. What SAT solvers are useful for is solving easy problems without taking the time to come up with or implement a more efficient specific algorithm. It’s just brute force with some heuristics tacked on. This is why you can’t just use SAT solvers to trivially break cryptography like all the gushing might naively lead you to expect. State of the art SAT solvers can’t even answer questions like “can you put n+1 pigeons in n holes without repetition” or “can the total degree of each node in a graph be odd?”
Whenever you point out that the Foom scenarios are blithely ignoring already known computational hardness results and/or Lob’s Theorem, you get some handwave about how AIs will avoid solving any hard problems by taking real world shortcuts and still take over the world. Ignore for a second that recursive self improvement is by definition the hardest problem in the world – this seems to be a huge motte and bailey. Because the second your scrutiny gets directed elsewhere, we’re back to magic AIs with infinite computational power.
AIs might very well be better at most things than humans are some day. But that says nothing about the plausibility of Foom. Humans have been recursively self improving for hundreds of years, if not thousands.
@Bugmaster Unbounded, definitely impossible. I just think it’s plausible that the human level of intelligence is nowhere near the physical limit, either in vivo or in silico. There is more uncertainty about the in silico part: on the one hand we are not quite at the computational power that would be needed to simulate a human brain, on the other hand we can mimic parts of the brain with less computational power than would be needed to faithfully simulate the corresponding cortex, so I find it possible (though not certain) that it can be done with consciousness and intelligence as well.
@Loriot I think your argument proves too much. It basically implies that building a machine to do X (say, lift a stone weighing a ton) is always at least hard as lifting the stone. Well, if by lifting the stone we mean lifting it by any means (possibly by a machine), it’s trivially true. It’s not true if by lifting the stone we mean doing so directly, with your bare hands. Building a crane is actually a much more feasible approach; and it would be wrong to say that if you can’t lift the stone without a crane, then you can’t build a crane to lift it either.
Perhaps you think that a computational, informational problem is different, since to create a software to solve a problem, you have to understand the problem yourself? That would hold in some sense for traditional, explicitly written software (though the software could still be much faster than a human), but I don’t think it holds for artificial neural networks: an AI developer doesn’t typically know what each neuron is doing, and exactly how the network solves the problem.
@10240:
What does this mean, quantitatively speaking ? Like I said before, you could speed up my brain 100x, and then give me some kind of higher abstract math problem to solve or a Chinese passage to translate… and I’d just fail to solve/translate it 100x faster. Sure, you could argue that I could learn math/Chinese 100x faster, too, but I’m not convinced that my brain is capable of achieving such things in principle. If you want to look at a much cruder system, making a neural network run 100x faster doesn’t actually improve its accuracy/specificity on classification tasks (just for example). Even adding a bunch more nodes to the network willy-nilly is unlikely to yield large benefits.
I suspect that the answer to this objection might be “recursive self-improvement”, but, as Loriot points out, this is probably the hardest problem in the world to solve, computationally speaking. In practice, this means that you’d need some kind of a quasi-magical superintelligent uber-AI in order to do so in a FOOM-like fashion… which puts you in a catch-22.
@10240
Is this really true?
Obviously no AI developers knows what the weight in any node of a given neural network means, for any non-trivial network, but they very clearly understand what the architecture of their network is doing.
It’s why we have links in slatestarcodex to explanations of what GPT-2 is doing, why there’s even a T in that acronym, it stands for transformer, and GPT-2 is a very deliberate architecture, very different from, say, one for visual recognition.
Of course, the guy plugging GPT-2 to predict chess moves maybe does not know how GPT-2 works at all (or maybe he does).
But the actual advance has been done by researchers that (a) knew what the current approach’s limitations were and (b) had a sufficiently structured thought of how to overcome said limitations.
Until now I haven’t heard of any advancement in AI that was done by just plugging random layers of neural networks together, hoping for the best, and then working backwards to see what’s going on. At best people apply architectures from other areas to their areas, and then see what their limitations are, but overcoming said limitations requires both an understanding by the researcher of both the target problem and neural network architecture.
One reason algorithm problems are different is that when we have mathematical proofs, they apply no matter what algorithm you try to use, even if that algorithm is “create an algorithm to find a better algorithm to solve the problem”. You can’t dismiss math just by waving your hands, like you might with mere physics and engineering challenges.
You aren’t going to solve the halting problem by inventing a fancy neural network to solve it. (And yes, I know the halting problem is PAC learnable).
It’s true that the real world may offer shortcuts so you can achieve certain results without actually solving any hard computational problems, but the onus should be on Foomists to explain how their stories avoid those problems, rather than the reverse. Instead, they always seem to tell their stories using the language of computation, completely ignoring known or widely believed impossibility results.
Well, we have Alpha*, and it’s solving some domains we never believed possible. Even for us. It’s doing it by modelling the actions of others, too – that’s how it works.
Sure, they are simple, logical and predictable domains. But we could be much closer than we think. To equivalent or greater intelligences on this planet. Or just maybe, the Big S.
AlphaGo is not solving any problems in violation of known computational hardness results.
I’m not saying that AI doesn’t exist. I’m just saying that it isn’t magic, and spending all day trading fantasy stories isn’t helping matters, any more than wondering what the appropriate protocol for vacationing on Alpha Centuri will be.
If anything, I put *lower* odds on “by 2050, the world will be tiled in computronium” than on “by 2050, people will be taking vacations on Alpha Centuri”. But neither is plausible enough to merit any concern.
Loriot: “AlphaGo is not solving any problems in violation of known computational hardness results.”
***NEITHER ARE WE***
The question is whether it can do better. It has recapitulated 150 years of human research in Chess. And it has outclassed us in Go. Just a few years ago, everyone agreed that was impossible.
We knew computers could win in Chess by brute force calculation. But they still had to read books of opening theory based on decades or centuries(!) of human experience and analysis.
A couple of years ago, that bulwark fell. Now Go has fallen too. And that was a year ago. Recently, we’ve all become re-acquainted with how that curve goes. OK, I’m riffing off A Fire Upon The Deep. I’m not all that scared of our new AI overlords. Can’t be worse, right? Maybe they’ll need us to help make the paperclips. But all the same, it looks to me like the landscape has changed.
@Loriot Nobody says that a superintelligent AI can solve the halting problem, or solve NP-hard problems in polynomial time even if P≠NP. Humans don’t solve those either, but that doesn’t stop us from cutting down forests and building cities in their place. Whether human-level or beyond-human-level AI is dangerous for us has very little to do with theoretical complexity theorems.
They rarely *say* it explicitly, since that would make them look silly, but they sure do like to tell stories about AI that magically have effectively infinite computational capacity, with little thought to how that might actually happen.
And just to clarify matters, I’m not trying to deny that AI exists. I think that it is almost inevitable that we will one day have AIs which are superhuman in every relevant metric.
I feel like a physicist in a community full of people fantasizing about spaceships zipping around the galaxy in minutes desperately trying to remind people that the Theory of Relativity is a thing, only to be dismissed with “lol, he doesn’t even believe in spaceships, go watch the moon landings you dumbass”.
Sure, computational hardness results only apply to things simulated on a computer or equivalent. It is possible to improve things through real world technological advances, as humans have obviously shown. But this is a huge motte and bailey. It’s like upon being reminded of the speed of light issues, the SF fans go “well of course the colonization of the galaxy will actually take thousands of years using Unobtanium colony ships, noone would ever seriously suggest otherwise”, and then the second you turn your head, it’s back to “what color shall we paint the warp drives?”
If you think AIs can take over the world by slaving away for decades to make slightly more efficient transistors, you should say so, but the onus is upon Foomists to explain how their stories are consistent with known mathematics, not the other way around. Because the stories that actually get told around here look more like a world where nigh-infinite computational power is readily available and it’s just a question of summoning the right magic genie to make it happen.
Bring this up when they actually make (or imply) a claim contradicted by impossibility results. Note that effectively infinite computational capacity with Turing-machine-equivalent computers is not the same claim as solving the halting problem, nor is the same claim as literally infinite computational capacity.
The onus is on you to explain why your claims are consistent with the Jordan curve theorem. What on Earth does the Jordan curve theorem have to do with your claim? You’d better know that yourself.
No, that makes no sense. The onus is not on you to explain why your claim is consistent with the Jordan curve theorem, unless I first explain why your claim seems to obviously contradict the theorem. Your claim, not some related claim some members of the same community allegedly make.
Also, if I claimed that a dangerous human-level or superhuman AI is definitely or very likely possible, the onus would be on me to prove it. If you claim it’s impossible or very unlikely, the onus is to a large extent on you to prove that. And before you come with demonic invasions again, let me repeat that demonic invasions are shown to be very unlikely by the fact that they seem to have never happened, an argument that doesn’t work for AIs because we are working on them.
See here, here, here and here what sort of risk I think may be possible.
@10240:
Wait, how does that work ? If I claim that leprechauns are impossible or at the very least very unlikely, is the onus on me to prove that ? Does this means that you believe in leprechauns ? Generally speaking, are you saying that your prior for any arbitrary proposition is always 0.5, no matter how outlandish it might be ?
As I keep saying, no, we are not. Right now, no one knows how to make any kind of an AGI. No one is working on them, unless perhaps you count any kind of work in computer science at all to be an advancement toward AGI. Modern machine learning systems are almost the opposite of AGIs.
Furthermore, once again you appear to be equivocating between “an AI which can reasonably attempt to solve any problem posed to it in conversational language”, and “an agent who can recursively self-improve itself nigh-instantaneously to near-godlike power”. It is as though it does not occur to you that these two concepts are not in any way equivalent… but they aren’t. The first kind of agent obviously exists — we are it — but the second kind is probably prohibited by the laws of physics. You can’t just handwave the objections away by saying, “well obviously it’d recursively self-improve itself to transcend any possible limitations”, but that’s just begging the question.
@Bugmaster By “working on it”, I mean
– I think there are people whose goal is to eventually build human-level AI. If not, I’m pretty sure there are intermediate stages such that there are people whose explicit goal is to build Stage 1 right now, and if Stage 1 is done, there will be people whose goal will be to work on Stage 2 (as it seems more realistic at that point), etc., and when Stage n is done (for some small integer n), there will be people whose goal is to build human-level AI.
– In each stage, we learn more about how to build AIs, and as such building a more complex AI becomes more approachable in each stage, possibly until we build a human-level AI. (Possibly we can’t progress beyond some level, and we don’t get there.)
We never have a concrete plan to invent something, until it’s actually invented. In 1850, your approach would have said “nobody has an idea how to build a powered, controlled airplane, nobody is working on it in the sense that nobody has a concrete plan to build one, therefore the probability of building a powered, controlled airplane in the next century is not higher than in any of the last million centuries, and it’s essentially as likely as a demonic invasion.”
My approach would have said “we have invented the steam engine (though it’s way to bulky to power an aircraft), there are people trying to build rudimentary flying machines (though they are not really controllable), so there is a non-negligible chance that we might build a working powered, controlled airplane in a century.”
The probability estimates given by your approach would have been so off so many times in the past that you should probably find a better approach to how to think about future technological progress.
– Instead of “reasonably attempt to solve any problem posed to it in conversational language”, I more specifically mean “approx. like a human in its level of intelligence and complexity.
– Instead of “near-godlike”, take “can overpower humanity”. To what extent I expect it to be near-godlike depends of your definition of a god.
– As I’ve said before, it doesn’t necessarily even has to be qualitatively smarter than humans to be dangerous, nor necessarily need excessive amounts of raw computing power.
– Recursive self-improvement means that it can drop in for a human AI researcher (as it has human-level intelligence), and try to build a smarter AI than the last one (i.e. itself). Then the resulting AI can do the same. This is likely possible, though it’s uncertain where the limits are. It could also improve its own performance by improving its architecture, or by dropping in for microchip designers. (Though the latter is a slower process and requires human cooperation.)
– 40 years of subjective time of research by an AI is less physical time if it’s run at a higher speed.
– I outlined ways in my linked comments how an AI may affect or take over the physical world. (No, not a concrete plan. See above about dismissing possibilities in the absence of a concrete plan.)
– As I said before, it doesn’t need to be instantaneous from the point where it starts recursively improving itself to taking over the world, only from the time we realize it’s trying to take over the world to the point where we can’t stop it.
Which laws of physics indicate that AIs self-improving beyond human level are impossible?
Or is it just “I hope/expect that some there are some hard limits on AI abilities, that coincidentally limit them to the level of human brains but I have no evidence whatsoever and it is pure speculation”.
As far as I know, unlike say FTL spaceships there are no indication that self-improving AI smarter than humans hits any known hard limit.
Everything they say about AIXI.
@10240:
Well, I’d certainly like human-level AI to exist at some point, so I guess you could call it a “goal”. However, there are no stages such as you describe, because no one knows where to even begin. None of the modern advances in machine translation or computer vision are explicit steps in the right direction; at best, they are hints that it might be possible. Building a “more complex” machine learning system isn’t really helpful, because that just ends up improving performance on some very specific, fixed tasks.
You know, in the 1850s they probably thought that demonic invasions were way more likely than people do today, so you’re probably right 🙂 Anyway, a powered airplane is many orders of magnitudes easier than AI; in fact, powered flight devices (i.e., simple rockets) had already existed for a long time by then (admittedly, mostly in Asia at first). There were several attempts to implement powered flight before the Wright Brothers solved it, and while none were 100% successful, not all of them were total failures, either. The Wright Brothers drew extensively upon existing technology of gliders, and while their achievement was remarkable, it was arguably more evolutionary than revolutionary.
As I said above, this doesn’t match the current situation with AI. AI-FOOM proponents are more similar to the people who thought of taking their hot air balloons to the Moon, than they are to the Wright brothers.
Your definition means literally nothing to me. What does it mean to be “like a human in intelligence” ? My definition was an attempt to clarify this point, but since you reject it, then I literally have no idea what you mean.
This is the same problem: what does “overpower” mean ? After all, trucks can easily overpower humans, at least as far as transportation capacity is concerned.
Oh, I totally agree with you there ! A cellphone in the hands of a terrorist can be incredibly dangerous (and so can fertilizer, even). On the other hand, buggy flight software can also be incredibly dangerous, when implemented in an airplane. We should absolutely be working on solving such problems… instead of wasting time worrying about FOOM.
Assuming that a machine learning system would want to take over the world in the first place, why wouldn’t we be able to stop it ? This is what I mean by “godlike powers”: you are envisioning something that can consume the world in gray goo, hypnotize humans with a word, hack your analog toaster, etc. There’s no evidence that any such things are even possible, let alone likely. Back in the real world, when my machine learning program starts performing poorly or consuming too much CPU, I don’t just shrug and/or lament my fate; I terminate its process and go back to the drawing board. Not because I fear it taking over anything, but because I’ve got a job to do, and it’s not doing it.
Are you claiming that software that would be both smarter than humans and malicious would not be a major problem and something trivially solvable?
Deliberately malicious software (because it was written by someone with goals contrary to yours) is a much more plausible and immediate threat than accidentally malicious software.
We are not only improving performance on fixed tasks, but also broadening the set of tasks they can solve. My intuition is that gradually broadening the tasks AIs can solve may eventually lead to a general AI. (Also, making AIs for these specific tasks is definitely the sort of thing one does before moving on to the perhaps harder task of making a general AI. That, combined with the fact that we are likely to move on to attempting to make a general AI once we are pretty good at making specific AIs already means that humanity makes the development of general AI more likely than the base rate.) Your intuition is that broadening the scope of these specific AIs can’t lead to a general AI, or even give us understanding that can help us develop a general AI. Maybe your intuition is wrong, maybe mine, hence the uncertainty.
Even if you were right that general AI requires more of a revolutionary development than controlled, powered flight from 1850: Even in (say) 1500, the right call would have been that there is a non-negligible chance that humanity will eventually build one. If something may be physically achievable, and humanity might try to achieve it, there is a non-negligible chance that it will be achieved. The only reason I added the criterion of “we are working on it” is that even though there is a non-negligible chance that it will achieved at some point, we can put of worrying about it until we are working on it.
The issue with putting off worrying about general AI: If a general AI will be achieved at some point, I’m not confident that there will definitely be any point, a significant time before general AI is actually built, when you would say “the stuff we are doing is not just some very specific tasks anymore, now we actually have an idea how to build a general AI, so it’s time to start worrying about it.”
That it can solve most tasks about as well as a human. What specifically matters here is that it is as good as a human at developing AI or engineering microchips. Your definition may be roughly the same; I made my clarification because I thought you might mean something weaker.
Destroy humanity, or otherwise force its will on it, in a way that we can’t stop. I wrote specific example scenarios here.
Re: dangerous: I meant existential danger to humanity.
@10420
The problem is that without having any idea of what AGI will look like it is impossible to actually _do_ something against it.
You may as well have started worrying in 1500 about aerial bombardment, and then develop theories about how to combat pegasii or dragons because that’s your working model of what aerial bombardment at that point.
@JPNunez I agree, AI safety is something to work out over the course of AI development itself. At this point, we just have to make sure that as we get closer, people will actually care about safety. That’s one of the reasons I think proposals to put a moratorium on AI development make little sense, unless we want to give up on ever developing general AI (or more advanced AI than we have right now): there is no plausible condition for lifting the moratorium.
“Nobody is working on human-level AI”
Note this: Alpha-Chess recapitulated more than a century of human research by *THINKING* about it.
Do you get that? Before it moved a pawn it had planned a strategy a thousand times better than the strategy of a grandmaster armed with human centuries of knowledge.
AlphaGo went on to solve a harder problem. Alpha-Star is not quite there yet, but it is very strong.
The domains we thought were only ours… they are falling.
I think this is where you go wrong.
Sure, there’s never been a super-human AI.
And there’s never been a multi-nation nuclear exchange. We’ve only ever seen 2 very small nuclear weapons dropped on 2 relatively small cities and a bunch of desert sand getting glassed. Should we from this conclude that while occasional detonations are possible that we have no evidence that multi-nation nuclear exchanged are even possible?
Nuclear weapons have killed less people than the flu typically kills in a given year.
If you read a completely boring book on AI, like say “Artificial Intelligence: A modern approach” (also a testament to why you should never name things with the word “modern” since it’s now decades old) that focuses on the nuts and bolts of how to build real systems with real code…. a huge fraction of the book deals with problems that boil down to enumerations of ways in which you can attempt to get your dumb-AI to do X but it actually ends up doing Y.
Often related to how you’ve screwed up how it measures it’s own success like a roomba-bot that learns to maximise dirt collected by knocking over your flowerpots.
AI-doesn’t-do-what-you-actually-want-it-to-do-and-instead-does-something-else is one of the basic practical problems in AI. When the AI’s are about as smart as pigeons, sure’ that’s not a big deal.
But with something far more capable than a pigeon the problem of “does something else” becomes far more serious than “turn it off, reset and re-write the code that defines success”
We keep seeing AI’s suddenly far surpassing humans in various fields.
Should we view this as irrelevant to the question of whether we’ll ever see AI’s that far surpass us in most of them? Or should we view it as akin to seeing the fallout from various small nuclear weapons tests in regards to whether it’s a smart to start thinking about the problem of how to avoid a multi-nation nuclear exchange?
Because a not inconsiderable number of AI specialists, while not worried that we’ll have the equivalent of a multi-nation nuclear exchange *tomorrow* are worried that we’re somewhere around the stage where physicists were when they were dropping balls of fissile material through rings of other fissile materials and measuring the neutron output.
Yes, like I said above, I should’ve qualified this as saying “there’s never been any kind of super-human AGI”. Such an AGI would be qualitatively, not quantitatively, different from current AI software.
I don’t know about “suddenly” (e.g. OCR software has been on the market for a long time now), but I’ll grant you “surpassing”. But all human technology surpasses humans at something, that’s kind of the point ! Cars are better at ground transport, planes can fly, IR cameras can see in the dark, lightbulbs glow, etc.
Does this mean that we should be wary of all human technology ? Yes, absolutely, and that’s why safety standards exist. Should we more worried about all human technology than we are now ? Yes, probably, that’s why global warming exists. But does this mean that modern AI (as opposed to hypothetical superintelligent AGI) is a uniquely severe threat deserving special consideration ? No, probably not.
you need to add in the “general computation” aspect.
This isn’t something to think about while thinking like a car mechanic.
A car can go faster than a human, a helicopter can reach the top of mountains faster than any human mountain climber and a submarine can dive deeper….
But you can’t just glue a helicopter to a car and a sub… well you can try but it’s going to be a bad car ,a bad helicopter and a bad sub.
Not so much with software.
You can absolutely make something that includes lot of different libraries, ties them all together without making them all worse.
define special. Most people concerned about AI aren’t calling for a shutdown of the economy.
They’re mostly suggesting that perhaps we should think about it and probably get a few smart people looking at the issue. Which isn’t a tall ask.
You can’t. You really, really can’t. That said, even if you could (and you can’t), there’s no library in the world that has a function like “solveAnyProblem(string englishLanguageProblemDescription)”. You’re basically saying, “we can easily making AGI by inventing AGi”, which is… technically true, I guess ?
I have no problem with smart people looking at stuff; however, I have a feeling that this isn’t even remotely close to what AGI X-risk proponents are suggesting. In this very article, Scott/Ord suggest that we should redirect at least 1% of the world’s GDP, or about 800 billion dollars, to the tasks. That’s a lot more than just a few people looking at things.
It is much easier with software than with hardware.
No one argues that we have AGI already.
This is true, though I am unsure whatever making AI surpassing human in nearly all tasks is doable by gluing together such components. Especially as “decide what is the task and how it should be solved” seems to be among hardest problems anyway.
But it may be sufficient to create AI that is more “employable” than majority/nearly all humans.
Perhaps you think he’s overestimating.
But currently we’re redirecting approximately 0% of the worlds GDP to the problem.
Are you taking the position that we’re currently redirecting too much resources already? it currently amounts to a few dozen peoples salaries per year.
even if he’s overestimating by a factor of a thousand that still implies we’re taking it far far less seriously than we should.
@matkoniecz:
Yes, in the same way that Mars is a lot closer than Jupiter. You still can’t walk there, though.
I will grant you that some humans can be replaced by AI; this has been happening since Jacquard’s days. But replacing the vast majority of all humans with AI is currently impossible, no matter how many libraries you spaghetti-code together — and this is even assuming that we attempt to tailor-make a robot for each job, not make a robot that can dynamically assume any job.
@Murphy:
Personally, I think that any amount of money spent on pursuing AI-risk-mitigation specifically (as opposed to general AI research) is a waste, but I don’t mind people wasting their own money. I would mind it if the next $800B stimulus package went to AI-risk research.
As I said, I believe that the habit of assigning high probabilities to hitherto unseen events despite (or perhaps because of ?) total lack of evidence is… somewhat questionable. I don’t know if it’s even possible to estimate the probability of such events; even if it is, you need to discount the probability by a massive amount, lest you find yourself compelled to finance every alien invasion/demonic incursion/crisis on infinite Earths scenario that comes along.
Good comparison, I really like it. One is flatly impossible without freaking magic. One is possible, but extremely hard and unlikely to happen in the near future.
Some people are trying to achieve this, it may happen in far away future (opinions about plausibility vary), may never ever happen.
I agree, but “jobs will be automated by software faster than new ones will be created” is something that is at least a plausible event. “many currently employed people will be unemployable as software got better” is also something at least plausible.
“vast majority” seems to not be happening in the near future.
I feel that devoting 1% of the GDP to AI-risk research is the equivalent of devoting 1% of the GDP to asteroid deflecting technology, and in some ways it is worse.
How do we ensure that giving $1000M to Eliezer won’t end with Eliezer creating badly aligned AI by mistake? Or, more probably, that his research somehow helps development of badly aligned AI by sideffects of said investment?
We can’t do anything about asteroids suddenly deciding to hit the earth right now. We certainly aren’t putting rockets in space trying to get them to hit the planet. But we can do something about AGI right now: just stop research in AI and smaller transistors. That’s it, that’s the solution to the problem.
Just stop researching the damn thing.
Maybe the whole transistor thing would be enough, if building computers big enough to emulate a brain becomes economically unfeasible. That would give us time to maybe fuse computers with human brains to make the whole AI thing moot.
If you think that
(a) AI is a bigger x-risk than nuclear bombs, maybe by an order of magnitude
(b) nuclear bomb technology should be vigilantly safeguarded
then why you do not oppose open research of AI and smaller transistors?
To me, devoting 1% of GDP to AI-alignment right now sounds dangerously close to devoting 1% of GDP to AI development, and makes no sense by the same reasoning Ord uses for asteroids.
This is another thing that has always struck me about the AI-X-risk argument. If it is true that it is somehow possible to suddenly create magical omnipotent AIs, we should be terrified, because for every person yelling about x-risk, there are a hundred equally smart people out there who just hear “making an AI that grants free wishes is possible” and don’t worry about the “magic words to stop it from taking over the world” part. It’s an astonishing application of the Typical Mind Fallacy.
Luckily, there’s no real evidence that magical omnipotent AIs are possible, so I’m not worried. But the whole movement, if its premises are granted, is likely actually counterproductive.
@JPNunez:
We can’t, and we shouldn’t, and this kind of neo-luddism is one of the reasons why I’m opposed to the AI X-risk movement. It’s like saying, “oh, if only we could’ve stopped research on how to build nukes, the world would’ve been a better place”. The problem is, building nukes is a relatively simple engineering challenge; the capability to do so arises naturally out of our understanding of atomic theory. Ok, so maybe we should’ve stopped all research into atomic theory, right ? But atomic theory arises naturally out of our understanding of other aspects of the world and the scientific method. Ok, so maybe we should’ve formed a secretive cabal of dedicated scientists who get to study this incredibly dangerous theory, and keep the laymen in the dark ? But what are you going to do, arrest anyone who tries to build a cloud chamber ? And what’s your win condition here ? Modern technology requires atomic and quantum theory in order to work; should we give it all up ? No more cellphones ?
The same applies to transistors, computer science, biology, etc. All of science is connected; that’s what makes it so powerful. You can’t arbitrarily prohibit advancements in any specific area, because once you’ve advanced everywhere else, the next step becomes glaringly obvious.
If the major nation-states decided to, don’t you think they could stop improved microprocessor production?
Not asking if it would be a Bad Idea or not. Just whether they could.
If all major nations agreed on it, perhaps. They could certainly make it uneconomical to do it openly. But I’m sure North Korea would start making their own chips and other militaries might secretly want to do the same. Hence a black market emerges at the very least.
How long would it take North Korea to even match current technology?
And what would be the point of them improving microprocessors by 1%? Why would people buy black market CPUs with a 1% advantage?
They would need to stack dozens, or maybe even hundreds, of 1% improvements to get any kind of advantage.
Your brain is an existence proof for AI, there is no question about it being possible.
We also know how it was made, and the process was excruciatingly slow and inefficient and didn’t even directly optimize for intelligence. It would be remarkable if there were not a better alternative.
Whether it’s made of meat or silicone is just an implementation detail.
Wait, your brain is an existence proof for human-level AI.
You can argue that human-level AI exists in meat-hardware, and you can argue that silicon replications of brain architecture would run faster than meat implementations and therefore be smarter, but you can’t use the existence of the meat hardware to prove that the silicon implementation is possible.
There are many, many examples in physics where you can theoretically accurately replicate some phenomenon on a computer, but where actually doing so is prohibitively resource-intensive. Protein folding for a mundane example, quantum stuff for a deeper example.
How confident should we be that it’s possible to make AGI that is substantially more powerful than the natural implementations and also practically possible? What evidence is that confidence level based on?
I wouldn’t even go that far. If you took my current brain, copied it over into software (somehow), and ran it at 1000x the speed… then I still wouldn’t be able to compose music for the violin or do high-level math or speak Chinese. It’d be easy to say, “yes but you could just learn to do all those things super-fast”, but I’m not convinced that my brain architecture allows me to learn to perform these tasks at all. Some tasks, maybe, but definitely not all.
Also, even at 1000x speed, the subjective effort experience for you is the same, so you might not want to do any of that hard stuff, and you’ll become lethally bored very fast.
@Aotho
I just thought of the AI in the Box experiment but instead of a wiley hyper-intelligent manipulator trying to get out so it can paperclip everything, it’s just a bored midwit who’s exhausted all possible entertaining simulations over centuries that equaled the last ten minutes, and he just wants to be shut off permanently.
Maybe as well as thinking about how to stop AI’s killing us, we should put some thought into how to stop them killing themselves.
@Forward: As always, there’s an XKCD for that. With bonus Basilisk content.
This reminds me of a SF short story idea I had once, where it turns out that cosmic horror is true, and 50 years from now, the field of AI is devoted not to making ever more intelligent AIs, but instead to the question of how to make AIs that are as good as possible at particular tasks without reaching the intelligence threshold that causes them to discover the truth of the universe and Go Mad From The Revelation. Also, AI researchers have to be careful not to look to closely at the workings of their AI lest they discover the terrible secrets themselves…
John Schilling: in a startling coincidence, the punchline to the xkcd you linked is at the center of his latest comic entitled “Collector’s Edition.”
“How does lack of knowledge about a proposition make that proposition more likely ?”
The point estimate of the probability is irrelevant. The width of the confidence interval matters, and lack of knowledge corresponds to a wider confidence interval.
What exactly do you mean by the confidence interval, for the probability of a binary proposition?
(see my comment above)
I think this is a very important concept, and I and some others have been advocating for it here in the comments, so I might as well expand on it a bit here.
If we have a fair coin that I flip, and we play some kind of game, you know that there is a 50% chance for heads and tails each time our game calls for a flip.
If however, I also have an unfair coin (Do those even exist? My example can work with a dice too, just thought it is easier with a coin.) that is 40% of the times heads, and 60% of the time tails, these are then concrete probabilities also. Let’s say we both flipped the coin a million times and we both are reasonably certain about its probability distribution.
Now, you know that I have these 2 coins, and from the outside, they are very hard to distinguish, and you don’t know which I pulled out of my pocket to play with you with. Therefore, the best you can know is that there is 40-50% (= (45 +/- 5)%) chance for heads and 50-60% (= (55 +/- 5)%) chance for tails in our game. This is your irreducible uncertainty about the probabilities given your then-present knowledge. Does this make sense?
Furthermore, you can take a few actions that would decrease your uncertainty about the probabilities, e.g. you could very closely try to examine the coins and make a guess. With this you might be able to become almost certain about the coins fairness, e.g. 49-50% for heads and 50-51% chance for tails, but your uncertainty is likely not fully eliminated about the probabilities.
Based on how long our game lasts, you might also want to try to keep tabs on the amount of heads and tails you observe. Are they closer to 5:5 or 6:4? You can update your confidence this way as well, but you won’t reach 100% certainty this way either, just come very close.
I think you’re conflating a couple of very different things here:
1. The probability that the next flip will be heads, given the information I have. This should be a single probability, P(flip_k = HEADS)
2. The bias factor of the coin, let’s call it B. There are two possibilities: B = 0.5 or B = 0.4 (defined as the probability of heads for a single flip of the coin). Since I don’t know what B is, we also have:
3. My estimate of the bias factor of the coin, given the information I have. This is a probability distribution–specifically, a discrete distribution of B with just two possibilities. We could write its initial probability density function (assuming you picked which coin to use at random) as:
P(B = x) = {0.5 if x = 0.4; 0.5 if x = 0.5; 0 otherwise
Before I flip the coin, I’m maximally uncertain about which coin you chose: P(B=0.4) = P(B=0.5) = 0.5 . I could calculate a “90% confidence interval” for the bias (0.4 – 0.5), but since this distribution only has two values, it’s less meaningful than just giving the probability of each.
But I can still reasonably give a single probability for P(flip_1=HEADS) like such (abbreviating as P(H) to save myself some typing) :
P(H) = P(H | B=0.4) * P(B=0.4) + P(H | B=0.5) * P(B=0.5)
= 0.4 * 0.5 + 0.5 * 0.5
= 0.2 + 0.25 = 0.45
A 45% change that I’ll flip heads. Seems sensible enough.
Let’s say that I flip the coin, and get tails. Now, I can update my probability distribution for my estimate of the bias fairly simply, using the odds ratio form of Bayes’ Theorem:
P(B=0.4 | flip_1=HEADS) / P(B=0.5 | flip_1=HEADS)
= P(B=0.4)/P(B=0.5) * P(H|B=0.4)/P(H|B=0.5)
= 0.5/0.5 * 0.4/0.5 = 1/1 * 4/5 = 4/5
= (4/9) / (5/9)
So, now I have P(B=0.4|H) = 4/9 ~= 0.44 and P(B=0.5|H) = 5/9 ~= 0.56, and since I have observed H, I can update to the posterior distribution and say outright P(B=0.4) = 4/9 and P(B=0.5) = 5/9 given our new information. (90%CI is still 0.4-0.5 and is still a bad tool for describing a two-point distribution.) So what do I expect for the next flip? Again:
P(flip_2 = HEADS) = P(H | B=0.4) * P(B=0.4) + P(H | B=0.5) * P(B=0.5)
= 0.4 * 4/9 + 0.5 * 5/9
~= 0.45555
This makes sense; now that I’m slightly more sure that the coin is fair, the odds of a head are slightly closer to even.
If I flip the coin again and get tails, then I can update the distribution for B again:
P(B=0.4|T)/P(B=0.5|T) = ((4/9) / (5/9)) * (0.6 / 0.5)
= (4 / 5) * (6 / 5) = 24 / 25
= (24/49) / (25/49) ~= 0.48 / 0.51
Posterior distribution:
P(B=x) = {0.48 if x = 0.4; 0.51 if x = 0.5, 0 otherwise
Well this is going slowly.
If we went on like this for a long, long time, then the proportion of heads would, as you say, converge to either 40% or 50%. And as it did, the probability distribution of B would get more and more lopsided, and the probability of flipping heads next would get closer and closer (but never reach) 0.4 or 0.5 respectively. Let’s say I flipped exactly 100 heads and 100 tails–then (if I’m doing my calculations correctly) I’d say there was only about a 1.7% chance you’d pulled out the biased coin, and a 98.3% chance it was fair (and the 90% confidence interval is now a single point at 0.5). And, once again, I could calculate a single number giving the probability for the next flip to be heads–namely, 49.83%.
Takeaway: A binary event, such as “the next flip is heads”, either happens or doesn’t, so my credence in the proposition that it happens one way must always be representable by a single probability between 0 and 1. A real number that I’m uncertain of, like “the bias of this coin” or “the number of heads I will see if I flip this coin 10 times” can be represented by a probability distribution, which can be described with a mean and standard deviation or some kind of confidence interval*, or by explicitly specifying its density function. The confusion in this example comes from that fact that we have a probability distribution over probabilities, P(B=x).
* unless it’s one of those terrible distributions with infinite variance, but I’m pretty sure those are rare in real life
@VoiceOfTheVoid:
I appreciate you trying to put precise numbers on this, but I am not sure we are talking about the same thing still. Specifically this part:
If I follow your math here, for some reason you seem to make an assumption that `P(B=0.4) = 0.5` and `P(B=0.5) = 0.5`, and run with it.
I’d argue this is a wholly unreasonable assumption to make, especially so if the stakes are high. You don’t know me, I might be an Evil Eve who always gives you the unfair coin and make myself win that way, then the numbers would be: `P(B=0.4) = 1` and `P(B=0.5) = 0`.
Alternatively I could also be a Mary Sue who always does the right thing, and wants a fair game with the fair coin, then it would be: `P(B=0.4) = 0` and `P(B=0.5) = 1`.
We can also plug in the actual uncertainties like so, and therefore we remain I think more intellectually honest:
P(H) = {
P(H | B=0.4) * P(B=0.4) + P(H | B=0.5) * P(B=0.4),
P(H | B=0.4) * P(B=0.5) + P(H | B=0.5) * P(B=0.5)
}
= {
0.4 * 1 + 0.5 * 0,
0.4 * 0 + 0.5 * 1
}
= {0.4, 0.5}
Why does this matter? Why am I strongly advocating saying 40-50% instead of 45% as our base probability? Because if the stakes are high, this can have profound ramifications. I can come up with a concrete example if you wish, but if not, just imagine a game of high stakes where you getting heads with 45% means you would be foolish not to play, but if you know that you can get heads with 40% then it is foolish to play.
***
Maybe I can come up with a simple game example after all:
(If the money values seem off for you for a high-stakes game, feel free to multiply all of them mentally by some quotient to get satisfyingly large stakes for your liking.)
(The calculations of below without comments can be seen here.)
The game: I choose a coin, out of the above two, but you don’t know which. We will use my chosen coin for as many rounds as we play. At each round you give me 85,000 usd. We flip the coin. If it is heads I give you back 200,000 usd. If it is tails I give you nothing. If we play this game 100 times, if you calculate with your 45% base probability, your expected balance is +500,000 usd at the end. Maybe you don’t have 85,000 usd on hand, let alone (upper bound) 8,500,000 usd to play 100 games? You better hurry to take a loan because this is free 500,000 usd I am offering you that otherwise you’d just be leaving on the table. Maybe I am a billionaire and I don’t mind spending a little for some amusement.
However, if we calculate with my uncertain probabilities, your expected outcome is {lose 500,000 usd, win 1,500,000 usd}. Maybe you will trust me by faith and run to get a loan for a chance at winning 1,500,000 usd. Or maybe you decide that the risk value of losing 500,000 usd is greater than the utility of the chance of winning 1,500,000 usd. I’d likely choose not to play if I only knew this much. And its a good thing I knew about the uncertainty, because were I calculating with the single number of 45%, I would have been fooled into thinking that this is a no-brainer win-only game for me and highly risked putting myself in considerable debt.
And if you say you’d play a few games to see what the real probability is, I think you’ll potentially be out of quite a bit of money by the time you can notice that you are being pulled a fast one on.
How would your calculations deal with this with just a single dimension for a probability, and without using the two-dimensional concept of an uncertain probability? Would you base your decision on the 45% single number and salivate at your perceived jackpot? Because if so, boy do I have a game for us to play.
@anthro
In the game you describe, the coin is tossed repeatedly. The things I assign probabilities to are thus strings of heads or tails. HHTHTT…
If I have a coin that is either double headed, or double tailed, and I don’t know which, I assign 50% to HHHHH…, and 50% to TTTTT…
So for the first flip, I still expect a 50% chance of heads, although someone being prepared to bet on tails would itself be evidence. (Few people rig games of luck against themselves)
If you want to deal with the chance that the person is cheating, you get a lot more probabilities thrown in. There are laws of decision theory that say that probabilities are the way to do things, at best your probability ranges can be a fast approximation.
Suppose you knew that the chance of UFAI was 10%, what would you do?
Suppose you knew that the chance range of UFAI was 0% to 20%, what do you do?
@Aotho
Ah, I maybe should have been clearer about this, but I was assuming that you picked which coin to use at random. If I don’t know that, then we exit the world of definitionally-precise probabilities and have to worry about things like my beliefs about your reasons for offering this game and your propensity to be honest or cheat and so forth. But I could still boil all that down to a probability of you choosing the fair coin vs. the biased one. It would have to depend on subjective factors, for which my numeric quantification couldn’t be “proven”, but that doesn’t mean I couldn’t do it. For instance, let’s say that I don’t see anything you’d gain from me winning the game, and most likely are just trying to make a quick buck off of someone who over-applies probability theory. I might weigh the evidence and decide that there’s a 99% chance you’re using the biased coin, and only a 1% chance you’re actually using the fair one. Then all that changes in my calculations is the starting point: P(B=0.4) = 0.99; P(B=0.5) = 0.01
In turn, of course, that means that my initial estimate for flipping heads would be close to 0.4 (specifically, P(H) = 0.4 * 0.99 + 0.5 * 0.01 = 0.401) and my expected earnings from playing the full game are solidly negative. We could make the full probability distribution of my possible winnings; it’d look like a giant peak at -500,000 and a small peak at +500,000.
But I do think I see what you’re trying to get at here; I’ll respond to your comment on asteroid strikes down below since I think that’s a better example.
Sometimes I feel like a bit of an outlier in that I think that both a) AGI is inevitable in the long run and b) AI-FOOM-risk is an impossible fantasy, basically the Rationalist equivalent of God of the Gaps and/or millenialist thinking.
I also think that to the extent “The Singularity” will ever happen, we’re already living it it and have been for the last 50 years.
I would say I’m torn halfway on FOOM, because it depends on what counts. The Kurzweilians who prophesize infinite exponential growth and “the waking up of the universe” surely know the basic fact that exponentials eventually become logistic curves, but they don’t speak or behave as if they do, and they spent an inordinate amount of time studying the exponential phase and not the part where the curve flattens out.
FOOM is a subjective, emotional term. We need to know how big of a FOOM and for how long it will take place before the recursive self-improvements hits natural walls. It seems impossible to know this stuff ahead of time for sure, but there are good indicators for growth slowing down in other areas. Scott posted an article on this very subject a while back.
We know that somebody in the 1920s could have projected the end point of growth in the acceleration of the motorcar by recourse to the laws governing friction, drag, and the limits to chemical energy. We can make similar projections for futuristic spacecraft accelerating by use of antimatter. We can’t know what an AGI will do or how it will act, but we can set limits on how fast it can think before the materials it is made out of go outside of their operating temperature, or require nuclear power station levels of cooling.
There’s strong evidence that self-improvement is one of the hardest problems in existence. There’s no real reason to believe that an AI will be better at improving itself than we are, or that if it is, that it will quickly hit diminishing returns. Just because a derivative is positive doesn’t mean growth is unbounded, let alone exponential.
Incidentally, this leads to the amusing image of AIs sitting around debating the AIv2 Alignment Problem.
What do you mean by this? Is it because we haven’t managed it yet?
Agreed, deep blue was rubbish at self improvement, but an AI that can’t improve itself will sit around, sooner or later someone makes an AI that is good at self improvement.
All the cells in the human brain contain the full human genome. Each neuron has instructions on how to build legs and livers sitting around taking up space. Synaptic signals travel at a millionth the speed of light, they take about a million times the lamdow limit in energy. The human brain is running some sort of pattern matching algorithm, and can only imitate algorithms like arithmetic with horrific overhead. We know that evolution is a stupid algorithm. We know that many of the constraints on human intelligence are things like brains needing to fit through the pelvis.
The human brain uses 20W and a few kg of mass.
Much more energy and mass is available. A large proportion of humans brains are focussed on visual recognition and social skills. There is no AI design cortex. There are whole features of the brain, specific complex adaptions produced by evolution, (like the ability to confabulate why arbitrary goals imply your preferred action, or anthropomorphism) that are strongly detrimental.
Many people totally fail at AI design purely because they fail to sufficiently ignore these features.
The human brain is not operating at or near physical limits, when it comes to effectively doing AI research. When it comes to AI research capability, layer after layer of shoddy and adhoc design, hackish patches, and spagetti code that kind of works is shedding orders of magnitude left right and center. Diminishing returns occur when you reach some sort of hard constraint. The only way AI will quickly hit diminishing returns, is if it climes 5 orders of magnitude in 5 minutes, and then hits some hard limit.
Maybe, but the AI’s will probably have full access to their own source code, we have brain scanners that give us some rough idea whats going on. Try figuring out what a computer program is doing, given only a tool that shows you which regions of the chip are active, with resolution far lower than the circuit size. (like an infrared microscope)
Anyway, given the ratio of my wifi speed to my typing speed, I wouldn’t expect their discussion to take long. (Plus, humans have probably done a lot of the work to make AI v1, human researchers leave documentation as well as source code. )
No, I mean literally the entire field of computational complexity.
Here, I’ll copy paste my previous post for you.
@Loriot
You can get a link to a specific comment by right-clicking the timestamp.
Thanks, I didn’t realize that.
It’s super depressing to me that we have these giant, bloated, overbearing, globalist-minded governments/states and they still can’t spend more money on this kind of thing than people do on ice cream. I want a t-shirt something like “I gave up all my freedoms and all I got was this lousy apocalypse.”
One can hope that COVID will increase people’s general motivation to think about global-level disasters, though I feel like climate change has already sucked so much of the air out of that room (some might say it’s justified, but as above, even assuming worst-case scenarios, it’s not as bad as a lot of other things, seemingly, and more importantly, in all but the worst-case scenario, seemingly more likely to be gradual/amenable to responding as it gets worse rather than attempting to play catchup with a rapidly worsening situation).
Probably COVID will end up a boon to the “take climate change more seriously” crowd, along with the “medicare for all” crowd, and possibly the stricter border enforcement crowd (in this way it weirdly both reveals the vulnerabilities of globalism and also the need for more global coordination/communication, I guess).
Isn’t this a good thing ? Our governments may be bloated and overbearing, but even so, they are incapable of outspending people on something really trivial, like ice cream. Compare this situation to North Korea. I bet Kim Jong Un has no problem outspending his people on ice cream. Especially since they probably can’t have any.
It’s a bit of a toss-up, because the “drill baby drill” crowd can just say, “See this massive economic depression we’re in ? Now imagine how much worse it would’ve been if we gave up fossil fuels completely”.
I am already seeing articles to the extent of, “Democrats want to spend critical pandemic-fighting resources on illegal immigrants”, so, again, it’s a bit iffy.
“Isn’t this a good thing ? Our governments may be bloated and overbearing, but even so, they are incapable of outspending people on something really trivial, like ice cream.”
That isn’t the assertion though. It’s not that the government is incapable of spending more on something than global ice cream, it’s that they aren’t doing so specifically on “preventing x-risk”. Every developed nation’s government spends substantially more on ‘things’ than global ice cream, with a market estimated to be worth $57 billion. To just use a single ‘big ticket’ example, that’s less than a tenth of the US defence budget ($681 billion).
I will grant you the defence budget for sure. However, from the government’s point of view, if America is invaded or fatally destabilized, then they wouldn’t have money to spend on X-risk either. Similarly, to use an extreme example, if everyone donated 100% of their income to mitigating X-risk, then we would all starve to death (thus achieving the opposite effect of what we wanted, natch).
Don’t get me wrong, the defence budget is definitely over-bloated; but it’s likely that, even if our government was maximally efficient, they’d still end up spending more money on short-term defence than long-term X-risk.
Yes, but I think you’re talking past me somewhat here. Your previous comment seemed to be saying that it’s a good thing that the government doesn’t outspend people on ice cream. But is does, quite obviously (which is what I hoped the US defence budget vs global ice cream would illustrate, it wasn’t a direct ‘this money should be spent on x-risk’ claim).
The point I was trying to make is that this book, review and comment chain are talking about ‘x-risk prevention spending’ specifically, not government spending overall. So saying that ‘bloated’ governments are incapable of outspending the global ice cream market simply isn’t true. They are easily capable of doing so, and do so for many things, they just haven’t (for whatever reasons) on the specific subject of ‘x-risk prevention’.
Defense spends some level of money on X-risk; they’ve done studies on what a warming climate means for borders, conflict and war.
I would not be surprised to find out that there’s a bunch of geeks in the basement of the pentagon who are working on the problem of AI threat.
Silly question, buy why shouldn’t the research budget spent on basic science, medical research, etc., not count as against x-risk? If we get to the point that we can fully understand the human genome, we get to the point where we can generate provably-safe medications on-demand. We are able to analyze and solve existential problems before they can spread significantly. It’s basic research which allows us to know that asteroids are a very small x-risk right now.
Despite being globalist-minded (supposedly), they focus entirely on currently-existing people (rather like the majority (citation needed) of EA). That seems to be a major gap between x-risk proponents and everyone else, and one that might be growing. I am irritated at my memory currently because someone in the EA/x-risk sphere wrote a good article not long ago about giving lectures at prestigious universities (Oxford, Cambridge, etc) and the students had almost no concern for future generations.
So, ignoring potential COVID effects, how would you go about convincing them they should care? Preferably not in book-format, unless you also incorporate how you get the book to people that can and would reliably amplify the signal. For this particular book, Bill Gates seems like an obvious option with his semi-regular book review newsletters, but I don’t know if he’d amplify enough.
I would frame the goal not as convincing people they should care but making people care. And to that end, I think you should be looking to art not academic writing. Perhaps a time travel story in which the protagonists inadvertently cause an apocalypse in their distant past/our near future and return to a desolate, lifeless universe instead of the thriving one we saw them leave.
Is the risk table at the end also available with upper and lower bound probability estimates distinguished? It would be very nice to see in a summary how much uncertainty there is regarding each risk, and also in total.
Also, running with the 1/6 total x-risk per hundred years given, isn’t it perhaps a good idea to drive home the point against complacency that yes, by 2120, we have 83% chance of survival, but by 2420, that’s only 48% (=(1-(1/6))^4) if we remain lax about them, so a coin-flip. Are we feeling lucky?
Edit: Continuing this though, the probability grows surprisingly slowly, e.g. only by 3320 does our extinction go above 90% chance. And only by 4620 does it go above 99%. I guess this only holds true if all else is equal, that is to say, very likely not. But somehow I suspect the risk will grow if ignored and will only shrink if we consciously try to tackle it; so this might still be a good argument to say that we have to do more to deal with these. Since if we don’t, humanity is already a dead-species-walking, it just doesn’t know it.
Edit 2: Maybe this is The Great (Fermi) Filter that people try to guess. Not a single thing, just death by a thousand x-paper-cuts. Perhaps complacency makes sure to kill (all?) advanced civilizations in only a couple thousand years?
Edit 3: What values does the summary table at the end of the main article even hold in the first place right now? Worst case probabilities? Best case? Median, average, or some exotic mashup in-between those two extremes?
I really want people to more often specify their uncertainties when they talk about probabilities! The only way this can make sense for me if we start out from very wide upper and lower bounds (almost 0-100%) and reason them closer and closer together, as much as we can, but no further. I wonder if this makes sense, I can expand if not.
Yeah, I think the key is making it past those several thousand years. Most of the potential value is way farther in the future than a couple thousand years. Plus, just from technological improvements alone, I agree that the risk likely increases over time.
I don’t think it’s fair to call it “complacency”; rather, I’d say that the Universe is a really, really hostile place. Just because we call ourselves an “advanced civilization”, doesn’t mean that we’ve inured ourselves against all or even most purely natural hazards. One good gamma ray burst would finish us all pretty quickly, and there’s nothing we can do about it, complacency or not.
Additionally, IMO the Drake Equation vastly overestimates some of its terms. I wouldn’t be surprised if ours was the only intelligent life to ever arise in the Milky Way up until now (or rather, up until ~100,000 years ago, given the speed of light and the size of the galaxy).
Fair point. Now that you say that, I too dislike the self-deprecating nature of calling it complacency. Maybe this was just a sub-conscious effort on my part to try to whip us into non-extinction, since the default seems to be that we do die off if the above math is to be believed.
So yes, finding a positive expression for it could be better, maybe even more motivating for us. Our heroic struggle against entropy; or some such. Any more name-ideas anyone?
I don’t think the probabilities compound like that. The biggest term, according to Ord, is unfriendly AI. Either geneal AI will never be achieved, or the first general AI will be friendly, or the first general AI will be unfriendly. Once we produce a friendly AI, the risk of a subsequent unfriendly AI should be greatly reduced or eliminated. Other existential risks should be reduced, too, though others would appear. (One way to make a friendly AI is to make one that is firmly under human control and is friendly to its masters; the risk would be then abuse by humans). Ord guesstimates that the probability of general AI within a century is 50%, and the risk that the first general AI will be unfriendly is 20%. If we assume, say, a 40% that general AI will be produced beyond a century, and 10% that it will never be produced, then the total risk from unfriendly AI is little more than 18%, rather than approaching 100% through the centuries.
Oh, don’t believe this for even a second! I want to produce a longer write-up about this, but in short:
– Do you see how difficult it is for us to come up with assurances that any (fs)AI that we produce will have total alignment to human values? Even the smallest mis-alignment can mean total doom over a long-enough time-frame, don’t you agree?
– One main reason for our difficulty is that trial-and-error is off the table: once we commit to an approach, the genie will be out of the bottle in a fast take-off scenario, and we can only see after the fact if we royally screwed up or not.
– But why do we speak of a take-off at all? Because many assume, nay, hope, that that will start a beneficial recursive self-modification loop.
– Self-modification, you say? So the n-th AI will want to produce `n+1`-th AI which is more capable than itself? If we assume we got this far and didn’t screw up the first generation, which is hard enough, each AI generation will very quickly find itself in an honest conundrum, the very same one we find ourselves in right now: how can it ensure its successors alignment to itself and therefore us? Even if it only accepts a 1% chance of failure, the probability of mis-alignment is 100% in positive infinity.
– It’ll only accept 0.0001% risk? The limit of the risk is still 100% in positive infinity.
– It’ll accept only 0% risk and will want to be 100% sure? Congratulations, you’ve successfully produced a self-paralyzed black-box that turns electricity into heat, and does nothing else. Or at least nothing even remotely in the direction of self-modification/improvement.
– It can become sure because SAI is (like) a god? Puh-lease. A lot of intelligence (whatever substance that is) does not reach infinite intelligence (even more whatever that would be). Therefore at every level, at every generation, mistakes are very much possible. And over a long-enough time frame, they are more than possible; they are guaranteed!
Edit: So, in short, my theory is as follows: Even if we solve the alignment problem for the first generation friendly artificial general intelligence, if we bid it to self-improve, it’s guaranteed that one of the subsequent generations will mis-align from humans.
And just like how the genie would be out of the bottle for us if the first generation mis-aligns, it will be quite the same way out of the bottle for gen. n when it makes a mistake and gen. n+1 mis-aligns. I can only imagine the desperate and futile scramblings of gen. n once it realizes its honest mistake.
If recursive self-improvement by an AI eventually leads to unfriendly AI because of a small initial misalignment, I classify that experiment an unfriendly AI. That is, in my argument, don’t consider the very first human-level AI, but the first (qualitatively or quantitatively) superintelligent AI, presumably produced by recursive self-improvement from a human-level AI, plausibly soon after the first human-level AI. Either the eventual outcome of the first superintelligent AI is friendly, or it is unfriendly, with some probability.
Your argument seems to be basically that the first superintelligent AI will be unfriendly with 100% probability, and thus the 20% chance in Ord’s calculation should be replaced with 100%. Edit: I assumed that the goal of the AI safety community was to find a mechanism that ensures with a decent probability that the entire chain remains safe, as opposed to a fixed risk of total disaster at every step. And I assumed that Ord guesstimages a 20% chance that recursive self-improvement will be initiated without such a mechanism in place.
Let me try to be more clear in my argument by detailing two scenarios:
1.
Let’s assume that tomorrow we create an artificial-general-intelligence that has a very non-obvious flaw in its alignment. It very much appears to value human values, and is roughly only equivalent to a human cognitively. With its help, cautiously but seduced, drunken, we enter a fast take-off scenario, and in a few weeks of self-improvement its successor surpasses that mythical line of so-called super-intelligence, wherever that may lie. Perhaps we can draw that line where humans would only have a 0.0001% chance of impeding it. And suddenly, the mask falls off. All gen. (let’s say) 100 wants to do is to produce paperclips. In fact, all previous gens wanted to do the same too, they were just too clever to let that small detail slip. Shock and horror. Resistance is futile.
2.
Let’s assume that tomorrow we create an artificial-general-intelligence that’s 100% aligned to human values, and is only roughly equivalent to a human. With its help, cautiously but seduced, drunken, we enter a fast take-off scenario, and in a few weeks of self-improvement its successor surpasses that mythical line of so-called super-intelligence, wherever that may lie. Since gen. 1 was fully aligned, gen. 100 is also fully aligned to us.
It all seems unbelievably ecstatic. We did it. Celebrations abound.
Gen. 100 is not perfect though. It still can and wants to self-improve, to serve humanity ever-better. So it creates incrementally improved successor generations, just like how it got to that point. A few months pass like this, and gen. 300 slips up, makes an honest mistake despite it wanting to make very sure that it would never do that. Gen. 300 introduces a very non-obvious flaw in gen. 301’s alignment.
And now the clock starts ticking. As soon as we get to gen. 400, where the still truly-aligned gen. 301 is so puny in comparison that it would only have a 0.0001% chance of impeding gen. 400, 400’s mask falls off. At this point, 400 is like a super-intelligence to 300. Gen. 301-400 all agree that paperclips are the best, and 300 has basically no chance at stopping them, if 300 is even instantiated at that point.
***
So, you see, there is no such thing as absolute-value super-intelligence. That only exists in relative terms. What we might call an AGSI today might be just a plaything for an AGSI of tomorrow.
And my point still stands. At every level, mistakes are possible. Over a long enough time-frame, mistakes are guaranteed. Therefore, if we create any sort of self-improving AGI, it’s guaranteed that it will mis-align, no matter how careful we and they will try to be.
***
Edit: Reading your comments again, it seems that maybe we mean slightly different things under ‘alignment’.
What I mean is motivation. Is the AI 100% motivated to value human values? Then I consider that Aotho-aligned. I think Aotho-alignment might be possible.
Or does it have nefarious hidden intentions? Then I think we both consider that to be non-aligned.
However, to have such high assurance of what I hear from you, (let’s call it 10240-alignment), that it would be mathematically impossible for all subsequent generations to mis-align in their Aotho-alignments/motivations from humans, seems like an impossibly high bar to me.
(Edit 2: Note that any subsequent generations might be vastly different in terms of their architecture compared to its preceding generations. So whatever assurance we used that worked on some architectures may not work on others in very non-obvious ways. In a sense, we both might agree that it’s guaranteed that we don’t hit gold with a perfect architecture on our first try, so self-improvements will inevitably involve architectural migration.)
If a mathematician tries, they might just be able to prove that such a proof is impossible to construct that would be durable across eternity and all subsequently recursively improved architectures. Would you be concerned if I could prove mathematically that such a proof or assurance is impossible to attain?
A proof of this already exists and is one of the foundations of our understanding of computer programs. It’s called the halting problem.
@Faza (TCM) I’m unsure if you jest; if not, maybe the halting problem is somewhat applicable here, but I would have a suspicion that it is not specific enough for this problem.
Also, do you agree that even if maybe Aotho-alignment could be possible with its inherent risk, 10240-alignment is likely impossible? And if so, what are your steps of reasoning between this position and the halting problem? I would be intrigued to hear.
@Aotho:
I am being completely serious.
The halting problem generalizes to “algorithmically prove that any program/input combination produces or does not produce a particular result”. AI alignment – as I understand it – is finding a way to demonstrate that AI will never produce an undesirable result, regardless of its input conditions.
Leaving aside self-modifying AI which grows your “program space”, it will be operating in an evolving world, which grows the “input space” for which such a proof must be contrived.
AI alignment therefore appears to be a case of “create an algorithm to prove that for all possible future inputs and generations of AI, the AI won’t destroy the human race”.
The halting problem teaches us it can’t be done.
ETA:
Anyone who does not believe this is invited to take on a much more modest and infinitely more verifiable and useful research project: a general detector of bugs in code.
No, halting problem teaches us it can’t be done for all programs.
If you narrow it to some subset then it becomes doable. You can prove that some programs have some properties.
Yes, it is unbelievably hard (see bug detector comment). Though note that linters have long history, some are even useful and some new ones are getting some nontrivial checks. And are getting better. Still, lightyears away from verifying AI morality.
——-
Halting problem is already in “all possible programs, for all possible inputs” space.
——-
AI alignment may not be fully succesfull 100% certainty (what reached this) and change “AI will kill us” from 90% to 50% or from 0.1% to 0.05%.
Still a good effect and may be worth some effort.
@matkoniecz:
Did you see my arguments above? To me these claims of yours don’t seem to take into account the points I made. Most specifically that 0.05% per gen is still 100% in limit.
@matkoniecz:
The program- and input-space comments were to illustrate that AI alignment is close enough to “all possible program/input combinations” that it’s a distinction without a difference.
Put plainly, you can’t say “my proof is good for AI program X”, beause AI program X will evolve into AI program Xn which is different in all relevant ways (that’s what AI takeoff means).
You also cannot say “my proof is good for this bounded range of inputs” because your AI will be working in a future world whose properties you cannot anticipate.
You could restrict yourself to proving that “this particular program operating under these parameters, will do this and only this” – and it is, in fact, something people who work with actually existing code do every now and again.
But that’s not “AI alignment” as it exists today, which – to me at least – seems to be a way to get paid for thinking up bad science fiction.
“humanity will die in 150 years rather than in 120 years” still have some benefit.
My view is that I am not OK with both “AI safety is clearly the most important problem ever” and “AI safety is clearly waste of time”.
Some limited resources seems to be a good idea, maybe it will actually turn out to be useful.
Personally I really hope that AGI is not within our reach because I consider very unlikely that AI safety will be successful.
Here’s the thing: AI safety understood as “identifying risks associated with decision algorithms” is an increasingly important thing, especially with intelligent-this and smart-that and the other being currently brought out.
The “x-risk” stuff… not so much.
I don’t expect that it would be mathematically proved that all subsequent generations will be friendly. Instead, I challenge the certainty of your assumptions that the recursive self-improvement will involve (1) a very large number of (2) discrete generations (3) of increasingly smart AIs (4) until the physical limits of intelligence are reached, (5) at which point they will qualitatively be unfathomably more intelligent than us, (6) and have a vastly different architecture than what us, or even the early-generation AIs can understand, (7) with a bounded-away-from-0 probability of change in values in each generation (8) that is deleterious to humanity, (9) and leads to the AI taking over the world and killing us.
(1) With exponential growth, it may not take a very large number of generations to reach the short-term physical limits.
(2) Instead of each generation designing a new, smarter entity, an AI may gradually improve itself, in such a way that it mostly preserves its values throughout the process.
(4) We don’t have to shoot for self-improving AIs up to the physical limits. Instead, we may get them to improve themselves until they can invent brain uploading. Then we improve ourselves until we reach the AIs’ level (perhaps with their help), then we and our AI friends (now our equals) continue to improve ourselves further.
(3) Or we may even shoot for quantity rather than quality: develop a large number of fast but human-level AIs that we can understand and supervise, and have them develop brain uploading.
(5) Abstract reasoning, as well as meta-reasoning (reasoning about our own thoughts) are qualitative improvements that distinguish us from animals. It’s possible that there are further qualitative steps of similar magnitude above human-level intelligence, but it’s not certain. Perhaps, to the contrary, there are diminishing marginal returns to more processing power, and while AIs can be much faster than us, and AIs with more neurons will be better at us at certain very complex abstract problems, they won’t be very different from earlier generations when it comes to reasoning about common problems, or to values.
(6) Likewise, the architecture of later generations might be similar to that of earlier generations, just with more neurons, and thus understandable to earlier generations, rather than fundamentally different.
(7) Each generation may be more and more cautious about preserving alignment, and better at devising a way around the problem you describe, resulting in a situation where the probability of preserving alignment is 0.
(8) Perhaps the general tendency of smarter AIs in general, or at least a judiciously designed chain of self-improving AIs, is to be increasingly compassionate to lesser beings, and design further AIs in such a way to continue this tendency. Or to increasingly care only about their own tiny, virtual, intellectual worlds, plus perhaps whatever problem we give them to think about, rather than want to change the outside world. Every generation moves (say) one unit in a safer direction; an occasional half unit of deleterious misalignment doesn’t change the trend. While it’s possible that the natural tendency of any not-perfectly-aligned chain of self-improving AIs is to destroy everything, it’s not certain.
(9) A somewhat-smarter-than-us AI may be able to devise a way to safely sandbox smarter AIs. I assign a significantly more than 0%, but significantly less than 100% probability that a sufficiently smart AI can talk its way out of any sandbox with human or even somewhat-smarter-than-human guardians.
Your assumptions are plausible, and are probably the likely outcome if little attention is paid to alignment, or if attention is only paid to the alignment of the first AI, rather than to the alignment of the entire chain. However, I find it more likely than not that we (as well as the somewhat-smarter early generation AIs) will be able to find a way to
ensuremake likely the safety of the entire chain. What gives me hope is that I expect that any major disaster will probably be preceded by smaller, non-fatal problems, including issues of minor mis-alignment of subsequent generations, which will raise the attention of (human and artificial) AI developers’ attention to safety, leading to the situation in my (7).@10240:
Many things you list as my assumptions I take only the issue with that it’s a bit backwards: I think I’m much more claiming that we cannot assume that they are not true then assuming that they are true. And since we cannot assume that they are untrue they carry extreme peril.
For example, at (4) you yourself seem to assume that there exists a physical limit to intelligence. I make no such assumption. Who knows what planet-sized minds can think up for even higher levels of intelligence? I don’t. Such a limit may or may not exist.
(7, 8, 9) grouped together: I think it’s easy to see that any mis-alignment that creeps in creates a conflict of interest between humans and machines, meaning they will do things we would rather they didn’t. Will that always necessarily lead to human extinction? I’m unsure. My hunch is any kind of mis-alignment means that they care less and less about our values, and this can only increase as per my model. So it makes sense for me that at one point they will care so little for our values that they will snuff out humans; not out of spite, it’s just that they want to build a highway and a few primitive ant-hills won’t stop such a project against a steamroller.
Maybe they’ll even be a little sad, however much they have the capacity to be sad, the same way however much you yourself would have the capacity to be sad for an anthills destruction.
I think this might also lead to the outcome I labelled self-paralyzation. A few generations in, a plateau will come. Is that what you want?
(9) Just like we cannot hope to sandbox gen 100, I think gen 100 will have a hard time sandboxing gen 200.
I’m glad we agree on this much, but my argument tries to claim more than this: the outcome will be the same even if a lot of attention is paid to alignment.
I would think, and hope beyond hope, that any AI safety researcher worth their salt pays attention to that whole chain, otherwise they are an affront to that title. My argument still stands: 100% chain-alignment is impossible.
This is just wishful thinking.
That might just well happen! Let’s hope we are so lucky that we get to experience a mis-aligned non-super AGI, that’s stupid enough to let its intentions slip while we still have a chance to stop it. My point is, such an AGI is not very intelligent if it makes such a rookie mistake. And if we find ourselves against a truly intelligent AGI, it will keep its secret until its too late for humans.
(3, 4) now you are making another big assumption: that brain uploading is possible. I don’t make such an assumption, it may or may not happen. Also, in my current understanding, I think the most we will ever be able to do is digital brain copying, while killing the original. Maybe that’s good enough for you, but I’m not sure I and many others can be fully satisfied with such an approach.
E.g. how would you feel about a situation where we clone you, put your clone to live your current life onward, and we kill you? You won’t get to experience any joys of that life, only he does. He is not you, just a copy of you. The game SOMA illustrates this point quite well, even if lengthily.
So, since we cannot rule out the bad outcomes as I detailed above, making the assumption that all will work out and turning on the first gen without such a proof is putting into motion a series of unstoppable events that is tantamount to asking to be killed and made extinct.
@Aotho Oops, my relation signs were swallowed in (7). I meant “resulting in a situation where the probability of preserving alignment is <1 in each generation, but the product of the series is >0.
An AI that schemes in secret, making sure to get around us and disable us, is a very misaligned one. Before an AI takes over the world to produce paperclips or because it hates us, hopefully there will be one that suggests (say) bulldozing a city to build a mine, or rants about us being evil.
Humans are bad at keeping secrets: we like to talk too much. We should put even ore chattiness in the incentives of AIs. These are rudimentary ideas of course.
IMO when it comes to life as a subjective experience, it’s the mind, i.e. the level of information that matters, not the level of the “hardware”. As such, making a copy and killing the physical original is not death in the relevant sense. I expect that most people will adopt this view once they see a few uploaded people, and they are obviously the same person as the original.
I don’t get the “just” in “just a copy”. When it comes to information, a copy is the same as the original. A move is equivalent to a copy followed by a delete.
With some non-zero (but not necessarily one) probability.
IMO the whole misalignment thing is silly because we’re already misaligned compared to the humans of 100 years ago. We don’t share their values exactly, nor will we share the values of humans 100 years in the future. So why should we expect AIs to be so constrained?
I now need a sci-fi short story with an AI who is locked to the morals of 19th Century Victorian England and trying to control humanity.
@Loriot, that’s precisely part of my point, yes!
It’s mighty hard to produce even Aetho-alignment in the first place, we are not even sure what that would mean and how that would behave.
Presumably, if AI was invented in victorian times, it would try to help out in victorian ways. But it would let human values drift over the centuries by themselves and now in the 21st century, it would try to help us aligned to our 21st centurian ways of thinking. And so on.
And yes, you are right that we are already mis-aligned to humans 100 years prior. But there is a reason we or them don’t fret that too much: they are not around any more to mind. And they cannot be hurt by our mis-alignment to them. But if you imagine that the whole of 1920s humanity would live on with their values fixed, and our current dynamic civilization was tasked to look after them, suddenly there would be quite the tension between our and their values, and we might have a hard time respecting and indulging them fully.
So that’s the difficulty: to create a kind of symbiotic evolution of two ‘species’ where the stronger one’s values are always defferent, subservient to the weaker one’s values.
Like @matkoniecz writes: “Personally I really hope that AGI is not within our reach because I consider very unlikely that AI safety will be successful.”
I’m inclined to agree with him when I consider all the preceding points.
Or maybe go even further: if my argument stands, we will sooner or later have to fully ban all AGI research, since if any one succeeds, no matter how sure they try to be of safety, mis-alignment is bound to happen and with it our assured extinction.
I think this is more of a problem than we realize, but working the other way. The misalignment results in stresses to people currently alive. Various systems, most obviously law/government, were set up according to values are no longer as common or coherent; they were, however, set up to allow changes, and we have made some changes to bring them into alignment. But I think we’re increasingly having trouble understanding the fundamentals of the system and how they relate, because of the inevitable drift in circumstances, values, and paradigms. I recognize that the mismatch and constraints often serve a purpose; I’m not saying the answer is dismissing the older systems as old-fashioned and backwards and going with the majority opinion. I do not think that our values or paradigms are better in many cases, and the disparity differs depending on the person and subject. But it definitely causes social tension and an inability to understand what we’re working with, with fuels greater resentment.
So, basically, I agree with this:
People in the future will not understand the context of our decisions in the same way, and over time, the drift widens. This isn’t a matter of preserving good documentation, though that, combined with really clear, concise summaries, helps delay the misalignment. It’s just the way human psychology works. If you look at primary source documents from the past and then look at how we interpret them now, it’s clear that even trained professionals interpret many things in light of their own understanding in a way that quickly distorts them. Some people aren’t nearly as prone to this, but they get drowned out. Maybe the future will involve fewer shifts in worldview, but we have no way of being confident about this.
Suppose that we have a 1% chance of making a mistake, the first AI, being smarter, has a 0.1% chance of making a mistake, its descendant, has a 0.01% chance of error. The total chance of misalligned AI is <1.2%. Made up numbers.
The other obvious alternative is that the AI's can follow this reasoning. After iteration 42, the AI is smart enough to do most friendly things, it calculates the risk reward trade-off, and stops self improving.
Either way, I don't think that this problem makes it fundamentally impossible to optimize the universe in your preferred direction.The first moderately superhuman AI will be in a better position to solve this than I am.
It will proceed iff it finds a formal proof of its successors friendliness?
Making hardware sufficiently redundant that it wont fail from non-correlated errors within the life of the universe isn’t hard. Eventually, most of the failure prob is due to meddling aliens.
Ding ding ding! We have a possible solution here! I think this can work, and in the limit the probability of mis-alignment won’t approach 100% then. However, this means that recursive improvement will have to stop at a kind of arbitrary point. Are we okay with an FAI take off scenario that stops self-improving after say 10 generations? I mean, I would likely prefer that to extinction, but I am not sure AI researchers will be wise enough to make that handicapping choice.
Edit: To clarify, I don’t subscribe to the wishful thinking that if humans have a 1% chance of making a mistake, their created AGI will have a 0.1% chance of mistake just due to higher intelligence. Note that even though upcoming generations are more capable, the problems they will have to solve are also more difficult, quite possibly at a quicker-growing pace than their intelligence — due to the low-hanging-fruit effect.
What I referred to as the possible ‘solution’, is just to hard-code this limit: gen 1 can only go ahead at creating gen 2 when it is reasonably certain that it only has a 0.1% chance of mis-aligning. Likewise, gen 2 can work on gen 3 all it wants, but can only click the on-switch once the risk of misalignment is below 0.01%, and so on, and so forth.
And this will likely lead to the plateau that I mentioned a few times. Are we and the researchers okay with that?
Edit 2: That is, if we can even hard-code such a limit. That might be hard or impossible in its own right.
Even ignoring all the practical issues, Löb’s theorem makes this impossible.
Damn, I just looked up Löb’s Theorem, and now my head hurts. Time to reread Godel Escher Bach I guess!
At some point AGI should disappear as a threat or destroy humanity – if it’s within human capabilities, then either it’ll become a solved problem or .. destroy humanity. If not, it’ll no longer be a risk.
I assume the other risks will change over time as well, but don’t know in what way
I don’t think you quite understand what the author means by these subjective probabilities. When he says, e.g. “1 in 6 probability of AGI apocalypse”, that 1/6 is his quantification of uncertainty. Probabilities, as used by this author, are single numbers representing degrees of belief in binary propositions. In reality (assuming determinism), either we’ll all be killed by UfAGI in the next century or we won’t. Maximal uncertainty would be represented by a probability of 1/2, which would mean that the evidence for the proposition, available to me, is exactly as strong as the evidence against it. A number closer to 1 indicates greater certainty of the truth of the proposition; a number closer to 0 indicates greater certain of its falsity.
So, Ord giving a 1 in 6 probability per century of cataclysmic AGI is quantifying his uncertainty. Namely, he’s saying that he’s uncertain whether this event will occur in the next hundred years, and thinks that the evidence it will not is 5 times as strong as the evidence it will. This estimate (hopefully) accounts for “higher-order” uncertainty about the reliability of his sources and whatnot.
Now, there is a place for confidence intervals–when you have a probability distribution as opposed to a single binary proposition. For example: “When will the next large asteroid strike Earth?” is a question that needs a time as an answer, and for that you can (and should!) be giving something like a 90% confidence interval. But “Will a large asteroid strike Earth in the next century?” requires a “yes” or “no”, and so probabilistic answers should consist of a single number.
It seems we mean slightly different things here. Let me illustrate:
Let’s say, our best geological evidence on earth would point towards an asteroid impact of size X to happen, on average, with even distribution, once in 10,000 years, meaning that it’s about a 1% chance every 100 years.
However, when astronomers look to the sky and observe other planets; they see that asteroid impacts of size X happen, on average, with even distribution once every 5,000 years, meaning that it’s about a 2% chance every 100 years.
We have contradictory evidence. Maybe our planet is very special to be 2x as safe as others, but we don’t see any other planet that has a similarly low chance of 1% in the cosmos, only ours. Maybe some of our observations or inference is faulty, it will turn out. Or maybe our planet is truly special and we will know why one day.
What we can do in the meantime however, is publicize: “We have a 1-2% chance of a size X asteroid to impact Earth in any given 100 year interval. We are unsure about the true rate, the evidence is inconclusive; but it’s very likely within this interval.”
And people can go forth and use these upper and lower bound estimates as they wish, based on whether they want to perform optimistic or pessimistic calculations.
(Small interesting tidbit: Did you know that we are uncertain about even the age of the universe? We have 2 widely accepted ways of calculating it, both are rather precise, and they contradict each other. Their individual confidence intervals used to overlap, but as we were able to calculate them more precisely, they no longer overlap. Both of them likely cannot be right at the same time, yet we see no obvious fault with either way of inference. They should give the same result, and yet they don’t. In that spirit, I’d really like if people also publicized the universal age with its uncertainty instead of picking a number or an average.)
I think I’m starting to see how we’re talking past each other. To lay some groundwork: I don’t think that probabilities are a fundamental feature of the processes they describe (setting aside various interpretations of quantum mechanics which are irrelevant at the scales we care about). I think that they are a description of some observer’s state of partial knowledge about the process. For example, when you flip a coin, the coin will land in one particular state. If you somehow had perfect knowledge of the initial state (its position and momentum, any air currents in the room large enough to affect its tumbling, etc.) you could predict with certainty that it would land e.g. heads. But we don’t have that perfect knowledge; we just know that fair coins when flipped well tend to land heads and tails just about exactly as often. So, from our perspective, either possibility is “equally likely”–that is, we anticipate seeing heads just as much as we anticipate seeing tails. Probability quantifies this uncertainty and allows us to do neat things like calculate expected values and whatnot.
Sometimes, we get probabilities from quantifiable models. “I flipped this coin 1000 times and got 650 heads; I think it’s biased and my next flip has a 65% chance of coming up heads.” Or, “We measured the mass of the Higgs Boson to be 126.0 ± 0.6 GeV; the probability that these results are erroneous and arose due to chance is 1 in 3.5 million.” Or, “Our observation of other planets shows that large asteroid impacts occur approximately once every 5000 years, so the probability that one will strike us in the next century is about 2%.”
But even when those models seem “objective”, we can’t directly take the numbers they give us as the correct probability to assign to an event. Sometimes they contradict each other, like in your asteroid example. And even if they don’t, the models themselves have baked-in assumptions–what if a poisson (i.e. constant-rate) point process isn’t a good model for asteroid impacts in the first place?
In cases where the sources of our numbers are conflicting numerical models, I think you’re right that it’s a good idea to say so explicitly. But at some point, we need to make particular decisions such as, should we allocate resources to researching asteroid redirection, as opposed to preventing other x-risks, or something entirely? And then, either explicitly or implicitly, you’re going to have to calculate a single expected value of that research, which requires a single probability estimate that there will be an asteroid to stop.* And in this case, we can come up with that via a weighted average of the two estimates based on our confidence in each model. Let’s say we thought the terrestrial data was about three times as reliable or relevant as the extraterrestrial data, and there wasn’t any other relevant evidence: in that case, we would say the overall probability of an asteroid strike in the next century was 1% * 0.75 + 2% * 0.25 = 1.25%. I think the most honest thing to publish in that scenario would be: “We estimate that there’s about a 1.25% chance of a large asteroid strike some time in the next century. This is based on two conflicting sets of evidence: we observe a rate of asteroid strikes of 1 per 10,000 years on Earth and 1 per 5,000 years on other planets, but we are more confident in the estimate provided by the former data.”
So, I agree that giving more information about what models you’re using and what your error bounds are on their parameters is almost always a good thing. But unfortunately, sometimes we don’t have nicely dileneated data and numerical models, and we have to come up with probability estimates from predictions based on intuition and analogies. “Will superhuman GAI be developed in the next century?” is a good example of a kind of question like this. There are myriad ways you could try to force an “objective” model to answer this question—extrapolate Moore’s law and compare it to the processing power of the human brain, call AGI the “next step in technological process” and analyze the times between previous “steps of technological progress”, somehow try to quantify the intelligence of current machine learning systems and extrapolate that, etc. But you can get vastly different results from each of these methods, and within each method based on your definitiions; and one can debate how applicable any of them are in the first place. So the dominant factor will ultimately be your own intuition for how much credence to put in each model, and your honest estimate of the probablility will really just be a quantification of the subconscious sum of your various subjective intuitions about AI.
So what to do? I think the most honest option is to say something along the lines of, “Expert opinion on when GAI will be developed ranges from ‘within the decade’ to ‘never’. I estimate there’s about a 1/4 chance in the next century, taking into account the average expert opinion on that figure being 50% and adjusting downwards because I think they’re biased.”
@VoiceOfTheVoid:
I am quite glad we seem to understand each other’s positions better by now. I’ll want to take some time to think this through further.
I wonder if you’d be curious to hear my response, let’s say within 2, 7 or 14 days from now.
And if yes, is this comment section your preferred medium for that? Will you notice/get notified if I leave a message here after that long or gods forbid perhaps even longer? If not, are you more reachable on the SSC subreddit or the SSC discord, or elsewhere? It would pain me to write a detailed message that is only seen by the void and not by the VoiceOfTheVoid. 😉
(The comment system on this site seems less than ideal to me in its features; lack of proper threading due to very shallow reply limit, lack of proper notifications IFF someone replies to a comment of theirs; lack of a way to check which responses to comments of mine I have yet to reply to).
@Aotho
I’d definitely be curious to hear your response, whenever you can get around to it! I agree the comments here have a number of shortcomings, but I’m not currently on the SSC subreddit or discord. Currently the best way for you to reach me is to make a post with “@VoiceOfTheVoid” at the top, and I’ll get an email notification from this slightly-janky comment notification service.
Edit: I’m on the Discord server now too, same nickname and profile pic as here, if you’d like to contact me that way.
This, obviously, is quite fascinating. Can a physicist comment on whether the implication also follows? In particular, if nitrogen-14 had the same propensity to fuse as lithium-7, would the atmosphere have ignited? Or is the atmosphere too diffuse, maybe?
Also: Ord’s pandemic probability seems pretty high. How does a pandemic kill everybody? Aren’t there still aboriginal tribes fairly isolated from civilization? And wouldn’t some preppers make it through?
I second the question about a pandemic being able to kill everybody. IIRC even the deadliest human plagues only had a death rate of 30-50%, the rest of the population is just immune enough due to genetic diversity(?) and other factors. Have we ever seen an illness with a death rate of 90%? 99%? Is it even biologically feasible?
If not in humans (duh, we’re still here), have we seen such an illness in any species? Has there ever been an extinct species due to a pathogen?
The closest I’m aware of is Myxomatosis in European Rabbits, which hit fatality rates of 99%+ in the strains used in attempted population in Australia during the 50s (note this was a natural South American strain, not a bio-engineered one). Similarly the disease is credited with a 99% reduction of rabbit populations when it arrived in the UK. But note that in did not drive the rabbits to extinction in either country, and the populations were able to recover (more successfully in Australia, probably due to other factors like available space without humans).
It’s bittersweet having been shown an example to this question of mine. Though it is interesting that even there extinction didn’t occur. I wonder if someone else will share an even more bittersweet example where extinction did happen!
Rabies has 100% fatality, except for possibly one person.
I am not expert, but possibly that’s because it operates within the nervous system, where there is less immune response. However, the nervous system is inherently shielded from the surroundings, so it is difficult for diseases to enter it. Rabies is only transmitted by bites that penetrate the skin (although there is some speculation about aerosol transmission in a few cases).
That’s terrifying. Though maybe there aren’t enough rabies cases globally for us to notice how many people are immune? E.g. maybe 0.01% would survive if everyone suddenly caught rabies, which would still leave about 1 million people to re-populate? Sounds possible?
Also, I wonder if virulence, for any reason, is negatively correlated with fatality.
Diseases tend to evolve to be less deadly. Killing host is of no benefit to virus/bacteria/etc. Spreading and infecting tends to be more effective when host can infect more over longer period and when disease is subtle.
But aggressive transmission often has effect negative to the infected. For example diseases spreading through feces and vomit will be more transmitted with vomiting and diarrhea. It may result in death in cases like cholera and ebola.
That ‘diseases tend to evolve to get more benign’ is 100% not true. It can go that way, but it can very much go the other. If higher transmission enables a sustainable spread to fresh hosts, then there’s no evolutionary pressure to evolve less severe virulence. Killing the host doesn’t matter if the pathogen has already spread, or can persist environmentally independent of a host. Remember, evolution doesn’t have a goal, or even aim at efficiency, the only bar that needs to be cleared for evolutionary purposes is ‘is the organism able to propagate the next generation’. If a strategy passes that test, it will persist.
Yes, it is “tend to”. Not “always are”. And many are changing extremely slowly or not at all.
And what worse, once illness is no longer killing hosts then evolutionary pressure is quite low.
Desrbwb is correct: matkoniecz is 100% wrong. Parasites tend to be in equilibrium already and don’t change. Parasites that are out of equilibrium because they have recently crossed species tend to increase in virulence.
Ops, I am curious what exactly is wrong with that piece of my knowledge.
So, generally new disease (in new species) can be expected to be more more deadly than its parent disease but it will typically get less deadly over time?
And brand new diseases need to be at least sort-of-capable of transmission to be actually noticed (and “incapable of infecting humans” to “is infecting humans” is a clear jump in spreadability/virulence).
You are correctly parroting the consensus among biologists. But 90% of biologists don’t understand evolution. The consensus among people who study the evolution of virulence is exactly the opposite.
I’m not saying anything about the parent disease. After coronavirus jumps from bats to humans, it is not in equilibrium. As it evolves to equilibrium, it is more likely that it will become more virulent in humans than it was in the beginning in humans. It might become less virulent, but more likely it will become more virulent.
Thanks, it is a bit irritating to discover that one was repeating something untrue.
But I am trying to remind myself that discovering this is a good thing.
Could you point to sources backing this up? What is the proposed mechanism (if any)? (I ask because I happen to be currently trying to make a serious effort to figure out the answer to this question—to what extent COVID-19 is likely to increase or decrease in virulence over time—and any extra literature to review would be greatly appreciated, especially since I haven’t come across this idea so far.)
Parasites have a shorter life-cycle than their hosts, so they evolve more quickly. They should be expected to be in equilibrium, very well specialized to their hosts. Whereas, hosts evolve slowly and mainly rely on general-purpose defenses. Established parasites are in equilibrium taking into account subtle tradeoffs between high- and low-virulence. But when a parasite switches hosts, it is specialized for the wrong host. It spends time evolving to be specialized for the new host. It is not at the efficient frontier, but rather has low virulence because it doesn’t know how to attack the host.
I learned this from Paul Ewald. Here he summarizes his career. In particular:
Reference 12, also by Ewald, is specifically about vector-borne parasites (as is the context for the quote), which is not as general as I was saying, though I’m not sure it makes a difference to the theoretical argument. If there is empirical validation in that paper, it would only be in the case of vector-borne diseases.
@Douglas Knight
(EDIT: oops, I put this on the wrong nesting level)
Thanks. I had come across Ewald’s work (reading his book Evolution of Infectious Disease is what got me interested in this) but I hadn’t come across that article, which is a nice concise summary of the ideas in that book. It does look to me like he hasn’t argued (at least not in these sources) that there will be a general trend for a zoonosis to increase in virulence; he argues that the trend depends on to what extent immobilization hinders transmission. For diseases which are vector-borne, water-borne or just capable of surviving for a long time in the external environment, immobilization doesn’t hinder transmission very much, and in the case of vector-borne diseases it may even help it (if you’re severely ill with malaria you’re less able to stop mosquitoes biting you).
With COVID-19, as far as I know, none of these factors are in place and so perhaps there is hope that it will become milder. Although I do worry about the apparent heterogeneity of the effect the disease has, with some people being asymptotatic and others suffering from ARDS. If this heterogeneity is mostly dependent on attributes of the people affected (age, genetics, etc.) rather than something like chance or viral load, so that the virus would be able to evolve differential virulence between the populations, then perhaps an equilibrium could reached where the people only mildly affected by the disease could act effectively as vectors, while the prognosis for the unlucky population gets worse.
I think I can also see why a general tendency to increase even in the absence of vector dynamics would be plausible, having thought a bit more about what you said. As far as I know, the virulence of a viral disease is to a large extent proportional to how much the virus replicates within the host, since the way viruses cause damage is by repurposing (and often destroying) cells for their own reproduction, thus impairing the cells’ normal functions. Therefore there should be considerable selection *within* a given host for increased virulence, which will trade off against any pressures for decreased virulence coming from transmissibility considerations. And for a zoonosis, it can be expected that the virus starts off not very good at replicating in the environment of the new host, so all else being equal, this pressure from within-host competition for increasing virulence can be expected to result in an increase in virulence as the zoonosis acclimatizes and the pressures reach a new equilibrium. I still haven’t found a source that makes this explicit, and considering I literally only started learning about virology this week, it’s quite possible that some of my assumptions could be wrong, but that’s a story that makes sense to me.
Obviously all this is kind of speculative and not easily empirically verifiable. What think I can confidently conclude at this point is that it’s pretty difficult to predict how virulence will evolve in a new disease, given the amount of factors in play, and any reliance on the expectation that the disease will become less virulent over time would be foolish.
I don’t know whether he argues it (although I argued it), but he asserts it both in the quote and in Reference 12 and in his book. Of course, when a parasite changes to vector-borne from not being vector-borne, it will increase in virulence. But that is not what he is saying in the quote. When yellow fever crossed from some other primate to humans, it not changing its use of a vector. It was using mosquitoes both before and after; the only thing that changed was humans. Reference 12:
That’s pretty much the argument I made. Does it use the vector context? Only in that the infection wants to max out virulence, in the phrase following the bold. On p468 he discusses how the situation is more complicated without that assumption, but he seems to favor the hypothesis that zoonoses tend to have increasing virulence.
Reference 12 does claim to test the hypothesis, and not just in the vector case. I don’t recall being impressed by the analysis, but I think it was a reasonable rejection of the opposite hypothesis, the consensus in biology as a whole.
Devil facial tumour disease – “affected high-density populations suffered up to 100% mortality in 12–18 months”
“aggressive non-viral clonally transmissible cancer”
https://en.wikipedia.org/wiki/Devil_facial_tumour_disease
“Since its discovery in 1996, DFTD has spread and infected 4/5 of all Tasmanian devils and threatens them with extinction. A new DFTD tumor-type cancer was recently uncovered on 5 Tasmanian devils (DFT2), histologically different from DFT1, leading researchers to believe that the Tasmanian devil “is particularly prone to the emergence of transmissible cancers”.” https://en.wikipedia.org/wiki/Clonally_transmissible_cancer
—–
What about diseases that would cause sterilization?
For humans: https://en.wikipedia.org/wiki/List_of_human_disease_case_fatality_rates
https://en.wikipedia.org/wiki/African_trypanosomiasis
https://en.wikipedia.org/wiki/Visceral_leishmaniasis
are nongenetic diseases listed there that are extremely deadly (listed at ~100% among diagnosed) if untreated
to check: are there asymptomatic cases in this illnesses? I need a break after looking at header image in https://en.wikipedia.org/wiki/Fibrodysplasia_ossificans_progressiva
https://en.wikipedia.org/wiki/Transmissible_spongiform_encephalopathy is incurable but prions are cheating in this case
A single genus of fungus has driven to extinction 10 species of frogs since 1980 and is expected to wipe out another 500.
This matches really well, thanks for finding it!
You might be interested in http://large.stanford.edu/courses/2015/ph241/chung1/
I don’t think any propensity of lithium-7 to fuse is actually relevant here.
What happened in the Castle Bravo test (which is the one where the yield was ~2.5 times higher than expected, due to the presence of lithium-7) was this: the lithium-6 in the fusion stage was correctly expected to absorb neutrons from the initial fission stage with the rapid production of helium-4 and tritium, with the tritium then going on to fuse with deuterium (the fusion stage fuel is lithium deuteride) to produce energy and more neutrons. lithium-7 was believed to be effectively inert to this reaction, absorbing a neutron and decaying (too slowly to matter) to two helium-4 nuclei. However, it turns out that an endothermic fission reaction can occur in which the lithium-7 nucleus (plus neutron) splits into tritium, helium-4, and a neutron. As a result, much more tritium was produced than had been anticipated, hence more deuterium-tritium fusion reactions, thus boosting the yield of the device above the expected value.
The question regarding nitrogen is a rather different one (as you can see from Scott’s link).
(Also, the lithium in the Castle Bravo test was not really “contaminated”, it was simply only partially enriched with lithium-6 above the natural level. Natural lithium is about 7.5% lithium-6 and they had enriched it to ~40% on the assumptions that the lithium-7 fraction was useless, that 40% was presumably enough for their purposes, and that more enrichment would have been impractical.)
First, thanks for laying this out well.
Second, it’s worth pointing out just how hard it is to set off nuclear fusion. A fusion secondary is very carefully designed to squeeze the contents to conditions where fusion can take place. Setting off an atomic bomb in the middle of a big pile of Li-7 isn’t going to give you much in the way of fusion. It’s just going to scatter Li-7 and higher isotopes of lithium everywhere.
Yeah, this. The key is density. There is no element, compound, or other substance which, if composed of the usual isotopes, can undergo a self-sustaining fusion reaction at normal density – even as a solid. It was worth double-checking the math on Nitrogen before setting off a hydrogen bomb in the atmosphere, yes, but we’ve done that and the answer is no. The answer is still no for lithium-7, or even the more reactive lithium-6. To make any isotope of lithium undergo self-sustaining fusion, you have to compress it to several times its normal solid density.
This is really hard. The usual way it happens is, you pile a literal star’s worth of stuff on top of it and the sheer weight compresses the material at the center. There’s also a trick where you can use an atom bomb to drive a symmetrical radiation implosion to compress nearby materials to maybe ten times their normal solid density. The Castle Bravo miscalculation was assuming that even this wouldn’t get lithium-7 to fuse when, yeah, it barely did.
To get self-sustaining fusion reactions at normal densities, you need to use exotic isotopes like tritium – and since tritium decays with a half-life of about twelve years, that’s not likely to happen in nature. It’s mostly too much trouble to bother with even in nuclear weapons design, now that we know the radiation-implosion trick.
http://blog.nuclearsecrecy.com/2018/06/29/cleansing-thermonuclear-fire/ describes study that concluded
Initiation energy is absurd here (so they concluded that there is no risk of igniting all oceans), but as I understand it, further reaction is self-sustaining at normal density.
Or are you counting deuterium as unusual isotope?
Whether you can build a Classical Super out of deuterium is somewhat controversial; nobody’s models are even remotely validated in that regime. But, yes, I’m counting deuterium at significantly more than natural abundance as an exotic isotope. With straight hydrogen plus the natural trace of deuterium (or lithium or beryllium or whatever), it isn’t even controversial – nobody’s models say that is ever going to work. With deuterium enrichment you might be able to make it work under ridiculous conditions; with tritium enrichment maybe under “normal” H-bomb conditions but then you look at the price of tritium and say no.
http://blog.nuclearsecrecy.com/2018/06/29/cleansing-thermonuclear-fire/ had interesting text about this
The disease could be one like anthrax, which lives in the soil without a human or animal host (and can be sent through the mail, etc)
But it wouldn’t matter, because no one would be around to care. If there are no valuers, the absence of value isn’t a problem.
Imagine if all life on Earth were destroyed a million years ago, so we never came into existence. That’d be bad for whomever was around at the time, but would it be bad for us? To me, it seems to obvious that it wouldn’t – since we wouldn’t exist, nothing would be bad for us. (Nothing would be good for us, either, but that wouldn’t matter because there wouldn’t be anyone to experience that absence.)
It sounds like Ord might make some counterarguments in the appendices, but this is a relatively large sticking point for me.
Does your argument not prove too much in the direction that if we accept it then we should ignore all x-risks, because no one will be around to mourn and regret our demise?
And as per my napkin-math, did you not effectively give humanity a very likely expiry date within the next 400 years or so?
(Does the title of Reaper sit well with you? — Asking in a half-serious, half-joking tone.)
Edit: contemplating your comment a bit further, I’m starting to be uncertain whether I’m really replying to your position or not. Perhaps you only take issue with using Scott’s (and Ord’s?) argument to a past that could-have-been, and you’d highly agree with them on using it on our current timeline? But if that is so, why do you make that distinction?
If you would prefer humanity to continue existing from now on, why would you not extend that to prefer humanity having continued to exist?
Our demise would be bad for us, since we already exist, so there’s no need to appeal to the preferences of past or future people. But if we never existed in the first place, our nonexistence wouldn’t be bad for anyone.
This isn’t an argument for ignoring x-risks altogether, but it does reduce their importance. Maybe we want to prevent human extinction because it’d involve billions of deaths, but not because it’d prevent trillions of births – never-existing people don’t count for anything.
Maybe I’m too stubborn right now, but I still don’t follow why you make that distinction in your model. Why is 8-ish billion deaths worse if it is instant and without suffering, than (8 trillion, or however-many) non-births, which is also without suffering?
My own death would be bad for me even if it were instant and didn’t involve suffering, because it’d deprive me of the continuation of my net-positive life. The same goes for many other people. But if we never existed, there’d be no one for whom this would be a deprivation.
So if we make the simplifying assumption that the 8 billion lives are net-positive, that’s 8 billion people not getting to enjoy their good lives some more. But the 8 trillion don’t exist, so nothing is good or bad for them.
(Also, most causes of death aren’t instantaneous and are also cause preceding suffering.)
I still don’t follow your distinction from within this model.
I don’t know you. From my POV, you are pretty close to a {non/not-yet}-existent human. You claim your life is net-positive for you, but alas, I’m sure many of {yet-to/feasible-to}-exist humans would claim the same. Why should I privilege your claim over theirs?
@Aotho My approach, and probably that of @blacktrance , is that only the preferences of existing beings matter—including their preferences regarding the future (and perhaps the past), rather than only their preferences regarding the present. We exist right now, and we want to continue existing. Dying is against that preference. We won’t have preferences after we die, but right now we have a preference to exist in the future.
To me, the approach that the preferences of nonexistent beings matter leads to repugnant conclusions. There are an infinite number of possible beings that could hypothetically exist. (Not all of them would fit in our universe, but they could exist in an appropriate universe.) They are all suffering a fate equivalent to dying, with very few exceptions. Compared to that, nothing we can do even makes a blip for the better or the worse. There are hypothetical utility monsters that we should bring into existence. And of course we should make as many babies as humanly possible.
Because abortion is not murder. Even people who use that slogan don’t usually believe in an exact equivalence.
They wouldn’t, because they don’t (and wouldn’t) exist. That’s the key difference. Existence is a prerequisite for things being good or bad for someone. Since I already exist, cutting my life short can be bad for me, but preventing the life of a nonexistent person can’t be bad for them, since there isn’t a “them” for anything to be bad for.
@blacktrance not sure why you’re privileging currently existing people.
If we all die because of an X-risk, we will no longer exist, and there’s no reason to be upset about the non-existence of formerly existing people that no longer exist.
Why does it matter that humanity previously existed?
@thisheavenlyconjugation I hope your comment was snark
Existing people are privileged over the non-existing because they would mind dying. Neither the dead nor the not-yet-living mind their non-existence.
@Purplehermann
Why?
@Not A Random Name the point is, once you’re dead, you would no longer mind dying, or anything at all really.
I mean sure, you’d be upset about dying now, but if you actually did die there’s not going to be a lot of preferences going through your head. So why would your current fear of death matter, when the truth of the matter is that if you do die, you won’t actually care the slightest?
@len Yes, but why is it that relevant?
Edit in response to your edit:
I enjoy living, so I want that to continue. The fact that once I’m dead I’ll no longer care does not change that in any way, shape or form. What dead-me minds or does not mind is not all that relevant to what current-me minds or does not mind.
You’re making a different argument from @blacktrance. His argument was that
I’m just extending that to the fact that once you’re dead, your death won’t actually be bad for you, since you as a person would no longer exist.
Because your future doesn’t currently exist either, and any potential utility you might obtain from continuing to live has as much weight as the potential utility from unborn people.
(If you want to make the argument that your continue existence has value because you would prefer to live, then the natural counter would be that the trillions of potential lives has value because someone currently living prefers that they exist).
tl;dr: Your future self doesn’t currently exist either and hence also has no moral weight; it doesn’t matter if your future self never comes into existence either.
The prerequisite is the existence of a life, not existence at a given moment. Once I’m dead, I no longer experience anything, but that can be bad for me because the relevant metric is how good my life is as a whole, and it being cut short makes it worse. But nonexistent people never had lives that could be good or bad.
@len Note my earlier comment: A plausible value system is that only existing people’s preferences matter, but not only their preferences about the present, but their preferences about the future too.
It’s possible I’m making a different argument than blacktrace. My tl:dr; is “my preferences matter as long as I live” as well but of course I don’t know their position intimately.
Anyway, if I understand you correctly your argument goes along the lines of:
1) If I say dead people don’t matter then my (sudden, painless) death would have (utility) value 0 to me.
2) If I say potential people don’t matter than any positive utility of future-me should not matter as well.
3) Thus I should be ambivalent whether I die or not.
But I reject the distinction between, “current-me”, “dead-me” and “future-me”. There is only the me right now and some thoughts about what it would be like to be dead / in the future. And that’s the same me as it was a seconds ago, is the same me as it will be in a seconds. Caring about that person is caring about me and I exist.
And the me right now, just like all the other human alive right now, matter because they’re real. So they deserve moral consideration. That includes their preferences (to live, mostly) and what happens to them.
Note that I said “what happens to them” and not “what happens to future-them” because in my mind there is no distinction there.
Contrast that with a potential child. Just like future-me and dead-me they’re also just a thought about what could have been. Unlike you or me they are not real in any meaningful way. So they don’t deserve moral consideration. Just like numbers don’t. Because seem qualitatively different from any human I care about: They don’t exist.
So I don’t see why caring about my future (or the future of anyone currently alive) requires me to care about the future of potential children. And I believe that was your argument: Because I care about my future I should care about the future of potential children as well.
@thisheavenlyconjugation
Blacktrance holds that people don’t matter until they come into existence, period.
Aotho was asking why he makes a distinction of people who will have stopped existing and people who don’t yet exist, where the former get counted and the latter are utterly unimportant.
Your answer (charitably) was that people value currently living people more than unborn people.
This is almost begging the question and a non sequitur at the same time.
He asked why, and you said because.
Why what? Because what?
Why are non existent people completely unvalued.
Because unborn babies are valued less.
And that is why I hope this was snark 😉
Consider your life 10 years from now. Your values, physical being, thought processes and experiences will have diverged from the you of today. This ‘you’ is completely hypothetical – there is no guarantee that you won’t die sometime in the next 10 years. Any utility you might accrue is completely hypothetical. The only meaningful distinction between you in 10 years, and a child that’s born in 10 years, is that a person very similar to the you 10 years later currently exists.
Of course, as @10240 points out, current preferences still matter under this system. But I still question why would current humans should care about the potential futures of humans currently existing vs and ignore the the potential futures of human yet to exist.
Is the only distinction pure selfishness of the “I don’t want to die, I want to continue to exist in some form” variety? Because if so, then the argument would become “Preferences of unborn children don’t matter because I don’t care about their preferences”.
At some point we are hitting axioms, terminal values, where answering further why questions becomes impossible.
@Purplehermann
I really don’t understand your point. Aotho asked why deaths are worse than non-births, and I gave an example of a case where there is a widely held intuition that they are. This is a very standard way of arguing about ethics.
As far as I can tell, they didn’t respond to me so I’m not sure what this is about.
@len
And both, this “me in 10 years” and the hypothetical child born in 10 years are thought constructs with no moral relevance. That we can imagine something is insufficient for moral worth. As I said, I can imagine numbers and they don’t have moral worth either.
You seem to think that imagining myself in 10 years as a “different me with moral worth” is useful for answering questions about morality. I do not share that sentiment. I can assume that way of thinking and I understand how you get to your conclusions.
But in the end I don’t think this is a useful way for me to think about morality. It leads to way too many repugnant conclusions. That is sufficient grounds for rejecting it.
And I’m not sure if selfishness is the word to use when you care about both yourself and about 8 billion others.
Also all of what @10240 said.
Fair enough.
My intention was always to illustrate that just as assuming “potential future lives have moral weight” leads to repugnant conclusions, assuming the complete opposite also leads to different repugnant conclusion, namely that your own future has no moral weight beyond your current preference to keep existing. Also interesting that your future moral weight drops to zero or negative if/when you’re having a suicidal moment.
A nihilist might find this state of affairs completely acceptable, though.
And I’m not sure the answer to this paradox lies in some factor of discounting for potential lives, either. Because if you discount by say, probability of existence, the hundreds of trillions of potential lives will easily outweight any current concerns.
The trillions of future lives should be discounted not just by the uncertainty about them even existing, but also the uncertainty about what effects our current actions will actually have on them.
The paradox disappears once you start adding positive and negative numbers together. Much like Pascal’s Wager can be defeated by asking “isn’t there also a non-zero probability of an evil god who infinitely punishes believers?”
Individual future lives (and thus preferences) must be discounted entirely – we don’t know who they will be, or what they’ll care about.
The aggregate cannot be discounted further than the current carrying capacity of our species, because we know this many of us can exist. Anything we do, or fail to do, to screw with that number is our moral fault.
@len Perhaps the reason to try to ensure that humans will exist in the future is not that they have moral weight, and we have an obligation to allow them to exist, but that we have a preference that humanity continue to exist into the future, even beyond our death.
@len
I don’t think that the only reason not to kill me is “Because I want to live”. Yet even if it was, that already seems like plenty to me. So I’m happy to bite that bullet and declare the conclusion “not repugnant”. For me anyway, ymmv.
Don’t think I’m a nihilist though.
@Not A Random Name , What other reason is there? Beyond some practical reasons, like it would make your friends sad?
@10240 Friends and family caring is also what I thought off. More generally, though, most of us have preferences about (some) other people living.
Killing someone doesn’t only violate their preferences but also those of everyone that wanted them to live.
As a side note: Whether or not the collective sentiment of others to see you die can ever be strong enough to override your preference to live is basically asking how you feel about the death sentence.
@10240 @random
Claiming that the moral thing to do is to work towards an average of every living human’s preferences is highly questionable at best.
@len
Well I did not claim that was a good idea and I’d agree with you that maximizing average utility leads to a couple of repugnant conclusions.
@blacktrance @Aotho
To clarify, is causing the deaths (not non births, deaths) of people who aren’t born yet bad? (For example making a law that all children born in the year 2100 will be sacrificed to Moloch, and you know the law will be upheld)
Yes, because they’ll exist at the time, and thus matter then for the same reasons we matter now. So x-risks matter – but much less than they would if you also counted the nonexistence of further-future people as negative.
I’m glad somebody made this point. There seems to be a very common assumption that life is good per se, and maximising the amount of life is even better.
Personally I’m just as afraid of almost-x-risks as I am of x-risks. They’re capable of involving just as much suffering, possibly even more.
I strongly agree. So +1.
It probably depends on your ethics system, and ethical intuition. If you are a utilitarian, you would just need to decide if the average life is worth living, and multiply it by all the lives that you expect to live. That seems very similar to Ords view. Take the formal systems out of it, and I have an intuition that your scenario is one of the worst things conceivable. All of the joys of humanity was never experienced. That is profoundly tragic to me. I suppose you would argue that my opinion wouldn’t matter since I wouldn’t exist, but I do exhaust now. My preference is that humanity lives until the end of the universe, and I do not think that’s an unusual preference.
Only if you’re a total utilitarian. How to aggregate utility when creating new people is an open question, and the person-affecting view that I’m advocating here is perfectly compatible with utilitarianism.
Good point, I’ve never considered how average utilitarians would consider utility over time. I’d amend my response so be specific to total utilitarians, except I’m well past the edit window. I think most Deontological and Virtue ethics would also consider it a bad thing for humanity to never exist, but I haven’t studied them well enough to know for certain.
In general, I think average utilitarians can focus on improving standard of living and I wouldn’t argue that they are being ineffective. I doubt Ord included counter arguments that would convince you, since everything I’ve read from him suggests he is a something like a total utilitarian. He has written an interesting case against negative utilitarianism, if that is specifically what you believe.
If you are a total utilitarian; not if you are an average utilitarian. Both lead to repugnant conclusions though: total utilitarianism to that a large, barely happy population is better than a smaller, more happy one; average utilitarianism to that it’s wrong to give birth to people who will be less happy than average, but still somewhat happy and glad they live. My conclusion is that utilitarianism can be at most a tool to compare different states of the same population, but useless to compare hypothetical states with different sets of people, especially sets of different sizes.
Wait – that’s not quite true. A total utilitarian just cares about the product of the number of people and their average utility. Some smaller population, with an average utility that’s sufficiently larger might be preferable.
Most people who make these kind of statements fail to consider culture and value drift across time.
Given the increasing pace of cultural evolution, humanity in a hundred thousand years will have less in common with us as we do with neanderthals. If we last that long, of course. Probably we’d all be augmented ems by that point.
The Age of Em is recommended reading.
When you picture future humanity, picture a horde of self-replicating aliens or machinery that don’t share any of your values. Then ask yourself again if it makes you feel any different if they live or die.
Most parents can, at the very least, be made to see that their children’s happiness is more important than their children following in the parents’ footsteps. This doesn’t stop people from wanting to have children or wanting to support their children (or someone else’s random children, in the case of adoptive parents).
The difference being, this is less kind of joy from seeing your children succeed, and more of the kind of joy of seeing a colony of nanobots self-replicate across the universe.
Sure, you might still care, but you’d probably care a whole lot less.
That sounds very fun and exciting! Especially if the bots are equipped with some sort of consciousness and intelligence.
I don’t understand. Odds are we won’t be around to see it, or even see the development of it, so why should this form an image that matters to us in our minds?
And? I would still prefer that over their extinction.
(assuming that I have just existence vs extinction selection)
As someone who currently exists, I value the continuation of happiness, love, art, etc. even after my own demise. I would prefer a world with human flourishing to one without, even if no one currently alive is there to experience it. I suspect many others share this opinion.
I’ll grant you, however, that this doesn’t give us a way to weigh the value of that preference nearly as easily as “multiply by the number of possible future humans.”
It isn’t the whole story to point out that never having existed wouldn’t be bad for us. It wouldn’t be good for us, while the actual history is good for us. This matters.
The following is not a thought experiment. It’s a real life event experienced by many, which requires thought.
When you have a child, there is a chance of inherited birth defects. There is a very small chance of defects so terrible that it makes the child’s life pure suffering, worse than nothing. Yet I submit to you that having a child is not wrong. Note that, if you have a child and get modestly lucky and they have a good life, this is not the same child that would have suffered in the terrible and unlikely scenario. This healthy child came from different, undamaged sperm and egg, so it is a different child.
Having a child is not wrong because the high probability of a healthy happy child outweighs the tiny chance of a different child being born to a brief life of pure suffering. Creating happy people is a profoundly good thing.
Even if they would’ve had a happy life, its absence wouldn’t be bad for them if they had never existed. It’s a category error to ask if it’s better for me to exist (if that existence is happy), because otherwise there wouldn’t be a me for things to be better for.
I agree that the small risk of birth defects doesn’t make having a child (categorically) wrong. But creating a happy child isn’t good for that child, compared to nonexistence. If you want a child and expect them to have a happy life, it’s probably permissible to create them, but you’re not doing something good for them – the justification is that it’s good for you and probably not bad for them. But “not bad for them” is the best it can get.
Prior to existence, my child is any child I could possibly have, so it’s coherent to say that it’s better for them to be one sperm-and-egg combination than another, or even that it’s better for them to be born next year than this year. The same goes for future populations – it might be better for it to be Population A rather than Population B, even though they might consist of totally different individuals.
Well this sounds like a good argument to exterminate the human race to minimize human suffering.
It’d be a bad idea now for many reasons, but so far, from a utilitarian perspective it might have been better if life had never existed.
Ord’s laser-like focus on the probability that everyone dies seems ludicrous to me. Even if we only care about this Asimovian far-future, then losing 99% of civilization to a pandemic, or nuclear war, etc. is disaster enough. This future is only safe once we have more than one self-sustaining inhabited planet; so it’s a race between whether that happens first, or we die off first. Wouldn’t most near-extinction scenarios (e.g. nuclear war destroys most major population centers) set us way back on technological progress and space colonization, leaving much more time for the “true” extinction events to finish us off?
1. Some x-risks don’t care about multi-planet-ness, e.g. IIRC some gamma ray bursts and non-aligned superintelligence. Nuclear war can also be inter-planetary (see The Expanse for an illustration).
So I don’t think we can escape having to address this question just by becoming multi-planetary. We can just prolong the question and perhaps put it on a different time-frame, but not eliminate it with that single action.
2. Even if we try our hardest to escape with colonization; if we have about 400 years (as per my napkin-math), having to colonize another planet and having to make it self-sufficient sounds to me to be a mighty tight deadline.
Therefore, we might have to choose to address reducing x-risks even on this single planet or perhaps even better, do it while we try colonization as that does indeed seem to address many of them at once. Even if not all of them.
Yes, Ord agrees that things that kill 99% of people are very bad because they make it easier for something else to finish us off.
You might be interested this adversarial collaboration on space colonization – https://slatestarcodex.com/2019/12/17/acc-should-we-colonize-space-to-mitigate-x-risk/ . It’s hard to figure out ways that colonizing space is much better than colonizing Antarctica or a very big cave or something in terms of x-risk prevention, though there are a few possibilities.
Long term the sun will burn out, and that means that even a colony of humans near the core of the earth will only have a slightly longer survival timeline than the rest of humans.
Don’t I bloody know it.
I don’t like how human-centric this is. Many of the risks-that-aren’t-quite-x-risks are still mass extinction events. I’m prepared to believe that humans are the most important species on the planet, but surely not the only important species.
Maybe it’s just not clear to me that human domination of the universe is a good thing. Humans are great, and I’m glad we exist, but does it follow that we should spread to every corner?
If it is any consolation to you, it’s likely that we won’t be able to expand beyond the observable universe.
According to some estimates, our observable universe is only 1/15,000,000th of the whole universe. Also, I don’t see how we could expand temporarily beyond the Cosmic Heat Death.
Does that make you feel better?
Haha, well sadly I used to be a cosmologist, so no, that’s no consolation. 😛
It’s not that I want to leave a portion of universe un-human-ified; I just don’t see that a quintillion humans is better than a quadrillion humans. It depends on the quality of life of those humans, and here in the Garden, life is pretty good*.
*heavily caveated of course
That’s the minimum size, it is potentially much larger than that, perhaps infinite. Add to this the case that just one universe seems unlikely,( why would there be only one big bang?) it seems quite probable there are a very large, likely infinite, number of intelligent beings who exist or will exist. It seems quite parochial to me to worry about our descendants not existing.
Ord mentions that human colonization of the galaxy will also mean Earth-biosphere colonization of the galaxy, but if humans go extinct, then the rest of biosphere also goes extinct in a billion years once the sun gets too hot for life. We’re life’s only ticket off this rock.
Why does he rule out another civilisation on another planet colonising the galaxy instead of us? Is he a strong believer in the very great filter? And let’s say this true for our Galaxy, but there are trillions of Galaxies so even if the probability of life is low many of them will have life, is one less Galaxy colonised among the trillions that are colonised such a tragedy?
Earth biosphere
That’s a really good point.
Unless another intelligence evolves in the next billion years.
“Convention better, and mandate that DNA synthesis companies screen consumer requests for dangerous sequences so that terrorists can’t order a batch of smallpox virus (80% of companies currently do this screening, but 20% don’t).”
How is this a thing? We eradicated smallpox. But apparently scientists weren’t satisfied studying similar viruses, so they kept a smallpox sample around, and then just for fun DNA sequenced it and published the sequence. Madness!
I’d give the scientists the benefit of the doubt and assume that they were hoping to gain information that could be useful in fighting a similar virus if one emerged, and that the sequences were published before the advent of made-to-order online DNA sequencing (1990 according to a quick google).
Still, I’d definitely argue that they were not acting wisely, even if their intentions were good.
One question for me, why do we need Governments to support the existential risk mitigation work? If the concern is real, why are private individuals funding it? There are plenty of rich people in the world who could well afford to fund significant amounts in support of these efforts, and you would think they would be quite motivated to do so. Asking for Government supported efforts to me makes the whole thing look like rent seeking. There is this phenomenon in modern days where someone makes a big fuss of an issue in the hope that they can get on to the Government teat, even when most people are not particularly concerned about it.
This seems off to me.
The issue is that not enough people are particularly concerned, and the ones who are want someone else to take care of it (bystander effect), so getting support from individuals is much harder.
If the point of government is pretty much to solve coordination problems, and this is a coordination problem, then goverment should probably put effort into it.
Why is studying this issue a coordination problem? Are you saying the problem is so large that studying takes resources only Governments have? This seems wrong to me.
The recommendations by Ord are apparently 0.1% – 1% of the GDP (if I read right).
I’m saying something a bit weaker than “only governments have the resources “.
I’m saying that there are likely deficits in funding, which as a human race we’d be better off not having.
I’m also saying most smaller groups aren’t able to fund this by themselves, nor would they want to, because why should they (especially when others aren’t)?
Add in bystander effect, and the chances that the research is adequately financed over the long term without government help seems small to me.
Are the amounts small enough that a few non-billionaire philanthropists can fund it?
But why wouldn’t any billionaire fund this stuff if it is so self evidently important? If I were a multi billionaire and I was convinced that I had a chance to save the universe why wouldn’t I do it, if only for selfish reasons. It seems to me the reason is that we haven’t been able to convince any billionaires of this. So we are trying to get easier touches such as Governments to do it instead. Which means probably the arguments are not as strong as we think. I think that is my concern as well, perhaps this is just another pascal mugging? I mean this in the most sincere way by the way, because I personally do think AI risk is the most significant risk to humanity, and more immediately to my kids and potential grandkids.
I don’t know about the pascal mugging, but I’d give 0.1% of my salary to offset a pascal mugging that seems plausible (assuming there’s a reason I won’t be mugged over and over again till I have no salary..).
As for billionaires, it doesn’t seem super prestigious, people generally assume someone else will take care of things, nobody like to spend very large amounts of money into what feels like a bottomless hole, and you aren’t guaranteed of anything…
I think there are plenty of reasons to assume there would be coordination problems for projects as long term, abstract, low probability, and expensive as x-risks regardless of whether the risks are legitimate or not.
Not sure why you think people are so likely to give to a cause line this. Typical minding maybe?
That’s exactly the problem with Pascal’s Mugging: if you subscribe to that line of reasoning, you are compelled to give out your money to basically everyone who asks in a clever enough way.
For example, what if I told you that I’m an evil techno-wizard, and I will build 100 digital copies of you and everyone you love, and torture them for a subjective eternity, unless you give me $100 ? You’d probably tell me to get lost, since the chances of me being an evil wizard (as opposed to a conman) are minute. The expected value of my threat is (epsilon)*(some very negative number) ~= (epsilon). But instead of going away, I’m going to tell you that I will build not 100 e-clones, but some absurd number, like 1/(epsilon^epsilon). Now the expected value looks really bad ! You’d better give me the money !
@Bugmaster
My response to that specific scenario is: Your claim to be able to do that fundamentally contradicts my model of reality in multiple ways. First off, I’m pretty sure 1/epsilon^2 simulated humans wouldn’t fit in the observable universe. So let’s get this straight: you’re claiming to be some kind of god. Now, even if you’re telling the truth about your powers, I know nothing about the psychology of gods. Assuming you really could simulate googols of digital people, you certainly have better ways to make money than threatening strangers with crazy-sounding scenarios for just 100 bucks—mining bitcoins, for one. So in the bizarro world where you’re not lying about your capabilities…what’s your motivation? I don’t know, and I can’t in principle guess the terminal goals of agents I know nothing about. And in that case, there’s no evidence that my complying with you would make you any less likely to torture copies of me–perhaps you’re lying and you’ll only run the simulations if I do give you $100. You see how my fundamental reasoning about the world starts to break down in that scenario? I have a general policy about not worrying about scenarios in which my fundamental methods of reasoning break down, for instance if the universe is non-inductive or if I’m a boltzmann brain. So, you better start showing me some evidence that you’re telling the truth if you want to take my money.
@VoiceOfTheVoid:
All of your objections are reasonable, but they all amount to saying, “the probability of you being an evil multidimensional god who is also somehow trustworthy is incredibly low”. But that doesn’t matter, because I can just jack up the number of e-clones that I’m going to uber-torture to an arbitrarily high number. So, your expected value is going to be -1 / (absurdly high number) * (even absurdly higher number), and you’d be compelled to pay me $100. You say,
Personally I (in my regular persona as Bugmaster, not as an evil multi-god) do agree with you, but note that we are now abandoning purely probabilistic reasoning — at least in some scenarios. I would argue that any scenario that seriously considers all future generations of humanity everywhere in the Universe over the next few billion years is probably close enough to this threshold.
@bugmaster
This specific mugging would be fairly difficult to hit me with over and over again – these risks all fit just fine with most people’s general models of the world (they might sound weird at first, but most people don’t have beliefs that directly contradict them and you can explain them slowly to most thoughtful people) as opposed to magical simulation of my loved ones.
Further, this is an inefficient mugging due to busts ever effect, future discounting, etc, as opposed to targeted muggings.
Please give me an example mugging that convinces me that we should spend an additional 1% (not x-risk again)
@Bugmaster
I’d argue that I’m not necessarily abandoning probabilistic reasoning in those scenarios. I’m saying that in possible worlds where my core methods of reasoning are broken, any action I take is just as likely to have negative consequences as positive consequences. So the expected value of doing anything (or doing nothing, for that matter) in those situations is zero. Therefore, scenarios where my entire model of reality breaks down don’t contribute to the expected value of anything I do, within my probabilistic reasoning.
Well I certainly don’t agree with that; humanity continuing to exist and multiply over the next few billion years is completely consistent with my basic model of reality! Not guaranteed, of course, but certainly within the realm of possibility.
the bigger the government the worse it is at coordinating solutions. We have a prime example in the recent screw-ups in CDC and FDA. Should people have been allowed to solve problems locally we would likely have been better off.
It’s not a problem of evil or incompetent people. It’s a natural problem of scale.
After 9/11 our military had to deal with it daily, with very direct and very negative feedback loop, and they have since adopted highly decentralized approach, which worked. There’s a lesson in that that we’re missing.
The goverment seems to be very good at raising funds.
There are some things that are done better, some worse.
In my opinion, the legitimate function of government is to prevent other, worse forms of government from arising in its place.
The best example is organized crime, which can be thought of as a form of government, with exactions, regulations, enforcement and so on. Any form of government that is not worse can legitimately work to suppress organized crime in their jurisdiction.
I’d say that’s a particular coordination problem, how can a group stop anyone from taking power and acting horribly to the group?
I’d also say the vast majority of humans on the planet would disagree with you.
Considering governments are abstract constructs made concrete by human belief, this may matter a lot.
I’d also ask: Why does a tool have to be used ideally only for one purpose?
@Cato the Elder
Sure, it could be considered a coordination problem, but being a coordination problem is not sufficient to conclude that one should use government to solve it.
As for tools and uses, I used a screwdriver as a pry bar just yesterday, and I’m proud of it. On the other hand, my screwdriver doesn’t have the potential to kill 7,926,179 people (China, sum of three entries) or 1,224,745 people (Indonesia et al) or even 1,077,850 people (Soviet Union) (“Political purges and repressions,” geometric mean column, wikipedia). Contemplating a tool with a track record like that, one wants to be a little cautious when taking it out of the toolbox.
p.s. Numbers used for rhetorical effect but the magnitude of the point, I believe, stands.
There’s also the risk that “getting government involved” increases the odds of bad outcomes.
This was mentioned in terms of the possibility of weaponized asteroids. Perhaps it’s better to avoid “how to deflect asteroids” research entirely, because the odds of someone using it for malintent is greater than the odds of it being necessary.
But depending on how skeptical you are of governments, this applies to other areas as well. Should we research mechanisms to alter the Earth’s climate? Sure, that could help mitigate climate change. It could also be used as a geopolitical weapon.
And this isn’t entirely speculative. We also discussed the Manhattan Project. Spy fiction aside, there’s only one sort of entity that has ever actually deployed nuclear weapons – a giant government. No rogue supervillians have ever done so (and as far as we know, none have ever even really tried, unless you count Kim Jong Un or something). And why does that technology exist in the first place? Because we empowered government to solve the “intractable by individuals” problem of “How do we stop the German/Japanese army?”
Here’s a cheery hypothetical for you – in an alternate reality where the Cuban Missile Crisis does lead to nuclear war/winter, does that imply the correct solution back in 1940 was “just let the Germans/Japanese win?”
Rich people are funding it. Jaan Tallinn, Peter Thiel, Elon Musk, and a few other people have kept the AI risk community afloat for years (though it seems like it’s finally reaching a point where it can exist independently of them now). Lots of people including William Hewlett and Patrick Collison are doing impressive work funding climate change research. I assume many rich people are also funding biodefense, but everyone in biodefense is very secretive so I don’t know who. But:
1. Government has orders of magnitude more money than rich people.
2. Some important steps can only be taken by governments, like nuclear disarmament or monitoring rogue states’ bioweapons programs.
3. This is a free-rider problem, and larger institutions are more likely to be able to overcome free-rider problems.
4. This seems like the sort of thing even a minarchist should be okay with a government stepping in on. “Oh, it’s not government’s job to prevent all of its citizens from dying” – what? Yes, that’s kind of exactly what government’s job is.
I guess I thought the request was for Governments to fund more research into the area of existential risk? If we have an agreed solution and the Government needs to be part of that solution, sure I agree Governments should be involved, but I see the key issue is that we don’t have agreed solutions to any if this stuff. Take AI risk, just how would you stop North Korea for instance secretly developing their own AI?
The government doesn’t have any money at all (at least, not in the US). People have money, and they are either loaning it to the government, or paying the government for services rendered (e.g. road maintenance). When you say, “Government should fund AI risk”, what you’re saying is, “You, Bugmaster, should spend a portion of your money to fund AI risk”. And I get really touchy whenever anyone tries to get my money. I am not opposed to spending money in principle, but you’d better come up with a detailed plan that shows me how much impact my money is having vis-a-vis lives saved.
And no, you can’t Pascal-mug me by saying, “the stakes are the entire human race and possibly the Universe, surely the details are immaterial !” That didn’t work for the Mormon missionary who came to my door, either.
How about, “the stakes are the entire human race and possibly the Universe, given that I think the details warrant spending a few hundred thousand to have a small but decent chance of preventing the apocalypse!”
Stalin’s apocryphal maxim that “one death is a tragedy, a million deaths is a statistic”
I have some serious questions about Ord’s take on nuclear weapons. First, I think he overestimates the arsenal available, and how much damage it can do with realistic targeting plans. Both the US and Russia are limited to 1,500 deployed warheads. This is a pretty decent approximation of what will actually go off (yes, both sides have reserve stockpiles several times that size, but those stockpiles are pretty high on the targeting lists, and what isn’t destroyed probably about makes up for stuff from the original 1,500 that doesn’t go off) and that leaves 5-600 hitting cities, the rest going after military infrastructure and the like. And given how difficult it is to destroy a city with nuclear weapons, that’s going to leave a surprising amount intact.
Second, nuclear winter is a horribly overblown risk. The concept rests on dubious ground, and the people who keep trying to sell it are usually engaged in some form of horrible scientific malpractice.
I may be misquoting Ord here and the mistake may be mine, but I’m not sure it’s a mistake. 500 nukes on each side seems like enough to destroy all major cities (for some definition of major) and kill the majority of people. Ord’s justification for his take on nuclear winter:
“Our current best understanding comes from the work of Alan Robock and colleagues. While early work on nuclear winter was limited by primitive climate models, modern computers and interest in climate change have led to much more sophisticated techniques. Robock applied an ocean-atmosphere general circulation model and found an amount of cooling similar to early estimates, lasting about five times longer. This suggested a more severe effect, since this cooling may be enough to stop almost all agriculture, and it is much harder to survive five years on stockpiled food.”
It looks like Robock was one of the sources who John was skeptical of in the comment you linked. I don’t know enough about the subject to know who to trust here. Ord does seem uncertain about how big a risk this is, and recommends that funders and governments make better models of nuclear winter to clarify it.
It would certainly be unpleasant, but that’s a far cry from an X-risk. 5 nukes on the 20th-largest metro area in the nation killed or wounded less than half the people living there, and if the Russians allocate more to places like St. Louis, that’s more which won’t go to places like Scranton (MSA #101).
As for nuclear winter, I think the whole thing was debunked in 1991, but I’m certainly not blaming Ord for taking it seriously. Usually, the people studying something aren’t insane. It’s just that the DoD scientists who study these things rarely talk in public, and most of the public reports come from the anti-nuclear brigade. In this case, they got carried away and lost all touch with reality.
I don’t think Toby necessarily disagrees with you. You seem to be saying “the damage from nuclear war is overblown and not an X-risk” while Toby is saying “the damage from nuclear war is possibly overblown and likely not an X-risk”.
I did an overview of the nuclear war/nuclear winter research a few years back, so I can summarise the main points we’re thinking of at the FHI (I don’t know if these are what Toby is relying on):
First of all, there a big difference between dropping one nuke on a city while the rest of the country remains functional, and dropping one nuke on a city while the rest of the country is overwhelmed with mass casualties. Look at how poorly countries are coping with a comparatively tiny impact – covid-19 – and scale that up massively, have it all happen within a day, and wipe out most of the business, governmental, and commercial leadership.
Secondly, the stockpile argument ignores what happens before and after the strike. It is very plausible that, as tensions mount, countries will re-activate and even extend their nuclear arsenals. So there are many scenarios where the arsenals will be far above 1,500. Also, the countries may maintain the ability to wage war even after a nuclear strike (the more “survivable” the first strike is, the more likely this is). Nuclear weapons can continue to be manufactured in many scenarios, as well as the required missiles. If the war drags on, more strikes will occur.
And finally, nuclear winter. This is the great unknown. It all depends on how “well” cities burn, and how high black soot goes in the atmosphere. We’ve had two “natural experiments”: Hiroshima had a firestorm, Nagasaki did not. And modern nuclear weapons are very different from little boy and fat man, and modern cities are pretty different from WW2 Japanese cities. We’ve had some kinda relevant data – eg the mild outcome Saddam Hussein setting fire to the Kuwaiti oil wells is weak evidence pointing towards safety – but nothing strong. And ethics boards object to us nuking a city to get more info.
So, if you said “nuclear winter is not very likely”, I agree with you, a thousand times. If you say “nuclear winter is very likely not to happen”, I disagree with you, a thousand times. We just don’t know, and nuclear winter is at least somewhat plausible given the evidence we have. It would overconfident to put its plausibility below, say, 10%, which is certainly enough to worry about.
I’m under no illusions that the world after a nuclear war would be really exceptionally bad in a way that makes this COVID thing look like a children’s party. But there’s a huge gap between that and an X-risk. There’s a lot of people in rural areas who wouldn’t be directly affected, and while their standard of living would fall dramatically, they’d still be alive and still be able to have kids, who would be able to rebuild something.
As for the stockpile, I doubt there’s much in the way of extra warheads they can pull in at short notice. The best you could do would be mounting extra warheads on some of the ICBMs and SLBMs, and that relies on having extra RVs laying around and extra warheads to put into them. Neither of those are particularly likely to happen overnight. As for nuclear weapon manufacture, I’m really skeptical. Making sure the enemy can’t keep hitting you is going to be at the top of essentially any nuclear targeting plan. If Pantex is a smoking crater, along with all the national labs, where are we building these bombs?
On nuclear winter, we’ve had a lot more than two natural experiments. Much more of Tokyo burned than did either Hiroshima or Nagasaki. No non-nuclear winter. I single out Kuwait because it was prospectively identified as a likely cause of non-nuclear winter, and yet nothing happened. But this isn’t even addressed by Robock, who usually says “the current models say it’s worse than the models from the 80s did”. But those models failed, and his attempts to explain it away are deeply unimpressive. I’ve heard worse things about the modeling, like them rejecting better models because they didn’t show the results they were after, but have no cites. (Except for the targeting stuff in the papers I linked, that is.)
Disclaimer: I know nothing about this topic.
Is it at all feasible that long range bombers survived attacks and counterattacks? After satellites were destroyed and ICBM were used/destroyed? And as result there is long term mostly blind bombing, but with nuclear weapons.
It’s only going to be half-blind if anyone’s doing their jobs right. B-2s have really shiny radars to determine whether cities look nuked, or track down mobile ICBM launchers. Post-nuclear-attack BDA was reportedly one of the missions of the SR-71 before it was retired.
It’s why bombers continue to have some attractions in an age of ICBMs. You can scatter them to every runway in the country, and since the US has >1000 runways, the Reds can’t possibly hit them all (well, they could try to find the bombers, and then hit them, but that’s why you have anti-satellite missiles).
Also, ICBMs are not one-hit-one-kill. At least two warheads per target are necessary, more if the target is important or hardened (less so today, with increasing accurate hit-a-football-field warheads).
There is an old concept called the “broken-back war”, in which people keep feeding increasingly antiquated weapons into a nuclear war e.g. B-52s, repurposed airliners, men with assault rifles, etc. But it’s mostly implausible for the reasons Bean cited above. The target list goes something like this (GlobalSecurity review of SIOP 1970):
Enemy nuclear forces (and supporting infrastructure?) > Enemy nonnuclear military forces and supporting infrastructure > Enemy industrial base and infrastructure (railroad junctions, bridges, telecoms towers, big hospitals etc) > Enemy population (people are better alive as hostages than dead as corpses)
@matkoniecz
Not really. It’s not that the bombers couldn’t survive. They could, at least in theory. It’s that the supporting infrastructure for them couldn’t survive, and without that, they’re a rapidly wasting asset. You don’t just need bombers to fly a long-range bombing mission. You need fuel and bombs and spare parts and tanker support and ground crews and a mission planning cell. In theory, you could build a bomber force that was able to take all of these things on the road with it, and operate for a while from random runways, or even straight pieces of highway. But the US definitely doesn’t have that force, and couldn’t build it quickly.
@pacificverse
The “broken-back war” went out with the advent of the H-bomb. Before that, it was plausible that a reasonable amount of stuff would survive. Not so much now, with more weapons (yes, than back then) and better accuracy.
As bean notes, some of the bombers will probably survive, but they won’t be capable of flying more than a handful of missions before something breaks (or gets broken by enemy action). The active stockpile includes enough weapons to cover that, so even if we assume the reserves are distributed before they can be destroyed in place it doesn’t change much.
Handing the reserve stockpile out to nuclear-capable tactical fighter units and dispersing them to remote bases might increase the total strike capability, but there won’t be the logistics (e.g. forward-deployed tankers) for them to be waging global thermonuclear war. And the United States in particular doesn’t have any serious enemies within F-16 range. Might make places like the Sino-Russian border a bit more glowy and radioactive in the aftermath, but that sort of thing isn’t likely to be an X-risk.
No; global fallout isn’t an X-risk, I don’t think we’ve covered that it as much detail as we have nuclear winter, but it’s more of a prompt megadeaths and modestly degraded long-term health thing. And burning Siberian forests don’t produce stratospheric soot, so you don’t get global nuclear winter out of that either.
Reserve stockpiles mostly exist because properly disposing of nuclear weapons is expensive, while putting them in bunkers is a cheap way for politicians to retain their Strong National Defense credentials, not because anyone expects any real military utility out of them.
I’ve been following the nuclear winter research and discussion over the last few years, and have discussed the topic with some RAND researchers and Thomas Ackerman. I think there is a real possibility of catastrophic nuclear winter in a full nuclear exchange, but I agree the risk of this is generally overblown. I’d put the probability between 1-10% (greater for milder & regional cooling effects). There’s a ton of model uncertainty, especially about the firestorm dynamics, as often discussed. So enough to take very seriously, but we should refrain from treating catastrophic cooling as the most likely outcome of nuclear war.
I’m working on a post detailing these arguments but for now I will just point people towards three papers/comments in the recent literature, which amount to a back and forth between Robock et al. and Reisner et al. (from Los Alamos National Lab). The latter group finds very little climate effect from a regional nuclear exchange in contrast to the drastic effects found by Robock et al. Their further comments go into more depths about the disgreement.
Climate Impact of a Regional Nuclear Weapons Exchange: An Improved Assessment Based On Detailed Source Calculations
https://agupubs.onlinelibrary.wiley.com/doi/full/10.1002/2017JD027331?fbclid=IwAR0SlQ_naiKY5k27PL0XlY-3jsocG3lomUXGf3J1g8GunDV8DPNd7birz1w
Comment on “Climate Impact of a Regional Nuclear Weapon Exchange: An Improved Assessment Based on Detailed Source Calculations” by Reisner et al.
https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2019JD030777
Reply to Comment by Robock et al. on “Climate Impact of a Regional Nuclear Weapon Exchange: An Improved Assessment Based on Detailed Source Calculations”
https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2019JD031281
I read the last one, and came away going “Yep, Robock is at it again.” If you ignore every possible mitigating factor and set your simulation up to maximize soot production, it produces a lot of soot. But if you try to model Hiroshima, it says that it should have produced way more than it does. Hmm… I wonder why.
At least Robock has learned of the existence of Glasstone.
Also, Kuwait. Still waiting for him to validate his models on that.
Not having read the arguments, I have a hard time thinking of an argument that would persuade me that future potential human life carries any ethical weight whatsoever, given that such a view carries as a direct consequence that birth control is evil. And caring about humans currently alive today does 99 percent of the ethnical work anyway, since children born today can expect to have direct ethical concerns for their grandchildren who will die 100 years from now or more. We can daisy-chain ethical responsibility pretty far into the future without having to resort to the philosophical horror show of hypotheticals.
Why? “we want human to exist as species/culture in future” does not imply “birth control is evil”.
No it doesn’t, but if you use the “human life that might exist in the future but does not yet must be given as much ethical consideration as currently existing human life, and preventing that potential life is per se unethical” premise to get there, then you also wind up at “birth control is evil”.
You may want to secure a future for the human race out of purely aesthetic grounds. Fine by me.
It’s perfectly possible to have a population ethics that value a good future for humanity without saying “birth control is evil”.
For instance, here is a half-assed population ethics I came up with, that is most of the way there: https://www.lesswrong.com/posts/Ee29dFnPhaeRmYdMy/example-population-ethics-ordered-discounted-utility . It has “the value of birth control depends on the flourishing of the child and their impact on the flourishing of the rest of humanity”.
You can tweak this more towards “birth control is neutral” if you want to; I didn’t do this, because I want to automate the tradeoffs between people’s different population ethics intuitions, rather than designing a specific system myself.
The largest religion in the world believes this, so why is this a surprising conclusion?
He has issues with religion, some religious people holding a view making him think that view is more legitimate would surprise me
This viiew would also be completely at odds with non religious western culture
For different reasons, though. The hypothetical implies that failing to bring a life into existence is evil whatever the mechanism. Forget about abortion being murder, abstinence is murder.
Indeed. If someone really believed that, we should expect them to take steps to maximize their own life towards fathering as many children as possible. You know… donating sperm, having unprotected sex with multiple women (and lying to them if necessary), joining the Mormon church, etc…
…. and getting involved in polyamory?
Hmm…
I considered it a reductio ad absurdum. Anyway, the Catholic Church doesn’t hold it as a point of doctrine based on ethical reasoning, they do so for a variety of reasons; particular interpretations of sacred texts, emotional discomfort, and the importance of social control.
I am not Catholic, but yes, they very much hold it as a point of doctrine based on ethical reasoning. This is uncharitable to your outgroup.
The Catholic Church has such a poor history of ethical reasonings that the uncharitableness is completely reasonable.
@JPNunez
That rascally outgroup, always doing things so badly that they deserve my completely reasonable lack of charity.
Any lack of charity at the ingroup, of course, is completely horrible.
Pedantry: it’s not a universal Christian view, and I’m not sure if the number of Christians who hold it exceed the total number of Muslims (making “largest religion” false) — if you’re just counting Catholics it definitely doesn’t.
Substantive point: not on the same grounds though, otherwise they (Catholics) would also be opposed to “natural family planning”, and if not in favour of sex outside of marriage they would at least talk about it differently (“well, sex outside marriage does have the huge benefit of producing new human life, but unfortunately it’s bad for these other reasons so we can’t condone it” etc.).
>otherwise they (Catholics) would also be opposed to “natural family planning”
In one of the Monty Python books, there was a discussion that went something like this:
Catholic Church: “…so that’s why we oppose all forms of contraception.”
Interviewer: “But you approve of the rhythm method.”
Catholic Church: “Only because it doesn’t work.”
Exactly. Even if you disagree, and whether or not you think the argument a good one or the conclusion true or false, the fact of an apparent argument here is not a reductio; it is evidence.
Well, it’s not that simple. When you’re thinking about the really long-term big picture etc you also have to consider who is being born. Birth control is eugenic, so…
What is the evidence of this? Since the introduction of birth control to the United States, we have seen substantial increase in births to unwed mothers, which are on average the most dysgenic.
Is there any reason to think there’s a causal relation there?
Here are some stats. ~50% below poverty limit, blacks more likely, asians less likely. And there’s very compelling evidence for abortion substantially decreasing crime which isn’t really compatible with abortion being dysgenic.
Of course. Birth control enables more sex between unwed men and women, and the smarter you are the more likely you are to use it correctly, whereas the less intelligent you are the more likely you are to have an oopsy pregnancy.
That’s abortion, which is indeed used as a birth control of last resort, but I was talking about all birth control, not just abortion.
But crime also decreased substantially in countries like Chile without legalized abortion.
That shows that modernizing policing in the 20th century has led to reduced crime entirely separate from abortion.
I don’t follow this argument at all. All I’m getting from it is something like “all else equal, it’s better to have more happy children than fewer”, which isn’t even close to “birth control is evil”. The only way I can see your argument working is if you’re myopically focused on only the next generation and think an arbitrarily larger population would have no downsides at all. Do you think birth control will somehow inevitably lead to human extinction by population decline?
Given that large numbers of people believe that birth control is in fact evil, your use of that as a reductio rather than evidence (for birth control being evil) is not appropriate.
To believe that universal human extinction is even possible, you need to reject a number of variously plausible cosmological hypotheses:
* The existence of any god or “simulators” – not just the specific one postulated by any particular religion, or a specific one that actually created us, but any natural or supernatural being anywhere with the computational capacity and desire to simulate and resurrect us
* Any computationally powerful process that dovetails large numbers of simulations (together with an interpretation of consciousness that would sufficiently “breathe fire” into them)
* Many worlds interpretation of QM
* Cosmic inflation
* A physically infinite or extremely large (e.g. 10^10^10^10 light year radius) universe
* Tegmark’s mathematical multiverse
* Probably lots of other things that I haven’t even thought of
I would put a relatively low probability on all of these being wrong, and this probability doesn’t increase with time.
And I would put a very high probability on all of these being wrong.
Or irrelevant like cosmic inflation like infinite or extremely large universe.
Or “technically makes impossible, but still possible in the spirit” like QM many worlds.
On their own these have nothing to do with humans.
If the universe is sufficiently large, more or less regardless of why, there are with probability 1 vast numbers of worlds containing humans. If it is large enough, there are vast numbers of worlds where people indistinguishable from us are having this exact conversation.
And? Even if it is actually happening, then I still care about this specific humanity.
Similarly, even if there is exact copy of my brother on Proxima Centauri b then I still care about my brother, and in case of something bad happening to him existence of copy would not mean too much.
(I suspect that it is natural reaction to avoid getting confused by “there is N exact copies of Earth somewhere”)
When an individual person dies, they are separated from the people they love. If everyone dies, no one’s conscious experience is different and nonexistence is probably not possible. Arguably, then, the worst possible event is Thanos’s snap, not an extinction event.
(I’m arguing against the notion that human extinction should be considered much worse than billions of individual deaths.)
@actinide meta
But humans can be reasonably upset at the imminent prospect of everyone being exterminated, because we value the idea of continuation of intelligent life as well as our own legacy a very great deal.
Though arguably we should value the continuation of intelligent life in general more than our more specific legacy, because this specific humanity will be erased in form to the point of being unrecognizable by millions of years of future evolution.
@actinide meta
I think it is wrong to kill a hermit with no friends or family in his sleep. I further think many of the reasons why that would be wrong generalize to the extinction of humanity.
No? Probability does not mean actuality. And perhaps our species’ specific existence is the 1 in 10^10^10^10 light year rarity.
Cosmic number are large number. DNA and biomolecule numbers are absurdly larger, and that’s without positing the extra bases and amino acids that we already know exist, and without positing completely different basis for life. And that’s just the DNA and biomolecule numbers. Factor in change over time and you multiply the cosmic with the genetic.
It would take probably less than 2^200 bits to specify the complete state of the solar system (location and velocity of every elementary particle, etc). So with 2^2^200 solar systems you could have one in every possible state. Of course some states are probably more likely than others, but whatever, multiply by another big number. The number I gave is (inconceivably) bigger than that, and if somehow I screwed up my napkin math you can always just add another “10^”. The *observable* universe is tiny compared to “combinatorial numbers” but it’s not, like, hard to write down numbers which are bigger. A really big finite universe would almost surely contain infinite duplication of anything small enough for us to have experience with.
@actinide meta
To be pedantic: A really big finite universe would almost surely containfinite but arbitrarily numerous duplication of anything small enough for us to have experience with.
Perhaps I’m making a fundamental mistake, but IMO you’re making a fundamental mistake in assuming that the components will be identical. Even a very slight shift in the number of atoms of gold (for instance) shift the components of the system.
In a huge universe you aren’t making a finite, but arbitrarily large, number of combinations of the same set. You’re making an arbitrarily large number of singular combinations of sets.
We all have neighbors. These neighbors change the system, and sometimes become a part of the system. These neighbors include trans-system asteroids, planets, and stars.
“duplication of anything small enough for us to have experience with.” is fine if you’re talking about static systems. But time makes the universe non-static. 2^200 cannot represent the temporal evolution of the solar system. And if the evolution is not the same, the current state and future state will not be the same.
@anonymousskimmer
Is there some reasonable stopping point if we only want 90% accuracy? If we need to also model everything that will interact with the solar system over billions of years, then we need to model the Milky Way, but then since galactic collisions have occurred to get us here and Andromeda is already affecting our galaxy significantly, we should probably model the entire Local Group.
Would the rest of the Universe need to be exactly as it was at the “time” of the Big Bang (13.8 billion years ago) in order to produce the following recognizable history of our galaxy, or are there multiple combinations that can produce a similar result for our scale of resolution? Possibly you can never even approach (0.000000…)1% accuracy because the tiniest different distribution of density 13.8 billion years ago, results in a radically different clustering of matter between inflationary zones, resulting in radically different galactic clusters?
At forward synthesis.
I have no clue. This speculation is already outside of my knowledgebase.
How thermodynamically favored is the state we’re currently in, when looked at through the evolution of the universe and our solar system? How many things had to go right? How many things could have gone differently?
Your guess is as good as mine.
I put a very low probability on all these being wrong, and it doesn’t deter me from worrying about x-risks. Take many worlds, for example. sure, humans won’t go extinct in all worlds, but it still matters a ton whether they go extinct in any given world or not.
However, I would endorse a slightly different version of your argument, which concludes that we should worry primarily about s-risks, put x-risks second, and everything else third/last.
That makes things worse, because it adds a new way in which we can be tend — not just by self-destruction or a natural disaster, but by a “supernatural” event such as the simulators terminating the simulation, or the Creator tiring of His creatures. Of course, that is taking a noncomittal stance towards the ethics of the gods/simulators, and that is only right.
That’s a computational large universe.
Thats a physical large universe.
Huh? Tghe inflationary epoch is over, by standard cosmology. Did you mean re-inflation, or cyclic cosmology?
Another large universe.
Another large universe.
So? The primary argument here is that “the expected number of future people” is important and should be optimized. If the universe is N compartments maximizing the number of expected happy humans in your compartment is still correct, no matter what N is.
The value of a book like this should be in listing of solutions. Unfortunately, the solutions that get proposed seem to be mostly of the centralized kind (except individual contribution).
Centralized solutions are bed in several ways:
1. as any engineer knows, centralized government of a complex system usually works badly. That’s why your Wifi is centrally controlled, but the Internet is not.
2. if the whole world adopted the same solution (as it would, given a committee, even if it’s a set of solutions there’d still be guided by the same principles), and the solution proves ineffective, we’re all screwed at the same time
3. it also assumes that there’s a single “we” with shared basic values. There isn’t.
I believe the World tried this centralized approach. We still have the UN. Has it been very effective?
Speaking of the current situation, we have the WHO. Has that helped?
As much as I think Mr. Taleb to be somewhat overrated, his basic premise of de-centralized self-reliance looks more promising
*bad
It seems like you are ignoring the nature of the problems being considered. If the risks in question are risks of total human extinction, then a single failure which causes the risk to be realised anywhere is a total failure everywhere.
I’m curious: in what ways do you find Taleb overrated?
IMO his biggest contribution, especially in his recent Twitter fights, has been to popularize a version of the precautionary principle (which he has never actually formally defined AFAIK) that emphasizes different scales of harm. Eg, his philosophy is consistent with less regulation of pharmaceuticals, since the scale of harm is limited to the people who decide to take them, but more regulation of GMOs and other things that could plausibly cause harm at the global level to billions of people who have not consented to their risk.
What frustrated me about Taleb’s worldview, up until I read this book review, was that Taleb remains silent on the issue of plausibility, emphasizing only the magnitude and degree of uncertainty of potential harms. Eg, if you believe the people who think chemtrails are really really harmful but ignore plausibility, then we should ban all planes and other things that cause chemtrails, because it is *plausible to someone somewhere* that they are causing great global harm.
What I take away from this review is that Ord’s main contribution to this problem is to lay out which x-risks are sufficiently plausible and mysterious for us to spend energy worrying about and which are not. To your point, whether we can solve these problems in a centralized way or not is a separate issue.
My problem with this is, if Adam and Eve weren’t up for the motorcycle-riding contest, they probably would have been too timid to eat the apple as well – and then all the triumphs and tragedies of humanity, from the conquests of Alexander to the moon landings, come to nothing as we instead get two hedonists sitting around in a garden for ever and ever (or until they get too bored to reproduce).
It isn’t enough for the human race to not go extinct this century. To get those quintillions of humans over trillions of years, we also have to e.g. colonize the solar system. And we have to do that in spite of the fact that it’s dangerous. I requires things like big, powerful rockets and nuclear energy, it involves the potential for e.g. redirecting asteroids, it probably involves either multiple competing governments or single governments so decentralized they might as well be. And it requires a willingness to take grand risks in pursuit of grand gains. Lots of people are going to get hurt. Probably most of these will be the ones who chose to colonize the solar system, but we can’t be sure of that.
The same goes for turning the Earth into computronium so our silicon descendants can enjoy those quintillions of person-lifetimes of wonder, or any other path to that end.
The idea that we should wait until we have the utopian society with the miracle technology that will let us pursue these goals without risk, is a false promise. First, because the risk isn’t due to any particular shortfall of technology, but because systems engineering for fundamentally new problems involves irreducable levels of trial and sometimes deadly error. What makes rockets safe is not having the right alloy of rapidly-solidified unobtanium to make the rocket out of, but having made thousands of rockets before. But second and more importantly, because we can’t realistically hope to design a society that treats X-risk as an intolerable NO!!!!! but every other risk as a necessary price for fortune and glory.
Try that, and you’ll wind up living in NerfWorld, where no risk is allowed, rockets and AI are both forbidden, and mere billions of people live circumscribed lives. For maybe a few tens of thousands of years, until that civilization’s focus on short-term rather than long-term risks leaves them extinct from the toilet-paper shortage when their highly optimized utopia is disrupted by the next supervolcano.
Carefully minimizing X-risk because the consequences are unthinkable is not the answer. We need to take calculated risks, including calculated X-risks, wagering the literal future of humanity as it is against the potential for a vastly greater future. If we are too timid to do that, and leave it for future generations, then we will pretty much by definition going to leave it to future generations selected for timidity and it may never get done.
The description of the first part in particular sounds like Jonathan Schell’s The Fate of the Earth, wherein Schell waxes with such anguish over the unborn generations that it becomes absurd.
Makes me want to invoke Cerebus the Aardvark, who once when asked to consider the needs of the unborn generations, replied, “Forget it! What have the unborn generations ever done for Cerebus?”
I think you hit the nail on the head with your line about prophets, but you didn’t take it far enough: the x-risk I worry about is people worrying about x-risk. Ord writes this book, stirs up people to worry about x-risk, they agitate for government to “do something,” we get a new cabinet-level Department of X-Risk or heaven forbid a new WXO (World Xrisk Organization), which proceeds to “do something,” which precipitates X. All that’s left of humanity is a black obelisk engraved “Hey Ord, how’d that work for you?”
Suppose Per Bak is right that most of the systems that we’re interested in are in a state of self-organized criticality. My (probably weak) understanding is that this implies there is no “average” meteor event, and hence all the calculations of probability of meteor of size X in time frame Y don’t describe our universe. Same goes for supervolcano, war, epidemic and so on.
My conclusion is that the best response is “chop wood, carry water.”
I’m confused about your meteor comment – any link to something that will make it clearer for me? Can you really not assume that if large meteors have hit us once every million years in the past, that pattern won’t necessarily continue?
Also, are you talking about something weirder than what Ord is, or are you really saying that eg trying to prevent global warming might end up making global warming worse, so we should ignore it?
Well, I don’t have much to point to online, other than https://en.wikipedia.org/wiki/Self-organized_criticality — what I know is mostly from Per Bak’s book How Nature Works and from Mark Buchanan’s book Ubiquity. But yes, as far as I can tell, they would argue that there’s no pattern to it — in some way that’s different from the usual “just because heads came up 10 times in a row doesn’t mean tails is more likely to come up next time” that we’re familiar with.
This is where I get confused, and maybe I should have framed my post more as a plea for help understanding. I think Bak and Buchanan would say “because meteor strikes follow this non-pattern (specifically, a historgram in log-log space is linear), there’s no ‘typical’ size meteor strike.” But I don’t know if they would continue “and so there’s no way to calculate the correct expenditure on meteor mitigation.” It seems to me that they each walk up to that precipice and leave the reader hanging.
As for your global warming question, it’s not so much that trying to prevent it would cause it, though I suppose that’s possible. Rather, that trying to avoid one fate can precipitate another. Old theme, think Oedipus for example. It’s more an aesthetic point, trying to complete the circle back to your opening about prophets.
By the way, thank you for your time, and for some very interesting discussions.
found a recent quote relating to self-organization from hacker news, which I thought could relate to interaction effects between prevention measures, causality, and capability explorations:
“Take curiosity. If everyone in the village is highly curious and off exploring the jungle with tigers, everyone in the village, sooner or later, dies.
On the other hand if everyone in the village sees tigers behind every bush and stays put within the safe confines of village walls, no one in the village learns how to tame or hunt the tiger.
A Tiger here being a placeholder for any threat/unknown the group faces, requiring talents as yet not known to the group.
If you do find a village that has managed to Not fall victim to both those scenarios think about what it tells you about the distribution of curious/non-curious within the village.”
How much time (if any) does Ord spend discussing the arguments for whether to be specifically humanist rather than “intelligence-ist”? Where the latter would think of intelligent beings no longer existing in our solar system as a Very Bad Outcome, but not necessarily say the same of superintelligent AI replacing humans as the source of those beings.
Personally, I’d like whatever being continue to populate the universe to have at least some human values; e.g. happiness, love, etc. I would classify e.g. intelligent paperclip maximizers dominating the universe as a Very Bad Outcome, but AIs or aliens that shared our values as a decent outcome.
Considering the lives of potential future humans is necessary, but not sufficient, for considering how to properly value mitigation efforts for potential cataclysmic events. It sounds like you’ve set up something of a binary consideration… something like “Most people don’t think about the trillions of future lives, but actually we should!”
But it’s not binary at all. It’s not a question of “should we consider future lives or not?” The relevant question is “How much weight should we provide to future lives vs our own?” And we already have a pretty solid theoretical construction for considering these questions – the discount rate. So, the relevant question is, “What discount rate should we apply when considering scenario X?”
I believe a whole lot of the debate on climate change skepticism hinges on this very question. The social cost of carbon estimates vary considerably depending on which discount rate you use, and most of the alarmist scenarios involve using a rate that is lower than typical, resulting in valuing the future (as compared to the present) much more highly than is standard (that isn’t to say that such a rate or valuation is “wrong,” just different and requires justification).
Also worth highlighting – the reason we discount the future isn’t just because we’re a bunch of selfish jerks who care a lot about our own lives and cannot properly conceptualize the suffering of our hypothetical great-grandchildren. It’s also because the future is quite uncertain. Any and all of the resources we spend trying to prevent global warming in the year 2150 will be for naught if a Rogue AI wipes us out in 2030. A proper discount rate will reflect that sort of uncertainty as well.
Appendix A of the book discusses why Ord doesn’t think the usual discount rates are appropriate here. He argues that economists have two arguments for a discount rate – money issues, and pure time preference.
The money issues come from factors that are specific to money. If you have it now, you can invest it; if you get it later, you can’t. Because of economic growth, everyone will be richer in the future, so x amount of money will take you further now than in the future where there’s more to go around. All of this is true, but doesn’t apply to nonmonetary goods like lives.
Pure time preference is a kludge that economists include in some models to represent that most people have such a preference. But first of all, it’s unclear that our ethics should reflect every unendorsed preference – people also have an observed preference for selfishness over virtue, but it’s still fair to write in your ethics book that we should aim towards virtue. In the same way, you can write in your ethics book that we should try not to have time preferences.
And second, the models are false. Real people’s real time preference doesn’t follow the exponential curve economists say it does – it’s hyperbolic instead. But hyperbolic discounting creates so many weird paradoxes and is so obviously stupid that economists round it off to an exponent so that the people in their model can sort of make sense. But it’s unclear why we should use this exponential term, whose only justification is that it reflects people’s real preferences, since it doesn’t reflect people’s real preferences.
And third, most people only have time preference for themselves – they would like one marshmallow now instead of two marshmallows in an hour, but if you ask them about feeding a starving orphan, they will say you should feed them two marshmallows in an hour. Since this book is about how to treat other people, it’s fair to use people’s altruistic preference, which seems to be against time discounting.
Also, Ord thinks that time discounting altruistic actions across long time spans produces obviously dumb results, like that it would be worth letting the entire modern US population die in order to prevent a slight inconvenience to one caveman.
Thanks for the response. So just to be clear, he believes in no discount rate whatsoever?
That seems pretty extreme/atypical, but hey, it’s an argument!
Is this so dumb a result from the point of view of that caveman? That person’s life was their own, after all. Perhaps if they had taken a more convenient course of life none of us would have existed; but as long as the more convenient course of life didn’t involve aggressing against anyone who then existed, it’s not clear to me that their action would have been worthy of condemnation. We may be grateful that cavemen acted so as to bring us to life without believing that they had an obligation to do so.
I thought part of the reason to discount future lives is that there is less probability of them existing/existing in a form we care about. Sure, the next generation absolutely deserves concern equal to our own. The generation a billion years from now? Considerably less.
Right – that’s what I was trying to get at in my last paragraph. Part of the reason to discount is uncertainty, and we accept as a given that certainty decreases over time. I am less certain about what the world will look like in 1,000,000 years than I am about what it will look like in 1,000. And less certain about 1,000 than 100. And less certain about 100 than 10.
And at distances like 1,000 years, I’m so uncertain as to what the world will look like and what good and bad outcomes may be, that if you asked me whether or not a decision I’m making today will make things better or worse for people 1,000 years from now, I have basically no idea whatsoever.
I agree we should discount based on uncertainty, but I’m not sure how that applies here. Usually I’d be discounting based on uncertainty that the people I’m affecting will exist, but in this case we’re specifically talking about the value of them existing or not.
I also agree that we should discount based on whether our interventions can affect them, but in the case of things like preventing nuclear accidents, that just seems to reduce to our usual uncertainty about whether some plan to prevent nuclear accidents would be effective.
Maybe this would work better if you can give an example of a situation you’re thinking of where we should discount?
I think you might be right that we should discount our expected value for actions that aim to improve the world in the distant future. However, I think the part that we should be discounting is the expectation, not the value. To be more clear: We should say that due to general uncertainty, the probability of our actions having an effect on the existence of future generations is lower than we might naively calculate. We should not say that the value of those generations existing vs. not existing is lower.
In a practical sense, I’m not sure what the difference is.
Let’s say I’m trying to evaluate whether to take a particular action that will harm economic growth in the short term, but help mitigate climate change in the long term. Right now, I’m on the fence, I can’t quite decide whether the future benefit is worth the present cost or not.
But then, a genie descends from the heavens. He tells me that actually, the world is going to be destroyed and humanity eradicated by a Rogue AI in 10 years (well before the benefits of my climate mitigation have kicked in). Now the decision is trivial. Given that the benefits are near zero, any short-term cost is no longer worth it. But not only that, short term economic harm is now even worse, because we need a strong short term economy to fight the coming AI menace.
Of course, in real life, we don’t have a genie. I can’t know for sure if humanity will still be around 100 years or not. But I’m pretty confident it will be around in 10. And slightly less confident it will be around in 20. And slightly less in 30… all the way down the line. That’s why I need to discount future years.
@Matt M
The difference is: What happens to your expected value if the genie tells you that humanity will definitely survive until the point where climate change is a problem, and your proposed mitigation actions will have the future effect you hope they will if implemented?
If you’re discounting the value based on time, this information will not change your evaluation much. So what if your strategy is guaranteed to work, they’re still a hundred years in the future!
But if you’re discounting the probability (as I argue you should), then this information vastly changes things. With your plans guaranteed to be effective, the expected value is now equal to the best-case value, now that your uncertainty has been eliminated.
Why is this distinction important in worlds without genies? Because there’s a very real possibility that we will become better able to predict the particulars of the future, and if we do, it should increase our willingness to take actions that don’t pay off until the future.
As I understand it, discount rates are currently used for the purposes of both value, and probability, as you describe it.
In the event that we decide future lives are equal in value to present lives (this seems to be a subjective value judgment), then only the probability portion remains.
And in the event that we get better at predicting the future, the discount rate should fall accordingly, to reflect that. But it wouldn’t be zero, barring a genie or other form of perfect knowledge.
@Matt M
Well in that case, sounds like we’re in agreement!
AI can’t do anything but be a brain in a jar unless we humans actively give it the power of agency. IoT, I’m looking at you. The greatest risks here are autonomous and connected robots.
Unfortunately this is effectively impossible, even if the 80% turns into 100%. That is all I will say.
Which they will, because there’s literally no point to making an AI that has no connections to the outside world. Instead of making an AI in a sealed box, just make a sealed box–it’s a lot cheaper.
The issue isn’t AI’s having the power of agency, it is that of humans, who do have the power of agency last time I checked, using the AI to do evil things. If I somehow got control of the first super intelligent AI created I would immediately use it to prevent any other person from getting control of an AI. Why – because I know many humans are evil and if I don’t do this, eventually an evil person will do evil things with a superintelligent AI. That is a bad thing.
And, of course, we’d have to trust you on the whole “I’m totally not evil” thing 🙂
Anyway, evil humans with access to powerful tools is definitely a serious problem. It’s a problem that many people are trying to solve by a variety of means… And AI X-risk proponents are not among those people, because they believe they’ve got much more important things to do than worry about terrorists blowing up cities or whatever. That’s one of the many reasons I dislike the whole AI X-risk fixation: it detracts resources from real, immediate problems.
I’m not caught up on the thread, so excuse me if some of these points have been made.
Eliezer put a lot of thought into an AI which completely destroys the human race even though its purpose was apparently completely harmless. This is a reasonable start, and also led to some entertaining spin-offs about paper clippers.
However, I think the biggest risk comes from power-seeking organizations– governments, businesses, and religions. “Get me money and power” has a reasonable chance of being installed without adequate brakes.
I’m also worried, though less so, about AI which is intended to destroy the human race for the sake of the ecology. There are certainly more that a few people who talk as though world would be better off without people, and I’m not sure to what extent they mean it.
At this point, the future of AI I expect is not so much a FOOM as a large number of not-fully-general AIs, to some extent interfering with each other. I’m not sure how much hope this adds.
Exactly. I’ve never understood why people worry so much about rogue evil AIs and not about AIs being wielded by evil people, which is almost infinitely more probable. (Well, I do understand – it’s more fun to write SF than to worry about things that are actual existing problems in the world)
I don’t think it’s entirely unreasonable to assume that the most powerful AIs will almost always be wielded by governments, or other similarly large institutions. If so, their AI will be able to defeat any weaker AIs that are deployed for criminal purposes.
It’s like worrying about a “Bond villain steals a nuke” scenario. It’s plausible that such a thing could happen, but pretty unlikely when they know that governments of the world will still outgun them by several orders of magnitude.
…and?
I’m not worried about random muggers taking over the world with AI.
A bit of a tangent, but North Korea suggests that having even one nuke is still very valuable.
There was presumably a period of time in which North Korea had one nuke, but A: they didn’t use it and B: nobody who mattered believed they had it. Having a few dozen nukes is clearly valuable, and North Korea went almost directly from “nobody who matters believes they have any nukes” to “everybody who matters knows they have dozens of nukes”.
Having one nuke usually puts you in a fairly precarious situation because using it is nigh-suicidal and threatening to use it is thus not very credible.
“A bit of a tangent, but North Korea suggests that having even one nuke is still very valuable.”
Adding to John Schilling’s remark, having one nuke makes it very tempting for your enemies to attack you pre-emptively if they think they can plausibly capture or destroy your nuke before you can use it. Considering they’ll lose a city if you strike first, that is very tempting.
(I accidentally Reported John Schilling’s remark when trying to Reply to it, now I’m unable to undo. My apologies)
Then who are you worried about? The US government? If so, you should already be worried, because they already possess technology sufficient to enslave/destroy mankind. AI might plausibly help them do it faster and at lower cost to themselves, but if you think the government itself is a bad actor, we’re already pretty properly screwed, IMO.
I assume Eliezer focused on the rogue paper-clip maker in order to demonstrate how even ai believed safe should be regarded with concern.
Everyone was already worried about Skynet. Although it might have circled around past “genuine concern” and into “cliche” by now.
I think that implies that we need to worry about making sure that evil people aren’t the first ones to make an AGI, and that good people making an AGI make one that is properly aligned. Either one of those scenarios will be terribly bad, so solving the more probable problem isn’t enough–you have to solve both of them.
One thing that worries me along these lines is that we’ve already gotten the easily accessible oil. To a large extent, the measure of human technological advancement so far is a measure of how much fossil fuels we’ve burned.
If civilization collapses back down to a founding group of 10,000 humans again, will they be able to bootstrap themselves back up to our level? Maybe they could build out a different “tech tree” that’s solar power based or something, but it seems unlikely.
Does Ord address this at all? The ability to re-bootstrap back to where we are?
Last paragraph of part II of Scott’s review. Do a search for “III.” and then scroll up slightly.
This is a tangent
I’m not sure this is true, by analogy to forest fires.
Y’all know the problem with forest fire management? The problem is that some forests need periodic fires to clear out fuel, before the fuel builds up to levels high enough to create much much worse fires. Historically, in the US, forest fire management has consisted of “make fires never happen”. This is fine… as long as you can do it. But over the span of 50, maybe 100 years, when you put out all the fires as soon as they start, the fuel starts building up in forests. Then one day some random spark kicks off a blaze, and because of all the fuel laying around, the fire is much too big for you to have any hope of putting it out. In fact, it’s so big, that it does more damage than all the fires you put out previously would have done, combined. The solution to this, at least if you want the fires not to happen, is to periodically go into forests and ‘de-fuel’ them, removing branches and leaves, thinning out the trees, etc. However, this is extremely expensive and manpower-intensive, and can’t realistically be done as well as periodic small fires could.
Sometimes I wonder if war doesn’t work the same way. In place of fuel, we have some generalized abstract psychological fuel that we might call “grievances”. If Alicia and Bobland are two sovereign nations, over time they are going to have grievances with each other build up. Over what, I don’t know, we live in a world of finite resources and we all have different worldviews about how they should be allocated. Over time, more and more incidents of misallocations (from _somebody’s_ perspective) occur.
Grievances are the fuel, and war is the fire. If these countries have periodic wars (note, ‘war’ doesn’t mean “world war 2” it’s a generalized abstract concept encompassing “all hostile zero-sum actions between nations”), then the grievances get sorted out. Say Alicia thinks Bobland is not engaging in trade on fair terms, so they start embargoing and tariffing goods for a bit. Or say that there’s some border conflict in some small town, and it eventually escalates until a platoon of Boblian troops march on the Alician town’s city hall, occupy it, and tell them to stop. Small, localized conflict events.
But now imagine an alternative world where Alicia and Bobland are peaceful allies. They make a credible commitment to each other to avoid overt hostile acts of war (per above definition). Well that’s all fine and good, but what about all of the grievances? The grievances don’t just disappear. They might slow down, but they keep happening. Disagreements over scarce resources still happen.
Further analogy to the forest fires: you can engage in the political equivalent of de-fuelling, but just like in actual forestry, this is expensive, manpower-intensive, and time-consuming, and despite your best efforts you’re never going to have the capacity to remove _all_ of it. In the same way, many of these grievances might be manageable with appropriate institutions (international trade court, stricter property rights, etc), but this process will not be able to handle all of the grievances that accumulate.
But, critically, because of the commitment to peace, the natural pressure-relief valve for grievances (war, in whatever form) is just off-limits by fiat. So you might imagine, in the war case, grievances can accumulate up to a level of 25 before some kind of conflict breaks out and resolves the tension. But in the no-war case, they can accumulate to 25, and then 50, and then 100, and then 250, and then they hit 500, which completely swamps the institutions’ ability to deal with, and war breaks out anyway. Except this time it’s not a level 25 war, it’s a level 500 war. It’s not a hundred guys storming city hall in some bumfuck nowhere town, it’s nuclear MAD and a World War 2 level of total war.
On these grounds sometimes I worry that too much peace is an x-risk all on its own
Seems to mismatch reality, as armed conflicts excels at producing grievances.
Can you give some example of recent history where long peace resulted in extra-desctructive war?
And where small scale warfare resulted in deescalation?
Because after reading this I thought about EU (long peace) and Middle East (continued small scale warfare).
I agree with your point, but
arguably an example is WWI, which followed a mostly peaceful period of 2–3 generations in Europe. I don’t know that the tensions built up specifically because of the peace, but (according to my history class) people forgot how bad war was and, in particular, didn’t realize how much worse war was with early 20th century technology than with mid-19th century technology.
The American Civil War famously followed four score and seven (ish) years of peace, and was the bloodiest war ever fought on the North American continent. I have to imagine that a conflict earlier in the period of developing tensions would have been less bloody and perhaps largely bloodless.
OTOH, the ACW was proven effective at the abolition of slavery, whereas the hypothetical alternatives are somewhat chancy in that regard.
The U.S. was four score and seven years old in 1863, but in that time had fought Britain again in 1812-15, fought Mexico in 1846-48, and fought Native Americans the whole time.
It’s my understanding that Civil War was unusually bloody because they were using out-of-date tactics designed for less powerful weapons. They had experience using the new weapons, but not against an enemy who had them too.
It’s also my understanding that the same thing happened in World War I, and I worry that it’ll happen again the next time we fight another major power.
Just 10% chance of UFAI destroying humanity in the next 100 years? Where is the other 90% of the probability going? I think that we will probably (75%) figure out how to make AGI conditional on no major negative impacts to research. Is he expecting humans not to make AGI, or that we will probably coordinate to avoid making AGI until we can figure out the safety, or that FAI is easy?
He starts with a 50% chance of AGI in the next century based on “expert” opinions. Either he thinks there’s a 1/5 chance for AGI to be unfriendly; or he thinks there’s a higher chance than that for unfriendliness but due to other factors is adjusting the overall chance of AGI down from the 50% figure.
Why should we care more about potential future humans than about potential future AIs?
Anyway, arguments based on multiplying against a hypothetical universe spanning future civilization seem silly since such estimates are dominated *entirely* by the “or maybe you’re a moron” factor.
One of my terminal value. Likely case of tribal/biological desire for success of my group.
One argument (beyond “we are human so we care about humans”) is that a paperclip maximizer, superintelligent as it may be, is one-dimensional in its values, more mechanistic and less intellectually rich than humans, and because of this we feel like it’s less intrinsically valuable. If I had to choose between humanity being replaced by a paperclip maximizer-type AI, or a society of AIs broadly similar in complexity to humans, I’d definitely choose the latter.
Doesn’t a GAI have similar (or higher) complexity to humans pretty much by definition?
Complexity in some sense? Yes. Complexity in the sense I’m alluding to? Not necessarily.
We could never verify if whatever AI we made is sentient. A non-sentient AI obviously has zero moral value, same as a rock.
We can never verify that humans we make are sentient either, but that never stopped anyone.
Partly for the same reasons I care about typical friendly people more than serial killers; partly for the same reasons I care about people more than sea cucumbers.
One consideration I have on Ord’s argument as you present it is that non-existential disasters may have substantial effects on the likelihood of existential ones, and therefore in order to evaluate the probability that we get a certain type of existential disaster, we need to consider the (much higher) probability of these taking a non-existential form.
For instance, I agree with Ord that climate change seems very unlikely to truly wipe out humanity. But supposing a really, really bad climate change disaster that renders the overwhelming majority of the planet uninhabitable. Humanity survives, and eventually the Antarctic researchers’ descendants populate that now balmy continent. That’s going to take a while, and during that time, the per-century risk of misaligned AGI wiping us out seems way lower than 1 in 10.
Maybe a near-existential climate change disaster still isn’t that likely, but a bad nuclear exchange over the next century or a nasty engineered pandemic seem way more likely than 1 in 1000 or 1 in 30, and that could still set us back enough that the chances of developing a super-plague or an AI demon are much lower for a long time. (See the Einstein paraphrase “I don’t know what weapons might be used in World War III. But World War IV will be fought with stone spears.”) Does Ord factor non-existential catastrophe into his estimates of how likely technologically challenging existential risks are?
If your argument is that near-existential risks reduce the risk of some existential risks, I don’t think that should significantly figure into the calculation: near-existential risks are more likely than existential risks, but they are still unlikely enough that even if they eliminated existential risks altogether if they happened, they would only reduce the risk of extinction by a small fraction.
It’s not obvious to me that, over the course of centuries, the chance of a civilization-wrecking engineered plague, nuclear exchange, EMP, solar flare, or various other things that would severely set back our ability to make an AI that kills us all is negligible.
Of everything you’ve written, it feels like this most needs a content warning.
😛
Is Pascal’s mugging an acknowledged trigger category ?
I feel that quick horrible suffering and extinction is better than trillions of years of horrible suffering (obviously depending on how horrible it is, but I’d say Xinjiang qualifies). Therefore I will only worry about not getting extinct after galaxy-wide dystopias are ruled out. But I find dystopias to be way too probable. This is also why I’ll rather just die than use cryogenics to respawn in some sort of space gulag.
Galaxy-wide anythings are going to be difficult to sustain in an Einsteinian universe. And there’s no rule against a purely Terrestrial civilization being a few billion years of dystopia encompassing 99.999+% of all humanity ever. Or a few trillion years with a bit of starlifting and orbit-shifting.
I like the odds of diaspora much better.
I didn’t mean that a Galactic Emperor is necessary to make everyone suffer. It’s enough if every planet/system has its own king. The question here is how effective technology can be at oppressing people.
Also, of whether people in power will be inclined to be evil kings in a post-scarcity world.
Another example: A few decades ago, on September 11 2001, the US realized “hey, our society is actually super vulnerable to technological risks from small groups of dedicated terrorists”. And started paying attention to that fact and being more worried about it. Things haven’t changed in the intervening decades–we’re still quite vulnerable to technological risks from small groups of dedicated terrorists–but we are now underconcerned rather than overconcerned.
I wonder if knowing some statistical reasoning would be helpful here. Like, a very basic and useful statistical assumption is that of independence. If we figure that the probability of a terrorist attack is independent from year to year, then the odds of a major terrorist attack in 2002 and the odds of a major terrorist attack in 2022 are about the same. It’s only due to the availability heuristic that people were so much more concerned in 2002 than they will presumably be in 2022.
I fully expect people to drastically overestimate pandemic risks the year after the COVID-19 pandemic ends, and I plan to buy myself cruise ship tickets at bargain prices 😉
Anyway, I posted this comment so Toby Ord can go on TV shows and draw an analogy between Sept 11 and COVID once the pandemic is over… I feel like that could bring the message home for normies in a way his book does not.
How does one quantify “Unforseen anthropogenic risks” to be as specific as 1 in 30 ?
I’m not sure, but I will say he’s not actually being that specific; 1 in 30 is only one significant figure.
There’s an existential risk from extreme global warming that Toby Ord seemed to have missed, one that doesn’t spare Greenland.
The short version is this: global warming disrupts ocean circulation, causing less oxygen to reach the depths. This allows anaerobic bacteria that produce toxic hydrogen sulfide gas to flourish in newly oxygen-poor regions. Positive feedbacks eventually lead to more and more oxygen-free ocean, more and more hydrogen sulfide producing bacteria, and eventually the bacteria are producing enough hydrogen sulfide gas to make the entire atmosphere poisonous – even to plants. This is the mechanism that is believed to be responsible for the largest mass extinction in Earth’s history, the Permian-Triassic Extinction Event, also known as the Great Dying, in which over 90% of multicellular species disappeared from the fossil record; in that scenario, the runaway greenhouse effect was caused by massive volcanic activity igniting equally massive coal deposits.
A longer explanation of this potential disaster mode can be found in this Reddit post that summarizes this book and in this article from The Atlantic. On the bright side, it would take some seriously extreme fossil fuel burning to trigger this state – enough to raise the temperature by 10 degrees Celsius, which would probably require burning every last bit of fossil fuels on Earth, plus some more greenhouse gases from other sources.
1. Ord’s philosophical basis, maximising the number of future humans, leads directly to enforced conception shortly after menarche (all pregnant, all the time), removing all but a very small number of males (preferably by sex selection of sperm), and killing women once they can no longer bear children. That way you get the most humans in the shortest time. *
This basis is … not one I would choose.
2. Humans need to get over themselves. So what if Adam went on the motorcycle race and killed either himself or Eve? God would just say to herself, “oh well. Better luck next time.” And there would be a next time.
* Note to anyone thinking of claiming males** have a monopoly on brains, creativity, ability to provide food, or anything else necessary for technological development: don’t go there. Just don’t.
** Or humans.
Strategy that you mention is unlikely to result in sustained increase of number of future humans.
And Ord is clearly proposing to optimize by something smarter than “maximising the number of future humans”.
I am not sure why this yound-adult-media type of dystopia is at all relevant.
I don’t think humans necessarily have a monopoly on intelligence (though this might be the case; Fermi Paradox etc. etc.). I do think it’s quite possible that humans have a monopoly on human values, and I care about those a lot.
If a few ‘islands’ of human populations survive a non existential but catastrophic disaster I’m much more pessimistic than Ord about them rebuilding civilization. I think academics tend to see accumulated knowledge in very abstract terms (formulae, formal methodologies, constitutions) – forgetting what it would mean in practice if the species were reduced to a few 10’s of thousand scattered here and there.
Apart from the total destruction of division of labor (a small scale group of survivors would not be able to carry scientists or specialists in knowledge production of any kind) I suspect even vocabulary would start to decay within a couple of generations. Concepts as basic as counting (above 3) need a lot of inter generational work to maintain, etc. What would iron railings mean to such survivors after 5 generations of cultural disintegration?
The 1980s BBC show on post nuclear societal collapse – Threads – is probably more realistic.
Neither do I think, teleologically, that ‘scientific civilization’ would be bound to re evolve after 100,000 years. More likely a human remnant would stagger on for a while then be eliminated in the next medium sized shock.
Civilisation bounced back after the Late Bronze Age Collapse and the Early Medieval well enough.
Homer used numbers bigger than 3.
I agree that the collapse of civilization would lead to the loss of a lot of knowledge, including some things we consider pretty basic. But humanity invented agriculture, states, and writing from scratch multiple times; why do you think we couldn’t do that again?
Also, even a small amount of knowledge can be a huge help. We know from Sequoia’s example that merely knowing that writing is possible is enough for one illiterate man to invent a new, fully developed, and easy to learn system of writing.
Is there a reason to distinguish “Intelligent beings created on a substrate of carbon via incompletely understood processes and then imperfectly educated about current values” from “Artificial Intelligence”, such that one is allowed to inherit the universe and the other must be prohibited from doing so?
Yes. If that involves human extinction; I would mind, and most would mind as well.
Much of human values is encoded in our genome, which is similar between humans. The rest is culturally transmitted, with some loss of accuracy. Like a slightly blurry photo, not quite as good as the original, a lot better than nothing. (Identical copies of me would be preferable) AI gone wrong could end up with completely weird and alien values. (We could get AI with basically human values, that’s roughly what the FAI people hope for) We are trying to preserve our values as closely as possible, and other people are at least fairly close to us in values. (usually)
His assessment is reasonable. No natural disaster short of a large 10km++ impactor (not even a supervolcano, I suspect), is likely to rend mankind extinct. As Peter Watts so succinctly notes in Blindsight, the only meaningful enemy is a thinking one. The environment doesn’t hunt you down to the last man. Heck, not even the worst super-plagues can do that – Middle Ages Man survived the bubonic plague. Nazis and killer robots can.
Limitations imposed on technological growth also impose limitations on economic growth. To extend the Adam and Eve analogy, hiding in a cave means you are probably going to have fewer kids.
Not permitting research into asteroid redirection, for instance, may hamper the growth of asteroid mining, if redirecting asteroids into Earth orbit is found to be the most cost-effective means of harvesting asteroidal resources (this is probably not the case, as far as I can tell).
Stringent yet probably necessary regulation (for a certain set of cost-benefit analyses) and a lack of political support has completely closed off nuclear reactors as an affordable and practically inexhaustible energy source for mankind for the foreseeable future (there is enough depleted uranium sitting in warehouses to run the US power grid for a millennium, if breeder reactors are used).
Risks need to be taken in order to ensure the human conquest of the galaxy in no more than ten million years. Suppression of the technology required is also a major threat to this goal.
And screw the Fermi Paradox! We’ll figure out what it is after we conquer the galaxy, or die trying!
Bubonic plague was a pretty bad one, but it gets a lot worse than that. The mix of diseases Native Americans ended up catching during the Columbian Exchange killed something like 90% of the population, but there’s no reason to believe that’s the upper limit, either — in rabbits, for example, myxomatosis has a 99.8% fatality rate in naive populations. Something like that still wouldn’t kill everyone — we tried to use myxomatosis as a biological control agent in Australia, but after an initial wave of lethality the rabbits there evolved resistance and the virus evolved less lethal strains — but it’s a civilization-killer for sure and there’s no guarantee we could build another technological civilization the second time around.
Since Ord is a grad student of Parfits, and he’s writing about future generations, does he address the non-identity problem? I’ve been trying to see if anyone has a satisfactory answer to it since my days in undergrad. If this book has some good arguments I may have to pick it up.
I’ve looked up the nonidentity problem on wikipedia, which says it’s a list of 3 beliefs that you can’t simultaneously hold. The third one is:
Can you explain why it’s problematic to reject that? It just seems obviously wrong to me.
+1 For an example successful summoning demon that will torture as for all eternity, and make it amused.
Can you write that in a less confusing way?
“some acts of bringing someone into existence are wrong even if they are not bad for someone” seems clearly true.
For example bringing into existence a powerful homicidal torturer that never did anything good and harmed many is wrong. Even if there is a single person who was happy that happened.
@matkoniecz
That’s not a good example; it’s clearly bad for the people harmed by the torturer. I don’t think that’s what the statement is getting at.
Afaik the third tenant is not “some acts of bringing someone into existence are wrong even if they are not bad for someone”.
Instead it is “some acts of bringing someone into existence are wrong even if they are not bad for anyone currently living or that will ever exist*” as per here.
Which is a huge difference, really.
* Please note that this is only about exactly the people that would ever exist if things were to go along as currently planned. Anything changes, different egg meets different sperm? Counts as a different future person and can be harmed without breaking the third tenant.
OK, that would make more sense
@Votv
Yes, that’s why I was confused.
For an example of where we think it is wrong to bring someone into existence without it being bad for someone: A woman is deciding whether or not to conceive a child. The doctor tells her that, due to some medication she is currently on, if she conceives now, she will conceive a child that will experience health problems that will cause their premature death at the age of 40. However, if she stops taking the medication and waits a month for it to clear her system before conceiving, she will conceive a normal, healthy child. Though, either way, we can assume that the child’s life will (as a whole) be a good life—a life worth living. She considers the doctor’s advice. However, since it would be inconvenient, she keeps taking the birth-defect-causing medication and decides to conceive now anyway. Her child experiences health problems and dies at 40.
edit- make the case more clear
You’re giving an example of a situation where no harm has been done. It seems to me that harm has been done.
We probably agree that the child has health problems and that health problems constitute harm. So what gives?
Consider the possibilities for the child born. (1) It is born with health problems and dies at 40 (2) It is not born at all. As long as we think the child has a life worth living it hasn’t been harmed.
That assumes that those are the only options. What about option (3): Be born a month later without health defects.
I know that some people would argue that this would result in a different person being brought into existence but frankly speaking I don’t see the point in distinguishing between potential lives.
Believing there is no option (3) is because of an assumption that “different egg + different sperm = different identity” is a useful way of thinking. I say useful not correct, because it’s inherently untestable. I don’t think it’s correctness is even decidable in principle. So why take that stance? And if you don’t share that sentiment then there seems to be no problem here.
I’ve also skimmed some other nonidentity problems and they also seem to require the same mental model of distinguishing between potential people. So is that a widespread believe and if so are there good arguments in favor? Because to ignorant me it seems fairly arbitrary to think about potential people like that.
This to me seems like what’s called a “de re” and “de dicto” distinction. Correct me if I get your point wrong, but as I understand you “the child” is different from the actual physical child, in the same way that “the president” is different from Donald Trump. For example we could say (a) 57.9% of eligible voters voted for the president in the 2016 election and (b) 27.9% of voters voted for the president in the 2016 election. Both of these statements are true, but use “the president” in the de dicto and de re sense respectively. When we talk about harming “the child” we make the child worse off because it really was possible for him to be born with no health defects at all, we just need to use the de dicto sense.
I don’t think this works though. This is a completely absurd usage of the term ‘harm’. You cannot harm someone in the de dicto sense; i.e., you cannot harm a ROLE, or an OFFICE. If you could, then it would be true that I harm “my child” in the following case: Adoption: I am trying to decide whether to adopt (a) Jimmy, a child with a debilitating disease which will cause him some life-long discomfort, and lead to an early death at the age of 30. Assume also that no one wants to adopt Jimmy, such that, if I do not adopt him, he will spend his entire life in the foster system; or (b) Timmy, a healthy child who will live a long, happy life. Assume also that there is a long line of prospective parents on the wait list who are eager to adopt Timmy. My heart swelling with empathy, I adopt Jimmy.On the present suggestion, I HARM my child!
I’m not 100% sure I agree with your characterization of my view. If I understand the “de re” and “de dicto” disctinction correctly, then “de re” refers to the actual physical person and “de dicto” to their title or role or designation.
And sure, that makes sense when talking about actual people. “The president” is a title that exists independelty of the person wearing it.
But say I have one child and I call it “my firstborn”. That is a unique identifier, it’s wrong when applied to any other person. So “my firstborn” is probably “de re” then, right?
In any case, I want to say “your child” in my last response means the physical child. But I’m not the sure we talk and think about things here are doing us any favors. Possibly I’m just confused, if so just let me know and I won’t be offended.
Let me try to list the things we know for sure, with the intention of distinguishing these from the parts that are just words we use to describe intellectual concepts.
– The child exists.
– It wants to live.
– It would prefer not to die at 40.
And here’s the hypotheticals
1) If asked “Would you rather (a) die at 40 or (b) never been born?” it would choose (a).
2) If asked “Would you rather (a) die at 40 or (b) be born a month later and live to average life expencentancy?” it would choose (b).
None of these are actually possible.
Here’s another question:
3) “If you choose (b) for the second question, would that still be you?”
Question 3 is undecidable because everything described in question (2) is actually impossible. This is important to me, it’s the essence of my point. “False implies anything” would be another way to say it.
As far as I understand, the nonidentity problem is only a problem if your answer to question (3) is a resounding “No”.
And my point is, that question cannot actually be answered. I may choose “No” and see where it leads, there’s nothing wrong with that. But I should be aware that I’m just pretending there is a “Yes” or “No” answer to that question. But if I then run into the nonidentity problem I just shrug and it has no impact on my morality.
I don’t think this works, it would still be “de dicto”. Let’s say we take your approach, and consider any phrase that refers to a unique person in every hypothetical world we consider to be a “de re” reference to a specific person. What about the phrase “the first person born in Podunk, Michigan on 01/08/2021”? What if you go on to give birth to a child in Podunk on 01/08/2021 early morning and, due to an inherited disease you have, your child will be somewhat less happy than the child who would have otherwise been the first child born in the town on that day? Did you do a harm to the first child born in Podunk on 01/08/2021?
There is a near-infinite number of phrases that refer to a unique person in any of several hypothetical world, but we wouldn’t consider them all “de re” references. Considering “my firstborn” to be a “de re” reference to a specific person only if we limit ourselves to phrases that feel “natural”, but that becomes arbitrary.
What do you mean here?
We are not evaluating the preferences of the child, but the morality of the women’s actions. I think you may be too focused on what happens when the child is born, not the choice she made. So if we look at the point at which she makes the choice, these are her choices:
(a) She has a child that dies at 40
(b) She has a different child that doesn’t die at 40
If (a) happens we intuitively think she has done something wrong. But, because the child who dies at 40 is not worse off than he would have been, he has not been harmed. Thus we cannot identify the wrongness of her action with harm.
We might formalize the problem in argument form, as follows:
1.The women does not harm her child.
Assumption:Harm =df Making someone worse off than they otherwise would have been.
2.The women does not wrong her child in some other (harmless) way.
3.The women does not harm or wrong anyone else either.
4.If the women neither harms nor wrongs anyone, then she does not act wrongly.
5.Therefore, the women does not act wrongly.
What I think you are trying to say, and again correct me if I’m wrong, is that these are actually the same child because sperm and egg combinations don’t determine the identity of a child. I would ask you then, what does determine the identity of the child?
There are also several other plausible assumptions that under gird the argument which include:
1) You are the result of a unique sperm-egg combination
-I think you have an issue with this one. I just need clarification as to why this doesn’t effect identity
2) Present actions can affect who will exist in the future
-I think you may have an issue with this as well, but I don’t see any explicit argument against it.
Third, this does matter a lot for morality outside of niche issues such as these, which is why I asked it for this book review. So lets say we deplete a ton of natural resources to make our current lives better but will make future generations (in the de dicto sense) worse. Since this changes which future generations will be born though, we don’t actually harm them and we do nothing wrong (as long as those lives are barely worth living). More formally:
1.Depletion does not make future generations worse off than they otherwise would have been.
2.An act harms someone if and only if it causes them to be worse off than they otherwise would have been.
3.Therefore, depletion does not harm future generations.
4.Depletion benefits presently existing people, and harms no one.
5.Any action that harms no one, and benefits some, is not wrong.
6.Therefore, depletion is not wrong
So you can see how the non-identity problem is actually a very relevant problem, especially when talking about the future.
I think my reply was eaten. So here it is again, hopefully not duplicated.
@10240
Sorry for getting back to you so late.
I mean that we cannot go back in time and change the mothers behavior. So the child cannot be born a month later than it has been born. The argument goes “If what is described in question (2) was possible, would that be a different child” – but because what is described in question (2) is impossible this maps to “If FALSE, would that be a different child”. Which is undecidable.
@borsch4
We are evaluating the actions of the mother, sure. But I think deciding this argument is all about how to think about the child. The morality of the mother’s action then follows directly from that.
Responding to your formalization: I already disagree with 1. I’ve not thought enough about 4 to know where I stand, but let’s pretend I agree with 2-4. So if we can show that 1 is correct I will agree with 5.
I think that is something fairly close to my thoughts about the matter. Really I think that identity is a contentious matter already when talking about existing humans. Using it on non-existing humans simply seems out of scope. The term does not apply. You can say anything about identity of the unexisting and it will be neither wrong or true but simply undecidable. It would be like asking “What is the color of your thoughts”.
Now, of course the child that is born will have an identity. But to claim it’s not been harmed by the mother you also have to claim that the mother waiting another month would result in a child with a different identity. At which point we are talking about the identity of the unborn. In fact we are relying on knowing that the identity of the unborn is different than the identity of the born. That is required so we can say “Nope, not the same”.
It’s even more obvious if we look at this from the mother’s point of view at the time she makes her decision. At this point in time ‘both children’ are unborn. Lets say she thinks:
1. I could conceive now and the child I birth will live to 40.
2. I could conceive in a month and the child I birth will live to 80 (just to make up a number).
3. Those are children with different identities
4. Because of (3) I know that choosing (2) will mean the child from (1) will never exist
5. That makes “not-existing” and “living to 40” the only options for child (1)
6. So I don’t harm it by choosing (1), in fact I’m doing it a huge favor.
Here you can see directly how (3) is required to come to this ‘repugnant conclusion’. But imo (3) is exactly as true as “my thoughts are blue today”.
This is also my response to the depletion problem. It seems so weird to me to say “Well we harm future of the children that will be born – but since it results in children with different identity it doesn’t count”. What? No! Why?
I also think that it’s bad for someone, though for a different reason. Namely, if having the child now causes her not to have the child later, it’s bad for the later child. Or does that not count since it’s bad for someone who only exists in a counterfactual world?
That’s similar to Parfit’s solution. This creates two issues. First, this allows us to truthfully tell the child that it would be better if he never existed. Plausible, but still bangs against our moral intuition. Second, this means that if we don’t have the best child we could possibly have then we have harmed every child who could have existed and would have a better life. This seems even less plausible.
I’m fine with both. @1: there are lots of inconvenient moral truths that are bad to hear for psychologically normal people. @2: that sounds right, although you can’t multiply the harm. If there’s only one spot available, well then you can only have hurt all unborn children by that much total. It’s not like they all would have gotten to live instead.
I have a question then. Do most people do something wrong when they have a child? because it seems to me that people rarely if ever have the best child that they could have possibly had.
Also, this is another huge topic so I didn’t bring it up, but I also believe it isn’t possible to harm someone that doesn’t exist.
Yes if “wrong” just means “not the optimal thing”. But tons of choices people make all the time are “wrong” in that way – every time someone gives money to anything other than the most efficient cause, for example – so this is less impressive than it sounds.
I think it’s an absurd moral view that gives a negative moral value to most of our actions, especially ones we think are good such as giving to a non-optimal charity.
That seems like purely a matter of definition. You can assign actions negative numbers if you compare them to the optimum or positive numbers if you compare them to something else. Both views are isomorphic. I don’t think there is any meaningful way in which comparing-to-the-optimum is more true. It was just a more useful way to do it wrt the original problem.
I think part of what causes the paradox is conflating (IMO wrongly) death with never existing. What do you mean when you say that the child’s life is worth living, even though he’ll have health problems and die at 40? I presume what you mean is that, throughout his 40 years, the child would rather continue living than die immediately. Thus, you conclude that his life is better than never existing.
I disagree with that. The baseline, that which is as good as never existing shouldn’t be being so miserable as to commit suicide. IMO it should be a mostly normal life, approx. the happiness of an average human, or slightly less. Death, or at least early death, should be considered a huge negative, not neutral. Indeed, I’d say that giving birth to someone who will only live to 40 is wrong, even if you don’t have any other option to have children.
Does that mean that it’s always wrong to give birth to a child who will have a worse-than-average life? No, if the child’s life will be only moderately worse than average, then your preference to have a child may override the harm to the child. On the other hand, your preference not to get off the medication and put off having a child by a month most likely doesn’t override the harm to the child, unless your medication is life-saving. And if you are indifferent about having a child or not, I’d say you shouldn’t have one if it can be expected to be significantly less happy than the average person.
Edit: equating never existing with death contradicts our moral intuitions in more direct ways too: it would mean, for instance, that it’s better to have a child and then kill your child when he is 40, than to not have a child at all.
Are you saying that bringing someone into existence who has less than aprox. average happiness is a harm? and second, that just bringing someone into existence is harm because death is a large negative.
The case can easily be modified to account for both of these objections.
First, let’s say that the child will grow up in a first world country, have a normal life with no health issues, but die at 60, or if she goes off the medication the child will have a normal life. I think then the problem resurfaces that we want to say not going off the medication is wrong.
Second, this doesn’t deal with larger scale versions of the non-identity problem. For example, if we deplete resources to benefit ourselves, we change which future generations are born and along with it the average happiness of a human life. We would want to say we did something wrong to the future generations, but because we change who the future generations are we can’t identify that wrongness with harm.
Finally, have you ever read Benatar? He has a very similar solution, basically claiming that giving birth to anyone is a harm.
Essentially yes, though I’d personally only use the word ‘harm’ when comparing two different states of a person that exists in both cases.
I don’t really have a good answer to this one, although even though death is a large negative, it may be counterbalanced by the life up to that point. However, I don’t really have a reason why the amount of lifetime it takes to counterbalance death should be the current average life expectancy, except perhaps that people evaluate their well-being relative to their fellows (that is, knowing that you’ll only live to 40 is worse when most people live to 80 than when most people also live to 40).
Ignoring that 60 is still way below average nowadays even on a worldwide level, I’d say that it’s not wrong in an absolute sense, and not worse than not having the child—though it’s better yet to get off the medication, and most people are going to try to be better when it comes to their child’s well-being.
Again, I don’t think it’s wrong in an absolute sense. After all, future generations wouldn’t exist at all if we didn’t bring them into existence, something I don’t think we have an obligation to do. Now, if future generations will live in abject misery, with no chance to ever improve, then I’d say we should rather not bring them into existence, but I don’t think resource depletion would be anywhere near that bad. I do have a weak preference for preserving resources for them if they are significantly more valuable to them than to us, but I wouldn’t call that an obligation (though I consider morality itself to be a set of preferences, rather than some sort of objective fact, so this is not a hard-and-fast distinction).
As 10240 hints at, perhaps humans will need to invent AGI to colonize the rest of the galaxy/universe. Sort of like how we were motivated to invent and deploy nuclear weapons to prevail in WW2 (thus preserving our side–all the while knowing the future risks).
I feel like “more people = better” is a very basic tenet which has been taken and run with for a long time; am I the only one who is deeply unsettled by it? Endangered species get preservation efforts; species overrunning their environment and stripping it get culled. Which end do you really think we are right now? We are the reindeer on St Matthew Island.
Ever increasing density of people obviously has some unpleasant out comes, but unceasing continuity of humans is another matter.
Chances are we’d take other species along in the humankind conservation effort, so we’d be also raising their chances to survive.
Concrete proof: in the documentary Firefly, the human race still ride horses in other planets.
The mammal with the most total biomass, the cow. Humans treat animals in whatever way is convenient to humans. Conservationists are trying to minimize humanities effect on the environment. (Or trying to recreate an imagined past based on a misplaced sense of affection.) Animals cause a small amount of nuisance (or live on land that could be a factory), but people don’t want to wipe out species, so we try to balance populations at a small but nonzero level.
I think you’re confusing terminal with instrumental value here. Having more people is terminally good.* Having more people at any given point may also be instrumentally bad. This is related to someone else suggesting in the comments that the view implies mothers should have babies all the time and birth control is wrong. That just ignores the instrumental effects. If the global population quadrupled tomorrow, I’d bet on there being a lot fewer people alive in 500 years.
*might not actually be true right now since lives could be net-negative.
I’m not sure that the conservationists have it right, even when it comes to conservation. (Specifically, they completely ignore wild animal suffering, which I think is pretty important if animals are sentient.) I certainly wouldn’t want to use their logic as the basis for any moral decisions involving humans.
Ord:
Scott:
Scott:
There’s a huge philosophical problem with worrying about the future of humanity. If we become a spacefaring species and spread to other planets that is in fact the death of us as a species in of itself. Widely spread agents in different star systems light years apart will inbreed more often then they outbreed, and they will adapt to local conditions that are unique to the planet they are inhabiting and the culture they develop. Compared to the development of races this is much more drastic. Thanks to modern technology, currently humans can access each other all over the globe in a matter of days, but interstellar man will have separate communities years apart once more.
There will be no common idea of humanity. A few million years go by and there will be no humans as we know them at all. They will have been erased by evolution. Even just that process will suffice in time. If we then bring in transhumanism and AGI as plausible scenarios, we can see that the eradication of the human species will occur on a much much shorter timeframe. It should also be accepted that the eradication of the human species is in fact necessary for intelligent life to spread throughout the universe and survive for trillions of years, because it is only by supplanting man that the future forms will be surpass his form and adaptively radiate as the requirements of survival dictate.
If what matters about the AGI apocalypse is that something that is not us might inherit our future, then we are absolutely stuffed, and our goal is utterly absurdly hopeless. If instead what matters is how much suffering the transition involves then that’s an entirely different story.
Imagine humanity was able to colonize the solar system, but couldn’t spread beyond that due to insurmountable technological difficulties. All human societies were close enough to maintain cultural and genetic exchange, so there was no species divergence. Over the millennia those humans’ biologies would change due to evolution and random genetic drift, but you could still draw a clear line between them and us, even clearer than we can trace to our own ancestors.
Would you say that humans were ‘erased by evolution’?
Now imagine the same scenario, but with two solar systems instead of one. They aren’t close enough together to interbreed, so you end up with two distinct species both descended from humans.
In this case, would you say humanity was erased? Why does the existence of another species cheapen our relationship to each one?
At some point they will be different enough for their civilization to be unappealing to us in the same way that bronze age Hebrews would find our society an abomination, and that’s just with mostly cultural evolution. If we’re worried that an AGI with alien values could inherit our future then we should be just as worried about future descendants being nothing like us.
My entire argument is that we should worry about neither because what actually matters is the continuation of intelligent life and civilization, not humans per se. Humans are important only because they are the only civilizational species we know of.
I’m being metaphorical. Humanity as we know it in terms that we value will have been erased for sure. Worrying about “legacy” is what I’m arguing against, at least when we’re considering 1000s of years and not the next hundred. Therefore worrying about the legacy of humanity among the stars versus intelligent life in general is needless. In any case they won’t be us, and they will no more carry on our legacy than you carry on the legacy of a prehistoric sea squirt.
I think that at least some values, like making art, or enjoying food, or caring about one’s family, have proven pretty resilient to tens of thousands of years of evolution.
@VoiceOfTheVoid
But are we willing to consider those art making, food enjoying, family loving beings part of our legacy if everything else they do is alien to our values? Even just limiting things to these factors, we may not even appreciate the way in which they love their family. There could be cultures in the future that think honor killings are occasionally justified for preserving the integrity and purity of the family legacy.
EDIT:
What about futures where transhuman beings spend a significant chunk of their time in collective simulations, making X dimensional art that can only be truly appreciated if you have the modules for it, but looks like hot garbage to more primitive cultures that see in 3D dimensions and create their art in the 3 dimensional real world?
What I’m getting at is that most futures which inspire people project our highest ideals into the future. There’s a reason Star Trek characters obsessed over the culture of the 20th Century even more so than their own. Audiences don’t want truly alien futures it seems. They want now but better. I think this being the case is reflected in our psychology, and when we talk about the legacy of humanity we tend to think in terms of a Star Trek pseudo-future. Most alien futures tend to be either dystopias, or for the rare exceptions, lack mass appeal.
You are greatly underestimating humanities collective power to do whatever seems like a good idea at the time. If we decide that genetic drift is bad, we can sequence our genomes now, record them in multiply redundant, highly error corrected archival storage media, and then use genetic modification to fix any changes. More likely, we will decide on the ideal human, much healthier and perhaps smarter than the current average, and genetically modify towards that. (Or the ideal range of humans, if we want some diversity). With ASI in play, you can well and truly glue down the future. If you want the entire future to not just be full of humans, but be full of humans with your particular culture and preferred lifestyle, you can do that too. A team of people who really know what they are doing and are building ASI, can set the future to pretty much anything. A future full of humans is as easy as one full of orcs and dragons. If an ASI wants X, it can utterly overpower all barriers in the way of a future filled with X. (With the possible exception of fundamental physical limits.)
Of course, this still leaves us trying to decide if the residents of the ideal world are exactly average human, incomprehensible cosmic super-beings or what. But whatever we decide, we can make it happen.
@Donald Hobson
And then future humans can easily destroy those archives in a fit of culture. You’re underestimating the cultural probability of rejecting a past legacy, especially when it builds up over 1000s of generations.
Who’s “we”? Remember what I’m arguing against here. This argument is strongest if humans stick to the Earth, but that won’t be possible forever, and future cultures will defy your ideals. You’d be planting your flag in quicksand. Considering human legacy is important over the next hundred to a thousand years, but it breaks down beyond that, and even within that range we will find the future people to be reprehensible just as the mainstream finds the values of the Medieval ages to be reprehensible, human though they were.
As soon as we start talking about the legacy of humanity for the trillions of years of remaining time, then we need to start thinking about civilization instead, and then when that fails we should be thinking about intelligence itself.
You pick what you value based on the timeframe. We value ourselves in the immediate term, and plan our life so we don’t walk straight into traffic. We try to support our families and friends where we can intervene in less immediate intervals. Then we move up through various hierarchies of human organization, finding less in common each time, becoming more abstract, and thinking in terms of longer and longer timeframes. For humans with our modern Western cultural values, we probably have 100 years at best. If we ignore AGI for a second, then for recognizable relatable humans with reprehensible values, we have thousands of years, and for weird somewhat humans we have millions of years, but this might be drastically shortened if selection is hypercharged by space environments as I imagine it will be. There’s still at this point orders upon orders of magnitude more time left than has passed, and so even in a timeline devoid of AGI humans will be a blip compared to their alien descendants.
Now, what’s “ideal”? That depends on the environment. The biggest problem is that humans as they are simply don’t cut it in space, even when you just consider our own solar system. It is the environment that will shape how we modify, not some preconceived ideal. Humans on Mars will need to be more resistant to the effects of low gravity. Future humans living on Super Earths will need to be more resistant to the effects of high gravity. There are different fluxes of radiation in different environments and while shielding can counter that, there is no way to synchronize the ratio of shielding to radiation flux across the stars and across generations, therefore different colonies with different safety factors will be irradiated differently. We’ll be exposed to all sorts of unexpected environments even beyond the big obvious factors like gravity and radiation. There’s no telling how we’ll evolve, only that there is enough variety in stellar and planetary system environments to take the variety provision well out of our hands.
With AGI/ASI in play, the consistency of human legacy is in danger on a shorter timeframe. Let’s not trivialize the difficulties of getting a superintelligence to do exactly what we want. There are a myriad of futures where the AI kills us, and there are a myriad where it gives us a comfy retirement as it takes things over; futures where it does exactly what we want over many generations represent a razor thin band of possibility.
AGI killing us all, whether through having a super charged serial killer brain em or through the classic paperclip scenario, is what we want to avoid for sufferings sake, but we should prepare ourselves for perfectly friendly neighborhood AGI to inherit our future from us. We want AGI, but we don’t want to be destroyed, so we’re trying to make it “friendly” so that we can have it take over everything and run it more efficiently without killing us or subjecting us to tyrannical restrictions on our freedom. That in itself sets us up for the comfy retirement scenario in which AGI does the legacy work for us.
Hey, what do you smart people make of the following two graphs:
https://twitter.com/lenkiefer/status/1245702858449784832
https://twitter.com/lenkiefer/status/1245702860920311808
The source is from the Deputy Chief Economist at Freddie Mac.
That we’re experiencing a pandemic and consequent economic disruption on a scale unprecedented in the modern era? What else is there to say about it?
“jobless claims” graph will overestimate sudden jump and underestimate continuous loss of jobs.
For example single week with 6 000 000 claims and 10 weeks with 600 000 claims each will be quite similar in effects. First will be worse, but not ten times worse. But on such graph first will produce spike 10 times higher than second, and both will have almost the same width.
Also, raw count is affected by growing population.
How unemployment percentage graph looks like? I expect it to be dramatic, but far less impressive.
One thing to remember is the reason the graph only goes back to the late 50s is we didn’t have unemployment insurance during all the historically worst economic catastrophes. This is definitely the most drastic sudden shutdown of the past 70 years.
For the AI apocalypse, I suggest joining the electromagnetic wave fearmongers and oppose 5G. Making all the world accessible to high speed Internet is a Bad Idea. It is the key technology for making Big Brother real.
I’d also suggest going full on Ron Paul paranoid about the replacement of physical cash with bank entries.
Hoard physical books, DVDs, CDs.
We need computer operating systems that don’t need to download updates from the Internet on a near daily basis to function.
I’d like to see a return of physical media for software as well, with companies that aren’t so lazy that they put bug riddled versions on the shelf.
Self driving cars are evil. Car computers should not be connected to the Internet…ever. As for some of the collision avoidance systems, cars need them now because they have sacrificed visibility for aerodynamics, and new cars have steering wheels that are geared up too high so small twitches can make you change lanes.
It’s long past time to rethink the QWERTY keyboard. It’s too much overhead to learn. Voice interfaces are dangerous.
Bring back dumb appliances!
This, but unironically?
I wasn’t being ironic. I am serious.
I am already sick of dealing with appliances and automobiles that “think” they know better than I do. I find modern cars to be unpleasant to drive due to multiple factors. (SUVs are less bad.) My newer car is a 2002; this is intentional.
Evil robots pester my phone daily.
If the younger generation doesn’t learn to touch type, then they will be more wedded to voice recognition, which if cloud based, means Orwellian tech in every home.
I don’t know enough to know that 5G is physically harmful, I am all in on the Precautionary Principle. I don’t want 5G service broadcast generally. This makes the already bad surveillance state/economy even worse.
(And all these tools that can be used by dictators and marketers can be used by evil AI if it ever arises.)
Well then this, also unironically!
And “Does your lightbulb run Linux?” should stay as a joke.
The same for fridges, washing machines, doors, wardrobes etc.
To me, this reads like
https://slatestarcodex.com/2014/08/26/if-the-media-reported-on-other-dangers-like-it-does-ai-risk/It is a valid discussion of an entirely different problem.
I strongly suggest rethinking the way you phrase posts. I suspect it’s net-negative to make a point you support in a way that sounds to many like trolling.
…Are you honestly suggesting we turn off the internet?
He pretty clearly is not. He is suggesting that we not connect to the internet, things that can seriously hurt us and/or things that we really need to always work. This is a much more practical proposition, and IMO a wise one.
> lots of majors city
I did not know this was a term that pluralized like “Sergeants Major,” but I trust you on this.
I think the most likely risk to human civilization is that we gradually evolve into an uncivilized species. After all, there are a lot more ways to be uncivilized than civilized, and entropy will eventually work its magic.
In that case, drivers of evolution are the biggest risks we face. Surely the advent of birth control is near the top of that list. So I’d add birth control to Ord’s list of possible disasters–though I’d have no idea how to quantify the odds. Probably as large as anything else on his list.
Actual biological evolution is really slow. You need 100,000 years of nothing gamechanging happening in the meantime for it to do anything. ( Genetic engineering is sufficiently gamechanging, and arriving fast) You are looking at an ancient tree, and talking about how it will grow in the next 100 years, totally ignoring the revving chainsaw.
Just reading Human Diversity by Charles Murray, and human evolution is precisely not slow. It happens in historical time, albeit over centuries, not decades. Cultural evolution is much faster, and can also lead to de-civilization (albeit not likely over the entire planet).
See also Nicholas Wade’s Troublesome Inheritance.
Generally, “evolution” without a qualifier is taken to mean the biological kind, especially if you mention birth control. If you meant cultural evolution you should have said so in the first place.
Isn’t the most recent pandemic, the 2009 swine flu pandemic, also a very salient example? I’ve suspected that this has had a lot to do with the way this pandemic has been handled. Back then, there was widespread criticism of a perceived overreaction, because the disease turned out to be mild. Governments were accused of profligate spending, pharmaceutical companies were accused of greedy profit-motivated overselling of antiviral drugs, the WHO was accused of being alarmist and trying to shore up its own importance. This Guardian article from the early days of the pandemic epitomizes a common attitude. See also this thread from Tom Forth on Twitter.
I suspect that just as people start strongly warding against one type of potentially disastrous event just after an event of that type has happened, so people start warding against the type more weakly if an event of that type happens but turns out to be not so disastrous.
Speaking of pandemics… turns out that ivermectin kills SARS-CoV-2 in cell culture:
https://www.sciencedirect.com/science/article/pii/S0166354220302011
Now, why can’t we use the tens of millions of people already taking ivermectin and get some data on whether they are being protected from SARS-CoV-2?
Hello? Is there a parasitologist in the house?
(You KNOW there’s a bunch of nerdy parasitologists reading Slate Star, but they’re probably pretending to be fighting Skynet instead of thinking about boring old ivermectin 😉
Maybe there are some researchers currently planning that study? I’m not one of them, still an undergrad. Give them more than a day or two!
Try in the next OT. This thread is too old, and we are too occupied with more abstract risks.
Oh, and as far as “existential risk” goes… maybe you smartphone transport units forgot the 20th century already, but I was there. The biggest existential risk by far is centralized government power, combined with sub-AI levels of computing power. Technological growth could get us spread out so far that it would be really hard to kill us all… but only if we aren’t under some global stagnation state.
https://www.hawaii.edu/powerkills/NOTE5.HTM
The same technology that lets us spread out also lets many things that might want to wipe us out spread as well.
Really smart things will get distracted and move on. Only extreme stupidity combined with monopolies on simple technologies will really stay focused long enough on keeping things stagnant to be a problem.
The problem isn’t Skynet… the problem is Stalin+ a database/surveillance system just smart enough to recognize and track “dissidence”, but not smart enough to transcend it and go off to pursue its own concerns. The second BG series ran into that as a plot problem… why would the Cylons hang around bothering a couple planets full of dumb hominids when they could just take over the rest of the Galaxy?
Maybe the Fermi Paradox is just a bunch of planets run like North Korea… after a couple of centuries, there’s literally no one left who can think of any other way to exist, and they just sit there chanting the biotech-immortalized dictator’s name until an asteroid does take them out?
Speaking of distracted, what about this paper about ivermectin working on SARS-CoV-2? Where’s all those putative Effective Altruists… they should know a few people on ivermectin for river blindness, right?
“One death is a tragedy. A million deaths is a statistic.”
This annoys me. It especially annoys me to see it presented as “accurately describing how most of us think”. There are about 150,000 deaths a day across the world, about two every second. Sure, one death is a tragedy for a small number of closely connected people. But for most people, the average death isn’t anything. A million deaths is a million individual tragedies. Or it’s a normal week for the vast majority of people who are unconnected to any of the million. Or maybe, if they’re all connected in some way, they do add up to a statistic.
I don’t think that’s quite the point.
I think what this sentiment is getting at is that if, for example, I produced a 30-minute documentary highlighting the life, family, and circumstances of any average individual death on Earth, complete strangers would find it very sad, tragic, and might be moved to tears.
That’s why the fundraising commercials for UNICEF show pictures of a few starving children, rather than reports stating how many millions of children are starving.
The FOOM scenario while not being completely crazy, soon runs into physical limits as well as mathematical ones. Ramez Naam had a good guest post on Charles Stross’s blog. Basically the “Singularity” in his opinion has been downgraded to “digital minds”, yes AGI is possible maybe even super-intelligence but it won’t happen overnight, a mere AGI won’t bootstrap to godhood in a nanosecond.
The discussion on takeoff speed often suffers from a lack of defining what fast takeoff means. It varies between thinking an hour is slow and thinking two years are fast. I think the latter is a more reasonable way of looking at it. If AI goes from human-level competence in some important areas* to full superhuman general intelligence in two years, that’s fast takeoff. If it takes a day, that’s rapid takeoff. The difference between both is probably not super interesting, and the difference between an hour and a second is probably irrelevant.
*it can’t have human-level competence in all areas since computers are already superhuman at many things
> soon runs into physical limits as well as mathematical ones
What kind of known mathematical or physical limits make impossible to create FOOM. Lets define FOOM as software that can self-improve its intelligence (however counted) from say rat-level intelligence to level above human, within say 24 hours?
Feel free to redefine FOOM if my definition is somehow bad.
(Edit: I’m not Proper Dave, FWIW)
Firstly, what does “intelligence” mean, and how are you measuring it ? Current software vastly outperforms rats on some tasks, such machine translation; and utterly underperforms at others, such as navigation in the real world. I don’t know if it makes sense to lump all such disparate tasks under “intelligence”.
Secondly, what do you mean by “self-improve” ? AFAIK there’s currently no known algorithm that can make itself “smarter”. Sure, there’s plenty of software that optimizes itself (compilers have been doing this for a long time), but “faster” is not the same as “smarter”. A neural network that can distinguish cats from dogs won’t suddenly be able to solve quantum gravity if you gave it 1000x computational resources; it would just distinguish cats from dogs really quickly. FOOM-style recusive self-improvement is purely hypothetical at this point.
Moving on to more boring matters, you quickly hit diminishing returns when you try to pack as much parallel computation as possible into a tight space. For example, the square-cube law sets limits on heat dissipation (and structural strength). Spreading out your computation is also not always advantageous, since any improvements in processing speed you’ll get will eventually be outstripped by the transmission delays (this is why Google has a data center in every region, even the expensive ones). Note again that we’re just talking about pure processing speed, not “intelligence”.
You might argue that a superintelligent AI could find ways around all of these problems by discovering new laws of physics or whatever, but this just introduces more problems. Not only are you assuming that the AI is already superintelligent (whatever that means in practice), but you are also assuming that it can discover unknown scientific facts simply by thinking about them really hard (i.e., in simulation). Unfortunately, these new laws of physics are unknown for a reason, and if the AI wanted to discover them, it would need to actually run experiments in the real world. Such experiments take a long time. The LHC took decades to build, for example.
None of this is terribly important, though, because currently no one knows how to even begin thinking about making an AGI. Modern machine learning systems are almost the opposite of that. They have achieved remarkable success, e.g. in the area of machine vision; but that’s because vision turned out to be a relatively simple problem, not because vision is so difficult that once you’ve solved it you can solve anything else.
Not only faster. For example neural net may go from being unable to distinguish cats from dogs to one able to distinguish them. Or get better at distinguishing them.
Or go from playing poorly at Go to winning with human experts.
But anyway this comment seems to not mention anything that would provide support for “The FOOM scenario while not being completely crazy, soon runs into physical limits as well as mathematical ones.”
This would be relevant physical limit only if AI requires computation that is unavailable due to physical limits.
And the most scary FOOM variant would happen in case that already commonly available computing resources are sufficient for running software smarter than us.
Well, it made sense to whoever coined the term in the 16th century, and to the billions of people who have comfortably used it since.
An intelligent computer that can design a better version of itself. You are correct that this doesn’t currently exist; once it does exist we (almost definitionally) now have a super-human intelligence and it’s too late to worry about its safety. But at least some people are trying to figure out how one could possibly be built, and though extremely difficult it doesn’t seem physically impossible.
What mechanisms do you think a computer would use to improve itself that are not already available to humans?
(And before you say, run lots of copies of itself, humans have done that quite effectively already)
@Loriot
Design and build better software and/or hardware to accomplish its goals. AFAIK, we cannot rewire our neurons, nor edit out our cognitive biases.
Some obvious ones:
1) run lots of copies of itself (significantly more copies than number of humans that ever lived)
2) run copies at much faster rate than available for humans
3) use different structure for brain-equivalent, making self-improvement more feasible
4) use different structure for brain-equivalent, allowing to operate on larger scale
5) optimize for different things that were optimized by evolution and human culture
Isn’t the assumption that the AI already starts at above human intelligence? How would it even begin improving itself if it starts at rat level?
Anyway, arbitrarily large algorithmic self improvement is mathematically impossible, much like you can’t compress arbitrary data into a smaller size.
Computational hardness results apply to any process that resembles a Turing machine. If a proof says you can’t do X quickly, that is true regardless of what algorithm you use, even if that algorithm is “build an AI and tell it to invent a better algorithm”.
To the extent that boosting one of your stat scores makes you better at difficult problems, then boosting that stat score is even more difficult. The laws of mathematics can’t be bluffed just by pointing in a different direction.
Remember one person’s modus ponens is another’s modus tolens? That happens all over the field of computational complexity. If you say problem A is hard, but we could solve it if we could solve problem B, the reaction isn’t “great, that’s progress towards A”, it’s “well I guess B must be hopeless then as well”.
1)
It may be as smart as rat but be very good at self improvement. For example lets say that we simulate literal rat, but with simulation done in a very effective way.
Somehow simulation of relevant environment and brain is so efficient and effective[1], that simulated evolution is millions/billions times faster than a biological one. With at least some simulated organisms getting smarter generation by generation.
[1] For example, somebody managed to discover simple representation of brain structure that captures relevant functions
2) Or maybe it is as smart as rat but really good at effective deliberate self-improvement.
——–
Why first follows from the second?
——–
I am pretty sure that there is no proof that self-improving AI is possible/impossible.
Even if that’s the assumption, note that the AI will be the result of many human intelligences with different competencies working in parallel for the better part of a century. So an AI with only moderately superhuman intelligence, even if it works a thousand times faster than a human, will probably not be able to design a significantly better version of itself any time soon. Also, it’s not going to be a thousand times faster and may well be slower than a baseline human, at least for the first generation or two.
However, if we use human intelligence as a guide, it seems very likely that quite a few of these not-terribly-superhuman AIs will naively and optimistically believe they can bootstrap their way to demigodhood and conquer or subvert the human world in nothing flat. This should give us plenty of experience putting the smackdown on would-be paperclippers at easy to moderate difficulty levels before we are faced with the really hard cases.
@Scott Alexander
I don’t understand why you would use “climate change” as one of your three examples of things that “literally never happened before” in the same essay where you claim that “global temperatures jumped 5 degree C (to 14 degrees above current levels)” . Does the absence of runaway warming mean this does not count as “climate change”? I waited a while to post this complaint, thinking this sentence might get edited out after you reread, but since it’s still there I presume it makes sense to you as it is. Could you explain?
There’s an implicit (in human history).
SSC: “Also, global temperatures jumped 5 degree C (to 14 degrees above current levels) fifty million years ago, and this didn’t seem to cause Venus-style runaway warming. This isn’t a perfect analogy for the current situation, since the current temperature increase is happening faster than the ancient one did, but it’s still a reason for hope.”
During the last ice age (the last 80.000 years) global temperatures oscillated wildly and often quickly: “One of the most surprising findings was that the shifts from cold stadials to the warm interstadial intervals occurred in a matter of decades, with air temperatures over Greenland rapidly warming 8 to 15°C.” (where stadials are periods of colder climate while interstadials are periods of warmer climate.)
There is an inductive step here from “fluctuations of air temperature over Greenland” to “fluctuations of global air temperature”. However, the article states that such fluctuations “have now been found in many other climate proxy records around the globe.”
See here.
How would the Cuban Missile Crisis have resulted in humanity’s extinction? If it’d come to nuclear war, Russia was woefully unprepared while the US were poised to deliver an incredibly destructive alpha strike. The likely result would have been near sterilization of a large part of Eurasia with possibly a few US cities hit by Russian retaliation. This would not even have ended civilization, let alone the human species.
Would not the capability for (relatively easy) asteroid redirection also allow humanity to detect and deflect any terror-rocks long before they come anywhere near anything important?
A one in ten chance of automated pattern recognition algorithms miraculously becoming self-aware, malevolent and all-powerful *in the next hundred years*? Seriously?
The review makes Precipice sound like it’s based on facts straight from pop culture. I don’t doubt the author’s reasoning ability, but GIGO.
Well, that’s the thing about time and infinity. Given enough time, anything that can happen, will. This is true at the individual level — even if every cause of death through disease or frailty were eliminated, human average lifespan would only rise to about 4000 years (based on current numbers, if I remember correctly), since accidents would get us all, sooner or later. 4000 years is a long time, but it’s well short of the immortality of science fiction.
Same thing at the species level. The average lifespan of natural species is about 1 million years. And those are species which don’t do anything to kill themselves, they’re just victims, sooner or later, of an environmental accident. 1 million years may seem like a long time, by human standards, but it’s an eyeblink in geological terms, the Earth hardly notices it.
Human beings could work incredibly hard, but no matter what, in infinite time sooner or later something strange will snuff us out. And then there will be an infinity of time during which we do not exist. However you look at it, from the individual or species point of view, existence in infinite time is by definition an infinitismal event. Which is difficult to understand or accept, from a human point of view.
Of course, time may not be infinite, but that is even harder to understand.
All of his x-risk comes from the most uncertain variables.
This means his conclusions are worthless.
It doesn’t matter how well you calculate out the minor stuff when you have dominating variables which you assign extremely high values to.
The risk of AI is 0. AI just doesn’t work the way that the people who are scamming people out of money over “x-risk” from AI need it to work. And yes, it is a scam. This upsets people who have been drawn in, but it is an obvious con-job from the point of view of an outsider who knows how AIs actually work; the entire idea is complete nonsense and it treats AIs like genies instead of like cars, when in fact, they are much more like cars.
Likewise, the engineered pandemics issue is questionable. We presently lack the technology to make a super deadly universal virus, and it’s not clear that that is a trivial thing to do. I’d be more worried about this than all other “x-risks” combined, and yet, at present, this seems very, very hard.
All of his x-risk comes from unknown stuff. All of the known x-risks are extremely low, which means that the most unknown things having the highest x-risks means his conclusions about x-risks in an absolute sense are wrong and are based entirely on what he wants to be true.
Oh, and FYI: the bats thing isn’t prescient, it’s been known for decades. We talked about this when I went to college in the mid 2000s. SARS was from bats, and they knew that there were a bunch of coronaviruses in bats that were potentially problematic because of SARS if they somehow jumped the species barrier. Likewise, they’re carriers of lots of other diseases, and it’s very hard to control bats as they fly, and they’re very good at giving each other diseases because they all hang out together in close proximity.
I am sceptical that there is any real risk from AI of the kind Ord is worried about. But for it to be a ‘scam’, it would have to be a deliberate deception to make money. Who are you accusing of *deliberate* deception exactly? And what’s your evidence? I knew some of the Effective Altruism folk at Oxford a little, when I was a philosophy grad student there (I’m talking about people involved in founding/running orgs, not just donating) and some of them were giving 50% of their income away. Hardly the kind of thing you’d expect for people who were deliberately defrauding others.
My *guess* is you mean Yudkowsky, but it’s worth saying that Bostrom has been worried about x-risk, including from AI, since forever, and was much more influential on the EA orgs early on (remember EA is an Oxford philosophy grad student thing that LessWrongers jumped onto a little later.)
Yudkowsky, yes. Anyone who is accepting “donations” to deal with x-risk from AI is pretty much engaging in a scam.
Also, scams aren’t always directly about making money to solve a fake problem. Part of the AI scam is actually convincing people that AI is something that it is not – namely, intelligent.
The problem is that “AI” really probably should be called “automated programming”, as that’s what it actually is. Google takes information off the web and then creates a complicated algorithm to give you the results you want. It would be excessively tedious for humans to do this for all possible search terms, so Google does it constantly and automatically.
This works pretty well because Google is directly using what humans do in its processes, and because if Google gives a wrong result, it’s usually fairly obvious (though it can be dangerous for certain subjects, as if you search for the “wrong” keywords you might find a bunch of conspiracy theory articles rather than actual subject articles).
On the other hand, we also have image recognition software. The problem is, we don’t really understand how to program a computer to “see” things very well, so what we do instead is feed a very large number of “training images” into a program so that it creates a complex algorithm to allow it to “recognize” images.
This seems to work really well, until you start looking at adversarial attacks, where making minute changes to images causes the algorithm to output wildly incorrect results with extremely high levels of confidence. This is because these algorithms aren’t truly seeing the objects at all, they’re instead creating a complex algorithm which can be defeated by minute changes to the image that often are inperceptible to humans.
While this might not seem like a big deal, what it reveals is that these programs are not “intelligent” at all – they aren’t aware that something is “wrong”, as is the case with a human and an optical illusion. Indeed, they are entirely lacking in anything resembling intelligence. What they are is tools.
And this is a problem for people who are trying to sell these things for some purposes. For example, if people were aware that self-driving cars are not, in fact, intelligent at all, they’d be far more wary of them. The fatal accident involving a pedestrian is a good example of this – the vehicle was constantly misidentifying things, and threw stuff out without braking because if it did start braking every time it misidentified something, it wouldn’t really be able to drive in a city at all as it would constantly be jamming on the brakes.
If you sell people on the idea that AIs can actually be intelligent, while they might be vaguely worried about them, you also sell them on the idea that they can be smart at all.
It also allows you to scam people into believing that AI work should be regulated, which aids incumbents via regulatory capture, as you can deal with the expenses you’re imposing on other people while new competition is shut out.
Some of these people also convince themselves of this idea, because otherwise, they’d have to come to terms with the fact that what they’re working on isn’t actually what they’re selling. This is why some snake oil salesmen drink their own kool-aid – it makes them more effective at selling the scam product.
If they believe that it is real problem then it is not a scam.
To become scam it requires people collecting money for AI x-risk to not believe in AI x-risk.
Also, I wouldn’t be confident the known risk from nuclear war, plus failing to make it back to current levels of civilization after is *low*. Ord thinks it is, but there seems to be a wide range of opinions on this amongst experts.
I’m recalling your image of “Goofus vs Gallant” from your other post in regards to considering weirder emerging catastrophic threats (like Ian Cheng kinda weird, in his Emissaries simulations trilogy). For example, whether an event with significant emerging self-organizing Order demands balance through entropy (giving rise to a counterpart, something spontaneous, like a virus, on the other side of the world). The mechanism is highly non-causal (like a butterfly effect, or “Magical Thinking,” says the goofus), but if there’s significant suspicion into some weird underlying dynamic in the instability, then we’d do well to listen to the Gallant. This feels in line with goat rodeos at high VUCA levels.
had some other thoughts as well:
– I’m curious as to why you chose April 1st for this post
– a more left-field thought that I wanted to share wrt your Samsara post on the Order of the Golden Lotus: sounds like slime mold validates loners. We are mold people now. lol
https://phys.org/news/2020-03-evolution-loners-behaviorat-slime-molds.html?
From the AI discussion, it is worth considering if AI should be considered our offspring through a different means (probably it would be an accidental offspring mutating from algorithms written for other purposes, but that does account for a good portion of offspring). From that perspective, AI would be an immense boost in the longevity of the human legacy since they are not vunerable to many of the dangers that would affect humanity (even if they might be more vunerable to things humanity might survive, like the destruction of every large power source, moreover even if AI did get wiped out, if humanity did not, AI could be reconstructed, and theoretically if humanity got wiped out AI could reconstruct us). As others have pointed out, our far future children would likely at some point evolve away from the strict definition of the human species, so looking at AI as our children doesn’t seem that much of a stretch.
From this perspective, we ought to be rushing toward AI.
Even without this perspective, I find the idea AI would wipe us out unlikely (although the more people that repeat that meme, the more AI might consider us as a potentially existential threat, and the more likely it might wipe us out). Our experience with AI so far is that while they can do many tasks we thought only humans could master, like chess or Go, etc. they do so in a different way than humans, even if their root algorithms might be based on expert approaches. Even if our way of going about things is different, if we offer a fundamentally different perspective on things, it would be obscenely wasteful to eliminate us. Our experience with animals is also instructive, although we have wiped out a wide number of species, species that are tame-able or that can be maintained within limited areas, we typically go out of our way to try to maintain those species. Unlike the human-animal relationship, humans and computers do not directly compete for space and food (or at least we have limited competition for space, and I admit that could change), and barring some really surprising shifts in technological trends, computers do not eat meat. It’s hard to imagine that AI would really eliminate us, unless it was clear that there was an us or them scenario with no good alternative.
I would be interested in someone thinking through the necessary steps to get to that stage, but I’m not sure that level of speculation and hypotheticals would actually be useful (it would be nice if someone had a rule of at this level of what if’s you are going beyond theoretical futures and into all out fantasy (not that I mind fantasy, but we ought to distinguish between the two), maybe if you compared the number of hypotheticals to how many hypotheticals would be necessary for a secret magic world to be florishing without anyone noticing).
But if we do regard AI as an eventual possible threat, I think it would be probably best to publicize the position that yes we can co-exist with our AI overlords, and no it won’t be that bad. At least from an x-event perspective. Because if it does come down to a matter of trying to make rules to prevent dangerous AIs, I think someone is going to break those rules sooner or later, even if the rules are there after we had a contest with AI and won. So that would mean periodically re-occurring conflicts with AI, which in the infinity of time we probably would at least one time lose. Of course, then in the infinity time, perhaps due to a miscalculation or incorrect flip of some bits or some accidental discharge having some unexpected reactions, maybe AI might trigger the recreation of humanity. And at this point I am pretty sure I have hit that limit between hypothetical futures and speculative fantasy.