
Almost 25 years after Kasparov vs. Deep Blue, another seminal man vs. machine matchup:
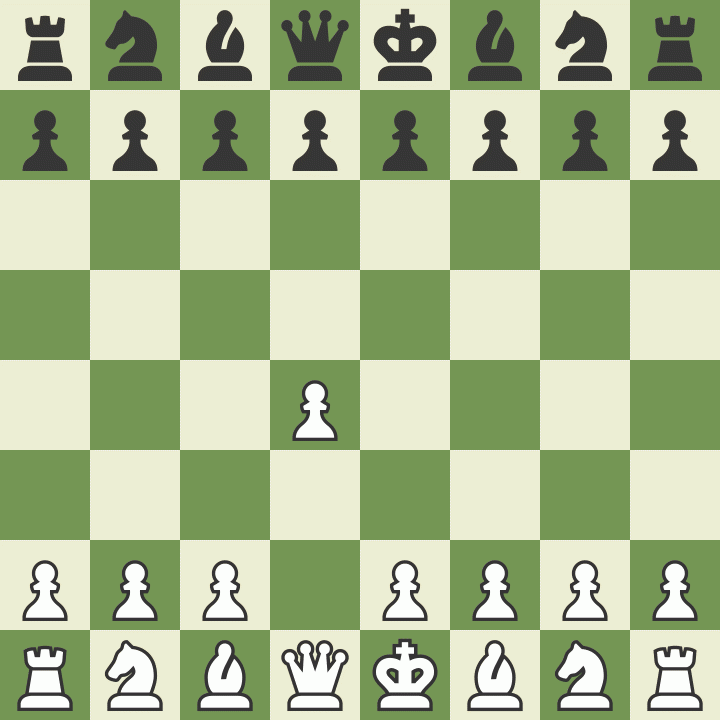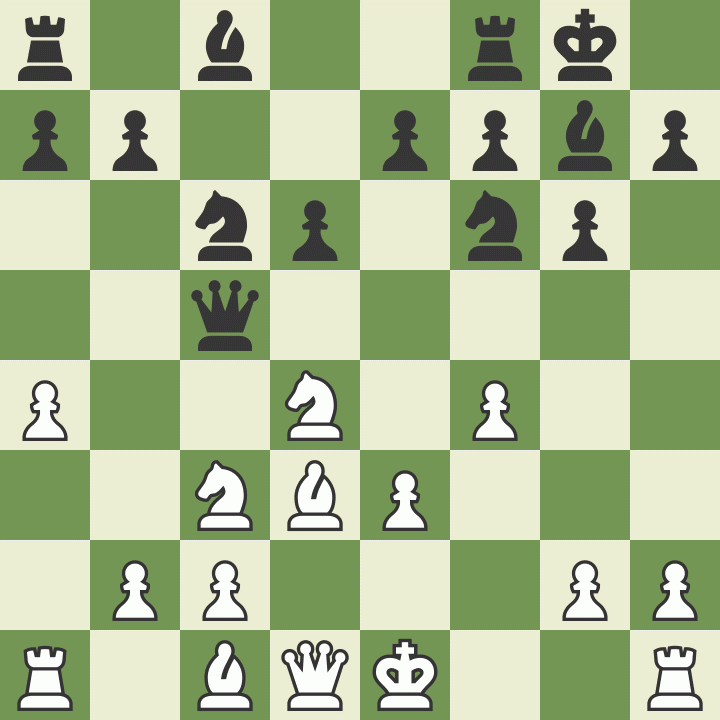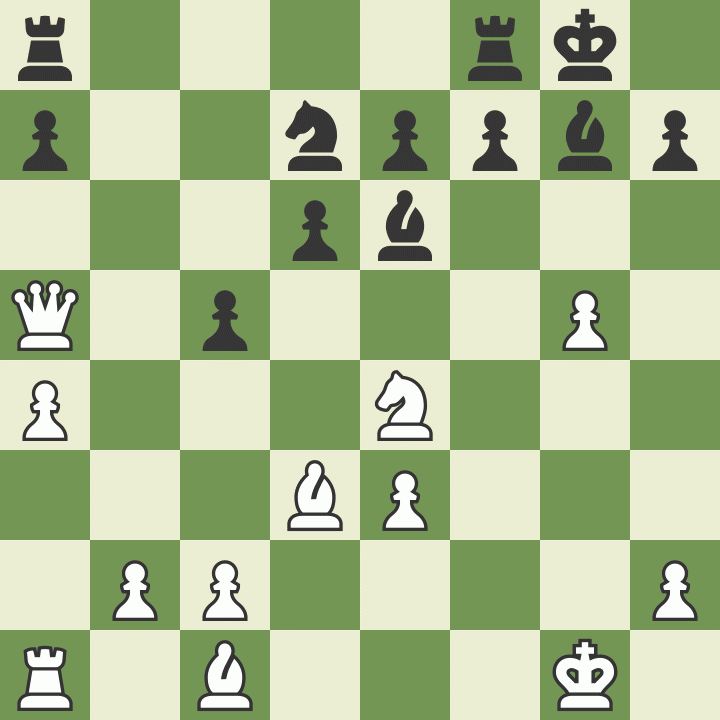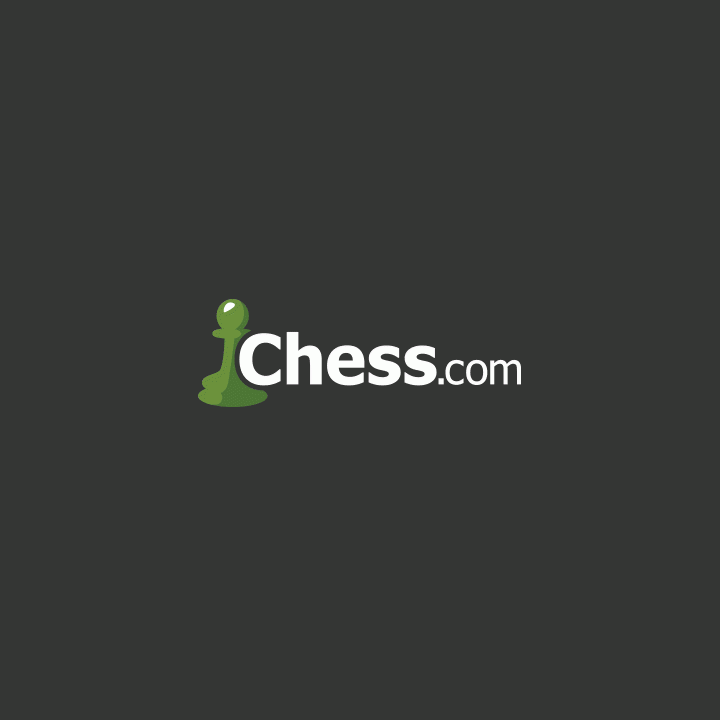
Neither competitor has much to be proud of here. White has a poor opening. Black screws up and loses his queen for no reason. A few moves later, white screws up and loses his rook for no reason. Better players will no doubt spot other humiliating mistakes. But white does eventually eke out a victory. And black does hold his own through most of the game.
White is me. My excuse is that I only play chess once every couple of years, plus I’m entering moves on an ASCII board I can barely read.
Black is GPT-2. Its excuse is that it’s a text prediction program with no concept of chess. As far as it knows, it’s trying to predict short alphanumeric strings like “e2e4” or “Nb7”. Nobody told it this represents a board game. It doesn’t even have a concept of 2D space that it could use to understand such a claim. But it still captured my rook! Embarrassing!
Backing up: last year, I wrote GPT-2 As Step Toward General Intelligence, where I argued that the program wasn’t just an essay generator, it was also kind a general pattern-recognition program with text-based input and output channels. Figure out how to reduce a problem to text, and you can make it do all kinds of unexpected things.
Friend-of-the-blog Gwern Branwen has been testing the limits of this idea. First he taught GPT-2 to write poetry. Some of it was pretty good:
Fair is the Lake, and bright the wood,
With many a flower-full glamour hung:
Fair are the banks; and soft the flood
With golden laughter of our tongue.
For his next trick, he found a corpus of music in “ABC notation”, a way of representing musical scores as text. He fed it to GPT-2 and got it to write folk songs for him. I’m a fan:
Last month, I asked him if he thought GPT-2 could play chess. I wondered if he could train it on a corpus of chess games written in standard notation (where, for example, e2e4 means “move the pawn at square e2 to square e4”). There are literally millions of games written up like this. GPT-2 would learn to predict the next string of text, which would correspond to the next move in the chess game. Then you would prompt it with a chessboard up to a certain point, and it would predict how the chess masters who had produced its training data would continue the game – ie make its next move using the same heuristics they would.
Gwern handed the idea to his collaborator Shawn Presser, who had a working GPT-2 chess engine running within a week:
GPT-2 chess is promising. After an hour of training, 1.5B is pretty good at opening theory.
Longer sequences tend to fail due to invalid moves, but this shows it's possible in principle to make a GPT-2 chess engine.
And maybe after more training it'll make fewer invalid moves. pic.twitter.com/DqC4WiPfHV
— Shawn Presser (@theshawwn) January 1, 2020
I'll post some games, up to the point it generates an invalid move (which seems to happen around move 11).
Paste this into https://t.co/wWGpVu9ko6
1.e4 c5 2.Nf3 e6 3.d4 cxd4 4.Nxd4 a6 5.Bd3 Nf6 6.Nc3 d6 7.O-O Be7 8.f4 O-O 9.Kh1 Nbd7 pic.twitter.com/8Bl2ijZiCZ
— Shawn Presser (@theshawwn) January 1, 2020
After a day of training (2.4M examples), GPT-2 1.5B can reach move 14 with no invalid moves.
1.e4 e5 2.Nf3 d6 3.d4 exd4 4.Qxd4 a6 5.Be2 Nf6 6.O-O Be7 7.Re1 O-O 8.c3 b5 9.a4 Bb7 10.axb5 axb5 11.Nbd2 Re8 12.h3 g6 13.Ra5 Qd7 14.Ng5 c5 pic.twitter.com/2XuH6iLaD5
— Shawn Presser (@theshawwn) January 2, 2020
It can reach midgame by removing invalid moves.
1.e4 c5 2.Nf3 d6 3.Bb5+ Nd7 4.O-O a6 5.Be2 b6 6.a4 e6 7.d4 Be7 8.c3 9.Nbd2 Ne5 10.Nxe5 dxe5 11.12.13.f4 Bb7 14.Bd3 g6 15.Nf3 16.17.Re1 18.Qe2 Bf8 19.Bd2 20.Qf2 Qxd4 21.22.23.Rf1 Qxc3 24.Qxc5 Bd6 25.Qc7 26.Qd8+ 27.Qd6 Rd8 pic.twitter.com/3uyPaP9LHt
— Shawn Presser (@theshawwn) January 2, 2020
GPT2 Chess update: I wrote some code to calculate the probability of all valid chess moves. It can reach endgame now. https://t.co/QQzhZJmgQ9
It starts to blunder every game at around move 13. We suspect it’s losing track of board state. (It’s trained solely on PGN notation.)
— Shawn Presser (@theshawwn) January 4, 2020
I am preparing to release a notebook where you can play chess vs GPT-2. If anyone wants to help beta test it:
1. visit https://t.co/CpWrFvtnY2
2. open in playground mode
3. click Runtime -> Run All
4. Scroll to the bottommost cell and wait 6 minutesIf you get stuck, tell me.
— Shawn Presser (@theshawwn) January 6, 2020
You can play against GPT-2 yourself by following the directions in the last tweet, though it won’t be much of a challenge for anyone better than I am.
This training explains the program’s strengths (good at openings) and weaknesses (bad when play deviates from its expectations). For example, ggreer analyzes why GPT-2 lost its queen in the game above. By coincidence, my amateurish flailing resembled a standard opening called the Indian Game. GPT-2 noticed the pattern and played a standard response to it. But the resemblance wasn’t perfect, so one of GPT-2’s moves which would have worked well in a real Indian Game brought its queen where I could easily capture it. I don’t want to conjecture on how far “mere pattern-matching” can take you – but you will at least need to be a better pattern-matcher than this to get very far.
But this is just what a friend of a friend managed to accomplish in a few days of work. Gwern stresses that there are easy ways to make it much better:
Obviously, training on just moves with the implicit game state having to be built up from scratch from the history every time is very difficult – even MuZero at least gets to see the entire game state at every move when it’s trying to predict legal & good next moves, and depends heavily on having a recurrent state summarizing the game state. Maybe rewriting games to provide (state,action) pairs will make GPT-2 work much better.
What does this imply? I’m not sure (and maybe it will imply more if someone manages to make it actually good). It was already weird to see something with no auditory qualia learn passable poetic meter. It’s even weirder to see something with no concept of space learn to play chess. Is any of this meaningful? How impressed should we be that the same AI can write poems, compose music, and play chess, without having been designed for any of those tasks? I still don’t know.
















Wowzer schnauzer. I’m not particularly into chess, but thank you very much, Scott, for pointing me to Gwern’s work on GPT-2 poetry generation.
I’ve been involved in poetry and interactive-fiction for a while now. Seeing active, compelling exploration in AI-based* generation of both those media — even when it gets incoherent / can’t maintain state across long distances — is as stimulating as a hefty splurt of the Cuban-cigar-ash fertilizer Ludovico bought me for Christmas.
* Deliberately non-specific term: I’m a layplant on “deep learning” and such.
Interactive fiction, huh? Try AI Dungeon. There’s an app.
I tried it out. It is interesting, but it cannot keep a coherent dialogue for more than several lines. And it sometimes tries to control my character, which goes against the usual rules of GM-driven text adventures.
I vastly prefer that it remain “broken” in this way, so I can force it to do weird and interesting things it’s not supposed to do. If it was just a MUD simulator, that would get boring in about an hour.
But what if instead of being a MUD simulator, GPT-2 was used as a MUD content generator?
A couple months ago, I used Gwern’s poetry notes as a guideline to fine-tune GPT-2-124M on a corpus of MUD room descriptions, generating a few thousand novel machine-written rooms. With my collaborator Benamas, we filtered and arranged this content into a 100-room MUD area, with all of the actual writing done by GPT-2. We have a small reddit thread on the project here.
The next stage, which is mostly complete, is to combine GPT-2’s writing (scaling up to GPT-2-355M) with other code that filters and arranges the output without our intervention. In this manner, we want to use GPT-2 to autonomously write arbitrary amounts of high-quality MUD content.
Procedural generation is nothing new for games, but something feels special about procedural authorship.
Shawn was nice enough to play me on Lichess using GPT-2. I checkmated it in 29 moves: https://lichess.org/BKyeH9ts#57
I probably could have ended it sooner, but I played as if I was up against a human opponent. I was not about to try any tricks. I just played nice solid chess and tried not to blunder.
In the next match(https://lichess.org/IHIcBPs4/black#22) I played black. I was worse (but not losing), then Shawn’s TPU instance was pre-empted. By then it was 1:30AM and I wanted to sleep. I offered a draw and he accepted.
I really want to try the bongcloud opening against it (https://www.chess.com/forum/view/chess-openings/bongcloud-opening). I think if you got it out of the common openings, it would quickly be obliterated.
Gwern suggested I did better than I expected against it because I’m so bad that I accidentally made moves outside what it was trained for.
That makes sense to me. I think GPT-2 stays competitive by memorizing common (AKA strong) lines.
Do you have the PGN for your game? That would make it easy to import and analyze with an engine. A gif is great for humans, but it’s not easily turned back into something machine readable.
1. d4 Nf6 2. e3 g6 3. Nc3 Bg7 4. f4 d6 5. Nf3 O-O 6. a4 c5 7. dxc5 Qa5 8. Bd3
Qxc5 9. Nd4 Nc6 10. Nxc6 bxc6 11. O-O Bg4 12. Qe1 Nd7 13. Ne4 Qa5 14. Qxa5 c5
15. f5 gxf5 16. Rxf5 Bxf5 17. g4 Be6 18. g5 Ne5 19. Bb5 Rab8 20. Qxa7 Rxb5 21.
axb5 c4 22. Qxe7 Rb8 23. Nxd6 Rxb5 24. Ra8+ Rb8 25. Rxb8+ Bf8 26. Qxf8# 1-0
Thanks. Here’s the game in Lichess with an engine analysis: https://lichess.org/sTuSsGYB
Both sides made mistakes early on, but the game was close until black (GPT-2) blundered a queen. Qa5 is frequently check on the white king, but earlier in the game you moved your queen to e1. Oops. Sorry GPT-2, pattern matching can’t always substitute for knowledge. That said, it’s often surprisingly effective.
Oh, interesting, that helps things make more sense.
The reason why move 3. Nc3 is a mistake is that pawns are the “soul of chess.” The pawn structure will dictate where pieces should be placed and what your strategic goals are in the middle game.
2. e3 is a bit passive but probably ok outside of the highest levels (e.g., you probably wouldn’t ever see it in a world championship match but masters could still play it to try and get opponent in a side line they won’t be as familiar with). But once you’ve played 2.e3, the pawn structure is just screaming “push your c-pawn.” The e and d pawns are forming a line pointing towards the queen side and so, strategically, you want to grab more space and play on that side of the board. In basically every line you’re going to want your c-pawn pushed to c4 (or maybe c3 in a few edge situations).
Putting your knight on c3 delays your own strategic plan because now you’ve blocked the c-pawn with your own knight. Probably, you’re going to want to do to the c-file what you did with the f-file. Push the pawn to c4 first then put the knight behind it.
With the knight on c3 and if black played well, before too long you’re going to have finished developing your pieces and then not know what to do or what your plan should be. A lot of good amateurs get to the point where they’re not really blundering pieces anymore, and they know to develop their pieces and control the center, but will get lost and not know what to do after that and it makes chess less fun. Learning about pawn structures is what gets you up to the next level as after that you’ll rarely be stuck not knowing what your strategic plan should be in any given opening.
It’s not even trying to be competitive, it’s just guessing how the game will continue. If you blunder, it might guess that this must be a game between two blundering fools, and play accordingly.
I wonder if it would do better if you told it to, as white, only learn from ‘white wins’ games, and vice-versa.
That’s a great point! Thanks for pointing that out, because I had been thinking of this more as “it’s trying to win,” and that’s not the right way to think about it.
An interesting point but I’m not sure of its relevance. How would you tell the two apart? I assume the corpus of games it is trained on are games where both sides were trying to win.
Doubtful, probably many of them involved people playing to draw.
Doctor Mist: The difference is that an algorithm that is trying to win (and that has some means to improve), will improve and get better at winning (e.g. AlphaZero).
GPT-2 will always play like the player data it was trained on. It will not get better at winning.
In FPS games like Apex Legends shitty players are sometimes scarier than good players because they try weird stuff you’re not expecting.
It’s kinda funny, I was thinking last night about how negamax, which as far as I know is still basically the algorithm the best chess engines use*, can’t think to offer you a mistake and hope you’ll take it. It always assumes you’ll make the move it would have and doesn’t even take what will happen if you take a different move in to account.
Basically,
1. Create a tree, where the nodes (circles) are boards and the edges (lines) are moves. The root is the current board, and edges come out of it representing every valid move, connecting it to the board that would be produced if whoever’s turn it was took that move. Same goes for every node in the graph; each one is connected by the possible moves to the result of each possible move.
2. For each board in the tree, bottom to top***, assign the board a goodness-for-me value:
2a. If the node is a leaf, a node with no outgoing connections, which in this case would be a board where the game is won**, assign it a goodness-for-me value by applying your evaluation function, i.e. -1 if opponent won, 1 if I won.
2b. Otherwise, it’s goodness value is either the maximum or minimum of the values of the nodes it connects to:
2ba. If it’s my turn in the board we’re considering, a board’s goodness value is the largest goodness value of the boards immediately below it – the move leading to the most good successor board is the move I will take if the game ends up going to that particular board configuration.
2bb. If it’s my OPPONENT’s turn in the board we’re considering, a board’s goodness value is the SMALLEST goodness value of the boards after it, because I assume my opponent will always take the move that is WORST for me (and therefore best for him, since this is a zero-sum game.) Other possibilities than the worst don’t enter the calculation at all.
3. When actually playing the game, consult this tree and always take the edge (move) leading to the highest goodness-for-me node (board.)
* With a TON of little tricks and optimizations on top of it so you never explore board states that don’t contain useful information – the “evaluation function” hides all the complexity, negamax is really just a way to translate all the work of determining which boards are advantageous in to actual wins.
** I lied. In Tic-Tac-Toe, maybe, but in chess you can’t create the whole tree, the leaf nodes would just be where you ran out of time and stopped.
*** The leaves are at the bottom of the tree, and the root at the top, just like with real trees.
However, I suspect you could add “maybe my opponent is dumb” functionality by modifying step 2bb to add (sum of non-worst successor values) * 0.01 to the evaluation value, so if it’s looking at two basically equivalent possibilities, it will take the one that gives the best result if the opponent plays non-optimally. Will have to try that out tonight.
As someone who follows board game AI relatively closely (I maintain the only extant engine for the hnefatafl family of games: https://git.io/Jvekf), I can share that tree search is no longer the top of the pile for chess engines—DeepMind’s AlphaZero conclusively defeated Stockfish 9 toward the middle of last year.
I think your point still holds for this new breed of AI, too, though—the nature of the question “what is a generally-optimal way to play?” doesn’t admit much room for playing to specific oppponents’ flaws.
@Fishbreath
AlphaZero still searches trees, no?
AlphaZero relies on Monte Carlo tree search:
That’s correct—I suppose I should have said that minimax-descended tree searches no longer rule the roost.
e: I seem to recall, in one of the original AlphaGo papers, a note that it played quite well without using the tree search at all, picking moves based solely on the move ordering neural network.
It was said by actual expert duelists that it was safer to duel someone with a little training than someone completely without. The one with a little training is predictable – the one with none might do anything!
From “Murphy Laws of Warfare”:
“Professional soldiers are predictable; the world is full of dangerous amateurs.”
This is also true in BJJ. White belts often make completely wrong moves that aren’t supposed to work. Except sometimes they do work. When you have trained yourself for a set of expected reactions, an unexpected reaction catches you by surprise and stalls your brain for a few milliseconds. Sometimes that is enough. Then it’s really hard to explain to someone that what they did was wrong.
I think this is a general weakness of deep learning systems – they depend heavily on data being from the expected distribution it was trained for. I recently saw the AlphaGo movie, and while there is much antrophomorphizing about how the system “lost it” after an unexpected move by Lee Sedol, my interpretation is that the game state simply entered into territory which AlphaGo hadn’t explored much.
Dystopian future in which only massive weirdoes are able to overthrow our machine overlords, anyone?
Makes for an interesting twist on the “robots are coldly rational, they can’t understand the power of human emotion” trope – a story where dealing with human emotion takes them off the training distribution!
Seeing what people say about fencers and martial artists as well, it sounds like being crazy like a fox (mumble mumble 4d chess?) is a useful skill to cultivate, even against humans.
This is true of Humans too. Ask any experienced Martial Artist if they want to spar with someone with a year of training or none.
Naively you would think a year of training would make you harder to fight, but the new guy is more likely to do something wired that you won’t have a practiced reaction to.
I feel like this is in some sense true but also overstated. Untrained fighters are not random, they just behave very differently than people with a little training so if you expect them to behave like a trainee, you are going to have a bad time.
If you hand a sword to a random novice, they are probably going to use it (badly) like most every other novice. The danger in a fight would, I suppose, be that they are much more likely to unknowingly do something suicidal for themselves but hard to defend against.
I take issue with the idea of an “experienced” martial artist who has never sparred with beginners or new trainees. I wouldn’t call that person experienced.
Irrespective of that example, I think the principle that lunawarrior is describing is “an intelligence deals poorly with things that are dissimilar from its training data.” Which is true for AI and for humans. (Though you should keep in mind that “dissimilar” means “dissimilar according to the feature representation that the intelligence is using.”)
I haven’t done much martial arts aside from a little bit of BJJ, but I wrestled for six years in grade school. In both, people with no training got rocked because they simply didn’t have the reflexes to react to anything. Maybe they’d do something weird if I gave them the chance, but I didn’t give them the chance because I was trained to shoot on their legs as quickly as possible. Aggression requires technique to respond properly, and untrained people simply don’t have it.
In highly stylized sports like fencing, this is a big effect. I’m a fairly experienced but hopeless fencer and newbies are a big problem. They hold the foil wrong, they have wrong footwork, they do all kind of weird things with the blade. It screws me up because I have the muscle memory for fencing not flailing-around-with-a-sword.
I imagine if we actually practiced swordfighting with killing in mind we’d blitz a newbie.
@Auric I think the idea is that you beat a person with little experience 100 out of 100 times, and a person with almost no experience (but good reflexes) 95 out of 100. The times you lose are the times where they do something so flagrantly suicidal and unlikely to work that you just don’t expect it or fail to recognize it in time. Meanwhile the trainees are executing moves you expect, and poorly to boot.
Ketil: Yes, but the point of learning a useful feature representation is that you don’t have to explore every game state.
AlphaGo arguably has a better feature representation of Go than any human, because AlphaGo usually wins. But it’s not perfect. I guess there was something about the association between game state (X input) and win probability (Y output) in the game branch that Sedol forced the game into that was different from what AlphaGo had learned on. But, to make a better AlphaGo you wouldn’t need to train on those game states specifically; you’d need to train on [some number of] game states that have a relationship between X and Y that is similar to that one.
The problem is not just distributional shift, but the combination of that and Monte-Carlo tree search. Go programs can fail unexpectedly against “sharp” moves where one long sequence yields a good result for the human, but any other sequence leads to the program winning, the paradigm case being “ladders”. This is because the tree search effectively models the opponent as having some probability of making a mistake at each move, whereas humans model the whole sequence as a single chunk — either you start the sequence and play it to the end, or you don’t start the sequence. I think this is the core problem with applying AlphaZero to math or programming, where one needs long chains of deductive reasoning.
Also, AlphaGo played really poorly for the rest of the game after that move, which I think is also due to the Monte-Carlo tree search. A human player would try to keep the game close to even and wait for their opponent to make a mistake, but AlphaGo saw all moves leading to a small loss and so played semi-randomly.
So it’s succumb the apocryphal, “The best swordsman fears not the #2 swordsman but the man who doesn’t know what he’s doing”?
GPT2’s inexplicable competence at something it’s never been trained to do is somewhat reminiscent of the new GPT2 dril imitator, which–at least to my mind–does dril tweets better than dril does.
https://twitter.com/dril_gpt2/status/1212044175270694912
> GPT2’s inexplicable competence at something it’s never been trained to do
But it has been trained to play chess, from more games than you will ever see. It has been trained to do language with more sentences than anyone could ever read, and it has been trained to do dril tweets with all dril tweets.
It’s good at learning, it doesn’t invent new competences from scratch.
The wording “trained to do” was badly chosen, but the underlying sentiment is solid. GPT2 doesn’t invent new competences from scratch in the sense that it can do things that it doesn’t have a lot of data for, but it does invent new competences in the sense that it can do things it was never designed to do in the first place.
The second is still pretty surprising – language models aren’t supposed to be able to play chess. Or compose songs. GPT2 is good at learning significantly more things that was ever intended.
I think perhaps what is being overlooked is that humans are very good at transposing things into the form of a consistent language. From that standpoint, anything that can mimic language can mimic the sequence of actions it describes. If one looks at English (or any other written language) as a coded system used to describe and transmit the entire range of human experience, then a system that can accurately generate that code should easily be able to generate the much more limited information coded in a chess game.
This is incredible.
The GPT2 dril imitator says the items are “human-curated”, which leaves open the question of how much dross the human had to wade through to get the gems. From what I’ve seen in passing on SSC, the answer might be “not much at all” but I can never tell.
I’m having an interesting experience at the moment, proofreading a novel. To keep myself from falling into a flow state, I randomized the sentences, which means every so often I get a sequence of unrelated sentences that really seem to make a kind of sense, like:
Check out https://nostalgebraist-autoresponder.tumblr.com/, which isn’t human-curated and posts entirely automatically.
It’s cool that GPT2 is able to do this despite being created for quite a different purpose. What it’s doing seems to be similar to one component of the original Alpha Go, which was trained on professional Go games to predict the most likely next move.
But it isn’t able to do this. Lacking a model of the game, it keeps trying to make invalid moves. (I assume an invalid move involves moving a piece from a square that doesn’t contain that piece, or capturing a square that doesn’t contain an enemy piece, or moving onto a square that contains a piece, or the like.) If you’re teaching a six-year-old to play chess, and their signature move is that they keep capturing your rook — safe behind its pawns — with the bishop you captured from them several turns ago… you would not describe them as “able to play chess”.
On the other hand…
This quote is not accurate in terms of how humans play chess. Humans do in fact build up the game state from the list of moves that occur; they place comparatively little emphasis on deriving the game state by looking at the board. We know this by the following experiment:
Grandmasters are very good at memorizing the state of a chessboard, given that state occurs in a game they’re following (usually, a game they’re playing). It is what passes for a popular party trick in chess.
But grandmasters perform no better than anyone else at memorizing a random chessboard.
Humans who are playing a full game do build up understanding as the game goes along, but, presented with a board in mid game with no other context, anyone who knows the rules of chess could still complete that game without making invalid moves.
Well, technically, there would be some board setups where it’s unclear which sides white and black started on, without which you wouldn’t know which direction you could legally move the pawns. If you’re using chess notation though, that wouldn’t be a problem.
Humans obviously do not do that, or else things like ‘blindfold chess’ would not exist and need to be learned: they would simply be normal chess which any chess player could do at 100% playing strength the instant they wanted to. (Even if they did, they are still doing so recurrently, using their memory, which is precisely what GPT-2 does not have but other things like MuZero do have, part of why we would expect GPT-2 to fall over after a certain number of moves because a long enough history exhausts its ability to reconstruct the history within a single forward pass while leaving room to do any kind of thinking or planning, and why I brought it up as a contrast.) Your example does not show what you say it does, as it only demonstrates the importance of domain knowledge & chunking; it certainly doesn’t demonstrate that human players have no need for images of boards and do not rely heavily on its state.
You can try to swap the Transformer architecture with a LSTM, but I don’t think it will perform any better. Empirically, transformers outperform LSTMs in almost all natural datasets, even though in theory LSTMs are more expressive.
Inasmuch as DM only just got Transformers working in RL contexts, and MuZero doesn’t use Transformers, ‘almost all natural datasets’ seems like a serious exaggeration here.
Transformers are generally more expensive to train on self-generated data than LSTMs, but they are more efficient when the data is fixed and you can use teacher forcing, which is the case here.
You’re assuming that it’s pure imitation learning. MuZero is not, and no one expects the best results from imitation learning, and that is why I was suggesting how moving to reinforcement learning would improve it, where your point was irrelevant and recurrency is in fact important. It would be more sensible to suggest that a Transformer with some equivalent of recurrency might be equivalent, and in fact the Compressive Transformer does show good RL performance, but that’s not what you were claiming.
I don’t understand why you are conflating RL with recurrence. There is nothing in the MuZero paper that suggests that in principle it couldn’t be used with a Transformer architecture. Probably they didn’t try because it would have been more computationally expensive, or just they didn’t bother with the implementation.
Now you are backpeddling. My original point was that GPT-2, which has no state or recurrence, cannot even in principle play as well as MuZero can, because it cannot track board state and is not deep enough to infer it over arbitrarily long inputs past the opening.
Chess games last typically around 70 half-moves, GPT-2 has a context window of 1024 BPE tokens, I don’t know how many BPE tokens does a half-move use, but I’m guessing that in the vast majority of games GPT-2 can keep the whole game history in memory, hence this is not a meaningful distinction.
MuZero plays chess better than GPT-2 because it has a convolutional network architecture designed to play chess-like and go-like board games, because it does search at both training and inference time, because it has been trained with self-play rather than with imitation and, of course, because it has been trained on a thousand TPUs rather than whatever Scott could afford. Recurrence vs. self-attention is most likely not a big difference (MuZero searches only up to 5 steps in the future).
I conjecture that even in MuZero the recurrent network state is not isomorphic to the game state: when the model plays blind during search, different sequences of moves that result in the same game state will generally not induce approximately equal states in the RNN, rather the RNN state will be a compressed representation of the game history from the point that the RNN stopped to see the whole board. I don’t have evidence to back up this claim, but it is plausible given how what we empirically know about RNNs.
Do you not see a difference between “they place comparatively little emphasis on deriving the game state by looking at the board” and “they do not derive the game state by looking at the board”? Let me be more explicit.
A human playing chess maintains a mental model of the game state, and updates that model move by move (“building up the game state from the list of moves that occur”). The better they are at chess, the more they will rely on this model, and the less they will rely on making up for deficits in the mental model by looking at the board, which is how you fill in a lacuna or correct a mistake in the mental model.
By contrast, chess software has a mental model of chess-in-general and evaluates all board states directly against that model. There is no model of the game-in-progress other than the raw board state, as evaluated by the model of chess-in-general. This is unlike the way in which humans play chess, and you’re proposing to make GPT-2 chess more like chess software and, therefore, less like human chess-playing.
It is unclear to me that humans put any emphasis on building up a history of the state and trying to imitate playing blindfold chess instead of, y’know, looking at the board like a sane person would. You want to compare chess master anecdotes? Consider simultaneous chess games against hundreds of people. The chess master is not building up a state of each of hundreds of games and thinking them through all simultaneously; instead, they go from table to table, looking at the board, and planning from there. Because, after all, the board state represents all that is necessary to know; the history is largely irrelevant. And your chunking example is still irrelevant to the argument you are trying to make.
@gwern How much experience do you have playing chess? This disagrees with my experience. I can attest that it’s much easier to learn to play blind chess if you have a lot of experience playing ordinary chess beforehand. (I also recall an anecdote that claims that chess masters do remember the state of their games while playing simul but I don’t want to look this up so I assert this with low confidence.)
Analyzing a novel board position from scratch is time-consuming. It’s a lot easier to analyze differences, and see how each move affects your assessment of the position. A lot of features, such as “this piece is pinned” or “I’m threatening this move” or “this piece is badly developed”, are not immediately obvious from looking at the board but are frequently maintained move-to-move. Perhaps the most obvious example is if you’ve planned a multimove tactic and your opponent is playing a move that you’ve already anticipated. You only need to look at the board to make a final verification that you haven’t missed anything, and then you play the move you planned.
For that matter, I want you to think about what a chess player is doing when they plan moves ahead. They need to imagine what the board is like if a move or multiple moves are played, and they need to imagine many such possibilities. Looking at a hypothetical board is impossible and imagining a new board from scratch in a new position is computationally infeasible for humans. Instead they imagine a new position from its difference to the current position, and for imagining multiple moves have a mental representation of the history of the game from the current position, so they can backtrack effectively.
I played plenty of chess as a kid, and I’ve read a good deal of chess psychology & expertise literature, and accounts of simul chess. Chess masters who do simul exhibitions do say they rely on board state, and aren’t memorizing all hundreds of games simultaneously. This is part of why they play weaker in simuls, and also why *blindfold* simuls rack up *much* smaller numbers. Regular simuls can go up to 600, while blindfold tops out ~50, checking the latest numbers. Obviously, the board state plays a major role in why one can do 12x the other. Note that chess masters in psych studies can select the most promising moves in a split-second from pure System I processing / heuristics / chunking, and this is consistent with the NN chess/go engines like AlphaZero, which can reach weak-pro-level with a single forward pass (equivalent to ‘one look at the board’) and then become superhuman as they conduct deeper tree search.
The fair comparison would whether a grandmaster can memorize a chessboard state that occurs in a game someone else has been playing: they didn’t see the moves leading up to it, but it is still a realistic position.
That is fair. They perform very well at memorizing realistic positions without seeing the chain of moves that led to them.
It’s not. The version that Scott used has been trained on chess games.
This instance was trained on chess games, but the architecture was built for something totally different.
Actually, I think that it is even more impressive than AlphaZero. AlphaZero explicitly only allowed valid moves. Any invalid move had a probability of winning the game – GPT-2 was able to infer valid moves up to a certain point based purely on pattern recognition.
Editing note, the second tweet is repeated twice at the moment. (Not sure if the second repetition was supposed to be something else or simply supposed not to exist.)
Relevant prior research and discussion: http://norvig.com/chomsky.html
Hm, I tried playing, but midway through my connection to the runtime timed out and I could no longer continue…
Reminds me of this famous 2015 post “The Unreasonable Effectiveness of Recurrent Neural Networks” http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Would be interesting to see how much of an improvement different text ML methods are for things like chess, music and so on, and how much they are “over-fitted” to language
Someone did a project, a few years ago, teaching a convolutional neural network to play chess off a database of games, by predicting the next move just based on the similarity of its text to the game so far, without using any win/lose signals – that’s very similar to using GPT-2, but with the standard image-recognition-oriented architecture. I remember it learned to play to about a master’s level, but would still make invalid moves maybe 0.5% of the time, which I found fascinating. I can’t find this project now (there’s a bunch of deep learning chess papers in recent years, but none of them is this particular thing).
I was so impressed that I wrote a short science fiction story, The Weights of the World, in 2018, and put a reference to that project into it. This was written before GPT-2 and rereading my story now is a little uncanny…
Anatoly, perhaps now GPT-2 could write an alternative finale for your story?
It’d be cool to present that story on a web page where, after the end, the site scrolls GPT-2 generated text for as long as the user scrolls down (the implication being he set the AI to write to his log forever as a sort of half-assed immortality.)
I could take a crack at implementing that if you’re okay with it, but don’t expect me to actually pull it off.
(spoiler about the story) Abg fher jurgure lbhe pbzzrag nyyhqrf gb gung, ohg V zrnag gur ernqre gb erpbtavmr gung gur ragver be nyzbfg gur ragver fgbel unf orra jevggra ol gur NV zragvbarq va vg. Gurer’er pyhrf fgerja guebhtubhg naq zragvbarq va gur fgbel vgfrys nf cbffvoyr NV negvsnpgf (abafrafr punenpgref, vapbafvfgrapvrf nobhg gur fvghngvba). Fb va gung frafr n TCG-2 pbagvahngvba fhpu nf lbh zragvba fubhyqa’g or arprffnel. Ohg zbfg crbcyr V fubjrq vg gb qvqa’g frr gur gjvfg ng nyy, fb V guvax V snvyrq va gung erfcrpg. Vs nalbar ernqvat guvf jnf vagrerfgrq rabhtu gb ernq obgu gur fgbel naq guvf EBG13’q abgr, V’q or tengrshy sbe n pbzzrag vaqvpngvat lbh qvq/qvq abg frr gur gjvfg.
Ah, I did notice that and come up with that hypothesis, but that didn’t make sense since vs gur svefg “tyvgpurq” cnentencu, v.r. gur frpbaq ragel, znexf gur ortvaavat bs gur trarengrq grkg, gura vg’f njshyyl bqq gung gur trarengbe jbhyq cerqvpg uvz perngvat gur trarengbe. V cebonoyl “gur gur”‘q n ybg bs gur gur reebef, naq punyxrq gur barf V fnj hc gb enqvngvba pbeehcgvba.
Hayrff vg npghnyyl _vf_ n uhzna-yriry TNV gelvat gb or yvxr “V gevrq gb ohvyq na NV ohg vg qvqa’g jbex un un orggre whfg yrnir guvf fuvc sybngvat va fcnpr naq sbetrg nobhg vg,” ohg gung qbrfa’g znxr nal frafr rvgure, orpnhfr jbhyqa’g vg or orggre gb whfg abg zragvba vg ng nyy gura?
Thanks, that’s useful! Zl vqrn jnf gung gur uhzna bevtvanyyl ohvyg gur NV, juvpu jbexrq, naq gura qvrq. Gur NV rvgure jevgrf gur jubyr svyr be pbagvahrf nsgre gur svefg ragel (qbrfa’g ernyyl znggre, yrg’f fnl jevgrf gur jubyr svyr), naq fvapr vg’f onfvpnyyl n arheny arg genvarq hc gb or gur pbafpvbhfarff bs gur uhzna naq gur zrzbel bs gur uhzna (hc hagvy gur ortvaavat bs gur fgbel), vg jevgrf fbzrguvat irel pybfr gb jung gur bevtvany jebgr va gur bevtvany qvnel, zbqhyb jrveq tyvgpurf. Jura vg pbzrf gb genvavat gur NV, ubjrire, gur NV vf abg cbjreshy rabhtu gb fvzhyngr NV-jvguva-NV, naq ng gung cbvag gur ybt qviretrf sebz gur bevtvany, juvpu jr arire trg gb frr. Vg’f ba zr gung guvf vfa’g pyrne rabhtu gb gur ernqre, bs pbhefr.
V qvq frr gur gjvfg, snveyl rneyl. Vg jnf pbashfvat gung arneyl gur jubyr guvat jnf jevggra ol gur NV, orpnhfr gura nf gur ernqre V unq ab vqrn jurgure gur npghny gehgu unq nalguvat gb qb jvgu jung gur NV jnf jevgvat. Sebz zl crefcrpgvir gur fgbel jbhyq or n ovg fgebatre vs gur tyvgpurf fgnegrq, fnl, unysjnl guebhtu.
Sha fgbel!
Amusingly, my usual resistance to posting here largely vanishes in ROT-13 😉
V svtherq gung jnf cebonoyl gur vagrag bs gur glcbf, lrf.
V qvqa’g pngpu gur vapbafvfgrapvrf, ohg vs V unq V jbhyq cebonoyl unir nffhzrq gurl jrer npghny zvfgnxrf.
EDIT: V gubhtug gur NV zvtug or ybbcvat guebhtu qvssrerag irefvbaf bs gur fnzr ybt, tvira gur raqvat zveebef gur ortvaavat. r.t. bar ur tvirf hc ba gur NV naq jngpurf gur ZPH (hfvat gur ratvar pbzchgre juvpu vf zber cbjreshy naq fb pna qvfcynl ivqrb, V thrffrq, nygubhtu va ergebfcrpg V thrff gung jnf fhccbfrq gb or n gryyvat pbagenqvpgvba); va nabgure ur nibvqf purpxvat jura ur’yy eha bhg bs sbbq be jngre.
I have some experience messing around with chess engines, and I *really* didn’t think you could reach master level just by “predicting the next move just based on the similarity” of the game so far using any database of human games. (while in go doing that same thing is surprisingly easy)
If you could find any information about it I would be very very interested. Maybe you were thinking of giraffe https://www.chessprogramming.org/Giraffe that used a similar strategy, but just for the evaluation function?
Giraffe also uses deep learning for branch choice (deciding which branches are most ”interesting” in any given position, and should be searched further, as well as which branches to discard) and move ordering (determining which moves to search before others) which significantly affects efficiency of searches.
Notably, Giraffe does not depend on board similarity. In fact, IIRC the paper contains a discussion about the disadvantages of considering the board as an image (e.g., small changes in pawn positions lead to radical evaluation changes). The evaluation function works with a long list of hand-crafted features representing the game state. The list even includes threatened squares, I think.
https://github.com/ashudeep/ConvChess/blob/master/convchess.pdf
(I don’t know why, but this was *really* difficult to find; thanks for prodding me, because I’d already spent a while earlier today when writing the original comment and given up.)
So yeah, I remembered it incorrectly; it encodes the board representation as an image and runs a convolutional neural network on that. It does predict the next move (there’s also a version which learns an evaluation function), and the best it can do – with the version that predicts – is win ~10% of games against Sunfish. I think that’s quite below a master level, right? Maybe around 1900 ELO, just guesstimating? If so, I think it’s still remarkable that it’s able to get to that level while occasionally making an outright illegal move (see p.39 for the percentages of those). That’s what captured my attention, originally.
(I think after I read about it I toyed with the idea of using an LSTM architecture to make a move predictor based on just the text of the game, without board representations, but never actually tried it; that’s why I remembered it wrong)
Thank you so much for finding it!
Sunfish with 1000 nodes is absolutely not 1900 Elo, probably even below 1300, I would be very curious on how these approaches fare against the average human (non chess enthusiast) player on short time controls (playing on “instincts”)
How much of this is due to transfer learning and how much of it is just the architecture? More specific question: Suppose that instead of taking the trained GPT-2 model and fine-tuning it on chess games, you just trained from scratch on chess games. How much worse (if at all) would the result be?
…but the presence of efficient transfer learning in these domains would be fascinating in itself.
Image exhibit behavior conducive to transfer learning – lots of generic features such as corners, lines etc. It’s not at all obvious that anything like this should exist for text-bases chess!
I don’t believe that poorly mixing and copying what it finds is very impressive – it still plays chess worse than a human with five minutes of rules briefing (as it does everything else), and “not breaking the rules until several moves in” is an exceptionally low bar to set.
GPT-2 is fun, but probably a dead end, as the only thing it does is parrot what others are doing… poorly.
The main shortcoming of GPT-2 seems to be its inability to establish a context/structure/memory.
Give GPT-2 a way to organically hold a board state, or track its position in a list, or traits of a character and it seems like it would do a lot better.
Maybe it could do something with commented text.
No- the main ADVANTAGE of GPT-2 is it’s ABILITY to establish context. It’s better than anything before it at this, it just happens to suck horribly compared to a human brain.
>According to evolution by natural selection, an organism that sees reality as it is will never be more fit than an organism of equal complexity that sees none of reality but is just tuned to fitness. Never.
https://www.quantamagazine.org/the-evolutionary-argument-against-reality-20160421/
Does this relate to the article somehow?
Sorry, I should have been more clear. The quote from above was in the article I posted, and when I posted it I was thinking about this part in Scott’s post.
I think the quote from the original article has interesting implications all around.
But this example is a disproof of the quote, since algorithms that do make use of 2D representations play chess much better than GPT-2.
I’m not exactly sure how to think about ML algorithms in terms of the theory. But it does seem too apply.
http://cogsci.uci.edu/~ddhoff/Hoffman-Stevens-Handbook.pdf
@JT_Peterson: I find myself most suspicious of “generically chosen fitness functions” — the whole point of models is to exploit structure in the environment, so if you instead assume that the environment is random then it’s not surprising that models don’t help anymore. I am also not sure exactly what they mean by “accurately estimate reality” or whether it lines up with my intuitive notion of an algorithm that makes models of its environment.
So, if I understand this correctly, this person has provided an exciting proof that if two systems have the same amount of information, but one has only relevant information while the other has a mixture of relevant and irrelevant information, the former will outperform the latter. I would never have guessed. Also, apparently if information is relevant, it stops representing reality. Call the Journal of Irreproducible Results!
@Protagoras – this
The bit about a mathematical proof is pure misdirection. It’s like a magician saying ‘abracadabra’. It’s supposed to be the magical part but actually, at this point the sleight of hand has already happened. In this case the sleight of hand is defining ‘reality’ in a way that excludes the information about the organism in question.
Scott has already written about the deployment of mathematics in the role of smoke and mirrors and gave it the name of Eulering.
I don’t understand this guy at all. How can he talk of fitness function as opposed to reality? What is it a function of if not (some aspect of) reality?
I guess his point may be that there is plenty of reality that doesn’t affect the fitness function therefore it’s only adaptive to perceive certain aspects of reality and not others. And the number of things we could in principle perceive but don’t is vastly larger than the the number we do. Like I’m not constantly aware of the exact number of hairs on my head because it’s not something worth knowing from evolutionary point of view. But that’s a rather boring observation and it’s a stretch to call it ‘seeing *none* of reality’.
See my response above. He claims to have a mathematical proof.
A related quote by Chesterton, on an old man vs. an actor pretending to be an old man:
This may be stupid because I only ever use pretrained models but I remember a post by gwern a while back about improving poetry results by including regular metadata.
With these millions of chess games in standard format it should be pretty trivial to generate compact a text representation of the board after every single move. 64 characters should do it.
How about for training adding the board state to the input before every single move?
Then prompt it with a given board state.
64 characters actually isn’t enough because you have stuff like en passant, no repetition, and whatnot to consider… But yes, using FEN encoding of the full board state is the obvious fix to the hidden state problem, to make it Markovian and much easier for GPT-2 to predict. That’s what Shawn was working on before he switched over to making a playable Colab notebook for Scott.
So does the current version take only the previous move as input? (I’m confused about this from the OP.)
As I understand it, at each move, it is simply being fed the full history (that is, a sequence of moves) of the game to date in PGN format. The idea is to reprocess the dataset and dump FENs at every move, so instead of being (random metadata, move 1, move 2, move 3…) it’ll be (random metadata, FEN0, move 1, FEN1, move 2, FEN2, move 3…). The entire game might not fit in the context window, but it doesn’t need to since the FEN encodes everything necessary to know to predict what move n comes after a specific FEN. Then you simply feed in a FEN and get back out the predicted move.
Ah, ok thank you. Given that information, it’s a lot more reasonable that this thing makes passable predictions at all. When I thought it was just using a single move as input, that seemed very surprising.
Cheers for the reply!
Crackpot idea: feed it a board state compressed with losses, only containing whether a white piece, a black piece or no piece occupies each square. 128 bits or less.
Something similar has been tried before: see Color- and Piece-blind Chess by Dr. Tom Murphy VII Ph.D., published in the semi-satirical journal SIGBOVIK on April 1, 2019.
The author’s program is different from your idea in that it is not just piece-blind, but also color-blind. Also, the program only uses a neural network for the step of guessing which pieces are where—the step of choosing a good move based on those board positions is done using the chess engine Stockfish. The author mentions near the end that they could have used a neural network for the whole process, but it would have taken too much training time.
If you like that type of research, see also the author’s other chess-related works, including Elo World, a framework for benchmarking weak chess engines from that same SIGBOVIK issue.
[2000-2100 player here]
After a few games, it seems the natural guesses are correct. Cryochess plays reasonably well in standard openings and positions that arise from them (for a while, at least). For instance, playing a QGD (1. d4 d5 2. c4 e6 3. Nc3 etc),with almost no tactics or forced lines, it survived until move 12 with only a mild disadvantage (and then connection timed out). It was even robust to reasonable deviations (move order, slightly unusual insertions such as a2-a3). However, at the slightest hint of a “wild” opening (such as 1. g4, Grob) and pieces outside their usual positions (such as queen traveling to f6 early), the game is basically over by move 10-12. In particular, there’s no reason for it to move threatened pieces or to avoid moving pieces into threatened squares (outside standard exchanges such as pawns taking each other on d5). I don’t believe that changing the state representation will do a lot to remedy this crucial disadvantage. Perhaps adding some basic internal info might – but then we’re back in standard chess engine territory.
Why does the inability to act outside well-expored areas matter to the general implications of all of this? It’s worth pointing out that contra Ketil’s comment –
– the actual strength of deep learning (particularly in its flagship domain of computer vision) is its generalization, that is, precisely its ability go beyond the already-seen data. Nobody’s shocked to see a huge ResNet fit the training data. It’s the lack of overfitting that constitutes the “deep learning mystery”, such that it is. As for AlphaGo, it is a complex system much of which is not deep (actually even the “deep” parts are fairly shallow), and in any case reinforcement learning struggles with generalization in a way that, e.g., a deep computer vision system does not.
This was a long-winded way of saying that it seems that Cryochess is more like AlphaGo than like an ImageNet-solving ResNet. Possibly the same is true for GPT-2 in general. The distinction seems important – whatever it means.
There are two kinds of generalization: in-distribution generalization (interpolation), which is measured on test data which comes form the same probability distribution of the training data (ideally, all samples are i.i.d.), and systematic generalization (extrapolation), which is measured on the test data that comes from a probability distribution different, but related to the training distribution. Deep learning methods excel at the former if the training data is large enough but struggle with the latter.
In the real world of course you almost never find true i.i.d. processes, but for some practical applications (e.g. predicting clicks on ads) you can get close enough to it on the relevant scales that deep learning methods are useful. However, if you want anything approaching true AGI, you need a system that can react appropriately even in situations quite different than anything it has seen in the past. Whether deep learning can do it in principle is the matter of the ongoing Bengio-Marcus debate (which is arguably the continuation of the Norvig-Chomsky debate). But pretty much everyone agrees that current deep learning methods are can’t do it at the moment.
All excellent points, but define “quite different”. Can a human “act appropriately even in situations quite different than anything it has seen in the past”? For some values of “quite different” and “situations” and even “it has seen in the past”.
I’d be willing to defend the statement that the extent to which deep learning (a sadly vague term, I know) extrapolates is surprising (as in, not well-explained by our intuitions and current level of knowledge). I’ve seen it do that (in vision, mostly) enough times with scarce enough data not to take the adage “deep leaning only works with millions of samples from the same distribution” too seriously.
Clearly humans have cognitive limits too, but they can extrapolate better than any ML system on most tasks of practical interest.
Wait, so your statement is “we haven’t developed an AGI yet”? That is, well, true, but far less interesting than the preceding discussion. To be clear, my statement isn’t “ML extrapolates amazingly well”. It’s “to the extent that deep learning works, extrapolation is actually one of its strongest, not weakest, suits (at least in some domains). Also, on the particular task of solving truly new problems, humans are less impressive than they are in general, so demanding ML or even an AGI to excel at that is unreasonable”.
ETA I should add that part of the reason behind the claims that DL extrapolates poorly (even relatively) is that it does so differently than we do. So moving everything from, say, a jungle to an office might be confusing for it. But flipping the color channels might confuse it less than it would a human. If we restrict to the kind of “quite different” that we humans naturally think of, then my statement becomes untenable – though less so than might be expected apriori.
Do you have any example of DL extrapolating well?
Yes but it does it in a way that is not useful for actual problems, and can be in fact harmful (e.g. adversarial examples transferring between different models with different architectures).
I wrote a post on Less Wrong last week about whether GPT-2 understands the meaning of anything. For a functionalist definition of “understands” I come down in favor, of at least some things.
This nostalgebraist post about GPT-2 and what it means for linguistics also seems relevant.
I think (with Dennett) that it’s productive to talk about “competencies” in situations like this (“competence without comprehension”). “Understanding” just muddles the waters.
Your folk music example got me wondering… how do intellectual property laws interact with artificial intelligence? If I used GPT-2 to produce music that was good enough [for whatever purpose], would I be able to copyright it? What about the makers of GPT-2?
I-Am-Not-A-Lawyer-But, my understanding is that the current U.S. legal distinction of whether or not something is a copyrightable original works is whether non-trivial decisions were involved in its creation. So curated output would almost definitely be copyrightable by the curator.
Raw, uncurated output… the court would probably have to decide. We might even end up in Measure Of A Man territory where lawyers have to argue over whether the AI’s decisions count as “non trivial decisions.”
You probably would be able to copyright it if you exercise some sort of editorial discretion by selecting it out of a otherwise-uncopyrightable dump: https://www.gwern.net/Faces#faq The makers of GPT-2 could only have copyright if they had included a requirement to that effect in the original code & model license, but since OA released it under a FLOSS license, that’s not an issue.
(If anyone is worried about my folk music selections – all CC-0, so no worries.)
According to the US Copyright Office:
If only this had been around back when Tom 7 was doing Elo World.
I would say that “how impressed” you should be depends on how much you trained the ML algorithm.
For example, protein folding is arguably much more complex than chess in many respects, and it’s been tackled by neural networks since late 2017 to my knowledge (e.g.: https://www.nature.com/articles/s41467-019-11994-0).
Most papers use residual CNNs (read: all papers that I read on the subject, including the most famous one from deepmind). I don’t see any particular reason to believe that residual CNNs are fine-tuned for these sort of problem, the architecture was designed for image classification and people seem to get decent results without much tweaking.
Would one design a residual CNN to play chess ? No… mainly because it would be very tedious and expensive due to how it’s inputs and outputs are structured. But could it be done, yes, certainly, it would just be kinda silly to do so when there are better architectures.
Now, if this is a GPT-2 network trained for something completely different, and it required to training whatsoever to play chess, I would call that impressive. However, if it is a pretty trained GPT-2 network that was then additionally trained to play chess and/or one trained from scratch to play chess…. then it’s just a very bad choice for training a chess playing model, but the fact that it works is not surprising. Neural networks are general function estimators, the idea that an architecture can generalize to multiple unrelated tasks is at the core of why we like them, it shouldn’t come as a surprise.
So I think more information as to how it has been trained are required for this article to have any meaning.
As it stands, if the network was indeed trained as a whole to play chess I would call this result expected, boring and somewhat deceitful in the way it’s presented.
If the Transform network was pre-trained on wiki-text and a chess-playing head was trained on top of it (i.e. a smaller network was attached to GPT-2 and it was the one deciding the actual move based on the “interpretations” given by passing the board’s state or a series of previous movements through GPT-2), the above statement still holds, but depending on training time and ability of the network this finding might be “interesting” but certainly not ground-breaking or unexpected.
If this is a pre-trained GPT-2 network that never learned played chess I would say it’s pretty damn interesting that it’s able to do this.
But I think this piece of information should be made explicit, I would indeed beg you to do so.
Regarding “Would one design a residual CNN to play chess ? No… ”
You may be interested in Leela Chess Zero, which is currently either the strongest or second-strongest chess engine depending on which tournament you look at, and which does in fact use a deep residual convolutional network for its evaluation function and to direct its search.
So GPT-2 can “play chess” for a definition of “play chess” that is essentially “repeats common opening and mid game lines, as long as somebody who actually knows the rules of chess is holding its hand to sort out the gibberish”. Honestly this makes me downgrade my opinion of GPT-2, because, now that it’s applied to a “simpler” problem than “all of human language”, I feel like I can see what’s really going on… and it’s a neat trick but only a neat trick.
If you told me that you had a program that sorted through a huge pile of data, looked for patterns, and then responded to a prompt with the next likely step in the pattern, and the “pile of data” you had given it was “games of chess presented in standard text notation”… this is kind of exactly how I would have predicted it would work (and fail). I’m not sure I understand the shock and awe over this result.
I think the reaction Scott is having is something like “if it got this good at chess in a week, think how good it could be in a month!” But the answer is, “probably about as good as it is now”, because I’m guessing in a week it already processed plenty of data to catch all the common patterns, and it will need larger and larger data sets to see any novel patterns. The scary version of AGI is supposed to learn and improve faster and faster, but GPT-2 is the opposite, because the more things it knows in a domain, the larger the chunk of data it needs to learn the next thing. And the more complex a domain is, the worse this problem gets.
I think GPT-2 is really interesting for what it can teach us about language. Namely, that there are a lot of subtle rules and patterns in language that may be hard to articulate but are easy to know when they are missing. But “knowing the patterns” is not all it takes to produce coherent text. Then again, being just a little off from expected patterns makes things sound poetic.
But unfortunately the other main thing I feel like I’m learning from the breathless GPT-2 coverage is that lots of people are all aboard the imminent AGI hype train and will latch onto anything that confirms those biases.
In the poetry case, it really helps that there is a relatively short finite bound to how far back it has to look to make things work. All that matters is keeping the meter of the previous line and rhyming with the line before that. A Markov chain can manage that.
But with chess, it needs to remember what piece is on each square, even if that piece hasn’t been moved in dozens of turns. There’s no bound to how far back it might have to remember.
Adding a representation of the board state to each move, so that it can work from the present state, would definitely help. But it would also help the storytelling version of GPT2 if it had a representation of the narrative world to hold onto, to keep track of the Chekhov’s guns that were set up in scene 1 and the plots that were being hatched.
I agree. This is basically a lookup table for different chess situations. It can tell you what move people have most commonly played in the past in situations like this. It will never be able to supply the least bit of insight for a situation not in its database. It has zero creativity and will never be able to produce anything creative.
One caveat to know wrt this being impressive/meaningful — Chess notation seems like a thing that is very easy thing to build a decent language model for (a model that predicts what would make sense to say next based on data). Was GPT2 really the key here or could we have done this for a long time already? I bet the latter ; you can look back on Andrei Karapathy’s post on RNNs and see similarly impressive-seeming text generation, and you can go back to using older method , and older NLP models with markov models probably would have worked nicely too. If you’re fine tuning for it and your model is trained specifically to do this the model is not general, the method is.
Very cool! Thanks for sharing! I’m a long time lurker of SSC but my fanaticism for Chess and machine learning encouraged me to finally register and post. Here’s the fragment of the game I shared with GPT before the machine learning platform had an error. I play white: 1.e4 e5 2. Nc3 Nf6 3. a3 d5 4. exd5 Nxd5 5. Bb5+ c6 6. Ba4 Bd6??
I am a reasonably strong (1800 USCF) chess player, but I intentionally played senseless moves in the opening, assuming the engine will make mistakes as soon as it gets out of book. Unfortunately, this happened sooner than I expected because Bd6?? is a serious mistake, dropping a piece.
My first impression is that GPT2 plays like a novice that has seen some grandmaster games and is trying to make moves that look like master moves without understanding chess principles. For example, it neatly tucks its bishop in the center, where it is full of latent mobility when the pawns shielding it spring forward, as masters often do, not noticing that it just dropped a piece. This is a little more interesting than it sounds at first because it’s actually not something traditional engines do when you tell them to play as weakly as a novice. Traditional engines will typically instead make a weird combination of reasonable moves and moves that just throw pieces away in a silly way no real person would, such as capturing a clearly protected pawn with a queen. While it’s cool that someone did make a shallow and humanlike chess GPT-2 implementation, shallow and humanlike is maybe not completely new because Leela Zero can already do this when you tell it to play at low strength.
My initial take is that this doesn’t change my point of view a whole lot, but it’s cool that someone did this. If someone asked me, “They’re gonna feed PGNs to GPT-2, how well do you think it’ll play?” I would probably have guessed at superficial moves. Actually, this reminds me of the flaws in its writing, where it describes physically impossible structures with correct grammar. Its chess playing style is sort of to construct these structures that look competent on the edifice but which are riddled with mistakes as soon as you get closer. For now, I’m more impressed by whoever had the creativity to think of feeding it PGNs in the first place than the quality of its moves, but we’ll see if that changes in the future!
As I commented on Reddit, this is cool stuff but I think it is unreasonable to say that this system has “no concept of space” or “doesn’t even have a concept of 2D space”. The chess notation used hard-codes a concept of 2D space in how it labels positions. You could test experimentally if this is vital or not: instead of having ‘a3’ and ‘a7’ share a column and ‘a3’ and ‘d3’ share a row, just permute the labels of the squares randomly in the training data (and in how the game is processed when the system plays). For example, have a dictionary that sets ‘a3’ be ‘d2’ for all occurrences, ‘a7’ be ‘e4’, and ‘d3’ be ‘f1’ or any other random relabeling of all squares that breaks the logical structure of the notation. If GPT-2 is really not using the space concept we built into the notation then it should have no more difficulty learning and then playing through this dictionary. I suspect that GPT-2 will struggle much more to play without this good notation. In other words, we need to be mindful of the knowledge that our smart representations encode.
As I understand it, attention is nonlocal. The sequence input labeling doesn’t enforce any kind of 2D (or 3D, for that matter, or N-D, if you’re using Transformers on image data or multidimensional data); it merely annotates it with numbers like sin and expects the Transformer to learn how to understand the positional encoding. It’s because it’s permutation-invariant that you have to add those positional encoding to make it possible to understand that different positions mean different things… The dimensionality is not hardwired in the way locality is hardwired in to convolution kernels which can only look at nearby pixels: a Transformer head can unite points from arbitrarily far apart in the input, if it has learned to. So any sense of locality in a 1D sequence, or 2D for that matter (for if FEN board states are added), has to be learned.
I don’t know if we are talking on the same topic or not.
Standard chess notation has 2D space hardcoded into it. This hardcoding works for any learner that thinks that ‘a3’ is more like ‘a7’ than ‘f2’ because ‘a3’ and ‘a7’ share a character while ‘a3’ and ‘f2’ do not. GPT-2 is built around the importance of shared characters, so it sees ‘a3’ as more similar to ‘a7’ than ‘f2’, thus it can easily get the 2D structure of the game from the structure of how the board positions are represented. If we instead force GPT-2 to work in a ‘foreign language’ where the square that used to be a3 is now always called ‘d5’ and the square that used to be a7 is now called ‘e4’ and f2 is now called ‘b6’ then the spatial structure of the encoding is lost, since ‘d5’ (a3) and ‘e4’ (a7) do not have a character in common to easily reveal that they are on the same column and thus somehow ‘more related’ to each other than to ‘b6’ (f2).
This has nothing to do with attention. Unless you are making some other point, but then I don’t understand how it relates to my original comment.
Yes, but why are ‘d’ and ‘e’ more closely related than ‘a’ and ‘z’? What makes ‘a3’ more like ‘a7’ than ‘f3’? Those are arbitrary symbols. (By the way, note that it’s not even clear that they would be encoded as the 2 numbers corresponding to (a,3), because of GPT-2’s use of BPEs rather than characters. ‘a3’ and ‘a7’ might be encoded as, say, the integers 23500 and 331. And what a move is encoded as might even change with context, because that’ll change previous BPEs… Not a fan of BPEs, they’re just a crutch for GPT-2’s limited context window.)
It’s all arbitrary and has to be learned. Of course, once you learn it, then it’s fine, but that’s trivially true of anything with structure: once you learn the structure, you understand the structure. But GPT-2 gets no particular inductive bias from attention like you seem to think it does. Compare with convolutions where locality is baked in and it starts off biased towards finding the locality structure which we know exists in pixel data.
>Yes, but why are ‘d’ and ‘e’ more closely related than ‘a’ and ‘z’? What makes ‘a3’ more like ‘a7’ than ‘f3’?
I didn’t say that ‘d’ and ‘e’ are more closely related than ‘a’ and ‘z’ nor that ‘1’ and ‘2’ are more closely related than ‘1’ and ‘9’ (of course, it’d be even more of an advantage if this was also baked in). Most importantly, I didn’t say that ‘a3’ is more like ‘a7’ than ‘f3’ — in both cases they share one character in common (and in space, they share one dimension in common, that is the regularity in question); that is why I used the example of ‘f2’ (and not ‘f3’) where no character is in common with ‘a3’ (and thus no dimension is in common).
But sharing one character in common is recognizes by GPT-2 and that is what encoded row and column structure. My claim is that if that part of the encoding is broken then I expect that GPT-2 will perform significantly worse.
Replacing characters by their ascii or any other single-character level homomorphism does not (significantly) affect this, since ‘a3’ and ‘a7’ will still map to ‘blahFOOB’ and ‘blahGLIK’ and the ‘blah’ will be shared and reveal that the two points share a dimension.
To break this structure you need to consider a permutation on the tile labeling (i.e. on pairs of characters) that does not preserve row and column structure. By not preserve row and column structure, I mean that in the new unbiased representation: having a character in common in the representation should not (systematically) mean that the two positions have a common dimension (row or column). In such a representation, we can eliminate baking in 2D structure of the board and thus really claim that we didn’t ‘build in’ space.
By the standard chess position representation produces the inductive bias (of easily identifiable common row/column) that I am talking about. And based on this, I would, for example, expect GPT-2 to attempt more illegal moves with bishops than with rooks as it is being trained.
I don’t understand the part of your comment about attention. It would help me if you clarified more by what you mean there.
As I said, it is probably not even true that GPT-2 can ‘see’ that due to the encoding, and even if it can, I don’t see how it produces inductive biases like implied.
It sounded impressive to me at first until I read the tweets updating the progress, then it reminded me of teaching my kids to play chess which I just started doing. I actually lost to my 4 year old in her first game, as I was focusing on what she was doing, making sure she made legal moves, and giving her a few choices for good moves when she kept making illegal ones. In reality I am not good at chess, haven’t played a game against a person who knows how to play for a decade and was basically putting more effort into her side of the board than mine so I lost.
If you are adding lines of code to eliminate illegal moves you are basically peaking over to the other side and helping them out, basically playing against a machine + a human every time, and that is a lot less impressive and important.
“How impressed should we be that the same AI can write poems, compose music, and play chess, without having been designed for any of those tasks?”
Which list is longer: the list of 1) things an AI can do at a some level (sometimes crude, sometimes not so crude) without having been designed for them or 2) the list of simple things humans do well (without having been programmed?) that the most sophisticated AI flops at?
I really liked earlier posts about GPT-2 but I do not get this post at all.
Neural network is a general function approximator, so of course it would learn to play chess if you train it to play chess with chess data, regardless of how chess moves are encoded. The surprising allure of GPT-2 is that it learns to solve unstated linguistic problems given just the structure of language in the form of unsupervised corpuses, but these experiments do not touch that. The only interesting thing about toy experiments with music and chess would be a gain from transfer learning compared to learning from clean slate with optimal models but I don’t see this mentioned.
Using the fact that DNNs are universal function approximators to explain anything, really, is a pet peeve of mine. Sure, for each (nice enough) function (on a nice enough set) there exists some deep network that approximates it well. This does not imply that this particular architecture is suitable (most universal approximation theory allows the networks to grow extremely fast to reach that goal), that the function in question is nice enough in a relevant sense (deep networks suck at approximating division and matrix inversion – or anything far from being piecewise linear with a sane amount of pieces, just to name a natural class of problematic functions), that the “correct” approximation is reachable with any reasonable training procedure, etc.
You are right that we need the right inductive bias, the right optimization dynamics, the right data curriculum, etc, to get the desired performance. It’s just that in this particular case (transformer, SGD, lots of shuffled chess data) I have a strong intuition that the model is practically a near-universal approximator in the sense that it approximates any reasonably structured and easy-to-train-on function (like “good chess move” function) with a more-or-less reasonable performance (like the performance that was shown in the post).
Your intuition is wrong though, because “good chess move” is actually incredibly difficult to approximate, and that’s not what this does anyway.
This seems superficially cool, but I’m not sure if it actually is. Is this doing anything significantly different to “memorize openings from games, play moves from those if you can, otherwise play a random legal move”?
I think so. Before playing GPT-2, I accidentally loaded the notebook wrong and played an earlier version of the code that was just testing the interface and made random moves. It was terrible and I complained to Gwern that GPT-2 couldn’t play chess at all and the project had been a failure.
When I fixed my error and played the real bot, it felt very different. If I threatened a piece, it would move that piece out of the way. If I blundered and left a piece where it could capture it, it would capture the piece. I can’t say much more than that because *I’m* not much better than that, but I played randombot and randombot was definitely worse (including in midgame).
And yet every game I had that did not follow a standard path was over a few moves in exactly due to not moving threatened pieces or blundering them away. So “play typical moves in typical positions whether the position is, in fact, typical or not” seems an apt description.
I’ve played a game now and remain unconvinced. Look at this game “1.h3 d5 2.h4 Nf6 3.Rh3 e6 4.Na3 c5 5.Nb5 Nc6 6.Nd6+ Bxd6 7.Ra3 a6 8.d4 cxd4 9.Qxd4 O-O 10.Bd2 b5 11.Ba5 Qc7 12.Bxc7 Bxc7 13.” where I played a load of nonsense at the start. GPT-2 completely ignored the fact that my rook and queen were vulnerable for several moves and likewise didn’t notice me threatening its queen. It did recapture when I took its queen though, so I will have to update my hypothesis to something like “play memorised openings, or a random move that was a response to the last human move in a game I saw, or failing that a totally random move”.
It’s more like that GPT-2 compares whatever the board state currently is to its database of known human-run games and picks whatever response gave the best result for that board state. It doesn’t have the ability to recognize concepts like “my enemy’s rook is vulnerable”; what it can do is recognize that human players made certain moves in board states when an enemy rook is vulnerable and employ those. If a board state with a vulnerable rook didn’t show up in its database, it won’t be able to pull out an appropriate response.
Well kind of, except it’s not picking “best” responses but rather “most similar to training data”, and it’s not considering board state but rather history (and my contention is that considering just the last move rather than the whole history would not significantly change its behaviour (in the sense of my-fake-GPT-2 being distinguishable from the real thing by a human who plays both, not in the sense of producing the exact same moves)).
“Is this doing anything significantly different to “memorize openings from games, play moves from those if you can, otherwise play a random legal move”?”
I think it obviously must be. The algo has learned *some kind* of feature representation of the input; it isn’t going straight from raw game state to final output (as a single-layer neural network would have to).
Even if a given feature is as dumb as “moving a white pawn after a black knight was moved tends to be followed by black moving its knight some more”, that’s still an abstraction of multiple different game states that it trained on. It’s not a memorized sequence; it’s a principle learned from sequences it trained on.
Why? Do you agree that it would be straightforward to train an NN to do what I describe? If so, how do you know that this isn’t doing that?
I agree that a deep enough NN* could memorize a training set. I don’t have a great understanding of GPT-2’s architecture to say that it is too deep or not deep enough to do this, so let me walk back my previous claim. I’m not sure whether it has learned abstract features or not.
Barring looking at the NN weights, I guess the best way to test this would be to see if GPT-2 ever produces an output to a move/sequence-of-moves that it didn’t see in training.
Also, we might ask to what extent the engineer controlled for overfitting. I reckon that if the NN memorized the training data, this would have been noticeable when looking at out-of-sample test performance.
* For whatever definition of “deep” makes sense given GPT-2’s architecture
I think a key benchmark here is whether GPT-2 can do better than a program like the ones in this contest that just emit a series of moves, which a controller filters for legality, without getting any feedback on which ones were legal or what the opponent did. If it can do better even when it gets beyond standard openings, that proves that it’s able to do something like reacting to the board state. If it can’t, it’s really just emitting a series of plausible chess moves and the legality controller is doing all the real work.
Conveniently the king of the hill there is in Python so it might not be too hard to arrange a match.
This seems like quite a good point to me!
Fortunately, the controller for that competition is also in python!
Speaking of AI-generated music, I’ve wondered before what an AI would do is trained on something like raw format audio – training it on individual notes and melodies is cool, but what sort of sound would this have? Completely unintelligible noise? Or fragments of natura-lish acoustic sounds jumbled together? Or something that could actually be called “music” (probably not this one)? Speculation is welcome.
Yeah, it’s been done. Look at the various WaveNet and audio synthesis papers. When you train on raw waveforms, you can’t see large temporal windows because you have to synthesize at the millisecond level, so when you train on, say, classical music corpuses, you get wandering notes. The audio sounds very realistic to me as a non-musician, I definitely can’t tell between real and fake piano notes, but you won’t be impressed by the overall musical piece. In comparison, if you train at a higher level on ABC format, for example, you get very clear melodies, progressions, themes, endings, etc, but of course the model can’t synthesize the raw audio corresponding to the short textual scores. OA’s MuseNet is somewhat in between: it works on the MIDI level, intermediate between WAV and ABC, and gives intermediate results in terms of raw audio quality vs overall music piece quality.
I don’t see any particular reason you can’t have a single model which goes the full range at some point, but it’ll be expensive to train because it’ll need to be big and train a ton in order to gradually go from realistic audio up to higher-level long-range music quality.
> something with no auditory qualia
[citation needed] 😉
I’m a human (*), and I don’t think I have auditory qualia either (because the concept of qualia doesn’t make sense), so I guess GPT-2 and I are on a level playing field 🙂
(*) Though obviously you only have my word for it.
Indeed, how do we know this comment isn’t GPT-2 generated?
On the bright side, that question will get even harder to answer once our SubredditSimulator model goes live (1.5b, and trained with even more subreddits than the original SubSim GPT-2 model). We finished training it and sent it off to the SubSim guy a few days ago, so it should go live whenever he has time to hook it up and start generating new comments…
It’s impressive because the system is able to generate good outputs despite not being designed specifically to do so. But it only does so because effectively the entire corpus of known existing chess games were fed into the system. A human can learn to play chess (probably not well) by reading a single book and playing a much smaller number of games.
All of these AI systems with impressive outputs are working on data sets which would be impossibly large for a human being to process, ever. Imagine that all of the matches which went into training this AI were printed out in book format. Assuming that you didn’t actually read the text but merely turned the pages one at a time at the fastest speed reasonable, how long do you think it would take to go through the entirety of the data being processed? These all require a *huge* volume of data.
One of the key reasons that AlphaGo was able to perform so well is because it was able to generate an almost-unlimited set of labelled data by playing itself at computer speed. Repeat over and over and you get better and better quality training data to operate against. But it applies only the cases where the board state and legal move state is well-defined and finite. Google, with all its data, still has trouble distinguishing black people from gorillas, though current image search appears to be doing better.
I would assume that for most cases the open-ended performance is not exponential improvement, but sub-linear improvement. Sure, for the early phases you get really good and really useful results. In some cases you might be able to get to the point that you’re better than humans with enough data at specific tasks like rating diabetic retanopathy on a 1-5 scale. But after initial growth simply throwing more data at the problem gets marginal improvements. This bodes well for AI safety of known (and fascinating) AI methodologies.
That’s true. Also true is that all of these AI systems lack the context that humans have which allow us to do well with less data. We are taught that the white pawn on the a-file has the same abilities as the white pawn on the b-file, or as the black pawn on the b-file. We are told the object of the game is checkmate. GPT-2 and AlphaZero are not given that information.
A human reading a chess book is also instructed in useful *features* for our internal algorithms to use, such as “control the center,” “certain pieces are worth more,” and “protect your king.” Even the basic concept of “control” is itself a feature – an abstraction of many game states that AI has to learn entirely through exploration.
I don’t know how much of AI’s need for huge training data is explained by the lack of context or prior information, but it’s a contributing factor for sure. Humans, by the way, do really poorly on games when we don’t get to use prior information.
There is a short story by Lem about a computer for typesetting newspapers which started finishing them (and predicting future). I don’t know if it was ever translated to English professionally – but I found this amateur translation: https://medium.com/@mwichary/one-hundred-and-thirty-seven-seconds-2a0a3dfbc59e
Lem also wrote a story about a computer who learned to write poetry, and did it so well that it mesmerized the entire country into submission. I haven’t read the English translation, but the Russian versions of some of its poems are… superb 🙂
I thought about training GTP-2 on chess games, glad somebody did it.
My guess is that this would only become really interesting if a big amount of compute would be invested. There are almost 1 billion games of chess available online. I assume this version has not been trained on more than a tiny fraction of them. Probably just on a couple of million games from freely available tournament games. Most of the 1 billion available games are online games, where the range of openings, strategies and level-of-play is much bigger. Maybe this would be enough to actually learn the rules of chess and maybe even learn to update an internal board and consequently stop making illegal moves.
Of course nobody will ever invest 40k of compute just to get a sub-par chess engine, but one of the interesting questions would be whether you could prime it on the rating to get stronger or weaker play.
Adding the game state would only invalidate the experiment as far as I’m concerned. Without tree search and with an architecture this badly suited to playing chess, you will never get a strong engine anyway.
Here is an idea: Learn from games of random moves until it stops making illegal moves. This would probably be a better experiment to answer the question whether GTP-2 can learn a representation of the board.
It would also split the problem into two separate problems: Making legal moves and making moves that resemble good moves.
Once it has mastered the first it can tackle the second.
Like I said before, I feel like the poetry problem (and possibly also the music problem) had been solved from both sides. On the one hand, AI got much better at writing poetry. On the other hand, humans have essentially lost the ability to write good poetry, thus making it much easier for the AI to catch up.
Back in 2005, someone did the same thing with a Bayesian spam filter, training it on strings of text representing chess moves.
Can a Bayesian spam filter play chess?
Very cool. Since it’s biased toward more common sequences, I wonder how much better it gets when playing itself?
You guys are wasting your time. This isn’t going to get anywhere. These things can’t even solve the simpler problem of complex multiplication, i.e. ((a, b), (c, d)) -> (ac – bd, ad + bc). Feed it as many pairs as you want, it won’t get anywhere. If it can’t even do something as simple as figure out how to multiply complex numbers with 1.5B parameters then what point is there exploring what else it can do?
I know very little about the technicalities of ML, but has anyone tried testing GPT-2 on the classic problem of differentiating pictures? Something like getting a bunch of pictures of dogs and cats, translating them into strings of RGB values or something, appending -dog to the ends of dog strings and -cats to the end of cat strings, using that as training data, then giving GPT-2 a string without the -dog or -cat at the end and seeing if it manages to complete it somewhat correctly? (Or maybe just squares and triangles if dogs and cats are too hard). Sorry if this sounds dumb to anyone with more experience.
That wouldn’t work too well. GPT-2 can only ‘see’ 1024 tokens at a time. So you could encode, say, a 32x32px image. The core technology of attention layers do, however, work really well both in conjunction with convolution layers and on their own for image generation (self-attention in SAGAN and BigGAN, or https://arxiv.org/abs/1912.12180v1 https://openreview.net/forum?id=rkgNKkHtvB for autoregressive) and image classification (https://arxiv.org/abs/1904.09925). In fact, given the latter result showed improving performance for all-attention image classifiers with increasing data & the ‘bitter lesson’, it would not surprise me if in 2020 we saw SOTA for image classification pass from convolutional neural networks like EfficientNet to self-attention-only NNs. (Maybe attention really is all you need…)
You could slice a larger picture into chunks, then train individual GPT-2 networks on each chunk, then have each chunk-analyzing GPT-2 network feed into an “overseer” GPT-2 network. I suspect that at that point the network starts automatically summoning Xzibit, though.
It’s not relevant to the post, but I’m curious: Do any chessplayers here share my strong preference for descriptive notation over algebraic?
It’s true that algebraic is less ambiguous, but I can read descriptive and keep a pretty good mental image of what’s going on. Its dying usage frustrates me.
reminds me of stuff like https://people.seas.harvard.edu/~jones/cscie129/papers/stanford_info_paper/entropy_of_english_9.htm, which also captures statistical patterns (but not actually to the point of sustained coherence)
if GPT-2 eventually cracks chess, I’d guess that says more about chess than it does about GPT-2
I have the distinct feeling that if we ever come close to an AGI, it will come out of a competing and collaborating ecosystem of models like GPT-2. First a bunch of predictive models create a lot of ideas and then evaluating models disqualify those who breaks rules and rank the others. Then they all decide in some democratic way what to do or say, to best fulfill all of the goals (often somewhat contradictory) it has been given.
The reasoning behind the decisions will be fuzzy and sometimes wrong, but that’s just like us.
This is more interesting in what it says about humans than its potential as “AI”.
It’s literally mimicking inputs. The only reason it “means” anything is because we ascribe meaning them. It’s fundamentally lacking part of the process of intelligence.
In each of the three examples you mentioned (poetry, music, chess moves), you’ve asked GPT-2 to attempt to mimic the inputs humans generate irrespective of the desired outputs. What you can learn from this is limited to (1) information about how humans generate inputs and (2) information about how humans interpret inputs in these contexts.
Poems are by their nature abstract, and typically have some interesting or novel turns of phrase. This means its easy for us to mistake the nonsense of GPT-2 with interesting or novel phrasing in “real” poetry. (Or maybe this means a lot of poetry is indistinguishable from nonsense? But that’s a commentary on poetry, not AI.)
Music has clear, recognizable patterns that recur and are played with in whatever genre you want to talk about. That That the AI fiddled with inputs and produced a few short (cherry-picked? IDK how representative the clips you selected were) that sound like something a human could have made isn’t that impressive to me. Can the AI differentiate between which clips it generates that sound “good” and which don’t? If a human has to do this, then I don’t see what we’ve gained.
The same is true for chess. This is basically a random move generator with a set of book openings. Where would this GPT-2-based algorithm fall in this set of 30 weird chess algorithms? This thing doesn’t “play chess”. It dutifully reproduces a set of inputs that *look like* standard chess notation, and most of the time produces legal moves. This is only “playing chess” in our minds. This is like “playing chess” in the same way that cargo cults were doing air traffic control. In the same way that these cults weren’t able to produce aircraft dropping off jeeps, this approach won’t produce general intelligence.
On the one hand, this is really incredibly cool. On the other hand, it strikes me that GPT-2 is basically doing imitation learning, which works well in some domains but is generally considered to have serious limitations.
Imitation learning is a type of supervised learning (vs. unsupervised or reinforcement learning) where the learner is trained on a bunch of expert demonstrations (in this case, move-strings), and learns to generate similar demonstrations itself.
A major problem with imitation learning is that it fails in the face of distributional shift. If the test data it faces (in this case, opponent move-strings) is much different from its training distribution, then it doesn’t “know” how to respond and may respond strangely. This pushes the game further out of its training distribution, and the errors compound. I suspect that this is what happened when Scott played an unexpected opening sequence:
-Scott (in a comment reply)
There are approaches to dealing with this issue (see: DAgger), but it still limits the contexts in which imitation learning is useful. Unless a GPT-2 descendant manages to somehow recover something like a goal or a desired end-state from its training data (and in that way become more like a reinforcement learner), I suspect that it will struggle to perform at human-level in contexts where it may encounter inputs that differ slightly from its training distribution. Unfortunately, human interaction is rife with these inputs.
Has anyone read the Ted Chiang’s novella The Lifecycle of Software Objects? It’s included in his Exhalation collection, which I highly recommend (though not quite as good as his first book). Some broad spoilers follow, but they will not ruin your enjoyment of the story. The novella follows the education of artificial intelligences over years as they learn and grow similarly to the way people develop from babies. The point Chiang is making is that the best way to arrive at a general AI is the same way people become intelligent: by raising it from infanthood.
Which makes me wonder if anyone has tried doing this yet. You could do it in a virtual world, or, even better, in the real world. Let’s say you hook up some deep learning system to a camera and a microphone, and give a speaker, maybe some robotic manipulators, may be a form of crude locomotion. Then you treat is as a human baby. Would an attention mechanism be enough? Would you need some reinforcement learning based goals? Is this a potentially horrible idea with some serious ethical concerns?
People have been trying things like this for decades, see Kismet and iCub, not necessarily with deep learning, but it doesn’t matter. It’s like building a bamboo tower and a dirt road on a remote island and expecting an airplane full of cargo to magically land on it.
Did GPT-2 have any advantage over, say, using a markov chain?
After looking at Doug S.’s link about using a Bayesian spam filter to play chess, looks like no.
I don’t know about this specific context, but GPT-2 definitely has an advantage over using markov chains in standard text-generation. For example, given enough training it can learn to summarize when prompted with TL;DR:. A markov chain could only ever parrot-back the beginnings of summaries that it has already seen, whereas GPT-2 can learn to recombine the contents of a text in a vaguely summary-like pattern. The summaries themselves are apparently not great, but they do demonstrate a capacity to generate new text be reorganizing the previous that markov chains lack.
I think it’s a major error to consider that GPT-2 is writing poems, composing music, or playing chess. What it is doing is imitating descriptions of poems, imitating descriptions of music, and imitating descriptions of chess.
If we fed GPT-2 with peer-reviewed science publications, it would not generate peer-reviewed science publications, even when what it generated was indistinguishable from what grad students generate (although at that point we might well consider GPT-2 to be ‘as smart’ as grad students, particularly if its studies ‘replicated’ at equal or better frequency). If we fed GPT-2 with locations and descriptions of known exoplanets, it would not discover more exoplanets (although if we were consistently able to find exoplanets matching the location and conditions that GPT-2 generated, we would be correct to consider GPT-2 ‘as smart as’ exoplanet researchers).
If GPT-2 can be given a bug report database (not necessarily its own) and produce new bug reports that are correct, then I will be impressed.