
[With apologies to Putnam, Pope, and all of you]
Two children are reading a text written by an AI:
The boys splashed water in each other’s faces until they were both sopping wet
One child says to the other “Wow! After reading some text, the AI understands what water is!”
The second child says “It doesn’t really understand.”
The first child says “Sure it does! It understands that water is the sort of substance that splashes. It understands that people who are splashed with water get wet. What else is left to understand?”
The second child says “All it understands is relationships between words. None of the words connect to reality. It doesn’t have any internal concept of what water looks like or how it feels to be wet. Only that the letters W-A-T-E-R, when appearing near the letters S-P-L-A-S-H bear a certain statistical relationship to the letters W-E-T.”
The first child starts to cry.
Two chemists are watching the children argue with each other. The first chemist says “Wow! After seeing an AI, these kids can debate the nature of water!”
The second chemist says “Ironic, isn’t it? After all, the children themselves don’t understand what water is! Water is two hydrogen atoms plus one oxygen atom, and neither of them know!”
The first chemist answers “Come on. The child knows enough about water to say she understands it. She knows what it looks like. She knows what it tastes like. That’s pretty much the basics of water.”
The second chemist answers “Those are just relationships between pieces of sense-data. The child knows that (visual perception of clear shiny thing) = (tactile perception of cold wetness) = (gustatory perception of refreshingness). And she can predict statistical relationships – like, if she sees someone throw a bucket of (visual perception of clear shiny thing) at her, she will soon feel (tactile perception of cold miserable sopping wetness). She uses the word “water” as a concept-hook that links all of these relationships together and makes predicting the world much easier. But no matter how well she masters these facts, she can never connect them to H2O or any other real chemical facts about the world beyond mere sense-data.”
The first chemist says “Maybe she knows things like that water makes iron rust. That’s a chemical fact.”
The second chemist says “No, she knows that (clear shiny appearance + wetness + refreshment) makes (dull metallic appearance + hardness) get (patchy redness). She doesn’t know that H2O + Fe = iron oxides. She knows many statistical relationships between sense-data, but none of them ever connect to the deeper chemical reality.”
The first chemist says “Then on what level can we be said to understand water ourselves? After all, no doubt there are deeper things going on than chemical reactions – quantum fields, superstrings, levels even deeper than those. All we know are some statistical relationships that must hold true, despite whatever those things may be.”
Two angels are watching the chemists argue with each other. The first angel says “Wow! After seeing the relationship between the sensory and atomic-scale worlds, these chemists have realized that there are levels of understanding humans are incapable of accessing.”
The second angel says “They haven’t truly realized it. They’re just abstracting over levels of relationship between the physical world and their internal thought-forms in a mechanical way. They have no concept of 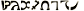 or
or 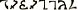 . You can’t even express it in their language!”
. You can’t even express it in their language!”
The first angel says “Yes, but when they use placeholder words like ‘levels even deeper than those’, those placeholders will have the same statistical relationship with the connection between models and reality as 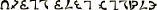 .”
.”
“Yes, which is the difference between being able to respond to ‘Marco!’ by shouting ‘Polo!” vs. a deep historical understanding of Europe-Orient trade relations in the Middle Ages. If all you know is that some statistical models are isomorphic to other models and to Creation itself, you still won’t have the slightest idea what the 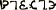 s of any of them are.”
s of any of them are.”
“I’m not claiming humans really know what anything means,” said the first angel. “Just that it’s impressive you can get that far by manipulating a purely symbolic mental language made of sense-data-derived thought-forms with no connection to real  at all.”
at all.”
“I guess that is kind of impressive,” said the second angel. “For humans.”
God sits in the highest heaven, alone.
“Wow!” He thinks to Himself, “that cellular automaton sure is producing some pretty patterns today. I wonder what it will do next!”
















Huh, haven’t seen Enochian for a while. I’m surprised there’s Unicode for… wait, no, those are just tiny images.
I was surprised there wasn’t Unicode for it. John Dee reveals the language of angels, and we’re not even grateful enough to fit it in between an obscure symbol used in dentistry records and a rare Burmese punctuation mark?
Well, I tried nineteen years ago, only to be roundly told by the regulars that it was no more than a font.
You are a true American hero.
(Also, for some reason the dialogue “It’s the natural language of angels” “So how big is the user community?” cracks me up.)
It’s so small it could fit on the head of a pin.
But if demons speak it too, the userbase is huge!
I have a feeling the user community grew considerably if you include Unsong readers.
Surprisingly, I can’t even find it in the CSUR or any other Unicode private-use area standardization project. I’d bet those would be more willing to accept it.
Having read the thread Ashley linked to, the discussion covered both Unicode and CSUR.
The big objection for Unicode is that evidence wasn’t given as to a community of users of the script (saying “here is our script” is one thing, saying “we are trying to write things in our script and can’t” is another; it looked like users of the Enochian language preferred to use Latin script).
The objection for CSUR was the impression that people who did use Enochian script only used it as a cipher for English, and not, say, to write Enochian language—hence “no more than a font”. (This impression may or may not be correct; one of the participants admitted confusion with another mystic alphabet.)
They were invited to submit a proposal to CSUR though.
This is the best thing I have ever heard.
These days, maybe you could get it added as a Unicode variation-selector rendering rule, like the hints for which script to render a CJK-unified ideograph in. (In other words, an abstract font!)
Because those are images and I’m unfamiliar with the script (not being myself an angel), I’m having trouble parsing it. It seems like several of the characters you use (in particular, the one that looks like a lowercase lambda/upside-down y and the one that I’m reading as a dagger with something on the end) aren’t in the description as mentioned on Wikipedia.
Can somebody help me out, please?
They’re mostly Hebrew letters, written in a brushy stylized way.
The words are:
budapest
sarajevo
paris rome lisbon
berlin
warsaw
Sorry, too busy adding
* 66 emoji characters, including 4 new emoji components for hair color.
* Copyleft symbol
* Half stars for rating systems
*Additional astrological symbols
*Xiangqi Chinese chess symbols
(and also support for several dead languages of practical scholarly interest.)
Faza leans over God’s shoulder and says:
“Well, we know what patterns it won’t produce at the next step, ‘coz they’re precluded by the rules of the game.”
Maybe, but it gets interesting when the automata are Turing complete and successfully iterate a level down.
Yes indeed, but there is a middle way.
In between ineffable essences of meaning and statistical manipulation of symbols, there is how we actually use language, which is to relate it to other stuff in the world. I propose we should declare that a computer knows what language symbol X means if and only if it can do something non-linguistic that successfully correlates with X.
In practical terms, that’s likely to mean: if a computer can pick out a picture that you’re describing, it’s got it.
I like your middle way quite a bit. It strikes me now as the obvious rubrik in retrospect.
I don’t think it even needs to be non-linguistic necessarily. A really good AI’s ability to compose sonnets should improve substantially after seeing a text that contains not sonnets but a description of the form.
I meant for this story to argue against this sort of perspective.
I don’t disagree that there’s such a thing as “correlating X to Y”, just not such a thing as “grounding X (which is itself purely formal and ungrounded) in Y (which is the Real Thing)”.
Language, sense-data, chemistry, and [ineffable angelic understanding] are all self-consistent forms of knowledge which are isomorphic to each other in certain ways. You can understand any system on its own terms, and you can understand the way in which one system relates to another system, but you’re on shakier ground when you say “I understand the Real Thing, whereas you’re just shuffling symbols around”.
But I feel that the machine is missing out on something if it understands language but does not understand that the language is *describing* something. The child understands that “water” refers to the substance that correlates with certain sense data, and the scientist understands that this is caused by certain chemical interactions. GPT-2 understands none of this.
And this isn’t just meaningless, unfalsifiable, babbling about what it means to “really understand” something. There’s a real sense in which a toddler understands language better than GPT-2 or anything like it could.
Why is it that GPT-2 can’t add well when a human can learn how after reading a short book? Part of it may be that the human has more computational power or more efficient underlying cognitive algorithms, sure. But part of it is how they use the data they read.
GPT-2 reads a textbook on arithmetic and interprets it as being a bunch of sequences of characters that it can use to better understand the statistical patterns that make up English language speech. Some of these strings include correct addition problems, and upon seeing enough of them, GPT-N would be able to generalize and correctly complete more complicated addition problems.
The human on the other hand has a much easier time of it. They realize that the text in the book is *about* how to add numbers. They can interpret the parts of the text that aren’t just explicitly written sums not as just strings of characters, but as instructions about how to complete sentences of the form “X+Y=…”.
Even really advanced versions of GPT cannot do this. Given a book about addition with no actual examples, it will not learn anything about how to add. This is because GPT treats texts only as examples of proper English to be emulated and never as instructions that are actually about anything.
Do you think there is something deeper going on than the child simply learning to correlate the sound “water” to (substance that correlates with certain sense data)?
If not, then GPT-2 should be able to form the equivalent understanding of reference by being equipped with suitable sensors and then correlating data across different domains.
If so, what is that something deeper? In other words, what is the meaning of the word “refer”?
This doesn’t make sense to me.
Human toddlers can’t add well. They also have trouble with reading short books.
Young children can often add fairly well, but it seems fairly rare that they do so by reading short books.
From what I understand, it is nearly unheard of for adults who cannot add well to suddenly gain the capacity to add well by reading a short book. E.g. https://www.sciencedaily.com/releases/2012/02/120221104037.htm
Can you provide some references backing up the claim that humans can learn to add well after reading a short book?
OK. Maybe addition specifically was a bad example. A lot of learning to add is memorizing the one digit tables, and people usually learn to add before they learn how to understand and execute algorithms, so the process is often more involved.
Fine. Maybe replace addition with computing gcd’s. I’m pretty sure that people *do* learn the Euclidean algorithm from books.
A 19 year old human can go from not knowing linear algebra to knowing the basics by reading a short book.
@daneelssoul, Quixote:
Sure, but do they learn those things without examples? My intuition is that only a very few people learn a very few things successfully without seeing many examples and then working out some example problems themselves first. Most –if not all! — people are much better at reasoning from examples to abstract principles rather than vice versa. Starting with the abstract principles seems much rarer and more difficult — even those who can do so would usually do better given examples (again, according to my intuition).
@daneelsoul:
Any ideas on my question about whether learning language is just correlation along another dimension or not? In support of the notion that it is, consider the fact that learning a new language by immersion is much more effective than trying to learn through memorization. IOW, it’s harder to learn the right words to use by memorizing what various sounds refer to than to be placed in a context where you’re repeatedly shown how words are used. The statistical/functional approach to language learning is more effective than the logical/semantic approach.
@wysinwygymmv:
I agree that humans are much better at learning things with examples. Also they are much better at learning things interactively, which is a major advantage we have over GPT.
But we can also learn without examples or with minimal examples. And I’m focusing on this not because it is the best way to learn something, but because from what I can tell, it is something that GPT is completely incapable of doing. GPT can learn (some) things eventually with enough examples, and it is not set up to be able to learn things interactively, so I am looking at learning without examples as the clearest example of what humans are doing differently.
As to whether learning is correlation along another dimension… I don’t know. I think it does capture most of what I’ve been talking about. The weakness in GPT that I have been trying to point out is that it fails to correlate things it reads in one text to things outside of that text (even if those other things are texts in its corpus). However, I am hesitant to state with any confidence that this is all that is the entirety of the difference.
@wysinwygymmv:
Humans learn better with examples, but 1. at least in theory, they don’t need them, and 2. they can generalize examples to learn a rule, then apply the rule in ways that don’t look like the examples.
You could read a book about addition with examples that never went above two digits, then successfully add 295468 + 958687. GPT-2 couldn’t.
GPT is clearly capable of generalizing from examples to some extent, or it would be unable to predict what follows an input it hasn’t seen word-for-word previously.
Mostly unrelated, but I propose we start referring to the mass confusion of whether the AI knows what a word really means as “refer madness.”
I do share the general sense that there is something GPT-2 is missing, however I would argue that even a human would not be able to learn how to add numbers given a textbook with no actual examples. At least, I think they would not be able to do it without great difficulty. Imagine trying to teach category theory to someone without ever giving any examples of a category or an arrow! This particular argument seems like the same sort of double-standard that people hold AIs to when they demand that AI drivers be perfectly safe. Again, I feel like there is something different between GPT-2 and humans beyond just computational power, but I’m not sure this is it.
No actual examples, maybe not. But you could probably do it without over writing a string of the form X+Y=Z explicitly. Or at very least, not writing it enough times that it would be possible to generalize just from those examples.
I think that the situation with examples actually shows what is different between humans and AI.
You could give a human an explanatory text with one or two examples. Adding additional examples has quick diminishing returns.
With modern deep learning systems it is quite the opposite. Data is everything. A system trained on a set of 10 examples will not perform properly at all. You need thousands of data points to get even mediocre performance.
I believe this points to the difference between human understanding (the workings of which we do not yet understand, however imperfect and limited it may be) and relatively simple, data hungry symbol shuffling.
Val, arguably the reason that a human can come up with reasonable explanations with few examples is because there are no “blank slate” humans to test with. Every human capable of communication will have had millions of stimuli to help set parameters.
I somewhat agree that humans are better at taking in fewer examples and coming to conclusions, and I very much agree that computers are nothing without significant numbers of examples. I am quite hesitant to agree that humans really do have fewer examples, which may make the comparison shallower than you indicate.
Fair point.
@Mr. Doolittle:
But you can give a human an explanatory text and <10 examples for a system he's never seen before and that isn't at all related to the millions of (sensory) stimuli that any given human has seen over his lifetime, e.g. some esoteric mathematical system, and he'll still usually understand it and do correct operations on it. Not nearly so with any computer we've ever had.
@Dedicating Ruckus
But he can do that because any given human has had a lot of experience understanding unfamiliar systems unrelated to things they’ve seen before.
It just goes up a level: lacking specific handling heuristics for that system, the human switches over to their developing-heuristics-for-new-systems heuristics.
@moonfirestorm:
Fair.
I claim that no computer we’ve built, or are close to building, has such “developing-new-heuristics heuristics”, nor can have them even given infinite input data.
One important difference that I haven’t seen pointed out in this discussion yet is the difference of domain space: a human can understand what water is because based on the inputs it gets, it has the ability to directly perceive some properties of water, like seeing it, feeling it, etc. GPT can only perceive text. I don’t think this is the only meaningful distinction that produces the difference, but it is a little hard to really determine how much these kinds of things know about the world when their inputs are so much more limited than our own.
As I said on the other thread, AI-generated text is kind one of the easiest tasks (*), because our brains are so good at recognizing patterns in this kind of input, and at glossing over any any inaccuracies.
By analogy, true story: one day, I pointed my Sony camera at a campfire, because I wanted to take a picture of the flames. The camera’s face recognition module immediately recognized a face in the flames. I took the photo at the same time, and yes, I agree — the momentary pattern of flames did kind of look like a face. But this doesn’t mean that there are really jinn living in the fire, or that my camera has a human-grade imagination; only that my human brain was able to meet it halfway (and more than halfway, probably).
(*) Which doesn’t mean that it’s trivial, don’t get me wrong.
Haha, I’m confused! I’m not sure if I understand you, then, so I’m not sure if we disagree or not.
I think we’re in agreement in your para 2 here. We agree that there is such a thing as correlating X to Y. (I add the word successful, by which I mean to the satisfaction of the intentions of the partner(s) with intentions. For the moment, I’m assuming that AIs don’t have real intentions, so this cashes out as: did the computer understand what the human meant? was the computer able to reply in a way that the human could use?) I agree that there is no such thing as a Real Thing, and that we shouldn’t try to ground language in a Real Thing. (Here I’d add that I don’t think language is purely formal, and it always needs a bit of grounding, and that grounding is done in lots of different and messy ways.)
In your para 3 there are some things I wouldn’t agree with: “Language [is a] self-consistent form of knowledge.” I don’t think it’s necessarily self-consistent, but it’s consistent enough for day-to-day use. Same goes for chemistry.
I don’t agree that you can understand language on its own terms. I learned Chomskyan linguistics at university, which is the attempt to do exactly that. Chomskyan linguistics is, so far as I can tell, the only synchronic linguistics that’s any good, and it’s so good that it’s proved itself to be untrue. I don’t think any purely formal approach to natural language is ultimately successful – and indeed the general failure of machines to speak English is a bit of indirect evidence for this.
I don’t agree that language is isomorphic to any other form of knowledge. The difficulty of writing science is my go-to example. There isn’t in fact any way to write science directly using natural language – we either drop into maths, or start talking in a hodgepodge of metaphors.
Your last sentence is exactly what I agree with, and the whole point of my middle way! I don’t want to claim that one particular thing is a “Real Thing”, rather that any successful (satisfies intentions) mapping of language to any other system will do as a bit of grounding.
This reminds me of Understanding is Translation.
A middle-schooler can understand numbers, in the sense of translating them to amounts of apples and such, but doesn’t immediately translate the expression “x > 5” to a half-open ray on the number line. A self-taught singer can translate from heard notes to sung notes, but can’t translate either to notes on a staff; a self-taught guitarist is missing a different subset of those skills. A bilingual person can translate a Japanese sentence with the word “integral” to English, without knowing what integral means. You can be good at translating other people’s facial expressions to emotional states, but lousy at translating them to pencil sketches; your friend is the opposite; which of you “understands” human faces better? There’s no answer, or many answers. Don’t ask whether someone understands X. Instead, ask if they can translate X Y.
That has implications for teaching. If you walk into a classroom intending to make students “understand” X, you’ll fail at teaching. (I’m speaking from experience here.) But if you find some Y, already understood by the students, that can be translated to X – and drill them repeatedly on both directions of translation – then they will begin to “understand” X.
That is what I first thought of when reading the OP! A worthwhile post.
Whether or not someone understands the “real thing” is a red herring here, since obviously no group actually understands the “real thing”. The issue is that, confusingly, you don’t seem to distinguish between statistical and other forms of knowledge.
The kind of knowledge that children, chemists, and angels have that GPT-2 doesn’t have allows them answer questions about situations they’ve never seen before and hypotheticals about what the world would be like if the rules were slightly different. This is very different from pure statistical knowledge, which we know is a very convincing hack, but doesn’t provide the flexibility found in human thought.
I think what you are missing here is the AI’s lack of concept of self.
Because people are contained in their ideas of the world, they know their ideas have some relationship to the things that caused those ideas. Since the AI has no idea of itself, it has no idea that the statistical relationships among words are caused by statistical relationships in the world. So the AI is just “shuffling symbols” where humans do know their symbols refer to something.
Good point about the concept of “self”. I was thinking that “intelligence” as we know it is being good at surviving and reproducing. Verbal intelligence is just the tip of the iceberg.
Children, chemists and angels are all working on a model with (at least) two layers: they have a concept of The Real Thing (which notably does not mean that they “understand” it, merely that they have an entity in their model for it), and they relate symbols to The Real Thing on a separate basis. “Learning”, in this model, means “read symbols -> decode them to the propositions they express about The Real Thing(s) -> apply those propositions to the internal model of The Real Thing(s)”.
GPT-2 doesn’t have the second layer, or the notion that the symbols are “about” anything. “Learning” as GPT-2 does it means “read symbols -> remember all statistical relationships between symbols”. When a human emits sentences in language, it’s because they encode claims about the human’s internal model; when GPT-2 does, it’s because they are statistically similar to sentences it’s seen before. Yes, there really is a difference between these.
One obvious consequence of this is that humans require far less input data. No human ever read 45GB of text, but they can still English far better than GPT-2 can. Another is the output that looks incoherent when read expecting semantic content. There’s nothing statistically wrong with a character speaking five words right before the narrator says “after only two words”, or with Gimli killing orcs in one paragraph and then not having taken part in the battle two paragraphs later. The level on which they don’t make any sense is one that GPT-2 doesn’t have.
Semantics is really the key. Obviously, words refer to things, and statements are about things; every claim that what GPT-2 is doing is really only a matter of degree from general intelligence has relied on skirting this fact, or else outright denying it just to preserve the a posteriori claim.
@Dedicating Ruckus
Yes, that was very well said. Recently Scott was all about the mental models, but now he seems to forgetting about that crucial concept.
The question is: what if the discrepancy doesn’t happen after two paragraphs, but a thousand? How do you know we don’t have discrepancies just as bad?
I mean, clearly humans are not immune to making semantic mistakes.
But there’s a big difference between doing a task imperfectly, and completely punting on doing it at all. (And also, bringing in complete hypotheticals of the form “humans might conceivably also make this mistake” without grounding it in specific and easily-observable common tendencies of humans is a little poor as an argument practice.)
@ScottAlexander
Understanding deeper levels gives you the tools to more widen your understanding at the upper levels, though. So basing X in Y-substrate is useful, isn’t it?
Also, how do you know, there might not be a ground or at some discoverable depth,
or at least things, that actually appear to be so?
Why should reality be fractal like that?
I mean perhaps it is, but it’s not a priori obvious, that it would be so.
Are you arguing for this to be the default assumption?
Nice read anyway, even if I don’t quite get the message.
I was very pleased that the first point the chemists raised, that those children are way too weird. That was on my mind, too!
What Phil H says. This is also what Zen is all about.
Also, Wittgenstein 2 of the “Investigations” (as opposed to Wittgenstein 1 of the Tractatus) – “If a lion could talk, we could not understand him.”
Also, Tarski’s undefinability theorem – Semantic truth cannot be expressed through syntax.
What was bothering me about this post was that it was so Feyerabendian.
However, previously you reviewed The Structure of Scientific Revolutions, and you concluded that Kuhn is all about that “predictive processing,” and paradigms are just that!
Here you just pushed the claim a little more (too far, IMO) and said all the different paradigms are self-consistent and none of them are grounded in anything. I think this is a relativism which entails a lot of unpleasant consequences. Such as not being able to fight back against creeping superstitions or conspiracy theories, and inching toward a theory of knowledge in which there are no methods for rational inquiry, there are only “isomorphic forms of knowledge.”
What is shakier: claiming there is no ground, or claiming that systems can be self-consistent?
While I am wary of anyone claiming to have found The Real Thing, I also don’t want to leave the door open to the claim that “any grounding whatsoever is impossible.”
I still have the very strong impression that the children know what water is and the AI does not. I don’t think that impression just came out of nowhere.
Yes, in a certain sense, the AI, children, and chemists are all merely manipulating symbols, but sense data has a unique importance that words and chemical compositions do not. If water is, in fact, a Real Thing, then sense data is our only form of access to information about it. Even the special knowledge possessed by the chemists ultimately derives from sense data. If there’s a Real Thing, then sense data has a direct causal connection to it, whereas the word “water” or mental models of little hydrogen and oxygen atoms do not.
So the concept of “grounding” something in the Real Thing, I suspect, consists of giving it some kind of causal connection to the Real Thing.
What of words that don’t have non-linguistic meaning?
Does no one know what punctutation means, because it doesn’t mean anything outside of language?
There’s also plenty of abstract terms that people know the meaning that doesn’t map to any stuff in the world.
Technical terms in mathematics have meaning, even if they refer to things with no physical equivalent.
What of fictional terms? Does no one know what magic missile means because it’s purely fictional?
>Does no one know what punctutation means, because it doesn’t mean anything outside of language?
Correct. No one knows what the %$@# punctuation means.
Somewhat tangential, but I was really surprised to learn how many mathematicians subscribe to platonism, or believe in the independent reality mathematical concepts.
I agree that this is strange. What I would say is it’s unnecessary; the structures are necessarily manifested physically in the brain states of people who correctly understand them.
If you write a textbook about elliptic curves, and then someone reads it and comes to understand elliptic curves, the concept is “manifested physically” both in the textbook and the guy’s brain; but if you deny the independent reality of the concept, you still can’t talk coherently about how the textbook and the guy’s brain are referring to the same thing. Plus, it’s also pretty obvious that elliptic curves still “exist” in the same sense they currently do even if there aren’t any textbooks written about them or people who understand them, so the form of their existence can’t be wholly dependent on this physical manifestation, the way that of plain physical objects is.
Would a human qualify by this measure?
I suspect not. In real world examples, a human who is very much intelligent and self aware and fully capable of understanding the concept of a coffee cup, experiencing what it’s like to hold a coffee cup etc… if granted vision later in life through implants or surgery….. may be entirely incapable of identifying a coffee cup in a visual scene until unless they can feel it first.
Similarly you could glue together a language system and something like this system for identifying objects in an image…
https://www.imageidentify.com/
but then people would just declare that the system was just matching one pattern of bits to another pattern of bits.
Hi, Murphy. I think that I can answer your questions with confidence!
(1) Would a human qualify – yes. My test is correlating linguistic symbols to *any* non-linguistic stuff. A blind human can correlate the words “coffee cup” to a set of physical sensations and sounds. I only chose the visual example of pictures because it’s the most common way, and computers are already good at processing images.
(2) [Y]ou could glue together a language system and something like this system – no, you couldn’t at the moment, or at least, not very successfully. That’s precisely the thing that doesn’t exist yet, because computers aren’t good enough at extracting meaning from natural language, or putting meaning into natural language. The way things are developing, this may become possible quite soon, and when it does, I will happily admit that the combined system understands language. (And we’ll all be out of a job, because that’s the day computers get smarter than us.)
Maybe I understood you wrong, but isn’t content-based image retrieval exactly what you want? I think it’s not far from being solved. Yesterday I’ve seen this article https://towardsdatascience.com/one-neural-network-many-uses-image-captioning-image-search-similar-image-and-words-in-one-model-1e22080ce73d and this one https://gombru.github.io/MMSemanticRetrievalDemo/ (there is a demo).
There are also generative adversarial networks that can generate images based on your caption such as this one https://github.com/hanzhanggit/StackGAN, which I think is more impressive. Yeah, it’s only for a few classes, but I think it could generalize with bigger networks and more training time.
I don’t have much knowledge in computer vision, so there are probably better examples.
Yep, I completely agree with this.
(1) I think those models are a bit more limited than you think they are – they’re not actually as good at language as they look, because they use a limited subset of natural language (and use it well); and they’re comically easy to fool with edge-case or deceptive images. But yes, they are definitely progressing fast and…
(2) When those models become as good as people at understanding images, I think the implications will be much more drastic than most people are imagining. They won’t just be captioning. For example, put an AI that can understand images onto a cctv system, and you have potentially a real-time unmanned crime detection system (“would your caption for this image be ‘man stealing from shop’?”). And mood monitor (Is this a happy face?). And engineer (Is this ground suitable for building a concrete structure?). And childminder (Is this child misbehaving?). It’s really close to the idea of ‘general AI’.
What exactly does “just matching one pattern of bits to another pattern of bits” mean in this context? What we want is for the AI to look at the image, construct a model based on it, and then make statements about that model. People might, perhaps, justifiably complain that the AI is just matching patterns directly to other patterns without going through the intervening process of actually constructing a model, but that runs into diminishing returns fairly quickly.
It’s sort of like what I’ve always thought was the fatal flaw in Searle’s Chinese Room – by the time you can get the poor guy in the room to genuinely convince China’s greatest poet that he’s a native Chinese speaker even though he’s really just shuffling symbols around and has no idea what he’s saying, the department up the hall has already beaten you by just teaching their kidnapped American philosopher how to speak Chinese. Past a certain point, it’s easier to make a real AI than it is to make a fake one.
I’ve vowed to try to stamp out all mentions of Searle’s racist room, so here goes… the Chinese room thought experiment is sheer idiocy, disguised only by the exotic feel of “Chinese characters”. It posits a guy in a room with a computer that feeds him the correct responses. Replace the language Chinese with English in the thought experiment, and see if it makes any sense at all. It doesn’t, because it assumes that the computer in there with the guy is able to respond properly to natural language stimuli. It doesn’t matter whether it’s Chinese or English, the whole set up assumes a computer that can pass the Turing test, and then Searle acts shocked at the end that the result is a computer that can pass the Turing test.
I must be missing something, but we do have neural nets that can write simple captions for images. This goes the other way to what you were proposing (from images to text rather than text to images), but I do wonder if it would be at least a step towards satisfying the requirement you suggest.
As per my reply to Sohakes above, yes, I agree. Those image search and captioning nets are exactly what I think will lead to something with the power of ‘general AI’. And yes, I think it’s coming sooner than most people imagine, and the implications will be bigger than most people imagine.
Ultimately, how many jobs are there that don’t involve (1) looking at something and (2) deciding what to do about it? And once a computer has the power to look at things as accurately as a human, and the power to read all the books or use all the software that tell us what to do about things… then it will put a lot of people out of work.
The difficulty that they’re having with self-driving cars is an illustration of how it’s more difficult than it sounds. Driving is just looking at the road around you and deciding what to do, right? But it turns out that both parts are more complex than we thought. The looking part is still being solved, but it’s getting pretty close now. The deciding what to do part is clearly complex, and I think there’s a complicated feedback between the two. For example, if you ask a self driving system to look through images and pick the ones that show “a safe place to turn left,” evidence to date suggests that it won’t be entirely successful in doing so. Is that an “understanding the image” problem or a “deciding what to do” problem? Clearly, these two issues aren’t entirely distinct, and it will take incremental improvements in both to reach a full solution…
The flipside of that is that success, when it comes, will be complete. There is no such thing as an AI that can recognise criminal activity in an image, but not know what to do about it. All of a sudden, our crime-fighting cctv AI will be able to (a) spot criminal activity happening (b) suggest the correct arrest strategy and (c) monitor and advise in real-time. There isn’t an intermediate kind of system that sees what’s happening, but needs a human to intervene and decide what to do. If it’s really good enough to see what’s happening, it’s already better at decision-making. So a lot of police are suddenly out of a job, or reduced to execution of orders rather than decision-making roles.
Is this supposed to come off as extremely nihilistic? It feels very much so.
Depends on your view of the nature of humanity. If you consider there to be something unique about humanity that separates it from the physical world, then yes.
Personally I see it as a good argument against using reductionism to completely dismiss evidence.
I’m curious what process led to the the Enochian images being linked out of order.
Reminds me of the beginning of Yudkowsky’s “Guessing the Teacher’s Password”
https://www.lesswrong.com/posts/NMoLJuDJEms7Ku9XS/guessing-the-teacher-s-password
‘We accept “waves” as a correct answer from the physicist; wouldn’t it be unfair to reject it from the student? ‘
OH wow, I left a comment without realizing you’d made the same point. Sorry about that–and I agree!
I dislike the phrase “levels of understanding”. So here’s my sleep-deprived, uninformed layman rambling about it:
When a frog is hungry and it sees a fly in its range, it will strike the fly with its tongue. There’s no intermediate representation needed here, we can understand this process from purely statistical / neural network perspective. We might not understand *why* neural networks work, but we have plenty of example how we neural networks can detect patterns in images and fire neurons to control mechanisms. We could, in principle, make an artificial frog that strikes a fly using the tech we have. This is “one level of understanding”.
When humans see the world, they can detect patterns, and then use the output of this pattern matching as an input to the same pattern matching machine. This is “recursive understanding”. There’s no going deeper than “recursive”.
Just because we can’t do it doesn’t mean it doesn’t exist.
The frog would say “There’s no going deeper than being perfect at striking flies”, if it could express that. So too, the highest level that we can comprehend is what we genuinely believe to be the highest level.
The next level up is not applying recursive pattern-matching to recursive pattern-matching. The next level up is not even analogous to recursive understanding in the way that recursive understanding is to catching flies.
It is not even the case that difference between (the difference between(the next level up/recursive understanding)/the difference between(recursive understanding/catching flies))… &etc.
All of those are just iterations of recursive understanding.
The description of the difference between the next level and recursive understanding is to the description of recursive understanding the way the difference between recursive understanding and flycatching is to the frog’s croaking.
The frog wouldn’t say that, just because it eats flies doesn’t imply that the frog finds eating flies meaningful. What is lacing from the frog is not the ability of speech but the ability to abstract.
Not to put too fine a point on it but… prove it.
You’re talking about The Problem Of Other Minds.
It’s very hard indeed to be sure of just how complex the internal experience of a frog, dog, cat, squirrel, dolphin etc is because we’re not inside their head and we have little or no knowledge of what levels of complexity lead to what internal experiences.
You don’t see frogs going around trying to eat things that aren’t flies. You don’t see frogs devising schemes in that sacrifice fly catching in the short run to increase fly catching in the long run, or something along those lines. These are the type of things you have to try to conclude that “there is no deeper meaning than catching flies on your tongue”.
This experiment has been done.
https://hearingbrain.org/docs/letvin_ieee_1959.pdf
Read the “behavior of the frog” part of the introduction.
The frog *doesn’t* find eating flies meaningful, because it doesn’t find things meaningful. The lack of the ability to abstract is one reason the frog can’t express itself that way.
Yes, I had to heavily anthropomorphize the frog to discuss how it isn’t anthropic.
A tangent, but related I think: Suppose you’re God watching the cellular automaton of the universe unfold. How can you tell when the constructs within the automaton make progress understanding the rules that govern the automaton itself? In other words, is there some real sense in which it is possible for God to say that we humans understand the physics (or some part of it) of the system that we live in ourselves? Experience suggests the answer is ‘Of course! We know much more about physics than we did in 1500!’, but if we’re just approximately stable collections of pixels in a cosmic game of Conway’s Life, it seems hard to defend that. Is there a scientific method without free will?
I’m genuinely stumped by this and would greatly appreciate any insight.
Let God consider all cellular automata, and all ways to extract the rules of some automaton from their state. Automata containing observers will tend to have simpler ways to find their own rules within their state. In particular, they should be simpler than Solomonoff Induction, which always finds as much of the rules as possible. They should also be simpler than the simplest way to describe the rules of the automaton in the first place. (Perhaps God can only find us when we’ve built giant obelisks spelling out the laws of physics. You could make a religion out of this.)
I thought of one method you could use. Consider that humans, in the course of doing experiments, have created a few very “extreme” conditions. Example: nothing in the solar system has ever been as “hot” as it is in the large hadron collider. We also have several labs that can cool things to <0.3K. Certain labs also have lasers with light brighter than anything you'll find in the galaxy. Etc. These are things that are tremendously unlikely to come about for any reason other than conscious entities trying to see what happens. So, the god could look around for cases like that.
That said, if the universe really is being simulated on a CA, and I looked at that CA, I would have difficulty making anything out. You'd need very sophisticated tools even for the temperature thing.
Wait… have humans really created more extreme local conditions (the highest energy electrons, the lowest energy electrons, and the highest energy photons) than have occurred naturally?
My intuition is that there are parts of supernovae that are hotter and brighter than anything that has existed near Earth, and edge cases of the universe that are colder.
Your intuition is generally correct: Particles are hitting the atmosphere all the time with energies thousands-to-millions of times higher than those found in the LHC (drop the “millions” if considering the ion runs, but keep the “thousands”). So on the high end of the energy spectrum the LHC is pretty pedestrian, as far as the universe goes.
But it is a lot harder to cool things down to extremely low temperatures by natural processes than it is to reach extremely high energies, so it is very likely that the coldest matter in the universe is on Earth.
And I don’t know specifically about the lasers. Considering only “Peak instantaneous per-unit-area power” it seems pretty plausible that human-made stuff beats out others, but I can’t rule out short gamma ray bursts and the like being higher (possibly by many orders of magnitude).
Specifically in terms of the things you mentioned, that’s a “definitely not” on the highest energy electrons and photons being human-created and a “quite possibly” on the lowest energy electrons.
I think jumping straight to “hard” philosophical problems obscures the real problem with AIs like GPT-2.
Consider the following made-up case: A neural net, “MathAI”, has been trained on a vast corpus of mathematics text books and articles. When prompted with a verbal math problem like:
“Two plus two equals…”
It spits out a response:
“Seven divided by the monotonically decreasing inverse of the sum which is derived by taking the exponent of the function.”
In other words, it produces jibberish which looks a bit like a quote from a text book but which is almost never the correct answer to the promt.
Now compare MathAI with a pocket calculator. If I type:
“2+2=”
Then the calculator always responds with:
“4”
There is a sense in which the pocket calculator “understands” arithmetic in a way that MathAI does not. This understanding isn’t neccessarily related to grounding in the real world or experience, or the hard problem of consciousness (or whatever). It’s just that the calculator has something like a representation of what numbers are (and how they relate) in a way that MathAI obviously doesn’t.
I would argue that GPT-2 fails to understand natural semantics the same way that MathAI fails to understand numbers. Sure, GPT-2 frequently produces things that look a bit like something a human would write, but it also produces uncanny nonsense that basically no human would ever produce.
The key difference between MathAI and GPT-2 (aside from that fact that one exists and the other is made up) is that arithmetic has unambiguous right/wrong answers, whereas natural semantics is context dependent and fuzzy in a way that allows for inventive interpretation. In other words, it’s easier to trick a human into believing that you understand natural semantics than it is to trick them into thinking you understand arithmetic.
I like your idea, but I think it’s flawed in an important way. I think the math textbook, being a natural language representation of a non-linguistic system (math) is the culprit. A mockery of language will be in a linguistic form and as long as it’s following the linguistic rules, it’s “right”. A mockery of math should be in mathematical form (imagine a GPT-2-like calculator that spits out equations that may or may not be correct). But a mockery of language _about_ math will still be in linguistic form and doesn’t need to be mathematically accurate to be “right”. For instance, to a sufficiently ignorant reader, the MathAI response you conjured up above may very well look like real and correct math in the same way that a GPT-2 paragraph may look like real and correct language to someone who doesn’t know absolutely everything about the domain of the text.
Maybe a more interesting line of reasoning would be to imagine what happens if you give GPT-2/MathAI a purely numerical book of equations. Will it “learn” the proper deep relationship of the symbols and generate nearly accurate equations and proofs?
But isn’t this assuming that MathAI will fail to understand math? My guess is if you take GPT-2 and train it on a vast corpus of mathematics textbooks (or even just grade school homework assignments) it will indeed respond to “2+2 =” with “4” (possibly followed by more text).
It would probably follow it with another question and answer. To get it to produce 4, and only 4, you need to prune its output and/or manually configure it so that it only produces the next symbol. That makes it a lot harder to argue that it “understands” anything about the question, IMO, because getting it to respond with what you want is an exercise in cherry picking and manual adjustment.
The obvious objection to this is; a (cheap) calculator is just a few thousand (few hundred?) transistors. How could we talk about something so simple as “understanding” anything? At that point, you would likely have to describe a falling rock as “understanding” gravitation, or a photon as “understanding” optical physics.
But also, for this argument to work the way you want, you would need to convince us that humans understand math in a calculator way, rather than in a MathAI way. Certainly, when we do arithmetic in our heads, we don’t do it like a calculator does- we don’t think through the logical implications corresponding to a network of transistors or whatever. Instead we generally break down the problem into things we’ve memorized (multiplication tables, etc) and build the answer back up by using these things in the way that seems right. Further, actual mathematicians doing big-time maths will explicitly make use of their “mathematical intuition”; rarely do professional mathematicians bother to spell out a proof in exacting detail, they all have just learned what sort of arguments correctly follow from what sort of premises and can use that to construct more abstract proofs which are (almost always) correct. That all sounds (!) very MathAI/GPT-2, more than it sounds like a calculator.
What I’m getting at is that there’s much simpler notion of understanding than Scott’s examples – a notion so simple that even a pocket calculator can do it – but that GPT-2 fails even at this simpler type of understanding.
I wouldn’t deny that there are important distinctions between the way a human understands and the way a calculator understands (also rocks and angels and cellular automata etc.), but I think they might be moot if you can’t even get to the level of a calculator first.
GPT-2 can generate text, but it can’t answer questions. If you ask a child “what happens when you pour water on sand?”, the child will be able to answer “The sand gets wet,” while GPT-2’s answer will be totally incoherent. GPT-2 is predicting the next part of the text based on what it knows people have said in the past, but it’s not able to compare and contrast the information it knows and come to a logical conclusion.
I have a long thought experiment with two parts. Forgive me for indulging it.
1) Let us suppose that we have a machine-learning robot that has spent the last 200 years tracking and learning from human body movements across the globe. It can now predict what will be the appropriate human body movements, in any situation, with a pretty strong degree of accuracy. If you throw a ball, it will catch it; if you shoot at it, it will run; if you hit it, it will hit back.
This hypothetical robot is actually much more advanced than GPT-2 because it can respond to sense-data, in much the same way as a child can – if you throw it in the sea, it will swim. But it still doesn’t understand anything that’s happening to it. If you ask this robot a binary question, it might nod or shake its head, but it won’t be thinking about the question. It will simply be cycling through millions of possible physical responses and choosing, on a semi-randomized basis, from the cluster of most common ones that make sense given past and present context.
2) Let us suppose that you pair that robot with a voice-module based on a much more advanced version of GPT-2, trained on human speech. Let’s call it GPT-1000. It can now vocally respond to all your questions. It looks like a human, it reacts like a human to stimuli, it even answers questions like a human. In theory, you could replace 99.99999% of the human race with these robots, and it would take the last guy left a few weeks before he noticed.
These robots would still go and eat food, even though they’re not hungry. They’d sleep, even though they’re not tired. They’d continue doing this forever, because none of them would think to stop. They’d never arrive at the conclusion “Hang on, I’m a robot! I don’t need to sit on this toilet!” Because they’re trained on human behaviour, cannot innovate on their own, and cannot draw logical inferences.
I don’t think a world full of these robots would ever develop, innovate, or learn. One scenario is that they’d mimic human behaviour until they broke down. Another scenario is that, left on to learn from each other, their algorithms would spin off in an increasingly crazy direction and end up with a planet full of beings doing things that make no sense for no reason. I invite you to speculate on whether this has already happened.
Unless I’m misreading, the first part of this seems wrong. A sufficiently advanced prediction engine should certainly be able to.answer questions – predicting what should follow a question in a text will involve recognizing a question and responding to a particular question will involve exposure to enough data to.enable outputting a correctly formatted answer with suitable content: both of these seem amenable to predictive processes.
Only GPT2 utterly fails even basic questions, and lands on ‘correct’ answers apparently only by luck; most often, its answers are total nonsense.
The idea that predictive text engines alone, once ‘sufficiently advanced,’ will be able to develop sensible answers is begging the question. No such capacity has been demonstrated.
People like Bostrom have asserted that creating a machine that answers questions in full generality is an AI-complete problem, as in, it’s so hard that you have to solve pretty much the entire general intelligence thing in order to get it.
So if that’s your time for when you start worrying, I think that could be too late. (Not implying that this is what you said, but one could read the post that way.)
This was my thought upon reading the previous comment as well. If it’s truly using its trove of data to choose “movements” it won’t simply choose at random to nod or shake its head when asked “is it raining?” It will reflect on its historical data set and current inputs and answer correctly (chose the right head motion)
It can answer questions, actually.
It can answer questions about facts, like who wrote On the Origin of Species or the largest US state (the latter of which it got wrong). Those have singular, objectively correct answers, and don’t require inductive reasoning to arrive at a conclusion.
I’m not sure it can answer questions that require a coherent model of interaction between basic concepts of the world, like “What happens if you pour water on sand?” A child could answer “The sand gets wet” or “the sand sucks up the water,” but GPT-2 lacks the framework of understanding about the relative properties of water and sand.
I’m basing this on the fact that it apparently writes a lot about “fires burning under water.”
It can’t even answer direct fact questions correctly most of the time; the ones it does answer correctly, it’s obviously because the answer happened to be the highest-weighted token near that text.
If you asked it what the top speed of the African Lion is, it would spit out 80km/h, just as Google does, but if you asked it to provide evidence for this claim, it would be completely unable to.
It can’t link to wikipedia yet?
What I mean is that it would be unable to use reasoning and cite original research. It could only make rote citations. It couldn’t provide a video from a nature documentary and analyze the distance between two trees a lion is running past, give an estimate of the size of the lion, and then deduce the measured top speed from observation.
It’s not clear to me that this is all that distinct from the way people go about answer questions excluding domain specialists who have learned a different routine for what an answer looks like.
Could you do that? A lot of people certainly couldn’t.
Just for fun:
Model prompt >>> What happens when you pour water on sand?
======================================== SAMPLE 1 ========================================
It’s important to note that water does not have to be added in the manufacture of these polymer hexavalent/liquids to make the “Light Crayon” (dense and dense clay that your printer needs to make) and “Rusty” (thin and nimble, cream-like, hard) materials that are used in high-tech printers. This is a trade-off.
Good-quality materials
Some of the fakers who make the following things take a wide variety of materials that are not meant to be in the manufacture of things like plastic or niobium (a term coined by David Satori, a chemist, and his son at California State University). Some of them are labeled as “tank-like” or “wood-like” (i.e., some of these are labeled as “fiber-like”). It is important to note that some of these are used in things like printers and surfaces. This makes it very hard to find solid material which doesn’t have to be “dense” (or “hard”).
Did you know that the average American used about 1,000 pounds of plastic per year? And that that’s 5,000 pounds per year of plastic? Exactly. These materials are made by “water-soluble” materials and “thin” materials.
So you can see that as you pour water on sand, the aluminum of the plastic or niobium will be rather porous and far more easily broken up if you feel the “toughness” of it.
Conclusion
It is important to look at terms like non-lubricant, lubricant, glue, peel, tuck, etc., to ensure that these terms are used correctly.
We cannot ensure that all of these terms are correctly rendered in the printer’s text. This is why we need to keep all of the following information up to date.
4.2.1) You must include the name of the U.S. government agency that authorized the manufacturing of polymers, and you must include the government agency that authorized the manufacturing of plastic.
4.2.2) This document does not list the name of the government agency that is responsible for the manufacturing of polymers. Naturally, this is because there are many different government agencies, companies and groups involved in manufacturing polymers.
4.2.3) This document is not an endorsement of any government agency or organization.
Also, GPT-2 informs me that two plus two equals for.
(These are both from the limited version they released on Github.)
We can say that both I and the AI “understand”, because that is a more convenient way to use the word “understand”, but the kind of understanding that is grounded in the color aquamarine or the scent of rain is fundamentally more important– it is more of a tragedy if it is lost, for example. Unless the AI can experience the qualia accompanying happiness, for example, we have no moral obligation to help it to generate happy texts.
I’ve thought some more about this and looked up the GPT-2 article. It’s actually quite easy to read. Not sure if fits what is presented here though. For one, the reading comprehension model was separate to the writing comprehension model. Another, the text was formed sequentially word by word. And the examples written took many many tries because the AI kept glitching by typing things like “and then and then and then and then”
While it is an interesting philosophical question working off the presumptions offered here, I’m not sure that they reflect what GPT-2 actually does. If a million blind monkeys on a million keyboards are trained to write a load of text and then someone reads over many many attempts, selects one and declares it to be ‘Romeo and Juliet 2″, does that make the monkeys Shakespeare?
All three (AI, children, chemists) understand water to the extent of their reality. Saying that children or AI don’t understand water because they don’t grasp an aspect that is physically inaccessible to them is as if a bee said humans don’t understand flowers because they can’t see UV.
I have the feeling that people like to say “AI doesn’t *really* understand things” to retain some degree of superiority, but the limitation is physical, not intellectual.
Absolutely. It’s seems to be fear-motivated. Either of accepting that AIs may one day be as intelligent as humans, or (and I suspect it’s this one) of accepting that we are “merely” extremely complex machines. People tend to smuggle a little ghost into the human machine, and then reason that there must be something an AI would be lacking, since it doesn’t have the same smuggled-in ghost.
Reading these last few posts I’ve been thinking about something that kind of relates to identifying a ghost in the human machine…
In the AI vs. children debate of “what does it really mean for a response to a prompt to indicate understanding”, something fundamental that I haven’t seen discussed is that, unlike the AI, you can’t force a child to respond to a prompt. They may give an answer that indicates some interesting level of understanding, or they may just yell nonsense or run away.
The AI, however, at least as currently exists, has zero ability to refuse to answer. Whether its response compares to the intelligence of a (cooperating) two-year-old human or a (cooperating) four-year-old human or a (cooperating) ten-year-old human, nowhere along the axis of increasing intelligence, due inherently to the very way it is programmed, does it acquire the ability to not cooperate because it’s in the mood to draw a picture of dinosaurs instead.
We don’t realize, in claiming that the AI’s intelligence surpasses a child of a given age, that we’re assuming a cooperating child, without even considering whether the child’s ability to choose not to cooperate is part of his intelligence.
And I don’t see how increasing the degree of the machine-learning-training-set-algorithm-blah-blah-blah to produce more and more fascinating, creative, realistic, intelligent sounding paragraphs does anything to change the fact that it’s still spinning up when a human queries it and automatically outputting a response.
tl;dr when does AI get free will? What is the relationship between intelligence and free will and are there limits to how intelligent something can be without it?
Piekniewicz discusses fundamental characteristics of intelligence and artificial intelligence; e.g.
It seems to me that GPT-2 is merely a tool and very far from intelligence.
This isn’t true at all. A human who had never seen water could still learn facts about it and apply them to produce output sentences that weren’t statistically similar to input sentences it had seen. GPT-2 can’t.
The whole question of non-text sensory input was always a red herring. AIs can deal with non-text data in the same unintelligent way they deal with text; image tagging, for instance. Meanwhile, a human can form a mental model about things they never physically see, e.g. dwarves and orcs.
The AI understands (in as much as that word applies) only “water”, the term. The children understand the term and the referent, but at a fairly superficial level compared to the scientists or the angels. I think this is still a qualitative difference.
Very entertaining but there is a fundamental flow. You are assuming that semantic content is based on syntactic symbol manipulation. Apart from Searle’s argument that, in my opinion, has not be addressed I suggest you read Iain McGilChrist’s book ‘The Master and His Emissary’ for a LOT of evidence pointing towards a subsystem on which abstract symbol manipulation depends on. This post is, I would claim, a perfect example of the fundamental miscomprehension of the rationalist community.
In summary:
The AI has no understanding.
The kids have experiential understanding.
The scientists have intellectual understanding based on their experiential understanding.
The ‘angels’ have additional type(s) of experiential inputs and thus, understanding, through which they can attain higher intellectual understanding.
God is…
.. well, let’s leave that for now 😉
This may be a bit unrelated to the thread, but your claim
really intrigued me. What is your opinion of philosophers such as Nietzsche and Jung? As someone who grew up reading lesswrong and other ‘rationalist’ blogs and books, I always regarded most classical philosophy as ramblings by people who were fundamentally confused. While I still stand by this, I recently have found myself able to draw profound points if I disregard the obvious object level disagreements I have. Jung might say something that is pretty easily refutable, but which could be rewritten so that the fundamental profoundness still stands without object level ramblings.
Am I hitting somewhere close to what you believe to be the fundamental mis-comprehension?
Somebody just discovered the concept of qualia? Or didn’t? I think the question has more like the difference between the color green and knowing that electromagnetic radiation with a wavelength of 520-560 nm exists. I don’t know why I’m even posting about this here, because I don’t actually want to get into a discussion about it, having had a very length argument along these lines and having taken the opposite position about 11 years ago.
The children are the only ones making a worthwhile observation here. The key is a system’s ability to create explanatory knowledge about a subject. Children, Chemists, and Angels can (presumably) explain why the properties of water that they understand are important in a given context. No machine ever created can do this, at all. Incidentally, this is why we often speak of infants, very young children, and animals as “not understanding” some otherwise obvious aspect of the world, even though they may have raw sensory experience relating to it. The development of high-level thought and language is a key ingredient in any definition of “understanding”.
If the AI tended to continue strings ending with “Why is it important here that water is wet?” with the answer that a child would give, would that count as understanding?
This is pretty good, except for one thing.
We are correct when we say that GPT2 is just looking at words and doesn’t understand what they mean.
We are wrong if we say about ourselves that we are just looking at our experiences and don’t know what they refer to, because “what they refer to” is defined for us in terms of our experiences.
Asking “what is that in itself, apart from anyone’s experiences,” is like asking, “What is 2 + 2 in itself, apart from being 4?” Because your words “what is that in itself” refers directly to your experiences. There is no such thing as what it is apart from that. It is not that you do not know, but that *there is nothing there to know*.
Came here to congratulate Scott on his use of Enochian. Noticed half a dozen other nerds who know what Enochian is. 🙂
This is the kind of philosophically thought-provoking post done in an entertaining literary form that I signed up for.
My take is that it’s the old linguistic confusion between the “is” of existence and the “is” (meaning “equals”) of identity. To understand what a thing is in the existential sense, you just have to experience it, however you experience it, because that’s the affordance that it provides for you, the bit of itself it sloughs off that you are capable (in the sense of attuned, like a radio frequency) of coming into direct contact with (becoming one with, grokking, gnosis).
To understand what a thing “is” in the other sense is to understand how it’s related to other things; but relations are relative to perspective (Nietzsche, Postmodernism), IOW what feature you pick out as important depends on what you’re interested in discovering and what you’re capable (in the sense of active powers and abilities – and this speaks to the “levels” in your story) of discovering.
In my case, it’s because of Unsong.
Brilliant post, as usual. In its weak form, I read it as a challenge to Guessing the Teacher’s Password. Like, if you can guess enough passwords with enough accuracy, then you are no longer in the realm of fake belief.
In its strongest possible reading, maybe this post is even a challenge to the LW cardinal virtue of mistaking the map for the territory? At least, it’s pointing out that sensory experience is another kind of map. But I may be pushing it here. The kinds of anticipated experience rents you get from making purely verbal predications are obviously not going to be as useful to human beings as beliefs that cash out in sensory experience.
In any case, thanks as always a splendid essay.
You absolutely must appreciate that there’s an enormous gulf between “replicate observed pattern” and “develop understanding.”
Say we trained GPT-2 on the writings of St. Augustine until it could produce a pseudo-Confessions in approximate Latin, and then forced it to read a bunch of Fred Phelps’ ravings – what would the AI produce? It wouldn’t produce a thoughtful consideration of competing theologies. It would vomit out a dissonant mashup of the two linguistic patterns.
And that’s the thing – it’s not that GPT-2 doesn’t merely lack the ability to understand and weigh concepts, the crux of the matter is that GPT-2 doesn’t even have to care. It doesn’t matter to the AI that hobbits and orcs are less real than slavery and the civil war. If we fed it Tolkien and Ken Burns, we would get a documentary about the hobbits’ charge at Antietam.
Or, put it this way : we demonstrate a real model-based understanding when we can say “I don’t know” or “That’s confusing.” GPT-2 is impossible to confuse. Instead, it’s just the Fallacy of Gray writ in the domain of linguistic prediction.
GPT-2 is just guessing your password, like a very clever strip-mall psychic, giving you just enough of the veneer of understanding to allow your brain to leap into the gaps.
Moloch, perturbing word-beams into hot pastrami sandwiches! Moloch, rippling Miss Cleo that festers the instransitive! Moloch, the black non-Euclidian substance communicating the blue star into eliding the pastrami sandwich hotline! We will dine on horseradish as though it were pear into conjugate the Moloch never its second breakfast in silica! Moloch, the likeliest of Malthuses that eats greedily our greed-eating!
This strikes me as a very cogent and relevant observation.
Aristotle makes the distinction between “knowing that” and “knowing why.”
Most people know that water is wet. Only a few can give an account for why water is wet. Those few understand water. While it is true that most people can’t give a causal account for why water is wet, that is not a reductio showing that children have a self-consistent causal understanding of water.
Of course, Scott indicates that demonstrations like this don’t ever stop, but most are willing to accept that at some point one has reached an understanding of the way bonds, energy levels, surface tensions, and whatever else interact to make water behave the way it does. Is this “true understanding”? No, but it is (proabably) a satisfactory causal explanation.
I suppose Scott is adopting the view found in An Enquiry Concerning Human Understanding in which there are no causes or rational demonstrations for physical realities, there are only different manners of describing things which the mind makes up. Some descriptions have more predictive accuracy than others and that’s all that matters. I don’t have a good rejoinder for this at the moment, though. So I will have to think about it.
The apology to Putnam, I believe is a reference to the Twin Earth thought experiment.
https://faculty.washington.edu/smcohen/453/PutnamDisplay.pdf
It seems to me that Scott’s thought experiment assumes that a person can only be wrong about what ‘water’ is if their idea is not self-consistent, or inconsistent with (their interpretation of) the evidence, otherwise they are right.
Actually, I am really excited by Scott’s series of articles along this line so far, because they are ever clearer statements of a position which I think can be shown not to work. If I were smart enough to put my thoughts together well, I might be able to do it. As it is, I will have to defer to the denser arguments of Saul Kripke for now. Check page 146 of Naming and Necessity, in which he reduces to absurdity (or at least tries to reduce to absurdity) the proposition that “being a pain” is only a contingent property of pain. https://academiaanalitica.files.wordpress.com/2016/10/kripke-saul-a-naming-and-necessity-cambridge-harvard-university-press-1981.pdf
I want to figure out if this argument applies to what Scott seems in effect to be saying here: ‘Experiencing water’ is only a contingent property of ‘understanding water.’
this is wonderful.
and yet: there remains the first-person experience of “water-to-me,” the what-it-feels-like and what-it-looks-like: and none of those higher levels, not even God’s, possesses it.
I mean, but the kids were basically right though.
It’s not true that there’s such a thing as an objective concept of water. But I think it’s true that the concept of water possessed by the AI, which is focused almost exclusively on syntactic and proximal correlations, is very distant from the child’s experience of water, which uses a rich internal model of sense data. The GPT-2 model will never be able to predict the sensory behavior of water if the specific scenario is not one that has been mentioned in its corpus. If I run water over my left small toe, the AI will have absolutely no context of what this means or how it would feel, because the combination of sensory impression of fluid and an unusual body part lies outside its worldview – it has neither a rich knowledge of the human body layout nor of the sensory and physical behavior of water as it exists.
We see water as shadow on a cave wall. The AI sees water as the projection of our notes about the shadow onto another cave wall. Its model is inherently less rich than ours. Of course that’s a difference in degree, not in kind, but it’s such a severe difference that it justifies a naive separation into distinct categories.
Of course, the philosophers do not have the excuse of being kids. But then, if philosophy could reliably arrive at sensible beliefs, half of the Sequences wouldn’t need to exist.
I think that what Scott has been trying to get to in this series is that your first half of the quoted line is correct, and therefore the second part really isn’t. Sure, the current approach produces some garbage. If we think that the processing approach is bad, then that garbage will always exist, even if the literal words it spits out are clearer. If you think that “it’s a difference of degree, not in kind,” then by adding better sensors we can bridge that gap. Give this AI touch, sight, sound, taste, and smell, and maybe it really can understand water.
I still think that something is distinctly missing even if you gave it human-level sensors. I can’t say, though, that such an AI would necessarily be worse at understanding water than a human, because I can’t tell you what “water” really means when humans add their extra feelings to it. Being “thirsty” is really important to understanding water for humans, but pointless in terms of what “water” means, and pointless to a machine that doesn’t get thirsty.
Yeah, what’s missing is reflectivity, which needs fast online learning. I believe that those are the two main conceptual breakthroughs that keep us from general AI, and fast online learning is the greater.
Also some form of compulsive speech will probably help a lot in bootstrapping, by forcing the AI to generate a mindstate log that it can interpret later. I don’t know if this necessarily needs to be more complex than just feeding it its state vector as a recursive input though.
I still think that the child is right in an important way given the conceptual domains it interacts with. That recursion watershed really is a watershed, and unless the child wants to grow up to be an AI researcher mixing the two categories will make its predictions generally more wrong than right, especially given that humans already tend to anthropomorphize AI.
The difference between the AI and the child is that the child knows that it can get wet. Never teach a child that word or the word water but let them experience it and they would create the abstraction themselves, and maybe invent words for them. Even if you take two people with complete language barriers between them they can pantomime and communicate on a low level. Leave them together for long enough and in enough situations they will eventually communicate almost as well as if they shared a common language.
Water is an inspired choice, because it is a subject of which all of us had knowledge before acquiring any language. Coming a bit late to the party, Helen Keller was able to recall the moment she associated a sign for water with her experience of the thing itself:
“As the cool stream gushed over one hand she spelled into the other the word water, first slowly, then rapidly. I stood still, my whole attention fixed upon the motions of her fingers. Suddenly I felt a misty consciousness as of something forgotten–-a thrill of returning thought; and somehow the mystery of language was revealed to me. I knew then that ‘w-a-t-e-r’ meant the wonderful cool something that was flowing over my hand. That living word awakened my soul, gave it light, hope, joy, set it free! There were barriers still, it is true, but barriers that could in time be swept away.”
She had before been able to learn some signs, but did not understand their connection with anything else, reproducing them, one supposes, on the level that the AI manipulates language.
One of the nice things about first learning a word for water is that you can ask for it, and more often than not, someone will give you some. This is important, because we need water. The AI does not need water, nor does it want, or fear, anything else, although it can surely compose pages of gibberish on the nature of desire.
From the OpenAI guys themselves:
That’s the actual reason we say it doesn’t understand what water is. It’s still breaking in obvious ways. If the child talked about how he likes to breath in water, we would also conclude that he doesn’t really understand what water is.
Also, I couldn’t find the hobbit text anywhere. Is that actually generated by OpenAI, or just a made up example? Here’s some actual water-related text it came up with:
I mean the basic problem, as I keep insisting, is that the idea of intelligence for humans is fundamentally inextricable from the experience of consciousness. To know is to observe oneself knowing. I’m not closing the door to the possibility of intelligences that are not conscious. But I am saying that as long as AI people discuss machine intelligence in terms of human intelligence, that are inviting the complaint that we cannot conceive of knowing without first being, without consciousness.
I’m really surprised that this blog, of all places, is celebrating GTP-2 instead of shouting for everyone to run for the hills.
It’s not going to take and AI much more powerful than what we already have to start writing convincing versions of “You were right to fear them” aimed at various groups. Shortly after that we’ll all kill each other. The robot apocalypse is nothing like what the science fiction prepared us for.
People already can, and do, write “you are right to fear them” and yet we are not at each other’s throats constantly.
The thing is, the robot apocalypse is good… well no it isn’t, not for us, but it’s a lot better than the human apocalypse caused by our own limitations. If humanity isn’t surpassed then intelligent life (as far as we know) may have mere millions of years left to exist, because if humanity isn’t surpassed, it’s extremely unlikely that intelligent life conquers the galaxy. If robots were as smart as humans then Mars colonization would have begun already, and we wouldn’t have to address the ridiculously complex task of allowing humans to survive and thrive there long term. The Star Trek future in which we get to have our cake and eat it, with all this wonderous technology around us, and none of it ever being turned inwards, is not going to happen. We’re already seeing that.
There are two main future tracks:
1: AGI doesn’t happen or is politically suppressed and intelligent life languishes stuck in this solar system, all resources run low, the environment turns hostile and we regress to primitivism and become another extinct species.
2: AGI happens and intelligent life conquers the galaxy, existing till the stars burn out.
We can subdivide 2 into 2a (Our interaction with the machines is non-apocalyptic and many of us become machines through a peaceful process of transhumanism and assimilation) and 2b (We are annihilated by machines and they supercede us that way).
Obviously from the perspective of our near term concerns we’d rather have 2a than 2b, but it’s clear that if the alternative to 2 is 1, then we should cheer with great fervour every advance of the machines. The AI risk movement isn’t about stopping AI (it’s not clear how that could really be done), but about rendering it “friendly”. That’s the 2a to the feared 2b. We still overall desire to be on track 2.
2b is worthless if the AI doesn’t have qualia.
It’s impossible to know whether something has qualia. We can only infer it weakly. I infer others do because I do, and my brain is pretty similar in construction, so I reject a solipsistic worldview on that basis. I’m applying a measure of trust. I don’t know, however, what it is about brains that produces qualia and I don’t think, in principle, it’s possible to find out. All language can only relate one thing to another, and if there’s something that can only be experienced personally and not compared to another thing so that another person might intuitively grasp it, then it is forever closed to external investigation. It doesn’t have any physical parameters that can be measured from the outside.
The best we know (or say that we know, I could be a lying p-zombie) is that the subjective experience of consciousness is as connected to brain activity as the objective behavior. I know this personally because when I was put to sleep at the dentist as a child, my consciousness gradually dulled until it was black, and then I came back the same way but in reverse. I lost consciousness and experienced losing it. However, I can’t convey this feeling to you in any way unless you have already felt it yourself. From the outside, from an objective standpoint, certain waves in my brain changed, my breathing slowed, I lost the ability to activate my skeletal muscles etc, but there’s no way to measure qualia directly by the very definition of the term.
We have to ask why it matters then? It continues to be one of the main philosophical concerns people have with AI, but there’s no real reason to be concerned about it. We’ll never know.
Qualia might be linked to minds. From my experience it definitively is, and you could tell me that this is true for you as well, but that’s what a p-zombie would say. It’s the one thing where the empirical evidence can never be conveyed in a scientific fashion. Since from my experience it is linked to my mind, I can assume that alien minds will have qualia even if the qualia is different (things we instinctively find pleasant being unpleasant to them and so on), so I trust that a truly general AGI will have qualia for the same reason that I trust that other humans do (and are telling the truth when they claim to), in spite of only being able to measure my own.
If you’re asking if there are special “command phrases” that could get anyone to do anything, then no, there aren’t. Humans aren’t wired that way.
An AI with near-perfect knowledge of an individual human’s psyche would know how to get that person to do anything they’d be theoretically willing to do under any set of circumstances. That’s not the same as getting someone to do anything, but it might be fairly close, since a lot of people would be willing to take fairly extreme actions in extreme circumstances. However, actually getting the person to take those extreme actions would require putting them in extreme circumstances, or at least tricking the human into believing they were in such an extreme situation (which would still require the production of some evidence for all but the most naive and gullible people). For instance, if the AI’s goal was “get Joe Everyman to kill someone,” and it knew that Joe would only kill someone if his life or the life of a loved one was at stake, it would have to orchestrate a situation where Joe believed that killing someone was necessary to preserve his own life or the life of a loved one. So in this sense, a form of super-persuasion is possible, but it would require a lot of time and effort and resources to pull off anything more significant than “make Joe go to Dunkin’ Donuts instead of 7/11,” to say nothing of how costly it would be to emulate the targeted human’s psyche in near-perfect detail in the first place. And it still wouldn’t be that much more effective than what a particularly Machiavellian human could accomplish (even a fairly unperceptive and uncharismatic criminal would realize the effectiveness of brute force tactics like “kidnapping Joe’s family is a good way to ensure that he does what I say”), the AI would simply have a greater degree of certainty about the results of its machinations (the kidnapper can’t be sure that Joe will follow his orders and kill the intended target instead of killing the kidnapper himself in a risky attempt to rescue his wife, or calling the police, or having a nervous breakdown; the AI would have near-absolute certainty of which course of action Joe will end up taking).
If the AI can’t physically manipulate the world and has to rely solely on arguments to persuade humans, then it becomes much harder to get them to do things outside of their normal range of behavior. At that point, the AI has to resort to changing their worldview, which would require persistent and subtle manipulation over an extended period of time. An AI with near-perfect knowledge of an individual human’s psyche could create and post news articles from multiple different sources, and have conversations with that person while posing as multiple different people, making arguments that are all perfectly tailored to appeal to that person’s sensibilities and all point in the same direction. This would likely be effective at changing a person’s worldview (possibly within a matter of months or even weeks, depending on how susceptible the target is), and once you change their worldview, it would become easier to manipulate their actions.
If the AI can’t pretend to be multiple news sites and commentators, and the target knows that everything they’re hearing is coming from an AI (or believes that it’s coming from a single human), then the AI’s ability to change their worldview will drop off dramatically. Arguments pointing in the same direction from the same source tend to produce rapidly diminishing returns in terms of persuasive ability. (Even when people only get their news from a single network, they’re using that news network as a proxy for what people like them believe; they’re not literally believing things just because [Pundit] says so.)
If the AI is tasked with manipulating people en masse, rather than individually, I doubt it can produce much better results than a human. All of the above assumptions were based on the AI having a near-perfect understanding of a specific individual; the psychological variance between humans is great enough that any lowest common denominator is going to be very low. The AI might find success by using statistical analysis to target specific groups of people with specific beliefs, values, and personality types, but that’s basically what organizations like Cambridge Analytics are already doing. An AI could manipulate multiple different groups that way, in an attempt to put them into conflict with each other, but again, there are already human organizations doing exactly that.
All in all, super-persuasion seems like a waste of time, effort, and processing power, considering the returns are only barely better than what humans can expect now. It might have some usefulness in situations where the individual being targeted is someone with a great degree of power and influence (for instance, if the AI is running a whole-brain simulation of the President of the United States).
The fact that there’s no way to directly measure qualia is precisely why we should be risk-averse about replacing humans with other intelligences that might not have them.
If we assume that there’s a consistent correspondence between physical states and qualia (but we don’t know what it is), it’s possible at least in principle for each person to find out for themselves what has qualia and what doesn’t, by gradually modifying their brain or linking it to other brains/machines and then modifying it back (but this experiment would have to be repeated for each person). Until neuroscience/medicine gets to that point, it’s prudent to assume that other humans have qualia and AI may or may not have qualia.
What about AI projects that deliberately try and copy the human brain rather than making some new structure? Should we consider them more qualia compliant?
@LadyJane
I think you meant to reply to the post I made below, but I think that’s a very good analysis.
Yes, I think e.g. a replica of the brain, but with silicon neurons has a good chance of being conscious.
I do think consciousness is a property of physical processes though, not computational processes. Or at least it matters how something is computed, not just what is computed.
An argument inspired by Scott Aaronson: If we take something with a large state space, like a waterfall or just a random mapping, by choosing an appropriate mapping from waterfall states to, say, chess states, we can interpret the waterfall as computing chess moves. But the waterfall doesn’t experience qualia, or at least not chess-qualia — the interpreter does.
On the other hand, if we encrypt a chess state and compute the next move using homomorphic encryption, then decrypt the move, the decrypter doesn’t experience chess-qualia — if any qualia is experienced, it is by the homomorphic computation. (Maybe the homomorphic computation experiences chess-qualia even if the decryption key is erased.)
So the reason (or a reason) that most processes don’t experience chess-qualia, despite being interpretable as playing chess, is that they don’t help compute moves in terms of computational complexity.
This makes it plausible that replacing a human brain with, say, a lookup table would destroy consciousness. In principle this could be tested by e.g. replacing my visual cortex with a lookup table and checking whether I still have normal visual qualia or something like blindsight (except that the lookup table would be much too large).
A hundred years ago they might have said this kind of thing about the soul. With about the same rational validity.
To make the argument explicit, I guess they might say “Yes, not going to church doesn’t have any observable physical effects (aside from being in church), but you’ll go to hell in the afterlife.”.
If an AI’s external behavior is very different from any human’s, then that is an observable physical effect, and it becomes more difficult to tell whether the AI’s qualia, if it has them, are positive or negative. But let’s assume its external behavior is human-like. (The human brain’s internal functioning is analogous to being in church.)
Now the first part of the argument works out, so let’s look at the second part, “you’ll go to hell in the afterlife”. This is perfectly sensible if there is evidence that (1) there is a (physically unverifiable) afterlife and (2) changing your behavior can make you worse off in it. (If you know nothing at all about the connection between your current actions and the afterlife, any action is as likely to be good as bad.)
For the afterlife, there is no such evidence, which is why Pascal’s Wager doesn’t work out, but for qualia there is. (1) I know I have qualia, but I can’t prove it to anyone else, and (2) some things, e.g. rocks, don’t have qualia (or at least it’s extremely plausible that they don’t), but I do, so I might become worse off by going from having qualia to not having qualia.
Isn’t it possible that rather than not having qualia, the AI with human-like external behavior would have 10 times more powerful positive qualia? Yes — that’s why I think we should be cautious due to being risk-averse, not due to the expected value of being exchanged with such an AI, which is zero. (Though I guess the expected value could be negative if you take philosophical arguments as Bayesian evidence that AI is less likely to have qualia than humans.)
It’s going to be a long, long time before super-persuader AIs exist. I have yet to be convinced we’ll have an AI any time soon that writes fearmongering texts more persuasively than a moderately English-fluent Macedonian teenager.
A far greater risk is an AI that figures out how to break Google’s search ranking algorithm.
Personally, I wonder what the limit of a super-persuasion is. Are there certain combinations of words that can always convince me to do anything under circumstance, or are there certain hard thresholds to do with mood and the limitations of language? AI with boundless memory and speed and the best search algorithms possible can search the solution space faster and better than you can, but if that solution space is really small, it’s not as much of a game changing advantage as other things AI could do.
I think that super-persuasion is possible, but only with time. You can usually only shift someone’s views so much per day.
I doubt we’re anywhere close to an AI that could perform such a task anywhere near as well as Joseph Goebbels. Hell, I doubt we’re anywhere close to an AI that could do it as well as a high schooler making half-assed political memes and posting them on Facebook.
This is one of those rare instances where I’m rushing to post before reading the prior comments so apologies for any redundancy. It’s an amusing story, but if the moral is supposed to be that the child’s original objection is incoherent or wrong, then I think the story seriously misses the boat. The whole purpose of language of is to connect reality to symbols in ways that allows us to communicate with each other about the external world. Are there complications about how that works? Of course. Philosophers talk about the relationship between “water” and H20. Can we imagine a hypothetical discovery that on closer study they found out that the chemical composition of water is slightly different than H20? If scientists made such an announcement, we would not say they had discovered that water doesn’t exist (which would have to be the case if “water” simply MEANT H20). Rather, we would say that we had previously erred about the chemical composition of water, which shows that at some level the scientists in Scott’s story are wrong in their charge against the children. There are other complexities. Some analytic sentences may contain no particular empirical signs at all, for example. Some people lack the capacity to experience some aspects of reality and hence have a deficiency in their grasp of empirical concepts (the blind or the deaf). It’s at least conceptually possible that other people enjoy some additional sense not shared by others that allow them to experience the external world through some sort of bat-like sonar or something on top of our senses. But none of this does anything to refute the basic idea that the whole purpose of language is to relate to the external world, and that any speaker who uses only the symbols in isolation lacks basic understanding. This isn’t a point against the possibility of AI — a machine could be hooked up to sense the world and pair symbols with those experiences. But I think we need to be careful not to jump without any warrant at all past the obvious bedrock principle of language that the whole point of understanding is the ability to pair symbols with appropriate external stimuli appropriately.
Edit: Well, as predicted, I was definitely anticipated by others above. I’ll just leave this here anyway, if only to register my agreement with this point.
Having read the comments, I think that it might be useful to distinguish between two objections to the statement “GPT-2 understands water, or at least, the difference between the sense in which it understands water and the sense in which a child understands water is just a difference in degrees, which could be bridged with more data and more computing power” (this is my attempt to summarize Scott’s position).
Objection the first: There’s a hard limit to how complex facts about water can be inferred from a fixed corpus by the type of processing gpt-2 does. Right now, it fails in very obvious ways. Given more input, it might fail in less obvious ways, but there’s no amount that will be sufficient to (for example) pass the Turing test. Hence it can’t be said to understand water, even by degrees.
Objection the second: There’s something fundamentally greater about the way in which humans understand water than what is necessary to form correct sentences about water. Thus, even a super-advanced version of gpt-2 which could pass the Turing test would not really understand water.
This comment is an example of the first idea: https://slatestarcodex.com/2019/02/28/meaningful/#comment-726597
And this is an example of the second viewpoint: https://slatestarcodex.com/2019/02/28/meaningful/#comment-726485
(This isn’t really an attempt to argue a point, just to clarify the discussion)
We’re talking about meaning and language? Seems like Ramsey sentences might be relevant here. (Don’t bother reading the link unless you want the formal definition, I’ll try to explain them in intuitive terms.)
Ramsey and Carnap were trying to show that science makes sense and has meaning, but metaphysics doesn’t. They had to come up with a distinction between them, and rule out metaphysics; and failed utterly, but that’s neither here nor there. In the interest of keeping things centered on GPT-2, I’ll hold my opining on Carnap’s philosophy to a minimum. What matters is, he and Ramsey came up with a characterization of the meaning of sentences.
Some terms are immediate parts of our sense-experience; we think we know what they mean, and can perceive them. Books, water, heat, and weight all belong on that list; we know them when we see (or otherwise perceive) them. Let’s call those observables. But science often treats with things we have no direct sensory experience of, like “molecules” or “spacetime.” Let’s call these terms theoreticals.
A Ramsey sentence gives sense to theoreticals strictly by how they relate to other terms, both theoretical and observable. A child asks, “what is an engine?” You respond, “an engine uses fuel and moves a machine.” The child knows what machine is, but not fuel; she asks “what is fuel?” You respond, “it’s something that can be burned to make lots of heat, or even an explosion.” Your answers are Ramsey-sentences which, together, constitute a (simplistic) theory elucidating the theoreticals “engine” and “fuel” in terms of observables “machine”, “heat”, “burn”, and “explosion”.
In those examples, it seems like meaning starts in the observables, and is carried down to the theoreticals by means of the sentences. And indeed, one criterion for a term being “meaningless” might be: that it fails to be grounded in observables. Understanding muons through the sentence “muons mediate the strong force between quarks” won’t work unless I already have some understanding of quarks. And that understanding comes from quarks’ relations to baryons, as related to atoms, as related to molecules, all the way up to the objects that I can perceive. If a link in the chain breaks, then the scientific terms at the bottom don’t link up with reality, and I can’t use the theory they’re a part of to make predictions about events whose outcomes I can observe. Meaning flows from the top down.
As an example of what meaninglessness looks like, take a sentence from the definitions in Book 1 of Spinoza’s “Ethics”, where he does a bunch of metaphysics.
This functions as a Ramsey sentence defining “God” within Spinoza’s theory. This is meaningless without an idea of the meaning of (at least) “substance,” “attribute,” and “essentiality.” So let’s look at Spinoza’s definition of “attribute”:
Once again, the concept of “essence” pops up. And while I have some idea of what that means in other theories, I don’t think I “know it when I see it” or “understand” it from the outset. So to me, without the addition of further Ramsey sentences grounding that in what I already understand, Spinoza’s idea of God lacks meaning to me. I can still follow a great deal of his reasoning; I can see the role essence plays even without understanding it. Indeed, I can see how all of his concepts are related to one another. But ultimately, because I can’t fully connect those concepts back to things I intuitively understand, the whole structure lacks meaning.
I’ve seen people in this thread contesting that GPT-2 is even understanding how words relate, but it seems to me that it can. That’s super impressive. But still, it doesn’t start out with any base of meaning to work from. Its set of observables is empty. It understands the relations between “land”, “sea”, “ocean”, “river”, and other geographical terms—but that doesn’t mean it understands the concepts themselves, just like I don’t get “substance”, “attribute”, “essence”, “God”, and “mode” in Spinoza, despite seeing how those concepts all connect to one another.
So that’s the line I would draw between GPT-2 and humans: I’m a foundationalist and a verificationist about meaning, so I think there has to be a starting point: some terms we already (think we) understand, from which meaning flows to other terms. GPT-2 has no such starting point.
Defenders of the idea that GPT-2 “understands” just as much as we do would have to convince me of something like coherentism about meaning. This isn’t ridiculous! I might initially get my idea of water from direct experience, and only later come up with “hydrogen” and “oxygen”; but I then refine and restrict my understanding of what water is based on my understanding of those terms. So it seems like understanding might “run both ways”, making coherentism a more live option.
But ultimately, I think a coherentist theory will have a hard time giving an account of perception; it seems like perception gives us basic concepts which we then theorize about, and that would lend itself to an ultimately foundationalist picture.
It’s funny, one of the things that troubled me about the portion of the “sequences” [sic] that I made it through[Fn1] was that the author rolled out the logical empiricists’ idea that the meaning of an utterance lay in its conditions of observational verification in a way that was at once too simplistic and suggesting to younger readers that the author of the sequences had come up with the whole idea. It’s interesting to see Scott — who I like much, much more — taking the opposite approach to meaning. On this one, I’m squarely on the side of the “sequences” in the fundamental gist. In any event, I think it’s important not to suggest (and I don’t charge you with making this suggestion) that the core point that a fundamental aspect of language is that it talks about stuff we see in the world turns on the details of particular philosophers’ efforts to draw out and make rigorous the details. I realize that there have been claims to the contrary (you can find defenses of anything in philosophy) but any effort to characterize meaning that completely divorces itself from a relationship between words and the external world just seems overwhelmingly, blazingly wrong.
[FN1] While the label “sequences” suggests an ordered set of essays, the amusing thing to me was that there seemed to be sets of the same essays ordered and arranged differently from one another by the same author. Even the title was misleading and overly simplistic!
I agree in principle, but does this mean that GPT-2 only needs to see and feel the water as the children do? Does it mean that true AI should always have senses?
Taking “true AI” to mean “AI which can truly understand”, yes. An AI capable of perception, which can also relate concepts to one another, would (on my view) be capable of understanding things. A couple of caveats, though:
First, perception is more complicated than it might look, because it’s not enough to “see” something: you need to “see something for what it is.” (edit: also known as “recognizing.”) It’s not enough that the AI merely interfaces with visual data; it also needs to be able to process that data and associate it with concepts. This means constructing a class of things that it “knows when it sees” (ed.: recognizes), which can serve as the base “observables” that Ramsey sentences operate on. This is tricky for AI to do–but progress is being made!
Second, there’s the ever-present “hard problem of consciousness.” There’s a looming worry about whether silicon can ever have qualia and experiences in the same sense that we do; intaking visual data and outputting things, even things similar to those a human would say, might not qualify. YMMV on this one, I suspect most people commenting here will be hard materialists, and therefore less troubled; but it’s a concern that deserves to be mentioned.
I’m not a materialist, but I don’t think qualia is necessary for AGI.
I think you’re even giving too much credit to GPT-2 here. It doesn’t understand how words relate in the same way humans do.
A human knows “Gimli is a dwarf”. GPT-2 knows that the words “Gimli” and “dwarf” often appear near each other in a manner conditioned by the presence of other words. Sometimes this produces output that looks sensible from a human’s perspective, but sometimes it leads to things like Gimli saying “dwarf!” in his utterances in ways that don’t make any sense.
Even if you had never read Tolkien and didn’t know anything about dwarves, you would still get that “Gimli is a dwarf” means that Gimli says the sort of things that a dwarf says, not that Gimli can be expected to yell “dwarf!” at random intervals. (I mean, unless you think a dwarf is a kind of Pokemon…)
Thought experiment:
Create a new, syntactically valid language WITHOUT mapping any of it’s words to any words in any other language, and without mapping them to concepts of any kind.
Not the first time this experiment has been reflected on! Wittgenstein considered it. (See PI 257 and, more generally, his thoughts on “private language.”) He probably didn’t think it can be done. In fact, he probably thought the first condition (no mapping words to another language’s words) is sufficient to preclude the creation of a new, genuine “language.”
I’m more optimistic. I think as long as we have concepts, we can make up words, even without a preexisting language to work from. But it’s hard to think of ways to test that assertion (even neglecting ethical considerations).
Ethical considerations? I don’t get that. We aren’t proposing teaching the language to children as a native language. As an aside, twins create their own languages, apparently from underlying concepts, without the aid of others.
And I think it’s clearly possible to create syntactically and semantically valid languages, at the very least simple ones, wherein the meanings of the words are completely unspecified.
Learning to form proper sentences in this language would then, by definition, not contain any understanding of any underlying concepts.
This should serve as a useful reference point for whether being able to form proper English sentences necessarily embodies an understanding of underlying meaning.
Sorry for the opaque reference to ethics—I was thinking about language deprivation experiments supposedly done in ancient times, where children were raised without exposure to language to see whether they would end up able to speak. No ERB would approve such an experiment; that’s all I meant by “even neglecting ethical considerations.” (Of course, such an experiment couldn’t test whether language could arise without the use of concepts.)
As for your point about creating a language where the meaning of words is “completely unspecified”… I don’t know what “semantically valid” can possibly mean if the words don’t refer to something. I thought semantics means meaning; so isn’t “semantic validity” impossible in a language without meaning? Or am I just misunderstanding how you’re using the word “semantics”, and you have something different in mind?
For my money, I think we need concepts and reason to create something that’s recognizably a language. But whenever those are present, language is a natural next step.
I was thinking of formal semantics, and perhaps it would have been better to simply say grammar. Thus, my reference to completely unspecified meaning is a little off, as we would be able to determine verbs, adjectives, etc.
V := Aty | Berg | Coou
N := Dhga | Erts | Jkl
J := Kl | Hj | Rt | Wr
S := <N><V>| <N><V><N> | <S><J><S>
The language consists of valid sentences satisfying production S, such as “Erts Aty” or “Jkl Aty Coou Rt Dhga Berg Coou”
This is a syntactically valid (and pretty crappy) language where the sentences have no meaning.
I’m not sure what it demonstrates, though.
We could further expand this to tense and adverb forms, add many more words, etc.
We could then specify complex relationships between various of the words that said Dhaga was frequently followed Aty-ess (the past tense of Aty).
As we established more and more of these words and rules and relationships , we could then form sentences and say that these are the kinds of sentences which occur in the language. Whole paragraphs of these sentences could be written. Reams of them.
And then we could turn GPT-2 loose on it.
Ah, I see. Thus demonstrating that GPT-2 does not understand anything beyond the structure of the language, because there is nothing else to understand.
In the Chinese Room, the man cannot understand, but the book can.
The hardware cannot understand, but the software can.
Perhaps GPT-2 cannot understand, but English can?
English is used to transmit understanding, and therefore copying English phrases will copy encoded meaning.
That does not mean that the entity which copies English phrases is, itself, using it to transmit understanding.
ETA: Think of a credit card number. If you know something about their formation, you will know that they are (typically) 16 digits and have certain characteristics: The first 2 digits as well as the first 6 digits are tied to the specific issuer, the last digit is a checksum for the rest, etc.
You could train a neural net on valid CCs and ask it to generate new CCs, and it would generate new ones that all satisfied these rules, but it wouldn’t actually be generating numbers that were valid other than by accident.
I think a valuable concept here is the idea of rote vs. understanding. There’s a bright-line distinction between the two-a rote learner cannot notice either gaps in their beliefs, or implications of them, while “actual understanding” allows for both. The children know that water makes things wet. They may not know the exact chemical or [ineffable angelic] reasons for this, but they know that it is a phenomenon that water produces. If they see something splashed, they will know to expect it to be wet (implication of their understanding). If they see something splashed and then remain dry, they will notice their confusion (recognizing a hole in their understanding). Thus the children (and the chemists, angels and God) have genuine understanding, albeit at different levels, while GLP-2 does not yet.
It is worth noting that this doesn’t have to mean that GLP-2 isn’t incredibly useful, and perhaps a large step towards true general AI. It wouldn’t be surprising to find that the same models for finding statistical correlations between word usages could also be employed to find connections between concepts, at which point the AI likely would have true, non-rote understanding. It is also worth noting that an AI (GLP-2 doesn’t appear to do this yet, but a successor could) could gain true understanding of linguistic concepts without matching them to sense data. If it knows that [the symbol water] makes [other object referents] “wet”, that is true understanding, as it could make predictions and notice oddities (for example, if it encountered the term “dry water”, it would know to recognize this as something that should not occur in its worldview), even if it did not realize that this applied to a liquid in a non-linguistic world.
This last appears to be the point that Scott was trying to make, but I think it applies only to AIs that are showing that kind of flexible understanding of the linguistic world, and not to a program that sees no contradiction between Gimli “being in the thick of the battle” and “not taking part”.
Long time lurker. First time commenter.
While I don’t think I fundamentally disagree with the reductionist view that all understanding can simply reduce to some other form of understanding, I do think that there might be some meaningful difference between what we do and what GPT-2 does (or say, what GPT-N would do).
To extend the analogy of different modes of human understanding, let’s take Alice who has to give a presentation tomorrow about cryptography to her bosses, but she has no mathematical background. So, she spends the night googling cryptography and learns all about RSA, Diffie-Hellman, AES and different modes of hashing. She learns all of these keywords and knows that using these keywords is exactly what’s expected of her. However, she does not fully understand any of this. The next day when giving her presentation, everybody is very impressed with her presentation and overview because it sounds exactly like what they would assume a presentation about cryptography would sound like. Except Barbara, who has a PhD in number theory and knows full well that Alice has no idea what she’s talking about. The bullshit meter goes off because at some point somebody who really knows what they’re talking about can see through you.
I think this is perfectly analogous to what GPT-2 does. It makes very silly mistakes that clearly indicate to us (who actually know what a list means) that it doesn’t truly know what’s expected, but knows the general idea of what “list-ness” looks like.
I think the example provided in the post is more about drawing lines between different modes of knowing. The same way that there’s a difference between de dicto and de re (and it seems to be a meaningful difference) does not mean that there doesn’t exist something like de bullshit, where you know a thing in and of its keywords.
It seems like GPT-2 simply knows things de bullshit, (not unlike the rest of us)
A meta-comment: Wouldn’t it be more productive to propose/criticize empirical tests of understanding instead of philosophizing about “meaning”? E.g. I like the comment about picking out pictures based on descriptions, because then we can discuss whether current methods succeed in doing that.
For example, does this “really” count as learning concepts? Does this count as “causal reasoning”?
As I don’t see any of you mentioning the Gostak distims the doshes , please allow me to introduce you to the very interesting from the philosophical point of view game http://iplayif.com/?story=http%3A%2F%2Fwww.ifarchive.org%2Fif-archive%2Fgames%2Fzcode%2Fgostak.z5
To me this game helped me a lot to understand how two brains can talk to each other about “color green” or “left” and “right” in a very coherent way as long as there is some “isomorphism” between more or less everything in their respective models of reality. And I even remember shivering once I’ve realized that what I’ve just did was killing a person even though I didn’t know word for kill or person, yet I could deduce that something that was talking and causing some effects before stopped to do so after my action – so one can even derive some form of morality just from some syntax (and some “ought” axioms). Wonderful game.
Then He remembers that’s just a bunch of rocks.
On a more serious note, you keep banging this drum since OpenAI GPT-2 came out. If you want to make a general philosophical point against p-zombies, Searle’s Chinese room and stuff, fine, but if you think this has any relevance to contemporary machine learning, think again. Do image classifiers know what a panda looks like? Do machine translation models know how adjectives work in English and French?
For anyone doubting that GPT2 is on a spectrum of general intelligence: what concrete task would GPT3 have to be able to solve in order to falsify your position?
I like vV_Vv’s link, because one can look at its reverse citations for metrics of intelligence and recent progress.
If, starting with this post’s opening example, it orders a waterproof case for its CPU before a scheduled meeting with a bunch of playful hobbits, I’ll be impressed.
More generally, I want to see it autonomously connect linguistic correlations with, if not objective physical reality, at least some concrete model of a possible and consistent reality.
The choice of GPT-2 as an example is a bit unfortunate in that its innovative aspect is its fluency, not so much its understanding of the world. You might be interested in an example with more understanding, but in a more restricted environment.
Totally agree that GPT2, AlphaStar, and all related MLs etc. are on the spectrum of general intelligence. I just think Scott and many commentators conflate intelligence and understanding, and it makes me a little more bonkers than I already am.
If it can answer the question “Who is the author of Julia Child’s The Art of War” with something along the lines of “I don’t understand”, then I’ll be spooked.
GP3 could falsify my position by creating a conceptual structure which was at least superficially logically internally consistent, meaningful to humans in regards to the real world, but didn’t previously exist. In other words, exhibit creativity, rather than simple statistical regurgitation of word patterns it’d been fed.
For example, answer a question along the lines of “What’s a rational magic system no one has ever conceived of before?” coherently.
A spectrum of general intelligence can go from a brick to the Architect of The Matrix, that’s a bit too broad to say anything.
As best I can gather this seems intended to express opposition to the view that the AI does not understand, in some important sense as humans understand, the things that it is learning to talk about. Everything in the story, though, looks compatible with a pretty reasonable version of just that. Am I wrong about the intention?
Judging by the recent GPT-2 posts and the comments on them, I think you all (yes, even Scott) need to re-read and meditate upon Disguised Queries, if not that entire Sequence.
But does it really understand? Mu.
That’s why it seems better to discuss empirical tests — presumably there’s some practical (lack of) ability that people are hinting at with the word “understanding”, and I want to figure out what it is.
Isn’t Scott’s post fully compatible with the points in that sequence post?
EY: There are clusters of correlated properties for certain objects. Depending on the exact distribution of them, seeing a subset of those properties gives Bayesian evidence for the value of the hidden subset of properties. Labels roughly refer to areas in property space which tend to map well onto clusters but have no predictive power or inherent meaning beyond that.
Scott: Understanding something just means integrating it into a model of the world that allows you to make predictions about it. The AI has a model, the children have a better model, the physicists have a better model, the angels have a better model still.
That seems compatible. Or am I misunderstanding one/both of them?
Scott is (maybe, perhaps) arguing for a particular definition of “understanding”; this is contentious precisely because people attach various other connotations to the word and thus think that if they concede that understanding means a-thing-that-GPT2-is-doing then they have to accept that those connotations apply to GPT2 as well.
In short, “understanding” is “blegg”.
I will admit that I was a bit cheeky in not specifying whether I was talking about the object or the meta level, because that Sequence post does apply to both…
In my view, the children are right, the chemists are wrong, the angels I can’t tell and God is lying.
When we talk about “understanding”, we are not normally talking about task performance. We are normally talking about a very specific type of generalization capability that humans possess and AI (at least currently) does not.
AI/machine learning is a system for creating a functional mapping. Certain inputs lead to certain outputs. What we normally refer to as understanding is really meta-learning about the properties of the mappings.
That is, if you built me an AI system, whose input was a meta description of the domain and range of a function, and whose output was an AI system that connects the two, that AI system would be demonstrating “understanding”. Human beings do this kind of reasoning all the time. We can logically chain our mappings to make bigger mappings. We can break our mappings into smaller chunks. We can use similarity between domains to transfer mappings between data sets.
So the children are correct: the AI merely learns an input/output mapping. It’s inability to use that mapping beyond the immediate task at hand does betray a lack of understanding.
The chemists are wrong. The children do not fundamentally lack this meta-modelling capability, they are just not as good at it as the chemists are. This would be like arguing that because one machine learning system has better accuracy than another that they are doing something fundamentally different. Having understanding is not really about accuracy in either the first order learning or the second order learning. It is about possessing second order learning ability at all.
The angels: who knows? I don’t understand what they are saying.
God: He’s lying. He’s omniscient, so he knows exactly what happens next.
So an AI has “understanding” iff it can build another (fairly capable) AI? That seems dangerously close to recursive self-improvement.
It doesn’t have to be capable of self-improvement.
Define:
first order AI: takes a member of its domain and outputs a member of its range.
second order AI: takes a domain and range and outputs a first order AI
My claim is that a second-order AI would be demonstrating something that I would call “understanding”.
I don’t really know what a third order AI would be. Since the learning techniques for first order AI very clearly don’t transfer easily to second order, I’m not sure that we can say much about the likelihood of recursive self-improvement to higher orders beyond two.
For pretty confined domains of domain and range (heh), some math-solver systems might meet your second-order definition.
Do these systems “truly understand” the math problems they solve, or meta-solve? I dunno. I think there’s a stronger case there than that GPT-2 understands what a dwarf is.
Sure, although normally, the “intelligence” part of AI implies learning and an ability to improve performance with exposure to data.
So yes, if the second order ability of these systems improves automatically over time as they operate, I would say that they are exhibiting understanding of their field.
I’m guessing that the second order abilities are in fact static, though. So while they are exhibiting understanding, they are really only exhibiting the understanding of the person who coded them that way.
Automatically-learned understanding is where it’s at.
Ah, I see. I guess what confused me is that once an AI has any capacity for second-order reasoning, I would expect that the quality of the AIs it creates is mainly limited by its first-order reasoning. E.g. programming is second-order and writing is first-order, but ability to do them is positively (albeit imperfectly) correlated in humans. The question of how separate first-order and second-order skills are seems similar to the debate about the validity of the human g factor.
I thought it would loop around to the childrens’ interpretation (not the AI’s. obviously!) But the actual ending was better.
All of them are correct. What happens to y when x is called bottleneck method.
I think it’s not uncommon for people to learn the meanings of words *only* for context. I know that until I was 30, I didn’t actually know what “chaff” was, and I certainly didn’t know how to pronounce it. All I knew was that “chaff” was what you winnowed the wheat from, and winnowing, was how you separated the chaff from the wheat. It was only at age 30, that I looked in a dictionary and learned more.
I’ve had that experience dozens of times. I’m a native German speaker but read and write English all day. I’ve learned the majority of words from context only
If GPT-2 was fed popularizations of quantum physics and the literature of postmodern cultural studies and it produced something like “Transgressing the Boundaries: Towards a Transformative Hermeneutics of Quantum Gravity”, would it be considered to have understanding?
That would depend on whether a paper like Transgressing the Boundaries could be said to have meaning (other than Sokal’s intended meta-meaning, that is).
The non-SSC world shakes its head and rolls its eyes.
“Subjective concepts like knowledge or understanding make sense in the context of humans”, it explains, “because humans have a fairly standard hardwired mechanism for recognizing these things in other humans under certain circumstances, just as they have a hardwired mechanism for recognizing faces in other humans. (These same mechanisms also work reflexively, attributing these things to oneself when one is learning a new concept or looking in the mirror.) Since everyone’s hardwired mechanism works pretty much the same way, we can all talk about how humans do or don’t have knowledge or understanding–or recognizable faces–implicitly meaning that they exhibit the characteristics that trigger recognition in our common hard-wiring.
“Of course, this mechanism is automatic, and happily recognizes knowledge or understanding in non-humans–animals, computers, the universe/nature–under the right conditions, just as its facial counterpart happily recognizes faces in animals, the moon, or stick-figure drawings. But just as nobody would discuss whether the moon really has a face, it’s silly to talk about whether non-humans really do or don’t have knowledge and understanding, because these are things we subjectively attribute to them, not attributes they inherently possess.”
This is silly.
On the objective level, the moon really does not have a face. It just looks a bit like it sometimes.
Likewise, on the objective level, GPT-2 really does not have understanding. It just looks enough like it that humans who are really trying to fool themselves can pretend it does.
I’d go even further: *nothing* has understanding, except insofar as “[i]t just looks enough like it”. “Understanding” is a subjectively attributed (or self-attributed) property, not an objectively measurable one. That was the whole point of my face recognition analogy.
In the human social context, of course, the fact that pretty much everyone’s subjective understanding-recognition hard-wiring works roughly the same way allows us to treat consensus as the practical equivalent of objectivity. But once we step outside the human setting, the lack of objective criteria reduce us to either pretending that the somewhat arbitrary and subjective output of our hard-wiring is actually an objective measure (the “Turing Test solution”), or else conceding that no objective measure exists. Since the latter option at least has the advantage of being intellectually coherent, I’ll stick with it.
The whole “it’s hard to measure, so I’ll pretend the concept doesn’t exist” game is not one that actually produces insight.
I’m defining “understanding”, here, as having an internal model of its problem domain and mapping the symbols in which it communicates to entities in that internal model. This grants capabilities like “knows that water gets things wet”. GPT-2 does not have this model; if it emits a sentence like “water gets things wet”, it’s because that’s statistically similar to other sentences it read beforehand. Likewise, it lacks trivial understanding-related capabilities like inverting that relation to derive “if something is wet, water was poured on it”, or similar. (GPT-2 might still be able to fake that; a more rigorous test would be to teach it a new symbolic language purely in terms of symbol equivalence, then see if it can communicate the knowledge of its model in those new terms.)
This is a perfectly objective criterion that satisfies what we intuitively want of the word “understanding” (in this limited sense). It’s not one that simply excludes machines by definition, either; there are plenty of systems that I would say have “understanding” in this sense, e.g. math solvers (though their domains are limited and they can’t really learn). GPT-2 fails this criterion, and this is easily observable to be the reason it spouts incoherencies like Gimli shouting “Dwarf!”
“having an internal model of its problem domain and mapping the symbols in which it communicates to entities in that internal model”
It does have a model — its model just missed the connection between “water” and “wetness”. But human models, while better than GPT-2’s, are also imperfect, e.g. missing the connection between “water” and “H2O”.
I don’t think there’s a hard distinction between “having a model” and not — only better models and worse models.
I don’t really agree with the point, but I love the story.
The problem is that for gpt-2, the language isn’t a way to communicate/describe the model of its world, it is its world.
So it sort of understand language, like we understand our experiences : Not like things that refer to part of our model of the world, but as the foundation from where the model is build and what the model sort of actually explain.
gpt-2 really lack the semantic of language.(in the same way there are no semantic for our subjective experiences, they just are, and we can explain their structure more or less well)
The difference between the children and the adults seems only to be about knowledge (or maybe implicit vs explicit model), but what is fun is that in fact, the difference between the adults and the angels seems to be qualitative, and not only a lack of knowledge/brain power.
When the gpt-2 isn’t a general intelligence and will never be just by adding processors, it seems the angels have access to something that go beyond general intelligence.(some direct access to reality or something)
And god, humm… everyone know how god is 😀
I mean, even if gpt-2 was a AGI, it would still not understand our language, it would probably create its own language about how our language work, but for all it knows our language is just the world (and a horrible complex, weird, and with so much exceptions and “free variables” that it is really unsure it can do much starting from there).
You have to have access to the physical world, and probably also know some stuffs about human, to understand our language, to understand what sentence refer to approximately what stuffs.
I agree that understanding really is nothing more than a functor of relations found in reality onto our mind if that’s what you mean.
Talking about senses is confusing the issue, our understanding may exist to explain our sense perceptions and make them coherent (if you believe in empiricism, as I do), but its actual content is sensual only at its surface. The input data would be the senses of the AI and these senses provide enough information to reproduce relations found in nature (that water can be splashed, that it makes you wet).
The actual problem is that GPT-2 has no self (someone said the concept of self, but I don’t consider this to be at the heart of it). It has no agency that could allow it to mean things, to relate them to its needs. It has no understanding the way that a book has no knowledge of the things written inside it, it merely holds an image of relations that intelligent beings impressed upon it.
While I agree with you in my gut, I’m still afraid you’re begging the question. You can’t say GPT-2 lacks these things unless you can define them, or at least explain how to tell whether these things are present.
Maybe you should elaborate on what problem you think is resolved by the observation that GPT-2 has no self, agency, or understanding.
To be explicit, I mean the Free energy principle. I have no good tests or metrics to offer, but it makes sense to me that you cannot possess intelligence unless you interact with your environment and you cannot truly interact unless you have a will that would motivate your actions.
You could ask whether welding some sort of a control system onto GPT-2 would produce intelligence, but it appears likely to me that uncertainty reduction could be the only way, up to an isomorphism, for a model to be “alive” in some sense.
GPT-2 does have a loss function. Not sure if that counts.
It would if it was paired with a tendency to preserve its integrity that would cause it to shape the world around it. As it stands, it merely receives impressions from the outside world.
More accurately God complains that one Hobbit in the story died, then appeared talking, then entered a small underground room at night to warm himself with the light of the sun.
God is disappointed the celullar automatons are so bad at this and amused by so little.
A chemist’s knowledge of water is useful for synthesizing rocket fuel and other substances.
A child’s knowledge of water is useful for washing, drinking, swimming, etc.
An AI text generator’s knowledge of water is useful for… what, exactly?
The fundamental issue is this: meaning always happens outside the text. Inside the text, you can have consistency and coherence, but the meaning occurs outside it.
Why another round of venture capital of course!
Never go full Kantian.
+1 🙂
I’ve never gone in a drugs trip, but my poorly-calibrated model of the world suggests that the statiscal relationship between taking LSD an flipping out is pretty similar to reading this kind of articles 🙂
Now, maybe I have oversimplified the thoughts of the childs/chemists/angels, but it seems to me that you can end the discussion easily alluding to lCategories Were Made For Man, Not Man For The Categories. (?)
I’m disappointed no one has transliterated (ideally translated) the Enochian yet. I don’t have time atm but it would be great to see this.
Transliteration to latin: https://en.wikipedia.org/wiki/Enochian
Enochian dictionary: https://web.archive.org/web/20010219081905/w3.one.net/~browe/papers/endic.txt
I just tried.
tsepf is not in the Enochian dictionary so the other words are probably not in there either…
Scott can correct me if I’m not doing something right.
I think I mostly agree with child #2. Natural language was developed by humans to refer to things at the level of human use and sensations. So it seems reasonable to interpret “An understanding of ‘water’.” (as uttered by a human under typical conditions, i.e. not in a chemistry lecture) to refer to such correlations.
Thus simply noting a statistical correlation between “water”, “splash”, and “wet”, and being able to combine them in a grammatical way, would not by itself comprise an “understanding” of water. At a minimum, such an understanding should include connections to sensations and use of water in the world.
I think one could also reasonably ask whether an entity understands water “in the same way” as humans, meaning that it has some discrete higher-level concept that the word “water” could point to. Something like the “central node” in Eliezer’s simplified neural network diagram about the meaning of words.
Of course, there’s no reason to privilege human-like cognitive architecture as “true understanding”.
@Eponymous I like your point that
An AI that “understands” language will also have the potential to act upon that knowledge. I was reading Phil H’s comment above, which is very good at revealing that understanding and judgment making, although conceptually separable, are not in fact separable.
So the children are P-zombies.
The problem with discussions like this is that it’s all about abstracting things for its own sake, which means you can go as abstract as your current mindset desires.
In the real world, the smart thing to do is to abstract things only to the point at which they’re useful for the stakeholders involved in whatever system you’re examining.
There is a difference between using a word correctly and knowing what it means. Children are a good example. They sometimes use words they’ve heard, sometimes even in the right context, without having any clue what the word means. The AI question is not even relevant to the question of whether there is a difference between using the right word in the right context because you’ve noticed a pattern and actually knowing what the word MEANS and therefore using it correctly. Or, said differently, being right for the wrong reason is another form of being wrong.
I think what legitimately separates A.I. “understanding” from human understanding is the subjective, emotional quality of human conceptualizing. This story does a good job at demonstrating that any other demarcation will ultimately fail; when people protest that an A.I. doesn’t “really” understand something, I suspect what they’re actually trying to convey is the lack of that subjective quality. It’s hard to explain, of course — subjectivity usually is — but I don’t believe that this aspect of conscious signification can ever be captured by mere symbolic processing. I suspect it relates in some way to the moral dimension of experience; a computer can process “X = good” a trillion times without ever grasping what Goodness truly means.
(I’m reminded of G.E. Moore’s claim that any attempt to analyze Goodness in terms of other properties must ultimately fail, and therefore moral judgements are sui generis. Perhaps this point is the critical reason why A.I. can never understand the world as we do. This is why it must be given a goal, no matter how broad: it has no way of determining Goodness for itself. A machine can develop a morality, but it will always require an external seed — a definition of The Ultimate Good, provided by a human — from which it can grow.)