
I recently got in some fights with psychoanalysts on the importance of parenting. They mentioned that one good test for genuine parent effects – as opposed to genetic effects, stress-related effects, toxin-related effects, et cetera – would be things that seemed to depend more on one parent than the other. In particular, in order to rule out intrauterine factors, we should be looking at effects that depend disproportionately on the father. For example, if young women with distant fathers are uniquely more likely to become lesbians, that would be a pretty convincing demonstration of the importance of parenting.
So I was interested to see a recent study that claimed a good father/son relationship – but not a good mother/son relationship – had a special role in sons’ development. University of Guelph, Parents, Especially Fathers, Play A Key Role In Young Adults’ Health:
The researchers found that young adults who grew up in stable families with quality parental relationships were more likely to have healthy diet, activity and sleep behaviours, and were less likely to be obese.
Surprisingly, they found that when it came to predicting whether a young male will become overweight or obese, the mother-son relationship mattered far less than the relationship between father and son.
“Much of the research examining the influence of parents has typically examined only the mother’s influence or has combined information across parents,” said Prof. Jess Haines, Family Relations and Applied Nutrition, and lead author of the paper.
“Our results underscore the importance of examining the influence fathers have on their children and to develop strategies to help fathers support the development of healthy behaviours among their children.”
Okay. Let’s look at the study. It’s a correlational study of 6000 kids age 14-24. They were asked to rate the quality of their relationship with each parent, then they were tested for various unhealthy behaviors: obesity, eating disorders, fast food intake, soda intake, TV watching, sedentariness, and poor sleep.
Among all participants, better relationships led to less disordered eating, increased physical activity, and better sleep. This was true both for child/mother relationship, child/father relationship, and child/generic-measure-of-family-functioning relationship. So far this isn’t surprising. There was no attempt to control for wealth, class, or anything else, let alone genes. And a lot of these children are still living with their parents, so good parenting is going to be important to them right now (the study didn’t separate children who were still with their parents from adult children who weren’t). No surprise to find an effect here.
Among no participants did better relationships affect soda consumption or screen time, whether it was the child/mother relationship, the child/father relationship, or the child/generic-measure-of-family-functioning relationship. Okay. I guess these are somewhat more neutral things that good parenting doesn’t affect much.
Among female but not male participants, better relationships decrease fast food consumption. This was true both for child/mother relationships, child/father relationships, and child/generic-measure-of-family-functioning relationships (I believe all marriages should be between a man, a woman, and a generic-measure-of-family-functioning). This suggests that maybe parents care more about their daughters eating fast food than their sons – or maybe those daughters themselves care more. In either case, this wouldn’t be too surprising.
What about the blockbuster result that fathers, but not mothers, affect male children’s obesity level?
The odds ratio for obesity with a good mother-son relationship was 1.04, confidence level (0.85, 1.27).
The odds ratio for obesity with a good father-son relationship was 0.80, confidence level (0.66, 0.98).
Okay. You are measuring seven different outcomes on two different genders of child. On thirteen of these tests, results are concordant between fathers and mothers. On one of them, results are discordant, in that with mothers the confidence interval included 1.00, but with fathers the confidence interval merely included 0.98.
You could either conclude that fathers have a unique ability to affect their sons’ (but not their daughters’) level of obesity (but not disordered eating, or fast food eating, or soda drinking, etc). Or you could conclude that if you do enough tests, 5% of the time something will fall just outside a 95% confidence interval.
Let’s see what the study’s Limitations section has to say about this:
We calculated 42 tests and did not adjust for multiple comparisons.
Why would you do this? If NASA preceded their missions with statements like “We are launching a rocket to Jupiter, but we did not adjust for the fact that it is very far away,” we would stop taking them seriously. But for some reason in the social sciences it’s okay?
All right, fine, let’s hear your excuse:
Of these tests, 25 were statistically significant at the 0.05 level, much larger than the 2 we would expect by chance.
This might work for individual results, but it doesn’t work for discordances between results, which is what they’re trying to show.
Suppose I want to prove that a certain medicine only works on people whose names begin with the letter M (and suppose in reality, the drug works on everybody). My experiment has 80% power to detect the drug effect when it works. I do fifty tests on fifty different populations – elderly Latino women, young black men, genderqueer Caucasian neonates, Thai rice farmers, unemployed auto workers, whatever – and divide each of them into a subgroup with M-names and a subgroup with other names. I’m actually simulating this right now in an Excel spreadsheet, and here are my results:
Among non-M-names, 42 of the populations test positive, which is much as expected – the drug works and we have 80% power to show that it does, so we should expect 50*0.8 = 40 positive results on average. A little random noise brings that to 42.
Among M-names, 43 of the populations test positive, which is also close to 40. So here everything is just as we would expect.
But! In six of the populations, the drug works “differently” for people with M-names and other names. For example, on Test 18 (let’s call this Thai rice farmers), the drug works for rice farmers who have names beginning with M, but doesn’t work for rice farmers who have names beginning with other letters.
So I report this in the literature as “Astounding! Drug works for Thai rice farmers with names beginning with M, but not for Thai rice farmers with names beginning with other letters!” Some annoying person comes back with “but you did a bunch of comparisons and didn’t correct for that”. And I retort “Aha! But actually 85 of my 100 tests came back positive, compared to only 5 that would be expected by pure chance, so clearly there’s something there! There’s an M-name effect after all!”
This is comparing apples to oranges. Yes, you’ve shown that your drug works. But you haven’t come close to showing that it works differently for people whose name begins with M. Your evidence doesn’t even suggest that it does.
But this is what this paper is doing when it says it has evidence that male obesity is affected by the father and not the mother, and claims it doesn’t need to adjust for multiple comparisons.
As Exhibit B, I present the graphs:
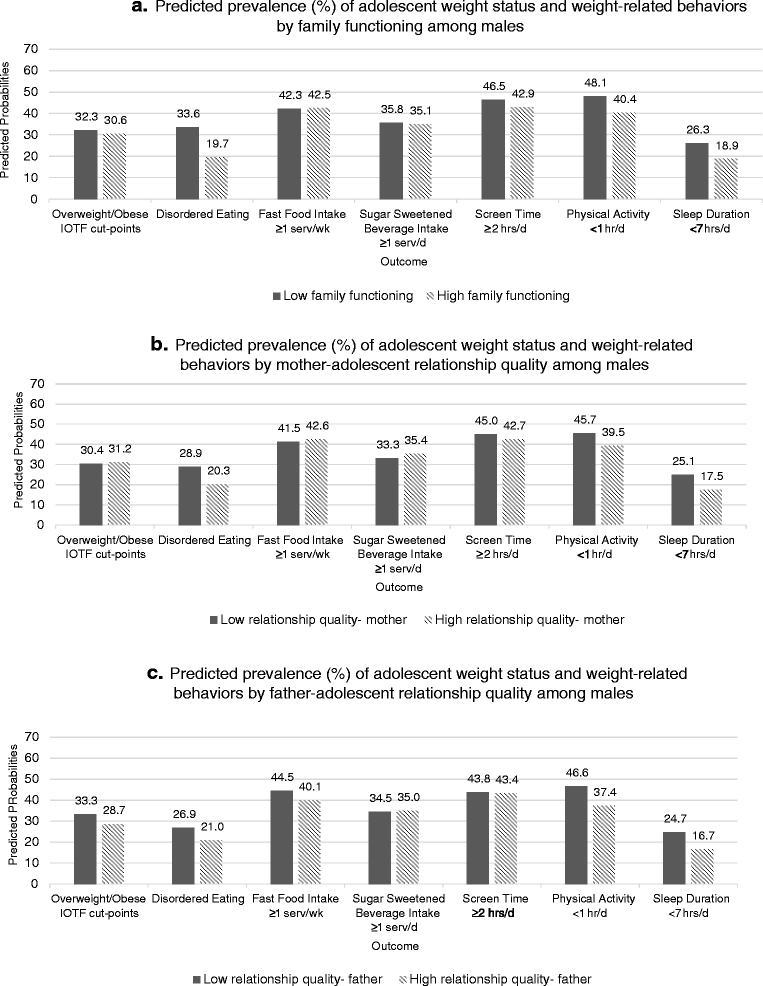
I think this is noise.
The paper itself mentions the father-son difference in one paragraph in the Discussion section, but doesn’t even find it worthy of mention in the Conclusion. It’s the press release that plays this up into the major finding of the study. Why?
Because the press release came out three days before Father’s Day.
Look:
In time for Father’s Day, a new University of Guelph study has found that parents, and especially fathers, play a vital role in developing healthy behaviours in young adults and helping to prevent obesity in their children.
I think overly cutesy university PR departments do a lot more damage than is generally realized.
On the other hand, one impressive thing about this paper is its willingness to cite large quantities of stuff. For example, a quote:
Level of bonding or closeness with a parent has also been shown to moderate the association between maternal-BMI and daughter-BMI [17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60] and parental and adolescent weight-related behaviors [17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61].
I am not going to go through 43 studies to see if any of them are any good, but I guess if there are 43 studies claiming these sorts of parental effects I should be a little more humble.
So: does anyone know of any good studies showing gender-specific-parent effects on a child that don’t seem obviously related to intrauterine or Y-chromosomal factors?
















I can’t comment on how good the study is, but here’s a candidate, using Swiss demographic data:
Women are more likely than men to attend church regularly, right? Maybe if a man attends church, it’s more of an indication of his having a very religious personality, whereas a woman’s attending church doesn’t tell us as much about her.
That is a good suggestion
That would not surprise me.
As a non-practicing Lutheran raised by a Lutheran mother and an atheist father who was also raised Lutheran, my experience certainly matches this. As my mother quit attending church after her parents died, it seems that it was more a matter of family and social conformity and expectations than any real religious belief; a man would simply come out as an atheist or agnostic and be done with it (as my father did… and I did).
Yes, and combining the difference in base-rates and the high correlation in couples, I believe that families where the father attends and the mother doesn’t are rare, so I suspect those numbers are noisy (although the paper implies that it is about divorce, and so such divergences might not be quite so rare).
But the point about sex differences applies as much to the children as to the parents. It would be better if the numbers split out the children by sex. But the effects are so strong, it seems that they must apply to both sexes. Thus the paper claims that a women attending church does tell us something about her: that her father did. That is a very odd claim.
I’m going to take a stab at this with some antidotal evidence
growing up, my dad took us to church essentially every Sunday (definitely enough to count as regular)
my mom, through what I’d mostly attribute to some social anxiety, and some degree of cultural inheritance, never attended physical church
my mom is highly religious, she listens to religious radio, watches religious programs on TV, listens to conservative talk radio, as best I know, has never voted for a democrat
her father was a Baptist missionary who worked in South America, her mother was also highly religious, but never physically went to church, I feel less confident in trying to pin an armchair psychological diagnosis on her, but I think it was more of a cultural thing for her, ‘women’s place was to make sure Sunday meal was ready when church is over’ sort of thing
————-
what’s I’d propose might be going on, when dad goes to church but mom doesn’t, the mom is significantly more religious
than the dad is in situations where the dad doesn’t go to church but the mom does
the Patriarchy isn’t quite dead yet
(fwiw, neither myself nor either of my siblings are current regular church goers)
Or maybe children’s obesity causes worse relationships?
Yeah, even if the correlations are real I can definitely think of multiple plausible causal relationships. Maybe I’m obese for largely genetic reasons but, being a teenager, I blame my parents, and thus rate my relationship with them lower.
Well, to be totally fair, if you’re obese for genetic reasons that’s definitely your parents’ fault.
I dunno, you could pretty safely blame your grandparents.
You never would have gotten those terrible grandparent genes if it wasn’t for your dumb parents!
More likely than this, in my experience, is parents being tough on their overweight kids. This effect seems strongest in mother-daughter relationships (though it’s not exclusive to them).
I once dated a girl who was perhaps 10-15 lbs. overweight, though with an hourglass figure that carried most of it in the right places. Her mother would browbeat her relentlessly over her weight, both in front of me and not. Their relationship might have been better if she had not been overweight, though perhaps her mother would have found some other detail to attack.
Bad parenting causes bad parental relationships and also causes ineffective treatment of obesity.
I’m surprised that “bad parenting causes bad relationships and also aggravates condition X” isn’t easily found to be true for lots of X.
Even if the paper showed what it claimed to, I would not assume it’s an effect of parenting. Rather, when discussing sons-father vs son-mother in particular I would expect it to be a y-chromosome influence; in the general case I would still expect it to be mediated by the mother’s ability to choose a good father or similar.
The human y-chromosome only has about 200 genes, 72 of which code for proteins, whereas the human genome as a whole has more than 20,000 protein coding genes. I’m sure that people who actually study genetics know a lot more than I do, but I’m still setting my priors pretty low for the probability that y-chromosome genes have a significant influence on anything other than basic sexual dimorphism. Especially since, according to Wikipedia, mutational deletions of y-chromosome genes usually have little impact beyond reduced fertility.
What about the epigenetic sperm effects, e.g. stress?
http://www.huffingtonpost.com/2013/06/16/dad-stress-sperm-epigenetic-changes-offspring_n_3437734.html
The idea is that stress on the father could both be passed epigenetically via the effect of hormones (or whatever) in the sperm, thereby changing gene expression in the son, thereby increasing his obesity likelihood *and* that stress might be a factor that leads to alienation between father and son. So in this case it’s shared causality between the correlated factors, not one causing the other.
It’s a shame that the article HuffPo cites isn’t actually studying epigenetics. The mice in question are hybrids, not from inbred strains, and therefore they are most likely studying genetics, if they aren’t just chasing ghosts. The number of animals is far too low to draw any conclusions.
But if you must yield to the siren song of epigenetics hype, note that 2 of the single copy genes on the Y chromosome are histone lysine demethylases.
Your numbers about the gene content of the Y are comparing apples to oranges wrt the rest of the genome, since many of those 72 proteins are members of multi-copy gene families, and code for the same protein, not distinct proteins. There’s only about a dozen single-copy genes.
That being said, it’s deletions mediated by the genomic structure of those multi-copy genes that lead to infertility.
Ascertainment bias is always a problem in human genetics. People see a lot of these deletions described by that Wikipedia article because there’s a high rate of rearrangements mediated by these multi-copy gene families, but also because infertility isn’t lethal.
In humans, the absence of a second sex chromosome is >99% in utero lethal. Contrary to what you probably learned in school, most patients with Turner syndrome are not X0, but mosaic for all or part of a second sex chromosome, which was just enough for them to survive.
Exactly which of the dozen single-copy Y genes are required in which tissues at what time is an open research question.
Yes, the difference between significant and not significant is not, itself, significant. If the error bars are 0.15 then a point estimate of 0.8 is significantly different than a null hypothesis of 1, while a point estimate of 0.9 is neither significantly different from the null nor from the other arm.
But the second effect was not 0.9; it was 1.04, on the other side of 1. If the father-son effect of 0.8 is significantly different from 1.0, it is also significantly different from the mother-son effect of 1.04. (OK, the real calculation is different, but the point about adding insignificant grains to make a significant heap really is the core.)
You are right about that, but I think he was just mentioning in passing that this sort of thing is a potential problem sometimes, before going on to the main point, which is the lack of correction for multiple comparisons. That is a big problem for the conclusions in the press release.
Good point, I am dumb, deleted.
Hold on, since we’re looking at the difference of two populations, shouldn’t we multiply our standard deviations by sqrt(2)? The one-sided width of the confidence interval (it’s probably 1.96 SD for a 95% confidence interval, not 1 SD) for moms and dads is 0.16, so the confidence interval width for the difference is 0.16 * 1.41 = 0.226. That’s still less than the difference between 1.04 and 0.8, but not by much. Your point is still well noted, but do you want to guess how often results that are significant at the p=5.0% but not at the p=3.7% level come out true?
It’s not right.
“The odds ratio for obesity with a good mother-son relationship was 1.04, confidence level (0.85, 1.27).
The odds ratio for obesity with a good father-son relationship was 0.80, confidence level (0.66, 0.98).”
What you want is the CI for the difference. Note that these two CIs for the OR share a lot of area: 0.85 to 0.98. For p<alpha for the difference, this area must be less than 5%.
These contrast confidence intervals require more power than CIs for single means or ORs. The confidence intervals for comparing group means are about 1.4 times as large for a contrast between two groups, for instance.
In this case, the mean of the single-arm CI widths are about .21 (.19 and .23) and .16 (.14 and .18). They are not symmetric around the ORs because odds ratios are somewhat non-linear effect size units. Still, the mean of these mean widths is about .185. Then we add the 40% extra length and get about .259. That's the single-arm width of the difference of ORs. The difference of the ORs is 1.04 – 0.80, so 0.24. Thus, a rough estimate of the difference of the ORs confidence interval is 0.24 ± .259. ergo -.019 to .499. So, 0 is included in this case.
I used some approximations and assumptions, so it may be not entirely correct, but it should be enough.
See Chapter 6 in https://www.goodreads.com/book/show/10765705-understanding-the-new-statistics
Here's a figure from the book demonstrating the idea: https://s32.postimg.org/67bkn77o5/contrast_means.png
One could demonstrate this more precisely with ORs, but the book does not contain the formulas for calculating difference CIs for ORs, so I would have to derive these from bootstrapping or something like that, which means that I would need to do more coding.
Skimming the paper, I think it reports enough numbers that you could reverse-engineer the exact numbers and then do a logistic regression with a binary parent-gender variable and get the exact CI to check against your approximation.
Scott, essays like this remind me of a question I’ve had about you for a long time:
Why would you choose clinical practice rather than go into research psychiatry? Couldn’t you have a vastly larger impact from a research position? Or perhaps impact wasn’t as large a factor in your decision as I’m assuming?
Interesting question, and I’ll be interested in Scott’s answer also.
As a psychotherapist and someone who’s done some research and also reads a fair amount of it, I think that mental health is in the stage where it would be more helpful to look for new hypotheses about mental health than to test hypotheses. In other words, we are not asking many of the right questions yet. So to research questions, is less enlightening. than to come up with “less wrong” questions than the ones we have asked so far. Personally I see that as a reason for both born clinicians and born researchers to spend at least some of their time in clinical practice.
For example, in this study, participants were “asked to rate the quality of their relationship with each parent.” It would be hard to get more vague than that. This reminds me of studies where people all over the world rate their level of happiness. What happens if people come from a family, or a nation, where one is considered ungrateful if one complains or says one is unhappy? Totally misleading data, of course. One more of many issues here is: If the relationship with one parent is particularly bad, does the child idealize the other parent, rating them very highly, since, by comparison, the better parent seems much better than they actually are?
I also remember reading a study, and I’ll have to see if I can locate it, that showed that abused women rated their partners more positively than women who are not abused. The explanation was that it might have been an attempt at a coping mechanism– a way of seeing their partner through rose colored glasses.
What if the study participants in the University of Guelph study saw their parents through rose colored glasses? Misleading data.
What if the participants had been further questioned: So your mother/father was good. What was good about them? I wonder if there would have been anything in common in subjects’ answers, or whether they would have been all over the map.
The zillion dollar question right now is: What questions do you ask a research subject if you want to find out the effects of their parents on them, or the effects of anyone or anything on their mental health?
I don’t think we know what many of those questions are yet. But when some skilled psychotherapists find ways to cure or help some mentally unhealthy patients what cures them, then we have more ideas on what questions to ask research subjects. It’s too bad that researchers and clinicians do not hang out together more than they do.
The number of possible questions one could come up with to ask social science research subjects, in order to find the determinants of their mental and physical health, is mind boggling.
Good relationships between scientists and artists could act as large driving forces of progress.
Scott isn’t a therapist, he’s a psychiatrist. Psychiatry is a field that’s almost entirely dedicated to medication management at this point, and you don’t need clinical experience to fix what’s wrong with psychiatry, you need lots of data and a reputable public platform. Arguably SSC is the latter, but likely not to the right establishment people.
As someone who’s nowhere near medicine, is this bifurcation you’re asking about actually a thing? As in, there are doctors who do research and doctors who treat patients, but few people who are members of both groups?
Because for my field (structural engineering), that’s pretty weird. I can’t think of any professors I had, or any doctoral students I interacted with, who hadn’t been out practicing before going back to academia. As a matter of fact, I’d think less of a PhD student who hasn’t spent some time actually doing design work.
Of course, I can’t rule out that I’m just limited in my interactions with structural engineering academics.
As far as I know, research doctors do complete residence (which is clinical experience), but becoming one requires an MD PhD. Scott hasn’t mentioned working on/having a PhD, so I’m assuming he isn’t/doesn’t, which suggests that he isn’t going to pursue a research career.
I guess put that way, there may not be a whole lot of difference. Doing the bare minimum to get a professional engineer license and going back to a PhD probably isn’t much different than doing a residency and going back.
Edit: I mean in terms of professional experience. In terms of how difficult a residency is compared to 4 years of design work, there probably is a lot of difference, in that the residency is probably a lot more difficult.
I’m not sure about the Ph.D. being required. Clicking through the “Research” section of the Mass General Hospital website, there seem to be a fair number of investigators who don’t have a Ph.D. I suppose it could be different for new, up-and-coming researchers though. Creeping credentialism and all that.
My uncle recently got his Ph.D. in medicine. He’s been a consultant for at the very least five years. Checking bing scholar he appears to have three peer reviewed journal publications as a first author. Things are different in Ireland/the UK/Australia/etc. than in the USA but you can definitely do research as a physician without having a Ph.D. My cousin appears to have three first author publications without having ever gotten a Ph.D. She’s also a Senior Lecturer at a British university. Given those two data points I think at least outside North America the lack of a Ph.D is no bar to being an academic and a physician. I know that the Dr. Med. in Germany/Austria/Switzerland is nowhere near as difficult as getting a Ph.D.
To be sure, in every discipline you are allowed to publish papers without a PhD, only the content is supposed to matter. Getting a research position without a PhD is a different thing.
In many disciplines academic and industrial careers are quite separate; engineering might contain exceptions, but it seems that clinical research is another exception, because there you do research by treating patients. I understand there’s also non-clinical research and doctors who don’t do research.
I can’t speak for psychiatry in particular, but medical research in general in the US is extremely incestual and very much prestige-based – and the prestige, if you’re a researcher, is based on where you went to medical school. Given that our host went to medical school outside the US, he is at a significant disadvantage vs someone who didn’t, even if his ideas are better.
I’m not sure what Scott’s answer to this question is, but as a current acute care nurse who could probably have a “vastly larger impact” in health care policy (or a wide variety of other areas): clinical practice is FUN.
I knew it was you after reading the comment, before even seeing your name (-:
I’m pretty sure that “research psychiatrist” is a subset of “psychiatrist”, which is in turn a subset of “people who have completed a residency in psychiatry”, which is what Scott is doing right now. Pretty much any psychiatric research at this point is going to include a strong element of either “What does this drug do to people’s minds?” or at least “How does this clever new alternative compare to the usual standard of care, which is drugs?”. And most governments are kind of picky about who they let go about dosing people with powerful mind-altering drugs. A research quasi-psychiatrist who had to find partners to do all the drug stuff would be at a substantial handicap, I would think.
So it may be premature to decide what sort of career Scott is going to have, though he can certainly speak to his plans if he wishes. If he proposes experimental testing of a chromatic spectrum of wonder-drugs, be afraid.
I don’t like research and I’m terrible at it. Research is a combination of wading through bureaucracy, going around recruiting subjects according to very specific protocols, doing really high-level statistics, and doing academic writing/academic publishing. I hate and am bad at all four of those things.
Yes, I like criticizing other people’s research. But I like criticizing Donald Trump too. That doesn’t mean I should run for President.
I’ve read a great deal of your work and I’ve never seen anything critical of Donald Trump. Perhaps you think it’s too obvious to be worth the time? Too much like something a smug blue-tribe blogger would do? I’d actually really like to read your take on Trump, since it seems like some of your readers are sympathetic to him.
Try google or the politics tag. Scott is extremely disappointed.
Frankly, one of Scott’s posts here has done more than any other single article to change my mind in Trump’s favor.
I hate and am bad at all four of those things.
I think that in the latter two categories, the stuff you do here for fun is closer to publication-quality than you think, and the reason so much published stuff looks so different isn’t that you are bad at it but they are.
But the first two items on the list would be enough to turn me away from the field, and the latter two might not be so fun if your livelihood depended on it.
Your blog post show you’d be a compelling academic writer. Ahem, from my POV you’d need to stick to sentences that are unambiguously true as written (well, more strictly) instead of assuming a charitable reader, but assuming that, your writing is excellent. OTOH, we also assumed wrongly you’d be good at math, so what do I know?
An observation and a question:
Observation: it’s worth noting that under reasonable assumptions, purely genetic traits will be more heritable from the mother than the father. Cool bit of very simple math. If you assume that men have more variability in observed traits (not just in genetic “potential”–i.e., that two men with very similar genes will have more variance in observed values of a given trait than two women with equally similar genes), then essentially observing a high trait value in a mother is much stronger evidence of “good” genes, and hence better evidence the child will test high as well. You can work this out mathematically with a simple hierarchical normal model.
Question: it’s definitely known that in general (not necessarily the potentials case I give above) men have higher trait variance. But other than the single-X thing, are there actual mechanisms we know this is implemented through?
Edit: I’m an idiot and can’t read.
I’ve heard of some protective functions of estrogen in e.g. mutations causing autism, such that women who have the mutations associated with autism in men have a reduced effect.
It also seems plausible that if men engage in a greater number of risky activities, or place/find themselves in a greater variety of environments than women do, that this will tend to bring heritability of relevant traits down for men on average. (For instance, number of limbs may be more variable in men because they tend to operate machinery with limb-removing potential more than women.)
One can assume both this and the genetic variability hypothesis (and it often fits data well, says the population biologist who told me to pick a smart wife based on this principle.)
Yes, I got overly excited and didn’t read your full comment. My mistake.
>”WHY WOULD YOU SAY THIS? WHY WOULD YOU WRITE “BY THE WAY, WE DID NOT ADJUST FOR MULTIPLE COMPARISONS” INSTEAD OF JUST ADJUSTING FOR MULTIPLE COMPARISONS? WHO DOES THESE KINDS OF THINGS?”
Thank you very much for the righteous rage here. It brightened up my day.
Yeah, I just hope I’m right about this. Usually when I get angry about something it turns out I missed something stupid.
Who does these kinds of things? People who want to get a significant finding so they can get a publication out of their data. Yes, I’m cynical.
I thought this was going to be another case of “Oh, what a cute undergraduate paper.” like the GitHub study.
Unfortunately, no. The lead author:
Second author: Harvard Catalyst.
Matthew Gilman, MD, of Harvard, with years and years of research experience.
Four other authors from Harvard.
A — not making this up — mathematician and statistician who got his ScD from the Harvard School of Public Health in 1999, meaning he’s been at this for at least 20 years, and is now a professor of mathematics and statistics at one of the most respected colleges in America (edit: by which I mean Amherst).
And actually this is what scares me most. People who write press releases can write dumb and untrue things; journalists who write for the Daily Mail can mis-inform a lot of minds. But they are mere side acts to the circus that is academia today. It’s not that the edicts going out from the seat of power are being misinterpreted; it’s that the seat of power itself is incompetent.
Harvard is the same school that has Jason Mitchell, a dude who doesn’t believe in science, running a psych lab. At some point you have to stop respecting this particular college in America.
Not that it’s relevant to your point, but by “one of the most respected colleges in America” I meant Amherst, where he is now. (I’ve added an edit to make that clear.)
Are you referring to Mitchell’s thoughts on replication? I think they were dumb, but I don’t think it’s fair to say that he doesn’t believe in science.
I am, and I disagree.
Harvard hasn’t believed in science for a long time. Problem is, it was even worse when it did. Jason Mitchell is an idiot, but at least he doesn’t work at Buchenwald.
I don’t know how standard this is in this field, but in my branch of acacdemia it was fairly routine to have people listed as coauthors who had essentially zero involvement with the manuscript or even with the experiment.
We studied the properties of certain crystals under certain conditions. The guy that grew our crystals was coauthor even though he never got within a thousand miles of our experiment (he just mailed them to us) and had no zero input into what we actually did with his crystals. Conversely I’m listed as a coauthor on a paper that I had literally nothing to do with other than that some of my data was used. My sole involvement was to reply “yes” when asked if I wanted to be a coauthor.
Politically it only helps you to have lots of coauthors – it lets you help out your friends/allies and allows you to associate your work with important people.
I imagine this is common, but it seems dangerous. What if someone screws up a paper you coauthored and it comes to light? At least in medicine people seem to care about getting these things right.
At least according to German guidelines, you’re responsible for the veracity of statements in the paper, and you can’t say “I didn’t check that”.
Not that these guidelines always mean much: in my field, Computer Science, nowadays it seems impossible to retract papers, even for accepted errors.
In medicine the standards for authorship are pretty low. When I was a wee undergrad working in a biology lab at a medical school, the director of the center wher I worked required my PI to put all the faculty on the floor as coauthors on his paper — whether they participated in the research or not. All of us who came from biology departments found this highly irregular, the MDs couldn’t understand why we thought it was odd.
Multiple authors on the study, so quite possibly one of them was like, “uh, we really need to control for multiple comparisons” and another was like “nah, it’s fine” but put a note in the Limitations section to soothe the conscience of the first.
Or they were not sure how to do it correctly so the safe thing was to just admit that they didn’t do it.
A professor of statistics isn’t sure how to control for multiple comparisons correctly?
That’s a much more frightening proposition than that he’s merely a villain.
Do not attribute to malice that which can be adequately explained by gross incompetence.
Sufficiently advanced incompetence is indistinguishable from malice.
It is still fairly standard statistical practice to not control for multiple comparisons, and make this clear in the paper. Readers (and the authors in the manuscript) then just mentally discount all found p values; essentially ignoring things which just make significance, and paying more attention to those with very low p values.
I don’t really see the problem with this, and it sounds like the authors in the paper did not try to exaggerate their father-relationship finding.
The problem exists with the notion of p<0.05=Truth and poor journalistic standards
Not adjusting does lend itself to misinterpretation.
Without that readers have to guestimate whether any particular P value is sufficiently small.
Is anyone else bothered that the simulation of 50 tests of divided groups with 80% power to detect a real effect only had six groups where one subgroup performed “differently” than the other?
On the assumption, stated in the article, that the effect we’re looking for exists in all groups and we detect it 80% of the time:
80% of non-M subgroups show the effect. Of that 80%, 80% of their yes-M subgroups also show the effect, so 64% of lines are concordant for “the effect is real”.
20% of non-M subgroups erroneously fail to show the effect. Of that 20%, 20% of their yes-M subgroups also fail to show the effect, so 4% of lines are concordant for “no effect”. This means 32% (= 100% – 64% – 4%) of lines are discordant, which is 16 lines for 50 tests. But somehow only six lines are actually discordant? That’s a third as many as there should be. What’s going on?
I wrote a script reproducing these conditions and found that over 100 iterations, the number of discordant groups ranged from 7 to 24. So 6 looks unusual, but not totally off the wall.
Maybe I made a mistake counting, I’m not sure. I didn’t keep the spreadsheet.
Scott, you’ve got “child/son relationship” there in one paragraph.
I spent the first 17 paragraphs of this essay trying to figure out what the title was about.
If you want to pick something apart I think this might be a good start:
The Effects of Father Involvement: An Updated Research Summary of the Evidence (2007)
http://www.fira.ca/cms/documents/29/Effects_of_Father_Involvement.pdf
Because it is by the Father Involvement Research Alliance which is bound to be biased but also probably a good place to find any evidence if it is at all there.
Er, how do you define “genuine parent effect,” anyway? Does it exclude such things as long-term effects of parental alcoholism and child abuse, for example?
Scott excluded “stress-related effects, toxin-related effects, et cetera,” so that excludes your examples.
Fetal alcohol syndrome is a well-established environmental effect, although probably exaggerated. Child abuse can have short-term effects, like death. I am not aware of any research that tests for causality of the long-term correlates. Indeed, most of of the results, eg, that abused children are angry, are probably genetic: the same genes that made their parents angry.
Have there been any long term outcome studies of people who were abused by foster or step parents? That seems like it would be an effective and pretty easy way of controlling for genetic effects.
https://en.wikipedia.org/wiki/Adverse_Childhood_Experiences_Study
This is a claim that having bad experiences during childhood tends to correlate with bad effects through the rest of life. I don’t remember it being discussed here.
Yes, I said that child abuse has long-term correlates. I am not aware of any study of abuse that admits that correlation is not causation. I am aware of that study and it is 100% correlative. Moreover, its definition of abuse is so broad (35% of population subject to emotional abuse) that the effects would be detected by existing twin and adoption studies. We know that emotional abuse as defined by that study has minimal effect.
I would be very surprised if child abuse created no causative correlation, because in some cases the individuals in question are left with traumatic disorders like PTSD. An individual of my acquaintance suffers from PTSD due to child abuse, and I find it hard to believe that had this person not been abused their genetically predisposed personality would mimic the effects of PTSD.
Technically meets your request, in the most obnoxious sense possible: girls with red-green colorblindness almost uniformly have red-green colorblind fathers, but their mothers are only a moderate amount more likely to be colorblind than those of non-colorblind girls. Neither intrauterine effects nor Y-chromosomes explain this result.
Probably a dumb question, but aren’t there 44 studies cited for the first statement and 45 for the second? Is 43 a joke going over my head?
No, I just can’t count.
This is the problem with publishing inconclusive experiments. The press will twist their lack of conclusions or even support of the null hypothesis into something that can be a headline, and then the public will believe that the thing the headline implies is true.
Don’t know if your interest is in gender specific epigenetic factors and basic science or not. This is a good experimental study looking at the effects of a paternal stress model on the behavioral phenotypes across two generations of mice where the paternal line only is exposed to elevated corticosterone – the predominant glucocorticoid in mice. The discussion includes references to where this may have happened in humans and it complicates the learning versus epigenetic transmission of behavior from one parent to their offspring. With regard to your study of interest, I think there is plenty of data to suggest that the BMI of the parent is reflected in the BMI of the children at the genetic level and therefore controlling for genetics is necessary.
I thought about some basic ways to look at the problem in humans. In any EHR system there are probably thousands if not tens of thousands of men of reproductive age who are on corticosteroids both acutely and chronically. It would potentially be a useful approach to look at cross sectional or even prospective studies to look for anxiety and depressive phenotypes in their offspring based on this factor and some of the other markers (miRNA) suggested in this study. If a signal is detected secondary studies could look at subgroups of men with hypercortisolemia from various states, including what are viewed as purely psychiatric conditions.
The biological complexity in these situations is enormous. As an example looking at the miRNA targets of just one of the authors markers (miR-190b) – there are thousands in humans. Recent studies suggest that metagenomic factors are extremely important in the transmission of obesity and metabolic syndrome. In that case, dietary fiber many be a robust predictor and should be controlled for. It seems like studies about phenotypic transmission across generations can control for genetic and disease complexity factors only at a very gross level and that soon – in order to be credible the populations will need to be screened for a large numbers of genetic, epigenetic, and metagenomic factors. Retrospective surveys of subjective psychological factors in the absence of that data won’t count for much. I think that there are even some long term developmental cohort studies that are currently trying to incorporate epigenetic factors into their design.
This paper is so obviously bad I’m not sure why you’re even writing about it. Was that thought something like, “This is how bad things are, guys; can you show me something better?”
I think that gender asymmetry isn’t disqualifying of something being genetic in origin, since prenatal development is asymmetric. Think about how Ligers (lion dad, tiger mom) are bigger than lions or tigers, while Tigons (tiger dad, lion mom) are small. Robert Sapolsky has an old essay discussing some of these asymmetries in development- he gives the example of a placental cancer that is caused by a father’s genes when they aren’t resisted by the mother’s genes, and so on. (Found it-)
http://discovermagazine.com/1999/may/war/
Scott, you’re right that researchers should adjust for multiple comparisons, but that is not the main problem here. The main problem was another common statistical fallacy, which is unrelated to multiple comparisons. I think you understood this implicitly given the simulation you did, but it can be explained even more clearly.
If my data let me reject the null hypothesis H1: “fathers have no effect” but don’t let me reject H2: “mothers have no effect,” this is NOT in and of itself evidence against H3: “fathers have the same effect as mothers.” If I reject H3 whenever (p1 < .05 XOR p2 < .05) then my rejection probability, even if H3 is true, could be as high as 50%. To see why, make the true effect just large enough so that P(p1 < .05) = P(p2 < .05) = 50% (This is assuming p1 and p2 are independent p-values for H1 and H2 respectively).
Furthermore this problem would not be solved if I use, e.g., a Bonferroni correction to adjust for 42 multiple comparisons. You can still make the true effect just large enough so that P(p1 < .05 / 42) = P(p2 < .05 / 42) = 50%.
Instead, if the researchers want to make claims about rejecting H3 they should use a test that actually tests H3 (and also adjust appropriately for multiple comparisons). Given that the CIs overlapped, such a test
would certainly not have rejected in the case you’re complaining aboutactually I think it’s possible it could have if the CIs were positively correlated with each other for some reason, but the point is you still need to actually do a valid test of H3.Scott talked about this:
No, overlapping confidence intervals do not imply that insignificant difference. In particular, while the case of (0.85, 1.27) and (0.66, 0.98) is not significant, but if it had been (.87,1.29) it would have p<0.05.
I agree Scott knows this and he made the point implicitly, but I’m also saying that
a) the problem would be there even without having done 42 tests, and
b) even adjusting for the 42 tests would not resolve the fundamental issue.
I also get p=0.07 assuming that the CIs are independent and the log(odds ratio) estimate is approximately normal — that’s lower than I expected, thanks for checking.
But the result could possibly be much more significant if the test statistics are positively correlated, which I think they might be: if I understand correctly, one is for the correlation of “obese son” with “good relationship with mom” and the other is for the correlation of “obese son” with “good relationship with dad.” But a son’s relationship with his mom and his dad are probably correlated, meaning the test statistics are probably correlated if you compute them on the same sample. If the correlation is 0.7, the p-value becomes 0.0009, which is even enough to survive the Bonferroni correction! (Unless I’m making a mistake, which I very often am 🙂
I have no idea whether 0.7 is a reasonable value, but the point is the correlation matters a lot.
R code:
CI.length <- log(1.27) – log(.85) # log(.98) – log(.66) is about the same
std.err <- CI.length / (2*1.96)
Z1 <- log(1.04) / std.err
Z2 <- log(.80) / std.err
## Independent Case
Z.diff.indep <- (Z1 – Z2)/sqrt(2)
2*pnorm(Z.diff.indep, lower.tail=FALSE)
## Correlated Case
rho <- .7
Z.diff.corr <- (Z1 – Z2) / sqrt(2*(1-rho))
2*pnorm(Z.diff.corr, lower.tail=FALSE)
That’s a very good point about independence. The correlation was .51 for sons and .61 for daughters.
That sounds a lot like the extremely common error described here:
https://web.archive.org/web/20160205050336/http://www.badscience.net/2011/10/what-if-academics-were-as-dumb-as-quacks-with-statistics/
Perhaps if people want to be more healthy, regardless of what kind of parenting they received, they should just take psychedelic drugs. No, seriously, there is scientific evidence for this here. Just a few examples– Can be used to treat addiction, obsessive compulsive disorder, end-of-life anxiety, and, in some cases, depression.
The fascinating, strange medical potential of psychedelic drugs, explained in 50+ studies
Welcome to Show Me the Evidence, where we go beyond the frenzy of daily headlines to take a deeper look at the state of science around the most pressing health questions of the day.
http://www.vox.com/2016/6/27/11544250/psychedelic-drugs-lsd-psilocybin-effects
So: does anyone know of any good studies showing gender-specific-parent effects on a child that don’t seem obviously related to intrauterine or Y-chromosomal factors?
There is this one: Father absence and timing of menarche in adolescent girls from a UK cohort.
Dunno how good the study is – I’m still boggling at this line from the abstract: Although father absence cannot be a direct target of prevention, family-based programs to address family processes influenced by maternal depression and socioeconomic disadvantage may be effective.
Because heaven fucking forbid we deliberately try to have fathers stay with their children and the mothers of their children, that would be wrong.
(Link via Robert Ver Bruggen‘s twit line – and it should probably be noted that he apparently reads SSC.)
I happen to agree with the quote from the study.
Context is important. Here “we” means “we, doctors”. I do not think doctors should decide they know how to treat social problems just because these social problems have some medical consequences.
Medical advice with respect to a divorce is a terrible idea.
“We doctors” seem to see it perfectly okay to “to address family processes” and to “alleviate socio-economic disadvantage” – ie, establish more offices (and hire more people) to manage “programs” for single mothers, and to hand out more money to single mothers, when it’s fairly clear that what is needed is not programs or money but a father in the household.
If medical advice extends to suggesting “adjusting family processes” it can extend itself to family counseling aimed at keeping families intact rather than promoting single parenthood.
(Note: not my field, and I speak as a disgruntled taxpayer/community member here. If people in the field can explain why we can not rather than will not have “fathers stay with their families” as a community/social/intervention goal, I would be willing to hear this reasoning.)
Fair point. I don’t think medical advice should get into any of that stuff, but you’re right that if they consider it fine to “adjust family processes”, they open themselves up to your critique.
As to fathers staying with their families as an intervention goal, I suspect that the goal is problematic. What you actually want is a normally-functioning family. The father’s presence is necessary but not sufficient. In particular, I suspect that if you’re successful at the goal of the father staying put, the number of cases of domestic abuse will go up. Maybe by a lot.
I think that people might take more care when selecting a mate if they expect the relationship to be long-term.
What you actually want is a normally-functioning family.
I’d settle for “better functioning families”.
The father’s presence is necessary but not sufficient. In particular, I suspect that if you’re successful at the goal of the father staying put, the number of cases of domestic abuse will go up. Maybe by a lot.
Everything has downsides, true, and we need to be alert for those when we make any intervention. But I’m pretty suspicious that the downsides will outweigh the ups here – it’s not as though most men beat their domestic partners, just as most women don’t emotionally abuse their spouses/bf/etc.
I suspect it may actually go the other way – children are at the greatest risk of abuse when they are living with men who are not their fathers. Also, there is no reason why we should assume that the 40% of mothers who bore children out of wedlock last year did so because they suspected the father would be abusive.
There are a lot of possible downsides involved with picking a spouse and staying married. I think we-as-society have over emphasized these to our young people, to our sorrow. The upsides – for them and society – are much larger.
The line is found in the body of the article as an unsupported assertion followed immediately by a citation that leads here:
https://www.scopus.com/record/display.uri?eid=2-s2.0-77950138828&origin=inward&txGid=0
Which implies that someone tried, and it didn’t work.
An answer that justifies this claim, while also somewhat trivializing it, is that this claim is about interventions on member of the group of people whose fathers have abandoned them. In which case preventing their fathers from abandoning them is a priori impossible on the simple ground that the horse has already left the barn. But to know what the researchers meant someone will have to pluck that article from beyond the paywall.
IMHO, the first point isn’t super-convincing, one social science study finding that an intervention doesn’t work doesn’t tell you much, and even a meta-review would only tell you that people are probably not getting good results with current methods, not that no intervention is possible. And if they meant it probably wouldn’t work, it would have been much clearer to say that.
Again IMHO, I like your second point a lot – if they mean that they’re specifically discussion treatment in cases where the father is already gone, the point makes sense. (
On the third hand, from a social perspective, it would also make sense to explore policies designed to keep fathers around in appropriate cases – for example, if your welfare or tax policy encourages people to split up or remain unmarried, you might think about adjusting things so that the incentive is at least neutral.
This seems to rely on the assumption that a gene would have the same effect in both males in females – e.g. if men with the gene are distant fathers, women with the gene are distant mothers. But that doesn’t seem valid. Imagine a gene makes someone more likely to commit violent crimes- I wouldn’t expect men and women with the gene to commit crimes at the same rate.
Just saw this study. Haven’t read it, but it exists.
http://www.research.ed.ac.uk/portal/en/publications/parentchild-relationships-and-offsprings-positive-mental-wellbeing-from-adolescence-to-early-older-age(5f5cdffa-b169-4350-a471-2128eaad405e).html
“Okay. You are measuring seven different outcomes on two different genders of child. On thirteen of these tests, results are concordant between fathers and mothers. On one of them, results are discordant, in that with mothers the confidence interval included 1.00, but with fathers the confidence interval merely included 0.98.”
These results are concordant. The CIs include the same values. These ORs are not p<alpha different according to NHST stats (most likely, hard to say without more data).
It's a good example of the "p<alpha for one sub-group but not another for X; therefore different subgroups are different for X" fallacy. It does not seem to have a common name yet. I will call it the NHST subgroup fallacy unless someone can think of a better name.
I think that The Difference Between “Significant” and “Not Significant” is not Itself Statistically Significant is pretty catchy.
I’m not sure if this is exactly what you want but it may be a good place to get started.
https://www.childwelfare.gov/pubPDFs/fatherhood.pdf
Do you know R or python+numpy? I think using those for your experiments instead of excel is probably faster and they have more features.
He’s mentioned before that he does not. He really should learn a bit, though. One-off scripts for data analysis or a Jupyter notebook or something don’t require you to become skilled in the black arts of computer science and software engineering or anything. Scott’s stats knowledge is clearly there and that’s the much harder part.
I’ve created an interactive visualization to explain this fallacy. Give it a try! 🙂
http://emilkirkegaard.dk/understanding_statistics/?app=NHST_subgroup_fallacy