
[WARNING: I am not a pharmacologist. I am not a researcher. I am not a statistician. This is not medical advice. This is really weird and you should not take it too seriously until it has been confirmed]
I.
I’ve been playing around with data from Internet databases that aggregate patient reviews of medications.
Are these any good? I looked at four of the largest such databases – Drugs.com, WebMD, AskAPatient, and DrugLib – as well as psychiatry-specific site CrazyMeds – and took their data on twenty-three major antidepressants. Then I correlated them with one another to see if the five sites mostly agreed.
Correlations between Drugs.com, AskAPatient, and WebMD were generally large and positive (around 0.7). Correlations between CrazyMeds and DrugLib were generally small or negative. In retrospect this makes sense, because these two sites didn’t allow separation of ratings by condition, so for example Seroquel-for-depression was being mixed with Seroquel-for-schizophrenia.
So I threw out the two offending sites and kept Drugs.com, AskAPatient, and WebMD. I normalized all the data, then took the weighted average of all three sites. From this huge sample (the least-reviewed drug had 35 ratings, the most-reviewed drug 4,797) I obtained a unified opinion of patients’ favorite and least favorite antidepressants.
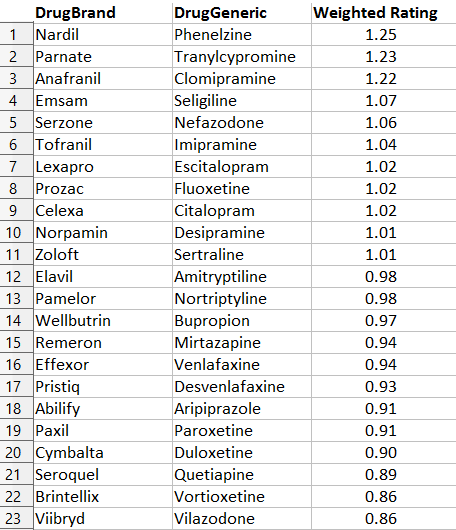
This doesn’t surprise me at all. Everyone secretly knows Nardil and Parnate (the two commonly-used drugs in the MAOI class) are excellent antidepressants1. Oh, nobody will prescribe them, because of the dynamic discussed here, but in their hearts they know it’s true.
Likewise, I feel pretty good to see that Serzone, which I recently defended, is number five. I’ve had terrible luck with Viibryd, and it just seems to make people taking it more annoying, which is not a listed side effect but which I swear has happened.
The table also matches the evidence from chemistry – drugs with similar molecular structure get similar ratings, as do drugs with similar function. This is, I think, a good list.
Which is too bad, because it makes the next part that much more terrifying.
II.
There is a sixth major Internet database of drug ratings. It is called RateRx, and it differs from the other five in an important way: it solicits ratings from doctors, not patients. It’s a great idea – if you trust your doctor to tell you which drug is best, why not take advantage of wisdom-of-crowds and trust all the doctors?

The RateRX logo. Spoiler: this is going to seem really ironic in about thirty seconds.
RateRx has a modest but respectable sample size – the drugs on my list got between 32 and 70 doctor reviews. There’s only one problem.
You remember patient reviews on the big three sites correlated about +0.7 with each other, right? So patients pretty much agree on which drugs are good and which are bad?
Doctor reviews on RateRx correlated at -0.21 with patient reviews. The negative relationship is nonsignificant, but that just means that at best, doctor reviews are totally uncorrelated with patient consensus.
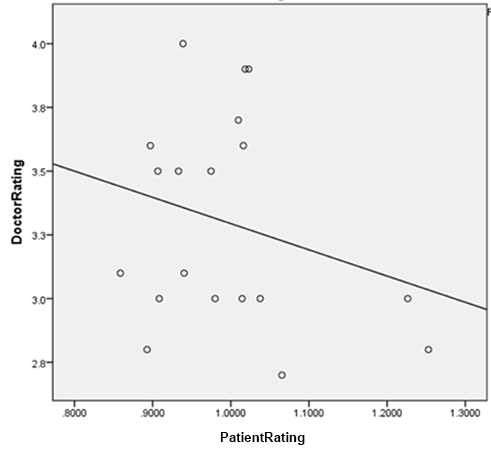
This has an obvious but very disturbing corollary. I couldn’t get good numbers on how times each of the antidepressants on my list were prescribed, because the information I’ve seen only gives prescription numbers for a few top-selling drugs, plus we’ve got the same problem of not being able to distinguish depression prescriptions from anxiety prescriptions from psychosis prescriptions. But total number of online reviews makes a pretty good proxy. After all, the more patients are using a drug, the more are likely to review it.
Quick sanity check: the most reviewed drug on my list was Cymbalta. Cymbalta was also the best selling antidepressant of 2014. Although my list doesn’t exactly track the best-sellers, that seems to be a function of how long a drug has been out – a best-seller that came out last year might have only 1/10th the number of reviews as a best-seller that came out ten years ago. So number of reviews seems to be a decent correlate for amount a drug is used.
In that case, amount a drug is used correlates highly (+0.67, p = 0.005) with doctors’ opinion of the drug, which makes perfect sense since doctors are the ones prescribing it. But amount the drug gets used correlates negatively with patient rating of the drug (-0.34, p = ns), which of course is to be expected given the negative correlation between doctor opinion and patient opinion.
So the more patients like a drug, the less likely it is to be prescribed2.
III.
There’s one more act in this horror show.
Anyone familiar with these medications reading the table above has probably already noticed this one, but I figured I might as well make it official.
I correlated the average rating of each drug with the year it came on the market. The correlation was -0.71 (p < .001). That is, the newer a drug was, the less patients liked it3.
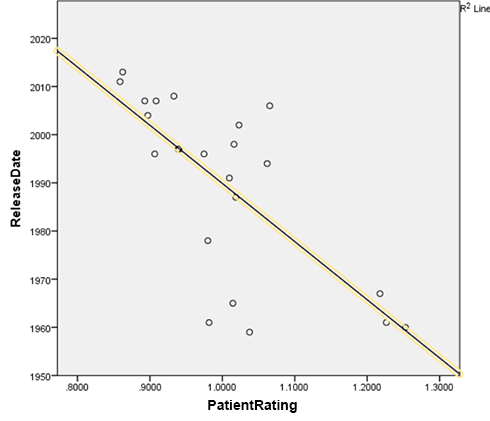
This pattern absolutely jumps out of the data. First- and second- place winners Nardil and Parnate came out in 1960 and 1961, respectively; I can’t find the exact year third-place winner Anafranil came out, but the first reference to its trade name I can find in the literature is from 1967, so I used that. In contrast, last-place winner Viibryd came out in 2011, second-to-last place winner Abilify got its depression indication in 2007, and third-to-last place winner Brintellix is as recent as 2013.
This result is robust to various different methods of analysis, including declaring MAOIs to be an unfair advantage for Team Old and removing all of them, changing which minor tricylics I do and don’t include in the data, and altering whether Deprenyl, a drug that technically came out in 1970 but received a gritty reboot under the name Emsam in 2006, is counted as older or newer.
So if you want to know what medication will make you happiest, at least according to this analysis your best bet isn’t to ask your doctor, check what’s most popular, or even check any individual online rating database. It’s to look at the approval date on the label and choose the one that came out first.
IV.
What the hell is going on with these data?
I would like to dismiss this as confounded, but I have to admit that any reasonable person would expect the confounders to go the opposite way.
That is: older, less popular drugs are usually brought out only when newer, more popular drugs have failed. MAOIs, the clear winner of this analysis, are very clearly reserved in the guidelines for “treatment-resistant depression”, ie depression you’ve already thrown everything you’ve got at. But these are precisely the depressions that are hardest to treat.
Imagine you are testing the fighting ability of three people via ten boxing matches. You ask Alice to fight a Chihuahua, Bob to fight a Doberman, and Carol to fight Cthulhu. You would expect this test to be biased in favor of Alice and against Carol. But MAOIs and all these other older rarer drugs are practically never brought out except against Cthulhu. Yet they still have the best win-loss record.
Here are the only things I can think of that might be confounding these results.
Perhaps because these drugs are so rare and unpopular, psychiatrists only use them when they have really really good reason. That is, the most popular drug of the year they pretty much cluster-bomb everybody with. But every so often, they see some patient who seems absolutely 100% perfect for clomipramine, a patient who practically screams “clomipramine!” at them, and then they give this patient clomipramine, and she does really well on it.
(but psychiatrists aren’t actually that good at personalizing antidepressant treatments. The only thing even sort of like that is that MAOIs are extra-good for a subtype called atypical depression. But that’s like a third of the depressed population, which doesn’t leave much room for this super-precise-targeting hypothesis.)
Or perhaps once drugs have been on the market longer, patients figure out what they like. Brintellix is so new that the Brintellix patients are the ones whose doctors said “Hey, let’s try you on Brintellix” and they said “Whatever”. MAOIs have been on the market so long that presumably MAOI patients are ones who tried a dozen antidepressants before and stayed on MAOIs because they were the only ones that worked.
(but Prozac has been on the market 25 years now. This should only apply to a couple of very new drugs, not the whole list.)
Or perhaps the older drugs have so many side effects that no one would stay on them unless they’re absolutely perfect, whereas people are happy to stay on the newer drugs even if they’re not doing much because whatever, it’s not like they’re causing any trouble.
(but Seroquel and Abilify, two very new drugs, have awful side effects, yet are down at the bottom along with all the other new drugs)
Or perhaps patients on very rare weird drugs get a special placebo effect, because they feel that their psychiatrist cares enough about them to personalize treatment. Perhaps they identify with the drug – “I am special, I’m one of the only people in the world who’s on nefazodone!” and they become attached to it and want to preach its greatness to the world.
(but drugs that are rare because they are especially new don’t get that benefit. I would expect people to also get excited about being given the latest, flashiest thing. But only drugs that are rare because they are old get the benefit, not drugs that are rare because they are new.)
Or perhaps psychiatrists tend to prescribe the drugs they “imprinted on” in medical school and residency, so older psychiatrists prescribe older drugs and the newest psychiatrists prescribe the newest drugs. But older psychiatrists are probably much more experienced and better at what they do, which could affect patients in other ways – the placebo effect of being with a doctor who radiates competence, or maybe the more experienced psychiatrists are really good at psychotherapy, and that makes the patient better, and they attribute it to the drug.
(but read on…)
V.
Or perhaps we should take this data at face value and assume our antidepressants have been getting worse and worse over the past fifty years.
This is not entirely as outlandish as it sounds. The history of the past fifty years has been a history of moving from drugs with more side effects to drugs with fewer side effects, with what I consider somewhat less than due diligence in making sure the drugs were quite as effective in the applicable population. This is a very complicated and controversial statement which I will be happy to defend in the comments if someone asks.
The big problem is: drugs go off-patent after twenty years. Drug companies want to push new, on-patent medications, and most research is funded by drug companies. So lots and lots of research is aimed at proving that newer medications invented in the past twenty years (which make drug companies money) are better than older medications (which don’t).
I’ll give one example. There is only a single study in the entire literature directly comparing the MAOIs – the very old antidepressants that did best on the patient ratings – to SSRIs, the antidepressants of the modern day4. This study found that phenelzine, a typical MAOI, was no better than Prozac, a typical SSRI. Since Prozac had fewer side effects, that made the choice in favor of Prozac easy.
Did you know you can look up the authors of scientific studies on LinkedIn and sometimes get very relevant information? For example, the lead author of this study has a resume that clearly lists him as working for Eli Lilly at the time the study was conducted (spoiler: Eli Lilly is the company that makes Prozac). The second author’s LinkedIn profile shows he is also an operations manager for Eli Lilly. Googling the fifth author’s name links to a news article about Eli Lilly making a $750,000 donation to his clinic. Also there’s a little blurb at the bottom of the paper saying “Supported by a research grant by Eli Lilly and company”, then thanking several Eli Lilly executives by name for their assistance.
This is the sort of study which I kind of wish had gotten replicated before we decided to throw away an entire generation of antidepressants based on the result.
But who will come to phenelzine’s defense? Not Parke-Davis , the company that made it: their patent expired sometime in the seventies, and then they were bought out by Pfizer5. And not Pfizer – without a patent they can’t make any money off Nardil, and besides, Nardil is competing with their own on-patent SSRI drug Zoloft, so Pfizer has as much incentive as everyone else to push the “SSRIs are best, better than all the rest” line.
Every twenty years, pharmaceutical companies have an incentive to suddenly declare that all their old antidepressants were awful and you should never use them, but whatever new antidepressant they managed to dredge up is super awesome and you should use it all the time. This sort of does seem like the sort of situation that might lead to older medications being better than newer ones. A couple of people have been pushing this line for years – I was introduced to it by Dr. Ken Gillman from Psychotropical Research, whose recommendation of MAOIs and Anafranil as most effective match the patient data very well, and whose essay Why Most New Antidepressants Are Ineffective is worth a read.
I’m not sure I go as far as he does – even if new antidepressants aren’t worse outright, they might still trade less efficacy for better safety. Even if they handled the tradeoff well, it would look like a net loss on patient rating data. After all, assume Drug A is 10% more effective than Drug B, but also kills 1% of its users per year, while Drug B kills nobody. Here there’s a good case that Drug B is much better and a true advance. But Drug A’s ratings would look better, since dead men tell no tales and don’t get to put their objections into online drug rating sites. Even if victims’ families did give the drug the lowest possible rating, 1% of people giving a very low rating might still not counteract 99% of people giving it a higher rating.
And once again, I’m not sure the tradeoff is handled very well at all.6.
VI.
In order to distinguish between all these hypotheses, I decided to get a lot more data.
I grabbed all the popular antipsychotics, antihypertensives, antidiabetics, and anticonvulsants from the three databases, for a total of 55,498 ratings of 74 different drugs. I ran the same analysis on the whole set.
The three databases still correlate with each other at respectable levels of +0.46, +0.54, and +0.53. All of these correlations are highly significant, p < 0.01. The negative correlation between patient rating and doctor rating remains and is now a highly significant -0.344, p < 0.01. This is robust even if antidepressants are removed from the analysis, and is notable in both psychiatric and nonpsychiatric drugs.
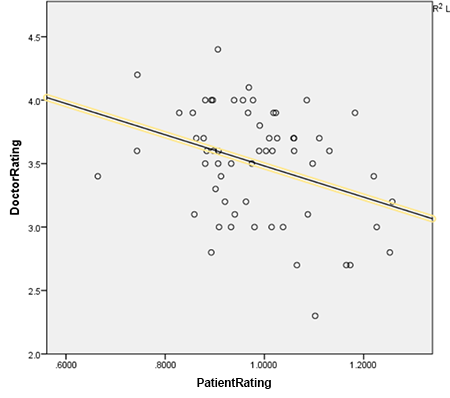
The correlation between patient rating and year of release is a no-longer-significant -0.191. This is heterogenous; antidepressants and antipsychotics show a strong bias in favor of older medications, and antidiabetics, antihypertensives, and anticonvulsants show a slight nonsignificant bias in favor of newer medications. So it would seem like the older-is-better effect is purely psychiatric.
I conclude that for some reason, there really is a highly significant effect across all classes of drugs that makes doctors love the drugs patients hate, and vice versa.
I also conclude that older psychiatric drugs seem to be liked much better by patients, and that this is not some kind of simple artifact or bias, since if such an artifact or bias existed we would expect it to repeat in other kinds of drugs, which it doesn’t.
VII.
Please feel free to check my results. Here is a spreadsheet (.xls) containing all of the data I used for this analysis. Drugs are marked by class: 1 is antidepressants, 2 is antidiabetics, 3 is antipsychotics, 4 is antihypertensives, and 5 is anticonvulsants. You should be able to navigate the rest of it pretty easily.
One analysis that needs doing is to separate out drug effectiveness versus side effects. The numbers I used were combined satisfaction ratings, but a few databases – most notably WebMD – give you both separately. Looking more closely at those numbers might help confirm or disconfirm some of the theories above.
If anyone with the necessary credentials is interested in doing the hard work to publish this as a scientific paper, drop me an email and we can talk.
Footnotes
1. Technically, MAOI superiority has only been proven for atypical depression, the type of depression where you can still have changing moods but you are unhappy on net. But I’d speculate that right now most patients diagnosed with depression have atypical depression, far more than the studies would indicate, simply because we’re diagnosing less and less severe cases these days, and less severe cases seem more atypical.
2. First-place winner Nardil has only 16% as many reviews as last-place winner Viibryd, even though Nardil has been on the market fifty years and Viibryd for four. Despite its observed superiority, Nardil may very possibly be prescribed less than 1% as often as Viibryd.
3. Pretty much the same thing is true if, instead of looking at the year they came out, you just rank them in order from earliest to latest.
4. On the other hand, what we do have is a lot of studies comparing MAOIs to imipramine, and a lot of other studies comparing modern antidepressants to imipramine. For atypical depression and dysthymia, MAOIs beat imipramine handily, but the modern antidepressants are about equal to imipramine. This strongly implies the MAOIs beat the modern antidepressants in these categories.
5. Interesting Parke-Davis facts: Parke-Davis got rich by being the people to market cocaine back in the old days when people treated it as a pharmaceutical, which must have been kind of like a license to print money. They also worked on hallucinogens with no less a figure than Aleister Crowley, who got a nice tour of their facilities in Detroit.
6. Consider: Seminars In General Psychiatry estimates that MAOIs kill one person per 100,000 patient years. A third of all depressions are atypical. MAOIs are 25 percentage points more likely to treat atypical depression than other antidepressants. So for every 100,000 patients you give a MAOI instead of a normal antidepressant, you kill one and cure 8,250 who wouldn’t otherwise be cured. The QALY database says that a year of moderate depression is worth about 0.6 QALYs. So for every 100,000 patients you give MAOIs, you’re losing about 30 QALYs and gaining about 3,300.
















This would require falsifying studies. The competition would have incentive to fund replication efforts: if Pfizer can show that Prozac is even worse than discredited-by-every-study Nardil, that would surely increase the sales of Zoloft.
Remember this post? https://slatestarcodex.com/2014/04/28/the-control-group-is-out-of-control/
There’s a lot of ways a study can be impacted by bias/priors that don’t involve falsification.
The SSRIs (a category including both Zoloft and Prozac) are generally assumed to be so similar that a study praising or condemning one (in contrast to MAOIs) would probably rebound on all of the others. The incentive of both Pfizer and Eli Lilly was to make SSRIs in general look good so that their own SSRIs looked good.
I’ve never heard of drug companies doing hit jobs on other companies’ drugs, though in theory it should happen. I hope we’re not giving any of them any ideas.
Drug companies regularly fund studies to show that their own drugs are better than competing ones.
But what patent holding company wants to get into a tit for tat war with all the others where the only winners are the generic drug manufacturers and patients.
It’s not quite MAD but it’s close.
On the other hand government bodies like the NHS do fund studies into generics, it might be worth comparing industry funded comparisons to state funded comparisons.
A really decisive study is very expensive. For example, when I took part in a phase III trial of the highly effective anti-lymphatic cancer drug rituximab in 1997, the first time I got the drug I had some minor but spectacular side effects (the Shivers). At one point, I counted 15 medical personnel crowded into my hospital room to observe my condition. (I was ecstatic that I was clearly getting Strong Medicine instead of a placebo.)
But, hypothesis generation studies can be cheap in the Internet era. If you want me to answer a lot of questions about myself and my experience with rituximab, well, ask away! I’m actually pretty fascinated by myself, and I’m glad you asked.
“I’ve never heard of drug companies doing hit jobs on other companies’ drugs, though in theory it should happen.”
Part of the problem is that the reigning mindset is the assumption that medicine ought to be like physics ,and what works for some should work for everybody. That’s Science!
But in reality, Zoloft works for some people and Prozac works for some people, but not exactly all the same people. And which order your doctor prescribes Zoloft or Prozac to you can be a very big deal to you personally at the time when you are highly depressed. Increasing the accuracy of doctors’ rank ordering of medicines to try out on individual patients would lead to a big absolute increase in human happiness, but drug companies don’t have much incentive to fund expensive research — such as how to figure out whether this individual patient should start with Zoloft or Prozac — that probably wouldn’t increase overall sales.
But if the research could be made cheaper by utilizing the propensity of people to sound off online for free (as I’m doing here), then perhaps the accuracy of prescriptions could be increased.
Problem is: data from people sounding off is close to useless for making actual predictions. People sounding off online will tell you homeopathy and ground rhino horn is great is far more than any well run RCT.
Go to an anti-vaxxer website and they’ll have lots of “studies” where visitors to the anti-vax website have filled in surveys saying how terrible vaccines are and listing every “side effect” they’ve “observed” in their children to the point that it looks like vaccines maim pretty much everyone who gets a dose according to the anti-vaxxers “data”.
Ben Goldacre suggests a more workable approach whenever we’re unsure which of 2 treatments is better: when the doctor is putting the details and what they’re thinking of using as a treatment the NHS system flags up that there’s a second treatment equally likely to be beneficial. If the patient agrees then the doctor hits the button and the patient is assigned to one arm or the other. It’s not blinded but it still generates better data than the current setup, shouldn’t endanger lives in the short term and should lead to better outcome for everyone long term due to getting better data about what treatments are most effective for who.
Okay, but you and I pay a fair amount of attention to people sounding off online about all sorts of things. So, what are we doing right?
That’s actually a serious question.
For example, after a quarter of a century of reading online opinions in both quantitative and verbal forms, I have a number of heuristics I apply almost unconsciously to sift the gold from the dross. These techniques could be formally coded and applied to giant amounts of data.
Heuristics regarding natural language are pretty difficult to code, though. You could maybe try some sort of machine learning thing, but there are a lot of potential ways that could fail.
“there are a lot of potential ways that could fail.”
True, but it might also eventually work.
I’m analogizing off the history of sabermetrics: for the first quarter century or so, what succeeded were small, focused data analyses that Bill James specialized in. The early attempts by Pete Palmer in 1985 and the like to move to a Unified Field Theory of ranking every player in history weren’t that successful. But the important thing was that a culture of data-driven argument emerged. Today, we’re pretty close to what Palmer wanted to do 30 years ago, but that’s because James nourished a culture of continual modest increases in insight.
Why wouldn’t we want to give them ideas? Frankly, if irrational boosterism is going to be in the mix, I want some irrational downerism to balance it out.
“I’ve never heard of drug companies doing hit jobs on other companies’ drugs, though in theory it should happen. I hope we’re not giving any of them any ideas.”
I think the bottleneck there would be doctors. They’ll convince their patients to take part in what they think is a legitimate study. Some will help a drug company make a drug look better than it actually is. But convincing doctors to help make a drug they know works look like it doesn’t is probably a bridge too far.
Another thing to consider is that the largest possible return on investment from clinical trials is earning a new indication from the FDA. Being able to tell doctors a competitor’s drug has a somewhat worse weight gain problem than your anti-anxiety medication is not nearly as impactful as telling doctors the FDA has now approved the drug for anxiety AND the manic phase of bipolar disorder.
And if you’ve read this far, perhaps you might be kind enough to explain why every psychiatrist who has prescribed valproate to my clients has used it as full time maintenance therapy when it’s only indicated for the manic phase of bipolar disorder?
@ Ryan
“I’ve never heard of drug companies doing hit jobs on other companies’ drugs, though in theory it should happen. I hope we’re not giving any of them any ideas.”
I think the bottleneck there would be doctors.
Something like that may be happening with studies that don’t need doctors, and each study taken alone may be conducted legitimately. For example, apparently there have been quite a few studies done on various effects of stevia (non-patentable) or aspartame (patented). One possible bad effect of stevia gets a study looking for evidence of Bad Effect X. One alleged bad effect of aspartame is studied, looking for evidence that clears aspartame of Bad Effect Y. (See also “data dredging”.) It is just a question of funding a study whose honest result will be useful to the source of the funding.
I recommend reading bad pharma by Ben Goldacre for some indication of the practices that pharma companies use to mislead as to the effectiveness of their drugs. Pharma companies probably have a vested interest in not exposing each other because developing new drugs is hard.
The problem with new drugs these days is that if a new drug is truly exciting then you don’t really need big studies to know that (although you might still do one to see if safety concerns). If I give you a drug and the next day you do not have cancer, and that happens in 80% of all cases, then I’ve invented a wonder drug! There’s a spoof article from the BMJ which points out that there have been a lack of RCTs to determine the effectiveness of parachutes, so how can we be sure they work?
The problem is that in practice new drugs tend to be, even if they are effective, just a bit more effective than their competition. And even if this effect is real, it might actually be quite hard to demonstrate. So there’s an incentive there to engage in the many bad practices companies do because they don’t want to waste that massive R&D budget producing a drug that isn’t any better than the previous drug.
One thing you always want to worry about when examining extremes in a data set is regression to the mean. This seems especially true if the extremes (the best scoring drugs) don’t have that many reviews; it’s much easier for a drug with few reviews to score highly.
Another possible factor: if I’m a patient on some psychiatric drug, what is it that motivates me to write reviews on these sites? I’m probably not motivated by the idea of providing rigorous scientific data; instead, I’m probably motivated by the idea of helping people. Letting people know that a widely prescribed drug sucks seems helpful in a way letting people know that it rocks doesn’t. Letting people know that a rarely prescribed drug rocks seems helpful in a way letting people know that it sucks doesn’t. In both cases, I may be motivated to share my data in the hope that it will change patterns of prescriptions for the better. There’s no “people need to know about this!” feeling if my SSRI works fine or my MAOI is a dud.
I think all of these drugs have enough reviews that I’m not too worried about low sample size. Nardil is one of the least-prescribed drugs in here, but the data comes from 181 different reviews. I think that’s enough that regression to the mean doesn’t have to worry me.
Why would patients wanting to counterbalance what they saw as prevailing opinion happen with psychiatric drugs, but not drugs in other fields of medicine?
Yes, Velociraptor singled out psychiatric drugs, but the effect is does happen generally, so you shouldn’t ask V to explain why it doesn’t.
It seems that we can look at the total number of reviews as a proxy for popularity and check whether this effect is significant, and maybe adjust for it somehow.
What if a “my doctor was wrong!!!11” effect makes reviewing the drug more likely?
Is there a correlation between sample size (number of reviews) and ratings?
Probably it would be better to stratify drugs by type, but here are some global correlation coefficients:
Cor(#reviews,doctor)=0.23
Cor(#reviews,patient)=-0.19
Cor(date,patient)=-0.19
Cor(date,doctor)=0.06
Cor(date,#reviews)=0.17
Cor(patient,doctor)=-0.34
So, yes, there is a correlation between popularity and rating, but it is not as strong as the disagreement between patients and doctors. (In fact, I’m surprised that the correlation between doctor rating and #reviews is so low.)
I’m not sure; I’m just throwing hypotheses at the wall to see what sticks. Here’s another one. Let’s say that when patients review drugs they’re primarily concerned with effectiveness (side effects are rare enough to not get represented much in review data), and when doctors review drugs they’re primarily concerned with side effects (stories about doctors getting sued are much more salient than the non-event of a patient receiving a drug, getting cured, and never coming back… this might be less true for psychiatrists?) You could imagine that all drugs in common use fall on some production possibility frontier that trades off safety versus effectiveness. If a drug is strictly dominated by some other drug, in the sense that it’s both less effective and less safe, no one will use it (or it will never be commercialized) and we won’t see it represented in our data. The net effect of this is that the most effective drugs on the market will tend to be the least safe and the safest drugs on the market will tend to be the least effective, leading to a negative correlation between safety and effectiveness. This negative correlation between safety and effectiveness leads to a negative correlation between patient scores and doctor scores. (If a particular problem has a drug discovered for it that’s both very safe and very effective, the topic of which drug to prescribe ceases to be interesting and such problems will not be covered in analyses such as yours. For example, you neglected to discuss painkillers, perhaps because painkilling drugs like tylenol are both safe and effective.)
Most of the instances in which I rate things occur when I’m browsing ratings: I’ve never sat straight up and felt a burning desire to review the pizza joint I went to last week, but when I am looking for restaurants and I see that it’s up there, I will generally say something about it, especially if my experience deviated from the norm. It isn’t always the case that I had a great/terrible time and feel inclined to say so–if it has five star ratings across the board I’ll mention that it was just a pizza place as opposed to the second coming of Christ.
It seems plausible that the people rating the drugs are the people who are looking for other medications, or wanting to see how their experience stacks up.
Good point. This is the kind of thing, however, that could be teased out from a questionnaire.
As far back as the 1980s, Bill James could scratch out a living just by thinking very hard all the time about baseball statistics. His perceptions and intuitions weren’t always right, but the process of desiring to explain his arguments in clear prose to other baseball statistics obsessives encouraged him to refine his views, with what appears in retrospect to have been positive results.
I bring this up because there would appear to be many fields more important to human happiness than baseball statistics that could use a Bill James and the culture he inculcated of independent-minded analysis, such as medicine.
Even with Bill James, the big money of drugs seemed to be a corrupting factor: the word “steroids” barely crossed his lips until maybe 2009, when he published a risible piece in Slate claiming that Barry Bonds’ late-career surge maybe had more to do with the type of wood in his bat than with PEDs.
But the point is that more data and more outsiders arguing over what it all means seem to be Good Things, and would likely be good for medicine.
The general view is the opposite: that if patients and doctors were legitimized to discuss medicine together in online forums, Jenny McCarthy-style crackpotism would run amok.
That’s quite possible.
Still, I have a certain amount of faith in intellectual elitism actually working, as long as the elitists go into the marketplace of ideas and take their lumps. It was pretty obvious in 1985, say, that Bill James was smarter and more interesting than most people writing about baseball statistics.
Not my opinion (which is that SSRIs just have a different set of efficacy/safety trafeoffs), but maybe the placebo effect is especially strong once the patient has gotten a warning that the drug may shut down their liver, resulting in a slow and painful death; when compared to a warning that they may have trouble sustaining an erection.
I’ve heard the suggestion that ECT and ketamine are such great treatments precisely because of the “industrial-strength placebo” effect: if something completely disrupts and resets your conscious processing, you have to sign all sorts of waivers to get it and wait weeks for a procedure room, etc. …then it’s gotta be one helluva drug, so maybe this time it’ll work!
Given that the hope generated by “maybe this time it’ll work” is precisely the chemical cocktail the intervention seeks to achieve, I’ve held two conclusions for a while now:
1. Whenever there are multiple lines of therapy for a condition, the first-line therapy will be a placebo. It got this way because FDA incentives (find a drug with the fewest side-effects that does at least something) weigh heavily in favor of pure placebos when placebos actually work somewhat. The second- and third-line therapies are probably placebos too. The fourth-line therapy probably has an effect on a subpopulation and a placebo effect outside of it (i.e. it fiddles with messenger proteins not everyone has.) The last-line therapy actually directly does something—it literally slides some gauge to the right, irrespective of its reference-point—and so it has all sorts of side-effects, some of which are due to misprescription, but most of which are just what it looks like when a drug is actually doing its job (like weight gain in antidepressants.)
2. When the real effect of a therapy is subtle, the placebo effect will, sadly, be stronger the more side-effects the drug has! The side-effects, after all, are observable, while the effect is mostly not; so the side-effects are how you know the drug is doing anything at all. This implies that, for the population who only need a placebo, a drug that’s nothing but pure side-effects will have a stronger therapeutic effect than one that’s a pure placebo. This is what I believe differentiates first- and second-/third-line treatments for most conditions.
I should note that I mean more by “side-effects” than just things like “I got a rash.” The best side-effects for pumping up the placebo effect are restrictions: things the patient has to keep in mind not to do. MAOIs may as well put you in a monastery for how many things they require you to keep in mind—no cheese, for example!—and this mindfulness can serve to do other interesting things to the brain. You can probably observe heightened Conscientiousness scores in people taking an MAOI, because they have to be Conscientious—something they may never have had to do before—to not get a bad drug reaction.
Recent study found similar antidepressant effects from laughing gas, which is chemically similar to ketamine (which is apparently why it was tested.)
Could you clarify? They’re both NMDA receptor antagonists, but they’re not the same type of antagonist, and the molecules look nothing alike.
Huh. For some reason I don’t think I’d actually thought about the idea of maximizing the Placebo Effect before: I suppose for some psychiatric medicines (like antidepressants), and also for things like painkillers, it might actually make sense.
Optimizing for it seems a bit tough, especially if you bring in the “hope” aspect that you pointed out- using placebos that fail before trying stronger placebos might weaken the later ones.
Outside of that, though… it seems like we could probably do studies on what affects how strong the placebo effect is; different types of side effects, different waivers, etc.
Related: placebo may explain why older doctors / older drugs are more effective. Presumably, older doctors come off as more authoritative. Both because of their obvious experience, and the attitudes of the older generation.
Of course, my immediate selfish reaction to this post was, “I have a medicated condition! Let me look up my drugs on these sites!” My condition is relatively uncommon (and my treatment even more so), so there wasn’t enough data to do statistics, but one thing that jumped out at me was that allergies were skewing the patient reactions a lot. If (as in my case) a drug is miraculously effective but 20-25% of patients have allergic reations, that brings down its patient rating a lot. (The allergic reaction in this case is unpleasant but not life-threatening, easily recognizable, and goes away as soon as you switch to a less miraculously effective treatment.) This seems like one of those cases where a higher prescription rate might be justified for a lower-rated-by-patients drug.
I didn’t look at the detailed comments for the drugs you examined, though, so I have no clue whether this is a major factor in your categories. And even if it is, it wouldn’t explain away much of this (troubling) trend.
Do bad allergic reactions to specific drugs correlate with other allergies? For example, if people who are allergic to peanuts are allergic to drug X 30% of the time but to drug Y 5% of the time, that might be helpful to a doctor trying to choose between X and Y.
Yes, drugs tend to cross-react with other drugs in the same class, though it is far from absolute.
So going by your table, there’s a big jump betwen #3 (Clomipramine) and #4 (Seligiline). The top two, as you noted, are MAOIs; the third one, looking it up, is a tricyclic.
…I’m sure this is basic background and you’ve said this before, but would you mind reminding us why tricyclics aren’t used so much (assuming there is an obvious reason like with MAOIs)?
Pretty easy to overdose and kill yourself, which isn’t so good when you’re giving it to depressed people.
Maybe people on first-line antidepressants are disappointed by anything short of a perfect cure with no side effects, while people on the antidepressants of despair are overjoyed at any improvement.
Yes, selection effects and benchmarks are a big deal. Scott said:
But they don’t have the best win-loss record, only the best rating. Which might be a response to low expectations.
This is along the lines of what I was thinking. If someone tries 7 medications from newest to oldest, they’ll probably give all the newer ones bad reviews and the old one that works a good review. So if you were someone who responded to an old medication you get more votes, as it were, and we would expect to see a correlation there. The correlation between release year and number of reviews is tiny in areas outside of psychiatry (-.02 vs. 0.47), so this remains as a possible explanation. This also would explain why less popularly prescribed medications have higher ratings in general.
Or it could be that a lot of depressions cure themselves over time, so the drugs of last resort are proportionately more likely to be in the right place at the right.
Rocky didn’t beat Apollo Creed (in the first, best movie), but we didn’t need him to; just going the distance was good enough for a happy ending.
That’s what I came to say. By the time a patient gets to try MAOIs, her expectations have been lowered quite a bit, compared to someone who gets a first-line SSRI and expects to not even need that anymore in 6 months.
Pity these lists are just pharmacological. I’d love to see how ECT compares.
ECT? What ECT?
(bad joke…)
Counter-point: The same principle (call it the “Rocky I” principle) ought to apply to non-psychiatric disorders. That’s not showing up in the data above.
Counter-counter-point: Scott chose (innocently, I’m sure) comparison conditions that seem to share a common trait. I don’t have any of the conditions that any of these drugs treat, but my extremely non-expert impression is that the other conditions are either not very painful on a day-to-day basis (hypertension, maybe diabetes) or are so effectively treated that the patient will judge different drugs solely on how unpleasant the side effects are (seizures). In other words, nobody goes on a website to write a rant about how Lipitor did NOTHING for him.
A better comparison would be to pick a chronic physical illness that is (a) very painful and (b) not easily treated. You’ll get the same sort of patients that you get for depression: ones who do fine on the first-line treatment, others who get increasingly desperate as the months and years go by until they find a “miraculous” drug that enables them to lead a semi-normal life. Crohn’s disease is a possible choice.
It does show up in the data. The difference is that for non-psychiatric drugs age does not matter, but that has nothing to do with the Rocky Principle, which is about doctors and patients having opposite opinions.
(Actually, the Rocky Principle is about patients liking rare drugs, which Scott did not test outside of anti-depressants. But surely the common drugs are the same as the ones doctors like.)
Perhaps ratings from patients are lower overall than ratings by doctors, because the patients were expecting a miracle cure and the doctors are more pessimistic (realistic).
What algorithm was used to determine the adjusted/normalized ratings?
And is it possible to look at each individual review, as opposed to the average rating? It should do something regarding regression to the mean (p-value would account for sample size) and rare but important “my liver exploded” cases.
If you visit RateMyProfessors.com, you often find that the numerical ratings can be augmented by reading individual reviews.
For example, if Professor Jones gets mediocre numeric scores, but his one star reviews tend to read:
“Yak yak yak. STFU already, Jones. Really hard grader. Who does he think he is, LOL!!!”
While the five star reviews tend to begin:
“Jones’ controversial reinterpretation of Weber’s hypothesis of the Protestant work ethic theory opened my eyes …”
Well, you can kind of figure out what’s going on.
(By the way, you can look up undergrads’ ratings of famous professors such as David Foster Wallace and Alan Dershowitz, which is pretty entertaining.)
I like to look up people from the rationalist community, such as Robin Hanson and James Miller.
Things I learned from doing this:
Tyler Cowen gets a poor rating because he is “Just another Neoliberal trying to pass of Neoliberal economics as natural. Failure to realize that globalization is a problem. Neoliberal economics are what has forced the global economy into the can. Inequality is part of Free Trade. Please quit teaching Economics like this ideology will save all.”
Eli Dourado is a GMU econ professor. And apparently Eli Dourado is his real name!
See, when I took econ at GMU I had Professor Bennett who deserves a terrible rating for spending each of every class ranting about how the government is evil, but that would still have been an issue if it was something I agreed with. I don’t think disagreeing with someone’s ideology is necessary and sufficient for giving them a bad rating unless it actively gets in the way of teaching.
Very, very few people will give a good rating to someone they disagree with, particularly ideologically. That whole principle of ‘I disagree with what you say but will defend to the death your right to say it’ was always hard to get people to adhere to (everyone looked at the ACLU lawyers defending the Klan funny) and now almost nobody believes in it anymore.
I looked up Paul Gottfried. Full of people claiming he’s pompous and others, usually conservative, claiming he’s brilliant. Not mutually exclusive, of course.
Any chance that the people on older drugs, are themselves older and/or have been on the drug for a longer time before these sorts of ratings sites have existed?
I could imagine that there might be demographics reasons which younger people might be more harsh / negative in their reviews.
Maybe it’s even that people who rate things closer to their initial switch onto the drug, as would be a higher proportion of people for the new / most prescribed drugs, weight the awkward period where they are still adjusting more strongly.
It would be useful to ask patients to volunteer in-depth information about themselves so these good questions could be answered with data.
Are there a significant number of drugs that are not just rare but have lost their regulatory approval, such that they wouldn’t even appear on these web sites? If so, there could be a survivorship bias effect in your analysis, since some current drugs might also end up being taken off the market at some point.
Generalizing your suggestion in part V: sounds like drugs have various qualities we would like to simultaneously optimize (average efficacy, reliability, frequency of side effects, severity of side effects, etc.) and doctors and patients prefer different tradeoffs of these qualities. Since different drugs are optimal according to doctors’ preferences than according to patients’ preferences, there will generically be a negative correlation between doctor and patient ratings, at least once you throw out the drugs nobody likes.
“Doctors love the drugs patients hate” gives the wrong impression, I think. The negative correlation is only possible because you have selected the best drugs on offer (i.e. the ones not obviously strictly dominated by any others). If we included some truly inferior drugs then doctors and patients would both give them low ratings and we’d get a positive correlation instead of a negative one.
Surely there is a strong selection effect here where the less effective drugs of the 1960’s have fallen out of use entirely since then. I’d expect this effect alone to produce a positive correlation between ratings and age. Of course this doesn’t rule out a real effect.
In addition to the selection effect, perhaps with the older drugs we know more about how to use them- the best dosage, what type of patient they work best for.
Another possible confounder is the “time to show effect”.
IIRC, SSRIs take a while (weeks to months) to take effect. If older medications are faster acting (this is what I’m not sure about) and the patients rate the medications shortly after starting to take them, then it’s normal that they would rate SSRIs as ineffective, while doctors take the longer view.
Is it possible there’s just some kind of hipster rarity effect going on here? “The same drug everyone else is on” doesn’t sound very appealing or effective, and anyone who browses drug rating sites will probably know if they’re on the standard first-line pill or not.
On the other hand, if you’re into this weird underground pill that nobody’s ever heard of then it probably feels -really- effective, especially if the side effects might kill you. Placebo research consistently notes that more dramatic placebos work better, and it’s hard to think of a more dramatic intervention than “ancient dangerous forbidden drugs”.
I think it’s because doctors and laypeople are grading medications on different criteria. The doctors are (presumably) going by the clinical studies and their broad experience in practice (e.g. “In a practice of thirty years’ standing, I’ve prescribed this to 68% of my patients and nobody’s liver has exploded yet”).
Patients will review on different criteria – yes, that it works/doesn’t work for them, but also for things like “This worked great on my depression but it also made me come out in a horrible itching rash which drove me crazy so I switched back to my old prescription”. Now, if Joe is only one of a very few people who come out in a rash when on Newdrug, Joe’s doctor will probably give Newdrug a positive review but Joe will give it a negative review.
Or maybe the doctors are going by which attractive salesperson dropped by with some free samples most recently.
Back in 1997 my doctor prescribed me Mevacor for high cholesterol because he had some freebies in his drawer. I went on the Internet (a very new thing in 1997), and came back to him and said, “Why not Lipitor? That seems to have been more effective in clinical trials.”
He said, “Sure. I don’t have any Lipitor samples on hand, but if you say it’s better, no problem. I’ll write you a prescription.”
I was thinking that. I’d somewhat expect the most frequently prescribed drugs to not get a particularly high rating. A kind of mass market, baseline, “not as good as the fancy stuff” rating.
I’m sure that can’t explain all of the results here, though, so the post is still terrifying.
Looking at the scatter plot, it seems like one could put the drugs into three clusters. Cluster A is the three really good drugs from the ’60s. Cluster B is from the late ’50s to late ’00s. Cluster C starts (depending on whether you include those two from the ’90s) at either about 1995 or 2005, and goes to present day. The trend then is that A is really old and really good. C is really new and really bad. B spans the entire period, and is middling. When you put all of those clusters together, you get a positive correlation between age and score, but within each cluster, there is no significant correlation. Of course, this could just be data mining, but it seems to me that rather than a straight line trend between age and score, there’s several different trends.
I think my sister is on escitalopram, I must check with her (her doctor is very good – or at least, she’s very happy with them: regularly checks her thyroid which is low, switches up her medication and doesn’t keep her on things that don’t work).
I get the “newest drug is least popular with patients” – people get used to being on whatever they were prescribed, including managing any side-effects, and then they get changed to a new thing which causes different side-effects and they haven’t had a chance to get used to it and let it build up, so there’s a lot of “I hate this Newdrug, I wish my doctor would put me back on Olddrug” until they get accustomed to it and get advice from other patients about “try this to manage the upset stomach/the hiccoughs stop after three weeks”.
I’ll offer two more confounders:
1. Survivor bias: Your including drugs effective enough to still get prescribed at all 50 years after first release. There were probably quite a few drugs that were released and after initial marketing dropped, even by potential generic manufacturers, because of poor performance. The real testing cycle for a drug is in that first decade, not just because of patents, but also because few drugs are worth any marketing after their addressable market shrinks. For psychiatric drugs, the time to tell if it’s working is longer and a bit less objective.
2. Selection bias: People who spontaneously fill out internet surveys are nit representative of the while population. For the doctors, there’s a bias toward the young and possibly less skilled. For patients there’s a bias towards the proactive. In both cases, there’s a bias towards the self absorbed, and a trust factor required to land at the right result.
“2. Selection bias:”
This is quite possible. Still, say that a Yelp-style survey identify Drug Z as a potential overlooked Godsend for people with Q traits? Then why not then scrape up the money to do a controlled gold-standard randomized trial of Drug Z for people with Q trait?
Ooh, survivor bias, good call.
I can think of one alternative explanation, which is that patients aren’t very good at determining what is treating their depression.
We don’t accept self-diagnosis of depression, so it stands to reason we should be skeptical of the converse, ie self-declarations of a drug working wonders.
If earlier studies testing depression overlooked this distinction, testing for self-declared improvements rather than asking more direct questions about improvements in life in precise ways that (it is my understanding) a modern test would ask, we would see the results above, as earlier studies were tested against exactly the criteria the website tests for, but modern drugs are not.
It would not surprise me to learn that this was the case. But I could stand to be corrected.
I think this is an important point. If you expanded the class of drugs under discussion to include, say, a cocktail of cocaine and heroin, one would imagine the subjective user scores would probably be extremely high, pretty much regardless of what condition it was treating. (Ref: Bowie, D., “Speedballs as treatment for space age ennui and gender dysphoria man”, Berlin Journal of Freaky Moon Age Daydream Studies, 1973). The point is we apply a filter on the front of this problem to account for our belief that health != hedonism, so I think it’s reasonable to apply a similar filter when looking at these results.
A safe version of a cocaine/heroine cocktail would be a wonder drug. It would justifiably deserve incredibly high marks. It would improve the lives of hundreds of millions of people.
Conversely, doctors are well-documented as having their own biases. “Patient drooled all over herself but finally stopped talking about having a suicide plan, or for that matter any other type of plan” is something I’d expect to have a high doctor review and low patient review. (Manic depression is perhaps the most obvious example of doctors openly favoring sedation over stimulation.) Rather than simply malign patients, the best use for this data would probably be just to observe that patient and doctor desires are in many cases very divergent.
Thanks.
We need to extend the Moneyball tendency from sports statistics to more important things in life like this.
One thing I’m getting from this is that a 1-10 rating doesn’t really capture the user’s response when that is “on behalf of my beloved mourned mother, who this product killed, I give it the minimum number of stars MINUS A BILLION. I mean, one.” 🙂
Also, I’m definitely persuaded by the likelihood of the rare side-effects bias.
But in terms of this specific post, I’m half-persuaded there’s a problem, but I also wonder if what’s going on is that modern drugs have fewer side effects and are on average less effective, but you more have to try several in turn to find one that works fairly well? So a lot of reviews like:
“I tried drugs A, B, C, D, E and they all sucked so I gave them one star, but F finally worked, 10/10.”
“I tried drugs B, C, D, E, F and they all sucked so I gave them one star, but A finally worked, 10/10.”
“I tried drugs C, D, E, F, A and they all sucked so I gave them one star, but B finally worked, 10/10.”
“I tried drugs D, E, F, A, B and they all sucked so I gave them one star, but C finally worked, 10/10.”
“I tried drugs E, F, A, B, C and they all sucked so I gave them one star, but D finally worked, 10/10.”
“I tried drugs F, A, B, C, D and they all sucked so I gave them one star, but E finally worked, 10/10.”
“I tried drugs A, B, C, D, E and F and NONE of them worked at all, I hate them all. And my doctor finally prescribed Z and it was amazing.”
So partly, rightly or wrongly, the old drugs are more effective but only prescribed when all the modern drugs failed. And partly, “worked well with rare side effects” gives a higher average rating. But also, the modern drugs only work for some people, but may work well for those people, so the ratings are full of people they didn’t work for, but that doesn’t mean they don’t work at all?
Excellent point. Still, you could ask patients what order they tried drugs in. Collecting data these days is a lot cheaper than in the past, you just have to figure out how to deal with the various biases that creep in.
My vague impression is that the medical research profession is not very open to Yelp-style big data collection. They have pretty good reasons for being skeptical about the quality of these potential massive amounts of data, but, like the man said, quantity can have a quality all its own.
The man was Stalin…but he’s still right. 😉
One of things the world needs is more data from users of different medicines on their characteristics so doctors can do a better job of matching patient to drug with less trial (and travail) and error.
For example, I was a patient in 1997 in a phase III clinical trial of the future non-Hodgkins lymphoma blockbuster drug rituximab. I was likely the first person on earth with my exact version of NHL cancer to get this futuristic monoclonal antibody. The only follow-up to the study was a very pleasant phone call five years later from my old nurse in the study, who was very happy to hear I was alive and hadn’t relapsed after five years.
If she’d asked me to go online and also fill in a 250 question survey about myself, I would have been happy to, since these folks saved my life. But that wasn’t part of the study.
Now there’s a big selection effect problem with cancer drugs, since if they don’t work, you probably aren’t going to be around to volunteer to help the researchers with their follow up research.
For psychiatric medicines, however, lots of people have tried lots of different drugs and have strong opinions on each one they’d like to share, as these voluntary online databases cited in this post show. It would be very interesting to see what personal characteristics correlate with effectiveness for drug X and what correlates with lack of effectiveness.
We should bring the power of Big Data to helping doctors and patients get to an individualized working solution faster. A clever researcher could probably devise a questionnaire for people with experience with different medications that would help psychiatrists get to the point of prescribing the individual Good Enough medication sooner.
Say you could cut the number of ineffectively treated months of depression by 5% by figuring out what seems to work better for different kinds of people. That’s not much in relative terms, but it’s just an enormous potential increase in human happiness in absolute terms.
A relatively small improvement in what to prescribe individuals for depression could rapidly add up to say, a million person-months of depression avoided on a global basis, or 30 million person-days.
The research team would want to devise the questionnaire to not make people with psychiatric problems feel like their privacy is being violated. And you’d want to add in reality check questions (What color was your pill? What shape was it?) to keep fantasists from cluttering up the database.
Volunteers who meet some level of apparent reliability and helpfulness in their online answers to questions could also be invited to participate in a free genetic / biochemical test by spitting into a tube and Fed Exing it to the researchers.
A lot of money is donated annually to medical research. This would seem like the kind of thing somebody could get a million dollar grant for from some philanthropist.
A big potential problem would be if the salesguys sit down and spam the questionnaire with a lot of 10/10 results. But I think you could get around that risk by using questionnaires not for ranking absolute effectiveness but for ranking relative. Use more controlled traditional studies for rating how likely Drug X is to work in general, but use this open online questionnaire for correlating Drug X’s effectiveness with various idiosyncratic online traits. This would reduce the payoff salesmen from spamming raves.
Here’s a quality-control precaution: ask survey respondents to spell the name of the medication rather than pick it from a multiple choice list. Treat the people who can spell several medications they’ve been prescribed with more trust than people who can only vaguely remember the name of the medicine.
That’s reasonable, but on the other hand, some people start out with problems with spelling, and others are distracted by their symptoms.
Perhaps it would make sense to keep your requirement to type in the drug names, but publish the results of various levels of demanding accurate spelling.
No, you’ve got it backwards. People who can spell multiple drugs are salesmen.
There could be a problem going forward if these online reviews databases become highly influential, thus motivating, say, sales managers to hire people in Belarus to enter bogus reviews.
But there’s not much evidence at present that much money is riding on these databases, so current data is probably not systematically gamed by pharmaceutical companies.
YES.
Along rather similar lines, 23andMe was generating lots of data about the relation between people’s genetics and other characteristics—whether they included what medical drugs worked for them and what didn’t, I don’t know, but they could have. Until the FDA stopped them.
No, 23andMe wasn’t generating much data and FDA didn’t stop that. What FDA stopped is taking other people’s data–the scientific literature–and applying it to their customers.
Looks like 23andMe claims credit for ~35 papers so far: https://www.23andme.com/en-gb/for/scientists/ (With 500k datapoints which have given research consent and filled out some of their many surveys, IIRC, that’s underperforming.)
“So for every 100,000 patients you give a MAOI instead of a normal antidepressant, you kill one and cure 8,250 who wouldn’t otherwise be cured.”
If we throw QALYs out the window and focus on mortality alone, this still seems like a great deal, since depression kills people too—around 38 of those 8250, based on this relative risk and US statistics (and if my math is right).
Even if I assume that the only mortality risk from depression is suicide, we still save about 1 of those 8250 people and break even on deaths, provided that the relative risk of suicide from depression is at least 1.9—which seems likely.
This is a very compelling argument. This sounds like a real failure of the system.
Not particularly substantive, but:
“And the only patient I ever put on last-place-winner Viibryd, all it did was make him more annoying, which is not a listed side effect but which I swear happened. Seriously, screw Viibryd.”
I know your hip-hop/blogger name is a deep look into the crystal ball away from your real name, but man, if I was your patient and read this I would be hurt, even though you phrase it as not-my-fault. I’m not even sure there is a way to soften this (although I would probably recommend you change it to “one of the patients…” so that they can plausibly be like, oh, that wasn’t me).
Feel free to delete this if you make an edit.
I knew someone who had a wild talent for saying the wrong thing.
She started taking an anti-depressant (sorry, I don’t know which one), and she became much better company. I asked her something tactful about the change, and she said that she didn’t feel different, but other people had become much nicer.
Makes a lot of sense; one of depression’s more interesting effects is to put a lighting gel in front of your mental models of people, so that whenever you try predicting or analyzing people’s reactions for their emotional content, you get back just the subset of predictions/analyses that make sense in the context of not spending any nerotransmittive Magic Points.
Imagine a neuron trying to potentiate its synapse, like a sparkplug, to tell you about an association to a current thought that would make you suddenly happier. It wants to transmit this information directly (as a thought), but also wants to add some neurotransmitters to relay the affect of the thought to more distant parts of the brain for integrative processing. But it finds its neurotransmitter store empty, and so not only does it fail to send the global signal—but it also fails to activate its synapse. So you fail to make the association at all. (Not literally what happens, but usefully predictive.)
Wouldn’t that predict that you’re bad at modelling people’s positive reactions, as opposed to their negative ones?
I’m rather curious about what kind of “wrong things” we’re talking about saying here, though.
Unfortunately, the only specific thing I can remember her doing is the weirdest, and least likely to be of general application.
I had a habit of adding little mildly humorous ornaments to what I said (sorry, none of them coming to mind). One person did find this annoying, apparently because he thought I was expecting them to be really funny, but I got along with people well enough.
The woman I mentioned started saying things in very much my style without imitating the specifics– not mocking me, just coming up with the same sort of things. She may have meant it as a compliment, but I was horrified– I thought I was more unique than that.
Speaking for myself, I think I can have a depressive symptom of finding it very hard to make small friendly gestures, even saying thank you or congratulations. It’s hard for me to expect that sort of interaction to go well. I don’t know if that’s typical of depressed people, but I do think there’s a general inability to imagine good outcomes.
When my father got a hearing aid, other people stopped mumbling so much.
By the way, a couple of decades ago I asked a psychiatrist what was so revolutionary about Prozac, and he responded that Pfizer’s breakthrough was marketing it in a single big pill so that patients typically took enough for it to have an effect. With pre-SSRI drugs, however, patients had typically said, “Well, I’m not really _that_ messed up, so I’ll just take one pill instead of the prescribed two,” and so they didn’t get enough medicine to do much good.
I have no idea if this is true, but it was pretty funny.
Pharmacists really need to educate people on more than just the side-effects and dosing schedule of medications.
For example, tell people at the checkout counter that when a prescription says “adult dose: take 2”, it means that each pill is a half-dose and they were split up that way to give your stomach an easier time breaking them apart, compared to big fat pills that can give a weird gutache-y (or pill-stuck-in-throat even after it’s gone down) feeling.
Also, maybe tell them that the pills that are big can’t just be made into smaller pills, even though their active ingredient is only a few mg, because the drug either wouldn’t work at all without the pill’s excipients, or would apply all its force to one little bit of tissue in your body—probably either your intestinal lining, or your liver.
I would be hesitant drawing any kind of conclusions from these sites because the data is just _so_ _bad_.
a) it’s a self-selected mess of bored people giving reviews of everything they’ve ever taken, really happy people giving great reviews two days after starting something, angry people who are convinced that This Drug caused This Unrelated Health Condition which has persisted for the five years after discontinuing and Doctors Are Covering It Up, etc
b) specificially regarding psychiatric drugs, some of them may have a brand name only, some may have one generic form only, some may have both, some may have many generics so people may not be taking the same drug. (please see: buproprion XL disaster)
c) I spent a long time down these specific rabbit holes when I had to pick between Enbrel and Humira. Another thing I noticed is that the numerical ratings can be bizarrely uncorrelated to the written comments. Some one star reviews can be like “I don’t think it did very much,” and some four star reviews can be like “it worked really well for awhile but then I got fungal septicemia and had to go off it and also I think it killed my sister.”
d) There’s a problem with support forums and stuff that they can get really depressing because they tend to be disproportionately populated by people for whom things aren’t going well (like, I have a genetic disease and sometimes I think I want to connect with people who share that experience, but it tends to make me more freaked out about my future and such). I think meds-rating sites are similar and are disproportionately used by people for whom at least one med is going very badly/has gone very badly recently or at least one condition is not responding to any treatment. This is also why I am going to try to not go reading all the reviews of whatever my dr puts me on next. I am already anxious enough about it without that >.<
I agree, but that the different databases correlate highly with each other to me means *something* is going on. It may not be a perfectly accurate collection of drug ratings, but there must be some consistent factor causing people to rate some of the drugs higher than others on all sites.
Online reviews are also notoriously fake. People talking up their product and badmouthing the competitor. You can buy good/bad reviews in bulk from professionals who make things look authentic.
I don’t know how big or what direction that effect is, but it’s something to be aware of in the online review world.
But the drugs that do the best are precisely the ones with *no* apparent pressure to buy good press. That doesn’t seem to fit with your idea of a confounder.
Hm. Could it be that the dominant factor is badmouthing the (still in patent) competition?
Re: antidiabetics, I’m assuming on your spreadsheet that the type 2 drugs are the antidiabetics (guessing this because metformin is in there).
I’m recently (slightly over two years) diagnosed Type 2 diabetic, and the only name I recognise on there is metformin (trade name of the formulation I’m prescribed is Glucophage). It seems to be the “old reliable” and my doctor certainly didn’t ask me about would I prefer anything else.
I suppose had I been unable to tolerate the side-effects of “This will cause you possible stomach upset and certain continuous bouts of diarrhoea* for a couple of weeks but then everything will settle down again”, or had everything not settled down again, I suppose she would have tried something else.
It also seems to be the medication of choice in the U.K., if the diabetes support forum I follow is any indication. I wonder if this is more a function of it being “the old reliable” or of relative cheapness, since both the Irish and British national health systems need to go for the cheapest prescription drugs where possible. Newer antidiabetics may be more expensive (I think metformin is out of patent, though I can’t swear to it) and so that means they’re more ‘last resort’ over here?
*TMI – it did.
Be glad you don’t live in a really cheap country, like Germany, that uses sulfonylureas first.
Metformin really is the best diabetes drug. When drug companies test new drugs, they don’t even bother comparing them to metformin. They compare metformin to metformin+new.
Metformin is a really, really good drug. It’s interesting that the ratings don’t show this. It’s very safe, it has the best evidence for lowering long-term endpoints, and its side effect might be preventing cancer (for some reason). These might be too long-term or weird to show up in patient ratings.
(Then again, as a doctor, I’d be expected to like the drugs that get bad ratings!)
I have to wonder does the lack of ratings/poor ratings for metformin have to do with the short-term side-effects when you start taking it? Because when they warn:
they are not joking. I didn’t have all of these (no vomiting, nausea and not really loss of appetite) but as for the rest – um. You don’t want the gory details of the first week 🙂
If I miss a Viibryd dose, all I can think about is tearing off my own flesh and how much I utterly fucking despise myself.
Then again, I’ve never really seen an overall benefit from an antidepressant, I just take them to avoid the side effects of not taking them.
To explain the old-young confounding: doesn’t it make sense that things that are around longer and have “stuck” are better? What I think your data doesn’t capture are older drugs that stopped being prescribed. I actually have no idea if that’s a thing, I’m not familiar with this industry at all.
Let’s maybe try talking about TV shows? That’s all I understand. We’ll pretend it’s 1999.
We are trying to decide if TV is getting worse over time. Well, let’s look at what’s on TV tonight. Seinfeld is great, and it came out in 1989. M*A*S*H is really old, also great! How about new shows? LateLine is on! This sucks! Veronica’s Closet? Eh. Nah gimme that Golden Girls, older TV is apparently better TV!
An outlier is that Family Guy is pretty good but also really new. But really, its goodness is going to lead to it sticking around for a while (still on TV today!) And as I alluded to already, we aren’t considering 70s TV shows that were immediately cancelled because they sucked, because we’re only checking what’s on TV tonight.
I understand that this is different because my commodity is changing (Season 8 Seinfeld is not Season 2 Seinfeld, but the drugs are staying the same for the 50 years). Maybe like, snack foods or something would be a better analogy, where standard Doritos aren’t better than the new PopCorners /because/ they’re older, but rather the fact that Doritos are old (and still around! unlike Betty Lou Chips) is a good indicator of quality. Again, the analysis only works by going to the convenience store and seeing what’s on the shelf: the things you don’t recognize are probably worse because they haven’t been time-tested. Yeah this is a better analogy, but I took the time to write up the TV bit, so I’m gonna leave that there.
Anyway, could drug prescription work like this?
I think the term for this is “survivorship bias”. It’s the same reason mutual/hedge funds which have been around for a long time have great performance in retrospect; the ones that didn’t are no longer around.
Literature is probably the best example of this. The random Jane Austen novel is going to be a lot better than a romance picked at random from those published this year. But Jane Austen isn’t a random pick from the authors who were her contemporaries.
But videogames tend to get consistently better, and some genres of movies, such as superhero sequels, are consistently better today than in the Superman III / Batman & Robin era.
My naive expectation would be that drug design would follow the videogame / blockbuster sequel path rather than the single-author novel path, but that seems less true than I would expect.
I think art is the wrong model altogether. Drugs should be following the technology model, getting better and better as time goes on (and even those thing which haven’t changed much should be getting cheaper to make). If they aren’t, we’re doing something terribly wrong.
Wouldn’t survivorship bias imply that *some* of our current drugs are as good as old drugs? I’m not seeing this.
And while this solves economists’ problem, in that it shows that they don’t have to worry the pharma industry is getting less effective, it doesn’t change anything for doctors, in that they might still want to preferentially prescribe old drugs.
But the older drugs are rarely prescribed.
Meaning that the total number of people who currently take them is dominated by those who have been taking them for a while. Because that is the drug that works for them.
Is levomilnacipran/Fetzima too new to have many reviews or is it just one you didn’t happen to pick?
I’m not sure why I didn’t include Fetzima, actually. I just checked and it is on the sites.
As per the newer-worse finding, Fetzima is really abysmal and it looks like if I included it it’d be near the bottom.
Do MAOIs cause euphoria?
One thing I’ve noticed is that people *love* stimulants. In my (very unscientific and small-sample) LW mental health survey, where people ranked all kinds of interventions {therapy, drugs, supplements, behavior changes} from 1 to 5, most things averaged somewhere between 3 and 4; meditation and amphetamines were around 2.
Is it possible that the “confounder” here is that MAOIs make you feel really good, and SSRIs “reduce depression” but don’t jazz you up?
It’s not really a listed side effect. I’ve heard stories of them doing that, but I think it was mostly in the old days when the dose was much higher. It’s certainly one possiblility.
Medications are like appliances and cleaning products. You can have the shiny new safe one that doesn’t work or the slightly scary, slightly dangerous old one that works incredibly well.
You probably already mentioned this, but there’s also the “standing the test of time” factor for meds, like anything else.
I also want to insert here that I think psychiatrists today are unreasonably concerned with avoiding addiction, and therefore avoid fast-acting, effective, low sfx drugs like benzos in favor of shiny new things that have less addictive potential but more sfx, take forever to kick in, etc…
For this reason, and also because I think practical experience is probably more important relative to textbook learning in psychiatry than even in other fields, it’s not only older drugs I’ve liked better in my experience, but older psychiatrists!
Depends on what you mean by “unreasonable.” Prescribing potentially addictive drugs is more likely to get a psychiatrist into legal trouble than prescribing ineffective drugs. While I think the relevant laws are terrible, it’s clearly the laws that are to blame; I don’t think it’s reasonable to expect psychiatrists to ignore such risks to themselves.
I switch my opinion on benzos once every couple of weeks, but right now I think there’s good reason not to prescribe them – a lot of studies show they stop working for anxiety after about a month (ie total tolerance) but you’re still addicted to them and have terrible withdrawal.
Some people seem to be able to stay on benzos forever without any tolerance or addiction problem, but it’s hard to predict who those people will be, and if you give it to people not in that group you’re screwing them over.
I have taken benzos daily for months at a time and in my experience they do not stop working for anxiety and panic attacks. They do stop working as sleep aids.
They were never addictive at all in the sense of “taking these makes me feel so good I want to take more and more!” Arguably they were addictive in the sense that if I stopped taking them I’d feel nervous, but I also felt nervous and was having panic attacks before I started taking them, so the fact that I would get nervous and start panicking again upon stopping taking them can hardly be blamed on withdrawal.
Titrating off of them for me was not completely painless, but not nearly as difficult as it seems to be made out to be. So long as it was gradual and I was otherwise in a pretty good state, it was very manageable.
For me they also have the benefit of being fast-acting and extremely predictable. I have weird reactions to all kinds of meds and those reactions cannot always be predicted by my own previous reaction to the same med. I took seroquel for years to counter the extreme insomnia SSRIs caused me and then stopped both for a few years. A few years later, a doctor suggested I try Seroquel again (again as a way to allow me to tolerate SSRIs), and that time it made me feel like I was literally losing my mind for about 8 hours.
Benzos, by contrast, only ever have one effect on me: calming, soporific, etc. And if I am not mistaken, paradoxical reactions to benzos are very rare. SSRIs, by contrast, seem to put half the population to sleep and keep the other half up all night. If you’re someone who’s already suffering from anxiety, the last thing you need is being uncertain whether a given drug will calm you down or freak you out.
Moreover, the fast-acting nature allows for usage of the sort I now engage in. Right now, I don’t take any meds at all and I feel fine 99% of the time. But maybe 2 or 3 times a year I wake up in the middle of the night feeling completely freaked out and panicky. A small dose of valium or klonopin at those times effectively nips the problem in the bud and I can go back to my normal life of being perfectly happy not taking SSRIs or any other med that requires I take it continuously for it to work, and which, in many cases, require that I take an additional drug just to manage the side effects of the first drug.
To me, it’s like, Scenario A:
Me: “doc, I sometimes feel panicky and anxious.”
Doctor: “okay, let’s try you on this drug which you need to take for a month before it starts to work and which will subtly alter your brain chemistry in ways we don’t fully understand but which seem to, long-term, result in fewer feelings of panic and anxiety, along with making you happier, etc.”
or Scenario B:
Me: “doc, I sometimes feel panicky and anxious.”
Doctor: “okay, next time you feel anxious, take this drug. It’s a drug which makes you feel not anxious.”
I did some shallow investigation of benzos recently and came away with the impression that taking them daily was indeed a pretty scary proposition (example comment: “I’d rather taper off narcotics than benzos”), but that they’re a very reasonable option to take as-needed if your anxiety/panic spikes in response to significantly-less-frequent-than-daily stressors.
I think you’ve settled on the correct opinion here. As someone who has taken Xanax recreationally, I observed tolerance building almost instantaneously, along with a craving to “chase” the bliss of that first dose. When that happens with any substance, I file it under the category “not to be messed with” (hello, opioids). It’s incredible to me that any human being can take benzos on a daily basis.
Years later, I ended up using it on an emergency-only basis for panic attacks. I found that every time I used a normal dose for an emergency (once every few weeks maybe), I would have to taper it off with smaller doses at the same time of day for at least two days afterwards, or I wouldn’t be able to sleep. Overall it helped me, but I still think it’s dangerous as hell.
Well they clearly affect different people differently. Benzos have never given me any sort of “bliss” or desire to take more than necessary, and I’ve taken Xanax, Valium, and Klonopin at different times. I have also taken them every day for extended periods and don’t find their panic-fighting or anxiety-calming effects to disappear, though they do weaken somewhat, and the sedative effects do disappear. I have also tapered off of taking medium-highish doses daily and it wasn’t really that bad. Felt more nervous than usual for a little while and that was it.
To me, dangerous is “gives you weird, possibly permanent movement side effects.” Dangerous is “may cause you to experience a hellish temporary psychosis.” Dangerous is “you might have liver failure.” Dangerous is not “you might like it too much.” By that logic greasy food is probably more dangerous than benzos. I would find it harder to give up cheese than to quit valium.
And why is everyone so deathly afraid of addiction anyway? I understand it’s a problem and that it can be devastating in some cases, but many people simply don’t have an addictive personality type, and to refuse to prescribe them a safe, effective drug on the off chance they’ll enjoy it too much seems to me a rather strange set of priorities, as is the thinking which says that it’s better for someone to live with chronic pain than to be somewhat addicted to painkillers. Is addicted to painkillers always a worse state to be in than in constant pain? Is addicted to benzos a worse state to be in than in constant anxiety?
All of this may make me sound very pro-drug. I am not. Actually, I am very anti-drug, and rarely take any pills of any kind, including over-the-counter meds, vitamins, etc. But if I do need a pill, I want something fast-acting, effective, and predictable in its action, and that’s how benzos are.
I think most mental health problems are better solved long-term with meditation, long walks, improved relationships, etc., and precisely for that reason I’m not on board with many psychiatrists’ push to get everybody on something like SSRIs that they can take for the long haul.
I’ve read people compare psychiatric meds to, say, insulin for a diabetic. For a few extreme cases maybe it’s like that, but for the vast majority of people I think it’s not. What most people need, imho, is something that works when they are going through a rough patch and a plan to change their lifestyle in such a way that the problems get under control more naturally and they can stop taking it.
And if it sounds like I’m downplaying the severity of peoples’ problems, I am not. I myself had daily panic attacks on top of severe anxiety, insomnia, depression, and OCD. All that got better through meditation and lifestyle changes, after which it wasn’t hard to taper off the drugs.
If you’re in a great place mentally, physically, and relationship-wise, quitting benzos is easy. If you’re not, you won’t even be able to quit fast food.
I find your description of Xanax strange, although that may be that your dosages were higher than mine. I agreed to my doctor prescribing me the lowest dosage pills for the shortest time in order to combat anxiety attacks, and they did work – by zonking me out.
It was “Okay, I don’t feel anxious now and also I must go to bed immediately before I keel over in a snoring heap”. I certainly didn’t feel any bliss (apart from the bliss of not wanting to claw my own face off with the panic attacks) but your experience makes me glad I insisted on the weakest dose possible 🙂
I don’t know how Valium would affect me, but I did get to see up close a family member becoming addicted to them. It’s a vicious circle: you take them because you’re anxious and panicky and they work. Then you get anxious about getting anxious, so you take a valium to head that off. Then you get anxious about getting anxious about getting anxious – and it ends up with constantly looking for refills of prescriptions, having a hoard of them on hand “just in case” and taking them practically all the time, because the side-effects of coming off them are indistinguishable from the anxiety and panic you started taking them for in the first place.
I think it is so funny how everyone worries about addiction to benzo’s and stimulants. I have been unable to get off of Zyprexa- it is withdrawal hell and the insomnia never goes away. Going off of Seroquel made me psychotic. If I miss a dose of Effexor I go into withdrawal. I went off of Adderall cold turkey and all it did was make me nap and eat for a week. Any psychiatric drug can be addictive- even if we don’t want to call it that.
The one thing this conversation proves to me is that drugs have very, very different effects on different patients, and I wish we could do some genetic testing to get to the bottom of it.
Yes, that would be nice. 23andme told me, for example, that I am a slow processor of caffeine. One can imagine doing something similar with many other substances.
Genes are a reasonable guess, but it wouldn’t surprise me if there are other factors (diet? allergen exposure? stress? something unfashionable I haven’t thought of?).
23andMe had one variant that it claimed indicated slow/fast processing of many different drugs. I don’t remember if it included caffeine.
Re. the patent problem, I am moderately against intellectual property in general, as I think you can’t have property in an idea (like “owning” a chicken salad recipe), and I think books, music, drugs, etc. would still get made and still find ways to be profitable, if maybe somewhat less so, without it.
Given some of the obvious negative incentives created by intellectual property in the realm of drugs, are we sure the benefits of having drug patents at all outweigh the costs?
(Of course, in my “eliminate drug patents” bill I would also abolish the FDA, which makes bringing a new drug to market so expensive that the patent is necessary to recoup).
Re: patents, whether you take the 20 years view or the 100 year view probably makes a big difference to how patents would fare.
Re: removal of the FDA.
Most of the cost of getting a drug past the FDA is being required to do clinical trials. I don’t think removal of the requirements to do proper clinical trials of drugs is going to do anything whatsoever positive for the effectiveness of drugs.
I get the impressions it’s more than just that, given the time and cost estimates I’ve read, though I’m the first to admit I am not very familiar with the process. One other more modest proposal I’ve heard is to only require safety testing, not proof of efficacy.
That said, I’d say that there is still going to be a private incentive to prove both safety and efficacy even in the absence of the FDA, because doctors aren’t going to prescribe or recommend drugs with no track record.
Paradoxically, eliminating the FDA might result in doctors prescribing *fewer* new drugs and more old drugs, which, as the patient data above indicates, may not be a bad thing.
There have been cases where the FDA has relaxed efficacy testing requirements for specific drugs in the face of political pressure and “patient group”(sponsored by company) campaigning (on the promise that the company would do the efficacy testing later) and what appears to have happened is that the efficacy testing was simply never done by anyone.
I’d recommend “Bad science”, “Bad Pharma” and “I Think You’ll Find It’s a Bit More Complicated Than That” by Ben Goldacre
There’s an old article by Sam Peltzman analyzing the effect of the Kefauver amendment to the Pure Food and Drug Act. The amendment (this is by memory) required that drugs be shown to be not only safe but useful.
Peltzman’s conclusion was that the introduction of the amendment reduced the rate at which new drugs became available roughly in half, while having no detectable effect on their average quality. His measures of quality (again by memory) were subsequent use by experts (hospitals, I think) and pattern of use over time, the latter on the theory that a few years of use provided more data than tests, so drugs that were no better than what was out there would tend to taper off over time relative to drugs that were an improvement.
A couple of points on the “eliminate IP” idea:
1. Something I only learned when I started teaching an IP theory class is that whether IP was a good idea was highly controversial in the 19th century, with quite a lot of competent people arguing against.
2. For a good account of the argument against, see _Against Intellectual Monopoly_. The authors, true to their views, have made the whole text available for free online:
http://levine.sscnet.ucla.edu/general/intellectual/againstfinal.htm
There’s a German historian that argues that the rise of German industry in the 19th century (and the relative decline of UK industy in comparison) can be explained by the lack of IP law in Germany.
Unfortunately his book has not been translated into English yet (and even in German it’s out of print and copyrighted) but here’s an English-language article about it.
Copyright law re: books – I know there was a huge push by British authors in the 19th century to get America to sign up to copyright laws because there was a large piracy market in America which involved publishers grabbing things like the latest book by Dickens, running off huge printings (liable to be garbled or not proof-read, particularly if they were ripping off the magazine serialisations – often making up endings for the stories which were still works-in-progress in order to have a complete book for sale) and not paying a penny to the original author.
This was a particular matter of annoyance when Dickens etc. were trying to break into the American market, because how could they sell official versions when people would be liable to already have the pirated versions, or they would be undercut by rogue publishers selling the cheaper knockoffs? This legal struggle went on for quite a while, if I recall correctly.
Pirated editions of anything are a grey area; it’s one thing (for example) for fans to put up episodes of a TV show that’s been broadcast in their country before elsewhere, or a fan translation of foreign language media, for free and for other fans. Where I think copyright should kick in is when money is being made, and piracy is a commercial operation (of course, if TV companies/publishers brought out the goods in the markets asking for them in the first place, piracy would be undercut).
I think the principle of it being intellectual theft is clearer to see if you imagine a publisher soliciting submissions of manuscripts. You send in your ground-breaking epic of gay timetravelling dinosaurs fighting a war IN SPACE!!! and the men who love them, and the next thing you know it’s in all the bookshops (or at least available online through Amazon) and is wildly successful. You don’t see a red cent of anything for your work, and when you contact the publisher they tell you to go chase yourself.
It’s easier to see there that you’ve been ripped off and that you are owed recompense for the fruits of your labours. So suppose your Gay Dinosaurs IN SPACE was already published in Britain, and the American version was a cheap rip-off by a pirate publisher? Shouldn’t you be equally owed recompense there also (not to mention if the pirate version was riddled with errors and the ending had been changed and your work of deathless prose had been bashed about to fit what the publisher thought would make it sell better)?
Thing is, you’re talking from a cultural context where you you’re used to the idea that things you write should automatically belong to you forever.
You know I sometimes wonder if the world would be a richer or poorer place without copyright, plenty of things would be different certainly and those who make their money from the current system will of course tell you the world would be a poorer, worse-off world for it.
It’s almost taken as a given that the world would have less creativity without copyright but I do wonder.
If the chef at your local restaurant had to pay royalties whenever he used a recipe published by a celebrity chef would you have a tastier and more enjoyable meal?
What if he risked being sued into the ground if he created a derivative work by altering the recipe slightly without a license?
or would you just have a more bland, unoriginal, uninspired and ultimately vastly more expensive meal?
If your hairdresser had to pay royalties whenever some kid comes in with a magazine picture and says they want their hair to “look like that”.
Would everyone have far more interesting hairstyles or would it just cost far more and see people getting sued for doing their own hair at home in a copyrighted style?
Both these things are creative and also involve a skill much like storytelling or playing a musical instrument and in both cases I’ve heard of people trying to get copyright protections extended to cover them.
Imagine a world where in the 17th century someone had decided that recipes and cooking should fall under copyright along with books.
You can be sure that were someone to call for it’s repeal 300 years later there would be no lack of “professional recipe composers” who would talk about how much work they put into working out new recipes and the time and effort it takes and how we’re bad people for implying that they haven’t worked hard and that they somehow don’t deserve a cut whenever someone follows their recipes.
of course in a world where we’re all free to take someone elses recipe, use it, copy it, publish it or even claim it as our own we know very well that fuck all harm has been done to the industry for the lack of legal protection on such creativity.
In a world where such legal protections existed and nobody ever knew such an open and unprotected situation as we have in this world it would be very easy to claim that there would be no creativity, no well paid chefs and that setting up a kitchen would be pointless since someone else would just copy the chefs recipes.
Similarly it’s taken almost as a given that the world would have less good books, less good stories and less origionality without copyright but try questioning that even for a moment.
Of course someone is going to complain that composing and cooking a good meal can’t be compared to composing and playing a good piece of music because….. well just because!
Who knows, the flip side of my argument is that perhaps if recipes had been made copyrightable 300 years ago and someone could charge you money every time you used their recipe there would have been more investment in automatic food preparation(for the sake of consistency, avoiding unintentionally creating unlicensed derivative works and accounting of who has used what recipe) and we’d all have autocooks like we all have MP3 players and every meal would be up to the standards of a master chef.
But we live in a world where everyone has family recipes but hardly anyone has family music.
I think there should be a middle ground 🙂
I don’t know about copyrighting recipes, but there certainly is the concept of a “signature dish” and look at the appellations contrôlées” in France; you can’t simply call your version of sparkling wine champagne.
The idea being to protect brands from dilution by knockoffs but also to preserve unique and authentic cultural productions.
I agree that regulation of every single thing is unfeasible and probably is a bad idea, and yes, estates and publishers have extended copyright on authors’ works for cashcows but on the other hand, with no protection of that nature, an author who has a success first book in what they project as a series can have their characters (not just similar but the exact same characters) used lock, stock and barrel by other writers and/or unscrupulous publishers, and the resulting glut of “Joe Taxi, Psychic Babysitter and Dog Whisperer Amateur Detective with his own bistro” novels mean that there’s no quality control, the public are saturated with five different versions and books coming out every week, unlicensed television and movie adaptations, and the original author getting no benefit and even losing (because the public isn’t buying their books).
Are we really in a new golden age of creativity because of sequels to “Gone With The Wind” and people able to write Jane Austen zombies?
How long would you stay in a job if the guy at the next desk was getting paid for the work you were doing?
The sequels to Gone with the Wind are either authorized, or covered by parody rules. Gone with the Wind has not fallen out of copyright.
Keep in mind: Shakespeare lived before there were any copyright laws.
Showing of his plays were attended by people who would take notes and attempt to memorize sections yet it is Shakespeare we remember and Shakespeare was reasonably wealthy when he died. People sought out his plays over those of competitors running rough copies.
Though I suspect it incentivizes rapid creation of new works rather than sitting on your laurels.
I also wouldn’t be surprised if some of his works were derivatives of other plays from the time.
There is a lot of derivative trash out there but also gold. Many young authors want to play in the imaginary worlds of others and some of them create remarkable works. 90%+ of fanfiction is awful but 90% of everything is crap.
http://en.wikipedia.org/wiki/Sturgeon%27s_law
@ Deiseach
I think we need a term for … it’s not quite “a fallacy” but “a ploy” sounds uncharitable … for arguing against an idea by immediately jumping to something way out onto a tacked-on straw bailey. We do have copyrights on music and texts, but people are not having to buy a license for singing at a party, fanfic, etc. Only when there’s enough money involved, to pay for enforcement.
I’ve seen the same fallacy(?) used elsewhere on other issues, even by usually-critical minds. Usually preceded by “So you want…” or “So you think…”.
“but people are not having to buy a license for singing at a party, fanfic, etc.”
Legally you can be sued for those things if you’re caught and someone feels like going after you.
that’s not a falacy. it’s the reason restraunts generally have their own song instead of “happy birthday”, people genuinely do get sued for performing it publicly.
Some authors *choose* not to bring the boot down on fanfics but lots do come down on it like a ton of bricks and go in lawyers blazing.
Two comments:
1. Back when the U.S. did not recognize British copyrights, it was still possible for British authors to make money in the U.S. The way they did it, as I understand it (I’m going by secondary sources and memory—this isn’t something I’ve researched myself) worked as follows:
Before the book is published in Britain, the author contracts with an American publisher to publish the book and pay him. The author sends the American publisher the completed manuscript early enough so that the American publisher has printed copies ready to sell by the time the British edition appears—which is the first time a pirate can get the text to copy. With the 19th c. technology of hand set lead type, setting type and printing a book takes a while, so the authorized publisher has the market to himself for a while. Most books make most of their sales early, so that period is, with luck, enough to repay the publisher the fixed cost of setting type etc.
If a pirate edition comes out, the authorized publisher now brings out a “fighting edition,” an edition priced close to marginal cost. That means that the pirate edition, priced to compete, never makes enough money to repay the pirate’s fixed cost.
Obviously this doesn’t solve the problem for a novel that has appeared as a serial, although it might explain why a pirate publisher would have to invent the final episode. Obviously it doesn’t work perfectly, but it apparently worked well enough so that some British authors made more money out of U.S. sales than out of British sales.
That particular approach wouldn’t work as well with modern technology, but _Against Intellectual Monopoly_, the book I referred to earlier, offers some more modern examples of people successfully making money off books without copyright protection.
2. For an entertaining diatribe against American pirate publishers by my favorite poet, see:
http://www.poetryloverspage.com/poets/kipling/rhyme_of_three_captains.html
I’ve been writing an essay on patents and developed on this example (I had heard you use it in a talk), the implications go a bit farther than it may at first appear. Here are the relevant paragraphs:
For this premise [that a copier will win the competition] to hold, at the moment that the copy enters the market as an effective competitor to the original, the copiers’ total capital costs must be less than the current remaining capital costs of the original producer. Otherwise the original producer will be able to price their product at the same or lower price than the copier. This analysis does change somewhat if one party is willing to take a lower rate of return on their investment, however due to economic pressures these will tend towards each other.
A direct corollary of this is that once the original producer has paid their invention costs they are at an advantage against any pure copier, who must not only outlay capital to begin production, but also capital to reverse engineer the original product. In some industries reverse engineering is relatively easy, such as figuring out how a simple mechanical linkage works. But in many others it is extremely hard, possibly just as hard as it was to invent in the first place, anything to do with organic chemistry is likely to have this feature (here there be dragons, many, many dragons).
Given the huge differences in sample sizes (and possibly variances) between the different drugs, did you do a one-way ANOVA to check whether the differences in mean rating were actually significant? I’d be a lot more impressed by the results you discuss if I could see the ratings as 95% confidence intervals rather than means alone. Also, exactly what kind of scale were you/the sites using that you get weighted average ratings between 0.86 and 1.25?
I’d have grabbed your data and checked myself, but I don’t run Office. Could you post a CSV version?
Here is a CSV version. (download link)
I converted using google docs. Both it and my copy of excel claim that the spreadsheet is raw data, not calculations, so no information lost in CSV.
Well, no information is lost beyond that lost by providing summaries in the first place. Summary data like this is not as easy to work with as having all the individual ratings; I just spent half an hour banging on lm/lmer in R trying to pull out confidence intervals for each drug, which should be possible since I’m explicitly telling it the weighting of each summary and that tells you the precision, but while it will estimate the coefficients it won’t calculate anything else!
Props for open data!
The problem is, user reviews are unreliable.
There are two things that I think are most likely to cause someone to write a review; something is particularly good or particularly bad. So if you take a medication and hallucinate bats for three days, you give it one star and write a diatribe. If you tried 10 medications that didn’t help that much and an eleventh that did, you write a rave review of that last one. But you never bother to review any of the other 10, so there’s no indication of how helpful drugs were relative to one another for the patient.
Also, people often jump the gun and never revise their reviews. So someone goes on a new medication and it’s awesome and they review it, and then a month later it’s not working as well and they go on to something else, but they don’t go back and edit their review because there is neither enough anger or enthusiasm to push them to.
Anyone who’s gone to a restaurant with great reviews on Yelp only to discover that the food is terrible and all the great reviews are because of the vast selection of beers knows that user reviews are only helpful to some extent. Even if you discount the one-star reviews that are only because there was such a long line that they decided to go elsewhere and the raves from people who haven’t been there in five years, the data you’re left with is still suspect.
Lexapro and Celexa are pretty much the same chemical, it was just changed around slightly to put it back on patent. They get the same rating, 1.02 and 1.02.
Effexor and Pristiq are pretty much the same chemical, for the same reason. They also both get pretty much the same rating – 0.94 vs. 0.93.
The three MAOIs on the list are numbers 1, 2, and 4, suggesting that these similar drugs of the same class end up with similar ratings.
Likewise, the two SNRI drugs on the list, Effexor/Pristiq and Cymbalta, are numbers 16/17 and 20, suggesting that these similar drugs of the same class end up with similar ratings.
Likewise, the two serotonin modulator/stimulators, Brintellix and vortioxetine, are 22 and 23, suggesting that these similar drugs of the same class end up with similar ratings.
Likewise, the bog standard SSRIs, Lexapro/Celexa, Prozac, Zoloft, and Paxil, are numbers 7, 8, 9, 11, and 19. Paxil is a bit of an outlier, but it’s a common position that Paxil is the worst SSRI – my boss actually gave a short lecture on this earlier this week, telling us why he was prescribing Paxil for a patient but we should never do this except in extenuating cases.
Likewise, the two atypical antipsychotics, Abilify and Seroquel, are 18 and 21.
Likewise, the tricyclics are numbers 10, 12, and 13, with the exception of third-place winner Anafranil. Anafranil is notably different from the other tricyclics because it has strong serotonergic and noradrenergic activity. If you read Gillman on TCAs he pretty much predicts exactly this – tricyclics are heterogenous, but clomipramine is the best.
What I’m saying is, chemically similar drugs are all clustered together here, which suggests that patient ratings are capturing some kind of real data about how these drugs work and what they do. If patient ratings were random or inaccurate, you wouldn’t expect them to reflect drug structure and function so accurately.
Does the date/rating correlation hold up within individual clusters?
Scott- maybe the next time you have a post with statistics, it would be interesting to first have a mini-post presenting the issue to see what hypotheses people come up with before they know the results.
I’m always surprised when very smart people are surprised that the patent system turns out to benefit the patent holders rather than their consumers in the same way that other government enforced monopolies benefit the monopolists rather than their consumers.
Great article, thanks Scott. Two points
1) I don’t get what your support is for the claim that looking at the date of a medication is better than asking for recommendations for it? To the contrary, presumably your best guess for what rating you’ll give a medication is the rating others give it. Or what am I missing?
2) Here’s a non-sinister explanation for anticorrelation between doctors’ and patients’ perceptions of medications: if patients don’t like a medication, then the doctors must, otherwise it wouldn’t be on the market. If you suppose that doctors and patients like different kinds of aspects of a medication, and that medications have to at least have an average rating of 5 to make it to market, then you get an anticorrelation: http://i.imgur.com/0RTxPpZ.png
The release date of a medication correlates with the weighted rating of all three databases better than the weighted rating correlates with any individual database.
Ah, that makes sense
re: 2) Doesn’t that only work if the underlying data is uncorrelated (or, at best, very weakly positively correlated)? If there were a strong positive correlation, then that would swamp the artificial negative correlation. Even if these results “only” show that the views of doctors and patients are uncorrelated, that still seems troubling.
Yes, in the likely case of some correlation in the existing data, it would just be one factor that is in the mix with a bunch of others
I’m all about believing doctors are bad at statistics, but here’s a scenario under which both the doctor and patient ratings could be accurate:
All doctors follow the same algorithm for all patients: prescribe drug 1, if it doesn’t work prescribe drug 2… Assume patients rate every drug they try. Each positive rating for drug N implies negative ratings for drugs 1…(N-1). All the patients who succeed on drug 1 but would have failed on drug 5 never enter any data, because they never try 5. Doctors meanwhile are accounting for this, and using the objectively best drug (pretending such a thing exists) first, which actually makes it look worse because it’s given more times to fail.
I’m not sure that works, at least in its basic form. But I think it can work with a slight modification. First, here’s why it doesn’t work as stated:
Imagine the same thing with coins: flip coin 1; if heads, stop. If tails, flip coin 2; if heads, stop. If tails … flip coin N. Just like in your example, every heads for coin N requires tails for coins 1 through (N-1). But that wouldn’t mean that coin N had any lower percentage of heads than coin 1 (they’d both be 50/50). The only difference would be that coin 1 has more flips.
Now, if—as some suggested upthread—there’s a correlation between the results of different drugs, my coin analogy breaks down. However, a positive correlation would only make matters worse: if people who had no result for drug 1 were more likely to have no result for drug N, then drug N should get lower scores, not positive ones. So, people being generally “drug resistant” wouldn’t save your theory.
On the other hand, your theory could be right if people’s responsiveness to different drugs is anticorrelated, which would be true if people sort into categories. For example, imagine everyone is either a Purple or a Orange and drug 1 works on 90% of Purples (and not at all on Oranges) while drug 2 works on 90% of Oranges (and not at all on Purples). If 70% of people are Purples, doctors would justifiably prefer drug 1. Drug 1 would work for 63% of those people. ((.70*.9)+(.3*0)=.63). Doctors would try drug 2 on everyone who didn’t respond to drug 1. Since most of the Purples responded to drug 1, the people who hadn’t responded would mostly be Oranges. Thus, drug 2 would work on 73% of the people who get it. (((.3*.9)+(.07*0))/(1-.63)).
So, after thinking through the implications, I’m inclined to think you have the right explanation after all!
You’re right, it does require responsiveness to be negatively correlated.
Has anyone suggested that disliked drugs could be more likely to be reviewed than liked drugs, relative to use? I don’t know if this is true, but it could be that getting side effects anger people enough to leave a negative review, but getting back to normal someone might not even think to leave a review.
Of course then again, if a depression medicine is less efficacious, then the person might not see the point in leaving a review.
This might well be true, but it doesn’t explain why old drugs receive better ratings than new ones.
Here’s a semi-serious hypothesis: People are more likely in general to review things on the internet if they had a really bad experience with it. MAOIs have high ratings because people who have a really bad experience with MAOIs die.
I can’t remember my source, but I think I heard that only 1/8000 people who get a hypertensive crisis with a MAOI die from it.
Oh, wow. That’s extraordinarily low.
Sometime I need to rant on how risk from MAOIs is overestimated. Did you know that MAOIs were on the market for eight years, no dietary advice given, before anybody even realized there was a chance they might cause bad reactions?
Did you know that after that, a team did a retrospective of 600 MAOI patients not informed at all about dietary problems for three years, and found that only about 5-10% of them got so much as a headache, only one needed hospitalization, and zero died?
Did you know a Canadian team monitored 300 MAOI users who did get dietary advice for ten years and reported zero adverse effects bad enough to require ER visits?
The 1 fatality per 8,000 hypertensive crises is from Seminars In General Psychiatry, which you cited in note 6 for the claim that MAOIs kill 1 per 100,000 patient-years. It appears to cite a single source for both claims, J Davidson (1992) “Monoamine oxidase inhibitors” in Handbook of Affective Disorders, ed ES Paykel.
These two numbers do not seem compatible to me: 1 hypertensive crisis per 12 patient-years?
That seems right to me; the average hypertensive crisis is a bad headache that goes away on its own. The study I mentioned above, which I can’t find an ungated version of, said that after patients got dietary advice there was a 2.2% chance of crisis per year, which suggests 1/45y, which is not THAT different from 1/12 and the difference probably involves how well the advice was given and how high-functioning the patients were.
You mentioned two studies above. One was of uniformed patients. Even they had a rate of 2-3% per year. Is the 2.2% for the informed Canadians? Maybe advice doesn’t do anything. But why are Davidson’s 1992 figures 4x worse than the uniformed?
(Maybe we can’t trust the retrospective numbers. You’re much more likely to remember whether you had a headache if you’ve been told ahead of time to go to the hospital.)
(It is easy for me to believe that advice doesn’t affect the rate of crises, but does affect severity.)
Please stop posting incredibly well written disturbing things like this.
I’m sure this is going to keep bothering me for days now.
(Just in case anyone is confused: yes the first sentence is a joke. The second is not.)
I will note wikipedia is with Scott about MAOIs:
“Monoamine oxidase inhibitors (MAOIs) are chemicals which inhibit the activity of the monoamine oxidase enzyme family. They have a long history of use as medications prescribed for the treatment of depression. They are particularly effective in treating atypical depression.[1] They are also used in the treatment of Parkinson’s disease and several other disorders.
Because of potentially lethal dietary and drug interactions, monoamine oxidase inhibitors have historically been reserved as a last line of treatment, used only when other classes of antidepressant drugs (for example selective serotonin reuptake inhibitors and tricyclic antidepressants) have failed.[2] New research into MAOIs indicates that much of the concern over their dangerous dietary side effects stems from misconceptions and misinformation, and that despite proven effectiveness of this class of drugs, it is underutilized and misunderstood in the medical profession.[3] New research also questions the validity of the perceived severity of dietary reactions, which has historically been based on outdated research.[4]”
New research also questions the validity of the perceived severity of dietary reactions, which has historically been based on outdated research.
So does that mean the “eat one slice of cheese AND DIE if you’re on MAOIs” warning is not really correct?
I don’t think I’ve done this rant yet, but it keeps going through my head. This sort of thing reminds me of Bill James in the 1970’s and 1980’s. James has a wildly different backstory.
James was a Vietnam-era vet (he served in South Korea) and came back and worked as a night security guard, and wrote on baseball in the daytime. He did analytical writing with the math skills of a bright high school student. At the time, no announcers ever said what platoon splits actually were and no one appeared to understand the skills that mattered.
James changed that. He move baseball analytics forward more than anyone, ever. He did the legwork. He got TV gigs, which he was relentlessly terrible at and then he got no more TV gigs. But he was a serious writer, and achieved fame and fortune through these skills:
1. Care about what’s actually true.
2. If the system is not trying to push forward number one, don’t care.
3. Be mathematically competent.
4. Know failure modes of statistical analysis.
5. Write really, really well.
Resulting in:
6. Change world a little bit.
James went from ditto copies and rejection slips to self-publishing to awesome fame in a non-internet era.
Scott’s trying to be the Bill James of everything, but notably psychiatry. I think he may well be succeeding. We want you on that wall. We need you on that wall. Fantastic and compelling piece.
Yup.
Great article. I’ve never posted on your blog before, but I follow it pretty diligently.
Something that comes to mind in regards to the negative correlation between patient rating and doctor rating that you didn’t mention is an unwillingness on the part of doctors to prescribe medications patients visibly enjoy too much.
Isn’t there a fear of a drug’s ‘abuse potential’, and a consequent felt pressure to stay away from drugs that feel too good?
I’ll quote Biopsychiatry on this:
“Amineptine (Survector) is a cleanish, (relatively) selective dopamine reuptake blocker. Higher doses promote dopamine release too. Amineptine is pro-sexual and liable occasionally to cause spontaneous orgasms. It is a mild but pleasant psychostimulant and a fast-acting mood-brightener. Unlike most other tricyclics, it doesn’t impair libido or cognitive function. Unlike typical stimulants and other activating agents, it may actually improve sleep architecture. Scandalously, amineptine isn’t licensed and marketed in Britain and America. For it is feared it might have “abuse-potential”. FDA pressure led to its withdrawal in Europe too. This drove amineptine onto the pharmaceutical grey market, discomfiting doctors and patients alike.”
I guess my overall point is this: it may not be drug companies marketing that causes the correlation– it may be an unwillingness to prescribe a drug that feels too good.
I deliberately avoided including any addictive drugs in my analysis for exactly this reason (some of these sites insisted on listing Xanax as an antidepressant!). I don’t think that’s what’s pushing things here, although as Sarah points out above the MAOIs might occasionally give people euphoria.
I’m not sure your amineptine narrative is entirely correct. Amineptine got in trouble for hepatotoxicity. Its cousin tianeptine seems to give about the same good feelings and have about the same abuse potential, but is legal in Europe. It never even applied for FDA approval in America for what I gather were complicated bureaucratic reasons, not fear that it would be denied for addictiveness.
You can, however, get it off of a bunch of websites without a prescription as a “research chemical” if you want it. Still haven’t been able to figure out whether this is legal or just tolerated.
Ahh, I didn’t catch that you did that. That makes your analysis more worrying, frankly. If abuse potential isn’t driving this effect, then it becomes even more suspicious. Not that abuse potential is always a good reason to stop drug prescription, but it would at least present doctors as well-intentioned and informed, if a little paternalistic. Your analysis presents them as ill-informed, though through a systemic error rather than through personal error on their parts.
Re: Amineptine, I agree, the Biopsychiatry narrative is a bit too convenient. That website is fun to read because of the many obscure drugs it name drops, but I wonder at many of it’s claims and the implicit claim throughout that Psychiatrists are immensely incompetent or under informed.
The wonderful world of research chemicals is so fun to learn about. The gray area of law and enforcement, where Modafinil is illegal without a prescription but possession is rarely prosecuted, Adrafinil is easily available but comes in sketchy powder packets, and SARMS float around instead of old-fashioned anabolics.
An analysis I’d love to see done or eventually do some work on of my own is whether Silkroad and the like caused a drop in sales of research chemicals since the original drugs were easily available for that time period.
Did people buy less Ethylphenidate when Ritalin was available on Silkroad?
Did people buy less 6-APB when MDMA was available on Silkroad?
It’d be cool to see because:
1. It’d be some interesting data on how substitutable similar drugs are with each other.
2. The overlap between the two customer bases.
Wonderful post, and thanks for the reply!
If I hadn’t looked it up, I would never have guessed that it has any addictive potential. I have never heard or experienced that tianeptine has any immediate feel-good or stimulant effect at the usual therapeutic doses. (A study I saw on its addictiveness investigated subjects who used it at 13 times the regular dosage.)
Funny you should mention Tianeptine and its grey market-ness. I’m taking some right now from Ceretropic. It does cause a very mild euphoria for an hour or two after dosing, but aside from that, it’s given me an invaluable uplift in mood. The euphoria is due to slight opioid agonism–which I’m told is too insignificant to be a concern unless you’re injecting the stuff or taking crazy super-therapeutic doses–but there are also several other hazily understood mechanisms of action. In any case, it’s definitely more effective than any SSRI I’ve tried.
As somebody for whom about five prescribed antidepressants have categorically failed, I can second Ian James’s experience in taking Tianeptine at recommended therapeutic doses, though I’m not thrilled about having to procure it from supplement companies – at least some of the more scrupulous ones perform in-house purity testing & provide certificates.
However, I’ve heard conflicting anecdotes about the drug’s long-term efficacy & desensitization potential, which causes me some concern.
I’m unclear on this based on your above reply, Scott – was Tianeptine excluded because of its abuse potential in megadoses, or was there simply not enough data from the sites you used to provide the same amount of validity to a potential measurement? The sites do seem to be US-centric, and the drug does exist in a gray area here.
It could just be selective sampling … that the top-rated drugs are the ones used by people who have gone through the trouble of finding the one that works best *for them*.
Suppose that
— patients rate only their first and last drugs tried.
— every drug is a “0.86” on average, but differs by patient from “0.5” to “1.5”.
— every doctor prescribes the bottom-of-the-list drugs first, then switches to the top-of-the-list drugs if the patient finds the others don’t work well.
Every patient first gets Viibryd, and the average is 0.86. Some patients figure, hey, it’s working! Others figure they can do better. They try others until they find one (Prozac, say) that works better than 0.86. In that case, Prozac MUST do better than 0.86. Otherwise, the patient would try a different drug and not rate Prozac at all.
In other words: the Prozac raters are a biased sample of users for whom Prozac works better than the more-prescribed alternatives.
(Related post by me: McDonald’s got bad ratings in a Consumer Reports survey, but that’s probably because of selective sampling, and would happen even if people like it just as much as any other fast food place.
Any thoughts on Moclobemide? Just found it via wikiing, and it sounds like it might have some MAOI-like efficacy without the problematic side effects, as well as maybe some specific advantages for elderly patients, but no incentive for anyone to get it FDA-approved.
My first thought before reading section IV was that the data was confounded by a rock-paper-scissors effect.
Hypothesis: There are different types of depression that respond well to different classes of medication (perhaps surpluses, deficits, or sensititivities/insensitivities to different neurotransmitters in different parts of the brain), but there is no reliable known way for psychiatrists to determine which kind a given patient has except by trying out different meds.
Call the newest, most fashionable class of drugs “paper”. The previous generation is “scissors”, and the oldest generation is “rock”.
Alice has rock-type depression. Her doctor prescribes paper to her, which treats her symptoms. Alice goes online and gives paper a 5/5 rating.
Bob has paper-type depression. His doctor prescribes paper, which has no effect. His doctor then switches him to scissors, which treats him effectively. Bob goes online and gives paper a 1/5 rating and scissors a 5/5 rating.
Carol has scissors-type depression. Her doctor prescribes paper, which makes her symptoms worse. The doctor switches her to scissors, which returns her to pre-treatment baseline. Then the doctor switches her to rock, which effectively treats her symptoms. She then goes online and rates paper as 1/5, scissors as 2/5, and rock as 5/5.
The end result is that paper has a rating of 2.3, scissors has a rating of 3.5, and rock has a rating of 5.
After reading through the other comments, I see that four of five people seem to have beaten me to this hypothesis.
On top of that, there’s the whole psychosocial component of depression. I know I’ve been avoidant of counselling, but one of the things any depression awareness/support site does bang on about is getting support from friends, family, group therapy, etc.
So patient A on drug X + good support (getting counselling, has family/friends to confide in and get tangible help, etc.) gets more relief and attributes this positively to drug X, or at least has a better opinion about how drug X helped them.
Patient B on drug X is isolated, doesn’t have outside help, doesn’t get the same degree of relief as patient A, and is more negative in their opinion of drug X.
Drug X is actually having the same effect on both A and B, but A’s additional interventions help as well, so A’s experience is that they’re seeing more improvement, so A rates drug X higher than B does.
Could time be a factor in this simply due to the accumulation of data ?
Let’s say that drug X is discovered, FDA-approved, and becomes widely prescribed due to its high efficacy. People rate it very highly, year after year. But, ten years down the line, a significant proportion of people who are on the drug develop the Exploding Liver Syndrome; as it turns out, the side-effects of the drug are cumulative over a long period of time. The drug is no longer widely prescribed, but its historically positive ratings remain.
I have no data to back up this story, obviously; it’s just a wild guess.
No, these numbers are from people entering information on the internet, not the 1970s.
There are also the problems that how positive a person’s perception of things is one aspect of depression with some drugs could handle better or less well then other aspects. On the plus side that aspect should correlate very well with user ratings. As long as this is questioning the medical establishment this list is rather narrow compared to the the know categories of drugs with antidepressant effects. I wonder what serotonin releasing agents or a dopamine agonist like Rotigotine would do in comparison?
The older drugs don’t have an amazingly beautiful pharma rep who brings doctors coffee?
This seems to be one of the quirks of insurance payments. If I was paying for a drug using a health savings account (my money) then obviously I would start with generic drugs, the cheaper the better especially if I need to take it long term. If I went to a doctor in France, where the govt pays I would expect heavy bias towards generics.
But I also recognize that if everyone did it that way, medical research would collapse and there would never be any more cool drugs unless the govt funded expensive research. There would also be strong govt bias to research low cost treatments rather than effective ones.
However, unlike other drug categories, I think there is lots of guesswork in depression meds. In other words the LAST depression med you try is the best one. Doctors try one, then another, then another… you rate the last one best because it worked. Since doctors are more likely to be marketed newer drugs, they try those first.
Because the super old drugs are tried as a last resort, they are actually more likely to work because the doctor knows that the other kinds failed.
So even if SSRIs were better (or had less side effects), all the people who aren’t effectively treated get something else. The probability of getting the treatment right goes up with attempts, hopefully.
That said, I do almost all my shopping online on Amazon and I love customer reviews. They aren’t perfect. But if 100 reviewers all gave a product one or two stars what are the odds I’ll like it?
For over the counter medicine, I go with well reviewed generics. And I research medicine for my family online even if it is prescribed.
I imagine the means by which the new drugs were designed would significantly influence the overall quality…..let me explain. Insulin that has been modified with a different amino acid here or there (novolog or humalog for example) can be explicitly designed to have a faster activity than Regular; Lantus (using a modified isoelectric point) is better than NPH (which started off as insulin + fish jizz but presumably they updated that synthesis over time…), etc, and so the newer drugs should absolutely be better in pretty much every metric here; but, I’m not sure what the means by which antidepressents or similar drugs have been designed really falls under this system as opposed to “ok, let’s change this methyl group over here and see what happens….at least we can patent it!” I imagine the first case in general would lead to more efficient/active drugs although certainly I could be completely wrong.
This is mainly about old classes vs new classes, not about differences within a class, not about changing a methyl group.
Speaking of atypical depression, I have a loved one who is depressed, but in a way where it seems like physical exhaustion/sleepiness often prevents her from doing activities that she would enjoy.. Her TSH is high enough to be outside the normal range according to the standards, but not high enough to be diagnosed as hypothyroid by multiple doctors she has been to. T3/T4 suppliments seem to have a moderately good effect on her. I previously did not connect this directly to her depression/rejection sensisitvity beyond the fatigue effects it had on her, but it seems all three are connected in atypical depression.
Here’s the problem: We don’t know how to find a doctor in NYC that it would be possible to have an intelligent conversation about this with. Based on previous experiences with doctors using outdated lab standards, saying things like “you’re just depressed” or just in general being inflexible and demeaning, I’d be wary of going to a doctor without a good recommendation.
Does anyone have recommendations for a doctor that would be up to date on the literature, would be open to alternative therapies such as modnafil, and would be willing to talk to patients in a reasonable way?
As a side note, any links for further reading if I want to educate myself on this subject?
This sounds just like me. I used to crash at about 7:00 p.m. each day and often be too fatigued to really do much. When my TSH finally got *too* high, I was prescribed synthroid.
As for doctors, maybe try the <a href="http://www.brodabarnes.org/" Broda Barnes Foundation?
She’s tried going to a doctor recommended by one of those natural thyroid groups, but the doctor ended up being a bit too….alternative for her tastes (think “quantum energy healing”). I was hoping to find a doctor who would be open minded, but with a more rationalist bend.
I wonder if there is the reverse effect of your boxing match analogy because of patient expectations.
Imagine scenario 1: a patient is prescribed a contemporary medicine, it more or less works, and has a decent side effect profile. It meets expectations and the patient says it’s fine.
Now, scenario 2: a person has failed on several medicines and doesn’t like any of them. Then, the last line therapy finally works. Since their expectations are lowered, they are ecstatic with an outcome that is otherwise just “fine” if the first line therapy had done it.
I don’t actually believe this story; just another potential explanation. Is testable in the data though: run a regression against attribute of typical front line vs second line vs nth line therapy.
Disclosure: I work in R&D at a big Pharma company.
Oh, that’s very pertinent! How many of the good/negative reviews are for “first drug prescribed” versus “tried everything else, this was the only one that had any effect”?
That might affect the negative reviews; if Drug X is the first one you’ve been prescribed, and it’s doing damn-all (as far as you can see), then you’re more likely to rate it negatively than if you’re on your second, third or fourth switch of medication – you might revise your opinon about Drug X because, compared to Drug Y which made you want to scratch your skin off, at least it didn’t do anything either way.
Do you have access to the variance in a given drug’s score?
You could easily be just chasing noise here- when you go to all the drugs at the end, the different databases are only moderately correlated. I’d bet the error on these points are quite high.
I don’t think so. You can easily get each individual review on the databases, but you can’t download all of them, so you’d have to list them by hand. Since there are thousands, I didn’t do that.
Sounds pretty programmable to me.
There’s at least one factor that escapes patients: the observation of long-term consequences, and interpreting them as the consequences of the drug. Naphazoline, for example, treats nose congestion as charm, and I would rate it really high, if I didn’t know that it’s likely to screw up my nose over time. Heck, I could have sworn that Tilorone and Cridanimod help with common cold, until I’ve read that no, RCTs are very very clear on that – short of DRACO, there’s no treatment for it. Moreover, laypeople will often give high ratings to homeopathy, alcohol, aromatherapy, acupuncture as ways to treat their conditions. So although the difference in patients’ and doctors’ opinions is alarming, it’s merely alarming, rather than invalidating the entire medical field.
My immediate thought when you got into the doctor/patient rating anti-correlation was that doctors might be more prone to recommend drugs less likely to kill people, and dead people don’t leave reviews. Drugs which have side-effects that are not ‘kills people’ would get more negative reviews simply because the negative reviews are being written; drugs which have side-effects that are purely in the ballpark of death will necessarily only get positive reviews.
The reason that can’t be the full explanation is that side-effects are not a binary ‘kills you’ / ‘doesn’t kill you’ on a per-drug basis (i.e. a drug will have some side-effects in either category), meaning that in practise even drugs that do occasionally kill the patients should in theory still get terrible reviews for other terrible side-effects, which doctors and patients ought to agree on. So I guess I wouldn’t expect a smooth anti-correlation slope, I would expect a break in the curve somewhere.
Of course, you mentioned half of the above already and I feel the rest was more or less implied, so this isn’t really a new idea.
Velociraptor made a similar point more convincingly.
Out of curiosity, why didn’t you use Bayesian regression for this? I’m always puzzled by how this and related communities love Bayes so much but never seem to actually use him for statistical inference.
Do you think that there’s an appropriate prior that would result in a significant difference from the standard linear regression?
Because I don’t know how.
Bayesian epistemology is more interesting philosophically than for routine statistical tasks. Let’s qualify that:
Bayesian Statistics: Using Bayes theorem more or less directly to compute a posterior distribution for some parameter given some evidence and a prior distribution. The answer is no different in practical terms, and it’s harder to use right now. The only benefit is a slight boost in philosophical correctness, which doesn’t really matter most of the time.
Bayesian Epistemology: Using probability distributions and Bayesian updating as your reference model for epistemological questions. Better than most other philosophical positions on epistemology, but not perfect. In reasonable formulations it’s just a reference model, not a religion, so it doesn’t actually require the use of Bayesian Statistics.
So I’ve been playing around a bit with your data. It looks like you don’t have the sample sizes for the doctor ratings?
Anyway, when trying to control for the different sample size for each drug by doing weighted least squares (which still assumes the doctor ratings have equal variance, wrongly), I get that the difference in correation between (say) the doctor ratings and other sets isn’t statistically different than between the other sets themselves (i.e. Doc Rating correlated with webMD not statistically different than AskAPatient correalted with DrugsCom,etc).
I could easily have made a mistake, but I think you need to test if the differences between your correlations are statistically significant.
I didn’t put in the doc sample size because I didn’t need it, but you can pretty easily get it off https://www.healthtap.com/raterx
Are you also getting that the correlations between different patient databases are around 0.5 and significantly different from zero? Are you also getting that the patient-doctor correlation is -0.34 and significantly different from zero? If so, how could 0.5 be significantly different from zero, but not significantly different from -0.34?
I’m just working with the psych drugs.
I get pretty wide confidence bands around the estimates (the correlations between the patient ranking data sets are all significant, but the error bar get’s pretty close to 0).
So with the ~ -0.21 (I get different numbers because of the weighted least squares, and because I’m comparing the different data sets, not to the total set), I get an error band that extends pretty far above 0, which has pretty sizable overlap with the other coefficients.
I don’t think weighting is appropriate here. That’s saying that the deviation from the trend line are noise and we’re more likely to have mismeasured the rating of drugs with small samples. But the samples aren’t that small. These scores aren’t sample error. The deviation from the trend line is meaningful and there’s one meaning per drug. It isn’t more meaningful for more popular drugs.
(More precisely, we should compute standard errors. If we take just the 22 drugs.com reviews of Phenelzine, they have a standard error of 0.4 on the 10 point scale, which in Scott’s normalization is 0.06. Substantial, but smaller than the gap between the top 3 and the rest. Moreover, when we include the reviews at other sites, the standard error will be much lower. Desipramine, with only 35 reviews total is the only antidepressant with a total standard error anywhere near that large.)
I was looking at how the doctor reviews compared to the other reviews, so I was not looking at the joint set, just the individual set, where some of the drugs had quite low sample size. More importantly, the range of sample sizes is pretty large.
In the doctor ratings, the samples are all much lower (<100 each).
Either way, when you have a wide range of sample sizes (from 35 up to ~4000), you expect heteroscadiscity so I would expect a weighted least squares to be a better fit.
Although it’s hard to know what the error actually looked like, how many average drugs had very good and very high reviews with nothing in between? Who knows?
In your last paragraph, you are talking about sample errors. Just use an upper bound based on a bimodal distribution. It gives about twice the empirical variance for the three I checked: patient reviews of phenelzine, above, and the best and worst doctor reviews: S-citalopram and selegiline.
━━━━━━━━━
Do you mean heteroscedasticity of the sampling errors or of the residuals? Obviously the sample size tells you something about the sampling errors. So, yes, there is heteroscedasticity. But so what? But the errors are small compared to the residuals. (At least they are small once you get up to samples of 35, but when comparing different patient sites, some are almost missing some drugs and then sampling error is a big deal.)
Or does this heuristic say that there should be heteroscedasticity in the residuals for reasons unrelated to sample error, that the size is a sign of weirdness about the generating process? Well, OK, but in that case, why do you need the sample errors? Just do a scatter plot of the residuals against the sample sizes.
(I originally thought that you meant population weighting. I hope you agree that is a terrible idea.)
A more expensive, but not outrageously expensive way, to collect end user data that gets around a lot of self-selection biases in user review databases is to recruit panels of people to fill out quarterly surveys year after year on their families’ experiences with medicines. It’s like the Nielsen panel that’s been measuring TV show ratings for 60 years.
When I worked in the marketing research business in the 1980s, we had a panel of about 10,000 households where we got all their supermarket and drugstore consumer packaged goods purchases.
We would have a deal with all the stores in town and our panelists would identify themselves to the store clerks when checking out. The clerk would scan the panelist’s unique ID bar code and all her purchases would be recorded.
This was expensive — it cost us millions per year, including modest incentives for participation. But it wasn’t extremely costly. A lot of nice people like the idea that their shopping choices are contributing to better understanding of what consumers want.
Drugs have a smaller sample size problem, but I suspect it wouldn’t be all that expensive to recruit, say, 33,000 households of an average of 3 people each for a sample size of 100,000. If you recruited smartly you could probably get maybe 20,000 individuals to stay with it for 5 or 10 years, reporting in a few times per year on what pills family members are taking and what their reactions are.
For all I know, there may be an existing panel like this.
I wonder how these results correlate with how the patient views the drug before being prescribed it. If there is an effect there I would expect to see a different graph for the USA, where drugs are advertised and anecdotally at least patients are more demanding, and UK patients treated on the NHS. Doctor suing culture is also stronger in the USA while cost may be more of an issue in the UK, making older drugs easier to describe here?
I’m in the UK and prescribed trazadone which I *heart*, whereas Prozac made me jittery as fuck with terrible stomach pains and suicidal ideation, so of course I’m on the side of older drugs 🙂
I will attempt to summarize the discussion.
The main observation is that patient and doctor ratings correlate negatively. The secondary observation is that for psychiatric medications, date predicts both patient and doctor rating.
Most explanations have the problem that they predict zero correlation, not negative. It seems that either the patients or the doctors must be wrong (or both). But merely explaining why one is wrong fails to explain the negative correlation.
Doctors might like new drugs because the read journals or are seduced by drug companies. (But doctors complain about their patients wanting the newest treatments!) Old drugs might be better because of survival bias. These explanations amount to saying that doctors are wrong and patients are right, but they really only predict zero correlation. Why are doctors so wrong they are opposite the truth?
Two explanations really attack the negative correlation. One is that patients and doctors make different trade-offs between short-term and long-term risks. The other theory is selection bias and anchoring on the patients. A patient that tries a rare drug (rare b/c disliked by doctors) after many have failed may be more impressed than a patient who got the same results from a first drug. This makes sense for the antidepressants, but I’m skeptical that it applies to the other categories.
It seems to me that both of those theories could be tested by a doctor examining the rankings.
Thanks.
It has been brought up that expectations regarding the drugs effectiveness could be confounding the reviews. Price could be contributing to said expectations, since older drugs are out of patent, you could get generics, which are usually cheaper than brand name ones. The lower the cost, the lower the standards for the drug’s effectiveness.
But I’m not 100% familiar with how prescriptions and health insurance works in the US, where I assume this data’s from.
Pingback: Link Roundup 5/1/15 | Aceso Under Glass
Some patients need to go through several drugs to find the right one. Perhaps patients using rarer drugs are more satisfied because it took them longer to find a solution that works, hence larger satisfaction.
A note about Effexor. I’ve personally found it rather effective for anxiety/depression, the best of several drugs I’ve tried. However, the *withdrawal* is notoriously horrifying. Many people fire their psychiatrists when they experience it. That must complicate its rep somewhat.
My guess is the doctors are skewed towards ease of prescribing, while patients who are sufficiently depressed and miserable are skewed in their ratings towards efficacy- even if it is less convenient such as involving blood tests or special diets. And while the SSRI’s might be pretty safe in most people (although they do increase risk of bleeding and seizures), they can have have big quality of life side effects- killing your sex life, mental blunting word finding difficulties, etc., not to mention osteoporosis.
Psychiatry really needs comparative efficacy research- but I guess there is just no money for it. A while ago I was thinking of changing antidepressants, and everything I read just seemed to say that they are all basically the same but the SSRI’s have fewer side effects so start with them. If all of the antidepressants have similar levels of efficacy, either they are doing nothing beyond an active placebo effect (the patient has side effects so knows they are on meds) or they are doing something we know nothing about. How else could Wellbutrin = Prozac = Nortriptyline?
I also think patient characteristics should matter. If it is your first depression at the age of 60, or your 10th depression at the age of 30, shouldn’t that influence what medication you should take? I haven’t seen the research on finding the right drug for the right patient very often- but then again drug companies have no incentive to market their drugs for only a subset of the market. And the DSM diagnoses are just checklists- not sufficient for research.
Bad Ad-Hoc Hypothesis for why MAOIs might be more effective at treating depression: because they make you give up a bunch of foods (cheese, beer), and perhaps you lose weight as a result. Losing weight would improve most people’s happiness in the long run.
Has anybody done an RCT of an MAOI vs. a placebo you tell people will kill them if they don’t give up cheese and beer?
I didn’t lose weight on them- but found them to be very activating at the high doses I took. The food restrictions make for a very active placebo effect in that you can never forget you are taking the drug, you always have to remember- maybe that could make them work better? Also, patients might be justifying what they are giving up (like their favorite pizza and beer) and justifying it in their mind by telling themselves that they feel better. Or maybe only seriously depressed people get put on them, and studies seem to show that the more depressed you are, the more likely you are to respond to medication vs a placebo.
Presentation of data note: outside of economics, it is common to put the independent variable on the X axis and the dependent variable on the Y axis. That is (probably) not relevant when comparing rating vs. rating, but when you use release date as a variable, you want that on the X axis. The intuitive reading of that graph is that patient ratings of drugs affect the flow of time (based on the data, they are pushing us back in time).
Inside of economics too.
It would be useful to have a field of study devoted to better understanding the pros and cons of different kind of recommendation systems.
For example, in 20 years of reading readers’ reviews of books on Amazon, I’ve noticed that with nonfiction books, it’s pretty easy to judge their quality just by rank ordering the reviews in order of how intelligent and informed the reader sounds and by going with the average opinions of, say, the three smartest sounding amateur reviewers. On the other hand, Amazon fiction reviews seem to be driven by how much the reader would like to have the main character in the novel as a friend, which is of course much more subjective.
It’s hard for younger people to imagine how much work it was to get good recommendations before the later 1990s. For example, it’s hard to explain the joy I felt in discovering the old Stuart Brent bookstore on Michigan Avenue in Chicago in May 1983. I was used to depressing B. Dalton-type mall bookstores where the average book was poor in quality and the most promoted books were awful. Suddenly, I discovered a bookstore where the small table of a dozen new nonfiction books out front was handpicked by a close friend of Saul Bellow. The first two books I picked up off his featured table were “Modern Times” by Paul Johnson and “The Last Lion” by William Manchester.
One problem is that people get distracted by wanting to argue about the underlying things recommended: Eh, doesn’t “Modern Times” have some serious issues? From the perspective of 2015 is Johnson as galvanizing as he might have seemed in 1983; Isn’t Johnson’s 1972 book “The Offshore Islanders” really closer to the essence of his idiosyncratic contribution, etc.
Those are all good questions in their own field, but they are a distraction from understanding the systemic reasons why Stuart Brent’s recommendation of “Modern Times” was so great for me personally in 1983.
Here’s a bit of movie dialogue that gets at how audience opinions can be subjective, but also can be objective.
In the movie “The Trip to Italy,” British comedians Steve Coogan and Rob Brydon go to fancy restaurants and insult each other and other celebrities for a couple of hours. The first topic is the last Christopher Nolan Batman movie, “The Dark Knight Rises,” and how incomprehensible Christian Bale and, especially, Tom Hardy (as bad guy Bain) are in the movie. Brydon concludes that he would never mention to Hardy that he couldn’t understand a word he said. Instead:
“If I see him [Tom Hardy] — ‘Loved “Batman.”‘
“‘Some people said they couldn’t understand you.’
“They’re just … WRONG.”
The joke is that an appeal to objectivity, to the superior aesthetic tastes of famous artists, to the judgment of history — “They’re just … WRONG” — can be pretty persuasive in aesthetic or psychological matters.
Tom Hardy would probably be reassured if Rob Brydon told him critics of his artistic interpretation of Bain were just WRONG. But asserting that people who say they couldn’t understand what you were saying were WRONG is a highly persuasive passive-aggressive stab-in-the-back. Assuming that random viewers weren’t conspiring to lower poor Tom Hardy’s self-esteem by lying about not being able to understand him, their statement they couldn’t understand what he wasy saying is pretty objective evidence that some people found what he was saying hard to understand.
Now you could argue that, say, selection bias was at work; the reason the dialogue in “The Dark Knight Rises” was so widely said to be hard to hear was because Batman movies particularly appeal to, say, the deaf community or to the elderly. Maybe that’s true.
Or, then again, maybe they just couldn’t understand what Hardy was saying.
Somebody get this hothead outta here! Whenever I hear that mercenary, that masked man–Bane–all I can think is “what a lovely, lovely voice.”
I’m not saying this from loyalty (not that I’m a hired gun or anything). For you to say this to “poor Tom Hardy” would be extremely painful. The way he sounds is part of his master plan, and you don’t even acknowledge how hard it is to act when he puts on the mask.
Your toothless criticism pisses me off.
Gnashing his Bane… with no incisors.
Do you feel in charge? Was there a bailey for which this offsetting motte is part of your plan? I’ve respected you for showing people of status the next era of Western civilization. But my ire rises!
(Anyways, why would I want to see a movie with just two actors? They didn’t get to bring friends? They found extras but had no charge card for them? Were they trying to grab a prize?)
Scott (if you’re still paying attention) One of the questions I meant to ask you over dinner last weekend was about very long-term side effects of SSRIs.
There is scattered but to me disturbingly suggestive evidence that the sanity of at least some iong-term SSRI users becomes extremely fragile and that going off or changing medications is associated with violent and suicidal psychotic breaks. If you dig into enough “and then he just snapped and started shooting/stabbing people” incidents, this emerges as a possible common thread.
Of course, such incidents are sufficiently rare to make generalization risky, and there are some obvious potential confounders. But my current judgement is that I would be very reluctant to take such drugs or to recommend that others do so. This is not quite a theoretical issue as someone close to me has recently self-diagnosed mild endogenous depression, and shares my concerns.
Your judgment is more informed than mine on this issue. Are we jumping at shadows here?
Pingback: What I learned this week: 18/2015 | suboptimum
Another problem with the ratings at Crazymeds is malicious false negatives. Any med where the 0 rating significantly outnumbers the total of 1, 2, and 3 ratings has been messed with.
Excluding them for your other criteria are reasonable. The wiki software isn’t really amenable to multiple ratings.
In your previous post, you had mentioned that doctors tend to avoid prescribing drugs that may well be incredibly effective in the median case because of rare, serious complications; giving 50,000 people lower sex drives is less of a liability than giving 3 people hypertensive crises.
Does this go a lot of the way toward explaining the negative correlation between doctor and patient recommendations? 50,000/50,000 people find SSRIs kill their sex drives, and give them low scores. 3/50,000 people get hypertensive crises from MAOIs, and give them low scores, and the other 49,997/50,000 have no side effects and give them high scores. Doctors, on the other hand, know that MAOIs are much more of a liability to them, and so consistently rate them lower than SSRIs.
Part of the problem, I would guess, is that 1-to-5 rating system is unlikely to reflect the high variance in something like MAOIs, compared to the low variance of SSRIs. MAOIs could flat-out kill 20% of their patients and they’d still only be able to give a postmortem minimum of 1/5, resulting in a still quite respectable final score of 4/5 against those 80% 5/5 scores. Compared to SSRIs which might consistently get 3/5s, of course MAOIs come off better, even though most people would probably consider a 3/5 sex life to still be better than a 20% chance of sudden death.
Yes, this is a good point. Someone who dies, if their relatives think to rate the drug at all, may be counted the same in the ratings as someone who just found the drug made them grumpy.
Amusing potential confounder when it comes to studies on issues like this: people for whom the drugs work are likely to be more enthusiastic about giving positive ratings than they should be, and people for whom the drugs do not work are likely to be more pessimistic in their ratings than they should be.
“MAOIs, the clear winner of this analysis, are very clearly reserved in the guidelines for “treatment-resistant depression”, ie depression you’ve already thrown everything you’ve got at. But these are precisely the depressions that are hardest to treat.”
I’d expect it to go the other way. After a long line of failures, any improvement will be met with a big yay!
Also, the biased sampling could be working the other way as well. Let’s just take SSRIs and MAOIs. It’s a filtering process. SSRIs don’t work. MAOIs work. MAOIs don’t work.
We’re seeing P(MAOI+|SSRI-). Maybe that’s higher than P(MAOI+). Similarly, maybe P(SSRI+|MAOI-) is higher than P(SSRI+). Maybe “treatment resistant” is just a way for doctors to blame patients for their failure to pick the right treatment.
Any thoughts about the possibility of people whose side effects aren’t severe enough to kill them, but are incapacitating enough that those people aren’t in good enough shape to leave reviews on websites?
I’m a 70 yr old retired RN who has lived with an episodic depression for decades. I thought Wellbutrin helped in my 50’s and pot wasn’t bad either. About four years ago nothing worked and I slid into a major depression for which I was hospitalized twice. I was very sick and took anti-depressants, a few at a time, from every major modern family of drugs. They did nothing for me. About six months ago I quietly tapered myself off whatever the last one was and was drug free. I actually didn’t feel better at all, felt worse if possible, much more anxious whereas before I had just been numb. I have a lovely OLDER psychiatrist who when she found out I had had no drugs in my system for six weeks, asked if I would try the MAOI’s. In the spirit of not giving up (a euphemism), i started Parnate. In under two weeks I definitely felt better, my brain was working again, no morbid thoughts, etc. I felt like my healthy self in six weeks, am now doing interesting work, having fun, etc. As for the side effects, I have easily adjusted to the diet, which isn’t all that restrictive. The worst side effect has been a wicked insomnia, so I’ve had to stop caffeine and alcohol. It’s manageable like everything because I’m NOT depressed and am so relieved to be well.
I studied statistics 40 yrs ago, so I didn’t understand all of your article, but I had to write in with my story. It’s true, nobody uses them, crazy!
Good work.
Here’s a hypothesis for the negative correlation between doctor and patient ratings. Suppose doctors know that Adrug, Bdrug, Cdrug are the best in that order, so they always start with Adrug, which usually works. If that doesn’t work, they go to Bdrug. If that doesn’t work, they go to Cdrug. If that doesn’t work, they take the patient off Cdrug and tell him it’s hopeless.
Patients who take Adrug are happy it worked, but they don’t know about any other drug, so they think maybe the others are just as good. Patients who stop at Bdrug say Adrug is no good but Bdrug works. Patients who stop at Cdrug say Cdrug is wonderful because every other drug has failed. Patients for whom nothing works say no drug is any good. Thus, Cdrug gets the highest ratings, even though for most people, it is Adrug that works best.
Pardon me if this has already been noted— I haven’t read the other comments.
In the case of a drug like Brintellix (which is still on patent and thus more expensive for the patient on most insurance plans), I would imagine that people paying the extra money to give it a try are those who’ve already trialed a few of the more common, generic alternatives–that is to say, people with treatment resistant depression. People with treatment resistant depression would be substantially less likely to benefit from any drug (brintellix included), and thus we’d expect the ratings to be lower.
I would think this dynamic drives at least some of the ‘newer antidepressants are less effective’ trend you identify.
I think you touched on this a bit, but the point that feels the most relevant is that these two datasets are not conditionally independent.
The patient ratings are conditioned on the drug being prescribed to them, so I have a hard time seeing much value in then correlating the datasets.
In a world where drugs have terrible side effects that the doctors know about but the patients do not, we would find the exact same data. Patients love the deadly drugs, because the doctors made sure that the drug was not going to kill this particular patient.
Of course the world isn’t like that, but given that your data can’t distinguish between the perfect world and this one, the rest feels like speculation.
One simple hypothesis why older medications would be better: perhaps every decade’s new drugs have roughly the same distribution of effectiveness, but only the MOST effective drugs stand the test of time. If this is the case, we’d expect there to be tons of old drugs from the 60’s which weren’t in this analysis because nobody uses them anymore.
I don’t know if it’s been mentioned already but one possible effect is that patients are more likely to bother to go and rate a drug online if either (a) it [finally] works, or (b) it’s the first drug they’ve been prescribed. So drugs commonly given as a first line of defence should have patient satisfaction levels correlating roughly to how good they actually are; anything usually prescribed 2nd/3rd/4th/etc will be given a great rating if it’s the miracle drug that finally worked, because people need to know about that so they can get help from it too, but if it doesn’t work where’s the incentive to keep going online every month or three to give another bad rating to another drug?
Would be interesting to see if the results from these databases line up with results from patient feedback that isn’t self-selected like this
Pingback: The Good Drug Guide and the Holy Grail of Chemical Paradise: MAOIs | wallowinmaya
Pingback: Genocea's herpes vaccine hits the mark in Phase II … | Herpes Survival Kit