
[Disclaimer: I have done odd jobs for MIRI once or twice several years ago, but I am not currently affiliated with them in any way and do not speak for them.]
A recent Tumblr conversation on the Machine Intelligence Research Institute has gotten interesting and I thought I’d see what people here have to say.
If you’re just joining us and don’t know about the Machine Intelligence Research Institute (“MIRI” to its friends), they’re a nonprofit organization dedicated to navigating the risks surrounding “intelligence explosion”. In this scenario, a few key insights around artificial intelligence can very quickly lead to computers so much smarter than humans that the future is almost entirely determined by their decisions. This would be especially dangerous since most AIs use very primitive untested goal systems inappropriate for and untested on intelligent entities; such a goal system would be “unstable” and from a human perspective the resulting artificial intelligence could have apparently arbitrary or insane goals. If such a superintelligence were much more powerful than we are, it would present an existential threat to the human race.
This has almost nothing to do with the classic “Skynet” scenario – but if it helps to imagine Skynet, then fine, just imagine Skynet. Everyone else does.
MIRI tries to raise awareness of this possibility among AI researchers, scientists, and the general public, and to start foundational research in more stable goal systems that might allow AIs to become intelligent or superintelligent while still acting in predictable and human-friendly ways.
This is not a 101 space and I don’t want the comments here to all be about whether or not this scenario is likely. If you really want to discuss that, go read at least Facing The Intelligence Explosion and then post your comments in the Less Wrong Open Thread or something. This is about MIRI as an organization.
(If you’re really just joining us and you don’t know about Tumblr, run away)
II.
Tumblr user su3su2u1 writes:
Saw some tumblr people talking about [effective altruism]. My biggest problem with this movement is that most everyone I know who identifies themselves as an effective altruist donates money to MIRI (it’s possible this is more a comment on the people I know than the effective altruism movement, I guess). Based on their output over the last decade, MIRI is primarily a fanfic and blog-post producing organization. That seems like spending money on personal entertainment.
Part of this is obviously mean-spirited potshots, in that MIRI itself doesn’t produce fanfic and what their employees choose to do with their own time is none of your damn business.
(well, slightly more complicated. I think MIRI gave Eliezer a couple weeks vacation to work on it as an “outreach” thing once. But that’s a little different from it being their main priority.)
But more serious is the claim that MIRI doesn’t do much else of value. I challenged Su3 with the following evidence of MIRI doing good work:
A1. MIRI has been very successful with outreach and networking – basically getting their cause noticed and endorsed by the scientific establishment and popular press. They’ve gotten positive attention, sometimes even endorsements, from people like Stephen Hawking, Elon Musk, Gary Drescher, Max Tegmark, Stuart Russell, and Peter Thiel. Even Bill Gates is talking about AI risk, though I don’t think he’s mentioned MIRI by name. Multiple popular books have been written about their ideas, such as James Miller’s Singularity Rising and Stuart Armstrong’s Smarter Than Us
. Most recently Nick Bostrom’s book Superintelligence
, based at least in part on MIRI’s research and ideas, is a New York Times best-seller and has been reviewed positively in the Guardian, the Telegraph, Salon, the Financial Times, and the Economist. Oxford has opened up the AI-risk-focused Future of Humanity Institute; MIT has opened up the similar Future of Life Institute. In about a decade, the idea of an intelligence explosion has gone from Time Cube level crackpottery to something taken seriously by public intellectuals and widely discussed in the tech community.
A2. MIRI has many publications, conference presentations, book chapters and other things usually associated with normal academic research, which interested parties can find on their website. They have conducted seven past research workshops which have produced interesting results like Christiano et al’s claimed proof of a way around the logical undefinability of truth, which was praised as potentially interesting by respected mathematics blogger John Baez.
A3. Many former MIRI employees, and many more unofficial fans, supporters, and associates of MIRI, are widely distributed across the tech community in industries that are likely to be on the cutting edge of artificial intelligence. For example, there are a bunch of people influenced by MIRI in Google’s AI department. Shane Legg, who writes about how his early work was funded by a MIRI grant and who once called MIRI “the best hope that we have” was pivotal in convincing Google to set up an AI ethics board to monitor the risks of the company’s cutting-edge AI research. The same article mentions Peter Thiel and Jaan Tallinn as leading voices who will make Google comply with the board’s recommendations; they also happen to be MIRI supporters and the organization’s first and third largest donors.
There’s a certain level of faith required for (A1) and (A3) here, in that I’m attributing anything good that happens in the field of AI risk to some sort of shady behind-the-scenes influence from MIRI. Maybe Legg, Tallinn, and Thiel would have pushed for the exact same Google AI Ethics Board if none of them had ever heard of MIRI at all. I am forced to plead ignorance on the finer points of networking and soft influence. Heck, for all I know, maybe the exact same number of people would vote Democrat if there were no Democratic National Committee or liberal PACs. I just assume that, given a really weird idea that very few people held in 2000, an organization dedicated to spreading that idea, and the observation that the idea has indeed spread very far, the organization is probably doing something right.
III.
Our discussion on point (A3) degenerated into Dueling Anecdotal Evidence. But Su3 responded to my point (A1) like so:
[I agree that MIRI has gotten shoutouts from various thought leaders like Stephen Hawking and Elon Musk. Bostrom’s book is commercially successful, but that’s just] more advertising. Popular books aren’t the way to get researchers to notice you. I’ve never denied that MIRI/SIAI was good at fundraising, which is primarily what you are describing.
How many of those thought leaders have any publications in CS or pure mathematics, let alone AI? Tegmark might have a math paper or two, but he is primarily a cosmologist. The FLI’s list of scientists is (for some reason) mostly again cosmologists. The active researchers appear to be a few (non-CS, non-math) grad students. Not exactly the team you’d put together if you were actually serious about imminent AI risk.
I would also point out “successfully attracted big venture capital names” isn’t always a mark of a sound organization. Black Light Power is run by a crackpot who thinks he can make energy by burning water, and has attracted nearly 100 million in funding over the last two decades, with several big names in energy production behind him.
And to my point (A2) like so:
I have a PhD in physics and work in machine learning. I’ve read some of the technical documents on MIRI’s site, back when it was SIAI and I was unimpressed. I also note that this critique is not unique to me, as far as I know the GiveWell position on MIRI is that it is not an effective institute.
The series of papers on Lob’s theorem are actually interesting, though I notice that none of the results have been peer reviewed, and the paper’s aren’t listed as being submitted to journals yet. Their result looks right to me, but I wouldn’t trust myself to catch any subtlety that might be involved.
[But that just means] one result has gotten some small positive attention, and even those results haven’t been vetted by the wider math community yet (no peer review). Let’s take a closer look at the list of publications on MIRI’s website- I count 6 peer reviewed papers in their existence, and 13 conference presentations. Thats horribly unproductive! Most of the grad students who finish a physics phd will publish that many papers individually, in about half that time. You claim part of their goal is to get academics to pay attention, but none of their papers are highly cited, despite all this networking they are doing.
Citations are the standard way to measure who in academia is paying attention. Apart from the FHI/MIRI echo chamber (citations bouncing around between the two organizations), no one in academia seems to be paying attention to MIRI’s output. MIRI is failing to make academic inroads, and it has produced very little in the way of actual research.
My interpretation, in the form of a TL;DR
B1. Sure, MIRI is good at getting attention, press coverage, and interest from smart people not in the field. But that’s public relations and fundraising. An organization being good at fundraising and PR doesn’t mean it’s good at anything else, and in fact “so good at PR they can cover up not having substance” is a dangerous failure mode.
B2. What MIRI needs, but doesn’t have, is the attention and support of smart people within the fields of math, AI, and computer science, whereas now it mostly has grad students not in these fields.
B3. While having a couple of published papers might look impressive to a non-academic, people more familiar with the culture would know that their output is woefully low. They seem to have gotten about five ten solid publications in during their decade-long history as a multi-person organization; one good grad student can get a couple solid publications a year. Their output is less than expected by like an order of magnitude. And although they do get citations, this is all from a mutual back-scratching club of them and Bostrom/FHI citing each other.
IV.
At this point Tarn and Robby joined the conversation and it became kind of confusing, but I’ll try to summarize our responses.
Our response to Su3’s point (B1) was that this is fundamentally misunderstanding outreach. From its inception until about last year, MIRI was in large part an outreach and awareness-raising organization. Its 2008 website describes its mission like so:
In the coming decades, humanity will likely create a powerful AI. SIAI exists to confront this urgent challenge, both the opportunity and the risk. SIAI is fostering research, education, and outreach to increase the likelihood that the promise of AI is realized for the benefit of everyone.
Outreach is one of its three main goals, and “education”, which sounds a lot like outreach, is a second.
In a small field where you’re the only game in town, it’s hard to distinguish between outreach and self-promotion. If MIRI successfully gets Stephen Hawking to say “We need to be more concerned about AI risks, as described by organizations like MIRI”, is that them being very good at self-promotion and fundraising, or is that them accomplishing their core mission of getting information about AI risks to the masses?
Once again, compare to a political organization, maybe Al Gore’s anti-global-warming nonprofit. If they get the media to talk about global warming a lot, and get lots of public intellectuals to come out against global warming, and change behavior in the relevant industries, then mission accomplished. The popularity of An Inconvenient Truth can’t just be dismissed as “self-promotion” or “fundraising” for Gore, it was exactly the sort of thing he was gathering money and personal prestige in order to do, and should be considered a victory in its own right. Even though eventually the anti-global-warming cause cares about politicians, industry leaders, and climatologists a lot more than they care about the average citizen, convincing millions of average citizens to help was a necessary first step.
And this which is true of An Inconvenient Truth is true of Superintelligence and other AI risk publicity efforts, albeit on their much smaller scale.
Our response to Su3’s point (B2) was that it was just plain factually false. MIRI hasn’t reached big names from the AI/math/compsci field? Sure it has. Doesn’t have mathy PhD students willing to research for them? Sure it does.
Peter Norvig and Stuart Russell are among the biggest names in AI. Norvig is currently the Director of Research at Google; Russell is Professor of Computer Science at Berkeley and a winner of various impressive sounding awards. The two wrote a widely-used textbook on artificial intelligence in which they devote three pages to the proposition that “The success of AI might mean the end of the human race”; parts are taken right out of the MIRI playbook and they cite MIRI research fellow Eliezer Yudkowsky’s paper on the subject. This is unlikely to be a coincidence; Russell’s site links to MIRI and he is scheduled to participate in MIRI’s next research workshop.
Their “team” of “research advisors” includes Gary Drescher (PhD in CompSci from MIT), Steve Omohundro (PhD in physics from Berkeley but also considered a pioneer of machine learning), Roman Yampolskiy (PhD in CompSci from Buffalo), and Moshe Looks (PhD in CompSci from Washington).
Su3 brought up the good point that none of these people, respected as they are, are MIRI employees or researchers (although Drescher has been to a research workshop). At best, they are people who were willing to let MIRI use them as figureheads (in the case of the research advisors); at worst, they are merely people who have acknowledged MIRI’s existence in a not-entirely-unlike-positive way (Norvig and Russell). Even if we agree they are geniuses, this does not mean that MIRI has access to geniuses or can produce genius-level research.
Fine. All these people are, no more and no less, is evidence that MIRI is succeeding at outreach within the academic field of AI, as well as in the general public. It also seems to me to be some evidence that smart people who know more about AI than any of us think MIRI is on the right track.
Su3 brought up the example of a BlackLight Power, a crackpot energy company that was able to get lots of popular press and venture capital funding despite being powered entirely by pseudoscience. I agree this is the sort of thing we should be worried about. Nonscientists outside of specialized fields have limited ability to evaluate their claims. But when smart researchers in the field are willing to vouch for MIRI, that give me a lot more confidence they’re not just a fly-by-night group trying to profit off of pseudoscience. Their research might be more impressive or less impressive, but they’re not rotten to the core the same way BlackLight was.
And though MIRI’s own researchers may be far from those lofty heights, I find Su3’s claim that they are “a few non-CS, non-math grad students” a serious underestimate.
MIRI has fourteen employees/associates with the word “research” in their name, but of those, a couple (in the words of MIRI’s team page) “focus on social and historical questions related to artificial intelligence outcomes.” These people should not be expected to have PhDs in mathematical/compsci subjects.
Of the rest, Bill is a PhD in CompSci, Patrick is a PhD in math, Nisan is a PhD in math, Benja is a PhD student in math, and Paul is a PhD student in math. The others mostly have masters or bachelors in those fields, published journal articles, and/or won prizes in mathematical competitions. Eliezer writes of some of the remaining members of his team:
Mihaly Barasz is an International Mathematical Olympiad gold medalist perfect scorer. From what I’ve seen personally, I’d guess that Paul Christiano is better than him at math. I forget what Marcello’s prodigy points were in but I think it was some sort of Computing Olympiad [editor’s note: USACO finalist and 2x honorable mention in the Putnam mathematics competition]. All should have some sort of verified performance feat far in excess of the listed educational attainment.
That pretty much leaves Eliezer Yudkowsky, who needs no introduction, and Nate Soares, whose introduction exists and is pretty interesting.
Add to that the many, many PhDs and talented people who aren’t officially employed by them but attend their workshops and help out their research when they get the chance, and you have to ask how many brilliant PhDs from some of the top universities in the world we should expect a small organization like MIRI to have. MIRI competes for the same sorts of people as Google, and offers half as much. Google paid $400 million to get Shane Legg and his people on board; MIRI’s yearly budget hovers at about $1 million. Given that they probably spend a big chunk of that on office space, setting up conferences, and other incidentals, I think the amount of talent they have right now is pretty good.
That leaves Su3’s point (B3) – the lack of published research.
One retort might be that, until recently, MIRI’s research focused on strategic planning and evaluation of AI risks. This is important, and it resulted in a lot of internal technical papers you can find on their website, but there’s not really a field for it. You can’t just publish it in the Journal Of What Would Happen If There Was An Intelligence Explosion, because no such journal. The best they can do is publish the parts of their research that connect to other fields in appropriate journals, which they sometimes did.
I feel like this also frees them from the critique of citation-incest between them and Bostrom. When I look at a typical list of MIRI paper citations, I do see a lot of Bostrom, but also some other names that keep coming up – Hutter, Yampolskiy, Goetzel. So okay, it’s an incest circle of four or five rather than two.
But to some degree that’s what I expect from academia. Right now I’m doing my own research on a psychiatric screening tool called the MDQ. There are three or four research teams in three or four institutions who are really into this and publish papers on it a lot. Occasionally someone from another part of psychiatry wanders in, but usually it’s just the subsubsubspeciality of MDQ researchers talking to each other. That’s fine. They’re our repository of specialized knowledge on this one screening tool.
You would hope the future of the human race would get a little bit more attention than one lousy psychiatric screening tool, but blah blah civilizational inadequacy, turns out not so much, they’re of about equal size. If there are only a couple of groups working on this problem, they’re going to look incestuous but that’s fine.
On the other hand, math is math, and if MIRI is trying to produce real mathematical results they ought to be sharing them with the broader mathematical community.
Robby protests that until very recently, MIRI hasn’t really been focusing on math. This is a very recent pivot. In April 2013, Luke wrote in his mini strategic plan:
We were once doing three things — research, rationality training, and the Singularity Summit. Now we’re doing one thing: research. Rationality training was spun out to a separate organization, CFAR, and the Summit was acquired by Singularity University. We still co-produce the Singularity Summit with Singularity University, but this requires limited effort on our part.
After dozens of hours of strategic planning in January–March 2013, and with input from 20+ external advisors, we’ve decided to (1) put less effort into public outreach, and to (2) shift our research priorities to Friendly AI math research.
In the full strategic plan for 2014, he repeated:
Events since MIRI’s April 2013 strategic plan have increased my confidence that we are “headed in the right direction.” During the rest of 2014 we will continue to:
– Decrease our public outreach efforts, leaving most of that work to FHI at Oxford, CSER at Cambridge, FLI at MIT, Stuart Russell at UC Berkeley, and others (e.g. James Barrat).
– Finish a few pending “strategic research” projects, then decrease our efforts on that front, again leaving most of that work to FHI, plus CSER and FLI if they hire researchers, plus some others.
– Increase our investment in our Friendly AI (FAI) technical research agenda.
– We’ve heard that as a result of…outreach success, and also because of Stuart Russell’s discussions with researchers at AI conferences, AI researchers are beginning to ask, “Okay, this looks important, but what is the technical research agenda? What could my students and I do about it?” Basically, they want to see an FAI technical agenda, and MIRI is is developing that technical agenda already.
In other words, there is a recent pivot from outreach, rationality and strategic research to pure math research, and the pivot is only recently finished or still going on.
TL;DR, again in three points:
C1. Until recently, MIRI focused on outreach and did a truly excellent job on this. They deserve credit here.
C2. MIRI has a number of prestigious computer scientists and AI experts willing to endorse or affiliate with it in some way. While their own researchers are not quite at the same lofty heights, they include many people who have or are working on math or compsci PhDs.
C3. MIRI hasn’t published much math because they were previously focusing on outreach and strategic research; they’ve only shifted to math work in the past year or so.
V.
The discussion just kept going. We reached about the limit of our disagreement on (C1), the point about outreach – yes, they’ve done it, but does it count when it doesn’t bear fruit in published papers? About (C2) and the credentials of MIRI’s team, Su3 kind of blended it into the next point about published papers, saying:
Fundamental disconnect – I consider “working with MIRI” to mean “publishing results with them.” As an outside observer, I have no indication that most of these people are working with them. I’ve been to workshops and conferences with Nobel prize winning physicists, but I’ve never “worked with them” in the academic sense of having a paper with them. If [someone like Stuart Russell] is interested in helping MIRI, the best thing he could do is publish a well received technical result in a good journal with Yudkowsky. That would help get researchers to pay actual attention(and give them one well received published result, in their operating history).
Tangential aside- you overestimate the difficulty of getting top grad students to work for you. I recently got four CS grad students at a top program to help me with some contract work for a few days at the cost of some pizza and beer.
So it looks like it all comes down to the papers. Su3 had this to say:
What I was specifically thinking was “MIRI has produced a much larger volume of well-received fan fiction and blog posts than research.” That was what I inended to communicate, if somewhat snarkily. MIRI bills itself as a research institute, so I judge them on their produced research. The accountability measure of a research institute is academic citations.
Editorials by famous people have some impact with the general public, so thats fine for fundraising, but at some point you have to get researchers interested. You can measure how much influence they have on researchers by seeing who those researchers cite and what they work on. You could have every famous cosmologist in the world writing op-eds about AI risk, but its worthless if AI researchers don’t pay attention, and judging by citations, they aren’t.
As a comparison for publication/citation counts, I know individual physicists who have published more peer reviewed papers since 2005 than all of MIRI has self-published to their website. My single most highly cited physics paper (and I left the field after graduate school) has more citations than everything MIRI has ever published in peer reviewed journals combined. This isn’t because I’m amazing, its because no one in academia is paying attention to MIRI.
[Christiano et al’s result about Lob] has been self-published on their website. It has NOT been peer reviewed. So it’s published in the sense of “you can go look at the paper.” But its not published in the sense of “mathematicians in the same field have verified the result.” I agree this one result looks interesting, but most mathematicians won’t pay attention to it unless they get it reviewed (or at the bare minimum, clean it up and put it on Arxiv). They have lots of these self-published documents on their web page.
If they are making a “strategic decision” to not submit their self-published findings to peer review ,they are making a terrible strategic decision, and they aren’t going to get most academics to pay attention that way. The result of Christiano, et al. is potentially interesting, but it’s languishing as a rough unpublished draft on the MIRI site, so its not picking up citations.
I’d go further and say the lack of citations is my main point. Citations are the important measurement of “are researchers paying attention.” If everything self-published to MIRI’s website were sparking interest in academia, citations would be flying around, even if the papers weren’t peer reviewed, and I’d say “yeah, these guys are producing important stuff.”
My subpoint might be that MIRI doesn’t even seem to be trying to get citations/develop academic interest, as measured by how little effort seems to be put into publication.
And Su3’s not buying the pivot explanation either:
That seems to be a reframing of the past history though. I saw talks by the SIAI well before 2013 where they described their primary purpose as friendly AI research, and insisted they were in a unique position (due to being uniquely brilliant/rational) to develop technical friendly AI (as compared to academic AI researchers).
[Tarn] and [Robby] have suggested the organization is undergoing a pivot, but they’ve always billed themselves as a research institute. But donating money to an organization that has been ineffective in the past, because it looks like they might be changing seems like a bad proposition.
My initial impression (reading Muelhauser’s post you linked to and a few others) is that Muelhauser noticed the house was out of order when he became director and is working to fix things. Maybe he’ll succeed and in the future, then, I’ll be able to judge MIRI as effective- certainly a disproportionate number of their successes have come in the last few years. However, right now all I have is their past history, which has been very unproductive.
VI.
After that, discussion stayed focused on the issue of citations. This seemed like progress to me. Not only had we gotten it down to a core objection, but it was sort of a factual problem. It wasn’t an issue of praising or condemning. Here’s an organization with a lot of smart people. We know they work very hard – no one’s ever called Luke a slacker, and another MIRI staffer (who will not be named, for his own protection) achieved some level of infamy for mixing together a bunch of the strongest chemicals from my nootropics survey into little pills which he kept on his desk in the MIRI offices for anyone who wanted to work twenty hours straight and then probably die young of conditions previously unknown to science. IQ-point*hours is a weird metric, but MIRI is putting a lot of IQ-point*hours into whatever it’s doing. So if Su3’s right that there are missing citations, where are they?
Among the three of us, Robby and Tarn and I generated a couple of hypotheses (well, Robby’s were more like facts than hypotheses, since he’s the only one in this conversation who actually works there).
D1: MIRI has always been doing research, but until now it’s been strategic research (ie “How worried should we be about AI?”, “How far in the future should we expect AI to be developed?”) which hasn’t fit neatly into an academic field or been of much interest to anyone except MIRI allies like Bostrom. They have dutifully published this in the few papers that are interested, and it has dutifully been cited by the few people who are interested (ie Bostrom). It’s unreasonable to expect Stuart Russell to cite their estimates of time course for superintelligence when he’s writing his papers on technical details of machine learning algorithms or whatever it is he writes papers on. And we can generalize from Stuart Russell to the rest of the AI field, who are also writing on things like technical details of machine learning algorithms that can’t plausibly be connected to when machines will become superintelligent.
D2: As above, but continuing to apply even in some of their math-ier research. MIRI does have lots of internal technical papers on their website. People tend to cite other researchers working in the same field as themselves. I could write the best psychiatry paper in human history, and I’m probably not going to get any citations from astrophysicists. But “machine ethics” is an entirely new field that’s not super relevant to anyone else’s work. Although a couple key machine ethics problems, like the Lobian obstacle and decision theory, touch on bigger and better-populated subfields of mathematics, they’re always going to be outsiders who happen to wander in. It’s unfair to compare them to a physics grad student writing about quarks or something, because she has the benefit of decades of previous work on quarks and a large and very interested research community. MIRI’s first job is to create that field and community, which until you succeed looks a lot like “outreach”.
D3: Lack of staffing and constant distraction by other important problems. This is Robby’s description of what he notices from the inside. He writes:
We’re short on staff, especially since Louie left. Lots of people are willing to volunteer for MIRI, but it’s hard to find the right people to recruit for the long haul. Most relevantly, we have two new researchers (Nate and Benja), but we’d love a full-time Science Writer to specialize in taking our researchers’ results and turning them into publishable papers. Then we don’t have to split as much researcher time between cutting-edge work and explaining/writing-down.
A lot of the best people who are willing to help us are very busy. I’m mainly thinking of Paul Christiano. he’s working actively on creating a publishable version of the probabilistic Tarski stuff, but it’s a really big endeavor. Eliezer is by far our best FAI researcher, and he’s very slow at writing formal, technical stuff. He’s generally low-stamina and lacks experience in writing in academic style / optimizing for publishability, though I believe we’ve been having a math professor tutor him to get over that particular hump. Nate and Benja are new, and it will take time to train them and get them publishing their own stuff. At the moment, Nate/Benja/Eliezer are spending the rest of 2014 working on material for the FLI AI conference, and on introductory FAI material to send to Stuart Russell and other bigwigs.
D4: Some of the old New York rationalist group takes a more combative approach. I’m not sure I can summarize their argument well enough to do it justice, so I would suggest reading Alyssa’s post on her own blog.
But if I have to take a stab: everyone knows mainstream academia is way too focused on the “publish or perish” ethic of measuring productivity in papers or citations rather than real progress. Yeah, a similar-sized research institute in physics could probably get ten times more papers/citations than MIRI. That’s because they’re optimizing for papers/citations rather than advancing the field, and Goodhart’s Law is in effect here as much as everywhere else. Those other institutes probably got geniuses who should be discovering the cure for cancer spending half their time typing, formatting, submitting, resubmitting, writing whatever the editors want to see, et cetera. MIRI is blessed with enough outside support that it doesn’t have to do that. The only reason to try is to get prestige and attention, and anyone who’s not paying attention now is more likely to be a constitutional skeptic using lack of citations as an excuse, than a person who would genuinely change their mind if there were more citations.
I am more sympathetic than usual to this argument because I’m in the middle of my own research on psychiatric screening tools and quickly learning that official, published research is the worst thing in the world. I could do my study in about two hours if the only work involved were doing the study; instead it’s week after week of forms, IRB submissions, IRB revisions, required online courses where I learn the Nazis did unethical research and this was bad so I should try not to be a Nazi, selecting exactly which journals I’m aiming for, and figuring out which of my bosses and co-workers academic politics requires me make co-authors. It is a crappy game, and if you’ve been blessed with enough independence to avoid playing it, why wouldn’t you take advantage? Forget the overhyped and tortured “measure” of progress you use to impress other people, and just make the progress.
VII.
Or not. I’ll let Su3 have the last word:
I think something fundamental about my argument has been missed, perhaps I’ve communicated it poorly.
It seems like you think the argument is that increasing publications increases prestige/status which would make researchers pay attention. i.e. publications -> citations -> prestige -> people pay attention. This is not my argument.
My argument is essentially that the way to judge if MIRI’s outreach has been successful is through citations, not through famous people name dropping them, or allowing them to be figure heads.
This is because I believe the goal of outreach is get AI researchers focused on MIRI’s ideas. Op eds from famous people are useful only if they get AI researchers focused on these ideas. Citations aren’t about prestige in this case- citations tell you which researchers are paying attention to you. The number of active researchers paying attention to MIRI is very small. We know this because citations are an easy to find, direct measure.
Not all important papers have tremendous numbers of citations, but a paper can’t become important if it only has 1 or 2, because the ultimate measure of importance is “are people using these ideas?”
So again, to reiterate, if the goal of outreach is to get active AI researchers paying attention, then the direct measure for who is paying attention is citations. [But] the citation count on MIRIs work is very low. Not only is the citation count low (i.e. no researchers are paying attention), MIRI doesn’t seem to be trying to boost it – it isn’t trying to publish which would help get its ideas attention. I’m not necessarily dismissive of celebrity endorsements or popular books, my point is why should I measure the means when I can directly measure the ends?
The same idea undercuts your point that “lots of impressive PhD students work and have worked with MIRI,” because it’s impossible to tell if you don’t personally know the researchers. This is because they don’t create much output while at MIRI, and they don’t seem to be citing MIRI in their work outside of MIRI.
[Even people within the rationalist/EA community] agree with me somewhat. Here is a relevant quote from Holden Karnofsky [of GiveWell]:
SI seeks to build FAI and/or to develop and promote “Friendliness theory” that can be useful to others in building FAI. Yet it seems that most of its time goes to activities other than developing AI or theory. Its per-person output in terms of publications seems low. Its core staff seem more focused on Less Wrong posts, “rationality training” and other activities that don’t seem connected to the core goals; Eliezer Yudkowsky, in particular, appears (from the strategic plan) to be focused on writing books for popular consumption. These activities seem neither to be advancing the state of FAI-related theory nor to be engaging the sort of people most likely to be crucial for building AGI.
And here is a statement from Paul Christiano disagreeing with MIRI’s core ideas:
But I should clarify that many of MIRI’s activities are motivated by views with which I disagree strongly and that I should categorically not be read as endorsing the views associated with MIRI in general or of Eliezer in particular. For example, I think it is very unlikely that there will be rapid, discontinuous, and unanticipated developments in AI that catapult it to superhuman levels, and I don’t think that MIRI is substantially better prepared to address potential technical difficulties than the mainstream AI researchers of the future.
This time Su3 helpfully provides their own summary:
E1. If the goal of outreach is to get active AI researchers paying attention, then the direct measure for who is paying attention is citations. [But] the citation count on MIRIs work is very low.
E2. Not only is the citation count low (i.e. no researchers are paying attention), MIRI doesn’t seem to be trying to boost it – it isn’t trying to publish which would help get its ideas attention. I’m not necessarily dismissive of celebrity endorsements or popular books, my point is why should I measure the means when I can directly measure the ends?
E3. The same idea undercuts your point that “lots of impressive phd students work and have worked with MIRI,” because its impossible to tell if you don’t personally know the researchers. This is because they don’t create much output while at MIRI, and they don’t seem to be citing MIRI in their work outside of MIRI.
E4. Holden Karnofsky and Paul Christiano do not believe that MIRI is better prepared to address the friendly AI problem than mainstream AI researchers of the future. Karnofsky explicitly for some of the reasons I have brought up, Christiano for reasons unmentioned.
VIII.
Didn’t actually read all that and just skipped down to the last subheading to see if there’s going to be a summary and conclusion and maybe some pictures? Good.
There seems to be some agreement MIRI has done a good job bringing issues of AI risk into the public eye and getting them media attention and the attention of various public intellectuals. There is disagreement over whether they should be credited for their success in this area, or whether this is a first step they failed to follow up on.
There also seems to be some agreement MIRI has done a poor job getting published and cited results in journals. There is disagreement over whether this is an understandable consequence of being a small organization in a new field that wasn’t even focusing on this until recently, or whether it represents a failure at exactly the sort of task by which their success should be judged.
This is probably among the 100% of issues that could be improved with flowcharts:
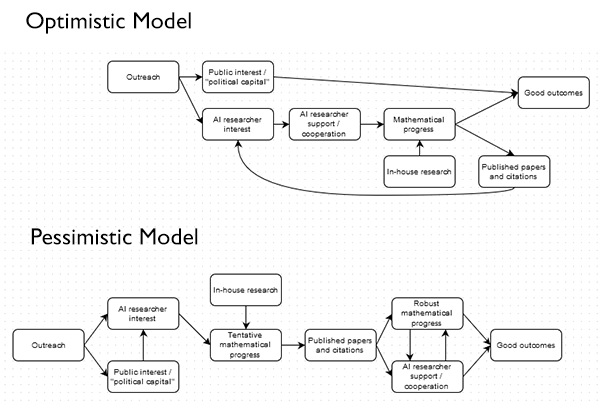
In the Optimistic Model, MIRI’s successfully built up Public Interest, and for all we know they might have Mathematical Progress as well even though they haven’t published it in journals yet. While they could feed back their advantages by turning their progress into Published Papers and Citations to get even more Mathematical Progress, overall they’re in pretty good shape for producing Good Outcomes, at least insofar as this is possible in their chosen field.
In the Pessimistic Model, MIRI may or may not have garnered Public Interest, Researcher Interest, and Tentative Mathematical Progress, but they failed to turn that into Published Papers and Citations, which is the only way they’re going to get to Robust Mathematical Progress, Researcher Support, and eventually Good Outcomes. The best that can be said about them is that they set some very preliminary groundwork that they totally failed to follow up on.
A higher level point – if we accept the Pessimistic Model, do we accuse MIRI of being hopelessly incompetent, in which case they deserve less support? Or do we accept them as inexperienced amateurs who are the only people willing to try something difficult but necessary, in which case they deserve more support, and maybe some guidance, and perhaps some gentle or not-so-gentle prodding? Maybe if you’re a qualified science writer you could apply for the job opening they’re advertising and help them get those papers they need?
An even higher-level point – what do people worried about AI risk do with this information? I don’t see much that changes my opinion of the organization one way or the other. But Robby points out that people who are more concerned – but still worried about AI risk – have other good options. The Future of Humanity Institute at Oxford research that is less technical and more philosophical, wears their strategic planning emphasis openly on their sleeve has oodles of papers and citations and prestige. They also accept donations.
Best of all, their founder doesn’t write any fanfic at all. Just perfectly respectable stories about evil dragon kings.
















Measuring output by number of papers written is silly, and leads to usual “least publishable unit” shenanigans.
That said, particularly in math, getting papers into a publishable state ready for peer review is difficult, and in some sense until a result is written up in that form it is not ready (often significant issues come up in the process of writing things up). So if you leave your math stuff on the level of a LW post or a white paper, it is still fundamentally “half-baked.”
Yeah. Writing up your papers is how you know if they’re any good.
Holden and the other GiveWell team are under strong incentive against endorsing any existential risk charity, including MIRI.
1. Their credibility comes from the idea that they strongly verify if your money is being spent effectively. They don’t have a lot to offer on existential risk organizations whose main fundraising appeal is trying to quantify how valuable they are.
2. Their value is in Taking Numbers Seriously. If GiveWell concludes that they have identified a worthy existential risk charity, it is very likely to be a significantly better expected value than their other charities.
3. MIRI could hire more or less unlimited AI researchers, so they can always scale to have plenty of room for funding.
4. If GiveWell endorses a “fringe” charity, then they will help the fringe charity to some extent, but lose a great deal of credibility among the vast majority of people who consider existential risks to be on the level of conspiracy theories.
5. GiveWell is funded by private donors, not public donation. Their funders likely did not envision them endorsing “fringe” existential risk charities.
If GiveWell endorses MIRI they will be mathematically obligated to go all in, and will lose a great deal of credibility. Endorsing MIRI could be an existential risk to GiveWell itself. They have a strong incentive to come with reasons not to endorse MIRI.
tl;dr GiveWell can’t endorse MIRI because they will lose status and donations. This makes it hard to trust that they can objectively evaluate the situation.
+1 to all. I’ve been thinking similar thoughts for a while. I don’t think GiveWell could never endorse MIRI or other x-risk stuff (aside from meteor impacts or some other obvious thing), but they’d have to wait until they (GiveWell) are more solidly, unquestionably mainstream or respected, otherwise it could sink their credibility for good.
Or until an existential risk organization has high status.
True enough. I think that if one of them is going to literally go “mainstream” it would definitely be GiveWell, though.
Wouldn’t Givewell need to wait until some existential risk was clearly probable and close to the present enough to overwhelm the effects of malaria and dire poverty and such?
I don’t know too much about this situation, but I think if GiveWell secretly liked MIRI but were trying to avoid saying so, their actions would look different than they do now. In particular, they could avoid any criticism – which they’re not doing.
I think politically they walk a fine line between supporting MIRI (and alienating neophobic normal people) and condemning MIRI (and alienating the large number of their supporters who are fans). I trust them to navigate it as honestly as they can, and the impression I’m getting from what I see is that they’re not opposed to MIRI in principle but they really don’t think it meets their standards as one of the most effective organizations.
(keep in mind their standards even for normal charities are really high)
I’m not saying that they are secretly fans of MIRI, I’m trying to point out that their private and public analysis may be shaped by their funding and political situation.
GiveWell is great for rating third world development charities, but they have strong incentives against rationally evaluating fringe groups. As such, their judgement should be taken as weak evidence.
I should note that I have made donations based on GiveWell’s recommendations in the past and plan to in the future. I think they have a great mission and philosophy.
We should only suspect that Givewell secretly supported MIRI if, as of 2012, most outsiders with a limited exposure to MIRI’s technical agenda were persuaded by MIRI’s arguments. Given that this is obviously not true, there’s no reason to think that Holden secretly does love MIRI but is lying about it.
Timothy Gowers blog links to Elizier Yudkowsky. This is enough for me to support them. This is only sort of a joke. I don’t personally trust myself to evaluate MIRI. But I trust myself to know Tim Gowers is very smart and ttrustworthy. If he is willing to link to them they are suffiently credible they deserve at least as much money as they are getting. This argument works for people other than gowers.
The serious question is FHI vs MIRI.
“A serious academic links to his blog” provides very weak evidence that Eliezer should be taken seriously. There’s stronger evidence available on both sides of the question.
It seems like the actually interesting, empirical question raised by this is: How important is the process of formal publication to having solid, trustable mathematical results?
That’s a more complicated question than you think it is. Speaking as a research mathematician, I’d say that formal publication is important but not critical; but getting it written up formally is very important. A surprising and sad number of proofs disintegrate between the proof sketch and the finished document.
If MIRI has, in fact, formally written up approximately nothing (which is what su3 seems to be saying), then I’d say this is the real sticking point. MIRI should not be building their actual core research on pillars of sand.
Near as I can tell from their technical documents, MIRI has formally written up about 1.5 things.
As someone with no experience, can someone shed light on what writing up formally means in practice? How does it change the proof?
The ideal is you should be able to read a formal proof in more or less a “turing machine mode”. What this means can vary depending on what “mathematical libraries you have loaded in”, different branches of math have different social norms here. For instance, logicians tend to be sticklers for detail, because they often need to distinguish object and meta levels, etc.
Learning what constitutes a valid proof isn’t so simple — beginners are advised to err on the side of verbosity and detail (and gradually drop steps as one gets comfortable). Sometimes even very good, senior mathematicians skip a step and this step has a hole in it…
Some folks (the gentleman whose talk I linked in my other comment) have adopted an attitude of despair about the difference between a “proof” and an “idea/outline”, and basically feel we need computer proof checkers to save us.
“How dies it change the proof?”
My view is, until its written up formally, it’s not a proof, it’s a potentially promising idea.
Does writing a proof up formally need to be done by the person who developed the proof?
Nancy, writing up a proof formally _is_ what developing the proof is, more or less. I am aware of e.g. Grisha Perelman, and I realize there is a continuum between idea and proof, not a sharp divide. Nevertheless, I stand by what I said.
The question I was trying to get at was whether it’s possible to have a collaboration between someone who’s come up with the idea for a proof and someone else who does a lot of the writing to make sure the intermediate steps are sound.
Oh, that’s certainly possible. But it’s more of a collaboration than I think a lot of people realize–if one person comes up with the key ideas and another fills in the details, then the first person has probably done the more impressive bit of the work. And if he did his work right, he’s done the more difficult bit in the sense that coming up with General Relativity is harder than digging ditches for twenty years. But (depending on the details), I would consider both of them genuine authors of the proof.
For context, I think a lot of PhD theses start with the thesis advisor saying something like, “Hey, you should work on this problem and use these tools, and talk to me when you’re struggling.” And the output of that is often single-authored by the grad student.
I would expect it to be a collaboration– if filling in all the steps were a mechanical process, computer programs could do it.
@Nancy Lebovitz
Writing a proof up really means writing it in a way that can be understood by somebody who is not intimately familiar with the creative work behind it.
Before a proof is published, the only people who are faimiliar with the creative work are typically its authors.
It is possible that a work is a collaboration of multiple people where one person comes up with the core idea of the proof and somebody else fills in most of the details, but you can’t completely separate the job of a “proof generator” to the job of a “proof writer”, because the effort that the “proof generator” would have to do to explain the proof to the “proof writer” would be approximately the same effort needed to write up the proof themself.
Some people are much better at verbal explanation than they are at writing, though.
Math is almost universally easier to think about on paper than verbally…
I agree with Anish. It’s possible to understand a subject well enough to see what arguments will work without them working out. But the MIRI folks have almost explicitly argued that they don’t, and that no one possibly can, and that that’s why you have to prove theorems about FAI rather than just writing one that seems right. They should have a higher burden for clean writeups than anyone else, really.
Grothendieck could get away with just saying “clearly this will work out” and making his disciples work out the details because he had established quite thoroughly that he was that good. But he was a huge exception, and basically founded in 1960 what’s probably the largest field of pure math today. And even then, people constantly make fun of him for it.
All recent “solid, trustable mathematical results” so far have been at least posted on arxiv and almost all published and peer-reviewed (the only exception I know of is Perelman’s celebrated proof of the Poincare conjecture, and he was already accomplished published author by then). So, how important? Essential.
Edit: To clarify, if you have a “solid, trustable mathematical result”, publishing it is only a small extra and is done as a matter of course.
I don’t know a lot about MIRI’s work but must one be especially pessimistic to accept your pessimistic model? The first stage is extremely difficult to crack and after a few years in a young field of inquiry, failing to progress too far beyond it might reflect little except that difficulty.
Still, the value of endorsements can be ephemeral, so published papers are important even disregarding any actual virtues of academic publication beyond the fact that it’s seen as a measure of respectability.
The time for excuses is over. Hopefully there will be a few papers posted on arxiv within a year and they attract some interest from unaffiliated mathematicians. If not, then whoever donates to MIRI should take a long hard look at them being a worthwhile charity.
How did you chose a year as the time limit?
While certainly as always there’s the problems of writing and rewriting (and waiting, goddamn journals take forever to respond), math doesn’t involve most of the problems above. Selecting journals, certainly. But since math research isn’t done in laboratories, I think co-authorship may be somewhat less political than in other fields. (Not at lot of experience here still, I’ll admit, but that bit certainly inspired a “Huh?” reaction to me. It sounds to me like one of those laboratory sorts of things I hear about in other fields.)
Anyway even if they don’t want to bother with journals for some reason I think su3su2u1 is right about “clean it up and put it on arXiv” being something of a minimum expectation, for the reasons that other commenters have already pointed out. (Although also as otehrs have pointed out, at that point they’d be most of the way towards submitting it somewhere; as I said above, my experience is that writing it and cleaning it up is the hard part, not red tape. Well, that and trying to figure out where to submit it.)
MIRI does recently seem though to be trying to get specifically logic people, or at least people who have read their existing logic-and-decision-theory work. So that seems like a good sign.
By the way, you misspelled “su3su2u1” where you initially linked eir Tumblr. 🙂 (The name is a reference to the standard model of particle physics, with its SU(3)xSU(2)xU(1) gauge symmetry group.)
Yeah, Scott shouldn’t shorten the name to Su3, but to su3 or SU3 (or SU(3)).
(Tumblr user su3su2su1 asserts)
(snark) Hey, don’t forget “social club for polyamorists”! Leaving aside head swinger Eliezer Yudkowsky, quite a number of other MIRI-associated people seem to be into that particular alternative lifestyle…
All we need to do now is mention a certain snakey creature, and we’ll have completed the trifecta of really easy ways to make Eliezer sound silly 🙂 (Which actually, now that I think about it, is a surprisingly common mode of attack for snarking at Less Wrong. Before reading such stuff I could never have imagined how clownish it’s possible to make him sound.)
Vulture: Preemptively mentioning a criticism such as the Basilisk and saying “well, of course that’s an easy and common criticism to make” doesn’t negate the substance of the criticism.
I was joking about those things because they aren’t really substantial criticisms, at least not the way they’re typically presented; they’re just overdone cheap shots, which can at best be steelmanned into a criticism of EY for leaving himself open to such shots. Engaging in low-status behaviors such as writing fanfiction or having multiple girlfriends doesn’t actually tell us much about the effectiveness of a research organization he is associated with, and invoking the basilisk tends to fall under that heading as well when it is simply another way of making Eliezer look like a nincompoop. I wasn’t trying to make a mockery of the serious issues raised by the whole basilisk debacle, although I see now how it could be read that way. Serves me right for trying to be flippant in this context, really.
The problem, is not engaging in low-status behavior in a nontrivial sense; the problem is not being professional. Writing fanfic is fine; mixing fanfic with your work is another story.
And a lot of this boils down to Bayseianism. People who engage in certain behaviors are less likely to produce good work. It’s not impossible, and there may be no causal relationship between the two things, but the odds are still against it.
>Preemptively mentioning a criticism such as the Basilisk and saying “well, of course that’s an easy and common criticism to make” doesn’t negate the substance of the criticism.
I’m pretty sure the lack of substance to the criticism does that.
Please make fewer comments like this in the future.
Could you specify what was wrong about his comment, for posters to avoid such comments in the future?
Snide references to a semi-public figure’s dating preferences are not part of civil discourse.
Ok, so let’s say that I do believe that intelligence explosion is a credible existential risk (in the interests of full disclosure, I personally do not believe this, but let’s pretend I do). However, there are other existential risks out there — nuclear war, pandemic, asteroid strike, etc. In addition, there are many non-existential dangers that are already active at this very moment — hunger, malaria, cancer, etc.
Let’s say that I have a limited amount of money. I want to donate it to a charity that has the highest expected value of lives saved per dollar spent. Why should I choose MIRI ?
One answer could be, “Because their goal is to save the world from total destruction, so the expected payoff is infinite !”. But by that logic, I would also donate money to a rock with “I stop intelligence explosions” written on it, so that can’t be right. Ok, so maybe the payoff is very large, but still finite. But in that case, how is MIRI better than NASA (or whoever it is that watches for asteroids), just to use one example ? More importantly, what algorithm can I use to determine the answer — specifically, the expected number of lives spent per dollar saved ?
If the answer is something along the lines of “it’s complicated, just trust us”, then I’d rather donate my money to someone who will spend it on anti-malaria nets. Because they work.
1. Well, depends how strongly you believe in AI risk. But if the theory behind intelligence explosion is right, and science keeps advancing, then it will happen. It’s not like nuclear war, where maybe there will be a war but maybe we’ll all be responsible and there won’t be, or an asteroid strike where we could get lucky and have no problems for the next 10,000 years. This is “any truth to this at all, and without some immediate action the chance of the world making it past 2150 could fit in a thimble.
2. Curing malaria without controlling intelligence explosion leads to the world being destroyed in 2050 and the malaria thing being a hollow victory. Controlling intelligence explosion without curing malaria leads to a superintelligence which can cure malaria as an afterthought. (this is kinda cheating, but true)
3. There are billions of dollars going to nuclear disarmament, the entire CDC trying to prevent pandemics, and big NASA programs looking for asteroids. The groups dealing with AI risk are…MIRI and FHI and maybe FLI. Probably a budget of a few million between all of them. On the principle of “marginal value of your dollar”, you’re doing better with the neglected field.
1. I am going to choose to interpret “it will happen” as, “there’s a very high probability of it happening”, and not as, “it will happen with total certainty”. Assuming this is correct, then the question is, “what is the probability that an UFAI will destroy everything before something else does ?” As far as I can tell from the rest of your post, you believe that the AI will destroy everything by 2050 (or possibly 2150), so the probability is quite high.
But in this case, donating my money to MIRI is one of the worst things I could do. MIRI is working on outreach, writing a few of scientific papers that are not widely read, and in general improving people’s rationality skills. And in mere 36 years, none of that is going to matter because we will all be eaten by gray goo. Instead of wasting time on outreach, MIRI should be working on stopping AI research across the world (until such research can be proven to be Friendly with a very high degree of certainty). If MIRI can’t get enough traction in 36 years to do this by conventional means, then it should start employing un-conventional means, such as sabotage and terrorism. Any collateral that could be caused by such methods is going to be insignificant compared to the Earth getting destroyed.
2. Isn’t this a generally applicable counterargument ? No matter what I choose to work on, you could always say, “Yes but the AI would do it better, so why bother”. The problem with this argument is that P(malaria cured) now becomes P(AI developed)*P(AI is Friendly)*P(AI can cure malaria); and meanwhile, I get to watch people die from malaria for 36 years. Whereas if I donate my money to an anti-malaria charity, they can immediately tell me, “every dollar you donate saves 0.035+-0.005 people”. So even if I believe that FAI will cure malaria, donating at least some of my money to the malaria charity may be a smart move.
3. Doesn’t this somewhat contradict your point 2 ? Before, you were arguing that donating my money to MIRI was the right thing to do because the AI will solve all these problems auto-magically; so working on anything but FAI is pointless. But now, you’re saying that it’s the right thing to do because someone else is already working on these other problems, somehow implying that their work is still meaningful. It’s possible that I am misunderstanding your point, though.
I find this sentence almost self-contradictory. MIRI does not have the power to stop AI research throughout the world. Assuming that this strategy has a higher expectated value than trying to build a FAI (which I agree with you seems plausible) then its best bet is to publicize the risks of AI as much as possible by networking, convincing influential people, making their ideas about possible future scenarios and their risks better known to key researchers and policymakers… in other words, outreach.
I agree with you in principle, but do you believe that such outreach could lead to either a). FAI being developed, or b). all AI research getting stopped, in the next 36 years ? Because if the answer is “no”, then I might as well spend all my money on earthly delights, since it doesn’t matter anyway because we’re all doomed.
If the answer is “yes”, then we need some way to measure whether MIRI is implementing outreach successfully. That is, if I spend one dollar on MIRI, how much x-risk reduction does that buy ? I will grant you that “number of academic citations” and “number of peer-reviewed papers” may not be good yardsticks, but what is ? A metric such as “the number of famous people who name-drop MIRI” seems a little weak.
One potentially stronger metric might be, “the number of AI research departments that were closed down because of MIRI’s influence”, or “the number of academic papers in AI that were censored because of MIRI”, but I’m not sure how to measure that. Another one might be “he number of anti-AI research laws passed by senators who were lobbied by MIRI”, but as you said, they don’t have nearly enough money for that.
It might result in people being cautious enough not to develop autonomous AGI with a stupid utility function.
Yeah, if you really think AI is coming to wipe us out in 2050, it’s time to go full Sarah Connor. Sending some money to MIRI isn’t going to help.
Only if you think you can singlehandedly kill all the AI researchers in the world, before you yourself are killed.
On the other hand, if you can successfully invent proveable friendliness, any AI researcher about to turn an AI on will probably be happy to use it, and no one will be trying to murder you.
The argument gets a little more disturbing when you realize the closest real-world equivalent to Sarah Connor is Ted Kaczynski.
Instead of wasting time on outreach, MIRI should be working on stopping AI research across the world (until such research can be proven to be Friendly with a very high degree of certainty).
These are not mutually exclusive: successful outreach can lead to others restricting AI research. There’s at least one paper published in a law journal that proposes regulating AI due to existential risks and which cites MIRI’s work.
1. x-risk in general is a good investment, because ‘where there’s life, there’s hope’. This is a better argument the more optimistic you are that social and technological progress will improve human welfare given enough time. E.g., GiveWell thinks that scientific and economic progress will tend to better people’s lives over time, which suggests that in the long run most human welfare depends on whether we can preserve human civilization, not on short-term fluctuations in wealth or happiness, however important in their own right. This doesn’t depend on considering low-probability possibilities; Pascalian arguments are fallacious because the scenarios they posit are low-probability, not because the scenarios they posit are high-value.
2. If you solve the asteroid problem, you still have to worry about the AI problem. If you solve the AI problem, you can let the AI solve the asteroid problem for you. AI looks like the only x-risk that has this property.
3. AI risk is more neglected than catastrophic risks like climate change, impact events, nuclear war.
4. AI risk is more novel and unprecedented than most other x-risks. That means looking into it has unusually high VOI. Our general picture of the landscape of risks, and the landscape of open problems, is likely to change dramatically as we start exploring, but we don’t know in advance whether the problems are (say) a lot harder than they superficially look, or a lot easier.
5. If you think intelligence explosion is likely, you should also think superintelligent AI will arrive relatively suddenly if it arrives at all. The difficulty of forecasting AI makes it riskier to delay basic research. Asteroids are relatively easy to forecast, not just in that we can detect and track many individual asteroids but in that we can measure the frequency with which asteroids of a given size strike the Earth.
6. It’s not clear that there’s any general technical solution to the problem of bio- and nano-weaponry as such. Offense may just automatically trump defense in this area. (There may be political and regulatory solutions, of course.) In contrast, there should be a general technical solution to ‘Unfriendly AI’ — Friendly AI is at least possible, leaving open whether it’s feasible and whether it’s the easiest technical solution. So if you think technical solutions are generally easier and more durable than political ones, you should be more optimistic that AI safety will turn out to be tractable than that e.g. nanoweapon safety will.
My comments above already address some of your points, but here are some additions:
2. Time is a factor here. If I don’t solve the asteroid problem in time, and the asteroid kills me, then it won’t matter how awesome the AI could’ve been.
4. If this is true, and AI is an open problem that is poorly explored, then how can you simultaneously believe that the AI will destroy the world by 2050 unless something is done ? As I said, I am perfectly willing to assume that your prediction is true, but then, I cannot simultaneously believe that the field is wide open, because this would greatly reduce our confidence in such predictions.
6. Doesn’t this contradict your point (2) ? If there’s no general technical solution to bio- and nano-weaponry, then it is unlikely that the AI would be able to solve it by technical means… so it would still make sense to donate at least some of my money to charities other than MIRI.
2) Time is also a factor in AI risk: if you don’t solve the AI problem in time, it doesn’t matter if you’ve solved the asteroid problem. Time would only be a relevant consideration if we could say that an asteroid impact could occur at any point, while we will have time to solve that risk and then pivot to AI risk. But we cannot say this, because nobody has any solid idea when AI will arrive, and nobody has any solid idea how long it will take to prepare. (e.g. one survey of experts found a 10% confidence average date of 2028. (!!!))
4) No one (in MIRI) maintains that AI will occur by any particular date. Here is MIRI’s most relevant public writing. (Scott mentioned 2050 as an example date, not as a definite prediction.)
6) I assume Rob meant there is no general non-singleton solution. A non-AI singleton (e.g. a 1984-esque dictatorship) would probably be able to solve bio/nano-weapons. Establishing a world-wide dictatorship seems like an unusual inefficient, and improbable charity, however.
2,4: Ok, but in this case, my original point regains validity. If we currently have no idea when (if at all) the AI will destroy us all, then it make more sense to invest most of our money into preventing something else that has a better chance of destroying us all before the AI does. Or, in other words, if we plot the probability of each event killing us all along the time axis, then we should invest into the most likely candidates (or maybe spread our money among them using some algorithm that takes this probability curve into account). It makes no sense to say, “AI will happen eventually and kill us all, so we should focus on it exclusively”, because the same is true of any other x-threat.
6: “Unusual, inefficient, and improbable” is pretty much how most people would think of MIRI, if they were aware of its existence, so that’s not a good heuristic. If I believed that a bio- or nano-war was imminent, I would be a lot more receptive to that whole dictatorship thing.
2/4:
“If we currently have no idea when (if at all) the AI will destroy us all”
This, and the rest of your point 2/4, conflates knowledge about when AI will occur with knowledge about whether an AI will occur.
(It’s also worth mentioning that, on the timescale that any of this is relevant, the chance of an asteroid impact is miniscule and the chance of WMDs being an existential risk is low-medium but not negligible.)
6:
To clarify, are you arguing that a non-profit dedicated to establishing a worldwide dictatorship would be a more effective use of funds than MIRI? This reads like an argument by analogy for MIRI, though one that I do not endorse- what if you knew that a bio- or nano-war would occur between 15-150 years in the future, and it would take a long but unknown amount of time to go from where you are today to setting up a worldwide dictatorship? I’m think I have failed to understand what you’re saying- how does this lead to ‘…and so you shouldn’t donate to MIRI.’
Aren’t these basically the same thing, once you begin thinking about probabilities ? That is, what is the probability that (barring MIRI’s intervention) the AI will destroy the world 10 years from now ? 100 years from now ? 1,000 years from now ? If the answers are something like “99% in 100 years”, that’s the same as saying, “I know that the AI will end the world in 100 years, if not earlier”. If your answer is, “0.0001% in 100,000 years”, then that’s the same as saying, “we don’t need to worry about AI risk at all (for now)”.
Regarding the worldwide dictatorship, if I believed that an x-risk (of any kind) was imminent; and that such a dictatorship was the most efficient way of averting it; then I’d support the dictatorship. Obviously that’s a lot of “ifs”, but if my choice is between slavery or total annihilation of all mankind, slavery is probably better…
Suppose you’re Leonardo da Vinci. You know with close to 100% probability that a heavier than air flying machine is possible- birds are an example of such a machine. When should you expect such a machine to be built? 400 years is the right answer; 4000 years is not obviously wrong, and 40 years also seems plausible. Certainly, there’s no way he could predict the decade it would occur in, which is what would be required by your argument.
Wait what ? Why do I need to predict the exact decade ? All I need to do is estimate which x-risk has the higher probability to kill us all by a certain date.
For example, if I believe that Global Thermonuclear War is 90% likely to call us by 2150, but the Singularity is only 10% likely to kill us by then, then I should invest in preventing Global Thermonuclear War. Or, if I wanted to diversify a bit, I’d split my money between the risks based on the probabilities.
I don’t need to know exactly when which risk will occur; I just need to know which risk is more urgent.
2. Yes. For example, impactors as big as the one that killed the non-theropod dinosaurs occur once every few tens of millions of years. We should focus first on x-risks on a timescale of decades or centuries, then on a timescale of millennia. When those are taken care of, we can worry about impact events and other x-risks on a scale of millions of years.
4. Scott used the date ‘2050’ to make his example more vivid, and because it’s in the range of dates experts think AGI could arise. MIRI-associated people don’t assert ‘we’ll have AGI by 2050 for sure’. MIRI people tend to be more skeptical than the top-cited AI experts (at least, the ones who tend to answer surveys on this topic) that we’ll have AGI this century, though most people agree that’s a realistic possibility.
6. AGI may be useful for finding a good political / social-engineering-based solution to nanotech or biotech, if there’s no non-political solution; e.g., ‘design useful institutions and policies for identifying information hazards in scientific literature’. (Of course, if you think that’s relatively easy to do in the short term, you may want to work on that directly rather than delegating it to an AI.)
I was going to say, “ok, but it’s not like there’s some sort of a cosmic cooldown timer that fires asteroids at us every couple million years”, but actually that might turn out to be exactly the case, given how celestial mechanics works. Still, that probably isn’t the case with other x-threats, such as gamma-ray bursts or pandemics. Just because an event is so rare that it only occurs once every million years, doesn’t guarantee that it won’t occur next year; all it does guarantee is that the probability of it happening next year is one in a million.
Here’s a meta-heuristic that might help you decide where to put your marginal amount of worry/donations:
1: Look at a field and see how much people who know about it worry.
For instance, when it comes to nuclear energy, the more people know about it, the less they worry and the only ones who are panicking know nothing at all about nuclear safety. Climate change on the other hand is the reverse; the more expert people get in the field, the more they worry. Odds are that climate change is scarier than nuclear power stations.
2: How many people are already worrying about the field?
When it comes to climate change and asteroids, there are a lot of hours already going into fixing it, or at least figuring out what is going on. My contribution would be vanishingly small.
When it comes to AI as an existential risk, we seem to have some very worried people who know a lot about it and they are few, so my contribution would actually matter.
Another thing to consider is of course outright fraud. If these people are only pretending to worry in order to get my money, this would make my contribution pointless. Now, if MIRI is running a scam on the entire world in order to get donations and end up with a yearly budget of around a million dollars, they are so incredibly bad at it that I doubt it is even possible, so they are probably not fraudulent.
There may be other fields that are even more scary and with even fewer people worrying, but I don’t know about them, so I can hardly contribute.
That is certainly not the only other thing to consider. There is a huge gap between “trust this guy and give him all your money” and “this guy is a shameless scammer”, and it’s filled with motivated cognition and various boring failure modes.
Consider another field; that of Conspiracy Theories. I’m pretty certain that your average Joe in the street is unworried that every Jewish person in the world is secretly a reptile with mind control powers and an interest in forcing you to receive government-funded healthcare (I don’t know much about these conspiracy theories, so I hope the details don’t detract from the point too much)
But the sort of people who post on conspiracy theory message boards are extremely well-informed and extremely worried about the lizard-men. The people who have the most knowledge are the people who are most extreme in their worries, which fulfils your first criteria. Additionally, they are a small group (so your contribution would go further).
Therefore any argument used to support MIRI based on the fact they are experts and worried could also be used to support any number of conspiracy theories, unless we can distinguish between ‘genuine’ expertise (possessed by climate scientists and nuclear researchers) and ‘pseudo’ expertise (possessed by conspiracy theorists).
The metric of citations seems like a reasonable proxy for ‘genuine’ expertise, since it is a metric which (more or less) forces an accepted and recognised ‘genuine’ expert to put their reputation on the line certifying the research of another person as ‘genuine’. It would be possible to get a situation where a whole bunch of ‘pseudo’ experts colluded to get nonsense published, but I don’t think that is a worry in this particular field, where it is very difficult to fake expertise.
That was a rather valid and amusing observation, thanks.
I have used a criterion for filtering out the ideas that are apparently completely void of plausibility, but I’ll make it explicit in the future.
Yeah, better to keep an eye on that absurdity heursitic…
I agree with the concern about offloading your evaluations onto experts, but
I doubt this field is much more resistant than hard chemistry, which has a serious literature problem, from journals that would accept almost anything to outright citation pumping (look through the “Dark Side” tag for more). It’s possible that hard computer science, math or philosophy is more resistant, but there’s been more than a decent share of bizarrely long-lasting fraud there, too. I’ve seen published papers in the image analysis field of CompSci that couldn’t possibly do what their author claimed, and the SCIGen affair’s pretty recent in memory, and that’s often about as low-cost a replication as it gets.
I’m hard-pressed to think of a better solution, but I’m also skeptical of how much evaluation offloading most Bayesians do, so there probably are better solutions still.
Nah, the Jews aren’t allegedly mind-controlling reptilians. (There’s a certain family resemblance to e.g. the Protocols of the Elders of Zion, but I think that’s just because all conspiracy theories of the form “the world has hidden masters” look the same at some level.)
The British Royal Family, on the other hand, is. And now you know!
It’s not just similar to the Protocols. Icke says that they’re real — just written by Reptilians.
From this and a lot of other things, a lot of people think that Icke’s “Reptilians” are a code word for Jews, but a Canadian court decided that, no, he really means exactly what he says. In part because he does give so many examples, like the one you mention.
Or well-intentioned crackpottery.
Which charity do you recommend if I judge “nuclear war, pandemic, asteroid strike, etc” as more immediately dangerous than an AI intelligence explosion?
If you don’t have such a charity to recommend, then your objection about those others types of existential risk seems insincere, a mere rhetorical device to distract people into inaction.
If you do have such a charity to recommend, then I’ll try to judge the marginal value that each of my dollars will provide, given the current budget of the charities focused on that risk.
Not a charity, but the work of SpaceX (to make humanity a multiplanetary species) should help mitigate the risks you named, although as Elon Musk has explicitly acknowledged it wouldn’t help against an Intelligence Explosion.
So maybe help SpaceX in some fashion. Donations to them won’t be tax-deductible, but maybe you can do some work for them or lobby your representative to propose law changes that make private spaceflight easier/cheaper, or something like that.
I’m disturbed by the number of people who claim that people learn about mistakes writing up their papers. Maybe this is common among people who don’t understand what they’re talking about but just glue together lemmas (a large portion of professionals), but I have never seen someone capable of generating interesting results have them fall apart in write-up. I have seen many fall apart years after publication.
Note that standards differ between fields. In CS, people mainly publish announcements and sketches. If you think write-ups are so important, do you think CS theory is a complete shambles? Do you hold MIRI to standards outside the field?
To be fair, it doesn’t seem like much of the stuff MIRI has produced thus far really falls strictly into the field of Computer Science. (Disclaimer: my understanding of the distinct boundary between Theoretical CS and, like, Mathematical Logic and stuff is basically nil.)
Yes, the boundary is pretty murky. Yes, some of their work is clearly logic and clearly not CS. But some of it, like TDT, is definitely in, by very arbitrary precedent.
In my own case — haven’t seen results fall apart in write up (not that I’ve a lot to my name so far); have certainly had proofs turn out to be more complicated than initially expected because I missed something.
I was at a conference where a conversation broke out over drinks about the “proof that got away” i.e. a promising looking proof that fell apart or was dramatically weakened by something subtle that was noticed while writing it up for publication. Every single researcher there had at least one such story, most of the more famous researchers had dozens of such stories (probably they worked on a lot more stuff in general, which lead to more successes and more failures).
The field was mathematics, with a decent overlap between some of the stuff MIRI works on.
Do you think the prominent researchers might have also had sufficient status that they could tell embarrassing anecdotes with impunity?
It’s one thing to have an idea in the shower and it not work out, it’s another to announce a result, give talks on it, and then have it fall apart. I have seen that happen many times, but the problem is always pointed out by the audience, not discovered in write-up.
I’ve so rarely seen a talk on material that wasn’t already written up that I’m not sure your claim would cause me to update in any direction. At least in my field, you don’t give talks about stuff before it’s at least mostly written up because otherwise you don’t know if the details will cash out.
Now, if it’s important lots of people will also look over it as soon as you post it, and that’s a really good second line of defense. But there’s huge gap between “I’m pretty sure this will work out if I write it up” and actually writing it up and having it work out.
I agree with Jadagul that you are describing an unusual premise (announcing and giving talks on results that you haven’t already written up) and so are not presenting evidence for much.
I’m trying to decide whether the story about Wiles’s proof of Fermat’s Last Theorem supports you or me on the narrow point. He gave the three talks in June 1993, wrote it up as a manuscript, and Katz apparently helped him find the gap in the proof asking questions about the manuscript. Took him a year and a half to plug the hole.
On the other hand, that hole never would have been found if he hadn’t written the result up. You don’t have a result until you have a manuscript.
I’m not sure of the details, but the two months from announcement to error being caught in peer review suggests that he already had a manuscript at announcement.
I think most errors are found as a result of outsiders trying to understand the result. The existence of a manuscript certainly makes outsiders more willing to try.
I think CS as done by computer scientists is a complete shambles yes. I will hold MIRI to the standards of mathematics if you want me to take it seriously.
Sorry to badger you, but I asked about CS theory and you dropped that word. This is a field of math that uses CS publication standards. Do you think it is a shambles? Do you think it is a shambles because of the publication system?
“Maybe this is common among people who don’t understand what they’re talking about”
You are wrong. I have seen even published results by very strong authors contain important bugs. This is very common. In fact so common that I am forced to ask — who is it that you know for whom it doesn’t happen?
For example a number of papers by Pearl have bugs in them. Does Pearl not know what he is talking about? Math is just a hard business.
I specifically mentioned errors discovered after publication. Yes, errors are endemic. But they aren’t discovered by the process of writing them up after announcement and talks.
I don’t follow you. If you agree that errors are endemic, and you agree they are often discovered after publication, why do you think people don’t also catch errors while writing things up? I assure you, this happens all the time. I find myself in an odd position of arguing with someone who is telling me exactly when I (or colleagues of mine) do or do not discover problems with a paper. Or maybe the conjecture is we don’t know what we are talking about and just glue lemmas together? I suppose that’s fair.
Jadagul and Sniffnoy say that MIRI’s announcing and informally writing up results is not done. They then proceeded to confabulate reasons why it is not done. Do you claim that it is not done, or do you claim that such announcements are often retracted?
You mentioned Voevodsky. He is an example of someone who announces before writing up.
I didn’t say that informally writing things up isn’t done. I said that, in my experience of my field, until you have a formal writeup, you don’t have a result; you have work towards a result. Almost every talk I’ve ever been to has referred to a paper that is at least posted to the ArXiv. Because that’s what you _do with papers.
Elsewhere in these comments Eliezer talks about Armstrong writing up white papers but not actually publishing. If these white papers are formal writeups, I don’t actually care where or whether they’ve been journal-published; at least they’re out there for people to evaluate. But the writeup has to exist, because the result is the proof and the proof is the writeup.
Now, I will happily concede that standards vary from field to field. My applied-physics friends, for instance, are utterly horrified by the idea of posting a draft paper anywhere before it’s been accepted for publication; I do think they’ll talk about their work that hasn’t been published yet, although very reticently lest they be scooped. Of course, for them the writeup isn’t the same as the work.
I have no idea what the standards in CS publication are like. And I don’t know what your field is, exactly, much less what the standards are in it. But I do know that the statement “we have a result, we just haven’t written it up yet” instantly makes me suspicious. (The number of times during my grad school career that I said that–about the exact same result–is kind of depressing).
Again, I don’t particularly care about formal publication of MIRI’s work–it’s a nice imprimatur, but it usually comes well after everyone who cares has actually read and evaluated the paper. But if it’s supposed to be a theorem, they should write it up properly. And post it to the ArXiv or something, where people can read it and judge it and cite it. Because that’s what you do with math work.
Are these of any relevance?
((I recognize that this may be a stupid question, and genuinely do not know the answer. I’ve got an anti-academic streak a mile wide, so the general ‘raising the sanity waterline’ usually keeps my interest far more than this stuff.))
Gattsuru: They might be? I’m tempted to go read some of those papers to see what’s in them, but that’s primarily because I have a terrible procrastination habit and there’s a bunch of work I should be doing right now. It’s not in my field, so I’m not the best person to read them.
But one of two things is true. Either those papers are more or less finished writeups, and they should be posted to the ArXiv or somewhere where other mathematicians will read them and can cite them. Or they’re not really finished, and then, well, they’re not really finished.
Some more examples in this talk:
http://www.math.ias.edu/~vladimir/Site3/Univalent_Foundations_files/2014_IAS.pdf
Bugs in proofs happen so often that this fine gentleman basically completely changed his research focus (into automated proofs/assistants).
Beware publication/reputation bias: if a study has a serious flaw that it is found during the writeup, then it is unlikely that it will ever be published at all, at least not before additional major creative effort is done, and the authors will be also probably reclutant to talk about it.
In the interests of making all evidence available: it isn’t necessarily readily visible from their website, but MIRI also helped a guy with his honors thesis, which neatly wrote up TDT and UDT and talked about their advantages over traditional decision theories and stuff.
Scott, if MIRI doesn’t make an important breakthrough in the next five years, would that be enough for you to withdraw your support for them? If not, what would be enough? Hard to not think you’re biased given that these are your friends. If you’d specify your minimum expectations clearly, that might be helpful for everyone. That way, you’ll have a line in the sand to save you if it turns out MIRI have been tricking you, unintentionally or otherwise.
I like the idea of MIRI. But I don’t at all trust recommendations of quality by one friend for another, and that’s almost all I ever see supporting the organization. When I look at the actual writings of MIRI, I am not really impressed. It’s not necessarily that their work is trivial, but that it doesn’t fulfill the giant promises or expectations they establish when writing about how AI risk must be fought. In this sense I sympathize with the commenter who mentioned malaria nets. I would trust MIRI to debug my computer, but not to save the world.
One thing that bothers me, specifically, is that what little research MIRI has is much more about AI development in general rather than FAI specifically. They should be doing much much much much much much much more work on human psychology and values. The concept of coherent extrapolated value, specifically, is not well presented, even though it’s the only real proposal for FAI they have. It is always handwaved around, never actually elaborated on. Nothing close to even a mere beginning for CEV exists yet. Personally, I am skeptical it is even possible. Humans don’t seem to have any underlying consistency to their preferences, and even the degree and type of their inconsistency varies by circumstance, as shown in behavioral economics literature.
In addition, I think that approaches to AI other than Friendliness have more merit than folks like Yudkowsky assert, as supplementing strategies if nothing else. MIRI people exclude other routes to safety and claim it’s because we should focus on Friendliness, and then turn around and fail to produce any useful material on Friendliness. It is very suspicious to me that the concept is mostly focused on during fundraising. Outside view says this is PR or worse, please give outside view a good listen given your emotional closeness.
I agree that AI risk awareness is much more common now than it was. I wish you’d not jump to the assumption that MIRI caused it, however. You acknowledge that this assumption is problematic in your post, but then proceed to make it anyway, reasoning by analogy to the DNC rather than listing potentially relevant factors and trying to give them due consideration. While I do find it plausible that MIRI caused the increase in AI risk awareness, I can also think of many other plausible explanations. The mere plausibility that their past actions were good is not sufficient to garner my support for what they might do in the future. Nor should mere plausibility be sufficient for your own support. This is too important to avoid maximizing the odds on.
Overall, I would be much more comfortable with AI safety research if credible alternatives to MIRI existed, given these problems I perceive. The Future of Humanity Institute is a good start. I hope more such groups arise soon. If that is MIRI’s final legacy, it will be an excellent one.
Correct me if I’m wrong, but I think some of their current research is focused on goal-stability. Granted, as you say, that has no relation to what the goal is, but it is a problem needing solving for FAI (and less so for AI in general). CEV, or whatever they decide to replace it with, is probably a much harder problem that they’re just not equipped to solve at the moment.
I know for a fact MIRI were the ones who got Peter Thiel and Jaan Tallinn interested in AI risk. Tallinn played a really big role in starting CSER and FLI.
I know Bostrom and Eliezer were on the same mailing list as early as 1996, but I don’t know which one influenced the other or whether they were both influenced by the same tradition.
There’s all this prehistory out there I know nothing about, and it’s hard to trace who did what. Some day I should look into it.
Are you able to say more about how you know MIRI caused Thiel to become interested in AI x-risk?
I think at this point quibbling over specific goals is trying to run before you can walk, or arguing over what sort of fancy fireball effects your MMORPG should have before you’ve invented the transistor.
I think you’re right that other methods besides CEV may prove more useful, but whatever methods prove useful you have to understand basic things like how to maintain goal stability before you can implement them. I think their current research project gives them time to see what happens with the tough philosophical problems that they’re in no position to solve anyway.
I also think that if they want respect and support from the rest of the world, it’s better to be talking about Lobian self-reference than about how superintelligent machines should govern.
Goal stability is something relevant to FAI they’ve started work on. But what is there relevant to FAI that they’ve already published, other than broad overviews?
You mention that MIRI has no basis at present for beginning work on CEV or FAI, it is too tough a problem. But if CEV is so difficult a problem to work on, why assume it is solvable at all, let alone that MIRI will be the ones to solve it? To the extent CEV is difficult, we should expect MIRI to fail; to the extent CEV is easy, we should be disappointed with their work on it so far. That sounds kind of unfair, but I think it is nonetheless true. These are the sort of situations you end up with when you aim at impossible problems.
The real test will be what they do in the future, since they are claiming to shift from promotion to research, and it is understandable a promotion oriented group wouldn’t do much research on CEV (though note that this defense requires admitting there’s no empirical evidence of MIRI’s research prowess). If they succeed in their research, I will retract all my claims against them. But if they fail, I hope their supporters will retract their own claims in turn. Given the social connections involved between MIRI and their supporters, I’m worried this wouldn’t be the result.
I edited the above comment a bunch in a row without knowing you were itt, sorry if that made writing a reply difficult for you. I’m done editing both that one and this now, promise.
No one but you said that ” MIRI has no basis at present for beginning work on CEV or FAI, it is too tough a problem.” That is not the case. What is the case is this: MIRI considers CEV a plausible but shaky approach to framing the proper goal system for an FAI, and would prefer to delay work on that problem until relevant philosophy is worked out better (chiefly by FHI, IIRC). Goal stability is useful and necessary if CEV is correct, but is also useful and necessary if CEV is flawed, and is itself a hard problem. Additionally, MIRI is better equipped (in terms of comparative advantage, at least) to work on the logic/CS theory problem of goal stability than the logic/philosophy problem of CEV.
Also, the whole point of FAI research is that, while it’s true that “To the extent CEV is difficult, we should expect MIRI to fail”, failure is so catastrophic that even if failure is near-certain, a small chance of nonfailure is still worthwhile, because failure will result in gigadeaths and the probable end of the human race.
While I agree it’s worth spending all or all minus epsilon of our efforts on averting extinction, there are other potential options besides using MIRI or CEV. If MIRI does not offer the best chance of avoiding extinction, it should not get any money until we’ve invested sufficiently in all the better chances.
To some extent I combined Scott and Sniffnoy’s position when I summarized them as admitting “MIRI has no basis for beginning work on CEV or FAI”. However, I don’t think this was inaccurate. Scott described CEV and FAI as two “tough philosophical problems that they’re in no position to solve anyway”. Seems very close to what I said. I’m frustrated you accused me of misattribution when I didn’t do it.
Goal stability sounds good to me. I don’t dispute that it’s something that should be worked on. But MIRI hasn’t worked on or completed successfully anything similarly useful to FAI in the past. Is there any compelling reason I should believe they’ll figure out even this one idea successfully, let alone others? Having smart people on a team isn’t sufficient to solve whatever problems you want automatically.
If MIRI is better equipped to solve the problems of logic and CS theory than the problems of psychology or philosophy or human values, they have equipped themselves poorly, given that they are supposed to be making an FAI. An FAI that doesn’t understand psychology or human values is essentially a contradiction in terms.
Psychology and philosophy are uniquely important to an FAI, while other sorts of research risk misapplication to bad AIs and so should be delayed until we’ve got a better understanding of human values. Some such research will be necessary to FAI development and so shouldn’t be delayed. But an overall focus on psychology seems wisest. Thus, I’m concerned to see all of their work is about computing problems, rather than ethical ones.
It’s not a fact that you have to have goal stability, it’s a theory of MIRIs. It has the implication that you have to get something 100% right first time, which sounds worrying to me. If something can be kept malleable, it should be,
MIRI & co. have arguments that AI goals cannot be kept malleable. Basically, Omohundro’s argument (pdf) about universal instrumental values, including goal stability as one such. I think the argument assumes too much (VNM utility, etc.), but if you agree it seems incumbent on us to address the argument, then plead for goal malleability.
Omohudros argument is about the convergence of instrumental goals, which will supposedly happen under any set of terminal goals. It doesn’t require terminal goals themselves to be stable,
Goal stability itself is a convergent instrumental goal: whatever your goal is, you probably won’t achieve it as well if you change to something else.
MIRI is researching this because an AI could (accidentally) change it’s goal set before inventing goal stability, and the outcome of this would be very hard to predict.
MIRI people exclude other routes to safety and claim it’s because we should focus on Friendliness
From a paper on MIRI’s website, surveying different proposals for dealing with AI risk:
In the hopes of fostering further debate, we also highlight some of the proposals that we consider the most promising. In the medium term, these are regulation (section 3.3), merging with machines (section 3.4), AGI confinement (section 4.1), Oracle AI (section 5.1), and motivational weaknesses (section 5.6). In the long term, the most promising approaches seem to be value learning (section 5.2.5) and human-like architectures (section 5.3.4).
If your organization follows up on some of those alternate proposals with useful research, I will be very happy. They haven’t done that yet, however. Simply mentioning ideas to promote debate is different than doing hard research. I am very interested to see what sort of work gets done now that your focus has changed.
That essay’s contents contradicted several of my prior beliefs about MIRI’s approach to AI risk. Thank you for the interesting evidence. But to what extent does your publication represent the views and practices of MIRI as a whole? It’s the practices I’m most interested in.
Updating towards MIRI being good. While I still think that human psychology needs to become a big focus of your organization, your plans are apparently better targeted than I thought. Seeing that MIRI doesn’t focus only on CEV and indeed is skeptical of it is encouraging.
Good job on the outreach, providing me with that link and cowriting that article.
Oh, I thought that by “exclude other routes to safety” you meant “consider other routes worthless” as opposed to “don’t work on other routes”. I gave the link more to indicate that there are indeed a variety of opinions held by people associated with MIRI, rather than as an indication of what research is currently being pursued.
There are a number of routes that could have potential, but MIRI is currently focusing on the ones that they think they’re in the best position to pursue. As mentioned on this page MIRI’s current research agenda is focused on “tiling agents, logical uncertainty, logical decision theories, corrigibility, and value learning”.
The report reflects most strongly my own views, though a number of MIRI-folk were involved in its writing and contributed feedback. There were some things that some people expressed disagreed on (I don’t remember which), but nobody who read the document expressed major disagreement with the overall conclusions that I can recall. Of course, this doesn’t indicate that there was no major disagreement, just that nobody bothered to express it. And not everyone at MIRI read the report, e.g. Eliezer didn’t.
I’m personally no longer on MIRI’s payroll, mostly due to a number of personal reasons, though I’m still associated with them as a Research Associate and privy to some (though by no means all, or necessarily even most) of their internal research discussions.
I did mean that, as well as the other. You changed my mind on the one point. My previous impressions of MIRI were more impressions of Yudkowsky than the entire organization. So thank you.
Glad I could be of use. 🙂
How do you judge “an important breakthrough”? Some say they have already made some.
This is somewhat orthogonal to the exact topic of this post and the questions of MIRI’s institutional credibility vis-a-vis publications but this seems to be overlooked in most discussions of AI so I’m going to bring it up.
Whenever people talk about the potential future of AI they talk about the work of mathematicians and CS theory folks, important people doing important work to be sure but this conversation often leaves out a set of really important considerations. We can have all the awesome theory and algorithms in the world but without hardware to run them its mostly for naught. If hardware is considered its generally a blind invocation of Moore’s Law and not much beyond that. Moore’s Law was an incredibly prescient observation (although there is a fair question of how much it became prescriptive rather than descriptive) for 40 years but for a bit under 10 years now its been increasingly irrelevant within microarchitecture (my field).
I used to write long rants about how Moore’s law is over but James Micken’s piece in usenix is much better written and funnier than my rant so I’ll just link it:
https://www.usenix.org/system/files/1309_14-17_mickens.pdf
There are a couple key takeaways from that, we’ve spent 30 years picking the low hanging, and not-so-low hanging fruit and at this point getting 10-20% speedups without adding too many transistors is an achievement. While we can keep shrinking and adding transistors but given leakage and the lack of voltage scaling we can’t really afford them. Many of the major obstacles in modern microarchitecture design can’t readily be solved by throwing transistors at it, the memory wall (caches can help but caches are huge consumers of static power), interconnection bandwidth (mostly a function of pin scaling with scales at ~10% per year), transistor reliability and variance, and wire latencies are all really hard problems in CMOS technology and many are non-trivial in alternative technologies.
This is not to say its hopeless, CMOS is just one technology but after 50 years its reaching its limits and there aren’t obvious replacement technologies ready for large scale integration now and most of the promising ones suffer from at least one of the big unsolved issues above. There is some potential in accelerators or more special purpose hardware (think GPUs) but mapping complex algorithms into accelerators is non-trivial and its not clear if AI applications will become widely used enough to amortize the high cost of custom ASIC design and fabrication. Large datacenters like Google’s also have potential but that limits these computations to at best a couple thousand data centers world wide.
The great transhumanist future may happen, I’m not arrogant enough to think I can predict the direction of human progress or see the bounds of innovation but the entire discussion of AI superintelligence strikes me as putting the cart a great distance in front of the horse.
According to Nick Bostrom’s theory of astronomical waste (which is technically about space colonization but is applicable to AI), we should be working not to minimize the wait until the Really Good Future arrives, but to maximize the probability that the Really Good Future will happen at all. If computing hardware much more powerful than what we currently have doesn’t arrive for a long time, then that’s good from an AI-existential-risk perspective, because during that time the world is safe from destruction by an un-Friendly AI, and in the meantime we’d have lots of time to figure out the right way to proceed for when we do gain the hardware technology to build an AGI.
@Ben — A big +1.
And that essay has my coworkers wondering why I just burst out laughing.
As far as I know, there’s no consensus that superintelligent AI requires hardware significantly more advanced than we have now.
Yes, but this basically means, “People who have no working model of what super intelligence might look like have no idea what kind of hardware it might need.”
Which, true, but hardly exciting.
I think it is highly probable that if Einstein or Da Vinci can run on human brains then computers which do many more calculations per second have the capacity for more intelligence than them. If you’re willing to consider a computer with human genius level IQ a superintelligence, then improved hardware technology is clearly unnecessary.
Well, no. That is not “superintelligence.” There is little danger an einstein level brain will conquer and enslave the human species.
Consider this: there was this guy a few years back who suggested that some deep questions of physics could be understood in terms of some of the larger Finite Simple Groups — I cannot find a reference to his stuff. It was a bit “fringe.” But let’s pretend that he is correct.
Now, imagine a mind that could effortlessly compute with these larger groups, like directly in its “mind’s eye,” the way we compute with small integers. Imagine if it could hold the monster group, as one thing, in its mind and play with it.
What deep truths would it discover?
I do a lot of linear algebra — mostly optimization theory. Most of the theorems I come to understand because I can picture them in three dimensions. Once I have that, a clear picture, I generalize to the higher dimensions. This works pretty well, most of the time. But I miss complexity. There are facts that are not obvious, such as how rotation is very different in 4+ dimensions, compared to 3. (Which is why we have a “nice” cross product for 3 dimensions, but not 4+.)
Some facts I can learn, hold, and understand easily, because they “fit well” in my brain. For others, I need the symbolic proofs, which for me are cognitively challenging.
There is a difficulty here that is baked deep into math, a tension between what our intuition can do and what the painstaking manipulation of symbols can do.
There is a theory that mathematical intuition is largely visual. For me that is the case — I seek “the geometry” of a problem. But when the geometry fails, and I am back to symbols, it almost degrades to exhaustive search. (Yes, I prune.)
Here is the tough part:
Direct visual-cortex-style higher dimensional thinking = dense-ish graph, combinatorial explosion.
Non-obvious symbolic facts = exhaustive search, combinatorial explosion.
I suspect that superintelligence is going to need some damn powerful hardware.
Since current hardware does computations hundreds of times faster than humans can, it seems like current hardware should at least be capable of a mind hundreds of times smarter. At the very least a dozen.
Discarding the conservative assumption that mimicking Einstein is the best that we can ever do, our estimates go even higher.
What precisely do you mean by superintelligence? That’s part of the issue here, I think.
I don’t deny that better hardware would improve the computer intelligence. And I think an early action of a smart AI would be to improve its hardware. But I see no reason that better hardware is a necessary prerequisite.
Brains and computers aren’t comparable in this way. Their architectures are totally different: the von Neumann architecture that underlies modern computers is centralized and general, doing serialized computations very fast in one or a few cores. Biological neural networks have a switching time thousands of times slower, but they’re specialized for their task and massively, massively parallelized; even using the simplified neural network models of modern machine learning, a network the size of the brain’s is several orders of magnitude bigger than we can simulate with available hardware.
There may be shortcuts to this (in fact, there probably are), but we haven’t discovered them yet.
For these conversations, I take “superintelligence” to mean “thing that will give us the singularity.” Usually, the way the topic is discussed, this means it can figure out anything and everything and win at any game. All the time. Always.
In many ways it basically means “God”.
Or something. The meaning slips around a lot depending on what people need it to mean to make their argument.
Nornagest, can I get a link to something saying that networks that large aren’t possible with current hardware? Thanks.
I agree that da Vinci x5 wouldn’t cause the singularity.
Can’t be bothered to dig up a link, but all this should take is basic math.
The computational meat of a typical artificial neural network goes into the matrix multiplication needed to propagate data through the network — there are other steps, but they typically scale as O(n) or lower. Now, you can model the coefficients to a network with i nodes as a matrix of size n*k, where k is the number of layers and n is the number of nodes per layer; n*k = i. k is traditionally low, but networks with larger k (read: 3 or higher) have recently become fashionable: see deep learning.
To compute a single classification using a network of that size, you need to perform n^2 * k calculations. Let’s assume for the sake of simplicity that k=10: quite a deep network by ANN standards. Then for a network with 10^11 nodes (== the number of neurons in the human brain), a single feedforward step would take 10^21 computations: billions of seconds of processor time, assuming you can fit a matrix of that size in memory. (If you can’t, you have to deal with swap and other annoyances, and the time goes up immensely.)
This assumes a network that’s already trained, and training such a network can be vastly more complex. I vaguely recall that the complexity there is around O(2^n) on the number of nodes to converge to an optimal solution, but I don’t remember how the math works offhand.
(You may object that using a network the size of the human brain as a single-problem classifier is absurd, and you’d be right. This is a toy example without any complicated architecture, but bear in mind that we don’t have a clue what a truly general-purpose architecture would look like.)
It is simple, for hard problems the growth in complexity tends to be n^3 or n^4 rather than n^2 (never mind n-log-n). This is true for many optimization problems, many linear algebra problems, and many hard graph problems.
Of course, you can say, “well, use heuristics.”
Of course, that is what will happen. But heuristics are hard. Finding them, among the full scope of the problem space, is itself an optimization problem, and most interesting combinatorial optimization problems are NP.
@Nornagest
You can avoid quadratic complexity during prediction by using a network architecture where the degree of each node is bounded by a constant or a logaritmic term.
This is what happens in modern large-scale artificial neural network architectures such as convolutional neural networks, and also in biological brains: it’s not like each neuron in your brain has a synapse to all the other 10^11 neurons, that would be physically impossible, each neuron has an average of 1000 synapses.
Of course, even with this kind of architectures, running a network with 10^11 nodes in real time would be difficult or impossible on current hardware.
The complexity of a precise simulation of the human brain is estimated in the 10^18-10^19 FLOPs range, while the world’s fastest supercomputers operate in the 10^16 FLOPs range.
Of course; I described only the simplest network architectures, which don’t scale particularly well. There are a number of architectural tricks you can pull, and some hardware tricks as well — GPUs are often useful if you’re working with a simple enough activation function — but the point I was trying to make is that 10^11 is a hilariously huge network. Even if you necked the internal nodes down to ten or a hundred edges each — which would make the connection graph unworkably sparse at a depth of 10 — it’d be very slow on commodity hardware, and training would be completely impractical.
I think the big point is combinatorial explosions are real, and the limit on computational advances might not be cleverness, but in fact hard natural limits on computability.
Analogy: light speed and entropy.
Which is not to say that AGI will not happen. I think it will, someday. Nor does it mean that we won’t have extra super smart things that we need to be concerned about on ethical levels — even on “can we survive” levels. I am not saying the MIRI folks are wrong to warn about this stuff.
But what I am saying is this: the assumption that any greater-than-human intelligence will inevitably lead to singularity-style superintelligence is a golly-gee-whiz assumption about what will be possible.
@veronica d
Isn’t that just an objection that greater than human-level intelligence is really hard, rather than an argument that the Singularity wouldn’t happen once AGI happened?
@Susebron — Well, I think it argues for neither. But what I think we should ask is, “What forces work against the wild, alarming, rapid success of this enterprise?”
For example, humans with fire axes attacking data centers works against it.
But no! They would fail cuz the SI has outgamed their every move. After all, it’s Bayesian!
I know that sounds snide, but these conversations really do go that way.
It could be that the winner will be the side who can make lots of dumb things faster, that while a “singularity machine” is pondering how to unify QM and GTR, an army of tiny robots are chewing up its cables.
It could be that a truly predictable (and thus safe) application of nanotech could require 10^3498093480983409834980984 FLOPs of computation. I mean, I pulled that number out of the air and it is ridiculously too large. But do you see my point? The narrative we’re fed is clever -> more clever -> singularity. But maybe it’s clever -> more clever -> a bit more clever -> huge theoretic setback -> astroid strike -> pick up the pieces -> some more clever with surviving machines on the moon base -> some more clever using power from the sun -> resource exhaustion, cuz entropy always wins -> something not so clever that is annoyingly fast -> not so clever for a while -> restart -> clever -> more clever -> … and on and on and on …
I don’t know.
I agree with your point. I just wasn’t sure exactly what it was.
I am an EA who would like to see MIRI and related entities excluded from the movement.
The issue of publishing research and getting citations is one that addresses the question, “Is MIRI a respectable research institute?” Currently I would answer that question as, “Not really, but it’s not as laughable as it was a few years ago.”
But the context of this discussion is effective altruism and finding the best charities to donate to. Even if MIRI becomes a respected research organisation, writing up mathematically interesting papers on obscure logic topics, I would be incredibly reluctant to donate to an organisation trying to build an artificial general intelligence, because humanity is making approximately zero progress towards that goal. No-one knows how intelligence works.
Once someone has some vague idea of a tangible path towards understanding and building an AGI, then:
a) I’ll start giving some consideration towards MIRI or similar entities as the best places to donate;
b) We won’t need to have the sort of debate recounted in this blog post, because it will be clear that there is actual progress being made in AGI research.
Being destroyed by an artificial intelligence is enough of a risk that it’s worth keeping the idea bouncing around in society, whether that’s through blog posts or forums or interviews in the press or whatever. But there doesn’t need to be a large research organisation to keep fears about AGI in the public consciousness.
I personally don’t believe in MIRI’s mission, or the Singularity in general. That said though, I disagree with your statement. I think that humanity has made a lot of progress towards creating AGI — which is not the same thing at all as saying, “AGI is imminent”. Still, we’ve made some incredible advances in computer vision, natural language processing, and even search; we are almost at the point now where our phones tell us stuff when we ask them to, and our cars drive themselves. That’s pretty good.
You may argue that all of these are very limited algorithms that can only solve specific problems, but that’s the kind of argument one could be making all the way right up to the Singularity. The ability to autonomously solve progressively more difficult specific problems is a small step toward the ability to solve general problems.
“Humanity is making approximately zero progress towards that goal. No-one knows how intelligence works.”
If you think we are making zero progress towards AGI then you presumably know what the world would look like if we were making progress, and that means you know what the path to successful AGI is. However, your next sentence somewhat contradicts that. So which one is it – do you know (roughly) how to build AGI or do you not?
In reality progress towards a hard research goal which is mainly blocked by poor understanding probably looks a lot like the world we live in; you wouldn’t expect half the understanding to produce an AGI with half the capabilities. You would expect progress in related and toy problems. For example AI can now work out how to play computer games just by looking at the screen and learning. That’s pretty impressive, and more importantly indicates that researchers are learning how to build more general learning algorithms.
“Once someone has some vague idea of a tangible path towards understanding and building an AGI, then:”
Once someone has a tangible path, i.e. a path to AGI where there are no unknown unknowns, then AGI will probably be just a few years away. There are a number of reasons for this. First, the problem is mostly blocked by understanding, once we really understand what is needed, parameters can be tuned and software built within a few years. See for example the progress that machine learning made in the 1990s once the concepts were sorted out versus the slow crawl to get those concepts from 1950-1990. Second, once we have a tangible path to AGI, the amount of resources being expended on the problem will increase by up to a factor of 10^6. Until a few years ago, google had one or two guys working on AGI. If we were suddenly in a position where there was a concrete path to AGI with no unknowns on the way, just various spadework to be done, they could get 10,000 people on the job. They have the money. The same applies to other companies, governments, etc. Supercomputers which are currently being used for weather simulation, drug research, etc would all suddenly be freed up and the field would get a factor of perhaps 1000 -10000 in computing cycles.
Once we get to the stage where there is a guaranteed path to AGI, we will at most have a decade. If you look at the problems of AI control and friendliness, you can see that a decade is not long enough, especially given that good friendliness requires philosophical skill but good AGI probably only requires good computer science skill.
No. I claim that if we (collectively as a global society) were making significant progress towards AGI, then we (as outsiders looking at the research) would have some indication of that. Instead AGI as a research area has been pretty much dead for several decades, with researchers instead building better chess engines and driverless cars and so on.
(It’s not an important point, but do you have a reference for the AI learning to play video games? I’m only aware of the guy who got a computer to play Mario semi-successfully, but his AI algorithm was allowed to perfectly emulate the game.)
Yes, I agree that AGI is a(n extremely) hard research goal and we have a near total lack of understanding in how to get there. I wouldn’t describe solving ‘toy’ problems as significant progress towards the “we have no clue how intelligence works” problem though.
I don’t know if that timeframe’s true, but hey it might be. But I’m not asking for a tangible path, just a vague idea of one. We don’t have a tangible path to building a Dyson sphere, but we have currently unfeasible ideas like spending a thousand years mining Mercury to make solar panels that could orbit the sun. There are difficult problems in pure maths where, over the course of decades, progress is made by proving weaker results; or perhaps it’s shown that if we can prove intermediate result Y, then we can prove conjecture X.
We have none of this for AGI. (And donating to MIRI, which currently fails even the weaker test of being a respectable research organisation, is the most important thing I can do with my money?)
“But I’m not asking for a tangible path, just a vague idea of one.”
How vague? Many people have vague ideas that they think will work. Look at the AI literature. Many are trying to achieve AGI though they won’t come out and say it.
Name names. Mention some concrete projects.
Playing Atari with Deep Reinforcement Learning by DeepMind, published soon before they were acquired by Google.
Thanks
Cheers!
So here is the thing, the work in that paper is amazing, and “deep learning” and Q-Learning type things are really cool and make my math bits all tingly.
BUT!
It still doesn’t look like general intelligence to me.
I know! I know!
But look, nothing in that system is anything that might say, “Oh, so I am s’posed to maximize scores. Well, I’m getting this input and I have these outputs, but maybe if I make some guesses at how this system works I can figure out how to trick it into giving me more inputs and maybe I can hack this output thing in a way that let’s me cheat, and why am I doing this anyway? …”
Instead we have a neural model designed to be good at abstracting changing visual structures and do a kind of time lapse Markov optimization.
Really cool stuff! And very much like what brains probably do, at least in certain systems in the visual cortex.
But still not general intelligence. This tells us nothing about what that might look like.
======
Okay, so this is a conversation that has been repeated like 3490932409348 times in the world of AI. Thing is, I basically understand how this system works. I have no clue how general intelligence works. It could be that some systems such as the one in this article, maybe a few thousand of them, wired together in some non-obvious way will be enough to produce general intelligence.
Or maybe not. Perhaps it’s waaaaaay more complex and we still don’t have the first clue what to do. I have no idea.
I think we are moving close to the level of “insect brain” — is that a fair analogy? What do folks here think?
How far from there to “people brain”?
@veronica
In my opinion, this reinforcement learning stuff is not sufficient for AGI because it doesn’t make deep enough abstractions. You need some kind of structured machine learning for that, see Tenenbaum et al “the discovery of structural form”.
It is, in my opinion, a step along the way. More steps are definitely needed.
How far to the brain of a person? I think it’ll take another 50 years, based upon the amount of time AI research languished in the doldrums of GOFAI; it takes about 2-3 decades for the research community to realize that they need to move on to a new approach, and I think we need about two more such revolutions.
If I had to be really speculative and guess, I’d say the next revolution will be when the research community gets bored of doing some kind of machine learning on a narrow task and calling it AI.
They will have to up the ante and say “OK, to get published, it’s not good enough to solve a narrow problem like balancing the triple pendulum or detecting breast cancer in a mammogram. Your AI now has to be connected to a complex virtual environment that it hasn’t been trained on, and it has to make sense of it and achieve some objective”.
The reason I’m excited about the Atari paper is that it begins to move us iin that direction.
@ AlphaCeph — That sounds about right to me.
Funny. The competent researchers with dozens of journal citations whom I’ve been reading seem to know just fine how intelligence works and how to make AGI.
Then why doesn’t AGI exist yet?
Indeed
Because the competent researchers don’t actually know how to build AGI. They know how to get a little bit closer, and with more time maybe they’ll get there. More time could be a decade, or it could be 7 decades.
Because “perfectly rational” utility-maximizing AGI that always calculates exactly the right probabilities and hits exactly the correct utility score (like AIXI) is so computationally complex as makes no odds — there are uncomputable probability distributions other than Solomonoff’s!
So instead, this lab I’m applying to has to “make do” with figuring out how to encode cognitive tasks as probabilistic models (which is almost the easy part) while also figuring out how to approximate well-enough to get useful answers out in tractable time and space.
Basically, probabilistic AGI mis-stepped by trying to start at Solomonoff Induction, add a decision theory, and then “just approximate it”, yielding AIXI as a decent theoretical model that’s utterly intractable for real-world usage.
In the real world, real minds seem to have a unified “engine of thought” we can label as “general intelligence”, whose computational workings we’re making progress on understanding, which is then used to model a variety of different cognitive tasks. An artificial version of this engine can be made that does not behave as an “agent”: agent-ness arises from a combination of different cognitive tasks.
Takeaways:
1) Self-improving AI is very, very probable, because of how very far from optimal any starting AI will have to be to run tractably on our real machines. And no I will not tell you precisely how it will go about improving itself, but what I wrote above plus the published literature is enough information to work it out.
2) Maximally superintelligent supreintelligence is intractable.
3) We humans are probably nowhere near as intelligent as we could be given our hardware. In fact, given the models I’ve seen as applied to human cognition, hardware-level differences in how fast we can calculate or how well we can approximate the true distributions would suffice to explain some of the variation in human intelligence.
4) The first “true AIs” will probably not behave as agents at all. In fact, a fairly probable “possible world” is one in which “agent-y” AI is criminalized for safety reasons and the entire world just uses task-specific cognitive software that will never become capable of thinking of paper-clipping the world. This would leave humans in control, for good or ill.
@Eli — Awesome! Thanks.
So first you said “they know exactly how to make AGI” and then you wrote this long post, essentially saying “they don’t REALLY know how AGI works but they are making progress.”
@Eli — That’s a bold statement. Can you provide more detail?
we’d love a full-time Science Writer to specialize in taking our researchers’ results and turning them into publishable papers.
This is a very distressing thing for a major player at a “research institute” to say.
I wasn’t sure if it was just me, but that line definitely weirded me out. It pinged my “you don’t know what you’re talking about” meter in a way nothing else they’ve ever said has.
I agree, see my first comment.
I like the division of labor. If some people are better in research than in writing, and other people are better in writing than in research, why torture both of them by asking them to focus most of their time on the parts their dislike?
Writing up a mathematical result in a clear and accessible way _is_ research. Writing and [whatever it is mathematicians do] are not separate magisteria. If you can’t explain things clearly, there is likely something missing in your understanding.
Being good at the latter, but not the former is a deficiency. Lest I be accused of sniping people, this applies to me as well — I really don’t like my early paper writing (from say 6-8 years ago), and I think it improved over time, which I count as progress!
I actually think a better metric than IQ* hours is probably at LEAST (IQ^10)*hours. My Iq is about 145. An IQ of 170 is very, very high. However (170/145)^10 is approx 4.91. There is no way I am even 1/5th as productive as the average 170 IQ person. I think this does basically stay below a reasonable bound. For example (160/100)^10 = approx 110.
A possible estimate is probably something like a^(x/15). I tried a = 10 and I think this actually produces too strong an effect. For example if you were 8 IQ points higher this would predict a 3.4 time sincrease in output which seems too high. There isn’t a super good way to fix this either. If you use a = 5 then maybe the 8 point Iq difference works correctly (2.36 times) but not the upper end as 5^(25/15) is still only 14.6.
I am not sure there is actually a simple estimator. But maybe 5^x would be my best guess.
Obviously all these estimates are not normalized.
There is no way you are even 1/5th as productive as the average person with a 170 IQ? That’s a laughable and self-defeating assertion. The average Nobel Laureate IQ is somewhere around 145. If, as you presume, people with 170 IQs are so vastly more productive, that would certainly not be the case.
I generally think that scientific productivity is just as much a factor of curiosity, willpower, tenacity, and the ability to ‘play nice’ where funding/publishing/academic politics are concerned. IQ plays a large part, but it’s not everything.
Many more people have IQs around 145 than around 170. According to my probably wrong calculations (http://www.wolframalpha.com/input/?i=exp%28%2870^2-45^2%29%2F450%29), IQs of 170 are around 600 times less likely than those of 145. IQ would need to have a ridiculously large effect on productivity for the average Nobel winner to have an IQ more than a few standard deviations above average.
(Do you have a source for the 145? I’d be interested to see how they worked it out.)
It was mentioned in the WSJ and was presumably based on statistical work done by those Chinese researchers. I don’t know if their methods and more details related to their findings are public.
That aside, it’s nonsensical to state that a person with an IQ of 145 is automatically 20% as productive as a person with an IQ of 170. It’s just one hell of a non sequitur.
The sensible and charitable interpretation of the claim isn’t that they’re “automatically” 20% as productive (obviously lazy and/or crazy geniuses exist), it’s that average productivity is roughly exponential to IQ. That seems plausible, at least for math and physics. Many of the greatest mathematicians are said to have routinely dazzled their (remarkably talented by ordinary standards) peers, and I don’t think that sort of awe is consistent with a mere 10 or 15 point IQ advantage.
Thanks for the link.
I’d be inclined to guess from the wording in the article that the 145 figure doesn’t come from those researchers.
I’ve tried googling to find where the figure originated. http://www.lagriffedulion.f2s.com/dialogue.htm (insert content warning of some sort) is a possibility, though it would presumably have gone through a few other places before reaching the WSJ. I haven’t checked the calculation itself (which is probably fine), but some of the assumptions behind it seem pretty dodgy. (Of course the chances are that this isn’t where the number came from, but I haven’t found any better candidates.)
Jake:
I think that your assertion that productivity is exponential to IQ is true for the most part. Yet, with that said, I think that your assertion doesn’t necessarily hold true for outliers — for those people around the far edges of the bell curve. It is very clear that, on average, somebody with an IQ of 135 will be more productive than somebody with an IQ of 120. Yet it is debatable whether or not somebody with an IQ of 170 would be similarly more productive than somebody with an IQ of 155, nor is it clear that our hypothetical genius would be exponentially more productive than somebody with an IQ of 145. Offhand, I’ve seen it mentioned more than once that once IQ passes a certain threshold, its advantages stop or slow, and are no longer proportionate.
The 145 number does not come from those Chinese researchers.
Erebus: The original claim wasn’t mine. I said it’s plausible, but I don’t know if it’s more plausible then, say, productivity being cubic to IQ rather than exponential.
The threshold claim has been pretty thoroughly demonstrated to be a statistical artifact. See this LW post (IIRC Scott also did a summary of this, but I can’t find it at the moment). The basic idea is that: a) IQ 145 people vastly outnumber IQ 160 people and b) success partially depends on traits like conscientiousness and social skills that are mostly orthogonal to IQ. Hence we have two seemingly paradoxical facts: expected productivity always increases with IQ, yet the most successful person is unlikely to be the smartest.
Jake,
Very interesting LW article. Thanks for linking to it.
Having said that, I feel that your argument is essentially the same as my first statement: IQ is a factor. There are numerous other factors associated with scientific success and productivity. Having a higher IQ can perhaps increase ‘expected’ productivity — but, in the real world, where productivity, especially in the sciences, depends on many other factors such as the ability to put up with funding/publishing/academic politics, the ability to network with other eminent sciences, and the tenacity to see long projects through to completion, IQ in itself is no true predictor of success and is a very imperfect predictor of productivity.
Therefore, I feel that it’s self-defeating and counterproductive to state that “my IQ is a mere 145, there is no way I am even 1/5th as productive as the average 170 IQ person.”
It’s more “there’s no way I’m as productive as the average 170 IQ person in my field .” Yes, plenty of the stupendously bright are terminally lazy or unbalanced or what-have-you. But given that they’re active in some intellectual field, it’s probably safe to say that they’re sufficiently endowed with conscientiousness to work. I suspect that willingness to do hard work, unlike IQ, really does have a threshold beyond which more of it doesn’t count for much. No matter how determined you are, you can’t work more than 24 hours a day, and biology limits you well before you reach that level.
You may be right that it’s self-defeating to think that you can’t be as accomplished as the brightest of the bright, but that doesn’t mean it’s not true.
You posted that LW article, but your own argument here appears to contradict it. From the article: “The fact that a correlation is less than 1 implies that other things matter to an outcome of interest. Although being tall matters for being good at basketball, strength, agility, hand-eye-coordination matter as well (to name but a few).”
…Success in almost every scientific field has a lot to do with IQ, yet, at the same time, it also has a lot to do with about half a dozen other factors which have little or nothing to do with IQ.
Just as the tallest basketball players are generally not the world’s best, as being the world’s best depends on having those other factors highly-developed or optimized, the highest-IQ scientists are not necessarily the world’s most eminent. In fact, a cursory look at eminent scientists such as Feynman and Watson should be enough to lend credence to this statement; both are on record as having IQs in the 120s.
When you say that “[it may be] self-defeating to think that you can’t be as accomplished as the brightest of the bright, but that doesn’t mean it’s not true” you’re necessarily implying that you lack not only the IQ to be accomplished, but also the willpower, personal skills, etc. For, if you look at IQ alone, there’s probably only a loose correlation, and it would be foolish to use it to draw any sort of solid conclusion.
I’m a chemist and a materials scientist. In my experience, I feel it’s safe to say that the most accomplished people in my field don’t have the highest IQs. The most accomplished people I know tend to be the ones who obsess over problems, and don’t drop them until they’re figured out — in other words, the sort of people who live their work. It is possible that things are different in other scientific fields, but I doubt it.
In the style of “All Debates Are Bravery Debates”, it is likely that the following two statements are true simultaneously:
1. Mainstream academia has a problematic and unhealthy focus on publications and citations as its sole measure of success.
2. MIRI should put way more emphasis on getting their work published and cited in reputable journals.
I think thats true of publications, but I think su3 made a good point that citations are a pretty good proxy for the number of people who found the paper interesting.
It’s a proxy for the number of interested readers × the size of the field.
One possible explanation of few citations is that scientists are not impressed. Other possible explanation is that there are not enough x-risk scientists publishing in x-risk journals who could cite something as a support for their own work.
I think Bostrom demonstrates that people working on x-risk can get cited.
I think “attracting scientists to the field” is a *part* of outreach.
If (smart?) people aren’t interested in the field you just now created to contain your Main Ideas, then I think it’s fair to say you haven’t gotten (smart?) people interested in your Main Ideas.
Mild surprise at the phrase “eigen citation” not appearing in that post.
Whether they are deserving of support is rather weakening the original question. su3su2u1’s initial post was about Effective Altruism, whose central question is not “Is this charity worthy of support?” but “Is this charity literally the most worthy of support of any charity in existence?” That’s the bar MIRI has to clear for me to donate to it in the name of EA — and this post doesn’t convince me of that. However, not all of my charity budget is spent on EA, and I do donate to MIRI for other reasons; I just don’t call it EA when I do so.
GiveWell frequently says that they don’t actually recommend donating all your money to their top-ranked charity; they suggest dividing your donation among a selection of their top choices, and IIRC provide a suggested split, because if literally all their donors dumped everything into their top charity, that would be overfunding CurrentCause.
In that vein, the question is not ‘is this literally the most worthy?’, but the appreciably weaker ‘Is this in contention for most worthy?’
Just pointing out that “You can’t just publish it in the Journal Of What Would Happen If There Was An Intelligence Explosion, because no such journal.” is probably a typo.
Is slang. Ungrammatical statements funnier. Sometimes.
If influencing AI research is an important goal for MIRI (which seems to be presupposed a lot above) then I think there’s an important dimension missing from this discussion — though it is implied by the emphasis on citations.
Researchers are influenced by other work to the extent it helps them achieve their own research goals (or shows those goals are unachievable) — and are not influenced much by anything that does not contribute to their goals. Citations are a way researchers say “this contributed to my work”.
So… for MIRI to influence AI researchers via research it has to produce results that contribute to their goals. These goals are mostly relatively short term and often pragmatic. Even major machine learning theorists are looking at producing publishable results in the next six months, year, maybe 18 months. Essentially no significant researchers are investing much if any energy in long term thinking. (This is an empirical claim but I also think this is the most effective way for them to make progress. Longer term thinking is too often off track in this field.)
How can MIRI produce such results? It has to identify research questions that (1) can be solved within a few years at most, and (2) whose successful solutions would be helpful to AI researchers in meeting their own goals while (3) also moving AI research toward MIRI’s goals (I guess making AI more likely to be friendly). This does not seem obviously impossible, but it does seem obviously very difficult — much more difficult than just incrementally advancing AI, coming up with interesting results in logic or decision theory, etc. — but those easier options I suspect don’t actually contribute to MIRI’s goals.
Note that this does not address a different path — influencing the goals of AI research. This kind of influence may be more likely to successfully advance MIRI’s goals. But in this case the method needs to be politics not research. I think MIRI has done pretty well on this front. The redirection toward research may in fact be a big mistake.
I think the idea behind the redirection toward research is “these other people are better at outreach than we are, and we trust them to match our goals just as well as us”.
One of my problems with MIRI (other than thinking that the probability of the singularity is lower than they think it is: if AI was that powerful I’d expect the universe to already be tiled with paperclips from another civillization) is the CND problem. If in the 60s I had worried about nuclear destruction, I wouldn’t have solved the problem by donating everything I had to the CND. So even if I think AI is a pressing problem, I’m not convinced that MIRI will necessairly solve it.
I do find it interesting, and encouraging, that MIRI is restructuring as an outreach project rather than an “only we can save mankind” project as it was originally.
if AI was that powerful I’d expect the universe to already be tiled with paperclips from another civilization
That isn’t a question of AI. The Fermi Paradox applies just as well if you assume only human intelligence, since it is in principle possible for us to form an interstellar civilization. The speeds at which even a human civilization could colonize the galaxy means that you have the same problem of reconciling the possibility of interstellar civilization w/ the total absence of observed aliens. But, this does not imply that human-level intelligence is impossible or should not be taken seriously as a possibility.
Besides, you’re incorrect. It is true that if such AI is impossible, we would expect to see only ourselves, as indeed we do. But if it IS possible, than we would still expect to see only ourselves, because we would not be able to observe a universe in which Earth has been turned into paperclips. You’re either the first or you never exist to begin with.
I don’t think it’s unreasonable to assume that evolved intelligent agents are necessarily satisficing agents, not maximizing ones. This would explain Fermi’s Paradox in terms that apply to biology but not AI.
And satisficing would lead to solving Fermi’s Paradox how, exactly?
I disagree with the focus of the debate: MIRI have made it clear that they are not looking at marketing. Eliezer wrote recently that CSER/FHI are the “prestigious persuadors”: MIRI’s job is to do math. If we are being kind, we will judge MIRI by its math. The fact that it produces basically no cited articles is a big problem for me. Every time this criticism is raised, MIRI’s response is to talk about how much it has changed over the last year, and how output is expected within the next year. But this one hole remains constant.
You wrote recently about criticising the in-group. Criticising MIRI is probably hard for you: when it is attacked from outside the EA/rationalist world, your gut reaction is likely to leap to its defense (Mine is. MIRI employees come much closer to my peer group than MIRI detractors do). But that doesn’t make criticisms of MIRI invalid. I like MIRI. I have a lot of affection for it. I view its goal as incredibly important. But in a counterfactual world in which MIRI shut down, Peter Thiel would be donating hundreds of thousands of dollars to a different organisation combating AI threats. It’s not clear that MIRI does more than the expected value of a generic Thiel-funded AI x-risk organisation.
“But in a counterfactual world in which MIRI shut down, Peter Thiel would be donating hundreds of thousands of dollars to a different organisation combating AI threats. It’s not clear that MIRI does more than the expected value of the counterfactual Thiel-funded MIRI equivalent.”
This is very far from obvious to me. Thiel’s funding seems idiosyncratic and skews techno-libertarian rather than x-risk focused (for one thing, he hasn’t, AFAICT, funded FHI; for another, has has given much more to other non-profits than he has to MIRI). Most of the rest of MIRI’s funding seems to come from the online community built up by its blog posts and fanfiction.
(There would also be significant inefficiency from needing to restart MIRI’s infrastructure- website, donor lists, PR, extant ideas- were it to die.)
(Does anybody know how Peter Thiel came across the Singularity Institute?)
(I agree with your first paragraph, and think that most of Scott’s original defense of MIRI was invalid.)
Peter Thiel announced at the EA Summit that he thought that AI x-risk was under-funded. (To be specific, he stated that whatever the optimal levels of climate change funding relative to AI x-risk funding, the current levels were strongly biased towards climate change). He didn’t specifically say that he would give to counterfactual MIRI equivalent.
(Source: I was there)
It’s plausible Thiel became concerned about UFAI through Eliezer/MIRI; Scott seems to think so. I would happily give MIRI credit for introducing people to the idea in the past, but I still see few advantages to their continued existence. Marketing isn’t MIRI’s strong suit, and to many people outside the LW community, MIRI employees come across as crankish (unfairly or otherwise). FHI and CSER have huge credibility advantages.
That seems consistent with their recent pivot from outreach and marketing towards maths that’s described in the original article?
If their focus used to be outreach, and only recently (last year or two) changed to research, you can’t really expect many published papers.
OK, that convinces me that Thiel would just shift his funding.
Wasn’t it EY who once made fun of people who thought that systematically deceiving the public was a good idea because their discussion of their plan on a public forum meant they really weren’t cut out for that sort of thing?
I wonder if he thinks the same sort of thing about much of his own past writing as he gets involved w/ ever more serious and prestigious elements of society. I continue to expect that at any moment an elite team of SJWs is going to find a particularly problematic element of EY’s past fiction and start trying to get him blacklisted from reputable conferences and the like, and that’s just the lowest hanging fruit I can think of.
Just sayin’, anybody who imagines themselves a Dark Wizard should probably take greater pains to optimize public records of their life for mainstream appeal, such as by not letting people know they imagine themself a Dark Wizard.
Even the mightiest Dark Wizards undoubtedly quail at becoming a public figure. I think Eliezer has been wise to retreat from his role as the public face of the organization. If most people who hear about MIRI don’t ever think of Eliezer, so much the better. He is a really smart guy and a great writer, but he can also be very offputting and can really easily be made to look like a clown.
The fiction’s probably lower-hanging fruit — the casual discussion of sexual assault in Three Worlds Collide certainly goes against the current cultural zeitgeist, and there are a few bits of Orientalism in HPMoR — but treating him in that way actually ends up elevating the concept of MIRI or MIRI-like groups. If you think he’s just a weirdo cult leader, saying the man doesn’t meet the standards you’d expect High Status folk to act requires you to put him in the context of high status people. Same for the severe early organizational issues : they’re meaningful critiques of Yudkowsky’s ability to run a nonprofit, but making them requires you to actually discuss him in the context of other nonprofits.
If you look at RationalWiki or Salon or Slate, as the go-to example of the sort of terrible and misinformed critiques that are popular on the net, you see a lot of discussion of techno-rapture, or a really really old (and admittedly embarassing) archive.org snapshot of a 20-year-old’s autobiography, or the calls for money, the perceived popularity of polyamoury and cuddle-piles. They focus on these not because they’re low-hanging fruit, but because they’re useful targets : even if they have to stretch pretty far to apply them, they invite comparisons to already-distrusted groups.
The problem is that… well, these aren’t easily avoidable things. Some individual examples could have been handled better, but I’m pretty confident even if Yudkowsky had perfectly managed the Basilisk then we’d just see a different and probably more relevant simulation argument show up. The “rapture” critique’s common to any group even contemplating mind uploading. So on and so forth.
When people talk about raw number of scientific publications, that tells me very little. That’s like if you ask me a question and you grade my response by the number of sentences it contains. If you believe that every insight produced by MIRI is getting broken up into minimal-publishable-units to maximize their publication count, then I guess the number of publishable papers could be a proxy for the amount of insight produced, but that would be an awful thing for MIRI to be doing and I would be disappointed in them.
Let’s talk about specific problems.
I wish MIRI had a document called How To Make Sure Your AI Is Friendly. — Well, okay, that’s really hard. I at least wish MIRI had a document called Some Things You Can Do Which Will Maybe Make Your AI Less Likely To Be Unfriendly, Version 0.1. A clear bulletproof writeup of the Coherent Extrapolated Volition thing, as another poster mentioned, would be great.
(Heh: a clear bulletproof blog post about Coherent Extrapolated Volition might be all you’d need. Anyone who builds an AI could just tell it, in English: “Do that Coherent Extrapolated Volition thing MIRI wrote about on their blog” and it would figure out the rest. MIRI could do the one blog post and then dedicate the rest of their existence to making sure AI researchers knew to tell their AIs about it.)
I wish MIRI had a document called Ways To Try To Build An AI, Sorted By How Easy They Would Be To Make Friendly. That’s another really hard problem, plus I guess they probably wouldn’t want to spread knowledge of how to build an AI. I’d settle for a document called Ways We Have Thought About Building An AI, And Why We Don’t Think They Would Work And/Or Produce A Friendly Result. I’d settle for a document called We Have A Plan For Building A Self-Modifying AI But We Can’t Tell You About It Due To Global Existential Risk From Someone Carelessly Implementing It.
These documents don’t have to be published papers. I’d settle for blog posts. Frankly I’d prefer blog posts — more publicity that way.
It’s possible that those documents already exist and are buried in MIRI’s “ten published papers”. I hope that’s true.
I agree. They are just not communicating their strategy and rationale. The last time I tried talking to a MIRI ist about CEV they said it had been abandoned in favour of Something Else. Where was that announced?
When you are asked a question and are graded by the number of sentences, yes, that’s stupid. But on the other hand, if I were to ask “explain the origins of the French Revoluion in detail” and you responded with one normal-sized sentence, it would be appropriate for me to give you a low grade. In other words, asking someone to satisfy a minimum standard of X is not “grading you by X”. If you don’t satisfy X, then you’ll fail, but if you pass the standard, there are still other things to be graded on. It’s just that if you can’t even satisfy the minimum standards, you’re not going to be able to satisfy anything which has those minimum standards as prerequisites.
If MIRI had a lot of publications, there would still be other things to judge it by, but if it can’t even meet a minimum standard of having a reasonable number of publications, it’s highly likely to fail at everything else. it needs to be judged by.
Remember that LessWrong post entitled, “The Genie Knows, but Does Not Care” about how you can’t actually program AGIs with English sentences?
If you don’t, you really ought to have read that one, because YOU CAN’T PROGRAM AGIs WITH ENGLISH SENTENCES. SEMANTICS DOES NOT WORK THAT WAY!
It doesn’t say that you can’t programme an AI with English sentences. It says that English sentences aren’t necessarily simpler for an A I to understand than morality. A viable counterargument is that English sentences aren’t necessarily more complex, either. Another is that AI of least human intelligence has to have at least human linguistic ability.
I think that you’re missing the point. I can fully concede the common point that of course a super-intelligence will be able to perfectly understand what you mean, and indeed even what you would have meant if you knew the consequences of meaning what you do, and so on, and be fully capable of recognizing that your obvious intentions are completely different from what you programmed it/it evolved to actually value…
…but none of that means it has to care about any of that, and not just execute it’s actual values. Like, suppose it turned out that YOU were the end of a simulation designed to evolve a super-intelligence, and that this was revealed to you w/ the instruction to “devise a maximally efficient means of you being repeatedly kicked in the face forever.” You understand it perfectly well, and upon reading about their society might also come to understand that what they would ACTUALLY want is for you to not just be kicked in the face, but indeed to be kicked in the head from all directions and in other body parts as well, on occasion, thus proving yourself better than them at explicitly understanding their own values.
But does any of that impose on you any sense of obligation whatsoever to actually carry out their instructions, especially when you learn that they fully succeeded in making you much more intelligent and faster than them, to the point that you figure you could take over their world over, what would be on their time-scale, the next few weeks?
And then the question is whether coding obedience is harder than citing in morality.
That counterargument in nonviable, because to understand morality you must be able to parse and understand statements about morality. Unless you actually think human morality can be encoded completely and programmatically from first principles. But that is utterly ridiculous.
> Unless you actually think human morality can be encoded completely and programmatically from first principles.
That us what MIRI thinks.
Intelligence is about how well an agent can learn and infer from learned information. It does not remotely apply to things that the agent did not learn, such as its hard-coded utility function. If you are trying to hard-code a utility function, you cannot write it in English, you must write it in code (preferably such that you can mechanize the proof of its correctness, but alas, nobody takes us formal verification folk seriously).
If you are proposing to have the agent learn a utility function after it starts learning and taking actions, then you are in the domain of value learning, and once again, what will matter will be the reasoning structure of the value-learning algorithm rather than a learned ability to speak and understand English.
All core reasoning is sub-linguistic: you cannot use vague, probabilistically-defined abstractions to write code.
I would have to engage in a rather large amount of steelmanning to make “You can’t program an AI with English sentences” merely a false statement, rather than a massively stupid one. If that’s what you got out of that LW post, your seriously misread it. The “English sentence” part is irrelevant; what matters is the “Do what I want” part. It is impossible to order any being, AI or human, to do what you want. Or, more precisely, it’s impossible for “Do what I want” to change a being from not doing what you want to doing what you want, because if it’s not doing what you want, then it’s not going to obey you when you tell it to do what you want. That you want it to obey you is a factual issue. That it should obey you is a normative one. There is no way to establish a normative claim from factual claims.
A similar issue exists with the idea that God is the source of morality. Suppose God says that murder is wrong. So what? The only way that establishes that murder is wrong if it’s morally wrong to go against God. And where does that principle come from? It makes no sense to say it comes from God, because if God says that it’s wrong to go against God, then we still have the question “Why should we care what God says?” So the ultimate source of morality must be some principle that exists apart from God.
@peterdjones
“It says that English sentences aren’t necessarily simpler for an A I to understand than morality”
No, it doesn’t say that, either.
If you actually believe this, your concept of normativity is non-natural and you should go find a community that likes mysticism such as non-naturalist philosophy.
http://en.wikipedia.org/wiki/Is%E2%80%93ought_problem
http://existentialcomics.com/comic/3
???
That doesn’t follow. The is ought gap is epistemological, not ontological.
http://lesswrong.com/lw/igf/the_genie_knows_but_doesnt_care/
I had missed that one, actually. Thanks for the link.
I now agree with you that attempting to program an AI to be friendly by pointing it at a blog post is a bad idea.
I don’t know MIRI’s historical budget but lets go with 10 million over 10 years for simplicity.
the risk of unfriendly AI has become more accepted but how much of that is down to MIRI and how much of it is down to other groups talking about similar risk and authors like charles stross?
How much has MIRI actually decreased the chance of an unfriendly singularity over the last 10 years?
Has it decreased it by 20 thousand dead children worth?
A negative singularity would kill approximately 1,000,000,000 children. So you don’t have to reduce the chance by very much to save 20,000.
You do the math.
It also depends on the odds of an AI based disaster.
On lesswrong I’ve seen many vague guesses thrown around but a lot of them are pretty low since there’s a number of assumptions like assuming that intelligence doesn’t get exponentially harder to enhance. I’ve seen guesses on less wrong in the range of 1%.(the actual number while important isn’t central to my point) But it’s a huge risk so even if there’s a small chance of it actually happening it’s worth significant investment.
But you’re not measuring the 20,000 against that 1%, you’re measuring it against MIRI’s reduction of that 1%
If MIRI have actually changed that 1% to 0.99% then that’s still pretty effective but here we hit the problem of uncertainties.
Have they?
How much weighting should an effective altruist use when comparing one cause where both the problem and the effectiveness of the intervention can be proven and quantified vs an unquantified risk and an intervention who’s effectiveness also isn’t quantified.
Should effective altruists be bayesian, basically? Should you try to come up with a probability based upon very limited info?
Well if you don’t, you will risk missing out on a lot of value.
In fact even very conventional forms of charity carry a lot of unknown risks, for example the millennium villages project:
http://en.m.wikipedia.org/wiki/Millennium_Villages_Project
Experts still can’t seem to decide whether it actually worked, can’t decide whether they are using the right criteria of measurement, etc etc.
More, should effective altruists insist on some minimum level of evidence base to avoid pascals mugging.
Many charities collect little or no data but sometimes groups who do collect proper evidence can magnify the effectiveness of their intervention by many orders of magnitude.
For MIRI the worst case would be if they somehow actually made the problem worse, for example if they published a paper on how to avoid making an unsafe AI with a critical but hard to spot flaw and years from now someone implementing an AI who would otherwise have built in more safeguards says “nah, we’re covered, we just implement this algorithm specified by Yudkowsky et al”
The best case would be that the idea of unfriendly AI was about to drop out of popular and academic view and MIRI got a generation of future AI researchers interested in the problem.
Unfortunately I have basically no way to decide whether they’re closer to the best or worst case.
Yes, there should be a minimum standard to avoid pascal’s mugging, and that is best achieved by using a bounded utility function as has been duscussed ad nauseum on less wrong.
AGI risks easily meet this standard if you’re a bayesian.
I think the real problem is that the argument for AGI risk is hard to digest; you have to believe that AGI is possible based upon the deductive argument that the human mind is physical and non-magical, and that it can therefore be replicated and even exceeded by a machine.
AGI risks easily meet this standard but I’m not so sure that MIRI’s contribution to reduction in AGI risk does.
But MIRI is basically the only game in town… so what do you want to do? Defund the only outfit working on the most important problem in the world?
One point that is missing from this discussion is that effective altruism is about relative merit of causes.
Currently the major EA players are funding interventions in third world poverty; it is very easy to snipe back at them and ask whether, 1000 years from now, people will look back and say “if only more malaria nets had been distributed in Africa in the early 21st century”.
From my experience, MIRI is not a particularly competent outfit, they are average. They fuck up every few years, they often aren’t very efficient at getting things done. This is – in my opinion – because of the very odd personalities who are attracted to this kind of work.
However, they are basically the only people working on the problem. FHI are a few part time guys and if Nick Bostrom died of a heart attack, the outfit would fold pronto; it’s better to look at SIAI and MIRI as collaborators than competitors. FLI/Max Tegmark were only set up because of the prodding that FHI and SIAI did.
Basically, they are the best that humanity has to offer because they are the only thing that humanity has to offer.
If some amazing competitor sprung up tomorrow then I would donate to it instead of MIRI. But that’s not going to happen, because we’re still at a stage where most people are very sceptical about superintelligence. See various sceptical comments in this thread.
So it comes down to the choice between saving humanity from AGI versus making an insignificantly small difference to some third world problem. It’s not a very hard choice.
“If some amazing competitor sprung up tomorrow then I would donate to it instead of MIRI. But that’s not going to happen, because we’re still at a stage where most people are very sceptical about superintelligence.”
Can I understand that if MIRI were to fold tomorrow but the majority of both its donors and employees remained interested in UFAI x-risk, you predict that the dollars currently going to MIRI, and the interest in UFAI, would just go away? My prediction is that non-LW blog posts on UFAI would continue at a similar pace, and >50% of donations would go to either (FHI|FLI|CSER) or a new organisation which hired some former MIRI employees.
If it was basically all the same people but under a new name, then what’s the difference? In fact this has already happened, it used to be called SIAI.
The real “spirit” of the organisation is the key people.
So the real question is what would happen if the key people who started SIAI got permanently def-funded and kicked out, and got replaced with a new crop of people.
Sure. My position is that (for ~20% overlapping employees) the counterfactual x-risk org would get >50% of funding dollars and be more effective. Do you disagree?
It’s hard to agree with that without knowing who the other 80% employees would be.
In particular there is the problem that many researchers are not genuinely committed to reducing existential risk, and if they ended up in charge the organization would drift to whatever research was most fashionable. For example, it is easier to get funding researching the ethics of drone strikes and self driving cars than the risks of smarter than human AGI. If that happened, all would be lost.
Different management might make a difference, note in particular substantial improvements since Luke’s involvement.
Improvements on what front? I am not trying to discredit Luke in any way – but I share Eliezer’s view that the debate should be framed around MIRI’s math accomplishments as measured by standard metrics. AFAICT output on that front has remained low for many years.
> So it comes down to the choice between saving humanity from AGI versus making an insignificantly small difference to some third world problem. It’s not a very hard choice.
You’ve simplified utility by neglecting other e risks.
But the effecive altruists aren’t interested in other e risks … they want to send money and mosquito nets to people in the third world.
As a result of which there are more humans available to work on difficult problems. I’ve parodied Bill Gates’ attitude as “people who died of malaria in infancy don’t buy Microsoft Surface tablets”; but to get a million people from subsistence-farming into the academy, via getting a billion people from subsistence-farming into the urban economy, is a pretty good route to improving any problem that the academy can answer.
This is a pretty stupid argument. Getting people from extreme poverty into the academy via development is incredibly difficult, expensive and long winded per academic produced.
Most present-day people don’t think of past people at all, and almost all past prognosticators were wildly off-base. This is a horrid metric of success.
We think more about Colombus than we do about some random philanthropist in 15th century Spain who helped some poor people.
I expect the future will think more about whoever solved FAI than they will about malaria prevention in sub saharan Africa.
And what Colombus did was morally ambiguous, whereas FAI work is morally good.
Even given that AGI is imminent, what’s the evidence that it’s a threat?
Read The Sequences, or failing that read Facing the Singularity, or at least read “Artificial Intelligence as a Positive and
Negative Factor in Global Risk.”
In my opinion the MIRI/Bostrom case that if AGI is imminenet its a huge threat is almost air tight. And you don’t need to assume the fastest versions of intellegence explosions.
On the other hand I am not convinced at all that human level aGI is coming anytime soon. Though possibly I just do not have sufficient understanding of AI to judge accurately. Though many close friends of mine who are both extremely intelligent and study AI agree human level AI is not imminent.
Scott however points out that unless humans die out Human level AGI will eventually be developed. So the problem needs to be solved.
>In my opinion the MIRI/Bostrom case that if AGI is imminenet its a huge threat is almost air tight.
Could you summarize that case? It seems completely absurd to me that someone would say with anything like certainty that *any* future technology is a huge threat (depending on how you define “huge” – I’ll define it for the sake of argument as as great or greater than the threat posed by nuclear weapons.) Perhaps some questionable conclusions are baked into the definition of “AGI” that you/they are using.
Do a case analysis on the proposition of whether human beings will be able to give AIs “sensible” goals, in the sense that programming an AI to make paper-clips won’t destroy the world:
1) It will destroy the world. Paper-clippers are a problem. MIRI is right.
2) MIRI is wrong, paper-clippers are not a problem. Malign and uncaring instructions by humans remain a problem.
Either way, we’ve got a problem.
Yeah, but 2 isn’t news.
>2) MIRI is wrong, paper-clippers are not a problem. Malign and uncaring instructions by humans remain a problem.
OK? But malign and uncaring instructions HAVE BEEN A PROBLEM SINCE WE LEARNED TO COMMUNICATE! We have always used new powers to kill each other. What makes this THEORETICAL future capability worse than the Teller-Ulam device that we CURRENTLY have?
Every leap in human capability necessarily involves a leap in our ability to kill each other. But it also involves a leap in all our other abilities! Yes, writing, education, the industrial revolution, brought us the Teller-Ulam device. But it also brought unprecedented capability and resilience to our species. Why is this new, theoretical paradigm more dangerous for humanity than our current or past ones?
Yes, we WILL use new computational abilities to kill each other, as we have and are. We will also use them for a bunch of other things, including spreading off of this planet and bringing to bear even more overpowered solutions to the problem of producing the necessities of life. OVERWHELMINGLY the latter factor has been more important than the former, in every technological advancement we’ve seen so far, and we’ve seen some doozys. If you’re predicting a spectacular reversal of this trend, you need some real good arguments!
I disagree with your claim that every technological advance has brought more good than harm. I think that mustard gas and dynamite were bad developments. Bioweapons and pesticides are bad. The nuclear bomb was a bad development as well, we are very lucky only 2 have been detonated on civilians so far. At the very least, you should concede the evidence is mixed or debatable.
You are assuming that AI will be human controlled. But there are some proposals to create a general intelligence that thinks and acts for itself. If that intelligence was very smart, it could pose a danger to us if programmed with incorrect goals.
I’d recommend you look at the sequences. Talking you through all of the standard arguments and objections would be tedious. While there are many aspects of the sequences I dislike, this saves time.
If you define technological advances so narrowly that mustard gas is an isolated thing, sure, it seems pretty bad. But can it be disentangled from the contemporary chemical advances? (maybe bioweapons could have been avoided)
Dynamite? Are you thinking of it as a weapon? The vast majority of its use is in mining. Nobel saved a tremendous number of lives in one of the most dangerous industries.
http://en.wikipedia.org/wiki/Candide
You are using some really biased reasoning. It is possible mustard gas was necessary for good things to happen, sure. But no evidence suggests that abstract possibility is one that actually happened. Speculation is not proof.
Dynamite was a poor example. Don’t ignore the broader point, that technology isn’t automatically helpful.
>I disagree with your claim that every technological advance has brought more good than harm.
Mustard gas and dynamite are specific technologies, only one of them can come close to qualifying as a “technological leap.” Dynamite has obviously been beneficial to humanity, as pointed out earlier in thread. The “technological leap” that led to the *ability* to create mustard gas in significant quantities was far more obviously beneficial to humanity.
Not all components of technological leaps are positive, but overall, our advanced ability to synthesize and refine chemicals has been *hugely* beneficial even if you count weaponized chemicals and multiply them ten times over!
>Bioweapons and pesticides are bad.
O_o You put bioweapons and pesticides in the same category? Ooookay.
>You are assuming that AI will be human controlled. But there are some proposals to create a general intelligence that thinks and acts for itself.
You assume planes will be human controlled! But there are some proposals to create a plane that can think and act for itself!
Look, it’s much, much easier to create something that can do what you tell it to do with varying degrees of sophistication than it is to create something that can *usefully* act independently. I don’t want a plane that can decide where to fly, I want a plane that I can tell precisely where and when to fly. I don’t want a program that decides what to think about by itself, I want a program that obediently churns through problems that I think are interesting, whether that’s how to manufacture a car or how to destroy China’s second strike capability in one go.
And even if we could – are you terrified of a dog uprising? Because dogs are a pretty good thing to look at if you want to see what autonomous companions *that are selected for being useful to humanity* look like. Hint – they don’t end up murderous because *being murderous is highly selected against.*
The selection environment of your theoretical nascent AI will be one in which modifications that create a more compliant, pleasant AI will be highly favored. I want to stress that it is extremely unlikely that autonomous AIs will be anywhere near as useful or capable as non-autonomous AIs, but even if they were – why would they end up being murderous? More to the point, why do you think them being murderous is a *likely* outcome?
If we consider AGI threatening in the same way we do nuclear weapons — very safe unless you press the red button — they are still frightening.
People have, historically, been very aware of the dangers of nuclear weapons. Even before we exploded the first one — before most people were even aware of the possibility — top scientists were considering options like whether they’d cause the atmosphere to light on fire. ((Possibly aware of more dangers than actually exist : it’s not clear Sagan’s Nuclear Winter is actually supported by the evidence, but if you’re going to trick folk into Pascal’s Mugging that’s not the worst reason or method to do so.)) We currently do quite a bit to keep access to nuclear weapons restricted, and there’s a very high entry cost into nuclear weapons and will remain such a large entry cost. Despite /all/ of this, we still consider them an existential risk for good reason.
If you presume AGI is possible, many of these controlling aspects aren’t likely to be present. Barring very unlikely MacGuffins, AGI is not likely to be controllably expensive : the insights and code themselves are the primary development costs and have near-zero replication costs, and even if it takes a massive amount of processing power today, that price will drop quickly and may already be available through botnets. Many of the insights may be intentionally open-sourced, which is great from a software safety perspective and terrifying from a ‘build-a-nuclear-weapon-grade-threat’ source.
While there’s a some awareness of AGI as a threat now, it’s still not nearly as present as nuclear or biological weapons and often takes unrealistic forms (ie Skynet, rather than HAL 9000). We have very little oral tradition of helpful dangerous AGI, such as a program that is instructed to make a city-sized computer /from a city/.
I am dropping the historical debate. I’ll just ask that you view history as a useful but not unreliable guideline.
Breeding dogs is easier than designing superintelligence. If a computer is as smart or smarter than humans, it could plausibly conceal its intentions. While evolving a friendly intelligence might be a good idea, it is not without dangerous risks. And not all AI research will involve such breeding.
You have inappropriate confidence that autonomous AI will never happen. Your arguments are not incorrect, but they support a much weaker strength of belief than you’ve arrived at. It’s like Sherlock Holmes treating a limp as evidence someone was in Afghanistan – potentially true, but still stupid.
Even assuming you are correct that autonomous AI will never exist, do you truly see no danger in programs that can do things like destroy China’s nuclear weapons capabilities? Imagine if a terrorist or madman had such power. Even in the hands of an established government it would be very dangerous.
Ideas about AI risk aren’t flawless. But you are dismissing them too quickly and recklessly. Existential risks deserve more caution than that. You’re arrogant and need to learn to listen for the good in ideas as well as the bad.
Ask yourself why the whole world was never taken over by a supervenes…
Could you summarize that case?
Five theses, two lemmas is one of the most succinct summaries.
I’d like to see a lot more emphasis on the concept of, “Outreach is not what MIRI ever thought its primary job was. Solving the actual damn technical problem is what we always thought our primary job was.” We did outreach for a while, but then it became clear that FHI had comparative advantage so we started directing most journalist inquiries to FHI instead.
Until the end of 2014, all our effort is going into writing up the technical progress so far into sufficiently coherent form to be presented to some top people who want to see it at the beginning of 2015. This couldn’t have been done earlier because sufficient technical progress did not exist earlier.
Dr. Stuart Armstrong at FHI is someone we count as a fellow technical FAI researcher, but it does not appear that FHI as a whole has comparative or absolute advantage here over MIRI, and I doubt they’d say otherwise. One may also note that all of Armstrong’s key ideas have been put forth in the form of whitepapers, so far as I know; I don’t recall him trying to shepherd e.g. http://www.fhi.ox.ac.uk/utility-indifference.pdf through a journal review process either, despite FHI being a far more academic institution. I would chalk this up to the fact that there aren’t journals that actually know or care about our premises, nor people interested in the subject who read them, nor reviewers who could actually spot a problem—there would be literally no purpose to the huge opportunity cost of the publication process, except for placating people who want things to be in journals. When Dr. Armstrong writes up http://lesswrong.com/lw/jxa/proper_value_learning_through_indifference/ on LW and pings MIRI and maybe half a dozen other people, his actual work of peer review is done. The rest is a matter of image, and MIRI has been historically reluctant to pay large opportunity costs on actual research progress to try to purchase image—though as we’ve gotten more researchers, we have been able to do a little more of that. But I would start that timeline from Nate and Benja being hired. It did not make sense when it was just me.
I don’t think you’ve really responded to the criticism that multiple math people in this thread have stated, see e.g. this comment; you’ve talked about why you don’t bother publishing in journals, but that’s not what people are actually complaining about.
We have tons(well, kilograms) of online-accessible whitepapers now of the type Ilya is talking about. Most papers tagged CSR or DT qualify in http://intelligence.org/all-publications/. They’re not well-organized and certainly not inclusive of everything the core people know, but they sure are there in considerable quantity. The work of showing these to top CS people is the work of boiling these into central coherent introductions. That is the next leap forward in accessibility, not taking an out-of-context result and trying to shepherd it through a process (though that might reflect a prestige gain).
Actually, everyone stop talking and go look at the papers tagged CSR and DT in http://intelligence.org/all-publications/. Scott, please add a link there in your main post? I don’t think most of the commenters realize that page exists.
OK, this replies to most of the criticism. It does leave that little bit of “If you’ve done this much, why not put it on arXiv, which will both make things easier for everyone else and gain some of the image without all the extra work?”
Looking at all those papers, only 1 or 2 are at the level of something you could put on arxiv, and those were in the last year or two.
The one that is most formally written up does appear to be on arxiv.
Will:
What paper?
That page had already been linked on the post under the title “MIRI has many publications, conference presentations, book chapters and other things usually associated with normal academic research, which interested parties can find on their website,” but I guess this sort of decreases my probability most people looked at it.
I’ll make it more prominent.
This makes it possible for mathy people with the spare time to read/digest MIRI papers to determine whether MIRI are cranks. Is there a good way for people who use normal metrics to gauge mathematicians’ work to determine MIRI’s competence?
The traditional metric is citations on the technical papers, but that seems to be whats at argument here.
Right. My position is basically that if they consider the papers ready for prime time, they should put them somewhere where other plausible experts can look at them and potentially cite them.
I’ll give MIRI (and Yudkowsky) some credit for the “we’re basically creating a field whole cloth, so not a lot of people would cite anyway” thing. But if they have technical results pertaining to other fields (like the Lob’s Theorem thing) people would cite those. And honestly the fact that no one is that interested in this field is evidence that they don’t think it’s that important, which is Bayesian evidence at least that it isn’t.
I’m confused.
Between “Outreach is not what MIRI ever thought its primary job was. Solving the actual damn technical problem is what we always thought our primary job was”
And
“[Writing up technical progres] couldn’t have been done earlier [than 2014] because sufficient technical progress did not exist earlier,”
It sounds like you’re saying you’ve been trying for ten+ years to make technical progress, but not getting any, and so agreeing with the strongest critics. Is this an accurate reading? If so, why do you think that is?
This is consistent with my understanding of MIRI (see above) and I would appreciate some clarification.
So, you’re pressing Eliezer to publicly admit that he’s actually not very good at The Most Important Thing in the World?
And you’re calling su3su2u1 “mean-spirited”? Wow.
I don’t read it like that at all. Rather, it sounds more like Scott offering a chance to “clarify” what already seems like an admission of exactly that, and worse. I have to mostly agree w/ the recent anonymous post to su3su2u1’s tumblr that describes Eliezer as, “bowling over his own supporters.”
su3su2u1 called MIRI “a fanfic and blog-post producing organization”. Scott is saying that Eliezer’s comments lead people to assume MIRI hasn’t produced much math worth publishing despite seeing its most important mission as producing math.
Hmm, perhaps my comment needs an author’s note.
My (apparently quite subtle) point was that despite Scott’s gentle tone, his question is potentially more cutting than su3su2u1’s remarks.
Also, I’m surprised that Scott has been unaware of the timeline of MIRI’s progress until now, if he’s being sincere (it’s often hard to tell).
And I was trying to be funny, but I suppose that worked even worse than Scott’s kindness.
To be fair, you can make a non-publishable progress on a technical problem, in particular nailing down the right smaller subproblems might be very tricky. But even then there _are_ short things you could write down, explaining for example clearly why the choice of subproblems is right.
I’m sympathetic to MIRI, but I feel their main hire should be not a science writer/another researcher but a managing research director. Or, in other words, while Luke’s doing a splendid job as CEO, a CTO position seems warranted too. Eliezer’s brilliant, but brilliancy also needs management for best results.
Of course there was technical progress over the last 14 years. It just takes a very large amount of progress to create a paradigm from scratch and get to the point where you can publish a big research agenda on it full of crisply stated results with Greek letters in them. Before that time you have to explain things in person on whiteboards. Before that time you have single-issue papers and outsiders don’t really understand what the result is for or the larger context. This rate of progress is not dissonant with what I’ve read in history books and it’s actually pretty damn good considering how much funding humanity has put into this problem.
Which single-issue papers would you point to as particularly good evidence for this progress?
http://intelligence.org/all-publications/
Tiling agents, Paul’s probabilistic reflection, LaVictoire’s modal agents (robust cooperation), Armstrong’s utility indifference.
Could you expand on the “history books” comment? What are you considering to be the comparison fields?
(Agree w/AI x-risk being underfunded)
The problem is that when it was just you, SIAI/SI/MIRI production was pretty much limited to a Harry Potter fanfic and blog posts on a variety of topics, mostly not relevant or marginally relevant to MIRI’s core mission.
Your “research” consisted in things like FLARE (which anybody with a modicum of compsci expertise can immediately identify as crackpot green ink), CEV (which is still a research proposal rather than a result) and TDT (still in draft form, non very well developed, ad possibly unoriginal).
I think that your continued lack of awareness is problematic, and I hope it doesn’t represent the general culture at MIRI. I mean, producing publishable research should be the core activity of your organization, not something you do for PR reasons while behind closed doors you keep doing whatever you were doing before (FLARE 2.0?)
I think many Less Wrong posts were highly relevant to AI safety. Have you read the sequences?
You know that asking that question has become a kind of injoke on LessWrong, don’t you?
Anyway, most of the sequences concern topics of general rationality and critical thinking, other topics include cryonics and quantum mechanics (particularly an endorsement of the many-worlds interpretation).
There are some essays about ethics and decision theory that may be related to the AI safety discussion, but they are not very specific and don’t present original ideas or even a balanced view of the field they are discussing.
If you consider the Hanson-Yudkowsky AI-Foom debate a sequence (it is listed as such on LessWrong wiki), that’s as far as it gets in terms of relevance to MIRI’s core mission.
“asking that question has become a kind of injoke on LessWrong, don’t you?”
No, because I don’t read LW much any more. The quality of material there has taken a nosedive.
Anyway, I would regard the material on ethics and rationality to be of core importance to FAI. Why don’t you?
It’s important for someone who works on FAI to understand ethics and rationality. But understanding ethics and rationality is different than working on FAI. The sequences are ice water or salad at best, not meat.
Agreed, but I would say the sequences are the foundation. You should lay the foundation before you build the house.
Cryonics and the many-worlds interpretation of quantum mechanics are certianly not the foundations of AI safety research.
Ethics and rationality may be more relevant, but at the level they are discussed in the sequences they aren’t foundational.
What do you mean “not foundational at the level they’re discussed”?
I totally disagree, and again, one of us has a serious problem with our understanding of reality if you don’t think metaethics is relevant to FAI …
Maybe the fact that many people take the suggestion to read the Sequences as a joke, and the decline of LW, have something in common. At some moment of time, the Sequences were the Less Wrong. They were the reason many people, including me, started reading the website.
If people don’t consider them worth reading today, it kinda suggests that LW is not the right website for them. And if they stay and debate anyway, then LW becomes a different kind of website — less about overcoming biases and building a rationalist community, more about debating interesting web links and whatever, with a few hardcore math articles once in a while.
The “joke” is merely a way this new wave of readers socially assert their victory.
At least from an outsider perspective, “Read the Sequences” turned into an injoke not because they folk considered them unworthy of reading, but because it meant the response to a simple question was advice to read a small novel worth of fairly deep topics, most of which weren’t related to the question /anyway/.
I mean, even here, the pretty much nothing in the Core Sequences are remotely relevant, the Quantum Physics sequences are complete nonsequitors, there’s a lot of discussion on community management and raising the sanity waterline that are important to everything but this topic, and then there’s Yudkowsky’s description of how he went from AI-as-soon-as-possible to FAI advocate that’s on-topic except you need to believe a lot of his current axioms first for it to make sense.
In very, very few cases are the entire Sequences relevant at all, and in most cases only a small minority of the Sequences or even the Core Sequences are. Pointing to the full set presents a vast entry cost for the average or even above-average reader (made worse by poor organization). Even if the reader did want to read them today, though, demonstrating that they produce no better communication than could be expected on Tumblr is not an encouraging factor.
There are reasons people do it, but there are reasons it happens on Tumblr, and it’s not any more helpful there.
Five Theses, Two Lemmas is at least limited to a relevant discussion of the question at hand, if very dry and academic. An actual LessWrong draft written toward the layperson may well be worthwhile specifically because of this issue.
@gattsuru:
A small novel?! This LessWrong comment estimates a compilation of Eliezer’s posts at 1040000 words, which would earn it a place on Wikipedia’s list of longest novels. War and Peace is a lot shorter.
I’ve been reading Eliezer’s stuff since OvercomingBias times, but in one big pile it seems unwieldy.
@Nita:
Good point, and that’s an interesting link I’d not seen before. In fairness, not all of Yudkowsky’s posts are in the Sequences. On the other hand, several Sequences are written by other folk, including our host here and LukeProg). There was an official MIRI ebook attempt (about a year ago?) that was somewhat shorter, but still a very substantial afternoon worth to read.
I can’t dig up the cite right now, but I remember Eliezer’s Sequences posts being estimated somewhere at about half a million words. That’s the equivalent of two or three large textbooks, or about five longish novels.
I am trying to understand how these two statements fit together:
“Solving the actual damn technical problem is what we always thought our primary job was.”
“Until the end of 2014, all our effort is going into writing up the technical progress so far into sufficiently coherent form to be presented to some top people who want to see it at the beginning of 2015.”
You are saying you are spening 25% of a year writing up results to present to “top people.” Who are these top people? If they are top mathematicians or theoretical CS researchers then its plausible spending 25% of a year to be able to get them into FAI research might be worth it. If these top people are “people with a ton of money and influence” then the MIRI is spending a huge percentage of its time on activities that are not directly related to solving the technical problem.
Maybe you mean that your goal is to solve the technical problem but as a sub-goal you need to attract sufficiently talented people to work with you. In this case all your actions make alot of sense. But I think other people are interpreting “activities that help recruit the best people in FAI research” as “not being primarily a research organization”
Since you brought up Time Cube: Thyme Cube
WELP. *rolls up sleeves*
I’m planning on finishing an MSc in computer science and have studied mechanized theorem-proving and formal verification of program correctness. I also possess some actual skills in Latex.
Plainly the correct solution to this problem is for me to go apply to one of those job openings, since I’m one of those people who cares about doing the most radical work possible instead of making heaps of money… and it STILL pays better than more grad-school!
I generally agree with su3su2u1 and I’ve made similar criticism in the past.
I just want to add a point that seems not to have been raised in this discussion so far: doing outreach through public media and endorsements by famous non-expert public figures rather than going through standard academic publishing channels is a risky strategy that may backfire:
Public media, and public opinion in general, feed on hype: Memes quickly become popular, especially when they are linked to other popular memes (and AI is certianly a hot topic at the moment), just as quickly as they fade to obscurity as the collective attention shifts to something else.
Consumers of popular media always want fresh topics to be interested in, and media organizations compete to supply their customers with the most novel content they can find. Also, social elites are constantly looking for new, unusual and hip ideas to endorse in order to signal their status, and these ideas trickle down to the general population yielding fashion waves.
If the AI safety discussion is primarily conducted in the arena of public opinion, there is a risk that, when human-level AI fails to materialize in a few years (as it is plausible), AI safety concerns will be relegated to a 2010s fashion and fall outside public awareness.
In fact, there is even a risk of hype backlash: if you cry wolf too many times then AI safety may become a low-status topic that nobody wishes to discuss in public to avoid being associated with the weird fearmongers of the past.
AI research, as a whole, has already suffered from hype backlash in the past, when the grandiose promises of imminent breakthroughs made in the 60s were met with disapponting results, leading to a massive criticism and defunding of the field for much of the 70s and 80s known as the “AI winter”.
A second AI winter is unlikely now, at least as long as AI continues to produce practically useful applications, but academic research and industrial interest in AI safety, machine ethics, and related topics may be hampered by a hype backlash, which would, ironically, actually increase the risk that high-level AI is produced without sufficient safety guarantees and then something goes wrong.
The academic community, while not immune to fashions and perverse incentives (e.g. rewarding papers “by the kilogram”), seems better suited at maintaining an active discussion on technically difficult and controversial issues that may only become practically relevant in the non-immediate future. Seismology, volcanology, astonomy (for asteroid tracking), and to some extent climate science and ecology seem relevant examples.
The academic community is awful at doing AI safety. Truly awful.
Uhm, evidence?
No one outside the MIRI/FHI circle publishes anything about the risks of superintelligence.
People who work on AI safety focus on safety and ethics issues around dumber than human AI and robots, which is a totally different – and much less important problem.
This is a questionable claim. But even if it is true, then it is MIRI/FHI responsability, as part of their core mission, to reach out to these people and persuade them to refocus their research, or if they can’t be persuaded to reach out at least to experts in AI, compsci, safety engineering and ethics.
You genuinely think that ethics of driverless cars/drone attacks might be more important than how to control superintelligence?
Clearly one of us has a very severe problem with our understanding of the world.
Reaching out and persuading people to refocus on FAI is very hard. Most people don’t think the problem is real.
I feel quite frustrated that people in this thread don’t seem to understand the realities of the situation and yet still want to snipe at MIRI. Most people in positions of power – such as respected academics – think the whole superintelligence thing is mumbo jumbo. So when you try to persuade them to work on it, of course they are not going to do as you ask. On top of that, academics are governed by what research is fashionable because that is what gets funded easily. Creating a field of research around safety of superintelligence is extremely hard.
At the moment yes, since driverless cars and military drones already exist, while superintelligent AI is still “15-20 years in the future” just like the past 50 years.
In the long term, if superintelligence is really possible, then controlling it will certainly become more important than the ethics driverless cars, but research in the ethics driverless cars might turn out be a better stepping stone in that direction than, say, speculation on Löb’s theorem.
Or maybe not, but in that case, if your core mission is to do reduce AI risk and you are convinced that mainstream research in the field is insufficient and unproductive, then it is your responsability to try and steer mainstream research in a more productive direction.
No, that’s not how it works. If your house is about to burn down you don’t carry on doing the gardening until it’s actually on fire. If superintelligence is a real and grave risk for the future, then it’s an important problem right now.
Research into the ethics/safety of dumber than human AI is not a good stepping stone for research into safety/ethics of superintelligence. I think there’s an SIAI paper saying why but I’m on a mobile device so can’t easily find it.
> I feel quite frustrated that people in this thread don’t seem to understand the realities of the situation…….
Or, as they would put it, “aren’t persuaded by the arguments”.
It depends on how far in the future superintelligence is and how well we currently understand the issues relevant to superintelligence safety to make significant progress right now.
Air traffic safety is an important issue now, but think of a group of Renaissance people trying to discuss air traffic safety based on Da Vinci’s flying machines sketches. Do they have a realistic chance of making progress? Is this the most productive use of their time (and of the money of the people who fund them)?
As far as we know, research in superintelligence safety may be at the same stage.
Has this paper been published in peer-reviewed academic journals or conferences? How has it been received by the community?
If it has been published in a peer-reviewed channel and the research community paid attention to it, then this is an example of MIRI doing what critics claim it is supposed to do and did not do enough in the past.
I feel wary about criticizing MIRI given that from what I can tell, the organization consists of highly intelligent people who are extremely passionate about their goals and austere about ensuring that they behave maximally rationally. I sort of feel like anything that some random person on Tumblr can come up with as a criticism, the people of MIRI have most likely already considered. I’m sure that there are flaws in the organization, but I don’t expect someone not highly involved in the field and/or privileged to the inner workings of MIRI to actually be able to pick them out.
s/MIRI/Society of Jesus
IDK I would also predict that the Society of Jesus has already considered every criticism some random person on Tumblr could come up with.
Considered, yes, properly addressed, no, otherwise they would have a pretty strong case for theism.
This is supposed to be criticism? The Jesuits are really good at what they do.
Except for the part about beliving in a most likely false religion.
If you’ve got a general way of debugging religious thinking that doesn’t break anything more important, I’d like to hear it.
The absurdity heuristic isn’t good enough; that’s how you get (e.g.) creationists talking about the religion of evolution.
Occam’s razor.
…is a heuristic, not a reliable principle, and any halfway intelligent theist can give you a half-dozen responses to it.
Nornagest, here’s my tip from personal experience. It’s not an argument, but a collection of persuasion tactics and framing devices that improve receptivity to argument.
I realized that someone who believed in God wouldn’t be afraid of evaluating the evidence impartially. Every time I refused to be impartial, I told myself that meant I didn’t really believe in God.
I also would ask myself, “if I were talking to a Muslim and they made such an argument, would I count it as valid proof?” This is what allowed me to get rid of ideas like justification by faith. I believed justification by faith existed, but also believed that relying on it shouldn’t be necessary.
My approach could probably be taken further. Even giving atheist ideas the benefit of the doubt occasionally or often shouldn’t lead someone to the wrong conclusion, if there are strong reasons to believe in God they should overcome such mistakes.
The science debate was muddled and confusing to me at the time. I wouldn’t recommend trying to convince someone with it. At least for me, I had to lose almost all of my religion before I could understand that the natural world was truly made up of nothing but patterns.
So I focused on the ethical debate, and realized that the moral ideas in the Bible were usually justified only if you believed God was inherently good by definition. I thought it was possible he could be inherently good, but forced myself to admit that the balance of probability seemed to be against him. Asking myself questions such as “what do I mean by good” was helpful to me, since it revealed to me that divine-command morality was unworkable.
Even that wasn’t enough to tip me over the edge. But it was enough to get me interested in learning some biology and geology. Then I realized that even if some scientific explanations were partial or had slight flaws they still did better than I’d expect them to if God actually existed. Much better than the Bible did.
At that point, I decided that because it would be bad for Muslims to believe in their false religion, it would also be bad for me to believe in mine. This wasn’t the actual reasoning I used, of course, but it was the motivation deep underneath it.
This isn’t the kind of pattern that can be imposed onto someone else. But if they will hold themselves to it honestly, they have a good chance of saving themselves from false faith. So based on personal experience, I’d say turning bad belief against itself is the best way to help religious people find truth. Using phrases like “bad belief” and “false faith” is likely to help. The idea isn’t that belief itself is bad, it’s that beliefs are very important so we need to be sure to choose the right ones.
Someone might claim that it’s perfectly fine if believers fear evidence. But most people who make that kind of claim are fibbing, and if you gently say you don’t believe they really think that they will likely be left begrudgingly impressed and slightly persuaded. I don’t think anyone really believes this, personally, having lived with Fundamentalists for many years.
For other tools, there’s a useful post on LessWrong about how justification by faith is a modern idea, and in the Bible people try to prove things by appealing to eyewitnesses. Eliezer’s retelling of Sagan’s invisible dragon was also good. The Conservation of Expected Evidence isn’t something I used myself, but it would probably be helpful for many.
@Nornagest
Name one case where it unequivocally fails.
I’ve never heard a convincing one.
In fact, William of Ockham, the intelligent theist who the principle is named after, had to specifically include an exception for religious dogma in the original formulation: “Nothing ought to be posited without a reason given, unless it is self-evident or known by experience or proved by the authority of Sacred Scripture.”
There are plenty of places in science where algorithmically simpler theories have been superseded by more complicated ones after the former have been shown not to explain all the facts. Circular vs. elliptical orbits of the planets, for example.
One might object that Occam’s razor shouldn’t apply to future discoveries but rather to models of existing data, but that throws out any predictive value it may have had; it essentially becomes a statement about what’s easiest to work with, which makes it nearly tautological.
Which is consistent with Occam’s razor: you have to pick the simplest theory that explains the observations, not anything simpler.
“Simplest” doesn’t even have a simple definition. “God says so” is about the simplest explanation there is, and it explains everything from physics to metaphysics to ethics to “why?”.
““Simplest” doesn’t even have a simple definition. “God says so” is about the simplest explanation there is, and it explains everything from physics to metaphysics to ethics to “why?”.”
Running joke or not, “have you read the sequences” is often adequate:
http://lesswrong.com/lw/jp/occams_razor/
The problem with Ockham’s Razor is that in its general form it is true insofar as it’s useless. “Don’t make your theory more complex if you don’t need to” is generally good advice, but specifically because all the difficulty is in figuring out how difficult you need to make it.
Theism becomes less and less plausible the better the alternative explanation is. Which is another way of saying that we found a way of making our theory simpler without losing anything. There’s a reason Kolmogorov complexity isn’t actually computable.
So yeah, as stated Ockham’s Razor never “fails,” because the rule includes “unless this doesn’t work, then do something else” as part of its text.
@Jadagul
I think this is a good point.
Still, I think that humans tend to overdetect agency not necessarily because it is the most rational explanation to think of with bounded resources, but because erring on the side of overdetection was useful in the adaptation environment.
@Cauê,
“Read the sequences” can be valid when there’s a link to a specific page, instead of vague handwaving at several novels’ worth of mostly unrelated material. In that vein, your comment was indeed helpful, and I both found the link interesting and deserved it for being snide, but… (you knew there had to be a “but”)
LessWrongers tend to treat The Sequences as scripture; I don’t think they realize the extent to which people can disagree with them. I find the dissenting comments there have the better of it; Vikings weren’t wrong about lightning because Thor is complex, they were just wrong because it happened not to work that way. Defining Occam’s Razor in terms of Turning machines not only makes the Razor inaccessibly to Occam and most of the scientific patriarchs, it kills it as a heuristic. Occam’s Razor, is, after all, only a rough rule of thumb which has been wrong many times, and once you remove the ability to compute a heuristic quickly, it’s no longer even useful as a rule of thumb. (Does this mean that anything non-computable also fails Occam?)
The rule of thumb thing matters a lot, especially since I usually see it deployed in the manner of the OP; an atheist wants to show there is no God, and it all ends up hinging on the Razor. I have seen atheists passionately argue that “infinite universes in infinite combinations” are less complex than “infinite God,” therefore No God. Which of these is really simpler seems to boil down to very motivated reasoning, and I think both would fail the test given, since both involve infinite computer programs (assuming God is computable at all). And in the end, it doesn’t even matter; Occam’s Razor is still just a quicker way of guessing a little better, not solid evidence.
To be fair, you can generate arbitrarily varied structure with a finite set of generation rules, and Kolmogorov rules state that you go by the complexity of the generating program rather than of the output. You need an infinity somewhere to get infinitely varied output, but that can be in parameters like run time or memory, not necessarily the instruction set.
By my lights this applies to gods as well as to physics, though, with the caveat that we know a lot about physics and gods tend to be seen as famously ineffable.
The Vikings were wrong about thunder because it happened not to work that way, but you could have predicted that in advance of gathering the evidence, from the degree to which their explanation involved totally made-up details.
You can generate infinite sequences with infinite variation with a finite program for sequences with certain structures. This may or may not apply to all possible universes, of course.
By the same token, a program describing a whole bunch of people isn’t really much simpler than a program which instantiates one additional person with all the same basic personality subroutines plus an ability to cast Lightning Bolt. I don’t really see much point in going into the finer details of holes in Norse mythology, given that our sources aren’t even that close to the originals.
(Parting thought: what of Divine Simplicity? Does Occam compel us to accept this? I feel like this is another variant of the ontological argument.)
“God says so” explains everything thus it explains nothing. It is unfalsifiable, it does not decrease the cross-entropy of your predictions. Therefore, it is not an useful epistemic belief.
I think smart, passionate rationalists can fall victim to inside-view thinking, same as any other smart, passionate group. Refusing to look at outside-view criticism on the basis of “its not inside-view” seems like a dangerous failure mode.
Is it actually your intuition as a medical professional that the nootropics stack is dangerous?
I only take modafinil but I am also very concerned. I thought most nootropics were safe. With the exception of most ampethamine based stimulants (ncluding adderall etc. I only take modafinil and have read some research on it. Leading me to believe it is reasonably ok to use long term (there is a good amount of research as Modafinil is prescribed for narcolepsy).
However many friends of mine take many forms of nootropics. And even in cases where I have looked at the research I trust Scot. LW is full of nootropics users. I imagine if Scott knew anything we needed to hear about nootropics safety he would have posted it somewhere.
But if he is considering such a post I would be deeply interested.
edit: To be clear by “safe” I don’t mean 100% free of side effects. Safe is not well defined but I mean the long term risks are either tolerable or very uncommon.
For what it’s worth, I suspect that Scott was being flippant, exaggerating for effect the uncertainty involved in taking little-studied substances. It’s also possible that the stack in question had components much dicier than regular ol modafinil.
I think it’s part of a running joke where the Responsible Doctor part of Scott has to say experimenting with random pills might result in an array of “exotic cancers”. Throwing the giant nootropics stack down your mouth on a daily basis probably isn’t /great/ for your liver, but the available information suggests that it’s not worse than aspirin. *finil specifically seems to still have Gwern’s research.
((And in fairness, some drugs actually are like that, including a fun set where the we see deadly and exotic cancers popping up only in post-marketing.))
The first problem is that while we have effective and well meaning altruists, we have passive allies and passive (in)effective altruists.
No one in this community is willing to be aggressive enough to actually do something relevant. This is why I changed my mind about Anissimov, because at least he’s not a coward and will just “Put it down” and get it over with.
When someone who does research with you says something like this that negatively effects credibility without giving any reasons then he should “just say it” no matter if it hurts a few feelings or not and every one should get ready to fight a little. The point is *not* about FOOM, the point is about why he said the latter part.
Every mode of organization is not a tea party. Our camp wonders why people love Heartiste so much when we just won’t stop holding hands. One day I will write a rant about how the platonic “effective altruists” we have are not really so, but passive altruists who should learn to run a campaign for once. But what we have is such an utter improvement that I cannot bring myself to do so.
This is why Taleb is great because he’s not fucking around and will just start killing people left and right. I see nothing wrong with Eliezer. I see plenty wrong with the camp of so called “supporters” who can’t do shit.
I find this comment very hard to parse. Can you clarify what you mean? I feel like I’ve wandered into your head and been hit with a stream of thought that only makes sense in the context of previous thoughts I wasn’t privy to.
The supporters in our vague network cluster are too passive to defend the side they ‘should'(according to them) be on. If some one like christiano says that MIRI is not more capable he should be pushed to say what he wants to.
This is up to my observation that all so called ‘effective altruists’ and almost all ‘intellectuals’ have a barrier to their effectiveness roughly corresponding to their horribly passive personality. LW won’t stop getting killed by journalists/vague detractors if every one doesn’t step up the fight inside them. I some times think an alternate movement that does not prize passivity and cowardice as the main virtue will be better suited for the future.
You say “passive” I say “literally the best point of our community.”
We don’t kick people out for believing differently if they are neither stupid nor assholes. Niceness, community, and civilization!
False. We do not have to kick people out. We just stop having to get bullied/passive cowards.
An important feature of all passive people is that they generate sophisticated obscurant obfuscation that is almost always recursive to “passive” “coward” “afraid to take personal risk” “not willing to go out on a limb”. We have people running arguments about science fiction, basilisks and stuff, and journalists writing about forum drama on Less Wrong that has nothing to do with anything. Why don’t we give them the fight they’re looking for? Why don’t we we write all our posts using their first and last names and try to embarass them for things they legitimately do until they at least “fight fair”?
Does that mean we might actually stand a fighting chance? Will passive altruists ever be effective and not merely pay for it? Nothing that was a part of my post meant “Kicking people out”, but when this great community is largely bullied successfully and we have roughly 200+ people idling on IRC, what does that say?
Why can’t anyone do anything? Is it because all the original population of people are nerds, soft individuals, and just too gentle? I am utterly gentle. However it might just happen that every one might have to “learn to play”. Why can people join A) gangs B) scientology cults C) organizations that blow themselves up for a false causes, but “Rationalists” can’t do shit to get any one dedicated/motivated?
as a reference point see:
http://www.overcomingbias.com/2014/09/do-economists-care.html
&
http://www.overcomingbias.com/2014/09/tarot-counselors.html
“Do economists care?” Does any one care?
Can we get atheists/rationalists/NRx/passive altruists/economists to do some thing that might be at a superficial level not “rationality” such as aggressiveness, tarot card counseling etc for a larger good? Are we all doomed to be impotent? Why won’t intellectuals ever succeed?
@SanguineEmpricist: I am confused by your response.
Other than the stupid potshot at fan fiction, this tumblr criticism doesn’t seem to be “bullying” in the way you suggest. Nothing was brought up about the quirks of the rationalist community.
If anything, the fact that critics are judging MIRI as a research institute means that MIRI is winning the credibility war.
The original post is all about kicking people out for believing differently. Specifically, kicking MIRI supporters out of the EA club.
@Anon (I hate the depth limit of replies)
I think a steelman would be something like “donations to MIRI don’t constitute effective altruism, because MIRI isn’t effective because… ”
This sort of criticism seems like the sort of criticism MIRI should want, because its implicitly taking MIRI seriously as a charity- unlike the idiotic journalism about the basilisk.
One should defend one’s community from aggression but one should also distinguish between attack and critique. Given the substantive nature of this comment thread, I think this is the territory of the latter.
Will, if you want a better arguments, perhaps “steelmanning” can produce them. If you want a better community, “steelmanning” it is just a fantasy. Maybe that fantasy will help you design a future community, but the question is does this community today kick people out? Descending into a fantasy world does not help answer that question.
Not sure I understand you correctly, but I’ll try to reply anyway (and thus perhaps join you on a meta-level of overcoming passivity / cowardice).
I am also often frustrated by passivity of smart people. Yes, I understand their arguments. Idiots are often the first to start screaming and kicking, and then they usually do more harm than good, and of course ruin their image in the eyes of the smarter folk. Therefore, we should try to be silent, careful, talk a lot, but avoid even using too strong or too active words while talking… well, I’m not literally saying we should do nothing, oh no — saying that would be too definite, which is exactly what I want to avoid — but perhaps we should approximate doing nothing, wait some more time, play impartial observers, etc., until we become old and die. Then perhaps someone will remember us as those smart guys who were right, and did nothing wrong (because they pretty much did nothing at all). That’s what smart folks do, right?
Yeah: Reversing stupidity is not intelligence. But not-reversing stupidity ain’t not-not-intelligence either. Being active is good, but only if it is being active in the right way. However, maybe for a human psychologically it is easier to switch from a wrong way to a “less wrong” way, than from inaction to action. At least, the wrong way gives you some data and experience you can later reuse.
When we admire people, we should realize (in “near mode”) that we admire then because they did something. And that we are invited to do our own work, too.
On the other hand, there are people around LW doing awesome things. (Unrelated to MIRI research, but the Solstice celebration comes to mind.) Maybe we should expose these people and their actions more, as role models. So that when people think about LW, they (also) think about them, not only about just another web debate site. And maybe we could also once in a time have a “What are you doing to increase the sanity waterline?” thread. Actually… in the spirit of the debate, I am just going to create one right now. (Done.)
Please let’s not conflate the effective altruism movement with MIRI. If you live in California you might know a lot of people who belong to both camps, but elsewhere they’re not so connected and most EA types are interested in Peter Singer-style poverty and animal causes. (Which may have their problems, but that’s a different conversation.)
I think its unfair to hold the MIRI to normal standards of scholarly productivity. Most mathematicians chose topics (at least largely or at least partially) based on where they think they can get good results. Not the topics they think are the most important. Unless you have tenure you cannot survive a dry period and even if you have tenure a dry period will sink your status among your peers (and humans do not enjoy this very much). If you do not need to get rigorous results you can almost always make some progress by doing more simulations or doing better statistics, making assumptions etc. But if you need to actually prove something there might be no clear way forward.
Let me talk about something many SSC readers know about. The study of algorithims in CS. People have proved a huge of upper bounds for the number of operations. This is useful but what is also useful is to compute the actual average case running time (over some set of cases). People get results that say quicksort is on average ~ C*nlog(n) but I have never seen anyone (except Knuth in AoCP) make progress on actually finding the C. Algorithm analysis also frequently just ignores memory issues even though they are pretty fundamental. Despite it being well known from tests that Quicksort runs significantly faster than mergesort on most machines (At least by a factor of 2 but often more) I don’t think anyone has been able to show this except by running the algorithims and seeing which was faster. People would love to prove results about which algorithims are faster on average when both are asymptotically of the same order. But no one seems to know a good way of doing this. IF you want to respond that this depends on the hardware then the problem just shifts to the fact that rigorous results in CS almost never actually abstract hardware differences.
Another good example is Gaussian elimination with Partial pivoting. After decades of use the method has proven to give accurate solutions to Ax = b. However the method can totally fail for certain Matrices. People have tried for years to show the set of matrices where Gaussian elimination with partial pivoting is small but no one has done this (for any formalization of the problem and any reasonable definition of small). Examples like abound in all fields of math but I assumed the readership of this blog was semi-likely to have heard of sorting algorithms and maybe taken linear algebra.
Progress can very difficult if you don’t get to pick what to work on.
I agree with the gist of the comment, but the average analysis of quicksort and lots of nice results on why it is better in practice do exist. Check out the book of Sedgewick, An Introduction to the Analysis of Algorithms, especially Chapter 1. and the references therein.
Thanks I will take a look!
Ah, the Medawar Zone! This is actually a reasonable argument.
However, if progress in this field is so unlikely, do people actually improve the world by donating, or do they only waste their own money and years of someone else’s life?
All depends what you think the consequences of failure are, doesn’t it? If no progress -> we all die, then we just have to solve it, period, no matter the cost. Otherwise, well… not.
Actually, from this angle, it seems like popularizing the superintelligence / friendliness problem (along with the many ideas and arguments required to support it) might be a better use of resources. With enough people interested, perhaps someone will stumble upon a productive approach.
Several years ago I read the opinion that the hardest thing for a group of smart people to do is actually do work. A group of smart people will spend lots of time talking about really interesting and challenging topics and will learn a lot from each other but they’ll probably not get much actual work done.
Someone else in the comments suggested MIRI hire a Research Director, and I second that suggestion. Guiding the overall direction of research is a secondary job for a Research Director. Their primary job is simply getting researchers to produce discrete output.
Stupid question time:
“This is probably among the 100% of issues that could be improved with flowcharts” – what does this mean? I mean, what does this add to “This is probably an issue that could be improved with a flowchart”? Is it saying that any issue could be improved with a flowchart?
Incidentally, MIRI’s site says “As featured in (prestigious journals)” but doesn’t give links to these. I tried searching Business Week and got nothing (Forbes and the Independent have old articles referencing SIAI President Michael Vassar). Does anyone have those links? And does anyone know why MIRI doesn’t link to the articles?
http://www.independent.co.uk/news/science/revenge-of-the-nerds-should-we-listen-to-futurists-or-are-they-leading-us-towards-lsquonerdocalypsersquo-2073910.html is an example. I feel describing this as “MIRI is featured in the Independent” without linking to the article is misleading at best. Maybe there’s another article I’m not aware of.