
The largest non-pharma antidepressant trial ever conducted just confirmed what we already knew: scientists love naming things after pandas.
We already had PANDAS (Pediatric Autoimmune Neuropsychiatric Disorders Associated with Streptococcus) and PANDA (Proton ANnhilator At DArmstadt). But the latest in this pandemic of panda pandering is the PANDA (Prescribing ANtiDepressants Appropriately) Study. A group of British scientists followed 655 complicated patients who received either placebo or the antidepressant sertraline (Zoloft®).
The PANDA trial was unique in two ways. First, as mentioned, it was the largest ever trial for a single antidepressant not funded by a pharmaceutical company. Second, it was designed to mimic “the real world” as closely as possible. In most antidepressant trials, researchers wait to gather the perfect patients: people who definitely have depression and definitely don’t have anything else. Then they get top psychiatrists to carefully evaluate each patient, monitor the way they take the medication, and exhaustively test every aspect of their progress with complicated questionnaires. PANDA looked for normal people going to their GP’s (US English: PCP’s) office, with all of the mishmash of problems and comorbidities that implies.
Measuring real-world efficacy is especially important for antidepressant research because past studies have failed to match up with common sense. Most studies show antidepressants having “clinically insignificant” effects on depression; that is, although scientists can find a statistical difference between treatment and placebo groups, it seems too small to matter. But in the real world, most doctors find antidepressants very useful, and many patients credit them for impressive recoveries. Maybe a big real-world study would help bridge the gap between study vs. real-world results.
The study used an interesting selection criteria – you were allowed in if you and your doctor reported “uncertainty…about the possible benefit of an antidepressant”. That is, people who definitely didn’t need antidepressants were sent home without an antidepressant, people who definitely did need antidepressants got the antidepressant, and people on the borderline made it into the study. This is very different from the usual pharma company method of using the people who desperately need antidepressants the most in order to inflate success rates. And it’s more relevant to clinical practice – part of what it means for studies to guide our clinical practice is to tell us what to do in cases where we’re otherwise not sure. And unlike most studies, which use strict diagnostic criteria, this study just used a perception of needing help – not even necessarily for depression, some of these patients were anxious or had other issues. Again, more relevant for clinical practice, where the borders between depression, anxiety, etc aren’t always that clear.
They ended up with 655 people, ages 18-74, from Bristol, Liverpool, London, and York. They followed up on how they were doing at 2, 6, and 12 weeks after they started medication. As usual, they scored patients on a bunch of different psychiatric tests.
In the end, PANDA confirmed what we already know: it is really hard to measure antidepressant outcomes, and all the endpoints conflict with each other.
I am going to be much nicer to you than the authors of the original paper were to their readers, and give you a convenient table with all of the results converted to effect sizes. All values are positive, meaning the antidepressant group beat the placebo group. I calculated some of this by hand, so it may be wrong.
| Endpoint | Effect size | p-value |
| PHQ-9 | 0.19 | 0.1 |
| BDI | 0.21 | 0.01 |
| GAD-7 | 0.25 | ≤0.0001 |
| SF-12 | 0.23 | 0.0002 |
| PHQ-9 Remission | 0.31 | 0.1 |
| BDI Remission | 0.55 | 0.049 |
| General improvement | 0.49 | ≤0.0001 |
PHQ-9 is a common depression test. BDI is another common depression test. GAD-7 is an anxiety test. SF-12 is a vague test of how mentally healthy you’re feeling. Remission indicates percent of patients whose test scores have improved enough that they qualify as “no longer depressed”. General improvement was just asking patients if they felt any better.
I like this study because it examines some of the mystery of why antidepressants do much worse in clinical trials than according to anecdotal doctor and patient intuitions. One possibility has always been that we’re measuring these things wrong. This study goes to exactly the kind of naturalistic setting where people report good results, and measures things a bunch of different ways to see what happens.
The results are broadly consistent with previous studies. Usually people think of effect sizes less than 0.2 as miniscule, less than 0.5 as small, and less than 0.8 as medium. This study showed only small to low-medium effect sizes for everything.
I haven’t checked whether differences between effect sizes were significant. But just eyeballing them, this study doesn’t agree with my hypothesis that SSRIs are better for anxiety than for depression; the GAD-7 effect size is about the same as the PHQ and BDI effect sizes.
It does weakly support a hypothesis where SSRIs are better for patient-rated improvement than for researcher-measured tests. The highest effect size was in “self-rated improvement”, where the researchers just asked the patients if they felt better. This effect size (0.49) was still small. But if we let ourselves round it up, it reaches all the way to “medium”. Progress!
What does this mean in real life? 59% of patients in the antidepressant group, compared to 42% of patients in the placebo group, said they felt better. I’m actually okay with this. It means that for every 58 patients who wouldn’t have gotten better on placebo, 17 of them would get better on an antidepressant – in other words, the antidepressant successfully converted 30% of people from nonresponder to responder. This obviously isn’t as good as 50% or 100%. But it doesn’t strike me as consistent with the claims of “clinically insignificant” and “why would anyone ever use these medications”?
(though of course, this is just one study, and it’s a study where I took the most promising of many different endpoints, so it’s not exactly cause for celebration)
If antidepressants do better on patient report than on our depression tests, does that mean our depression tests are bad? Maybe. Figure 4 from Hieronymous et al helps clarify a bit of what’s going on:
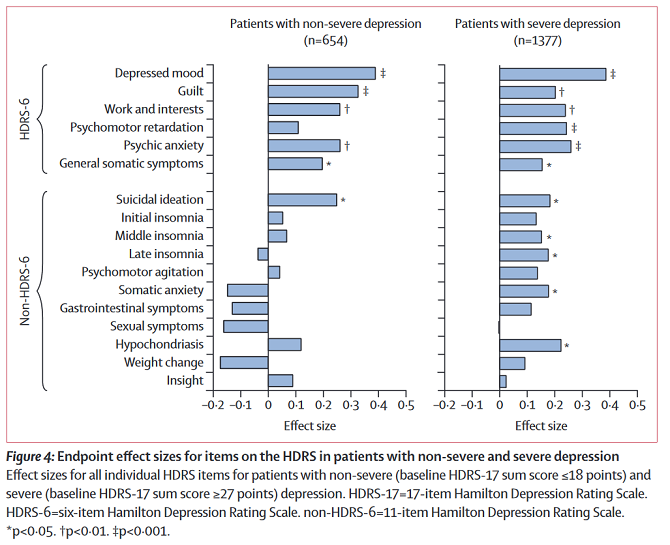
At least in less severely depressed patients, antidepressants are more likely to produce significant gains on vaguer or more fundamental symptoms (like “depressed mood” or “anxiety”) than on specific symptoms (like insomnia or psychomotor disruptions). Probably patients care a lot less about “psychomotor disruptions” than researchers studying depression do, and they just want to feel happy again. This study’s finding of an 0.4 – 0.5 effect size on patient response closely matches Hieronymous et al’s finding of an 0.4 – 0.5 effect size on depressed mood.
Like most studies, PANDA used a one-size-fits-all solution based on a single antidepressant. This is a reasonable choice for a study, but doesn’t match clinical practice, where we usually try one antidepressant, see if it works, and try another if it doesn’t. In patients like the ones in the study, who had failed treatment with sertraline, a usual next step would be to try bupropion. An even better idea would be to screen patients for more typical vs. atypical depression, start people on sertraline or bupropion based on the symptom profile, and then switch to the other if the first one didn’t work. The STAR*D trial did something like this, and got better results than an SSRI alone. I haven’t done the work I would need to compare this to STAR*D, but it seems possible that the extra push from targeted treatment could bring our 0.49 effect size up to the 0.7 or 0.8 level where we could actually feel fully confident prescribing this stuff.
















I think you are underselling an effect size of 0.49.
For example, IQ is mean=100, standard deviation=15. A pill that had +0.49 effect size on IQ would increase IQ by, on average, 7.4 points. Any treatment in the real world that increased IQ by 7.4 points would be considered the absolute real deal and we would all be hailing whoever created it as a hero for our times. We wouldn’t worry at all about the fact that it wasn’t a “large” effect size like 1.0 (a 15-point IQ increase) because we know that IQ is complex and polygenic and probably involves lots of processes going right (or wrong), so we know that is unreasonable to expect a 15-point gain. This isn’t something simple like you cholesterol level that is probably controlled by one or two key molecules.
Like IQ, depression is complex and polygenic and probably involves lots of processes, so an effect size of 0.49 is a damned miracle and should be considered as wonderful (for depression) as +7.4 IQ boost would be (for intelligence). Also, just as +7.4 IQ probably would have much bigger practical impact in the tails (on either side), the equivalent for depression would probably have a much bigger impact on the most extreme cases.
Your comment interacts with Scott’s piece to remind me of the Flynn effect, in which the scores a population achieves on IQ tests famously rise over time, at about 0.25 points per year. (That is, successive cohorts get successively better scores. It’s not a within-cohort finding.)
IQ tests are also famously dominated by a single factor, Spearman’s g. But, so far as I understand it, investigations tend to show that the gains from the Flynn effect on IQ tests are concentrated in questions that are not heavily g-loaded. Something is increasing scores, but (if you’ll excuse the somewhat sloppy terminology) whatever the cause is, it isn’t that people are just generally getting smarter.
This reminds me of the phenomenon discussed above in which antidepressants have a big effect on patient self-assessed improvement, while having much weaker effects on objective criteria. The Flynn effect has a symmetric pattern going on, where assessment shows a big improvement, but the more basic underlying endpoint doesn’t.
That said, I can offer an alternative explanation of the outsized self-assessment effect by analogizing to a blogger’s observation on playing Borderlands: he said that as your Borderlands character gains experience, you pick up a bunch of little perks, like firing your gun 1% faster, or recovering health 1% faster. They’re all small.
But over time they stack up. When you take 10% less damage, and you heal 10% faster, and you fire 10% faster, and your bullets deal 10% more damage, and you miss 10% less often………
All of those numbers are 10%, but overall you’re a lot more than 10% better than you were when they were all 0%.
Depression isn’t supposed to follow a bell curve.
When we claim that depression is a distinctive disease, we’re claiming that it is bimodal, with depressed people very far away from the general population. Of course, the null hypothesis should be that the depression instrument is garbage. The very basic piece of justification of a depression test should be that it has such a distribution. But it’s hard to find documentation of that.
Here I suggested that null hypothesis and Richard Roman dug up studies that various versions of the Hamilton inventory do pass this hurdle, with 4-5 standard deviations between depressed and healthy people. Thus, when we say that a drug has an effect size of 0.5, we’re saying that it cures 1/10 of depression. (I think that this study, with only mildly depressed people has only 2 standard deviations to cure, so its effect size of 0.2 is again 1/10.)
That is very surprising for me. I always thought that depression is part of bell curve that we arbitrarily marked as “this is excessive”. I thought the same about PTSD, anxiety and most of other psychological issues. Maybe even all of them?
For example, just because I sometimes cringe after I remember about a stupid thing that I did when I was 9-years old does not mean that I have PTSD. But PTSD is that something like that happens ousing the same mechanism, but with massive effect. That puts it out of acceptable part of the bell curve.
The same for phobia, OCD, body dysmorphy, autism etc.
Obviously this does not mean that depression/PTSD/etc is not real! The effect is real but I though that there is no clear line. Note that even with seemingly obvious things like blindness there is no really clear line. People with minimal residual sight are also legally blind – what makes perfect sense.
——
I tried reading https://slatestarcodex.com/2018/11/07/ssris-an-update/#comment-689261 but it is not clear to me. Is there somewhere a graphical representation how depression (or some other psychological issue) forms something else than bell curve in general population, with depressed/PTSD/Autism/ADHD/whatever population clearly distinct?
These are not mutually incompatible pictures. Depression, PTSD, and so on, naturally supervene on all sorts of ordinary experiences and phenomena that (also non-pathologically) occur on a spectrum of phenomenological gravity. But if these phenomena become predominant and overwhelming they can tip the balance of one’s existential reflective equilibrium into various undesirable attractors that are qualitatively very different from “just a bit more of the same”.
As the old Witters put it, the world of a depressed person is totally different from that of those not suffering of depression. As in case of trauma, it’s a difference between the world being a place where sometimes bad shit happens versus the world being an existential trap full of dangers, devoid of hope or any positive futures in one’s abstract decision theoretic map, boring and banal and tedious and gray and at the same time vaguely or acutely menacing, with some high-grade guilt-tripping thrown in for good measure, about not enjoying the little things in life, guilt-tripping over guilt-tripping since you know it’s counterproductive, etc. etc. (These are not “just” psychological “failure modes”, but often have to do with objective features of one’s life and the world at large, and depressive realism for instance is an actual thing for some people.)
> When we claim that depression is a distinctive disease, we’re claiming that it is bimodal,
I don’t think this is necessarily true. For example we all agree that hypertension is a disease, yet there’s not some bimodal distribution to blood pressure. Instead there’s a smooth curve starting at 110/60 that smoothly and monotonically extends out to 180/110.
Some diseases are bimodal and others are not. And indeed, hypertension and hypotension are actually kind of vague for this very reason, as where natural variation turns into a disease state isn’t always clear.
The range of variation is very important as well. If there’s very large differences between depressed and non-depressed people, then small effect sizes are less useful – so even if there is a continuous spectrum, and we do draw an arbitrary line of “depression” somewhere, if that line is five units away from normal, and we move people 0.4 units, sure, we saw an improvement, but it wasn’t necessarily a very large one. So if being depressed is very far from being “normal”, a small effect size means that you didn’t help them very much.
As they noted in the link, the gulf between the “depressed” and “non-depressed” people was five standard deviations in that test, so nudging someone half a standard deviation is not necessarily an enormous improvement in standard of living. If depression and non-depression were only half a standard deviation apart, then that nudge would completely cure them.
This is consistent with what I’ve seen in depressed people in general – the medication is helpful, but the effect size is fairly small and they still have problems, just not quite as bad as they were before.
https://en.wikipedia.org/wiki/PandaX
Pandax laboratory. this is great.south african gospel music
It would be remiss of me not to mention pandas, the data analysis library.
I stopped reading after the second paragraph and scrolled down here to make sure somebody mentioned it already. One doesn’t simply skips pandas in a community like this.
Huh, that was close. It’s buried as a third post already! 🙁
Yes, I’m surprised Scott didn’t mention it.
There’s also PANDA for network analysis:
https://sites.google.com/a/channing.harvard.edu/kimberlyglass/tools/panda
For a sec I thought the title was “Real World Depression Monument”. Which would be a nice monument.
https://www.tripadvisor.com/Attraction_Review-g28970-d10768256-Reviews-Depression_Breadline_sculpture-Washington_DC_District_of_Columbia.html
There are casts of that at the Grounds for Sculpture in New Jersey and
the Walmart MuseumCrystal Bridges in Arkansas too, though both are closed now.The Depression Breadline statue is worth a 5 minute view, It gets lost in the other larger and more popular Washington memorials.gospel music 2020he way to FDR memorial.
The second figure is confusing. These are effect sizes at 12 weeks for sertraline, among two different groups, across two tests? Does that mean somatic anxiety went up in less-severely depressed patients (along with gastrointestinal symptoms, sexual symptoms, and weight change)? I could see the drugs having gastro, weight, and sexual side effects, so maybe those track, but I feel confused.
Yes, but the lack of asterisk means it wasn’t significant.
Ahh, I see, that contextualizes the analysis below the graph. Thank you!
I’d be interested to see a comparison to a second, untreated, control group.
My understanding is that placebos make a significant difference to depression, but normally you can’t prescribe them, so I think when you’re computing the value of an antidepressant the important comparison point is “no treatment”, not “reassuring sugar pills”, and that might push them up to a larger effect size.
Certainly my own experience with antidepressants was that they made me feel massively better even when I was cycling home with them in my backpack, before I’d even started taking them.
Why can’t you prescribe a placebo?
Either you have to lie to or mislead your patient, which isn’t ethical, or you have to tell them the truth and make sure they understand it, which I suspect (although I may be wrong) will severely diminish its effectiveness.
There may be some people who would benefit from being told “here’s a sugar pill; sugar pills help a lot of people feel better via the placebo effect”, but I doubt it’s as good as giving them things with fancy medical-sounding names and telling them they’re antidepressants, and I’m not on board with doctors significantly misleading their patients, even for their own good.
So for a doctor to ethically provide something that will give significant placebo effect to most patients, I think they probably have to be able to honestly explain to them that there may be a non-placebo effect.
Funny enough, that’s exactly the niche for homoeopathy and accupuncture etc:
You have placebos prescribed with somber ritual by caring people who believe they work.
Anecdotally, the couple of times I have had a doctor / psychologist screen me for depression and anxiety, I felt that the questionnaires used were incredibly problematic — and I basically had to pick answers that gave the result I wanted, because the questions were so vague and hard to match to my actual life that there wasn’t really a good answer for most of them.
I don’t remember what tests these were, and they might have been pre-screens, of a sort? I don’t think anyone who met me in person and just talked would have disbelieved that I was severely depressed. Yet questions like: “how often in the last two weeks have you been bothered by feeling little interest or pleasure in doing things” (I googled PDQ-9 and grabbed the first question, which I definitely recognize from my doctor) — that’s just so hard to answer.
Let me demonstrate by speaking for myself a few years ago: I felt plenty of interest in staring at the internet, playing video games and going about my dismal routine, but no interest and some dread of socializing or doing anything new; I wasn’t bothered by it really, because I was so checked out, but at moments I would realize that it really bothered me; those moments weren’t really in the last two weeks, because I’d been in this state for months or years and I just remembered that they happened at some point; I’ve been failing to sleep regularly for months, but that kinda dampens my mood, so I don’t really feel much of anything, so although I feel little interest, I’m not bothered by it, but I should be, and clearly something is going on —
so I end up putting “several days” because there’s just no way to capture reality in such an oversimplified question, yet I figure that what the question is getting at probably does apply to me, so I should give it some credit?
Anyway, point is, I’m not surprised at all that you get low and confusing signals if your data is as bad as these tests seem to be. But maybe some of the other ones are better?
“how often in the last two weeks have you been bothered by feeling little interest or pleasure in doing things”
I think that’s a terrible question because it seems to assume “oh, you’ve only just started feeling really bad and your doctor immediately gave you this test so you can honestly say that three weeks ago you were fine and normal but now you only want to lie in bed all day”.
But what about “well it took me six months to get up the guts to talk to my doctor about this and then it took me another two months to get them to agree to give me a test like this”? “Only happened within the past two weeks” doesn’t cut it there, but it seems to be “oh well if this is long-standing and not sudden onset – and the test says so! – then it’s not, like, real depression or whatever by our score when you add up all the little ticky-boxes”.
Or “I am no longer even bothered by loss of interest, that is how I noticed that something went wrong” situation.
You seem to have misunderstood the question. They are asking about how often you felt anhedonic or uninterested during the past two weeks. That could begin 6 months ago, a year ago, does not matter. On the other hand, if you have not felt uninterested in the past two weeks, you do not have the symptom.
On the other hand, if you have not felt uninterested in the past two weeks, you do not have the symptom.
Which is another not-helpful thing, because maybe the past two weeks were relatively good but over the past year+ I’ve been feeling like shit.
“Oh well since you managed to scrape up enough energy to pass for normal last week, you’re not depressed! Never mind that you have a solid year before that of lying awake in bed until 3 in the morning wishing you were dead!”
I know all measurements are going to be rough and approximate, but sometimes you can’t slice it neatly into two-week segments. The main reason you may have been able to get up and go to your doctor and talk about being depressed was that this was a relatively okay time where you had the energy and lack of “what is the point even trying to do something” to get tested, and now the test is saying “well this isn’t depression if it didn’t happen in the past two weeks”.
“how often in the last two weeks have you been bothered by feeling little interest or pleasure in doing things”
I’ve had fairly severe depression and anxiety, and I couldn’t possibly give a good answer to that question. When I was untreated, the reality was ‘I almost always feel little interest or pleasure in doing things’ and ‘I don’t have the energy to decide whether that bothers me or to keep a count of the times it does.’
I can’t imagine the answer I ended up giving being strongly correlated with any actual improvement in my condition. In fact, my answer to that might well get worse as I improve and have the energy to count instead of just making up a number.
Yeah, that’s what I’m trying to get at above.
(1) “I have little pleasure or interest in doing things but it extends a lot further than two weeks”
(2) “I have little pleasure or interest in doing things, but I am in such a grey slough of despair that I’m not even bothered anymore, I just expect to feel like this forever”
(3) “The recent past, as in the past two weeks, I’ve been able to pull myself together enough to be functional, so I have had some interest in doing things – such as getting help for my problems – so ‘I have not been often bothered'” (and how frequent is “often” anyway? Once every day? Twelve times a day? Every second day? Slow but growing lack of interest?)
(4) – which would seem to be the preferred answer: “Normally I love my life and have lots of pleasure and interest in my activities! But over the past two weeks, it has been 10 times out of 14 that I have had no pleasure/interest!”
Stupid question time: what exactly is meant by a clinically significant finding? What I mean is, do the researchers/drug companies/doctors expect that to be “I used to want to throw myself out a window, but now after 12 weeks on FlyHi I am frolicking through the meadows picking buttercups and warbling with the birdies”?
Because I don’t think it works like that, which is why in the real world situations patients go “Yeah I’m still depressed, but after 12 weeks on FlyHi I no longer want to throw myself out a window, so that is much better as far as I’m concerned”. Also, 12 weeks seems like a very short time to get a really big change in severe depression.
The smallest amount that a patient or doctor could plausibly notice or care about if it weren’t being carefully measured, but there’s no good definition for how to determine this.
“In patients like the ones in the study, who had failed treatment with sertraline, a usual next step would be to try bupropion.”
Not in the U.K. it wouldn’t be. For some reason, it’s only licensed for stopping smoking.
There’s a Telegraph article here:
https://web.archive.org/web/20181024140355/https://www.telegraph.co.uk/health-fitness/body/could-antidepressants-be-killing-your-sex-life/
(It’s an archive.org link to avoid the paywall).
Welbutrin is only approved for depression in the US and Canada AFAIK. Elsewhere it’s only for smoking cessation.
It is approved for depression in Germany. Probably some other European countries too.
I suspect that part of the problems here involve an attempt to quantify depression or determine objective signs when it’s really hard to attempt to understand the experience from the inside. My (least) favorite example of this is the 1-10 pain scale.
You deal with a patient who has a broken leg and states that their pain is 9/10 and give them 5mg morphine or something. You come back 20 minutes later and they still rate their pain as 9/10 but they are visibly more comfortable, their blood pressure and heart rate has come down to something reasonable, they aren’t fidgeting all the time, etc. Do you treat this the same way as before and give another 5mg morphine because they have 9/10 pain? How do you reconcile the patient’s self-reported experience with the objective findings?
It’s possible that certain elements of the human experience are just too non-linear to be measured in nice charts like that.
For a study here you switch patients to a different SSRI, how do you deal with the control group?
If they don’t improve on cane sugar pills, do you start giving them sugar beet?
As far as I remember (and I may be wrong), they did not deal with the control group in the STAR* trial. For those who did not respond to SSRI antidepressant citalopram, half was blindly continued on it and half was blindly switched to a non-SSRI antidepressant bupropion.
I would like to highlight a few points on which Scott was somewhat vague, unclear or incorrect:
1. Scott is somewhat more positive than the authors of the study. The primary outcome of the trial was PHQ-9 test at 6 weeks. That was the measurement that failed to show statistically significant effect. On PHQ-9, according to the authors, “we found no evidence that sertraline led to a clinically meaningful reduction in depressive symptoms at 6 weeks.”
2. This was not a trial on depressed patients, contrary to what the context of Scott’s discussion suggests. Only 52% of participants were diagnosed with depression. 46% of the participants were diagnosed with anxiety, with some overlap between these two groups (30%). 15% had subclinical depression/anxiety and 15% did not have depression and anxiety.
In other words, this was a trial on any patient for whom “there was uncertainty (from general practitioner [GP] and patient) about the possible benefit of an antidepressant.” The authors were agnostic about the diagnosis: “use of clinical uncertainty as an entry criterion avoids diagnostic or severity criteria”.
3. Accordingly, Scott appears to be incorrect in rejecting his own prior hypothesis that “SSRIs are better for anxiety than for depression”. The trial’s results are emphatically in favor of it. The primary depression PHQ-9 test difference was insignificant. In contrast, the anxiety GAD-7 improvement was highly significant p<0.0001
4. Finally, Scott is wrong that the trial “does weakly support a hypothesis where SSRIs are better for patient-rated improvement than for researcher-measured tests.” All of the questionnaires in the study were self-rated. None of them was clinician’s impression or clinician-rated.
1. It’s good that the authors chose a primary endpoint, but it’s also fair for me to notice that most other depression tests at most other times were significant.
2. Fair, will edit to make clearer.
3. The difference between significant and nonsignificant is not always itself significant, and eyeballing the real results instead of the headlines, I notice things like d = 0.21 for BDI vs. 0.25 for anxiety, I don’t find this particularly interesting.
4. Maybe I was wrong to use the word “self-rated”, I meant “rated by a test” vs. “rated by your own gestalt impression”. Will edit.
Lots of kudos for this response.
What’s the probability of getting a p-value of 0.049 assuming there was no p-hacking?
Assuming what true effect size? And does 0.048 count, or only values 0.0485 < p < 0.0495?
Two things:
1) The standard categorization of effect sizes is misleading. A true “medium” effect size is ENORMOUS, something like “liberals think social equality is more important than conservatives do”, or “people who like eggs eat egg salad more often than people who don’t”. http://datacolada.org/18
2) The standard python package for data analysis is also called “pandas”
Thanks, that’s a great link.
Effect size for interventions should be expected to be larger than effect size for observations. The questions in your link are analogous to: what is the correlation between two questions on the depression inventory? It is small, but when we treat depression, we would like to have a large effect. An analogous question is: what is the effect size on eating egg salad of offering it as one of two choices on the menu, vs neither of two choices on the menu?
For selective breeding, the typical effect size is 30.
(What is the effect size of offering egg salad as the only choice on the menu, vs not a choice on the menu? 10?)
There’s also PANDA (Private ANonymous Data Access).
Are there any studies that follow the economic outcomes of people who are prescribed various anti-depressants. I wonder if economic (or possibly academic for certain segments of the population) activity could be used as a measure of the effectiveness of various anti-depressants. Its possible that an anti-depressant could make people productive without fixing the underlying issue, but my understanding is that depressed people often tend to be reluctant to do anything, so trying to measure the compatibility with society could be a good way to gauge the effectiveness of a treatment. It seems after all that this is a common thread among almost all psychiatric disorders, that they disrupt an individuals ability to participate in society.
One of the challenges in defining a clinical trial (or statistical test of type, really) is determining which variables you will control and which you will not. The trade-off is that by controlling things more strictly, you hopefully reduce your noise/error term, and increase the likelihood of detecting a significant effect. But the cost is that this often makes your results less representative of real world practice and necessarily more limited in scope.
In clinical trials, I believe this is a reason for both over- and under-estimation of effects. In cases like this, where the prescription/administration protocol is restricted to ensure that results can be compared, you can under-estimate effects. In other contexts, where membership in certain subpopulations (think demographic or genetic confounders) modulates a treatment’s efficacy, doing population-level assessments underestimate effects within the subpopulations. The opposite can be true when you attempt to generalize results from specific treatment regimes/conditions/subpopulations to broader contexts.
Are there studies that let the psychiatrists change the SSRI/anti-depressant for individual patients in the experimental group? Is it possible that giving a patient a specific antidepressant doesn’t improve many of them, but giving a patient their best antidepressant (or best of 3) would produce way better results? Like in practice I assume you wouldn’t just stick with Zoloft if it’s clearly not working, you’d swap around SSRIs and see if one was better/had less shitty effects.
Switching ain’t-depressants isn’t necessarily simple. They have long half lives and can have pretty significant side-effects as you come off them. Different drugs will have different recommended approaches for quitting or switching.
I’m not super familiar with the literature on this topic, but I’ve never seen a study that did this, and I don’t expect to anytime soon, for the reasons HeelBearCub mentions.
However, I’d also argue that it’s not a coincidence that basically every effective antidepressant affects neuroplasticity to some degree, and that we have contradictory pressures over the course of successful psychotherapy – we want to increase neuroplasticity (in combination with an altered neurochemical environment) to help patients quickly break out of depressive thought patterns at the start of therapy, but comparatively decrease neuroplasticity to help entrench a patient in more useful thought patterns once they’re established and to prevent remission in the long term.
So there’s a plausible mechanism for a shifting regimen to be more effective than any specific antidepressant alone.
Is anyone else tweaked by the idea that Scott really wants to know how helpful anti-depressants are for curing depression in people who may not be depressed?
I understand that, from a clinical perspective, we don’t have reliably determinative diagnostic tools for depression. So it’s a real world scenario, and you’d like to know helpful we might expect it to be.
But it seems to me that this is a little like measuring the outcomes of chemotherapy on a group of people who may or may not have a cancerous tumor. I would think that would tend to mask the effectiveness of the intervention in a study. It might tell you about the outcomes for this treatment protocol, which can be super useful, but it doesn’t say as much about the effectiveness of the drug at treating depression (or cancer).
My understanding is the point of doing the study this way was to mimic how anti-depressants are most commonly prescribed out in the world — ie, mostly by general practice docs on people who have not been definitively diagnosed with depression, but who present with things that seem like depression or anxiety or various sub-clinical levels of one or the other, or kinda sorta in that direction.
So in that sense it seems different from looking at chemotherapy on people who don’t have cancer because out in the world, chemo isn’t used that way.
Yes, I understand. That’s why I made a point of emphasizing outcomes for treatment protocols.
But the design doesn’t seem particularly good at telling you how efficacious the drug is at treating depression, the thing Scott seems to be emphasizing. I wouldn’t think we should expect that the study would have very strong results.
Yes, I see, sorry I didn’t read your comment as closely as I could have.
If I’m understanding the study right, it shows the drug does not have very strong results for treating things that more or less look like depression in real world settings. Which is pretty much how most studies of antidepressants look, even in more controlled settings, right?
So nothing about this study seems particularly surprising to me. There are other studies showing that “normal healthy” non-depressed people also experience some mood improvement from taking SSRIs, even in the very short term. And those effect sizes aren’t very big either.
It’s been my anecdotal experience as a clinician that people’s responses to SSRIs (and associated antidepressants like Wellbutrin or Effexor or tricyclics) are highly individual, varied, and unpredictable. So I could see how on average, they come out as mildly helpful when really what seems to be happening is that they are awful for some people, hugely helpful for others, and not worth the bother for yet others. So it seems to me all these studies are aimed too broadly.
My experience of people with typical vs “atypical” depression tracks Scott’s in terms of Wellbutrin being generally better for the latter, but also the latter group tends to be an even bigger mixed bag in terms of medication response which makes generalizations even harder.
I’d be hard pressed to say in aggregate what all the antidepressant efficacy studies have gifted us with in terms of accumulated wisdom.
This is the sidest of side points, but the “guilt” scale on the Hamilton test caught my eye. It corresponds to the way that I naively use the word “guilt”, but I’m told that that phenomenon should more properly be called “shame”.
I want to join in here and say that I have found the pop psychology efforts to clarify the distinction between guilt and shame to be maybe not always that helpful. There seems to have been an effort (in last ten or so years?) to say that guilt is how we feel pertaining to “bad” things we have done while shame is a feeling that speaks to feeling “bad” as a person. And sometimes along with the idea that guilt is an okay/useful/normal thing to feel while shame is not.
I find that distinction unhelpful partly because of what you say, which is that a lot of people’s “naive” sense of the word guilt is what yours is and it seems like a fine word to use to capture a flavor of emotional experience. When people say “I feel depressed” or “I feel anxious” or “I feel restless,” they are often pointing to variable but overlapping experiences that we humans have, but don’t all have the same. Because of this interpersonal variation, the word, whatever it is, seems like the beginning of a conversation about what it feels like to you and how you see it affecting your life.
Some people call the feeling pertaining to “bad” acts “remorse” or “regret.” Some people voice what might be considered as “excessively guilty feelings” about a wide range of acts but do not feel that they are in some essential way “bad” people; but as a practical matter, these excessively guilty feelings get in their way just as much as if it were a more global feeling of “shame.”
Two points, both aimed at Scott, and an aside:
1) I’m going to echo and expand on what Scchm said above (point 3).
There are a variety of ways that data can produce different p-values, but given the same n, I expect that the low p-value for anxiety represents a great deal of consistency in outcomes. If you put the data on a graph with some appropriate error bars, you’d see two distinct regions, before and after treatment, where the error bars have little to no overlap.
That means that although the effect size might not be massive, sertaline (and plausibly other SSRIs) is a very reliable intervention for anxiety. It is extremely likely to make an anxious person feel at least a little better.
Conversely, I expect that the much higher p-value and comparable effect size for depression represents a much greater deal of variability in those data. As a person who has taken a lot of antidepressants, and who has talked with a lot of people who have taken a lot of antidepressants, this matches my intuition: sometimes SSRIs completely fix a person’s depression, sometimes they have a slight effect, sometimes they do nothing, and sometimes they make it worse. Depression itself is also inherently very variable – sometimes it goes away on its own for inscrutable reasons, or changes in response to life factors that are completely outside the domain of a research trial.
I’d expect the effect of an SSRI on depression to be much less reliable than its effect on anxiety. These results appear consistent with that.
So when you say you have a hypothesis that SSRIs are better for anxiety than they are for depression, what value set are you using to determine “better”? Does reliability of an intervention factor in, or is it just average effect size?
2)
Your back-of-the-envelope estimate here should represent a minimum value, because that 30% change is the net effect.
In my experience, sometimes, for some people, antidepressants make depression worse. But we’ve got a pretty good feedback loop to mitigate that effect – people who feel like an antidepressant is making their depression worse tend to stop taking it, or switch to a different medication. Because such patients are often encouraged to stick with an antidepressant for a while, such patients wouldn’t reliably be lost to attrition during the course of a study that lasts only a few months.
In a study like this, we should consider that an antidepressant might also convert some responders to non-responders. In order to achieve a given net effect, each responder who’s converted to a non-responder must be balanced out by an additional non-responder who’s converted to a responder.
That means SSRIs may be, to some degree, more useful for treating depression than your calculations indicate, because of how we keep doing things that seem to work (generally capturing non-responders who convert to responders) and change tactics when things don’t seem to be working (generally excluding responders who convert to non-responders).
(aside) I am, however, giving some serious side-eye to the authors’ decision to run data analysis on log-transformed as well as non-log-transformed test scores, and then report p-values on both, as well as reporting p-values on multiple other post-hoc analyses. I’m not familiar enough with the literature to know if that’s standard, but it seems super sketch, as does the consistent use of 95% CI despite the large variety of different analyses performed. The very small p-values in this study seem legit in spite of this, but I definitely wouldn’t trust any part of an interpretation that’s based on, say, a p-value of 0.094 (see supplementary material, p6, final sentence). Ditto for their interpretation of the BDI results.
(Disclaimer: I didn’t actually read the research paper.) So this study shows a modest superiority of the SSRI vs. placebo, but I’m not sure that even this small effect is real. Antidepressants have side-effects, and side-effects are known to enhance the placebo effect. People think to themselves, “This pill makes me nauseous and tired, so it must be a very powerful drug, and I bet I’m going to feel better soon”.
But even if we assume that the small effect is real, does that mean we would be justified in using the drug to treat depression? Maybe not. Robert Whitaker has done an outstanding job in documenting the long-term harmful effects of antidepressant drugs, so we should balance any short-term positive effects against the very real possibility that the drug will worsen depression in the long-term.
I remain puzzled why psychiatrists are so fond of prescribing antidepressants. These drugs seem ineffective at best, and harmful at worst.
I land where you do on many days, and yet I see people for whom the right antidepressant is hugely helpful for a time and for some that the side effects (at least as they experience them day to day) are not very bothersome, and so the trade-off seems very simple to them.
I don’t know what percentage of people who have tried antidepressants have that simple straight-forward experience. My sense is that it’s a minority of people and that the larger group has side effects that make it not worth the price of admission or the benefit they get poops out in a few months or the improvements are modest even if the side effects are also modest. But I could be wrong about that — are there studies of that question I wonder?
And then there’s a whole swath of people who found them helpful but then find getting off of them incredibly hard, like just agonizingly hard, wind up taking them for years well past when they want to be taking them, because they can’t get off of them, not because they are still helpful.
The thing is: what are the other options? If you’re a doctor and not doing psychotherapy and you have patients who don’t want to (or can’t) change the circumstances of their lives, start a dedicated exercise or meditation practice, make other big lifestyle changes, and also don’t want to do psychotherapy, then what do you have to work with in the half hour you have to meet with them?
I don’t know how often psychiatrists see this side of things, but over on the psychotherapy side, we pretty often see people who have been on antidepressants for months or years and come to therapy and say, “I’m ready to get off of this,” and they’re now stable enough, presumably because of the antidepressants or other factors, that they can focus on making some lifestyle and cognitive changes, and then the drugs were like a bridge from a semi-crisis state to a more personal growth and recovery state. That seems like not a bad thing.
It does seem to me that the potential costs and downsides are pretty consistently underplayed by prescribers. But that may be my biased perspective because I’m a bit phobic about medical intervention generally and people who have been to medical school don’t tend to regard routine things like colonoscopies or antidepressants to be any kind of big deal.
PANDA Pandemic Panders to Pedants!
No article on depression should ever lack a depressing headline.
Meanwhile, in the real pandemic, government that banned PCR test kits and put tariffs on masks now confiscates PPE from hospitals:
https://www.latimes.com/politics/story/2020-04-07/hospitals-washington-seize-coronavirus-supplies
So obviously, the solution to depression is to ban and confiscate all antidepressants, anti-SAD lights, etc. Pretty soon, everyone will either die of depression or be immune. Problem solved.
I’d expect the effect of an SSRI on depression to be much less reliable than its effect on anxiety. These results appear consistent with that.sinach
Welbutrin