
[Update 10/2/23: See also here]
A few weeks ago I published results of a small (n = 50) survey showing that people’s moral valuation of different kinds of animals scaled pretty nicely with the animals’ number of cortical neurons (see here for more on why we might expect that to be true).
A commenter, Tibbar, did a larger survey on Mechanical Turk and got very different results, so I retracted the claim. I wasn’t sure why we got such different results, but I chalked it down to chance, or perhaps to my having surveyed an animal-rights-conscious crowd who thinks a lot about this kinds of things vs. Tibbar surveying random MTurkers.
Now David Moss, from effective altruist organization Rethink Priorities, has looked into this more deeply and resolved some of the discrepancies.
The problem is that I did a terrible job explaining my procedure (I linked to the form I used, but the link was broken when Tibbar did his survey). In particular, I included the line:
If you believe [animals have moral value] in general, but think some specific animal I ask about doesn’t work this way, feel free to leave the question blank or put in “99999”, which I will interpret as “basically infinity”
About 5 – 10% of respondents took me up on this. Tibbar didn’t make this suggestion, and none of his participants did this.
Moss surveyed 490 people on Mechanical Turk, and did not offer people a “basically infinity” option. However, many (20% – 40%) of his participants said the question didn’t apply to specific animals.
He found that when he ignored these, he got the same (low) numbers as Tibbar; when he counted an N/A answer as a vote for “basically infinity”, he got the same (high) numbers that I did.
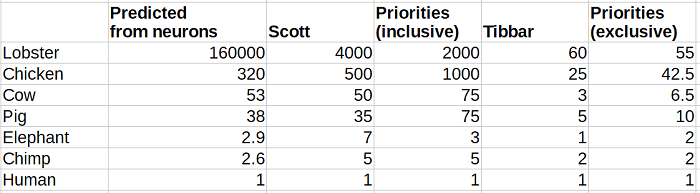
This graph measures people’s perceptions of how many of each animal is morally equivalent to one human. “Priorities (inclusive)” is Rethink Priorities’ survey, with refusal to vote counted as “basically infinity”. “Priorities (exclusive)” is Rethink Priorities’ survey, with refusals to vote thrown out. I think this demonstrates pretty well that you can get either mine or Tibbar’s numbers depending on which choice you make.
But Moss also points out that all of this is just a fragile balance between people who say every life is worth the same regardless of species, versus people who just spam the box with as many nines as they can.
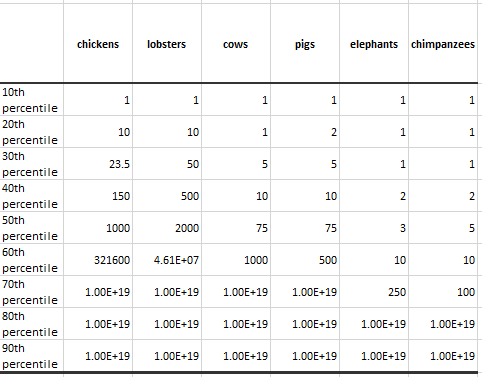
So it’s not clear how much we should be drawing from this in any case. Whatever. I still think it’s neat.
The moral of the story is to always explain your procedures really well before you try to replicate something. Also to make sure the link to your procedures actually goes to your procedures, although maybe no one other than me has ever made that specific mistake before.
















I would have thought that the moral of the story is that without replication of an experiment (especially by someone else), one should be very wary of making any statements about weather the results are actually true. Replication crisis and all that.
“Okay., now that you’ve stated that 1000 chickens are worth one human, imagine this scenario: There’s a fire in a building and you only have the time to save one human or a cage full of 1500 chickens. Which one do you save?
I would be astonished if anywhere near as many people pefer to save the cage full of chickens as said that that many chickens would be worth as much as a human.
Might even be better to phrase it as something realistic: “Would you send in a firefighter at great risk of death to save a cage full of 1500 chickens?”
Make it a more unclear phrasing: If an autonomous truck carrying 1500 chickens notices a pedestrian stepping in front of it, and calculates that the only way to avoid the pedestrian will require swerving and crashing, killing at least 75% of the chickens being transported, should the logic prefer to swerve and crash or strike the pedestrian?
If Minecraft has taught me anything, if my chicken coop catches fire, I will soon have a pile of cooked chicken.
You and/or your readers might be curious to see that I tried something similar (on mturk) with humans of different ages (including prenatal), published here.
Ah, it’s nice to know that about 20% of respondents share my speciesist position of denying any moral weight whatsoever to all non-human animals, including apes and elephants. Some of us are just resistant to cute baby elephant pictures.
Humans FTW!
And then the aliens arrive…
At which point it is permissible to change a lot of beliefs all at once. Including whether you have ten coins in your pocket or whether France has a king.
The question isn’t whether France has a king, nobody cares about that. The important question is whether the king of France is bald.
No, the important question is whether ALL current Kings of France are bald.
What’s the last hominid you would kill?
I am not sure, since we don’t have good information on their capacity for integrating in out network of social relationships with us, potential usefulness in economic interactions and capacity for retribution. I am pretty sure I would have no problems killing australopithecines or homo habilis. I might have some qualms about Homo erectus, there is insufficient information. I would draw the line at Neanderthals and Denisovans, most likely.
Who would you kill if your daughter’s life was on the line?
Any non-sentient one.
Since what people do is much more believable than what they say it seems that if one wanted to find out how we value things we would do some research into what is spent on saving the lives of various things. How much is society willing to spend on saving the life of a human? A dog? A lobster? How much does the average American spend to save the life of an unrelated person? Much more than for dogs, but maybe not so much compared to what is spent on beer.
> The moral of the story is to
always plot the distributions instead of looking at medians or averages.
+1
If you asked me how many cow lives is worth one human life, I would say infinity. If we need to kill 17,000 cows to save one human, kill the cows, sure. [1]
If you asked me how many cows we are allowed to torture to make one human’s life more convenient, I would probably come down to some number. Maybe in the hundreds, I don’t know, but I can see this tradeoff much easier.
[1] Well, there is still value on human life, expressed in dollars, and if there is something causing us to have to kill cows to save a person, I suspect it is going to be repeated, and we might wish we saved Person B for 9000 cows and Person C for 8000 cows, instead of killing all 17,000 cows on Person A off-the-bat.
How many human lives can you make more inconvenient to save one human life? Is torturing a cow worse than killing one? Does logical extrapolation of your stated values result in a conclusion that you do not endorse?
I don’t see why that’s necessarily the case: A simple model that is internally consistent (and one that I happen to agree with. also to keep the matter on the central idea of the issue let’s assume in this thought experiment that there are no other factors that come into play, like other people starving because they could have eaten the cows or something):
If given a choice between killing some number of cows to save one human and killing a different number of cows to save one human, I will choose the lower number of cows.
However, there is no number of cows for which I will choose sacrifice the person to let the cows live
Usually when people use the wisdom of crowds they trim the extreme results and it becomes more accurate not less.
How do you know, unless there exists at least in principle a method of measuring the accuracy of the claim?
There are plenty of situations in which this can be easily measured, i.e. wisdom of crowds guessing the number of jellybeans in a jar, etc.
Let’s take that specific case: Is the squared error of the average (or median?) estimate of the number of jellybeans in a jar greater or less than the average (or median?) squared error of the individuals estimating it?
It has to be squared error, or something similar, because the average error of all of the people making an estimate is the same as the average error of the people making an estimate.
Hi Scott, while you’re in the mood for retraction, could you revisit your Method of Levels review? 😉
Broken links from scientific papers to their materials are definitely a thing and I see them regularly (though it probably often is link rot over time and not a broken link from the start)
I was just logging in to reply that i feel the probabillity that “although maybe no one other than me has ever made that specific mistake before.” seems as close to 0% as your beliefs regarding 1 and 0 probabilities will allow you to go.
Certainly it was the first time for a suitably small reference class of “People trying to link to Scott’s procedures on Scott’s blog”.
Another possible confounder, particularly on the MTurk data, could be innumerate people thinking bigger numbers mean more valuable animals, in the same way that some people think 1/3 is larger than 1/2 because 3 is larger than 2.
Or the survey respondents rationally following their incentives rather than wasting time.
@Rachael: I’m confident this isn’t an issue in this study. We checked for innumeracy in our pilot studies and found it was a slight issue. After we reworded our question and no one we could tell was making the equivalent mistake.
Also @deciusbrutus we can use attention checks to make sure respondents are answering questions rather than trying to speed through the survey as fast as possible to maximize money earned. So I’m confident that also isn’t a issue here.
(I’m Peter, I work with David Moss – the author of the follow up study mentioned here – at Rethink Priorities, a new EA research organization.)
I don’t think you considered the attention checks as an adversarial action against professional mTurks trying to maximize their income. They will be paying enough attention to the input requirements to avoid being caught by attention checks, and even to avoid detection by ‘this person entered data too quickly’ checks. In fact, any standard form of detecting them that has been disseminated enough for you to notice has also been disseminated enough for them to notice and adapt.
@deciusbrutus Are you just thinking from first principles about human nature when thinking about how MTurkers work, or do you have personal / anecdotal / empirical experience? Do you have thoughts on how high the rate of MTurkers deliberately failing to give good-faith responses would be and/or how much this factor should make us disregard results?
Attention checks aren’t perfect but the general principle – as well as the use of MTurk to get worthwhile insight – has been well validated and studied empirically. I have a discussion of the strengths and challenges of MTurk that could serve as a basis for further discussion.
I turked for a couple of months in 2017. I was doing it partly out of curiosity and partly because I had an esoteric reason to want a little bit of earned income though I am nominally retired. For the most part I tried to be legit and answer surveys honestly, but I’m sure there were times when I was sloppy (especially for that tiresome page asking whether I am currently feeling happy? sad? fearful? brave? hungry? alert? tired? et freaking cetera, which seemed to show up just everywhere).
After the first day or so, I rarely had any trouble recognizing an attention test just by its shape on the page, before I even read it to make sure. I could have gone a lot faster by catching those but then making no particular attempt to look within myself for whether I was happy/sad/fearful/brave/etc.
That said, I did have a small handful of HITs rejected, allegedly because I had failed an attention test. But this seemed totally unrelated to whether I had been alert or tired, whether the survey was short or long, or whether I had been engaged and interested or contemptuous and hurried. I attributed it to bugs in the system. Perhaps I actually failed attention tests that were too subtle for me to notice — but in that case, they also ruled out my good-faith attempts to answer honestly.
At the time, I figured these surveys were all being done by students as way of learning survey methodology, because the population of turkers was so clearly a terrible sample if you hoped to learn anything about humans in general. Since then I have learned that I apparently guessed wrong, which terrifies me about public policy over the next few years. I see in your paper you conclude that this is not a problem, largely by comparing it to the alternatives; I sure hope you are correct.
How do you manage to take proof that MTurk recruits a biased sample, and instead of looking at the bias it actually has, look under the streetlight at the parts of the sample that you can see and decide that those parts do not matter to animal advocacy?
The problem I’m pointing at isn’t that marital status and housing type matter to animal advocacy, it’s that any selection process that selects for marital status or housing type also selects for some hidden variables that you cannot conclude are irrelevant to animal advocacy.
The fact that one of the things you are really selecting for is ‘number of MTurk surveys completed’ means, at the least, that you should be looking at the population of MTurks weighted by number of survey completions. Surveys about MTurks taken through the MTurk system already include that weight, almost exactly as much as other surveys of the same size (it’s unclear if MTurk-tracker is weighting results by user or by survey).
I wonder how different the responses would be if the questions were framed in a more visceral way. For instance: “You’re given a choice between two buttons. One will kill a single healthy adult human, the other will kill 55 lobsters. You must press a button within 5 seconds, or both the human and the lobsters will be killed.” I’d imagine you wouldn’t get too many people who chose the human.
Hell, change it to 2000 lobsters and I still wouldn’t choose the human. I suppose there’s some arbitrarily high number of lobsters that would make me choose the human instead, but it would have to be a situation where the existence or genetic diversity of the species/sub-species was at risk, or the balance of a local ecosystem was at stake, or something along those lines.
Whereas with some other animals, like cats and dogs, I could see a lot of people choosing to save a fairly small number of them (probably around 5-12) over saving a human.
Your idea reminds me of the Moral Machine. Those researchers were trying to understand moral judgments when it comes to self-driving vehicles. They were trying to understand how much a pregnant woman’s life is worth relative to an elderly woman’s. So, they prepared an experiment where they show images and ask “is it better if the car kills this pregnant woman or these three elderly women”. A bit bizarre, but someone could do something like that for animals.
I don’t know much about this literature, but as I commented above, I have the impression that people are more able to reach consensus if they vote in choices that come in pairs, rather than assign a numerical number directly.
This seems bunk. When presented similar choices I always chose action over inaction, but it told me I don’t value the lives of the elderly.
Creating false dichotomies just leaves you to misinterpret external causes as internal.
We’ve seen in other surveys that people’s opinions differ fairly dramatically when you frame it in a concrete rather than abstract way, so this would be a good opportunity for follow up / further study.
(I’m Peter, I work with David Moss – the author of the follow up study mentioned here – at Rethink Priorities, a new EA research organization.)
All those studies had the same result: There is no consensus about the relative values of humans and animals.
Yes, but there is an interesting trend. I think a pairwise poll (where you vote “it’s worse killing animal A than B” and so on would work better than assigning scores. It’s like when people rate each other looks. People are much better at reaching consensus if they do it by lexicographical rank than continuous rank. And, in the end, you can convert the pairwise rank into a numerical score.
Are we normalzing everyone’s continuous rankings? Is it not a mathematical fact that continuous rankings normalize to lexographical rankings?
Even if mathematically it’s the same thing, human beings might operate better voting in pairs. It’s just a supposition, I am not a psychologist.
You have to make some false assumptions about people’s beliefs to do that.
Pairwise comparisons would fail to recognise tied/near-tied preferences and create an arbitrary consensus.
Not if you asked the right questions: Is it worse to boil ten lobsters alive, or one chimpanzee?
I think this might be the right direction to go in: people might disagree less about how much lobster vs. chimpanzee lives matter than about the two vs.-human comparisons.
Of course, then we’d have a scale with no idea where to put humans on it, but we can chalk that up to “people just disagree”.
I looked at the data from Scott’s study, and observed that people tended to agree more about the relative value of animals than they agreed about the value of nonhuman animals relative to humans.
I think that’s partly because people generally are bad about assigning value to a single human life consistently.
Interesting math update, but it does reinforce my prior that survey data is pretty unreliable on such things and we should look more to results when figuring out what people like.
Indeed, this extends to my skepticism of Democracy.
By skepticism of Democracy, do you mean the whole “it’s the will of the people” thing or are you actually skeptical that it’s the best system humanity has come up with so far?
Because I’d argue that if you “look more to results” the evidence is pretty solidly in favor of more robust democracies however i agree that anyone arguing that they’re “following the will of the people” after getting 57% of the electoral college is probably not on solid epistemological ground.
Because voters dont often have good information, they are rarely significantly impacted by results, its only done on fairly long intervals instead of on a continuous basis like consumption is.
The evidence is not for more robust democracies, its for extremely limited democracies. Lowering voting requirements has consistently resulted in worse policy. And the more successful democracies have limits where legislation is not allowed over all things.
You have to compare democracy to the other political systems that are available today, though. It looks pretty good compared to something like how the USSR ran things, or various dictatorships.
I agree that having limits on power is very important. Unfortunately, there’s a trend for those limits to get chipped away over time.
I’m interested in how we’d quantify this, because voters don’t actually vote for policies, but for parties, and these parties don’t generally represent the whole array of policies equally, but fall into big left vs right blocks, sometimes all the way to the extent of having a two party system in first past the post countries. Maybe there’s some more indirect way this happens, where lowered voting requirements make parties attempt to chase new demographics with new eccentrically crappier policies, but that would imply democracy involves significant competition in policy terms, even though you can genuinely guess quite accurately what the Republican and Democrat candidates will be calling for without having to check. The major way that parties change is by shifting two dimensionally to become lefter or righter, so is it really granular enough for lax voting requirements to have this effect?
Also curious as to what this is based on. Comparing, say, modern Australia (which legally requires people to vote) to places with much smaller portions of the adult population permitted to vote or actually voting (say, ancient Athens or regency England), does not seem to me to provide clear support for that conclusion, but a rigorous analysis of a broader range of cases would be wanted in any event, and I have no idea how it would turn out. If Clutzy has done that, I’m very curious to see the data!
Becausing Voting is equivalent to Surveying?
Ballot design certainly has an effect on the result, but parties tend to focus elsewhere on schewing the result.
Polls provide accurate reflections of the final results, in spite of differences in the way surveys and ballots take voter’s vote.
You can do test-retest reliability on different ballot designs. For example this research on Score Voting: https://www.rangevoting.org/RateScaleResearch.html
Shows that some ranges work better than others, e.g. a 9 point-scale is statistical significant better than a 101-point scale for test-retest reliability.
TBH, democracy seems more robust against some of these mistakes than you’d ever think. Remember that democracy usually picks the median voter, who almost by definition is a moderate and not an extremist. The Central Limit Theorem is an important cornerstone of our democracy.