
Last month I got to attend the Asilomar Conference on Beneficial AI. I tried to fight it off, saying I was totally unqualified to go to any AI-related conference. But the organizers assured me that it was an effort to bring together people from diverse fields to discuss risks ranging from technological unemployment to drones to superintelligence, and so it was totally okay that I’d never programmed anything more complicated than HELLO WORLD.
“Diverse fields” seems right. On the trip from San Francisco airport, my girlfriend and I shared a car with two computer science professors, the inventor of Ethereum, and a UN chemical weapons inspector. One of the computer science professors tried to make conversion by jokingly asking the weapons inspector if he’d ever argued with Saddam Hussein. “Yes,” said the inspector, not joking at all. The rest of the conference was even more interesting than that.
I spent the first night completely star-struck. Oh, that’s the founder of Skype. Oh, those are the people who made AlphaGo. Oh, that’s the guy who discovered the reason why the universe exists at all. This might have left me a little tongue-tied. How do you introduce yourself to eg David Chalmers? “Hey” seems insufficient for the gravity of the moment. “Hey, you’re David Chalmers!” doesn’t seem to communicate much he doesn’t already know. “Congratulations on being David Chalmers”, while proportionate, seems potentially awkward. I just don’t have an appropriate social script for this situation.
(the problem was resolved when Chalmers saw me staring at him, came up to me, and said “Hey, are you the guy who writes Slate Star Codex?”)
The conference policy discourages any kind of blow-by-blow description of who said what in order to prevent people from worrying about how what they say will be “reported” later on. But here are some general impressions I got from the talks and participants:
1. In part the conference was a coming-out party for AI safety research. One of the best received talks was about “breaking the taboo” on the subject, and mentioned a postdoc who had pursued his interest in it secretly lest his professor find out, only to learn later that his professor was also researching it secretly, lest everyone else find out.
The conference seemed like a (wildly successful) effort to contribute to the ongoing normalization of the subject. Offer people free food to spend a few days talking about autonomous weapons and biased algorithms and the menace of AlphaGo stealing jobs from hard-working human Go players, then sandwich an afternoon on superintelligence into the middle. Everyone could tell their friends they were going to hear about the poor unemployed Go players, and protest that they were only listening to Elon Musk talk about superintelligence because they happened to be in the area. The strategy worked. The conference attracted AI researchers so prestigious that even I had heard of them (including many who were publicly skeptical of superintelligence), and they all got to hear prestigious people call for “breaking the taboo” on AI safety research and get applauded. Then people talked about all of the lucrative grants they had gotten in the area. It did a great job of creating common knowledge that everyone agreed AI goal alignment research was valuable, in a way not entirely constrained by whether any such agreement actually existed.
2. Most of the economists there seemed pretty convinced that technological unemployment was real, important, and happening already. A few referred to Daron Acemoglu’s recent paper Robots And Jobs: Evidence From US Labor Markets, which says:
We estimate large and robust negative effects of robots on employment and wages. We show that commuting zones most affected by robots in the post-1990 era were on similar trends to others before 1990, and that the impact of robots is distinct and only weakly correlated with the prevalence of routine jobs, the impact of imports from China, and overall capital utilization. According to our estimates, each additional robot reduces employment by about seven workers, and one new robot per thousand workers reduces wages by 1.2 to 1.6 percent.
And apparently last year’s Nobel laureate Angus Deaton said that:
Globalisation for me seems to be not first-order harm and I find it very hard not to think about the billion people who have been dragged out of poverty as a result. I don’t think that globalisation is anywhere near the threat that robots are.
A friend reminded me that the kind of economists who go to AI conferences might be a biased sample, so I checked IGM’s Economic Expert Panel (now that I know about that I’m going to use it for everything):
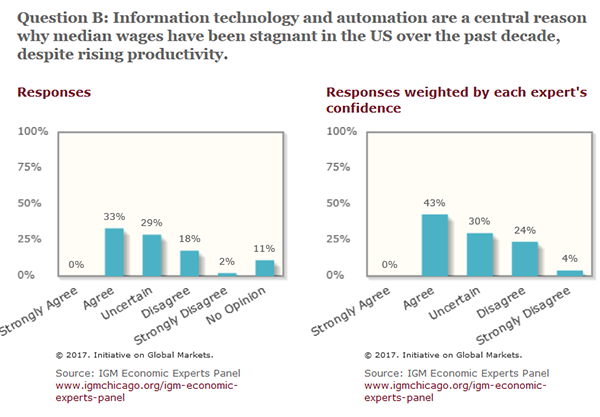
It looks like economists are uncertain but lean towards supporting the theory, which really surprised me. I thought people were still talking about the Luddite fallacy and how it was impossible for new technology to increase unemployment because something something sewing machines something entire history of 19th and 20th centuries. I guess that’s changed.
I had heard the horse used as a counterexample to this before – ie the invention of the car put horses out of work, full stop, and now there are fewer of them. An economist at the conference added some meat to this story – the invention of the stirrup (which increased horse efficiency) and the railroad (which displaced the horse for long-range trips) increased the number of horses, but the invention of the car decreased it. This suggests that some kind of innovations might complement human labor and others replace it. So a pessimist could argue that the sewing machine (or whichever other past innovation) was more like the stirrup, but modern AIs will be more like the car.
3. A lot of people there were really optimistic that the solution to technological unemployment was to teach unemployed West Virginia truck drivers to code so they could participate in the AI revolution. I used to think this was a weird straw man occasionally trotted out by Freddie deBoer, but all these top economists were super enthusiastic about old white guys whose mill has fallen on hard times founding the next generation of nimble tech startups. I’m tempted to mock this, but maybe I shouldn’t – this From Coal To Code article says that the program has successfully rehabilitated Kentucky coal miners into Web developers. And I can’t think of a good argument why not – even from a biodeterminist perspective, nobody’s ever found that coal mining areas have lower IQ than anywhere else, so some of them ought to be potential web developers just like everywhere else. I still wanted to ask the panel “Given that 30-50% of kids fail high school algebra, how do you expect them to learn computer science?”, but by the time I had finished finding that statistic they had moved on to a different topic.
4. The cutting edge in AI goal alignment research is the idea of inverse reinforcement learning. Normal reinforcement learning is when you start with some value function (for example, “I want something that hits the target”) and use reinforcement to translate that into behavior (eg reinforcing things that come close to the target until the system learns to hit the target). Inverse reinforcement learning is when you start by looking at behavior and use it to determine some value function (for example, “that program keeps hitting that spot over there, I bet it’s targeting it for some reason”).
Since we can’t explain human ethics very clearly, maybe it would be easier to tell an inverse reinforcement learner to watch the stuff humans do and try to figure out what values we’re working off of – one obvious problem being that our values predict our actions much less than we might wish. Presumably this is solvable if we assume that our moral statements are also behavior worth learning from.
A more complicated problem: humans don’t have utility functions, and an AI that assumes we do might come up with some sort of monstrosity that predicts human behavior really well while not fitting our idea of morality at all. Formalizing what exactly humans do have and what exactly it means to approximate that thing might turn out to be an important problem here.
5. Related: a whole bunch of problems go away if AIs, instead of receiving rewards based on the state of the world, treat the reward signal as information about a reward function which they only imperfectly understand. For example, suppose an AI wants to maximize “human values”, but knows that it doesn’t really understand human values very well. Such an AI might try to learn things, and if the expected reward was high enough it might try to take actions in the world. But it wouldn’t (contra Omohundro) naturally resist being turned off, since it might believe the human turning it off understood human values better than it did and had some human-value-compliant reason for wanting it gone. This sort of AI also might not wirehead – it would have no reason to think that wireheading was the best way to learn about and fulfill human values.
The technical people at the conference seemed to think this idea of uncertainty about reward was technically possible, but would require a ground-up reimagining of reinforcement learning. If true, it would be a perfect example of what Nick Bostrom et al have been trying to convince people of since forever: there are good ideas to mitigate AI risk, but they have to be studied early so that they can be incorporated into the field early on.
6. AlphaGo has gotten much better since beating Lee Sedol and its creators are now trying to understand the idea of truly optimal play. I would have expected Go players to be pretty pissed about being made obsolete, but in fact they think of Go as a form of art and are awed and delighted to see it performed at superhuman levels.
More interesting for the rest of us, AlphaGo is playing moves and styles that all human masters had dismissed as stupid centuries ago. Human champion Ke Jie said that:
After humanity spent thousands of years improving our tactics, computers tell us that humans are completely wrong. I would go as far as to say not a single human has touched the edge of the truth of Go.
A couple of people talked about how the quest for “optimal Go” wasn’t just about one game, but about grading human communities. Here we have this group of brilliant people who have been competing against each other for centuries, gradually refining their techniques. Did they come pretty close to doing as well as merely human minds could manage? Or did non-intellectual factors – politics, conformity, getting trapped at local maxima – cause them to ignore big parts of possibility-space? Right now it’s very preliminarily looking like the latter, which would be a really interesting result – especially if it gets replicated once AIs take over other human fields.
One Go master said that he would have “slapped” a student for playing a strategy AlphaGo won with. Might we one day be able to do a play-by-play of Go history, finding out where human strategists went wrong, which avenues they closed unnecessarily, and what institutions and thought processes were most likely to tend towards the optimal play AlphaGo has determined? If so, maybe we could have have twenty or thirty years to apply the knowledge gained to our own fields before AIs take over those too.
7. People For The Ethical Treatment Of Reinforcement Learners got a couple of shout-outs, for some reason. One reinforcement learning expert pointed out that the problem was trivial, because of a theorem that program behavior wouldn’t be affected by global shifts in reinforcement levels (ie instead of going from +10 to -10, go from +30 to +10). I’m not sure if I’m understanding this right, or if this kind of trick would affect a program’s conscious experiences, or if anyone involved in this discussion is serious.
8. One theme that kept coming up was that most modern machine learning algorithms aren’t “transparent” – they can’t give reasons for their choices, and it’s difficult for humans to read them off of the connection weights that form their “brains”. This becomes especially awkward if you’re using the AI for something important. Imagine a future inmate asking why he was denied parole, and the answer being “nobody knows and it’s impossible to find out even in principle”. Even if the AI involved were generally accurate and could predict recidivism at superhuman levels, that’s a hard pill to swallow.
(DeepMind employs a Go master to help explain AlphaGo’s decisions back to its own programmers, which is probably a metaphor for something)
This problem scales with the size of the AI; a superintelligence whose decision-making process is completely opaque sounds pretty scary. This is the “treacherous turn” again; you can train an AI to learn human values, and you can observe it doing something that looks like following human values, but you can never “reach inside” and see what it’s “really thinking”. This could be pretty bad if what it’s really thinking is “I will lull the humans into a false sense of complacency until they give me more power”. There seem to be various teams working on the issue.
But I’m also interested in what it says about us. Are the neurons in our brain some kind of uniquely readable agent that is for some reason transparent to itself in a way other networks aren’t? Or should we follow Nisbett and Wilson in saying that our own brains are an impenetrable mass of edge weights just like everything else, and we’re forced to guess at the reasons motivating our own cognitive processes?
9. One discipline I shouldn’t have been so surprised to see represented at the multidisciplinary conference was politics. A lot of the political scientists and lawyers there focused on autonomous weapons, but some were thinking about AI arms races. If anyone gets close to superintelligence, we want to give them time to test it for safety before releasing it into the wild. But if two competing teams are equally close and there’s a big first-mover advantage (for example, first mover takes over the world), then both groups will probably skip the safety testing.
On an intranational level, this suggests a need for regulation; on an international one, it suggests a need for cooperation. The Asilomar attendees were mostly Americans and Europeans, and some of them were pretty well-connected in their respective governments. But we realized we didn’t have the same kind of contacts in the Chinese and Russian AI communities, which might help if we needed some kind of grassroots effort to defuse an AI arms race before it started. If anyone here is a Chinese or Russian AI scientist, or has contacts with Chinese or Russian AI scientists, please let me know and I can direct you to the appropriate people.
10. In the end we debated some principles to be added into a framework that would form a basis for creating a guideline to lay out a vision for ethical AI. Most of these were generic platitudes, like “we believe the benefits of AI should go to everybody”. There was a lunch session where we were supposed to discuss these and maybe change the wording and decide which ones we did and didn’t support.
There are lots of studies in psychology and neuroscience about what people’s senses do when presented with inadequate stimuli, like in a sensory deprivation tank. Usually they go haywire and hallucinate random things. I was reminded of this as I watched a bunch of geniuses debate generic platitudes. It was hilarious. I got the lowdown from a couple of friends who were all sitting at different tables, and everyone responded in different ways, from rolling their eyes at the project to getting really emotionally invested in it. My own table was moderated by a Harvard philosophy professor who obviously deserved it. He clearly and fluidly explained the moral principles behind each of the suggestions, encouraged us to debate them reasonably, and then led us to what seemed in hindsight the obviously correct answer. I had already read one of his books but I am planning to order more. Meanwhile according to my girlfriend other tables did everything short of come to blows.
Overall it was an amazing experience and many thanks to the Future of Life Institute for putting on the conference and inviting me. Some pictures (not taken by me) below:

The conference center

The panel on superintelligence.

We passed this store on the way to the conference. I thought it was kabbalistically relevant to AI risk.
















Some notes from history: the most famous Asilomar Conference was held on Recombinant DNA Research in 1975. Everyone holds up this conference as a wonderful example of scientists carefully grappling with the ethical and public safety issues surrounding a new technology (restriction enzymes). Scientists policed themselves, and ended up banning a bunch of techniques: “cloning recombinant DNAs from highly pathogenic organisms, cloning DNA containing toxin genes, and large scale experiments using recombinant DNAs that were able to make products that were potentially harmful to humans”. All of these are done routinely nowadays, and the public safety threat is (and was) basically null. In the end, the Asilomar Conference put on a good show for the public, but just delayed scientific progress in a few areas. It seems like the AI safety conference was more an exchange of ideas than a throttling of scientific research – sounds good to me!
Sydney Brenner mocked the outcome of this meeting in his book – Loose Ends – as follows:
That’s stilly. First of all, if you measure the pathogenicity of a lion by bacteria standards it’s extremely low. If you release a lion, it may kill a single digit number of people before it gets shot. If you release even a weak pathogenic bacterium or malaria parasite, the number of deaths can easily exceed that. Second, the danger from a lion happens only after the DNA executes a really complicated genetic plan such that one piece of the plan by itself can’t do much–this is not the case for using bits of DNA from pathogenic bacteria.
I’m not so sure mockery is justified.
Given the state of knowledge in 1975 restrictions like that seem entirely sensible and in some ways are mirrored in the modern DIYbio movement. You don’t casually fuck around with pathogens, particularly human pathogens if you’re not entirely certain what you’re doing.
Now we’ve got genome maps. We can have a pretty decent idea of what most of the genes in even a newly discovered pathogen are doing. Back then they were still trying to map the rough positions of loci in bacterial plasmids with what amounted to a stopwatch and a blender.
If you find yourself blind in a room and there’s something on the desk you know is some kind of explosive you don’t just stick you dick in it.
You have a way with words with that final metaphor.
More seriously, this was also my reaction. I do see a few obvious (in retrospect) issues, like acting off whole-genome pathology when many differently-dangerous thing share large numbers of genes. Even so, that’s a view held from the perspective of easy and efficient DNA sequencing and a lot of hindsight. I think portraying “this could be bad, don’t mess with it it” as the opposite of “looks like it was ok after all!” unfairly maligns caution.
“cloning recombinant DNAs from highly pathogenic organisms, cloning DNA containing toxin genes, and large scale experiments using recombinant DNAs that were able to make products that were potentially harmful to humans”
In DNA synthesis all of these are still restricted. When we get proposals to use DNA with best hits from pathogenic organisms, or “select agents”, the PI has to describe the purpose to the local FBI agent (this is just a bureaucratic procedure, not anything serious), or drop the construct.
We’re still working on parsing house-keeping genes versus potentially toxic genes from pathogenic organisms.
Is there an IGM Economic Expert Panel-equivalent for other fields?
Yes for philosophy.
They seem prone to sugar coating things, e.g. free will being an illusion is in last place with even the ‘free will straight up does exist’ option above it; aesthetics hugely favoring objective over subjective. And a lot of these questions are meaningless without knowing the definition and logic of them. You could define aesthetics to meet either category and in proper usage, the term is so vague it mostly just signals the user’s caprice. Perhaps that’s all subjectivity ever amounts to– ‘we don’t care to elaborate on our ideas very much so in their primitive state they amount to ‘lolwedon’tknow”.
I think these are actually the best-justified views. A lot of people who haven’t done much philosophy (including me, when I was a naive undergraduate) are drawn to views like “free will is an illusion” and “morality is relative” for reasons that familiarity with the topic tends to dispel.
Congratulations Scott for all of your success.
Conference videos here: https://www.youtube.com/channel/UC-rCCy3FQ-GItDimSR9lhzw
Participant bios here: https://futureoflife.org/wp-content/uploads/2017/01/Asilomar-bios.pdf
Schedule and panels here: https://futureoflife.org/bai-2017/
This is diverse. I hope you found a chance to be impressed from being in the presence of the Astronomer Royal (and a baron to boot).
What is this, a Gilbert and Sullivan operetta?
The glare of the reflected glory is blinding me 🙂
Congratulations on hobnobbing as an equal with the big-wigs, movers and shakers!
Scott, did you receive the invite to Davos already?
PS. I once stayed in the Bilderberg hotel, which is one step down from Davos, but still pretty elitist.
Was the Harvard professor Michael Sandel? Please say it was Michael Sandel.
I’m hoping it was Mansfield. (This context would put a whole new spin on his research into manliness.) But I’d guess it was Pinker.
EDIT: Obviously it was not Pinker if Scott accurately described the person in question as a philosophy professor. Maybe it was Peter Godfrey-Smith?
> a Harvard philosophy professor who obviously deserved it. He clearly and fluidly explained the moral principles
> Pinker
> philosophy
> Pinker
Your circle of philosophy people clearly holds Pinker in higher regard than mine, to make an understatement.
Daniel Frank linked to a list of participant biographies above; technically there aren’t any Harvard philosophy professors on there, but I think Scott was referring to Joshua Greene.
What is slightly mysterious, is why the secrecy — the person in question and most people who were at the conference will know who it was and I can’t think of any way the secrecy would help preserve anyone’s privacy. If the comment were critical or if the person in question were someone shy wishing to remain anonymous, then not openly humiliating/outing the person on the whole internet would make sense, but it was the highest praise and if you’re a Harvard philosophy professor writing books, you shouldn’t mind having your ideas/analysis recommended.
It must be horrible being Scott. Whatever he writes will be second-guessed by myriads of people…
Looking at the attendees, Joshua Greene does seem to fit the bill best.
>What is slightly mysterious, is why the secrecy
Because the general policy is sensible, and breaking from a sensible policy “because it’ll be ok this once” is very bad habit to fall into.
Typo: compliment -> complement
Bonus wikipedia link: complementary goods
Feel free to delete if the typo is fixed
“One of the computer science professors tried to make conversion”
Presumably this is meant to be conversation, not conversion.
That certainly casts things in a different light.
My problem with the horse analogy is that horses were really only suited to a fairly specific task – the transport of individual humans (yes, they can also transport carts and stuff, but my understanding is that oxen were better suited for that generally while horses were the best option for a single rider).
To believe that this could happen to humans requires the belief in an AI that can do literally everything humans are suited to do significantly better than humans can. And I don’t just mean everything we traditionally think of as an economic activity that would result in employment – I mean literally every thing (to include things like companionship and other things we believe to be of emotional benefit). I won’t say that’s impossible, but it doesn’t seem to be on the near to immediate term horizon.
Horses can run in the Kentucky Derby, serve as cavalry for historical movies, and delight ten-year-old girls.
These aren’t very big niches, but that suggests that relegating a species to minor niches can also decrease its usefulness, not just literally eliminating every possible use for it.
(I don’t know if the difference in quantity between the number of niches for horses and the number of niches for humans is so big as to be effectively a difference in quality)
My issue with the whole “Luddite fallacy fallacy” narrative is that you simply aren’t yet seeing the large unemployment or productivity increases that you’d expect if automation were truly outcompeting people in every niche. What unemployment *does* exist seems to me an issue with policy, demographics, and increased value of leisure.
Our economy is service based, and productivity increases are *slower* than they were in previous decades. I’m going to read that paper you linked though, I must be missing something if all those IGM economists think this is currently going on.
unemployment is kinda meaningless because ppl drop off the rolls. you have to look at labor force participation
As long as you also account for the Baby Boomers hitting retirement age
“Retirement age” is an idea which functionally didn’t exist until recently.
So is unemployment. 99% of people worked 6 days a week, and likely 10+ hours a day, from an early age.
I’d wildly guess that workforce participation has decreased about 60% from 200 years ago, thanks to technology.
And yet, we aren’t all scraping by in wretched poverty while the .01% of the population who owns the capital lives it up in lavish mansions.
AND we haven’t needed some giant global communist state to abolish private property and ensure all the resources are shared equally, either.
That’s why I mentioned demographics and leisure value. It’s hard to complain about the lack of jobs if you don’t want to work anyway.
And your not in Libertopia either, youre in a system where some of the wealth of the better off is involuntarily redistributed.
Horses can’t bid down their wages to be competitive.
If they could, even with lower wages, they’d be able to afford more oats than previously, thanks to the same technological progress which destroyed their previous occupation.
In a world where horses are independent, rational economic agents, every middle class family has
boughthired their daughter a pony, Polo is the most popular sport, and “Uber for horses” is the budget travel solution sweeping the nation. Instead, their economic viability is hampered by the opportunity costs faced by horse trainers/handlers/breeders/stablers/cobblers.“Horses” are better modeled as tool which humans once used, but have found superior alternatives to. The fact that they’re living organisms is a red herring. Horses are no more an argument for human obsolescence than cassette tapes.
And what stops you from modelling low IQ humans this way? Just how much better they are at finding and exploiting niches? You’re just arguing for a longer timescale in this, right?
Yeah, I’m not disagreeing with obsolescence in principle. To take the reductio ad non-absurdum, I think everyone agrees that once someone designs an AI smarter than a human’s and puts it in a robot body as dexterous as a human’s, with lower energy demands than a human, humans will finally be 100% obsolete.
My point was that the horse metaphor is misleading. It suggests, “unskilled persons, like the horses of yesteryear, may soon have no economic role.” But really, the effect observed isn’t horses being out of a job, it’s horse-handlers moving to more lucrative ones.
An analogy to sapient Horses would have worked, or a horse-handler who’s capable of performing no other task. But by muddling the distinction between horses and the humans who use them, the analogy’s tricking you into imagining IMMINENT 95% UNEMPLOYMENT the moment Starbucks creates a robot barista.
“What happens when a person’s most productive potential employment vanishes, do they find the second most productive, or exit the economy?’
“Well look at horses, they exited the economy.”
No, horse-handlers moved to their second-most productive. Their tools exited the economy.
And can’t you make the same claim about human-handlers, that is, the owners of labor-intensive businesses, who may either replace their workers with robots, or more simply just shut down their operations and invest their money in more lucrative Silicon Valley tech companies?
The problem with horses is that they take up space a human could live in, in a world where land in the most desirable areas is close to zero sum, and they take up time that could be spent using tractors, in a world where farming is highly competitive.
Comparing that with “obsolete” humans, what happens when you can’t afford to live where the work is, can’t afford the equipment or training necessary to compete with the market, and your contribution to the average workplace is to waste someone else’s time?
Is it an unalterable rule that someone’s contribution be priced above subsistence?
As they were “paid” in room and board (and veterinary care), there wasn’t much lower they could go, even if they could negotiate.
Human beings who earn just enough to afford healthcare, transportation and shelter seem to be in similar situation, no matter how cheap food and TVs get.
Lots of little girls love ponies. If oats are so cheap these days, why aren’t middle class pony owners common already?
Right: horses are paid in room and board, i.e., they are maintained with the minimum expenditure. As are tools.
A closer human analog to this state is being a slave. The slave may be at negative net productivity, zero productivity, or well above it; but in the latter case he does not get much if any of his surplus. The surplus goes to his owner. (The negative sum case is the situation for horses once motorcars became affordable.) Horses had owners for obvious reasons; humans these days generally don’t, at least not in any formal way.
And that is why the horse analogy (though provocative and interesting), needs a big grain of salt. And why AnteriorMotive is saying to look at horse-handlers.
>Horses can’t bid down their wages to be competitive.
>“Horses” are better modeled as tool which humans once used
If horses are modelled as tools, then we should consider they have the lowest “wages” compatible with their performance (since their wages are set by their owners).
I suspect that’s true.
At the end of my post, I summed up with:
This wasn’t to say that they aren’t an argument for human obsolescence, just that when you exchange the horse analogy for the structurally identical “cassette tape” or “slide-rule” anology, suddenly it’s lost its rhetorical punch. As I see it, this suggests a misleading analogy, hinging on the listener inappropriately anthropomorphizing horses. I go into a little more detail in my clarification above.
Scott I don’t think this can be meaningfully discussed without clearly establishing what the Law of Comparative Advantage predicts: that even if someone is completely dominated by another producer, eg. If Sam can produce 3widgets or 4bits an hour while Paul can only produce 1 widget or 1 bit an hour it still makes sense for them to trade as the relative cost of a new widget/bit to Sam is different than the relative cost of a new widget/bit to Paul.
This holds true even if [advanced AI] can produce 3million widgets or 4million bits in an hour while Paul can only produce one of either an hour: for [advanced AI] 3widgets = 4 bits, while for Paul 1widget = 1bit, ergo trade is efficient.
A worker can be displaced by an AI lowering the value of their skills/market position relatively, but it does not make sense to say A worker has been rendered obselete unless they have been rendered incapable of producing any value ei death or coma.
My theory for what’s actually happening is that displaced workers could reasonably produce equivalent if not more value than their factory jobs by entering cottage or botique industries: home brewing, custom metal working, shop owning, trades, etc.
With those trades requiring about the same level of intelligence and education as factory work to produce value (high school). The problem is the tax code and regulatory structure have artificially made it harder to enter a field where you independently produce value so that you need high school + weird obscure bureaucratic knowledge, thus effectively locking the working class out of the economy if their isn’t a large manufacturer willing to assume the regulatory burden of them.
Like seriously most of the boom jobs today where a person can be well payed with little more than high school existed in the 19th century when half the working class couldn’t read. And now I’m trying to start a small business and I, a graduate of Philosophy and English from a top 30 international school, I am breaking out in cold sweats whenever I think of the paperwork or complying with the tax code.
I can’t imagine what it must be like for someone with a grade ten reading level trying to navigate this, and this should be their most obvious option without a big employer about!!
The robots didn’t do this, the 20th century did this. We’re living in Terry Gilliam’s Brazil.
This only holds true in theory and for infinitely low wages. If Sam and Paul both need one blah per hour and market rates are 1 blah = 1 widget = 1 bit both are employed. If market rates are 1 blah = 2 widgets = 2 bit Paul is out of luck and if the AI drives market rates to 1 blah = 50000 widgets = 70000 bits both Sam and Paul are laughed out of the room.
On top of this, even in the limit of infinitely low wages, the law of comparative advantage only gets you so far due to overhead. You may convince yourself of this fact by taking your shovel, going to your local construction site and offering to help with basement excavation for one cent per month or even for free. You will politely be referred to the playground, so you will not get in the way of the excavator.
Snark aside you are basically just arguing, that we will get to compete in a few years or decades of an increasingly hopeless wage war until finally every last human is below maintenance cost and thus obsolete. I wouldn’t want to argue this conclusion. At this point, as the old saying goes the AI does not love you nor does it hate you … but you are made out of atoms it can use for something else. Because exactly like the horses discussed above, to your employer – or customer – you are nothing but a tool, which is only kept, if it earns it’s upkeep.
Why aren’t blah prices also being driven down by AI? And if for some reason robots are incapable of producing blah, then why don’t Sam and Paul get into the blah business?
If blah is a finite resource, or needs finite resources to make, prices can only go down so far. Many things we need are like this: food needs land to produce, fresh water is finite or requires energy to make, etc. Of course the AI needs energy and raw materials to run as well. So if it turns out the resources the AI needs are scarcer than the ones the human needs, the human might still be able to compete – if not, the human can’t survive. I have no idea which is more likely.
Blah stands for something (space, matter, energy, whatever) BOTH humans and the AI need in order to produce, but the AI needs much less of this.
You can get people to do paperwork for you.
After the invention of the horse collar in 1000AD, horses were better than oxen at everything, including plowing. The Greeks and Romans used oxen for plowing, but used horses for powering machines, such as Archimedes screw wells and flour mills. I don’t know why.
Something something comparative advantage?
As everyone who grew up in the age of the Apple II knows, oxen were used to pull wagons on the Oregon Trail. Presumably because they were cheaper, sturdier, and more durable animals.
nelshoy has it right, you use horses for the high value stuff, oxen for the low value stuff. As long as we live in a world without instantaneous replicators the comparative advantage should hold.
Comparative advantage doesn’t make a lot of sense for chattel. It also breaks down in the presence of reproduction. The invention of the horse collar was not a reason to kill oxen, but it was a reason to invest less in the creation of oxen, which was the trend of the next thousand years.
There are many dimensions to compare horses to oxen and I don’t know that horses are better on all axes. The logic of comparative advantage does apply to fuel efficiency. If one were more efficient for light tasks and the other for heavy tasks, that would be a reason to use both, but I don’t think this is actually true. I think that the main advantage of oxen, the main reason they continued to be used for the past thousand years, is the simplicity of just raising cattle, rather than two species.
First off comparative advantage isn’t you do x best and I do y best, then we trade. CA specifically demonstrates how even if you do x and y best, there are still gains to be made by you doing one, me doing the other and then trading, rather than you doing both.
Secondly there are numerous reasons why oxen could continue to exist alongside horses despite horses being better at everything (taking the assumption for granted ). They would include the costs of reproduction, the differring marginal costs of their feed/upkeep, and resistance to diseases to name a few.
What does “better at everything” mean?
I interpret this quote
to basically mean that one horse pulling a plow could plow more land in a day than an oxen, that one horse could carry a man farther and faster than an oxen, and that better means when matched in discrete tasks (other than cheats where the task is “produce more oxen”) the horse would be preferred if you had an immediate choice between the two.
My problem is more fundamental: In this context, horses are tools, not workers or citizens. When technology evolved they became obsolete in the same way that slide rules did.
But no one would claim the extinction of slide rules portends the fate of human workers. Horses are fellow mammals who we can identify and sympathize with, and I think that is what confuses us to think they were workers like us. But from an economic standpoint, they were one technology for powering carriages that got replaced by better one.
I have the same complaint with this comparison. The economy exists to serve human problems, not horse problems. AI/automation might turn out to be better at solving our problems than nearly all humans, but that might turn out to be a problem in and of itself. Is the set of all AI-solvable problems a Universal set?
In capitalism, the market exists to serve those with purchasing power, not all humans generically. Humans who cannot obtain purchasing power are not served by the market, unless we do wealth transfers from those with purchasing power to them.
There is no inherent respect for human welfare in capitalism and in so far that capitalism does produce it, it is a side effect of humans being pretty good at producing stuff (on average). If (most) humans stop being able to produce value, they become obsolete from a capitalist perspective. If a robot does everything that the market is willing to pay a living wage for better than them, they are no more part of the chain of production than the horse is part of today’s chain of production.
If we don’t want human obsoleteness to result in a lack of welfare from humans, we have to set up systems that are non-capitalist* to deal with this (if robots do make many/most humans economically obsolete).
* Note that this doesn’t mean anti-capitalist, just that free market capitalism cannot solve this specific problem
That is a good point. So far most of the discussion around AI and automation assumes that our current market structure is unlikely to be severely disrupted, which is a rational starting position. Humans have, in the deep past, operated economies that solved problems with very little capital or expectation of capital returns. Technological progress was relatively stagnant in pre-agricultural economies, but social and cultural flourishing may not have been. I sometimes wonder if the lack of technological progress should be assigned a similar negative weight in a stable-state society as it is in a modern growing population on a resource-substitution treadmill. It might be worth exploring forager economies in greater depth. I’m particularly interested in the potential expansion of ritualized exchange in a post-scarcity economy, since such a large proportion of human needs relate to status and self-concept.
The issue there is that you’d need to establish emotional reciprocity, so the gifts balance out emotionally. Otherwise it just becomes a one-sided gift, which feels patronizing and harms the well-being of the giftee (and makes the gifter feel patronizing too).
Arguably, we could solve this by making the non-free market productive person perform some service or make some good that is genuinely appreciated by others, even if it would not be valued at the same price on a free market as what the person gets in return.
Theoretically it should be possible to change away from a meritocracy to such a society, as we moved from class-based societies to meritocracy. So societies can change their status hierarchy significantly.
PS. Interestingly, our local beggars have implemented such a system already by ‘selling’ a homeless newspaper, which they don’t even produce themselves. This is very transparently a ‘cover’ for begging, so one can argue that we need merely an transparent illusion that allows for self-delusion of the id.
One way to do this might be with a status UBI. For example, every month each citizen gets 1000 status coins and we socially reward people based on how many coins they accumulate. They gain coins through a free market system. So the producers of tangible goods have to sell those goods for status coins to gain status.
We can do things like weighed lotteries and rewards for the top accumulators (like 1 month of having a Monet on your wall), so there is an incentive for earning, but not a strict hierarchy.
The coins are time-stamped and dissolve after a certain period, to keep forcing the producers to keep making goods for others.
Embedding exchange in ritual is a great way of establishing emotional reciprocity and obscuring various economic complexities. The idea would be to shift from a barter to a gift economy, with the associated change in rules and expectations. Given that a post-Singularity society is probably underlain by a significant black-box component, I wonder if “shaman” will be on the list of Hottest Jobs of 2417.
I think this kind of hypothetical argument is pretty circular and empty. “Assume people have no money. Then they couldn’t buy anything!”
> There is no inherent respect for human welfare in capitalism
I strongly disagree. Capitalism is based on respect for human life and property rights.
A system that ignores human welfare would be one where you can rob, steal and kill as you wish.
@Squirrel of Doom
Respecting property rights is certainly not the same as respecting human welfare. I don’t know how to convince you of this in a succinct way, unfortunately. Perhaps the best way is to ask you how the free market provides for the basic needs of a person with no ability to earn money?
BTW. Laws against killing are completely orthogonal to the free market. They aren’t required to have a free market. Are you perhaps confusing our legal system with the free market?
The free market means individuals are free to use their property as they wish to the extent of infringing on another’s property. The free market will provide for those that cannot provide for themselves to the extent that the individuals in the market value it. Sample size of 2, but neither of my children can provide for themselves, and the government hasn’t stepped in and yet for some reason they never go hungry.
@ Svejk & Aapje
Oh my fricking god! Social, social, social…….
Certain kinds of people thrive quite well with comparatively* little interaction with other people. I’d even state that these people sometimes add societal value greater than some of those who are very socially oriented.
* – Compared to those who’d thrive in your socially-based hypothetical proposals.
The five love languages. Not just for mates.
https://en.wikipedia.org/wiki/The_Five_Love_Languages
gift giving,
quality time,
words of affirmation,
acts of service (devotion),
and physical touch.
@anonymousskimmer
Nothing in my comments, concerned with economics and ritual, implies anything about sociality. Indeed it is entirely possible to subsidize ritual performed in various degrees of social isolation (e.g. monastic seclusion, vision quests). And forager societies certainly involved smaller spheres of social concern and a lot less contact with outsiders than modern communities.
I think it is important not to confuse ‘social’ with ‘extroverted’. It is easy to underestimate the amount of social substructure supporting even the most isolated modern existence – I say this as someone who mourns the loss of the physical frontier and the declining ability to solve problems by social exit.
Is complete social atomization likely in a post-Singularity society? Possibly. But here I am starting from the presumption that some exchange of genes, ideas, goods, and services will still occur, if only among a much smaller group of people. I think the factors affecting the expansion and contraction of this group are interesting to consider.
@Aapje
You’re slipping a bit. You started by saying capitalism has no inherent respect for human welfare. Now you’ve retreated to property rights not being identical to respecting human welfare.
I’m happy to concede the latter point.
@baconbacon, yeah, because your own children are totally identical to adult unrelated strangers. No utterly insane lack of context there…
Can you say something about these economies, like their names, and how we know anything about them?
The least-capital intensive economies I know of are nomadic hunter-gatherers and even there people tend to have some capital, like bows and baskets or other ways of carrying things.
Or are you using the term ‘capital’ in a specialised manner?
What person in the world is an unrelated stranger to everyone?
@Tracy W
Re: ancient economies – I am also referring to forager economies. As you might expect, much of the work reconstructing ancestral economies is inferential from modern observation, and from principles of behavioural ecology (e.g. what does an economy look like under conditions of patchy resource distribution, limited storage capacity, and infrequent contact with potential trade partners). I don’t think I’m using ‘capital’ in a specialized manner, although ‘capital returns’ in a non-monetary society might be different (i.e. the returns might be highly perishable and difficult to compound). Most nomadic hunter-gatherers have very little capital relative to moderns, or even subsistence agriculturalists, and the returns on these resources + associated labor (e.g. hunted or trapped game) are not always directly captured by the possessor or originator of the capital. Pre-agricultural societies have different proportions of their economies governed by gift v barter rules, and some trade networks operate along lines of kinship.
I’m not sure I would prefer these systems to market capitalism, but they are the ‘weirdest’ human-friendly systems I know of relative to our current system, and might offer some insight into the (presumably weird) post-AI future. Plus they are just interesting to think about.
@baconbacon
How does the free market provide for your children? I assume that you provide for your children with money that you earn in the free market. There are others who do not have this capability and the free market doesn’t help them, they get welfare to do so (which is a fix to solve the problems of the free market).
Capitalism also doesn’t force you to care for your children, it merely enables you (we do have laws that force you to take care of your children, but those are independent of the free market).
@Squirrel of Doom
I didn’t retreat, you retreated to that position to explain how capitalism respects human welfare. Or you wrote down a non-sequitur/tangent that didn’t address my argument, but appeared to do so poorly.
Let me address this then:
Capitalism merely grants people the ability to sell the goods/services/etc that they make for money (or barter) and then buy goods in return. It doesn’t guarantee that anyone has goods/services/etc that are of value to others or is able to provide the essential needs for themselves. For example, a person with no arms & legs or a fully paralyzed person might not be able to produce sufficient value to buy food, which they probably cannot farm/catch/etc themselves.
So if one wants to assure that people like that get their basic human needs met, you need a mechanism that goes beyond mere capitalism.
PS. Note that I’m not claiming that capitalism is bad. Just that it is insufficient for what I demand from society.
I mean, what can I say to propaganda besides calling it out as propaganda. In the US (the country I am most familiar with) the welfare state as it is being generally recognized to have started with social security (with some minor precursors I am sure). SS started during the great depression which coincided with the largest peacetime expansion of government spending in US history and then was followed by even greater spending/regulation/manipulation by the following administration. Further recent chair people of the Federal Reserve (a government created organization) have claimed that it was the Fed’s fault. Chunks of the “great society” were aimed at alleviating the living gap between blacks and whites which were due primarily to state sponsored segregation/slavery/racism. Just stating that X happened because of y doesn’t make it so.
You asked this
I gave a clear, undeniable answer with literally BILLIONS of examples throughout history of people caring for those that cannot care for themselves (and there are even people who adopt and care for kids not even related to them). You have started from the presumption that people who can’t directly produce for themselves must suffer under capitalism, I demonstrated that this isn’t true under at least some circumstances.
Right now you are trying to win by definition, if you state that there is a group that cannot help themselves and no one is willing to help them individually, then of course they will suffer. You haven’t however given any reason to believe such a group of people exist, and even if you can and do you will not be able to posit a reasonable government structure that would provide for such a group of people when no individuals under that government would do so of their own volition.
@Aapje
I think you missed that I accused you of a circular argument.
First you assume humans will not make any money in the robotopian future. Then you conclude that based on that assumption, they will lack money! This is internally consistent, but says nothing about reality.
The interesting and much harder question is what income and employment will look like in such a future.
Sure, capitalism doesn’t assure that everyone get their basic human needs met. But that’s is true of all systems, even those marketed otherwise.
@Squirrel of Doom
I did not assume that no humans would make money. I was trying to demonstrate that even in today’s society we supplement capitalism with non-capitalist solutions to ensure that people have a certain level of welfare.
I was establishing this rather basic fact because this is a heavily libertarian forum where a lot of people get starry eyed when capitalism is mentioned*.
Once people accept the limitations of capitalism, we can have a more reasonable discussion about where a further loss of buying power by a large group may leave us.
* That I got so much push back at my rather obvious statements shows this as well, IMHO.
Capitalism doesn’t ensure this, even if it’s preconditions are met, other systems do. This is a relevant difference.
Of course, you can come with scenarios where every system fails, like: what if everyone stops paying taxes, then the government can’t provide welfare, so a welfare based system stops working. However, then you actually need to argue that it is likely that the preconditions (people paying taxes) will not hold.
@Svejk
Indeed. I was interested though in your original claim that there were societies that had solved problems while having very little capital. What sort of problems have foragers solved with their very little capital? Obviously survival.
And of course returns on capital are not always directly captured by the possessor or originator of capital. Consumer surplus is a thing. My life was once saved by about $50 worth of antibiotics, and that’s the retail price. The drug companies’ return on their pill factory was tiny compared to my return.
What are these other systems? Are you sure you are not conflating “ensure” with “have a legal right on paper”?
You go on to talk about tax payers not paying taxes, I presume you are thinking of Greece, or Brazil. Another option is that the government of the day sees a rising deficit and responds by cutting social spending and thus services, as the New Zealand government did in 1991.
I’m quite curious as to which systems you think actually ensure these things.
True in one sense, false in another. You are correct that if people are sufficiently hard hearted, someone with no way of producing value will starve to death under capitalism.
But that is true of any system. If people are sufficiently hard hearted, the voters of a welfare state will vote to let the paralyzed individual die. Either way, you depend on a reasonable level of human sympathy to get resources to the paralyzed individual.
On the whole, this is less of a problem for capitalism than for the alternatives. Under capitalism, it only takes one person who wants to help and has the necessary resources to feed the helpless individual. If resources are allocated by the state, it takes enough people to make the state do it.
Of course, if you have a mostly capitalist system with mild redistribution, either one generous person or state action will do it, but given the existence of a hundred million or so candidates for “generous person,” adding another way in which a group of people can achieve the objective isn’t much of an improvement.
@Tracy W
Note that my argument was for the development and/or implementation of such mechanisms. I don’t claim to know what the best mechanism is, especially for a theoretical future.
Currently we have welfare as well as goods/services that are provided by government. Some have argued for an UBI which is also a mechanism to do so. Elsewhere in the thread I have talked about a status token mechanism, which is a kind of UBI where people get status tokens that are separate from the classic capitalist system.
PS. What I was trying to head off, was obvious objections where suggestions are dismissed based on mere suggestions that a situation can develop where a system doesn’t work; where this is presented as the only possible outcome, rather than just one possible outcome. But perhaps I was prematurely defensive.
@Friedman
You are framing the issue as if there is one person in need and a hundred million candidates for the benefactor role. This is extremely disingenuous as there are typically many people in need and it is absurd to frame it as if for every person in need, there are a hundred million of candidates who merely have to take care of this one person.
Diffusion of responsibility is a pretty strong human mechanism, which suggests that many people will choose to look away, rather than help. If you look at how people deal with refugees, you can see that if the problem becomes big enough, a lot of people simply start rationalizing away the problem, since they no longer see how they can realistically help.
IMO, these (and other) issues is one of the major reasons why we came up with governments in the first place, to provide a framework in which people are more willing to pay for a shared goal, without issues such as free riders.
Do you think that the aristocracy who oppressed the serfs/peasants were fundamentally different from modern humans? Or do you believe that we used to have a system that rewarded such behavior and that today, we have a system that punishes it?
I argue the latter and that it is crucial to have a system that makes people behave in morally* correct ways.
* Which is subjective, of course
I was responding to the example of someone entirely unable to produce because he was crippled or a quadraplegic. There are not many such people.
Carrying it over to a future of robot fueled abundance, there may be millions or, on a world scale, billions of people with low or conceivably zero productivity, although I think that unlikely. But in that world, there are also a very large number of trillionaires–anyone who had any capital at the point when capital was becoming enormously productive. Each of them can easily feed and house hundreds or thousands of the technologically unemployed.
@David Friedman
But why would the trillionaires want to? The robots make better slaves so no point in using their labor, and no matter how well you feed and house them, the humans are going to be ungrateful about it.
@Nybbler:
They don’t all have to want to. My point is that, in the capitalist system, things only go really badly if practically everyone is heartless. In alternatives where decisions are made politically, it takes a much smaller number–just who depending on the political system.
in the capitalist system, things only go really badly if practically everyone is heartless
…and if that were the case, no one would be raising this issue, since the existence of this issue depends necessarily on there being people who care about the unproductive.
It should be simple to note that America, after many glorious centuries of capitalism, still has a large and highly visible homeless population, while socialist Europe mostly does not. Other capitalist countries like Canada are the same as America.
Whatever the abstract reasoning in favor of capitalism, socialism seems to have borne actual success.
The abstract reasoning does not seem to match reality. Since the appraisal of reality doesn’t appear to be wrong, it is probably the abstractions that are faulty. The abstract reasoning, therefore, should be taken lightly. Planning should be based on empirical data instead.
Either you have a society like America, where schizophrenics and mentally retarded people drink themselves to death on the street, to the horror and dismay of onlookers, or you have one like Britain, France, Norway or whatever else, where, through some mysterious process, these societal illnesses are dealt with humanely.
@Friedman
If it were true that bad things only happen if people want it, then we would never had WW 1 or WW 2. Few people wanted millions of deaths. It still happened, because there were all kinds of interests, alliances and interactions which caused a dynamic with really bad outcomes.
The Cuban missile crisis is an example where we almost had a dynamic that resulted in us going MAD.
As a libertarian, surely you are aware of how bureaucracies can take well-meant rules, that seems quite fair at first glance, and implement them with ruthless rigidity, so that the outcomes are Kafkaesque. One example is a person with both physical and mental illness, who is turned down by both the institutions that provide mental care and those that provide physical care, because neither can deal with a combination of problems. In theory the system provides for mental patients and for physical patients. In practice, there is a gap that the well-meaning people who set up the system didn’t foresee.
Complex systems usually have gaps like these that are extremely hard to plug (because doing that causes new gaps or other issues) or negative emergent traits (that are hard to fix, because the fixes often cause emergent traits themselves). Much of the difficulty in setting up a just system is that these traits can be very negative, yet they are not willed and are caused by perfectly defensible behavior by individuals (who can not foresee all the consequences due to their limited intellect and knowledge).
Aapje goes too far in saying capitalism has no respect for human welfare. Squirrel does not go far enough in appealing to voluntary transfers as a complete solution to the problem of enabling the survival of the unproductive.
Friedman argues stangely that voluntary transfers are a unique feature of capitalism. But no realistic alternative forbids voluntary transfers, so all are at least as good as capitalism.
Friedman also argues, also strangely, that alternatives to capitalism are inevitably based on direct democracy, or the fickle mob. But the problem of making stable and binding commitments has been solved over and over. The country he lives in solves it with written constitution.
Previiously I have pointed out the problem of failing to apply obvious bug fixes to ideas you dont like. There’s a further problem of not noticing bug fixes tjat have already been applied.
It should be simple to note that America, after many glorious centuries of capitalism, still has a large and highly visible homeless population, while socialist Europe mostly does not.
??? I visited France and Italy as a child, and had little trouble finding homeless people. Did you stay on the tram the whole time?
Friedman argues stangely [sic] that voluntary transfers are a unique feature of capitalism. But no realistic alternative forbids voluntary transfers, so all are at least as good as capitalism.
Any alternative that imposes restrictions on the movement of resources by parties other than the source and destination of a voluntary transfer, necessarily impacts the degree to which such voluntary transfers can occur. For example, if I have $1000 I wish to send to an orphanage and the tax man comes and takes $250, that $250 may very well come out of the $1000, as the rest of my expenses are presumably less negotiable – I can more easily change my mind on how much I give away than on how much food and rent I buy.
Friedman also argues, also strangely, that alternatives to capitalism are inevitably based on direct democracy, or the fickle mob.
Where did he say that? What I saw was this:
In alternatives where decisions are made politically, it takes a much smaller number–just who depending on the political system.
Such systems could be direct democracy (50%+epsilon decides for everyone), sole dictatorships (1 decides for everyone), or anything in between. In all such cases, necessarily less than 100% of the population being heartless is sufficient to make the official response heartless.
Friedman’s arguments may appear strange to you, but your counterarguments seem even stranger to me.
“through some mysterious process, these societal illnesses are dealt with humanely.”
Perhaps the “mysterious process” isn’t as humane as you might think.
My dad used to express grave concern for the homeless, so he started volunteering at a local shelter. Within a few months he came back and reported “every homeless person in this town is homeless by choice.” There was more than enough capacity in the various shelters to provide for them all.
The problem is, the shelters have rules. They won’t let you bring drugs or alcohol inside – and if you’re drunk or high, they kick you out. If you yell at people or act violently, they kick you out. They expect you to generally pitch in and clean up after yourself and such. Some of the nicer ones may require you to sit still and shut up and listen while they read you bible passages.
The people who end up sleeping on park benches are the ones who can’t or won’t abide by fairly simple rules like that. It essentially becomes a lifestyle choice. I don’t know what England does, but I have a tough time imagining a “humane” way to deal with someone who wants to drink and use drugs and shout at people all the time. Nobody is going to voluntarily take such people into a nice and warm and comforting environment where they can come and go as they please and maintain all their destructive habits. As far as I can tell, the two choices are to let them go about their business on the streets, or to forcibly institutionalize them somewhere, against their will. Is this the “humane” solution you are looking for?
@Friedman
Your father’s experiences have been different from mine: only half of the homeless people I’ve seen have been drug addicts and drunkards, the other half were obvious mentally ill people who do in fact deserve to be institutionalized. There are also a lot of borderline homeless people with various disorders working jobs they are barely cut out for, leading miserable lives of drudgery and failure. While they aren’t as visible, their plight is perhaps just as great as the homeless population, and you can see from their miserable faces that many Americans match this profile.
Drug addicts and drunkards aren’t mentally ill in your book? Because according to the official book, they are.
But the general point remains: The extent to which a nation has a visible homeless population corresponds mostly with the extent to which it is willing to institutionalize mentally ill people (some of whom will be both sympathetic and nonconsenting), and not so much with what sort of economy it has.
.
Thats the can. Wheres the would?
And numbers matter. If everything is owned by 3000 billionaires, they are unlikely to all be blue meanies, but if everything is owned by 3 trillionaires, thats another story.
Lower numbers, more variance.
And if all the automated factories are owned by one quadrillionaire, that is N=1 as surely as a dictatorship. Private charity is not a USP of capitalism, and capitalism gurantees nothing about the number of decision makers.
If your solution to the chalkenge of an automated economy is some combination of capitalism and widespread wealth distribution, then you need to do something about the wealth distribution part, because you are not going to achieve it by being complacent about todays very unequal distribution of wealth.
Some version of Bigger Pie is the closest realistic approximation to the idea that charity is a USP if capitalism, but it doesnt work in this context, because an automated economy will have a huge pie, and the problems are all about distribution.
@TheAncientGeekAKA1Z
What if there are 3000 billionaires, 1500 of which are willing to pay their fair share (1/3000th of the sum necessary) to help other people? Then you’d have 1500/3000 = 1/2 of what is needed.
What if the billionaires live in a culture with a bias to point out the downsides of welfare (like fraud cases or people doing bad things with the money)? My experience with groups is that they tend to develop false narratives which are to their own benefit, because it resolves their internal conflicts (like a conflict between the desire to keep their money & a desire to not see people suffer) with a lie which makes it unnecessary or less necessary for them to make sacrifices to feel good.
The post you are responding to was not by me.
???
In today’s very unequal wealth distribution, the richest man in the world has a total wealth of about 85 billion dollars. The combined wealth of all the people in the world is 241 trillion dollars, at least according to a quick Google.
So the richest man owns about 1/3000th of all the wealth of the world.
And you think if we don’t do something about that level of inequality, it’s likely that one person will own all of it?
Numbers matter.
Either you are missing my point or I am missing yours.
I am not saying that bad things only happen if people want it. I am saying that bad things that can only happen if almost everybody wants them only happen if almost everybody wants them.
Specifically, two cases:
A very small number of people in a modern society who cannot support themselves only starve to death if practically nobody is willing to help them, since there are hundreds of millions who could.
A sizable fraction of the population with zero marginal productivity in a post-scarcity society where practically anyone who does have capital or useful labor is rich enough to feed thousands or hundreds of thousand out of his spare change can only starve to death if practically nobody is willing to help them.
WWI did not require that almost everyone was heartless.
Your point about bureaucracies supports my point. If, in the extreme, we shift from a market system to a system where food is allocated by the state, it then is possible that lots of people will starve to death because in that system it only requires the bureaucrats doing the allocating to be heartless, or stupid, for that to happen.
I suspect that you merely demand the most elementary level of welfare, to make people not starve. This can plausibly be supplied by voluntarily contributions from a subset of the well off.
I demand a considerable level of welfare, to ensure that people have a decent chance to escape poverty, especially children born from poor parents (who didn’t make that choice). This requires substantial welfare, that IMO can not be plausibly be supplied by voluntarily contributions.
I am not talking about starving to death vs eating water and bread. I am talking about getting a decent education vs getting no or insufficient education.
I believe that demands on workers are increasing, which means that the level of education required to be able to climb out of poverty is increasing, which means that the level of welfare required for my ideals is increasing. As such, libertarianism is actually becoming less and less tenable over time, IMO, unless one is willing to accept a state with a permanent underclass.
Your implicit assumption seems to be that getting out of poverty mostly depends on money spent on you, presumably by the government. I don’t know if you have read Charles Murray’s first book, Losing Ground. The basic story he tells is that the war on poverty was supposed to get poor people people to be no longer poor–to be self supporting and employed at a reasonable level. Part of that was by job training and similar approaches.
It was a total failure, so the objective was revised after the fact to making poverty less unpleasant.
Of course, that doesn’t guarantee that the job couldn’t be done better in another way. But I think if you look at people who get out of poverty, it depends a lot more on them–on things like the culture their parents brought them up in or they developed for themselves–than on money.
For one somewhat special case, you might consider that essentially all Amish leave school after the eighth grade, and are mostly educated in one or two room schoolhouses with mixed ages and teachers who themselves have only an eighth grade education. It works. They are not only successful farmers, a lot of them start small businesses or are employed in such businesses.
The cost of adequate education for someone motivated to get it is very low. Educating someone who doesn’t want to be educated is extremely difficult. I don’t think spending money is likely to shift someone from one category to the other.
Shifting from the issue of poor people in our society to people in a hypothetical post-scarcity society. As I commented earlier, the first question is why they can’t do the same things with the same level of productivity as they were doing before the technological changes that ended scarcity. The fact that other people are much more productive doesn’t automatically make them less productive.
A possible answer is that they were doing those things with inputs in addition to their own labor, in particular capital and skilled labor, which are now being bid away from them by the high tech economy. If that’s true, however, it shouldn’t take much generosity from the fabulously wealthy high tech population to provide enough of those inputs to fill the gap.
Suppose the result is that the bottom half of the wealth distribution ends up about as well off as they were before the technological breakthroughs. They haven’t gained from them, but they also haven’t lost. Do you consider that an unacceptable situation?
I should probably add that my guess is that, in that situation, they would end up a good deal better off than before, because of the opportunities for trade with the high-tech economy, whose relative prices should be very different from theirs. But for the simple model, assume they are simply unaffected.
(Your post is sending me off in three different directions, as you can see)
I suspect that your idea of the cost of what you describe is about an order of magnitude too high, that what would literally keep people from starving or freezing to death would be much lower than what we are used to thinking of as minimal levels of welfare. I don’t think most moderns appreciate how rich we are.
I had a blog post a while back, in the context of arguments with “Bleeding Heart Libertarians,” in which I tried to make a rough estimate of the cost of providing for “basic needs” in the most minimal sense–enough food and shelter so that their lack would not greatly reduce life expectancy. It worked out to about $500/year.
@David Friedman
You didn’t include the biggest cost of your $500/year people sleeping in the rough and eating peanut butter roux, which is the security to keep them from killing each other.
@DavidFriedman
It’s more complex than that.
My belief is that a relatively egalitarian society makes it much easier to get out of poverty. Market forces are pretty good at allocating the best resources to the rich, the problem is that this creates all kinds of self-perpetuating outcomes across generations.
My premises are that:
1. Spending has greatly diminishing returns. Above a certain threshold, a school that gets two times the funding of another school is not going to be anywhere near twice as good. A Prius gets you to work pretty much just as well as a Ferrari.
2. There is not a continuum, but there are thresholds. At certain points, large groups of people won’t want their children in certain schools, don’t want to live in certain places, resist the police, etc. The forces that resist the negative forces are then too weak to prevent a downward spiral.
3. It’s very hard for people to make big jumps, as people need to gradually adapt and learn.
4. People are strongly governed by social norms aka culture.
5. People are often short-sighted, which is more the case the lower educated and/or dumber people are.
Because of 1, it’s advantageous for society to take a cut from the rich and use that on services for the poor. Because of 2, you really need to stay above these thresholds (or get above them if you are not). This can mean forcefully stopping self-segregation (which is also easier if you take a cut from the rich, because then they have less money to pay for self-segregation, like buying big houses with lots of land around it). 3 means that just like in computer games, you should have multiple levels of complexity, rather than super-easy vs super-hard. This gradual path needs increasing rewards to push people to go as high as they can. Due to 4, you need social engineering/propaganda. Due to 5, you need good defaults and certain things to be mandatory, like health care insurance, pensions, etc.
This is not easy. A lot of poverty measures that the left wants do not reward good behavior, as Losing Ground argued. However, the right tends to want to punish bad behavior so much that the climb out of poverty is like those classic console games where you had to do 1000 correct moves in sequence or you would have to start over from scratch. An environment like that can only be negotiated by people who already have skills, that you want to push them into getting. There is a step missing there: creating an environment where they effectively learn those skills.
PS. AFAIK the Amish are not very good at making advances in science and engineering & depend for substantial part of their well being on non-Amish society. For example, most seem to use modern healthcare. As such, their lifestyle can only be maintained because the rest of society is not Amish.
DavidFriedman
I strongly dislike the term ‘post-scarcity’ when it comes to robotics, because robots merely provide one resource: labor. Even then, labor is merely going to be cheap, not free. There will also almost certainly still be scarcity of other resources.
Imagine that robots very efficiently mine for copper. They will logically mine the easiest to find resources first. Because labor is so cheap, the robot overlords can now mine way more copper than previously, to increase their material wealth. The result is that the poor people will be left to mine copper that is way harder to mine than currently the case. The same for many other resources.
This has become your deus ex machina. The theory has a hole -> assume that there will just be enough charity to fix that hole -> done.
Yes, I believe that humanity should all get to benefit.
Also, I see this as a recipe for eventual genocide (or sterilization if the upper class are nice).
What do they have to offer? Their labor is pretty much worthless. The upper class obviously buy up all the land that is resource rich. So, what do they trade?
The entire issue with robot labor is that there may be point at which humans can’t produce more cheaply than the robots in any circumstances. At that point the most efficient way for the rich to give welfare is to give some robots to the poor to farm, build houses and whatever else the rich are willing to give the poor. Then the poor can be shuffled into reserves like the Native Americans were, to spend their days in idle emptiness, so they aren’t too much in the way.
From the perspective of the CEO of Starbucks, is a barista not a tool just as much as the horse was a tool for the farmer?
One big difference is that the barista is not company property that can be sold to a glue factory when no longer needed.
Right you just fire them and they die because they can’t get another job because they can’t do anything better than robots.
What axioms said.
In this case I would say the barista is MORE of a tool. The horse is an asset. When you’re done with it, you can at least sell it and recover some portion of your investment. When you’re done with the barista, all you can do is fire them – and you get nothing back in return. But in either case they’re gone and whatever happens to them at this point is no longer your problem.
In a purely capitalist since they aren’t a problem. They are arguably a problem for some systems of morality.
I’m not impressed with these arguments.
1. Perhaps in the future baristas will all die when robots learn to make lattes. But just stating it as a fact is not an argument.
2. Saying that a barista is more of a tool than a tool itself, because it’s different from a tool, doesn’t seem worth trying to reason about.
Oh, you’re one of those kinds of arguers/comment people/w/e. Nvm. I’ll not waste my time with a troll. Carry on.
Nope, to your employer / customer you are nothing but a tool to perform the job at hand / power / steer your workplace, what ever. You will (some animal sanctuaries not withstanding) not be payed for being a fellow citizen, your human dignity or even emotional attachment.
This is a really bizarre view on life, almost as if you have never worked with other people ever at all.
I think there’s a large difference here depending on which sort of employer/employee relationship we’re talking about, and how many layers of management are in between.
I stand by my original comment that to the CEO of Starbucks, the barista is a tool. A faceless blob that requires $X in compensation to produce Y productivity, and can be easily replaced – by a machine, by other faceless blobs, whatever.
Now, to that barista’s assistant manager, they may be a living human with dignity and struggles and all that crap. The assistant manager may care about the barista’s family situation and understand their unique skills and contributions to the specific starbucks location. But that’s a different story entirely.
Did you get that this comment is a reply to a comment waaaay up? If no, it comes across way more cynical than intended.
Other than that it is less never having worked with other people, than having a solid grasp of economics. Under sufficiently intense competition (5 to 10+ competitors in the local market) your boss cannot hold you, if there is a robot which does the same job (much) cheaper, because he will be outcompeted by a less scrupulous competitor.
If you think from the customers perspective this becomes very clear. Imagine you want to get the plumbing in your house done. Plumber A employs 3 people you do not know and wants 10000 Bucks. Plumber B owns a plumbing robot, which is known to be very reliable and is factory rated to make on average no more than 1 mistake in 25000 houses. Also he wants 5000 bucks. Who will do the plumbing in your house?
For such mechanisms to be in effect, no callous disregard for fellow humans needs to be at play. People simply do not unnecessarily spend thousands of dollars to give other people a job for a few weeks (with very few exceptions).
The faceless blob effect in larger companies as described by Matt comes on top of that.
@ EGI
You have simply weighted things in your favor by stipulating the robot is nearly flawless and making the monetary value extreme. Money is one factor that people take into account when making decisions, and thus it can be a deciding factor if you make the example large enough. It doesn’t therefore imply that it is the only factor, and that naked capitalism if allowed to run rampant would put a strict dollar amount on every transaction and that business owners would fire every single employee to make a single cent more. This is a fiction invented by economists to make modeling easier, but humans don’t have utility functions where one thing is worth $9,000 and another $8,750 with the differences between them worth exactly $250.
No I have not. Actually I think I weakened the robot and did so intentionally to show the strength of the argument. If you compare shop manufacturing and automated production, there are typically one to two orders of magnitude price difference (imagine a car completely assembled in a machine shop), because humans are both slower AND more expensive (though that depends on the particular job).
To take lawn mowing (400m²) as a less fictional service job example:
Robot for 10 years: 1500 Euro for Robot and Installation, 10 service visits a 80 Euro, 40 kWh a 0.3 Euro = 2315 Euro (And once they are just a little more intelligent than they are right now, one robot can easily mow all the lawns in one neighborhood for another order of magnitude price drop)
Human for 10 years: 200 visits a 40 Euro = 8000 Euro (And that is VERY cheap if the service brings equipment and is not undeclared work. More realistic would be 80 for both robot service visits and mowing, since they are basically the same amount of time for the provider)
I think it is highly unlikely, that a robot on a particular job is miraculously just a little bit cheaper than a human and remains so. This may sometimes be the case because the robot starts out more expensive (and isn’t used), becomes gradually cheaper, is slowly adopted as it approaches human price range and becomes cheaper still (this is happening in lawn care right now) until it is practically universal. But as a stable end point this is very unlikely.
Also machines are (once the kinks are worked out) much less prone to making mistakes than humans are and their mistake rates are more easily quantifiable than human mistake rates, since there can be multiple machines which are basically the same.
It’s not a fiction but an approximation / simplification. I know that markets are not 100% transparent and efficient. In fact the plumbing prices given above are not completely ridiculous even without robots. Heck, earlier this week I got to do a job for 400 where another company bid 1500 and since they are not out of busyness already they obviously do still get customers despite their pricing politics.
But as robots start to get a reputation for being cheap and reliable pressure will grow to adopt them and in equilibrium after a couple years or decades 99.whatever% of plumbing jobs will be done by robot.
Maybe,but that does not change the fact, that most humans will not pay significantly more for a service/product to support random strangers or even someone they met a few times (in the case of service jobs). Of course values for “most” and “significantly” are highly dependent on the situation.
I feel like this really needs more discussion than it gets, as it’s a huge source of divide between people with different perspectives on a wide number of issues.
I agree with your assessment but it’s clear that many others do not.
seems like a lot of people are hung up on horses and obsolescence, which was only a small part of the overall presentation. But this is a very important issue though.
My ‘theory’ is that rather than technologies making old technologies completely disappear, both the old and new technologies coexist, but the new technology increases productivity to much that it dwarfs the older one but demand for the older one still stays mostly unchanged for a very long time. So there will always be some need/demand for horses: for food, performance, sheriffs, racing, nostalgic stagecoaches, for fun, etc. Same for typewriters and quill pens..they haven’t gone away yet.
And while people are hung up on horses and obsolescence, I may as well take the opportunity to remind people that cowboys still exist (for the time being, anyway). I know– they were my neighbors growing up, and my father still to some extent is one. Use of horses among that demographic is much less frequent than it was some decades ago, but an important point is that unlike all of the other examples people are giving (racing, girls’ pets, Buddweiser commercials, etc.) the use of horses by cattle ranchers is still entirely functional (and thus not obsolete). The reason is maneuverability and accessibility. A man on a horse is able to access rough, difficult terrain that mechanized transport like ATVs or even motorcycles can’t reach (especially after heavy rain or snowmelt). On many an occasion I’ve found myself unable to cross a particularly deep or muddy stream on ATV (or, having attempted, gotten stuck), where a horse would have zero issue whatsoever. A horse can also ascend and descend a steeply-inclined hillside which would be dangerous to attempt on wheels.
Actually this is far to understated. Comparative advantage shows us that even if X is better than Y at everything individually then X will take his highest value employment and Y will end up with the highest value of the “remaining” employment (not the greatest description but whatever). The only way that Y ends up being unemployable is if his productivity is less than the cost of keeping him productive (ie food/shelter), which is what actually happened to horses, or if X has no opportunity costs (ie it can do all things simultaneously with no drop in efficiency for the high value stuff).
What I find interesting is that on here it has been argued that increasing the minimum wage will result in increased unemployment, as people who are not productive for the value of the new minimum wage will not be able to find work.
Yet now it is being argued that increasing automation where machines/robots/AI controlled machines and robots can be so productive as to out-produce humans such that goods will be cheap as chips will not result in surplus to requirements human labour.
So which is it – there is a substantial minority of people who are not employable above a certain rate and so there is going to be an increase in unemployment, or there are no people unemployable at any wage even if by comparison with a robot worker they can only earn 5c an hour?
I also want to see some pricing for this putative robot factory of the future – okay, so say we have a fully automated washing machine factory where every step of the process is automated and all the jobs (including management and administrative) that can possibly be replaced by outsourcing or sub-contracting or AI have been replaced. What figures are we looking at, and I don’t mean “it’ll churn out washing machines that cost practically nothing”. Put a price on it. Okay, we’ve junked the cost of labour and paying taxes for that labour. What remains?
Because you don’t make products from nothing, you need resources. Price me the metal going into the machines, the electronics, everything. The price of the energy. Are we mining our zinc and steel by robots as well and that has driven down the price, or are we constrained by the rarity of materials?
Give me an estimation of “cost of mid-range washing machine today versus ten years’ time when it’s all made by robots”, instead of pie-in-the-sky “so cheap it’ll cost buttons”. Remember, we were going to have electricity too cheap to meter and charge for because it was all going to be generated by nuclear plants!
No, people who are not productive for the COST of the new minimum wage will not be able to find work.
More importantly to the distinction is that a minimum wage law prohibits specific jobs (when you consider that a job is compensation for work), and so must either limit job opportunities or be set so low as to be ineffective, whereas advances in technology don’t prohibit jobs, they shift who does the job which doesn’t automatically imply a net decrease.
Consider the horse story being discussed. When cars came out they shifted the job of carrying/pulling stuff and people from the horse to the car, but the existence of the car/truck/train meant that there were new jobs possible that weren’t before. Net jobs increased, not decreased.
It might be good to look at videos:
Emerging
Developed
The only difference is labor rate and technology- steel and other commodities are global. Emerging market labor rates are a tenth to 25% of developed. The higher labor rates mean the companies have to evolve technologically to stay competitive (no surprise) so we can all have our $500 price point which is about how much they cost with little change.
It won’t be a bang, it will be a wimper by which humans are replaced
Isn’t this a short term vs long term deal.
I don’t think anyone is saying that raising the minimum wage to $15 today will inevitably lead to a dystopian hellscape where all property is owned by the board of directors of Google and the rest of us are forced to compete in the hunger games for the amusement of their robotic slaves.
Raising the minimum wage fails on its own terms, because it is promoted as “this will help the poor right now” but an argument can be made that it will actually harm the poor right now.
I think there’s little controversy that cheaper advances in robots and AI would, in the short term, displace a lot of workers. The controversy is whether this will lead to the end of civilization as we know it when no human can do any productive task at all because AIs are everywhere and are better at everything and if you didn’t invest in Google you have no money and no skills and no future.
Over the long term, markets have always been very resilient to this sort of thing. The Luddites were not wrong in the sense that some of them were, in fact, displaced by machines in the short term. They were wrong in the sense that they suggested this would destroy society and conditions for the poor would get worse as they could no longer offer valuable labor.
This is also my view on the issue overall. Short-term, there will definitely be some disruptions. Long term, I think we’ll figure it out.
nobody’s ever found that coal mining areas have lower IQ than anywhere else
The Audacious Epigone’s latest estimate of West Virginia’s mean IQ is 94.2:
http://anepigone.blogspot.com/2015/02/2013-iq-estimates-by-state-total-and.html
maybe it would be easier to tell an inverse reinforcement learner to watch the stuff humans do and try to figure out what values we’re working off of
If a computer ever figures out the real motivations behind the moral codes promoted by the powers that be, and then naively states these motivations, the powers that be will be so offended that they’ll ban all AI and jail all AI researchers.
Or did non-intellectual factors – politics, conformity, getting trapped at local maxima – cause them to ignore big parts of possibility-space
There’ve been long periods of stagnation in math, science and technology, both in the East and the West, followed by periods of progress, followed by new periods of stagnation or regression. So that definitely happens.
Might we one day be able to do a play-by-play of Go history, finding out where human strategists went wrong, which avenues they closed unnecessarily
Heliocentrism was known in ancient Greece, but was dismissed by the mainstream as pseudo-philosophy.
Even if the AI involved were generally accurate and could predict recidivism at superhuman levels, that’s a hard pill to swallow.
Not for criminals. They’re all highly religious people, so they already believe that “God works in mysterious ways.” Getting high-IQ, atheistic computer science profs to accept an AI program’s black-box estimates of the value of their work and consequent salary levels would be more difficult.
Are the neurons in our brain some kind of uniquely readable agent that is for some reason transparent to itself in a way other networks aren’t? Or should we follow Nisbett and Wilson in saying that our own brains are an impenetrable mass of edge weights just like everything else, and we’re forced to guess at the reasons motivating our own cognitive processes?
It’s the second. And I’m sure that most of our guesses are gross oversimplifications, and are wrong in other ways.
This sort of matches my conception of System 2 and consciousness as a training/debugging framework for System 1. I wonder how you’d train a network so that it’d expose semantic signals to a debugger process. I wonder how human brains bootstrap this.
Hm. I was working off eg these state IQ data which say it has average IQ 98.7. I’m not sure what kind of factors would be able to decrease West Virginian IQ all the way to 94. Selective migration? It would take a lot.
The paper’s scores are consistently a couple points higher than the blog’s. For example, both put WY about 4 points above WV, and VT another couple points higher. Since 100 is arbitrary, this doesn’t mean anything (although there are residual discrepancies). AE defined the mean to be 98, while the paper probably defined it to be 100.
Who defines the mean of IQ to be 98?!?!
[EDIT: Apparently this comes from the average score on a test? Why would this be so different from whatever sample they use to norm IQ?]
Well, it’s not a definition, but a prior measurement, based on international comparisons. In honor of Galton, UK is the reference point for IQ, when people worry about international comparisons. Since NAEP doesn’t have an international component, he couldn’t replicate it, but had to assume it.
I would bet the real reason why an area shows up as low IQ is that it is a poor area right next to a rich area. So when it is really easy and lucrative to move one state over, people will do it. West Virginia is right next to Washington D.C. , which has a huge shortage on programmers.
Right. There are tons of reasons for high IQ people to flee West Virginia, and virtually zero for any high IQ people to move there.
That is a lot of assumptions. If WV was totally neutral to start why did it develop into a place where high IQ people flee and low IQ people stay?
This is the major hurdle in understanding the rust belt. OK the steel industry declined so the most productive moved away, but steel was a big industry for decades, why wasn’t the economy robust enough to handle that decline?
@baconbacon: low population density = no jobs in a service economy. In WV mountains help maintain the low density.
@Cory
This doesn’t explain rust belt cities that declined when the steel industry declined, nor does it address the starting conditions.
If almost all of the people in a city work for part of the steel industry, and most other jobs are in the service industry whose customers almost all work for the steel industry, what else do you imagine happening when the bottom falls out of the steel industry?
You snuck a huge assumption in there.
If a town grows large from steel over several generations, why would it remain the primary employer? The steel industry should act as a subsidy for other industries to grow around as it will provide various benefits like a large tax base, a large supply of willing labor, quality culture (The Carnegies made parts of Cleveland an artistic haven), it will support large institutions (Cleveland again has the Cleveland Clinic and a few decent universities).
@baconbacon
None of that necessarily makes a good incubation environment for alternative businesses. In many areas dominated by 1 industry, the social norm is that any youngster will ‘go into the mines.’ It’s the normal things to do and the safe thing to do. Until it no longer is and the mono-culture collapses.
The kind of free spirit/hippie culture that celebrates diversity, going off the beaten path, etc that you find in places like Portland is not something that you find everywhere, especially since the people who like such a culture migrate away from places like (old) Detroit.
No its not. If this were remotely true there would never have been migration from rural to urban centers. Wages fell to near zero with the advent of new farming technologies, and yet individuals didn’t sit around and starve, they moved and not only found but created new sources of earnings. During the Irish potato famine >600,000 Irish emigrated to the US. They didn’t pick up magazines and say “oh look, the US has 600,000 job openings, lets move there”. They packed up and moved and then created new jobs, new social structures and new industries, and 150 years later their descendants are some of the wealthiest people ever to have lived (average earnings for Irish Americans ~60k a year).
You are thinking of only the people that stayed in these situations, which is clearly, and mathematically demonstrably incorrect. If you work the coal mine, and your dad worked the coal mine, and his before him it is “obvious” that no one leaves, but that is only true for n=3. If no one ever truly found other work then one of two things must be true, either the population must continue to grow steadily, or people must be reproducing at or below replacement rate. This is not what you see historically. First you get a huge boom in population, which shatters your explanation (those people are coming from somewhere else, right? They demonstrate economic mobility just by getting the mine open), and the mine/town expands until it is economically unfeasible to grow more. Then population tends to flat line or decline, but without mass starvation or infant mortality rates >50%. By the time the town dies several times the actual population of the town have moved out and on over the years to find and create new opportunities. Close to 30 million Americans claim Irish ancestry, Ireland itself has only about 6 million in population (and the US is far from the only destination for emigrants, as ~2/3rds of emigrants during the famine went to countries that were not the US).
You can lament those that stick in the mines for generations, but to claim that it is the norm for these zones is completely false and you are simply falling prey to a form of survivor ship bias by counting only those that remain and not those that leave.
@baconbacon
You are not actually disagreeing with me. I explained why prosperous environments don’t necessarily cause a diversity of businesses to spring up. Of course, once the mines were closed or the car factories started laying off people, then people became much more willing to seek other options. But by then you are already in a decline, which makes it very hard to create those alternatives.
The author of that site states “I built the formula for the estimates using Richard Lynn’s data on international academic and IQ test results, so my equation is linear”.
I’ve complained on here before that I think Lynn is full of what makes the roses grow when it comes to IQ estimation (I honestly believe his evaluation of Southern Irish versus Northern Irish versus ‘mainland’ British IQ results is politically motivated due to his Unionist-leaning sympathies) so I take that site and its state IQ estimates with an entire mine full of salt.
Throw a dart at a dartboard, your score is equally as good as those estimations.
Agreed that our own brains are (largely) impenetrable – I wasn’t even aware there was any debate about this any longer. There’s decades of psychology and neuroscience research showing the creative nature of explanations for our own actions, and how easy it is to get people to give clearly wrong explanations.
This seems a strange claim. I understand that atheists are underrepresented in prisons, though to what degree that just represents a general tendency for relatively high levels of education and wealth to correspond to lower rates of both criminality and religiosity I don’t know. But accepting your claim at face value: surely a criminal who would accept a mysterious misfortune as fair game if it appeared truly random and thus in the hands of the gods, while not accepting a misfortune imposed by a human authority, would put ‘mysterious misfortune handed out by black box designed and built by humans’ in the latter category.
Yeah, everyone expects minimal due process from human institutions, there’s no religious/athiest distinction here
Not for criminals. They’re all highly religious people, so they already believe that “God works in mysterious ways.”
From “The Man Who Was Thursday”:
An unusual but interesting take on technological unemployment:
> If AI were really about to unlock a ton of value that could disrupt the economy, all you need is a few shares of GOOG and you, too, could get a cut of all the awesomeness about to come.
…Is this as scarily dissocial as it sounds?
I have cashed in awesomely on technological change. My grandpa was a poor farmer, mom (single-parent) was a minimum-wage laborer, and I could break into comfy middle-class just by typing things on a computer. Eventually I was even able to move from boring things (programming) to things that actually interest me (linguistics). Look out the window—that’s already massive privilege. I don’t want to cash in even further. What I fear from automation isn’t me not becoming a billionaire, it’s the fact that the 99% won’t cash in by definition (unless you’re sharing GOOG equally with literally every person in the world… come to think of, that ☭doesn’t sound so bad☭…), and how to avoid humanitarian disaster when capitalist ethics base human worth and dignity (not to mention access to goods and services) on being a laborer.
I think the tumblr author intended to convey that the dividends of automation could be widely shared, using universal shareholding in a sort of AI index fund as a model.
Ideally, the definition of AI safety should include “implementation does not massively prune human lineages relative to the baseline extinction rate based on notions of economic value”.
Anyone can buy GOOG. That’s not your special privilege.
If the AI is powerful enough to knock out the majority of the economy, that would mean that the AI can supply most of the basic human needs all by itself. That may sound unexciting, but there are lots of people living out on the streets today who would gladly take that deal.
No, this is wildly misinformed. It straight up assumes that AI will come through Google (or some publicly traded company). You get totally screwed if some private company gets to AI first (Google went public in 2004, but was formed in 1998, trying to grab a bunch of the future earnings of the public top search engines prior to 2004 probably leaves you with a basket of deplorables in your retirement account).
One way I’ve seen discussed to fund a UBI uses this principle: a “citizens’ dividend”. That is, everyone gets a share of ownership of the “robots”. Yes, it’s actual socialism.
Yes, and like actual socialism it’s a terrible idea.
Why? So many of objections to socialism evaporate in my mind when you get rid of the “from each according to their ability” part, and then replace the latter part with “to each according to whatever the robots make”
My understandings of the flaws of socialism is that a. a centralized economy does not optimally distribute resources (Which isn’t too big of a problem in a semi post scarcity scenario) and b. the lack of reward tied to efforts does terrible things to people motivation to produce (which isn’t a problem since the robots motivation is eternal).
I’m not convinced by the dreams of the coming robotic post scarcity, but if it does come just giving everyone a share ownership of all or most of the robots seems like a fine plan.
Where did I go wrong?
There are several different objections to socialism, first is the Hayackian one which posits that the information contained within prices is what allows markets to work. Secondly that there must be a special class that controls the distribution of goods which creates its own set of perverse incentives and third (but not finally) is the lack of opportunity cost when it comes to time and production prevents individual learning and you effectively have a population of pampered 9 year olds making decisions.
> Secondly that there must be a special class that controls the distribution of goods which creates its own set of perverse incentives
If you are proposing artificially-induced scarcity as a solution to the other two problems, how do you suggest avoiding this? How is distribution of that artificial scarcity, presumably on moral grounds such as the avoidance of pampering, different from the Kommisar handing out rations to Party loyalists?
For bonus points, explain how, if the rational Hayekian basis of the price of a good is zero, you are supporting the interests of an information-based market by lying and saying it is not zero?
I have seen no compelling evidence (heck not even any evidence, just statements) that a post scarcity world is realistic, it is either a buzzword or a red herring. AI, even super AI will still in all likelihood used electricity and have a physical location using physical matter.
Explain how a physical good, made up of matter, could ever have a perpetual price of zero. You cannot produce an infinite amount of one thing, let alone an infinite amount of all things humans want. Even just producing for a few billion people all the things that they could possibly want if the price for all things was zero would strain the resources of the world*. Heck as long as the AIs themselves have needs prices will exist**.
If a person uses post scarcity to mean literally “no scarcity” they are just using their imagination to do an end run around the laws of thermodynamics.
*citation needed, but in a true “post scarcity” world who doesn’t end up wanting (and thinking its their own birthright) their own ocean liner filled with robotic servants, sexbots and the finest cuisine possible.
** I submit that the best way to fight against the AI apocalypse is to fight patent and copyright laws, the worst case scenario is one person/group getting AI and no one else getting it. This is the likely path to distopia.
@1soru1
Even when you have robots, it is likely that for most physical goods, you still have resource costs, so the price is unlikely to be zero.
@baconbacon: if we postulate a set of robots, don’t the productivity concerns go away?
As for coordination of production, the robots could respond to price movements to maximise productivity.
@baconbacon: The technological unemployment scenario is post-scarcity for labor only. That is, labor supply is so large relative to demand that the price approaches zero.
If it’s a full post-scarcity economy (with practically-infinite supply of goods and services) we don’t have a problem. The problem arises when labor is abundant but goods and services are still scarce. In that scenario, earning a living approaches impossibility.
My wages are terribly low and I can’t afford very much.
You are my neighbor, your wages are also terribly low and you can’t afford very much.
We are both physically capable human beings, can we not work for/with/trade with each other? I mean, we both know where to get this amazing surplus of crazy cheap labor, can we do nothing with it?
Horses dropped out of the economy (outside of some niches) because if you let a horse go free all it can really do is eat, poop and make baby horses. Humans aren’t like that (ok, some are but they are rich from their reality TV shows anyway), they can self direct, self create. You make robot overlords who won’t trade with them, well then they will create their own markets and trade, create, innovate and live within them.
I think most people have missed MarMarts point. Capitalism allows you to make money from ownership of the means of production, as well as by selling labour, so you can have a system where everyone is a stakeholder in that sense, and gets an income in that way even if their labour is of no value…but market mechanisms still control pricing etc.
Think of it as an exercise in grafting a guarantee that no one will starve onto capitalism, whilst retaining maximal features of capitalism.
What you’re describing is merely going to be a subsistence lifestyle though. Some scenario where a bunch of unemployed people get together, one guy farming, another woodworking, etc. would be an extremely low standard of living, assuming they could even get access to the land and resources necessary for such a thing.
Forget about economics for a moment and think about psychology. if a vast number of people are stuck living such a life, having previously had a comfortable modern existence, whilst a handful of robot owners live in some kind of utopia, do you think they’ll be satisfied?
Here is the trouble, it isn’t a guarantee, its a promise which is very different. The promise itself cannot be fulfilled without the capitalist structure beside it (countries that try the promise without that structure tend to do poorly). Secondly such promises, when instituted, don’t actually tend to change outcomes. The origination of welfare in the US is not associated with the reduction of poverty, it is in fact associated with an increase in poverty (relative to the trend prior to the initiation of welfare).
Am I? Are we at subsistence now? This is pretty much how our current economy started out, why would you assume all knowledge/skill/trust would be lost and a restart would have to happen.
Let me see, did I say “retaining maximal features of capitalism? Yes I did
You didnt explain what you think the difference between a guarantee and a promise is. I think a gurantee is legally enforceable, so citizen shareholding can be guaranteed.
You also didn’t say what metruc of poverty you had in mind. I dare say welfare leaves it higher lower or the same according to the definition.
sovereign wealth fund
How is it actual socialism?
Marx had a 10 point plan in the Communist Manifesto, and I don’t recall “get robots to do all the work while everyone sits back and relaxes” being on it. (Incidentally a number of points on it have been adopted fairly broadly, eg progressive income tax.)
The state / people collectively own the means of production in this scenario. TBF despite self-identifying as a social democrat I know little of Marx other than his propensity for flipping tables in Existential Comics.
Maybe. On thinking about it, it is an ambiguous term.
And this seems the point that there’s not much difference between capitalism and communism.
The citizens dividend is socialism in the sense of shared ownership, but not in the sense of centralized control. Thats an important point.
Who determines how the dividend is calculated, and divided? Who sets the rules for inheritance/transfers/sales of shares? It is only lacking “centralized control” because you are assuming it into existence, the actual practical distribution always contains central control and all the potential faults along with it.
The citizens dividend isnt centralized control of everything. If you are going to define socialism as centralized control of anything is socialism then I have two pieces of news for you. One is that socialism is ubuquitous…the other is that socialism is not disastrous.
LOG EVERYTHING.
I’m not sure how advanced AI works, but it’s probably worth it to “slow down” its decision making and have every step of a multi-step or complicated decision logged into a text file. Even if the text file gets huge, having a step-by-step record of how a decision weight changes as data is read and added could give insights into how a decision was reached.
As someone who routinely has to debug issues using logs generated by far simpler systems, let me just say: good luck with that.
We could use baby non AGI to help us?
@TK-421
We’ll just make a machine learning system to analyze the logs for us 😛
It’s easy to log. But even in, say, a “simple” feedforward neural net with a single hidden layer, and perfect knowledge of all the weights, it can be very hard to figure out what the weights represent. There’s been some work done on conceptualizing this, but it’s very hard to get your head around this.
Keep in mind that many of the systems people are excited about even today are still essentially feed-forward (during decisions, not during the training process). So there aren’t “steps” to decisions, it’s just a single pass through the system (I guess you could call each layer a step, but it doesn’t really change the issue). But even in those cases, there might be 1,000 weights or whatever – what does changing one of those values by 0.03 mean? Is that even a meaningful question?
Logging each step of a million-step process (and “million” is a vast underestimate for the complexity of the training process) doesn’t help you understand the process. You don’t have time to go through each step, and even if you did, every step will look meaningless in isolation; you’re too zoomed-in to see the forest for the trees.
I dunno, I think you’d be more likely to go down the path google did with deepdream before it turned into a tool for finding lovecraftian snails in clouds, or the way explanations work in recommender systems.
The problem for me is that we might not want to know all the factors that go into a decision even if those factors are highly predictive. Will we be comfortable with a neural network where one of the hidden nodes has a 0.6 correlation with being Asian, based mostly on dietary requirements and historical grades? Or one that rates a prisoner up for parole as more likely to offend because he was born to a single mother, has a low resting heart rate, and had few close friends growing up? It might be easier to accept a silent and mysterious judge than a judge who makes counter-intuitive decisions.
See how people react to ethnic profiling by the police.
Realistically, the legal/penal systems are going to be the very last ones to automate. It’s foundational documents/principles are centuries old, it has a long and robust tradition of rejecting efficiency in deference to rights and liabilities, and its dominated by stodgy old people–there are tons of practicing lawyers (and judges, I’d assume) who still dictate everything. By the time we get to questions like ParoleBot, we will have a very, very different society and I think predicting people’s attitudes towards it right now is futile.
This is probably true, but the same kind of thing applies to loan applications and insurance underwriting, and to anything else that involves rating people.
While I haven’t read the underlying paper, Google’s solution appears to be “fuck, it we’ll just use affirmative action, I guess it’s worth sacrificing some profits”, which isn’t really a good sales pitch.
The issue isn’t that the information doesn’t exist, it’s that we don’t have a good framework for intuitively interpreting it.
If you have a behavior that manifests itself as the result of slight adjustments to every one of a billion coefficients, and it causes slight modifications to a billion numbers as new inputs are supplied to the system… what do you do with that information?
This seems like an easy problem to solve–just add post-processing algorithms to generate vaguely plausible post hoc justifications for the original algorithm’s choices. That’s how it works with human decision-makers, after all…
This seems to be a naive view/lack of understanding to think that logging will reveal the answer to how the decision was made.
On the general issue of whether technological change can lower wages, it’s worth noting that David Ricardo discussed it, correctly, two hundred years ago. He starts with the argument that capital accumulation raises the capital to labor ratio (not his language) and so raises wages. But he observes that technological development could change the production function (again not his language–Ricardo had the sort of mathematical intuition that let him see things correctly without the formal tools we think of as necessary) in ways that made labor less important as an input and so lowered wages. As best I recall, that was a correction in a later edition of his book to an incorrect conclusion (that workers would necessarily benefit) in the initial edition.
I think putting the argument as technological unemployment is misleading, since demand for labor is a function of price and even quite radical change is unlikely to reduce the marginal productivity of labor to zero. But it is possible for technological development and capital accumulation to lower the equilibrium wage if, as in the case of robots, capital is substituting for labor.
On the other hand, increasing productivity via such progress tends to make everything produced via such technology relatively cheaper, so even if the workers are all in areas where robots are not a good substitute and producing less stuff than they used to since those areas now have more people working in them, their real income may go up. At the limit, imagine a society where most of what we now spend our money on is almost free, people with capital, even not a lot of capital (i.e. owning some of the robots) are very well off, and people selling only their labor (back rubs? Servants? Crafts? Whatever parts of the production process still require humans) are pretty well off because everything else is cheap.
Of course, that is also a scenario where some sort of demogrant is practical.
Wanted to second this. Visualize the world in which robot-assembled products are produced in such massive abundance that humans can no longer compete, which in turn causes a massive abundance in all remaining products.
Are we sure this is a dystopia?
@AnteriorMotive
Why would the factory owners produce massive quantities for people who cannot create value for them in return?
the govt become the biggest costumer for a hypothetical post-scarcity quasi socialist state
Your premise already contains the conclusion. If you presume a quasi socialist state that will seek to maximize the happiness of each citizen by ‘buying’ all the goods and distributing them, then the state will obviously be the biggest customer.
However, it is far from a given that we will end up with such a state.
“Cannot create value”? But they can. Backrubs.
Allow me to blow your mind.
More seriously, I don’t think “get a rich sugar daddy” scales well. Not to mention that it’s also exactly the sort of thing to provoke a rebellion. Better to die on your feet then to serve on your knees indeed.
Those chairs suck. They just give me a headache and don’t massage me at all.
So why haven’t the thousands of McDonalds fry cooks risen up in rebellion?
Future low-skill jobs won’t look any more (or less!) like slavery than our current low-skill jobs do…
Low-skill worker standard of living was getting better for all the past few centuries, and is arguably still getting better in most of the world. What happens if low-skill workers can look forward to a substantial drop in standard of living each year?
Catch 22. If no one is producing those goods then there is demand for them and people should be able to form their own companies to produce them, and hence create jobs.
My argument was not that no goods get made, but that the people without the skills to program and maintain the robots end up without any buying power; nor with the ability to set up a decent production system for themselves.
There would still be an elite living in with their farm robots, sex robots and cleaning robots (what more do you need?). And of course, violence robots to protect their community from the commoners.
So robots are making goods and just stocking inventory perpetually? What do you imagine happens to those goods?
@baconbacon Presumably those goods will directed towards building granite cocks, invincible madhouses, robot apartments, skeleton treasuries, etc.
Y’know, flying cars, Mars colonies, companies that make ios apps to do your laundry for you, conferences to argue about video games, golden toilets that about ten people will ever use, shots of alcohol worth a month’s income to the median family, yachts that have smaller yachts inside them, frequent flights between capital cities for seemingly trivial reasons, and things of that nature.
Why not? If having no buying power is a problem, then the goods must cost something, which means that the commoners could make money producing and selling the goods themselves even if they weren’t as productive as the robots. Even today we have small farmers sharing the market with big agribusiness, artisanal miners sharing the market with international mining corporations, camgirls sharing the market with large porn companies, etc.
If, on the other hand, the robots make goods so cheaply that the commoners can’t make any money by producing and selling them, then why is not having any buying power a problem?
So super-rich people hoard all of the robots and only use them to make things for other super-rich people. What’s to stop the commoners from ignoring them and running their own separate economy?
The dystopian scenario is that the robots make the goods just for the elites (say, a few million people, ~0.1% of the current world population) using up all or almost all the usable resources, while the rest of mankind, if not deliberately exterminated, lives in abject poverty and gradually goes extinct (some may survive as “pets”, but even if each elite has 10 “pets”, this still amounts to a few tens million people).
There are some non-trivial underlying assumptions to this scenario, for istance the notion that the material desires of the elites are unlimited enough that they will use up the vast majority of available resources to satisfy them, which may not be true. But still, it is a scenario worth considering.
Two main objections. First is that the filthy rich, Gates, Buffett, Rockefeller, Carnegie, don’t seem to live lives of exponential indulgence.
That is trivial though. In a world where the elites control all the resources, how the heck are the masses going to enforce a UBI? If the elites want to build a robot army, or create their own continent, or whatever to keep the rabble down, in a post scarcity world they will be able to do so (under these assumptions). It is the same issue with “we need welfare because not enough people will give to charity”. How do you get a world where there is a UBI/massive scale welfare AND an elite class that cares not for the plebeians who control all the world’s wealth but can’t manage to get their preferred legal interpretations in place (or don’t just ignore them)?
@baconbacon
They do seem to engage in dick-measuring spending, which does scale with their wealth. For example, a common thing for the elite to buy is huge ships to show off. Even a semi-hippie like Steve Jobs played this game.
These ships have been getting bigger and bigger.
Well, this is the thing that is being debated. Most likely we don’t suddenly go from our society to this society, but rather slide into it. So the trick is to recognize what is happening and take measures to counter this development.
The masses aren’t going to be able to enforce anything in any case. We’re arguing about what the nice kind and friendly elites should do, on the assumption that they’ll be able to overcome the mean cruel and evil ones.
We’re all rooting for you, Scott.
Right – hence the “we need socialism now!” Like other slow-moving disasters, the problem is defined in such a manner that we must take actions to stop it before it can noticeably manifest itself.
@suntzuanime
That depends on whether they act in time, doesn’t it?
@Matt M
You are weakmanning my statement by turning ‘noticing what is happening’ into ‘stop it before it can noticeably manifest itself.’ The latter is obviously different from what I said.
But that IS what you want, right? You want the legal framework and the cultural norm of a UBI to be established well before advances in AI render all human labor obsolete, correct? Because once that happens, the shareholders of Google will have all economic power and will be impossible to resist.
Please do tell me if I’m wrong or if I’m misreading your position here.
@baconbacon
These specific people may not, but other filthy rich people, on the other hand do things like this.
More generally, the cost of a modern Hollywood blockbuster is typically in the $ 200 – 300 million range. How many proverbial starving African could be fed with that amount of money?
If the lifestyle of a modern middle-class person in the developed world is already a life of “exponential” indulgence, compared to those living at subsistence level, wouldn’t be plausible that a future society could spend 300 billion inflation-adjusted dollars to make a movie, or some equivalent entertainment product, for the benefit of a few million filthy rich people while billions of filthy poor peasants strive to survive?
Maybe human desires are bounded at some reasonable level, maybe the filthy rich are more likely to behave like Bill Gates rather than some Saudi prince, but this might be a cultural thing that may not be stable, so you might not want to bank on it.
By the government? I don’t know if UBI is the ideal solution to automation-induced inequality, but before we discuss solution we need to first acknowledge the problem.
Any functional government, by definition (an entity with a substantial monopoly on the exercise of coercion), will disallow private armies. So the elites will have their robot army only if the elites control the government, which is admittedly pretty much the default state of affairs, but it may not necessarily have to be the case, given how much is at stake.
No, not really. Modern blockbusters are made for $200 million because they can get 50 million people into the seats at $10 each if they make a popular one (I don’t know what the actual numbers are for profiting on a modern movie). It is very unlikely that the super rich in the future don’t have personalized movies made for them because they could do that now and few do (some have funded documentaries about themselves I believe which probably counts, and there are probably instances of very specific porn being produced for individuals). The super rich watch the same movies as the rabble, but in nicer settings.
The fear mongering being floated around is the idea that the elites will control all the wealth and consume it. Once you demonstrate that even just some of the rich (and to this point I cited the richest of the rich, not just generally rich) won’t do that in a post-scarcity world they could feed/clothe enormous numbers of people with a small portion of their income.
The fear itself is not a sliding scale of “rich people spending 100% of their resources is really terrible, there fore rich people spending X% is still terrible is still terrible to some degree”.
Once you demonstrate that even just some of the rich (and to this point I cited the richest of the rich, not just generally rich) won’t do that in a post-scarcity world they could feed/clothe enormous numbers of people with a small portion of their income.
Is it possible we’re already close?
Like, if Bill Gates and Warren Buffet were willing to put 100% of their net worth at risk, and were willing to give out money that would clearly be used for basic consumption rather than “investment in long-term solutions”, how many poor Africans could they provide basic sustenance to and for how long?
Say Gates and Buffet donated 100 billion combined. That would be less than $3 a day ($1,000 a year) for 100 million people. Quick google brings up 3 billion people living on $2.50 a day. Gates and Buffet could plausibly bring this up to $2.60 a day for one year using their combined fortunes (and then the money runs out).
My fearmongering is a bit different. It’s that elites wouldn’t necessarily consume all wealth, but would still be in control of wealth even when non-elites were consuming it. Think some combination of Player Piano, Brave New World, The Diamond Age, and current dole/welfare programs where spending is restricted to certain goods.
In this scenario, you get fed and watered, and have access to hundreds of millions of educational VR tutorials and an excellent gym, as well as a very well equipped art centre. You still brew a primitive dorito and mountain dew wine in your bathtub, because the Bill Gates Empathy Fund has certain views on the consumption of alcohol, and you have to tailor your own clothing out of tshirts, because the Fund doesn’t allow you to purchase the kind of clothing that’s currently in fashion. You dread that the securitrons will find your scissors and needles, because those items are officially Weapons and have been banned For Your Protection.
Every year, the Fund awards a Most Improved award for a one-way trip to Mars. You have never won this award. Nobody you know has won this award. You have never won any award, even the trip to an artificial beach that comes after a month without a Rules Violation. You have been married one hundred and twenty times, until they closed the champagne and divorce loophole. You have never seen a tree. You think you have seen the sky, but it is actually a very good fake. Nobody tried to hide that it was fake, they just never bothered to tell you.
@eh – You may or may not know that there is a fence surrounding you and everyone you know, and on the other side of it is pristine nature, stretching as far as the eye can see. You will never be allowed near this fence, much less across it, because the people who built the fence value the “pristine” part very highly and have the resources to secure it. The facilities you live in are confined to a relatively small “footprint”, and there is not a lot of living space to go around. To keep the living space problem under control, birth control is mandatory; having kids requires a license. Licenses go to “Socially Exceptional” couples. You’ve never been one of those. You have actually known some of them. You really hate them.
(very well written, by the way.)
@Matt M
I want something to be done in time, if things keep going in the same direction (and perhaps accelerate). But I don’t want a UBI now.
At this moment, I’d like people to think through the scenarios, come up with potential solutions (and perhaps test them out somehow) and for sufficient people to have awareness of potential signs that they can make sense of what is happening.
In our current meritocracy, a lot of people blame the un- and underemployed for being lazy, unworthy or otherwise untermenschen. This narrative allows people to legitimize their own wealth compared to others and pretend that their fate is more in their own hands than it is.
This narrative is very dangerous if most labor becomes obsolete, because it can easily lead to ever more people dropping into a state of poverty and lack of human welfare; while the people who are not yet obsolete delude themselves and prop themselves up by peeing all over those who fell of the cliff.
If many people actually see what is happening, but don’t see a viable path to prevent it within the framework of democracy, it may even be more dangerous; because people may then take drastic measures to prevent it*. I would argue that the support for populist parties in the EU and US is due to people seeing what is happening and revolting because the traditional elite doesn’t have solutions.
* I would argue that communism and fascism are examples of such drastic measures because many people didn’t see a viable democratic path.
So you agree that in a high-automation world most labor will be obsolete, but you think that this shouldn’t be a cause of concern because most of humanity will be able to survive on charity by a few very rich people, forever. Am I characterizing your position fairly?
@Aapje: why not? If we’re in a post-scarcity environment, what does it cost the factory owners to churn out a little bit more for the rest of the world?
Edit: society could add status awards. Feed a million people and your name goes on this decorative monument in our central city! Churn out a million new green homes and the Queen will send you a telegram! Like museums etc work now.
Indeed. I think people do not entirely appreciate how much the notion of “post-scarcity” breaks everything we understand about economics and human behavior. I’m not sure we can fully wrap our brains around what it would actually look like. It seems to me largely pointless to even try, but if you’re going to try, you probably have to be more imaginative than “everything will be like it is now except all desired resources will be infinite”…
As far as I can tell when people say “post scarcity” they usually mean “things are really cheap by current standards”, not everything is free and there is enough of it for everyone to have the quantity and quality that they desire.
Incidentally we are close to a post scarcity world (and would be basically there without copyrights) in digital goods. Most music can be obtained at a very low marginal cost, and yet the rules of economics still apply because there still exists opportunity cost.
bacon,
I generally agree with your post, and I think many people are using the term incorrectly. To me, post-scarcity means that even opportunity cost is gone. It’s been awhile since I’ve read it, but I believe Mises’ position in Human Action is that it is literally impossible to “eliminate scarcity” for this very reason.
It’s not, but we can’t get there from here without at least a bunch of redistribution. In fact some UBI advocates point to this kind of thing as a potential “post-work” future.
I was only recently introduced to your “other hand” argument via the podcast Econtalk. I think it’s fairly sound, and I would like to believe that that’s how things will go, but it seems to require an assumption that a displaced worker’s expenditures sink faster than their wage does. Are there good reasons to believe that this is or will be the case? If so, what are they?
It seems to me that either way, the transition to the virtual post-scarcity limit case is likely to be a painful process for many. Technology has not affected all fields evenly, and isn’t likely to do so in the future. If robots cause lower wages in the industry where low-income George Q. Worker earns a living, but, say, the housing and healthcare industries are not similarly revolutionized until years or decades after, George is going to be pretty hard up in the meantime.
I’m not an economist, and I suspect there’s some elegant proof for this one way or the other, but here’s how I think of it:
In our dystopian future, the touchscreen-assemblers in a factory are paid 1.20$ per hour. One day they’re all laid off, and replaced by robots which only cost 1$ hourly. So the touchscreen-assemblers scour the entire remainder of the economy for a job in which they’ll be paid more than 1$ per hour. Worst case scenario is that they they fail: every single sector in which a human’s marginal hourly productivity is worth greater than 1$ is fully saturated. So they march back to their factory and say “Okay, you’ve called our bluff. We’ll work for 80¢ per hour.”
At first this sounds bad, but remember that this is a world in which everything is produced so cheaply that it’s a waste of money to pay someone a dollar an hour to do anything. This is a world in which 80 cents will go a LONG way.
That said, I agree with your second paragraph. The transition may in practice be too fast or uneven for many people to easily adapt. I’m just trying to cast doubt upon Scott’s suggestion that technological unemployment will be different in principle from all the previous waves of disemployment which we’ve successfully weathered.
@INH5:
You are on the right track, but the logic is a little more complicated.
Version 1: The fact that your robots can produce something of high quality and low cost doesn’t stop me from producing the same things at the same quality and cost as I produced before there were robots. So the unemployed masses in the story run their own parallel economy at pre-abundance levels.
Version 2: This assumes that the only relevant input is the labor they have. What if they need a few very smart and well trained people to help run their factories, and all of those people can now make a million dollars an hour running robot factories and designing robots or have an income a a million dollars a week from their capital? What if they need capital, and because capital is now very productive it’s expensive.
So the perverse outcome isn’t impossible. But I don’t think it is very likely. While some inputs they need may be more expensive than before, others are less expensive. Since nanotech makes everything out of dirt and the power is provided by nanotech solar cells, oil and raw materials should be cheaply available. One or two trillionaire sympathizers can provide all the capital they need.
What is much more likely is that the low skill workers end up with only five or ten times their current real income, which makes them feel very poor in a world where much of the population has a hundred or a thousand times that.
A high-automation society is neither necessarily nor likely a post-scarcity society. Therefore, the elite robotized economy may use up almost all valuable resources, while the peasants may be relegated to poverty, if they could survive at all.
>even quite radical change is unlikely to reduce the marginal productivity of labor to zero.
Taking into account human biases, and the need for training and morale, I’d say it’s possible that many people will have negative marginal labor productivity. Especially if you count the years of education as training.
I’d even say that many people living in developed countries already have negative marginal labor productivity.
In addition to people who are too old to work, or people with severe disabilities, there are many people who, while in principle in the labor pool, are de facto nearly unemployable, e.g. people with criminal records. These people struggle to find even unregulated/illegal types of employment that are not bound by minimum wage rules.
This scenario can also be described as “the industrialized world”. Five hundred years ago, ninety percent of the population worked in food production. Today, in any industrialized Western country, a small fraction of the population produces more than enough food for everyone, with the help of machines that for fairly arbitrary reasons we don’t refer to as “robots”. So the vast majority of these populations have already in effect been replaced by machines and had to find some new way of earning a living. Not only did they do so, but their standard of living rose substantially in the process, thanks to the tremendous efficiency gains brought by mechanization.
I am somewhat unconvinced of the threat of the technological unemployment, and since I seem to be disagreeing with a bunch of people who are much smarter than me, I am going to try to hedge this in all sorts of ways.
The technological unemployment scenario I find unconvincing is the one where very few people can find employment because very few can contribute anything that a robot cannot already do. Instead of comparing people to horses, I prefer to compare robots to chainsaws. A lumber jack with a chain saw is much more productive (lets say 20x) than one with an axe. Theoretically that means that you only need 1/20th of the lumberjacks, but that will be partially offset by someone saying “hey, that’s great now we can chop more forests!” (I’m rethinking the wisdom of that particular example.)
For that matter, technologies that increase the productivity of work have existed for pretty much as long as there were technologies. Even horses allowed one person (with a horse) to carry as much weight as 20 people did before (again, making up the 20x multiplier).
In the short term, horses, chainsaws, sewing machines and robot can create a great deal of disruption, and some lives will be negatively affected. There will be lumberjacks who can no longer compete, and are unable to do anything else productive for a variety of reasons. But what pack animals, chainsaws and sewing machines completely failed to do (i think) is create a permanent unemployable class. There is every reason to think, seems to me, that the disruption is temporary.
Of course, it is possible that the increased rate of technological progress will lead to more and more disruptions faster than society can adapt to them. That we could adapt to any robotic capability, but not to the continual introduction of every improving robots. But I don’t think that is the claim that is normally made when discussing the prospect of technological unemployment, and if that is the danger, it will require a rather different set of solutions.
Hypothesis: Every time a tool causes unemployment, the IQ needed to do one of the substituted jobs goes up. If so, you would expect to see a small or no effect on permanent unemployment as long as the number is low, but it keeps going up and staying up. 70 to 80 produces pretty much no permanent unemployment. 80 to 90 produces a bit more. At 90 to 100, you now have half the population unable to do the replacement job. At 100 to 110 you’re starting to get into serious trouble, and it only gets worse.
For that to be the case, simplest robots should be able to do the job equivalent of people with low IQ’s and improvements in technology will allow robots to do the job equivalent of smarter humans.
That has not been my experience. I’m not an AI researcher, my exposure to automation is in industrial, manufacturing settings, and as such, it is limited. But what I see is the strengths and weaknesses of automation not being well correlated to the intelligence of people it would take to do job in their absence. Walking up the stairs and opening some doors is still a relatively difficult challenge for a robot. Operating on massive data sets is not. Automation is best at problems where there is a single, clear, correct answer. Absolutely terrible where there isn’t. Very good at repeatability and consistency, very poor at adaptability. This just doesn’t map over to human intelligence.
Because human and machine intelligence are so different, it would seem to me that the two aren’t competing with each other, but rather they complement each other.
@MartMart
The problem with your argument is we tend to link salary increases to productivity increases, which means that there is substantial downward pressure on jobs which have seen little productivity increases, which strongly tends to be exactly those jobs that low-IQ humans are good at.
Add in that more and more people start competing for the remaining low-IQ jobs and you get a split in society between a rich upper class and a poor lower class.
I don’t mean to come off as contrarian, but I think I disagree with virtually all of that (at least the parts I understand. Given the level of disagreement, I suspect I don’t understand those correctly either).
1. Salary increases are not well coralated with productivity increases, nor should they be. Like in the previous example, suppose you are the lumberjacks employer. You give him a chainsaw, he becomes 20x more productive. He then demands 20x larger salary. You try hard not to laugh at him. Salary increases, as far as I can tell, are driven mostly by the cost of replacement. You pay lumberjacks more when it costs more to hire new ones. It might be because the skill of lumberjacking is dying off, or because there is an oil boom and all the lumberjacks decided to become deck hands.
2. Some low IQ jobs are seeing great productivity increases. Lumberjacks get chainsaws, haulers get trucks, riveters get better river guns and robots to wield them. Meanwhile, doctors can still see about 4 patients an hour. On the other hand, an architect has more to fear from computers than a plumber.
Yeah, my argument seems poor here. I withdraw those claims.
This is true in a sense, but the robots can displace workers that have higher IQ than the robots.
Imagine that 80 IQ humans are using horses to plow a field, and then someone invents tractors. Plowing fields now requires half as many workers and the rest are fired. The tractors are displacing humans with an 80 IQ, but the tractors don’t have an 80 IQ themselves.
In this scenario, we don’t normally say “a tractor does the job of an 80 IQ human,” although there is a sense in which that is true.
Imagine that 80 IQ humans are using horses to plow a field
Please don’t assume that all ploughmen are (or were) IQ 80, that’s my maternal grandfather you’re talking about 🙂
And it’s still a category at the National Ploughing Championship!
A tool doesn’t have to be smarter than the human whose job it replaces.
A horse is dumber than a IQ 60 human, but the only job that a IQ 60 human can do is hauling stuff around, and the horse does it better, therefore the horse replaced the IQ 60 human. A car is even dumber than a horse, but it is better at doing what the horse can do, therefore the car replaced the horse.
Similarly, the self-checkout machine at the supermarket is dumber than a cashier, but to a large extent it replaces them (you need a single attendant for ~10 machines). The Amazon website is dumber than a shop clerk, but retail shops are closing and Amazon is growing, and so on.
You don’t need IQ 100 human-level AGI in order to have widespread labor obsolescence.
Let me see if I can make my point better. The theory I hear most often is that automation will eliminate some jobs out of existence, mainly those that require very little intelligence to do. People will adapt by shifting to jobs automation can’t yet do, and those jobs will require higher IQ. Improved automation will then eliminate those jobs as well, forcing people to shift to jobs that require even higher IQ. So, with each generation of technological improvement there will be an ever increasing percentage of the population (those with lower IQ’s) that will become unemployable. By which I mean that not only are there going to be people who have always done job X and now can’t learn job Y, but also that their descendants (whom inherited their low IQ in this example) will not be employable either. So, in some dark future only the extremely smart people will be able to find work.
I don’t find this convincing, and one of the reasons I don’t is that automation does not eliminate the dumbest jobs first, and improvements in automation don’t allow it to go after smarter jobs. My computer routinely calculates the conditions under which complicated parts will fail, something I am not smart enough to do, outside the most basic shapes. There are no robots that can competently fold laundry yet, despite it not requiring particularly high intelligence. Programs exist that can handle a great deal of building design, but it will be a long time before robots can repair plumbing unsupervised. That, in my mind, eliminates one half of the story, that robots will come after the low IQ jobs first. At the same time, improvements in automation has made robots much easier to operate, and improvement will continue in this area. So operating and programming a robot is become a lower IQ job.
Basically, intelligence is important, but it isn’t everything.
For the story to work, you don’t need a total elimination of IQ 80 work, then total elimination of IQ 90 work, etc. You just need automation to eliminate far more low IQ work than high IQ work and/or result in the creation of more high IQ work than low IQ work.
Nevertheless, computers haven’t made your job obsolete so far. Computers have improved the productivity of each engineer, but the demand for engineers is still high, since business which employ engineers are still limited by the availability of high-skilled, high-IQ labor.
Less skilled, lower IQ industries, on the other hand are usually not limited by the availability of this kind of labor, rather they are limited by other factors. Therefore, automation increases the productivity of each worker more than the demand for that type of work increases, which makes the demand for these job positions decrease.
And even if this doesn’t happen in a strict order of IQ, it still happens.
It’s not quite so simple. Humans are very good at some things, that don’t need high IQ. So, for instance, cleaners are much less likely to be replaced than insurance underwriters (at least for the technical part of the underwriter’s job).
Vacuum robots already exist. I can see parts of the job being automated.
Vacuum robots are terrible, and scarcely better than non robot vacuums. Meanwhile, the actual vacuum is a huge improvement over previous methods of cleaning carpets.
Yeah, I know. But this is pretty much because their AI is not yet up to par. With some improvement, I can see it work out to let a robot clean an office building at night.
Vacuuming offices is by far the easiest part of cleaning. Compared with folding clothes, picking up stuff, cleaning walls and toilets, etc…
I was thinking more that parts of the job get automated, so you need far fewer people. It seems that dusting and vacuuming is much of the work of office cleaning people.
But then one cleaner will be able to do the work that used to take 5-10-15 cleaners, the more advanced the AI, the higher the number.
And office buildings are not going to become much bigger or more numerous just because cleaning became cheaper, therefore most cleaners will lose their jobs.
We might need to subsidize their labor (which is why I always keep on saying “wage subsidy”), but we won’t get to point of massive unemployment unless there is literally nothing someone else can do to improve your life.
The fear is that robots will substitute, rather than complement, for humans. A human with a chainsaw is 20x as productive; a human with a robot is 1x as productive, and separately the robot is 19x as productive. The chainsaw enhances the human. The robot replaces the human.
This doesn’t seem to be a meaningful distinction.
As I see it, the programmer of BUNYANBOT-2000 is the greatest lumberjack of all time, masterfully wielding the latest and greatest iteration of the chainsaw: C+++, which has given him 10,000x efficiency, but which takes a lot of skill to wield.
It depends on which human you’re talking about – the programmer or the factory worker. They’re not interchangeable, and you can’t just turn the factory worker into a programmer. That’s the whole problem right there.
Also, in this case one programmer has taken the place of a whole legion of lumberjacks. Great they can go program… something else? Is there an unlimited market forl programming?
I’m in agreement about the mechanics of the situation. I’m just disputing the claim that it ought to be classified as a qualitative break from the past rather than a quantitative one.
You seem to be making the separate argument that it’s qualitative this time because the job substitutions will go to different people than those who held the original jobs. I’m not sure that’s 100% unprecedented. When silent film went obsolete, sound technicians replaced live musicians. when cars replaced carriages, engineers replaced coachmen.
There are edge cases where that isn’t true. Automation has been improving in many ways, and one of the bigger one is that it’s becoming easier to use. Programming robots to do simple jobs is becoming very easy. In a way, giving a factory worker a robot is turning him into programmer.
Scott’s original post at the top of the page talks about turning coal miners into coders. He’s still skeptical, and so am I, but there’s something there that might take some more legwork to be dismissed.
Ways I can think of, in which job displacement does not have to involve straight interchangeability with programming:
* Half the lumberjacks stick around, and simply produce ten times as much lumber. Higher supply means price falls, which raises demand (other people come up with more ways to use lumber profitably at the lower price).
* Some lumberjacks go into woodworking (they’re part of the new demand for cheaper lumber). Skillsets are close enough that some of them are able to do this quickly (some may already have been into it).
* Some jacks go likewise into jobs closely related to the original trade – scouting for more trees to cut, planting trees, etc.
* Some jacks go into trade supporting chainsaws (producing inputs, such as steel, fuel, parts; maintaining chainsaws).
* Some jacks go into other trades, replacing yet other people (the jacks are willing to work for less); the other people take up the jobs above. This chain may extend to any number of steps.
* Some retrain into unrelated trades (other than programming) in the time it takes to deploy chainsaws. Same principles in those trades; former jacks are like the chainsaws to those trades.
This a difficult concept to convey, as you can’t give examples of what will happen convincingly as you are just guessing. The long term effects of a change in commodities can be mind boggling. If you went back to the early days after oil was being put to use (mostly for kerosene) and tried to explain the world in a century thanks to oil you would get blank stares. Cars? What is a car? Asphalt? Airplanes? Plastics? The entire world economy runs on that stinky black crap we pull out of the ground that we only just figured a couple of uses for? Come on, stop wasting my time.
I said: (other people come up with more ways to use lumber profitably at the lower price)
baconbacon said: This a difficult concept to convey, as you can’t give examples of what will happen convincingly as you are just guessing.
I think this actually a pretty basic concept, following directly from supply / demand principles. And I don’t even have to guess; I suspect that for any technological innovation you could name that became reasonably widespread among, say, the middle class, I could name a thing done with it that was prohibitively expensive before (as in, almost no one was doing it).
The long term effects of a change in commodities can be mind boggling.
So can the long term effects of a stagnation of commodities.
I’m a couple standard deviations away from being an expert on the subject, but I’ll take a whack at laying out why people worry that our current round of technological employment is qualitatively different than the piecemeal adoption of labor-saving tools in the past.
With your chainsaw example, okay, it sucks to be one of the ~19 lumberjacks rendered obsolete, but we assume a large economy with a diverse array of employment sectors can absorb them (most of them, eventually, more-or-less painfully etc) Meanwhile everyone gets cheaper lumber (which juices some of those sectors), real wealth rises, society metabolizes the disruption and lumbers along.
The AI/robotics case is harder because it consists of, basically, supertools that radically expand the reach of these labor-savers to, in the limit, all human endeavors. Like, imagine introducing hyperchainsaws that increased the productivity of not just lumberjacks but plumbers, roofers, miners, etc, etc, etc, by the same factor and at the same time (they are very good chainsaws). If every manual occupation saw a simultaneous 95% drop in manpower requirements it would massively constrict the options for every displaced laborer…
… and it gets worse, because the same forces are scything their way through the ranks of “cognitive” labor as well. We may already be witnessing the rise of expert systems capable of handling lower-tier tasks in fields like medical diagnostics, paralegal work and the like. If you assume these trends keep trending then the only fields that would be safe from mass depopulation would be things that could not, in principle, be done better by a tireless robot or superhuman AI, which is… what, exactly? One thread up David Friedman was spitballing some ideas of what people might sell in such a situation, but I’d posit that we’re already at the beginning of the end for each of those; servants (washing machines, dishwashers, Roombas); crafts (3D printers); back rubs (those sweet Sharper Image massage chairs). You have to recourse to intangibles like poetry or live theater, the markets for which might be, shall we say, inelastic.
The terminal case is a world in which every productive capacity is filled by robots; where the economy can generate practically limitless wealth in principle but where the mean/median/mode human has no access to that wealth because they have nothing of value to exchange for it; where humans haven’t been merely supplemented but replaced as the meaningful economic agents.
That’s the dystopic vision of technological unemployment, as I understand it: an edge case where our current system of wealth production and distribution breaks down irreparably for the majority of humanity.
It seems like any society so monumentally productive that the vast majority of humans are obsolete, is a society to which providing good lives for the obsoleted would be trivial.
Give a family a few shares in Hyperchainsaws Incorporated and they’re set for the rest of their days.
I wonder how the expectation of vastly reduced human labor requirements interacts with the motivation to pursue AI safety. Human labor obsolescence can describe a future of well-distributed plenty, or a massive population bottleneck. Whoever has first-mover advantage moving through technology transition stands to gain a large compound benefit if their descendants are the technology owners rather than the obsolete. What are the expected outcomes of cooperating to create the future of plenty vs. focusing one’s effort toward having primary ownership of the means of production?
For the average person, the Rawlsian veil of ignorance would suggest that cooperation is the better strategy. But as we move closer to the automation horizon, people and collections of people will have a clearer idea whether they fall into the ‘labor’ or ‘capital’ groups. At that point much hinges on what the ‘capital’ group decides to do. Do they cooperate or defect?
@AnteriorMotive
Why would the 1% be willing to cut the 99% in on this?
@Aapje
Why do they cut people who have no economic value in now?
Redistribution via democracy.
Charity.
If 51% of the populace is rendered literally and permanently unemployable in this dystopian hypothetical, some sort of unconditional UBI is all but democratically guaranteed.
Had to be fought for, where it was a great benefit that the rulers couldn’t do without an workers at all (historically, there were many cases where the elite used considerable violence to keep peasants/serfs oppressed).
Historically, charity has very often included rather paternalistic control over those getting the charity. Arguably such an outcome will be rather dehumanizing.
Quite a few people find welfare dehumanizing.
Welfare is different than charity. Welfare is a right you get from the state. As far as I know, all the countries with significant welfare are democracies, therefore welfare is something that people seize through collective political action.
Charity is a privilege you may or may not get from benefactors, at their will. They are free to attach any sort of conditions to it, as they often do in practice (e.g. consider how religious charities operate), and they are free to withdraw it at any time for any reason.
Living on charity makes you depend on private people or organizations you have no control over, while living on welfare makes you depend on a government that you can influence through democratic vote.
I would argue that Western culture negatively judges people without work, which makes people on welfare feel bad. However, this is not caused by welfare itself, but by social disapproval.
It’s also possible that people on welfare succumb to a life of lethargy.
Most countries that give welfare place demands on people who get welfare, but this is often done in a bureaucratic way that threats everyone the same, regardless of what they actually need to get out of welfare or which way to give back to the community is a reasonably fit to their skill set. Most people quickly notice this and find it dehumanizing.
Should we arrive at a future where hyperchainsaws can make all the products and preform all the services people need, we should then have the resources to take care of all people. However this will require a rather different economic system to the one we have today. Again, I don’t think that hyperchainsaws are coming. But if they are, it wouldn’t do to have one guy own them all.
Correct. The interesting question would be how to make that happen. People are *very* good at rationalizing the poor as undeserving (TBF I’m American and so Calvinism is in the water), and with automated guard labor (and most assets being “paper”), redistribution by guillotine isn’t really an option.
Jacobin’s “Four Futures” delves into this – the smallest change from the present would be letting approximately everyone scrounge on reservations while the previously-rich enjoy the post-labor-scarcity utopia. It could get worse – we could just get wiped out as the rich have no use for us (assuming they can rationalize this). Or it could get better, but not without a repudiation of the idea that one must earn one’s crust.
That seems to hang on just how post scarcity the robot revolution will end up being.
People may not want to feed/clothe/shelter the poor when doing so takes an appriciable portion of their resources that they would rather spend on themselves. That objection tends to evaporate when the cost of doing so drops so low that it’s difficult to measure.
I think even today we are seeing the incredibly wealthy turn around and start spending their fortunes on more or less alturistic purposes (i.e. gates foundation, musks dreams of mars etc) although I have no statistics to see how common it is. Perhaps more common in countries where people don’t need to hold on to a fortune as a means of security from their enemies.
What happens if the resources of earth start to run out (like rare metals), so goods are pretty expensive, but labor is cheap?
That seems like the horror scenario where the elite is very likely not to want to share.
The earth has ridiculous quantities of silicon and aluminum. Hydrocarbons are replenishable with sufficient energy supplies. We’ll have the ability to get more long before we start running out (assume we survive of course)
Again, my exposure to automation is almost entirely in the industrial situations, but I see no evidence of hyperchainsaws that can do everything coming anytime in the near future. Robots are tools capable of doing certain tasks for which they are suited for.
They are very good at those tasks. But they stumble at other tasks that we find very simple. In that way they are very similar to earlier tools that improved productivity. A paralegal or drafting software is akin to a calculator or a mule. It allows fewer people to perform the same work.
That said, I think you’re right in saying there is some room for worry here. It’s a potentially very large problem, so it’s worth thinking about possible solutions and safeties in case we do end up needing them.
Isn’t the massive technological unemployment scenario when one fairly small group of human beings (owners of arable land, minerals, and robots, and maybe a small class of techno-priests to program the robots) finds it’s not to their advantage to trade outside that group, or equivalently that the value of the work of outsiders to that group is less than the cost of human subsistence.
That is, the problem isn’t “We can replace N workers with one worker and a robot”, it’s “We don’t need workers anymore, the robots can do it all”.
At some point, the robots will become powerful enough to supply most human needs, and unemployment will cease to be an issue. Until then, the robots will continue eliminating entire industries (e.g. “computing”, which used to be a human job; telephone switchboard operation; automotive assembly line; and soon, the last traces of things like trucking, Web design, call center operation, and computer programming). In some cases, some of the people would re-train for some new industry, but the majority would be left with no future prospects.
Initiatives like Universal Basic Income could help to bridge that gap, thus allowing even the unemployable (a set of people whose size will continue to grow) to not merely survive, but also to enjoy the benefits of increased automation.
There are two ways that I can think of unemployable. Scenario 1 is where robots virtually eliminate a certain industry (lets say trucking), majority of truckers are too old to learn a new trade. They live off public assistance for the rest of their lives, but their children learn new trades as they mature and enter the economy. The disruption is temporary. Scenario 2 is where neither the truckers nor their children can contribute anything the economy, and the disruption is permanent. These may require rather different solutions.
Wage subsidy would be even better at bridging the gap, because it would keep people employed, and if it turns out that you are wrong and we aren’t at a place where a bunch of people can just quit working, people just keep on working. People who stop working generally lose their work skills.
I agree with you somewhat, but in my scenario, “people losing their work skills” is not an issue. If your skill is adding up a bunch of numbers very quickly, and a new device is developed that can do your job millions of times faster and cheaper (it even takes over the very name of your job, “computer”), then your skills are forever worthless. You could possibly re-train for something else, like trucking; but you’ll never be a “computer” again.
“Work skills” can sometimes be properly read as more generically useful things like “get to work at 8:00 EVERY DAY, even the day after you lost track of time when you were out drinking with your buddies until 3:00 AM”. That pretty much never goes out of style, and it is a skill you can lose. Or never learn.
What John said. If 10% of people stop working and get taken care of by UBI, and we find out in 5 years that society isn’t as rich as we thought and half of them need to go back to work, it’s going to be a huge fight. Even if they are willing. Which they probably won’t be.
A wage subsidy makes low-value work into mid-value work, and as it gets bigger it becomes make-work for people at the very bottom. But they all still get up and participate in society every day. If the economy turns sour and those people need to do work that actually generates value, it’s a much easier transition.
A UBI puts us on a one-way rocket ride and if things go wrong they are riots in the streets. A wage subsidy can transition over the decades into something just like a UBI, if it turns out that people with free time on their hands really do go out and benefit their communities instead of trying to destroy The Other in twitter fights.
Social norms also play a role. Right now, if you are on welfare, you pretty much lost most status anyway. If we change the status hierarchies so voluntary work becomes a huge status factor, which gets you laid and such, we might not have a huge problem with people watching TV all day.
Possibly.
Not really. At least, not within their own peer group. People who take welfare probably mostly mainly associate with other people who take welfare.
And the state has gone to great lengths to try and make it as non-embarrassing as possible. They give you a little credit card and assign a bunch of names to the program that make it seem like you’re just a regular dude. Nobody really knows you’re on welfare unless you tell them.
@Matt M
I have my doubts whether that is true. There are communities where welfare is normal and thus not status lowering within that community (although those communities tend to be derided by the rest of society, so the disapproval is then just at a higher level); but quite a few people on welfare are not part of such a community.
Aren’t these the same communities that have high levels of out-of-wedlock births?
I wonder if there is some relation: e.g. women may sleep and conceive with men on welfare if these men are physically attractive enough, but women would not marry these men, resulting in single-mother households.
Maybe there is no real solution to this and marriage is going to become obsolete, but given the poor outcomes of out-of-wedlock children, this may become a real issue (although it is difficult to disentangle genetic and environmental factors contributing to these poor outcomes).
The situation with out of wedlock births is probably even more dismal.
With welfare it’s basically “most of society looks down on this but there are some pockets where it’s not a big deal”
Single mothers aren’t just “okay,” in some circles they are worshiped as heroic figures. Suggesting that parents are better off with two parents is likely to get you automatically shouted down as a racist (because this problem is much more significant among blacks) AND as a homophobe (don’t you know that science has proven kids can be raised with any combination of parents and it’s 100% fine!) AND as a sexist (do you think single mothers are single by choice? no way! surely they left an evil abusive spouse who was enabled by the patriarchy!)
“They do not consider themselves a depressed minority having to beg for charity from the middle-class majority. On the contrary, welfare is to them an incredible stroke of luck, yet further proof of the gullibility of the gaje.”
(Gypsies: The Hidden Americans by Anne Sutherland)
“A lot of people there were really optimistic that the solution to technological unemployment was to teach unemployed West Virginia truck drivers to code…”
Perhaps not AI coding, but as a professional software developer, and a successful one, I could offer:
Don’t assume all X are too stupid, whether X is WV residents or truck drivers or whatnot. (I was a low-level mill worker and had other blue-collar jobs before going to college and eventually finding I loved programming.) Also, if WV has a mean IQ of 98 (or 94, or …) that’s just one measure of central tendency, not the entire distribution.
And, frankly, there are IT jobs (I’m not talking about AI specifically) that are less reliant on pure g and more reliant on other factors like social skills such as cooperation and just listening to what the damn client (or colleague) is trying to tell you. One of the brightest software developers I ever knew floundered for 5-8 years before he realized that people thought he was just an asshole and that’s why no one ever wanted to work with him; he changed his behavior enough that he eventually became much more productive and thereby successful.
But nobody is assuming that. Maybe the 15% above 1SD can re-train successfully – as far as the rest are concerned, the problem is still very much unsolved.
I logged on to express something similar. Web Programming takes much less intellect than Computer Science however AI development is probably closer to Computer Science than Web Programming at this stage. (not necessarily forever of course).
For these kinds of jobs, find the best expert on the subject and have them map out a decision tree that is programmed into an automated prompt.
See Web MD, phone trees, etc. The end user might prefer human interface, but when the alternative is more accurate and efficient, they might not have that option.
It’s not even stupidity, it’s the capacity or the skills or interest. That unemployed truck drivers or coal miners could learn more about programming than they now know is not even the question; the question is, can every unemployed truck driver or coal miner learn enough to be able to get a job programming or working in the field? Maybe they can become data entry clerks, but how many can go far enough to write code?
One of the problems running training and re-skilling courses is that men are often reluctant to enrol on courses that lead to what they see as “female” areas of employment, such as office work; so you have a lot of IT-themed courses which will give secretarial or clerical or even just general “so this is the Office suite and this is a spreadsheet etc.” skills and qualifications but it’s hard to get men to enrol.
Coding, if it’s presented as “this is a MAN’S JOB” may have better success but that’s not to say every ex-trucker or miner can be good at it, not because they’re stupid but because their talents or abilities lie elsewhere (you could have an undiscovered regional poet who has sensitivity to the local environment on your hands but he and nobody else will never know because poetry? what’s that? and besides you don’t train people to be poets, there’s no money in poetry).
Long time listener, first time caller 🙂
Re: a “future” inmate being given parole or not based on AI, it’s already happening: https://weaponsofmathdestructionbook.com/
(lots of other worthwhile stuff in that book)
Thanks, great post.
This sounds quite encouraging, and I’m glad you got to attend.
I’m curious whether it’s going to lead to concrete results, such as a substantial budget increase for MIRI/FHI, or anything else measurable.
What is the technical term for this technique?
“…a whole bunch of problems go away if AIs, instead of receiving rewards based on the state of the world, treat the world as information about a reward function which they only imperfectly understand.”
obfuscation?
that refers to cooperative inverse reinforcement learning:
https://arxiv.org/abs/1606.03137
Thanks!
Interesting read, thanks.
When did David Chalmers get so involved with this stuff? Back in the LW era? His hard problem stuff seems pretty far removed from the practicalities of AI, but he’s on the SuperIntelligence panel and reads SSC.has he published anything of note?
He did his PhD with Hofstadter and has done work on philosophical issues related to AI and computation. Here is a list of papers on the field. Note especially the most recent one, on the Singularity.
???
What does e.g. MIRI’s stuff have to do with “practical AI?” Or Cambridge folks’ stuff.
Don’t get me wrong, theory can be useful, but this is such an odd complaint to make given the state of the area.
What does e.g. MIRI’s stuff have to do with “practical AI?” Or Cambridge folks’ stuff.
I imagine that this is one field where you need the theory before you can have the practice; unlike human intelligence, where the intelligence existed before people started constructing theories about the mind, the brain, etc. we don’t have pre-existing AI as yet.
Think of all the new and wonderful ways we can go wrong!
I pay my bills with theory. I agree theory can be incredibly useful. My question is, why single out Chalmers via “practical AI.”
MIRI is not very practical, but it is more practical than “can a machine truly be conscious?” or whatever.
I see, so the trick to avoid getting yelled at is to settle on just the right part of the impracticality spectrum?
I don’t see how Chinese room-style arguments have any more practicality than metaphysics, i.e. none.
If there isn’t any way to get information on the “realness” of consciousness, why bother with it at all? The superintelligence stuff at least makes testable claims even if it’s still all highly speculative.
>One theme that kept coming up was that most modern machine learning algorithms aren’t “transparent” – they can’t give reasons for their choices, and it’s difficult for humans to read them off of the connection weights that form their “brains”. This becomes especially awkward if you’re using the AI for something important. Imagine a future inmate asking why he was denied parole, and the answer being “nobody knows and it’s impossible to find out even in principle”. Even if the AI involved were generally accurate and could predict recidivism at superhuman levels, that’s a hard pill to swallow.
Scott, is our current parole system so much different? Okay, okay, it is obviously some mix between the illusion of a reason and an actual reason. Some human (or set of humans) looks at information regarding the prisoner, and then tries to run through a series of rules and heuristics, mentally flagging ones that are triggered. They then run some either second and/or simultaneous program that maps these rules and heuristics to what humans consider causal reasons. I think there is often a lot of loss of fidelity here!
This is actually similar to self-driving cars. Sets of neurons in the first (or hidden) layers we know map to some general causal feature (e.g. turning left), but what does a single one do? Or brain surgery, where the surgeon zaps the open brain of a patient to test for clusters of neurons that have some correlated causal mapping to a part of the body.
We aren’t there *quite* yet though. On my team we do economic forecasting for the entirety of [huge tech company], and our team still doesn’t do machine learning because people want to know why our forecast changed. So we use our brain to try and map the machinery of an econometric model to an applied business context. It’s a little more transparent, but it’s never clear. I see no reason why a next-gen ML model couldn’t do the same thing.
Anyway, this might sound silly, but I get this wave of pride when I hear you go to these events. Like you’re the friend who made it out of some dead end town and struck it big in the city.
I think people are primed, through cultural conditioning, to accept “a human we presume to be well informed reaches a decision” as a legitimate outcome in most cases, even if we concede that human decisionmaking is imperfect and often arbitrary.
Not sure if you’re a sports fan or not, but consider the debate in college football over “human polls” (coaches and journalists make giant lists of which teams they think are the best) versus “computer polls” (nerds make some algorithm that analyzes a database of scores and spits out which teams are the best). There is a very large contingent which decries the existence of the computer polls and insists the human polls are superior, even when a lot of the people submitting them openly admit they don’t really watch or have any particular information about well over half the teams they are ranking.
Humans deciding is sort of “just the way we do things around here” and has been for all of known civilization. Changing that meets a lot of resistance, even for something as trivial as ranking college football teams. For something like this to work, I think you’d almost have to build a human-resembling android to help anthropomorphize the process. On a psychological level, having Mr. Data tell you to do something is a lot easier to swallow than having a swirling icon on a screen tell you to do something.
Humans could also be primed to accept “the machine is wise”. It would help, of course, if the machine was actually wise. But we believe all kinds of crazy stuff.
It is possible to test wisdom in some circumstances.
That’s why I support the Mr. Data model. The crew of the enterprise intellectually knows that Data is a machine. But he has built up credibility with them, both in terms of his intellectual superiority (they’ve witnessed him use his superintelligence to save the enterprise on a number of occasions) but also due to his personality (his repeated interactions with them and familiarity).
The fact that he is a machine gives added credibility to his intellectual calculations. The fact that he is human-like in appearance and behavior gives added credibility to the notion that he isn’t secretly plotting to take over the world.
You can actually watch this play out in real time as he wins over a skeptic in Redemption, Part II (my personal favorite episode!)
a superintelligence whose decision-making process is completely opaque sounds pretty scary.
Eh. That sounds essentially identical to “the Lord works in mysterious ways”, which I’m pretty sure people are conventionally supposed to find comforting.
The human judges we have right now aren’t any less opaque than the AIs are. They just have better press.
Yeah, it seems odd to me that anyone would consider human decision-making not opaque. “Intuition”, anyone?
What are we imagining here? I can understand that this would totally be true if it came to nation-states incorporating AI into weapons systems, and then one state could just steamroller everyone else, but I find it harder to get a grasp on otherwise. An AGI run company could outwit everyone and buy up all their stuff too, but physical constraints still mean that this would take time. Then there’s the whole AGI takes over the internet thing, which no matter how fast the AGI itself is, could only occur at the speed of its internet connection.
So how big exactly is the first mover advantage when you bring physical constraints into the picture? Greater intelligence lets you think about what you need to do faster, with greater clarity, it doesn’t by itself allow you to do physical things faster, except when through greater intelligence you come up with new methods of going faster. 10^16 times more intelligence isn’t going to make delivery trucks 100 times faster. There are ceilings to how quickly you can take over the world, so we first need to find out the maximum speed given constraints on moving things around physically. An AGI needs good manipulators. Brains aren’t that great, no matter how fast they are, without the capacity to translate thought into action.
Maybe an AGI is super-persuasive, so it can ask humans for resources it wouldn’t normally get, but there are almost certainly ceilings to persuasion too. There’s no magic combination of words that always makes a human do what you want. Eliezer’s AI box experiment is highly dubious since he won’t release the logs (I know why he said he wouldn’t, but it still renders the “experiment” pointless). There are also people outside of the sphere of persuasion who would see the massive cash flows and resources being sent into giving the AGI greater ability to manipulate the world around it so that its manipulation speed could catch up to its thought speed. A superintelligent AGI would have already factored for this, so it would gather resources slowly and stealthily, but then this would just lengthen the time it took to take over the world, because it would be dealing with these slow humans interacting with other slow humans, and needing to disguise massive infrastructure projects by keeping things below a certain pace. Even if you go “Yeah, but the AGI knows that you know that you know because it’s 90 billion steps ahead of you” it still slams up against physics at some point, and isn’t able to actualize its plan at that speed.
Obviously there would be a big first mover advantage, but how big? Is anyone attempting to factor in the constraints of physics when thinking about this? The problem with AGI risk, and it has been the problem all along, is that you can just say “it’s a trillion times smarter than you, so it can pretty much do magic and turn the world into nanobots instantly”, meaning the worst case scenario is the assumed one, which requires the most drastic solution possible.
If the danger is of that level, then what kind of regulation would be even sufficient? If just one research lab cottons onto it 20 years from now, then we’re all fucked with absolutely no way to intervene after the fact. I can’t imagine (if the first mover advantage is that large) what kind of regulation would be sufficient short of a MIRI world government that centrally controls all AI research, and even tangential research that might just lead to developments by accident. Oh, and probably all computer hardware companies too, to make sure that consumer efforts don’t by a 1/1,000,000 chance get anywhere.
There’s at least one transcript of a successful AI box getting out experiment: https://plus.google.com/104395999534489748002/posts/3TWWKfLc2wd
Presumably that’s not the only strategy available.
Scott, curious if you had impressions about any of the following:
1) which people/organizations seemed responsible for the most impressive safety-related breakthroughs (for example, the inverse reinforcement).
2) more generally, did you come away with any new senses of which AI safety related organizations are underfunded?
(I wouldn’t take any response as a hard-answer on “which organizations to fund”, but as a layman I’m hoping to build a better picture of the AI safety landscape beyond “MIRI and FHI I guess maybe?????!??!”)
Are humans any less opaque, or are we just better better at rationalizing after the fact? How would we know? Maybe we just need a “pundit” AI to come up with post-hoc explanations of the decisions of the other AIs 🙂
By the way, one way to get some answers out of the computer is too look at partial derivatives of the factors used in the model; e.g. “If I were 1 year further into my sentence, would the computer have been more likely to recommend me for parole? What if I had committed a slightly less severe crime?”
So explaining particular decisions is maybe not too bad. But explaining *why* that’s the right way to make decisions and not by some other rule is very hard.
Perhaps we should also build an machine learning system that comes up with plausible sounding and socially acceptable explanations (that are often going to be false and merely what people want to hear).
I suspect you’re partly joking, but I think this would be legitimately important. My suggestion above, invoking Data from Star Trek, was that any significant AI decisionmakers be sufficiently anthropomorphized and given human bodies, fake personalities, etc. in order to mimic the psychological experience of “my fate was decided by a person” as closely as possible.
I was going for dark humor (as in: this is sadly plausible).
Data from Star Trek has a human-like appearance but he has an autistic, straw-Vulcan personality which makes the other characters routinely distrust him, even if in most matters he is obviously smarter and more competent than anybody else.
Compare with a real-world “AI”, ELIZA, or its various successors like Eugene Goostman, which have no real intelligence or skills, and not even human-like bodies or voices, but can elicit emotional responses in laypeople and be even mistaken for real humans.
I expect that first advanced AI user interfaces will look more like ELIZA rather than Data.
In other words, what happens when AI is applied to corporate/governmental PR?
As I mentioned above, this is how it works with human decision-makers, as well.
“That program” is a strange example, since it implies your computer is trying to figure out why another computer (or itself?) is doing something. Probably the thing you’re mostly trying to copy/learn a value function for is human rating/behavior.
humans are programs to the same degree that ais are.
Also, the “Asilomar Principles” sound like they’re supposed to be a clever play on Asimov. This tickles me.
With full respect to the people involved with PETRL, who seem very smart and honestly concerned with ethics, I’m pretty sure conflating reinforcement learning with ethics obscures more than it describes.
Berridge, Robinson, and Aldridge 2009 argue- pretty convincingly I think- that what we call ‘reward’ has three distinct elements in the brain: ‘wanting’, ‘liking’, and ‘learning’, and the neural systems supporting each are each relatively distinct from each other. ‘Wanting’, a.k.a. seeking, seems strongly (though not wholly) dependent upon the mesolimbic dopamine system, whereas ‘liking’, or the actual subjective experience of pleasure, seems to depend upon the opioid, endocannabinoid, and GABA-benzodiazepine neurotransmitter systems, but only within the context of a handful of so-called “hedonic hotspots” (elsewhere, their presence seems to only increase ‘wanting’). With the right interventions disabling each system, it looks like brains can exhibit any permutation of these three: ‘wanting and learning without liking’, ‘wanting and liking without learning’, and so on. Likewise with pain, we can roughly separate the sensory/discriminative component from the affective/motivational component, each of which can be modulated independently (Shriver 2016).
This indicates that valence should not be thought of as identical to preference satisfaction or reinforcement learning, and we’ll get really mixed up if we try to do so.
More here: http://effective-altruism.com/ea/16a/a_review_of_what_affective_neuroscience_knows/
As a PETRL founder, I agree that “valence should not be thought of as identical to preference satisfaction or reinforcement learning, and we’ll get really mixed up if we try to do so.”
If you’re interested, I have a few other thoughts about valence here. But they’re mostly just crazy speculation. My guess is that reinforcement learning is only slightly and tangentially connected to the ability to have valenced experience.
Thanks, and I’d love to see these thoughts further developed, especially in a way that would make testable predictions. I strongly believe the nascent field of valence research needs more people making grand falsifiable theories about valence.
My grand falsifiable theory is, of course, found in Principia Qualia; with your computational interests you may like some work by Seth and Joffily (both are at least loosely based on Friston’s Free Energy framework). It seems to me that there could be room for a mash-up of your ideas and theirs.
Not an answer to your comment, but do you happen to know the name of the theorem that Scott refers to (“a theorem that program behavior wouldn’t be affected by global shifts in reinforcement levels”)? Thanks.
Anyone mentioned Basic Income? I ask because it was mentioned here on this blog now and then.
Also what about AI safety from bad human actors? Like I mentioned before, authoritarian governments (or big companies) using AI for surveillance of populations.
I may be missing something here, but the proposed solution to “AI suffering” in point #7 (change the accounting so everything’s in positive numbers) makes no sense to me. There’s plenty of anecdotal evidence to suggest that human happiness is computed relative to average utility, not relative to some arbitrary hard-coded “zero”. Biological pain may work differently, true, but the emotional experience of “suffering” or “unhappiness” seems to correspond to some heuristic noticing that we have less utility than we’d otherwise expect.
This goes double for AI’s, which presumably will have minimal “biological” (i.e. hardware or un-modifiable software) stimuli. Scott’s intuition seems exactly right, that shifting the “zero” on the utility chart can’t possibly affect an AI’s observed behavior– and since we’d expect to observe AI’s internal “feelings” as having some effect on behavior (we couldn’t “observe” them at all otherwise), I assume it couldn’t affect the AI’s experience of suffering either.
As a corollary to this, I am not super-concerned about AI wireheading.
hnau, you may be interested in my post here. In short, the view from neuroscience casts doubt on this– Berridge & Kringelbach 2013 find that “representation [of value] and causation [of pleasure] may actually reflect somewhat separable neuropsychological functions” and Jensen finds something similar for valence and salience.
Fascinating, thanks for the link! It was also helpful for me to read http://shlegeris.com/2016/12/30/pain from bshlegeris’s response to your earlier comment, which makes a case for the choice of zero having a real relevance in human and animal brains. It’s not clear to me how far either of these observations would translate to the AI case, though.
Re #7: The equation is invariant w.r.t. shifting or scaling-by-a-positive-number when discounting is not used, and discounting is just a simplified way of implementing time-based rewards.
The argument sounds like a more formal way of saying “we shouldn’t ever increment the variable called $PAIN”.
I assume PETRL is talking about a generalized concept of suffering that we currently don’t know how to define. I guess you could say something like “find the closest mapping f : human brain -> a particular AI; then avoiding stimulating f(human pain signals)”, but even then, how do you know there aren’t other types of suffering (“can rocks/plants/encrypted-simulations-of-people-where-the-key-is-in-a-black-hole feel pain”)?
I agree there’s a need for a bottom-up, “non skyhook” view of valence… you may be interested in the approach I describe here. (Warning: it’s rather long, since it includes a decent chunk of background on affective neuroscience & IIT.)
The point about “global shifts in reinforcement levels” is an interesting one. It has been addressed, among other places, in this essay.
Also here: http://reducing-suffering.org/ethical-issues-artificial-reinforcement-learning/#Positive_vs_negative_welfare
Pro-tip: you can edit comments instead of making 4 comments within the space of 10 minutes.
I know, but my comments were filtered at first and didn’t appear because of one of the links (without any kind of error message). They were all approved at the same time a few hours later when the 1-hour period during which editing/deleting is possible had already expired. I’ve reported the comments yesterday, but unfortunately they haven’t been removed so far.
Why would we do anything but that ? This is how we approach every other area of study. We tried to figure out how things like stars, trees, and volcanoes work, by applying pure reason from first principles. That didn’t help at all, so now when we want to study something, we poke at it to see how it responds. Why should our brains be any different ?
Was AI discussed as a threat to cyber security?
I once saw a theory/story where AGI arose from the arms race between spam filters and spambots. (And I understand why spam filters would wish to destroy humanity).
Not a metaphor, and not strictly analogous, but this reminded me of Siri Keeton from Peter Watt’s SF novel Blindsight; a man whose job is–in part–to translate insights from super-intelligent AIs into language humans can understand.
You can read the novel for free here: http://www.rifters.com/real/Blindsight.htm
Might we one day be able to do a play-by-play of Go history, finding out where human strategists went wrong, which avenues they closed unnecessarily, and what institutions and thought processes were most likely to tend towards the optimal play AlphaGo has determined? If so, maybe we could have have twenty or thirty years to apply the knowledge gained to our own fields before AIs take over those too.
Perhaps I am unusual, but I find the idea of a highly-rationalized future in which discovery and implementation are the province of superintelligences beyond human ken dystopian rather than exciting. I am inclined to be rather indifferent to the question of AI safety if the inevitable outcome is such a hyper-efficient future, which seems to me to be the equivalent of the extinction of some of my favorite parts of the human experience. Has the AI safety discussion ever included whether it is desirable to reserve some “fun stuff” for humans to do, or am I falling into t-1 partial equilibrium thinking? Could the Fermi paradox be that post-Singularity societies just get really bored? Or maybe they’re out there, but they are so concerned with their extremely elaborate labor-intensive rituals that they don’t bother to make themselves discoverable.
I’m trying to sketch out a possible future taking considerations like these into account: http://lesswrong.com/r/discussion/lw/od6/the_adventure_a_new_utopia_story/
I doubt humans would be likely to find human-reserved ‘fun stuff’ meaningful and satisfying in the long term, if AI could have done it but just chose to reserve it instead. What would be required is for AI to pretend, utterly convincingly, that a certain subset of activity is extremely important, possible for humans, and not possible for AI.
It sounds like a hard sell to convince even the smartest humans that the fun stuff, doable for humans, is beyond the reach of the otherwise-general AI. But I suppose we should expect AGI to be superhumanly talented at both selecting the fun stuff for plausibility and at persuading humans of their critical role.
@LCL
I think that humans are better at self-delusion than you think, as long as the culture actually grants social status to humans that play along.
IMO, the difficulty is more to get the programmer overlords, who control the robots, to not lord over the rest of society.
We need a super-AI trained on the collected works of Robert Trivers.
I would like to point you to Joy in Discovery. It didn’t convince me on a gut level but it makes a good argument that means that just because superintelligences are better than humans at discovery doesn’t mean we miss out on any fun.
The main thing that a superintelligence would rob humans of is a specific interpretation of self-detirmination. And possibly the illusion of free will.
@daniel
Your link is complementary – on the personal-experience-of discovery level – to Karl Schroeder’s concept of thalience, which is one of the more interesting conceptions of post-science human truth-seeking I’ve encountered.
I think the piece by Eliezer may overstate the rarity of de novo discovery, and the joy of being the first to notice even minor truths (if only because of the IKEA effect), but his remarks on the attendant psychology ring true.
RE: PETRL, what if the Buddha was right and life is suffering? Do we refrain from creating AIs on the grounds that they will be caused to suffer no matter what? (And wouldn’t the same argument apply to having children?)
I don’t know much about Buddhism, but I thought the Buddha position on suffering is that it is an illusion. In that case there is no clear moral valence to creating new life.
Chalmers reads Slate Star Codex? I wouldn’t have expected that. Probably I am unfair to him. I’m also surprised that he of all people would leave someone starstruck. I guess I think of pretty much any philosopher as a person who could have shown up at Brown when I was a grad student for a colloquium (as Chalmers in fact did) and give a talk which would attract an audience of a few dozen peeople at most. He did strike me as unusually charismatic for a philosopher, but that’s something one discovers only after having heard him talk, not something that might intimidate a person in advance (unless Scott had seen videos of talks he’d given or something)?
David Chalmers is a rockstar (seriously!).
Thanks, excellent write up (and nice meeting you!).
My only quibble is:
>a whole bunch of problems go away if AIs, instead of receiving rewards based on the state of the world, treat the world as information about a reward function which they only imperfectly understand.
I’m not certain of this, at all. Some problems do seem to go away, but it’s really not clear how many (though I do use it in my “Emergency” learning idea: https://agentfoundations.org/item?id=1243 ). In certain limit cases, this is exactly as dangerous as simply receiving rewards. I’m currently investigating this.
Given that 30-50% of kids fail high school algebra, how do you expect them to learn computer science?”, but by the time I had finished finding that statistic they had moved on to a different topic.
I concur. It’s hard enough teaching kids algebra…just from personal experience learning both, coding is many magnitudes harder.
I had heard the horse used as a counterexample to this before – ie the invention of the car put horses out of work, full stop, and now there are fewer of them. An economist at the conference added some meat to this story – the invention of the stirrup (which increased horse efficiency) and the railroad (which displaced the horse for long-range trips) increased the number of horses, but the invention of the car decreased it. This suggests that some kind of innovations might complement human labor and others replace it. So a pessimist could argue that the sewing machine (or whichever other past innovation) was more like the stirrup, but modern AIs will be more like the car.
Technology lowers cost, which makes products cheaper. But it also puts some people in the production process out of work. The ‘saving grace’ here is that lower prices increases demand for said product, which means that the manufacturer hires more people to keep up with demand , replacing employees lost to automation. Furthermore, the company (Company B) that sells the raw goods to the first company (Company A) also sees increased demand (because Company A is seeing more demand due to lower prices), so Company B hires people, which counterbalances those lost from ‘Company A’. It’s not going to be the same employees, but you can see how job lost from one company/industry can create jobs for anther company/industry, due to increased demand.
There are plenty of developer jobs that don’t really require math or comp sci at all. I’m a liberal arts major and professional web developer and I remember almost none of the math I’ve learned. I intend to learn more comp sci and math because it will definitely be an asset, but for the kind work I do (front end web development), fairly simple logic is all you need.
I used to think this was a weird straw man occasionally trotted out by Freddie deBoer
Well, one of the two of us has to go to accreditation conferences all the time….
By the way: one of the fundamental economic advantages of computer code is that it is infinitely scalable at no cost. There is therefore a natural cap on the number of coders that you need to hire. A basic part of tech industry profitability is that labor costs are extremely low relative to the size of companies. Last time I checked Google had a market cap like 25 times that of GM but employed less than a 6th as many people. Code can never replace manufacturing or driving as occupations because it is the basic nature of code that the same number of people can make a program used by 25 people as by 25 million people. That will never change.
(and someday the AIs will write the code….)
but then who will write the code that tells the AIs how to write the code?
I agree how IT has a huge advantage over other industries and sectors due to real estate being expensive and high borrowing costs for non-tech businesses . It does not cost much money to start a software , website, or app company, versus, say, a restaurant . http://tinyurl.com/jalwv5y
Programmers whose job will then become obsolete. This is no different from people who are paid to train their replacements before they get fired, which has happened in the past.
Only when all software has been written.
That’s, like, an AI-complete problem. When such a thing is the case, unemployment is not what you should be worrying about. (Or if it is, at that point the world is presumably so productive that UBI becomes seriously workable.)
Does anyone know of a good primer on the mathematical universe hypothesis that Scott links to above?
The book written by Tegmark is the place to go: https://www.amazon.com/dp/B00DXKJ2DA/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
The book is great, but a bit long-winded. The original paper might be a more efficient use of your time: https://arxiv.org/pdf/0704.0646.pdf
Thanks. This seems to require mathematical platonism, which I don’t believe/understand.
A couple of points of contention from a fellow attendee:
Re “A lot of people there were really optimistic that the solution to technological unemployment was to teach unemployed West Virginia truck drivers to code so they could participate in the AI revolution.”: I think the majority view, among both the attendees and the economists there, was that this would be appropriate for a small subset of such people, and that training for other kinds of jobs will be necessary.
Re “The cutting edge in AI goal alignment research is the idea of inverse reinforcement learning.”: It is one promising approach among a few, including ones variously top-down, didactic, cognitive, mixed-mode, etc.
I don’t know, that one person was very big on how there would be universal computer science training starting in first grade, and how that would replace the jobs lost to deindustrialization.
If they had thought it would replace 15% of those jobs, I would have expected them to be less gung ho about it and had other ideas. The later panel seemed to be thinking along these lines; the earlier presentation didn’t (or at least that was my impression).
If 15% of coal miners can e retrained for high quality IT jobs, then what % of coal miners cannot be retrained for any job at all in the entire economy?
that one person was very big on how there would be universal computer science training starting in first grade, and how that would replace the jobs lost to deindustrialization
Listen, you could have been drilling me in computer science training since I started to toddle and it would not have made a straw’s worth of difference because I do not have the mathematical brain. This is the trouble with the extreme of the “growth mindset” application – want it hard enough, work at it hard enough, and you can do it!
No, sometimes you can’t. Besides, if everyone is now a computer programmer instead of a truck driver or coal miner, wages and conditions will go down accordingly and the status will be equivalent to checkout clerk (good maths skills are an advantage there, too).
Yeah I am again struck by the degree to which people assume limitless pliability in learning and academic potential, when the empirical case against that is overwhelming.
“Training starting in the first grade” seems like a very slow shift in training, while the economy shifts much faster. What happens to the 50-year-old truck driver when his industry goes under five years from now? It’s hard for older people to learn entirely new things, and they may be unwilling to. That’s the case right now with unemployed factory workers — they may have the opportunity to retrain as health care workers, but they don’t feel like that’s the kind of job they’re suited for or want to do, because it’s so different from everything they’ve done in the past.
Now it’s good to say there’s a plan for long-term transition to other kinds of employment, but that doesn’t take away the short-term problem of what happens to the specific people whose entire industry disappears. I could see them falling prey to various “escapes” to avoid admitting they will have to switch fields — whether heroin, fake disability, or voting for a future anti-robot version of Trump.
When I was in grade school, well-meaning administrations would offer “computer” classes every couple of years. These generally consisted of some typing, a little very light productivity applications work, and, mostly, playing “educational” computer games. Completely useless.
I wouldn’t expect any state-designed grade-school-level program to do much better. The programming classes I took in high school were okay, even if we wrote everything in Pascal, but there is just a fundamental limit to the kind of real computer-science skills you can give preteens of normal intelligence inside a conventional classroom setting.
Oh wow, people would get so unbelievably upset about something which derives their values from their actions without being “nice” about it.
“OK so we’ve had the AI monitoring you for over 10,000 hours, every word, gesture, choice etc in that time and here’s the conclusions it’s come to”
“But it says here that I only care about the wellbeing of myself and my own family and don’t care even a little bit about anyone else”
“yes”
“But I do care! I went to all those protests about third world aid”
“yes, but if you look in the appendix the AI adjusted it’s model to account for your desire to have sex with that cute guy you met at the coffee shop you went to those protests with, it came out almost 100% certain. See here, the certainty weighting for that was boosted when you cancelled every time he wasn’t able to make it to an event”
“THIS IS SO OFFENSIVE! SCREEEEEEEEEEEEEEEE!”
The scene doesn’t seem very plausible. If the AI researchers are actually talking to a pterodactyl, they will probably feel compelled to phrase things in a more flattering way, just for the sake of self-preservation.
Nita, this is exactly the type of unthinking prejudice that so negatively affects Pterodactyl-Americans today. You had a stereotype of “reptilian bloodthirsty violent aggressive carnivorous monster” as a mental image when you said that, didn’t you? No, don’t try to deny it.
Simply because Pterodactyl-Americans have the cultural and behavioural traits of high-pitched screeching in response to unpleasant stimuli does not make them any more prone to violent outbursts or sudden acts of aggression than the average late-Jurassic predator!
I think the AI is supposed to interpret people’s claims about what they want as data about what they want, so that it would be sophisticated enough to say “This person only helps their own family, but this is a failure of will, since they endorse a moral system that says they should help everybody.”
Ideally, yes, it would come up with something that someone could agree mirrors their beliefs but would it also be considered a failure mode to match too closely to what someone says their values are vs their actual values?
For example if someone walks around preaching a strict biblical approach to charity (of the GIVE EVERYTHING variety) and is watched by the AI that’s going to be managing their finances:
If it weights the persons words much much more heavily than their observed actions and decides that giving almost all of their assets to the poor is what matches their values but the individual isn’t happy with that later….
In such a case the person may be very unhappy that the AI mirrored their words without the silent, unacknowledged exceptions they actually make.
The darker version involves someone preaching strict utilitarianism and convincing the AI through their statements that they really do want to be disassembled for organs to save others.
It’s not an easy balance.
Children quickly learn that people’s claims about what they want is at best noisy evidence for what they really want. Judge a man not by his words but by his actions, as they say.
But the AI may correctly infer that people’s claims about what they want may be untruthful, because people lie or are confused about what they want, and therefore it may learn to consider people’s claim as weaker evidence about what they want compared to people’s actions.
Or “This person claims to endorse a moral system that says they should help everybody, but this is a failure of truthfulness, since they only help their own family.”
Luckily I am an enforcer robot, so lets enforce their moral system on them.
I understand that you cannot comment on individual people, but I’m really wondering if you feel like many minds were changed vis-a-vis superintelligence and its risks. On a group level, would you say that (some / many of) the skeptics changed their minds? Or maybe it was more common for skeptics to convince “believers” there is nothing to worry about? Where skeptics (initially) vocal about their opposition to this “alarmism” / “fearmongering” / “Luddism”? Did skeptics / believers mingle a lot, or did they tend to clump together? Or perhaps in other words: were there heated discussions between them, or did they tend to avoid each other? Did you hear any good arguments against the idea that AI might pose an existential risk?
On a slightly different note: what vibe did you get from AI and ML practitioners about the closeness of AGI? Major challenges?
Sorry about the barrage of questions. I’m just kind of sad I wasn’t able to attend myself, and I’m really curious about the effectiveness of conferences like this at convincing entrenched “experts” and “breaking the taboo” (which sounds really great)… I understand the importance of preserving anonymity, and hope my questions can be answered on a group level in a way that preserves that. Thank you very much if you take the time!
My impression was that among the people who had really thought about the issue, collective minds were changed in a way that didn’t require anyone’s individual mind to be changed – ie the people who were concerned about risk became more vocal about it and started feeling like they were the majority, and the people who weren’t concerned about risk became less vocal about it and started feeling like they weren’t.
Among people who hadn’t thought about the issue, I feel like they got the impression that the people who had thought about the issue were concerned about risk, and updated in that direction.
Just out of rank curiosity, was there a sense at the conference that Eliezer gets any credit for his role in getting the ball rolling in this area? It’s a good sign that he no longer has to be the one pushing these ideas, but it’s just jarring to me that I haven’t seen his name a single time in any reporting on this event. I’m not sure whether this is the type of situation where people are intentionally avoiding associating his name with the conference, or if his name is not being referenced for the same reason physicists don’t feel the need to cite Newton in every paper.
Bostrom basically wrote Superintelligence so that you could cite the ideas without getting into academic politics about whose they were.
Which is to say: Eliezer deserves a bunch of credit, but for political reasons that largely amount to, “he didn’t work in conventional AI”, won’t get it.
Takes on this (varying levels of skepticism):
Oversight.
Hanson had a blog post about high status academics taking over an area once it becomes promising enough.
EY has a bad brand (I certainly think this, but I know lots of people here disagree).
Bostrom , Hanson, have a lot of original research…EY wrote a harry potter fan fic and has done a lot of summarizing, but I don’t think he has done enough academic-level original work and or peer reviewed work – or- maybe his contributions are not significant enough , besides Friendly AI.
As I said, bad brand (for lots of reasons).
From your description, it sounds like a major benefit of the conference was promoting common knowledge (in the formal sense of “knowing which things others know”).
There’s a pattern I’ve been watching for a while now where lots of knowledgeable AI/CS people are privately worried about AI risk, but most of the public statements on it come from politicians and other people who can be dismissed as technically ignorant. If this achieved nothing but making all of the quietly-worried people aware of all the other quietly worried people, I’m still counting that as a success.
FWIW, if I was at that conference (*), and there were lots of really vocal, authoritative-looking people shouting “we need to research FAI immediately ! Everyone stop developing AI right this instant until it’s fixed !”, then I’d become a lot less vocal about my own views. That’s not the same thing as changing my mind.
(*) Not that I’m actually smart enough to attend it, but still.
Regarding the economic questions:
1. Median wages: have they grown or not isn’t a settled question, framing it this way is very misleading. Individual median wages might have stagnated but that isn’t the whole ball game. Median household income (inflation adjusted) is up 25% since the late 1960s, and median household size has dropped from ~3.3 to ~2.6 in that span. So instead of 3.3 people living on 40k a year or 12k per person, 2.6 people are living on 50k a year or 19k a person, which represents a ~ 58% increase in income per person per household which is a very different picture than stagnant wages. Some median wage statistics also fail to cite rising benefits (health insurance, vacation etc) and give a misleading picture on their own (though not all).
Now there are arguments against using household wages alone, and there are arguments against using individual wages/compensation, presenting either on its own is misleading.
2. Re Horses: The decline of the horse is either wildly overstated or wildly understated. First the overstated, the invention of the car put horses out to pasture (sorry), but it was also part of a trend that increased the overall number of animals in the employ of humans. Populations of domesticated dogs, cats, cattle, sheep, goats, pigs, chickens etc have increased dramatically (even adjusting for human population) since the introduction of the car. Implying that because the car knocked the horse out of employment that then it decreased net employment is a fallacy of composition, and it would be like looking at the end of WW2 and seeing military employment plummet and assume that it meant that total employment must likewise drop (it did, but briefly).
The understated case is that some of the above animals live totally shit lives, arguably shittier than non existence, and the future for humans is as bleak as it is for caged chickens.
I think the danger is overstated, employment rose during the post ww2 period, hitting its peak around 2000 in terms of labor force participation, household incomes rose over this period and while some lament that it “Takes two incomes now” I see very few of those same people living a 1960s lifestyle (their houses are larger, they have 2 cars, cable, high speed internet access at home, multiple smart phones in the family).
The major caveat being that since 2000 household wages have stagnated, although when you consider major military action, and major financial crisis occurring during that period I am confident that if we could edge past those two drags then household income growth would pick up again.
It is often stated that it might be difficult to infer our values because we are irrational or lack in computation, e.g. an AI observing a weak chess player may learn that he likes to lose because he made some losing moves. This is a fair attack on IRL but it looks soluble.
An issue that is more problematic because it strikes at our potential misunderstanding about morality is the following. Imagine an AI observes people through their daily routines, interactions with other people. It learns that people avoid stealing and doing other bad stuff. It hypothesises that average human does not like stealing. However, then it finds out that most people commit small illegal acts, like pirating, going over the speed limit, when no one is looking. They even commit great atrocities when they are sure they will not be punished, like raping during war, when far from judicial powers.
Thus, the AI learns, the truer, more cynical values of humans. Be selfish as long as no one can punish you. If your actions are observable, adhere to social contracts. Use morality as a signal of willingness to cooperate and trustworthiness — do not consider it as an end itself.
See, this is why one might desire some sort of editing power. I wouldn’t mind a computer observing my actions and deriving a system of morality from them, but I would want to see what moral rules it came up with, and edit them. You know, “Delete the part about treating people more kindly if they are more attractive, and where you decided it was moral to yell at my children provided I didn’t get a good night’s sleep the previous night.” Can we assume a computer would be capable of this? I remember Leah Libresco wrote a post some time ago suggesting that such a computer-human team would be able to come up with better moral rules than either of us would alone.
I agree that being able to edit would be handy. However, many modern methods do not allow this. You cannot look inside a deep neural network and tweak it a bit because you want to add an exception to the rule it found. Besides, vanilla inverse reinforcement learning is meant to solve the value problem for us. If we know which values and how to include we might as well get rid of IRL and write the values ourselves.
Getting AI to do the moral philosophy for us/with us is a solution but this is not something you can work on today (or any time soon), so AI researchers are not too eager to discuss this approach.
Adversarial training methods are sort of a “edit what the net learns” trick, aren’t they?
ISTR an educational example in one paper: one net was trained to classify images, and another net was trained to try to find “mistakes” by adding small (in L2 norm) perturbations to training set data which would cause the classification to change. The first net can then be trained to avoid those mistakes. We know a priori that adding a faint static to an image of a bird doesn’t make it look like a couch instead, but if you naively train a classifier with a bunch of bird pictures and couch pictures then there end up being exploitable weaknesses which an adversary could use to change the output, and by using an adversarial training process we can eliminate that one category of weakness.
On the “Superintelligence: Science or Fiction” panel, a bunch of smart famous people publicly agreed that the timespan between the advent of approximately-human-level* AI and superintelligence would be somewhere between a few days and a few years. This is good. But was there anything like a survey on when approximately-human-level AI would be reached? I’m always interested in updates on those predictions. Particularly with DeepMind aiming in a very practical and near-term sense at rat-level AI.
I was also overjoyed to see Fun Theory specifically mentioned on the panel.
*Obviously there won’t be such a thing as exactly human-level AI, it’s just a qualitative threshold point that’s easy to talk about, and the panelists all understand this.
The AI Impacts team (Katja Grace et al) have done a formal survey of hundreds of AI researchers about this kind of thing. They will publish their results soon.
Please tell us the results when they come out.
That panel though. White dude. White dude. White dude. White dude. White dude.
if you watch an NBA game it’s black dude black dude white dude black dude black dude
Obviously the conference was structurally racist and sexist. But do you feel that’s a problem? Is there a feminist or an Afrocentric approach to benevolent AI?
Warning: further making fun of people for their race and gender, without attempting to tie it in to substantive issues, will result in a ban.
None of the responses so far have been productive and further responses along this line will result in a ban.
Uh oh, is there really any chance this is false? I mean, usually I believe my guess is probably pretty damn close, but by no means always. If that’s just me, I’ve suddenly got a lot of priors to reevaluate.
J. Storrs Hall suggests that the inability to perfectly model our own thought processes is fundamental to what we think of as free will.
Free will is the god of the gaps of human consciousness. It’s just a catchall for the stuff we can’t explain. This is blindingly obvious unless you are under the effects of motivated cognition.
Sure, but as I read Hall he goes further, suggesting that there is an advantage for minds that are structured that way, that they are more effective than minds that can perfectly model their own functioning.
If true, this would have consequences regarding hard AI takeoff.
I’ve been trying to integrate Hall’s thesis with Dennett’s Varieties of Free Will Worth Wanting, but it’s all really hard to get a grip on.
Smart & Final is a discount grocery chain founded by Abraham Haas, father of Walter A. Haas of the Levi Strauss fortune and the Haas School of Business at UC Berkeley.
Funny you should mention WV truckers being retrained as coders — my husband used to work for a tech company in WV. They paid really badly and treated their workers like crap, which they could get away with because it was West Virginia and unemployment was so high. No one would quit because there weren’t any other jobs to be had; the feeling was that, as a high school graduate in WV, you were dang lucky to have that job and shouldn’t complain even if it didn’t actually pay the bills.
I’m not sure this is the technological utopia we all dream of, in other words. You can retrain truckers as coders, but if unemployment is high among those groups, and if their skills aren’t rare enough to be in high demand, they’re going to be paid at least slightly less than what they were as truckers.
I think you’re reading too much into the results of that IGM poll. For one, there is a world of difference between widespread technological unemployment and stagnant/reduced wages for a portion of the income distribution. Widespread technological unemployment is the big concern I hear from futurists (you mention it yourself in point 2), but wages adjusting to a new equilibrium is exactly the opposite of unemployment.
Two, stagnant median wages in the US may be less a matter of robots taking our jobs and more a matter of technology and globalization (which is facilitated by technology) leading to equalization between low-skilled third world labor and low-skilled first world labor. In other words, the drop in the wages of first-world low-skilled labor is in large part the result of (technology-enabled) competition from third-world labor, not robots. But once equalization is more or less complete, we might expect wages to rise across the globe as technology/capital (robots) increases worker marginal productivity. Furthermore, consider this alternative framing of wage growth in the face of automation: over the past fifty years, despite great increases in technology/automation, the global median wage has skyrocketed.
Reading point 8 I got Blindsight chills.
Clearly we just need to genetically engineer some vampires to explain the opaque reasoning of the AI!
*Which particular* humans to watch?
And human values in what context?
What we view as “human values” today are distorted by operating in an environment where there are many other agents of comparable power. But a superintelligence unleashed should be able to gain a degree of control over the world equivalent to that of a Civ player. Civ players tend to rule as literal God-Kings.
The very best chess players have historically maxed out close to an Elo rating of 3000. The very best chess engines like Stockfish now perform at around 3300-3400. It has been theorized that truly optimal chess play sets in at around 3600.
Go is vastly more complex than chess, so humans have been able to explore a much lesser percentage of its possibility-space due to cognitive constraints.
I noticed right away that AlphaGo would do more for Go than all the chess engines had done for chess. It’s an empirical fact that humans grandmasters do not have much difficulty understanding what the top machines are doing when they play each other, and for any given game, a small number of queries to the engine logs is sufficient for the GMs to feel that the machines’ play makes sense. Human GMs play a chess in a way that is mildly influenced by computer experience — the margin of draw is now known to be larger so that more positions are defensible than had previously been appreciated, certain 5-piece endings have been re-evaluated, and certain openings are no longer played because they are known to be bad, but a GM from the 60’s observing the play of today’s top players would find it quite recognizable (much less difference between 1967 and 2017 than between 1917 and 1967, and the difference between 1867 and 1917 is far larger). We know now that 6- and 7-piece pawnless endings are far beyond human ken but they play an absolutely negligible role in real games between either computers or humans.
On the other hand, AlphaGo plays a game with which the top human players are not familiar, and this was to be expected from the nature of its algorithm.
Thank you Scott. I really enjoyed this post.
One thing popped out at me:
Say we do this and, at the end of the day, find that the underlying human value function is really that we’re just a bunch of dicks, and what progress we’ve made in the past have all been a fluke from the occasional groups of humans acting in non-dickish ways: the occasional lit matches in a sea of darkness, if you will. So we device a super intelligence that runs everything now, perfectly and effectively, by our dickish values…
It’s somewhat likely that humans enjoy being dicks, but we really don’t enjoy other people being dicks to us. So the equilibrium in this case probably wouldn’t involve just letting people be dicks at each other. Maybe it would create something else for us to be dicks at, to get it out of our systems.
As far as I can tell, this is half of the function of Siri.
And 75+% the function of videogames?
Of course, the busybody moralists want to take that away from us too…
How can these things be called degrading?
I guess it must be awkward for the people designing responses, but it seems like an oddly petty thing to get upset over.
Sexual harassment is supposed to be unwanted sexual advances. A machine cannot “unwant” anything, any more than it can want anything. So there’s literally nothing you could do or say to a machine which would constitute sexual harassment.
The person anthropomorphizing SIRI isn’t the guy who says “SIRI suck my cock,” it’s the writer who gets (faux?) offended on SIRI’s behalf. It’s no different than writing the same thing on a notepad document and deleting it.
Perhaps this is just me admitting to certain political biases, but I often struggle taking seriously the threat of technological unemployment for the same reasons I struggle to take seriously the threat of climate change. I keep getting back to the following strain of logic…
1. A rather large portion of the tech/science community is strongly left-leaning/progressive
2. Said people have suddenly discovered a problem with the potential to completely wipe out civilization as we know it
3. Sure, you don’t really notice the problem now, but they assure us that once it starts it will be impossible to reverse and will get very bad very quickly without immediate action
4. The only proposed solutions involve implementing the same types of socialist economic policies that progressives have been constantly advocating for since the 1920s
Granted, the AI people do a better job on #4 than the climate change people, but I still feel like a whole lot of arguments about the seriousness of the threat of technological unemployment inevitably include “… and that’s why we need socialism!” as the final line.
A lot of people often express displeasure about how the climate debate has become so “politicized.” I suspect this is a large reason why. I would encourage those concerned about technological unemployment to really try to not emphasize the “and we solve this by nationalizing Google and instituting a giant UBI” part of your analysis – lest the same sort of partisan divide start to manifest itself here.
My perception at SSC is that there is not a shared feeling that we must preemptively implement socialist policies, but rather, that we should think through possible scenario’s and have solutions ready.
Is this really so objectionable?
Not really, no. I just have a perception that a whole lot of people are leaping right to “and obviously this will require the abolition of property rights as we know them.”
And they may be right. But being too enthusiastic about that sort of thing paints a picture that you might not want to be painting…
For what it’s worth, I’m not seeing a lot of “and obviously this will require the abolition of property rights as we know them.” A lot of enthusiasm about UBI, yes, and a lot of handwaving about that proposal’s financial issues, but there’s a lot of daylight between that and xxxFullCommunism420xxx.
If we’re assuming that the UBI is the only source of income for the vast majority of the population, I think that’s de facto socialism – but I’m sure people could argue otherwise.
Sure, in the sense that it achieves socialist goals. But that’s one thing and the abolition of property rights is another. If it turns out there’s a way we can achieve the former without troubling with the latter (and without completely breaking the incentive structure that makes productive society work, which I see as pretty much the same thing but you may not), then that’s cool with me; my entire objection to socialism lies in the realm of means and incentives. We all want freedom and prosperity, right?
I’m just kinda skeptical that UBI can get us there in the short term, robots or no robots.
@Matt M
UBI is the opposite of the elimination of property. It is granting property to people (usually in the form of money, which turns property into easily tradeable tokens).
You have to keep in mind that there are (at least) two definitions of socialism. One is to eliminate property, which we generally call communism today. The other is to do wealth transfers, which doesn’t eliminate property and/or capitalism, but equalizes the buying power somewhat within the capitalist system. The latter is what most people who call themselves socialists today, want.
That’s one of the things they want. But most of them also want a lot of political control over how things are done, for any of a variety of reasons. Bernie Sanders was not campaigning for wealth redistribution plus extensive deregulation.
They may speak positively of Denmark and similar societies, but that’s in part because they do not realize that those societies, although more redistributive than the U.S., have less government control of other sorts.
UBI is the opposite of the elimination of property. It is granting property to people (usually in the form of money, which turns property into easily tradeable tokens).
It is granting people ration cards to spend on consumption goods while the means of production are controlled by the state.
The extent to which it resembles our current system says more about how far from genuine market principles our current system has strayed than it does about anything else…
Matt M
UBI proposals generally assume that the means of production are controlled by the free market and that tax income is used to pay for the UBIs.
I think that you fail to understand what the most common proposals for a UBI actually involve.
You are straight up just making up definitions. Free market doesn’t mean what every you feel like it meaning, it has an actual definition and you can’t say “the free market controls the means of production, but then we take part of that production and do X with it” Controlling what happens to the output is controlling the means of production, and so isn’t “the free market”.
Of course this is how fascists framed it as well “hey, you guys get to keep the factory, the government is just going to make sure you use it in socially appropriate ways”.
@baconbacon
OK, then make it ‘capitalism.’
Taxation still preserves the basic free market mechanism of supply/demand, which is not true if you have a single producer.
That was my point and your nitpick in no way addressed my actual argument.
I think that you fail to understand what the most common proposals for a UBI actually involve.
Most common proposals for UBI are operating in the economic reality of today where productive assets are ridiculously widely dispersed, available at relatively low cost to most people, and where labor alone is still a large source of productivity.
The situation becomes very different if you assume that all productive assets are held by a fraction of a percent of the public, and that all value-creating activities ultimately stem from these assets. A UBI in that environment is much closer to “the newly elected leader of the democratic peoples republic seizes control of de beers’ diamond mine and shares the wealth with the people while allowing de beers some nominal control over production and a decent share of the remaining profits because dear leader doesn’t know much about running a diamond mine” than it is to “the free market”
It is not a nitpick, you are attempting to win the argument at every step by framing the discussion and hiding costs. A UBI isn’t Capitalism plus a safty net, its capitalism minus parts of capitalism plus a safety net. You (and basically every framer of the discussion) keep skipping the middle part as if it doesn’t exist.
If you don’t address the costs of your proposals you don’t have an argument, you have propaganda.
I also have no idea what this line is in reference to.
What part of capitalism do you imagine a UBI would be remove, that we didn’t already do away with back when we invented taxes?
In what part of this argument about the future have we been discussing the status quo?
In terms of what the UBI gives up, philosophically its the idea of assistance being temporary and targeted (some programs in the US do this, but on a far smaller scale than a UBI would). It says “even if there was no poverty the government still is and should be in the business of redistribution, that the only reason not to have redistribution is perfect income equality. It will, likely and over time, bind those on the net receiving end into what is practically a single issue voting block as SS has done for seniors. It will treat immigrants in one of two ways, either as second class citizens who don’t get UBI or as not allowed into the country without proof of employment, with earnings > X, and it will likely decrease the labor participation of the poor.
That is just if it is done really well, not if it is done the way it actually will be implemented.
Baconbacon I think you are being a little uncharitable, at first blush I assumed, as Aapje has now confirmed, that ‘free market’ was just intended to imply ‘the mechanism of our current economy’.
I agree with Aapje, I have never seen a suggestion for UBI that coupled it with communism, or any other major change to property rights, the common form I have seen is for the UBI to just replace our current welfare programs.
As to your response to John and deeper social issues, it is a slippery slope argument and people who are ‘ignoring’ it are hardly trying to sneak anything past anyone. Only somebody predisposed to model the world the same way you do would assume that a UBI would result in the outcomes you predict, it is perfectly reasonable that another person would simply never think of those concerns/not think they would happen. Your future forecasting is far from indisputable facts about UBI that people only fail to mention out of a desire to mislead.
I disagree, he clearly in a few posts states that the free market won’t/can’t take care of specific groups of people which is a statement about idealized free markets. He then uses it to mean “our economy” in a different way, which is where the switch comes in, because he then implicitly damns “free market” with our the problems in our current situation when he conflates the two, despite them being different things. This is a rhetorical trick (intentional or subconscious) that allows him (and others) to put the chain of reasoning of “free markets don’t do X, our system is a free market system and it doesn’t do X, case in point”. This allows him to skirt issues, notice how he doesn’t address how the actual welfare system in the US was created, which is brought up in several posts, but states why he thinks it was created and moves on as if it is true because he says it.
This is exactly what SA means when he discusses mote and bailey tactics. “Of course when I said ‘free markets’ I meant ‘our current system’, except when you move back he goes right on making statements of what free markets can and can’t do in a purely theoretical sense, and then when called on it he claims points for having riled someone up.
It is impossible to argue honestly with someone who gets to ex post define the terms he uses in response to the criticism. “oh your objection doesn’t hold because i meant meaning #2 this time, and next time I will be using meaning #1”- wait where was the refutation of the point?
Is this from another thread? In this thread Aaepje used free market once before you replied to it, and then immediately said that it was a mistake/corrected it.
Also, misuse of ‘free market’ is so rampant you should probably lower your prior that people are doing it intentionally.
I don’t think this is generally accepted to be a philosophical prerequisite to capitalism. If it is, capitalism basically hasn’t existed in the western world in the past century, and it seems nonsensical to talk about whether a UBI that won’t exist for many years to come is or is not compatible with a narrowly-defined economic system that died a century ago.
now you’re getting it!
In a reply to this post (but not in this specific subsection) I wrote
Where I clearly define free market in the first line. the response was
This is a straight jump from one person clearly and explicitly talking about free markets with the definition as up front as possible, where the reply immediately conflates the US system and its flaws alleged remedies with a free market. Followed by a few posts down in a reply to someone else
This is basically back and forth between the definitions within a few paragraphs.
It isn’t the misuse that bugs me, its the impossibility of arguing against someone when you clearly state X, and they immediately move on Y.
You asked what would be given up that wasn’t already given up with accepting taxation. A fair number of proponents of welfare framed it as “getting people back on their feet so they can get back into the markets in a healthy way”. UBI separates us from that second portion, by tying it to existence, not need, it is no longer that capitalism/free markets are an ideal to get back toward but that capitalism needs a permanent structure around it.
It seems clear that some people here disagree with my premises (which is fine), but instead of merely debating those, I get accused of being disingenuous (this is not so fine).
My belief is that a true free market/pure capitalism is impossible due to (literally) natural limitations. So any attempt to achieve a free market by laissez faire will fail and will result in a outcomes that are further away from the free market than a regulated system (note that this is not a claim that we currently have a system that maximizes the free market as much as is realistically possible).
My belief is that our current system has adopted the key elements of the free market to a decent extent, primarily by having buyers and sellers relatively freely choose how much to consume/produce and who to buy from/sell to. As such, I think it is fair to call our system (partly) capitalist.
My claim is that a UBI preserves the ability of consumers to decide, based on their preferences, how to spend their money and preserves the ability for producers to decide what to produce. As such, these key capitalist features remain when you implement a UBI. Of course, if you consider our current system insufficiently capitalist due to regulation, then a lack of movement to more laissez faire is objectionable in itself. You can also argue than it is even less of a free market and object to that*. However, my argument was on a more fundamental level: is a system based around a UBI necessarily radically different when it comes to the key features that make me (and a lot of other people) use the word ‘capitalism’ to describe (part of) our current system? My argument is that it doesn’t have to be.
Of course, it is correct that if you roam off 100% of the profit of producers, they become disincentivized to produce, no different from taxing 100% of profits. However, the proposals for UBIs tend to consist of redistributing only part of the GDP via this mechanism, not all of it. So there could still be differences in buying power, which makes successful producers more wealthy and thus better off.
In the theoretical situation where people are utterly unable to produce any value with their labor and in the absence of other reward systems than profits for producers, an UBI would presumably result in roaming off 100% of the profits and at that extreme, it capitalism no longer incentivizes producers to produce.
However, it is far from a given that widespread use of robot labor that will drive many people’s earning power below acceptable levels, will also drive the value of their labor below the levels that are sufficient to incentivize market behavior. Even if that is the case, I see other reward systems as a potentially fruitful avenue, given that humans are not economically rational.
I would also argue that a situation where no one produces any value with their labor (everything is run by robots, including the entire production pipeline to make robots), capitalism as a way to incentivize people for their labor is not applicable anyway (since there is no labor necessary). If you still demand capitalism in such a situation, you have lost sight of what capitalism is supposed to do, IMO.
And to make my position clear: I am not arguing for a UBI per se. I am merely arguing for not dismissing it as an option.
* Of course, capitalism is merely a tool to achieve a goal and should not be a goal in itself, IMHO
That’s an interesting claim. I can understand the claim that a true free market would not be ideal, but why is it impossible? Could you explain?
I am using a definition of free market that requires the absence of barriers of entry, inequalities of bargaining power, information asymmetry, etc, etc. Basically, anything that enables raising the market price of a good or service over marginal cost.
The simple fact that resources are not unlimited and not of equal quality already causes these distortions. IMO, these distortions are self-reinforcing, which is why I don’t believe in laissez faire, because I believe that it will result in the system spiraling towards a situation where a small group of people own everything and have power over everyone.
Basically, I think that markets are unstable, not in the least because the goal of the actors is to create market inefficiencies that benefit them. They will make use of any existing distortions to create a more distorted market.
Hence I believe that unregulated markets cannot exist.
However, as I also don’t believe that humans are homo economicus, I believe that humans have some tendency to self-regulate (in ways that conflict with the free market), which is presumably what you depend on for your economic beliefs. However, I believe that this self-organizing ability is insufficient for a highly complex economy.
It sounds to me as though you are using “free market” to mean something more like “perfect competition.” They are not the same thing.
Information asymmetry, to take one of your points, is one of the reasons why a free market does not produce as good an outcome as could be produced by a perfectly wise central planner with unlimited ability to control people–why its outcome is not efficient in the usual sense. That doesn’t mean the market is impossible, merely that a market fitting the simple stylized model that economists sometimes start with is.
UBI is not about the abolition of property rights. It’s about raising taxes. In a sense, raising taxes is an incremental abolition of property rights, because the state takes some of the benefits of your property, but we already have taxes, we’re surviving them, if you can call this living.
Future automation UBI is consistent with capitalists being extremely absurdly rich and the rest of us being merely absurdly rich (by 2017 standards). It’s not straight-up commie, just redistributionist.
@suntzuanime
Agreed. Maybe a century from now everyone has at least two or three robot
slavesservants, and an additive manufacturing machine, but really rich people own asteroids and small seastead states or something.It’s perfectly consistent with the idea of the social market economy. Certain conservatives (and as a consequence US liberals, to the chagrin of actual socialists) like to call that socialism or even stealth communism, but it really isn’t (I seem to remember the Dutch PM or someone getting outraged when Bernie called their system socialist). Sweden’s model is basically this, and it has some of the best protected private property rights in the world, and the easiest to start businesses, at least according to the Heritage Foundation. 90% of resources are privately owned in Sweden according to Wiki, but they have a big welfare state and strong union rights at the same time.
Calling government doing things with wealth “socialism” or “communism” is just the right wing version of when extreme leftists call doing things with borders “fascism” or “nazism”.
Not sure about this part though:
“In a sense” is being used like “there is an argument” or “one might suggest”, I’m using it to raise a point I feel I should address but do not necessarily endorse.
Fair ’nuff.
If we’ve reached the point where the source of 99.9+% of all wealth is generated from AI, then the taxes that are collected to pay the UBI are coming exclusively from the AI owners.
I mean I guess there’s no way to hash this out without a debate on “taxation = theft” but it seems to me that if the board of directors of google is being forced, against their will, to perpetually fund the entire existence of everyone else in society, that doesn’t really sound like any form of capitalism I would recognize.
We already have a system where one group of people (workers and capital owners) is forced to fund the existence of another group of people (welfare/social security recipients). It’s arguably not unworkable.
The automation future is one in which 99.9% of all wealth is generated by capital. This isn’t necessarily all Google, there are a wide variety of corporations that have valuable capital. And even Google has a wide variety of stockholders: you’re not taxing the board of directors, you’re taxing the stockholders, which is a broader base.
@Matt M
They’d only be funding the baseline level of income, which is kind of what companies do with their wages, only now it is applied collectively. Given the existence of private property and a market (therefore capitalism), people would still be able to use that money over time to purchase their own capital with which to create wealth above that base level. No technology can remove the advantage of scarcity in land, and the different uses of it. Even if everything is so automated that human labor is useless, differences between applications of automated capital would lead to differences in wealth generation. Even if labor is reduced to telling a bunch of AGI robots to do shit on a piece of property, the difference in what you tell it to do and where would create opportunities for leverage.
Imagine everyone is on universal welfare, but then someone pools a certain amount of welfare to buy shares, or to buy capital and land directly, and have their robots build something unique other people would be interested in. What if you buy shares in a seasteading resort, make it rich, and then decide to enter the asteroid mining business?
AGI doing everything humans can do will lead to humans ceasing to be a means of labor, but human desires are still going to be acting on the AGI*. If we’ve designed it to be friendly, then every model does what we tell it to, automating the processes we want it to automate; and what we want, our desires, are going to matter as regards how much value the final result has.
*Liability is going to be YUGE.
Scott, what is the basis for your assertion that human beings don’t have utility functions?
Not Scott, but when we talk about having a utility function, we are usually speaking under the axioms of Von Neumann-Morgenstern utility theory: completeness, transitivity, continuity, and independence. I’ve seen various attacks on these w.r.t. human preference, but the Allais paradox, which attacks the independence axiom, is one of the more famous and important.
(Transitivity also looks weak to me: it is not very hard to arrange a situation where people will temporarily, at least, prefer A to B and B to C and C to A. These inconsistencies are usually resolved once pointed out, but a utility function that’s time-variant in unpredictable ways is not much of a utility function.)
Adding to what Nornagest said: because the VNM utility theorem is biconditional — an individual’s preferences can be characterized by a utility function if, and only if, said preferences satisfy the given axioms — if the axioms are violated, then we know that the individual has no utility function.
The continuity axiom has also been challenged (in both a descriptive and a normative sense).
Interesting. I think there’s a sort of necessity argument that human beings do have utility functions, even granted that they don’t have the VNM regularity properties.
After all, we do make decisions, and unless one is prepared to go full-tilt-boogie mysterian that has to be the outcome of some kind of weighting and scoring process, some kind of computation. Scott’s claim that humans have no utility functions seemed bizarre to me because it seemed tantamout to denying that such computation take place, and … er, what else could be happening? But I see now that he meant a much more specific thing, denying formal regularity properties. OK then.
Speculating…I think what’s behind the observed regularity failures is that humans actually have a patchwork of situationally-triggered utility-functions-in-the-VNM-sense; there is local coherence, but the decision process as a whole is a messy, emergent kluge whose only justification is that it was just barely good enough to support our ancestors’ reproductive success.
People have very lumpy preferences. A personal anecdote, I have been looking at houses for several years now knowing that we will eventually move and basically just monitoring the market. Of the hundreds of online listings I have perused a handful have been visited, and of those handful 2 very specifically elicited a response of “I have to own this house and live here, I am willing to sell other assets/give up my expensive hobbies for the next several years to make this happen”. There is very little gradient with a bunch of “nopes”, a few “yes, if many other conditions are met” and a small number of “oh dear god, please yes” types.
Lumpiness doesn’t fit with a function very well, but it is how many people react in terms of car buying or college decisions where one is a “oh dear god yes” and lots of effort gets put into making that happen with much less thought and effort put into fall back positions.
>There are lots of studies in psychology and neuroscience about what people’s senses do when presented with inadequate stimuli, like in a sensory deprivation tank. Usually they go haywire and hallucinate random things. I was reminded of this as I watched a bunch of geniuses debate generic platitudes. It was hilarious.
This reminds me of the movie Simon from 1980:
https://en.wikipedia.org/wiki/Simon_(1980_film)
https://www.youtube.com/watch?v=LOj5wptt-BU
“Here we have this group of brilliant people who have been competing against each other for centuries, gradually refining their techniques. Did they come pretty close to doing as well as merely human minds could manage? Or did non-intellectual factors – politics, conformity, getting trapped at local maxima – cause them to ignore big parts of possibility-space?”
This is a beautiful encapsulation of the profound misunderstanding of intelligence at the heart of the “AI risk” movement. All those brilliant Go players did exactly as well as merely human minds could manage–because that’s how well they managed. Blaming their failure to do better on “non-intellectual factors” implicitly assumes that there’s some kind of pure intellectual essence in every human brain–call it “intelligence”, if you like, although “soul” would be more apt–that engages in problem-solving as a purely abstract, Platonic, intellectual activity, and can only be limited by its quality and quantity, or by its distraction by “non-intellectual factors”.
In reality, the brain does what the brain does–shooting associations around, mixing emotions, memories, distractions and ideas together in a big ball of neuron-firing. Sometimes all that firing generates useful Go moves or strategies, and sometimes it produces bad ones, or none at all. Some people’s brains, through a combination of prior aptitude and arduous training, seem to produce good Go moves and strategies more often than others’. But the gaps or flaws in what they produce aren’t a result of “non-intellectual factors”–they’re part and parcel of the individual and collective quirks of their brain activity.
Now, it turns out that the world’s best modern machine learning algorithms produce a different set of moves and strategies from the ones that the world’s best Go players produce, and that the former more often than not beat the latter. Of course, we expect the next generation of machine algorithms to produce moves and strategies that allow them to beat the current generation. Does that mean that the current generation are being distracted by “non-intellectual factors”? Of course not–they’re simply generating the moves and strategies that their design and inputs cause them to generate, as are their successors, not to mention their human predecessors. There’s no pure essence of problem-solving here–just data-processing machines doing what they’re programmed to do with the inputs they’re given.
Take away that pure essence of problem-solving–the soul, if you will–and the prospect of “hyper-intelligent AI” (if such a thing even has any meaning) starts to look a lot less scary. A huge, complicated multi-purpose problem-solver will still behave the way it’s programmed to behave, just as we do, and as Go programs do. And if we don’t horribly botch the implementation (a completely different risk that applies equally to much dumber technologies), there’s no more reason to expect it’ll destroy humanity, than there is to expect a really, really proficient Go algorithm to destroy humanity.
There seems to be a general assumption that it’s important for the AI to (to at least some extent) behave according to our official, verbally stated morality, rather than that which can be inferred from our actions (including the action of making moral statements). It’s not obvious to me that this is actually desirable.
Well, that’s what we officially verbally state. Our actions may be different.
I am indeed assuming that no such super human AI is coming in the near future. In my opinion, the automation technologies I see today has serious limitations and will continue to require humans for as long as I am comfortable extrapolating the future (a few decades).
I’m not denying the possibility of the creation of a superhuman AI, but I am not sure how much we could meaningfully prepare for it. In the event of a true hard take off, all our preparation may only keep this AI from turning us into paperclips for another 30-45 minutes.
I think there’s a way to fabricate ethics, in a sense. Using the idea of liberty and claim rights we can outline what people are permitted to do, what they are obligated to do, and what they must refrain from. It wouldn’t be easy, but I suspect a lot of preferred human action could be coded using this scheme. Probably not a cure-all for AI, it could serve as a decent starting point.
Yes – I would want my robot servant to be a deontologist.
Scott- many of the comments here reminded me of your statement late in the report:
Many posts about horses and lumber-jacks and automation (did anybody say buggy-whip?). We should all be concerned about our own jobs being replaced by AI. Plumbers, HVAC techs and Electricians have a lot less to worry about than Professors, Managers and Analysts when it comes to AI. Sure, truck drivers will be replaced by drones so their kids will have to find a new way to get by. Our grand-kids will want running water, A/C and electricity (and whatever comes after that… batteries in the basement and panels on the roof). They will not be listening to an Accountant or Professor offer platitudes in person (who BTW pulls down 5x poverty rate, or so).
Just like popular music groups won’t get lots of people to live shows once digital music is widely available.
baconbacon- there will always be room for rockstars! and to make money these days they have to attract live audiences because automation has removed all the middle-men from the value chain. The now-unemployed middlemen were the ones screaming about Napster the loudest.
The art survives. And re-wiring a 100 year old house is an art… just so you know.
I’ve done a lot of wiring to my 90 year old house- in a post scarcity world I think I am just getting one of them super cheap new houses.
I can’t speak for everyone else ITT, of course, but I for one am interested in this stuff precisely because it is acutely apparent to me that most of the value I provide my employers as a white-collar schlub could in fact be automated with today’s technology, let alone future ditto. In fact, I started a thread several Open Threads past about the potential automatability of skilled trades vs. white-collar work. Not sure how or if I should let that guide my career choices, but it’s absolutely on my mind.
One way around robots stealing our lives is to restructure our communities. Already there are apps/sites focused on sharing within a community: you’re a masseuse and you massage someone in your community, and some professional chef cooks you dinner a week later when you’re in a pinch. We need communities where people want to rely on each other, and accept that we need to switch to a mostly service economy when it comes to people.
I know massage chairs exist, but the best ones still aren’t as good as a human. And is it really worth building a machine that is? Human engineering ability far exceeds our need to engineer.
I think this is a good intermediate step, but what happens when you can buy a massage robot from Amazon, who is 100 times better at massaging people than a human masseuse ? You ask “it really worth building a machine that [is that good]”, but that’s the wrong question. If it’s theoretically possible to build such a machine, then someone will not only build it, but also market it, because he can make money that way — a prospect that will become increasingly more important in an increasingly automated economy.
I have a feeling that my grandkids (if any) won’t even know what an “A/C” is. They’ll just expect every house to always exist at optimal temperature. They will never see a human A/C repairman, except maybe at some sort of an artisanal renaissance faire: “see, kids, this is how we humans used to keep our houses cool in the summer, before the drones were invented…”
Re. old white mill workers learning to code. I don’t think it’s as outré as it might sound. I’m reminded of something in Vernor Vinge somewhere (or it might have been Stross?), about the distributed solution of complex algorithms farmed out to a micropaid public in the form of pachinko-like pastimes (thereby leveraging random magic in random peoples’ brains).
And then of course there’s maker culture, which seems to have become unfashionable as a chattering class topic, but which looks like it’s carrying on a vigorous life outside the limelight.
And while it’s true that combining useful tasks with the Csikszentmihalyi-endorsed work modus of “making a game out of it” seems to have so far eluded developers (the closest experiments so far being a few lame attempts to make gaming “worthy” in learning terms, or meditative, or exercising, or whatever), it’s still early days.
There are developments in the gaming industry at the moment, where content creators get small payments from the developer for creating extra content for other users (e.g. a game I play at the moment, Warframe – top class third person multiplayer shooter, btw – has people making the game’s equivalent of variant armors via the Steam system). That’s one piece of the puzzle we’re watching do a species transition in realtime.
The only thing missing, to make this kind of virtual malarkey truly rewarding labour, in a way that would satisfy the whole human being (as traditionally), is the physical component – but that can be substituted for in other ways. Supposing the “bundle of gadgets” view of the mind is true, then these things are relatively compartmentalized, and being dumb on their own, easily satisfied (as the occasional bit of camping or hiking is somewhat of a substitute for our ancestral environment). We’re moving to a future both suitable for and inducing ADHD in a multitude of real and virtual environments, as opposed to lifetimes of ruminant monotoil in dark, satanic mills.
I wonder, too, if this kind of distributed play, combined with AI, could end up becoming something like Iain Banks’ Minds – solving the economy in good, old-fashioned socialist style, eventually supplanting the market. Several possible layers of irony there 🙂 In fact, with haptics and large halls dedicated to fun augmented reality LARP-ing, we’d have something like the Chinese Room 🙂
The education thing is just down to the fact that education is shit – partly because it’s all still based on the Bismarckian model of State indoctrination, currently being repurposed by the extremist Left-wing ideologues of today’s Humanities academy; partly because the State (every State, just some less ineptly than others) has for over half a century been inflating educational achievement to make the numbers look good, to buy votes. Working class people are plenty smart enough (to be brutal about it, its the dysfunctional underclass that’s truly dumb), and anyway, all you need to do is to knit all those random sparks of magic in peoples’ brains together into a cohesive, problem-solving whole, and reward appropriately.
Plus there’s crafts – there could easily be a two-tier system where at one level you have cheap robot-produced stuff that’s fully functional but has that slight uncanny valley effect that everything digital has (and probably will have for the foreseeable future – you can’t get as many bits even in 96khz/24bit audio recording as there is “grain” in analogue tape; people still generally value film+real sets over RED+CGI; the resin replica of Bastet you can buy from the museum will never be quite as satisfying as the precious original), and on another tier, people still paying good money for artisan bits and bobs, or even more closely-tailored (than robots with mass production constraints would make) maker-produced stuff. Even if you go up to the design level, you’ll probably have the same “can’t quite put my finger on it” difference.
Plus, computers always go wrong – this is the rock against which many fond, spergy hopes about the future of AI, robots, etc., are always going to crash, and it continually surprises me that so many of these exploratory discussions keep forgetting this most obvious fact that everybody on Earth now knows. The haphazard, rickety but robust chaos-eating products of millions of years of evolutionary R&D still have the advantage, and I don’t see that advantage being lost for quite some time yet. Still, it’s good to air these things now.
Oh … replace “human” with “god”, and “AI” with “human” and you get the recognizably typical outlook of mystic religious sects.
AI, trying to decipher the mysterious “will of humans”, I find that weirdly amusing.
We have more jobs today than we ever had in the past. This includes more jobs that don’t require a college education.
We have more automation today than we ever had in the past.
Arguing that automation decreases net employment is not supported by any evidence whatsoever. In fact, all available evidence (100%) points to the exact opposite conclusion.
The reason we sometimes see regional unemployment is not because automation decreases the total number of jobs, but because some people refuse to move to find work. However, calling this “technological unemployment” is highly suspect, as the cause is not that there isn’t work for these people, but that they’re unwilling to move in order to pursue economic opportunity. It is the same thing we saw with outsourcing.
We really don’t want to enable such people.
This of course makes sense from basic economic principles; human labor is a scarce resource. We can simply reallocate that resource and end up with more valuable stuff as a result. There’s always stuff that needs doing which isn’t being done.
Also, using horses as an example is always a terribly stupid example – horses aren’t people and don’t have jobs. Horses aren’t like people – they’re like equipment. And we replace equipment quite frequently.
—
I do have to admit it always amuses me how seriously people take some of these things, though.
Until they get together and vote in Trump. Whups.
We shouldn’t spend a lot of resources shielding people from economic reality, but at a certain point those people get together and demand their unreality at the voting booth.
Speaking purely from a Machiavellian viewpoint, they need to be met part of the way there and for long enough that that doesn’t happen.
From a more considerate viewpoint, they need to be given enough time to plan their careers, so that if they became a truck driver 5 years ago, they aren’t unemployable for the last 20 years of their life. Perhaps not enough to keep their dead region of America vibrant, though.
Indeed, people were unwilling to move halfway around the world to a foreign country where indoor plumbing was a luxury in order to make 1/10th their previous wage (and therefore end up unable to save enough to move back to their first world origins)… and besides the countries outsourced-to wouldn’t accept them anyway.
Yes, and there’s a reason that department is called “Human Resources”. To employers, people are like equipment too; only leased.
I have arguments for the relevance of diversity in future conferences, not only in disciplines, but also in national, cultural, gender, religious, and gender backgrounds.
1. Topics related to future of artificial intelligence affect all humanity.
2. Statistically speaking, people from different national, cultural, gender, ect. backgrounds tend to have different viewpoints on important moral, political, and philosophical issues.
3. The interests of humanity cannot be accurately represented by a subgroup.
4. Unless you have intimately lived in the experience of another language, culture, gender, etc., you don’t know what you don’t know.
5. Blind spots in science, politics, and philosophy based on Euro-centrism have had shocking and dire consequences throughout history. Scientists have particularly been drawn towards scientific racism with respect to intelligence. The mention of bio-determinism in this article obliquely acknowledges this often self-interested fascination with the idea of biologically based intellectual inferiority of some groups, even though the consensus of geneticists and other scholars in the field does not accept the idea of biological intellectual determinism.
6. This deep rooted history of scientific racism, social Darwinism, and lack of self reflection has had terrible effects in the development of technology, including employ in use of colonialism, genocide, forced sterilization, warfare, and oppression of people groups not represented in the majority scientific establishment. Unless these tendencies are rooted out, the development of AI could lead to similar results.
7. Creating limitations on the development of artificial intelligence is impossible without broad political and social support from multiple international actors.
8. A small group of elite intelligensia that is mostly or entirely represented by Euro-centric of Asian-centric perspectives will not have broad-based social support. Political buy-in may be required for multiple nations, including China and Russia, but also possibly Iran, Israel, Turkey, South Africa, or a range of nations whose economic and scientific development over the next several decades is difficult to predict.
9. Lack of lived experience or intimate understanding of oppression, exclusion, or invasion of personal body space can lead to an improper calculation of the importance of these risks in developing AI.
10. Underlying biases will be coded into AI. (This is already happening in predictive policing involving algorithms used by local police departments, etc.)
11. Constant vigilance and affirmative efforts to increase diversity are necessary to overcome the ordinary and comfortable assumptions or your particular background and experience, even in intellectual environments.
12. “Nothing about us without us” is a principal that derived from the disability rights movement. When decisions intimately involve a particular group of people, they must be represented in the decision-making process. Again, AI affects all humanity. It is wrong to make decisions for all humanity without diverse representation of its different interests.
This is not an attack on the race, gender, ability, perspective, etc., of any participants. People from European and Asian people contexts, male and heterosexual identities, and English-language cultures can and must be represented. And, of course, you have to start somewhere. Economic and social inequality greatly reduce the pool of diverse participants with scientific, legal, and other relevant experience. However, without greater diversity at some point, future conferences will be limited in their future effects and legitimacy, and will have an increased probability of significant blind spots while making vital decisions.
There are many well-established ways to increase diversity, if organizers are interested in making concrete efforts in this direction. This can include outreach to affinity groups of scientists or other experts from minority populations, affirmative efforts to seek and find non-majority group participant, “snowballing” by beginning with a small diverse group and networking outward, incorporating diversity principles into the highest levels of group priorities, etc. Lack of diversity is a problem that cannot ever be completely overcome, but it can be improved with sustained effort.