
At the beginning of every year, I make predictions. At the end of every year, I score them. Here are 2014 and 2015.
And here are the predictions I made for 2016. Strikethrough’d are false. Intact are true. Italicized are getting thrown out because I can’t decide if they’re true or not.
WORLD EVENTS
1. US will not get involved in any new major war with death toll of > 100 US soldiers: 60%
2. North Korea’s government will survive the year without large civil war/revolt: 95%
3. Greece will not announce it’s leaving the Euro: 95%
4. No terrorist attack in the USA will kill > 100 people: 90%
5. …in any First World country: 80%
6. Assad will remain President of Syria: 60%
7. Israel will not get in a large-scale war (ie >100 Israeli deaths) with any Arab state: 90%
8. No major intifada in Israel this year (ie > 250 Israeli deaths, but not in Cast Lead style war): 80%
9. No interesting progress with Gaza or peace negotiations in general this year: 90%
10. No Cast Lead style bombing/invasion of Gaza this year: 90%
11. Situation in Israel looks more worse than better: 70%
12. Syria’s civil war will not end this year: 70%
13. ISIS will control less territory than it does right now: 90%
14. ISIS will not continue to exist as a state entity: 60%
15. No major civil war in Middle Eastern country not currently experiencing a major civil war: 90%
16. Libya to remain a mess: 80%
17. Ukraine will neither break into all-out war or get neatly resolved: 80%
18. No country currently in Euro or EU announces plan to leave: 90%
19. No agreement reached on “two-speed EU”: 80%
20. Hillary Clinton will win the Democratic nomination: 95%
21. Donald Trump will win the Republican nomination: 60%
22. Conditional on Trump winning the Republican nomination, he impresses everyone how quickly he pivots towards wider acceptability: 70%
23. Conditional on Trump winning the Republican nomination, he’ll lose the general election: 80%
24. Conditional on Trump winning the Republican nomination, he’ll lose the general election worse than either McCain or Romney: 70%
25. Marco Rubio will not win the Republican nomination: 60%
26. Bloomberg will not run for President: 80%
27. Hillary Clinton will win the Presidency: 60%
28. Republicans will keep the House: 95%
29. Republicans will keep the Senate: 70%
30. Bitcoin will end the year higher than $500: 80%
31. Oil will end the year lower than $40 a barrel: 60%
32. Dow Jones will not fall > 10% this year: 70%
33. Shanghai index will not fall > 10% this year: 60%
34. No major revolt (greater than or equal to Tiananmen Square) against Chinese Communist Party: 95%
35. No major war in Asia (with >100 Chinese, Japanese, South Korean, and American deaths combined) over tiny stupid islands: 99%
36. No exchange of fire over tiny stupid islands: 90%
37. US GDP growth lower than in 2015: 60%
38. US unemployment to be lower at end of year than beginning: 50%
39. No announcement of genetically engineered human baby or credible plan for such: 90%
40. No major change in how the media treats social justice issues from 2015: 70%
41. European far right makes modest but not spectacular gains: 80%
42. Mainstream European position at year’s end is taking migrants was bad idea: 60%
43. Occupation of Oregon ranger station ends: 99%
44. So-called “Ferguson effect” continues and becomes harder to deny: 70%
45. SpaceX successfully launches a reused rocket: 50%
46. Nobody important changes their mind much about the EMDrive based on any information found in 2016: 80%
47. California’s drought not officially declared over: 50%
48. No major earthquake (>100 deaths) in US: 99%
49. No major earthquake (>10000 deaths) in the world: 60%
PERSONAL/COMMUNITY
1. SSC will remain active: 95%
2. SSC will get fewer hits than in 2015: 60%
3. At least one SSC post > 100,000 hits: 50%
4. UNSONG will get fewer hits than SSC in 2016: 90%
5. > 10 new permabans from SSC this year: 70%
5. UNSONG will get > 1,000,000 hits: 50%
6. UNSONG will not miss any updates: 50%
7. UNSONG will have higher Google Trends volume than HPMOR at the end of this year: 60%
8. UNSONG Reddit will not have higher average user activity than HPMOR Reddit at the end of this year: 60%
9. Shireroth will remain active: 70%
10. I will be involved in at least one published/accepted-to-publish research paper by the end of 2016: 50%
11. I won’t stop using Twitter, Tumblr, or Facebook: 95%
12. > 10,000 Twitter followers by end of this year: 50%
13. I will not break up with any of my current girlfriends: 70%
14. I will not get any new girlfriends: 50%
15. I will attend at least one Solstice next year: 90%
16. …at least two Solstices: 70%
17. I will finish a long blog post review of stereotype threat this year: 60%
18. Conditional on finishing it, it won’t significantly change my position: 90%
19. I will finish a long FAQ this year: 60%
20. I will not have a post-residency job all lined up by the end of this year: 80%
21. I will have finished all the relevant parts of my California medical license application by the end of this year: 70%
22. I will no longer be living in my current house at the end of this year: 70%
23. I will still be at my current job: 95%
24. I will still not have gotten my elective surgery: 80%
25. I will not have been hospitalized (excluding ER) for any other reason: 95%
26. I will not have taken any international vacations with my family: 70%
27. I will not be taking any nootropic daily or near-daily during any 2-month period this year: 90%
28. I will complete an LW/SSC survey: 80%
29. I will complete a new nootropics survey: 80%
30. I will score 95th percentile or above in next year’s PRITE: 50%
31. I will not be Chief Resident next year: 60%
32. I will not have any inpatient rotations: 50%
33. I will continue doing outpatient at the current clinic: 90%
34. I will not have major car problems: 60%
35. I won’t publicly and drastically change highest-level political/religious/philosophical positions (eg become a Muslim or Republican): 90%
36. I will not vote in the 2016 primary: 70%
37. I will vote in the 2016 general election: 60%
38. Conditional on me voting and Hillary being on the ballot, I will vote for Hillary: 90%
39. I will not significantly change my mind about psychodynamic or cognitive-behavioral therapy: 80%
40. I will not attend the APA meeting this year: 80%
41. I will not do any illegal drugs (besides gray-area nootropics) this year: 90%
42. I will not get drunk this year: 80%
43. Less Wrong will neither have shut down entirely nor undergone any successful renaissance/pivot by the end of this year: 60%
44. No co-bloggers (with more than 5 posts) on SSC by the end of this year: 80%
45. I get at least one article published on a major site like Huffington Post or Vox or New Statesman or something: 50%
46. I still plan to move to California when I’m done with residency: 90%
47. I don’t manage to make it to my friend’s wedding in Ireland: 60%
48. I don’t attend any weddings this year: 50%
49. I decide to buy the car I am currently leasing: 60%
50. Except for the money I spend buying the car, I make my savings goal before July 2016: 90%
Of 50% predictions, I got 8 right and 5 wrong, for a score of 62%
Of 60% predictions, I got 12 right and 9 wrong, for a score of 57%
Of 70% predictions, I got 13 right and 3 wrong, for a score of 81%
Of 80% predictions, I got 13 right and 3 wrong, for a score of 81%
Of 90% predictions, I got 16 right and 1 wrong, for a score of 94%
For 95% predictions, I got 9 right and 0 wrong, for a score of 100%
For 99% predictions, I got 3 right and 0 wrong, for a score of 100%
This is the graph of my accuracy for this year:
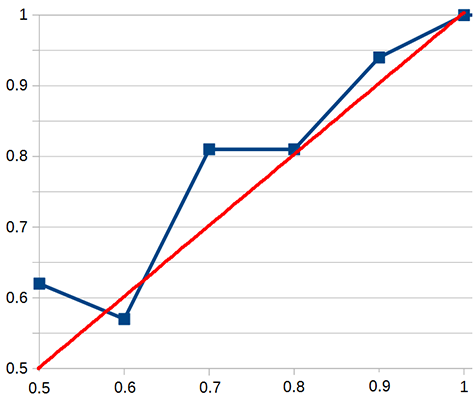
Red is hypothetical perfect calibration, blue is my calibration. I am too lazy and bad at graphs to put in 95% right, but it doesn’t change the picture very much (especially because it’s impossible to get a very accurate 95% with 9 questions).
The 50% number is pretty meaningless, as many people have noted, so my main deviation was some underconfidence at 70%. This was probably meaningless in the context of this year’s numbers alone, but looking back at 2014 and 2015, I see a pretty similar picture. I am probably generally a little bit underconfident in medium probabilities (I have also gotten lazier about making graphs).
Overall I rate this year’s predictions a success. Predictions for 2017 coming soon.
















These are some of my favourite things. What falsified the Lesswrong prediction btw? It’s still open and I can’t see any interesting changes in the site’s traffic:
http://www.alexa.com/siteinfo/lesswrong.com
Or maybe I can…
It’s kind of undergone a successful renaissance compared to where it was at this time last year. A hard decision, because it’s so new I can’t say for sure that it worked, but overall I think I have to call this one against me.
What did they change? I am out of the loop.
I’ve seen more worth-reading stuff on LW in the last month than I had the previous several years put together. Also, there are more posts in Main between November 27 and now than there were during the entire rest of the year.
Thank you very much for pointing this out, I haven’t been on LW in a while and so hadn’t noticed any change.
Here is an idea: let’s take the ones you got wrong, and try to figure out why. First, the list:
14. ISIS will not continue to exist as a state entity: 60%
18. No country currently in Euro or EU announces plan to leave: 90%
22. Conditional on Trump winning the Republican nomination, he impresses everyone how quickly he pivots towards wider acceptability: 70%
23. Conditional on Trump winning the Republican nomination, he’ll lose the general election: 80%
24. Conditional on Trump winning the Republican nomination, he’ll lose the general election worse than either McCain or Romney: 70%
27. Hillary Clinton will win the Presidency: 60%
31. Oil will end the year lower than $40 a barrel: 60%
45. SpaceX successfully launches a reused rocket: 50%
and
2. SSC will get fewer hits than in 2015: 60%
7. UNSONG will have higher Google Trends volume than HPMOR at the end of this year: 60%
10. I will be involved in at least one published/accepted-to-publish research paper by the end of 2016: 50%
14. I will not get any new girlfriends: 50%
16. …at least two Solstices: 70%
17. I will finish a long blog post review of stereotype threat this year: 60%
19. I will finish a long FAQ this year: 60%
20. I will not have a post-residency job all lined up by the end of this year: 80%
28. I will complete an LW/SSC survey: 80%
43. Less Wrong will neither have shut down entirely nor undergone any successful renaissance/pivot by the end of this year: 60%
45. I get at least one article published on a major site like Huffington Post or Vox or New Statesman or something: 50%
49. I decide to buy the car I am currently leasing: 60%
I think it’s clear what drove most of your world predictions failing, namely Trump and Brexit. It can be folded into the larger narrative a lot of people had of “the Left is doing great, everyone is doing fine, we’re a happy family”, and that lets you include ISIS in there too; people sort of assumed Obama and the Left would be competent enough to wipe them out, on account of that being a good idea, but they’re of the Islamic persuasion and a bit too much non-interventionism so there it is. Oil might be related to that too, or it might not since I don’t really know much about oil prices (I’m seeing 53.72 a barrel, so maybe not). The re-usable rocket thing just seems kinda, xD, but it’s a cointoss so life moves on.
as to the life things, I have no idea heh. How did you not complete a single survey at 80%? I would assume that a prediction like this is insanely biased, because you can just do it and spot yourself an 80% prediction completion. Then again you didn’t, so maybe that’s just my inner game theoretician that other people don’t have growling at them 24/7. That prediction does involve something long, and you missed two other “longs” so maybe you overestimated your own capacity for lengthy effort, or how busy you would be. Also, I don’t know about you, but I wouldn’t have pegged you for participating in that kind of a research paper, or especially getting an article in HuffPo or Vox. Your shit is too powerful for the likes of the mainstream media (conservative included, don’t get me wrong). Well, that’s all I got. Hopefully you or other commenters will find this useful, and happy new year to the squad.
How much of the personal stuff can be traced back to Trump/Brexit/current event generally being more interesting than expected?
Seems like at least a few of them could be, was his greater traffic a function of his writing seeming more relevant in this election cycle and spreading virally
Similarly, attention to event might have consumed time that could have been spent doing more secular projects
That said his calibration looks pretty good to me
Also, I don’t know about you, but I wouldn’t have pegged you for participating in that kind of a research paper, or especially getting an article in HuffPo or Vox.
Whatever about the research paper, I can see why Scott put in that “eh maybe maybe not” about an article in the Huffington Post or Vox. He has gotten linked and mentioned by a lot of places and people, some of which and whom several people have even heard of! 🙂
So there’s a not-impossible chance that HuffPo or somewhere might be interested in “If you want to write us an article for free, and we pay you nothing but have all rights to use it as we see fit, chop it around, stick a clickbait headline on it and you can deal with any shitstorm that ensues without help or support from us, we might be willing to consider it”.
i see your point but I still disagree
huffington post can’t handle this type of power bar none, no matter what kind of paper they are getting out of it.
Congratulations! Fellowship or attending? (Or other?)
Attending. Thanks for the congrats. Feels good.
Congratulations on career progression and success! May you thrive in it!
O frabjous day!
Congratulations!
> 39. I will not significantly change my mind about psychodynamic or cognitive-behavioral therapy: 80%
Out of curiousity, what are your current veiws and what would it take to change them?
Cognitive behavioral therapy can, with heroic effort and very good patient targeting, work better than nonspecific effects from talking to a nice person, though in practice most of it doesn’t.
Psychodynamic therapy works as well as nonspecific effects from talking to a nice person.
As for changing them? Evidence, I guess. Shedler’s work on psychodynamics is the closest thing I’ve seen, but it’s so far beyond my priors (and so well-criticized by Coyne), that I’m ignoring it by now. If a neutral team replicated it, I might think differently. I’m also going to try to get analyzed, and if I find it’s a transformative experience that might help too.
I think CBT works well for certain people and in a limited range, but because it works(ed) so well, there’s been a tendency to try it out on everything and it really has become flavour of the month.
Which means it will get recommended to people for things it won’t do much/anything to help, and then that will probably mean a lot of people will think “Well, this crap is really crap, it’s all the same with therapy isn’t it, just talking and nothing happening”.
I was
kindavery bitter when my bout of it did damn-all to help, but with a bit of distance to reflect on it, I’m not the type for whom it’s suited and my problems are too deep-rooted and long-standing for it to work in the “ten sessions and that’s yer lot” programme our Department of Health has rolled out.If you are going to get analyzed, then I hope you try some kind of more modern but still generally psychoanalytic therapy– not the old fashioned strict Freudian analysis. The traditional Freudian analysis is really past its expiration date by now– so old and out of date and untouched by any information or developments that happened since Freud’s death.
Here is one of the more modern psychoanalytic methods, Past Reality Integration, although there are a number of other modern methods. The author is Dutch but her book has been translated into English. Alice Miller was a patient in a kind of therapy that was based on this, benefited greatly from it, and then changed her mind about whether it was a good idea for all patients. However, I don’t think she endorsed any other form of therapy instead, before her death. Preface to the book is here, and then the book itself as described at Amazon.
https://www.pastrealityintegration.com/sources/downloads/Foreword_Marc_Luyckx.pdf
https://www.amazon.com/Past-Reality-Integration-Mastering-Conscious-ebook/dp/B005LBQNBS/ref=la_B00AJPTA5W_1_1?s=books&ie=UTF8&qid=1483320380&sr=1-1
In case you don’t know who Alice Miller was, she was one of the most famous, if not the most famous, critics of traditional Freudian psychoanalysis on the planet. And her criticisms are quite brilliant and well regarded. Here is the Amazon page for her books, which are easy enough reading for lay people, as well as mental health professionals.
https://www.amazon.com/Alice-Miller/e/B000APM0AI/ref=sr_tc_2_0?qid=1483320817&sr=1-2-ent
Also, a good case can be made that the type of psychotherapy makes far less difference than the personality qualities of the therapist, so I hope you will see someone who has improved the lives of other people.
If e.g. you are lucky enough to find a psychotherapist who is one of the most observant, insightful, enlightened, and compassionate individuals on the planet, it’s probably going to be a very enriching experience, no matter what school of psychotherapy the therapist believes they are practicing.
Good job.
I’d say you did much better than average regarding Trump.
Would you say you overlooked the Bernie phenomenon?
60% chance of Hillary winning was certainly more conservative than a lot of pundits and pollsters were willing to give, so definitely congratulations on that one.
These predictions were made before Trump won the nomination, when it was a lot more obvious that Clinton was going to lose.
I’d say you were overly optimistic about a 99% chance of no earthquake in the U.S. killing over 100 people. The 1971 and 1994 San Fernando Valley earthquakes could easily have killed over 100 people (I think they each killed around 50) if they hadn’t happened to take place during the predawn hours when 95% of the population were tucked in bed. In 1994 many hundreds of people survived their apartment buildings collapsing ten feet into the basement parking garages because they were on their mattresses when they dropped 10 feet. Several big buildings, such as a major shopping mall in 1994, fell down that would have killed a lot of people during hours when they were open.
The WTC collapses in 2001 showed we aren’t immune to worst case scenarios coming true.
I’d put the odds of an earthquake killing 100+ in any one year at 3 or 4%.
The 20th Century saw 4 earthquakes in America that killed >100 people.
The 3 big California earthquakes in my lifetime, 1971, 1989, and 1994 each killed around 60 people.
Only 4 people have died in American earthquakes since 1994, perhaps due to better construction, perhaps due to seismics forces accumulating that will be very, very bad in the future.
Interesting comment!
However, awful as it was, I’m not sure 9/11 really qualifies as a “worst-case scenario.” The first plane hit before many people had arrived at work, and both planes hit fairly high floors, so most were able to evacuate and the buildings took a long time to collapse.
Flight 93 obviously didn’t reach its target while the Pentagon hijackers could have hit other targets with more people and/or symbolic importance (Capitol, White House). If one of the planes had hit the White House as intended, President Bush was, unbeknownst to the hijackers, out of town.
Right. New York isn’t a really early to work town, so 8:46 am meant quite a few workers weren’t in the WTC yet.
I didn’t have any friends of friends who died in the WTC, but I heard multiple accounts of friends of friends who were on their way to the WTC when they got word.
To sum up my highly scientific opinion on seismology: It’s bad juju to taunt the earthquake gods.
The flip side is that building design keeps getting better and more earthquake resistant. Hopefully this means in the future that fewer people will be killed should a large earthquake occur.
Sadly, the drastic restrictions on new building construction mean that many fewer new more-earthquake-resistant buildings will be built than otherwise.
I think I used the very simple technique of checking how many years it was before a US earthquake killed > 100 people. I think it was 1964, suggesting that there haven’t been such earthquakes in the past 50 years, suggesting that the risk is about 2% per year. The closest I could come to that in my bin system was 1% – also, I assume we’ve upgraded our infrastructure since that time.
It’s possible to go Inside View and say that you think we just got really lucky, but I’d prefer to take Outside View on this one.
California has become substantially more densely populated and less affluent since 1964 (both trends underreported in statistics since they’ve largely been driven by illegal immigration).
In the places that are affluent, the trend has been towards cheaply-built multi-story McMansions and away from smaller single and split-level houses.
The Bay Area has been less affected by these trends, but the increasingly expensive property market has made illegal squatting in unsuitable dwellings a more common and even middle-class phenomenon, as seen with the recent Ghost Ship fire disaster.
And the statewide drought has increased the risks from fire in wooded areas.
I suspect there are two broad classes of phenomena:
The first, in which the more Years Since the last occurrence, the less likely it is to happen next year: e.g., bubonic plague epidemics or famines.
The second, in which the more Years Since the last occurrence, the more likely it is to happen next year. Earthquakes might be a good example of this, along with economic crashes.
Telling them apart, however, isn’t foolproof.
Tangentially related, I found this article about the Cascadia subduction zone fascinating (it’s a huge fault that last slipped in 1700 that we only recently discovered/understood): http://www.newyorker.com/magazine/2015/07/20/the-really-big-one
“we now know that the odds of the big Cascadia earthquake happening in the next fifty years are roughly one in three”
Regarding SSC traffic, how much of the spike over 2015 comes from the Crying Wolf post? Seems like that one was shared by a lot of high-visibility people on social media.
2015 had its own toxoplasma-infected viral hit (“Untitled”) though I’m sure Crying Wolf was bigger. It’s not every day that Ann Coulter tweets out SSC articles.
https://twitter.com/anncoulter/status/799899221361037312
Most of the advantage came from that post, but even subtracting that 2016 was very slightly better.
37. US GDP growth lower than in 2015: 60%
This appears to be either indeterminate, since 4th quarter growth isn’t out yet, or false, if you use the Atlanta Fed’s 2.5% estimate for the 4th quarter.
2015: 0.6%, 3.9%, 2.0%, 1.4%
2016: 0.8%, 1.4%, 3.5%, 2.5% (?)
I was using Q1-3 estimates, I think.
Looks like you’d be near-perfectly calibrated if you simply bumped up all your 70% predictions to 80%. Any thoughts on simply doing that for your 2017 predictions?
Re: 50% predictions, it occurs to me that with a sufficiently large sample, it might actually be more meaningful to flip a coin to determine the prediction-direction. Then, the closer the coin-flips are to being 50% accurate at the end of the year, the more confident you can be that you correctly identified binary unknowns with even chances for each possibility. (You should also still record which way you’re “leaning” on each issue, just to see if perhaps your hunches are better-informed than you might expect.)
The coin flip doesn’t work, right? If you try this with 100 tautologies (“1=1,” …, “100=100”), then you’ll assign half of them to “false” predictions and half to “true” predictions, even though they’re all logically 100% likely to be true.
Surely if you’re assigning 50% confidence to tautologies, then you’re wildly miscalibrated…? Which is exactly what that would show?
Say that for some reason your 50% predictions are actually tautologies. If you go with your plan of using a coin to decide whether to actually predict P or ~P, then you will end up predicting half of your statements as tautologies, and the other half as antitautologies, so by definition 50% will come true and you will seem well calibrated (despite obviously not being so, as tautologies have a 100% chance of coming true). So your method as JR and I have understood it won’t necessarily correctly signal calibration (sometimes it will say you are correctly calibrated when you aren’t).
Actually, I think you’re right, although I’m not sure your tautology explanation is sound. (Consider that someone who doesn’t understand advanced mathematics guessing whether particular theorem-like statements are true or false would be in exactly the situation you describe, but would nonetheless be well-calibrated in stating that their expectation is 50% confidence for each guess of truth or falsehood.)
The problem with my proposal is that there’s no real information in the final result. Suppose 70% of the coin-flip predictions come true; this probably doesn’t mean that you’re poorly calibrated, it just means the outcome of the flipping was improbable. Similarly, in general, 50% predictions made in this fashion will always tend towards a 50% correctness ratio, regardless of how “well-calibrated” the predictor is. (I think this is perhaps what you’re trying to get at above?)
Yes, I think the same thing applies regardless of how likely your predictions are to come true, but it’s easiest to see with tautologies. Regarding your example of someone guessing theorems: that person is possibly doing the right thing in that they are making the best guess they can based on their knowledge, but they aren’t well calibrated. Calibration means that your estimates for how likely something is to occur match the actual probability. If you guess 50% chance of truth for a load of tautologies you will be mis-calibrated, because 100% of them will come true. If you guess 50% chance of truth for a load of statements, half of which are true and half of which are false, then you will be correctly calibrated, but that isn’t the example JR proposed.
I don’t think that’s what Scott means by “calibration” at all. I think he means it as a measure of how well he recognizes his own ignorance or lack thereof.
How would that be different? What part of calibration are you saying isn’t captured by the difference between x% and the proportion of your predictions of x% that came true?
I think we can make an assumption that our list of 50% predictions is not merely a list of tautologies that we are gaming so as to guarantee “correct” calibration.
Given that, identifying things that are equally likely to happen is still probably useful. Randomizing our “correctness” metric (will or will not occur, will increase or will decrease, etc.) seems reasonable.
See my comment below about the strength of the 50% prediction. Stating that something is 50% likely to occur is a strong statement, but stating you have 50% confidence in a prediction is as weak as a prediction can be.
If well-calibrated just meant good at knowing the probabilities of events, then there would be no problem with Scott’s 50% predictions, and he wouldn’t ignore them as “meaningless” every time around.
Argh. I said that we needed someone to research actual mathematics on this. Nobody has done this and this thread is full of this kind of speculating about how to make statements well calibrated. Neither you nor I know this. Nobody on the thread knows this. And I find it hard to believe this is not a well-studied area; it’s just that none of us are experts on it.
This has become painful to read.
To chime back in, rlms has been interpreting the matter exactly the way I was: I used tautologies as an example of the most extreme limiting case, but the general point is that 50% predictions will ALWAYS agree with coin flip statistics, no matter what the content of the prediction statements. If the conclusion of the coin flip experiment is “yep, correctly calibrated” for ANY set of 50% predictions, then the experiment provides no information. I hadn’t considered Douglas Knight’s point that it can show you something about whether the form of the prediction statement (e.g., “It is true that Clinton will win the election” vs. “It is false that Clinton will win the election”) biases the prediction, but as far as I can tell that wasn’t your original concept?
Also, seconding Jiro’s call for some real math on this. I can identify why I don’t believe your solution to the 50% calibration puzzle is sufficient, but I’d love to see an argument that’s definitive.
A: 2+2=5
B: actually, 2+2=4
A: 2+2=5
C: We need some real math to clarify this confusion.
B: Yes, we need some real math.
Really, B?
@Douglas Knight
Well, one should be able to provide a proof that, “really, 2+2=4, at least if you accept certain axioms…”
Yes, there is a singularity, but it is a continuous consequence of what happens at 50%+ε.
Specifically, if you enter every questions in both positive and negative versions, then everyone is perfectly calibrated at 50%. If you also assume that an agent’s miscalibration is continuous, then the amount of data needed to detect miscalibration increases without bound as you approach 50%.
And that’s what Scott does for the bins other than 50%: he normalizes the question to predicting the more likely event, destroying the information of the original phrasing.
There are some biases that are not symmetric about 50% and the duplication destroys information about them (but doubles the amount of predictions at, say, 70%, reducing noise). I would not call such biases miscalibration, but that’s fairly arbitrary.
Moreover, using a diverse set of questions is pretty similar to adding negated questions. If your questions are uniform, as in Christian’s example of predicting whether your unit tests will pass, then it may be useful to keep the whole 0-100 scale.
@JR:
Your contention that 50/50 guesses will always work out as well calibrates isn’t true.
Take a small example. Guess that each individual stock in the Down Jones will/will not rise with 50% confidence. Guess half of them will go up, and half of them will go down.
Most of the time you will be poorly calibrated on these guesses, because the performance of the Dow Jones stocks tends to be linked. Usually they will all tend to rise or fall together.
Douglas Knight, why is it “legal” to enter every question with 50% probability in both positive and negative form as the first step of your argument? This produces a highly (anti-)correlated set of outcomes, but the way we check for “good calibration” implicitly requires that we consider uncorrelated scenarios.*
The goal of “calibration,” as I understand it, is to check whether claimed knowledge of outcomes is systematically biased with respect to actual knowledge of outcomes. But assigning a probability of 50% to a binary outcome is equivalent to claiming 0 knowledge about the outcome, in which case the “calibration” of the claimed knowledge is undefined. This will probably make Jiro’s eyes bleed for containing no real math, but I feel it clears up everything in my mind.
That said, Scott’s approach for the 50% bin — registering a “success” if the scenario described in the given phrasing occurs — does allow you to check whether (i) the phrasing of the question biased the prediction, or (ii) the predicted scenarios were correlated (e.g., as in HeelBearCub’s stocks example; thanks for pointing out that I was assuming an absence of correlations).
*The simple comparison between fraction of successful outcomes and the predicted probability only makes sense under very specific conditions regarding correlations. For an extreme example, I could construct a dataset with N = 100 by repeating the claim “Probability that Clinton will win the election: 60%” 100 times. But because of the correlations, the number of successes should NOT be drawn from a binomial distribution B(100, 0.6), and noticing that 0% of the outcomes were successful doesn’t prove miscalibration.
Douglas Knight, I’m comfortable saying the coin flip experiment doesn’t provide information without appealing to “real math” beyond what people have argued here. But I’m not confident that I know how to interpret the fact that it’s possible to meaningfully check calibration on 50.0001% probability estimates (with large sample sizes) but apparently not 50% probability estimates. It is not true that 50% probability is utterly meaningless, or that calibration in general is utterly meaningless. But there is a singularity when you try to calibrate 50% predictions that is reminiscent to me of other situations where people try to non-rigorously apply mathematical concepts to limiting cases, and that’s something I’d like to see treated with a more careful mathematical discussion. Or do you just consider it obvious that calibration of 50% predictions is inherently meaningless and leave it at that?
Anyway, I see that my phrasing implied that I think batmanaod’s approach might allow for calibration of 50% probabilities after all, while in fact I consider it definitively useless in that regard. What I meant (but didn’t say clearly–sorry) is that I haven’t seen an interpretation of 50% calibration that strikes me as definitively correct.
There’s nothing special about 50%. If you predict all heads on hundreds of independent fair coin flips, you’ll be well- calibrated, same as you would with all tails or any other particular permutation. But if you predict with 95% probability that several hundred d20s won’t come up 1 (or won’t come up any particular number), you’ll also be perfectly calibrated.
Yes, but all of Scott’s statements are of the form “[It is true that] X will happen,” for which the only alternative is “It is not true that X will happen.” E.g., for the “Marco Rubio will not win Republican nomination” prediction, he doesn’t care whether it was Trump, Bush, or Cruz who won instead. The thing that makes 50% special is that “50% chance X is true” = “50% chance X is false,” so you can rewrite a logically equivalent statement to count as either a “success” or “failure” of the prediction, no matter what the outcome. Contrast this with “95% chance d20 won’t come up 1” and “95% chance d20 does come up 1,” which are not logically equivalent.
OK, but for the purpose of calibration, “success” isn’t privileged with respect to “failure”, so it doesn’t matter that you could re-write them either way. I guess there is one thing you can do with that fact, which is to hedge; if you predict both “X is true” and “X is false” you’ll be perfectly calibrated on a 50% prediction.
That’s actually pretty clever.
When are you flipping the coin? Before assigning probabilities or after? If after, you’re just destroying information. You will always be perfectly calibrated, as JR says.
If you take your list of questions, flip coins and rewrite half of them before assigning probabilities, then you can test whether the phrasing of the question biases you in favor (or against) the question. Maybe that’s a question you want to answer, but it is a different question than calibration. If you should be asking this question, you should be asking it of all questions, not just the 50/50s. So you can eliminate the 50/50 box and still ask the question.
Anyhow, I don’t think that this would actually work if Scott is both generating and assessing the questions, because he has already looked at the question before flipping the coin.
The coin flip is to decide whether to phrase the prediction positively or negatively (“x will happen” vs “x will not happen”). If there’s leeway about which version of the prediction is positive, then you simply decide before flipping which way corresponds to heads.
It only makes sense when applied to the 50% confidence predictions. The point of a 50% confidence is that you believe you have literally no insight into which of two possible outcomes will occur; you think they are equally likely. But Scott seems to continually get more than 50% of his 50%-confidence predictions “correct”, even though, again, the point of the prediction at that confidence level is to predict that he has no insight or information about the outcome, so on the graphs he posts in his retrospectives, he’s miscalibrated at 50%. But because the *directions* of the predictions are not actually random–Scott probably phrases his 50% predictions to favor the outcome he’s “leaning” towards, meaning he hasn’t really internalized his belief that he has no knowledge of the outcome–the result is actually meaningless, which is why he casts the 50% predictions aside in this year’s retrospective.
Coin flips solve this problem by ensuring that the actual stated prediction value is random, so that when he compares the results, if the actual events were really equally likely to go one way or another, he’ll demonstrate that he’s well calibrated.
The only real flaw is that even if Scott doesn’t know which way something will go, the “real” probability of it happening one way or the other is unlikely to actually be 50%–it’s actually a fairly strong statement to claim that two possibilities are equally likely. But I believe that on average, lack of knowledge and randomized prediction selection should actually still lead to correct predictions about binary outcomes roughly 50% of the time anyway, just as on a multiple choice test with evenly distributed answer choices (i.e. there isn’t a preponderance of B’s and a lack of E’s), randomly selecting answers should give you, on average, 1/n correct answers where n is the number of choices per answer. This is true even though each individual question has a single correct, non-random answer.
I don’t think it’s a stronger statement than saying something is 60% likely to happen. Or any other percentage.
Why are you calling out 50% as particularly strong?
I’m not; it’s just that 50% confidence is *supposed* to be a maximally *weak* statement in these predictions. In any case, see above; I have changed my mind about whether coin flipping would work.
Here are my 2016 predictions calibration results:
http://www.unz.com/akarlin/prediction-calibration-results-2016/
This was quite fun, better than the traditional way of going about predictions. Thanks for the inspiration!
I am interested in questioning Scott’s assessment of #46: “Nobody important changes their mind much about the EMDrive based on any information found in 2016: 80%” and also in surveying what other people in this forum think about it.
For those who don’t know, the EMDrive is essentially a rocket engine which violates several very serious parts of physics. Depending on which model you want to use in describing the EMDrive, you either: have to throw out conservation of momentum, which is one of the most fundamental principles in modern physics; question special relativity by supposing that there is in fact a universal rest frame; or throw out the Copenhagen interpretation of quantum mechanics and replace it with pilot wave theory, which explains quantum mechanics in a deterministic fashion. Any one of these would be a very big deal. Violation of conservation of momentum could possibly be leveraged to produce infinite free energy.
At the start of 2016 I considered the EMDrive to have something like 1:1,000,000 odds of being anything other than quackery. As a result of NASA’s recent publication I would reevaluate those odds to something more in the ballpark of 1:1,000 odds of being quackery and maybe 1:10,000 odds of being the precursor to the most important discovery in physics in the past fifty years. Those are still very poor odds; I think the most likely explanation by far is simply that the experiment was bad. But I am at the point where I would really like to see the experiment replicated, and a decent amount of scientific capital directed toward this research. In particular, I would be in favor of funding an effort to test the EMDrive in space.
So, while I am still overwhelmingly skeptical about the validity of the EMDrive, I would nonetheless describe myself as having had a quite marked opinion change in favor of further research. I certainly wouldn’t describe myself as being someone “important,” but perhaps there are important people out there with similar opinions as mine. Does anybody reading this agree?
As a layman who has been following this story not particularly closely for quite a while now could you clear something up for me? You see, when the story of Eagleworks testing some sort of propellant-less thruster started making the rounds they were talking about a design they came up with themselves called the Quantum Vacuum Plasma Thruster (which sounded weird but not impossibly crazy to a layman like me, I don’t have nearly enough knowledge of physics to know why the idea of a thruster that reacts on the quantum vacuum like a propellor reacts on water shouldn’t work). But then the more mainstream press accounts of the experiments started talking about the EMDrive; which I had heard about years ago and dismissed as crackpottery out of hand, and I assumed that the inventor of the EMDrive had simply started claiming that the QVPT was in fact his EMDrive and that the lay press had ran with that as a more interesting story.
But now it appears that they were in fact testing the EMDrive all along and that is indeed the design that shows some promise, whereas next to no information on the QVPT has been released in years, and I am just terribly confused. Why did they start testing the EMDrive in the first place when nobody could come up with a satisfactory explanation for the claimed effect? What happened to the QVPT? Did it show no promise or did they simply shift their efforts to the EMDrive?
My understanding is that the original inventor created something which shows some promise. However, his original explanations for how the whole thing works are apparently completely wrong. Basically, he is a quack that accidentally built something that works.
Also, we’ve known how to make “reactionless” drives for a long time. Shine a laser out the back. Photons have momentum and thus can accelerate the spacecraft forward using only electrical power. The exciting thing about the EMDrive is that as-measured it would provide about 6x the thrust per unit of energy. Probably more if we actually understood how it worked and could optimize it.
It’s impossible because there is only one vacuum state, and it has zero momentum.
When a propellor accelerates a ship from being still to moving, this can conserve momentum because the water changes its state from being still to moving backwards. That is, the propellor works because the water can be in two different configurations which have different momentum. However, the vacuum is the unique state which has the lowest possible energy; there is only one configuration of vacuum. So, if you want a drive to accelerate forwards by interacting with the vacuum, then it has to change the vacuum into something that is not a vacuum and has backwards momentum, i.e., the drive emits particles backwards. [Well, there may some loopholes between “not vacuum and has momentum” and “particles”, but you’re still emitting something].
I guess you just have to believe me when I say I intended “changed their minds” to “switched to believing it worked / didn’t work”. I would hope there would at least be some change in probability over the course of a year of experimentation.
I was surprised to learn that anyone cared enough to do experiments. But the experiments disproved it and they moved on. I’m not talking about NASA — they didn’t care, so they didn’t do experiments.
I did my own copycat predictions for 2016, finding that I was unsurprisingly somewhat overconfident:
http://aleph.se/andart2/future-studies/checking-my-predictions-for-2016/
The big challenge is coming up with a large and wide set of questions.
I can’t remember: Did Scott first post his questions without giving his own probabilities?
If not, it would be nice if he did. He is very good at coming up with a large interesting set of questions. If he posted his questions first, without his probabilities, then other people could come up with their own probabilities on those questions without being anchored by his answers.
When you look to 2015 calibrations, they also include a failed oil price prediction – expect the other way (“20. Oil will end the year greater than $60 a barrel: 50%”). Another similary is a failer prediction about an international trade-based treaty/organization (last year TPP, this year EU) not breaking up.
A question on this: does it include any wars with non-state organizations (i.e. Hezbollah or Hamas)? Not that it changes the outcome either way, just curious…
I am a blind reader of this blog and my screen reader makes no distinction between normal, bold, italic, strikethrough, etc. text. Is there any chance someone could post a copy of the list that either separates it into indivdiual lists for true and false predictions or labels the individual predictions?
This comment (https://slatestarcodex.com/2016/12/31/2016-predictions-calibration-results/#comment-449065) includes a list of predictions labelled false, if that helps.
If that’s not sufficient, I can easily assemble either of your suggestions for you. Which would be your preference?
I find it awesome that blind people are able to read along here…
Anyway, here you go:
Correct predictions:
WORLD EVENTS
1. US will not get involved in any new major war with death toll of > 100 US soldiers: 60%
2. North Korea’s government will survive the year without large civil war/revolt: 95%
3. Greece will not announce it’s leaving the Euro: 95%
4. No terrorist attack in the USA will kill > 100 people: 90%
5. …in any First World country: 80%
6. Assad will remain President of Syria: 60%
7. Israel will not get in a large-scale war (ie >100 Israeli deaths) with any Arab state: 90%
8. No major intifada in Israel this year (ie > 250 Israeli deaths, but not in Cast Lead style war): 80%
9. No interesting progress with Gaza or peace negotiations in general this year: 90%
10. No Cast Lead style bombing/invasion of Gaza this year: 90%
11. Situation in Israel looks more worse than better: 70%
12. Syria’s civil war will not end this year: 70%
13. ISIS will control less territory than it does right now: 90%
15. No major civil war in Middle Eastern country not currently experiencing a major civil war: 90%
16. Libya to remain a mess: 80%
17. Ukraine will neither break into all-out war or get neatly resolved: 80%
19. No agreement reached on “two-speed EU”: 80%
20. Hillary Clinton will win the Democratic nomination: 95%
21. Donald Trump will win the Republican nomination: 60%
25. Marco Rubio will not win the Republican nomination: 60%
26. Bloomberg will not run for President: 80%
28. Republicans will keep the House: 95%
29. Republicans will keep the Senate: 70%
30. Bitcoin will end the year higher than $500: 80%
32. Dow Jones will not fall > 10% this year: 70%
33. Shanghai index will not fall > 10% this year: 60%
34. No major revolt (greater than or equal to Tiananmen Square) against Chinese Communist Party: 95%
35. No major war in Asia (with >100 Chinese, Japanese, South Korean, and American deaths combined) over tiny stupid islands: 99%
36. No exchange of fire over tiny stupid islands: 90%
37. US GDP growth lower than in 2015: 60%
38. US unemployment to be lower at end of year than beginning: 50%
39. No announcement of genetically engineered human baby or credible plan for such: 90%
43. Occupation of Oregon ranger station ends: 99%
44. So-called “Ferguson effect” continues and becomes harder to deny: 70%
46. Nobody important changes their mind much about the EMDrive based on any information found in 2016: 80%
47. California’s drought not officially declared over: 50%
48. No major earthquake (>100 deaths) in US: 99%
49. No major earthquake (>10000 deaths) in the world: 60%
Correct predictions, PERSONAL/COMMUNITY:
1. SSC will remain active: 95%
3. At least one SSC post > 100,000 hits: 50%
4. UNSONG will get fewer hits than SSC in 2016: 90%
5. > 10 new permabans from SSC this year: 70%
5. UNSONG will get > 1,000,000 hits: 50%
6. UNSONG will not miss any updates: 50%
8. UNSONG Reddit will not have higher average user activity than HPMOR Reddit at the end of this year: 60%
9. Shireroth will remain active: 70%
11. I won’t stop using Twitter, Tumblr, or Facebook: 95%
12. > 10,000 Twitter followers by end of this year: 50%
13. I will not break up with any of my current girlfriends: 70%
15. I will attend at least one Solstice next year: 90%
21. I will have finished all the relevant parts of my California medical license application by the end of this year: 70%
22. I will no longer be living in my current house at the end of this year: 70%
23. I will still be at my current job: 95%
24. I will still not have gotten my elective surgery: 80%
25. I will not have been hospitalized (excluding ER) for any other reason: 95%
26. I will not have taken any international vacations with my family: 70%
27. I will not be taking any nootropic daily or near-daily during any 2-month period this year: 90%
29. I will complete a new nootropics survey: 80%
31. I will not be Chief Resident next year: 60%
32. I will not have any inpatient rotations: 50%
33. I will continue doing outpatient at the current clinic: 90%
34. I will not have major car problems: 60%
35. I won’t publicly and drastically change highest-level political/religious/philosophical positions (eg become a Muslim or Republican): 90%
36. I will not vote in the 2016 primary: 70%
37. I will vote in the 2016 general election: 60%
38. Conditional on me voting and Hillary being on the ballot, I will vote for Hillary: 90%
39. I will not significantly change my mind about psychodynamic or cognitive-behavioral therapy: 80%
40. I will not attend the APA meeting this year: 80%
41. I will not do any illegal drugs (besides gray-area nootropics) this year: 90%
42. I will not get drunk this year: 80%
44. No co-bloggers (with more than 5 posts) on SSC by the end of this year: 80%
46. I still plan to move to California when I’m done with residency: 90%
47. I don’t manage to make it to my friend’s wedding in Ireland: 60%
48. I don’t attend any weddings this year: 50%
50. Except for the money I spend buying the car, I make my savings goal before July 2016: 90%
False predictions (World events):
14. ISIS will not continue to exist as a state entity: 60%
18. No country currently in Euro or EU announces plan to leave: 90%
22. Conditional on Trump winning the Republican nomination, he impresses everyone how quickly he pivots towards wider acceptability: 70%
23. Conditional on Trump winning the Republican nomination, he’ll lose the general election: 80%
24. Conditional on Trump winning the Republican nomination, he’ll lose the general election worse than either McCain or Romney: 70%
27. Hillary Clinton will win the Presidency: 60%
31. Oil will end the year lower than $40 a barrel: 60%
45. SpaceX successfully launches a reused rocket: 50%
False predictions (PERSONAL/COMMUNITY):
2. SSC will get fewer hits than in 2015: 60%
7. UNSONG will have higher Google Trends volume than HPMOR at the end of this year: 60%
10. I will be involved in at least one published/accepted-to-publish research paper by the end of 2016: 50%
14. I will not get any new girlfriends: 50%
16. …at least two Solstices: 70%
17. I will finish a long blog post review of stereotype threat this year: 60%
19. I will finish a long FAQ this year: 60%
20. I will not have a post-residency job all lined up by the end of this year: 80%
28. I will complete an LW/SSC survey: 80%
43. Less Wrong will neither have shut down entirely nor undergone any successful renaissance/pivot by the end of this year: 60%
45. I get at least one article published on a major site like Huffington Post or Vox or New Statesman or something: 50%
49. I decide to buy the car I am currently leasing: 60%
Italized:
40. No major change in how the media treats social justice issues from 2015: 70%
41. European far right makes modest but not spectacular gains: 80%
42. Mainstream European position at year’s end is taking migrants was bad idea: 60%
18. Conditional on finishing it [i.e., a “long blog post review of stereotype threat”], it won’t significantly change my position: 90%
30. I will score 95th percentile or above in next year’s PRITE: 50%
From the moment I saw these two predictions, something jumped out at me as being pablum about them
4. No terrorist attack in the USA will kill > 100 people: 90%
5. …in any First World country: 80%
Namely, given the constant drumbeat of terror attack after terror attack, big and small, successful and unsuccessful, lone wolf and organized, 3 deaths up through several dozen, does it really matter if any single attack broke triple digits? I mean I guess you were still correct, but it seems you were correct about something that was superceded by other events.
On a related note, when I first saw that one I thought to myself – ‘wait, what about Nice? Didn’t that one break 100? Or is it that France is no longer considered a First World country?’
It didn’t break 100, I learned after looking it up. But although there was no attack causing more than one hundred deaths, a ‘major attack’ definitely happened which I had mentally coded as ‘the sort of attack he’d predicted wouldn’t happen’. He was still right, though.
Incidentally if you’re curious about other arbitrary number cut-offs, the Uppsala Conflict Data Program (UCDP) uses 25 battle-related deaths per year as the threshold to be classified as armed conflict, and – in common with other datasets such as the Correlates of War (COW) – a threshold of 1,000 battle-related deaths for a civil war.
I think the big lesson here is that very large terror attacks are rare enough in the US and Europe that merely large ones (10-99 deaths) seem like very large attacks, because they are still larger than what we expect or what we might see in an average year. The fact that you think of an attack that killed, say, 80 people as “a major attack” is just a matter of what we’re used to. Someone in a more terror-prone country would see this result as a much bigger success than Americans or French people would.
It’s kind of like how people always think our own age is extraordinarily violent or has so many wars around the globe. If there is more war than last year, it seems awful, even if objectively fewer people died than the average for a decade ago.
I think one lesson to take away is rather that very large body-count attacks never happened in France, ever, for decades, and now they do. In the context of terror attacks in France and what might be termed ‘the average/historical rate’, the 86 people who died in Nice corresponds almost exactly to the total number of people killed in France as a result of terror attacks of any kind during the 30-year period 1980-2010 (89 deaths) (link). Similarly, the number of people killed in the Bataclan attack (130) corresponds to the total number of people killed in terror attacks in France from the year 1958 to 1995 (131). During the 20th century, there was exactly one terror attack in France (the 1961 Vitry-Le-François train bombing) which cost more than 10 lives. There have been three such attacks just in the last two years.
Why not instead take away the lesson that very large body-count attacks used to happen in the UK, Spain, and the US, but now they do not any more? I see that you are Danish, so there is no real justification for you to cherrypick French statistics over these others.
The events you mention were all single events. I’m well aware of the problems related to how to properly deal with outliers in other contexts. The French situation to me seems different. As mentioned above France has recently had 3 attacks with highly unusual body counts within a very short amount of time. It was in my opinion pure luck that the number isn’t four, rather than three, considering the events of the 2015 Thalys train attack. When you’re doing time series analyses, that’s the point where you start to seriously wonder if there was a structural break/significant systematic change in your DGP. If you’d made a time series model from French data from the 20th century, what would have been the likelihood of obtaining an outcome with 3 attacks with more than 10 deaths within two years?
Relatedly, country-specific effects are obviously going to be important in any reasonable terrorism model.
(To make this point more clear, the two statements:
i) ‘France seems to experience an increased number of high-casualty terrorist attacks these years, compared to the historical average’ and
ii) ‘The risk of terrorism in most of Western Europe is at current probably not higher, and may be lower, than it was in the past’
…can both be true. I focus on France mainly because that country seems to be of some interest in the context of terrorism on account of being the (Western) country where people are currently frequently getting killed in large numbers by terrorists).
Strange, my recollection of the September 11th attacks was that they were, in fact, four events. Do you really want to put so much weight on the metaphysics of event-individuation?
As you can see from the link I posted below, the annual number of terrorist attacks in Western Europe is higher today than it was from 1998-2012 but substantially lower than in the period 1972-1996. But you are clearly changing benchmarks on the fly to justify a conclusion formed in advance of seeing any evidence, and I’m not really interested in participating in this exercise in hysteria-driven data manipulation.
So you’d also have ignored that the risk of terrorism in Northern Ireland might have been different from the risk of terrorism in the rest of Western Europe during The Troubles?
I’m not making claims about the development of terrorism in Western Europe, I’m making claims about the development of terrorism in France, because France might in some respects be considered ‘the new Northern Ireland’ – I don’t really know how I can make this more clear, I thought I had made it abundantly clear in the comment above. It looks like something is going on in that country which is unusual and which is worth understanding better.
Given that when people put words into my mouth, they lose the privilege to interact with me, I also consider this discussion, and hopefully (if I can remember your name) all future discussions with you, over. You put words into my mouth and simultaneously claim openly that I’m the one arguing in bad faith? You should be ashamed of yourself.
You are gerrymandering the reference class. Even if the distribution of terrorist attacks in Europe were random in time and space, many years would still see clusters of attacks in one country or another, more commonly in larger countries like France. You have no principled reason to be especially worried about the french, and appear to have focused on the country solely because it hosted the most recent cluster. This is statistical malpractice.
Your methodology here is fatally flawed, for several reasons. First, there is not a clearly delineated question you are trying to answer. Second, the data set you intended to use was not fixed in advance– there is every reason to think that if last year there had been zero terrorist attacks in France and three in the Netherlands, you would be talking now about the alarming rise in Dutch terrorism. Third, the metric you are using was also not fixed in advance, and it was not until after you saw the data that you alighted on the highly-unnatural-sounding “number of discrete terrorist attacks causing more than 10 fatalities” (rather than, say, “total terrorism-related fatalities”). With so many degrees of freedom you are guaranteed to be able to reach just about any conclusion you wish to about terrorism. You have lost yourself in the garden of forking paths.
You may be interested in this database. It only starts in 1970, but in the range that it covers, it has about twice as many fatalities in France as wikipedia.
In Western Europe, it lists a single attack with 101+ deaths; 7 attacks with 51-100 deaths; 33 attacks with 11-50 deaths. (It breaks many attacks into multiple smaller attacks.)
I do not have any interest in continuing this particular discussion (which I categorize as an avoidable waste of time; I’m by now almost certain that I had already once in the past blacklisted EK), but thanks for providing the link, which all people who are interested in these topics will now have the option of perusing/analyzing if they so desire. I might have a look at it at a later point in time (for now I’ve bookmarked it); from a brief look at it, it looks like a neat resource.
(I meant twice as many deaths in 1980-2010, where the attacks are all small. Wikipedia does not miss half the deaths 2010-)
It looks like the drumbeat is mostly in your head. It’s good to keep in mind that the death toll of the September 11th attacks is about an order of magnitude greater than the death toll of all other terrorist attacks in US history combined.
The correct time to make this sort of complaint is in the predictions post, not the retrospective post. It’s easy to nitpick predictions when you know how things actually turn out.
In my defense (or is it?), I nitpicked them then too, and inquired specifically why he picked 100 as the cutoff. I’m just bringing it full circle, curious what he thinks the value of those particular predictions were, beyond a somewhat vacuous in retrospect “I was technically correct”.
Scott, *please*: Hunt down a mathematician/statistician and find out the proper way to measure how good you were at predicting when your predictions were made at less than 100% certainty and less than 100% of them come true. Every time you do this, people speculate on the proper way to figure out how right you are when you say something has a 60% chance of coming true and it does. Nobody here actually knows how to figure out how good you are under those circumstances, but I can say one thing: the proper method of figuring it out isn’t obvious.
Unless you do this, the numbers you get are pretty useless, no matter how much we argue about it.
Also, to other commentators: will you please stop saying “these predictions don’t count because they were only made true/only falsified by rare events/the lack of rare events?” Making a prediction takes into account rare events and some types of events being predicted are mainly driven by rare events.
I haven’t followed the debates on these topics, but I feel reasonably sure that some of the people who have discussed the merits and demerits of particular ways of evaluating/interpreting the results and the predictions in these threads presumably do have backgrounds in statistics and mathematics; a subset of the SSC readers have that sort of background (I sort-of-kind-of have that kind of background myself, as I’m a member of Statistics Denmark’s research programme, though I would hardly call myself A Statistician), and people like that would in my view be more likely than others to engage in debates of that nature. In the context of this topic, I don’t think you can just pick out An Official Statistician and then that guy will have The Answer.
There doesn’t seem to be a large enough subset of such people to have actually given us an answer in the past.
As I said, I haven’t followed these debates so I wouldn’t know. But in that case it might be worth being careful about even assuming that ‘an answer’ necessarily exists. It might not, it might all just be a matter of dealing with various tradeoffs. I don’t think it would be very hard for me to come up with a variety of different types of loss function specifications which would each penalize inaccurate predictions (or groups of predictions) in specific and dissimilar ways, each of which might have merits in specific contexts.
He is measuring calibration correctly.
I have some background in maths and statistics, but this is slightly out of my field and probability is notoriously difficult thing even for professionals get right (at least without there remaining some other school of professionals disagreeing whether you got it right or not). And US is right that getting an Answer form a Statistician is not way to go, especially not many Statistician do this kind of “calibration” games. The beautiful thing about mathematics is that at least in theory, you can judge the soundness of the theory on its own merits, not by some Authority.
I don’t have the time to work it out fully, but my first reaction was that the thing was okay:
Usually when people express their degree of belief, like, “I’m 99% sure about this”, they don’t mean much anything. Or rather, they are not working on a basis of any proper definition of what they mean by that. The usual is to introduce the concept of betting: on which odds you’d be willing to bet that thing happens.
Now, taking that “I predict that thing X has 60% probability of happening” means “X belongs to class of things that happen with 60% of the time”, well, on surface it feels like it would be consistent with any reasonable betting ratio interpretation. And then it sounds reasonable you could measure how consistent you were about your usage of terminology “60% probability” like Scott does.
However, after I typed that I started to wonder if there could be bias introduced by self-selection the statements. For example, obviously, if you had only 1 statement in the class of “60% confidence”, and then you observed whether you got it right or wrong, you’d have a terrible precision. So you need quite many statements in each category to get an accurate number.
And that got me thinking, that in general, the whole thing seems prone to some kind of selection effect when it comes to picking the statements one chooses to include in test. Suppose you make 10 statements in the category “I’m 60% confident that this thing happens”, and happen to be right in 6 cases, in other words, perfectly calibrated according to this test. But assume that for whatever reason, by chance, you left out 6 other claims you would also describe to have been 60% sure about. Maybe you just did not think of them, but if somebody had asked, you would have said you are 60% sure. But it happens that in those extra 6 cases, you would have been mistaken in all of them? So if you’d included them, your calibration would have been quite off. Are you very good ‘calibrating yourself’ or just avoiding the questions you can’t reliably assign a probability to?
On the other hand, that happening is not very likely, especially if you are well-calibrated. One might be able to estimate chances but I have a feeling it might give me headache how to do it properly…
The whole problem might be mitigated by someone else coming up with and asking the questions, but on the other hand, I don’t know if that actually ensures that you’d get a representative sample the way, either.
Furthermore, sticking to nice, round numbers could have weird effects. Maybe not. Not sure. Discretizations like that often have effects. [Addendum. It might be fun experiment just give each statement a probability as precise as you want, and then when you have the data, see what happens when you try out different discretizations.]
Another thing. Scott says that the 50% degree of belief category is meaningless. Why is that?
edit. As a summary of sorts, the thing one should look into is when and how the test could fail in measuring the “consistency of testeés usage of probability statements”.
Well, I did some research, and in climatology and ML producing this kind of graph from probabilistic forecast data / binary probabilistic classifier outputs is known as reliability diagram. Idea for this kind of expert ‘calibration’ is apparently popularized by Tetlock in his book Super-Forecasting, which I don’t have read and also don’t know what kind of justification Tetlock gives.
The literature should be able to provide some analysis how the diagram behaves as a function of sample size, selection of bins, etc, so I’ll take a look at that. The possibly more problematic part would be in the premise that there is some kind of general forecast ability to measure and measuring it like this makes sense (the self-selection and other related sampling problems I wondered about above). After all, the ability of make probabilistic predictions about various statements about the politics and the world in general as far more …fuzzy concept than say, simple binary image classifier or a weather forecast. Maybe Tetlock actually provides an explanation in his book? (but I’ve got the impression that the book Superforecasting is more of pop science book, and I’ve been very disappointed by their kind previously…)
But still I’d like if someone could comment on my musings above. Douglas?
Yes, people can cheat. So what?
Calibration (not to mention log scoring) is precise.
These questions are just as binary.
Does it matter if there is a general ability to forecast? Ideally one would make lots of forecasts and score different categories differently. Certainly one expects to be more accurate (as measured by log score) in some fields than others. Some questions are more difficult than others. But calibration doesn’t depend on difficulty level. For more difficult problems, one makes less confident predictions.
Is there a general factor of calibration? I think so. I think calibration is mainly (1) desiring to make predictions, rather than cheering and (2) knowing what 70% means.
Being good at avoiding assigning probabilities to things you are very uncertain of the probability of is not a bad thing. If you make 10 60% predictions, and get 6 right, you’re within the ballpark. If you can’t predict the probability of that thing, knowing that you can’t do that is a good thing.
Basically, it is the difference between a known unknown and an unknown unknown – knowing that you don’t know something is better than not knowing that you don’t know something.
>44. So-called “Ferguson effect” continues and becomes harder to deny: 70%
What evidence justifies calling this a correct prediction?
This article is from a source that is likely opinionated.
The facts as stated in the article appear pretty bad.
Two years of double-digit increases in homicide rates in many major American cities. An increase in murders of Police officers.
Other statistics showing a reversal of decades-long declines in crime rates. Anecdotal and statistical evidence of reduced Police activity, and reduced trust between Police and community.
However, I’m curious what other evidence, pro and con, is available.
Yeah I don’t find this article all that convincing. Homicide is up, that much is clear, the author then claims that it must be because the Ferguson effect because straw-opponents don’t offer convincing alternatives.
People have retreated from denying correlation to denying causation because it has become harder to deny correlation.
Chicago, frankly, is pretty good evidence for it – 538 ran an article on it:
https://fivethirtyeight.com/features/gun-violence-spiked-and-arrests-declined-in-chicago-right-after-the-laquan-mcdonald-video-release/
Chicago is probably the best evidence for it, as is the fact that other cities saw a spike after their respective incidents followed by a decline (Baltimore got massively worse 2014-2015, then a bit better (but still worse than 2014) in 2016). Chicago hasn’t reversed its trend and the number of cops is still down, as is the homicide solution rate, and crime rates have gone up.
The other reason why the Ferguson effect appears real is that only a few cities are showing large spikes, which is consistent with certain cities which have had problems having their police force stand back and let shit burn instead of intervening.
It’s probably too late… but, please, drop the 50% bucket. Forcing a 50% prediction to either 45 or 55 is no worse than the current situation of forcing a 55% to either 50 or 60.
How about: 55, 70, 80, 90, 95, 99?
What’s the difference between 95 and 99 when there are less than 15 questions combined throughout both categories?
My predictions for 2016 were an unqualified success! I maintained perfect accuracy and perfect calibration for the fourth year running by predicting of each day that the sun would rise that day (i.e. that the Earth would complete its diurnal rotation) with a confidence infinitesimally less than 1.* This also represents a huge victory for the frequentist interpretation of probability, as all of my predictions were made without the aid of hypothetical priors, solely on the basis of the straight rule of induction.
My predictions for 2017 are the same. Off to a good start already!
*Only four years running because I foolishly reduced my confidence that the sun would rise on December 22, 2012 to a mere .9999999998. Lousy Mayans.
> 11. Situation in Israel looks more worse than better: 70%
Is not well-defined. Its being counted as true, as well as the use of “looks” rather than “is”, suggests it is not about the actual situation in Israel, but about perceptions of it in some unspecified but presumably quite restricted circles.
Even more striking is the implied meta-prediction that Israel (with 5 related predictions) is going to be by far the most important country in the world in 2016 (besides the US). This one was spectacularly wrong, as were the complementary implied predictions that nothing as interesting was going to happen in Turkey, France, Germany or the U.K., each of which is by any objective measure (population, economy, membership of NATO etc. etc.) way more significant than Israel. Not to mention the entire world outside Europe and the Middle East (Latin America? India (population more than 150 times Israel’s)?, Subsaharan Africa?). If the author had expected 2016 to be the year when this vast conspiracy of cartographers was to be finally exposed, he should have given a prediction to that effect.
But I fear I might be guilty of category error when treating this as an exercise in geopolitics, when it is meant as more closely related to the author’s own professional interests.
I feel your last paragraph is likely approximately
correct. Or more probably that the exercise is more closely related to the author’s own geopolitical knowledge; I think a random American probably knows a lot more about the politics of Israel than of India..
A random American may well have the illusion of knowing something about the politics of Israel, but I would question how solid might that knowledge be. The preceding essays here attempt a critique of a single misleading NYT op-ed about education, that many commenters seem very reluctant to accept. But the NYT’s campaign of misinformation about Israel is much more comprehensive, comprising of hundreds of op-eds and thousands of articles over many years, for the most part as misleading as this one if not more so. I suspect many random Americans would have an even greater difficulty in seeing through them.
Some of the other predictions about Israel also seem strange.
> 8. No major intifada in Israel this year (ie > 250 Israeli deaths, but not in Cast Lead style war): 80%
According to this criterion the original intifada wouldn’t qualify as major. The second one would, but only for 2002, so this prediction would have qualified as “true” for 2000 and 2001. It is difficult to imagine how such a major intifada could happen these days without a confrontation with Hamas in Gaza, so the Cast Lead exemption would still make it “true”.
7. Israel will not get in a large-scale war (ie >100 Israeli deaths) with any Arab state: 90%
Israel borders 4 Arab states. Of these it has seemingly stable peace treaties with two (Jordan and Egypt). The other two, Syria and Lebanon, don’t really exist as states anymore. A war with a sub-state organization like Hizballah (assuming it would not be otherwise engaged, as it currently is), or with a non-Arab state like Iran, wouldn’t qualify. The last war that would was 43 years ago, in a very different landscape. And why is the casualty threshold for large-scale Israeli-Arab war so much lower than for a major intifada? Maybe because a minor intifada was arguably already underway when the predictions were made, so a higher threshold was needed to make the prediction almost certain, while an Arab-Israeli war is so unlikely by itself it didn’t need this fiddling.
9 is subjective and not very risky.
> 10. No Cast Lead style bombing/invasion of Gaza this year: 90%
This seems like the only “real” prediction here. Was its success due to a deep understanding of Hamas’s situation and strategy or to pure luck?
Other predictions don’t seem much better:
>16. Libya to remain a mess: 80%
What’s the definition of “a mess”? Is any Arab country currently not a mess? Any non-Arab country besides Switzerland and Singapore?
Would even those most wildly optimistic about Libya expect it to stop being a mess in less than a year? How long after their defeat in 1945 did Germany and Japan stop being a mess? Wouldn’t the continued existence of North Korea make Korea as a whole still a mess, despite the amazing advances of South Korea since the 1950’s?
How would we even know if Libya stopped being a mess? Presumably by the absence of any reference to it in American or British news media. But such absence could be due to indifference rather than unmessiness. Many other African countries are very messy but completely absent from the news. Or maybe we would have to wait for some article positively extolling Libya as a model of success for the Arab world? But how reliable would such an article be? I seem to recall such articles right before the Arab spring, presumably paid for by Gadaffi’s petrodollars.
An even more puzzling omission, in light of current preoccupations, is of any mention of Russia and Putin. Ukraine and the Syrian civil war are mentioned, but we get no hint they have anything in common. These predictions were made about 3 months after Russia stepped up its involvement in the latter, so failure to mention Russia was a refusal to look at the present and immediate past even before it was a failure to predict the future.
Also no mention of Iran, which was the main geopolitical focus of Obama’s second term.
Doesn’t the three-parent baby (http://www.abc.net.au/news/2016-09-28/world's-first-baby-born-from-3-parent-technique-report-says/7883386) count as (weakly) genetically engineered?
Seattle Rationality did a group prediction/calibration party for New Years’ heavily inspired by the prediction posts you’ve written. With some guards against anchoring, it seems to work pretty well – thanks for giving us the format!
(I wrote about it here (https://eukaryotewritesblog.wordpress.com/2016/12/31/throw-a-prediction-party/) in case anyone else is interested or wants to do this as a group activity.)
“24. Conditional on Trump winning the Republican nomination, he’ll lose the general election worse than either McCain or Romney: 70%”
Well, Trump got fewer votes as percentage of eligible voters than did either McCain or Romney, losers both — Trump 27.2% versus 28.1% and 27.4%. Worth partial credit?
Trump didn’t win the election, Hillary lost it. Millions of Democrats who’d voted for Obama decided not to vote for her.
are you basing those on more recent numbers? because votes keep getting counted for a while after the election ends and I’m hearing that people who said stuff similar to you changed their tune. does this still hold up with updated data?
Also worth noting that E. Harding did better than either Scott Alexander or myself on Trump and Brexit.
His comment:
Registering an account to start commenting here just because I want to do this for the coming year. Looking forward to Scott’s predictions, too, to see how they measure up! 🙂
WORLD
1. Hillary Clinton and some number of her associates will face serious legal consequences from crimes that have not yet come to light. 70%
1a. Conditional on 1, the legal proceedings will widely be described as a political purge. 95%
1b. Conditional on 1, the number of associates charged will be very large (more than a hundred people). 60%
2. Queen Elizabeth II will die this year. 80%
2a. Conditional on 2, King Charles will be on the throne at the end of the year. 60%
3. Marine Le Pen will become the President of France. 60%
4. ISIS will control significantly less territory than they do now. 90%
4a. Conditional on 4, it will be widely held that Trump committed severe war crimes to accomplish this. 99%
5. Terrorists radicalized by online internet communities will become an increasingly visible problem in the West. 80%
5a. Conditional on 5, at least one such attack will be committed by a /pol/ user who will post on /pol/ about their attack before and/or during and/or after it. 80%
5b. Conditional on 5, some of these terrorists will be Muslims, and we will see the formation of a prominent Islamic fundamentalist version of /pol/. 70%
6. Donald Trump’s approval ratings with Republicans will rise over the course of the year. 80%
7. At the end of the year, a greater percentage of the population will be Republicans than at the beginning of the year. 60%
8. Though Barack Obama intends to become a pundit after leaving office, he will essentially take the rest of the year off to relax and will put off serious attempts to impact American politics after leaving office until at least 2018. 60%
9. There will be at least one serious attempt to impeach Donald Trump this year. 70%
10. Donald Trump will not be impeached this year. 90%
11. There will be at least one serious attempt to assassinate Donald Trump this year. 60%
12. Donald Trump will not be assassinated this year. 80%
13. Donald Trump will face serious gridlock in Congress as a result of more Republicans than Democrats defecting. 70%
14. Star Wars Episode VIII will be the highest-grossing film of the year worldwide. 95%
15. Star Wars Episode VIII will make less money than The Force Awakens worldwide. 80%
16. Justice League will widely be considered a flop at the box office. 70%
17. Cars 3 will make more money worldwide than Coco. 80%
18. Despicable Me 3 will be the highest-grossing animated film of the year worldwide. 80%
PERSONAL
1. I’ll finally get my goddamn driver’s license. 99%
2. I will be attending college at the end of the year. 80%
3. I will have a girlfriend at some point during the year. 90%
4. I will have a girlfriend at the end of the year. 80%
5. I will finish writing my current novel in Q1 2017. 70%
6. I will finish writing my current novel in 2017. 95%
7. I will finish writing (at least) two novels in 2017. 80%
8. I will begin selling e-books online in 2017. 90%
8a. Conditional on 8, I will be deeply unimpressed with how much money I make doing so by the end of 2017. 80%
9. I will visit my uncle during Spring Break 2017. 80%
10. I will obtain at least one new electronic device in 2017, such as a new pair of headphones or a cable to send data from my electric keyboard to my laptop. 80%
11. I will purchase at least one video game in 2017 that I do not already want. 60%
12. I will still be in touch with my current best friend at the end of 2017. 90%
This seems absurdly low. Do you think that there is a 40% chance that Charles dies during this year or invalidates himself?
I think there’s a pretty high chance that he abdicates; he’s a lot less popular than his mother and his son, as I understand. I am an American, though, so my knowledge of the subject is not first-hand.
Abdicates in favour of his son? I think that’s highly unlikely. In my opinion there would be a significant chance of republican opinion either ending the monarchy or or delaying his coronation. I agree with Aapje that 60% is very low though.
@johnvertblog
The populace seems to prefer that he becomes King.
I think that you may underestimate how much the Britons value tradition, which can overcome a lot of the popularity gap.
The Britons may also favor William having more time to spend with his young kids, while they may feel sorry for Charles being heir-apparent for nearly 65 years. People may also believe that he will most likely not live as long as his mother anyway.
The whole point of a monarchy is that it’s not supposed to be a popularity contest.
The method of choosing the monarch is not a popularity contest, but that doesn’t mean that popularity is unimportant.
Most (Western) monarchs seem very aware that their institution needs popular support to survive.
The surprisal of your prediction results is calculated by summing across all buckets -num_correct*log2(p) + -num_incorrect*log2(1-p). Of your 95 scored prediction results is 63.26 bits or 0.6658 bits per prediction.
Just predicting everything at 50% would yield 1 bit per prediction (95 bits total).
Had you been more confident about your 50 percent predictions and moved them all up to 60-percent you would have scored 63.02 bits (0.6634 bits per prediction).
This surprisal factor is equivalent to the amount of information needed to transmit the results of the predicted events given the sender and the receiver both having your predicted probabilities of the events (ignoring issues surrounding the skipped predictions).
PS – Congratulations on some of the personal stuff, it seems like you had a good year.
Scott, I’d encourage you to plot expected errorbars for reference. For example, your “miscalibration” at 70% is within 1 standard deviation of what you’d expect for 16 predictions. As long as the prediction statements are uncorrelated, the number of successes in a probability class p should be drawn from a binomial distribution B(N,p), which has mean fraction of successes p (obviously) and standard deviation sqrt[p*(1-p)/N]. If you plot additional red lines for expected + sigma and expected – sigma, I think it would be much clearer how good the calibrations are.
I don’t have the math skill to do this myself, but enough people are doing this kind of thing now that it might be worth making a widget or something to make this kind of thing easier.
Scott, you should give yourself a half point for world events 18. The UK government has declared an intention to leave the EU, but they definitely haven’t shown any sign of having a plan.