
[Epistemic status: Not original, but worth mentioning]
I’ve been using scatterplots of different states and countries a lot here lately. For example, this one in the discussion about guns:

And this one in the discussion about national happiness:
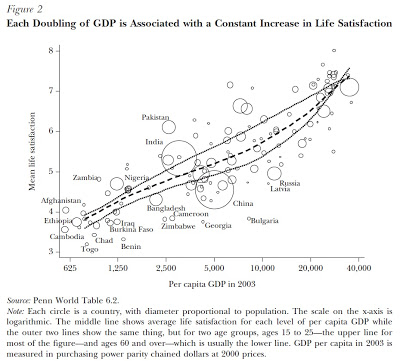
Hopefully we already know that we should worry about confounders like income and race and those kinds of things when we’re looking at a graph like this. But recently I learned it’s even worse than that. Consider for example this:
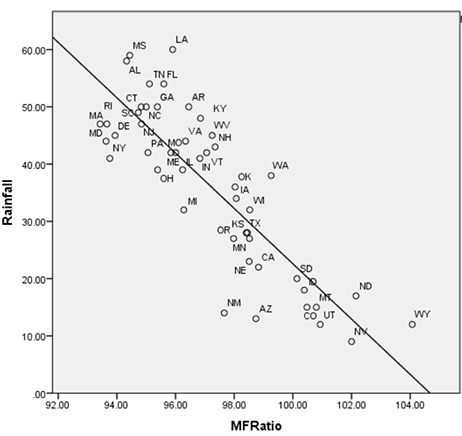
This is the average yearly rainfall in the lower 48 US states vs. their gender balance (measured in number of men per 100 women). The correlation is about r = 0.84 (p ≤ 0.0001), much higher than anyone’s ever found between guns and crime, or income and happiness, or most other things people make regional scatterplots about. So what’s going on? Do women cause rainfall? Does rain drive men away? Or is there some confounder that causes both rain and womanhood?
I don’t think it’s any of these things. I think it’s a coincidence.
“But you said p ≤ 0.0001! There are forty-eight data points and the fit is almost perfect! How could it be a coincidence?”
But I don’t think there are forty-eight data points. I think there are three data points. For 48 data points to all lie the same line is very impressive. For three data points to all lie on the same line is much less so.
I think that Southern states have more women (probably because they have a higher male incarceration rate, and incarcerated men aren’t counted) and more rainfall. Mountainous western states have more men (probably because the jobs there tend to be in manly mining/forestry type industries) and are pretty dry. And other states are somewhere between those two extremes.
Within these regional categories the rainfall/gender relationship is random – on the scatterplot it would look like a circle. But between these three regional categories the rainfall/gender relationship is very strong, making the whole chart consist of three circles in a line. Crucially, because these are kind of amorphous circles and they blend into each other, you can’t tell that that’s what’s going on. Here’s my graphic depiction of this:
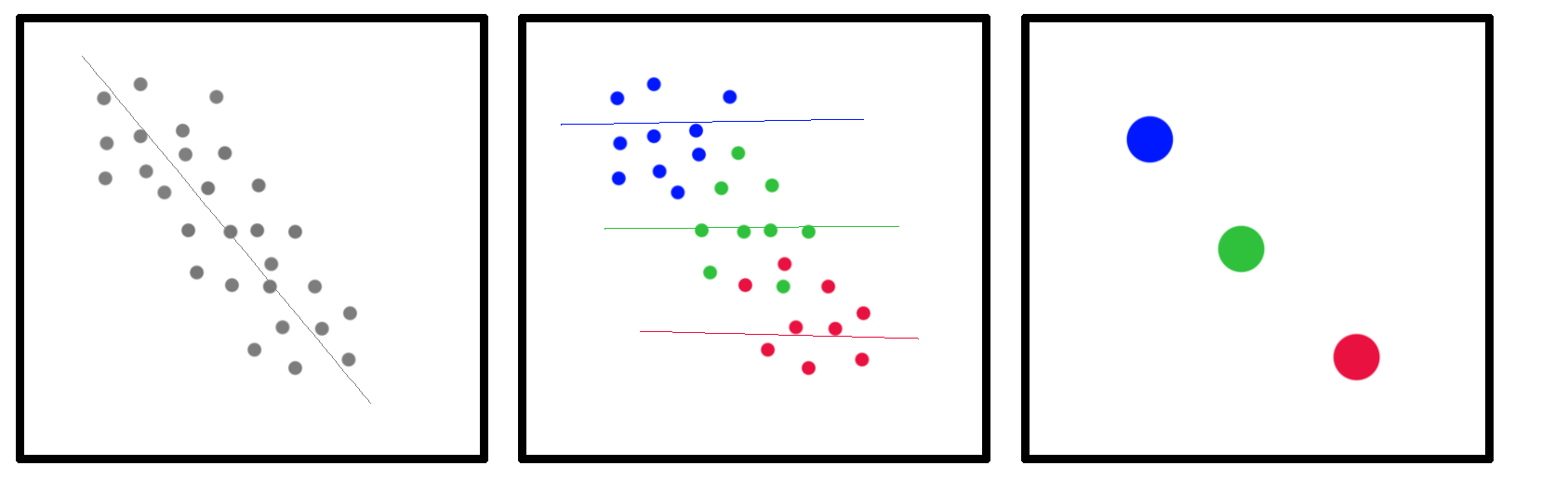
In the first box, the gray points show what looks like a very significant correlation – the further right you go on the horizontal axis, the further down you go on the vertical axis. The gray trend line confirms the strong relationship. In our US state example, this was a correlation between many women and high rainfall.
In the second box, the gray points are revealed to be grouped into three regions: blue, green, and red. In our US state example, blue is the female-skewed and rainy Southern states, red is the male-skewed and dry Western states, and green are all the other states with pretty average rainfalls and gender balances. Within each region, there’s no relationship between rainfall and gender, as shown by the horizontal red, green, and blue trend lines.
In the third box, we see what I’d argue is the correct interpretation of the data. There are three big data points – the South, the West, and the Rest – and they do sort of form a line but nobody cares about a line between three data points.
If I go back to my statistics packet and repeat the rainfall/gender correlation with only three points – the Southern average, the Western average, and the Other average – I still get r = -0.84, but now p = 0.3. The statistics have no reason to think it’s anything other than pure coincidence – and indeed, with that small a sample size, why would they?
I think most real studies are smart enough to control for this – although it’s really hard to determine how exactly you should be doing that and leaves a lot of wiggle room for people who want to fudge their way to a preferred result. But basic scatterplots do not control for it, and so almost every regional scatterplot is suspect.
This is why I was happy to see the income/happiness correlation broken down further:
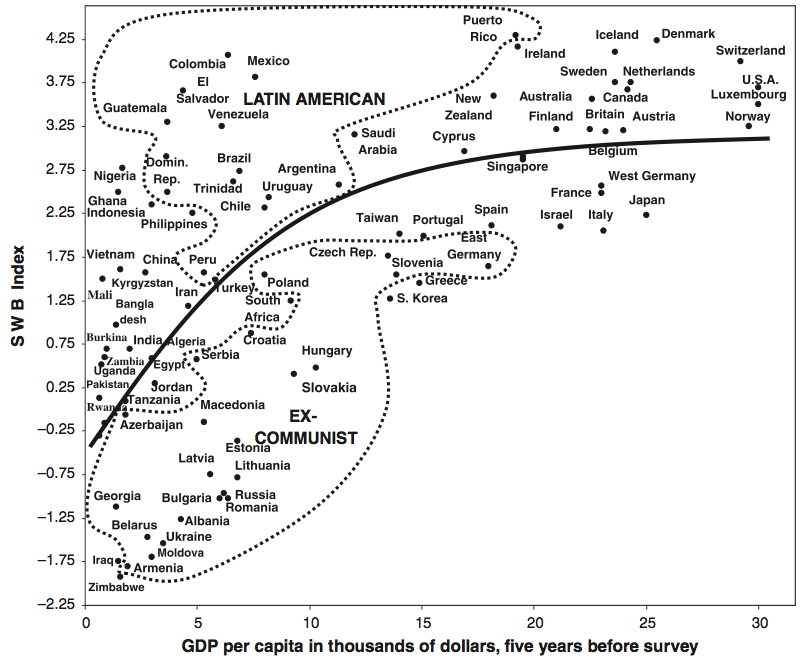
This makes it clear that the income/happiness relationship is primarily cluster-driven, with clusters of ex-Communist countries, Latin American countries, and Euro/Anglosphere countries (if you’re willing to do some more work, you can sort of make out clusters of African and Asian countries). None of these clusters show a strong income/happiness relationship except for the ex-Communist one, which suggests this might be the same kind of confounding as the rainfall/gender example above.
…unless I’m biased and reading too much into this. It’s really easy to change your conclusion just by changing your clusters. For example, if Puerto Rico counts as Latin American, then that creates a pretty impressive happiness/income relationship within that cluster. If it counts as Euro/Anglosphere – it’s part of the US, after all – then there is no income/happiness relationship within either cluster. So which is it?
Or what about this? I claim that the apparent income/happiness relationship within the ex-Communist countries is actually an artifact of Europeanness. The richest ex-Communist countries, like East Germany and the Czech Republic – are also the happiest only because they are closest to Western Europe, which is both happier and richer than the rest of the world. Likewise, the poorest ex-Communist countries, like Armenia and Georgia, are also the unhappiest only because they are the furthest and least Western European of the bunch.
Once we start going there, we can pretty much prove or disprove anything we want based on our own intuitions about how to group things. I am suspicious of this, but I’m also equally suspicious of not doing that – do you really just want to let it pass that Puerto Rico, the closest Latin American country to the Euro/Anglosphere cluster, is also politically Euro/Anglosphere?
Overall there is no good answer and I would recommend against drawing any strong causal conclusions from a scatterplot unless someone has very carefully addressed these concern.
EDIT: Inty gives a great (ie horrifying) example in the comments, and Theo Jones discusses more formal tests of spatial autocorrelation. Some people bring up the possibility that some of the rainfall/gender relationship is causal after all, since drier states will have less farming and be forced to turn to mining/forestry to support themselves; this is possible but probably doesn’t explain the whole relationship, and even if I’m wrong about this one the point is still important.
















Surprised how close India is to Pakistan on the chart, and Chile to the rest of SA. Interested to read about further analysis on this issue.
Why would you expect Chile to be further?
Chile is weird among South American countries ancestry-wise. They’re something like 90% Amerindian, whereas the rest are closer to 50% or lower.
Edit: Whoops, completely wrong, I was thinking of Peru, at 80% Amerindian.
Peru is only 37% indigenous according to
Wikipaedia. You sure you’re not thinking of
Bolivia?
Or Paraguay? (95% mestizo, 90% Guarani-speaking)
Careful. These sociological race data are often misleading. Better to use genomic estimates. See: https://www.researchgate.net/publication/298214364_Admixture_in_the_Americas_Regional_and_National_Differences
A comment about the happiness thing – While it makes sense to compare self-reported happiness over the same culture in different times, I’m not sure it makes sense to compare it between cultures. My impression from the Latin-Americans and Eastern europeans I know is that the first tend to try to signal that they’re happy even when they’re miserable, and the second are the other way around. This is fairly anecdotal, but seems like something that could easily be true.
do you really just want to let it pass that Puerto Rico, the closest Latin American country to the Euro/Anglosphere cluster, is also politically Euro/Anglosphere?
Mmm – but you need to include culture versus politics, surely? Is Puerto Rico culturally more similar to the U.S. than other Latin American states (e.g. is there a better chance that although a few very rich people have a lot of money, the lower classes have relatively higher incomes than the same socio-economic classes in comparable Latin American countries?)
Because what about Argentina, then? Very much influenced by the Euro-Anglosphere – lots of Brits going out to run beef ranches in the Argentine, they have a cricket team, and remember that little to-do over the Falklands/Malvinas? Yet they’re within the Latin American bubble and not up there with Puerto Rico.
Conversely, what about Mexico? Can’t really get much closer in proximity to the U.S.A. (“Poor Mexico, so near the US, so far from God!”) and that’s not up near Puerto Rico, either.
So it’s possible that Puerto Ricans may derive advantages from (let us say) being able to be legal immigrants to the USA that Mexicans don’t, and feel that they are more “American” than “Spanish”?
I’ve pointed out a similar thing to one of my lecturers before! It was in Social Neuroscience, and we were looking at a graph that plotted countries on % of the population with some allele to do with mu opioid receptors against depression prevalence in various countries. But really, there are only two data points- Asian countries and European countries (with a handful in neither). And what’s more, if you treat these two as separate categories, you can eyeball a Simpson Paradox. Here’s the graph: http://img.medscape.com/article/725/467/725467-fig3.jpg
I can’t tell if there really is a correlation in the opposite direction, and I haven’t gone to the tedium of making this graph myself, but the fact that it’s plausible is very troubling.
That’s horrifying. I hope so much that there was more to that study.
Good news and bad news.
The good news is that there was more to the study- it was a review of other studies looking at whether or not you could find a direct effect of genetic contribution on culture.
The good news-cancelling bad news is that every single other graph is the same:
https://scan.oxfordjournals.org/content/5/2-3/203/F1.large.jpg
https://scan.oxfordjournals.org/content/5/2-3/203/F2.large.jpg https://scan.oxfordjournals.org/content/5/2-3/203/F4.large.jpg
Study here: https://scan.oxfordjournals.org/content/5/2-3/203.full
Huh! That’s the most intuitive explanation of Simpson’s paradox that I have seen. The explanations I had read just had two binary conditions, and a table with four numbers, and then you can check that if you do the math you get the effect, but there is very little intuition.
By making one of the conditions continuous instead of binary, and showing a plot, suddenly you can see what is happening!
Simpson’s paradox has a really easy intuitive explanation:
Doctors cause disease. If healthy people see a doctor, they only get healthier. If sick people see a doctor, they only get healthier. But if you meet a random person and they say “I’ve been to the doctor a lot recently,” you assume they’re really sick, cause sick people spend more time with the doctor. In both subpopulations having just been to the doctor correlates with health, but in the whole population it correlates with sickness.
That’s great, thanks!
I quite like Wikipedia’s example graph as well.
What is the correct answer to Simpson’s Paradox?
If group A outperforms group B, but B-1 outperforms A-1 and B-2 outperforms A-2, which is better, A or B?
The correct answer is you want the causal effect. If you can condition on a pre-treatment variable to get a more refined effect, do so. Otherwise do not. Simpsons reversal does not happen with causal effects, so more info is always strictly helplful.
Simpsons paradox is a paradox because people confuse conditioning and causality in their heads (specifically they think the former is the latter even when it’s not).
The explanation I like, even on a binary table, is the model of good hospital vs bad hospital. People know that good hospital is better, so most of the severely ill or injured people go there, while people with minor issues can deal with either, no problem. Good hospital is not so much better than bad hospital that it can handle the harder work and still get a higher success rate.
The aggregation of gun murders with gun suicides makes the top correlation plot even more difficult to justify. I can easily imagine definite clusters for each type of death but the addition of the two confuses those relationships.
I have an odd thought…
If DC is included as a “51st State”, does it mess up the scatter-plot for gun-ownership vs death-by-gunfire?
Come to think of it, what happens if we include Puerto Rico or Guam?
If I can trust the table on Wikipedia (data given for 2010), Wyoming has a nearly nonexistent homicide-rate. Most of the deaths in the high rate given in the scatter-chart above must be suicides
https://en.wikipedia.org/wiki/Gun_violence_in_the_United_States_by_state
Same table has Louisiana with the highest homicide-by-gunfire among the 50 States. (DC is on that chart, and is reported to have a homicide-by-gun rate is double that of Louisiana.)
When I peruse that table, I notice that the top-10 States for homicide-by-gunfire all have large urban centers. While the bottom-10 States for homicide-by-gunfire have very few urban centers.
It would probably do horrible things to the scatterplot, but that’s because DC is entirely an urban center — and a dangerous, crunchy one at that. (Gentrifying rapidly, though.) It would be like if you took South LA and made it its own state.
Yeah, it’s a big outlier with very few guns and a very large amount of crime.
For those confused by DC stats, DC is a lot like Chicago where they tried to legislate the guns away. There are tons of guns in DC.
The underlying reason is actually demographic – DC is overwhelmingly black. Blacks commit 50% of homicides in the US, despite being only 13% of the overall population; the black homicide rate is actually more than an order of magnitude higher than the non-Hispanic white homicide rate.
https://www.fbi.gov/about-us/cjis/ucr/crime-in-the-u.s/2014/crime-in-the-u.s.-2014/tables/table-43
(Note that the FBI stats include both Hispanic and non-Hispanic whites under “white”)
As DC is like, 80% black, it is waaaay blacker than any state. Thus, it has a ridiculously high homicide rate.
You can see why looking at this graph of blackness of a state vs homicide rate:
http://imgur.com/nMDWu5q
DC would be way off the right side of the chart.
Why are large urban centers so dangerous? Prague or Vienna are ‘large urban centers’, yet I’ve travelled around them extensively and there were really no parts that seemed unsafe.
Same for London, parts were a little grimy and looked more like Africa, demographically speaking, but overall there was no real or perceived danger, not like one felt for example in a village with 70% Roma population by which I was at a scouts’ camp once. (Not getting beaten up there was walking a fine line – be too belligerent and stand-offish and they’ll beat you up for that, be too scared and they’ll gang up on you bc you seem scared.)
I think at least some of it has to do with the US’ unique racial demographics, though I would be interested in seeing how much urbanicity mattered after adjusting for that.
I also think that this fear of the inner cities was more true 20 years ago when crime was much higher.
A point I’ve never seen made ever is also one of crime per square mile.
A rural county that’s nothing but a giant 1000-way Hatfield-McCoy feud is probably pretty safe to take a drive through. Everyone’s getting murdered, but everyone is 3 people per mile
On the other hand, a 78/100K murder rate in a neighborhood with 10K people per square mile had 20 murders last year along the equivalent of my walk to the ice cream shop. And I don’t go there ever because ahahah, WTF.
So urban neighborhoods are insanely dangerous per-block even if they were paradoxically safer per person.
meyerkev, you’re a person, not a square mile, so you should care about at crimes per person, not per square mile. A standard example is that there are fewer street crimes at night than during the day. But walking at night is more dangerous because there are so many fewer people that the rate per person on the street is higher.
“A rural county that’s nothing but a giant 1000-way Hatfield-McCoy feud is probably pretty safe to take a drive through. Everyone’s getting murdered, but everyone is 3 people per mile ”
At a tangent …
The actual Hatfield-McCoy feud consisted of three McCoys getting in a fight with a Hatfield and badly injuring him. His relatives took the three prisoner and, when he died, killed them.
No more violence associated with the feud for the next five years, until the governor of Kentucky sent posses into West Virginia, without the permission of its government, to try to arrest the Hatfields who did the second killing and bring them back to Kentucky for trial. They killed one, arrested nine others, one of whom ended up convicted in a Kentucky court and hanged.
Some Hatfields responded by an attack that killed two McCoys. That was the point at which the feud hit the newspapers. Also the point at which it ended, so far as further killings were concerned.
Total deaths: Six killed by Hatfields/McCoy conflict, two killed by the government of Kentucky or people acting for it.
The conflict between the states made it to the Supreme Court, which held that Kentucky had acted illegally but that there was no remedy—once it had possession of suspects it could try them.
Nothing to do with the point you are making, but I like pointing out popular historical errors when I come across them.
I know I’ve been reading the comments here too long when I saw “Hatfield-McCoy feud” and immediately started scrolling down for the David Friedman clarification post.
Still really cool though: the image I always used to get in my head when thinking about that conflict was families growing up hating each other and trading shots on a shared border, in the absence of law enforcement. That’s pretty far off the mark.
Huh, I thought the feud was went on longer than that, and that some McCoy relatives worked for the Baldwin-Felts Detective agency during the Battle of Blair Mountain, but that must have been some historical fiction I read.
My inner razor would suggest that high population density = high crime rate would explain a pretty significant portion of the issue.
Give a violent criminal lots of easy targets, and he’ll use that opportunity
Anyone would think that socialist nonsense about generous welfare systens, gun control, and police who aren’t thugs, actually works.
Then why is crime so much higher in Europe?
The reality is that European city centers are completely “gentrified”. There, it is the suburbs where poverty is concentrated.
So… All we have to do to make the cities safe again is to raise the rent to above the median income like they’re doing now in NYC, SF, LA, Boston…
OK, do we have any ways of doing this that don’t require me to spend $2500/month to escape the mold?
You could do all that, or you could assume Cliff has no clue what he’s talking about. Europe is a place of 450 million people, and I can from the top of my head name half a dozen large cities that’d disprove his claims.
Large European cities with non-gentrified city centers? I’m curious. To me as a central European, the idea of crime-ridden inner cities does sound alien.
Europe does not have a higher rate of the kinds of crime that are likely to leave you dead.
At least in the British case, this is confounded a good deal by different ways of counting homicides: http://rboatright.blogspot.com/2013/03/comparing-england-or-uk-murder-rates.html
No idea about the continent, though.
TheAncientGeek:
True, not dead. But it is still true that big cities in Europe have higher crime rates than smaller towns, ceteris paribus.
I am very skeptical about the “dangerous suburbs” claim. In fact, I think that crime in European cities is more “evenly spread” with some notable exceptions of ethnic “ghettos” in some of them (for example Neukölln in Berlin, Molenbeek in Brussels, parts of Paris and London). And actual suburbs (satellite townships close to a big town or a city) are actually more safe than the cities, I think, even in Europe. There does not seem to be a phenomena of dangerous “inner-cities” in Europe, that’s true. The city centres tend to be the most expensive locations.
Also note that Switzerland is not nearly as much into the “socialist nonsense” as other European countries (and overall it is more pro-free trade than the US), yet it is the safest country in Europe. They manage by having a limited welfare-state and being very very rich (which is at least partly due to not being so much into the “socialist nonsense”).
As for gun control, we’ve already talked about this, but Austria, Switzerland and the Czech republic are examples of European countries with very relaxed gun laws (in some respects even more than some US states, although mostly they are slightly more restrictive), yet the crime rate is relatively low, to very low in all of them. Austria has a generous welfare state with high taxes, Switzerland has a limited welfare state with low taxes and the Czech republic is somewhere between those two, I would say.
I’ve never been to the US, so I cannot compare directly, but at least from the coverage by the media, it does seem that the police in Europe are more polite than their American counterparts.
In any case, it is too easy to jump into conclusions, especially if those are the conclusions one wants to make in the first place.
There are a whole bunch of things about Switzerland that don’t scale or can’t be reproduced.
I don’t know if you meant to say that the Czech republic, etc, were low in violent crime because of their lax gun laws, but if that were the only factor, you would expect the US to look very different. If there is some either factor that makes the US violent, that is an argument for gun control, not against.
I reckon there are a bunch of factors that all happen to line up in a lot of American cities, and might not line up as well in other countries. Poverty, density, police resources and policing style, demographics.
It seems from a distance that America is happy with and designed around car-owning urban sprawl. Relatively limitless developable land means large areas can be left behind, as sorting them ends up being difficult and expensive.
London, on the other hand, is pressed for space, (although population density remains low for Europe due to preferred housing type), and not designed for roads with modern traffic levels. Central living is a luxury to avoid a bad commute.
Thus, to turn a profit in property development, businesses turn inwards. This is not an unalloyed success. London property has become a go to area for speculators, especially as interest rates are so unappealing. Central London is being informally cleansed of poor/normal people.
Back in the eighties, when a house was primarily somewhere to live and local authorities still had significant stocks of social housing, the middle of London was a bit broken and shabby but much more interesting as a place to live.
There was a whole council house square in Vauxhall (a modest walk from the centre) which the local authority could not afford to repair to code. The whole thing was squatted, keeping some of the rot at bay and deterring vandals. They even opened the old corner shop as a cheap coffee bar.
This kind of living was far from uncommon. All now in the hands of private developers via housing associations and Thatcher’s “right to buy” social housing legislation. (Social engineering really since money raised was specifically banned from rebuilding of replacement homes)
Sorry, got a bit ranty there
However, even in Europe, the crime rate is probably higher in bigger cities than in the villages. I read an article on die Welt, where they compared crime rates of different federal states. But then I adjusted those crime rates for population density (they even included the city-states and made no distinction between those and the other German states) and suddenly, the differences were much smaller. I think that Bavaria was the safest state, but it is also the richest one. What was interesting is that Bremen turned out to be significantly more dangerous (i.e. much higher crime rate) than Berlin after adjusting for population density. I don’t have a good explanation for that. The only thing I can think of is that Eastern Berlin might have a lower rate of reporting crimes than the “fully western” Bremen, driving the apparent crime rate down, but I am not too convinced by that myself. Or Berlin has consistently had a better state government than Bremen and has introduced some regulations which effectively reduced crime…
In any case, this is a thing in Europe as well. You may feel safe in Prague, Munich, almost everywhere in Berlin, most places in Paris, but the crime rate in all of those cities will still be higher than the crime rate in more rural areas (or smaller towns) in their respective countries (with some exceptions such as a former mining town with a high unemployment rate or something like that).
Large urban centers aren’t inherently dangerous. Plano, Texas boasts a homicide rate of 1.4 per 100k. In Canada, you’re actually more likely to get murdered in rural areas than urban areas.
The actual cause is that the black homicide rate in the US is about an order of magnitude above the white homicide rate – just north of 50% of homicides are committed by blacks. And in particular, things are especially bad in specific “bad parts of town” – poor, black areas (though there are a few bad poor Hispanic ones down along the border).
For reference, the national homicide rate in the US is about 4.5 per 100k. The homicide rate in St. Louis was 49.9 per 100k in 2014.
The reality is that this is somewhat deceptive though; murders aren’t random. In Chicago, you’re 98.5% less likely to be a shooting victim if you’re white than if you’re black. As such, white people in Chicago see a relatively normal shooting rate, while black people in Chicago are shot ridiculously often.
Mystery resolved, rain causes suicides and suicides are gun deaths, everyone go home, scatterplots are absolved.
And since more men commit suicides, that explains all the women.
The aggregation of gun murders with gun suicides makes the top correlation plot even more difficult to justify
Would there be combined gun murder-suicides (the usual “male ex-partner/spouse kills female ex-partner/spouse, possibly children or other family members, then turns guns on himself” reports) that causes such aggregation?
Those do exist, as well as non-domestic-violence-related murders where the killer commits suicide shortly thereafter, but they’re a fairly small percentage of suicides. According to the internet, it’s estimated there are around 1000 to 1500 murder-suicides per year in the USA, total – presumably at least some of those used knives or other non-gun methods. Meanwhile, we had around 38,000 suicides in 2010, of which around 19,000 used guns. The number of gun-related homicides that year was around 11,000. So the 1000 or so gun murder-suicides really don’t justify lumping together two much larger numbers that describe substantially different things.
They do it on purpose to lie to the public. Homicides and suicides don’t correlate at all on a state-by-state level.
http://i.imgur.com/QRb0AKP.jpg
The reason they combine gun homicides and suicides into the misleading “gun deaths” category is to deliberately deceive you.
There is absolutely no correlation whatsoever between homicide rate and gun ownership on a state-by-state basis.
http://i.imgur.com/zNMflzq.jpg
There is, however, a correlation between gun ownership rate and suicides.
This, however, is likely an example of storks bringing babies, and in fact, is probably caused by the exact same effect – rural areas both have more guns and more suicides, but the cause is probably not guns causing suicides, but the demographics of rural areas leading to both. Rural areas have a significantly higher (20% higher) rate of depression, and poorer access to mental health care. Note that rural areas don’t appear to cause depression; rather, it is probably a result of demographics.
http://www.ncbi.nlm.nih.gov/pubmed/17009190
Why is this? Well, among other things, rural people are whiter and poorer than urban residents. White people are much more likely to own guns than other groups, and rural people own more guns than urban people for fairly obvious and logical reasons.
That said, I haven’t done cluster analysis on it yet.
Another problem with guns = suicide is that Japan has a very high suicide rate and very few guns. The US has only a middling suicide rate.
But in any case, rolling suicides and gun homicides into a single category is obviously problematic, because as you can see above, homicides and suicides don’t appear to correlate at all on a state-by-state basis. The only reason to do it is to skew the numbers to get what you want – namely, a slope indicating that guns = death.
This is the spacial autocorrelation problem. Its worth noting that there are formal tests to measure (and sometimes adjust) this (ie. Moran’s I) that are better than the clustering method you use. See, for instance http://www.ats.ucla.edu/stat/r/faq/morans_i.htm and https://geodacenter.asu.edu/drupal_files/spdepintro.pdf
It would be interesting to re-run some of these correlations that way.
Edit: grammar
I wrote a little R script to analyze the data in the gun chart, and test for and adjust for spacial autocorrelation.
The Moran’s I test found statistically significant autocorrelation p = 5.1^-06.
Post adjustment the strength of the correlation was weaker. The Pearson’s r before adjustment was -0.975, after adjustment r = -0.255. Note — Pearson’s r not r^2 (because the adjustment created a multiple regression-like situation there is a bit of a trick to getting the r^2 that I’m too lazy to look up)
My code is at
https://raw.githubusercontent.com/theojones2/autocorr/master/main.R
Do you think the same issue would affect the more serious studies like MA&H (2007) discussed here?
It looks like they explicitly adjust for spacial autocorrelation. So, they do mitigate this issue.
From page 658
To take into account the possibility that the data may be spatially correlated, in this case within census region, we ran models that clustered observations within regions and made appropriate adjustments to standard errors for accurate hypoth- esis testing.
Although less knowledgeable authors who don’t attempt to adjust for the autocorrelation could easily get bit.
In reasons to RFTM before using a new R library, I have a two corrections. The before value should be 0.45. The sign of the correlations should be positive. (misread summary output)
One note, the process for generating the adjustment model is stochastic, so there is some variation between runs. The 0.25 was the first value I got when I ran it and one I’ve been able to reproduce, but its towards the low end of the output. 0.3 is a more typical output.
So, there is still a difference between the before adjustment model, and the after adjustment model. Only 0.45 versus 0.3, instead of the more drastic shift.
You can use set.seed() to ensure reproducible results.
I’ve skimmed your FAQ link about Moran’s I, and it seems to me that it should work to detect correlations between values of any metric space where the distance between two points is defined. This seems pretty cool, and I wonder about what it can be used for except for distances (both on the plane and on a sphere, depending on the scale). Has it seen any use besides spatial correlation? I can think of other uses such as colors (on which you can define a metric space), Hamming distances, and so on, but I can’t see cases in which they might be useful in practice.
Distance based measures come up all over the place. Some classic work on spatial correlations looked at the distance between Polynesian islands and dialects. More recently, kernel methods in machine learning have used distance (well, really similarity) measures over strings, graphs, sets, image features, audio, probability distributions, etc. etc.
Thanks, this notion of spatial correlations seems to be as interesting and as coolas I imagined it to be.
Kudos on the high-value post.
…. that may actually be useful for an analysis that someone in my office is doing.
One day, Google or Facebook will dump all of the world’s social data into one massive supercomputer, and perform Clustering and Principle-Component-Analysis along every conceivable dimension. The future is now.
In other words, we can expect a lot more of these problems.
But what if they’re not spurious? Most of them are, but you can sort of sketch out a causal mechanism for a few them.
For instance, they list divorce in Maine as correlated (r=0.993) with per capita margarine consumption, which at first glance seems clearly spurious. On the other hand, what if the types of fat that people consume impact their behavior? See for instance: https://slatestarcodex.com/2014/02/18/proposed-biological-explanations-for-historical-trends-in-crime/
More tenuously, what if science spending causes people to feel small and alone in the world? What if people eat more chicken when oil prices are high because they can’t afford more expensive types of meat?
Those are possible. They could also be “just-so stories.” If you feed a metric ton of data sets in and keep running correlations off of each other, you’re going to find both good and spurious correlations. You have to actually *validate* these correlations in some manner before you try to use them in policy.
Not to mention that a “spurious” correlation might actually have some relation; there could be a common factor that causes both.
I’m not sure it’s even the margarine consumption in Maine that it’s comparing it to.
“Damn it, woman, you serve me up margarine instead of proper butter for my breakfast toast one more time, I’m divorcing you!”
“But Harold, margarine is better for your cholesterol levels than butter”
“I don’t care, it tastes wrong and doesn’t melt properly, I want butter!” 🙂
@Deiseach
Using margarine instead of butter is a pretty good reason to divorce or otherwise cut off all ties to someone. I mean does anyone really want someone like that in their life?
I know this was not the point but still – I think margarine is actually pretty bad. It contains trans fatty acids which are on of the worst things you can eat. Butter is much better, even lard should be healthier.
Also, it tastes wrong and doesn’t melt properly.
Butter is healthy and wholesome. Margarine is an unnatural abomination.
It might not be spurious, if higher margarine consumption is a good proxy for social class.(Assuming lower social classes are more likely to divorce.)
No no no, obviously the output is causal by definition, like with using PCA to suddenly invent “g.”
But what if it is the colouring used to make the green jellybeans green that causes the acne, not the jellybeans? 🙂
This is an excellent point, and it’s not even hypothetical.
More generally, long-time readers of this blog should have by now let go of the notion that interactions between almost any two (or more) elements of this our complex modern world may be expected to be predictable.
It’s possible, but it’s also possible that a 1/20 chance of finding a spurious correlation happened when you try a bunch of correlations.
That’s why reproducing experiments is so damn important
I am feelin’ oppressed, CatCube, by your insistence on evidence-based medicine to the detriment of other ways of knowing. We will never achieve feminist glaciers with this frame of mind! 🙂
One day, Google or Facebook will dump all of the world’s social data into one massive supercomputer, and perform Clustering and Principle-Component-Analysis along every conceivable dimension. The future is now.
They will think I want pregnancy testing kits and to join Google+, based on what they currently recommend me, neither of which is true.
This also works with some time series, where the dependent variable has trends with lower resolution than is used for the data points. E.g. the famous correlation between Democratic presidents and economic performance. If you treat every year as an independent data point, it looks impressive, but economic cycles last for several years, so they’re not really independent.
I get what your’re saying, and agree that this kind of thing is a problem.
but: in any specific example how do you know that the bigger reference classes you’re drawing aren’t just post-hoc coincidences themselves?
In other words, how do you know that the grouping of things like ‘southern states’ or ‘Latin american countries’ is a real and meaningful cluster and isn’t gerrymandered or something you’re only seeing coincidentally?
That’s what I meant with the last couple of paragraphs about where you put Puerto Rico and such.
Missed that.
Agree completely.
It’s a complex problem.
Beware Simpson’s paradox.
http://emilkirkegaard.dk/understanding_statistics/?app=Simpson_paradox
Hierarchical data analysis really difficult. Unfortunately, most data is hierarchical, whether the study has data from the different levels or not.
Related (and updated last Friday): http://plato.stanford.edu/entries/paradox-simpson/
Is there a version of Spurious Correlations for geographic correlations?
You’re really eroding my faith statistics one blog post at a time.
I’m starting to get to point where I figure you could demonstrate that up is down using statistics, and that the effort required to detect statistical “engineering” is much, much greater than the effort required to do it, especially considering that it’s easy enough to do accidentally.
It seems almost harmful to expose yourself to any form of correlational data, unless you have the resources, skills, and time to scrutinize it properly.
It’s a little less concerning when you can do an interventional experiment versus forming hypotheses purely from observation, but not by much…
Tl;dr: statistical wizards can make the numbers say anything. Cover your eyes!
Oh, you’re really not going to want to read this
Also, I notice that the solution to these artifacts is to apply fancy statistical method X. But it always seems like you could retool whatever method X is to induce a pattern in the data that isn’t there. Or you could deny what really exists in the world by saying, “naw man, it looks like there’s a pattern, but if use this fancy stats method, it’ll vanish.” In my head, I’m picturing this topsy-turvy alternate reality where women really can cause rainfall and they hide it by getting you to post this.
I guess I’m saying statisticians will always have jobs, inventing and uninventing patterns
I suspect this is an issue in many studies that are controlling from income. Even if they can measure income accurately, what they really want to control for is general economic situation. If you only measure individual employment income your low-income bucket will include people who are independently wealthy, homemakers, college students, single parents, unemployed and people in prison. Sure, many studies do better by counting family income and including savings.
Two 20-year-olds might have the same low income and no savings, but if one of them can get $10k from his parents in an emergency, then he is in a much better economic situation. It seems very difficult to control for such things in a study.
To be fair, this makes your data a lot noisier, and will decrease the significance of your data, most likely. Though there are ways of dealing with this, like doing multivariable analysis.
Still, the more statistical tweaking you have to do, the less valid your numbers are, generally speaking – every time you compensate for a new statistic, you’re increasing the size of your error bars.
Maybe it’d be more accurate to depict something which has been compensated for with a field of blurry points to indicate the potential “true values” because you don’t really have data points anymore, you have data estimates.
This makes me think of Thurber’s fable of the “The Fairly Intelligent Fly”, as quoted by Edward Tufte’s Data Analysis For Politics And Policy:
That’s more of a surfactant message, rather than the deeper reasoning issue.
Moral: You can’t rely on one rule of thumb for everything in life.
which could be argued as a subtype or cousin of:
Moral: Reversing stupid does not make smart.
The danger isn’t statistics! – it’s information from people you can’t trust. Sure, it’s possible to make a graph seem to say almost anything, but it actually takes *some* work to do that; not always much, but more than it would if they didn’t give data. That’s why statistics are useful.
People you can trust are still vulnerable to making mistakes. A great example is gun deaths vs gun ownership; anyone who graphs the data will get the same results, but if you dig a bit deeper, you discover that homicide rates and suicide rates don’t correlate. Moreover, no one sane cares about gun deaths – just deaths. Being beaten to death by a lead pipe isn’t preferable to being shot to death. People jumping off bridges is actually worse than them shooting themselves. So even using “gun deaths” isn’t useful – you need to look at all deaths, and then see if guns have an impact on them, or if they’re merely changing the proportions.
Even people you can trust can be sloppy and ask the wrong questions. And if someone asks the wrong question, you might not even go back and think about what the right one was.
Is Australia statistically significant?
If so, up is down.
Nice examples of being fooled by spatial autocorrelation.
For some more formal discussion of how this applies even to state-level policies (say, on minimum wage or gun control), see Barrios, T., Diamond, R., Imbens, G. W., & Kolesár, M. (2012). Clustering, spatial correlations, and randomization inference. Journal of the American Statistical Association, 107(498), 578-591.
http://scholar.harvard.edu/files/imbens/files/spatial_10mar23-1.pdf
Part of what is implicit in these scatterplots is often an interest in counterfactuals — how would one variable change if we changed one of the others?
Without this implicit interest, there may not be much of a problem: the purely descriptive story about the states rainfall and % female is true.
You could regard this as a subset of the problem with null hypothesis testing in general. The problem is that in addition to the specific non-null one you are testing, there are an infinite number of other possible hypotheses that might pass a statistical test. Most of them you will never even think of. And there are an infinite variety of variations of the supposed-null-hypothesis that might also pass a test. So to set up a null hypothesis and a non-null that you test is likely to be creating a strawman with little real significance.
Or you could think of this issue as being about correlation between the data points. The higher the correlations, the more you have to correct the variance upwards, thus reducing the possible statistical significance.
Either way, it shows how hard it can be to collect data that will be truly useful: you actually have to know a lot about what you are measuring. Horrors!
How often does the opposite case occur?
i.e. the data shows what appears to be a strong trend that is initially dismissed as spurious or otherwise flawed, only to eventually be proven as a strong, even causative, correlation?
Those factors aren’t all independent coincidences. Mountainous Western states have economies dominated by manly mining, forestry, and similar industries in significant part because they receive little rainfall. First, because this meant that they have been historically ill-suited for farming, the sector of the economy that employed more than 90% of the population before the Industrial Revolution, and even today creates difficulties with having to import food over long distances. Second, because a lack of water makes it hard to sustain large towns and cities. Third, because low amounts of rain tends to be correlated with unpleasant climates and this creates further disincentives to settle in these parts of the country. All of these factors combine to shrink the job markets in industries other than ones like mining, logging, and ranching, all of which tend to be dominated by men for the same reasons that other dangerous and unpleasant manual labor jobs tend to be dominated by men.
There are exceptions, particularly in the last 60 years as air conditioning has made factor 3 less relevant. For example, Phoenix, Arizona has seen rapid growth in the last few decades because the combination of being less than a 6 hour drive away from the West Coast and having low development costs due to being surrounded by an endless expanse of desert has attracted a lot of investment in spite of Phoenix’s very inhospitable summers. A similar thing has happened to a lesser degree to the Albuquerque metro area. These places have more diversified economies and thus a gender ratio less skewed towards men, which is why New Mexico and Arizona are outliers on the scatterplot.
(However, the gender ratio of Las Vegas and by extension Nevada is significantly skewed towards men when you exclude tourists – Las Vegas has something like 1.03 male permanent residents for every 1 female permanent resident – so I can only conclude that Vegas style tourism industries employ more men than women in spite of what I would have initially guessed.)
But apart from those exceptions, low rainfall really does keep women away, albeit through indirect mechanisms.
I think this is probably true, but it does not invalidate Scott’s warning in general.
I mostly agree with this comment. If rain causes society and society causes gender imbalance, then I think the association between rain and gender imbalance is quite relevant. I’m not saying I agree with NN’s points (I don’t know enough to agree or disagree), but his analysis kind of explains Scott’s “coincidences”.
On the topic of happiness, where different cultures and genetic backgrounds are very likely to play a role (both in “real” subjective well being and it’s measurement by self report), I think geographical clustering might be obscuring real relationships between GDP and happiness. Even in this case, though, I can think of a meaningful association in which between GDP shapes culture and culture shapes happines.
Ecological suties are hard.
The almost flat horizontal distribution of Asian countries suggests that GDP is of little relevance to happiness.
Or that our measure of happiness is a bad measure of happiness. If you rate 0 as “as unhappy as possible” and 10 as “as happy as possible”, that sounds great, until you realize that someone in a poorer country may define 0 and 10 very differently from someone in a richer country because the person in the richer country may believe it is possible to be happier than the person in the poorer country, and/or may set 0 well above where the poor person puts it. If 0 is “lose my job and girlfriend” for the rich person and “being shot and left to die in a ditch” for the poor person, then the rich person’s 0 may well register much higher on the poor person’s scale. What do they have to complain about? They have a full bank account, a house, have many months to find a job before they’re in real trouble, ect. Meanwhile, the poor person can barely make rent and would be out on the street in a week if they lost their meager income.
I don’t trust any measure of happiness; they’re all way too mushy.
I think the West’s balance of industries is at least as related to its topography and resources than its rainfall.
The gender/rainfall correlation breaks down once you get outside of these areas – for example, Hawaii has the highest rainfall in the country but is pretty male, and Alaska is wetter than most of the West but the most male of all. North Dakota is much more male than South Dakota because it has an oil boom. Etc. I agree farm-ability is one aspect but I don’t think it’s producing the whole effect. I also doubt it dominates the North/South differences.
Topography has a significant impact on rainfall due to rain shadows, so you can’t treat those as totally independent factors either.
I also don’t think that Alaska is a very good counter-example, because like a lot of the West it is inhospitable and poorly suited for farming, just for reasons that have nothing to do with rainfall. Hawaii is hard to compare because islands are different from parts of the mainland in a whole bunch of ways, most obviously in having significantly higher transportation costs to and from the lower 48. And yes, North Dakota’s oil boom has a significant impact on its gender ratio, but Louisiana and Texas also have large oil industries and they are less male than South Dakota, so that clearly isn’t the only factor involved.
As for the North/South difference, I don’t think that difference is quite as pronounced as you make it out to be. The most female states in the scatterplot are Maryland, Massachusetts, Rhode Island, Delaware, and New York, which few people would consider to be part of the South. Meanwhile, Texas is usually considered part of the South and it is both less rainy and more male than, for example, Pennsylvania. Taking a closer look at the scatterplot, it seems to be divided more into East/West clusters than North/South clusters.
As for Louisiana and Texas, they have a lot of oil in absolute terms. They don’t have that much as compared to the rest of the economy as North Dakota.
If the oil economy is split 75% male to 25% female and the rest of the economy is 50/50, a state with 50% oil economy would be split 62.5%/37.5%. A state with a 10% oil economy would be split 52.5%/47.5%.
By only looking at the size of the oil industry you are ignoring a lot of the picture.
Yes, but why are the non-oil sectors of North Dakota’s economy so much smaller than the non-oil sectors of the Texas and Louisiana economies? I suspect that the reasons for that have a lot to do with rainfall.
Rainfall in North Dakota is low, but not as low as the intermountain West. It might be a combination of low rainfall, scarcity of non-petroleum resources, and distance from major waterways.
Portland and Seattle have total number of days with rain far in excess of most all other cities with high annual rainfall (though Rochester is also on this list). It appears there is a correlation between total number of days with rain and high rainfall, but it isn’t overly close eyeballing it. What makes your map even more curious is that the applicable geographic entity surveyed, states, includes states like OR and WA divided by a mountainous curtain that renders one side of the state dry and the other side wet. Thus producing the moderate placement of WA and OR on the overall rainfall chart (lower than TN for heaven’s sake).
Yet, most of the populations of WA and OR are located in the rainy western half of the state. So, how does one evaluate the impact of rain on the m/f balance for places like Portland and Seattle where days with rainfall are high, total amounts of rain are moderately high but where total amount of rainfall for the entire state are middling?
https://www.currentresults.com/Weather/US/average-annual-precipitation-by-city.php
So what you really need is to do is sum the average rainfall*city pop, and divide by the state population to work out how rainy the state appears to its inhabitants.
Or maybe a function of both days of rainfall and total rainfall would be even better.
Of course, this is all pretty silly. If we went down to a level of granularity where ‘rainfall’ has any meaning (cities), then I really doubt there would be much correlation. Washington is a good example of why this won’t work. Either the entire state looks moderate (false), or the entire state looks wet (false, as I had to explain to everyone I met from out of state while living in Eastern Washington.)
Are we sure rainfall is not just a proxy for coastalness and urbanity? In the regional statistics I work with, “urban-rural” maps on to “female-male” rather cleanly–i.e women prefer large cities more than men do.
E.g., cities as harems by Robin Hanson.
Applying the word “harem” to places where the sex ratio is between 1 and 2 is stretching the definition so far that you’re stretching the definition of “stretching the definition”.
That Hanson post does not seem very convincing. If he’s going to evoke 1300s France, he should understand a few basic facts.
Such as the reason people like woodcutters, charcoal burners and shepherds were itinerant was not “Oh, we’re too low-status to get women” , it’s because of the nature of their work/occupations; they were itinerant because things like transhumance (you move your flocks where the grazing is). Woodcutters and charcoal burners, once they’d exhausted resources in an area, moved on to the next until the new growth had restored the first area.
Feck’s sake: “gee, why would men move around even though moving is expensive? oh it must be because they couldn’t get laid”. No, it’s because the occupations you’re using are itinerant ones. 20th/21st century USA urban centres may or may not operate by the same criteria: American populations seem to be expected to be more mobile when it comes to seeking work and taking up employment than in a European context, for one.
I’ll be more impressed with Big Brains Of Big Names when they exhibit some common sense. And this is why I regard a lot of evolutionary psychology “just-so” stories with a jaundiced eye.
Hanson missing the forest for the parasites that live in the bugs that live in the bark on the trees? I’m shocked, shocked!
Okay, tidying up that Hanson suggestion a bit: let’s take 1300s France.
Low-status men are men who don’t have land of their own and are not otherwise settled tradesmen (tinkers are peripatetic semi-skilled tradesmen). They are farm labourers and the likes who are itinerant and peripatetic due to their work. Mainly single because (for instance) a single herdsman can live in a bothán on the side of a hill while pasturing his employer’s cattle (which may be a herd composed of all the cattle owned by various parties in the village) during the summer grazing season; a married* man with a family (and this being the 1300s sex means babies more or less) can’t do likewise.
Low-status women go into jobs like dairymaids on farms, which are not itinerant in the same way, or into domestic service, which means clustering in urban centres for employment. This gives some colourability to Hanson’s “cities have a top tier of a few high-status men and high-status women, a middle tier, and a disproportionately female low-status tier”.
Work for low-status men who don’t have land (or other means to provide for a family): work that is itinerant, largely rural-based
Work for low-status women who don’t have land (or dowries for marriage): work that is sedentary, based in urban centres
This at least avoids the fucking stupidity of “low-status men in 1300s France couldn’t get laid so that’s why they moved about a lot”, because really Mr Hanson, you are going to maintain that there were gangs of virgin male shepherds, charcoal burners, etc. wandering the paysage and avoiding women like the plague of vile seductive temptresses poor but honest men like themselves could not afford to
bangmarry those harpies were? I take my leave to doubt it! Sometimes it may have been convenient for Ploughboy Tom to leave Farmer Jones’ employ and up sticks for the next village because he got Dairymaid Jenny pregnant and wasn’t prepared to/able to marry her. I’m sure a lot of men moved about because they wanted to marry and were trying to earn enough to enable them to do so; that’s not at all the same as “couldn’t attract a sexual partner”. “Couldn’t attract a marriage partner due to lack of assets” is a different thing, and not only low-status males suffered from this; in the 19th century long engagements were common until men in junior positions (like curates, for one instance) could work their way up to a position to enable them to get married. Kipling’s stories have plenty of civil servants out in India not permitted to marry or unable to marry until they had a secure enough position; young single men with no wives would certainly engage in dalliances with the “natives” but the idea of intermarriage was unthinkable, as a rather brutal short story of his about his colleagues intervening to prevent a young Englishman from marrying a Eurasian girl and ruining his life demonstrates.What the hell this has to do with late 20th/early 21st century American cities and the male to female ratio, I have no idea. Industrialisation means that both men and women moved to large urban centres for work and employment opportunities.
“Cities as harems”? What is this guy smoking? I suppose it’s simply “lived all his lives in cities, has no clue what actual country living is like” or am I mistaken?
*This need not be a formal arrangement, it could be a “jumped the bundle” type thing. Point stands: man and woman living together having sex on a regular basis are going to have the patter of little feet on a regular basis as well.
@Dieseach:
This pattern (first money then marriage) is not limited to pre-20/21st century Europe. From talking to people, I’ve come to a conclusion that many in the Czech Vietnamese minority probably also think that way (and presumably Vietnamese Vietnamese do so too) today. First money, they you can hope to find a girl whose parents would not chase you away if you proposed to her. The Vietnamese also tend to be really hard-working, which may have something to do with this (but the women are also, so maybe not).
It might be changing though, since while the first generation Vietnamese immigrants were usually very much against their kids having relationships with Czechs (and Vietnamese parents are supposedly quite strict so doing it against your parents’ will is not an option), I’ve seen mixed pairs (of teenagers or people in their early 20s) much more often over the past few years, which suggest that the next generation is more relaxed about this which provides the Vietnamese with an alternative where they do not have to make money first (however, Vietnamese men tend to be quite small and women usually prefer men taller than themselves, so this could be another problem for them…especially since men usually don’t mind smaller women).
Los Angeles receives less than 15″ of rainfall in an average year, counting as a desert in most classification schemes. It is nonetheless the largest city on the US west coast.
So the scatterplot you put together to illustrate your hypothesis, may not be as pretty as you had hoped.
Are you talking to me? No scatterplots here.
I mean that urbanity might be correlated with rainfall (but imperfectly of course, as the Los Angeles example illustrates), so that it’s the urbanity that drives the gender distribution, not rainfall.
Scott:
There are a few things going on with the rainfall / sex ratio correlation:
– Military bases tend to be in dry parts of the country for reasons of functionality and economy (e.g., land that is too dry for farming is cheap for runways).
– For historical reasons, blacks tend to live in the rainier eastern half of the country, and blacks tend to have a low male to female ratio. First, other races tend to have about 105 males born per 100 females, but blacks only have about 103 males born per females. Second, black men tend to shoot each other or die of AIDS or whatnot at higher rates than other races, so blacks typically have fewer males alive relative to females than other races.
This is why we need more 3-Dimensional graphs, and more and more easy/intuitive ways to present them. Have a third “Europeanness to Asianness” axis for Inty’s example clears up that whole mess.
You can use color.
You CAN use colour, and that appeals to me as a person . . . but then with both 3D and colour you can do 4D graphs!
5D if you use Luminance as well, somehow. Maybe.
Color by itself has three dimensions (red, blue…)
Shape and size of dots could encode more dimensions.
There is no need for “actual” 3D. Just encode dimensions above 2 with color and such. The sky is the limit.
I once tried making a 4D plot using horizontal position, vertical position, point shape and point color but the people who looked at the draft insulted me, so I decided to leave out the least interesting of the dimensions and use point shape and point color redundantly for the third one. So if you want people with IQ below 150 to actually be able to understand the plot, even 4D is stretching it, let alone 5D and more.
The number of degrees of freedom in your display device is not the number of degrees of freedom in your perceiving device.
Data visualization and visual psychology are fields with a lot of literature you can look at to get a better handle on what the limits are (quite lower than “the sky”)
Color has three dimensions at the receptor level but has a rather different set of constraints at the cognitive level. Assigning one channel to each dimension doesn’t really work (people don’t naturally parse yellow as red+green for instance.) Assigning a continuous variable to hue doesn’t work either (heatmaps using rainbow scales constantly perform poorly when tested.)
Color has at least two dimensions at the cognitive level, hue and brightness, and I didn’t read the literature but I think you can assign a continuous variable to hue if you limit it to a narrow range, such as the hues between red and blue.
Furthermore you can use a variety of hues if your goal is not a continuous representation but to distinguish between clusters such as Western, Latin American and so on.
There is a program called “DataDesk” designed for exploratory statistics, things like 3D scatter plots that you could look at from different angles. My father’s comment on it was that it was the first statistics program he had seen with which someone untrained in statistics would do more good than harm.
That sounds pretty positive. I just want readily accessible 3D graphing, and have done since my brief encounter with one in a secondary school IT lesson.
Okay, obviously my self-taught statistics is not as good as I thought.
I thought a P-value was (roughly) the chance that a correlation at least as strong as the one seen could be a result of sampling error.
If there are 48 states in the population, and you sample all 48 of them; or if there are three regions and you sample all three of them; then there’s no possibility of sampling error. The P-value should be zero by definition, right?
Since Scott knows WAY more about statistics than I ever will, I accept that I’m wrong. But what have I misunderstood?
You harbor a common misconception about sampling and the difference between a sample and the sampled population, which I will try to dispell.
You are not sampling from 48 states in order to investigate something about those 48 states. This is useless, as you don’t need to sample: you alredy have the full data you’re interested in. The interest in sampling from 48 states it to draw conclusions that are valid across spacetime (in the past or the future for those 48 states, in the present for territories outside those 48 states or any) and in a counterfactual universe (for example, in which you manipulate rain). If the sampling method is valid, you can go pretty far in answering these questions, as counterintuitive as it might seem. The problem with sampling is that in order for naïve (or not so naïve) statistical methods to work, you have to select the sample randomly from the population. In this case, the ideal would be to select 48 states randomly from different territories and time periods (past and future) and counterfactual universes. If you’re happy with only drawing conclusions that about US, you can sample from the 48 US states alone, but you must still sample from past, future and counterfactual universes. This is obviously impossible. In the real world, your sample is the set of 48 states in the present, and this is the sample you use to answer questions about such things as the possible impact in changing rainfall patterns.
For me, the easiest way to understand this is to think about a clinical trial of a new drug D. You want to see if the drug is effective in treating condition X. What is your population? Is it the set of all patients in the world suffering from X? No! It is the set of patients with condition X who will EVER take the drug, not only in the present but also in the future! This means that you can use as a sample all patients suffering from X right now, even if this is the whole “population” of patients suffereing form X at a given time. Assuming condition X doesn’t change with time (nor does it interact with the changing world in a relevant way), this is valid, because the set of all patients suffering from X right now is a random sample of all patients who suffer or will suffer from X in the future. In practice, you won’t usually study the drug in all patients in the world, unless it is a pretty rare disease, but it IS a valid way to test the drug.
Good (and some not so good) statistics books will explain this to you and prove rigorous results about comparisons between populations and the use of p values. If you’re interested in statistics, I would advise you to get a book and study the basics at least to the point in which you understand the frequentist approach to comparing population means.
It’s really about variation, and sampling error is just one kind.
Each point’s specific value is presumably the outcome of a number of factors, each of which may vary from time to time. *This* data set is going to be different from a future data set because of such factors.
The data could also deviate from the regression line because the actual underlying function (whatever it is) is different or more complicated, of course.
If you measure the entire population, you don’t need inferential statistics. Calculating a p value is nonsense. You cannot have sampling error if you measured every member of the population.
Calculating p values for data like that means that one is implicitly assuming that there is some larger population of (hypothetical) states and we only measured some of them.
I love coming up with situations in my head in which statistical techniques fail spectacularly for a given dataset. I’d like to thank you for your willingness to dive into the literature and find ways in which things do fail spectacularly, and teach me new and different ways in which things can go south (with varying amounts of spectacle).
In this case, this is little more than a variant of Simpson’s Paradox, but Theo’s comment about Moran’t I made me learn something new today. This means I have to thank you for having grown a community of smart and interesting people, from which I learn a lot too.
A different perspective on clustering (equivalent to Scott’s).
Another way of vieweing the problem Scott highlights (the lack of independence between populations that are geographically clustered) is to imagine comparing two perfectly homogeneous countries (with different legal systems, governments, cultures, ethnic backgrounds, diets and GDPs). If you try to correlate the GDP with the crime rate between these countries, you might get a correlation, which won’t be very impressive because there are only 2 datatpoints. Howerver, if you divide country A into states A1, A2, … , A10 and country B into B1, B2, … , B10 you now have 20 datatpoints which will make your correlation shine, even though the data is the same.
Before you compare populations, thing about what would happen to your results if you divided each of the population into 10 subpopulations which are perfectly representative of the parent population. You’ll feel a little dirty comparing populations for the rest of your life.
Does it matter that states have very different population sizes, and so do nations?
Right, with the disclaimer that I know nothing of statistics, isn’t the actual sample size the population size? Every single person is a datapoint. If the way we calculate P causes using population size as sample size to yield really high p-values, that sounds more like a problem of the formula for P.
No, it is the actual number of data points in your sample. If you take one measurement per person then it is the number of persons, if you take one measurement per state it is the number of states etc.
Actually, I detest presentations which actively work against intuition, and I think charts which imply that groupings which have wildly different population sizes are all the same size are a problem. I don’t want to see maps that show something by state– or worse, by country– they show huge regions as having homogeneous large impacts of something which might be more intense somewhere else, or just in a small part of a large region.
For a different sort of not good enough, see this list of Islamist attacks. While the list is a great deal better than nothing, all attacks regardless of death count are the same size on the page.
O/T: is this sounding too good to be true?
I’m wary because (a) I don’t believe there’s any such thing as a free lunch and we’ve been here before with “nuclear energy will make electricity so cheap, it won’t be worth metering!” (b) yes, I’m sorry, I can’t believe a fella in Castlebar has beaten out (say) Silicon Valley entrepreneurs on this (c) there’s always a catch.
All that being said, does it at least sound plausible, or is “nanotechnology” being used in the same sense as “abracadabra”?
I was impressed by this part, seeing as how we’ve spoken about robots and automation (emphasis mine):
What day was it published?
Says April 3 right up top, so if it’s an April Fool’s joke they were a bit late.
They have a website so I don’t think it’s a spoof story (at least, not from a journalism angle; the header image the website uses makes me roll my eyes and facepalm, though: obviously-a-model standing in front of a blackboard covered with cod-equations is not looking very rigorous from a science viewpoint).
It sounds like yet another get-rich-quick scheme that is throwing around a lot of buzzwords, riding on the back of “climate change: Something Must Be Done” and enticing investors to sink a lorryload of cash into their
researchcompany, until they get bought out by Google or somebody and the founders retire to sit on a heap of money while the crowd that took them over get stuck with the “uhhhh – this is not reaping the results promised” aftermath.But I know Sweet Fanny Adams about the tech or the science, so maybe I’m doing the equivalent of the guy who turned down Steve Jobs?
Yeah, they’re clearly representing themselves as a legit company. I don’t know enough about solar power to evaluate the scientific claims, not that they give us much detail to go on, but since I’m not in a position to invest with them anyway I’m happy to let others go first and see how well it performs. Although they claim to have more than 6,000 of these systems installed and running already, so clearly others have already gone first and it would be very interesting to hear what some of them have to say about it.
The first thing that’s off putting about the text you quote is claims like “80 percent efficiency” or even “up to 100 percent efficiency”!
100 percent! A typical solar panel these days, have efficiencies from 10% to 20% (maybe a bit more?). Using exotic (and very expensive I hear) materials some people did panels with ~45% efficiency. Thermodynamic limit of efficiency of solar panels was around 60% at most if I remember right.
This suggests that there’s a wool-putting-over-the-eyes attempt in some way, Thermodynamics being the ultimate limit and all. (Or maybe this is a late April Fools?)
Source: I studied Solar Energy on an intro level and did my graduation project on solar heating. (Physics major)
Yeah, that’s a reason I’m very sceptical about the report as-is. “We have an incredible new technology that gets results way, way above anything else in the field!” always sounds a bit dodgy and frankly is more along the lines of “I have invented a perpetual motion machine, even though they said it couldn’t be done!”
Then again, it’s not a science report but a business report-cum-breathless cheerleading. That’s why I’m wondering if there is any factual grain of sand re: nanotechnology in the story, because if this bloke is doing something that can reputably get better results, it would be fascinating.
But I definitely would like to see more hard facts and less “this is gonna make pots of money!” reporting.
The efficiency claim is enough to suggest you run, not walk, from that one. Current mass market utility solar PV gets about 15%. The best (and most expensive) commercial solar panels get in the high 20s with the theoretical maximum efficiency around 35%. See, http://physics.ucsd.edu/do-the-math/2011/09/dont-be-a-pv-efficiency-snob/
So, their efficiency claim probably is impossible, even in theory.
Nothing involving converting energy is 100% efficient. It would violate thermodynamics if it were. If I recall correctly, the current theoretical maximum is around 80%.
An additional point of skepticism is that he says that it is based off of nano-technology and it is difficult to explain how it works. Aka: Don’t look at the man behind the curtain. At least he didn’t invoke ‘quantum mechanics’.
Thirdly, the article states he was 700K in debt and lacked assets 13 years ago. This sounds like an underdog setup and raises the question of where the development funding came from. His background is in electronics and finance, not physics.
That part in bold is another point in favor of this being BS. It is simply trying to curry emotional favor. It is also rather nonsensical, as I can make any task require an infinite number of jobs if I add enough pointless steps.
Then there is this, which contradicts earlier statements:
“Every stage highlighted there was more scope. Then I got to 83pc efficiency with Photonomi’s technology and I can’t see it progressing much more than that.” – I bet this is the truest statement about the tech in the whole article.
I don’t like dismissing people just because they use the word “efficiency” without regard to the first law of thermodynamics. The word predates Kelvin and Carnot by about three hundred years; it has legitimate colloquial uses, and even in technical contexts the definition isn’t always “work output divided by energy input”. Rather like laughing smugly at someone trying to sell “organic” food; yes you’re very smart to know that all food is organic, but it’s possible you just walked past the best food on that particular grocery store shelf.
That said, looking for more detail, I find nothing on their web site, and a broader search comes up with this white paper. Which is also lacking in hard technical detail, but talks about turning low-temperature diffuse energy into concentrated high temperatures to run a heat engine in a way that either violates the second law or is hiding a very thermodynamically inefficient step somewhere. And if they know enough to A: actually build such a gadget and B: use these words to describe it, they ought to know enough to recognize that using the words that way will have every hard scientist and engineer in the audience running away thinking “fraud”!
Which may still leave them enough of a market to make megabucks, so long as all they have to deliver are hopes and dreams and can skip town before they are called on for kilowatts or BTUs.
Lets see.
They claim it’s protected by trade secrets, not patents and the only thing that appears published about it is this:
http://www.surfacepower.com/pdf/Photonomi-group-white-paper-on-daylight-energy-nanotechnology.pdf
Their website appears to be little more than a collection of stock photos and their locations are a few little offices.
If they’d really got something working that did this they’d patent it worldwide and make hundreds of billions even if they only charged a pittance for the patent.
Otherwise someone will take it apart, figure it out and be selling their own copy within 6 months. If it isn’t all hot air.
Realistically I’m betting that they generate a load of investor hype, get a pile of money and then the people with the money will disappear to a beach in some country without an extradition treaty.
That paper makes me want to punch this guy in the face.
So basically “and then magic happens” 🙂
Nice collection of jargony buzzwords, should soak a few investors for a good chunk of cash, and presumably he’s hoping some big
greedyfar-sighted company will swoop in and buy him out before he has to produce some actual results to go along with this hoopla.Good lord is that serious? It looks like they literally just tacked “nano” and “laminar” in there as many times as possible and hoped it sounded sciencey. “Magic happens” would be more believable.
Note: laminar applies to fluids, not photons. I guess photons are pretty “nano” though.
I guess photons are pretty “nano” though.
I’ve got radios that deal in photons taller than I am 🙂
Are you certain?
Yes, but now I can’t find where I put them.
It is probably not a coincidence that the Philippines are right next to the Latin American clusters seeing as how they are a former Spanish colony.
Do you suggest that the Spanish spread happiness around the world? If only had every country peacefully resigned to the might of the conquistadors. The world of Spanish hegemony would have been a much happier place today! 🙂
Great post!
You write “I think most real studies are smart enough to control for this” but unfortunately in cross-national studies in psychology, this error is the norm rather than the exception (and regularly published in top journals). You can control for the clustering using spatial regression models (as I think someone noted before) but that does not address the fact that sometimes relations are different at different levels (individual, state, country, region). In many cases the level at which the relation is found does matter from a theoretical point of view.
We have commented on some especially problematic examples, see http://journal.frontiersin.org/article/10.3389/fpsyg.2014.01110/full and
http://www.sciencedirect.com/science/article/pii/S0022103115000657
This has long been recognized in comparative organismal biology (since 1985), with the fundamental error being non-independence of data points – unlike rolls of the dice where each roll is independent, more closely related species will (generally) have more similar traits. There’s even explicit statistical methods to correct for it, called Phylogenetic Independent Contrasts (now under an umbrella term of Phylogenetic Comparative Methods), which can measure things like correlated evolution, phylogenetic signal (i.e. influence of ancestry), multiple optima, etc. Conversely, there is also a paper titled “Why not to do two-species comparative studies: limitations on inferring adaptation”, which more broadly points out that it’s no longer excusable to treat species as independent anymore.
The problem, for these graphs and in biology, is how the points are related; in biology, you need to know the phylogeny to use these methods, while in other cases you need to know, for instance, how to group the various states/countries. I guess we’re lucky, because we only have one type of relationship to worry about (ancestry), while in something like economics, there’s a constantly shifting web of numerous, diffuse and hard-to-quantify relationships, any or all of which could have varying levels of influence.
How is this different from plain old confounding? Southerness causes both rainfall and excess-of-women?
In a plain old confounder, all the datapoints are still independent, but the cause is different (e.g. “murder rates go up in the summer as do ice cream sales, but instead of ice cream causing murder or vice versa, high temperatures cause both”). In non-independence, there are fewer datapoints than it seems because they aren’t truly independent of each other (“e.g. increased herbivory correlates with smaller size, but we only looked at rodents and cats”). In the first case, you still have N data points, you just need to add another measurement to each (daily/weekly temperature). In the latter, because of the strong effect of taxon membership on diet and size, you really only have 2 data points.
If I take daily measurements of ice cream sales and the drowning rate over a year, I will also have very few data points (the season) plus whatever other things are causing inter-season variance.
In other words, confounders cause non-independence. I suppose that non-independence does not always cause (linear) confounders.
Is that the difference (that confounders are modeled as linear)? Or is the difference that confounders are adversarial-nondeterministic and non-independence is random?
EDIT:
I think my confusion was sample-level vs. model-level. If your model includes confounders that you are not aware of, that will make your samples interdependent in arbitrarily annoying ways.
Are the changing seasons a confounder or non-independence? Is college racism (https://slatestarcodex.com/2014/12/03/framing-for-light-instead-of-heat/) a confounder?
Scott, it doesn’t work that way
Correlation is not causation. But it certainly doesn’t preclude causation. (Indeed, in a causal relationship, you’d expect to see correlation.)
For what it’s worth, there is a very strong correlation between self-reported happiness and fertility rates – at least when you look at high average IQ countries only. See my posts:
A Tale of Three Maps – The Unz Review
Fertility and Happiness: A Global Perspective – The Unz Review
Also for what it’s worth, if you use a somewhat objective metric, happiness around the world correlates with suicide rates.
What are you disagreeing with me on? Do you think that income is related to happiness, through fertility or something?
I am saying that once you adjust for culture, income and happiness may not even be correlated, forget about causal.
I think he’s saying happier people tend to have more children (because of optimism about the future, perceptions that society affords your kids more chances to get on in life, ability to afford them, perceived ability to afford them – e.g. the economy is going great, wages are going up, we can re-mortgage our newly valuable property etc.) which gives a higher fertility rate, and that this may align with higher income.
Money doesn’t make you happy but it allows you to buy a better grade of misery 🙂
I think it goes both ways with kids. Folks who are optimistic (which would correlate with happiness) about the future will have more kids, but also having children itself can bring happiness to many. Kids–at least until their teen years–have this sort of unconditional love and insist on a lot of interpersonal contact which tends to make one happier.
Probably doesn’t do enough to counter clinical depression, and certainly won’t counter horrible economic times, but having family around helps.
If income and happiness are both correlated with culture, then a causal link is suggested.
“(Indeed, in a causal relationship, you’d expect to see correlation.)”
Not necessarily: see http://worthwhile.typepad.com/worthwhile_canadian_initi/2010/12/milton-friedmans-thermostat.html
For the lazy,
“If a house has a good thermostat, we should observe a strong negative correlation between the amount of oil burned in the furnace (M), and the outside temperature (V). But we should observe no correlation between the amount of oil burned in the furnace (M) and the inside temperature (P). And we should observe no correlation between the outside temperature (V) and the inside temperature (P).
An econometrician, observing the data, concludes that the amount of oil burned had no effect on the inside temperature. Neither did the outside temperature. The only effect of burning oil seemed to be that it reduced the outside temperature. An increase in M will cause a decline in V, and have no effect on P.
A second econometrician, observing the same data, concludes that causality runs in the opposite direction. The only effect of an increase in outside temperature is to reduce the amount of oil burned. An increase in V will cause a decline in M, and have no effect on P.
But both agree that M and V are irrelevant for P. They switch off the furnace, and stop wasting their money on oil.”
Ahem.
> Western Europe, which is both happier and richer than the rest of the world.
HELL YEAH WE ARE, WOO
We’re richer, and we like to tell ourselves we’re happy!
See? Look how wide we smile! We’re happy! Happy happy happy! Unhappiness is a sign of bad luck or lack of success!
Happy!
Grrrrrrr>.<
I’m not going to stop feeling good because you think I should do so, thank you.
I’d love to read a collection of these sort of “beware what you read in the news” stories compiled into a guide to critically assessing news/blog stories (aimed at those without background in that sort of thing), Something like a mini sequences for critical thinking, but instilled with Scott’s intellectual charity and fairness rather than “winning” like LW. It seems like there’s so many good articles and comments on SSC that its a shame not to spend a little more time organizing it into something more structured/systematic. Or perhaps somebody could suggest something like that that already exists?
http://nothingismere.com/2015/09/12/library-of-scott-alexandria/
Not exactly what I was thinking, but I’ve seen this and its a great resource thanks!
“This is the average yearly rainfall in the lower 48 US states vs. their gender balance (measured in number of men per 100 women). The correlation is about r = 0.84 (p ≤ 0.0001), much higher than anyone’s ever found between guns and crime, or income and happiness, or most other things people make regional scatterplots about. So what’s going on? Do women cause rainfall? Does rain drive men away? Or is there some confounder that causes both rain and womanhood?
I don’t think it’s any of these things. I think it’s a coincidence.”
——————————-
I’m probably misunderstanding this, but I don’t see why you’re convinced that there isn’t a real causal relationship here
specifically, that lack of rainfall causes a place to have a lot of industries that are male dominated (mining, oil extraction, etc etc), which in turn causes the gender balance to tip towards men
conversely lots of water leads to agriculture based development original, which squares reasonably well with keeping a lot of women around
why isn’t that a real causal relationship?
You seem to be saying, “well holding the thing that’s the causal relationship constant, there’s no relationship”
I’m confused as to why you’re doing that
I’m amazed at the gender/rainfall correlation in North American countries. Does is also hold true in the Latin American country of Puerto Rico?
Neighboring Russia ruins any chances of happiness.
Lol. I lived in Russia for a time (three years to be exact). The people are incredibly hospitable and warm, but depression and existential hopelessness is like the national pastime. The thing the Russians are most proud of is that they are really good at toughing out the terrible situations that happen (usually because they put themselves into it). Their culture exalts a sort of grim determination with no hope.
Zhalka Zhalka.
In Soviet Russia, the depression has you? 🙂
Statistics are completely useless without an underlying hypothesis/model for your data.
The main problem with the first chart is that it links gun deaths (not all deaths) with gun ownership. Well no shit, more microwaves owned means more microwave-associated burns, but that doesn’t mean that they are evil demon-possessed contraptions that need to be banned. But I think we are trying to use policy to reduce violence in general, not just one special kind of violence.
I understand why you’re annoyed, but I’m prepared to allow it since gun deaths are a big fraction of total deaths, and other deaths aren’t inversely correlated with gun deaths (yes, I checked). That means gun deaths is just a less noisy way of looking at the (large) component of total deaths that might respond to measures relating to guns.
But there’s a (small) negative correlation between all homicide and gun ownership in developed countries.
http://crimeresearch.org/wp-content/uploads/2014/03/OECD-and-Small-Arms-Survey.png
When it comes to states, I found this with a cursory google search. Similar to developed countries: basically no correlation
http://i.stack.imgur.com/eEGky.jpg
Why would we just exclude this data?
I’ve never seen anyone define “developed country” to mean OECD member before.
Are you trying to say that the data set isn’t good enough?
No, the data set was not good enough to deceive me.
Here is another correlation among ✌️developed✌️ countries: population and per capita homicide.
The companion piece to “beware scatterplots” ought to be “beware any fitted correlation that is clearly driven by a few outliers” (which is a condition one checks for by looking at a scatterplot)
This fails to consider the situation where other deaths have several components, and one of those components is correlated with gun deaths and another component is inversely correlated, and the inversely correlated component reacts more strongly to measures related to guns than the regular component.
For instance, suppose high crime areas have two components:
1) More deaths of all kinds, including more gun deaths, due to crime
2) Fewer deaths because guns are successfully used in self-defense.
Measures intended to control guns may very well affect the second component more than the first.
“gun deaths are a big fraction of total deaths”
???
Looking at your chart, the highest figure seems to be about 18/100,000. If everyone lived to a hundred in a steady state world, total deaths would be 1000/100,000. So gun deaths in the highest death state are something well under two percent of total deaths.
That’s a big fraction? Am I missing something?
Possibly “deaths” should be implicitly read as “deaths of young healthy people that we might be able to prevent, as opposed to sickly old people who are going to die of something pretty soon no matter what”.
But even then the “gun deaths” are far from being a majority, particularly once you exclude the ones that come from old people committing suicide.
I thought Scott addressed this reasonably well in his original gun post, fwiw.
Speaking of happiness and scatter-plots, some of you might enjoy the online game “Guess the Correlation,” by Omar Wagih. Just stumbled across science writer Ed Yong’s delightful description of how addictive it is. (“Please make it stop,” he begs!)
“The 8 Bit Game That Makes Statistics Addictive”, at:
http://www.theatlantic.com/science/archive/2016/03/the-8-bit-game-that-makes-statistics-addictive/475848/
Dryness ~ male surplus is related to the fact that military bases tend to be located in lightly populated Western states: Air Force bases tend to be in sunny places that are good for flying (e.g., Area 51 in NV is intentionally a clone of the Right Stuff test pilot base at Edwards AFB in CA: the CIA and Lockheed guys flew around looking for a superflat dry lake bed ideal for an extra-long runway and found one at Groom Lake in NV).
Other military bases (e.g., armor-training Fort Irwin in the Mojave Desert) are where vast tracts of land can be bought up cheap because you can’t grow crops on them for lack of rainfall.
It would seem like you could take the same content as this post and righly headline it “Embrace Regional Scatterplots.” If you can take datapoints from 50 states and notice that there are only a couple of causal factors driving the variation, well, that’s a triumph for science.
What about ex-communist state Kyrgyzstan? It was a part of USSR and on the graph is pretty happy?
I think there need to be some serious qualifiers on this argument, that currently aren’t there.
I paraphrase your argument as
“””
P(observed correlation) = 1 = P(causal relationship) + P(confounded relationship) + (p-value = P(points randomly form observed correlation)) + P(clusters exist) * P(clusters randomly line up in observed correlation)
Often P(clusters exist) is high and P(clusters randomly line up) is around .1 because there are only three clusters, so your P(observation|not causal or confounded) is not legitimately anywhere near as small as your calculated p-value.
“””
I think this argument makes sense. However, in your post, you completely gloss over the P(clusters exist).
In Inty’s example, we have a ethnic and cultural division between Europe and Asia- the cultural division makes P(Asia and Europe clusters in suicide rates exist) reasonably high, and the ethnic division makes P(Asia and Europe clusters in allele frequency exist) reasonably high.
In the rainfall/MF example, you have a geographic division that makes P(southern, mountainous, and other clusters in rainfall quantity exist) reasonably high, but you never establish that P(geographic clusters in MF ratio exist) is reasonably high.
This is important because P(clusters randomly exist && clusters randomly line up) < P(points randomly line up), because the first strictly implies the second and contains additional claims.
As such, I find this argument compelling in Inty's case and the income/happiness case, but highly dubious in the rainfall/MF ratio case.
Nate Silver of 538 just linked this post (http://fivethirtyeight.com/features/more-democrats-are-feeling-the-bern-probably/). Has SSC infiltrated the public consciousness? Or at least, the consciousness of politically-aware data nerds?
I took this warning to heart! And I remembered it today, when I came across the following article:
http://www.pewresearch.org/fact-tank/2016/04/19/5-ways-americans-and-europeans-are-different
Specifically, the infographic titled: “Generally, poorer nations tend to be religious; wealthy less so, except for U.S.”
http://www.pewresearch.org/fact-tank/2016/04/19/5-ways-americans-and-europeans-are-different/ft_16-04-14_religioussalience-update/
In that regional scatterplot, some countries are clustered with others in the same region. The most obvious exception is Asia/Pacific, which has a greater range for both wealth and religious salience. I’m curious to know what others think: does the the poverty/religious salience correlation seem to be somewhat cluster-driven?
Religiosity and income both appear to be cluster-driven. The US is an outlier in terms of religiosity, but fits in with the Anglosphere in terms of income (though it is the richest).
I’m not sure that it is a particularly useful correlation, though. Look at how spread out the Asian countries are; Vietnam, South Korea, Japan, and China have pretty variable income but similar levels of religiousity. That suggests that other things are afoot, I think – the most likely being culture. Nearby countries tend to have their cultures influence each other, and culture probably influences both income and religiosity. The high variability in that region of Asia may indicate that Vietnam is in a good place to develop and will become another Asian Tiger once its economic practices change, or that there is some other X-factor which Vietnam happens to be missing.