
[Epistemic status: This is really complicated, this is not my field, people who have spent their entire lives studying this subject have different opinions, and I don’t claim to have done more than a very superficial survey. I welcome corrections on the many inevitable errors.]
I.
Newspapers report that having a better teacher for even a single grade (for example, a better fourth-grade teacher) can improve a child’s lifetime earning prospects by $80,000. Meanwhile, behavioral genetics studies suggest that a child’s parents have minimal (non-genetic) impact on their future earnings. So one year with your fourth-grade teacher making you learn fractions has vast effects on your prospects, but twenty-odd years with your parents shaping you at every moment doesn’t? Huh? I decided to try to figure this out by looking into the research on teacher effectiveness more closely.
First, how much do teachers matter compared to other things? To find out, researchers take a district full of kids with varying standardized test scores and try to figure out how much of the variance can be predicted by what school the kids are in, what teacher’s class the kids are in, and other demographic factors about the kids. So for example if the test scores of two kids in the same teacher’s class were on average no more similar than the test scores of two kids in two different teachers’ classes, then teachers can’t matter very much. But if we were consistently seeing things like everybody in Teacher A’s class getting A+s and everyone in Teacher B’s class getting Ds, that would suggest that good teachers are very important.
Here are the results from three teams that tried this (source, source, source):
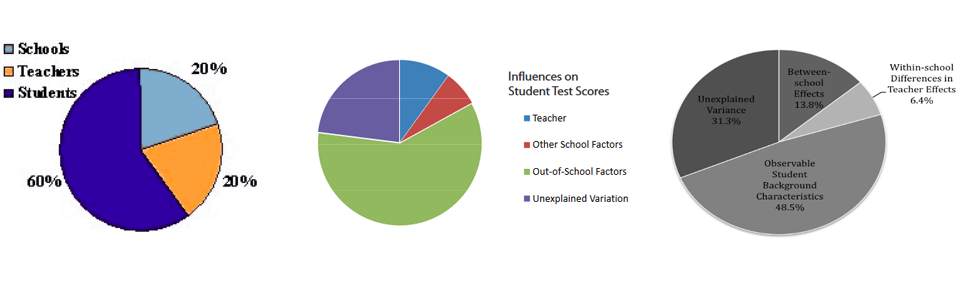
These differ a little in that the first one assumes away all noise (“unexplained variance”) and the latter two keep it in. But they all agree pretty well that individual factors are most important, followed by school and teacher factors of roughly equal size. Teacher factors explain somewhere between 5% and 20% of the variance. Other studies seem to agree, usually a little to the lower end. For example, Goldhaber, Brewer, and Anderson (1999) find teachers explain 9% of variance; Nye, Konstantopoulos, and Hedges (2004) find they explain 13% of variance for math and 7% for reading. The American Statistical Association summarizes the research as “teachers account for about 1% to 14% of the variability in test scores”, which seems about right.
So put more simply – on average, individual students’ level of ability grit is what makes the difference. Good schools and teachers may push that a little higher, and bad ones bring it a little lower, but they don’t work miracles.
(remember that right now we’re talking about same-year standardized test scores. That is, we’re talking about how much your fourth-grade history teacher affects your performance on a fourth-grade history test. If teacher effects show up anywhere, this is where it’s going to be.)
Just as it’s much easier to say “this is 40% genetic” than to identify particular genes, so it’s much easier to say “this is 10% dependent on school-level factors and 10% based on teacher-level factors” then to identify what those school-level and teacher-level factors are. The Goldhaber study above tries its best, but the only school-level variable they can pin down is that having lots of white kids in your school improves test scores. And as far as I can tell, they don’t look at socioeconomic status of the school or its neighborhood, which is probably what the white kids are serving as a proxy for. Even though these “school level effects” are supposed to be things like “the school is well-funded” or “the school has a great principal”, I worry that they’re capturing student effects by accident. That is, if you go to a school where everyone else is a rich white kid, chances are that means you’re a rich white kid yourself. Although they try to control for this, having a couple of quantifiable variables like race and income probably doesn’t entirely capture the complexities of neighborhood sorting by social class.
In terms of observable teacher-level effects, the only one they can find that makes a difference is gender (female teachers are better). Teacher certification, years of experience, certification, degrees, et cetera have no effect. This is consistent with most other research, such as Miller, McKenna, and McKenna (1998). A few studies that we’ll get to later do suggest teacher experience matters; almost nobody wants to claim certifications or degrees do much.
One measurable variable not mentioned here does seem to have a strong ability to predict successful teachers. I’m not able to access these studies directly, but according to the site of the US Assistant Secretary of Education:
The most robust finding in the research literature is the effect of teacher verbal and cognitive ability on student achievement. Every study that has included a valid measure of teacher verbal or cognitive ability has found that it accounts for more variance in student achievement than any other measured characteristic of teachers (e.g., Greenwald, Hedges, & Lane, 1996; Ferguson & Ladd, 1996; Kain & Singleton, 1996; Ehrenberg & Brewer, 1994).
So far most of this is straightforward and uncontroversial. Teachers account for about 10% of variance in student test scores, it’s hard to predict which teachers do better by their characteristics alone, and schools account for a little more but that might be confounded. In order to say more than this we have to have a more precise way of identifying exactly which teachers are good, which is going to be more complicated.
II.
Suppose you want to figure out which teachers in a certain district are the best. You know that the only thing truly important in life is standardized test scores [citation needed], so you calculate the average test score for each teacher’s class, then crown whoever has the highest average as Teacher Of The Year. What could go wrong?
But you’ll probably just give the award to whoever teaches the gifted class. Teachers have classes with very different ability, and we already determined that innate ability grit explains more variance than teacher skill, so teachers who teach disadvantaged children will be at a big, uh, disadvantage.
So okay, back up. Instead of judging teachers by average test score, we can judge them by the average change in test score. If they start with a bunch of kids who have always scored around twentieth percentile, and they teach them so much that now the kids score at the fortieth percentile, then even though their kids are still below average they’ve clearly done some good work. Rank how many percentile points on average a teacher’s students go up or down during the year, and you should be able to identify the best teachers for real this time.
Add like fifty layers of incomprehensible statistics and this is the basic idea behind VAM (value-added modeling), the latest Exciting Educational Trend and the lynchpin of President Obama’s educational reforms. If you use VAM to find out which teachers are better than others, you can pay the good ones more to encourage them to stick around. As for the bad ones, VAM opponents are only being slightly unfair when they describe the plan as “firing your way to educational excellence”.
A claim like “VAM accurately predicts test scores” is kind of circular, since test scores are what we used to determine VAM. But I think the people in this field try to use the VAM of class c to predict the student performance of class c + 1, or other more complicated techniques, and Chetty, Rothstein, and Rivkin, Hanushek, and Kane all find that a one standard deviation increase in teacher VAM corresponds to about a 0.1 standard deviation increase in student test scores.
Let’s try putting this in English. Consider an average student with an average teacher. We expect her to score at exactly the 50th percentile on her tests. Now imagine she switched to the best teacher in the whole school. My elementary school had about forty teachers, so this is 97.5th percentile eg two standard deviations above the mean. A teacher whose VAM is two standard deviations above the mean should have students who score on average 0.2 standard deviations above the mean. Instead of scoring at the 50th percentile, now she’ll score at the 58th percentile.
Or consider the SAT, which is not the sort of standardized test involved in VAM but which at least everybody knows about. Each of its subtests is normed to a mean of 500 and an SD of 110. Our hypothetical well-taught student would go from an SAT of 500 to an SAT of 522. Meanwhile, average SAT subtest score needed to get into Harvard is still somewhere around 740. So this effect is nonzero but not very impressive.
But what happens if we compound this and give this student the best teachers many years in a row? Sanders and Rivers (also Jordan, Mendro, and Weerasinghe) argue the effects are impressive and cumulative. They compare students in Tennessee who got good teachers three years in a row to similar students who got bad teachers three years in a row (good = top quintile; bad = bottom quintile, so only 1/125 students was lucky or unlucky enough to qualify). The average bad-bad-bad student got scores in the 29th percentile; the average good-good-good student got scores in the 83rd percentile – which based on the single-teacher results looks super-additive. This is starting to sound a lot more impressive, and maybe Harvard-worthy after all. In fact, occasionally it is quoted as “four consecutive good teachers would close the black-white achievement gap” (I’m not sure whether this formulation requires also assigning whites to four consecutive bad teachers).
A RAND education report criticizes these studies as “using ad hoc methods” and argue that they’re vulnerable to double-counting student achievement. That is, we know that this teacher is the best because her students get great test scores; then later on we return and get excited over the discovery that the best teachers’ students get great test scores. Sanders and Rivers did some complicated things that ought to adjust for that; RAND runs simulations and finds that depending on the true size of teacher effects vs. student effects, those complicated things may or may not work. They conclude that “[Sanders and Rivers] provide evidence of the existence and persistence of teacher or classroom effects, but the size of the effects is likely to be somewhat overstated”.
Gary Rubinstein thinks he’s debunked Sanders and Rivers style studies. I strongly disagree with his methods – he seems to be saying that the correlation between good teaching and good test scores isn’t exactly one and therefore doesn’t matter – but he offers some useful data. Just by eyeballing and playing around with it, it looks like most of the gain from these “three consecutive great teachers” actually comes from the last great teacher. So the superadditivity might not be quite right, and Sanders and Rivers might just be genuinely finding bigger teacher effects than anybody else.
At what rate do these gains from good teachers decay?
They decay pretty fast. Jacob, Lefgren and Sims find that only 25% of gains carry on to the next year, and only 15% to the year after that. That is, if you had a great fourth grade teacher who raised your test scores by x points, in fifth grade your test scores will be 0.25x higher than they would otherwise have been. Kane and Rothstein find much the same. A RAND report suggests 20% persistence after one year and 10% persistence after two. Jacob, Lefgren, and Sims find that only 25% of gains remain after one year, and about 13% after two years, after which it drops off much more slowly. All of this contradicts Sanders and Rivers pretty badly.
None of these studies can tell us whether the gains go all the way to zero after a long enough time. Chetty does these calculations and finds that they stabilize at 25% of their original value. But this number is higher than the two-year number for most of the other studies, plus Chetty is famous for getting results that are much more spectacular and convenient than anybody else’s. I am really skeptical here. I remember a lot more things about last year than I do about twenty years ago, and even though I am pretty sure that my sixth grade teacher (for some weird reason) taught our class line dancing, I can’t remember a single dance step. And remember Louis Benezet’s early 20th century experiments with not teaching kids any math at all until middle school – after a year or two they were just as good as anyone else, suggesting a dim view of how useful elementary school math teachers must be. And even Chetty doesn’t really seem to want to argue the point, saying that his results “[align] with existing evidence that improvements in education raise contemporaneous scores, then fade out in later scores”.
In summary, I think there’s pretty strong evidence that a +1 SD increase in teacher VAM can increase same-year test scores by + 0.1 SD, but that 50% – 75% of this effect decays in the first two years. I’m less certain how much these numbers change when one gets multiple good or bad teachers in a row, or how fully they decay after the first two years.
III.
When I started looking for evidence about how teachers affected children, I expected teachers’ groups and education specialists to be pushing all the positive results. After all, what could be better for them than solid statistical proof that good teachers are super valuable?
In fact, these groups are the strongest opponents of the above studies – not because they doubt good teachers have an effect, but because in order to prove that effect you have to concede that good teaching is easy to measure, which tends to turn into proposals to use VAM to measure teacher performance and then fire underperformers. They argue that VAM is biased and likely to unfairly pull down teachers who get assigned less intelligent lower-grit kids.
It’s always fun to watch rancorous academic dramas from the outside, and the drama around VAM is really a level above anything else I’ve seen. A typical example is the blog VAMboozled! with its oddly hypnotic logo and a steady stream of posts like Kane Is At It Again: “Statistically Significant” Claims Exaggerated To Influence Policy. Historian/researcher Diane Ravitch doesn’t have quite as cute an aesthetic, but she writes things like:
VAM is Junk Science. Looking at children as machine-made widgets and looking at learning solely as standardized test scores may thrill some econometricians, but it has nothing to do with the real world of children, learning, and teaching. It is a grand theory that might net its authors a Nobel Prize for its grandiosity, but it is both meaningless in relation to any genuine concept of education and harmful in its mechanistic and reductive view of humanity.
But tell us how you really feel.
I was originally skeptical of this, but after reading enough of these sites I think they have some good points about how VAM isn’t always a good measure.
First, it seems to depend a lot on student characteristics; for example, it’s harder to get a high VAM in a class full of English as a Second Language students. It makes perfect sense that ESL students would get low test scores, but since VAM controls for prior achievement you might expect them to get the same VAM anyway. They don’t. Also, a lot of VAM models control for student race, gender, socioeconomic status, et cetera. I guess this is better than not doing this, but it seems to show a lack of confidence – if controlling for prior achievement was enough, you wouldn’t need to control for these other things. But apparently people do feel the need to control for this stuff, and at that point I bring up my usual objection that you can never control for confounders enough, and also all to some degree these things are probably just lossy proxies for genetics which you definitely can’t control for enough.
Maybe because of this, there’s a lot of noise in VAM estimates. Goldhaber & Hansen (2013) finds that a teacher’s VAM in year t is correlated at about 0.3 with their VAM in year t + 1. A Gates Foundation study also found reliabilities from 0.19 to 0.4, averaging about 0.3. Newton et al get slightly higher numbers from 0.4 to 0.6; Bessolo a wider range from 0.2 to 0.6. But these are all in the same ballpark, and Goldhaber and Hanson snarkily note that standardized tests aimed to assess students usually need correlations of 0.8 to 0.9 to be considered valid (the SAT, for example, is around 0.87). Although this suggests there’s some component of VAM which is stable, it can’t be considered to be “assessing” teachers in the same way normal tests assess students.
Even if VAM is a very noisy estimate, can’t the noise be toned down by averaging it out over many years? I think the answer is yes, and I think the most careful advocates of VAM want to do this, but President Obama wants to improve education now and a lot of teachers don’t have ten years worth of VAM estimates.
Also, some teachers complain that even averaging it out wouldn’t work if there are consistent differences in student assignment. For example, if Ms. Andrews always got the best students, and Mr. Brown always got the worst students, then averaging ten years is just going to average ten years of biased data. Proponents argue that aside from a few obvious cases (the teacher of the gifted class, the teacher of the ESL class) this shouldn’t happen. They can add school-fixed effects into their models (eg control for average performance of students at a particular school), leaving behind only teacher effects. And, they argue, which student in a school gets assigned which teacher ought to be random. Opponents argue that it might not be, and cite Paufler and Amrein-Beardsley‘s survey of principals, in which the principals all admit they don’t assign students to classes randomly. But if you look at the study, the principals say that they’re trying to be super-random – ie deliberately make sure that all classes are as balanced as possible. Even if they don’t 100% achieve this goal, shouldn’t the remaining differences be pretty minimal?
Maybe not. Rothstein (2009) tries to “predict” students’ fourth-grade test scores using their fifth-grade teacher’s VAM and finds that this totally works. Either schools are defying the laws of time and space, or for some reason the kids who do well in fourth-grade are getting the best fifth-grade teachers. Briggs and Domingue not only replicate these effects, but find that a fifth-grade teacher’s “effects” on her students in fourth-grade is just as big as her effect on her students when she is actually teaching them, which would suggest that 100% of VAM is bias. Goldhaber has an argument for why there are statistical reasons this might not be so damning, which I unfortunately don’t have enough understanding grit to evaluate.
Genetics might also play a role in explaining these results (h/t Spotted Toad’s excellent post on the subject). A twin study by Robert Plomin does the classical behavioral genetics thing to VAM and finds that individual students’ nth grade VAM is about 40% to 50% heritable. That is, the change in your test scores between third to fourth grade will probably be more like the change in your identical twin’s test scores than like the change in your fraternal twin’s test scores.
At first glance, this doesn’t make sense – since VAM controls for past performance, shouldn’t it be a pretty pure measure of your teacher’s effectiveness? Toad argues otherwise. One of those Ten Replicated Findings From Behavioral Genetics is that IQ is more shared environmental in younger kids and more genetic in older kids. In other words, when you’re really young, how smart you are depends on how enriched your environment is; as you grow older, it becomes more genetically determined.
So suppose that your environment is predisposing you to an IQ of 100, but your genes are predisposing you to an IQ of 120. And suppose (pardon the oversimplification) that at age 5 your IQ is 100, at age 15 it’s 120, and change between those ages is linear. Then every year you could expect to gain 2 IQ points. Now suppose there’s another kid whose environment is predisposing her to an IQ of 130, but whose genes are predisposing her to an IQ of 90. At age 5 her IQ is 130, at age 15 it’s 90, and so every year she is losing 4 IQ points. And finally, suppose that your score on standardized tests is exactly 100% predicted by your IQ. Since you gain two points every year, in fifth grade you’ll gain two points on your test, and your teacher will look pretty good. She’ll get a good VAM, a raise, and a promotion. Since your friend loses four points every year, in fifth grade she’ll lose four points on her test, and her teacher will look incompetent and be assigned remedial training.
This critique meshes nicely with the Rothstein test. Since you’re gaining 2 points every year, Prof. Rothstein can use your 5th grade gains of +2 points to accurately predict your fourth grade gain of +2 points. Then he can use your friend’s 5th grade loss of -4 points to accurately predict her fourth grade loss of -4 points.
This is a very neat explanation. My only concern is that it doesn’t explain decay effects very well. If a fifth grade teacher’s time-bending effect on students in fourth grade is exactly the same as her non-time-bending effect on students in fifth grade, how come her effect on her students once they graduate to sixth grade will only be 25% as large as her fifth grade effects? How come her seventh-grade effects will be smaller still? Somebody here has to be really wrong.
It would be nice to be able to draw all of this together by saying that teachers have almost no persistent effects, and the genetic component identified by Plomin and pointed at by Rothstein represents the 15 – 25% “permanent” gain identified by Chetty and others which so contradicts my lack of line dancing memories. But that would be just throwing out Briggs and Domingue’s finding that the Rothstein effect explains 100% of identified VAM.
One thing I kept seeing in the best papers on this was an acknowledgement that instead of arguing “VAMs are biased!” versus “VAMs are great!”, people should probably just agree that VAMs are biased, just like everything else, and start figuring out ways to measure exactly how biased they are, then use that number to determine what purposes they are or aren’t appropriate for. But I haven’t seen anybody doing this in a way I can understand.
In summary, there are many reasons to be skeptical of VAM. But some of these reasons contradict each other, and it’s not clear that we should be infinitely skeptical. A big part of VAM is bias, but there might also be some signal within the noise, especially when it’s averaged out over many years.
IV.
So let’s go back to that study that says that a good fourth grade teacher can earn you $89,000. The study itself is Chetty, Friedman, and Rockoff (part 1, part 2). You may recognize Chetty as a name that keeps coming up, usually attached to findings about as unbelievable as these ones.
Bloomberg said that “a truly great” teacher could improve a child’s earnings by $80,000, but I think this is mostly extrapolation. The number I see in the paper is a claim that a 1 SD better fourth-grade teacher can improve lifetime earnings by $39,000, so let’s stick with that.
This sounds impressive, but imagine the average kid works 40 years. That means it’s improving yearly earnings by about $1,000. Of note, the study didn’t find this. They found that such teachers improved yearly earnings by about $300, but their study population was mostly in their late twenties and not making very much, and they extrapolated that if good teachers could increase the earnings of entry-level workers by $300, eventually they could increase the earnings of workers with a little more experience by $1000. The authors use a lot of statistics to justify this assumption which I’m not qualified to assess. But really, who cares? The fact that having a good fourth grade teacher can improve your adult earnings any measurable amount is the weird claim here. Once I accept that, I might as well accept $300, $1,000, or $500,000.
And here’s the other weird thing. Everyone else has found that teacher effects on test scores decay very quickly over time. Chetty has sort of found that up to 25% of them persist, but he doesn’t really seem interested in defending that claim and agrees that probably test scores just fade away. Yet as he himself admits, good teachers’ impact on earnings works as if there were zero fadeout of teacher effects. He and his co-authors write:
Our conclusion that teachers have long-lasting impacts may be surprising given evidence that teachers’ impacts on test scores “fade out” very rapidly in subsequent grades (Rothstein 2010, Carrell and West 2010, Jacob, Lefgren, and Sims 2010). We confirm this rapid fade-out in our data, but find that teachers’ impacts on earnings are similar to what one would predict based on the cross-sectional correlation between earnings and contemporaneous test score gains.
They later go on to call this a “pattern of fade-out and re-emergence”, but this is a little misleading. The VAM never re-emerges on test scores. It only shows up in the earnings numbers.
All of this is really dubious, and it seems like Section III gives us an easy way out. There’s probably a component of year-to-year stable bias in VAM, such that it captures something about student quality, maybe even innate ability, rather than just teacher quality. It sounds very easy to just say that this is the component producing Chetty’s finding of income gains at age 28; students who have higher innate ability in fourth grade will probably still have it in their twenties.
Chetty is aware of this argument and tries to close it off. He conducts a quasi-experiment which he thinks replicates and confirms his original point: what happens when new teachers enter the school?
The thing we’re most worried about is bias in student selection to teachers. If we take an entire grade of a school (for example, if a certain school has three fifth-grade teachers, we take all three of them as a unit) this should be immune to such effects. So Chetty looks at entire grades as old teachers retire and new teachers enter. In particular, he looks at such grades when a new teacher transfers from a different school. That new transfer teacher already has a VAM which we know from his work at the other school, which will be either higher or lower than the average VAM of his new school. If it’s higher and VAM is real, we should expect the average VAM of that grade of his new school to go up a proportionate amount. If it’s lower and VAM is real, we should expect the average VAM of that grade of his new school to go down a proportionate amount. Chetty investigates this with all of the transfer teachers in his data, finds this is in fact what happens, and finds that if he estimates VAM from these transfers he gets the same number (+ $1000 in earnings) that he got from the normal data. This is impressive. Maybe even too impressive. Really? The same number? So there’s no bias in the normal data? I thought there was a lot of evidence that most of it was bias?
Rothstein is able to replicate Chetty’s findings using data from a different district, but then he goes on to do the same thing on Chetty’s quasi-experiment as he did on the normal VAMs, with the same results. That is, you can use the amount a school improves when a great new fifth-grade teacher transfers in to predict that teacher’s students’ fourth-grade performance. Not perfectly. But a little. For some reason, teacher transfers are having the same freaky time-bending effects as other VAM. Rothstein mostly explains this by saying that Chetty incorrectly excluded certain classes and teachers from his sample, although I don’t fully understand this argument. He also gives one other example of when this might happen: suppose that a neighborhood is gentrifying. The new teachers who transfer in after the original teachers retire will probably be a better class of professional lured in by the improving neighborhood. And the school’s student body will also probably be more genetically and socioeconomically advantaged. So better transfer teachers will be correlated with higher-achieving kids, but they won’t have caused such high achievement.
After this came an increasingly complicated exchange between Rothstein and Chetty that I wasn’t able to follow. Chetty, Friedman, and Rockoff wrote a 52 page Response To Rothstein where they argued that Rothstein’s methodology would find retro-causal effects even in a fair experiment where none should exist. According to a 538 article on the debate, a couple of smart people (albeit smart people who already support VAMs and might be biased) think that Chetty’s response makes sense, and even Rothstein agrees it “could be” true. 538 definitely thought the advantage in this exchange went to Chetty. But Rothstein responded with a re-replication of his results that he says addresses Chetty’s criticisms but still finds the retro-causal effects indicating bias; as far as I know Chetty has not responded and nobody has weighed in to give me an expert opinion on whether or not it’s right.
My temptation would usually be to say – here are some really weird results that can’t possibly be true which we want to explain away, here’s a widely-respected Berkeley professor of economics who says he’s explained them away, great, let’s forget about the whole thing. But there’s one more experiment which I can’t dismiss so easily.
V.
Project STAR (Student Teacher Achievement Ratio) was a big educational experiment in the 80s and 90s to see whether or not smaller class size improved student performance. That’s a whole different can of worms, but the point is that in order to do this experiment for a while they randomized children to kindergarten classes within schools across 79 different schools. Since one of the biggest possible sources of bias for these last few studies has been possible nonrandom assignment of students to teachers, these Tennessee schools were an opportunity to get much better data than were available anywhere else.
So Chetty, Friedman, Higer, Saez, Schanzenbach, and Yagan analyzed the STAR data. They tried to do a lot of things with predicting earnings based on teacher experience, teacher credentials, and other characteristics, and it’s a bit controversial whether they succeeded or not – see Bryan Caplan’s analysis (1, 2) for more. Caplan is skeptical of a lot of the study, but one part he didn’t address – and which I find most convincing – is based on something a lot like VAM.
Because of the random assignment, Chetty et al don’t have to do full VAM here. It looks like their measure of kindergarten teacher quality is just the average of all their students’ test scores (wait, kindergarteners are taking standardized tests now? I guess so.) When they’re using teacher quality to predict the success of specific students, they use the average of all the test scores except that of the student being predicted, in order to keep it fair.
They find that the average test score of all the other students in your class, compared against the average score of all the students in other randomly assigned classes in your school, predicts your own test score. “A one percentile increase in entry-year class quality is estimated to raise own test scores by 0.68 percentiles, confirming that test scores are highly correlated across students within a classroom”. This fades to approximately zero by fourth grade, confirming that the test-score-related benefits of having a good teacher are transient and decay quickly. But, students assigned to a one-percentile-higher class have average earnings that are 0.4% higher at age 25-27! And they say that this relationship is linear! So for example, the best kindergarten teacher in their dataset caused her class to perform at the 70th percentile on average, and these students earned about $17000 on average (remember, these are young entry-level workers in Tennessee) compared to the $15500 or so of their more average-kindergarten-teacher-having peers. Just their kindergarten teacher, totally apart from any other teacher in their life history, increased their average income 10%. Really, Chetty et al? Really?
But as crazy as it is, this study is hard to poke holes in. Even in arguing against it, Caplan notes that “it’s an extremely impressive piece” that “the authors are very careful”, and that it’s “one of the most impressive empirical papers ever written”. The experimental randomization means we can’t apply most of the usual anti-VAM measures to it. I don’t know, man. I just don’t know.
Okay, fine. I have one really long-shot possibility. Chetty et al derive their measure for teacher quality from the performance of all of the students in a class, excluding each student in turn as they try to predict his or her results. But this is only exogenous if the student doesn’t affect his or her peers’ test scores. But it’s possible some students do affect their peers’ test scores. If a student is a behavioral problem, they can screw up the whole rest of their class. Carrell finds that “exposure to a disruptive peer in classes of 25 during elementary school reduces earnings at age 26 by 3 to 4 percent”. Now, this in itself is a crazy, hard-to-believe study. But if we accept this second crazy hard-to-believe study, it might provide us with a way of attacking the first crazy hard-to-believe study. Suppose we have a really screwed-up student who is always misbehaving in class and disrupting the lesson. This lowers all his peers’ test scores and makes the teacher look low-quality. Then that kid grows up and remains screwed-up and misbehaving and doesn’t get as good a job. If this is a big factor in the differences in performances between classes, then so-called “teacher quality” might be conflated with a measure of how many children in their classes are behavioral problems, and apparent effects of teacher quality on earnings might just represent that misbehaving kids tend to become low-earning adults. I’m not sure if the magnitude of this effect checks out, but it might be a possibility.
But if we can’t make that work, we’re stuck believing that good kindergarten teachers can increase your yearly earnings by thousands of dollars. What do we make of that?
Again, everybody finds that test score gains do not last nearly that long. So it can’t be that kindergarten teachers provide you with a useful fund of knowledge which you build upon later. It can’t even be that kindergarten teachers stimulate and enrich you which raises your IQ or makes you love learning or anything like that. It has to be something orthogonal to test scores and measurable intellectual ability.
Chetty et al’s explanation is that teachers also teach “non-cognitive skills”. I can’t understand the regressions they use, but they say that although a one percentile increase in kindergarten class quality has a statistically insignificant increase (+ 0.05 percentiles) on 8th grade test scores, it has a statistically significant increase (+0.15 percentiles) on 8th grade non-cognitive scores (“non-cognitive scores” in this case are a survey where 8th grade teachers answer questions like “does this student annoy others?”) They then proceed to demonstrate that the persistence of these non-cognitive effects do a better job of predicting the earning gains than the test scores do. They try to break these non-cognitive effects into four categories: “effort”, “initiative”, “engagement” and “whether the student values school”, but the results are pretty boring and about equally loaded on all of them.
This does go together really well with my “behavioral problem” theory of the kindergarten class-earnings effect. The “quality” of a student’s kindergarten class, which might have more to do with the number of students who were behavioral problems in it than anything else, doesn’t correlate with future test scores but does correlate with future behavioral problems. It also seems to match Plomin’s point about how very early test scores are determined by environment, but later test scores are determined by genetics. A poor learning environment might be a really big deal in kindergarten, but stop mattering as much later on.
But this also goes together with some other studies that have found the same. The test scores gains from pre-K are notorious for vanishing after a couple of years, but a few really big preschool studies like the Perry Preschool Program found that such programs do not boost IQ but may have other effects (though to complicate matters, apparently Perry did boost later-life standardized test scores, just not IQ scores, and to further complicate matters, other studies find children who went to pre-K have worse behavior). This also sort of reminds me of some of the very preliminary research I’ve been linking to recently suggesting that excessively early school starting ages seem to produce an ADHD-like pattern of bad behavior and later-life bad effects, which I was vaguely willing to attribute to overchallenging kids’ brains too early while they’re still developing. If I wanted to be very mean (and I do!) I could even say that all kindergarten is a neurological insult that destroys later life prospects because of forcing students to overclock their young brains concentrating on boring things, but good teachers can make this less bad than it might otherwise be by making their classes a little more enjoyable.
But even if this is true, it loops back to the question I started with: there’s strong evidence that parents have relatively little non-genetic impact on their childrens’ life outcomes, but now we’re saying that even a kindergarten teacher they only see for a year does have such an impact? And what’s more, it’s not even in the kindergarten teacher’s unique area of comparative advantage (teaching academic subjects), but in the domain of behavioral problems, something that parents have like one zillion times more exposure to and power over?
I don’t know. I still find these studies unbelievable, but don’t have the sort of knock-down evidence to dismiss them that I’d like. I’m really impressed with everybody participating in this debate, with the quality of the data, and with the ability to avoid a lot of the usual failure modes. It’s just not enough to convince me of anything yet.
VI.
In summary: teacher quality probably explains 10% of the variation in same-year test scores. A +1 SD better teacher might cause a +0.1 SD year-on-year improvement in test scores. This decays quickly with time and is probably disappears entirely after four or five years, though there may also be small lingering effects. It’s hard to rule out the possibility that other factors, like endogenous sorting of students, or students’ genetic potential, contributes to this as an artifact, and most people agree that these sorts of scores combine some signal with a lot of noise. For some reason, even though teachers’ effects on test scores decay very quickly, studies have shown that they have significant impact on earning as much as 20 or 25 years later, so much so that kindergarten teacher quality can predict thousands of dollars of difference in adult income. This seemingly unbelievable finding has been replicated in quasi-experiments and even in real experiments and is difficult to banish. Since it does not happen through standardized test scores, the most likely explanation is that it involves non-cognitive factors like behavior. I really don’t know whether to believe this and right now I say 50-50 odds that this is a real effect or not – mostly based on low priors rather than on any weakness of the studies themselves. I don’t understand this field very well and place low confidence in anything I have to say about it.
Further reading: Institute of Education Science summary, Edward Haertel’s summary, TTI report, Adler’s critique of Chetty, American Statistical Society’s critique of Chetty/VAM, Chetty’s response, Ballou’s critique of Chetty
















The economic effect found is not pure abstract money, but more the answer to the question ‘are you capable of functioning in the working class, or are you going to have difficulty holding down even a minimum wage job?’
Thing is, isn’t the argument that parents have very little effect on anything based adoption studies? Which naturally are going to be screening out the worst 5-10% of potential parents; the ones who can’t get it together enough to persuade the adoption agency that they are safe with kids?
Adoption is also expensive, so that seems to screen out poor parents.
Adoption is one type of study, but more common are studies comparing fraternal to identical twins. They produce the same result.
Not only that, but everything that I’ve looked at indicates that the adoption process isn’t even remotely random at any level. For example, here’s a description of the “matching” process from an adoption agency’s “Guide to Connecting Adoptive Families with Waiting Children”:
Adoption agencies during the postwar years tended to do a decent job of screening out from adopting couples with overt problems like alcoholism. Steve Jobs’ adoptive parents are a good example: people who weren’t above average in much except not being worse than average in anything.
i want to applaud everyone involved in the ensuing subthread for debating this topic that formerly belonged to the class of topics that must not me debated in a fruitful manner. This seems also to be a showcase where Scott’s reign of Terror policy is superior to the rules of olden days. This blog is the only place where i enjoy reading the comments. Thank you everyone for being this cool.
Edit: i am referring to the thread below, but i guess its okay to leave this here-above the thread- as advertisement for it =)
RE: the lower heritability of intelligence in younger children
I remember being fairly close friends with certain kids in elementary school that that later, as we progressed into and finished high school, I was like “Whoa! We have nothing in common.” Basically, it boiled down to there being much less of an intellectual difference between us when young as compared to what there was at the beginning of adulthood.
BTW, this actually made me kind of sad, as the friendships back in the day were genuine.
IQ tests have questionable predictive validity in young kids. With minorities, you often see a pattern where they score high as young kids (normalised against their white peers), but as they age, they regress to whatever the mean is for their adult population.
https://robertlindsay.wordpress.com/2011/01/19/iq-and-achievement-in-british-black-children/
Participants in Sandra Scarr’s Minnesota Transracial Adoption study found something similar: impressive early results for adopted black children, but as they aged their scores collapsed.
Naively that sounds to me that like it would be strong evidence for relative non-variance of inherent “intelligence” across different ethnicities, -Why would children with bad smartness-genes start off as smart as their peers? Why would there be a different shape of pattern of development, rather than just a lower one?
Kids of different races develop at different speeds. Being slightly more mature compensates partially for lower mean “grit” but as they grow up they all catch developmentally so the difference in mean “grit” becomes more visible.
This results in a widening of the gap in middle school that vexes very much the educational establishment as it contradicts their nurture theories.
Expanding on that, I have at least seen it claimed that children with sub-Saharan ancestry walk earlier than children of European ancestry. It was part of a more general argument about different optimal reproductive strategies in different environments. Interesting argument–whether correct i don’t know.
http://www.scientificamerican.com/article/being-more-infantile/
Neoteny correlates with grit across species
I think it implies that the tests are relatively poorer measures of innate ability when children are young, but become better measures when they grow older.
“Why would children with bad smartness-genes start off as smart as their peers? Why would there be a different shape of pattern of development, rather than just a lower one?”
But — this is exactly what you would expect. To take an extreme case, a chimpanzee will beat a human baby of the same age pretty much for the first year before it starts falling behind as the human baby’s language acquisition starts to kick in. And after two years, even a low-IQ human baby will have left behind any “high-IQ” chimpanzee.
“High innate ability” for the purposes of human education means “*potential* for *adult* ability”. It doesn’t matter if you are the first in your pre-K class to realize the square peg goes into the square hole if this is all you have in you and you never develop beyond this point. Nobody (except maybe the severely mentally disabled) has reached their full potential when aged 5, but the older you get, the larger the fraction of your peers for whom mental development is slowing down because they are reaching the limit of their potential. At age 15, some people might have reached their fully “mature” adult cognition while others keep getting smarter for another 10 or 20 years.
In addition, I suspect it may also be that statistics for young children are “noisier” because the age variation within your sample (i.e. your “bin width”) corresponds to a more significant fraction of subjects’ lifetime.
@Rath
Excellent point about the noise level. I imagine that’s a significant issue.
@Ryan ‘s first post in this subthread Well it can’t imply that alone. -That’s an interpretation, not an implication, I think. There has to be some known else which is not equal for those results to imply that, in which case it’s the else that implies it.
Or maybe that’s “semantic”, (I’m not sure, but I don’t think so).
Anyway, if you feel like telling me, Is your rationale about the same as anon’s below? (which I will look up), or more along the lines of preexisting knowledge (-general) of IQ tests, or is it something else?
(I can think of one reason it might become less “innate-G-loaded” as people age
-with kids you’re more likely to be getting a raw result, -no preparation, less time to fake or create an inclination/aptitude that isn’t natural to you. (I can think of reasons it would be less accurate too, just thought this one might be a bit less obvious (-meant purely literally) and so perhaps have some interest)
@anon
Sure let me try to lay things out more clearly. Twin/adoption studies tend to group influences into three categories:
Shared environment – basically school and parenting
Genetic influence
Non shared environment – everything else which isn’t the first two
The observation is that when a child is young the proportion of IQ scores which one attributes to shared environment is at its highest, but then as they grow older shared environment drops to very little influence while genetic attribution rises in proportion.
The first part of my hypothesis is that young children are not equally unprepared for the kind of challenges posed by an IQ test. So for example an IQ test may ask children to listen to a series of numbers and then repeat them back to the test taker. If a child happens to play that numbers game at home with their parents, they’ll have an advantage over unprepared children, and the test will mis-evaluate their IQ to some degree because of it.
The second leg is that as children grow up their interactions with their parents are much less likely to include things like the numbers game. And their schooling will be a lot less about teaching analytical thinking and more about filling their heads with information. High school students will then be much more equally unprepared for IQ tests compared to elementary school students.
The way the hypothesis explains the observation about shared environmental influence on IQ in young children is that parenting is not actually affecting a child’s general intelligence, rather it is preparing them for the kinds of challenges posed by IQ tests.
both points make a lot of sense to me so I have no more to say really. Well, one more -they were also fairly novel to me.
thanks
Look at development among different species of apes. The apes that reach sexual maturity sooner develop certain abilities much more quickly than those that take longer to mature and initially may even appear “smarter” – but those that take longer end up with the higher overall intelligence.
Humans are a type of ape.
Consider how much computing power it takes to render a high definition photograph compared to a low definition photograph (this will be readily apparent to those of us who remember what it was like 20 years ago when computers had much less processing power – I recall a 1 megabyte photograph taking 3 HOURS to render). You might say that human intelligence is similar – having a hi-def understanding of the world takes more processing power and more time.
Look at differences in how long it takes for different races to reach sexual maturity. Notice how closely this matches IQ scores. Never speak of this under your own name.
well shit, that certainly would constitute a mechanism if true. I’ll look it up and see what I think, -thanks.
@Anon
Do we know whether the puberty/IQ relationship is one of causation or correlation? Because if it’s the former you might be able to close the IQ gap by giving puberty blockers to some people for a couple years. (Has anyone tried giving puberty blockers to monkeys to delay puberty and seeing if the delayed monkeys are smarter?)
@Ghatanathoah
Has anyone tried giving puberty blockers to monkeys to delay puberty and seeing if the delayed monkeys are smarter?
or checkedthe test scores of transgendered people who were diagnosed young enough to have been put on puberty blockers for a while as part of their treatment?
@ Ghatanathoah – very interesting idea. I am far more interested in solutions than in finding someone to blame, and that looks like an interesting angle of attack. I hope someone with the means of looking into this does so.
Yes – some r/K-like effect, maybe?
Chimp babies often score higher on measures of infant intelligence than human babies.
http://www.express.co.uk/news/uk/82917/Baby-chimps-smarter-than-toddlers-at-nine-months
MawBTS – might be related to r/K.
Thanks for the article illustrating the point that an early high may mean a later low – and also illustrating another point – that loving relationships early in life can play a very positive role in development.
@ Some Troll’s Legitimate Discussion Alt:
Probably not a good test case. People suffering from mental illnesses like gender dysphoria may differ in important ways from the rest of the population, leading to questionable results.
As far as I know, neither people who were castrated nor people suffering from Kallmann Syndrome show unusual levels of intelligence, but I’ve never seen a study on it.
Perhaps I shouldn’t get hung up with your analogy, but it doesn’t take *any* computing power to display a photograph (there is some computing power needed for a photograph in a compressed format, but that’s not inherent to the photograph). And I’m not aware of the verb “render” being used in the context of photographs; it refers to producing computer graphics, not live-action photographs.
@RCF
This was a bit over 20 years ago, and the computer was about 5 years old at the time. It had 1 megabyte of usable RAM and a 40 megabyte hard drive, with a 386 chip.
Regardless of the proper terms for describing it, with those sorts of resources it was obvious that a low resolution image loaded fast, a medium resolution image loaded more slowly, a high resolution image loaded very slowly, and that the effect was geometric.
In short, higher resolution required a lot more resources, and when your uncompressed image size is larger than the size of your RAM you realize that displaying a photograph does take considerable computing resources including memory swaps with the hard drive. Perhaps you have always worked on powerful enough machines that the resources required are trivial, but that does not mean that no resources are used.
A lot of other people have given you the genetic development theories, but let me offer a more environmental one that also seems to have a lot of evidence for it:
Imagine a parallel world where schools are have lots of mandatory bodybuilding classes. As a result, all children have super-ripped abs.
After they leave school, people are no longer required to work out all the time. A lot of them therefore lose their ripped abs. But some people have inherited the sort of brain chemistry that enjoys a good workout. These people keep working out, and stay ripped as adults. Your doppleganger in this universe laments that their friends don’t want to go work out at the gym anymore and aren’t are ripped anymore.
Intelligence may be similar. Most people have the potential to be intelligent if they work at it. But some people enjoy exercising their intelligence more than other people, and so they become more intelligent. And whatever personality trait causes you to enjoy exercising your intelligence is hereditary.
School makes all the kids smarter by forcing them to perform cognitive work they normally wouldn’t choose to. But once it ends, some people choose to stop.
+1
thanks for interesting argument (and funny casual use of “ripped”, and with “laments” in the same sentence. Really that’s bloody great lol)
How is that environmental? “And whatever personality trait causes you to enjoy exercising your intelligence” – presumably this trait is heritable as well, which ruins the argument. It could, then, only be environmental in a world where ONLY that type of school could expose you (mandatory, no less!) to such an effect (otherwise you can stumble into it yourself and because you “have inherited the sort of brain chemistry that enjoys a good workout” you pick it up yourself without environmental manipulation). Kinda like a “forced addiction” to something society considers “good” that you end up enjoying afterwards. Too unethical and paternalistic for me even if it could be done…
@Y Stefanov
What I meant when I said environmental was that my explanation offered an environmental reason for why children start off smart (forced cognitive exercise) whereas the other explanation was hereditary (natural growth patterns). In both explanations the reason for why some people stay smart later is hereditary.
I think that most people with a personality trait that enjoys cognitive exercise would have also ended up intelligent in a world with no schooling. What I am trying to explain is why they are briefly matched in intelligence by other people who don’t enjoy cognitive exercise, and will choose not to perform it if given the chance.
This is a nice theory, but the problem is that we see the differences in IQ by the end of mandatory schooling. If we only saw the differences at age 28, this would be plausible, but we see them at age 18.
It is undoubtedly true that working at being smart keeps you smarter according to many observed “smartness” characteristics, but it has seemingly very little impact on IQ.
J.P. Rushton covered the differences in development rates across races in his book. According to him, not only do blacks walk earlier, but they accomplish many tasks earlier, beginning with lifting their heads earlier as infants.
This strikes me as one of the strongest arguments in support of the HBD worldview, since you can always put together relatively sophisticated arguments to try to attribute racial differences in [grit] to mismeasurement and/or environment, but it’s tougher to use these arguments to explain why blacks would develop earlier. Granted, you can’t get directly from this step to innate racial differences in adult [grit], but it’s a short step to there.
I’ve actually never heard an anti-HBDer/blank-slatist intelligently address this argument — would they attack the idea of racial differences in development rate, argue that these differences are still somehow environmental, argue that this is still unconnected to adult [grit], or all of the above?
Thanks for that information.
I would add that HBD is not merely about [grit]. Humans have a great variety of qualities, many of which are excellent and praiseworthy, and there would be significant variety in those qualities even presuming that [grit] remained constant.
One reason for addressing HBD is so that all those excellent qualities can be appreciated and encouraged whatever their source.
Apparently some researchers in Africa have suggested possible cultural explanations for this:
@NN
Very interesting. Could the solution be as simple as allowing children to develop on their own terms, rather than “assisting” them in ways that atrophy their intellectual abilities?
This might apply to other childrearing techniques, too. One interpretation of research on spanking and other corporal punishment might be that corporal punishment atrophies a child’s moral development by removing the necessity to develop a moral system on their own.
You may be aware that among non-human apes, those that reach sexual maturity earliest have the lowest intelligence, and those that take longer to reach maturity have higher intelligence. The early-maturing apes develop much more quickly and therefore may seem more intelligent when they are very young, but do not develop their intelligence as fully as the late-maturing apes.
Of course humans belong to the ape family, and adult human IQ scores seem to parallel age of sexual maturity (e.g., menarche in females) as averaged by race – but all humans are the same and race is merely a social construct, so we must ignore such facts.
Oh, that explains why men are smarter than women. We finish puberty later.
Wait, I didn’t get this memo. I thought there was (an hypothesis of the presence of) a higher variability, but not a higher mean.
(What haru said.)
Men have higher variability in intelligence, not a higher mean – I’ve seen studies that claim means higher for men, higher for women, roughly the same, but all within <5 IQ points of the same number.
This can, however, lead to a perception that men are smarter, because of, well, there are a lot more high-achieving ones compared to women. Meanwhile the other bell curve tail – the nearly sub-sapient, the severely crippled in agency, the socially inept – get ignored, unseen.
So can I coin ‘rule 35’ or is that one taken? No matter how obvious you think it is you’re joking, someone on the Internet is guaranteed to take you seriously.
If you trust the wikipedia, you will find out several interesting things about the male-female intelligence difference.
First, historically everyone knew that men were smarter. This is pretty much universal across culture (though that is not in wiki), and of course it is only evidence that our forebears were ignorant and sexist, since they cannot have known much about people without modern science. This is one of many prejudices discarded in the 20th century, when equality flowered as the highest ethical value.
Second, that many (most?) modern IQ tests are constructed specifically to equalize the measured IQ of men and women. Wiki: “When standardized IQ tests were first developed in the early 20th century, girls typically scored higher than boys until age 14, at which time the curve for girls dropped below that for boys.[27][30] As testing methodology was revised, efforts were made to equalize gender performance.”
Thus, to the extent that you equate “intelligence” with “scores on modern IQ tests”, intelligence will be equal between the sexes. True by construction.
Third, that there are a handful researchers now who believe that men are slightly more intelligent than women. In general, what these people are saying is that g, the general factor of intelligence, should be what we use for “IQ”. (That is, that we should not construct IQ tests for equality.) And that men are higher on g.
But there are many more on the side of equality. And they have a lot more papers and test results, etc.
Fourth, it does seem to be generally accepted that there are various subjects in which men are smarter, and others in which women exceed men. That is, the sexes are unequal. This makes it exceeding improbable, in my opinion, that male and female “intelligence” will be equal, unless it is done by construction (or definition). But of course actually defining intelligence is quite the sticky wicket.
If men are better on certain subjects, and women are better at other subjects, and both are clearly related to “intelligence” (as opposed to physical qualities or even mental endurance), that would imply there probably isn’t a single ‘g’ factor across the sexes. Unless we can come up with some non-arbitrary weighting between the subjects.
Anonymous made a quantitative statement and everyone else is making qualitative statements…
I estimate the ratio of standard deviations at 1.1. Summers’s infamous calculation was based on a ratio of 1.2, which he indicated was an upper bound.
There was as study talking about how men actually do better than women in traditionally assumed “women’s domains” like reading and verbal intelligence, if they changed the setting. In particular when they made it look like a game instead of a test.
Pretty interesting.
@anon with same blue color as Nybbler:
Are there any studies in the opposite direction? Women doing better in previously-considered men’s domains, given a framework adjustment?
(I vaguely remember something about girls doing better at pairs programming.)
This also reminds me of the Gender Genie. When I put in analytical meta posts/comments of mine, it guessed male. When I put in fiction, it guess female. And I do have the perception of being able to discern fanfiction author gender, based on not just the type of fic they prefer (e.g. time loop, canon divergence, crossover, smut, fix-fic), but how they write that particular type of fic.
@arbitrary_greasy
The same study (Granted it had a small sample) found women did worse when the tests were framed as a game, suggesting the current model is better for female style on that particular area. We can probably do way better for everybody if we learn what to exploit in more detail.
Gender Genie… Pretty interesting. Some of my comments come as Strong Male and a few came as 50/50. Some fiction I wrote comes as Weak Male 60 male 40 female. I too have an easy time guessing someone’s gender by how they write.
(Weak emphasis could indicate European.) lol.
Interestingly, Scott’s formal style from the “Coordinate meannes” post comes as Weak Female with Male informal style. I think this is related to the “Women are better teachers” thing, somehow.
@Nybbler:
g is the general intelligence factor. It is a controlling factor which influences performance across all areas of intellectual ability.
g-theory does not exclude the possibility of other kinds of intelligence; it is possible that there are other factors which improve our “intellectual ability” at specific tasks independent of g. In fact, we know some of these exist (practicing at a skill). It wouldn’t be surprising if there are genetic factors involved in some things as well.
@Leonard:
That’s both interesting and kind of depressing. However, that’s only meaningful if older IQ tests predicted g stronger than newer ones.
Does IQ predict g as well for men as it does for women? Does it predict outcomes as well? If IQ for women is overestimated, then it would suggest that they would somewhat underperform relative to their IQ.
Does that actually happen?
Academically, women are massively outperforming men at every level of education below PhDs (where women only have a slight 52% majority) in the West. Though that is likely due to factors other than cognitive ability.
But neoteny correlates with intelligence, and women have more neotenous traits (e.g. absence of facial hair…)
That may be true when looking at blacks and whites in the US, but internationally things aren’t so clear cut. Somalis and Nigerians reach puberty later than white Americans, and Japanese reach puberty at about the same age as black Americans. Also, over time average puberty ages have decreased at the same time as average IQ scores have increased.
In addition, some studies have found that low Vitamin D levels are associated with earlier puberty. That seems like a major potential confound, since it seems likely that black people will receive less Vitamin D from both sun exposure (because more melanin in skin = less Vitamin D) and their diet (because black people are far more likely to be lactose intolerant than white people and so will be drinking less Vitamin D fortified milk).
There are at least two different possibilities here:
1. Reaching puberty later causes higher intelligence. If so, earlier puberty due to better nutrition should be associated with falling IQ, which doesn’t seem to be the case.
2. Reaching puberty later is correlated with higher intelligence due to some factor that causes both. If so, there is no reason why other factors affecting age of puberty, such as nutrition, should affect intelligence.
David Friedman makes good points.
We also know that the end of puberty can be sped up due to better nutrition, and also that better nutrition (especially micronutrients) can increase IQ – so in this case, good nutrition may result in earlier puberty and higher IQ.
As for Nigerians and Somalis – please remember that there is more genetic variation in sub-Saharan Africa than in the rest of the world put together. Traditionally, many Africans noticed intelligence differences between tribes, and who knows what results we might get if all were equal (such as by providing sufficient nutrition and reducing disease loads in early childhood)? We might also note that some models hypothesize a “modular” approach to intelligence, that what we think of as “intelligence” may in fact be a collection of many smaller “intelligences” or “instincts” with multiple causes. (If so, we may ultimately discover that some of these instincts evolved in different populations relatively recently, and that no individual has all or even most of them.)
And then, if my observation is relevant, it may be only one of multiple variables – of which one variable might be the cause of both slower development and higher intelligence. Still, if correct it would explain an early high and later low in some populations.
@NN –
Looking closer at the information you provided, and the dates thereof (1965-1985) I will note:
During this period, Japan was the only Asian nation at or approaching 1st world status, which suggests that they were eating much better than others in the region.
At the other end of the scale, during this period Nigeria and Somalia were very poor countries, and even wealthy families were unlikely to have as much food as was available in Japan at this time.
Likewise, even in the U.S. during this era access to food quantity or quality tended to be associated with race.
So what that chart is really comparing is likely well-fed Japanese with poorly fed Somalians, well-fed U.S. whites with poorly fed U.S. blacks, and so on. A weighted analysis would raise the age for those with easy access to plenty of food, and reduce it for those without.
That does not even address issues such as vitamin-D or the presence of synthetic hormones in the environment that may accelerate puberty.
The average age of menarche was decreasing at least through the 50s, but the Flynn effect starts in the 30s. I would want to see evidence of sex differences in the Flynn effect in the 30s -50s if this hypothesis is true.
Also, stressful domestic environments are associated with a decrease in the age of menarche. If that stress is causal, we might merely be seeing two correlated factors (menarche, IQ) with a shared cause, at least in women (assuming minority status induces stressful domestic environments).
It’s not clear to me whether domestic stress has been ruled out as driver for earlier onset of puberty in boys, or simply not studied.
@HeelBearCub
Age of menarche is still decreasing, likely related to absence of a father or presence of a stepfather, which seems to be causal. Historically in America, this was far more common for black families than white families, and even as the numbers for both have grown this disparity remains.
If we presume that it is not actually earlier puberty that affects intelligence, but that both share the same cause, this will create a fair amount of noise in this particular signal.
Other factors that affect age of menarche (which is itself only a proxy for rate of development) include nutrition, obesity, and a polluted environment with synthetic chemicals that mimic various hormones. With all these factors combined, historical data may be more useful than modern data.
And lost in all this noise there might be an idiocracy effect as a result of the welfare state. [Despite common beliefs, evolutionary selection can act within just a few generations. If anyone doubts this they should take a look at the dogs winning dog shows now compared to the same breeds less than a century ago – in many cases they look like completely different dogs. Two concepts that may be useful here are “punctuated equilibrium” and the creationist concept of “micro evolution” (i.e., natural selection occurring within an already available set of genes).]
I would like to stress that age at menarche is only a proxy for rate of development and length of childhood – it should not be considered causal in itself. If this hypothesis is correct, there is most likely a common cause for both rate of development and intelligence.
Also possibly related are some parts of the autism spectrum, as high functioning autism is correlated with a denser development of neurons and higher intelligence, but also some developmental delays, such as in developing speech.
Dogs reach sexual maturity within 1-2 years, so a century could easily contain way more than a “few” dog generations, especially when we’re talking about selective breeding.
@NN
Of course you are correct that dogs have shorter generations than humans.
“Few” is also an imprecise number.
And in this case, a century is an outer bound.
If you look I think you will find significant changes in a much shorter time, in dogs and in other species.
And a welfare state may also impose selective breeding, even if it was never intended.
It is certainly worth consideration, anyway.
@David Friedman:
There’s a third possibility: the correlation is entirely spurious.
The odds of any randomly chosen trait having a rank order which matches with the IQ distribution of blacks, whites, Asians, and Hispanics is 1 in 16 simply by chance. A 1 in 16 chance is very high; there are far more than 16 traits you can look at. Looking at other traits, like, say, height, or 100m running speed, doesn’t give us the same distribution.
There’s no particular reason to believe that age of onset of puberty is linked to IQ, so the fact that we found a correlation shouldn’t really be regarded as meaningful to begin with, as it is quite likely to occur by chance alone, and was simply called to our attention because it happens to correlate in the same way.
Is there an individual correlation between age of puberty and IQ?
@AlexP:
I can only speak for myself.
I’ve only taken one actual IQ test in adulthood, when applying for employment, and their policy prohibited them from telling me the results – but they could tell each other and everyone was pointing at me and whispering to each other, and one ventured to tell me that the score was considerably higher than they usually see. They turned me down for employment because my score was too high.
I got a perfect score on the verbal portion of the GRE – and considered that portion of the test dead easy. I did much better than average on the math portion as well, roughly at the low end for engineers, but I’m no math genius.
I may have said one or two words when I was three, but didn’t really start talking until I was 4.
My balls dropped when I was in my early 20s.
But, on the other hand, I was early to shave and for my voice to deepen, though I am pretty hairy overall so that may be unrelated.
I certainly don’t claim that there is a single cause. There is much that we are only beginning to understand.
Nonetheless, we need to understand the causes if we ever hope to actually do something about it.
You probably had a lot more common interests in the day.
I’ve noticed the exact opposite- my best friend from preschool (preschool!) with whom I had very little contact with afterward turned into the sort of person who goes to advanced high schools and writes poetry, and my best friend from elementary school is currently in an advance program equivalent to the one I’m in. I’m not certain if we would have remained friends, since their were other factors involved that prevented that, but the intellectual level seems about comparable.
If you aren’t assuming that teachers’ groups will oppose *anything* that might link the teachers’ pay and job security to their performance, you need to get more cynical. Their attitude is more like “Good teachers are super valuable, and all teachers are good teachers.”
But if we were consistently seeing things like everybody in Teacher A’s class getting A+s and everyone in Teacher B’s class getting Ds, that would suggest that good teachers are very important.
That’s a bit chicken-and-egg, though, as good teachers will get the good students – after all, these are the ones who will get good test results and push the school up the league table rankings, so they need all the encouragement and pushing by the teachers to get their marks up even higher.
Students who are considered non-academic or likely to get poor results will get the less good teachers, because Johnny is never going to go to university and as long as he can read and write at a basic level that’s good enough.
Unless the school has a majority of disadvantaged students or is specifically for the less academically performing, it will not have good teachers working with less able students. And unfortunately, standardised test results are a very blunt instrument. A teacher may have worked miracles to get Johnny and Susie getting Ds or low Cs on their tests and have improved them greatly, but put that beside Posh Kids’ Academy where the final year is getting multiple A1s, and even though the teacher in the first school may be better than the teacher in the second, they don’t look as good based on the results. So a first glance says “teachers in Posh Kids’ Academy are better because the students get higher grades, so I’m going to try and get my kid in there”.
EDIT: I’m going by the Irish marking system here, the American one seems crazy by European standards 🙂 Here, a D is enough to be a pass (barely, it’s not a great mark, but it’s not the same as failing).
There are also some interesting exceptions, e.g. Maria Montessori teaching retarded children and bringing them to the level of average children.
Not sure how to scale this up, though. I was thinking about having special certificates that would be available only for teachers who tried teaching retarded children and received great results — such achievement could be used later used as a proof that this teacher’s results do not depend on them getting gifted students — but I imagine that someone who wants to teach e.g. quantum physics could be quite dissatisfied with such requirements.
The skills needed for teaching children with behavioural or developmental issues can be different from those required for teaching average children and may not cross over. A teacher who gets great results with the average class could do badly with the special needs class; the teacher who can bring out the potential in a special needs child may not do anything particularly noteworthy with the normal child.
Oy… language.
There hasn’t been a great deal of research specifically focusing on the Montessori method however similar methods derived from it have been evaluated for general education such as the Open Education Model, and failed to demonstrate efficacy. http://pages.uoregon.edu/adiep/ft/bereiter.htm
Given the period of time Montessori was working, it is possibly the case that many of the individuals she was working with were simply misdiagnosed, or that symptoms which were severe when young gradually decreased over time.
Standard first-line intervention for children with disabilities, at least in the US, already have demonstrations of some disabled individuals achieving close to normal functioning. However, even some of the children in the active control groups achieve some improvement, even if that improvement isn’t as great as standard intervention.
http://survey.interactingwithautism.com/pdf/treating/129.pdf
http://www.cdzjesenik.cz/Autismus__complex_trerapy_fulltext_pdf.pdf
I teach physics in secondary education (Europe, 16-19 year olds). I would certainly agree there are good and bad teachers. But I would rabidly oppose any government-operated scheme to evaluate teachers and pay them according to their performance: already just because of the incentives this will introduce and the unavoidable *reaction* to such incentives on the part of the teachers. Such a scheme might get rid of a few bad eggs, but it will also create a Kafkaesque nightmare for all the average and good teachers that are allowed to keep teaching (and you cannot fire *all* teachers below average, because you will then end up with class sizes of 50, which even the best teacher will not be able to tackle)
It also sounds about right to me that 1 SD in teacher quality (measured as per my gut feeling), might very well account for 0.1 SD in student performance. I am pleased to see that these studies have managed to come up with any kind of plausible result at all.
So, this is the effect size you are going to get *if* your scheme is working out as planned, and you would do well to compare it to the scheme’s prospective cost and the collateral damage it will cause.
I also strongly support Scott’s intuition on the high impact of misbehaving students. A high-quality teacher is not the teacher that has the best skill in explaining an elementary physics problem. The best teacher is the one who manages to either pacify or otherwise neutralize students who have a negative effect on focus and attitude. Actually, the surest way to become a “good teacher” in any measuring scheme is just getting rid of the two most obnoxious students in each class as quickly as you can — maybe more “traffic accidents” will happen near schools, or mysterious “food poisonings”, if Obama has his way? (I did say Kafkaesque; but you can also just give them the lowest grade you can possibly concoct and watch them drop out, and nobody will be the wiser; thinking about this, this may actually be an unintended but beneficient outcome of the entire exercise. of course this only works in secondary schools you can actually drop out of).
I’m a little curious about this. Do you
a) Oppose paying good teachers more than bad teachers, full stop?
or
b) Theoretically favor paying good teachers more, but not based on some sort of top-down standardized evaluation?
or
c) Something else I haven’t thought of?
If b), how would you decide which teachers get paid more?
I’m not the one you put the question to, but I think his (reasonable) concern is that if you had such a system, teachers would game it. One obvious way of doing so is to teach to the standardized test rather than to what kids need to know. Taking it a step further, teachers might cheat, either in the process that grades standardized tests or by managing to see the test in advance and coach the kids on the specific questions in it.
Teaching to the test isn’t always bad.
@edward scizorhands see my post about coming out and making things a game officially and openly, on the basis that that’s what happens and/or will hapen anyway, and it isn’t so bad. and the important difference between having kids compete in an academic competition that also involves some small amount of training, and calling it a game, which would be fun and exciting, and calling it an education, which is demotivating simply by virtue of being false.
@David Friedman
Your use of the conditional mood is most amusing.
>teach to the standardized test rather than to what kids need to know.
The solution, obviously, is to put what kids need to know on standardized tests. Force test-makers to write good tests by letting students take notes with them into the exam.
Matt Ygleasias: http://thinkprogress.org/yglesias/2011/05/05/200863/half-of-adults-in-detroit-are-functionally-illiterate/
Under those circumstances, I find it difficult to be seized with worry that schools are going to be ruined by teachers “teaching to the test” too much. It is true that school districts that have started taking testing more seriously now need to step up and also take the possibility of outright cheating more seriously. But the fact that huge numbers of kids are passing through school systems and not learning basic literacy drives home the fact that districts also need to take checking to see if the kids are learning anything more seriously.
@Anon.
Beware Campbell’s law. Even if the tests are good proxies of “what the kids need to know” when they are designed, the moment you start using them to incentivize students and/or teachers, people will find a way to game them.
I dunno, how would you game a test that consists of “give student a copy of the nation’s tax code, a packet of relevant documents to a hypothetical financial situation, have them file a filled-out-by-hand tax return?”
Reading comprehension, arithmetic, practical skills, win-win!
If someone could “teach to the test” for basic literacy, we’d all end up winners.
Teaching to a standardized test is only bad if the test is bad.
The real issue, honestly, is that the government is probably too far away from the teachers to do a good job of evaluating their performance; it is likely that principals would have a better idea (and, frankly, it seems like that’d be something a principal should be responsible for).
Neither. He’s saying that our governemnt would almost certainly fuck up such a system and it would result in either being useless, because everyone is above average: http://thehill.com/blogs/pundits-blog/defense/210313-why-all-va-executives-are-above-average or acctively harmful, and end up incentivizing requiring teachers to do unhelpful things in order to get paid.
I agree that too much interference is a bad thing. In the US, most of us would just be glad to get rid of those teachers who do not understand English and can not do basic arithmetic. Unfortunately, we have seen ample evidence that many school ADMINISTRATORS are not capable of these feats.
Most of the drama you see has to do with people demanding equal rates of success for students who will never be capable of achieving equal success due to factors beyond anyone’s control. Among the intelligent, the debate is only about an excuse for getting rid of the very worst teachers. Every one who can has already withdrawn their children from the government schools. Don’t take it too much to heart.
I was scrolling through on my phone and accidentally hit ‘report’ on this comment. I don’t seem to see an ‘unreport’ or its equivalent though.
Fun fact: there’s no evidence private schools are better than public schools. In fact, there’s significant evidence that, on average, they’re actually somewhat worse.
The idea that public schools are bad is not actually founded in reality. Many of the best high schools schools in the US are public schools.
This is not true at the university level, but that’s not terribly surprising.
“In fact, there’s significant evidence that, on average, they’re actually somewhat worse.”
Link to evidence in support?
As someone who has attended both public and private schools, I cannot merely disagree – I must laugh at you.
If you are measuring resources available, then of course public schools have much more – but if you look at the whole picture: staff, curriculum, learning environment – then private schools with at least half the funding of a public school will beat them.
I imagine you would need to look at ALL private schools, not just ones specifically intended as very rigorous academically. And make sure you are comparing performance in similar populations.
Theory 1, the number of private schools is dominated by small, religious private schools.
Theory 2, the SSC comment population isn’t a good place to get representative anecdata about broad private school performance.
Theory 3: in order to maintain local differentiation, public schools and nearby private schools will have inversely correlated academic quality.
” But I would rabidly oppose any government-operated scheme to evaluate teachers and pay them according to their performance”
How about a scheme not government operated?
We have, after all, “schemes” to do the equivalent in lots of private market contexts–some employees get paid more than others because their employers believe they are more valuable, some self-employed people make more money than others because they are better at what they do.
Suppose K-12 was entirely private, either paid for by parents or via a voucher scheme by the government. Schools private firms, for profit or not for profit. Parents decide which school to send their kids to.
Parents want their kids to learn, so have an incentive to choose schools with good teachers to the extent they can judge–and parents have detailed information on what is happening to their own kids. So the schools, like other employers, have an incentive to try to attract good teachers, get rid of bad ones.
Private schools are, on average, somewhat worse than public schools.
This means that people are actually pulling kids out of better schools and putting them in worse schools.
Assuming the public is capable of making rational decisions is your first mistake.
“This means that people are actually pulling kids out of better schools and putting them in worse schools.”
It might be true, but it doesn’t follow from the claim that the average private school is worse than the average public school, even if that claim is true. Some public schools are worse than average, and those might be the ones kids are being pulled out of.
People in hospitals are less healthy than people not in hospitals, and users of dating sites are less likely to get married in the next year than non-users.
Or as Megan McArdle put it (http://www.theatlantic.com/business/archive/2007/10/vouching-for-vouchers/2168/):
American high school teacher here, strongly seconding the misbehaving student hypothesis. Skilled veterans are distinguished primarily by their ability to sustain a classroom environment where negative behavioral tendencies are less likely to express themselves. I get a lot of the lower-rung students and it’s very, very common for them to get suspended for things they’ve done in other rooms while having only a few minor issues with me.
Also, my theory has long been that correlations between class size and student success later in life are mostly behavior related. It’s not just that a larger class raises the possibility of drawing a bad apple, but that larger classes *exponentially* increase the probability that you’ll end up with two or more radioactive students who, individually, would not have been issues, but together feed off each other and pour toxicity into the classroom.
It’s not hard to imagine that, if some of a student’s formative classroom experiences take place in a behaviorally-distracted room, this might negatively shape their own habits of comportment and scholarship.
Much of the controversy around inner-city charter schools also seems to stem from schools playing up the importance of behavior to the point where they (over?)zealously discipline students and find ways to drive out the undesirables. The articles always play up the injustice angle on the kid forced out, but they never seem to interview the classmates and their parents who are glad to see them gone.
Teachers benefit from disciplinary back-up from the office so that they can get troublemakers out of the classroom fast. Plus it shows the troublemakers that the authorities are on the side of the classroom order. Private high schools, for example, typically make an assistant football coach with a neck wider than his head the Assistant Dean of Discipline who is in charge of putting punks in their places with afterschool detention periods and the like. Typically, the guy put in this role likes this job, while people who like teaching The Great Gatsby don’t like the Being a Hard Ass part of their jobs.
Unfortunately, the Obama Administration is crusading against “disparate impact” in public school discipline, which discourages schools from using techniques that leave a statistical paper trail that can be counted up and denounced as racist (oddly, charges of sexism in disciplining boys don’t interest the White House). So, public schools tend to ask teachers to handle discipline problems themselves in ways that don’t generate statistical paper trails. This must be discouraging to the teachers who’d rather send the punk off to the office and get back to the Great Gatsby.
I think their real attitude is more like, “protect the union and senior teachers above all else, because that’s the best way to maintain our money and power; we’ll give a shit about the kids when they pay union dues.”
Having worked in local government education and seen (some of) the Irish education system up close, and with a brother who is a teacher, I’m laughing at this.
Yes, bad teachers have an effect on students. But speaking purely from personal experience, I could read before I went to school and no teacher – good, bad or indifferent – had an effect on that part of my learning. I always liked history, and my interest and good grades in national exams had nothing to do with my teacher, who pretty much disliked me and called me stupid in front of the entire class.
I am hopeless at maths, and my best (and the entire class’s best result) was in the Intermediate Certificate (national exam taken at age 15) – all down to our teacher, who achieved her results from pure fear (I’m not joking, one day I was literally shaking with fear before her class, everyone was terrified of her).
The lesson from that is to get a nun who can strike fear and terror into the students to teach classes 🙂
As to the non-effect of parents on their kids, this recent Irish study is making amazing claims for what happens when you mentor parents and the effects on very young kids. I’m a bit sceptical – yes, I do think that helping parents at risk be better parents is very damn important because in our schools (and one in particular, and the Early School Leavers service), I saw the results when you have absent, uncaring or simply overwhelmed parents, but the likes of this claim make me raise my eyebrows:
.
It’s that easy to increase IQ? In which case IQ cannot be merely innate, it must be heavily influenced by environmental factors. Or maybe IQ tests (particularly in very young children) are not measuring that elusive whatever it may be g factor, but rather evaluating how good you are at taking tests. So getting parents involved in helping their kids to be better able to read, write and understand test questions has an effect?
I remember working hard in certain subjects I disliked and would otherwise have slacked off in solely because I liked the teacher and wanted to earn his respect.
IQ gains of that magnitude due to experimental interventions are common enough in small kids. They invariably fade away in a few years.
95% sure those IQ gains disappear a few years later. I mentioned this in the post – early IQ is relatively environmental and easy to influence; later IQ is more genetic and much harder.
I just hope every keeps in mind that what the evidence really demonstrates is the ability for interventions to influence the score a child makes on an IQ test. The test and the score on the test are a hopeful attempt to measure g, they are not in fact g.
It may not even demonstrate that. It may demonstrate the ability of researchers to generate the result that they, or their funders, want.
One lesson one should get from many of Scott’s posts is that the claimed results of research are quite often bogus. Before you have any confidence in such results, you need multiple researchers with different biases working on the subject and critiquing each others’ work.
I have officially been one-uped:)
But I wouldn’t be surprised if early interventions can help some young kids get over crucial milestones, like learning to read or learning. For example, an 80 IQ adult who learned to read as a child will have a better life than an 80 IQ adult who didn’t learn to read.
Teaching skills is valuable regardless of IQ.
I think all of the intervention studies are confusing a measured IQ score for actual innate ability. They hope the intervention is actually making the student smarter, but in reality they’re making the student score artificially high on the IQ test. IQ tests are very finicky, sufficient test preparation can render the score meaningless. Steve Sailer posts here from time to time, usually armed with links to test prep scandals at exclusive east coast private elementary schools as a specific example of the general case.
I think it’s quite possible the results are genuine, but also fading.
I think what’s going on is that IQ is like a muscle that can be increased by regular exercise. Schools have near-totalitarian control over their students and can force them to exercise.
Once students are no longer forced to exercise their IQ reverts back to normal, unless they are the sort of people who like exercising in the first place.
IQ becomes genetic later in life because once people are free of school, many of them choose not to exercise.
As a parent, I’m willing to give the idea that brief outsiders could have more of an effect on my kids’ behavior than me.
Because the kids are constantly and repeatedly fighting against me and my spouse. Deep down, they know that giving in to us might help in the short-term but will work against them in their long-term goals of being able to do whatever the hell they want. (This is probably factually incorrect in the real world, but what matters is the model in the kids’ head. And it seems my kids have the same model in their head that I did when I was a kid: parents are the ones stopping you from eating ice cream all day, so they are, in many ways, the enemy.) Kids don’t have things like jobs that will distract them from their constant attempts to whittle away at mom and dad.
Yet, an outsider can show up and whip them into shape.
Interesting. I don’t remember ever feeling like that as a kid, and I see no evidence that my children did.
I wonder if this is a random variable or a result of different approaches to child rearing. It’s a mild version of the more general issue of why some children end up disliking their parents, as pretty clearly happens.
I don’t remember feeling that way either. My mother always thought most other parents were idiots for micromanaging their kids. “They act like police” she would say (in her youth my country was a police state).
My sister and I were always better behaved than the other kids and my mother naturally thought it was because of her superior parenting. In part I agree, but I also think my sister and I spoiled my mother a little, in that she believes every child would behave well if their parents did what she does, but that really only works if the child is like me, my sister, or your children.
I was always the same way, too: pretty much the ideal child in terms of being well-behaved and polite. There were very occasional times when I would misbehave in some minor way—I wasn’t literally a perfect child—and those times I would usually get a (light) spanking.
But in general, there was very little friction between me and my parents.
One of the only things I can think of is that they would sort of intermittently insist upon having us call them “ma’am” and “sir”—but they wouldn’t stick to it. And I always found that awkward and didn’t like it. But that’s what their parents had done, and most of my cousins (especially on my mother’s side) were required to do it.
For my sister, it was the same way when she was little, but as she became a teenager, she started to fight more (verbally, not physically) with my mother.
If anything, though, I think school (which was private, but very conventional) made me worse by picking up things from the other kids.
The funniest thing is that—I don’t know why—but before I started school, I would always speak in complete sentences, never saying “yes” or “no” on their own. “Will you read the book?” “I will read the book.” That was the unusual thing, but I was really polite and “formal” in other respects, too.
Actually, my father still talks about how when I was very little, I would sit with him and watch the 40-hour lecture series on astronomy by Dr. Alex Filippenko. Of course I didn’t understand all of it, but I found it very interesting. He would also read to me a lot. I especially remember the Narnia books, a collection of Brer Rabbit stories, and a collection of Greek mythology for children.
I feel like being exposed to books and documentaries, etc. had a pretty strong effect on me. But on the other hand, he read more to me because my siblings were less interested in it and would get bored. I’m skeptical of claims that parenting has no effect vs. genetics. I feel like genetics sets the potential, which can be actualized to different degrees.
I have observed very different parenting styles within black and white families in the U.S., and on the surface your explanation makes sense. On the other hand, I can also think of enough exceptions to the rule to give me pause. It is certainly worth considering as at least a partial explanation.
Yes, but parenting styles are not randomly distributed. Maybe your father read to you a lot because he was part of an experiment, but more likely he was predisposed to do it genetically and passed on that predisposition to you as well. You have to control for that to avoid drawing wrong causal conclusions.
“I wonder if this is a random variable or a result of different approaches to child rearing.”
Probably quite a lot of it is wired into differences in the kids, but looking at what seem to be fairly large differences in how well different people get pets to behave[*], I rather suspect causal effects of childrearing differences matter quite a lot. At least one of my brothers has remarked of my mother “she trained horses, didn’t she?” and while I’m not sure what aspect he meant to emphasize, on one aspect I think he nailed it: my mother seems to been unusually careful about being consistent in basic ways that recognizably map to basic animal training practices, and to have put some careful thought into not creating perverse incentives by being consistent in confusing or otherwise dysfunctional ways.
I don’t get enough exposure to key moments of other parents’ childrearing to have a lot of data for comparison, but I was once memorably flabbergasted when I saw a child at breakfast ask for something, be told “not unless you finish that other thing,” finish that other thing … and then be refused the original request. I mean, of course intellectually I could get my mind around it, but at some ordinary-assumptions level it had been just unthinkable to me until I saw it happen. And having intellectually gotten my mind around it, I naturally imagined (and, I fancy, later occasionally observed) long years of foreseeable frustrating parenting consequences from not being taken seriously at basic commitments and negotiations and explanations.
Also ISTR you (David Friedman) recounting one of your children remarking that in your role as parent, you tried to have coherent reasons for rules and avoid just appealing to just-because parental status. That is a tendency that in my experience differs quite a lot between families, and seemed strong in my family. By analogy with how much of a difference simple forms of consistency make in dealing with other animals, I find it plausible that that sort of high-intelligence-social-animal consistency could make quite a lot of difference in dealing with humans. (And I think I see some strong effects like that in some other social institutions, not just families, but there are so many confounding factors that I can’t guarantee that I’m seeing it correctly.)
[*] sometimes in ways that tend to cancel out individual variation in the pets, like different household members getting the same pet to behave, or one individual observed in interaction with multiple pets
In my experience, teenagers mostly act without any conscious thought at all as to why they’re making confrontational and self-destructive decisions.
The reasons they give are after-the-fact justifications in the flavor of whatever media and peer interactions they’ve been consuming.
I say this both as a former teen and teacher of teens.
Lots of fuss over so little. Of course, much of the fuss isn’t really about students, but about who gets to control education funding and policy. And that’s just more reason, IMO, to drastically decentralize education. Stop making teachers and schools accountable to bureaucrats and start making them directly accountable to parents. Not that parents are better able to make these sorts of calculations, but at least they have local knowledge of their own children.
Agreed. Unfortunately we seem to be running in the other direction.
Stop making teachers and schools accountable to bureaucrats and start making them directly accountable to parents.
But the problem there is that parents judge schools by test scores (the league tables in Britain and Ireland which every newspaper loves printing) and so they want to send their kids to the school with the best test results. Standardised tests are the natural outgrowth of this, because how else can you judge school A against school B? Very little is taken into account that school A may be located in a disadvantaged area, etc.
Bureaucrats churn out things like standardised tests and the various programmes in response to pressure from parents and industry; parents want a measure that Junior is going to get good grades so he can go to a good college to get a good degree to get a good job. Industry and business want STEM subjects and kids who can work long hours, take instruction, and be productive. Teachers’ unions have the interests of their members to consider. And there is never enough funding for “frills” like the arts, or psychological services, or intervention programmes (unless they can prove they’ll earn their bread by “this programme means the students will raise their test scores/get grades two levels higher than if they weren’t selected for it!”).
Wow, that’s an actual problem? When I tried to imagine what would happen if schools would be accountable only to parents, and the only thing state would do is to make students take standardize tests and publish the results for every school… I imagined that the parents would probably completely ignore these results, and choose by completely different criteria such as shiny school uniforms, or marketing skills of the school principal. So… this seems to me like a good thing.
Even if you would know for sure that school A has worse outcomes than school B merely because it’s in the disadvantaged area, wouldn’t it still be a rational choice to put your children in the school B?
Sounds like a lot of my property taxes will be blown trying to raise substandard students to average in School A. School B will likely have more money and give my kid a personal iPad and Fitbit (which Ferris Bueller’s high school now does, I believe).
wouldn’t it still be a rational choice to put your children in the school B?
If your child can get into school B, which is vastly over-subscribed because every other parent in the catchment area and outside it is trying to get their kid in there.
And if your child has special educational needs or has a behavioural problem, which means school A is the only school that is willing or able to take them, then it makes a big difference if the school is under-resourced because it’s seen as a dumping ground for the dummies.
I think you are assuming parental choice within a government run system of schools.
Some grocery stores have higher quality food than others. I don’t observe them turning away customers who don’t meet their standards. If there is a reproducible way of teaching better and school A, which is doing it, only can accommodate some of the students whose parents prefer it, either school A expands, school B copies what A is doing to get students, or someone starts school C imitating school A. That’s what normally happens in private markets. It isn’t perfect, because parents have imperfect knowledge, but it seems to work much better than state run systems in a lot of other contexts.
It also doesn’t always work well with schools because well-trained kids are not necessarily as easily-reproducible as just ordering more cans of spam, and good teachers aren’t as reproducible as ordering more shelving/building on another annex.
Not to say there aren’t some ways of mass-producing education, or making up for the weaknesses of some teachers with structural programs, but if it were easy we’d have done it by now.
I think this is taken into account very much. Parents don’t want to send their children to a school in a disadvantaged area, so if standardized test scores are heavily confounded by that then from the point of view of parents they are even better.
“Standardised tests are the natural outgrowth of this, because how else can you judge school A against school B?”
One way is by how happy your kids are in school A, how happy they were or your friends’ kids are, in school B. One reason parents sometimes pull their kids out of the public schools in favor of a private school or home schooling is that the kid is obviously miserable and not learning much in the public school.
And vice-versa, in my home town there were several cases I know of where parents pulled their kids out of private schools to send to a state school. In one case, two weeks after he’d started.
(There were limited private school options and several of the private schools were Catholic which was inconvenient if you weren’t.)
That needs some qualification. Some parents want the school with the best test scores. Some parents want the schools with the best athletics. Some parents want a school that will pass on their preferred religious teachings. Let a thousand flowers bloom.
Also, so what? My point isn’t that parents can do a better job at judging school or teacher quality, only that they can do a better job at judging what their children need. One-for-two beats zero-for-two.
Also, parents face a budget constraint, either in the form of funding or some other constraint like geographic distance or pedagogical preference. Generally, people make better decisions when directly exposed to the results of those decisions than they do when making collective decisions in the abstract, when they are much more likely to default to ideology. There’s a reason that business class air travel costs so much money; people tend to be much more thrifty when they’re spending their own opportunity costs.
It is a rational choice to choose not to send your kid to school in an underprivileged area; in fact, student quality is a major predictor of outcomes. Underprivileged areas have poor student quality, and more students with behavioral problems. Why would you want to send your kid to such a school? Literally every negative factor is lining up there.
I think they also tend to have worse teachers, since educated, well off parents are more able to pressure the system on behalf of their kids.
There are places where teachers and schools are directly accountable to parents — they are called private schools in the US (confusingly enough they are called public schools in the UK). I fervently encourage as many parents as possible to utilize their services.
On a very small point: they’re also called private (or more commonly independent) schools in the UK. A small group of independent schools that are quite old are called Public Schools – because at the time they were established it was to indicate they were not private in the sense of being run for personal profit of an owner, or restricted to a particular parish, region or group.
Schools operated by the State are just that State Schools.
Interesting. Thanks for the explanation.
Thanks! I have always wondered about that.
A number of the best high schools in the US are public schools.
I went to a public high school far better than pretty much any private school.
The sad reality is that private schools aren’t better than public schools.
So why do people believe they are?
Its a con. Duh. How else are they going to scam you out of money?
Marketing is a powerful thing.
There’s no real evidence to suggest private schools are superior; indeed, there’s some evidence to suggest they may be inferior, on average.
Private school students get better scores on average. Same goes for charter school students.
The problem is, they’re richer on average. And richer students are higher quality students.
Once you start comparing these students to demographically similar peers in public schools, the advantages vanish. Meaning you’re paying a bunch of money for no advantage at all.
Can you offer evidence for that claim? Prep school students are likely to be from higher income households, but prep schools are a small fraction of private schools.
Checking online, it looks as though parents with incomes of $75,000 or more send only a slightly higher fraction of their kids to private schools than the average (13% vs 10%, roughly). But I wouldn’t be surprised if parents with very low incomes almost all send their kids to public schools.
Where are the figures on output measures controlling for parental income?
The usual source cited in these arguments is “The Public School Advantage” by Lubienski and Lubienski. Here is the Lubienski’s first big paper http://epsl.asu.edu/epru/articles/EPRU-0601-137-OWI.pdf . I am not knowledgeable enough to say if it is right, I’ve just heard this argument enough times to know what gets cited.
Didn’t you see “I went to a public high school far better than pretty much any private school”? What more evidence do you want?
This is supposed to be the rationalist sphere but on subject after subject — dieting, health, education, child rearing, dating, etc — we see strong claims based on little more than anecdotes and gut feelings, occasionlly backed by a plausible sounding just so story.
@Anonymous:
Any “anonymous” commenter can post most anything they like here. But then they get asked for citations. And then there is much less, “his gut is right!” style commenting.
Now, there are certain topics where I see more unfounded assertions and rah-rah, but generally it’s not the case.
@DES3264
Thanks. Is Lubienski the source Titanium Dragon is relying on?
If so, it’s worth noting that it is only looking at math, not education in general. The analysis is sufficiently complicated so that I would want to see responses by people criticizing it before forming any opinion on whether it is correct.
One point that occurs to me, which may be a problem with the analysis. They control for the fraction of students in a school with various characteristics. But students are affected by the characteristics of other students.
Suppose it turns out that a school where average home resources are 3 (few books etc. at home), on average, tests one point worse on some test than one where it is 5. One interpretation is that being a student whose home doesn’t have books makes you, on average, likely to do worse. Another is that having other students like that in your classroom makes you likely to do worse. Since the regression seems to be run on schools, not students, I don’t think it can separate those, although I may be misunderstanding it.
It matters from the standpoint of TD’s claim. If the private school has students with better home backgrounds and the result is a better educational environment, that’s a good reason to send your kid there.
You’re paying to keep the low-quality students away from your kids, so they can actually learn. The private school I went to in the South was no better than a good (not spectacular, just good) public school in a nice suburb in New Jersey – but it was no worse, either. It was orders of magnitude better than the public schools available to me.
Our football team’s starting offensive line contained more National Merit Semifinalists than the entire local public school system.
Now, if you compare us in private school in the South to those kids in a good public school in NJ after controlling for parental income, of course we don’t look like we get better results than public school students. We don’t. What we got was something that functioned like a good public school in a place that didn’t have them.
What I want to know is, how do you become a finalist? Is there anyone who actually achieves “national merit”?
There’s 16,000 semifinalists out of which there are 7400 finalists. There’s nothing above finalist.
@Devilbunny
Exactly.
One of the private schools I attended was a little Fundie church school where they taught Creationist “science”.
Still better than the local public schools, at least for the majority of pupils.
@onyomi
I was a National Merit semifinalist but not finalist. To be a semifinalist all that is required is to get a test score in the top 1% on the PSAT.
To become a finalist you then need to show a pretty high GPA (current standard is GPA>3.5) and add recommendation letters, a transcript, info on extracurriculars, and write an essay.
(I didn’t meet the GPA cutoff)
More here.
Back when I was a national merit finalist the merit had its own exam. At least, that’s how I remember it.
Or maybe I was a semifinalist. I know there was one higher step, but I thought that was “Merit Scholar” and got money.
I don’t recall whether I got “finalist” or not, but I just always thought it was funny how this term “semifinalist” was always thrown around (my high school also liked to brag about how many of these it could produce), yet no one mentioned what one was a finalist for. It sounded like there was some kind of competition going on, but it was really just a recognition.
From the website: http://www.nationalmerit.org/s/1758/interior.aspx?sid=1758&gid=2&pgid=424
1.5 million kids take the PSATs, the 50,000 highest scorerers are eligible for semi-finalist or commendation status. There are 16,000 semi-finalists, selected on a state by state basis (i.e. each state gets a number assigned depending on how many total test takers they have, then an individual state cutoff is determined) and the other 34,000 get commendations. Of the 16,000 semi-finalists, 15,000 go on to become finalists, which requires getting a similar SAT score, having had decent high school grades, getting a school endorsement, and writing an essay. Finally, around half the finalists receive a $2500 national merit scholarship. The winnowing process from finalist to scholarship is opaque.
Beyond the $2500 scholarships the organization acts as a conduit for a variety of private scholarships including those offered by employers to children of employees and those offered by colleges to finalists that indicate that school is their first choice. These latter scholarships are not national merit scholarships as such, but are generally worth more money.
@onyomi – I believe others have answered the process question as well as it is likely to be answered. IIRC there were ten semis in my class, eight of whom became finalists. I believe I was the only one who actually became a National Merit Scholar, but at that point it was mostly window-dressing – a lot of schools will provide full rides (tuition, room, and board) for semifinalists who list that school as their #1 choice. At the time, both Alabama and Florida did.
Neither shows up on those “public Ivy” lists, but both will give the interested student a good education, and “free” is a very good motivator.
I ended up taking a full ride elsewhere, and graduated with no debt (in fact, some other small scholarships I had ended up giving me around $2500/year, so I could pay for my books and have a little spending money without working). My parents paid for my health and car insurance, and gave me an old car, but other than that, I was off the family payroll.
I was, at the time, an excellent recruit academically, and was admitted to Ivys – but the generous financial aid packages to middle-class kids would have meant that my mother would have had to keep her income down in later years in order to keep our family income in the zero-family-contribution zone. A four-year guarantee was quite valuable. An Ivy diploma would have been worth more, but then again, I was a middle-class kid far from the social circles of people who obsess about such things. And, in the long run, it seems that it matters very little outside specific industries – politics, media, i-banking, consulting, parts of Silicon Valley.
Have you seen a PTA meeting? The feds do a crappy job of managing education, but I guarantee that parents would do an even worse one.
You are confusing two very different forms of parental input.
Restaurants are controlled by the customers. There is no equivalent of a PTA–I don’t go to a meeting of other customers to tell my favorite restaurant what to serve. But if I don’t like what it serves I go elsewhere, which gives the restaurant a strong incentive to serve things its customers like.
Sure, a commercial model would probably work — daycares and private schools seem to do OK. But I didn’t read j r as suggesting that.
If I’m wrong, I’m wrong.
A good analogy. Consider some of the other things it implies, however.
I live in a U.S. state with an “open enrollment” policy that allows parents to enroll their child in any public or charter school they want, so long as they don’t expect transportation services. And schools get money from the state in proportion to enrollment. Perfect, yes?
I’m a teacher in this state. Here’s what I’ve seen:
Yes, good schools grow… and keep getting better, because parents who care and can afford to transport their kids do so. As a necessary consequence, you also get shrinking schools populated by kids with poorer or less-informed parents.
But wait! For every parent who relocates their kid for academic reasons, there are two others who relocate them for… sports. Maybe three. It’s up there. So the real arms race among schools hoping to increase enrollment and thus funding takes place on the field/court, and the most powerful person in the high school is the head football coach. This is how you get a high school with a 1.5:1 male-female gender ratio.
That’s not all! We get all sorts of mid-semester movement where students who are sucking it up in one school get sent to a different school in hopes of a clean slate. Sometimes they genuinely don’t know that their transfer grades follow them. Sometimes they’re just taking their chances, thinking the grades have nowhere to go but up. Shopping around can mean shopping for easy grades just as easily as it can mean shopping for academic quality.
One major point of disanalogy is that it’s easy to tell whether you like the food at a restaurant when compared with whether or not your child is getting an education that will serve them well later in life. Schools may advertise on such a basis, but that’s different from offering such a thing. As Scott’s massive and not-terribly-conclusive post here illustrates, no parent is going to be able to tell the difference. I’d guess that the free market would optimize more for marketing than education, especially since the feedback on education quality is so incredibly long and cloudy. See the for-profit college space, where the survivors aren’t the best educational institutions.
On the other hand, Coursera and EdX and the like are both doing well and offering good educational stuff, so the for-profit education space isn’t universally bad. Ditto with many private schools. Also, it’s possible the market would shape up relevantly different in the grade school market than in the college market.
But the children of the parents who care enough to keep teachers accountable are already doing well. We still need to help the children whose parents dgaf.
We could also make it far easier for people who don’t want children not to have children. A crazy idea, I know.
How much easier to not have kids do you want it to be?
For one thing it’d be nice if people didn’t have to take a bus hundreds of miles to end an unwanted pregnancy. For another it’d be great if by the time they were biologically capable of procreating all kids were aware of how procreation works and how to prevent it.
Nah, I think that wouldn’t be nice at all. It would end with a dead baby, for starters. I thought you wanted people to not have babies, not to kill them.
And I strongly resist the implication that any significant fraction of pregnancies are the result of people not understanding that PIV => pregnancy. You’re going to have to do quite a bit of work to convince me this is a major effect of people who don’t want to have kids ending up with kids.
Anon, you might be interested in Edin and Kefalas’ Promises I Can Keep. At least in the case of teen single mothers, it appears that lack of knowledge about or access to birth control is pretty much never an issue.
I suspect most teen pregnancies aren’t actually unwanted. Biology is a bitch and wants teens (especially but not exclusively teen girls) to want babies.
There’s no baby until after birth so there’s no dead baby as a result of an abortion.
And TheNybbler biology doesn’t want anything. It isn’t the type of object that is capable of having wants to begin with.
Not only does biology want things, it wants to be anthropomorphized. Or at least gynocanidomorphized.
Interesting.
I have heard that programs that gave out subsidized IUDs were effective at reducing the teen pregnancy rate, so it may be that making going off birth control more inconvenient than staying on birth control is the key.
The idea that more contraception = fewer unwanted pregnancies/fewer abortions (or the converse, that abortions come from lack of contraceptive access) is logically sound, but not held up by the facts.
“I suspect most teen pregnancies aren’t actually unwanted.”
My view as well.
Back when birth control and legal abortion were relatively new issues, the argument was that they would prevent “unwanted children,” with the implicit assumption that most births to unmarried mothers were unwanted. Birth control became legal and widely available, abortion became legal–and the rate of births to unmarried mothers went sharply up, not down.
The obvious conclusion is that most of those births were not, and are not, unwanted.
Norms around marriage changed greatly around the same time. Part of the reasons for this probably had to do with the availability of contraceptives, abortion, etc., but part probably didn’t.
It depends on which kind of contraception you are talking about. There seems to be pretty strong evidence that greater access to long lasting reversible contraceptives like IUDs and implants does reduce abortion rates.
It may well be true that many supposedly “unwanted” pregnancies and births aren’t actually unwanted, but LARCs make going off birth control inconvenient, and we know that even trivial inconveniences can have large impacts on human behavior.
@ Nornagest
Norms around marriage changed greatly around the same time.
Right. For a more relevant metric, try ‘teen pregnancy’ … and compare to ‘married teen pregnancy’ for the ‘marry early, divorce early’ demographic. And figure in the Quiverful movement (which probably was in part backlash from the Sexual Revolution, so QED if you like).
Probably especially so in this case, because having to take a positive action to reverse the birth control requires the desire to be made explicit, brought out into the open so one is more likely to examine it intellectually.
How much easier to not have kids do you want it to be?
It doesn’t happen unless you go to some lengths* to actually make it happen, easier.
*Not simply PIV intercourse.
because having to take a positive action to reverse the birth control requires the desire to be made explicit, brought out into the open so one is more likely to examine it intellectually
Right, except…
We have already the example of what happens when a social class consciously and explicitly delays reproduction until they “intellectually” decide to have kids – and it’s not compatible with those women having kids. It’s esp not compatible with those women having relatively trouble-free pregnancies and an average rate of healthy kids.
Furthermore…it’s bad enough when it’s social/work expectation pressures dropping birthrates through the floor. Using government programs to provide birth control for low-income/disadvantaged women, and especially using government funds to pressure women into choosing long term methods (esp the ones that need direct intervention for reversal, and a (costly?) doctor’s appointment for that intervention) which we know/expect/hope will reduce or eliminate the number of kids a woman will have…
Surely I’m not the only one who sees a potential problematic issue at play here…
And I’m not even getting into the health risks of barrier-free non-monogamous sex, or the emotional impact of “free love” – all of which appear to be larger risks for women than for men.
If it was as simple as “inject/swallow these drugs and you won’t have babies and can have all the sex you like but otherwise everything will be fine”…well. That would be one thing. But it would not be the thing we have now.
If the biomechanical system that is the human body evolved to be two pretty discrete sexes, living in close social groups, pair bonding, bearing and raising children, and having a brain whose proper function was pretty tightly wound around the hormonal play of its body…then it seems to me that a social shift away from bearing and raising kids is a pretty major step that maybe we should not be leaping towards.
Scott looked into this a while ago: https://slatestarcodex.com/2013/06/01/literally-inconceivable-contraceptives-and-abortion-rates/
IUDs are the way to go.
Or we could go back to sterilizing poor people, I guess. If you paid people to get sterilized, you could get a lot of sterile teens.
Which one is it? It can’t be both. And as for the health and success — put them up against the children born to teens. Bet they end up with better outcomes.
Sounds like fear, uncertainty, and doubt to me. What specifically is the concern and where’s the evidence for it?
Both, obviously. Did you misread? (Or did I? Because those questions seem like a non-sequitur.)
Pretty sure if you control for being married for the duration of the kids’ upbringing, the teen mothers will get better results on health. Just on the basis of gene damage due to advanced parental age – never mind any problems due to a reproductive system that was never used while it was new, or one that had gotten some kind of STD at some point during sexually active twenties.
The concern is messing up our ability to physically and culturally reproduce.
The evidence for the former are the western birthrates. I don’t think I need to even provide a link; just googling it will provide you all the material you could want. Unless you’re part of the Human Extinction Movement or some adjacent thoughtspace, this is a pretty pressing concern.
The second is considerably more difficult to prove, but the basic argument goes essentially like this: Up until recently, we’ve actually had a system that was able to reproduce itself memetically, via parent-to-child osmosis. What one thinks of the system is largely irrelevant; the pertinent property is that a monogamous, natalist, patriarchal society is proven to be able to survive from one generation to the next indefinitely.
Whereas the proof for the same kind of socioreproductive ability for the modern polyamorous, anti-natalist, egalitarian society is rather scant – largely because it’s very, very new. Ultimately, time will tell whether this system is stable and capable of surviving the test of it, but I’m not sure everyone is willing to leave the question of to whom belongs the future in the hands of the unforseeable currents of human history. Some might even be under the impression that they can do something about the outcome!
(If you ask me, the future humans will be more like those who reproduce most now. More Amish, more Muslim, more hardcore Catholic, more criminal and aggressive, more polygynous, more Black.)
It can’t both be impossible for a group of people to reproduce and when they have kids they are unhealthy. I don’t know how I can make that point any clearer. For the second point, I see no reason to correct for anything, I’m interested in a straight up comparison. Finally, you certainly do need a link to show that humanity is in any danger from extinction via failure to reproduce. If you think it is too obvious to need evidence I suggest poking your head out of whatever strange ideological bubble you’ve managed to find yourself enmeshed in. (Alt right? Quiverfull? MRA?)
@ anon
It can’t both be impossible for a group of people to reproduce and when they have kids they are unhealthy.
Successful reproduction includes having healthy kids. And yes, it’s both – birthrates for women in their 30’s and 40’s are not good at all, and the children of those women are less healthy than the children of women in their late teens and early twenties. (And it’s not just the age of the mother – older fathers contribute even more to autism risk.)
For the second point, I see no reason to correct for anything, I’m interested in a straight up comparison.
Why? Why are you not interested in confounders? And you would be incorrect wrt health of children born to teens – while early post-puberty pregnancies have a health risk of underweight infants (and in limited immunity passed on to the infant through breast milk) this pretty much levels out by late teens.
Finally, you certainly do need a link to show that humanity is in any danger from extinction via failure to reproduce.
That is not what I said. Something does not have to cause extinction tomorrow to have significant negative effects. Step back and consider the possibility – separate from what you think might be best for you – that sub-replacement birthrates among the most well educated Western social classes is Not Good.
If you think it is too obvious to need evidence I suggest poking your head out of whatever strange ideological bubble you’ve managed to find yourself enmeshed in. (Alt right? Quiverfull? MRA?)
Oh, keep on trying! You haven’t gotten to bingo yet!
To some minimum standard such that the kids are capable of reproducing themselves. Not to some arbitrary threshold of health.
A culture of waiting until 30s and 40s to try to have kids can’t be incompatable with having kids if lots of people do. That’s not how the English language works. You can just say you misspoke you know. As for the birthrates they aren’t that great unassisted but not coincidentally members of that culture have access to cutting edge reproductive medicine.
Because the positive effects of the culture you are attacking outweigh the negatives in terms of child outcomes, and it would impossible to modify the culture so as to produce earlier childbirth without destroying it. It’s a package deal, and not only are the kids fine they have the brightest outlooks of any newborns on the planet.
The worst case scenario is that in 100 years American society will start to look like how you want to transform it now to maybe prevent that outcome. The cure is worse than the disease. And there’s every possibility that technological and/or economic change and/or fashion will intervene and there won’t be any problem.
Consider please, that my comment implied that I am not worried about the extinction of humans in general – I’m not at all concerned for Africans or Muslims not being able to reproduce, because they seem to have that covered very well. I’m concerned for *my* people.
True enough.
It does appear to be incompatible with replacement birthrates. Having just one kid will mean that the next generation is half the size of the previous.
If merely reproducing – something you are designed to do – requires expensive treatments, that’s hardly a good thing.
Prove it!
You’re probably right, which doesn’t bode well for the culture.
There’s just not enough of them.
Becoming Brazil is hardly what the pro-natalists want. Especially since Brazil is sub-replacement too.
Have you considered that some of those you consider your people don’t consider you, their people?
If you have one and your sister has three (two of which are fertility treatment twins, maybe) your parents are covered.
Are there some numbers you wish to offer at this point? Also note that we skim off the best of other cultures (in and out of the US) and convert them
One could say the same thing about glasses and seeing. Heck, the neo-social-Darwinists probably do. Something, something mutational load. For myself I’m fine with a society of glasses wearers.
I asked first and you waved your hands in the air with “after correcting for single mothers” or some such nonsense — which I think concedes the point.
That’s right you all advocate for Atwood’s dystopia instead. No thanks. I’d rather Brazil than that.
@ keranih
the children of those [30’s and 40’s] women are less healthy than the children of women in their late teens and early twenties.
What are some examples of cultures and sub-cultures otherwise comparable to ours, where this is applied? Respectable Victorians and pioneers, and early 20th Century town-dwellers, had a very firm standard that a man could not marry till he had an income and a house ready for children.
From things you’ve said elsewhere, I get the impression that you favor abstinence for teens. But that won’t produce these healthier babies either.
Well, if it’s good for parents to be young, and it’s good for parents to be financially secure, then it seems to me that what we ought to do, as a society, is to make it easier to be young and financially secure.
My preferred method would be to shorten the period of life where schooling interferes with one’s ability to make a living (that is, return us to a situation where an 8th grader can do most work, a high school graduate nearly all, and only the most specialized require postsecondary education).
But other methods are possible; straight up downward generational subsidies, for instance. For your more traditional, grandparents taking a greater role in early childhood while the parents finish their education. For the dirty-old-cuck crowd, an arrangement where an older man supports a young mother and a younger man’s biological children.
Yes, and it doesn’t apply. I’m not American (which isn’t even a proper ethnicity, unless you narrow it down to a specific subset). I know who my people, and experience so far suggests that they too consider me part of them.
Sure.
https://en.wikipedia.org/wiki/Demography_of_the_United_States
Last time the US had an above-replacement TFR was in 1971. By 2014, it’s 1.862. The promille figures in the table above that suggest that the group driving most of this sorry statistic are the whites. Granted, even these awful figures are a damn sight better than the stats of my people in my country, but the same principle holds.
Or rather, you think you do. There is a pretty strong case for the immigrants – and their descendants – are who are changing the United States more to their liking, and less to the liking of the original Anglo-Americans.
Having poor eyesight and having poor reproductive ability are quite different. One is not essential, the other is.
No, it doesn’t. Single motherhood is not an inherent function of age. Being old is.
You, on the other hand, made an assertion that needs backing – that somehow, the next generation is in an excellent position, so much that it outweighs their reproductive prospects. How can anything outweigh those? If you’re not likely to reproduce, what exactly do you have, really?
Never read it. Having read the summary on Wikipedia, no, I’m more partial to a setup like Franco’s Spain.
If you do reproduce, what exactly do you have, really?
I think maybe you need to work to coming to grip with your own mortality. Once you are in a healthy place maybe you won’t be so attracted to this weird pseudo-religion of a reified metaphor.
The fact that you think we should want to turn the US into fascist Spain in order to “save” it, really says it all.
keranih, I think the point is that where having kids is a choice, the only societies that choose to have a replacement+ birthrate are (1) non-industrial (so an 18 year old can be as productive as a 35 year old), (2) religious (3) with mores that are rigidly socially enforced.
At that point, such people are not “my people”. Are they yours? Outside of (I presume) the color of your skin, what would make them “your people” more than any other such society that currently exists?
Sorry, but it’s pretty clear (and I have 2 kids of my own) that almost any society that have the traits of modernity that most of us would consider necessary for pleasant living also result in a sub-replacement birth rate.
And in about 1,000 years, we’ll have to worry about it. But not now.
Firstly, I’d like to note that we appear to have come quite a long way from my first point, which was to question how much easier we want to make avoiding parenthood. This appears to equate to “forcing women to have children” in some people’s minds.
Secondly, I’m not finding where I talked about “my people” anywhere in this thread. (Someone correct me if I’m wrong.)
Thirdly – to this general point –
What are some examples of cultures and sub-cultures otherwise comparable to ours, where [women tended to have children in their teens and twenties]? Respectable Victorians and pioneers, and early 20th Century town-dwellers, had a very firm standard that a man could not marry till he had an income and a house ready for children.
The point that we are delaying social maturity for our young people – particularly middle to upper class – until mid twenties at best is well made. Again, is this really the best thing?
More significantly, I think, we have decided that – despite different biological demands – it is best to expect men and women to have the same career goals and paths. I suggest that this is a mistake, and that while we absolutely should permit people to set their own priorities, we should anticipate that women will want to pursue education/career around childbearing and early raising of children, and allow our professional expectations to match that.
Please note that I’m not saying that we should give women higher grades on an exam because they might be nursing a baby while writing an essay, or equal pay if they don’t have the same work experience. Just to step back from the idea that it is possible for most women to both raise kids and have an equal-to-their-brothers career, and that choosing kids over a career is…bad, or something only stupid or culturally backwards people do.
From things you’ve said elsewhere, I get the impression that you favor abstinence for teens. But that won’t produce these healthier babies either.
I favor abstinence outside of marriage. The most traditional approach has been to discourage kids from sexual activity before they are ready to marry, and over look sexual activity in the period immediately before marriage. I think the shift to normalizing sex outside of marriage (or instead of marriage) was a cultural mistake.
keranih says:
May 23, 2016 at 9:53 am
Sorry, but this confuses me. You want us to stop “delaying social maturity for our young people [ie having babies?] – particularly middle to upper class – until mid twenties at best”. But you don’t want them having sex before marriage either.
That describes what the Victorians and other ‘traditional moral systems’ did: no marriage without a house and job, no sex without marriage. — So, were they all wrong, by your standard, in postponing babies till late 20s or later? Isn’t that the Old Testament standard too? Have all the moral cultures got it wrong till now? Aren’t there any current cultures that have got it right, that you could point to? Amish maybe? But where are cultures comparable to ours, who go in for teen marriages/babies?
Are you proposing some whole new moral system?
I’ve asked on a later thread for you to clarify your big picture. Maybe that will help my confusion here.
@ houseboat –
This does clarify what you were asking in the later thread, but I’m still not clear on what your confusion is.
Yes, sexual experimentation should be limited to those one is married to. Failing this, it should be limited to those one is open to marrying. If the sexual intercourse leads to pregnancy – as the process is supposed to lead – and one isn’t married at that point, you get married. Your intercourse led to the production of another human and you’re responsible for that life.
As for “what if you don’t have a job or a house yet”? Firstly the house is a distractor, and there is no reason to assume that people can’t keep an infant or two in a one bedroom apartment. As for the job – the social history of my people is full of young men who abruptly set aside the thoughts and ways of children and settled into working well and hard once they had dependents. But that was in the times when it was expected that a man who impregnated a woman would marry her and take care of that child. Today, society takes the attitude that sex is not related to any sort of responsibility, so it is of no concern to the man that a woman he had sex with is now carrying a child.
As for ‘well, who does this?’ I’m detecting a note of amazement, as if restraint in sexual activity and/or devotion to providing for children is something crazy that only insane backwards barbarians engaged in.
And it’s not like we had great models to follow for democracy, secular government, women’s sufferage, normalization of homosexuality, and half a dozen other great leaps forward. Why do we have to insist that someone else go first in this?
@ Keranih
As for “what if you don’t have a job or a house yet”? Firstly the house is a distractor, and there is no reason to assume that people can’t keep an infant or two in a one bedroom apartment.
Duh. ‘House’ generic for a secure home suitable for raising a baby in.
As for the job – the social history of my people is full of young men who abruptly set aside the thoughts and ways of children and settled into working well and hard once they had dependents.
But where – in the current economy – does a job suddenly open up for him?
Yet despite all the doubts about such systems, important decisions about people’s careers are being made in place like New York. See https://www.washingtonpost.com/news/answer-sheet/wp/2015/03/25/how-is-this-fair-art-teacher-is-evaluated-by-students-math-standardized-test-scores/
VAM is bad, but it’s not like they had a really robust teacher evaluation system before. Or that the unions are offering one now. This is better than random, and maybe better than nothing.
You are underestimating the negative morale effect of being incorrectly labeled by an algorithm as a “bad teacher,” or watching this repeatedly happen to your peers, in an environment where it is already an undervalued, undercompensated, overstressed job — at least those (low income) schools where VAM is a concern.
I’m not underestimating anything because I’m not estimating anything. I’m pointing out that “VAM is bad” (regardless of how bad you think it is or for what reasons) is not particularly meaningful without some comparison. One possible comparison is “nothing,”‘ which I said VAM was “maybe” better than. I’d certainly be interested in a defense/comparison of either other methods or of nothing.
“Teachers shouldn’t be evaluated based on a simple numeric scale” is a sentence that is correct, in a vacuum.
The problem is that, because of civil service rules and union rules, the only controls the public has available to them must be numeric.
The alternative is “no controls whatever on teachers, let them do whatever they want.” Which will be roundly rejected.
In reality, teachers should be evaluated the way that other professionals are evaluated: by judgment calls of their superiors. This is completely incompatible with civil servant and union rules.
To clarify/pick nits, I think that the requirements are more that they are objective (in the sense of not depending upon any particular observer) and reasonably repeatable/reliable.
Quantifiable is preferred, but not necessary. A reliable non-numeric rank-ordering would be sufficient, I think.
The VAM produces quantifiable/numeric information. I think that the problem is the instability of the results, rather than the lack of numbers involved.
“In reality, teachers should be evaluated the way that other professionals are evaluated: by judgment calls of their superiors.”
That only works if it is in the interest of the superiors to make those calls on the basis of how good a job the teacher is doing.
It is very much in the interest of parents for their children to be well educated and happy, so they have the right incentives. It is in the interest of the owners of a private school for parents to send their children to that school, which gives them the right incentives at second hand. It’s much less clear how you give school administrators the right incentives.
@ David Friedman:
But there’s no evidence that private schools are better than public schools. You can predict private school performance by demography just as well as you can predict public school performance.
This suggests that whatever incentives are supposedly in place in private institutions are, in fact, no better than those in public ones.
Titanium Dragon:
Average cost of private schools is lower than public schools, so if results are the same that’s evidence of better incentives in the private schools. Beyond that, you so far have not offered any support for your claim about the comparison controlling for demongraphics.
Re the STAR study. So the initial assignment was random, but might there have been non random changes afterwards?
Not corrected to ‘grit’ (yet – growth mindset!).
This discussion seems to solely concentrate on movement of kids’ intelligence (or some proxy thereto) as a cumulative property which gets added to each year to a greater or lesser extent, but I think there is another paradigm which is not explored. Consider a graph of age vs. intelligence of a child. Assume it is some kind of ogive-like thing. This post talks in terms of shifting the curve up and down, but teachers I know have often talked about developments occurring earlier or later, i.e. shifting the curve left or right. Pupils may develop a certain skill (such as reading fluently) earlier than average and the standardised tests will notice that and they will have made above average progress that year, but next year, the average child will catch up with them and they will seem to have made below average progress (is this just bog-standard reversion to the mean, or something more complex?).
Another difference in paradigms is intelligence as a number vs. intelligence as a list of skills. Are becoming able to read, write, multiply, etc. simply matters of crossing intelligence thresholds, or does it necessitate specifically going and learning certain skills?
Tl;dr: Studies assume schools fill children with intelligence, like a tap fills a bucket with water. Might be a bad assumption.
Indeed. Is impossible to separate what school influences from growing up, especially because there is no control group in developed societies as everybody goes to school
There have been some comparisons with homeschoolers and they made the schools look bad, but the homeschooling parents are a self-selected group and is hard to eliminate all confounders.
I rather thought the general thinking is that intelligence is innate and the point of education is to teach knowledge and skills as best as possible given starting intelligence (and all other resource constraints.)
Ultimately the teachers’ unions are weaving the rope that will be used to hang them. Teachers can’t affect educational attainment, it’s all the socio-economic background of the students? Awesome, we can cut salaries to the minimum wage without worrying that we won’t attract the same caliber of teacher.
If they had the long-term interests of their membership at heart, they would behave very differently.
That is not at all what the teacher’s unions are argueing.
Rather they are suggesting that the standardized tests used fail to capture much of the value contribution but particularized human evaluation (sitting in on classes) is able to capture this. Just because the effects captured by these tests are largely the result of genetic, social etc.. factors in no way implies there aren’t other effects.
More relevant would be a study comparing lifetime outcomes of similarly situated students assigned to teachers who receive poor or good evaluations from fellow teachers.
I believe there are many problems with the tests (which in my opinion is a good reason to try improving the tests, not throwing them away; but we probably shouldn’t fire teachers because of them in the meantime), but there are also many problems with human evaluation — all kinds of prejudice, not just the usual ones, but also things like prejudice against using an unusual teaching method.
If we use the analogy of how doctors would hate to be hired and fired based on some highly noisy tests, we should also remember how well human evaluation worked for Dr. Semmelweis.
Damn. I’d never heard that story before. There’s a fable in there somewhere about the science crisis. Guy gets near-perfect experimental results but has no theory to explain why, so let’s commit him to an insane asylum and beat him to death.
Other professionals, like programmers and lawyers, deal just fine with being evaluated on fuzzy measures.
Go post in some programmer forum about how you are the boss of a bunch of programmers and want to promote/fire based on something objective, and ask for ideas of what what should be. Go on. It will be fun.
Seriously. I am supposed to be evaluated “objectively” on a .05% bad debt write-off. We’re already at .065% for the year, looking to be a huge .09% at the end of the year. But of that, .037% is a problem that I wouldn’t consider my fault.
But upper management might not see it that way. It’s rather fuzzy. Maybe they feel that I didn’t follow up aggressively enough and I deserve to get knocked.
And other people might think that if we’re collecting 99.91 cents on every dollar that really shouldn’t be considered that big of a deal. Old upper management didn’t think so.
And that’s the most “objective” measurement we have.
EDIT: I should add that this “not my fault” thing is not me complaining. It’s a problem that has been escalated to the CFO of a Fortune 50 company making millions of dollars. I think that if it’s been escalated to that point, then I have obviously done everything I can, but there’s no recourse if my immediate manager decides it is my fault and dings me for it….and it’s “objective!”
My wife has to do a yearly self-evaluation in which she states her goals for the past year, her boss’ goals for the past year, and to what extent she achieved these, and this gets compared to what the boss wrote. Except she works on a top secret program, so she and her boss can’t legally tell company HR what they do.
I think my comment was unclear. Reading it a few hours later I’m not sure I meant what it says.
It’s extremely rare to be able to judge professionals based on purely objective means. (Salespeople are the one big exception, and even then you need some judgment.)
Most professionals are just fine with their continued employment depending on a bunch of soft evaluations done by fallible human beings.
The teachers I met were dead-set against this as well.
The unions are mainly against the use of very noisy metrics like VAM for hiring, firing and compensation. That shit would drive me nuts if I was a teacher.
Pretty sure the same sort of deal would occur if you did value added doctor scores or whatever. This would not mean that doctors should not go to med school.
That would be fine if they were willing to use the same system used by virtually every other industry in the country — managerial discretion for hiring, firing, and compensation. But when they insist on seniority as the sole metric they don’t have a lot of room to complain about anything else.
To be fair, seniority as the sole metric is common enough for unionized civil service. It’s not unique to teachers. It’s a shitty system, but there’s a historical reason for it in trying to prevent things like the city police department being an extension of the Irish mafia.
If you assume the facts
1. teachers are hard to evaluate objectively
2. unionized civil servants must always be evaluated objectively
there is an obvious good solution.
Sure, teachers shouldn’t be civil servants. Unfortunately, as it stands, they are mostly employees of local governments and changing that is a separate fight from changing the way you evaluate the ones who are.
Edit: I should add it’s also a fight I don’t give a shit about because I don’t have any kids. Obviously, for many here it’s more than an academic curiosity. Of course, if I’ve learned anything from Scott, it’s that parents who want high achieving kids shouldn’t worry about teacher quality and should put most of their effort into attaining a high-IQ spouse.
“Edit: I should add it’s also a fight I don’t give a shit about because I don’t have any kids.”
You will be interacting with other people’s children when they grow up–to be your doctor, stock broker, burglar, … . So the effect of their schooling on how they turn out should be of at least some interest to you.
@David Friedman:
Well now, we are in definite agreement there. 100%.
I am a little confused though, because my mental model of your position is that the kids will end up being what they end up being regardless (absent some extreme trauma or the like). Is that model wrong?
It’s definitely my position that how current Americans that I interact with have turned out is sufficient for my needs. If we can make them even better, cool I guess.
“because my mental model of your position is that the kids will end up being what they end up being regardless ”
I don’t think I have made that claim.
Judith Harris, whose work I like, thinks that the parental environment has little effect on how children turn out, but the peer group environment substantial effect. It isn’t my field, but my guess is that both schooling and peer group can have a substantial effect on people.
That’s one of the reasons I am in favor of a voucher system, since I would expect it to do a better job than our current institutions.
“Unschooling” doesn’t mean “do nothing because it doesn’t matter.” It means “help kids learn what they want to learn instead of forcing them to pretend to learn what someone else has decided they should learn.” I think the latter approach is likely to have undesirable consequences.
You’ve got an unclosed parenthesis:
(“non-cognitive scores” in this case are …
This isn’t a comment, just a suggestion that people try the new upvote extension thingy:
https://slatestarcodex.com/2016/05/15/open-thread-49-5/#comment-358115
It won’t be terrible efficiently unless we all coordinate behind it.
Voting has a pernicious influence on conversation.
I think I’m happy to let it be terrible inefficiently.
“Grit” is a technical term in this context, isn’t it? As it’s currently written some student might read that and think Scott Alexander is implying that the very particular kind of, what is it- determination, focus, purpose, unwaveringness, robustness of goal?, -etc, that the word grit normally refers to, in its non technical sense, is known to be “the” form of self direction that people should focus on developing and improving, or worse the only one that matters, or works, when actually no one has even claimed that, -the choice of the word grit for the supposed quality that has apparently been identified, is, -granting no methodological issues at all, only inspired by the common word of those letters and sound. -It’s not intended to be a measure of one’s propensity for the enjoyment of whisky, or throaty coughs. At a minimum it’s far broader, and arguably it doesn’t share a great deal at all of the particulars of “grit”‘s normal use, -which define grit in normal use (-as opposed to e.g. “perserverance”, “dedication” “purity of purpose”, etc, etc, etc) and I think the distinction is important and misleading enough that if it can’t be explained that “grit” is a technical term here, it’s better to take it out altogether than leave it in. Also, it might be funny if there were two crossings out?
I could be wrong about some of this, but if I’m not, I think it’s fairly important -I know I certainly might have taken that at face value a few years ago.
Also, is “grit” even that well established? Like, is it just a retroactively fitted thing they made up, having access to all the results before they built their models, or was the process carried out such that, that couldn’t be what’s going on? The definition is close enough to self-referential that I assume some correlation actually exists, but has that actually been established, properly?
As far as I can tell, the two-in-one purpose of using “grit” in the post was to mock whoever came up with the term, and to complain that people are not very keen on hearing about “innate ability”.
So, most of your comment, unfortunately, seems to be misaimed.
I might have been a bit slow there, but I assume there are other mongoloids like myself that could use a neon flashing sign for retards in case we take away that scott is somewhat genuinely, though jokingly, “endorsing” “grit”, as the scientifically sanctified “sum qua non” of what you need to achieve in life, and end up very confused if not outright taking it on faith. Because I can attest for myself that I have been at least that stupid, and am currently just borderline cogniscant enough to unravel it a bit for myself.
It’s likely that everyone who hadn’t seen Scott’s earlier grumbling about grit ended up similarly confused. So, don’t despair about your ~innate ability~ to the point of identifying as a ‘mongoloid’ just yet.
Grit has been properly studied and in a number of papers has been shown to be not correlated with IQ and also a major determinant of standardised test scores (hence I sometime glibly say IQ + grit = SAT). There is controversy over whether it is a different thing to big-5 conscientiousness or not with reasonable papers arguing either side.
See: https://characterlab.org/tools/grit
Thanks
reading this page, https://upenn.app.box.com/v/duckworthpeterson, these questions on the “grit scale” look like a self report of actual success. Of course people who have achieved goals which took years of work are on average more successful, a goal which took years of work to accomplish, is itself a success. People who say they have been successful are on average more successful (was it supposed to be only account for 4% of variation?) than people who don’t. What the fuck am I reading here? Is this for real?
I have achieved a goal that took years of work.
.65 .62
I have overcome setbacks to conquer an important challenge.
.68 .53
I finish whatever I begin.
.54 .68
Setbacks don’t discourage me.
.58 .59
I am a hard worker.
.44 .70
I am diligent.
This is exactly the kind of retroactive bullshit I expected it to be. People who report empirical success in:
being dilligent,
working hard,
not being discouraged by setbacks,
have consistently finished what they begun,
have conquered important challenges (through setbacks, but that’s a bit of an afterthought at this point),
and have achieved a goal that took years of work,
-are not such complete liars as to be making it all up, or so reticent as to deny what they’ve been able to do, -their self report of their own EMPIRICAL past success is not completely worthless. Time for Champagne all round, and another round of funding.
Perhaps this is an interesting result (perhaps not), but what it really really does not look like, is a newly discovered personality trait which correlates greatly with success, -when you’ve just taken a direct-proxy, -at best (some of it isn’t even a proxy), for actual past success.
Somebody fucking shoot these people. Or no, they’re idiots, they don’t deserve it. But still maybe it would set an example. Ehh seems kind of harsh still.
The other 6 reverse scored items are less retarded. This “flightiness” scale might not be completely 111% meaningless, but it is at at least three points a proxy for past failures and difficulties:
“New ideas and new projects sometimes distract me from previous ones” Being distracted implies a failure of focus, not a changing of mind, so this item is worse than worthless.
“I often set a goal but later choose to pursue a different one”. If you’re often setting goals and choosing different ones chances are this “goal setting” thing either really isn’t your style (-it’s not exactly a SET goal, if you just do something else instead. perhaps organising your life with a different methodology would work better for you), or, you’re just having a whole lot of trouble with life in general.
“I have difficulty maintaining my focus on projects that take more than a few months to complete”. This is a self reported measure of ability to dedicate oneself to something, or sustained focus, not variability of interests (as it’s supposed to be.)
I’m also sure if they’re measuring “the most successful lawyers doctors etc”, in terms of success purely in their chosen main field, in which case of course people who have less variable interests will have their achievements concentrated more densely in their main field, than in other places. I hope they at least got this basic fundamental thing right, in how they were measuring success.
I guess I’ll keep reading. Maybe, it gets better.
please get better
I hadn’t thought of it as measuring some proxy of self-reported success – I guess that makes sense. Self Reported grades is one of the largest effect sizes (d=1.33) in Hattie’s list of educational achievement (http://visible-learning.org/hattie-ranking-influences-effect-sizes-learning-achievement/)
I do believe that Grit correlates strongly with conscientiousness which would sort of collapse a personality trait and self-reported grades as highly correlated – which would really be strange.
It is difficult to get a man to understand something…
are you saying I’m being dense? (I realise that question might be “ironic”, -feel free to roll your eyes and say thank god or whatever seems most appropriate if so)
But if so, why? I just posted some thoughts about a thing I was reading. Is it your opinion that the thoughts suck?
I guess what Im trying to say is, come at me bro?
No, I wasn’t talking about you. But if you want me to judge you, I’ll judge you for not understanding my comment.
As for your original comment, striking out a term and writing a replacement is an idiom. If you haven’t seen it before, it may be hard to figure out.
I didn’t express any desire to be judged, but as I’m sure you will judge most objectively, feel free to go ahead with that contingency of yours.
Perhaps at the same time you could make a judgement on the clarity of leaving such ambiguous comments (-however much they are so) in such ambiguous places on threads.
And why not try to recollect a little saying about, what was it, sticks and red houses?
(And obviously it’s clear that the strikethrough represented a term that has been replaced. If there’s some other idiomatic meaning, your meaning would have been much clearer if you provided it. If there isn’t, this is literally the dumbest veiled insult I have ever read. My contingent congratulations)
@anonymous,
Douglas Knight was not replying to you originally, he was replying to James Brooks.
Perhaps you should cut out that third cup of coffee.
Since no one’s mentioned it yet, green anon, I assume Douglas Knight was just quoting the first part of the saying “It is difficult to get a man to understand something when his salary depends on him not understanding it” – presumably with reference to the people pushing the ‘grit’ model.
@brian donohue you’re right. I thought the reply was located at the point in subthreads where you can’t reply. Either the thread structure has changed since yesterday (do they expand out as more replies are added?), or I confused another post I saw at the set limit of the subthread structure with Douglas Knight’s post.
But rereading my response, it looks like an unambiguous good faith attempt to check if I was being insulted, so my initial mistake was just a harmless misunderstanding. I stupidly thought I was being insulted, but sensibly went to politely check.
So clearly I could have done with another cup of coffee (a 1st cup in this case), as that could have reduced the chance that I would make the initial mistake, but could not have affected my response to the insults that followed my checking if I was indeed misunderstanding something:
“if you want me to judge you”.
-that Mr Knight believes I have a masochistic desire for his (negative) judgement. (and there’s a big bloody difference between being called a moron and a masochist)
“…I’ll judge you for not understanding my comment”
-that particular references are transparently understandable to people who read them, which isn’t an insult to me, but to reason, so an insult all the same and all the more:
half of a quote and a trailing off… ..is not something which one can deduce the meaning of other than via a familiarity with the reference being made, which I did not possess, hence this har-har is nonsense parading as sense, without even the decency to make an effort at obfuscation or deception)
“As for your original comment, striking out a term and writing a replacement is an idiom. If you haven’t seen it before, it may be hard to figure out.”
-that my OP was based in my not understanding that a struckthrough word followed by another might conceivably represent a word being replaced.
And, what are the chances that I haven’t seen that before?
so yeah I made an avoidable blunder to start off with, but did not take any action on the basis of that blunder, other than to check if I was indeed misunderstanding things, and so did not burn any residual coffee in my system until it was made quite clear that yes, “fuck you buddy”, was Douglas Knight’s position (though it be a new one, rather than one preexisting).
Thanks for pointing that out to me though
And thanks winter shaker
I am open to being convinced I was in the wrong, e.g. the most obvious weak point I see is that my that my checking post might be possible to take as initiating hostility. But I think it’s sufficiently self effacing, humurous and straightforward that that seems unlikely-
“are you saying I’m being dense? (I realise that question might be “ironic”… “.
isn’t exactly fighting words
Or of course that Douglas might have thought it amusing to take me up seriously on my humourous hypothetical invitation, in which it seems he would have been right.
but I could be missing something else entirely, or something else than that, and would be grateful if any such important oversight shall be was pointed out to me, but until such a time, shall retain any and all fondness, for coffee-fuel resembling rantish responses. (and quite likely beyond such a time, but certainly until)
I think the grit thing is a joke, injecting humor into an otherwise info dense article
I look forward to this euphemistic terminology spreading, so the next time we hear about a “gritty reboot” it will be a staid intellectual film.
I think “grit” suffers from a problem I don’t have a great name for. Maybe call it world wars over tiny marginal gains. We all went to school with some number of kids who simply did not give a damn about school and put no effort into it. Call that zero grit. Call “normal” grit 100. Now let’s set up complex evaluations to try to distinguish 102 grit from 98 grit and establish the statistical effect of that difference on standardized tests at p<.05. There's probably not much money in that in the normal labor market, but perhaps you can get a government grant for the research.
I hope there’s some great name for the problem you outline. There probably is
It’s a humorous way to point out you can’t talk about race and intelligence.
If it’s that its subtle as fuck. Doesn’t sound right to me
I think Scott wrote a post once talking about the heritability of height and its relationship with performance at playing basketball, because writing about the heritability of IQ and its relationship with income was too controversial.
In the current literature in a variety of fields, genetic explanations of things are out of vogue, even though there seems to be strong evidence for the genetic nature of a variety of attributes. One of the reasons that this is true is that people are concerned about being racist, as if these things were genetic, that would constitute evidence of ‘natural inferiority’ which is clearly false and racist. It would also contradict people’s assertions that poor outcomes are solely due to discrimination, both explicit and implicit.
Well I happen to agree that people are expected as a religious duty to not have an opinion on that question, but that would still be subtle as hell if it’s what he meant, because I can’t see the link between “grit” being a bullshit term, and, like, not being allowed to have an opinion just in case you go off and invade poland, shoot up a church, reinstitute slavery, and/or become marginally less pleased with the aesthetics of the universe, or whatever.
-I think these two rough meanings are more natural fits:
“we’re not allowed to say natural ability because admitting any differences at all is not done by enlightened *empathetic* folks”
or “I have some reservations about the concept of innate ability, so I’ll use this far more ridiculous term to replace it as a (hilarious) show of my commitment to avoiding using concepts that are slightly imperfect where possible”
I also think there’s an opposite temptation to use a really rough kludge model that pointlessly throws away loads of relevant information to show how rough and brutal you are. “If the model works half OK (for me), the map can fuck off” (all the better if their are negative externalities, the more the better!)
There are ways to teach something very much like “grit” to children and also to adults.
I hate the title of this book, but I just assume that the author’s publisher made up the title to try to sell more copies. Of all the books I’ve read about the psychologies of success, this one is the real thing, complete with illustrations and studies of teaching this way of focusing, and the changes it made in the students’ pursuit of their goals. One teacher had a class full of “disadvantaged” kids learning and understanding Shakespeare and doing very well at it.
Mindset: The New Psychology of Success Paperback – December 26, 2007
by Carol Dweck (Author)
http://www.amazon.com/Mindset-Psychology-Success-Carol-Dweck/dp/0345472322/ref=sr_1_1?s=books&ie=UTF8&qid=1463676687&sr=1-1&keywords=Mindset
God damn it, don’t bring this up.
Why not, by the way:
https://slatestarcodex.com/?s=growth+mindset
You don’t have to curse at me, Adam. I am new here, so I didn’t know Scott had written about it before. If you hadn’t cursed at me, I would be thanking you for showing me where Scott wrote about it before, but since you did, I won’t.
Some people can’t give information or anything else without canceling it out with an insult or curse. Such is the nature of our current bashing culture.
Sorry, didn’t mean it to be mean. Do you watch Archer? You know how Archer and Lana are always cussing and yelling as if they seem to be mad but we as viewers know they’re not really mad but it’s funny to watch people act mad? That’s what I was doing. And yes, I’m socially inept enough that most of my interpersonal behavior is informed by mimicking how sitcom characters interact with each other.
Thank you, Adam.
Archer? No. I haven’t seen it.
I guess we need to start having have far better role models in sitcoms, video games etc. It seems that a lot of people get more of their info from the virtual world than from the real world.
I always got the idea that Lana is legitimately mad at Archer because he is a horrible person. Which is made worse by the fact that she is trying to suppress her attraction to him.
(We should have a TvTropes style spoilers thing on here, to be honest)
Hey Jill, I think you took offense where none was intended because you and Adam were using totally different communication styles.
You might find this Status 451 post helps you to understand this better.
https://status451.com/2016/01/06/splain-it-to-me/
Here in Australia, within certain contexts we cheerfully and lovingly call people cunts. With no offense.
What if teacher’s influence is way more relevant because it occurs in context of peer groups with only one or few adults? That’s about the only scenario that parents don’t ever get into. Teachers can, and do, touch group dynamics directly.
I think this is a good point. One (haphazard) explanation is this. When parents try to give their kids non-cognitive skills (habits, attitudes, etc.) it apparently doesn’t take. Presumably there’s the step where parents make them go through the motions of trying to pick up the skills, and then the kids (on some level) say “I’m not going to keep doing this”.
Peer groups are an often-cited factor in “non-shared environment”. Teachers can make a whole peer group/class go through the motions of picking up skills, so maybe kids are saying “my peers are doing this too, so this is a thing now”. (Presumably the kids aren’t picking up on the fact their peers are only going through the motions too, but e.g. the bystander effect is founded on a similar principle.)
Possible tests: look at kids who aren’t taught in groups (e.g. homeschooled kids (good luck with confounders)); look at kids who are raised in groups (e.g. orphanages or kibbutzes (even more confounders)).
This was my first thought. If the influence hierarchy goes something like Parents < Peers < Genetics, and if teachers can have a significant impact on how kids socialize one another, then teachers are working further up the chain than parents. Framed in this way, it seems very plausible that especially good or bad teachers can have a greater impact on future outcomes than parents.
How is it a long shot that students influence the scores of class members?
Students in the same class are aware of other student’s performance and compete against them. At older ages that competition occurs via test scores and at all levels it occurs in competition for praise and approval Students in the same class are likely to work together on projects and homework and good study habits, attitudes and ideas.
In college I never attended lecture nevertheless the interaction with fellow students made a huge difference that friends who went to less prestigious schools didn’t experience. Obviously, the effect wouldn’t be as large at earlier ages but still seems plausibly large.
Indeed. The power of peer effects strike me as both obvious and abundant, both for good and for ill. I can recall dozens of instances in which I competed against my other students to be the smartest, from elementary school through high school. It’s not hard to imagine which peer effects raise student achievement.
That never worked for me; I wasn’t interested in who was “first in the class” or beating classmates. They did better than me in a test, I may have sulked (if I cared about the subject if I thought it was one of my good ones) but I never went “Grrr, I will study even harder so I will beat Sally in the next test!” Often I was “they got first, that’s great, good for them” because I didn’t care.
I was very much self-motivated, or unmotivated if you like 🙂 Of all the vices, envy is the one I do not suffer from, so appeals based on emulation (which is close to envy) never worked for me: if you do well, good for you. If I care about the thing, I’ll be glad. If I don’t care about the thing (like sports or maths), it’s nice that you got first place in the country but it’s meaningless to me.
That did mean I worked at subjects I liked and slacked off on subjects I wasn’t interested in, but I was capable of getting reasonable results in most subjects (except maths and later on business studies), so I never suffered too much.
I would probably have benefited from the discipline of “Buckle down and work hard even if you don’t care about the thing” but competitiveness doesn’t work on me; I have never cared about “winning” and appeals/cajoling/threats along the lines of “Sally and Jane and Martina got higher marks than you, don’t you care, aren’t you ashamed?” evoked “Good for them, no, and no” in me.
@Deiseach:
By your own admission, you aren’t in the middle of the “social effects” bell curve. I think that is probably relevant when we are talking about peer effects on total populations of students. I think I am supposed to throw the words “Typical Mind Fallacy” in here.
In any case, I would feel pretty comfortable in saying that individual children will tend to have individual needs as far as education styles are concerned. If that is “true”, it would be really nice if we could figure out what works best for each child, rather than trying to design something that only works for one cohort of children.
I was very interested in being the best in the class, but only when I was first or second in the class. I had no chance of competing in art or gym (yes I am a nerd cliche) so I didn’t really bother there.
I probably got special attention and support for being the best in academic subjects. Unfortunately this doesn’t scale.
You lucked out. I was math olympian, spelling bee champ, trivia champ, state champion in cross-country and track, winner of multiple regional art competitions. I wish I’d only been good at math so I wouldn’t have wasted so much of my 20s on art and sports.
[humblebrag]
Sorry, for the sort-of snark, but it’s a fairly impressive list to be complaining about.
I was a pretty impressive kid (heck, I was even good-looking back then), but haven’t done much of note as an adult. It’s a legitimate regret, although I guess I’m still reasonably young.
Physical exercise seems to be good for mental health and intelligence, so a moderate dose of athletics was probably good for your math ability.
I was pretty accomplished when I was a kid- though pretty much only in math and science, unlike you.
As I’ve grown older, I’ve realized that personality wise, I’m not really cut out for greatness. I’ll never win a Nobel Prize, or become CEO of Goldman Sachs, or found a billion dollar startup. Though I suppose I could theoretically still get lucky, I’m more or less content to be a a mid-high level professional.
I don’t think not being specialized enough was your problem. In fact, I wish I were better at sports in high school.
Not a long shot at all – see this huge list of effect sizes in achievement of students in school education and note that you have “Peer influences” (d=0.5) and “Classroom behavioural” (d=0.63). In Hattie’s books (where this research is summarised) he talks a lot about the climate of the classroom and a students engagement in learning.
http://visible-learning.org/hattie-ranking-influences-effect-sizes-learning-achievement/
So the observation is that teachers with classrooms of more intelligent students tend to produce higher year over year gains on standardized tests. One mechanism I propose, having literally lived the experience, is that sufficiently intelligent students understand concepts immediately after you explain them to them, and then out of boredom they’ll help the teacher explain them to the students who didn’t pick it up immediately.
There’s also the issue that if the whole class understands something the first time the class can move on to the next subject. However, if even one student is confused, it can mean spending extra time on the original subject, robbing the students that understood the chance to learn something new.
I know I always had problems in class that when the teacher would have to go over something multiple times that I would lose interest, and it would be very difficult for me to ever regain concentration, even after the class moved on to a new subject. I always did better with teachers that would only take questions at the end of class.
If that’s the case, doesn’t that lend credence to the parents of “good” school districts not wanting students from “bad” school districts to be bused in?
Yes – and that’s the problem.
The parents of the smart kids will want their kids to have smart peers, and the parents of the
dumbcompletely equal in every way kids will also want their kids to have smart peers – and these desires are not compatible.Too true…. and the government operates under the assumption that a sprinkling (or equitable redistribution) of smart kids will magically uplift the rest. The opposite happens to be true more often than not …
I can see how smarter kids disproportionately benefit each other when in the same environment whereas a few smart kids surrounded by not so smart ones are bored/stunted and not very beneficial to their below-average peers.
I don’t have research to cite but I do believe that a smart kid is a resource best utilized to benefit other smart kids. Kinda like the way it works with athletes on a team ….
@Y Stefanov:
I wouldn’t go too far in that direction. If we are talking one or two standard deviations, it will probably benefit both parties to have some mixture. Smart kids learn the material better by explaining it to average kids, the average kids benefit from the repetition and personalized explanation. However, the smart kids will need some of their peers to be of roughly equal intelligence, and the average kids will too. In both cases, a lack of intellectual peers will lead to problems (smart kids won’t be challenged, won’t find really good friends; average kids will feel dumb instead of just normal).
But when you jump to one kid with an IQ of 180 in a classroom where the average IQ is 80 – no one will benefit, and the high IQ kid will definitely be stunted if this situation is long term.
Anecdotally, it involves the smart kid repeatedly asking “why are you so stupid?” and the stupid kid smashing the smart kid’s head into the asphalt.
@Garrett
Anecdotally, is your head feeling any better?
Much so, in many different ways.
Actually, not so smart.
But as someone who felt he was the target of merciless mockery throughout primary and secondary school, I understand.
*headache* Yeah, I endorse “I don’t really know”…
I wonder if there could be any problems in using tests to measure achievement at all? Something like, since standardised tests are introduced, every year teachers and teacher-evaluators succumb to the pressure to teach more about the test and less about everything else.
So students who are generally more capable and are going to earn more, start off with an advantage on the tests, which slowly shrinks?
A quick digression/rant on the subject of standardized testing: it’s almost rote now to dismiss it as hopelessly biased, affected by class, preppable, containing racist questions, poor at predicting college performance, etc. etc. and so many schools are switching to SAT-optional.
Yet in all this time I’ve never heard anyone suggest an alternative that’s better. For starters, GPA is just as, if not more biased, just as preppable, and with no better ability to predict college performance, with the added disadvantage that it undergoes basically no scrutiny. That is, the tests that teachers use to compute a student’s grade might be rife with the same prejudices allegedly found in the SAT, it’s just that the SAT happens to be scrutinized and nothing else is.
Moreover, you would think that in a hypothetically racist and classist society, being subjectively judged by a teacher prejudiced against you would be the single worst way to be evaluated, while being objectively judged by a standardized test identical to those of your privileged classmates is the single best way to be evaluated. But it seems unfortunate that because it’s the most easily quantified evidence of the achievement gap, standardized testing is held up as a scapegoat for the entire achievement gap, even though the presumed biases underlying achievement gap affects literally any other part of the college application more. Indeed, I would argue that privilege is more magnified everywhere else in the application:
* help writing their essays
* help with their regular schoolwork
* parents actively engaged / pressuring their teachers and the PTA
* more time to engage in extracurriculars (ever hear of inner-city working teenagers captaining the lacrosse team?)
* additional advantages in the admissions process (interview coaching, legacy connections)
Finally, I don’t think it’s a coincidence that schools are moving to SAT-optional instead of SAT-not-allowed. The former has the tremendous advantage of still receiving SAT scores from above-median students, thereby significantly inflating the school’s overall “average SAT score” and thereby US News rank.
The SAT is by far the most equitable part of the college application.
Grades aren’t given out based on comparing you to other kids in the country but rather other kids in your class. If classes were random draws of kids, we might see the same distributional issues regarding race/income and grades that we see regarding standardized test scores. But we don’t. What an “A” means in an algebra class in one place is different from another. This makes grades less useful as far as predicting performance, but it does mean that if you rely more heavily on grades (or factors like class rank, which explicitly compare you to your classmates) and less heavily on standardized test scores, that does change the demographic distribution of who comes out on top. Although sometimes in odd ways.
If elite colleges were to switch to just relying on standardized tests for college admission (ideally with some additional protections, like the kind of security and adaptive testing (CAT) that we use for the GRE), they would certainly get a more economically diverse group of students, so there’s that.
On the other stuff besides grades/test scores, absolutely these are more game-able by rich kids. Which I don’t think is incidental to why schools use them.
Well, IMHO that’s plainly wrong. (Also, it depends on country.)
But I guess it’s tempting because it’s so simple.
Well, gosh, then. We do see the same distributional issues/magnitude of differences in terms of race/ethnicity and parental income when it comes to grades as we do to test scores! I’m convinced!
It is probably more accurate to say that grades are given out based on comparing you to students in your teacher’s prior experience. Not in any straightforward or rigorous way, but that’s who the tests you take and the assignments you’re given will implicitly be normed on.
Fitting grades to the achievement curve of your classmates is rare in high schools in the US (and might now be forbidden by policy? but there’s too much local variation for me to say), but it’s still common in college. It usually doesn’t matter much, though, especially since I remember seeing it mostly in very large classes.
This is so. Even if a teacher doesn’t grade on a curve, they are likely to retool an assessment if all the students do poorly.
I’m not sure why you think elite colleges, which with a tiny handful of exceptions, are private organizations, have an obligation to transform themselves into organizations that would be aesthetically pleasing to you. Maybe you can make it explicit?
I said nothing about them having that obligation. I was discussing the different types of students that different admissions procedures would lead to admitting.
“If elite colleges were to switch to just relying on standardized tests for college admission (ideally with some additional protections, like the kind of security and adaptive testing (CAT) that we use for the GRE), they would certainly get a more economically diverse group of students, so there’s that.”
It might be just the opposite. A kid in a poor neighborhood is competing for grades with other poor kids, so his grades make him look better, relative to actual ability, than a kid in a rich neighborhood. So relying on grades or class rank makes it more likely that the kid from the poor neighborhood will be admitted than relying on standardized tests.
I believe the Texas higher education system, in order to avoid legal restrictions on affirmative action, went to a “top X percent of any high school can get in” system–that’s by memory and it may have been more complicated than that.
Another problem with grades is that they frequently measure an ability to game the teacher more than comprehension of the subject. I know I got some bad grades in classes where I clearly understood the subject matter better than students receiving much higher grades, and possibly understood the subject better than the teacher – and I suspect a good part of that was my refusal to parrot back what the teacher had said.
This was especially true in French classes, where my inability to hear some of the phonemes used in French made it literally impossible for me to parrot back what the teachers said, even though I could read it reasonably well. I know one teacher was astonished when I performed well on a required end-of-course standardized test which didn’t require me to get the gender of every noun, adjective, and verb all neatly aligned. (I might mention – I thought this was a funny example, but French was one of my worst subjects – yet I can probably read it better 25 years later than 90% of those who were getting A’s in the class at the time. Still can’t understand it when it’s spoken.)
Depends on your grading methodology.
There’s nothing wrong with grading children based on absolute values. Having a class of students who all get 90%+ on the exams and giving them all As is entirely acceptable. Indeed, that should be your goal as a teacher – for all the students to master the material.
For some data on this, look at Table 9 here. The average first-year college GPA of black students is 0.26 points lower than that of whites with similar high-school GPAs. SAT scores overpredict black college GPA, too, but the overprediction is lower at 0.16 points. Similar but generally less pronounced overprediction is found for other non-Asian minorities versus whites and for low-SES versus high-SES students.
The fact that the most widely used college admissions criteria are biased in favor of low-achieving groups has been known for decades, but in non-expert discussions the opposite is routinely assumed to be true.
Well I got a middling A grade in my maths leaving exams (count for almost everything in my country) despite being about half a year behind, and my IQ was probably like 100 at the time, maybe even 90, or 80, because I’d been having headaches like hell, not sleeping, blablabla, (unknown at time medical issue) but I got an A just because I was able to drum enough of the shitty formulaic past exam papers into my head to regurgitate it the next day (or next hour) and forget it all in time for the next exams.
Do we have a better system? Not that I know of, but there’s a massive massive, unbridgable difference, between holding something up as the best we have, and as something that is fundamentally solid and trustworthy. There’s a lot of great things to be said about it, -the most obvious being that even if it’s a total game, at least it’s a game with clearish, unsubjectivish (though only in some subjects) rules. But imo the difference between presenting this to kids as a competition/tournament/game, which is what it is, -and the best thing we’ve got for the economy, ordering things, and whatever else it’s for, -and an education, which it in no fucking way resembles, is the difference between truth and lies, -justice and empty obfuscating nonsense.
At the end of the day one of the main aims of the system is to rubber stamp you with a rating, to determine what kind of jobs you can get, and arguably also to make you more pliable for managers, and to generally “standardise” you. If we call a system with that as a primary purpose an education, we’re just lying. In point of fact it’s barely even a fucking training (and it’s further from achieving training, when it causes itself education, -simply because it’s confusing).
But if this rating tournament is instead a part of our society’s great game, it’s a little bit fucking cracked, but is it a bad kind of cracked? I think it isn’t a bad way to live at all. You’re fighting for your place in the world with your intellect, -what could constitute a better life? What could give a child more purpose and motivation? (What could give them less than to give them a rubber stamping daycare, call it an education, and barely provide a training?)
So yeah, use the best thing we have and shut up, not because it’s actually good, but because that’s the game. Why would we have a genuine education system at this point in human history /development?
Don’t tell them they’re getting an education, just tell them, that’s poker, kid. That’s the best arrangement we have, and it’s not so great, but it’s not so bad either is it? Kids are tough, and generally idiots, and generally less fond of bullshit than adults.
Of course you can also do things like making the tests not be shitty formulaic repeats year after year, but in the meantime why not be honest about things? And afterwards it’s still going to be a rating system, training sorta-system, and just this inertial thing that happens to exist, first second and third (in no particular order), and an education about 20th, so why not be honest afterwards as well?
I totally agree that GPA is worse though. I think, relatively speaking, having decently-competently designed tests would be a great bastion of objectivity, given how pathological I think things are otherwise, (or perhaps already is, if testing is competently designed anywhere), and that even rubbish tests are probably better than subjective measures. They’re certainly fairer, more transparent, and more clear (therefore more motivating).
But I think that’s an argument for just abolishing the whole thing. Home schooling seems to work, and most of what is learnt in standardised education is never used again. As far as tournament grading goes, it would be more effective for identifying conscientious people, if you didn’t confound the factors of motivation and general intelligence, by forcing people to be there, and to learn things in narrow preprescribed ways.
*kids are generally not idiots*
At a slight tangent …
Standardized tests are very helpful for home schooled students applying to college, since they don’t have the other sorts of information schools want.
One of the things colleges ought to care about is writing ability. They currently test it by having the student send them an essay–with no way of knowing whether he wrote it himself and, if he did, with what assistance. Many students visit schools they are applying to–it would be easy enough to put the visiting student in a room with a word processor and a short list of essay topics and give him half an hour or an hour to write an essay. For students who don’t visit, you could do the equivalent with the assistance of alumni scattered around the country. If many schools did that, the alumni could be replaced by writing testing centers in scattered cities.
Why doesn’t that happen? Do the schools want to bias the admission procedure in favor of students who can afford admission coaching–including coaching on their essays? There is no way of entirely eliminating such bias, but one could try to minimize it.
Well, for one thing, it would lower their US News and World Report college score.
I believe that “selectivity” in admissions is one of the prime drivers of the score, which means you want as many applicants as possible, which encourages applications which are very easy to complete. It wouldn’t surprise me if this is one big reason why the “common app” has become so, well, common.
It appears that acceptance ratio is only 1.25% of the overall score.
http://www.usnews.com/education/best-colleges/articles/how-us-news-calculated-the-rankings?page=3
Ah, nice. I think that has changed over time? But I could be wrong of course.
The SAT does have a writing portion now, but I think it’s optional. It was mandatory for most of the past decade. Assuming the test proctoring service isn’t lying, they at least know the kid actually wrote that.
My views on college writing are pretty dismal, though. I worked in my university’s writing center and math center as an undergrad, and though plenty of people were terrible at both, at least the terrible at math people tended to not be math or engineering students. The worst writers I ever encountered were grad students studying education. Hopefully they were just trying to become administrators, not teachers.
But the SAT writing exam has to be more or less machine graded–graded by humans but using a very mechanical system, hence a poor measure of writing ability.
I believe they send the actual essay to colleges with the score report. Or at least they did in the 1990s.
Excellent post. A new reader and mid-time lurker but I had a question/thought that I was hoping someone far smarter and knowledgeable can help with:
If the genetic ‘determinants’ of IQ affect a person later in adult life and the environment (SES, school, etc, etc) affects them earlier on, wouldn’t there be sticky selection effects that SES will cause that may affect life outcomes in the end?
Wouldn’t this issue of sorting at an early level be a policy problem if we’re inefficiently sorting early high IQ/late low IQ and early low IQ/late high IQ persons?
Great summary of a complex literature, where it’s almost impossible to find people who both understand all the arguments (I don’t myself) and don’t have a vested interest in one conclusion or another.
I’ll put out there that I don’t think it’s impossible that teachers really could have effects, despite the evidence that parents do not. First, my sense is that genetically sensitive measurements of parent effects are almost always underpowered compared to most of these teacher studies, which use huge administrative data sets. Second, maybe if peer effects really are important in a way that adult mentors are not, the fact that teachers can influence the peer environment to a degree might be important. Third, my own experience is that it’s much easier to teach someone else’s kids then your own, maybe because your own kids have learned to ignore all your tricks long ago.
It’s also worth noting that your teachers (at least in certain cultures) also a) spend more time with you than your parents especially in two-person working households, b) aren’t emotionally attached in the same way and may be more neutral enforcers, and c) get some degree of training on dealing with bad kids/peers that parents may not have.
It would be interesting to see similar studies including home schooled children.
I don’t suppose there’s enough adopted twin home-schoolers to do a study on, sadly.
I could see kindergarten teachers having comparative advantage at teaching the sort of behavioral skills needed to function nondisruptively in a classroom (sit quietly where and when you are told to, be nice to your cohort of 20 age-peers, raise your hand to answer, etc) that aren’t applicable at home. I get the impression that sort of thing is more of the point of kindergarten than the academic content (but did not go to kindergarten myself… and had behavioral difficulties in elementary/middle school, come to think).
.
I was thinking about that, but given the similarity between Chetty’s kindergarten results and his 4th grade results, it’s hard to believe they’re two totally different processes.
There wasn’t kindergarten in my time 🙂 You started school at four, finished at seventeen (unless you were going on to university).
Speaking as a non-parent, what I see nowadays with nursery school and kindergarten etc. strikes me as a form of childcare more than education. Usually both parents are working, you have to do something with the kids while the parents are out of the house, and childminding is very damn expensive.
So sticking them for a couple of hours a day into nursery school or whatever is pretty much babysitting plus the kinds of things the parent(s) would be teaching them if they were at home with the kids instead of at work. Real education starts when they’re old enough to start ‘big school’, e.g. five or so.
I’m probably prejudiced here as my bedridden grandmother taught me to read*, write, draw, etc. and when I was in fourth class, it was she who taught me how to do long division when I could not make any headway with the school method. So, as my mother said, by the time I was four and a half and started school, I could already read, write, count, and say my prayers, so the teacher didn’t really have much left to teach me 🙂
*Also my father helped teach me to read and that, plus the freaky genes on the paternal side which means that side of the family practically comes out of the womb able to read, meant I was way beyond the “Dick and Jane” primers when we started learning to read in school.
I think there’s some confusion due to you not knowing how things work in the States (and Canada). Children usually start kindergarten at age four or five (you start school in September if you are age five by some date), and that is what is required; everything before that is pre-school.
Yeah, it’s something similar here: formal school starts at age four/five. Before that you have creches and playschools and nursery schools and daycare and all the rest of it; I was a bit muddled because now, since 2009, the government will pay for two years’ pre-school for children so that’s still privately provided (although there are organisations like charities such as Barnados that run toddler groups etc) but paid for with public money.
So children nowadays are, in a sense, “in school” from the age of two or so, but how much of that is actual learning and how much of that is, as I said, really a childminding service is hard to qualify.
Just anecdotally, we put our daughter in preschool for two main reasons:
1) We wanted her to get used to working with and listening to adults who were not her parents.
2) We wanted her to get used to dealing with children as peers. There aren’t a ton of kids her age nearby, so it’s most of the socializing practice she gets.
My wife stays at home, so taking her to preschool is actually less convenient. We teach her letters and numbers and such at home far more than she’s learned at school. But on those two points, preschool has done wonders for her.
I have no idea if that will ever show up on standardized tests?
What is American primary school teaching like? Over here in Ireland, you have one teacher per class (that is grade) and they teach everything: English, Maths, Nature Studies, Music, etc.
Is it the same in the USA or do larger schools have “This is the Maths teacher, this is the English teacher”?
In my experience, it’s the same for primary school, with maybe one part-time music teacher or something. Middle school, which starts at about grade 6 or 7, which would be a person’s seventh or eight year of schooling, is when subjects are separated.
I’m not sure it’s the same in every district. For kindergarten through fifth grade, I had one all-encompassing teacher that taught all the academic subjects, one art teacher, one physical education teacher, and a band teacher but band was voluntary, not something everyone did. I also had a separate teacher for GATE sessions and they moved me to higher grades for the reading and math hours, so I ended up with different teachers for those, but it was just the next year’s ‘everything’ teacher.
1st through 5th grade, they still divided the day into discrete units of subject matter, even though it was mostly taught by the same person. In kindergarten, the whole day was just crafts projects and learning how to spell your name. I think. Honestly, I barely remember kindergarten and I missed over a month due to illness. We also had early birds and late birds in kindergarten through 5th, which meant half the students attended all classes between 8 AM and 3 PM, and half the students attended between 10 AM and 5 PM. In retrospect, I wonder if that was a study.
In 6th through 8th, teaching became fully differentiated and every teacher only taught one subject. It stayed that way in high school, which is 9th through 12th grades.
There’s some local variation depending on whether your district picked up one or another trendy educational fad thirty years ago, but usually it works something like this: from kindergarten (age 4-5) through fifth or sixth grade (fifth for me), you will have one teacher who teaches you everything. You may also have a separate gym teacher who handles the physical-education side of things; I don’t think kindergartens do this, and first grade might not either, but my memories are very fuzzy that far back. I definitely had gym class by second grade.
Starting in sixth or seventh grade (age 11-13), students transition to a more segmented model, called “middle school” or “junior high”. Schools here are larger, and have separate teachers in separate classrooms for different subjects. English, history, and civics are often combined as a double-length “homeroom” class taught by one teacher. There are normally few elective courses in middle schools, though students may have a couple of minor choices available to them, e.g. between shop and computer lab. This is also where schools start systematically doing extracurriculars, like band and sports teams, though you’ll sometimes see them earlier.
High schools start in ninth grade, for students age 14-15. These are fully separated between subjects, and students (or their parents) are often nominally free to choose the classes they take: in larger high schools this usually includes a number of different electives, such as music, art, shop, etc. Graduation requirements normally dictate a lot of those choices, though: my high school required four years of English, four of math, three of history, three of science, three of a foreign language (Spanish, French, and German were offered), and some other stuff I don’t remember.
Depends very much on the district or the school.
Where I went to kindergarten (most started age 5, turned 6 during the year) I attended the last year that kindergarten was a half day – each teacher taught two classes, morning and afternoon. It was mostly crafts and play time, with occasional instruction in other things. The most academic it got was to teach us to write our own names and count to 100.
Grades 1 and 2 at the same school – a single teacher for all subjects, except an occasional specialty like gym or art – and that not on a regular schedule, and in grade 2 some students got occasional special instruction by other teachers.
Grades 3 and 4 at another school: grade 3, two teachers, both of whom taught most subjects but each had a specialty or two and the classes would switch teachers. Best readers also went to another teacher for reading. Grade 4, again two teachers, but now more specialized – one taught Reading and Social Studies, the other taught Writing and Math. (Reading teacher wanted a book report for every book I read, so I almost stopped extracurricular reading for that year. Some people just don’t understand incentives.) All students in grades 4 and 5 shared a Science teacher. Both grades: separate instruction in gym and separate and irregular/occasional instruction in art, music, dance, and other subjects. This school is considered one of the best in the United States.
Grade 5 – another school. One teacher taught everything, even gym, with very rare exceptions. (They got the one male teacher in the school to teach us boys a single session of sex ed, which consisted of the boys trying to get the teacher to say “boobs” while the teacher pretended he had no idea what that word meant. Also some talk about sperm, eggs, and puberty which most of the kids already knew about.)
Grade 6 – middle school, same school system as grade 5 – organized much like grade 4 described above.
Grade 7 and 8 – skipped a grade by going to another type of school, one teacher taught K-5, the other teacher taught 6-12. Both the best and worst school I attended. Academically it was quite poor, but every student could read and write and do basic math, there was more practical instruction on finances than all my other schooling put together, and it was the only school I ever attended where there was no bullying (and virtually no teasing). Frequent field trips and activities which involved everyone from Kindergarten through 12th grade.
Grades 9 through 12 – another school, each teacher specialized in one or two subjects, and we changed classrooms and teachers throughout the day. Pretty typical for high school.
I hope that gives you a general idea of schooling (and the variability thereof) in the United States.
What I had was:
there were multiple teachers per grade level, usually 3, and each had about 30 students. and those teachers taught all of the ‘academic’ subjects, but for things like music and art, the school had a single music/art teacher that all the years/classes rotated off on and you ended up going to each like once a week.
Has anyone ever considered that the time spent endlessly measuring things probably more than negates any improvements that are brought about on the basis of these measurements (assuming that the changes do make any improvements). I’m doing a masters degree at the moment and I realised the other that even with a conservative estimate on how long it takes to mark the essays we write, the staff spend more time assessing what we’ve done than actually teaching us – how can that be a sensible way to run an educational institution?
At masters level, it would be plausible that there could be a rather effective education system that provided no ‘teaching’ (as in, lectures or instruction) beyond a recommendation on best resources and assumed that students read the material themselves, perform and submit relevant work, but then spend 90%+ of their effort on reviewing the students work and providing corrections, criticism and other feedback. Grading would be a side effect, but meaningful feedback is IMHO the most important part of education.
Yeah that would be a good system. It would really suit me anyway. I don’t get any feedback whatsoever on the work I do apart from a grade.
The two “Jacob, Lefgren and Sims” papers in paragraph 12 of section II appear to be the same paper, in the guise of two subtly different PDF files.
About the fading: How much of it is caused by the passage of time vs. differences between the tests? For example, imagine I have a great teacher in medieval history and get a good test score. Even if I still remember everything a couple of years later that will not help me much on the 20:th century history test. Is the fading different in subjects that build on previous knowledge more, such as math? In general, do the standardized tests in the studies mostly test knowledge of that years curriculum or more broad ability?
“a one standard deviation increase in teacher VAM corresponds to about a 0.1 standard deviation increase in student test scores.”
Useful stat fact: Suppose you have a linear relation y = ax + e, where x and e are normal (so that y is also normal). If the correlation between y and x is r, which implies share of explained variance r^2, then this implies that if x is +1 stdev, then y will be +r stdev.
So this result (roughly) implies that teacher quality and student scores have a correlation of 0.1, and that teacher variation accounts for about 1% of variation in students’ scores.
(I think a lot of people know the rule of thumb that you square a correlation to get the share of variance. But I think fewer people know the interpretation of standard deviation as dy/dx).
Actually, now that I think about this, it is rather obvious from the definition of correlation. Like Corr(x,y) is basically:
E [ (x-Ex)/sx * (y-Ey)/sy ] = E [ Zx * Zy]
So if you set Zx = 1, the interpretation follows immediately.
Wait, I just got to your conclusion. You write:
“In summary: teacher quality probably explains 10% of the variation in same-year test scores, which corresponds to a +1 SD better teacher causing a +0.1 SD student test score improvement, which isn’t that much.”
+1 SD teacher -> +0.1 SD outcome means teachers explain 1% of variance, not 10%.
The claim is not that teachers explain 10% of the variance of raw score, but 10% of the variance in the difference of scores in consecutive years. Which should be much lower than the variance of the test scores, because the scores in consecutive years are correlated.
Whenever I comment about education here I feel like Don Quixote jousting against windmills. But I just can’t let it go because … I really think good teachers are important.
I think the statement “having +1 standard deviation of teacher quality over several years has covariance of <.1 sigma with test scores or income later in life" is interesting and useful. On the other hand, I think it's dangerous to draw the conclusion, as Scott seems to like to do, that "and therefore consistent teacher quality is not that important" (or at least has covariance of <.1 with "quality of life"). This assumes that there are not many components to the "life" function which are orthogonal to both test scores and income. But this is kind of ridiculous. It's the sort of argument that you can extrapolate to say that computers can do anything that humans can 1000 times better because they can perform more operations per second.
I think it's useful to think about the effectiveness of cello teachers or ballet instructors. We can agree that there is a subjective measure of being a good ballet dancer or musician. I haven't studied this question too closely, but based on musical people I know, it is very, very difficult to learn either cello or ballet without a decent teacher. Yet (controlling for family background and genetics), the measure of how well one dances is almost certainly un-correlated or negatively correlated with test scores or future income.
There are several classes of measurements which seem to be highly correlated with various other measures of success and also seem to be largely genetically determined. One is IQ and test scores. Another is height. It would make sense that school tests essentially measure IQ, since they're designed to be agnostic about the specific interests and styles of teacher and student. Then there is the measure of projected income which, while correlated with questions like "does the student know how to interpret data" or "does she have a criminal record?" are negatively correlated with things like "works in the arts" or (controlling for family background) "has PhD." I would in fact argue that in the graduating class of many a university, our notions of "fulfilling employment" are negatively correlated with income.
So this evidence does not contradict the proposition that a good teacher, like a good ballet instructor, teaches students a skill which is largely orthogonal to income or test scores. There's a lot of anecdotal evidence of scientists becoming interested in a particular subject because of a good high school or middle school teacher. There have been at least some attempts to study this (see e.g. http://www.ncbi.nlm.nih.gov/books/NBK26411/ from a random google search). Obviously this could be due to retroactive rationalization, but in order to convince me of that, you would have to actually evaluate these claims by e.g. comparing different students of the same teacher.
Based on my subjective experiences, I tend to think that the phenomenon of teacher influence on academic career choice is real. For example, people who graduated from my high school have a noticeable tendency to be chemistry majors: our best science teacher happens to be a chemist. I don't think this is a coincidence. Then I know people who read history books because of a good history teacher, people who got interested in math through a local math club, etc… Given all of this, I would say that the model that seems to be popular here, which I might call the "IQ-plus model", suffers from a paucity of parameters. Remember: the fact that X is correlated with something important and Y is uncorrelated with X does not mean that Y is unimportant. It might just mean that it's hard to measure.
“It would make sense that school tests essentially measure IQ, since they’re designed to be agnostic about the specific interests and styles of teacher and student”
It depends on the test but in my experience school tests largely measure obedience/desire to do well on tests. There was very little I did at school that would be particularly difficult for anybody that put the work in, very few kids weren’t intelligent enough to get As.
Connecting this to the adjunct discussion, I think this is a large part of the problem: there’s loads of people who can get good grades if they work hard, can do a PhD and do alright on it if they work hard, but hard-work can only take you so far if you only have average intelligence. When you get to that top level its not a matter of meeting some abstract marking criteria, you actually have to produce good worthwhile work.
Just to back up your final point, the way my A-Level classes worked was that we had different teachers teaching different parts of the same subject. My 2 best teachers were in Maths and Physics and I (and most of the rest of my class and every other class these 2 teachers took) did better in the exams that covered the material they taught.
It’s not that those teachers taught the easiest bits either – they actually taught the hardest.
I went on to do Physics at University, which along with Maths was a much more common choice out of my school than the other sciences. I attribute that to the quality of those 2 teachers in particular, and the awful teachers we had in Chemistry and Biology.
re fulfilling employment:
i do indeed think that economic measures are very bad at measuring life outcomes for this reason. The market incentives are such that people are steered away from occupations that are seen as useful and fulfilling to occupations that few people want to do. Of course one could argue that is a good thing because markets are rational, but i have the impression that doesnt hold up for alot of fields. For example it seems to me that medical personnal are accepting horrible working conditions and understaffed institutions because their work is important. Of course you could stop working overtime and let the management and consumers figure out, that maybe it would be worth to have more staff and less 32 hour shifts, but people would die and they need help now.
I am not claiming to know how to fix this, it seems that markets are the worst form of allocating work except all others but i would like to read your thoughts.
tl;dr the economical effects of people choosing professions they deem good (rather than pleasant) are contrary to the demand for workers. That leads to suboptimal wages and working conditions in important occupations.
“the economical effects of people choosing professions they deem good (rather than pleasant) are contrary to the demand for workers. That leads to suboptimal wages and working conditions in important occupations.”
What defines optimal wages? If there are some jobs that people really like doing, whether because they deem them good, are fun, give status, or whatever, that tends to drive down wages–and should. That’s markets working.
Look at the other side of it. Is it “non-optimal” if unpleasant, dangerous jobs pay higher wages?
my intuition is that unpleasant/dangerous or pleasant is one factor in choosing a career and moral value of a job another. they both draw people to certain professions. while we dont need incentives for pleasant jobs, i do want incentives for morally important jobs, e.g. nurses. (i know this is fuzzy, but thats my intuition)
I think it depends on whether one sees “moral value”(whatever that may be) as a part of pleasantness of a job or whether one expects people to become nurses despite the unpleasentness of the job but because they think a nurse brings more total utility to the world than someone who helps make a shinier iphone, or to make an extreme case, a big time drug dealer.
This is of course totally dependant on my values and kind of reverse engineered from the “why do these make so much money and those so little” intuition.
I think i understand your point. its just that my intuition is different and i dont know how to decide which view is more right.
so… is there such a thing as a “moral value” to a job that is independent of the pleasantness when we decide if we like the incentives the market produces?
i just had a similar thought about status… before i make up my mind: can anyone recommend god reading on status and maybe specifically how it is simillar or different to money?
@chaosbunt
I have long distinguished between social wealth and material wealth. We have long associated the two because they tend to go together, but social wealth is social connections and social status, whereas material wealth is things and money which can buy access. Plenty of people living in trailer parks are materially wealthier (in ways like access to healthcare, climate controlled shelter, and travel) than the wealthiest kings of two centuries ago – yet we call them poor because relative to other people they have limited access to these and much more – whereas fame might allow them access to a great deal that money alone would not.
As the world becomes materially wealthier, it will become increasingly obvious that social status is by far more important.
Let me see if I can restate your argument:
We have some career which potential entrants want, not because they like doing it more but because they believe that doing it has good effects–saves lives in the case of medicine. Their alternative jobs which they don’t see in that way would pay them $50,000/year. If a career in medicine paid the same amount for the same work they would much prefer it, and there are enough of them so that, in that situation, they drive the salary down to $40,000/year.
On those terms, the career is unattractive to anyone who does not share their view of its value, so no such people join it, but there are enough of these people so that the new equilibrium is as described.
Medical labor is now cheaper than it would have been absent the special preferences, so more of it is used, so more lives are saved, so the people with those preferences have gotten what they wanted–and paid for it. It looks equivalent to a situation in which such people worked ordinary jobs and contributed $10,000/year to subsidizing medical care, again not because they enjoyed doing so but because they considered it a good thing to do–arguably the usual incentive for charity.
So far as I can see, the only problem with this situation is that it seems unjust that generous people end up worse off. But that’s true of any altruistic expenditure, given that you don’t count their preference for saving lives in the same way you count their other preferences–as representing something they value, hence something they get for their money.
Hm. What is the purpose of schooling?
I wonder if all these efforts to “improve schooling” are misguided, because they are trying to improve things which aren’t what an education’s utility is about.
(Now that I have a little bit of time to expand.)
As near as I can pinpoint it, the purposes of schooling are:
– Teach people the basics of reading, writing and counting, so that they might be minimally effective in a technological society. (I know people who have problems with these three. Their lives are predictably difficult, and they rely a lot on other people to do those for them.)
– Indoctrinate into the schooling’s sponsor’s ideology and build loyalty to them – be it one’s parents, the Church, the state, or foreign interests. The sponsors directly benefit from this, and I find it hard to find any institution of learning that doesn’t have a quasi-(or fully-)religious bent towards some point of view, such as Blue/Red Tribe values, Catholicism, Communism, etc.
– Select the most meritorious pupils/students for positions of prestige, wealth and power. To this purpose, it doesn’t much matter what is being taught, so long as it is difficult, and that examinations are not corrupted – such that morons don’t get to be doctors, statesmen and bankers. (It creates a sort of stratified society, based on one’s credentials, which are used as a proxy for merit.)
Meanwhile, everyone seems to think that the purpose, the telos of schooling is boosting intelligence and cramming knowledge into the minds of the students. I’m not sure why that is. The first one doesn’t seem to work at all, whereas the second cannot be anything but a means to some other end, given that most of schooling (excepting vocational training and the like) imparts knowledge that is largely useless outside of impressing others with one’s erudition.
– Keeping kids off the streets so they aren’t out vandalizing everything while the adults are at work
Fair enough.
(Though this sounds like something largely incidental, rather than purposeful. After all, early children’s education ripped them away from helping with their parents’ subsistence agriculture, which is sort of reverse of this. And both parents working outside of the home only became usual with the propagation of women’s liberation.)
Not necessarily – one of the first priorities for handling a major regional crisis, after the initial incident (think Haiti post earthquake) is reopen the schools, in order to get the young men (13 to 19, between the age of puberty and marriage) off the streets and engaged in something productive and supervised.
@Edward Scizorhands – Bingo! School as we know it is largely glorified babysitting.
That’s why no amount of research (about how ephemeral knowledge is, how little extended hours of schooling contributes to actual success, or how harmful it is for developing brains is to wake up extra early to attend 7:30 am class) will effect most school practices.
Wouldn’t the ideology have some effect on child outcome? I would imagine teaching Marxism to kids and all of the ideological blinders that come with it would produce far worse effects, in a neoliberal capitalist enviroment, than teaching neoliberal capitalism. As the students will have to navigate neoliberal capitalism when they grow up, and their success will be measured by their ability to do so (ie. Earnings).
Thus it seems really counter-productive to have the very left wing fringes of the blue tribe teaching students (as was the case at my school and many others), as this is the education that would least prepare kids for the modern economy.
To your point about bare-minimum less-than-this-and-your-prospects-are-retarded-for-life items that school teaches, might I propose adding broad spectrum political philosophy (so people don’t turn into antisocial hyperpartisan self lobotomizers, with no comprehension of how someone not stupid or evil could ever disagree with them), personal finance ( so they don’t wind up like Neal gabler (ie. Intelligent but incapable of managing their own life)) and basic entrepreneurship (so that if no one wants to hire them they’re not just fucked forever).
It seems perfectly compatible that schools are useless for boosting intelligence, improving temperment, or cramming complex knowledge into kids heads, but that they could still boost life outcomes if they focused on improving basic things that most people fail at.
This would also suggest that there would be alot to gain from scrapping elementary school music, social studies and history (none of which seem to produce long term retention in any student that wouldn’t have studied the matter on their own (and really how many years do students need to watch holocaust movies (this is pretty much all anyone retains (or demands) of history class)) in favor of broad spectrum how-to-have-an-independent-non-fucked-up-life studies.
(Interestingly this is the approach the military takes (just make sure they have the basics down, and are not completely fucked in any major way) and they seem to have strong results)
You think this is teachable? To people who can’t get hired?
Very much so.
I’ve known several mentally disabled people who would never have gotten hired at most any job but who worked their way up from doing odd jobs for neighbors to having their own little yard care business or computer repair business (the man was severely autistic) or tree clearing business (once they had made enough to buy some equipment). One even had an employee.
I don’t think most of them made more the 30-40 thousand a year, in their best years. But the alternative for them was being permanently unemployed so that was a major step up.
This is more common in wealthy rural areas (community helps get these things off the ground) but I don’t see why (if the mentally disabled can do this rural areas) lower end able people couldn’t do this in cities, I mean it’s basically what the law of comparative advantage predicts should be happening, it just seems most people have lost the basic ability to produce value without a boss telling them to.
(By the way, there seems to be an idea (broadly supported) that this is what most people did back in the day and we’ll into to the industrial Era. What changed? I have a vague feeling it was an unintended consequence of how the welfare state and employment laws were constructed, but I haven’t seen a definitive presentation of the argument.)
(Does anyone know when we stopped being economic actors to whom comparative advantage applied, and instead became strictly employees/consumers to whom the unemployment could last years??? (something comparative advantage would seem to preclude))
Well, I’ll be goddamned. That is mighty interesting, and a lot more convincing than I expected.
A couple points:
This still leaves it open to question whether entrepreneurship can be taught. Practical skills, sure–but I do wonder whether you can teach someone to have the necessary initiative and so on. Maybe something like “this is how to advertise, these are the kinds of laws you might have to deal with”?
To some extent, people are trying to do this in urban areas. See: hair braiders in the Black Belt, danger-dog stands and fruit carts in Los Angeles, etc. Occupational licensing and other regulatory barriers get in the way.
I don’t know how much human capital your guys had to work with, but it seems at least possible that there may be lots of people with a lot less. (It’s probably easier to make a living as a 125 IQ autist than as a 75 IQ neurotypical.).
In my country, immigrants often are discriminated against by companies (or they are genuinely less capable because of language barriers or whatever) so they open their own small businesses.
I was under the impression that this happens in lots of countries. Apu and Moe are popular characters on the Simpsons and they share that same stereotype.
Saint Fiasco
We have the same thing here in Canada, our Chinatowns in particular are run by business people who can just barely speak english (and I can’t imagine being employed by most mainstream company) but they’ve managed to source cheap goods, identify a market and run one of the most hyper-capitalist parts of my city, Toronto. (I’m not sure how they tackle regulations with the language barrier, most of them do belong to some type of Tong or other organization so maybe they have a system for getting people up and running, handling bookwork ect. (Or they have one guy who owns the business whose very competent/English fluent, and the people I’m seeing are the family class immigrants).
For any economists their might be a research paper hear
Also this is the way most rural communities still work. Of the 20-40 kids in my class growing up maybe 40% had parents who ran their own business (counting farmers since they aren’t answering to a boss; and indeed have one of the most capital intensive businesses around). So it’s totally possible to have an economy were a significant percentage of people run their own business and produce value without having to answer to a boss or be the kind of person who did well in school and got multiple degrees.
Indeed these people were slightly below average in terms of education but were probably in the top 10-20% of earner. Indeed almost all of them are making vastly more than they used to just 10 yeas ago without changing their business. It seems the basic skills to run a small business are just getting scarcer. (My dad for example went from a uni drop out running a failing bakery in the 90s (great Canadian recession of ’91) to almost being in the 1% without significantly changing his business. Basic small business skills are just that scarce now.
I think regulatory requirements are the biggest barrier. Foreigners get a bit of slack because they don’t know the laws and the authorities don’t want the bother of enforcing the law too closely on immigrants they can’t communicate with, and in rural areas I see a similar dynamic – even those who speak English don’t really understand the law, but the authorities are on the same level and interpret the laws as they see fit because they are desperate to keep their tax base from leaving – so they have lax enforcement. Perhaps the fact that everyone knows everybody also plays a role.
To why this doesn’t happen in cities–my model is that many areas in which not-very-high-functioning people have a comparative advantage (yardwork, home cleaning, running errands, watching kids, etc.) are ones where there’s lots of potential for destroying value through theft, incompetence, or negligence. In small communities where everyone knows everyone, you can minimize this risk–if you hire your neighbor’s simple child to do some chores, you can vet them a little first, and if they break your china, lose your dog, or pocket a necklace you know where to find them. Neither of these tend to hold in urban areas.
Alan and arbitrage
I’m not so sure either of these give us a full explanation.
As to regulation yes any thing food or occupational lisence related will hit a wall, but that’s still less than 40% of the economy and even their you really have to attract attention for a police officer or regulator to even notice you and that really only going to happen unless you’ve had some success.
For example it would have been totally possible to have had an Uber style industry for yourself without the Internet and without an app (you would have just needed to establish a market of 100-300 (maybe less if they use you for commuting) or so people who know your reputation, would like cheap rides and have your phone number (easy enough if you build up from 5 or so to start).
Less hypothetically we know old timey freelance paper boys would sell papers in the streets and shoe shine boys could do a brisk business without having a boss, so where are the modern analogies on the low end (all I can think of are bottle ladies).
It seems there Aren’t Less oportunities for independent wealth making today (almost definitionly there are more (more money in the economy/more people/more wealth in general))
So why isn’t it happening? Comparative advantage predicts that if Some are down on their luck and need money, while others have money and are not perfectly happy, trade will happen. But it isn’t happening.
I want to lament modern schooling and the welfare state creating a culture of asking permission instead of taking initiative and hustling.l but I have no evidence.
Actually it might have been world war 2 and mass mobilization. Think of a plucky immigrant kid fresh off the boat whose always trying to come up with ways to make money and get rich, i bet you imagine someone from the 1930s or before.
It could be ww2 just destroyed independent initiative and created an entire culture that’s just waiting for the next set of orders.
In his essays Paul graham talks about how the military culture of ww2 (hierarchy, obedience, seniority, your job as a lifetime position) blended into credentialism and the corporate culture of the day (mass mobilization and mass production being to the 40s-70s what computations and networks have been to 80s-today) to make the weird not capitalism/not socialism dream world that we think of when we think of the fifties (the Era when you would go from womb to home to school to high school to college to job to grave without any of the uncertainty (or interestingness) of the prewar period or post 1980 period)
Maybe our minds and culture just aren’t wired to think in a capitalistic manner now that the depression, ww2 and 30 years of new deal corporatism have broken our instincts for it? Maybe this is what those rural republicans talk about when they talk about cultures of helplessness? That most just can’t comprehend solving problems on their own initiative without a boss, teacher, parent, or government official to tell them too?
Like it’s not hard to reach people attend church, clubs, volunteer, go to events, etc. And I can grantee you will find people who have needs you can meet. Hell buy a folding table and set up shop on a busy street corner. And yet it seems like such a rare thing for people to go from unemployed to self employed this way.
Hmmm
@Luke the CIA stooge:
I have seen both adults and children doing what you are talking about in Ecuador, Peru and Paraguay, children in Bangkok and Indonesia, adults in Spain, Argentina, Lithuania, Ukraine, Moldova, Zambia, and Turkey.
Probably some more, and some of those were probably more flea market stuff that just happened to be in very public places – I just named a few off the top of my head that I remembered.
The things that strike me are that these are places that are relatively poor with little in the way of welfare programs. I presume that there are are also either no laws or weak enforcement preventing individuals from selling on the streets.
By contrast, wealthy welfare states combine a reduced need for this type of entrepreneurship with prohibitory regulations and also child labor laws.
So, if you are poor in the United States, and you want to start a business like this: how will you handle tax compliance, both for income tax and sales tax? is your business license up to date? is your peddling license up to date? which locations for selling have you cleared with the authorities and local businesses that are reluctant to have competitors hanging out on the sidewalk in front of their business? Given that America has a car culture, where are you going to find your customers that is not in an area where peddling is outright prohibited? Already you’ve spent about $500 and several days of labor including travel using transportation you don’t have presuming you are competent to handle all this stuff yourself, and you have yet to purchase your stock. If you do not comply with all of the above you will be arrested and charged which will incur significant expenses you can’t afford, and if you are a child the consequences for you and/or your family may be even more severe.
On the other hand, just surrender from the start and the welfare state will give you money. Not enough to really live on, mind you, but enough to scrape by and much less hassle.
Now, as to your question – I can’t imagine why we aren’t as entrepreneurial as we used to be….
The thing is though i have seen exceptions in Toronto, their are several dozen people. Either poor or visbly homeless, some not even that. who have set up these street corner peddling stands. And their doing fine. some have beenthere for years without inciddent.
Maybe Toronto’s a weird exception (the city is generally know for it’s indifferent not giving a fuck (even for building permits (outside a few neighborhoods that care/ and a very active historical perservation socitey) its like sure whatever (once read we had more skyscrapers going up here than manhattan))) but it could also be that cops aren’t really dicks in most western societies and won’t ask to many questions if you aren’t doing any harm, or will let you off with a warning.
My point is there seems to be an assumption, not even that a feeling, that you can’t do these things or the hammer will come down and really i just don’t see any of it being enforced nearly as hard as people imagine it would be. Sure there are technically rules, but those are their so that a cop can intervene, if he feels he should, and i just don’t see cops wanting to be dicks in most jurisdictions. The rules only exist if someone
complains and a cop is having a really bad day, and, going by the examples i can think of, those two aren’t that common in large cities
It might be a hang over from school (try peddling goods at recess and you will 100% get shut down), and this would make sense, the examples you give and the image i have of people who do this are kids who (do to poverty or it being the 1920s) aren’t in school. So maybe universal education killed mass entrepreneurship?
Also think of scalpers at concerts or baseball games, what they do is actually illegal in most jurisdictions, and no one gives a fuck. So why don’t other people tap into the possibilities that come with living in a world where no one gives a fuck?
Again i think it has to be cultural or a weird hangover from growing up without independence and expecting a hierarchy to support you. Because their are just too many sub-cultures where these kinds of things are the norm, and successfully so.
@Luke the CIA stooge
You have good points, but I have also got the impression that when it comes to what the authorities can do to screw someone over for breaking the rules, new immigrants aren’t aware and the homeless don’t care.
But for someone who has a car or other property that could be taken by forfeiture or a civil case, they are reluctant to operate outside the rules because they could lose big. They could lose everything.
Everyone involved in each aspect of the process has a different purpose.
I guess? But I’m talking about the institution in general. The kids might well have a purpose of wildly fornicating with their peers, but that hardly makes it part of the purpose of schooling.
So I guess Scott finally banned the Schelling email. Had the most annoying time getting this comment through.
Well, are you asking for the purpose of the people who pay for it, who regulate it, who send their children to it, who enforce truancy laws requiring it, who show up to teach, who show up to hire teachers, who would never consider voting for someone who disagreed with “Education is the key to our future,” etc.
One possibility, if I understand your explanations well enough, is that early school test scores better predict earnings than later year test scores. Thus, early childhood tests measure basics (reading, writing, arithmetic), while later tests measure increasingly irrelevant knowledge (or at least irrelevant to the earnings of most individuals). Also it might suggest that early childhood knowledge is not very correlated with later childhood knowledge, even though in some cases (such as with math) it is cumulative. Your line dancing class probably didn’t affect your earnings potential, unless you tried to become a professional line dancer. Further confounding the studies, I would expect earnings to follow a normal-like distribution (not exactly but close enough), so in aggregate, variations in earnings as correlated with early childhood test scores might be proxying for something else, like career selection or outlier skewing.
Assuming early-age IQ scores are heavily influenced by environmental factors, it is reasonable to guess that early-age IQ scores also correlate with traits like adult discipline…above and beyond the correlation with a later-age IQ score which regressed to mean.
You don’t score higher test scores in school for that, but you might earn a premium in the work place for those traits.
Two IQ 110 kids, Kid A and Kid B. Kid A is naturally a 110 and remains that way through school. Kid B is only at 110 at age 5 through discipline, yadda yadda. Kid B regresses to a mean of 100, but the discipline stays and thus Kid B earns higher wages than similar Kid C, who has always been IQ 100 and had a crappy kindergarten teacher.
So the test score vanishes, but the early-age kindergarten teacher would be strongly correlated with future income.
I don’t know. Shot in the dark.
“but the discipline stays” is rather a loaded assumption … Most people don’t just “learn” discipline like it’s a trick that they somehow exercise later in life effortlessly. Most people tend to understand and appreciate the value of discipline but few are able to consistently exercise it.
So it’s not the teacher as such, it’s the age at which intervention happens? I think that could account for the “kindergarten teacher” effect (if such really exists); a kid who is dropping behind their peers at an early age is likely to lag further and further behind as they go through the educational system and will end up with poor or no qualifications and so in a worse job?
Whereas if the kid is identified as being weak in some areas at an early age and gets the appropriate teaching and support and intervention, all that will help bring them up to a functional level with the rest of the class, and this means they don’t fall behind as they advance, so they have better end outcome?
That would make sense rather than “a good kindergarten teacher will mean you end up making $80,000 more over your working life” as though the only thing the teacher does is inspire you to learn or something.
Alternative Theory – the inspiring teacher vs. the switch-off teacher
Assume for the moment that there are three types of teacher – (this description is going to be flippant and tongue-in-cheek but does fit with a lot of the existing research). One teacher (the bad) will switch you off from learning and also result in you having lower test scores that year. The second (average) will not change your desire to learn but will cause your test scores to return towards the mean. The third (great) will inspire you to engage in learning and cause you to have higher test scores.
Having an inspiring teacher will make you much more likely to go into further education, and to hang out with geeks. The bad teacher will mean you think education is for losers and ignore it at all costs. This fits with the finding that your test scores quickly revert after getting a bad teacher. It also fits with the finding that a bad teacher can cause a big drop in the number of people going to collage.
tldr: A bad teacher flips a switch in students that says “learning isn’t for me” that doesn’t change even when an average teacher comes along and helps them improve their test scores.
I’m in general agreement, except that I think the more common effect of bad teachers is to convince students that they are incapable of learning. If they’re relatively lucky, they’ll just be convinced that they can’t learn one subject, but it’s quite possible that they’ll give up on learning all academic subjects, or even give up on learning at all.
Unlikely …. my impression is that kids are overly confident of their own abilities. Most who fail to master a subject (because they’re not bright and/or the teacher is bad) will claim they chose not to because it’s “stupid” or “irrelevant” or “boring” or something along these lines. Few kids will ever say “I didn’t do well in math because my raw intelligence was insufficient to keep up with he material.”
Some kids blame the subject or the teacher, while others blame themselves. In my experience it’s the girls that most often blame themselves.
I wonder how many different filters there are in the problem student metric. On one hand, I remember raging at the injustice of the preferential treatment given to a problem student in my elementary school; he was offered encouragement and reward for the rare times his behavior would meet the minimum standards the rest of us were held to as a matter of course. Seeing a bully get rewarded for occasionally not bullying did not make 3rd-grade Robert want to have anything to do with my 3rd-grade teachers.
On the other hand, there are a bunch of inferences that you could make about my 3rd-grade class from the fact that we had a problem student. One: That it was likely my school existed in a place that had the demographic groups which more often contain problem students. Two: that the teachers were unable to make the problem student not a problem student. Three: That the administration was not willing to expel the problem student for being a problem student.
I haven’t read the studies, so I’m not sure how much of this was associative. For all I know, the problem student metric operated by carefully infiltrating a large number of classrooms, injecting carefully-calibrated problem students, and measuring the outcomes from them vs. the controls (while making this effect invisible to non-experimenters, preventing high-achieving parents from pulling their kids from the problem student class to a private school and confounding the numbers). But until I do see tests like that done, I’m going to be skeptical.
The education of their children is something people are willing to spend a great deal of sweat, tears, and treasure on, on top of being a political football, a proxy for culture-war topics, and really complicated in general. People will try to game it to hell and back.
Studying education reminds me of trying to do drug trials when there were a large selection of possibly-sick people who had Very Strong Opinions on getting or not getting the drug, who had the ability to influence the random selection process, and who were not necessarily representative of the general population. If the experimental group shows progress, does that mean that the drug works, or that the people most motivated to Try All The Treatments hacked their way into the control group, but it was actually their highly-motivated diet and exercise that helped?
This is a general problem for social science in general, I think. Subatomic particles may be fiddly and quantum, but they very rarely actually lie to experimenters. Students, teachers, administrators, and parents lie all the time.
Can we please stop citing the Benezet study as if it is remotely good evidence? The entire experiment is conducted by a man who has staked his reputation and maybe his job on the outcome. There’s nothing even close to blinding. There’s no formal assessment of students’ abilities. No, really, the claim that the treatment group is “just as good” is entirely based on Benezet’s feeling that yeah, they were pretty good. The papers are available here, and you’ll notice there isn’t anything like a “results” section. It’s just Benezet sharing some anecdotes.
As far as I can tell this is the only source available for the study (it’s the only one the Benezet Centre lists, and I feel like they would know.)
Search for “Guy Wilson.”
thanks for this. A nice overview of the studies
I spent one year as a teachers aid in an underprivileged school in Cleveland. That was 17 years ago so take this as you will, but this is how the system “worked” there and then.
Teacher Turnover was high. Out of 15 teachers at least 2 would leave every year. A few veterans ran the school either because they had union power or their years meant they had the contacts to find a better job any time they wanted and the principal dreaded having to hire 6 or 7 new teachers in a single year.
No official list existed, but the kids with the most issues NEVER ended up in the most experienced teacher’s classes. Nor did their siblings or first cousins. If a kid moved into the district in the middle of the year to live with his aunt/grandmother they never ended up in an experienced teacher’s class. If a kid moved in with both parents they always ended up there.
The new teachers either moved from another district or were straight out of school. The most difficult students always ended up in the straight out of school classes. I worked in a class with one of the new teachers. If there was 1 problem kid I spent the 3 hours that he wasn’t in a special class entertaining him (not teaching just sort of hanging out and doing anything he wanted as long as he was quietish). If there were 2 problem kids (they missed lots of days of school or were shuffled around between the least experienced teachers when one had enough for a while) nothing got done and you just got through the day.
If there were 3 problem kids for more than 1 day in a row the day would end with that teacher spending half an hour alone in the classroom crying quietly.
Suspensions seemed random at first. Kids would do almost anything without getting suspended some days and their parents would get calls for almost nothing. As long as there was no blood a kid could shove, yell or throw things some days and get suspended for singing loudly on another. When the latter happened it was basically always because another kid was coming back from suspension, or there was a class activity/outing or there was going to be a couple of substitutes because there was a conference going on and some of the veteran teachers were going.
If I recall correctly 3rd year teachers openly talked about how they wouldn’t have kid X in their class the next year (it was a mixed grade school so you had 1st and 2nd grades together, 3rd and 4th and 5th and 6th) even if they were supposed to. No 4th year teacher ever had to say anything.
Thanks a mil, baconbacon, for your report from your work experience, in the place where the rubber hits the road.
THIS is why it’s important to have direct experience, or talk to people who have direct experience, with a problem. Most people reading all this research on the subject have no clue that these sorts of things go on.
The structure of a system ensures often certain outcomes, and rewards certain behaviors by certain particular types of participants, and punishes other behaviors by others. Some of the findings of these studies may be due primarily to the structure of the system, not to the effects of teachers on pupil performance at all.
The same is true of our political system, where good public servant Congress members are punished, and skilled fund raiser Congress members are rewarded for fund raising and for serving the special interests that pay them. The U.S. certainly has the best government that mega-corporations’ political donations can buy.
This reminds me of a couple of other things. A book I read mentioned “the toilet syndrome” where problems are “solved” by sending them off somewhere else, and then somebody else has to deal with them, not you.
Of course there is a big element of power politics in this, because the toilet owners have the power and the downstream folks do not. Thus the saying “Shit flows downstream.”
Power politics is always there in economics too, such that it really makes no sense e.g. to posit a “free market” where everyone has equal freedom and power. Of course, they don’t. The foreign slave labor that made some of the items probably all of us own without realizing it, do not have the power and freedom we do.
And, looking at system issues, CEO pay that has been skyrocketing for years, as a multiple of average worker pay, is not responding to simple market factors. It’s responding to a system in which CEOs are given the power to reward themselves monetarily at higher and higher rates. It certainly is not because their work is so much more valuable to society than e.g. the work of British junior doctors.
As in the school, some folks have lots of power to get big rewards for themselves. And those rewards may tend to punish other workers. In other cases in the economy, the punishment may fall on lower status workers and/or on consumers, on people who breathe in the pollution created by someone at a company located in their community etc.
Power politics is a part of most or all systems. But in the U.S. we tend to be so power blind– wanting to believe that everyone is equal– that we are often clueless about this aspect of systems.
I suspect there’s a multiplier effect on executive pay from the total size of the company – that is, what’s perceived to be at stake should the executive in question make a mistake.
Startup of ten people? No big deal, no big salary/bonus either.
Startup of ten people plus a year’s wages for a thousand other people (i.e.: venture capital)? More caution in hiring your executives.
Multinational corporation with hundreds of thousands of employees in a hundred different countries? Very significant pressure not to screw it up by hiring someone even a fraction less competent than you can hold out for (compare with the amount of money spent on political office).
Somewhat related: I have a friend who works in one of the worst public schools in Chicago. He won’t leave because he’s a True Believer, but he is one of the most senior teachers at the school (at 29). Average tenure is ~3 years.
His focus is almost entirely on class discipline. He says that the first year his school gets students (he works at some special charter program), the focus is almost entirely on making sure the kid follows rules. Learning is a complete distant second, almost a “if the kid happens to learn anything, great.”
He talks extensively about classroom management skills and shutting down trouble-makers. He often talks about a contest of wills with the trouble-making students. Given that he’s a hardcore Irish Catholic, not sure he breaks that often. He often describes giving looks to students that silently say “I fucking dare you (to say something).” His words, not mine.
His distant concern is getting kids to think about the future. To put it in familiar terms, he seems a proponent of the “culture of poverty” thesis. He has a hard time getting his kids to imagine and therefore work for a future that doesn’t involve food stamps/welfare/etc. He envies suburban schools in part because there’s a built-in assumption that you will be going to college, and which college will you go to? In his school, there is a built-in assumption that the dole will provide a substantial or majority portion of your income, and you should build your life around that.
A good friend of mine was a teacher at one of the worst schools Baltimore right after he graduated, and he had a very similar experience. 90% of his time was spent with classroom management and that remaining 10% was spent on the two or three students that seemed to care about learning.
I was a first year teacher with similar experience. I was never a second year teacher.
I have a really hard time buying that parents have little non-genetic influence over their kids. A simple example is abusive parents. I think it’s pretty easy to see that children who don’t experience abusive home environments have better test scores and even higher incomes later in life. So at the very least, given a child of any IQ, I can almost guarantee that I could greatly influence that child’s later income by being really terrible to that child. It’s likely far easier in the negative direction than in the positive but I think this ability alone casts great doubt on the idea that parents have minimal impact.
The argument I’ve heard around these parts is that absent abuse, nothing really has a significant effect. Take that as you will.
At bare minimum you could give them a severe enough brain injury to permanently lower IQ if your shitty genes weren’t sufficient.
Nobody claims that parents cannot hurt their kids with sufficiently severe abuse. It is known that they can, i.e., via studying feral children. However, (a) almost all parents don’t severely abuse their kids, and (b) because of (a), when you do any kind of study involving statistically significant numbers of people, the effects of any severe abuse will be adulterated to statistical insignificance.
Or study dead children.
As a clarification, your (a) is completely false. The ACES study conducted by the CDC shows that significant abuse happens quite frequently and has much more effects than just school performance.
Emotional abuse is at 35%, physical abuse at 15%, sexual abuse ranging between 6 and 15% depending on sex.
This is far from insignificant.
http://www.cdc.gov/violenceprevention/acestudy/ace_brfss.html
I think that study, while interesting and eye opening in terms of prevalence, says nothing about the significance of the incidents.
Correlation is not causation. “Abuse” as measured by BRFSS is common, but as far as anyone can tell, has no effect. Severe forms of abuse too rare to move the average might have an effect.
“Significant” and “severe” are different.
Severe abuse is, i.e., locking a kid in a room for the first N years of her life, never speaking to her.
As for the ACES survey, I would not take it too seriously. The CDC has the incentive to find problems, and very little incentive to not find problems. Thus you must read their output very carefully to despin it. For example, in the ACES study emotional abuse is “A parent or other adult in your home ever swore at you, insulted you, or put you down.” I am surprised it is as low as it is. My mother swore at me once. The real finding here is that somehow 60% of people make it to adulthood without a parent ever swearing at them even once! Who’d have guessed that?
Beyond that, your assertion that abuse has effects is at best a hypothesis. What the survey shows is that abuse is correlated with later-in-life problems. This is no surprise: all human traits are heritable and the vast majority of people are raised by their genetic parents or very close relatives. But of course, like most such surveys no attempt is made to control for genetic causation. (Do note that this would not have been hard to do: a single question like “were you raised by your genetic parents or adopted?” would have sufficed.) Genes are by far the strongest causal link between the traits of parents and children.
For example, in the ACES study emotional abuse is “A parent or other adult in your home ever swore at you, insulted you, or put you down.”
I’d assume (or hope anyway) that they would factor in the frequency/severity when deciding whether to count that as abuse. I mean, yeah, even in a generally well-adjusted family there are going to be occasional fights and outbursts where parents and children alike will swear, lose their tempers, say unkind things, etc. No one is perfect.
However, if that’s happening on a daily basis then it’s probably abuse.
Yup, this is hugely controversial.
Logically, it seems obvious that an extreme childhood environment can have lasting effects (e.g. starvation, exposure to toxins, growing up in a pre-industrial civilization).
But the general result across many many studies is that variance in home environment explains approximately none of the variance in adult outcomes. (It usually explains a little bit of childhood outcomes).
This might just indicate that the variation in home environment in these studies is small relative to the range that causes measurable effects. But that in itself is quite significant.
If you are a Romanian orphanage- level bad parent then yes, but there are not a lot of Romanian orphanage- level bad parents in the studies.
I recommend “The Nurture Assumption” (third link in this post) for a good treatment of this. Anything shorter probably wouldn’t be convincing.
Not that this means anything, but I did look at link for The Nurture Assumption. I saw that the front cover endorsement was by Malcolm Gladwell and I cringed.
Ditto on The Nurture Assumption. Scott isn’t just making this up. There is good evidence for the insignificance of the effects of parenting on children’s development.
A very interesting book for a variety of reasons.
How common is it for abusive parents to be more abusive to one child than to their siblings? If that is common, then it is possible that abuse won’t always show up as a shared environment effect.
That being said, I am myself skeptical of the research that supposedly finds that shared environment has little effect on life outcomes, but for different reasons. Specifically, I am skeptical because we know that some environmental factors have strong effects on IQ, because we know that average IQ scores in America have increased by 2 standard deviations in the last century (known as the Flynn effect), and that increase is far too fast to be due to genetics. Whatever environmental factors are responsible for this increase are almost certainly shared environment effects and almost certainly vary across the US, so by all logic they should show up as shared environment effects in these studies, but they don’t. It is far easier for me to believe that there are systemic flaws in current behavioral genetics research than to believe that the Flynn effect is caused by some kind of magic spell that equally impacts every household in America.
Adoption studies generally don’t include really bad parents.
I know that adoptive parents make efforts to avoid kids with obvious problems or kids whose parents were particularly messed up.
The question is how well these methods work.
I think you misunderstand the original comments – the strongest filtering is of the adopters, not the adoptees. Adoption agencies are pretty good at not letting people likely to be bad parents adopt.
If early IQ scores don’t predict adult IQ scores and adult IQ scores are the thing that we have all the correlates to various positive life outcomes then why are we calling child IQ tests, IQ tests. Seems like they are measuring something else other than g.
Early IQ *does* predict adult IQ. Just not perfectly.
But correlation with parental IQ increases with age. One interpretation is a bigger environmental effect in early childhood. Another interpretation is that many genes have their effects later in development (e.g. at puberty). Another interpretation is that brains develop at different rates.
For comparison, think about a kid’s height percentile at various ages. It’s predictive of adult height, but as time goes on it becomes a better predictor (and becomes more correlated with parental IQ). But this isn’t because height is more environmentally determined at a young age.
Do you have a study on the height thing? I have thought that was right but cant track it down.
I guess IQ is just a weird measure because it’s a percentile that looks like an absolute. If I say a kid is 90th percentile for his age it is intuitive that isn’t some timeless thing but a point in time measurement. However when you say an 8 year old has an IQ of 125 it somehow seems more intrinsic and permanent.
How intelligence seems is an interesting thing.
Studies show that if a classroom is randomly divided into 2 groups, and the researchers falsely tell the teacher that Group A is very intelligent and Group B not so much, you come back after a while, and voila, Group A’s performance is better.
The studies seem to actually measure the effects of your whole shared class environment while attributing all of that effect to the teacher.
How about the rather obvious possibility that a lot of that effect can be caused by the particular set of classmates that you had? They will influence not only your academic performance, but also your after-school circle of friends and connections. The circle of contacts obtained in school years can easily have a strong direct effect on future academic performance and life earnings, and also on things such as habits, values, behavioral problems and even e.g. risk of incarceration.
I have seen far too many people for whom the main reason for rather important decisions e.g. which career path to choose, relocate to big city or stay where you are, deciding to attempt a robbery, choosing a college, starting a drug habit, etc were driven essentially by “meh, I’m not sure, but I’ll do what the same as my mate decided”, influenced (at least partly) by their friends from school age.
I was coming here to post the same.
The physical condition of the school is another non-teacher factor.
If the school is miserably hot or cold, this would presumably affect how much students learn.
Has anyone done studies about the possible effect of violence in the school?
Violence would be a can of confounding worms to try to study, I think.
I think we have a winner here.
I think you’re on to something with the “non-cognitive effects.” While it is hard to believe that a good fourth-grade teacher could really impact lifetime earning by $1000 a year, I think that elementary school teachers impart more in terms of socialization than they do in terms of information, and that large differences in income arise from social class and social ability. To give an extreme but clear example, a smarter than average working-class person lacking either the drive or ability to join ranks with the gentry is likely to earn much less than an gentry-class person of average intelligence, even if the working-class person is “better educated” as measured by stardardized testing.
Personally, what I remember most about my elementary school teachers has very little to do with how well they prepared me for standardized tests. I remember their personalities, apparent world-views, and organizational skills. I don’t know if this means anything, but my favorite teacher (second-grade) had moved across the country from New York and enjoyed wearing heels and red lipstick. To me, she was an icon of class and beauty of a sort I’d never come across in person before. As an adult, I’ve now moved across the country to New York and love to wear heels and red lipstick. Coincidence? Maybe. Something that will impact my lifetime earnings? Probably. The rent here is not cheap, for one.
That sounds like another confounder. If your lifetime earnings are boosted just because you moved to a place where earnings are higher but expenses are also higher, it doesn’t mean that made your life any better.
It certainly is a confounder, but if I’m not mistaken I don’t think they corrected for cost-of-living in the studies comparing the adult earnings of former students.
Randomization by itself should control for that. I was just making a joke about your specific situation.
Wouldn’t this apply to parents as well? Then we would expect a big shared environment effect on noncognitive scores and income, which we don’t see.
For all the attention that Chetty’s study has gotten, I’ve seen little discussion about the mechanics of how math scores might bump up your income in adulthood, particularly regarding path dependency. If I recall correctly, Chetty didn’t find a correlation for reading test scores, just math.
Even in schools where there is “no tracking,” kids inevitably tend to be put in math groups, which eventually in middle and high school become separate tracks, where it gets increasingly difficult to “catch up” to the higher math group (you might have to take two math courses in one year, for example).
Your math group largely determines which students are in the rest of your classes as well, intentionally or not, and specific math courses can also be a prerequisite for courses in other subjects, and the high level math courses are important for college admission. Also SAT, etc.
It is easy to imagine that a if a good math teacher manages to bump a few students up a track, or a bad one bumps them down a track, that would have measurable knock on effects through high school, college, and career track as well.
If that’s the case, it is as much an artifact of the role and structure of math in the larger system as teaching quality.
Interesting. I wonder if, on average, careers that require good math skills pay more. Seems likely.
Also, if a person doesn’t have at least a basic grasp of arithmetic, I don’t see how they can handle money well.
That is actually a really interesting supposition, AND offers a plausible explanation for disappearing affect.
The average of kids who bump up a level might do better income wise, yet their grades might be worse. I would hope that someone looked at this in the study.
Anecdata: I lived in Switzerland for on year during 8th grade. As a result, I lost a year of math progress versus where I was in the U.S. system. As a result, I did not make it all the way to Calculus which was the only AP level math class available to me at the time.
I made it as far as interviewing for admission to MIT, but did not get admitted. I have to wonder whether the lack of math advancement made a marginal difference there. Although, I really loved the college experience I did have, so I don’t regret not getting in.
I was schooled overseas for most of elementary and all of middle school. Upon re-entering the public school system for high school the administrators deemed my education abroad as inferior and so put me in the lower track classes without even considering the school I was coming from (which is laughable). I spent a day in those classes, reported to my parents the peer/teacher level, and they spent several weeks arguing with the school to reconsider my case.
Ultimately my parents were successful and I was able to jump up to the groups on the advanced tracks. I owe my parents a lot for that, and it certainly influenced my outcomes (at one of the “top 20” public schools in the country no less).
“If I recall correctly, Chetty didn’t find a correlation for reading test scores, just math.”
Schools generally have more of an effect on math scores than reading scores. Kids seldom do math just for fun (present company excepted), but a fair number of kids read outside of school. So, better teaching or whatever can move the needle on math scores more than on reading scores.
How much of the growing dependency of IQ on genetics as you get older is seen in other things.
They are basically comparing adult parent IQ with age X child IQ.
Are there studies comparing adult parent height with age X child height, for example? Couldn’t the correlations for these increase during childhood as welll?
What you’ve got here is FUQed – a Fundamentally Unknowable Question.
With sufficient time, money, and approval to run double blind experiments, it seems very fundamentally knowable.
Assuming the best method of teacher evaluation is actually static over a time period sufficiently longer than the study period.
If the brains of humans are changing so fundamentally from day to day that basic teaching methods can’t even be compared then why do we even bother with teachers at all? Might as well set the kids in front of a screen playing endless static and hope for the best.
With these studies, teachers are defined as “bad” or “good” according to their effects, but the good teachers are not the best possible teachers. Even good teachers in a school are probably good because of their personality and are using similar outmoded instructional methods that the bad teachers use (although I’d like to see survey’s of the teaching activities of “good” and “bad” teachers). Educational psychology has found some methods, particularly methods of reading and recall, that have small but significant effects (e.g., retrieval practice ala Roediger, deliberate practice, self-explanation while reading, and so on, as well as more informal classroom management techniques). I wonder how much using all of the effective methods might move the needle. It might be that teaching explains so little variance simply because no one really is teaching properly.
There have been a lot of attempts to modify the curriculum/ teaching methods. Common Core is an example. Unlikely, that there is some magic bullet out there that has not been tried.
Common Core is a set of standards, not a set of teaching methods. I’m not saying that there is a magic bullet. I’m saying that there is a set of teaching/learning methods that has been experimentally established (normal caveats apply) in educational psychology that are almost never used at any level in education. Each one doesn’t have an enormous effect, but cumulatively, you might find sizable positive outcomes.
It’s strange to say that the effect of teaching is minimal when we know that most teachers (including the “good” teachers) aren’t using the most effective methods. At best, we know that teaching with outmoded methods only explains a little of the variance in learning outcomes, but that’s not the “sky is falling” or “it’s all genetics” result that people make it out to be.
Common core also contains some instructional methods. Haven’t you seen all the discussion about the new math, where children are marked wrong for putting the correct answer without showing intermediate steps or estimations that could be helpful in finding the answer?
For some math, this is true, but it’s not really what I’m talking about when I’m talking about teaching methods. I’m referring to more domain-general things like retrieval practice, elaborative interrogation, self-explanation, distributed practice, etc., and these are applicable in almost any course (and, as I’ve been saying, rarely applied in practice). Those domain-specific methods may work well for math where, along with elementary reading, there is a lot of research on domain-specific teaching methods. For higher-level courses, particularly high school and university levels, domain-specific research is very rare.
Very interesting stuff. The biggest message I take from this is that whatever the theoretical debates, we should DEFINITELY not be using VAM to evaluate teachers. Does anyone imagine that the incentives / potential punishments offered by the VAM program somehow get individual teachers to do a better job on a day to day level? In what way could teachers be assumed to be cranking it up a notch in response to these very abstracted financial incentives?
Another problem with the VAM model is that it’s not going to give good signals for gifted teachers. I was in a full-time gifted program in 4th and 5th grade, where the teachers only taught the students in the program. Some of them were very good (and others were only adequate), but when the students you’re dealing with start in the 99th percentile (yes, the program was approximately that selective), the best teacher in the world is statistically indistinguishable from an average teacher.
It is also known that top students find ways to exceed no matter who their teacher is. It’s the apathetic who have the most to gain or lose from the teacher lottery.
Unfortunately, we tend to reward good teachers by letting them teach precisely those classes favored by the students who need their skills least.
That depends on what we’re optimizing for. If we’re going for standardized test scores, then you’re correct. The people who test well will do well regardless of their teacher, because they’re already into the noise. But the same isn’t necessarily true of longer-term benefits. I owe a lot of my writing skills to a single excellent teacher in 4th and 5th grade. I’m not a fantastic writer, but I was horrible before, and that could have had serious repercussions down the line.
-Edward Gibbon
It’s interesting that amount of money earned per year is a thing measured as if it’s all important. When studies indicate that, beyond a certain not so large amount of money earned per year, money is just not that important to happiness. But I guess money earned per year is easy to measure.
But I would never consider someone earning a high salary and hating their job to be more successful than someone earning an adequate salary at work they love waking up every morning to go to.
In these studies as well as others, there is the assumption that the factors determining the result that interest us, are the factors that are easiest to measure. It seems to me that parental behavior in the home environment, and other non-school influences, often have a huge effect. But parents are not too forthcoming with info about whether they are physically or sexually assaulting their kids, or looking the other way while a family “friend” or relative does so, is likely to have a huge effect on kids’ behaviors and school performance. There is a good book by a psychiatrist who worked with kids like this.
The Body Keeps the Score: Brain, Mind, and Body in the Healing of Trauma Paperback – September 8, 2015
by Bessel van der Kolk M.D.
http://www.amazon.com/Body-Keeps-Score-Healing-Trauma/dp/0143127748/ref=sr_1_1?ie=UTF8&qid=1463671545&sr=8-1&keywords=The+Body+Keeps+Score
Parents don’t abuse their kids enough for it to show up in the studies.
Bessel van der Kolk was a recovered memory nut. He now is some other type of nut:
http://www.nytimes.com/2014/05/25/magazine/a-revolutionary-approach-to-treating-ptsd.html?_r=0
Child abuse is not an infrequent occurrence.
https://en.wikipedia.org/wiki/Child_abuse
That article you cited is not so negative. Van der Kolk has some promising sounding techniques that seem to have helped some of his patients, at least temporarily, perhaps longer. But he needs to find funding and get more research done on his treatment methods, and to do it in a rigorous way.
As for the recovered memory controversy, it is not so black and white. The controversy happened because unfortunately, some therapists asked leading questions and caused patients to come up with memories that turned out to be false. But that does not mean that memories of trauma can not sometimes be kept out of consciousness and then later remembered. In fact they probably can.
A memory which is recovered is not so 100% certain that it can be taken as true for the purpose of a lawsuit or other legal matter. And that was being done, back before the controversy, which was the other problem with it.
But what stands up in a courtroom as evidence, and what is useful in psychotherapy, are 2 different things.
And nothing about that controversy invalidates this guy’s treatment techniques.
That’s some disparity in child abuse rates estimates in the US. CPS gives 0.9% versus 25% from Finkelhor D, et al. (10% of that is physical abuse). Based on phone interviews, the survey is linked. For physical abuse it excludes spanking.
Seems sadly high, but not with glaring methodological flaws.
But it is quite important to government tax collection, and after all, they’d like some return on their investment.
Income and intelligence are very correlated. Very few adults take standardized tests, so income is the next best thing. Since the main purpose of schooling is to impart knowledge/intelligence, then it would make perfect sense to use income as a measure of how successful the schooling was.
You imply that more knowledge was imparted to those who felt compelled to take the highest paying careers– perhaps despite their misery in such careers. Not necessarily so.
Yeah, the causation could go another way. I think the most likely scenario would have a third factor C (let’s call it “grit”) behind both A, school success, and B, income. In which case we’d still see a correlation between A and B, but B would be totally useless for measuring success of interventions on A.
Well, as I said, income and IQ have a very strong correlation, so it would seem that the most intelligent do, despite the supposed misery of it (though the high income people I know seem to be happier than the low income people, so I have severe doubts that there is increased misery with increased income).
It is possible that there is a third reason, I would guess “IQ” is more likely than “grit”, but Just because there is the possibility that there is a third reason doesn’t necessarily make income a bad marker in the absence of a better one.
Also, a very large portion of the population looks at school as a way to get a good job. I would guess it is a large majority. So from that perspective alone, it is legitimate to use income as an indication of school’s value.
Actually income and intelligence are not very correlated – estimates range from 0.23 to 0.5, and the former is much better supported (by a meta-analysis – Strenze 2006) than the latter.
This is a fascinating look at an important topic, but one of its fundamental assumptions is that the Prussian education system is the correct method to school students. That is, we’re on the right track with a school system that takes kids in, classifies them by grade, and then teaches to 30 of them at once.
(I’m getting in before David Friedman shows up to wax rhapsodic about unschooling.)
That’s a pretty bold assumption. There are a lot of folks out there who are educating their children outside of the traditional school system. We* are homeschooling our kids. In part because we want to be able to impart our values to our kids, but also in part because we can teach to their level and let them pursue the subjects they’re interested in. My six year old is doing third grade math right now because he loves it. My eight year old is reading well above grade level because it’s one of his favorite things to do. They’re learning to love learning for its own sake.
I’m given to understand that there’s good data** showing that homeschooling kids score 15+ percentile points above their peers in standardized tests. And some alternative teaching methods (Montessori?) do nearly as well.
So maybe the answer isn’t, “Identify good teachers,” so much as, “Identify better teaching methods.” The Prussian educational system was designed to turn out working-class cogs. It’s an industrial model***. And maybe the model is outdated for current educational purposes, and we need to find better schooling models.
* By “We” I mean, “My wife, with my occasional input.”
** I know that there are confounders all over the place with data from homeschoolers. Most specifically, it’s a pastime of the middle and upper-middle classes.
*** And let’s be fair: At least a good part of the current educational system is designed to be babysitting for kids of families where both parents work.
My educated guess is that the top factor that make homeschooling better than mass education is that the classes are so much smaller. If classes were reduced to 1-4 pupils per teacher, I’d figure that results would shoot up… (say, are there any studies on the effectiveness of learning versus pupil/teacher ratio?)
Yep. It probably doesn’t do anything.
https://en.wikipedia.org/wiki/Class-size_reduction
Are we reading the same article? Because most of the results seem to show that there is a correlation between decreased class size and better grades. Anyways, the difference between teaching eighteen or twelve students is a lot different than teaching a single student.
The problem is that the effects are largest on the lowest-performing students, and one of the most noticeable improvements is in class discipline.
This suggests that the real benefit may simply be a lower probability of having a bad actor in your classroom due to having a smaller class size, and certainly a smaller probability of having two.
Anecdotally, I can tell you from my own high school experience that people did just fine in classes of 30 well-behaved students, but when my brother went through, his class had more bad kids in it, and it became a problem. Same class size, but one year it worked great and another it didn’t, all because of the kids involved.
Are there any studies on people who find being in classrooms 7-8 hours a day surrounded by a bunch of social drama completely saps the energy which might have been used actually learning something?
I used to blame laziness for my poor grades in high school, but in retrospect, I couldn’t go to 7 hours of academic lectures per day and then go home and get a lot of additional research and writing of my own done.
This happened to me, though only freshman year. I got into a private school that was an hour away, so had to commute there, and I had to go in an hour early for band, then stay three hours late for cross-country practice. By the time I got home, I was exhausted, so I did pretty much zero homework the entire year and got mostly Bs and Cs in my classes. When we did the standardized testing in the spring and I came back with the top score for my grade, all the other students were wowed because they thought I was an idiot. I was just tired. I transferred back to the normal school that was walking distance and didn’t have a state champion cross-country team that trained us like maniacs and I got As the rest of high school.
You might have a point, but that’s a decision for parents on the margin. We’re not going to remake the entire school system right now. We’re stuck on our current path and need to reform our current system.
From a policy perspective, we can make it easier to homeschool/unschool/charter schools. I am not even sure what the challenges are.
I do know that public education was mind-numbingly boring to me.
Which influential entrepreneurs went to Montessori school?
Larry and Sergey from Google are the notable example, but curious who else is on the list.
https://www.quora.com/Which-influential-entrepreneurs-went-to-Montessori-school
If you’re interested in randomized experiments rather than the morass of correlational contradictions, check out a new paper: “The Production of Human Capital in Developed Countries: Evidence from 196 Randomized Field Experiments” http://scholar.harvard.edu/files/fryer/files/handbook_fryer_03.25.2016.pdf Fryer 2016. My take: as expected, lots of small effects and the more rigorous an experiment, the smaller. The iron laws of evaluation…
When I was in school I spent more time around teachers and classmates than I did around my parents. My impression was that in developed countries kids spend even more time in school.
I think Scott is overestimating how much influence parents have compared to teachers and peers. Sure the parent can choose where you go to school (indirectly selecting the teacher) and they can forbid you from hanging out with bad kids (indirectly selecting your friends) but surely they don’t have as much influence as an actual good teacher or an actual good friend.
Some parents are good teachers– and good resource finders– for their kids. When they are, that’s makes a huge difference. Some parents help their kids– or find other help for them– if they have trouble making friends or have trouble performing in school, and other parents don’t even notice what’s going on with their kids.
There’s also the “village” (takes a village to raise a child) effect. If the kid is in a church youth group or community program, even if their well meaning parents don’t have much in common with the kid or can’t understand their personality, goals, or talents, another adult mentor maybe does. Maybe they find an adult mentor who is similar to them in talents or goals or personality issues, who knows precisely what to do about some situations about which the kids’ well meaning parents are clueless.
There are many possible influences, both good and bad, many of which are not measured in these studies.
That being said, I do think that peers have a huge effect, because those are the people the kid spends most of their time with, and they are the ones who are most instructive about “how to be a kid this age.” And kids for sure pick up each others’ attitudes toward school performance.
In fact there have been some articles written about how in some public schools, black children have to rebel against their peers, rather than being included with the group, in order to excel at school. Because some school-focused black kids have the experience of being put down by peers for “trying to act white” if they study hard and make good grades.
The influences can’t all be measured but their combined effects are measured in the studies that Scott analyzed. Well at least their effects on income are studied.
The results of those studies Scott finds suspicious for many reasons, one of them being that it’s weird that teachers can have that influence when studies show that whatever influence parents have, it does not affect the income of their children when they grow up.
Are there any studies that show the influence that parents have not on future income but on more fuzzy touchy-feely things? My understanding was that as long as you weren’t an abusive parent, your children would grow up to be as well-adjusted as their lost twin.
On the value-added measurements: I’m married to a teacher, and I support standardized testing. My wife does well on VAM-type measurements. But there are some confounders I don’t see addressed in the literature.
As I was reading this, I was thinking “What of the disruptors?” And then Scott addressed that. Similarly, children with similar test scores may have dissimilar classroom effects (Joey the Inert Rock is not as harmful as Jane the Screaming Terror.) The later Chetty study referenced gives me pause, though.
The other problem with value-added measurements is that we end up measuring some other things. You let people work the angles, and a reasonably competent teacher will kill a VAM-style metric.
Let’s go from fifth to sixth grade math. We’ve got five fifth grade classes of 30 kids apiece. Ms. Sweetness teaches one of those classes, and she knows no math at all. Her kids mostly test badly on standardized math tests, but they are otherwise good students; Ms. Sweetness is good at other things so the administration likes her and doesn’t burden her with disruptors. I want those kids in my class. What I don’t want is bright, lazy disruptors.
But I don’t want Mr. Dolt’s students, who also suck at math, because Mr. Dolt gets the personality dregs. None for me! I also want the pull to handpick some other students. Hey, I don’t need the gifted class – I’ll do fine with the regular kids.
And what will happen if we measure teachers by VAM? First off, teachers are mostly bad at math, so they will campaign for the gifted kids hard, and there will be ill feeling. Second, the smarter teachers will angle to prevent disruptors from showing up. Third, someone will figure out ways to game the system. Any time you have a statistical measurement system, gaming the system occurs. (It’s harder for baseball players like Scott Alexander, where some statistics really matter, but even that is impure.)
That doesn’t mean it’s not worthwhile; just giving up is no answer. Teacher quality matters, and treating teaching like an unmeasurable, or as a popularity contest, isn’t right either.
Of course, these are just my opinions. I could be wrong.
Side note 1. I’ve read some of the studies on parenting effects being near-zero, and I believe they are mistaken. (Bare assertion without evidence; much much much longer response required. And I might be wrong.)
Side note 2. I guess it’s possible that IQ is mostly environment-based for young kids, but it was pretty clear when I was five that there were pronounced intellectual dissimilarities between children.
Side note 3: My school instructional circumstances were sufficiently abnormal (and, to this day, aggravating) that I may be biased in unhelpful ways. I don’t think this is true, but that’s my brain talking.
Good points, JRM, particularly about ways that teachers may game the system.
The only thing I’d take issue with is the implication that pronounced intellectual dissimilarities between children at age 5 must be due to genetics. The most impactful time for the environment to affect a person is in the womb (which e.g. is sometimes full of cocaine or alcohol) through the pre-school years. And abuse, neglect, various toxins in the home environment or other bad experiences can really mess up a kid’s ability to function normally.
– Conan, what is best in life?
– A 1600 SAT. WAIT, I GUESS IT’S 2400 NOW.
Nope, it’s back to 1600.
Huh. TIL.
When I think of my very best/favorite teachers, I can think of many ways they influenced how I think or things I know in their area of study.
I have a really hard time mapping *any* of that to the factors that influence my income at my job… most of them didn’t even matter for standardized tests. In fact, I probably could have done better on the tests had my teachers been in my opinion *worse*, and spent more time on “teaching to the test.”
My success at my job is mostly based on abstract reasoning (mostly innate), experience in my field (post school), independent research (by definition, independent), and social skills (learned at school, but most definitely not taught by teachers).
I worry that we may just not have good metrics to find the areas where teachers matter… or maybe even that good teachers don’t matter at all in the metrics that should concern the State.
On fade out — given standard curricula and no individualized instruction, why should gains in (say) math skills persist? If you get a great 5th grade teacher and really understand fractions, then you’ll go to 6th grade and…spend more time learning fractions, and the kids who had a lousy 5th grade teacher will mostly catch up.
Sorta depends. I tutored at a public elementary school near my college last year and the problem with this is that some kids just don’t pick up the material the first time around and can’t understand subsequent concepts.
For instance, I worked with a fifth-grader who had apparently never learned what exactly division was. If a kid doesn’t understand the concept of division, fractions aren’t going to make any more sense, and it’s not obvious to me that those gaps are going to get filled in during the course of ordinary classroom instruction. It took me about an hour and a half of (mostly) one-on-one time to get her doing basic two-digit division problems like 32 divided by 8 equals 4, but I don’t think it stuck.
I had the same experience with a student in my HS physical science class. Try teaching velocity = distance / time using simple integers and getting blank stares.
The teacher effects are set using a baseline of the other children in the class. But the other children are ‘peers’, and studies of parental effects find peers play a larger role than parents. Although in the later case, those peers may include the teachers themselves, I assume?
Anyway, thanks for the detailed analysis complete with common sense checks. I share your incredulity at kindergarten’s effects on long term income–or much of anything else.
The closest cognitive model I can imagine to synthesize these is one where a persons (non-genetically derived) behavior is a sort of sum of all their observations, with only a small multiplier for amount of time. So seeing some disruptive kindergartners will normalize behavior that later may make advancing in a job slightly harder (but could it have a positive effect on, say entreprenuership?) Still not terribly convincing, but conceivable.
Classrooms could act as a sort of feedback affect (in the acoustic sense) where each child is slightly affected by one disruptive student, internalizes that to a degree, then all affect each other further down the path?
In reading about the statistical shenanigans with respect to VAM, is anyone else visualizing angels and pinheads while hearing disco music? (/sarc off)
One possible, but important, corollary to the Carrell study: that 3-4% figure you’re talking about comes from having an extra disruptive student in your class every year through elementary school. (So an extra disruptive student in grades 1-5 results in a 3% reduction, not a 15% reduction.) So the effect might not be so unbelieveable as it sounds when comparing it to single-year effects. At least, that’s how this blog summarizes it, though I can’t find a clear-cut explanation in the paper itself.
As it happens, I’m a teacher myself and have taught in a fair diversity of settings. Student behavior has a much bigger effect on classroom environment than I thought before going into teaching. It’s also seems mostly clear to me that there the variance in student behavior is much larger than the variance in teacher quality. I think the real difference between a 25th percentile teacher and a 75th percentile teacher is relatively small. But the difference between a 25th percentile student and a 75th percentile student in terms of disruptive behavior is large. (Keep in mind that a given school likely doesn’t have the whole range of behavior in any representative fashion. So most readers of this blog will underestimate the disruptiveness of a 25th percentile behavior student if they think of a 25th percentile student from their school growing up.)
Scott, you’ve mentioned having some experience teaching before, but you rarely post about it or mention it. I know I would love to hear more about your experiences, and I’m sure many of your other readers would as well.
Yeah, I’ve wondered if you could come up with a pithy phrase à la economic inequality for student disruption: “5% of the students cause 90% of the chaos” or something like that.
We have plenty of data on this! At my school, which draws from a reasonably diverse section of my city both racially and economically, as measured by number of times sent out of class:
4% of students cause 50% of disruptions
7% of students cause 60% of disruptions
10% of students cause 70% of disruptions
14% of students cause 80% of disruptions
22% of students cause 90% of disruptions.
The 10/70 one is probably easiest to remember because of the round numbers.
There’s reason to believe these numbers probably undercount disruptions given the most disruptive students have a disproportionately higher share of non-logged interventions.
Also, for context, I’ve seen the box-plots of scores on a particular set of diagnostic tests for my school compared to some of the above average suburban ones. People pay a lot of attention to the difference in means, but the real story is the difference in variation. Our means aren’t that far off, but the bottom 25% of kids academically, pretty close to the number of kids we saw creating literally 90% of the disruptions in our school, practically don’t exist in the suburbs.
Also, I suspect that an awful lot of school selection done by parents is done on the basis of behaviour; only evidence is that it’s what parents with options have told me, and what my family did.
Basically, I think behavioural issues are very nonrandomly shared between schools.
Parents routinely speak to each other about which teachers are best, and lobby principals to assign their children to a favored teacher. If we presume that smarter, better connected parents are more successful than average in getting their child assigned to a mutually preferred teacher, we can also presume that the children being taught by that teacher will be smarter and better behaved than average. This introduces not only genetic bias but environmental bias, as these students will be surrounded by more intelligent peers.
I still recall a moment in second grade, when I was part of a small group of “advanced” math learners waiting to be readmitted to our regular class while a film finished there, and discussing among ourselves the concept of negative numbers, something which no teacher had yet introduced to us. Multiply those sorts of interactions a thousand times, and you can see how one’s peers can be more influential than one’s teachers.
Interesting point.
“I don’t understand this field very well and place low confidence in anything I have to say about it.”
So you decided to write a long blog post about it?
As they say “the best way to get the right answer on the Internet is not to ask a question, it’s to post the wrong answer.”
This is known as Godwin’s Law.
Plus I view such posts – every post here, in fact – as a Request For Comments.
I don’t know what would be a better way to learn, and to learn what you missed, than to post like that, here.
Godwin’s Law is “As an online discussion grows longer, the probability of a comparison involving Nazis or Hitler approaches 1”.
You’re thinking of Rule 34.
Started to type “You may not be getting the joke. This was actually an example of the phenomenon in question.”
Paused, deleted to write “Except Rule 34 is actually…”
Paused, achieved satori.
Rule 34 is “If you can imagine it, there’s porn of it on the internet.”
You’re looking for Cunningham’s Law.
(If you were deliberately trying to invoke Cunningham’s Law there, nicely done.)
Heh. Brilliant.
Experiment time!
Take a STAR-sized sample.
Kick out the “disruptive” kids, year by year (to the non-experiment schools).
Just use everyday random-ish teachers and nice, big class sizes.
See what we get. (Step 3 – Profit!)
If we get significant improvement, probably we can conclude disruption is “the big thing” (or “a big thing”), partially validating beliefs from Ages Past about “how schools were so much more effective when they could kick kids out or seriously discipline them”, and suggesting that we can stop worrying about trying to make every class 10 students, taught by the most gifted ultra-teachers we can find.
(Guessed probability of that being the outcome? Greater than zero, but not real high.)
Mostly the above is a response to data from the post and an amplification of an intiution re. complaints from teachers that “you can’t measure how well I’m teaching from tests” – which has always confused me, given that the alleged job is “teaching kids various academic things like reading and math” – one would think that “their ability to read and do math” was in fact very well, if not trivially, measurable.
If, on the other hand, we’re to believe that the key to teaching is really, instead of teaching mere skills, non-cognitives or minimizing disruption, well, that’s fine and good; we can adjust the system for that.
The obvious reform would be to drastically change teacher qualifications, to “someone who can more or less read the textbook well enough to not cause reading and math skills to actually atrophy*, but handles the non-cognitives really well”.
(If they try to tell is “you can’t measure those and thus can’t ever tell if we’re doing it right”, well, fire the lot of them and build robots.
I kid, but only a little. Anyone telling you their job performance can’t be measured is selling you a bill of goods, as a first approximation heuristic.)
(* That happens the second schooling ends, I imagine, down to whatever level of utility daily life supports.
In fact, that might be the biggest thing to think about re. mandatory education – can we defend it in general as anything buy subsidized daycare warehousing, given the numbers we have for ability decline, and the way, well, almost everyone never touches a damned thing they learned in school from the moment they graduate?
I mean, I’m a voracious reader, a trained philosopher, and a computer programmer, two-odd SDs higher than average in IQ.
And I also forgot pretty much everything I learned in trig and geometry the second I left the classes – even if I regret it now, sometimes, when remembering trig would be handy for various projects.
Can we realistically expect skills education to have a long-term measurable benefit to anyone beyond “whatever it is they actually use day-to-day”?
In a fairytale dreamworld we might talk about education ‘opening doors and broadening minds’, but we’re never going to get that from mandatory public education in any sort of broad way.)
I think we’d have to adjust for the loss of scores from the disruptive students (which I assume are generally poor).
Are you skeptical that kicking out disruptive students would produce higher educational outcomes in general, or that it would lead to less worry over class size and so forth?
It seems that one thing shows through all the ins and outs – standardized test scores aren’t good for much, at least considering alter life earnings. If the teacher effects fade out and later earnings are correlated mainly with non-cognitive effects that don’t fade out, then why should I bother with standardized test scores and VAM?
If it’s correct that having disruptive students in a class lowers everyone’s performance, then larger classes should underperform smaller ones on the average, simply because larger ones would have more of a chance of having a disruptive student on the average.
Interesting if that were the main factor behind better performance of small classes. OTOH if, as I have read a few times, it’s not really true that smaller class sizes are better, that ought to disprove the disruption theory.
Seems like it should be possible to make some headway here …
I think the findings were generally “not cost-effective” rather than “not effective”. Unfortuantely, no way to get past paywalls at the moment (apart from paying, I suppose)
http://www.jstor.org/stable/1164099
How much of kindergarten class quality is due to teachers?
Couldn’t we correct for this using a median or trimmed mean instead of a regular mean for class earnings?
This is depressing, my kindergarten teacher was awful. Who know what I could have achieved?
Look at youth soccer (as we call it in the colonies): In 27 seasons (3 kids for 9 seasons) I have observed a very real difference in performance based on the coaching. And that can be measured in the way the kids play on the first game compared to the last game (passes, goals, excitement, and beating teams they lost to before). Sure some kids are ringer, but to bring the whole team up on a system (lesson plan) and then execute it on the field is great to watch. So if we want to really pay teachers for performance then we need to pay them based on the class performance, and also let them decide how to teach it (not via state mandated plan). You fire the bad ones after 3 losing seasons (which is kind of how private schools work). Sadly, in public schools, the only way to go above the teacher pay band is to get into administration and stop teaching. There’s an incentive plan for you!
Well, in educational policy I kind of expect incentives as perverse as a hypothetical child of Ed Gein and the Marquis de Sade.
A general thought on “decay” of learning and the like: reminds me a little of the “set point” problem in weight loss.
People talk about both of these as if, assuming they are true (that there is a lot of educational decay and strong “set point” effects pulling you up to your pre-diet weight) it would therefore mean education and/or diets are useless.
But if your goal is “these kids will stay good at writing essays and with a strong command of Ancient Greek history even if they never write or engage with Greek history again,” then of course you’re doomed to fail, as you would be if your goal is “after I get down to my goal weight I never have to worry about exercising or watching what I eat again.”
To be skinny in a world predisposing us to eat lots of processed food and lead sedentary lifestyles requires a constant effort (for most, at least; there are lucky ones who just have low appetite or whatever) and to stay a good writer or good at algebra or conversant with Greek history also requires continuous effort, especially if your job and daily life don’t frequently draw on your knowledge of ancient Greece (I think most don’t).
Instead of wring our hands about how difficult it is to make kids retain what they learn, maybe we should be asking why it isn’t getting continually reinforced by what comes after, as it should be. And if the answer is “because it’s irrelevant to real life or anything else we want to teach these kids” then maybe we should rethink whether we want to teach that thing to everyone in the first place.
What strikes me as I read all this is a major and I think fundamental question that doesn’t seem to be addressed. Specifically, how much of the apparently low variation in teacher quality is based on who becomes teachers? I can see two factors here.
First, most states (AFAIK) have fairly similar requirements to obtain a teaching license, even if there may be some variation in e.g. PRAXIS scores that are required. Second, given how poorly teachers are paid in the United States and how dissatisfying the job can often be, doesn’t this suggest that it only draws more passionate people who are then going to be generally better teachers? In other words, if those who become teachers are generally of greater inherent teaching ability (because of some combination of passion for the job and minimum qualifications to get it), wouldn’t this suggest a high average quality of teachers, which would then mean that there wouldn’t be significant variations among them? Meaning if only the top 10% of people (by my admittedly-arbitrary “teacher quality” metric) even become teachers, then the variations we’re looking at are only among that 10% of people, rather than between something closer to 100%.
I also think we need to look at international comparisons. There are countries (e.g. in Scandinavia) where being a teacher is hugely competitive and pays extremely well (compared to many other places), and these countries tend to consistently outperform their counterparts. This despite often having shorter school days (but they also give more planning to the teachers, for example). You’d have to try to control for the socio-economic differences of the populace, naturally, but I think that too would go a long way to explaining the relatively low effects seen in these studies. If other countries’ teachers have demonstrably greater effects on their students, this suggests that there are other things going on in the U.S. and that the numbers we have so far are not the whole picture.
Are you arguing that US teachers should be better, because only the most driven choose that profession, or worse, because many otherwise good teachers pick other more lucrative careers?
Not really. My suggestion is that teachers are a self-selected group through a combination of specific standards required to get the job and the nature of the job (i.e. not lucrative with plenty of other quality of life issues), so similar people in terms of ability and training end up becoming teachers. In other words, the minimum “quality” of a teacher can only be but so low (at least on average), since the people who would be truly horrible at it by and large either can’t meet the basic requirements or decide to do something else. Sure, you’ll have some lousy ones end up there here and there, but when we look at large numbers their effects would be minuscule. This in turn would at least partially explain the lack of significant variation in results from one teacher to the next.
Say you’re getting ready to go to 5th grade, and you’ll end up getting one of two teachers. Both teachers had to choose that path, and they clearly didn’t do it because they wanted to get rich. They also had to graduate college (including successfully student teaching), and score well enough on the PRAXIS to become certified to teach in your state. This means that while their quality may vary, it won’t vary as much as it might absent all those requirements.
If just anyone could come in off the street and start teaching, the quality from one teacher to the next would vary wildly. But since that’s not the case, we’ve eliminated a large percentage of the population from possibly entering a classroom, meaning those that are left have greater amounts of training and academic credentials than the average. After all, only 30-35% of Americans even have college degrees, and only a subset of them become teachers (specifically, the people who choose to and who go on to receive specific training). So rather than having one teacher with 0 ability and another with 100 ability (using my arbitrary scale), you’re instead choosing between one teacher with 100 ability and another with 105.
So it makes sense to me that teachers’ influence is so small compared to their peers, simply because there’s a higher floor for teachers (in terms of qualifications), which in turn means less overall variation in ability. A one or two standard deviation difference in quality may not actually be that much, which in turn would explain the small effects.
“Second, given how poorly teachers are paid in the United States and how dissatisfying the job can often be, doesn’t this suggest that it only draws more passionate people who are then going to be generally better teachers?”
My memory from at the figures a few years ago is that teachers average less pay than college graduates in general, but not less than college graduates with the same level of academic qualifications. On average, college students majoring in education are towards the low end of the ability distribution.
I don’t know how one judges nonpecuniary effects. Teachers have the summer off–but may have to do work during the summer preparing for the next year. They often have tenure. If reasonably successful they spend most of the day as high status people relative to the kids they interact with. But I can see that, especially if unsuccessful, it could be a pretty unpleasant job.
Quite a different sample than teachers.
Attracting better employees by paying less. I like it. We should become business partners.
Haha, I do think it happens sometimes. But my thesis doesn’t require this to hold; all it requires is that the people who become teachers form a cohort with a sufficiently small amount of variation to account for some or all of the size of the effects being so small.
I heard that the last generation of teachers was probably smarter, because women had few opportunities and “teacher” was one of them, so women who might otherwise have become professors or researchers became teachers instead.
A lot of these studies were done in the 80s and early 90s (which is why their students are adults today), so I think they would have captured both that generation and the current generation, which should increase possible variance.
A few points:
In Scandinavia, students do not do better in spite of fewer hours in school, they do better because of fewer hours in school. Kids need that down time to process what they’ve learned and let it settle.
I know education isn’t really like filling a glass with water – but let us presume for a moment that it is. Have you noticed what happens when you turn on the faucet full blast to fill up a cup? If there is any pressure, it starts filling fast but then with the constant stream of water going in it never fills up – if you suddenly turn off the faucet you will find that the glass is only about half full – with all that roiling water, most of it just spilled out. People are like that when it comes to learning.
As for finding the best quality teachers – talking to actual teachers I’d say the best way to keep the good ones would be to let them have more control over what they teach in the classroom.
Right, I agree that fewer hours are an advantage. My point there was more to question how useful it is to try to understand differences among teachers under the current U.S. educational system, especially if they’re as small as the research suggests. Instead, I wonder if we wouldn’t get more use out of looking at more fundamental changes.
Scandinavian students don’t do well in international comparisons at present (with the exception of not-really-Scandinavian Finland, and even Finnish scores have sunk recently.) Sweden’s decline has been particularly bad:
http://www.oecd.org/sweden/sweden-should-urgently-reform-its-school-system-to-improve-quality-and-equity.htm
This is just nonsense. The Scandinavian countries do well because they’re filled with Scandinavians. And Finnish-Americans outperform Finns.
Partly true, but Finnish schools today do much better than Finnish schools 40 years ago, so teaching quality does make a difference.
I strongly suspect that a lot of the noise is itself caused by the fact that standardised tests do not test intelligence, but instead some proxy of it. (I’m in the UK, so I don’t know exactly what US standardised tests are, but I’m guessing they’re testing knowledge of a pre-specified syllabus, probably mostly literacy and numeracy).
The purpose of school is not to teach you facts, it’s to help you become more intelligent in general. You’re learning mostly useless facts now as practise for when you have to learn useful stuff later – in your case, no you didn’t remember any of the line dancing, but presumably having spent that time actively trying to get better at something helped for when you had a specific skill you needed to acquire. Teachers are mostly interested in actually trying to help children grow more intelligent, tests are measuring their ability to get children to pass the tests. They’re correlated but only weakly.
> The purpose of school is not to teach you facts, […]
It’s to keep you busy to let your parents earn a living?
Alternate explanation:
The purpose of school (one of them) is to allow you to demonstrate your innate ability by learning useless stuff. “Becoming more intelligent in general” does not seem to apply, given the apparent inflexibility of g.
This would seem to suggest that the thing that causes people to earn more money as adults is not the ability to do well on tests but some other skill or attitude which we can call, just for the hell of it, moxie. So if we were to hire and fire teachers based on test scores, it seems we would lose some great moxie-imbuing teachers while retaining moxie-deficient ones who will give kids the temporary skill to get better test scores but lead them to low-paying jobs. So if the purpose of school is to get students good salaries as adults (is that the purpose of school?) then VAM would seem counter-productive. Until someone can come up with a test for moxie, the whole idea of grading teachers seems to fall apart.
I blame my low-income on my sixth-grade teacher. He was my favorite teacher, and his class was the one in which I began to think I would like to make my living as a writer, and here I am, a starving writer. But perhaps by sixth grade it was already too late; this may be the fault of my kindergarten teacher for failing to give me the moxie that might have prevented me from getting out of better-paying occupations because I just wasn’t enjoying myself.
(I should probably tell my mom that my slacker lifestyle isn’t her fault at all, because she has had no influence on my life whatsoever. She’ll doubtless be relieved.)
When I was in middle and high school I was pretty sure we weren’t being sorted to teachers randomly. Kids who were put together were put there for a reason.
Of course thats a sample of 1 school, examined through the lens of 1 student, and then remembered, uhhhh, a lot of years later, so take it for what it’s worth (nothing).
I’d be willing to bet that my schools went to some effort to keep classes together between years, inasmuch as changes in requirements allowed it. One could imagine positive effects of that policy, but it would also tend to concentrate the effects of disruptive students, etc.
As someone who does the sorting at my school, I can assure you it is mostly non-random, though Scott’s summary is apt:
(Though I don’t personally think super-random is a good way to describe this)
We typically get ratings from teachers of how much time/attention students require, and try to evenly distribute high-need students across classes. We also get lists of which students shouldn’t be in classes with one another.
Then of course, there are times when a student’s combination of math/foreign-language forces them to take a particular set of classes.
Contra Nornagest’s intuition, we make no effort to keep classes together across years. And if one class got a reputation for being especially disruptive, we would make all the more effort to distribute those students as widely as possible.
The exception is if there’s only 3 students taking Klingon for their foreign language and on the super-advanced calculus track, and in orchestra, where only one section of each of those sections runs per day, you will likely be with those other 2 students for the rest of your life in nearly all your classes.
I have two kids. Aged 8 and 5. They are asleep when I leave in the morning and I get home at 6pm and they go to bed at 8:30pm. During this time they eat, do their homework and become sleepy.
Their teachers get them after breakfast for hours five days a week and send them home with pent up energy.
Sure, I get them on weekends, but we camp and do sports and grocery shopping and chores. Not exactly test score boosting.
Did you mean to mention certification twice?
It’s microhumour!
I notice that the “nurture doesn’t matter much” view is often used by people like Bryan Caplan to argue in favor of a laissez-faire approach: if your kids don’t like soccer, don’t make them go to soccer practice.
But couldn’t the opposite, Amy Chua view also hold true: if kids mostly turn out how they’re going to turn out and you’re not going to make them into happy adults by being nice to them, why not force them to learn to play three instruments and speak four languages? They’ll be glad they already put those hours in and have those skills once they’re adults, and, at least on the “you’re not likely to screw them up too badly with anything short of serious abuse” theory, not be any less well-adjusted than they would have been otherwise.
Plus, having skills seems a big contributor to adult happiness; both because they get you jobs and because people enjoy being able to play the piano. Arguably, having skills might even be a bigger contributor to adult happiness than the memory of a happy childhood?
Your second and third paragraphs seem to contradict the premise you lay out in the first paragraph.
Anyway, if *really* doesn’t much matter than it seems like laissez-faire would be more enjoyable. Unless, I guess, you enjoy the conflict and power tripping involved in the tiger parent method.
Part of what I’m getting at, I guess, is that it’s plausible that there’s no way to significantly improve your child’s general IQ, general tendency to be hardworking, general predisposition to being a criminal, etc.
But we know that there is a high correlation, between, say, taking piano lessons and being able to play the piano, or going to French school and being able to speak French.
I think right now there’s a sense that every child needs some kind of very general and vague education which will teach him or her “critical thinking” skills and make him or her a good citizen in a democracy, etc. but maybe critical thinking and good citizenship are precisely what we can’t teach, whereas we could be teaching children how to, e. g. do their taxes.
But we could find happy and successful adults that credit piano playing, being bilingual, lots of unstructured play, golf lessons, spending lots time with their grandparents, reading novels, or many other things growing up. Without some really strong evidence that piano mastery is head and shoulders above everything else I wouldn’t want to burn my daughter’s stuffed animals in front of her because she hasn’t mastered Für Elise.
I think schools should spend more time explicitly teaching students social skills. It used to be unnecessary because children didn’t have any other option other than socializing but with video games and the internet, more and more people are being left behind when younger and struggling to catch up later in life.
Schools can’t teach social skills. Social skills are learned by interacting with peers. Some students won’t learn for various reasons and will become the whipping posts for their more-skilled peers; you can simply cull most of those, because once the buttmonkey, always the buttmonkey.
Schools may not necessarily be capable of teaching sociality but they can force students in those situations. Some students won’t learn until they are forced in to social interaction. In this day and age, it’s easier to delay interacting with peers until you’re older. And trying to learn social skills when you’re 18 is a lot harder than when you’re 12.
Let’s say that once a day, students take 15 minutes to telecommunicate with a stranger from somewhere around the world. I bet that would be more beneficial than basically every other thing they learn at school.
Strangers elsewhere around the world aren’t peers, and that kind of interaction won’t foster development of in-person social skills. Getting the students to interact with each other will, but the buttmonkey problem is as inevitable as the Johnny who can’t learn to read; more so, in fact, as any sufficiently large group will have at least one buttmonkey by necessity and not just by statistics. The buttmonkey will learn only the skills necessary to being the buttmonkey, and will thence become the buttmonkey when dropped into any other group, but that’s just life.
And half the people on this board just shuddered.
The genre of “my childhood was shitty and therefore I’m on expert on childhood” never fails to disappoint.
If this wasn’t intended to apply to both sides of this debate, it certainly is a happy accident.
Personally, one of the things I hate about formal schooling is the artificial nature of the socialization it teaches.
In real life you don’t constantly interact with the same group of 20-40 people all your same age. You have to interact with kids, older people, people from different social classes and backgrounds (schools may have integrated racially, but they still tend to sort along such lines)…
This thing where you interact only with a small group of people your own age plus occasionally much older authority figures, imo, tends to create a “Lord of the Flies” sort of situation which is not only unpleasant for many, but also isn’t that useful for learning how to socialize as an adult.
Now that I think of it, one of the often cited disadvantages of homeschooling–that it doesn’t offer enough chance to socialize–may actually be an advantage from an adult perspective. As an adult, if you want to have friends outside your workplace, you need to actually make an effort–call people up, arrange activities, find groups who share your interests… it’s not much like high school where you just find the other jocks or goths or DnD nerds and hang out with them all the time by default.
@Anon
Let’s say that schools didn’t teach kids to read. Most people over an IQ of 100 learn anyways but many of those under average never bother. Then, when they become an adult they suddenly realize how important reading is in the real world and wish someone had taught them when they were younger so they don’t have to painstakingly go through that experience now. Would you simply dismiss their concerns or would you be more sympathetic?
Learning to speak multiple languages especially seems like something that could be useful in all sorts of ways, from potentially having more opportunities in work to having an easier time when traveling to foreign countries.
“You didn’t screw them up by making them less able to function in later life” is not the same as “you didn’t take away a lot of utility from them right now”.
A big part of it would be why bother forcing them to learn something like cello, that has very little real-world use, when you could instead be doing something fun with them?
I was forced to play the piano when I was a child, hated it, and having touched one in years and I couldn’t play it to save my life today. What purpose did that serve?
Learning to play the cello has little real-world use if you are not going to be a cellist or don’t like music in general, but how do you know which kids are going to love music and which aren’t unless they’re introduced to it?
Forcing people to stick with things they have no interest or aptitude in, beyond a certain introductory point where it’s “yeah I know it sucks but you have to learn grammar or basic maths”, is counter-productive and I agree it should not be done because you’re doing it out of some notion of snobbery or “it will help them to get on later in life”.
But schools introducing kids to a range of things from cookery to music to maths is all part of an education: not training kids to be good little worker drones, even if the drone-work is nowadays going to be coding instead of working on an assembly line.
The kids whose parents can afford or have a background in art and culture and museum trips and foreign languages will get exposure to those at home, but the kids who come from houses where there are no books and nobody has ever seen a picture on a higher level than velvet Elvis paintings, what about them?
For everyone here who says “I hated having to learn an instrument or I had no interest in art but I loved taking things apart, they should teach that and none of the fancy-pants stuff”, there’s someone who says “I had no idea about music or Shakespeare until I encountered it in school*”. If we start tinkering around with “you don’t need art or dance, you do need to keep grinding away at STEM”, then we’re not giving an education, we’re stuffing sausages for the consumption of the business world.
*I love reading. We had no books at home from a combination of no money to buy them and lack of interest. I used to scavenge old books mouldering in mildewed boxes or dusty cupboards in neighbours’ houses. Because I went to school in the days before “let’s teach Relevant Texts To The Youth in English class”, there were lots of books on the bookshelves, even if dusty and not read until I came along.
That’s how I got my first exposure to Shakespeare before having his work taught as part of the Official Curriculum (which I do admit can drain the life out of it) and how I developed my love of Dante (from a really comical, looking at it now, early 19th century translation into English by an Anglo-Irish Protestant who was so Low Church he footnoted all references to the Blessed Virgin as really meaning an allegory of Divine Mercy). That’s where I found Chesterton (to the regret of many of you, I’m sure, who have to put up with me flinging chunks of quotations at you) and McDonald and Lewis and a lot more.
If I was in a Modern Relevant No Frills No Old Stuff School, I’d have come out with nothing more than a middling qualification and no appreciation of anything in life higher than “get a job make money buy stuff”. I’ve never had any job that will make me rich or even reasonably well-off, but I’ve got more riches from poetry, art and music (even though I can’t sing or play an instrument) that make up for it.
My point wasn’t that cello, or the arts in general, shouldn’t be taught. On the contrary, I’m very much in favor of exposing your children to as many different things as you can. What I was getting at was that forcing your child to do something like play the cello at the expense of something different that they actually enjoy is counterproductive. How would you have felt if your parents thought all that reading you were doing was a waste of time, and instead forced you to go out and play football, even if you hated it.
I have a Chinese neighbor whose mother was a tiger parent. She’s a highly skilled professional and makes good money. She’s the most nervous person in the neighborhood though, as if she’s always terrified of being judged, even around very easygoing people.
I think there’s always a balance.
Personally, my mother tried to get me to learn some skills like playing piano – and it didn’t get very far. I learned how to play the piano … badly – and forgot. Later I learned how to play the trumpet … even worse – and later forgot. Neither did much for me. It wasn’t my interest. Only thing I play now is the radio.
My father never tried to get me to master any one skill, but he taught the basics of all sorts of skills. He taught me the basics of drafting and map reading and by bits and pieces taught me the basics of military thinking and military history (among other accomplishments he had attended the Army’s Command and General Staff College). He got me involved in the Boy Scouts and pushed me to earn a total of 66 merit badges, which is a great way to get an introduction to a lot of fields. At one point he got a friend to take me up in a small plane to teach me the basics of flying – and I never pursued it further but I have retained at some level some of the basics – a general knowledge, if you will.
There’s lots of people learning specialized knowledge, but my specialty became general knowledge, and I have continued it on my own. I’m pretty sure it has been more useful to the world than if I had wasted time on piano or art or the other sorts of things that parents like to impose on children but I wasn’t interested in – and though my knowledge in these fields is often fairly shallow I just turn the whole thing sideways and that shallowness becomes my depth – and I haven’t mentioned half of it.
One possible exception would be foreign languages, as that seems best learned in childhood – though in my case it is probably best I did not, as due to a rare quality of my brain I don’t decode spoken language well – even in my native English half of what I hear is guesswork based on what I think I should be hearing. I am very glad that my mother was NOT a tiger mom – not that she didn’t push me sometimes – she did – but that she cut me plenty of slack and gave me plenty of opportunities to learn on my own.
Forcing people to do things they have no aptitude for is cruelty. There’s a certain amount of “you have to do this, I don’t care if it’s boring or you don’t like it” that goes into child-rearing because you have to teach kids the basics of being a civilised human and that applies to education and general skills as well.
But forcing kids to do things because “this will help you get a better job” is not going to make the child love the piano or Italian. They’ll be less likely to play the piano for enjoyment once they’ve got the good job and no longer have to pretend to be cultured (they’ll probably be too busy early in their career putting in the long hours anyway to have time for such pursuits).
People play sports for enjoyment and health and social reasons, but that’s a very different attitude to professionals who make a living out of it. Do you think Serena Williams ‘enjoys’ tennis or plays a friendly few sets with a pal just for fun, who cares who wins? It’s a job and even if it’s their passion, it’s not going to be approached on the same level as someone who does it for the love of the thing.
Someone who was forced to learn an instrument or three languages or attend ballet class because “it’ll help you get on in life” is going to have a different approach to such than if they wanted to learn or found out they were good at it. It’ll be work for them, not something they do for pleasure.
Is making them do chores cruelty? Homework from classes they suck at?
Is it cruelty to make a person earn a living, even if they don’t have any particular aptitude for anything sellable?
It’s a lesser cruelty than letting them grow without usable skills but it’s still cruel. Just because the benefits are greater than the costs doesn’t mean you can ignore the costs and make no effort in minimizing them.
No, that’s what I said about “you have to make kids do things they don’t want to do”. Doing your homework, your chores and so on is part of it.
But making your kid learn the piano when they’re not musical, hate the instrument, and you’re only forcing them to take exams so you can boast about Jessie has Grade VI and she’s two grades ahead of the rest of the kids her age is cruel. You’re not teaching, you’re grinding sausage and you’re making the kid hate something they might otherwise get value from. If they learn to hate music now, they’re not likely to take it up later and that’s a source of human pleasure and enjoyment and intellectual stimulation lost to them. A child who can rattle off a piece by Brahms with correct technique but no interpretation because they loathe the composer, the instrument and the whole world of “grinding for exams” and are only doing this out of fear and compulsion has not been educated, they’ve been trained like a dancing bear.
A minimum amount of “you have to grind away at this boring task” belongs to everything in life, but after that, making your kids do what you want is not helping them.
I want to distinguish between chores and homework.
The chores are things that need doing, and it’s only fair that the kid, who benefits by lots of work done by other members of the family, should do some of them. That requirement isn’t for the kid’s good, and you (probably) don’t claim it is.
The homework, like the piano lessons, is something you are making the kid do because you claim it is good for him. The homework, like the piano lessons, might end up making the kid dislike what he is being compelled to learn and doesn’t want to learn. The only difference I can see is that you (Deiseach) presumably believe the homework is good for the kid and the piano lessons are not. But then your argument reduces to “you should only make kids do things that you think are good for them when they really are good for them,” which nobody is likely to disagree with but is a bit hard to implement.
If I had children I would actually force them to learn music and languages. Those skills seem much easier to learn as a child (and for most people impossible to learn as well as an adult).
However I would mostly take an unschooling approach with respect to academics. (beyond basic literacy).
You can force children to learn 3 instruments and 4 foreign languages, but if they don’t inherently* enjoy or have talent for it, then they probably won’t retain those skills as adults.
Take for example Scott’s story about he and his brother’s experiences with playing piano. In my personal experience, I played piano and saxophone, and I was pretty good at matching finger combinations to symbols on a sheet, but my half tonedeafness and complete lack of rythym put a big ceiling on my development. I doubt I could Happy Birthday on a piano today.
Why would improved teaching of third grade material result in higher scores on tests that measure material tought in fifth grade AT ALL?
Also, I’ll add my voice to the chorus saying that standardized tests don’t measure what we want to improve. My objection to the VAC principle isn’t the massive firings implied by the regime, it’s that we are creating an incentive gradient that leads to optimizing for tests scores at the expense of desired performance.
Why would improved teaching of third grade material result in higher scores on tests that measure material tought in fifth grade AT ALL?
I could understand it if it meant “when you are being introduced to the topic in third class, a good solid knowledge of the basics means that you are not trying to catch up in fifth class because you don’t really understand it, so you’re struggling with the more advanced material, and so because you are capable of understanding the more advanced material, you get better results on your tests”.
But that doesn’t seem to be what or how they’re measuring, so I have no idea how it works.
Why would improved teaching of third grade material result in higher scores on tests that measure material tought in fifth grade AT ALL?
Because learning depends, to an unappreciated extent, on existing knowledge. The more you know about a topic, the easier it will be to learn more pertaining to it.
That seems to provide both a strong basis for “you retain the improved learning forever” and “your year-over-year increases rapidly become dominated by the effects of next year’s teacher” and “teachers who get students who had large improvements last year have large improvements this year”, all of which were things that were observed. (The last a big oddly, where teachers in y+1 whose scores improved a lot were correlated with having students who in year n improved a lot)
Looking from the other direction, a bad teacher might persuade someone that he couldn’t or didn’t want to learn.
I had a really bad relationship with my grammar school maths teacher. In what is equivalent to the 9th grade, I had a “4” in maths (on the scale from 1 to 5, 1 being the best, 5 failing the class). Then I switched schools, hoped never to have to do maths again and for quite roundabout and questionable* reasons I ended up studying it at the university, eventually getting my master with a summa cum laude and deciding to continue with a PhD. I wonder how many people more talented than me (despite the good results in my master, I think I am still at best an average PhD student, there are definitely people a lot smarter than me around…also a lot more focused and less lazy 🙂 ) were discouraged by such teachers to study fields they would love to study and excel in . Or in the words of Paul Lockhart “I worry that the most talented mathematician of our time may be a waitress in Tulsa, Oklahoma who considers herself bad at math.”
*I did not have very good reasons to start studying maths at the university, I forgot why I actually did, but I think the main reason was that I knew people who applied, I knew the maths faculty carried a lot of prestige and I thought “I don’t want to end up worse than them”…the only good reason was that I really liked the stats class in my highschool (i.e. 10th-13th grade) because the teacher actually forced one to think which was not the case of most other classes)
Claim 1:
Claim 2:
It’s not a coincidence that these two things go together.
– – – – – – – – – –
In the mathematics classroom:
Method A: teach a set of templates that will be similar to the questions in the final exam.
Method B: use the minimum amount of rote learning needed to master basic techniques, then challenge the students with problems that mix up the techniques in different ways.
For motor learning (e.g. sport, playing a musical instrument, occupational therapy for relearning everyday movements after an injury):
Method A’: blocked practice. Do many repetitions of the first skill, then many repetitions of the second skill, and so on.
Method B’: randomised practice. Move between skills in unpredictable ways.
Students/patients find method A’ easier and more comfortable, and it’s less work for the teacher/trainer to implement, but there’s a body of evidence showing that method B’ leads to better retention. (Sorry that I don’t have citations to hand—it’s a few years since I studied this.)
For school subjects such as mathematics, I’m not aware of any serious research comparing long term retention for methods A and B. But I can make a fair guess as to which one leads to happier students (in the short term) and better teacher ratings, and which one is in the best interests (long term) of the students.
(See also previous discussion of standardised testing for engineers.)
– – – – – – – – – –
My conclusion: claim 1 isn’t something we should take for granted.
Scott, I appreciate the effort you put into compiling all this, and I wish reading had left me with a better feeling about education in our country.
I am biased against unions and particularly biased against unions for educated professionals, and largely view teacher’s unions as self-focused consumers of public funds and largess. I also am appalled by the various reports that show horrifically low literacy and math skill levels among graduates of public schools. And the accounts of teachers trying to manage disruptive, ill mannered students without the support of parents complete the triad of being sure that our system is broken.
This article of yours indicates that the situation is even worse than I thought – because we can’t even measure what we’re doing, so it remains impossible to assess the effect of changes, and thus any sustained positive progress would be so unlikely as to be a miracle.
Perhaps I should add a special mention of our education system to my evening petitions, as it appears logic and rationality aren’t getting us anywhere…
The blame doesn’t lay with unions, though. It lays with colleges of education, esp. those that produce k-6 teachers, and their emphasis on “whole language”, “discovery learning”, “inquiry-based science”, etc.
Some of those methods are good, and some not. Montessori methods emphasize discovery kinds of learning. And lots of talented hard working successful people went to Montessori schools.
http://www.dailymontessori.com/montessori-questions-answers/famous-montessori-educated-people/
Ok, suppose teachers really CAN influence performance and we institute incentives and “merit pay” – has someone considered how that in itself changes the teachers and the teaching profession/culture? Some unintended consequences maybe …
Would teaching at a school begin to resemble more closely the ruthless working environment at law/investment firms where people with sociopathic tendencies tend to outmaneuver everyone else? How many of those super VAM teachers will be attracted, thrive, or even remain in this environment?
One more thing – Goodhart’s Law will basically obliterate the usefulness of the indicators driving compensation.
It’s still going to select for people who can tolerate working with kids (and do it well) for most of the day regardless of how cutthroat competition is between teachers. I don’t think your average sharkish corporate lawyer would do a great job teaching kids algebra.
I think a more likely scenario is that making teacher pay more competitive (depending upon incentives) would attract more people who are at least somewhat inclined towards education in the first place.
I favor research on testing how much value is added by different teachers. But from being familiar with how long it took to make progress in analysis of sports statistics, it seems were probably a decade or more away from having a decent system.
And keep in mind that baseball statistics stem from achievements where for every 18 baseball players competing, there are 4 umpires (who together make over a million dollars a year) watching them like hawks. As a value-added analysis gets more common, so will attempts to game the metrics.
are there good value added metrics on pitching coaches?
Regarding the STAR experiment:
Suppose you look at the most disruptive students.
1. I strongly suspect that these students would themselves have lower achievement than the average
2. I strongly suspect these students will go on to earn less than the average
3. I think there’s a better than even (say, 70%) chance that the classmates of these students will learn and achieve slightly less than they otherwise would have
Thus 3 can predict 2 even in the absence of the student’s disruptive behaviour causing their classmates to earn less.
I’d like to see more anecdotes as a basis for finding out what to study– in particular, which teachers have made the most difference (good or bad) in people’s lives. My impression is that a small proportion of teachers have very large effects on some students.
Now that I think about it, I don’t have a feeling for what proportion of people have a teacher who made a big difference.
I’m not sure that people actually know one way or the other. I have very positive memories of two English teachers during high school that I credit with teaching me how to write decently. But in the counterfactual world where I had mediocre teachers instead perhaps I would still have gotten there. Maybe later on in life, but it’s hard to say what kind of difference that would have made.
I can think of a couple teachers who were very bad at teaching. One did not maintain discipline in his class and paid for it (though he learned, and became the ultimate hardass the next year); the other just didn’t understand kids. Both were intelligent and nice people.
I can think of some others who just weren’t particularly good, and some that were good, and a couple who were excellent.
But I can’t think of any that made a huge difference in my life. I expect that if any three teachers had been replaced by an average teacher, I would have turned out pretty much the same. But I can imagine that someone with a different family background could have had their life changed by one or two of those teachers.
I think the only teacher who made a big difference to me was my father. I’ve had some good teachers in school, but I don’t think I would have turned out much different as a result of one of them not being there.
I wonder if kids who ‘benefit’ from a better than average history teacher in classes t and t+1 but ‘lose’ from a worse than average math teacher in the same classes earn more than kids who have it the other way round. Or compared to kids who had ‘almost average’ history and math teachers. If the first earn more than the second and the third, I think it would support the theory with caveats.
Notes from the demand side:
Our local school provides convenient examples of the trends that are reinforcing teacher effectiveness via intensive parental involvement. Their goals appear to be threefold.
First, get more favorable attention for little Schnookums.
Second, get more of little Schnookums’s friends in the same class to reinforce socialization, homework coordination, playdates, carpools and the like.
Third, if you don’t get what you want in points First and Second above, then sue, or at least threaten to sue. Rinse and repeat for each grade.
Some of the more activist parents have taken the following steps to assure that their goals, and by proxy, those of their offspring, are met and exceeded. Here is how they do it.
Get to know the Principal, front office staff, district staff and teachers. Have them on speed dial.
Let them know that you are on the case for little Schnookums that you expect results.
Camp out in line starting at 4:00 am, or earlier as necessary, to secure the coveted spots for Kindergarten. Enlist your trusted allies to hold places, get coffee refills, etc.
(But don’t trust them too far since their kid represents a rival threat)
If you don’t get the teacher and classroom that you want, then escalate to get results. If that means suing to avoid being put into a portable classroom instead of a permanent structure, then do it, under the guise of concern about the distance to the bathrooms.
Volunteer in the classroom to make sure that Schnookums gets more attention. Also do that to remove or neutralize any kid that interferes with that attention, including having that kid go sit in the corner or hallway unless told not to.
Recognize that teachers are people with needs, and meet those. Arrange to bring in the teacher’s favorite latte, snacks, lunch and other treats. Pay for the teacher’s weekly mani-pedi appointments. Set up dates for single teachers.
Those are a few of my favorite observations about the current state of our local school. While greater parental involvement should be desirable, there comes a tipping point when things may go wrong. Perhaps your schools have less dysfunction.
The end results were different but I recognise the attitude from my own school, Ivy 🙂
We have (I should say “had” as I don’t work there anymore) the pupils who fall into the disadvantaged area category; not all of them, but a substantial minority have behavioural problems, are eligible for special needs assistants, come from troubled backgrounds, etc.
Where we got the screaming parents rushing in threatening physical violence, going to the local media (radio and newspapers) and going to sue us was over disciplinary methods. Anything that meant little Johnny or Mary got into trouble and the parent was being asked to be responsible was put down to prejudice (‘that teacher has it in for my child! they’re always picking on them!’), other kids being bullies, discrimination, ‘my Johnny or Mary never did anything wrong’, claims that Johnny threw a chair at the teacher met with counter-claims that the teacher hit Johnny beside the lockers (this is why we have CCTV in the corridors to prove that didn’t happen).
Not all the parents were like that; many of them were trying their best and co-operated with the school and got involved. But there is always that minority who will game the system to get their own way.
Seems to me that while ‘grit’ and ‘g’ may be substitutes in certain tasks (most especially schoolwork), they’re pretty much independent things. Very high ‘g’ and low ‘grit’ gets you a genius dilettante; very high ‘grit’ and low ‘g’ gets you a ‘hard worker’ in need of a lot of supervision. Very low ‘g’ and ‘grit’ gets you a bum. Very high ‘g’ and ‘grit’ gets you an eventual Nobel Prize winner or similar.
A contrary view comes from the old quotation about the clever and lazy being the best qualified for the highest leadership roles.
http://quoteinvestigator.com/2014/02/28/clever-lazy/
I think they’re not that contrary; I was trying for extremes, and further the original quote was referring to military officers. Someone high ‘grit’/low ‘g’ is probably a terrible officer, but might be fine in a position where they’re closely supervised. Someone very high g and low ‘grit’ but not so low as to give up at the slightest adversity might well be a very good officer.
Also see Heinlein, “The Tale of the Man Who Was Too Lazy to Fail” (summary here)
https://en.wikipedia.org/wiki/Time_Enough_for_Love#.22The_Tale_of_the_Man_Who_Was_Too_Lazy_to_Fail.22
And attribution of the general idea to efficiency expert Frank B. Gilbreth, Sr., circa 1920:
http://quoteinvestigator.com/2014/02/26/lazy-job/
I have found the concept applicable myself.
Today in my high school psychology class we started our developmental psychology unit, today we had a discussion on the classic ‘nature vs. nurture’. After reading SSC for 3 months and especially after learning about all the studies on genetics and environment’s measurable effects, the teacher seemed like he had absolutely no idea what he was talking about. Just about everything he said made me want to raise my hand and say, “but what about all these studies and data that seem to show that this whole thing is a million times more complicated than you are making it seem and there is actually a huge amount of disagreement among experts on these topics?” Also, Outliers (Malcolm Gladwell) was brought up way too many times as an example, and if that’s not bad enough no one–not even the teacher–could even restate the book’s conclusions correctly and pretty much completely mangled the original meanings of a book that is already questionably accurate.
@57dimensions:
Still in high school? Well, high school has taught you an important lesson that will be important throughout life:
Many of the persons who will be put in a position of authority over you will have no idea what they are doing or what they are talking about.
Of course, you will still have to deal with the fact that they have been placed in authority. Try to treat them gently – one day you may be in their place.
Yup, still in high school. It’s lunch period right now. But luckily I’m a senior and my last day is Friday.
I’ve definitely noticed this with many authority figures, but usually once I’m not under their direct control anymore. I volunteered at a local elementary school for two years, in a very good school district I should say, and wow it made me look at my school experience in a totally new way. The teacher was good for the most part, but she was barely holding the classroom together and enforced a lot of arbitrary rules. Also, she was always very short tempered with the 2nd graders, but perfectly nice to me, even though in reality I identified more strongly with the kids since it really wasn’t that long ago that I was in that position. I would have been terrified of her if I had had her as a teacher.
Also, hearing many of my mother’s anecdotes of her work experiences as a surgeon and interactions with hospital administration definitely affirmed the notion that people have no idea what they are doing.
And don’t worry, I’m sure I won’t have a problem treating them gently, my social anxiety around authority–no matter how informal–prevents me from being anything but deferential.
You’ll probably appreciate Steven Pinker’s review of Outliers
Haha thanks, it was great. I liked his books when I read them in middle school, but now some of his case studies seem to hold up far better than others. Thinking back, I think The Tipping Point is probably the best, since it doesn’t completely rely on very technical concepts that can’t easily be condensed for a pop-psychology book. Outliers had some good chapters that seemed reasonable, like the one about Canadian hockey players, but I am much more skeptical about his far reaching conclusions in others, especially since many of them rely on the back stories of individuals.
I had some thoughts, but ended up writing a post about it.
Thanks for posting the link to your post. I enjoyed reading it.
Very interesting post, education realist.
Taking myself as the only subject I have any direct experience of, I can say that in primary school (from Junior Infants to Sixth Class) had you measured my progress on reading and maths, it would have gone something like:
—————————————————-> Reading
————————-> Maths
And that would have been a false picture, because I could read before I started school at nearly five and was routinely reading the primers for classes one or two classes ahead all through (until Sixth Class when the rest ‘caught up’ and we were all more or less on the same ‘age appropriate’ level) while as the contents of the maths classes got more complex, I think I was going backwards (as I’ve said before, I had to learn long division from my grandmother as I could NOT learn it the way it was taught in class).
So a truer picture of my progress would have been:
Base rate reading ability:
———————————————->
Progress between when I started and when I finished primary school, e.g. what I (feel I) learned:
——–>
Base rate maths ability:
——–>
Progress between when I started and finished:
<————————— (yes, that is going backwards; I fell behind more and more on comprehension and was grimly simply rote-learning off the methods and plugging in the numbers without knowing what the hell I was doing, because I’m pretty sure I’m dyscalculic only that wasn’t around as a diagnosis in my day, no more than dyslexia: you were either stupid or lazy, and since I had no trouble with other subjects I couldn’t be stupid so I got tagged as “lazy” and nagged, badgered and blamed for Not Doing The Work Because You’re Bone-Idle)
So how fair would it be to compare my reading progress (as measure by innate ability rather than what I’d learned) and my maths progress and average them out and then judge the teachers by the score results?
I can also see why secondary schools measure “proficiency” rather than “what level do you read at?” because apart from those who do read at “third grade/sixth grade” levels, you have a class that is broadly all at the same ‘age appropriate’ level and you can take two pupils and have them read out the same piece of prose. One will do it slowly, reluctantly, stumbling over pronunciation of some of the words and bored out of their mind while another will do it easily and fluently and with understanding, but they both are able to read the piece without mistake or missing words. So how else do you measure progress other than on comprehension of the topic, ability to write an essay, parse the piece, etc.?
Nothing odd about the case you describe at all; it’s a known issue that has been thoroughly discussed. It leads to teachers in top schools with 100% of kids above average getting terrible VAM scores because only 86% instead of 92% of the kids hit their expected target–and that was because they were at 100% the year before, and were at 98% the next year. When in fact, that’s almost certainly due to test variances. (In some states, the third grade reading test is notably harder than the second grade’s, for example.)
Everyone, now that you’re at the end of this, at around 1 0 a.m. on May 19, Baconbacon had a great post about some of the power politics of schools that can make it totally nonsensical to try to test students for the purpose of determining teacher competence.
It seems that in every problem where a system is involved, it’s essential to look at the power politics. This makes it hard to do accurate research on systems. Who is going to trust some stranger researcher enough, that they will make themselves vulnerable, by telling the researcher sensitive information about power politics in the system? No one.
However, in many systems, the people with the most power, seniority etc. may be able to pull in all the systems rewards to themselves, while punishing people of lower status. And the “competent” label and/or promotions or salary increases, or even keeping their jobs while others lose them– these are all rewards. And the high status people often have the power to “tilt the board” their way, so that all of the rewards slide directly into their own laps and others get nothing.
I greatly enjoy this and other comments about where the rubber hits the road– where people have direct experience as teachers or teacher’s aides, or parents.
I’m not remembering now who made the recent comment about the schools bending over backward to please demanding parents– who were not demanding a learning experience for “Little Schnookums.” They were just demanding more attention for “Little Schnookums” and for him or her to get their own way, from the teacher and the school.
Oh, here it is. Ivy’s post, not far above. May 20, 101 p.m.
>In summary: teacher quality probably explains 10% of the variation in same-year test scores
The interesting question is what happens when you pile that 10% gain on year after year. Is your return the same? Diminishing? Increasing? I can see plausible arguments for all 3.
It may be that the most successful teachers by the metric of how much students earn later in life are the ones who were the least successful at beating the initiative out of their students by turning them into desk-sitting robots.
It may also be that kindergarten and first grade are by far the most critical time for students because that’s when they learn basic literacy, and students who fall behind at that stay behind at it forever. When I was in elementary school it seemed that the only things school really taught were basic literacy and arithmetic. But then I had a typing class in junior high which was very helpful, so now I think the only things early education really teaches are literacy, arithmetic, and touch typing.
I think, on average, the desk-sitting robots end up making more than the laying-about-on-a-friend’s-couch robots.
Training to be a desk-sitting robot is an effective prelude to being a laying-about-on-a-friend’s-couch robot.
So here’s my batshit theory:
– Humans have an innate competence factor or quotient. Let’s call it CQ for now.
– CQ is not a combination of wotgher factors – it is itself an elemental than influences all other things
– Spending time around competent individuals, no matter what it is they are doing or how they are interacting with you (if at all), causes that competence to rub off
– More competent teachers in school impart their competence, and the more years under a competent teacher (or master), the more competent each child will be in adulthood
This is what I guess all those studies are aiming at. Perhaps high CQ individuals can naturally figure out effective behaviours and habits (ie they have the ability to create, assess and switch between functional and coherent systems of behavior) – these habits can then be copied by others, even if they lack the nouse to figure them out themselves.
(parents naturally have similar CQ levels to their children, and will have similar habits so there won’t be as drastic or dynamising a gain from the child copying them as they would an adult with differing skills, hence why 20-odd years of parenting can matter less than a year under a good teacher)
Interesting. Apparently your CQ is not genetic, or else it could not rub off from one person onto another. Maybe this is something that is role modeled to kids or others, and then they pick it up.
Thinking about your theory makes me wish there were more people on TV, on the Internet, in movies etc. who were better role models, since these folks are the most observed people– not flesh and blood humans.
I’m not entirely sure how you read “innate” as not genetic, but alright. As explained towards the end of the post, high CQ individuals naturally figure out effective techniques and devise functional measures to resolve situations. Any human with an able body and brain could copy these means, but only a high CQ individual could naturally develop them. Ergo an individual’s day-to-day competency rises with every year they spend interacting with/learning from/watching a higher CQ.
As for tv role models, it’s just another example of how malincentivised our society has become. The best way for cheap tv networks to rake in mad dough is to appeal to the lowest denominator, and that entails putting scum on a pedastal.
Yes, I see that you think there’s a genetic component to this. I think it’s possible it could be primarily environmental though.
The difference between a child who has constructive role models in the home and the one who does not have them is very large. To develop naturally, in a constructive way, requires some support. If the parents aren’t providing that, but the teacher is, the skills will, of course, be developed more slowly that if the child has constructive role models both at home and school. If so, the slow development is not caused by lack of innate ability.
It states right in the opening sentence that it’s “innate”. There’s no room for interpretation here. If you want to make a similar batshit theory where CQ or whatever is cultural, by all means, but understand that’s not what I’m saying nor is it integrated in my batshit theory. In the lexica I’ve developed, Competence and CQ are different things, and although competence can be gained from others, the amount of competence that may be imparted is capped by CQ.
That aside: yes, the crux is that no matter how much input (or competence-imprinting) the parents perform for their child, they will always have more competence to acquire if they also have a teacher. The higher CQ this teacher, the swifter and greater the impact.
Wait, what? TV characters are almost uniformly hypercompetent outside of sitcoms. Just look at all the crime procedurals.
So I’ve seen a few things suggesting that disruptive students are very harmful to their peers’ education. If so, wouldn’t an important educational intervention be to identify disruptive students quickly and remove them from the classroom?
If you can find a way to help them to fit in and not be disruptive, that would be better. But sometimes that may not be possible.
This is a super thorny area of contention. Removing disruptive students quickly might do the greatest good for the greatest number, but the disrupters also need an education and have rights, and, fairly or unfairly, skew more towards minority demographics.
“but the disrupters also need an education and have rights”
At some point, does their disruptive activity change what their rights entitle them to?
We believe people have a right to life–but it’s still legal to execute murderers or kill in self defense. Do you want to argue that someone who goes out of his way to make it hard to educate him is entitled to have additional resources spent on his education to compensate?
He’s a kid. Whether he goes out of his way to make it harder to educate him is irrelevant; he’s not fully responsible for his own actions, on account of being a kid.
I think people give up quickly, or at least too easily, on trying to heal the disrupters. The book I mentioned before, The Body Takes Score, has some interesting ideas which I hope more research will be done on, on how to help “problem” kids, many of whom have apparently been abused or neglected at home.
I know it’s convenient for some to assume that every 7 year old is totally responsible for their own actions. But it makes a difference what their home environment is like– a LOT of difference. So mental health services and other kinds of help for “problem” kids are a must. Not in every case will they be able to be helped, but this should be a big priority, especially since they disrupt not only their own education, but that of their classmates.
Do you want to argue that someone who goes out of his way to make it hard to educate him is entitled to have additional resources spent on his education to compensate?
Depending on their age and circumstances. I know there was one kid at the school where I worked who was very disruptive and seemed to be getting away with murder, to the point where I was “why the hell don’t they just expel him?” and his parent didn’t help (they would turn up and defend him no matter what he did and put all the blame on teachers out to get him).
Then when he graduated (as was pretty inevitable) to the Early School leavers’ Programme I also worked at, I saw the other side of the coin. He had behavioural and anger management issues which were not being addressed, he was easy to manipulate, his parent had had another child in the meantime and had dropped all interest and attention in him and he was left floundering with no means of coping, so my attitude did change: he wasn’t being disruptive because he was a jerk, but because it was the only way he knew to get attention from his parent, and he had no coping skills apart from whatever he would be taught in school as to how to deal with pressure, stress, the expectations of a routine, and self-discipline.
So that was a case where effective intervention early would have helped a lot more, but parental interference (as long as it suited the parent) blocked all efforts.
There was another kid who was sly and manipulative who used to use this kid as a cat’s paw; wind him up, set him off, and sit back and enjoy the chaos. He was the one I rather vindictively hoped would end up in prison, I have to admit.
It’s not just that, it’s that if schools are ranked and funded on test results, the lesser-achieving pupils will drag down the test scores.
So you don’t want them to do the tests at a higher level, maybe you don’t want them to do the tests at all. Letting Jonny sit an exam where he only gets a D or a C will cost you money, whereas if only Susie, who is guaranteed to get an A, sits the exam you are better off. So you discourage them from sitting exams, which means they don’t get qualifications and that has a knock-on effect. Maybe you can expel them and let some other school take the responsibility for educating them. If you’re the last school in the chain and you have to take them (there’s a legal requirement that they be educated and if the parents are going to be fined/run the risk of imprisonment for not sending kids to school, they’ll force you to take them), what do you do with them if you don’t have the resources to teach special needs/behavioural problems?
If they’re simply shunted off to a spare classroom where all they do is play video games or surf the Internet and pass the time until they can legally leave school and not be your responsibility anymore, that has a social cost as well as a personal cost to the pupils themselves.
There’s a false dichotomy between “we need to evaluate teachers and fire them based on a single, easily quantified metric” and “we need to maintain the current system where teachers can’t be fired for any reason.” I bet if you tried to quantify most workers’ productivity, you would have as much difficulty as you do with teachers in all but the simplest jobs. And yet, businesses manage to figure out who to hire and fire largely without metrics like VAM.
I think the issue is that most of the information is lost when converted into a standardized metric. A principal knows about standardized test scores, but he also knows how many parents are complaining, what sorts of complaints they’re making and whether those complaint are valid, whose students are having the most behaviour issues, who shows up late or takes excessive sick days, who goes above and beyond to teach, and so on. VAM reduces all that to just the test scores.
The solution is to give each school an incentive to serve their customers and the autonomy to decide the best way to do so. You know, like the businesses in practically every other industry besides schooling.
The thing about the education system is it’s rotten through and through. The teachers unions have rules which give them lifetime tenure and they claim are necessary to protect them from short-sighted scheming evil adminstrators? Well, maybe those rules aren’t so great, but the administrations are as about as bad as they say. So give the principals full latitude and you’ll probably end up with the best buttkissers instead of the best teachers.
Completely agree. But that’s under the current system where administrators are bureaucrats rather than entrepreneurs with a personal financial stake in the success of the school.
Interesting. Maybe it’s the principals and other school administrators that are most in need of evaluation. It seems they often pile the problem kids onto the new hire teachers and then don’t give them any help or support in dealing with them. Just a baptism by fire.
I think of companies I deal with by phone where I keep getting asked to do an online feedback survey about the low level employee I dealt with. The low level employees seem to be doing the best they can, but the system itself is screwed up.
It’s the higher level folks who make the system dysfunction like it does, and who don’t train any of the low level employees to do their jobs well, and who don’t give them the info they need to handle my requests. It’s these higher level folks who need to be evaluated– and fired, if they are unwilling or unable to do a better job of getting the system to function well for its customers.
That’s something about research– a hidden agenda in the questions one asks. Why not ask the basic questions first. E.g. what is the purpose of a school? How could you tell whether it was functioning well? Which school employees– or maybe the school board– should be observed or evaluated– and in what way– to find out whether the school is functioning well, and how it could function better.
And where’s the power to make or change the way the school functions or malfunctions? And if it’s functioning badly, why? And where is the dysfunction located? Maybe it’s even in the parents’ unrealistic demands. Or maybe it’s in the home life of the children, who live in such a chaotic or abusive environment that it drains their capacity to learn at school.
There are tons of possible questions besides “How can we hire and fire teachers in a way that results in higher scores for the students on standardized tests?”
Or maybe it’s in the home life of the children, who live in such a chaotic or abusive environment that it drains their capacity to learn at school.
The Breakfast Club is not just a brat pack movie.
The school where I worked runs one:
If you can’t even guarantee that all the children starting class in the morning have had something to eat, I don’t think “hire and fire teachers on the test results of those kids” is much of a good sorting mechanism.
Possible idea: Apply meta-VAM to principals, where they’re given a numeric score on the median VAM improvements of the teachers.
Or maybe “privatize” the schools by letting the parents freely choose and make school funding a linear function of the student count. Then we wouldn’t need to bother with all these questionable metrics.
Or maybe “privatize” the schools by letting the parents freely choose and make school funding a linear function of the student count.
This sounds basically the “school of choice” system that Michigan uses. I imagine it’s an improvement on having students stuck in the school they happen to be closest to, but it’s not a panacea. (For starters, parents select based on things like athletic facilities, which is fine, but it’s not necessarily the best way to improve academic results.)
make school funding a linear function of the student count
Then you have three hundred parents fighting each other for their kids to get the first fifty places in School A which has the great results, and School J which is where the kids with special needs/behavioural difficulties go is a sinkhole because (a) my kid isn’t going there, it’s a dump, so screw them I’m not paying to support them (b) smaller numbers attending mean lower capitation grants (or however it is funded) (c) government, whether local or national, isn’t going to throw money at poorer/disadvantaged areas unless they’re required to legally (some parent or group of parents brings a test case to force them to provide funding and resources) or there’s a huge massive media campaign about “the next generation of loser kids is growing up, Somebody Should Do Something” (d) because it has the reputation of being a dumping ground for the losers and troublemakers, you can’t attract the good teachers who know they’ll be able to walk into a job at School A where the cream of the crop go, and since the cream do well on tests which means the teacher gets rewarded commensurately, it makes sense to go where the money (and lack of risk of getting things including chairs thrown at you, being verbally and physically assaulted, etc) is
Unhappily, there is no simple easy single answer.
Man, 100% of this just makes me want to scream and burn down the entire school system and replace it with something better and never use standardised testing ever again. 🙁
One question I have to ask is whether or not perhaps the metrics being used are misguided to begin with. We know that IQ and g are not really very easy to change. Many of these tests are heavily g-loaded. But we aren’t actually trying to improve g or IQ in school, we’re trying to teach skills.
Another entirely reasonable reading of the results is simply that the test for any given year tests you on the skills you were supposed to acquire in that year. A good teacher does a good job with this; a bad one does a poor job with this. The benefits of those skills on future standardized tests diminish because they aren’t heavily tested in the future (and the effects of a bad teacher diminish for the same reason), but you have still acquired those skills. Later on in life, when you are called upon to use those skills, you can use them, if you were taught them well.
Thus, you’d see someone benefiting in the long term despite their scores not changing, because the tests are g-loaded and are intended to test skills acquired from this year of school, while the actual skills taught in previous years are retained and used later on.
I suspect if you instead gave people a comprehensive test of all skills they had acquired, rather than the skills expected from any given year, you’d see a larger effect from the early good teachers on the sections which taught those particular skills.
Thus, having a particularly good kindergarten teacher making a big difference later on down the line because they teach a lot of basic human interaction stuff in kindergarten makes sense – that’s not stuff that shows up on later tests, but it is certainly relevant.
I think if you start trying to compile a list of skills that a) you learned/used in fourth grade, b) you did not use in 5th grade, c) you recall well at 25, and d) are relevant to your adult life outcomes, you are going to have list that is really, really short. I’m not willing to boldly assert it, but I’m guessing it is zero.
Assuming the research is correct, whatever the teacher imparted needs have been “used” going forward, because it’s not just going to pop back up 15 years later, but not have an impact on academic performance after two years.
I will also say, that having been exposed to great teachers, my motivation to excel in poor teachers classrooms was lower. That’s another possible mechanism of affect. You know how to do better, but you choose not to when exposed to a poor(er) teacher. Not sure if I buy that, though.
Hey. I’ll admit I read the beginning and end and not the middle ( I wanted more graphs.)
Note on the end. Do you mean 50-50 on whether this is a real effect. I assume you are just using it as a proxy for I don’t know. You might find it interesting to ask yourself which way you would bet on an even bet as a way of refining your I don’t know a little. The superforecasting book has some good points about how people use 50-50 to mean I don’t know, and that refining a little is a great way to be clearer about your expectations and beliefs.
Tom
I think it’s easy for people who have “won the environmental lottery”– i.e. people who grew up in fairly safe homes with parents who were decent role models in most ways– to think that differences among kids are mostly genetic. But it makes a huge difference if a kid has been abused or neglected, e.g. if their only parent at home is a drug addict.
It’s also easy if you have “won the environmental lottery” to expect every kid to act responsibly, and to imagine that every kid in the same class has the same ability to follow instructions and be reasonably calm. If they’ve got PTSD from abuse experiences, they may have much lower abilities than the average kid in their class. And it may have nothing to do with genetics at all, or with a choice to act irresponsibly.
Also, a fetus having heavy amounts of cocaine or alcohol in the womb, is, of course, environmental, not genetic. And there, the damage done may be irreversible, making the idea of “responsibility” fairly meaningless.
These kids should get evaluated, and if the means to evaluate them accurately isn’t yet available, research should be done to develop a new method. If the disrupter’s dysfunction is irreversible, they should be in a separate class, with a teacher who is trained to handle this. And if it is reversible, of course you want to determine that and to determine what treatment method would help them to heal from trauma if they had trauma, and also help them to function better.
It’s awful that, in some schools, disrupter kids are shoved into the most inexperienced teachers’ classes, because those teachers don’t have the seniority to demand an easy class. And there the kids stress out the new teacher, who has no clue about how to handle them, and disrupts the learning of all the other students in the class.
The new teachers, the disrupter students, and the whole class are screwed over then, while they take their standardized tests. And the tests then “prove” that the more experienced teachers, who demanded and got a class without any disrupter students, are the best teachers– since their kids score the highest.
Let’s say that it is found – or, worse, perceived – that getting put in the “normal” class benefits the disruptive student. We know, however, that it also harms the other students, who get disrupted. Do you:
A) Sacrifice the disruptive students.
B) Sacrifice the non-disruptive students.
(Correct answer: http://pastebin.com/M0H1YEQA)
I read your “correct answer.” What I wonder about is the motivation for that answer. What if the school officials or researchers make up date that supposedly shows that normal kids benefit from being in a classroom with disrupters? Why would they do this?
What would be the point of making sure disruptive students stay in the classrooms with normal students, thus disrupting their education? Would it be so the school can save money? And/or would it be all about power politics i.e. since the low status new teachers can be saddled with the disrupters, and the higher power teachers can get all easy to teach students? So that the higher power folks (including administrators) like it that way, and keep it that way, and fail to see any problem?
Disruptive students are disproportionately likely to be minorities. Making them stay in the classroom prevents the school from being accused of racism.
Any evidence, or is a statement like that supposed to be self-evident?
@Anonymous:
Common knowledge. But google “minorities suspended” if you want to sample some of the reporting about it. Reports about it hit the education news sections regularly.
I’m always amazed at the fact that the abused / malnourished child population is always not really emphasized all that much when talking about these things. Like, even if everything is 100 percent of outcome differences for children who are not seriously abused, genetic, we can hardly call ourselves an equal opportunity society, (and this question of equality of opportunity really seems to be a big subtext in these type of debates) since our foster care situation is so abysmal, and minors really have no legal mechanism to press for their rights, unless they have a benevolent guardian.
I mean, I suppose in the scheme of things it is a relatively small population (or is it? I have no idea, except abusing your child and getting away with it seems like it would be extremely easy thing to do) there is an interview on youtube on a psychopath talking about how he basically planned and groomed his daughter for being OK with being repeatedly raped. I’m not sure the origin or authenticity of it, but it is quite disturbing. He also was probably caught if he’s having an interview about it, but perhaps it not?
Also when people say none abused children, how is the line between abuse and bad parenting drawn? I could see abuse being defined as a huge population or a relatively small one.
Child abuse is not uncommon at all, in the U.S. and elsewhere, unfortunately.
https://en.wikipedia.org/wiki/Child_abuse
The earning more money without having higher test scores seems to fit with the signaling model of education.
If signaling is all that matters, or most of what matters, the fact that you got a slightly higher test score should help you earn money even if you forget everything on the test / don’t perform better on future tests.
Who exactly is picking up whatever signals are given off from a kindergarten assessment test?
First grade teachers?
Don’t imagine the effect is very big after twelve more iterations of Telephone, though.
Looking at the teaching situation as one example of a larger issue, this may be one more case of how American society is fairly blind to power relationships. We are constantly deciding to solve problems with engineering type solutions, when the problem really lies in power politics relationships.
If the system is effed up due to powerful people “tilting the game board” so that the rewards fall only into their laps and not into others’ laps, there’s no point in attempting to manipulate the (e.g. education) game board pieces in various ways– and expecting that that will cause a more successful outcome for the overall system. If you are ignoring the fact that the board has been tilted, you are pretty clueless about what you’re doing here.
If disrupter kids are shoved into the most inexperienced teachers’ classes, because those teachers don’t have the power of seniority to demand a class of all easy-to-teach students, engineering solutions won’t work. E.g. testing students, and then firing teachers whose students score poorly, is not going to help anything at all. It will likely make the problems worse.
While the researchers are busy trying to devise a system to hire and keep the best teachers, what’s really happening is that the high status senior teachers are finding and keeping the best students, who score the highest on the researchers’ tests. So the result of the research is to intensify the problems of the system.
You have a system where “Them that has, gits”, and then you do research that converts it to a system of “Them that has, gits even more.”
A typo in the last section: “This decays quickly with time and is probably disappears entirely …”
I think you should be able to test in the data whether it is plausible that disruptive children are contributing meaningfully to the variance in teacher quality. If this theory is right, you should observe auto-correlation in teacher quality experienced by individual students across years. I.E. disruptors will tend to bring down all the teachers they get, so you will see more students than randomness would imply get “unlucky” teacher assignments. No?
Is the data public?
I volunteer my son to drop into a classroom to find out the effect of disruptive children. Someone else’s kid will need to be the control.
“value of good teachers”? Nonsense. Everyone knows that teachers only want money money money, and that’s why the settle for 30, 50 or maybe 70 grand a year, because they’re completely incompetent and they could never possibly make more than that. (This is orthodoxy in certain right wing circles, no?)
To be clear on the meaning of how much variance is explained by teachers … variance means variances. In the absence of teachers, or a really horrible or amazing teacher, it can explain a lot more. Not sure? Try giving them a monkey as a teacher for a year and see how much of variance is explained by that.
He mentions 40% genetic effects. The issue might be this. Is the genetic association that the kid is lazy and stupid, or that they give “crazy and creative answer” instead of just regurgitating whatever they’re told? In a standardized testing environment, a 100% score tells you the student is good at regurgitation, but perhaps nothing about whether they can ever do anything novel on their own. And, for that matter, such types are presumably useless, due to excessive conformity, in the eventuality that a revolution or social movement might be needed.
I think the main reason for rapid decay is that learning is additive. So … you mastered grade 3 math like there’s no tomorrow. What good is that for doing better in grade 5 math? You still need another good teacher. I bet the effect is worse in the other direction though. If you cannot master grade 3 math, then grade 4 math might be tough no matter what, and you might prefer to spend math class watching the lights flicker.
Finally, there is no consideration of the dangers of “teaching to the test”. So … teachers who want bonuses need perfect recall on curriculum. So they take short cuts that will achieve good results THIS YEAR at a cost to more general abilities to think. I’m lucky. I teach in China, where standardized tests are one of the main ways to evaluate teachers. But foreign teachers aren’t subject to this. So I’m probably the only teacher any of the students will ever get who can disregard half of the learning objectives of the year to focus on things like good study habits, finding personalized ways to learning, general motivational stuff, etc. Is it my right to do so? I guess someone will make some noise if it bothers them. Next year I’m changing subjects and standardized test performance will be key. I’m not looking forward to the change. I will have to focus 100% on passing THAT ONE TEST, no matter the cost for longer-term learning or cognitive abilities. Fuck it. I’ll try to do both and tell the students exactly why and how I will try.
Oh dear, being linked to by Marginal Revolution was not a good thing.
We’ve already been infected with E Harding and Steve Sailor, Nathan W was only a matter of time. At least we probably won’t have to worry about prior_approval since Scott has nothing to do with the Mercatus Center.
Not that I was angry, but Cowan has his “stop read” moment and I stopped here (2nd paragraph):
Please don’t misunderstand my stopping for anger, only want to insert that the test score example is bogus. Teacher 1 instructs twenty children tracked for low-achieving math while Teacher 2 instructs twenty high-achieving students. Teacher 2 is judged as the better teacher every time by the numbers. Teacher 1 is, in the mean time, getting 12 students to pass when only 7 had a shot to begin with.
There is nothing more predictive in testing performance than average tax assessment value of homes in a given district. When this is reality: good teaching is best determined by Justice Potter Stewart’s judgment on the obscene.
Perhaps the best way to resolve this issue would be to track the same group of Kindergartners through to grade twelve. I’ll apologize here, because I am an English educator not a statistician. You could then make predictions of future performance based upon their performance on assessments pre-dating their first introduction to standardized tests and measure the prediction against actual performance. When you see a jump:
-Part of the jump could be maturity (which is slightly informed by teaching)
-Part of the jump could be developmental (I feel as if maturity and development are discernible)
-Part of the jump could be teacher oriented
For the third, you’d have to control for five hundred variables (that is hyperbole for a lot, and I’m not sure where to begin enumerating them). Only once you run through a statistically relevant number of sets would you then begin to make a crack at measuring effective instruction.
By that time, you have to deal with teacher turnover and natural attrition because before you’d have four graduating classes nearly a two decades would have passed.
The twin idea is much better than mine; however, like you, I will not deny the efficacy of parenting.
Am I completely off base because I’m a bitter teacher?
Reasonably convincing until here. Your prior about kindergarten teachers and parents is totally backwards. Kids spend most of their day with their teachers, who are actively focused on creating an environment conducive to learning (i.e. focused on behavioral issues), far more than they are focused on teaching. Sure, teachers claim that teaching is about learning academic subjects, but the early years are primarily about learning about how school works, i.e. how the system works, i.e. appropriate behavior. Kids spend relatively little time with parents, mostly when the kids are tired or, on weekends, when the parents are. As they get older, parents get kids into structured activities, and kids thus spend even less time with parents. Of course parents have little influence.