
[Warning: The following post contains statistics done at 4 AM and not double-checked.]
By far the most interesting result from my utility and QALY survey earlier was the striking last name imbalance in readers of this blog. 93 people took the survey intended for people A-M, versus 34 for the N-Zs.
American last names begin with A-M 62% of the time (most of the imbalance is in M; I blame the Scots and Irish). StatTrek informs me that a 62% balance giving me results at least as lopsided as 93-34 should happen by chance only 0.5% of the time. Perhaps people just took the first survey no matter what their name was? Maybe they were turned off by the somewhat more complicated instructions on the second survey? It seems to be a mystery.
(as, indeed, is why about 85% of respondents came from Juneau, Alaska. Must be one of those coincidences :P)
I would like to think the survey showed that most people are pretty anti-death. The survey with death as the floor didn’t give great evidence for that, since I specifically told them to act as if death was a good floor in order to judge other things properly. But in the version with prison as the floor people consistently rated death significantly worse than states like prison, being in a starving African country, or being in North Korea. The survey was not really aimed at discussing death or suicide, so I would like to think it was less about signaling than some direct reports might be.
The next most interesting result was in the Relationship question. Single people consistently said a relationship would be about 1.54x better than their current single life, but people in a relationship estimated singlehood would only be about .85x as good as their current life; these numbers are obviously not reciprocals of each other. I blame myself; in the wording of the question, I asked single people to imagine a relationship with their “ideal” partner. For anyone with a remotely good imagination, this is a very desirable state. People in real relationships, even very happy relationships, probably can’t live up to that “ideal partner” standard, so it may be rational for these numbers to be different and not a sign of bias at all. On a similar note, men expected that women have significantly lower quality of life, but women did not expect men to have significantly higher quality of life; this failure of matched reciprocals seems much less excusable.
But what about the utility calculations? This was a mix of good and bad news.
The three methods of determining utility correlated extremely haphazardly with one another. Sometimes they would correlate as high as .7 or .8, other times not at all. There seemed to be no pattern to on what questions they would correlate, nor to which of the three would correlate best with which other of the three methods. The best I can say is that correlations between the three methods on the same question always seemed higher than correlations between different questions, which is good, I guess.
But once they were averaged out, they came up with remarkably consistent results. The lists of averages on each method correlated with the lists of averages of both other methods at > 0.9 level.
There was a very wide range of answers on each question; even something as uncontroversially bad as blindness would get utility weights of anywhere from 0.1 to 0.9. The standard deviations, once each question was standardized to be between 0 and 1, were pretty consistently around 0.2.
But most people had very similar preference orderings, and most people agreed on which things were only mildly bad (only tiny deviations from 1) versus worse. I feel like although the data were very noisy, there was also a very real signal in there.
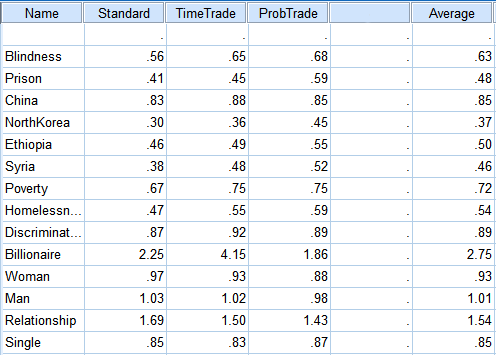
Another encouraging fact is that even with different floors, the people on Survey 1 and the people on Survey 2 came up with almost the same results once they were adjusted onto compatible scales:
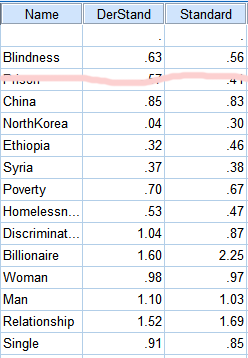
Last point. I put “blindness” on there because many people in health research have studied the negative utility of blindness and I wanted to see if this test, amateurish and haphazard as it was, would get the same results they did (which might in turn legitimize some of its other numbers). The CHUM-T gets a utility weight for blindness of .63. Tufts’ database of utility weights lists numbers between .4 and .69 (also other numbers for various technical terms that mean blindness, but I think the exact wording is important here).
So I guess if I can conclude anything from this, it’s that utility measurement is very hard and produces confusing results, but that this test doesn’t seem to be any more wrong than others.
You can download the raw data in .csv format here. Tell me if you find anything cool.
















Is there a conceivable experiment that, in principle, could verify or falsify utilitarianism?
That would depend what you mean by utilitarianism.
What would that even mean? Utilitarianism isn’t an empirical theory, its metaethics.
It isn’t even metaethics, it’s normative ethics. But it’s possible they mean something slightly different than how it’s normally used in academia.
I think falsifying utilitarianism is a category error, but I’m currently studying microeconomic models of welfare, and this is alerting me to an ever-growing number of problems with VNM-utilitarianism, as well as utilitarianism in general.
They tend to fall into one of two categories: failing to capture salient behaviour characteristics, and generation of unaccountable utility artefacts.
An example of the first would be procedural preferences, which you can’t specify as exogenous to the model. An example of the second would be caring preferences, where one agent’s utility function contains a term for the utility of another agent, resulting in arbitrarily huge feasible utility sets that don’t seem to actually correspond to anything.
When it comes down to it, it’s only a model.
I took part of the survey, but it was long and hard to think about. There’s a selection bias here against people who accidentally close tabs.
The billionaire thing was problematic because the interest is plenty to completely support various people I care about. Not just the billion, the interest.
Nevertheless, people were willing to rate such states as “life imprisonment”, “being stuck in a war zone”, and “living in North Korea” as significantly better than death, and other people were able to, with remarkable consistency as to numbers, rate death as significantly worse than those states.
But … but … wasn’t that in your instruction for the A-M test (which I am too lazy to look for)? That regardless of our own philosophy or feelings about death, we were to consider it as the most terrible thing?
PS. Laziness now being on the side of not getting out of my chair, I looked up the A-M test, which said:
“Floor” is an especially bad state intended to be worse than most of the states on this list. On this version of the survey, the floor state is “dead”. If you are currently suicidal, or are committed to philosophical positions that make even minor decreases in your quality of life worse than death, then death will not be an effective floor state for you. You may either stop taking this survey, or you may take this survey as if you did not have these philosophical positions and considered death to be a terrible evil.
I suspect that the number for life imprisonment came out too high due to selection effects. First, there is the one that houseboatonstyx pointed out. And then one might venture to guess that most of the people who took the survey like to engage in a lot of intellectual and solitary activities like reading and thought, in Far Mode, that they could pursue those in prison, and that the human ability to adjust would take care of a lot of the rest.
Sorry, this was supposed to have been a top level comment.
Darnit, totally forgot about that. Have deleted that section.
Even if you ignore that instruction…
I quite like my life, and I don’t want to die. For me death would be very bad.
But that doesn’t mean that I expect everyone else to feel similarly.
I think a big problem with trying to gauge the “utility” value of things is that different individuals put hugely different values on things. So if you are looking at “how do we spend the aid budget” it might make sense to do a survey and find what “most people” care most about and so forth; but if you have an individual person who for some reason *really does* have a choice between “death” and “North Korea” (for instance they just got caught being an illegal NK immigrant to China and the Chinese state says “we could execute you for your crime or send you home) then I think the “right” thing to do is not to say “in our survey 99% of people preferred NK so home you go” but to offer them the choice and see what they personally prefer.
I’m in favour of letting people kill themselves if they want to because I’m in favour of giving people as much choice as possible. For me “having the right to make my own choices” has a huge utility.
This, exactly. When I considered the possibility of rating one of the options as worse than the floor state, I self-selected out of the survey.
>>For anyone with a remotely good imagination, this is a very desirable state.
http://lesswrong.com/lw/dr/generalizing_from_one_example/
I saved the survey but when I tried to take it it had been closed, so I don’t think my answer went through, but I rated life with an ideal partner as being less happy than single life. I could go into the reasons, but I don’t see it as necessary to do so. Just please know that some single people *choose* to be single.
Having said that, my idea of being single (I have some FWBs) may map to what you consider your relationships with multiple women, in which case it’s a definition problem.
(If you’re a girlfriend of mine reading this some time after May 2013, know that I am obviously only kidding and that life without you would be much less happy)
Yep. If we’re going to complain mildly about the wording of choices, then “if you’re single, imagine an ideal partner” was no more appealing to me than a plain “if you’re single, imagine you don’t have an ideal partner”.
Maybe it would be better worded as a choice between “if you’re currently single, do you want to be in a relationship?”, although that could have unintended consequences for “if you’re currently in a relationship, do you want to be single?” – someone in a relationship might imagine that they could find a better partner than their current one and be willing to dump that person for the better choice.
… I might be skewed, since I am not just ‘single’ but have had no romantic interaction whatsoever, ever, and ‘ideal partner’ just sort of rounds off to ‘a good partner’ in my mind. Although I don’t know how much variance that is…
Respondents to the second survey would prefer to be discriminated against???
“I wouldn’t join any club that would have me for a member!” as the joke goes.
Did you exclude the 15% of people who didn’t come from Alaska from the surname stats?
I confess to chickening out from taking the survey, for two reasons:
1. I find it extremely difficult to consider “first world problems” like relationship status on the same scale as things like dying, living in North Korea, etc.
2. When I got to the second section, I’d discovered I’d been inadvertently “cheating”: I’d produced my answers in the first section in part by reframing the questions in terms of probability tradeoffs in my head (also by trying to think of natural experiments and revealed preferences).
I abandoned my answers and meant to come back later when I had more time and mental energy, but I seem to have missed the window.
A possible pointer towards the idea that people almost always prefer to continue living– are considered to be a form of torture. I thought mock executions were forbidden, by the Geneva Convention, but it looks as though they’re considered torture without being on an official list.
In any case, mock executions aren’t really rare, but I’ve never heard of someone being tortured by being offered a fake opportunity to commit suicide.
I’ve never heard of someone being tortured by being offered a fake opportunity to commit suicide.
I’ve never heard of it in real life, but it’s shown up in fiction. The first example that leaps to mind is this from the 2002 remake of Count of Monte Cristo:
http://youtu.be/QjZgNVf_lfU?t=8m15s
The relevent portion of the clip starts at about 8:15.
“Perhaps people just took the first survey no matter what their name was?”
Or you could have a disproportionate number of Scottish/Irish/Scots and/or Irish-descent readers 🙂
Re: the prison versus death alternatives, your prison wasn’t really that terrible. If it had been a choice between “You will be in a prison in North Korea/China so it’s likely you will be starved, abused, tortured, etc.” then more people might have decided death was preferable. As it was, a guarantee of food, shelter and no abuse wasn’t the worst thing out there.
The next time he should add “(If your last name starts with Mc, O’, or similar, pick a version according to the first letter after that.)”, and/or split A-L and M-Z.
I think that the 1.3 result makes sense for having billions of dollars, and 2.75 might make sense for many people for the upgraded personal traits that would typically cause them to earn a billion dollars.
I rated the billionaire option close to the high mark, and this was not my thinking at all. It was, rather, this: I have to work fairly long hours to roughly keep up the lifestyle that I want. I like my job, but at least half the time I’m working, I’d rather be doing something else. Part of the time that I’m not working, I’m doing chores that I wouldn’t have to do if I were a billionaire. I frequently worry about money, which takes its toll. I also still depend partly on my parents, the snag being that they have a somewhat different idea of the good life than I do. Having to work also keeps me from the kinds of leisure that would require prolonged absence, like travel. If I did not succumb to addiction or ennui, the combined extra free time, peace of mind, freedom, and lifestyle boost, as well as the money I could invest to make my work more enjoyable and fulfilling were I a billionaire might very well be worth two to three times my current utility.
Pingback: Raikoth: Laws, Language, and Society | Slate Star Codex