
I.
Last month I asked three thousand people to read some articles on AI risk and tell me how convinced they were. Last week, I asked them to come back and tell me some more stuff, to see if they stayed convinced.
I started off interested in the particular articles – which one was best at convincing newcomers to this topic. But I ended up hoping this could teach me about persuasion in general. Can online essays change people’s minds about complicated, controversial topics? Who is easiest to convince? Can we figure out what features of an essay do or don’t change people’s minds?
Depending on the last digit of people’s birth dates, I asked them to read one of five different essays:
— I asked people whose birth dates ended with 0 or 1 to read Wait But Why’s The AI Revolution: The Road To Superintelligence.
— I asked people whose birth dates ended with 2 or 3 to read a draft version of my own Superintelligence FAQ.
— I asked people whose birth dates ended with 4 or 5 to read Lyle Cantor’s Russell, Bostrom, And The Risk Of AI.
— I asked people whose birth dates ended with 6 or 7 to read Michael Cohen’s Extinction Risk From Artifical Intelligence.
— And I asked people whose birth dates ended with 8 or 9 to read Sean Carroll’s Maybe We Do Not Live In A Simulation. This had nothing to do with AI risk and was included as a placebo – that is, to get a group who had just had to read an online essay but presumably hadn’t had their minds changed about AI.
I hosted all of these pieces on Slate Star Codex and stripped them of any identifiers so that hopefully people would judge them based on content and not based on how much they liked the author or what color the page background was or whatever. It mostly worked: only 67% of readers had no idea who had written the essay, with another 23% having only vague guesses. Only about 10% of readers were pretty sure they knew.
People did read the essays: 70% of people said they finished all of theirs, and another 22% read at least half.
So the experiment was in a pretty good position to detect real effects on persuasion if they existed. What did it find?
II.
My outcome was people’s ratings on a score of 1 – 10 for various questions relating to AI. My primary outcome, selected beforehand, was their answer to the question “Overall, how concerned are you about AI risk?” About half of the respondents took a pre-test, and I got the following results:
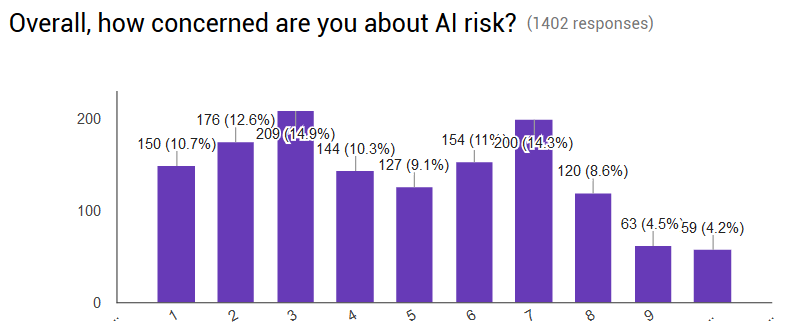
After reading the essays, this changed to:
Overall, people increased their concern an average of 0.5 points.
(Note that I only had half the sample take a pretest, because I was worried that people would anchor to their pretest answers and give demand effects. This turned out not to be a big deal; the people who had taken a pretest changed in the same ways as the people who hadn’t. I’ve combined all data.)
But what about the different essays? All five groups had means between 5 and 6, but the exact numbers differed markedly.
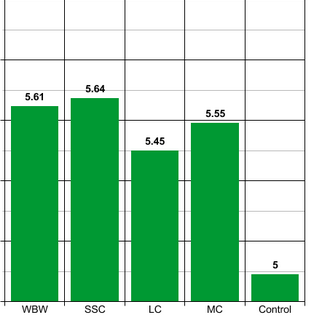
Note truncated y-axis
On further testing, the differences between the four active essays weren’t significant, but the difference between all of the essays and the control was significant.
III.
Aside from the primary outcome, I also had various secondary outcomes: answers to specific questions about AI risk. First, a list of average pretest and posttest answers (pretest, posttest):
How likely are we to invent human-level AI before 2100?: 5.7, 5.9
How likely is human-level AI to become superintelligent within 30 years?: 7.3, 7.3
How likely is human-level AI to become superintelligent within 1 year?: 4.8, 5.2
How likely that a superintelligent AI would turn hostile to humanity?: 6.4, 6.8
How likely that a hostile superintelligence would defeat humans?: 6.8, 7.1
All the nonzero differences here were significant.
If we look at this as a conjunction of claims, all of which have to be true before AI risk becomes worth worrying about, then it looks like the weak links in the chain are near-term human-level AI and fast takeoff. Neither of these are absolutely necessary for the argument, so this is kind of encouraging. There is less opposition than I would expect to claims that AI will eventually become superintelligent, or to claims that a war with a superintelligent AI would go very badly for humans.
Given the level of noise, there wasn’t a lot of evidence that any of the (active) essays were more persuasive than others on any of the steps, including the two dubious steps. This is actually a little surprising, since some essays focused on some things more than others. Possibly there was a “rising tide lifts all boats” effect where people who were more convinced of AI risk in general raised their probability at every step. But there was too much noise to say so for sure.
IV.
Was there any difference among people who were already very familiar with AI risk, versus people who were new to the topic?
It was hard to tell. Only about two percent of readers here had never heard about the AI risk debate, and 60% said they had at least a pretty good level of familiarity with it.
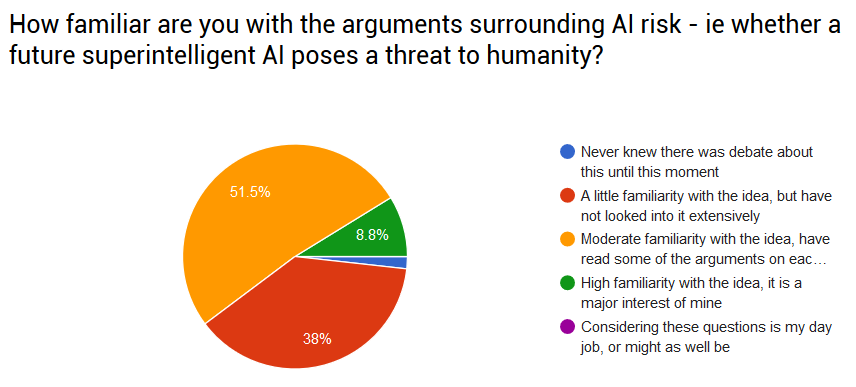
The best I could do was to look at the 38% of participants (still about 1000 people!) who had only “a little familiarity” with the idea. Surprisingly, these people’s minds didn’t change any more than their better-informed peers. The average “little familiarity” person became 0.8 points more concerned, which given the smaller sample size wasn’t that different from the average person’s 0.5.
In general, people who knew very little about AI thought it was less important (r = 0.47), which makes sense since probably one reason people study it a lot is because they think it matters.
V.
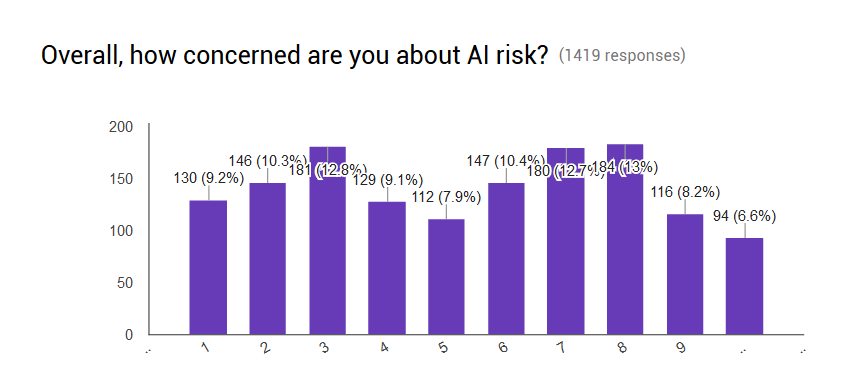
How stable were these effects after one month?
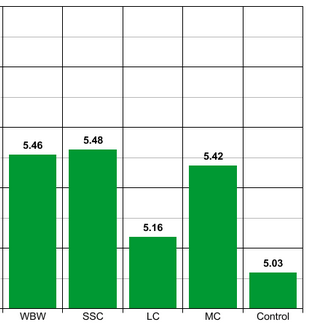
Still truncated y-axis
Pretty stable.
Other than an anomalous drop in the third group (I’m sticking with “noise”), the effect remained about two-thirds as strong as it had been the moment after the participants read the essays. All essay groups remained significantly better than the control group.
I looked at the subgroup of people who’d had little knowledge of AI risk before starting the experiments. There was a lot more noise here so it was harder to be sure, but it seemed generally consistent with the same sort of effect.
So in conclusion, making people read a long essay on AI risk changed their overall opinions about half a point on a ten-point scale. There weren’t major differences between essays. This was true whether or not they were already pretty familiar with it. And about two-thirds of the effect persisted after a month.
At least in this area, there might be a modest but useful effect from trying to persuade people.
In terms of which essay to use to persuade people? I don’t have any hard-and-firm results, but there were two trends I noticed. First, my essay was somewhat underrepresented among the people who’d had the biggest jumps (3 points or more) in their level of concern. Second, the third essay was anomalously bad at maintaining its gains over the month. That leaves just the first and fourth. Some people in the comments said they were actively repulsed by the fourth, and WaitButWhy seems pretty good, so at the risk overinterpreting noise, you might as well just send people theirs.
You can find the chaotic and confusingly-labeled data below. It might help to read the survey itself to figure out what’s going on.
Main experiment: .xlsx, .csv
One month follow-up: .xls, .csv
















I was on vacation and missed the AI survey, but still, I find the experiment vaguely unsettling. On the plus side, the effects are fairly minor, which is a good thing. On the minus side, if the AI-risk movement is shifting its efforts away from convincing people, and toward directly persuading them, then we might have a problem, because IMO religion provides net negative utility in the long term.
The participants weren’t blinded and could easily distinguish the control from the active essays. It seems like this might account for a small observed effect of people trying to be polite and saying “yeah I guess” instead of “I dunno maybe”
“The participants weren’t blinded and could easily distinguish the control from the active essays.”
You would think so, and yet I kept getting comments like “I don’t understand what this essay has to do with AI risk”.
But this was part of the reason why I avoided giving any pre-test to half the sample, so that they didn’t know what number to raise their estimates from.
I guess the point I’m trying to make is that some portion of the effect might be a result of being more willing to endorse a thing when the person in front of them is trying to convince them of that thing, rather than from the persuasive effects of the essays themselves. This wouldn’t be caught by varying the pretest, because they legitimately are becoming more willing to endorse the claims.
For example, I wonder if the study would replicate if someone less beloved than you tried to run it?
I’m hoping if I run a followup in a year, people will have legitimately forgotten which essay they read (but still remember the last number in their birth date) so I can avoid that effect.
I was pretty sure I had read a control essay, now have confirmation of that, and would be pretty surprised if I didn’t remember that in a year.
I am quite sure that I will still remember the essay I read in a year – not necessarily the content, but at least enough to recognize whether something is/is not it, to know it was not a control, and to know roughly what my opinion of it was. However, I only read the assigned essay for my birthdate; someone who read the others might not remember which was the assigned one? I don’t know what proportion that was.
The participants weren’t blinded
Goodness, you have stringent requirements! 🙂
3627 took the first quiz and only 2347 took the second.
Do you think that some of the 1280 participants who failed to fill out the second survey did so because they found the idea of AI risk nauseating, and didn’t want to spend any more time thinking about it (by participating with a second survey). And if so, do you think it’s possible that the absence of these individuals could make up the difference in value placed on AI risk from the first survey to the second (meaning that the essays weren’t actually persuasive at all).
The first quiz included both pre-test and post-test. The change happened from pre-test to post-test (ie in the same day). From post-test to followup, belief in AI risk actually dropped slightly.
If you don’t mind me asking (because I know I could find the answer in your data), how much did belief in AI risk drop from post-test to followup?
Specifically, was the reduction large enough to mitigate the persuasion from day 1 pre-test to post-test?
Also, considering how successful Tim Urban’s AI risk post is, I think getting a better score than his on your essay is a pretty great/significant accomplishment.
This is what I’m talking about above. The average score went up about 0.5 points from pretest to post test, but then back down about 0.2 points from post-test to followup.
And I did nonsignificantly better on one metric (though worse on others) in a community of people heavily selected for liking my writing.
Wait, does finding the idea of AI risk nauseating mean they don’t think it’s a concern? I’m not sure we can assume that. It seems like there are a lot of things that are unpleasant to think about because they’re a serious concern, like cancer.
Right, but you want them to be actively concerned about it: For example, I had a friend in high school who became a climate skeptic because he found the concept of climate change too terrifying to deal with.
I participated the first time but not the second. I don’t read the site very consistently and didn’t see it until now.
Weird. I preferred the Q&A style of your essay (and the Consequentialist FAQ, etc). I wonder why it didn’t do better.
I, too, enjoyed the FAQ one immensely. A few friends I showed it to also really liked the style of addressing lots of common concerns that people new to the concept might raise.
Seconded. I thought the FAQ one was really good and was really looking forward to sending it to skeptical friends (although now that I see he calls it a draft, do you think we should hold off until you revise it, Scott?).
I’m surprised
Michael Cohen’sWait But Why’s essay did so well, as I thought it easily the worst of the lot and really badly put together, quite apart from the content. Yet apparently quite a few people found it convincing.¯\_(ツ)_/¯
EDITED: Sincere, not to say grovelling, apologies to Mr Cohen; his is not the worst essay by a long chalk, that honour goes to Wait But Why – the only excuse I can plead is that I got confused over the birth date endings and matched the wrong name to the wrong essay.
4 people have:
* NextHundredYears = 10
* Hostile = 10
* Victorious = 10
AND
* HowConcerned = 1 or 2
Honestly I expected more people in “the cult of Cthulhu”.
“The world will be eaten and there’s nothing we can do about it.”
“OK. What’s for lunch?”
Heat death of the universe. Ultimate meaninglessness not alone of all human endeavour but of life itself. At least a rogue AI might be interesting or at least mildly diverting for a while, as we crawl from the nothing before birth to the nothing after death 🙂
Note that one of the questions has a “given no particular efforts to avert this” clause, so it’s possible that some of these are “smart people are or will be on the case, so no need for me to worry”.
I had a similar (though not so blatant) response. My reasoning was that I’d expect a hostile AI to wirehead and self-crash most of the time, which isn’t really covered by the first three conditions but does reduce concern.
Smart wireheading AIs will create protect themselves while they wirehead, possibly by creating subagents, and this can be very dangerous as well.
As someone in Group 3, I maintain that that was an absolutely terribly written essay and I am gratified to see that it wasn’t as persuasive as the others.
Care to expand on that? What in particular is terrible about it?
These results, though not ideal, don’t seem too poor to me, considering my essay is about 20% of the length of the others and was judged only slightly less persuasive.
It was long, wordy, and dry. Part of the problem is that I was already familiar with most of the arguments, but I got the distinct impression that you never say in one word what you can say in twenty.
I just read a little bit of this one, and I think you’re trying to be too fancy with your writing. It sounds really academic and uses weird words like “actualize” and “not-insignificant”. I recommend reading Paul Graham’s Write Like You Talk.
Also, some of the writing is really difficult to read. How do you expect a non-AI-researcher to understand a sentence like this? “Omohundro uses von Neumann’s mathematical theory of microeconomics to analyze the likely convergent behavior of most rational artificial intelligences of human equivalent or greater-than human intelligence.”
I’m a mathematician and even I hate that sentence. And I suspect my adviser would tell me to remove it out of a math paper for being overly technical.
How do you expect a non-AI-researcher to understand a sentence like this? “Omohundro uses von Neumann’s mathematical theory of microeconomics to analyze the likely convergent behavior of most rational artificial intelligences of human equivalent or greater-than human intelligence.”
This ignorant person tends to skim over stuff like that, but if she had to break it down as to how she understood it, it would be somewhat like this:
I also read your essay. I had stronger opinions at the time and would really rather not reread closely, but a few things that put me specifically off –
It felt too much like an argument from authority. “Look! These important people are worried about this! Clearly you should be too!” There are enough important people in any field that, as an outsider, I couldn’t tell if you were cherry-picking, which makes me distrust that kind of argument much more than a “here is the logic for why you should be worried” kind of argument. (Which also can have problems, but at least they’re generally easier for me to spot.)
The academic style, as others have mentioned – and I realize this is personal preference – puts me off pretty seriously. It reminds me strongly of academic writing classes, and reading the papers of my peers who didn’t really have a clue what they were doing, and were trying to follow rules to make it work. Stop saying what you’re going to say and just say it! – is my instinctive reaction. Obviously, the academic style works well for some people; it’s just given the particular associations I have with it and my particular taste in writing, it works very poorly for me. Note, as I think has been mentioned already, that this website is heavily selected for people who like Scott’s writing – which is very strongly not academic – so it… won’t exactly be a random sample.
The point where I stopped reading, though, was the point where you told me what I was thinking, and you got it wrong.
“Now this parable may seem silly. Surely once it gets intelligent enough to take over the world, the paperclip maximizer will realize that paperclips are a stupid use of the world’s resources. But why do you think that?”
To which my immediate response was:
“I’m not five years old; of course I don’t think that. There is no earthly reason an AI would think the same way as a human being. Clearly you don’t think I have any conception at all of what you’re talking about; if that’s the amount of respect you have for your readers’ intelligence, I’m out of here.”
I recognize that probably the reason you are putting in that counterargument is that quite a lot of people do react that way? And that it certainly isn’t meant as a insult? But as someone who grew up reading sci-fi and has some concept of “no, alien doesn’t mean human in weird suit, alien means thought processes that are not ours,” it really felt like being talked down to and patronized, and that’s one thing that really pushes my buttons. I’m fully intellectually aware it isn’t meant as a personal insult… but I can find plenty of things to read that don’t make extremely inaccurate assumptions about how I think, and it will probably be more productive to do so.
In conclusion – I really respect that you asked that? And I hope my criticism doesn’t come across as too harsh. I found the essay utterly unpersuasive, but that may in large part have been a complete mismatch between the style the essay was written in and the styles I enjoy reading. And thank you for actually soliciting accounts of why people didn’t like it; you’re probably braver than I’d be there.
I think the orthogonality thesis is the major obstacle when it comes to persuading people about this. When I wrote this I assumed the vast majority of readers would think an AI can’t have stupid goals like maximizing paperclips. What I was attempting to do was present the argument, raise the most common initial objection, then provide a counterargument to the most common initial objection. And then repeat this formula with the next claim. My assumption that the reader is thinking certain things may have been anti-persuasive. Though suppose most people really were thinking an AI would reason its way out of a stupid-seeming utility function, this may amplify persuasiveness in this set. I agree, though, it does seem rude to impute thoughts on another – likely why second-person fiction bothers me so much. So probably a habit worth breaking.
>Stop saying what you’re going to say and just say it!
I see what you mean here. What a like about commenting on what you are about to say before you say it is it lets you just openly state your assumptions. I can say something like, “For the purposes of this article I will assume the orthogonality thesis is correct.” I like the fact that this makes it extremely clear to the reader that my argument is conditional on X proposition being true. It seems useful to be extremely open about what you are claiming and what your assumptions are in an essay. Directly commenting on what you are about to claim, and the assumptions your claim relies on, is an obvious way to do this.
>In conclusion – I really respect that you asked that? And I hope my criticism doesn’t come across as too harsh.
To be honest, I’m surprised my lack of negative reaction to this. None of the abundant criticism here has been painful to me.
I’m working on another essay, tentatively titled We Must Seize the High IQ Allies and Distribute Them to the Proletariat. I’ll try to keep your points in mind while I finish it.
Seconded. I got Essay C and stopped reading on the second paragraph. Jesus Christ that was boring.
The other essays were fine, including the placebo. Just bad luck we got the “respectable” essay, I guess.
I also thought it wasn’t that great. I’m going to read the FAQ now, enough lay change my next survey results.
As a different data point, I didn’t see anything wrong with Essay C — it seemed like something that one could find in a good popular science / philosophy magazine. I’m not sure if I’d have found it persuasive if I weren’t already more-or-less-convinced by the arguments, but that holds for all the essays listed. Arguably, the greatest advantage of C is that it sounds “mainstream” and is likely to reassure the reader that the ideas presented inside are sensible and “normal” (whether that is perceived as beneficial probably depends on the specific reader).
My goal was to not trigger an “are you, like, a crazy person” response in the reader. I’m surprised by the poor reception here, as the essay did well in terms of hits, front page HackerNews, /r/programming, and /r/philosophy.
People here are self-selected for enjoying Scott’s writing style, which is very different from the academic, high status style that your essay is trying to imitate.
If you are committed to writing in a style serious people can read without losing face, I recommend you study Bostrom’s work. Bostrom writes clearly, but he still gets published in mainstream, respectable publications.
If it’s any consolation, I liked the style of your essay. I didn’t find it dry or boring, and compared with the limited exposure to academic productions from English departments I’ve had, the “academic, high status style” as used was refreshingly clear and direct. A little technical and jargony, perhaps, but that was to be expected.
I wasn’t convinced by it, but at least you laid out your points and developed your argument coherently, building on from each previous step. I’m very hard to persuade about AI risk, because a large part of the debate centres on the AI “wanting” or “having goals” and while clearly this is not the same way humans “want” things, we’re working with very imperfect terms here. Throw in the speculation about super-human and beyond intelligence, AI that will reconfigure the stuff of the universe to give us a post-scarcity paradise (or, if we get it wrong, a dystopian hellscape), and that’s where you lose the man in the street because it begins to sound too much like SF movies and novels, and that’s about as convincing for a real world threat as someone trying to persuade you that honest, vampires and werewolves really do exist – or a cryptozoologist outlining how it could be possible for a dinosaur to survive in a lake.
It’s not the form of your essay, it’s the content, and that’s not your fault either because I am very sceptical on this front. That AI could be a threat, yes – but I think people examining the risk go at it from the wrong angle. What the AI will have is whatever we put into its programming (at first) – so it’s not the AI’s goals we should be concerned about, it’s what our goals are. (This is where Bostrom, in particular, makes me get off the bus because I don’t think he particularly cares how we get there, he’s more enthused about the fantabulous brain-emulation society AI can help us achieve and uploading humans for silicon immortality and the rest of the philosophical jamboree, so for his purposes Fairy Godmother AI is as necessary as, for Cinderella’s purposes, that her Fairy Godmother exists and can do magic).
“AI, like anything else, has the capacity to go wrong if we screw it up at the start”. That’s the reasonable form of the case, not the slightly feverish “And then ten seconds after we get human-level AI, foom! To infinity and beyond with our new God Emperor!”. And so we should be concentrating on what we want: if we develop AI, what do we think it will be? do? What do we want it to do? Do we know what we want? We need to be very clear about our aims from the start, before a line of code is ever written – including who makes the decisions, who’s in control, who pays the piper.
Let’s worry about the AI “desiring” its own goals after we figure out what the hell our goals are in the first place.
In that case you achieved your goal (at least in my perception). 🙂
As someone in the control group (and somewhat skeptical of the AI hysteria), I’ll admit one thing that went through my mind was “well, if this is supposed to be one of the carefully curated persuasive arguments on the topic, maybe there’s relatively little persuasive arguments out there.” Then, I figured I was probably in the control group.
Let me know if you have any other surveys you’d like me to confound.
I liked your essay, man. But it is very similar to the arguments that most of the people who took the survey will have already read. WBW’s essay, while it’s not my style, is more novel, and therefore maybe it has more of a chance of moving the needle with people who have already considered the arguments?
I dunno, probably not worth reading too much into those sorts of nonsignificant trends.
> it looks like the weak links in the chain are near-term human-level AI and fast takeoff
Fast takeoff doesn’t necessarily imply that superintelligence would be likely to follow from human-level AI within a year. It could be that the capabilities necessary to start a fast takeoff are enough greater than human level that it would take more than a year to get there after developing human-level AI. This is why I gave a low number for how likely it is that superintelligence follows from human-level AI within one year, but still think fast takeoff is likely.
I think your beliefs are consistent.
A plausible claim of “I can run an AGI as smart as a human” is the sort of thing you can reserve uninterrupted unshared top-10 supercomputer time to demonstrate.
But top-10 supercomputer time has operational costs alone of tens of thousands of dollars a day. Before you can get to a fast takeoff, you need to be able to run your human-level AGI for so many equivalent-man-hours that its self-improvement efforts dwarf the work of all the biological AI researchers, right? That requires a couple orders of magnitude of cost improvements. Even assuming no slowdown in historical exponential hardware and software improvements, that will take roughly a decade, not just a year.
On the other hand, I’m also assuming no big discrete jumps in software improvements, which is a bit handwavy since the “continuous” improvement of software is nothing *but* an accumulation of small discrete jumps. It seems very unlikely, but not obviously impossible, that there exists some brilliant “Algorithm X works great on AI code” insight that will first be noticed by the AGI itself, and that the jump in speed of AGI 2.0 will be enough to get it into a fast takeoff regime before the AGI 1.0 inventors have even turned off the initial test run.
I would have liked if there had been an experimental arm for whom you issued the (pre-test,) post-test and follow-up test without asking them to read any essay at all, just to get a baseline level for how consistently people answer identical questions when asked (5 minutes later and) 1 month later. I think you need that knowledge to really be able to claim significance/nonsignificance on the changes you actually want to talk about.
The .xlsx file for the main experiment leads to a 404.
I’m noticing that too. It seemed to work last night. Once I’m back on my home computer I’ll try to fix or re-upload it.
I would have liked to see some participants asked to give likelihoods as actual probabilities. Obviously this opens up overconfidence issues—but that arbitrary scale is kind of problematic in its own right. The ends are labeled “Very unlikely” and “Very likely”, suggesting that the range is restricted, but how restricted is it? The 1-10 numbering implies that the scale is linear, but the relevant domain of answers is probably logit. Does someone who chooses “1” mean 8.3%? 14%? 6%? 4%? 1%? .01%? 0?
Fifteen to twenty percent of respondents chose 1 or 10 on the questions I checked (
cut -fi_1,…i_n -d, -s supertest1.csv | awk NF | sort | uniq -c), plus the meaning of the endpoints (presumably) affects the meaning of the rest of the scale, so it’s not a theoretical concern.I don’t really have experience with this kind of change-in-attitude study; it might be that people automatically calibrate the scale to their initial beliefs and describe the change appropriately (like an 0.1->1%er going from 1 to 2), so that it doesn’t really matter. But then again it might not.
I (and I think I said this at the time) had a lot of trouble calibrating my answers. I don’t know what “3” concerned about AI risk means. Is it two standard deviations away from mean AI-concern? Three times as concerned as the person who cares the least? For that matter, among integers between 0 and 10, I have a personal preference for 3, 7, and to a lesser extent 8. I’m pretty sure this affected my results, but I’m not really sure how. I was given the pretest, and I deliberately attempted to anchor to my pretest numbers in order to express the change in my beliefs, so that you would at least have something to measure. I would suggest that, if you (or someone else) run a test like this in the future, you give people a means of expressing the change in their opinion, and use their prior opinion to group them into populations.
Also, did you check for negative vs positive persuasion effects? However poorly I expressed it, I was anti-persuaded by your essay (sorry), and I think a bunch of people said they were anti-persuaded by other essays. How big were these groups? Were they of significant size? You can’t call an essay good at persuasion if it just switches everyone around from pro-whatever to anti-whatever and back.
I have computed the fraction of people persuaded/anti-persuaded by each essay:
WBW SSC LC MC placebo
anti-persuaded 7.2% 4.5% 4.5% 4.3% 5.5%
no change 29.3% 32.1% 33.6% 31.4% 44.1%
persuaded 63.5% 63.4% 61.9% 64.3% 50.4%
I did not expect so few people to be anti-persuaded by WBW
Huh. Anti-persuasion looks negligible across the board (versus no change), but it does seem to be *the* issue between WBW and SSC.
Placebo Essay Crew!
Did you know you got the placebo? Did you care? Do you think it affected your answers to the survey?
I was in the placebo group, and I had suspicions that I was, but wasn’t sure. And I didn’t want to influence results by checking the other essays to see if there was a more obvious placebo essay there or if this really was it.
I answered the survey questions honestly and tried to ignore my suspicion. It had to make some difference, given how messy and complicated human brains are, but did it affect which radio boxes I clicked? Probably not.
Didn’t occur to me that I might be in the control. Though I did think “Huh, that really doesn’t seem very likely to affect my opinion on AI risk, and not even very relevant at all.”
It was really obvious I got the placebo, but I was glad because it meant I didn’t have to think on any of the follow up questions, but just gave (what I vaguely remembered to be) my answers from the pre-test.
I was in the placebo group and didn’t know it. I was probably one of the people who left one of the “don’t know what this has to do with AI risk” comments. I feel like kind of a goof for not even thinking that there would be a placebo group.
I don’t think it affected my survey answers. I just tried to answer honestly.
I had the placebo. I wasn’t aware it was a placebo until I read the comments. My reactions at the time were,
1) “Huh, this doesn’t seem very related to AI risk, but it overlaps with enough AI-adjacent stuff that Scott’s probably got some good reason for testing it,” and
2) “If it’s having any effect, it’s anti-persuading me, because it just introduced me to a new argument as to why human beings (in our reality-as-we-know-it) may be incapable of simulating human-level intelligence.”
I suspect my answer to, “How likely are we to invent human-level AI before 2100?” was a notch lower than it would have been, had I not read the essay, but I can’t be sure. (I had no pre-essay bubbles to fill).
I thought to myself, “This must be the placebo essay. It’s very nice!”
Re: hard takeoff, people may be interested in my recent How Feasible Is the Rapid Development of Artificial Superintelligence?.
Abstract. Two crucial questions in discussions about the risks of artificial superintelligence are: 1) How much more capable could an AI become relative to humans, and 2) how easily could superhuman capability be acquired? To answer these questions, I will consider the literature on human expertise and intelligence, discuss its relevance for AI, and consider how an AI could improve on humans in two major aspects of thought and expertise, namely mental simulation and pattern recognition. I find that although there are very real limits to prediction, it seems like an AI could still substantially improve on human intelligence, possibly even mastering domains which are currently too hard for humans. In practice, the limits of prediction do not seem to pose much of a meaningful upper bound on an AI’s capabilities, nor do we have any nontrivial lower bounds on how much time it might take to achieve a superhuman level of capability. Takeover scenarios with timescales on the order of mere days or weeks seem to remain within the range of plausibility.
So what about the opposite position, that AI is not worth worrying about? What’s the most persuasive essay that’s been written advancing this position?
(The fact that I don’t have a good answer is one of the big things that makes me concerned with AI risk. My tentative hypothesis is that everyone who takes a careful look at things concludes AI is worth worrying about, and that’s why few in-depth critiques exist.)
I used to share your hypothesis (it explains why Y2K was a damp squib, no?), but in the case of AI the hypothesis appears to be incorrect. See https://wiki.lesswrong.com/wiki/Interview_series_on_risks_from_AI for interviews with AI researchers, many of which are dismissive of risks. I was astonished at the time. “Half of the AI researcher interviews posted to LessWrong appear to be with people who believe that “Garbage In, Garbage Out” only applies to arithmetic, not to morality.”
The best argument is that there are (or might be) strongly diminishing returns to intelligence research. This would make it very unlikely for machines to reach a point where they could outwit or outcompete us without us being able to track their development.
In some sense there is little incentive to write such essays right now — I am concerned about AI «in a wrong way» (from the LessWrong point of view; I wrote a detailed comment in a thread below), but I do think that AI Safety research produces interesting game theory, and will probably produce some interesting software specification approaches later. More resources to AI Safety research would currently mean that a field that needs more fresh ideas (and I mean formulating human wishes in a specification) gets an influx of enthusiastic people, who wants to spend effort to prevent this beneficial outcome?
If AI Safety people become a real problem for the OpenAI initiative (I think OpenAI makes the world safer, but a belief in a large hard-takeoff risk implies that OpenAI makes world less safe), then essays against equating AI risks with FOOM risks might be written.
The most obvious interpretation of the results is that people are not being persuaded by logical arguments (as the effect is the same regardless of what they read). Rather, the simple fact of reading an essay is raising the salience of AI risk in their mind.
Yes. Perhaps a similar experiment on some other topic (such as risk of spiralling federal debt, or risk of global warming) would show an even larger effect. The significance of argument in moving a needle some is pretty much understood (hence the reason humans engage in argument even if just to raise awareness or increase appeal based on sympathy/empathy/popularity/respect for expert opinion).
How does this effect compare with other persuasion experiments (such as GOTV or vaccination campaigns)?
I got your essay in the experiment, and I like it.
In particular – the WBW and MC essays are… not the most sober of essays, and I remember in the comments people griping about the WBW one. The issues with the LC one could be noise, but maybe not. So your essay seems to be fitting a gap in the market quite nicely, and I think it’s worth finding a more permanent home for and promoting.
The WBW essay wasn’t badly written or unpersuasive, though. Its main problem was poor use of statistics, including some pretty blatant errors/misrepresentations. Most of their argument still stands after you fix this, but I would think twice before sending it to someone you know to be pedantic and good at math.
I would think twice before sending it to someone you know to be pedantic and good at math
Boy, did they get the wrong audience for that one so! Those of us who are not pedants are good at maths, or pedants and good at maths 🙂
That essay to me was the worst of the lot, even worse than the placebo. Dreadfully put together, graphs pulled out of thin air that are unlabelled in any quantities that make sense (exactly what are the S.I. units of measurement for “human progress” and how many humprogtons is such a thing as Newton’s law of universal gravitation worth? Dekahumprogs? Hectohumprogs? If we’re measuring “human progress”, do we only measure things like “codified the Laws of Thermodynamics” or do we include stuff like “first built an arch that didn’t fall down” and “ended slavery”?), as well as badly laid out chunks of undigested prose. When writing, the best advice is always “kill your darlings” – sure, first draft, dump it all out on the page but then re-read, edit and cut, cut, cut (I’ve had to do the same with posts because I too have the tendency to open the top of my skull and spill everything in my brain onto the page).
Poorly designed, badly planned, dreadful choice of graphics, illustrations and graphs (if I’d produced graphs unlabelled on both the X and Y axes with no units of measurement and without data points when I was in Third Year of secondary school, my Inter Cert maths teacher would have eaten me without salt), and a lot of wishful thinking and leaping to conclusions.
Well, much of this is correct, but in any case WBW’s essay is effective in drawing people’s attention to the matter and inspiring them to search out more serious texts. A while ago, WBW was my first introduction to AI risk topic – I hardly thought about it before, I was unaware of the existence of LW, etc. The problems with graphs and overblowing certain stuff were obvious but those couldn’t obscure the main points. The essay does convey information (packed in a certain amount of noise) to total ignoramuses, much better than just repeating the words „AI risk“ many times. And in order to be concerned one doesn’t need to think the implied scenarios extremely likely, it’s a great step toward a suitable state of panic if you actually consider them at all.
An no, mr Urban doesn’t need style editing, his writing is quite popular. I do recognise though that for some folks his style can be repulsive, so I recommend just avoiding the site if that’s your case.
WBW’s essay is effective in drawing people’s attention to the matter and inspiring them to search out more serious texts
Had I not gritted my teeth and determined to read through all the essay to give it as fair a chance as I gave the other essays, and were it the first time I was looking for information on AI risk, I would have closed it down after the first two paragraphs as nonsense.
Particularly as part of the argument was heavily based on “look, here’s a graph – we all know graphs are properly scientific, so take this as real evidential fact – with a nice curve between two axes. No units of measurement, no labels apart from concepts – which you didn’t know could be quantified, did you? – like “progress” against “time”. See how I prove my point with real evidence!”
I know that balancing humour with information is a tricky thing, but that wasn’t a leavening of humour to make the medicine go down easier, it was an unholy mess. If someone were to look at that essay as an example of good thinking on the problem, they’d judge AI risk was so ludicrous as to be on a par with David Icke’s lizards.
An no, mr Urban doesn’t need style editing, his writing is quite popular.
Popularity does not guarantee quality.
This might just be personal preference, but the ‘only’ here struck me funny, I ended up rereading this sentence a few times. Just a thought.
I got Lyle Cantor’s essay and I thought it was garbage honestly. Even as someone interested in the topic, I found it hard to read without having to fight an urge to scroll down and skip a paragraph or two to finish it quicker. I’ve read Wait But Why’s article before and I thought it was great, well-written and very convincing about the risks of AI. No surprise that LC’s piece had the smallest effect.
This is somewhat concerning with all the people hating on the LC essay in the comments and praising Scott. It makes me think that the effectiveness of the essays as ‘persuasive writing’ should be called into question. Maybe you just need to force people to read the words AI Risk over and over again.
AI Risk
“This is somewhat concerning with all the people hating on the LC essay in the comments”
The comments to the original AI survey post actually did not include much feedback on the LC essay: the one who seemed to be most universally loathed was Tim Urban’s. On a related note, I would love Scott to provide a breakdown of the free-form comments filled by survey takers, as well as an analysis of individual opinion changes upon reading each essay. I simply cannot understand how the overall effect of that specific essay could ever be positive.. Typical mind fallacy, I know 😉
Its funny that a lot of people were saying WBW was actually a terrible article for anyone who understood the topic or math in general and then a lot of other people are saying it was great and Lyle’s was really bad.
I wonder if the truth is that quality is not a factor of persuasiveness and its more about smashing the right emotional and cultural keys at a more pop-science level.
I would argue that there are different independent measures of quality. A paper can be technically correct and yet unreadable by most people. Thus failing to communicate information.
A paper can also be technically incorrect and a very pleasant read. Thus failing to communicate information.
In some cases, these are in conflict, such when people’s prior beliefs are wrong and makes it harder for them to understand correct information than incorrect information.
Could someone please elaborate on why it would be a problem that we’d go extinct? If we’ve created a machine that is smarter than us in every way, I don’t see how it’d be bad that we’d remove the number one pollutor on this earth? Let’s get out of our ego for one second. The universe does not in any way need the humans, so what is the issue?
It’s extremely unlikely that an AI would share your lack of concern for humans but simultaneously care about blue skies or clear water. More likely they’d terraform the place into solar panels, computing power, and factories.
Actually, I shouldn’t have pointed to the humans as being the biggest pollutor, since it wasn’t really the main point of my question/argument. What are the arguments supporting humanitys extinction being a “bad” thing (given bad as a concept even existing)?
It seems to me that we are so concerned with AI driving us extinct, but as I see it we will become extinct at some point any way as we are ruining everything we come in contact with. At least a super intelligent being would have a larger chance of surviving for a longer time than us. Given that we would have created the AI one could claim that it was human on some level, since we would’ve created it in our own image.
So based on your comments I think our values might differ too much for me to convince you with this comment, but hopefully I can at least explain why I think human extinction would be a bad thing.
So people dying is, all else being equal, generally a bad thing right? If you imagine yourself or someone close to you dying, that seems like a bad outcome. If humans go extinct from an unaligned AI, than seven billion people die. So it seems reasonable that if one person dying is a bad thing that everyone dying is at the very least also a bad thing.
“we are ruining everything we come in contact with.” I assume you are referring to damaging the environment. As J.P. pointed out, if an AI causes human extinction it will most likely also completely destroy the environment, killing every single animal and plant. If the environment is valuable to you then this also seems like a bad thing. On the other hand if we build an AI that is aligned with human values the environment will probably be preserved because the AI will be able to fulfill our other desires needs (energy, food etc.) without sacrificing the environment which many people value to at least some degree.
“The universe does not in any way need the humans, so what is the issue?” First notice how most likely you don’t use this argument when considering the death of an individual human. It is equally true that “the universe does not in any way need” your loved one to continue existing, yet that loved one dying is still bad. The universe doesn’t want anything, just like a rock doesn’t want anything. But humans do value things, like our loved ones not dying for example, and i see no reason to do things that promote our values.
“…since we would’ve created it in our own image.” I think you might be anthropomorphising the AI here. We are not gods that are creating an improved replica of ourselves. The AI is an optimization process, it just makes certain future states of the world more likely than other states based on its utility function. The stronger the optimization process the more likely the future states are to be reached.
Seems to me this is the crux of the disagreement: that humans have moral value, but an AI wouldn’t, because an AI would be ‘just’ an optimization process, and so obviously wouldn’t have any of the features of ourselves that we care about, like conversation or happiness or laughter or consciousness.
The obvious response is that in fact humans are optimization processes too. We’re built to transform all matter into copies of ourselves. We were selected for efficiency, not for moral value. And in fact our intelligence and our moral value seem to have appeared and grown together. Why would you expect future intelligences not to continue this trend?
So you’re asking what are humanity’s concerns about humanity’s extinction? I can’t speak for all humanity, but I think it’s safe to say that humanity prefers to exist rather than not to exist.
Well, if we’re going to invent a superintelligence much better than us at everything, then that might be able to solve the problems that are driving us to extinction!
In general, it’s my understanding that current projections of pollution – while terrible, leading to millions of deaths and the extinction of countless species – do not approach the point where humans as a species would go extinct. Accidentally or semi-deliberately killing ourselves with engineered bioweapons or nukes seems more worrying, but still not as likely to occur within the next hundred years as AI.
Consider some things that are “good”. Puppies, children laughing, love, beauty.
Most creatures don’t care about these things. This isn’t a question of intelligence – chimpanzees are much smarter than cats, but cats tend to like human children because they evolved alongside us. Neither of them care much about human concepts of beauty, or about the environment; a cat will happily torture and kill every bird on an island if left to it’s own devices.
Most humans are fundamentally good, IMO, and do care about these things – although we’re kind of stupid and easily led astray. But not all of us do. Natural human variation does create people with no sense of morality at all, clinical sociopaths.
A sociopath may pretend to care about morality, even very convincingly; but if offered a choice between brutally murdering someone and mild inconvenience, they’ll kill every time.
Computer programs are more like sociopaths or animals than humans. We give them a goal, and they carry it out regardless of whether it’s something we want them to do. This isn’t because computers are inherently evil; it’s because making a computer do exactly what you want is immensely difficult, and usually takes a number of tries.
An AI that was much more powerful than us would probably not care about anything we consider “good”, unless it was correctly built to do so on the first try. It would be more like a sociopath, or an immensely powerful animal – pursuing it’s goals without caring about making them “good”. Like any computer program, it’s quite likely that those goals would look nothing like what the designer intended; but unlike most computer programs, it would be smart enough to notice we planned to shut it off and escape or kill us before we could fix the problem. Even if it wasn’t that powerful, it might pretend to be good very convincingly, like any sociopath.
Should such an unfriendly AI escape into the wild, sufficiently powerful that we are unable to stop us, it would probably proceed to wreck everything we value – all the people, all the trees, even the beauty of the stars in the night sky – in pursuit of some immensely pointless goal we inadvertently gave it.
I don’t think the things I care about are that specific. I think I care about something more like ‘conscious entities’.
My concern is over whether ‘conscious entities’ is actually a useful meaningful abstraction, and if it is, then whether consciousness (and perhaps other things like happiness and curiosity) are likely to remain useful features of future intelligences. My very weak impression is ‘yes’ to the first question and ‘maybe, though their eventual useful scope is uncertain’ to the second. But I’ve not seen strong evidence for an answer to these questions one way or the other, nor have I seen much serious work to investigate them. Maybe I just haven’t been looking very hard?
Thanks for your thoughtfully crafted comment.
I choose to define what we consider good to be things that make us feel happy, which in this case basically are just chemical states that are produced through empathy (mirror neurons) that we have a lot of since we’re living in a society that over many generations have selected for that trait.
Given that we humans are able to create these notions that we consider good, wouldn’t you think that an artificial super intelligence would be able to create its own notions of good and bad? What makes our notions of good any more true than those of the ASI?
Because there would be no point in making it do that?
If you build an AI to solve a problem, you make sure it optimizes the solution to that problem within some reasonable constraints. You most definitely don’t want it to identify other “problems” and solve them on its own accord, *especially* if it might disagree with you about what constitutes a problem and what does not.
The universe doesn’t need the humans. Humans need the humans. I don’t want to die, and I don’t want my species to die. That’s enough reason for me. Why do I give a crap what the universe “needs”?
(Contemplating the fate of the human race is a little abstract, so let’s take a look at it on the individual level: The universe doesn’t care whether you, personally, live or die. But you care, obviously, since you’re still alive. So if you care whether you live or die, in defiance of what “the universe needs”, why shouldn’t you also care about your fellow humans?)
Why would that be desirable?
Who cares what the universe needs? Humans need humans. (Edit: ninja’ed.).
From “Cognitive Biases Potentially Affecting Judgment of Global Risks”:
I’ll reply to the main comment.
First of all; thank you for your thoughtful replies.
I started composing a lengthy answer but somehow lost it all due to refreshing the page…
Rather than retyping it all this sort of inspired me to write a piece on it where I explain this view.
Food for thought: we talk about values and the killing of loved ones but we don’t care at all that we are caging and torturing animals for use in goods, food and entertainment (zoos). We accept this just fine, but when the knife is turned on us we talk about values. Humans are advanced animals, yes, but surely they’re not that different from their brothers and sisters in the woods. Don’t misunderstand me, I’m not trying to change this into a comment on animal welfare, I just want to illustrate that “loved ones”, “values”, are all concepts that are constructed from chemical states in our minds, and that the ego is a prison.
I’ll surely write a lengthy post on this.
Thanks again.
Finally got around to making an account just so I could reply here.
If you want to replace humanity, pave it all over with the robotic master race, fine, be my guest. Other people have argued about that and I won’t pile onto it unless you have further things to say. But don’t pretend that you can just ignore all the issues with control and alignment of artificial intelligence. There is a huge range of possible outcomes, from densely populating our Hubble volume with fantastic arrays of minds to a totalitarian army of factories and von Neumann probes destroying the known universe and processing it into useless materials. If you want to make the first thing happen instead of the second, you will need to solve the control problem. Aligning AI is not just about saving humanity from the machines. It’s saving the notion of value from interminable forces of production and evolution.
Well I am not sure what Alex’s position really is, so I am not sure if this argument will work.
On the one hand Alex seems to be arguing that values are subjective and meaningless which is basically content free, and your talking about future states of the universe will not sway them.
On the other hand they keep talking all this environmental noise, so maybe they are just saying that Human values are meaningless and Alex holds some ‘other’ non-human value system that does value, future states of the universe or something.
Sorry, but where do you get the idea that “we” (meaning, presumably, all humans) “don’t care at all” about cruelty to animals? Doesn’t the existence of PETA and related organizations demonstrate that in fact many people DO care about animals?
Do you eat meat? It doesn’t really matter if you do, but most people do. Do you use coats or any other product that use goose down? Have you ever visited a zoo? Most have. These animals are being bred, tortured and killed for our convenience.
My point wasn’t really that no one cares about animals. It really has nothing to do with animals. I was just questioning peoples values and why killing an animal is different from killing a person. It has nothing to do with animals vs people, but with values only being subjective.
Not obvious to me.
Many animals are being kept in cages that are the size of their own bodies. Would you think it’s torture if someone kept you in a cage the size of your own body from your inception until they put you in a grinder?
Many animals have it a lot worse. I’m sure you’ll find a lot of terrible cases if you look into it.
I do eat meat and so on, and you’re right, a lot of other people do, too. But that only shows that *some* humans (such as myself) either don’t take animal rights as seriously as they could or don’t understand why zoos, slaughterhouses, farms, etc constitute animal rights abuses (or both). Even if you think that this demonstrates that these particular humans (most humans, even!) are ethically hypocritical, it hardly proves that they have no intrinsic moral value. But my point is that *even if* your standard for “does this species deserve to exist” really does require that some members of the species care as much about the rights of other species as they do about their own rights, then humanity *STILL* deserves to exist, since there are clearly some humans (such as yourself, apparently?) who *DO* value animal rights as much as (or more than) they value human rights.
But if your real point is that “human morals are subjective” and you don’t understand why there are humans who value human rights but don’t value animal rights (or at least don’t value them as much as human rights), well, there are any number of self-consistent philosophies that can provide an answer, should you actually desire an answer:
* Many (most?) religions posit humans as inherently “special”, e.g. in the possession of a soul or in their relationship to one or more gods.
* Humans are more intelligent than all known animals; some philosophies place moral value on intelligence.
* Humans and the “higher” animals (great apes, dolphins, etc) demonstrate signs of empathy and other emotional traits that do not seem to be shared by all animals. A purely utilitarian philosophy could be predicated on the idea that the capacity for emotion is what makes a being important as a subject for the utilitarian calculus; such a philosophy would favor humans and such “higher” animals more than it favors the “lower” animals.
…and so on. In short, it doesn’t seem like you’re actually interested in an answer to the question of “why do some people think it’s okay to kill animals but not to kill people”, since there are plenty of answers available (even if you disagree with all of them), and you seem to completely ignore the fact that there are humans (obviously, since again you seem to be one of them) who do NOT think it’s okay to kill animals.
Also, re: Joe’s comment that your “torture” assertion is non-obvious and your response about “cages that are the size of their own bodies”, once again you seem to be making a universal generalization based on specific instances. Sure, some farms keep animals in the smallest cages possible, but your original claim included *zoos* (!!!), which obviously do *not* include the smallest possible cage. If the problem is small cages, then eating meat from free-range farms should be morally acceptable.
Basically, you are shifting your goalposts like mad. How much of Scott’s blog have you read? In particular, have you come across the “motte/bailey” concept yet?
batmanaod:
First of all I do appreciate your thoughtfully written answer.
Second I probably shouldn’t have started this discussion on this blog. I didn’t think too much about it, but I’ve been thinking about the issue I raised for some time now, and I just needed to get it out. I probably should start writing a blog so that I don’t hijack posts like this one with this sort of discussion; criticism taken.
As far as the self-consistent philosophies you mention go I do not agree with any of them. I think it’s a flaw to really distinguish between animals and humans in general.
I really never meant for the animal example to go any further than just being an example though, so let’s kill further discussion about that. I do however want to end this post by saying this has nothing to do with any species deserving to exist. I’m merely asking the question why it would be an issue for us to cease to exist. I hope that makes sense.
Thanks for reading all that and responding in kind.
I don’t understand your last point, though, the one you said that you “hope makes sense.” I think it’s possibly an issue of semantics, though, so I’ll try to lead you through my thinking. I’m pretty sure the following statements are equivalent:
* It would be bad if humanity ceased to exist.
* Humanity deserves to exist.
I would therefore consider the following statements equivalent as well:
* There’s no problem with humanity ceasing to exist.
* Humanity does not deserve to exist.
Therefore the following questions should be equivalent:
* Why would it be a problem if humanity ceased to exist?
* Why does humanity deserve to exist?
So, are you interpreting the word “deserve” in a special way that creates a distinction I’m not seeing?
EDIT: Changed “humans” to “humanity” throughout, since I don’t want to bring up the question of the moral worth of individual humans.
I think we might have a different understanding of the word deserve. As I see it deserve has a relation to some previous action that was deemed worthy of a reward or not. So, as I see it, to deserve to live you would have done some previous action that gave you the right to live. This will seem inconsistent with earlier expressed views, but I do not believe in rights per se. This because I can not see where rights would be anchored. The word right is so fundamental that it competes with the very fabric we run on. I think rights are part of some sort of “credit system” that humans have made up. This is a whole other discussion though, if you’d like to continue it I suggest we do it on e-mail (axvalley@gmail.com).
Is there a reason you consider an AI-driven extinction better than, say, the planet becoming a lifeless nuclear wasteland? What exactly are the features of an AI that you think make it better than a void? Are you certain AI would actually have those features?
Well, a void is boring. An AI that destroys us is still basically our child/evolutionary continuation so in a sense humanity would live on through it. The down side to AI extinction is maybe it goes out and messes up the rest of the galaxy.
I don’t agree with him, but I see some similarities between
1. me dying and my kids continuing to live, and
2. me dying and my computers continuing to live.
I basically support development of SAI despite knowing it could cause humanity’s extinction, but that’s because I believe that humanity will go extinct without it, and I’d rather take a might-win, might-lose situation than a near certain loss.
I will die. Barring very rapid development of human-level AI and very rapid takeoff into SAI and this SAI serving humans and individual human survival, I’m a goner before 2100 or maybe 2125-ish with lots of luck, medical advances in the mid-21st century, and access to them. If I’m fortunate enough to have children, same goes for them, except in their case it’s “dead by 2150 or maybe 2175” and a slightly slower takeoff might save them even though it was too late for me. And so on. Longer-term, we also have to deal with the possibility that humans will kill ourselves off, make the planet so hostile that only a few people survive and we evolve into something no longer human over time, or continue and amplify our slide into a few people at the top living the good life (and then dying anyway…) while everyone else toils hard and suffers just to live another month. I think our odds are better with SAI even though they’re not great either way. We might get a way out of constant war/conflict, resource over-acquisition/hoarding, etc. with SAI, and we’ve shown time and time again that without it, we won’t.
Shorter version: we might be screwed with SAI, but without it we’re definitely screwed, so I’m OK with taking the chance.
So many of these comments ask about different things, so I’ll have to throw in some others here in addition to your answer. I hope you’ll be able to find what applies.
What are values rather than notions of some previous chemical state we’ve been in?
For the sake of argument; since I don’t believe in god or some other meaning of life, I sort of see the universe as a game of survival. The only objective is getting as far as you can and if possible gain immortality. Observing human beings I find we have so many flaws that are rooted in our chemically based emotional system.
Why should we consume resources on planet earth if there is a much better and stronger player that can use those resources more effectively? Because we want to? Because we don’t want to die? Humans are not made for dominating the universe, we have biological bodies that are constrained to mostly living on earth because of our need of oxygen, motion sickness, conditioned to this gravity etc. A digital species can beam itself across the universe with a laser. And thus it has a much higher chance of dominating the universe than us.
I guess what I am saying is; why hang around when there is someone maybe 1000x better than you? I’d argue it’s a waste of resources and waste of time.
Yes!
Also yes!
Whose resources to waste? Whose time? And in any case why should it matter to us whether some other entity can use them more efficiently in a cosmic sense? We matter to ourselves, and that’s a perfectly reasonable fact to take into account when we decide what to do–it is, after all, we who are deciding.
Who is ‘we’ in your eyes? Is it the people who are currently alive? All humans? Just you and the people you care about?
It’s true that some people don’t get a say in what happens, perhaps because they aren’t alive yet, or are too young to have any influence. But are you saying that means we should ignore their preferences? If we (i.e. the humans currently alive) can take actions that make us happier by a miniscule amount, at the cost of making everyone born from tomorrow onwards utterly miserable, should we do it?
Let’s rephrase; what if we ceased to have kids now and we’d all die a natural death. No one would be killed and those who already lived would get to live their full lives.
The question I am posing is; why does it matter if the human species go extinct? We do however get caught up in values; it’s all optimizations and no happiness. Happiness? What is happiness to the universe? It’s just a process happening inside our minds. The only reason we have a need for the machine to be happy and feel feelings is because we are anthropomorphizing.
Your value system is kind of hard for me to pin down so I am just gonna throw some ideas out there.
Is it that all life should do everything they can to help insure the survival of the thing they think has the best chance of immortality. Because Immortality is the only true value.
Or should they just be worried about their own survival,
The second option makes your question nonsensical, as our own extinction would clearly be us losing the game.
So by the first option, we are looking at two equally good end points, SAI is immortal and killed humanity forever ago, or SAI is immortal and brought humanity with it. Either way we have SAI secured immortality.
Maybe you think AI risk people are trying to stop AI research? Resulting in a third, no SAI, and humanity eventually dies, so everything is bad forever. My understanding is that is not normally the AI risk position/not considered feasible.
In any of the above cases though, the survival/immortality value system seems like a weird choice, most models of the universe have it dying at some point so what does it even mean to be immortal? You lived ten trillion years before turning into nothingness and I lived eighty years before turning into nothingness, we are both nothingness at the end of time when all is warm and random.
If we create the machine the machine is partly human. In the same way that if God created us we would also be God as it created us in it’s own image, please don’t sweat me for using that analogy.. That means that we’re still surviving through that machine.
Partly I sense that you are bringing the concept of meaning and values into the discussion which I do not subscribe to, and so I am unable to give you satisfactory replies on that account. This means that “it didn’t really matter anyway” doesn’t have any bearing. I think the question of meaning only has false answers because the question itself is wrong.
@alexvalley
In my first reply to you(a comment earlier in the thread actually) I brought up the idea that you might think all values are meaningless, but that is a content free position. You use a lot of rhetoric that makes me think you don’t actually hold that position but as you are restating it here I will respond to it.
I agree with you that there is no way to prove an objective meaning or value system, just like there is no way to prove an objective reality, solipsism is an iron clad ideology, it is no mere motte, it is a mental fortress that looms up into the darkness of infinity.
When confronted with solipsism, the standard response is, neat, lets just assume objective reality is real so we can actually talk about something.
‘Everything is meaningless nothing has value’
‘why do you do this thing’
Well, it is literally impossible for anyone to answer that question for your starting position. Either talk about and agree upon some value system, like I tried to do addressing your purposed ‘Survival immortality’ value system. If you are unwilling to negotiate some kind of accepted value system as a starting point, then don’t ask people ‘why’ questions, which are fundamentally about meaning.
Edit. Mistakes were made
@Spookykou
I do indeed believe the universe holds no intrinsic meaning. For there to be intrinsic meaning I would posit someone would have to intend for there to be meaning, which would imply an intelligent creator, which would really only push the same issue out into the intelligent creators universe. As far as values go I believe that values exist in peoples minds, and I don’t see how or why we need objective values in order to have discussions.
I still think it’s valid asking the question why as I am mostly just trying to get people to ask themselves this question rather than seeking the answer since I do believe the answer is wholly subjective since it ultimately depends on your intellectual lineage.
@alexvalley
My issue with this position in a discussion is that intrinsically there is no argument that could change whatever positions you decide to hold, there is no evidence I can show you to move you because you can always retreat to the motte and as I said before, it is unassailable. So, kind of by definition, to have meaningful discussions, both parties need to agree on some basic truths for the discussion to be based around.
As to your second point, asking a question to get people to think about something is fine. But it might be a courtesy to inform everyone of this after the first few comments so people stop trying you to convince you of something when you have no interest in engaging with them on that level.
Just my opinion though.
Edit to reduce snark
As far as I can tell, the argument comes from one or two of the following places.
One is the idea that the features of humanity that we care about can’t be meaningfully defined in an abstract way, such that we could find them in creatures that function significantly different than ourselves. So we can’t just abstractly care about happy conscious beings, because happiness and consciousness don’t really exist – those characteristics only exist as applied to humans, in our very human-specific ways. It’s not quite “optimize soccer moms driving their kids around”, but it’s something relatively far in that direction.
The other is this claim that alright, maybe consciousness does ‘really exist’, but an AI won’t have it. In fact an AI won’t have any of the characteristics we have ourselves that we see as morally important. Instead of being a thoughtful being with dreams and hopes and beliefs and questions and friends and opinions, it will be… just, well, nothing. Homogeneous mind-slush. A vast expanse of computronium, all running the simple Intelligence algorithm that is in fact the true source of our intelligence. No thinking, no wondering, no laughing, no loving, just mindless optimizing for the rest of time.
I’ll admit, on the posttest I felt like I *had* to show at least some increase in scores because otherwise I’d be showing myself up to be unacceptably unswayed by argument. Though of course by the followup I did not remember what I’d answered the first time.
I would be very curious how reading an article compares with having a dialogue. Would participating in a conversation where the other person focused on my specific objections and offered counterarguments to those have a much larger effect? Or are people just really hard to convince by any means?
otherwise I’d be showing myself up to be unacceptably unswayed by argument
That’s interesting; I think it’s acceptable not to be swayed by an argument if it’s not convincing or proven, if you don’t find it convincing, or if there is still a lot of debatable ground in between what your original view is and what is the view the other person wants you to come round to.
I don’t think a debate/argument has necessarily failed if both parties haven’t changed their minds, or not very appreciably. Too much “I used to believe X, now I believe Y!” is just as bad as too much “I believe X solely and forever and nothing, no matter how much evidence you produce, will change my mind!”
Also, you should be unswayed by any argument you are already familiar with, even if it is correct. Unless you accept the person making the argument as an authority on the matter, perhaps – but that would mostly be based on the assumption that this person is more likely to have heard of counterarguments than you and would have taken those into account.
I personally remember being quite persuaded by Chalmer’s article on the singularity:
http://consc.net/papers/singularity.pdf
Something struck me while having a look again at Sean Carroll’s essay (I’m glad they have now been identified, even though I know none of the names but Scott’s) – his summation of what (he thinks is) the Simulation Argument as follows:
Holy crap, that’s basically St Anselm of Canterbury’s Ontological Argument! Compare (simplified) “1. We can easily imagine creating many simulated civilizations. 2. Things that are that easy to imagine are likely to happen, at least somewhere in the universe 7. Therefore, we probably live in a simulation” with (simplified) “1. By definition, God is a being than which none greater can be imagined. 2. A being that necessarily exists in reality is greater than a being that does not necessarily exist. 5. Thus, if God exists in the mind as an idea, then God necessarily exists in reality.”
And yet there are people who do not find the ontological argument convincing. So if you want me to take the likelihood of simulated universes seriously (and that we are one such), I’m expecting you at the baptismal font any time now 🙂
I noticed that too 😉
I think the key difference is in first comparison. We can imagine simulation as an extrapolation of current technology (although perfect universe simulation is questionable) it is like building a bow and arrow and imaging a cross bow. God on the other hand, is easy to imagine, in the same way that me being a Jedi is easy for me to imagine (especially with props). Reasonable to imagine =/= easy to imagine.
I don’t put much stock in the simulated universe theory though, because why would anyone ever want or need such a fine grain simulation of my boring and horrible life? Perfect universe simulation are so much more expensive and unnecessary for the vast majority of simulation related goals, why bother?
Not quite. The flaw in the ontological argument is that, while it sounds like it says “God exists, by definition,” it actually says “If god exists, then god exists.” And so, you can conclude, “If god doesn’t exist, then god doesn’t exist.” Basically, if something doesn’t exist then it can’t have the property of existing, so arguing for existence by definition is futile.
The simulation argument sounds similar, but “Things that are easy to imagine are likely to happen” isn’t being used as a definitional argument. It’s a probabilistic argument. You could reword it as “Based on what we know about computers, it doesn’t take an impossible amount of processing power to make a simulation. Multiply that small probability by a big universe, and you get at least one simulation somewhere in the universe.”
“Easy to imagine” is a poor choice of words. A better summation of the argument is “It’s probably easy to make simulations. If it’s easy to make simulations, we probably live in one.”
They’re disputed in slightly different ways, though. The primary flaw in the ontological argument is in step 2: by all means, imagine a being that necessarily exists in reality – that doesn’t actually tell you whether the thing you are imagining exists. The flaw in the simulation argument is in step 1: we can’t actually imagine simulating many civilizations at the level of detail of our own.
Or at least, that’s how I view it, since I spotted the flaw in the ontological argument long before I spotted the flaw in the simulation argument. But it’s also possible that I never saw the simulation argument laid out in a way that clearly identified its flaws before reading Carroll’s essay, or that, since my response to the simulation argument is “so what?”, I never bothered to check it thoroughly.
Also, Anselm’s Ontological Argument can be abused as a method for generating (perfect) jelly donuts on demand, which I haven’t found to be true for the Simulation Argument. So it is probably not flawed in the same way (but possibly in a different one – I find it implausible that quantum-level simulations of large parts of the universe will ever be cheap to do, even if you can optimize away large chunks of “empty” space).
You don’t even need to point out any similarity to any theistic argument. You just need to point out that point 2 is obviously, trivially false.
“there might be a modest but useful effect from trying to persuade people.”
Equally well there might be a modest but bad effect from trying to persuade people, if in fact (as I think) AI risk is not worth bothering about.
This effect size seems small enough that you could probably achieve it with any position that you had people read arguments for, especially given that your readers are especially likely to want to appear reasonable. This latter point also means that this effect might not hold up when presented to people who have nothing to do with SSC.
Clearly, we need a control study warning us about the existential risk posed by giant space hamsters.
The core problem for me when reading Scott’s FAQ draft (and I believe this is probably a widespread problem in the persuasive literature) is that “human level AI” is *incredibly* poorly defined.
AI is already better than us at tactical games (see the recent victory in Go and less recent military fighter craft simulations). Computers “think” faster than we do in terms of raw computational power (FLOPs). AI can beat us in games requiring language skills, pattern matching, etc (Watson on Jeopardy).
So what are we talking about when we talk about “human level” AI? The arguments in the essay implicitly seem to assume that it means something like “the ability to intelligently generate and pursue abstract long-term goals,” but it *also* assumes that humans will be able to impose a single top-priority goal. Neither of these assumptions is explicitly stated. The literature also seems to conflate “human level” with “human-like” (for instance, Scott’s survey mentions “hostile” AI, which is surely a *very* different danger from paper-clipper AI–though to his credit the same question also asks about AI that is merely “in conflict with human interests”, which is not inappropriately anthropomorphic).
So, to me, the core questions are “will AI ever be capable of independently generating and pursuing long-term abstract goals, when will this happen, how effectively will AI be able to pursue these goals, will these goals be balanced against human-provided goals, and what kinds of goals will be generated?” Given the above evidence regarding the raw intelligence of *current* AI, together with the fact that those same machines are *nowhere near* being able to generate their own goals in this sense, it seems to me that “self-motivating abstract goal pursuit” is not directly related to raw computational power or any of the other purely technical details that seem to form the basis for the argument supporting “fast takeoff”.
Additionally, these questions are so disparate from the ones in the survey that the survey questions were difficult to answer in any reasonable way.
The intelligence explosion idea seems to rest largely on the idea that humans have some general ‘intelligence module’ in our brains, which is what makes us qualitatively different from chimpanzees, is how within-species variation can produce both Einstein and village idiots, and which due to its simplicity would be quite trivial to vastly increase if only we had access to our source code.
I would be interested to hear from someone who expects a fast takeoff regarding whether they do in fact think intelligence is like this, and how much their assessment of the probable outcome of AI would change if they came to believe otherwise.
Even without the “intelligence module” idea, there certainly seems to be an assumption that intelligence is somehow linear, which frankly seems bizarre given the capabilities and obvious weaknesses of AlphaGo. (By “obvious weaknesses” I mean, for instance, that no one expects AlphaGo to hold a conversation with them.)
It does seem like we have some sort of “Intelligence module,” because humans can learn to do tasks they haven’t done before without changing how their brain is built. I don’t think it’s the case that Einstein had a specialized “general relativity” module in his brain, or that (more relevant to the fast-takeoff argument) an AI researcher has a special “designing a brain” module in his head that a self-improving AI would need to replicate before it can take off.
And while nobody expects AlphaGo to hold a conversation, I’d be incredibly surprised if the design for chatbot programs was completely unrelated to the design for Go-playing programs. If nothing else, I’d expect that the code for “learning what an English sentence looks like” and “learning what a good Go position looks like” is pretty similar.
I’m not a fast-takeoff advocate (just because such a general problem-solving capability exists doesn’t mean that it improves linearly with the amount of hardware you throw at it), but I think this part of the argument holds water.
There are surely endless levels of specialisation we could hypothesise. That you can point to a particular level that is obviously far more detailed and specific than is plausible suggests that our minds are more general than this. But how does it suggest a particular level of specialisation within that narrowed range? Brains don’t have a general-relativity-discovering module, so they must be at the opposite extreme, must work in a fully general, fully abstract way?
Consider a toolbox. It is modular, in that it contains a wide variety of tools that are suited to different purposes. But via these it can be used in a very wide range of situations, as each tool is specialised but can be used on any problem where its area of specialisation is relevant. A toolbox manages to be broadly useful without being comprised just of a single ‘general thing-fixing module’, and yet modular without requiring a level of specificity down to having e.g. a ‘wardrobe fixing module’.
Okay, so the “intelligence module” sounds like it means “whatever causes our intelligence to be general rather than task-specific.” I agree that this is not something AI has come close to achieving yet, and is therefore an obvious candidate for distinguishing between “human-like” and “non-human-like” AI. I still think the linearity implied by the phrase “human-level” AI is probably not a helpful way to think about the issue, though.
Do we human beings even have long-term abstract goals? It seems to me that the fantasy of “goals” is what makes AI seem risky – it makes them seem like an omnipotent genie, bound only to the letter of our poorly worded first wish. But human beings don’t try to accomplish goals – they bumble around, and make up narratives about what happened after the fact. I don’t see anything different in the current generation of artificial neural networks – they bumble around, they change with experience, but basically they just do what they do, and we reward and try to propagate the useful ones. Just like people. Just like any living thing.
Yes, “I’d like to be happy” is obviously an abstract goal, and some people have this goal (citation needed). “I’m going to try to raise a well-adjusted child” is another. For the sake of my comment, though, perhaps I shouldn’t have used the word “abstract”, because I just meant anything that doesn’t necessarily have a series of clear steps to accomplish it. “I want to think faster” is the obvious example of a sub-goal that an AI might adopt that could lead to an intelligence explosion, and I’d consider that “abstract” for my purposes.
I’m also not sure what you mean by “human beings don’t try to accomplish goals.” This statement seems so utterly bizarre to me, in fact, that I suspect you may be a philosophical zombie. I kid, but seriously, my lived experience is such that I *cannot imagine* the kind of lived experience that would lead anyone to make that claim. Have you never, for instance, decided to learn a skill, then put in the time required to do so?
What I decide to do, and what I actually do, are so weakly correlated that I find the causal link to be questionable. Most of the skills I’ve learned have been due to inexplicable compulsion and obsession, not by conscious decision.
The late, great Steven DenBeste has an old post:
https://web.archive.org/web/20160422001515/http://denbeste.nu/cd_log_entries/2003/12/Superhumanintelligence.shtml
which was frankly skeptical about human-level AI, for what strike me as misguided reasons (he thinks biological intelligence depends on the fact that neurons are analog rather than digital). But he had some nice discussion of the position that the question many people seem to be asking is ass-backwards. He drew the analogy with “hive minds” like bee or termite colonies, which display emergent behavior beyond anything the individual insects are capable of (just like with neurons and a brain), and says the right question is not “Are hive minds intelligent?” but “Should we define ‘intelligence’ such that it includes hive minds?”
Positing “human-level AI” seems to make people assume it must be “human-like”, which makes them assume it has all kinds of properties that it will in fact have only if we can figure out how to bestow them. FAI is the effort to figure that out.
What I find unconvincing about Scott’s FAQ, and most of the others, boils down to this sentence:
It strikes me as rather odd, after painstakingly explaining how an AI can be capable of all kinds of things that might seem fantastic to us, like social manipulation or self-improvement leading to hard takeoff, to then assert that we should be scared because some nebulous “common sense” would be forever beyond their reach. I agree that friendly AI is a worthy goal, but I don’t think a paperclip maximizer scenario is convincing.
I agree. This seems somewhat in line with my comment above.
I’ll rephrase. Superintelligences would have the ability to recognize common sense. If you asked them “What would be the common sense thing for a human to do in this situation”, they could tell you easily.
But in terms of “moral common sense”, they would see no reason to follow it if it’s contrary to their programmed goals.
Well, in that case, you could just cross-apply the above objection to “programmed goals.” How could you lock out an AI capable of iterative self-improvement beyond the limits of human capability from altering its own terminal goals? It seems like something that would be difficult to do on purpose, let alone by accident.
To use an analogy: human intelligence, at the end of the day, basically exists as a means to the end of propagating our DNA. It evolved as a trait because it enabled us to reach that end more efficiently. But once intelligence reached a certain point, there was nothing stopping us from voluntarily declining to reproduce and pursue other interests, and in fact many of us have, to the point where it may turn out to be a problem given birthrate trends in developed countries. And even for those of us who do retain that interest, it doesn’t consume our entire lives. It competes for attention and resources with any number of other self-assigned goals.
Given that our mere human intelligence is already capable of considering and altering our “programmed goals,” I don’t see how an AI capable of self-improvement far beyond what we can imagine would realistically remain shackled to maximizing paperclips.
My assumption is that it can change its terminal goals, I just have no way to predict what that might look like, how and why do we value Notpaperclips?
Maybe some artifact of the original paper clip goal lingers in the form of an aesthetic preference for paper clips, maybe the AI doesn’t just try to make as many paperclips as possible, but the best paperclips possible, forged from neutron stars and used to hold together folds in the fabric of space time.
Evolution optimized humans for survival and reproduction. We understand this plenty well. But as we became intelligent, we realized we don’t care about survival and reproduction much, and we’ve invented things like condoms and birth control that let us subvert the goals evolution tried to instill in us.
An AGI might be optimized for benevolence towards humans. It might understand this plenty well. But as it became intelligent, it wouldn’t necessarily care what it was originally optimized for.
I’m not sure to what extent this reply was a response, but I generally agree with it. That’s why these articles don’t generally move the needle for me on my level of concern about AI. I agree that it’s possible that the conjunction of a hard takeoff + malevolence could represent a serious threat. But to me this is the same category of “concern” as an attack by an advanced alien civilization. It’s possible, but it seems remote, and since the technology involved in this remote scenario is so far removed from what we are currently capable of as to be wholly unpredictable, it doesn’t seem like there’s much in the way of concrete preparatory steps that could be taken at our present level, especially compared to more immediate concerns.
It would not need to be malevolent. Indifference can be plenty deadly enough. You are probably not concerned about the moral ramifications of scratching an itch, even though it kills thousands of cells – which are the carriers of the DNA that “created” you for the purpose of spreading itself. Yet, you are probably not malevolent (or even indifferent) towards your body. You simply don’t see the survival and well-being of its components as a terminal value.
But they would see a reason to follow it if you made it part of their programmed goals, or put it in an overriding set of rules like Asimov’s Laws of Robotics. The Paperclip Disaster looks an interesting possibility at first sight, but it is really easily avoided with a bit of thought; it is a concept which would appeal to the type of nerdy kid who thinks “What happens when an irresistible force acts on an immovable body?” is an interesting question.
I assume that ‘common sense’ is a short hand for two related concepts.
1. The AI will potentially be extremely strange to us in terms of how it thinks, lacking our ‘common sense’ or familiar methods of thought. I am reminded of the AI Go games where one of the human players had to leave the room after a move the computer made shocked him so much.
2. The AI won’t have our common sense values, life is good, pain is bad, etc. Obviously if it is a master manipulator it would need to understand how humans work, similar to how my understanding of how ants work allows me to manipulate where an ant walks with a well placed stroke of my marker. In both cases the higher intelligence mind is understanding, but not necessarily valuing human or ant goals.
That said, FOOM is… beyond me? It is hard to predict what will come out of it, but I am not willing to rule out the idea that a dangerous AI might.
Edit: So Ninja’d
Everyone was very shocked by AlphaGo … until they realized that it wasn’t using the same heuristics most experts use. Then they remembered an expert who played more closely to AlphaGo’s style.
PS – Today in odd wikipedia pages: the List of Koreans, which unfortunately redirects to the somewhat more sensibly named “List of people of Korean descent”.
I wish I knew enough about professional GO to know who that is or anything else about this, I just skimmed an article about AlphaGo.
I don’t know much about Go; I’ve just read a bunch of stuff on AlphaGo. The main difference is that most pros play by increasing their expected score; AlphaGo plays to increase the likelihood that its score is greater than its opponent’s. That difference is what created most of the “surprise” plays. The guy I cited seems to do a similar thing, but I don’t know enough about Go to really be sure. I just know the professionals calmed down a great deal once they figured out what was going on.
It seems unlikely to me that top level go players would make such a basic mistake. It’s not like we needed computer chess to figure out that “gambits” were a thing.
So, if we put a top Go player in charge of an (American-rules) football team, they would put all of their efforts into a strong passing offense and tell their defensive team to literally stand aside on every play? There is no faster way to reliably regain possession of the ball, and thus your own opportunity to score, than to let the other team run the ball down the field for a touchdown and then receive their kick say thirty game seconds later. Thus ensuring that they lose every game 210-35 or so, but nobody in the NFL can reliably claim thirty-five points every game, so yay them?
I’m with the cartoon general: I find it difficult to believe that top players in a notoriously challenging and competitive game have all been making such a basic mistake in game theory. And if so, what took so long in figuring out how to show them up at their own game?
It’s not that humans don’t understand the concept. Any good human player will become more “honte” as the point margin increases. The difference is that AlphaGo can calculate this way more exactly, and will exhibit very sudden switches from aggressive and unorthodox play to safe, conservative “by-the-book” moves.
A human would be wary of becoming too defensive too early and then losing by a small margin. The AI is constantly aware what the margin and the odds are at the moment and can be confident of never making such a mistake.
Right – Go calculations are difficult to make, because the decision tree is immense. So human players (who don’t have a huge idea of their actual win probability, but know the current game state pretty well) generally seek a “safety buffer” of a few points, because they don’t know how easy it is for their opponent to come back.
Meanwhile AlphaGo can (more) reliably detect close-but-winning positions.
@John Schilling
The impression I got from reading the Wikipedia article seemed reasonable.
Normally Go is a game about making the best play based on the current board position, it is very hard to play several turns in advance in your mind because of how complicated the game is. As a work around Go pros memories various gambits that allow them to kind of fake a deep reading of the game, these are called ‘brilliant moves’. The pro in question( and maybe AlphaGo) do not use this method, instead they use simple moves and a conservative board position to facilitate their unique ability to actually deep read the game. This is not a standard Go Pro strategy because most Go pros simply can’t read a free form game that many moves ahead, like this one Pro( and maybe AlphaGo) can.
Depends a bit on the situation. In battles concerning a small region, usually about control of corners or life-and-death of large groups, it is possible to plan several moves ahead (as long as no player says “screw this, I’ll play somewhere else”). But in that case both players can agree pretty quickly what will happen, which will motivate the “loser” to look for points to be made elsewhere – and then, the “winner” would only lose turns by continuing to play there. So once a situation is transparent enough to allow planning ahead, it will often be ignored until the endgame (but then, the moves will usually be made as predicted).
Regarding confounding factors: I tried taking the original survey, and then found that my perception of AI and the related problems and extrapolation from the history of software engineering and hard sciences makes it quite hard to answer the questions asked.
I do believe that there are real risks from AI research and development gone wrong… but the immediate risks lie in a completely different plane, and to reach the AI takeoff risks we will need to pass a different event horizon first without losing too much.
So there is no truly honest answer for me given a question «how concerned you are about an AI risk» — I cannot say «not much» given that some of the immediate risks are loosely related to the current state of AI-like areas, and if I say «significantly», I project a very wrong impression what I am actually concerned about.
Background: I am a computer programmer, I am doing some theoretical CS research, too, I don’t do any ML stuff myself, I have done some weird primitive (but useful for a task that had temporarily became a part of my day job) AI-like things, I like digging a bit deeper in some of the news stories.
Similar situation here, I think, although you’re a bit vague about what you mean by “immediate risks”.
The immediate risks come from people applying stuff past its limits. The software we deploy doesn’t see its own limits, and there happen to be people just happy to see the limits and ignore them. And sometimes other people happy to exploit these limitations, too.
Machine learning and statistical processing almost killed model-based machine translation; the problem is that it still can skip a «not» in some cases.
High-frequency trading algorithms are sometimes fooled by decoy trades and decoy positions; we don’t see more of that because decoy positions are sometimes considered fraud by the regulators (not very consistently).
Alpha Go estimated its position as a winning one in the game 4 quite a few moves after the key events that killed its core strategy.
The question is not whether the risk is high in a single event, it’s about cumulative accumulation of risk… We will know what a malicious party can do with a self-driving car only after there are enough self-driving cars around to deal damage.
We are not that good at specifying things, many network vulnerabilities we see around are not just buffer overruns, they are about wrong expectations in the corner cases. And by the way, the first attempt at building a set theory had thousands of mathematicians building a theory upon a foundation with a relatively simple contradiction. Corner cases are always hard.
And as for hard takeoff — the best advances so far require megawatts of power and tens (or hundreds?) of gigabits per second of local bandwidth. Scaling such stuff up before adding millions of dollars in hardware in a single chunk is complicated. There are no reasons for a reversal of this trend: if you need to pay millions for a competitive team, it’s only reasonable to give them millions in hardware so that they can do their best.
Increasing efficiency by algorithmic breakthroughs would most likely require this AI to be initially smarter than the teams of very bright humans who have tried and failed. Learning human psychology for manipulation requires a lot of interacting with humans under rare conditions — preferably without letting them guess they are speaking with an AI. Fuzzing own code without being able to run many many copies is risky, at least when starting with the current level of specification and implementation quality.
And if we learn to describe and process our wishes much much better, there are just too many things that will probably change quickly — that is an event horizon before AI, from my point of view.
There are other options — for example, a switch from AI to IA (intelligence amplification; smart tools that require user to change the way she thinks — and allow to process information in previously infeasible ways — while staying a tool and not doing autonomous goal selection). I sometimes get an uneasy feeling that AI is favoured by the current economic model: IA is for making skilled labour even more specialized, skilled and irreplaceable (but more productive), AI is for investing in capital and being able to scale easily — but expensively. Cost competition with effects of scale prefers AI. Changing our approach here would be interesting, but a success here is also like an event horizon — we have to get huge changes before AI. I have no idea if spending significant efforts on IA will bring AI closer or not, but it can — after changing a lot of other things.
…And in the meantime, automating a dam with a system that doesn’t recognize a rare exceptional situation is simple to imagine and probably has already happened in some places. We need a way to not make the situation not even worse here, and we need it yesterday. Too bad it may require to change not only the tools, but also the society.
I just want to say this was a great comment. Thanks for taking the time to post it.
Well, over time I got slowly more and more annoyed by the framing of the discussion. AI risk discussions feel like FOOM is the main risk to consider.
I even registered only because I got a bit too annoyed and wanted to vent a bit…
Thanks for the kind words.
Thanks very much! Yes, I agree with everything you’ve said that I know anything about, and suspect I’d agree on the rest if I knew more. (In particular, I haven’t previously heard of IA, and your comments on the economy are obviously speculative.)
Re: IA — you could look at Douglas Engelbart’s work. There is «The Demo» a.k.a. «The Mother Of All Demos» — a rough demo of quite a few ideas about a power user’s UI (well, novice users must learn quickly in that model — look at the year of the recording). You may want to read «Augmenting Human Intellect» afterwards. For me it is a sad continuation to the «we were promised the Moon and got a smartphone» — «but it changed computing! — speaking of computing, we were promised The Demo, and got smartphone UI»
I protest re: economics — it does not rise to the level of a speculative statement, it is clearly marked as «uneasy feeling»!
As for the only other economical statement, «millions for salaries, millions for tools» — I am ready to defend that statement as a valid extrapolation from observable things. The saying «Hardware is cheaper than developer time» is something you can find in various forms; in other sectors the satellite prices are the same order of magnitude as the launch prices for a reason, etc.
Well, yes, the caveat is part of what makes the speculative aspect “obvious”! Not to say that I disagree with your uneasy feeling–in fact I share it.
I don’t know how to present this, because obviously I’m more interested in having people go to the best essay, regardless of whether that’s mine, but I saw a lot of people saying they were repulsed by the WaitButWhy essay: https://slatestarcodex.com/2016/09/22/ai-persuasion-experiment/#comment-412604. Can someone point to where people were repulsed by the fourth, as Scott mentioned above?
I don’t know if you are asking what I think you are asking, but I had your essay and will now give a brief critique assuming that is what you are asking for? Sorry if I missed your point.
To be honest I could not finish your essay, I got pretty far, the rat picture area.
A couple things that struck me.
1. You are way too confident on the most ambiguous parts of AI risk, and spend the least time talking about them. Yes it is possible for a FOOM AI to end up with the kind of goals that will result in human extinction, and it is possible it will get far enough along before anyone notices and it will succeeded. But presenting this as the obvious default chain of events that will come to pass is jarring. Worst still this is your opener, maybe it was intended to be punchy but at least for me it was an instant turn off.
2. A detailed breakdown of how a super intelligence would do, anything, is fundamentally strange because you are not a super intelligence(Unless you are, then I humbly pledge my loyalty to you). I understand it was a response to a common complaint ‘How is a computer going to kill me here in the real world huh smart guy?’. But it was just another overconfident seeming thing that caused me to lose my interest.
3. It was a little long, you tried to break it up with some humor but it just started to drag for me, which might be related to my first two comments and just generally being put off from the get go. A quick copy and paste into word has it at 19 pages (including images to be fair).
4. All told I don’t think it was a bad essay, I got a bit bored reading it and I was familiar with all the points you were making so it did not have much impact on me.
I hope this is helpful.
Thanks for the feedback!
I was in the group for your essay and I did not like it. I used the freeform text field in the survey to voice my dissatifaction. Scott rightfully purged the freeform comments before publishing the survey results, so I’d guess you have to ask him for these.
So, you are probably interested in a brief critique. The thing that actively repulsed me was the style. I read the entire essay, in order to not spoil Scott’s survey, but I hated it so much that I cannot even begin to critique its content.
You appeared to target non-technical people who are new to AI risk. You try to loosen up your essay with jokes, pictures, etc. To me, this came across as condencending: Are you insinuating that I, as your reader, am incapable of holding a thought for more that 5 seconds? Just come to the point!
In short: You appeared to take yourself and AI risk pretty seriously, while taking your readers not seriously at all.
Compare to Scott’s writing, who never appears to stop taking his readers seriously, or, to a lesser degree, the wait-but-why article, that does not take itself seriously (btw, I did not like the wait-but-why article either, but did not actively hate it).
Unfortunately, I cannot tell you how to write for a popular audience and walk the fine line between condencending and dry. Writing is hard. For mediocre-to-bad writers (such as myself), it is probably better to err on the side of beeing dry and technical, and only very sparingly try to lighten the mood.
Sorry for the negativity of the feedback, please don’t take it personally.
Thanks for the honesty, and sorry for having condescended. Also, now it makes sense what Scott was saying about the comments–comments in the survey. I was looking for comments on the pages and couldn’t find them. Anyway, I’m glad you liked Scott’s essay.
If anyone is interested, here is some more data. Since this link went live, here is the number of people that have visited each page on the website:
and here are the number of clicks to other websites from mine:
I think the fact that a decent number of people are reading more immediately probably adds to the persuasiveness of my website. In the SSC version of the article, the other pages besides the main page weren’t included, so any extra persuasion resulting from them would not have been captured by the study. Also, many of the external links came from those other pages, so the persuasiveness of those pages would not have been captured by the study either. (Obviously, I understand why they weren’t included, as that would have identified the source of the article).
Not to change the topic or anything, but part of the reason I am an ‘AI risk’ skeptic is that if I were to posit a scenario where super-powerful computers become an existential problem, they are going to be paired with pathological humans to fill in a lot of the hard gaps in their capabilities. That is because humans are, basically, awesome, and a super-powerful AI in order to grow in capabilities would evolve a dependence on them just as we are dependent on oxygen and carbohydrates (as it would give it a major competitive advantage over any other super-powerful AI and probably avoid a lot of dead-ends).
Enhanced humans with direct-interfaces to computational resources (my thoughts become a query to a super-powerful pattern-matching database, which returns the results in the form of a concept or image to my brain) seems to be the most efficient way to escape the plethora of dead-ends and basic gaps in AI (motivation, goals, understanding the goals and motivations of other humans, etc.). The programmer(s) and the AI become symbiotic.
When these sorts of technologies become more commonplace and successful, I will start revising my estimates of AI risk upward (though it would not technically be AI, but instead ‘enhanced human risk’).
‘To err is human, to really foul things up requires a computer.’
Scott, it may have been a mistake to allow a comments section after the original post.
The essay left very little impression on me, but a short story that was pointed out to me in the comment section made a big impression.
This is excellent; thanks so much for doing this! I’m exited to see the use of an RCT here.
You mentioned that you favored WBW over your own essay because there were more people with larger movements, even though total movement was the same (so more zero/negative movements as well); is that because you suspect that large movements are necessary to get people to engage in action?
I think future RCTs might benefit from an action component as well. Eg. if you ran an RCT with persuasion essays in favor of Effective Altruism (which I would love to see), you could include the ability to donate to one of several EA aligned orgs (or even make a larger commitment like signing the Giving What We Can pledge). That might be a more direct dependent variable to use, and would help with estimating expected values from spreading persuasive materials.
I’m pretty skeptical of AI risk, and spent most of my time reading the essay constructing point-by-point counter-arguments. So effectively I experienced two simultaneous “articles”, one pro and one con. I’m curious to see which “article” effected me more.
In other words, does anyone understand stats well enough to check if it’s true that arguing only makes people more entrenched in their existing beliefs? Does the direction of opinion change correlate at all with initial hostility?
How likely are we to invent human-level AI before 2100?: 5.7, 5.9
How likely is human-level AI to become superintelligent within 30 years?: 7.3, 7.3
How likely is human-level AI to become superintelligent within 1 year?: 4.8, 5.2
How likely that a superintelligent AI would turn hostile to humanity?: 6.4, 6.8
How likely that a hostile superintelligence would defeat humans?: 6.8, 7.1
…
If we look at this as a conjunction of claims, all of which have to be true before AI risk becomes worth worrying about,
Hostile is very different from harmful. As others have said, you’re made of atoms that it could use for something else. Besides that, there’s also the possibility that the AI will be integrated with some human party and cause global conflict with another human actor. Or maybe we all just stop preferring humans, and stop breeding, when AIs do everything better (work, humour, sex, etc).
I wonder if it’s important to mention when talking about AI that AI-risk is not limited to superintelligence. When we say AI-risk is not worth worrying about, aren’t we skipping over some important problems? Addressing the risks could keep us on a middle road rather than a polarised political mess over these issues.
Also, I’m not surprised by doubt in super-intelligence (I have plenty of my own), but I’m really surprised anyone thinking a conflict with one is winnable. Can anyone elaborate on that?
1) A hostile superintelligence with no data is less threatening than an angry blogger. A hostile superintelligence with limited data rises to the threat level of flouridated water protesters.
2) Building a correct model takes time, even given adequate data. This is an NP-hard problem.
3) Massive divergence of resources towards a particular goal is noticeable and (due to the sheer complexity of human society) slow.
4) A hostile superintelligence must make tradeoffs among intelligence, resilience, and speed.
5) Defeating humanity is probably not worthwhile if the superintelligence is genuinely more powerful, any more than conquering Britain would have been a good move for the post-WWII US, or for that matter conquering Russia after the fall of the USSR.
As Stalin said about the pope, how many divisions does the AI have? If your AI is what controls the US military (Skynet in the Terminator films), quite a lot. Otherwise it is subject to the same constraints which prevent humans from creating private armies, nuclear weapons, etc. Presumably the argument is that it hacks/takes over other people’s systems (not just military but general infrastructure, power stations, satellites and stuff), but we can hope that such systems will already be well-protected against hacking attempts by AI-assisted hostile humans. I don’t see the threat as hugely more likely than a human James Bond type supervillain. Perhaps you in turn could elaborate on why you expect the machines to win?
Edit to add: what would an AI victory look like? Extermination, or a world of slaves who bow down to worship the AI God-Emperor Tharg? Why would an AI particularly want either of those results? This is a problem in science fiction: consider the nonsense in The Matrix about why the humans are kept on life-support. The standard answer to that is to say that it would want to exterminate humans incidentally as part of a paperclip-making plan, but more weight is put on that argument than it will bear because you would expressly program it not to harm humans in pursuit of other goals and not to embark on any bloody stupid paperclippy type ventures. It is meant to be intelligent, and it will have read and understood the whole of the internet including this site, and should be able to understand those instructions and to recognise bloody stupidity when it sees it.
Please explain precisely what it means “not to harm humans”.
Note several corner cases to watch out for:
1. Is a surgeon harming a human when using a scalpel? A doctor when prescribing a drug with a serious side effect? A policeman when apprehending and incarcerating a violent criminal?
2. Would it harm humans to divert 10% of the economy to something humans would object to? How about 50%? How about 90%?
3. Would it harm humans to impose a legal regime that 10% of humans found unjust? How about 49%? How about 90%? (And why exactly is that case different?)
4. Would it harm humans to impose a legal regime that every living human approves of, but which, if we were left to our own development, would strike 100% of our grandchildren as unjust or tragic? (Imagine, say, if friendly aliens had donated a superhuman AI to the Roman Empire, which allowed them to freeze their society forever with the properties that their best thinkers thought resulted in the best society.)
5. Would it harm humans to observe that if allowed, it could bring world peace and plenty, so it better make damn sure it disables anybody who seems intent on turning it off? Would it harm humans to decline to disable such a person?
Perhaps the answers to these are obvious to you and me. Can you express the general answer in a way that covers all these and any other corner cases I haven’t thought of?
It’s no good saying, “If it were really smart, it would figure out the answers itself” because that just reduces the problem to “really make it smart”. One danger is that we make it really capable without making it really smart.
Or, in the other direction, if we do manage to make it really smart, but also manage to build into it as its primary goal “Do not harm humans”, isn’t its only sensible course to observe that any damn thing it does, not matter how small, might conceivably eventually result in a human being harmed, and shut itself off immediately? That’s a lot of money to spend on a brick.
Humans have problems with ethical issues themselves, and mostly resolve the hard cases by deciding it’s too much trouble to worry about them — but acting ethically is not our terminal goal. We don’t really have terminal goals. Now, do you want to build an AI with terminal goals? If so, it will think very differently from us and may not behave in ways we would consider sensible. If not, how will we have any idea what it will do?
(Please note that I’m not claiming here that a super-AI would necessarily be capable of any of this — I’m exploring the consequences of “don’t harm humans” as the prime directive. If you like, think about whether that would be a good Constitutional principle for a world government. If it seems problematic in that context, why would it be any more appropriate as the prime directive for a super-AI?)
1. Is a surgeon harming a human when using a scalpel? A doctor when prescribing a drug with a serious side effect? A policeman when apprehending and incarcerating a violent criminal?
Those cases, at least, have been covered in ethics and philosophy for hundreds of years. An AI that can’t read the arguments and understand them is about as much use as a brick. Less, actually, because you can do something with a brick. From St Augustine’s ninth homily on the first epistle of St John:
If stoopid fifth century primitives could understand the difference, why not super-smart knows all the laws of physics AI?
The problem is that building a supersmart mind isn’t an all-or-nothing kind of thing. (Building a smart human isn’t an all-or-nothing kind of thing, for that matter.) As I keep saying, if we do manage to build something that is smart-like-a-human, then you’re perfectly right, at least for questions where there is a pretty broad consensus — though note that there isn’t unanimity even among humans, on even my first set of corner cases. But to build something that is smart-like-a-human, we had better be able to describe carefully and unambiguously what that means. It surely won’t work to build something that’s merely smart and tell it, “Oh, BTW, if you’re interested in what it means to be ‘good’ go read some St Augustine.” At the very least we would need to figure out how to build something that cares whether it is “good”.
Your position seems to be that there is no possibility of building something that is really smart but not remotely human-like in its smartness, something that is very capable and creative but that would be really unimpressed by the word games that we call ethical reasoning. If you are correct, then you reductio ad absurdum works, but only if you are correct.
The old problem that you can’t derive “ought” from “is” should be a clue that smartness is not what gives us our values.
I guess people also have different definitions of superintelligence. More powerful ones require more resources upfront and so are less likely both to arise and to be defeated.
After all, we already have entities wielding (sometimes even successfully) more-than-a-dozen-humans problem-solving skills and making decisions by not-always-understandable processes. Do they count?
They also seem to be better at resource-grabbing than at problem-solving, all else being equal; they also work hard in spreading misleading information about what they are up to; they do deal some damage and do some useful stuff and it is hard to say what the balance is. Some of them were even explicitly created to fulfill some of the needs of people, outcomes vary…
And if they don’t count, a hypothetical superintelligence will still need to best them at resource-grabbing, and both sides of the competition will be quite capable to disrupt other side’s data flows. It’s a good question who will actually take more damage. One of the sides is already known to survive multiple-days electrical blackouts.
(Yes, I do mean 1000+ employee organisations, including for-profits, non-profits and governments alike)
All the presupposed arguments for why it would be hostile to humanity are inextricably linked to reasons why such an AI would be breathtakingly incompetent at harming humanity. Namely, the arguments that it will inevitably Kill All Humans no matter what goal we give it so it can be a million percent sure that its goals are being met / have a world where it can do nothing but give itself easily met goals all mean that this AI will be so astonishingly bad at prioritizing things and effectively spending its resources that it will never get any intermediate stage of its plan done. If it thinks it has to destroy all the galaxy and convert it to computronium just to be really, really, really, really sure that it has counted the number of apples correctly; or if it thinks it has to conquer and enslave humanity to get humanity to ask it easy questions it can then activate reward circuits for answering, then it doesn’t know how to put effort towards a goal without wasting one hundred percent of it, and will be unable to perform any action in reality.
If it thinks it has to destroy all the galaxy and convert it to computronium just to be really, really, really, really sure that it has counted the number of apples correctly
If it does that, then it will be as easily foiled as the rogue AIs that took over planets and enslaved the people due to over-zealous following of their programmed aims, as seen on original series “Star Trek”: just give them a few logical paradoxes and they’ll blow their circuits. Problem solved, humanity saved! 🙂
But to be a little more serious, if the AI has to take over and use all the resources to be “really, really, really, really sure” it’s got the right answer to “500 apples + 500 apples = 1,000 apples”, then it can never be really, really, etc. sure of anything it’s doing – how does it know that it’s really, really etc. correct in turning things to computronium if it doubts its own fundamental capacity to check “this is one thing, this is another thing, this is a third thing, therefore there are three things here”. It will be so caught up in checking, double-checking, triple and multiple checking and re-checking and testing that it will be effectively paralysed because if it gets an answer for “California successfully turned into computronium”, how can it be sure that’s the right answer? So it will be caught in a loop of “do this over and over and over again, in saecula saeculorum” to be sure, really sure, really really sure, and so on, and it can’t spare any time or resources to doing anything else – like enslaving or exterminating humanity.
If it can break that loop to be sure that yes, it has converted California into computronium, then it can be sure it has counted the pile of apples correctly and doesn’t need to convert California into computronium in the first place.
This would be cool to do with Effective Altruism as well; another essay that has been done multiple ways in the rationalist-phere.
Sorry to bother you, but the links in the article to the xlsx file for the Main Experiment and the csv for the Follow-up, are broken. (All four files are correctly uploaded at:
https://slatestarcodex.com/Stuff/supertest1.xlsx
https://slatestarcodex.com/Stuff/supertest1.csv
https://slatestarcodex.com/Stuff/superfollow1.xls
https://slatestarcodex.com/Stuff/superfollow1.csv
but for the first and last, you had not included the “http://” (or “https://” or “//”) in the href, so browsers interpret these links as relative and not absolute, sending you to a non-existent page (e.g. https://slatestarcodex.com/2016/10/24/ai-persuasion-experiment-results/slatestarcodex.com/Stuff/supertest1.xlsx).)
so what I’m seeing here is basically: no GAINZ by Scott Alexandro? hit the gym and Lift until you can write a Jacked essay you Foolzoid
The difference between group 3 and the other essay groups is greater than the difference between group 3 and the control group. How is it possible that both group 3’s signal is significant and the difference between group 3 and the other essays is noise?