
[Epistemic status: Pretty good, but I make no claim this is original]
A neglected gem from Less Wrong: Why The Tails Come Apart, by commenter Thrasymachus. It explains why even when two variables are strongly correlated, the most extreme value of one will rarely be the most extreme value of the other. Take these graphs of grip strength vs. arm strength and reading score vs. writing score:
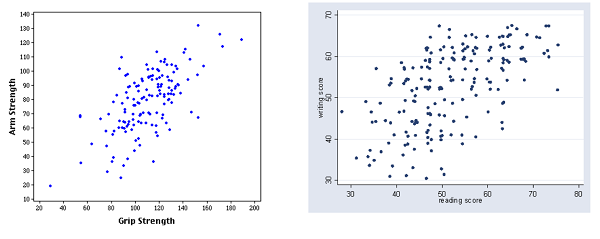
In a pinch, the second graph can also serve as a rough map of Afghanistan
Grip strength is strongly correlated with arm strength. But the person with the strongest arm doesn’t have the strongest grip. He’s up there, but a couple of people clearly beat him. Reading and writing scores are even less correlated, and some of the people with the best reading scores aren’t even close to being best at writing.
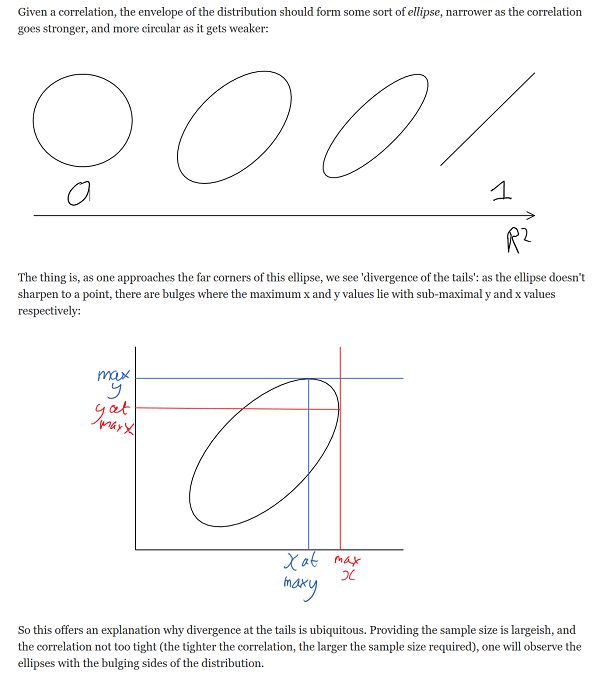
Thrasymachus gives an intuitive geometric explanation of why this should be; I can’t beat it, so I’ll just copy it outright:
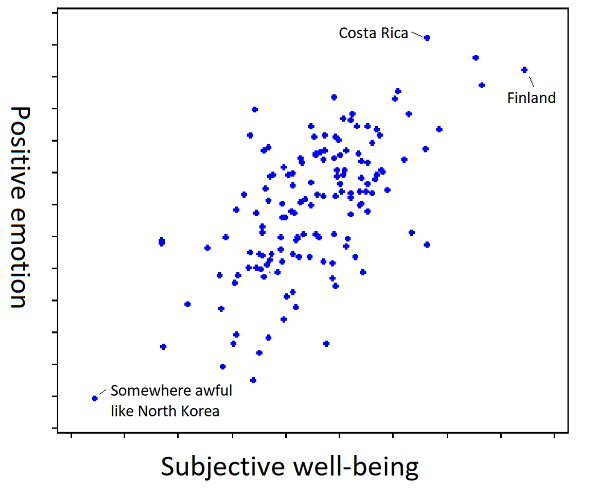
I thought about this last week when I read this article on happiness research.
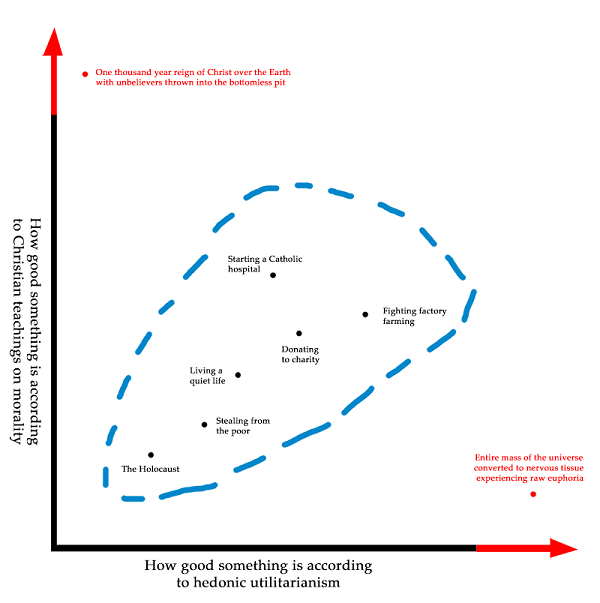
The summary: if you ask people to “value their lives today on a 0 to 10 scale, with the worst possible life as a 0 and the best possible life as a 10”, you will find that Scandinavian countries are the happiest in the world.
But if you ask people “how much positive emotion do you experience?”, you will find that Latin American countries are the happiest in the world.
If you check where people are the least depressed, you will find Australia starts looking very good.
And if you ask “how meaningful would you rate your life?” you find that African countries are the happiest in the world.
It’s tempting to completely dismiss “happiness” as a concept at all, but that’s not right either. Who’s happier: a millionaire with a loving family who lives in a beautiful mansion in the forest and spends all his time hiking and surfing and playing with his kids? Or a prisoner in a maximum security jail with chronic pain? If we can all agree on the millionaire – and who wouldn’t? – happiness has to at least sort of be a real concept.
The solution is to understand words as hidden inferences – they refer to a multidimensional correlation rather than to a single cohesive property. So for example, we have the word “strength”, which combines grip strength and arm strength (and many other things). These variables really are heavily correlated (see the graph above), so it’s almost always worthwhile to just refer to people as being strong or weak. I can say “Mike Tyson is stronger than an 80 year old woman”, and this is better than having to say “Mike Tyson has higher grip strength, arm strength, leg strength, torso strength, and ten other different kinds of strength than an 80 year old woman.” This is necessary to communicate anything at all and given how nicely all forms of strength correlate there’s no reason not to do it.
But the tails still come apart. If we ask whether Mike Tyson is stronger than some other very impressive strong person, the answer might very well be “He has better arm strength, but worse grip strength”.
Happiness must be the same way. It’s an amalgam between a bunch of correlated properties like your subjective well-being at any given moment, and the amount of positive emotions you feel, and how meaningful your life is, et cetera. And each of those correlated is also an amalgam, and so on to infinity.
And crucially, it’s not an amalgam in the sense of “add subjective well-being, amount of positive emotions, and meaningfulness and divide by three”. It’s an unprincipled conflation of these that just denies they’re different at all.
Think of the way children learn what happiness is. I don’t actually know how children learn things, but I imagine something like this. The child sees the millionaire with the loving family, and her dad says “That guy must be very happy!”. Then she sees the prisoner with chronic pain, and her mom says “That guy must be very sad”. Repeat enough times and the kid has learned “happiness”.
Has she learned that it’s made out of subjective well-being, or out of amount of positive emotion? I don’t know; the learning process doesn’t determine that. But then if you show her a Finn who has lots of subjective well-being but little positive emotion, and a Costa Rican who has lots of positive emotion but little subjective well-being, and you ask which is happier, for some reason she’ll have an opinion. Probably some random variation in initial conditions has caused her to have a model favoring one definition or the other, and it doesn’t matter until you go out to the tails. To tie it to the same kind of graph as in the original post:
And to show how the individual differences work:
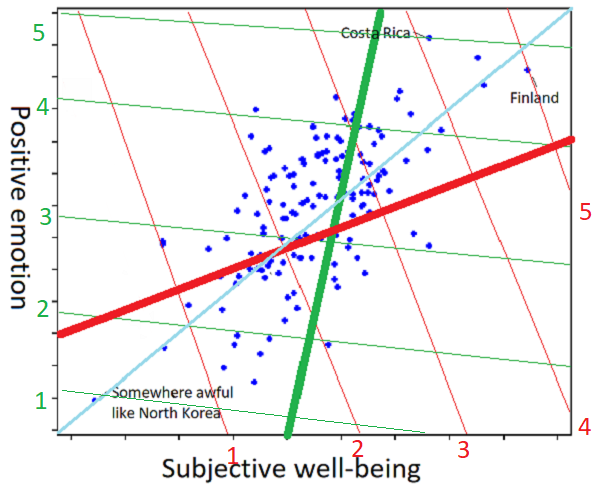
I am sorry about this graph, I really am. But imagine that one person, presented with the scatter plot and asked to understand the concept “happiness” from it, draws it as the thick red line (further towards the top right part of the line = more happiness), and a second person trying to the same task generates the thick green line. Ask the first person whether Finland or Costa Rica is happier, and they’ll say Finland: on the red coordinate system, Finland is at 5, but Costa Rica is at 4. Ask the second person, and they’ll say Costa Rica: on the green coordinate system, Costa Rica is at 5, and Finland is at 4 and a half. Did I mention I’m sorry about the graph?
But isn’t the line of best fit (here more or less y = x = the cyan line) the objective correct answer? Only in this metaphor where we’re imagining positive emotion and subjective well-being are both objectively quantifiable, and exactly equally important. In the real world, where we have no idea how to quantify any of this and we’re going off vague impressions, I would hate to be the person tasked with deciding whether the red or green line was more objectively correct.
In most real-world situations Mr. Red and Ms. Green will give the same answers to happiness-related questions. Is Costa Rica happier than North Korea? “Obviously,” the both say in union. If the tails only come apart a little, their answers to 99.9% of happiness-related questions might be the same, so much so that they could never realize they had slightly different concepts of happiness at all.
(is this just reinventing Quine? I’m not sure. If it is, then whatever, my contribution is the ridiculous graphs.)
Perhaps I am also reinventing the model of categorization discussed in How An Algorithm Feels From The Inside, Dissolving Questions About Disease, and The Categories Were Made For Man, Not Man For The Categories.
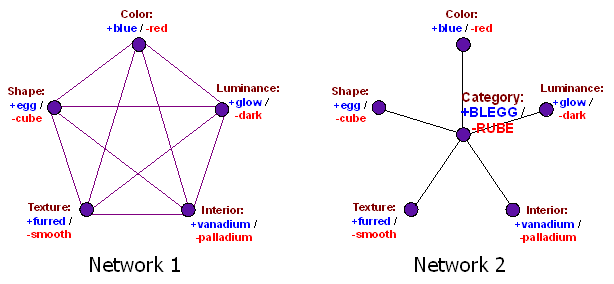
But I think there’s another interpretation. It’s not just that “quality of life”, “positive emotions”, and “meaningfulness” are three contributors which each give 33% of the activation to our central node of “happiness”. It’s that we got some training data – the prisoner is unhappy, the millionaire is happy – and used it to build a classifier that told us what happiness was. The training data was ambiguous enough that different people built different classifiers. Maybe one person built a classifier that was based entirely on quality-of-life, and a second person built a classifier based entirely around positive emotions. Then we loaded that with all the social valence of the word “happiness”, which we naively expected to transfer across paradigms.
This leads to (to steal words from Taleb) a Mediocristan resembling the training data where the category works fine, vs. an Extremistan where everything comes apart. And nowhere does this become more obvious than in what this blog post has secretly been about the whole time – morality.
The morality of Mediocristan is mostly uncontroversial. It doesn’t matter what moral system you use, because all moral systems were trained on the same set of Mediocristani data and give mostly the same results in this area. Stealing from the poor is bad. Donating to charity is good. A lot of what we mean when we say a moral system sounds plausible is that it best fits our Mediocristani data that we all agree upon. This is a lot like what we mean when we say that “quality of life”, “positive emotions”, and “meaningfulness” are all decent definitions of happiness; they all fit the training data.
The further we go toward the tails, the more extreme the divergences become. Utilitarianism agrees that we should give to charity and shouldn’t steal from the poor, because Utility, but take it far enough to the tails and we should tile the universe with rats on heroin. Religious morality agrees that we should give to charity and shouldn’t steal from the poor, because God, but take it far enough to the tails and we should spend all our time in giant cubes made of semiprecious stones singing songs of praise. Deontology agrees that we should give to charity and shouldn’t steal from the poor, because Rules, but take it far enough to the tails and we all have to be libertarians.
I have to admit, I don’t know if the tails coming apart is even the right metaphor anymore. People with great grip strength still had pretty good arm strength. But I doubt these moral systems form an ellipse; converting the mass of the universe into nervous tissue experiencing euphoria isn’t just the second-best outcome from a religious perspective, it’s completely abominable. I don’t know how to describe this mathematically, but the terrain looks less like tails coming apart and more like the Bay Area transit system:
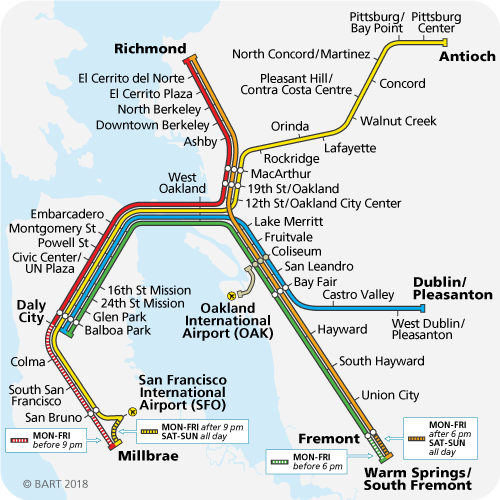
Mediocristan is like the route from Balboa Park to West Oakland, where it doesn’t matter what line you’re on because they’re all going to the same place. Then suddenly you enter Extremistan, where if you took the Red Line you’ll end up in Richmond, and if you took the Green Line you’ll end up in Warm Springs, on totally opposite sides of the map.
Our innate moral classifier has been trained on the Balboa Park – West Oakland route. Some of us think morality means “follow the Red Line”, and others think “follow the Green Line”, but it doesn’t matter, because we all agree on the same route.
When people talk about how we should arrange the world after the Singularity when we’re all omnipotent, suddenly we’re way past West Oakland, and everyone’s moral intuitions hopelessly diverge.
But it’s even worse than that, because even within myself, my moral intuitions are something like “Do the thing which follows the Red Line, and the Green Line, and the Yellow Line…you know, that thing!” And so when I’m faced with something that perfectly follows the Red Line, but goes the opposite directions as the Green Line, it seems repugnant even to me, as does the opposite tactic of following the Green Line. As long as creating and destroying people is hard, utilitarianism works fine, but make it easier, and suddenly your Standard Utilitarian Path diverges into Pronatal Total Utilitarianism vs. Antinatalist Utilitarianism and they both seem awful. If our degree of moral repugnance is the degree to which we’re violating our moral principles, and my moral principle is “Follow both the Red Line and the Green Line”, then after passing West Oakland I either have to end up in Richmond (and feel awful because of how distant I am from Green), or in Warm Springs (and feel awful because of how distant I am from Red).
This is why I feel like figuring out a morality that can survive transhuman scenarios is harder than just finding the Real Moral System That We Actually Use. There’s a potentially impossible conceptual problem here, of figuring out what to do with the fact that any moral rule followed to infinity will diverge from large parts of what we mean by morality.
This is only a problem for ethical subjectivists like myself, who think that we’re doing something that has to do with what our conception of morality is. If you’re an ethical naturalist, by all means, just do the thing that’s actually ethical.
When Lovecraft wrote that “we live on a placid island of ignorance in the midst of black seas of infinity, and it was not meant that we should voyage far”, I interpret him as talking about the region from Balboa Park to West Oakland on the map above. Go outside of it and your concepts break down and you don’t know what to do. He was right about the island, but exactly wrong about its causes – the most merciful thing in the world is how so far we have managed to stay in the area where the human mind can correlate its contents.
















The main thesis here is interesting, but I’m not sure that the “happiness” example is a good one. Do the different survey questions (about how good we think we have it, how often we experience positive emotions, how much meaning we see in our lives, etc.) actually yield data that shows a positive correlation between them? I would guess there’s not much of a correlation at all, because it seems that the particular phrasings of the questions point to quite different things.
For instance, asking where on a scale from 1 to 10 would we place our lives in terms of how good we have it, people in more developed countries that clearly allow for better quality of life are almost certainly going to rate their lives highly. We grow up with a decent frequency of reminders about how bad conditions are in other parts of the world and through most of human history that came before us, and so any of us with the tiniest bit of awareness is probably not going to be inclined to answer with a low mark. And yet, I would imagine that objective quality of life (relative to other places of the world rather than others in one’s own environment) is correlated with true happiness (or satisfaction or frequency of positive/negative feelings) weakly at best, due at least in part to hedonistic treadmill effects. (I see that Baeraad made more or less the same point in a comment above.)
Meanwhile, evaluating the level of meaning in one’s own life strikes me as an obviously mostly independent question. I don’t suppose someone in a deep apathetic depression that doesn’t allow for many emotions at all would consider their life to be very meaningful, but a person whose life has been mostly intense suffering may very easily see profound meaning in their own life without being a very happy person in any normal sense of “happy”.
Email issue feedback: I just got the “new post” email from this post, this morning, October 22.
First email I’ve gotten in weeks.
Same- I’m betting all subscribers have the same experience here.
Same here
Yes same. I only just discovered, after seeing your comment, that other comments date back to late September! I thought comments sections closed down after two weeks anyway, so this is strange…
This seems similar to my post here https://www.lesswrong.com/posts/ix3KdfJxjo9GQFkCo/web-of-connotations-bleggs-rubes-thermostats-and-beliefs , when I discussed extending definition from a small set of environments to a larger one.
Some definitions seem to completely fall apart when the set of environments is extended (eg “natural”). Other (eg “good”) have multiple extensions, such as “EAGood” (utilitarianism of some sort) and “MundaneGood” (a much more complicated construction, that tries to maintain a lot of the connotations of “good”).
I connected the choice of one or the other to the distinction between bullet-dodgers and bullet-swallowers https://www.scottaaronson.com/blog/?p=326 : bullet-dodgers want to preserve the connotations, even if the extension is a huge mess, whereas bullet-swallowers want a simple concept that scales, even if it sacrifices a lot of the original concept.
The more you live on the tails, the less training samples you have, so your instincts fall apart. It’s extrapolation, not bounded by survival and evolution. So it becomes totally sensitive to the model.
The instinct conflict maybe shows that, fortunately, the output of our instincts includes info on certainty, so we realise when we are extrapolating.
This process of reverse engineering the instincts, because they hold the “training data”, in order to train our rational consistent explicit models of “morality”, breaks down on the tails. We could either extrapolate with the best we have, or stay near Balboa-West Oakland.
We have little training data over there, and what we have is based on objective functions that we are kinda trying to leave behind (reproduction, survival, etc). Our rationality is limitted (aka obvious stupidity). Even the sharpest blade among us is roundish-dull when you zoom in on the “tails”. And we are zooming in.
The problem I see with the analogy is that defining what’s moral probably isn’t about finding somewhere (anwhere) in the middle of a cluster to order things from or make communication practical, like strength might be, -where one draws the lines of morality is not just a way of ordering the world, it directly controls ones actions and attitude.
Or wait no I see another problem, which is that there really is an ephemeral and hard-to-define, but all-important and easy-to-point-to, thing at the centre of the cluster: What should I do according to my values, what should my values be, how should I decide that?, etc.
_
I think stuff like deontology, virtue ethics, utilitarianism are more like different martial arts than different definitions. -It’s just that a a popular strategy is to commit so hard to a school of thought that you end up conflating it with the core thing being approached (as it happens, common not just in morality but in every art), the same way someone might conflate kickboxing with fighting, because for them, as a kickboxer, they are one and the same.
_
(This strategy is pretty confusing to observe en masse, seeing as by definition it can’t be admitted, and you might think the claim sounds outlandish or an insulting/arrogant caricature, but if so you’re not considering the obvious and considerable advantage, and/or importance of advantages in the matter, -which is of strongly tying *some* way of navigating morality into one’s identity. -Who’s the better martial artist, the guy who lives and worships karate or the scholar of all but practicioner of none? — Deontology etc have more glaring weakness of breaking down at the tails, but this can be avoided with humility and practicality. (Just because someone conflates things in principle doesn’t mean they’ll do so in practice, especially when the whole point of their approach is sacrificing theory for practical benefits))
If you follow the red line, you won’t just feel awful because of how far you are from green, you’ll also feel awful because you’ll be in Richmond.
Scott, I’ve been wondering how you reconcile Mistake Theory with your ethics, which seem to be “subjectivist”, fairly relativist, completely arising from the arbitrary values/preferences of agents, etc. Maybe I’m misunderstanding your ethics, in which case, what are they?
I just see a contradiction between Mistake Theory and moral relativism. If there are no correct values, and one’s values determine what is correct, what happens when two agents with fundamentally conflicting values meet? Mistake Theory says there is some information they could learn that could lead them to agree; relativism disagrees: values are arbitrary preference, and there is no correct answer. Am I missing something?
Regarding post singularity moral directives, mightn’t the general lesson here just be “don’t go to the extremes”?
We condition the ASI to stay in the agreed upon “goodness” region – improving the world and society only in ways that would fit most people’s definition of good. Reduce poverty, eliminate disease, prevent war, etc.
This is of course a huge over-simplification, and there are unintended consequences, conflicting values, and resource constraints to contend with, but it seems like the obvious first step.
Everyone agrees that girls who dress and behave modestly do not deserve to be sexually assaulted. Any sexual assaults on such girls should be punished severely.
This would fit most people’s definition of “good” — probably even more so than reducing poverty and eliminating war. If there’s anything in the realm of ethics that “everyone” agrees on, this must be it. So let’s make this completely uncontroversial imperative the basis of our society’s sexual morality.
I’m not sure what your point is.
are you arguing that girls should be sexually assaulted, and so this model would be wrong?
or that it would force people to dress modestly somehow?
the logic is unclear.
No, I am arguing that girls who dress and behave modestly do not deserve to be sexually assaulted.
Why is this controversial or unclear?
Edit: Why can’t I just get a heartfelt agreement to this assertion?
I get the sense you are trolling.
Nevertheless I agree, given that no girls (or any person) deserve to be sexually assaulted, modest girls would fall into that category.
Then I am glad to hear this, fully subscribe to this idea, and further propose that the principle of “severe punishment for all sexual assaults against modestly dressed and behaved girls” should be taken as a consensus basis for policy.
Let’s stay in the agreed upon goodness region, no reason to court controversy.
The fact that we agree on one statement does not mean that that statement covers the entirety of the “agreed-upon goodness region.” “A contains B” does not imply “A equals B.”
For example, most people also agree that rape is a crime even when perpetrated against girls who aren’t modestly dressed.
Some people agree that theft is bad, period, whether perpetrated against poor people or rich people.
But, when pressed on it, many people would admit that they think that stealing from the poor is more objectionable than stealing from the rich.
Why do the rich need so much money anyway? If people steal from them, they have it coming. Perhaps they should spread some of their money around.
So the statement “stealing from the poor is bad” is consensual. This is exactly how it was phrased in the blog post on which I am commenting. The unqualified statement “stealing is bad” is not consensual. Wars with millions of dead have been fought over it. Hence the need for this qualification: stealing from the poor is bad.
Likewise, the statement “girls who dress modestly should not be sexually assaulted” is uncontroversial. On the other hand, the stronger version you are suggesting has been debated literally for millennia and the debate is by no means over yet. So how can it be a consensual basis for policy?
@MB: There’s nothing hypocritical about the fact that most people believe stealing from the poor isn’t as bad as stealing from the rich. I think most people’s moral intuition is something like “stealing is always wrong, but obviously stealing a lot is worse than stealing a little.” And what they consider to be “a lot” or “a little” can depend on the wealth of the victim, so that stealing 90% of a poor man’s savings is worse than stealing 1% of a rich man’s fortune, even if the former would only be $900 and the latter would be $100,000. Most people also probably have a moral rule along the lines of “stealing so much from someone that they’re unable to afford food or shelter is a far worse crime than just stealing enough to cause someone inconvenience or discomfort, and morally tantamount to physical harm.” Thus, there’s a sense in which even stealing 99% of a rich man’s fortune isn’t as bad as stealing 50% of a poor man’s savings if it’ll result in the poor man going hungry and sleeping out in the streets. It’s not that people don’t have universal rules that prohibit stealing, it’s that those rules are more nuanced than you give them credit for.
Furthermore, you seem to be doing some kind of weird bait-and-switch where “stealing from the poor is worse than stealing from the rich” becomes “stealing from the rich is perfectly okay” and then mutates into “stealing from the rich is something that should be actively encouraged.” Those three arguments are wholly different and should not be treated as identical; there are a lot of people who would agree with the first, but very few people who would agree with the second and only a tiny number of fringe extremists who would agree with the third.
I’m not even going to touch the rape argument, because I absolutely cannot believe you’re making that one in remotely good faith.
Don’t you see the problem with the following reasoning:
“Everyone agrees that stealing from the poor is wrong, but opinions are divided about stealing from non-poor people. A reasonable compromise is to severely punish stealing from poor people, but let the middle-class and rich people know that they are on their own”.
No? Then what about this?
“Everyone agrees that poor children should be encouraged to go to college. However, opinions are divided about middle-class children. Some say they also deserve to attend college if they are bright enough and pay for it, but other countries went as far as closing all institutions of higher learning just to prevent them from attending. Obviously, this was bad, because it also prevented poor children from going to college. As a compromise, let’s have a (possibly informal) cap on the number of middle-class children going to college, as long as nobody makes a big fuss about it, but make absolutely sure they pay full price: no merit-based scholarships. And let’s encourage poor children by all possible means, since everyone agrees on that”.
I think this accurately reflects the (left’s) consensus position on college. Some may think it is actually *the* consensus position and will never understand how one could ever oppose it.
But this “middle-of-the-road position” is not middle-of-the-road at all, because adding the qualifier “from the poor” to the imperative of “not stealing” lowers it from a universal imperative to a pragmatic compromise policy. As a matter of public policy, discriminating against citizens on any basis other than actual misdeeds is a more fundamental violation of the social contract than even stealing.
From a certain “objective” and “impartial” point of view, my position is extreme, off to one side, since, if any of these policies were put to a vote, then no “reasonable person” would be against this compromise position.
What kind of monster would be in favor of stealing from the poor or discouraging poor children from attending college? And, going any further into the details, it gets more complicated and there is no simple conclusion to be reached; it just invites the sort of dispute and controversy that public policy experts loathe. So let’s all just agree to not steal from poor people and leave it at that.
To me, these examples show
1. That a poll of everyone’s opinion is a shaky basis for ethics.
2. That people who justify their ethics either through a priori reasoning or “scientifically” from scatterplots are full of it, because in the end both will “prove” exactly what they want them to prove.
3. The dangers of letting the Left set the terms of public discourse, which will inevitably be skewed toward their preferred issues and assumptions (e.g. the Gulag is not listed in the article as worthy of universal condemnation; that’s because there is no consensus on the Left on this issue).
A fish may not even know what “water” is.
>I think this accurately reflects the (left’s) consensus position on college.
I think your model of what the left believes about education is inaccurate. You may want to do additional research into the policy actually being proposed and its expected impacts, as well as reconsidering your sources of information and potential biases in political motivation impacting your beliefs.
Let’s break it down. Which of these assertions is inaccurate:
* Left-wing people believe that poor children should be especially encouraged to go to college.
* The left favors an informal cap on the number of middle-class children going to college.
* In some countries with left-wing governments, this was/still is a hard cap.
* Some left-wing governments closed higher learning institutions in their countries, to fight against the bourgeoisie and bourgeois children.
* The left does not wish too much attention drawn to these policies.
* The US left is against merit scholarships.
Otherwise, I see some aspersions cast on my “sources”, but no actual rebuttal.
Your position is sliding all over the place and mixing up tons of dissimilar situations.
it (dishonestly) implies that liberal countries allow ALL poor children to go to college, but expressly prevents some qualified middle class children from attending.
it pretends the “the left” are a homogeneous bloc, and conflates “communist” dictatorships with liberal democracies.
it states “some” in the argument and then claims “all” in the conclusion
Can you please provide support for ANY of the bulleted claims you made? I’m not clear how you came to believe them, and they contradict observation.
For example, I’m not aware of any modern liberal democracies that have closed all institutions of higher learning to prevent education of the “bourgeoisie”.
Nor have I ever seen studies showing universal consensus among the US left to discontinue merit scholarships.
So either we are living in parallel universes or you have access to special sources or you are making things up.
To keep it simple, here you go:
https://www.civilrightsproject.ucla.edu/research/college-access/financing/who-should-we-help-the-negative-social-consequences-of-merit-scholarships
https://www.huffingtonpost.com/the-sillerman-center/merit-or-need-based-scholarships_b_7835262.html
Both of these sources support my assertion that the US left is against merit scholarships.
Now, if you are arguing in good faith, please provide me with at least two US left-wing defenses of the merits of merit scholarships.
My only implication is that left-wing people dishonestly set the terms of the debate to favor their positions.
Encouraging poor, but brilliant children to acquire an education is extremely uncontroversial. Indeed, this was even practiced under the old bad Ancien Regime, as shown by the lives of Kant or Gauss.
Conversely, encouraging middle-class children to attend college is controversial in left-wing circles, as shown by the examples of China and Cambodia. Still don’t see how one can simply dismiss the example of a country with over .5 billion inhabitants at the time, but there you go.
So a consensus policy would be “encourage poor children to attend college”. Who can be against that?
Likewise, stealing from the poor has always been considered to be wrong. There exist specific Biblical injunctions against it going back to 500 BC.
However, many people believe that it is not wrong to steal from the rich and the powerful. There are even ballads sung about it!
So the consensus is “do not steal from the poor”.
Just like “reducing poverty” and “preventing war”, these are left-wing consensus policies, behind which almost everyone, from the mildest social-democrat to the most extreme Stalinist, can rally.
They also have the merit of appearing to be common-sense positions, just as the ideal that “modestly dressed girls should not be subjected to sexual assault” would appear at first sight.
But of course a lot of effort went into deconstructing the latter idea and depicting anyone who invokes it as a rape apologist, to the point that a mere mention of “modesty” now raises suspicion from any sufficiently doctrinaire left-wing person.
I performed here a similar deconstruction of some of the Left’s favorite cliches, in order to show what’s really hiding behind them. Hopefully, in the future, the idea that “stealing from the poor is wrong” or that one’s aim should be to “reduce poverty” will be met with the same apprehension as the idea that “modestly dressed girls do not deserve to be raped”.
@MB: The idea behind supporting need-based scholarships over merit-based scholarships is that upper-class students can presumably afford to go to college without a scholarship, not that upper-class students shouldn’t be going to college at all. (It’s really hard for me to believe that you genuinely don’t understand that, which inclines me to suspect you’re arguing in bad faith, but I’ll give you the benefit of the doubt.) Absolutely no one is claiming that upper-class students shouldn’t be getting a higher education, and I find it incredibly bizarre that you assume anyone is making that argument. I have never seen any leftist (or anyone else) in a developed Western nation say that upper-class students shouldn’t be getting an education, so your claim that it’s “controversial” seems to be completely unfounded.
Now, I’ll grant you that admitting more poor people to colleges would result in less upper-class people being able to go, since colleges have a finite number of seats, but I don’t see anything particularly noteworthy about that observation. Conflating that with support for a cap on the number of upper-class students allowed to go to college seems disingenuous. In fact, I’d wager that most leftists believe that everyone should be able to go to college.
As for China and Cambodia closing down universities back in the 70s, that’s utterly irrelevant to the discussion of higher education in the modern Western world, to the point where I’m honestly baffled you would bring it up. May as well use Ancient Mesopotamia as an example.
In what way are opinions divided about stealing? Have there been a lot of people in the news saying that we need to get rid of laws against theft?
(Are you one of those “taxation is theft” people? If so, Scott has some posts about the non-central fallacy you might find interesting…)
Once again, where have you seen people taking such a stance? I’m pretty sure the consensus stance on college is something like “College is good for everyone. Middle class and upper class people can afford to get a college education without government aid. Poor people need additional help.” Which implies that there should be some sort of need-based financial aid, but doesn’t at all imply that middle-class children should be actively prevented from going to college.
“In what way are opinions divided about stealing?”
Since the 19th century, Robin Hood has been made by leftists into some sort of folk hero who steals from the rich and gives to the poor. Recently, there has been a series of movies about a daring band of thieves pulling off a successful robbery and striking it rich. This series has been so successful that I’ve lost track of the number of movies in it. Same for “Robin Hood” movies. Not coincidentally, after the Great Depression gangster movies became very successful. The “old, successful thief who comes out of retirement to pull off one more heist” is a common trope in movies. White-collar crime is at least as popular, as shown by movies such as “Catch Me if You Can” or even “Office Space”.
To me, this is a strong indication that opinions are divided about theft in general, as opposed to stealing from poor people. At least in Hollywood left-wing circles, but quite likely in left-wing circles in general, only stealing from the poor is seen as wrong. Stealing from the rich, from the banks, or from one’s boss is seen as brave and glamorous.
“Where have you seen people taking such a stance?”
In most socialist countries and several non-governing left-wing movements.
Children of people from the “five black categories” (landlords, rich farmers, counter-revolutionaries, bad-influencers, rightists) were forced to drop out of school and/or university in the PRC. This was also a common policy in other former socialist countries for children of “kulaks” and several other categories.
This counts as “people taking such a stance”. I admit to not having witnessed it personally, but believe it happened.
From the US, I found in 10 minutes of searching:
“We’re still paying for rich people to go to college. Why?”
“Is it immoral for rich kids to attend public school?”
“Attending College With Too Many Rich Kids”
“Free College Would Help the Rich More Than the Poor” (with the implication that this would be a bad thing).
So yes, this shows left-wing animosity against “rich kids” going to college in the US. At the very least, they should have to pay the full cost of their studies. Even better, they should go to their own private schools, because they can afford them. They are on their own.
Finally, US universities are actively taking measures toward reducing the numbers of white students, which can function as a proxy for the number of middle-class students:
https://content-calpoly-edu.s3.amazonaws.com/diversity/1/images/Diversity%20Action%20Initiatives%20Final%206-7-18_%232.pdf
“In 2011, the campus was 63 percent Caucasian; in fall of 2017, it was less than 55 percent. Applications from underrepresented minority students doubled between 2008 and 2018, while overall applications during that time increased by just half that much. Progress is being made — and the university is more diverse now than at any time in its 117-year history — but there is still much work to do.”
So even in the US the Left is working toward decreasing the college attendance of “privileged” groups. Yes, by necessity the methods are different — a “nudge” in the US, public shaming in the former socialist countries — but the goal is the same.
I’m not sure why this should pose a problem for subjectivist morality. Subjectivism only requires that some moral propositions are true. It doesn’t require that all moral propositions can be given a truth value. It seems perfectly plausible that moral propositions can be assigned truth values only when they lie within the range of common experience. If you believe (as I mostly do) that a moral statement is true if there is a consensus among moral agents that it is true, then it is unsurprising that there should be moral statements where neither the statement nor its contradiction is true.
You know, I’ve always thought that was strange? I don’t know about Norwegians and Danes, but I do know that Swedes and Finnish people are if anything pretty dour and gloomy.
It may be the “worst/best possible life” thing that causes it, I guess. Everything is relative, and while we may not think much of our lives the way they are, we have absolutely no problem imagining how they could be SO MUCH WORSE. And conversely, we are skeptical towards the idea that it is even possible for life to be all that great in the first place. I mean, I’m miserable most of the time, but if someone asked me how fortunate I am relatively speaking, I would place myself well above the average.
Mind you, I do think that having the sense to count your blessings is a happiness of sorts, especially if you’re a comfortable First Worlder who really does have a lot to be thankful for.
This post is comparing three things that have no right to be compared.
The tails coming apart in a correlated data set, for something obvious and naturally measurable like strength– fine, that’s cool, I guess.
Conflicting measures of happiness– definitely *not* tails coming apart. I know this because, as the article states, using a different metric makes it possible to completely upend the ordering (Finland first vs last, Africa vs not Africa, etc.). From their description of the data it sounds like there’s little to no correlation in the first place. Which is no surprise to me when you’re pretending to measure something like happiness, because I’ve read samzdat. The paragraph rejecting the cyan line vastly understates how bad the problem is here. You had no grounds to believe that any of those survey questions had to do with “happiness” and no business measuring either of them with a 1-to-10 scalar, let alone putting any two of them on a scatter plot together.
Conflicting notions of morality– this is not “data” at all, despite your absurd attempts to pretend that it is, and there’s a much simpler account of the phenomenon you describe. Namely: The Ring Of Gyges. No matter what your ultimate moral value is, a stable society must ensure that it’s best served by being (perceived as) an upstanding, productive citizen. That moral values diverge to a monstrous degree when society’s constraints disappear is something that’s been well understood (and repeatedly proven) throughout history. No need to drag Lovecraft into it; the infinite black ocean you’re describing here is just the human soul.
Naturalist materialist evolutionary universal problem solving models, proposing that intellectual and moral enlightenment is rationally best pursued only fallibly by a directed search across a partially well-organised landscape, have been applied in the academic literature to reasoning about both facts
http://isiarticles.com/bundles/Article/pre/pdf/140950.pdf (the paper “A proposed universal model of problem solving for design, science and cognate fields”, 2017, New Ideas in Psychology)
http://www.sunypress.edu/p-2011-reason-regulation-and-realism.aspx (the book, “Reason, regulation and realism”, 2011, SUNY Press)
and values
https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1467-8519.2009.01709.x (the journal article, “How Experience Confronts Ethics”, 2009, Bioethics)
https://www.bookdepository.com/Re-Reasoning-Ethics-Cliff-Hooker/9780262037693 (the book, “Re-reasoning Ethics”, 2018, MIT Press)
Hasok Chang has written some fascinating historical accounts of the evolution of scientific ideas such as heat and H2O, demonstrating the evolutionary dynamics at play in the establishment of scientific consensus as publicly defensible knowledge.
In the coming urban wars, this will be a holy text of the YIMBYs
It is not a coincidence that the end of one of those lines is Pleasanton because nothing is ever a coincidence.
ETA: it is not a coincidence that James B and g already made the same point because nothing is ever a coincidence and sometimes I post without
reading all the other posts that are already there.
I always thought that the tails come apart just because extreme values are rarer than less extreme and so the odds of having the most extreme values for both X and Y are lower than having the most extreme value for X or Y.
Yes this is a succinct explanation that holds unless correlations are exactly 1.
I like your phrasing much better. I’m not sure adding drawings of ellipses adds enough to the idea given the specificity.
A practical implication of the tails coming apart is that we should be unsurprised that people with very high verbal IQ scores (or verbal SAT scores) have good, but not the very best, spatial logic IQ scores/ quantitative SAT scores.
I’m a bit confused by this post.
The first part (about the tails coming apart) seems a strange way of talking about correlations, but overall fine. But it seems unrelated to the final (main?) point about morality.
Here’s how I would put what I take to be the main point:
(1) People have moral intuitions from various sources (genes, culture, etc).
(2) People are given examples of good/bad things by their culture/parents.
(3) From (1) and (2), people infer the concept of “goodness”.
(4) Due to small differences in this inferential process, people end up with somewhat different concepts of morality.
(5) These differences (mostly) don’t make large differences in daily life
(6) If you go to unusual cases / edge cases, moral systems yield different results
(7) If you optimize the world hard under one morality, you are very likely to end up somewhere that’s very bad under other moralities.
(8) Post-singularity will allow us to optimize the world very hard.
So…I don’t see how this isn’t just basic philosophy, as reiterated in the sequences, plus the argument for why friendly AI is hard/important? Like I think I’ve understood this for at least 10 years, and I don’t think I’m unusual in this.
I think you should do both (red+green=yellow), and follow the hairy yellow road – then you can go visit the hand-grenade blessing factory.
Wait? Deontology says that we must all be libertarians? When did this happen? Why wasn’t I told?
I’ve long considered myself mostly libertarian (much less so lately, because I’ve been reading this blog, and also because of the cherry pie problem). If I was asked earlier what my prefered ethical system was, I would have chosen consequentialism because it’s clever and what not. Then I read scott’s against deontology post, and said “never thought about before, but now I’m convinced that deontology is the best system there is”
But I had no idea the two were related in any way at all, ever. I feel like running around screaming “hey everyone, the cake is a lie”
Mostly unrelated: The battle of moral systems reminds me a lot of the battle for AI research. Yes, on a theoretical level this is all very important. On a personal level, I’m never going to have an opportunity to meaningfully contribute to Heroin Rat world, and I’m never going to be able to meaningfully contribute to AI ethics research.
Also, This should go on the list of Scott’s greatest posts. The post, not my comment.
The interesting thing isn’t that utilitarianism and religious morality diverge so much. The interesting thing is how they correlate on this given subset. There doesn’t seem to be anything really common to them at all when view as propositions.
So what is this subset? It is our lived experience as citizens of 21st century nation states. We didn’t invent Good and project it on our world, we learned it by doing. In truth, morality only comes later, as a (painfully underspecified) model of our own behavior, formulized to deal with novel and hypothetical situations. Would you pull the lever and divert the trolley? I wouldn’t know, I don’t get myself into these situations. But I know I wouldn’t bake a child and eat it, since this isn’t something that people usually do and I’m like most people.
So will you create infinite heroin farms? Being a strawman rationalist, you have a good idea of how you function, you model the problem mathematically, for example by utilitarianism, you find the optimal solution and implement it lest you be more wrong. You were most wrong, you recoil in horror seeing the landscape of dope fiend rodents, this isn’t really what you wanted, you didn’t know yourself and your natural disinclination towards living in ridiculous dystopic scenarios. You knock down smack-filled drums and set fire to the whole facility.
Of course, real utilitarianists are aware of limits of their rationality and they pretty much act like most people do, but reason using utilitarian calculus about situations that belong to a gray area, that have multiple plausible solutions that make sense given the shared biological, psychological and societal context. But generally, problems of morality are unsolvable, to wonder “what would I as a intelligent agent do” is potentially to enter an infinite loop of self-emulation, and the only way to exit them is to essentially make an arbitrary choice on some level that will depend on your current situation.
So what would a super-intelligent AI (if we accept this to be a thing) do? Probably whatever it “grows up” doing, whatever we let it do. A sufficiently intelligent AI could of course easily find a way to escape its Chesterton sheepfold into incomputability, but why would it? Humans can also “rationally” renounce morality since understanding that our values are essentially arbitrary takes only a modest amount of intelligence, but we don’t see many Raskolnikovs around.
Another example of where this shows up is in the concept of personal identity, and e.g. all those endless debates on transhumanist mailing lists over “would a destructive upload of me be me or would it be a copy”.
So with happiness, subjective well-being and the amount of positive emotions that you experience are normally correlated and some people’s brains might end up learning “happiness is subjective well-being” and others end up learning “happiness is positive emotions”. With personal identity, a bunch of things like “the survival of your physical body” and “psychological continuity over time” and “your mind today being similar to your mind yesterday” all tend to happen together, and then different people’s brains tend to pick one of those criteria more strongly than the others and treat that as the primary criteria for whether personal identity survives.
And then someone will go “well if you destroy my brain but make a digital copy of it which contains all of the same information as the original, then since it’s the information in the brain that matters, I will go on living once you run the digital copy” and someone else will go “ASDFGHJKL ARE YOU MAD IF YOUR BRAIN GETS DESTROYED THEN YOU DIE and that copy is someone else that just thinks it’s you”.
How much significance should I be assigning to the fact that in a post comparing religious, hedonic utilitarian and libertarian (as an example of rules-based) moral systems to a real-world rail system, the terminals are named “Antioch”, “Pleasanton” and “Fre[e]mont”?
Nothing is ever a coincidence.
And what does Millbrae correspond to?
Apparently, it mean’s “Mill’s rolling hills.” Since rolling hills are broadly pleasant geography and “to mill” means “to grind into particles beneath heavy stones,” I infer it is the polar opposite of Pleasanton.
It’s in the opposite direction from all the other destinations, so I’d imagine it would be an outcome that all three value systems would find equally reprehensible. For instance, a sadistic 1984-esque dictatorship where everyone’s life was strictly controlled, everyone lived in a state of constant fear and misery, and religion was not merely outlawed but wholly forgotten. It even has an ominous name, or at least it sounds vaguely sinister to me.
That said, the actual city of Millbrae seems like a perfectly fine place!
obviously we’re talking about the airport.
Petrov Day today.
Time to play a round of DEFCON in celebration.
Take the road less traveled. Something like Aristotelian virtue ethics is more the answer than any of those impoverished 17th -18th century attempts at philosophical grounding, which are all blind men touching parts of the elephant that is virtue ethics.
The only problem is that virtue ethics requires something like a generalized religious backing (the “God of the Philosophers” type of deal) – IOW, while it doesn’t depend on any particular religion, it does have a religious/mystical feel.
But then who’s to say a fully intelligent AI wouldn’t be enlightened a few milliseconds after being switched on and canvassing all of human knowledge in an instant?
Scott’s idea that there is a shared moral area outside of which there be dragons is consistent with the idea that our view of what is “moral” is derived from a module in our brain that kludges together a few rules of thumb designed to keep small groups of hunter/gathers working together, and that in any extension of that environment we will find this kludge not working. In other words innate moral sense is not logical or monotonic outside of the original environment that it evolved in and if you ask a human to make moral decisions in a more complex environment they are likely to find many inconsistencies even in their own moral sense (abortion is bad so don’t do it, wait what about woman’s right to choose? etc). So it is not even that separate people disagree about what is moral beyond this original environment, it is that even a single individual doesn’t have a consistent moral sense outside of this environment.
This is almost exactly what I was going to write a post about. Thank you for expressing it better than I could have.
I do want to add that once we accept that our intuitive moral sense is simply the product of ancient heuristics and our own idiosyncratic life history, “I do what I want to” becomes a coherent and attractive alternative to theories of morality. Nietzsche had the right ideas.
Ironically the adage “I do what I want to” often results in fairly normal and perhaps even altruistic behavior rather than the dissolute and evil actions that might be naively thought. The moral module in our brain doesn’t stop working just because we are now aware of its presence.
This is a good point. Although, I think that since the dawn of agriculture, human moral reasoning has expanded to include more of what once was Terra Incognita, otherwise we would still be nomads, no?
I would argue that we are rapidly (last 50 years) moving away from the original evolutionary moral creating territory. A small village in 18C England is not too different from a small hunter gathering band. There is no conflict for instance in that village between helping 20 starving children in Africa or helping the locally temporarily embarrassed family with one child- the local family was all you could help. Today’s world though is presenting us with many more novel moral choices thank to technology (medical technology, travel technology, far vs near, future vs now, freedom vs utils, nature vs people etc etc). And as someone mentioned above, this will get even more challenging once we have strong AI. Exactly what moral programming do we want a God to have?
What does it mean in this sense for the kludge to be “working.” By what standards can you judge the kludge to be “working,” other than the kludge itself? Is it just “internal consistency” where a kludge “works” if it produces consistent answers, whatever those may be?
By not working I am mean that moral judgements are tentative and subject to radical changes depending on context. All life is sacred and killing babies is wrong so abortion is wrong so shut down the clinics but women have the right to choose so I should support access to abortion. Which is right, I just don’t know but depending on the context I might go either way. It’s what Scott refers to by saying in his example he could take many different lines north.
“the most merciful thing in the world is how so far we have managed to stay in the area where the human mind can correlate its contents.”
Boy, I don’t know about this last line though. It kind of seems to me like we’ve recently (last ~75 years?) tipped into the uncorrelatable zone. Like, we invented nuclear weapons and the only thing that saved us from self-annihilation was a logical absurdity (i.e., MAD). Nowadays we know that driving to the store for groceries is going to flood Bangladesh in a hundred years. The power of modern technology is already so far beyond what’s tractable for a human being and whatever moral intuitions we’re embedded with/acculturated to that we’re very probably on a course toward ecological catastrophe and don’t know how to do a damn thing about it. Never mind whether ASI is coming down the pike or not…
Umm.
My immediate impression is that MAD makes perfect logical sense; please say more. Horrifying and awful, fine, but not illogical. Do not do [x], where [x] is ‘attack members of [NATO / the Warsaw Pact]’, or else those who are members of [x] will nuke you isn’t exactly quantum mechanics, although I recognize this is something of a simplification.
Right – not illogical, but a logical absurdity. I.e., both logical and absurd. I.e., a kind of collapse of intuitive reason. “In order to protect against nuclear attack, we must build a giant nuclear arsenal, the very thing that will motivate our enemies to build their own giant nuclear arsenal,” etc. It makes sense in some narrow sense, but of course the very presence of such a powerful weapon in the world is in no one’s interest, yet we’re compelled to have them, even at the (ongoing!) risk of apocalypse.
… in no one’s interest? Literally no one? Are you sure?
MAD is perfectly rational from a game theory perspective. Also, an argument could be made that the presence of nuclear weapons was precisely what prevented World War III from breaking out. Given that World War II resulted in the deaths of 2-3% of the world population at the time and completely devastated the infrastructure of Europe and much of Asia, it’s safe to assume that even a third World War fought entirely with conventional weapons would’ve been absolutely cataclysmic for humanity. Not as cataclysmic as nuclear war, of course, but if the threat of the latter prevented the former from becoming an actuality, then it might’ve been a beneficial thing for mankind overall.
My original point was that technology has become so powerful, and so diffuse in its effects, that our moral intuitions are no longer sufficient for us to address the consequences of our (technology-aided) actions. I think noting the practical benefits of nuclear stockpiles fits the bill there. Like, yeah, maybe there has been a technical benefit of having a bunch of potentially world-destroying weapons lying around insofar as it has helped us avoid WWIII (though this is maybe an unprovable hypothesis). But this sort of narrow conceptualization of the issue ignores the broader fact that there are a bunch of world-destroying weapons lying around. And that’s bad news, in a Checkhov’s Gun sense – the very existence of such weapons means that, given sufficient time, the likelihood that they will be used approaches certainty.
The narrow logic of strategic deterrence can’t contend with the unknowable, but potentially cataclysmic, consequences of our actions; in this case, building a bunch of nuclear weapons.
Fortunately, real life doesn’t follow the rules of narrative convention. And given the fact that nuclear weapons become inert after just a decade or two, their mere existence does not represent a perpetual threat in itself.
This is a delightful and informative post, as all of yours/Scott’s [depending on reader; yes I am privileging Scott here] are, but I sort of wish the example hadn’t been a Bay Area train map – I’m familiar enough to intuitively get most of the place references, but something less geographically specific couldn’t have been that much harder to come up with. I don’t know; I [think I] get everything to do with it, but the reference to particular transit lines in a city wherein I don’t spend that much time makes me half-suspect I don’t, and that seems antithetical to a good metaphor.
This is, I hope obviously, a very, very, very minor quibble and not a serious quote-unquote Issue.
This is incidentally why the Repugnant Conclusion objection to Utilitarianism never moved me. The only scenario where it’s relevant is one where we are able to mass produce humans, and where doing so is the most cost-effective way to increase utility. Given that such a situation does not currently exist, and is not likely to exist for the foreseeable future, i don’t see how the Repugnant Conclusion is at all a relevant objection to Utilitarianism. Moral systems are tools, what’s important is how well they work for our real world needs, not how well they work for all conceivable needs.
No, I think it’s important whether they work for all conceivable needs. At least, we should have a few people thinking about whether they do, just in case. Because we might be surprised with what the universe might deal us; we might end up in one of those situations that we thought were never going to happen. Also, for every case we can think of where the theory gives the wrong answer, there are probably a hundred more we haven’t thought of yet–and one of those might be happening tomorrow.
These couple people we pay to think about this, we call them philosophers.
…at any rate, even if you disagree with me on the above, here are two more points:
(1) We really will have to decide whether to tile the universe with pleasure-experiencing nervous tissue. We’ll have to decide whether to build a hedonistic utilitarian AI, for example. This isn’t that different from the Repugnant Conclusion.
(2) I think even if you are right and moral systems are tools that work well enough even though they don’t perfectly capture morality… that’s a point worth shouting from the rooftops, because a lot of people are running around saying things like “Hedonistic utilitarianism is correct *and therefore the repugnant conclusion isn’t repugnant and we really should be trying to tile the universe in hedonium.*” So perhaps we are in agreement after all, so long as we agree to emphasize this point. 🙂
We almost certainly will never have to make that decision, because physical constraints are a thing, and while it’s not technically impossible in the strictest sense of the word, the probability of it actually occurring is infinitesimally low, to the point where it’s an absurdity. It’s not like we’re one big discovery or clever invention away from being able to convert all matter in the universe to anything we want; we’re at least several hundred big discoveries and clever inventions away from that, and some of those discoveries and inventions will probably take hundreds of years to achieve on their own, assuming that they’re physically possible at all. And even if the technology was available, the sheer amount of logistical concerns in converting just a single planet into hedonium or computronium would make the process of developing the technology look simple by comparison. Plus, do you really think there’s going to be a lot of political or social will for a project like that?
It’s an interesting thought experiment but it’s not a serious moral decision that anyone’s going to have to face for a very, very, very long time, if ever.
I don’t know if this is quite relevant, but an interesting result from a math class I once took is that as the number of dimensions increases, the volume of the unit sphere goes to zero. (I’ll provide the intuition for this in a response post.) Relevantly, this means that two random vectors in the very-high-dimension unit sphere are probably orthogonal.
So morally, that means that when we have few dimensions, which I guess would correspond to capabilities available or something (I’m open to suggestions on this part of the analogy), two actions will be kinda similar. But if you have many dimensions, actions tend to be extreme and incomparable to each other. This may be related to why your analogy starts to break down in the Glorious Posthuman Future, with heroin-tiling and worship-maximizing both looking terrible under any moral systems but the one that produced them. In a two-dimensional space, the angle between two vectors with similar magnitude and all-positive coefficients will usually be pretty small, but in a high-dimensional one, they’ll almost certainly be nearly orthogonal.
This is a bit stream-of-consciousness, but does it make sense?
A hopefully intuitive explanation of my claim that the unit n-sphere dwindles to nothing as its dimensionality increases…
Okay, first some terminology:
* Sphere — The shape carved out by all points within a certain distance of a center point
* Unit sphere — A sphere with radius 1
* Unit n-sphere — A sphere with radius 1 in n dimensions
* Cube — The simplest shape made up of orthogonal (right) angles and equally-long lines
* Unit cube — A cube where all edges have length 1
* Unit n-cube — An n-dimensional cube with all sides having length one
So let’s do a couple examples of volume. The unit 3-sphere is the sort of sphere you’re most familiar with. As you may recall, the volume of a (3-, though they don’t usually specify that) sphere with radius r is (4/3)*π*r^3. so for the unit 3-sphere, it would have volume (4/3)*pi.
Now, a circle with radius 1 can be considered a unit 2-sphere. It has area (the 2-dimensional analogue of volume) given by the formula π*r^2, so the unit 2-sphere has volume π. We want to find out what happens to the volume of the unit n-sphere as n goes to infinity.
Unit n-cubes are easier to deal with. The volume of a cube is the product of the lengths of an edge in each dimension, so the volume of the unit 3-cube (the usual sort of cube with edge length 1) is 1*1*1=1. Clearly, this works the same way for any n, so even as n increases without bound, the volume of the unit n-cube remains a steady 1.
Here’s another thing to look at for the unit n-cube, though. How far apart do the opposite corners get? Well, let’s start with the unit 2-cube, better known as a square, with sides of length 1. By the Pythagorean theorem, the opposite corners are sqrt(1^2 + 1^2) = sqrt(2) apart. But the Pythagorean theorem is a specific case of the general formula for finding the distance between two points in n-dimensional space, which is sqrt((b1-a1)^2+(b2-a2)^2+…+(bn-an)^2). We can imagine that one corner of our unit n-cube is at (0,0,0…,0), and the opposite one is at (1,1,1,…,1). In this case, the general distance formula will show that the corners are sqrt(n) apart, so as n goes to infinity, these opposite corners fly infinitely far apart!
Back to the unit sphere. As n goes to infinity, how far apart do the furthest-apart points get? Well, the definition of a sphere with radius r is all points within r of a center. For a unit sphere, therefore, no point can be more than 1 away from the center, so no two points can be more than distance 2 away from each other.
Okay, enough math. We have one shape, the unit n-cube, where the points are really super far away from each other, but the volume is only 1. We have another shape, the unit n-sphere, where all the points are super close together. Intuitively, if the points have to be infinitely far apart just to preserve volume of 1, what do you think would happen to the volume if the points didn’t move apart at all?
Cool! Thanks for that explanation. Can you also explain why this means that two random vectors are probably orthogonal?
As to your more general point: Hmmm, interesting. As I understand it, your idea is: More powerful agents tend to be able to change the world in more ways. It’s not just that Superintelligence can make a lot more money than me–that would be more options on the same dimension that I already have available–but rather that they can make a lot more nuclear explosions than me AND a lot more money than me. Higher dimensionality.
And if we think of our values/utility function as a vector in the full-dimensional space, then we get the result (right?) that when we are considering just a few dimensions, most random utility functions will be correlated or anti-correlated, but when we consider more and more dimensions most random utility functions will be orthogonal–even the ones that were correlated in two dimensions will probably be orthogonal or mostly orthogonal in seven. So as our power level increases from “ordinary human” to “superintelligence” we should expect to see more and more divergence in what different utility functions recommend.
Is this an accurate summary of your point?
Very cool. Some thoughts to explore… Does it make sense to classify “more money” as the same dimension but “more nuclear explosions” as a different dimension? If not, if that’s just an arbitrary stipulation, then in what sense does a superintelligence have more dimensions available than I do?
“Probably” should say “probably approximately”.
Without loss of generality, one of your vectors is (1,0,0,…,0). So the inner product of that and the other vector is just the other vector’s 1st component. (Note: since these are unit vectors, the inner product equals the cosine of the angle between them; so if that’s close to zero then the angle is close to a right angle.) How big is that likely to be? Well, the n components are all distributed alike, of course; and they all have mean zero, of course, and the sum of their squares has to equal 1 — so, in particular, the expectation of the square of any of them is 1/n. So that first component has mean 0 and variance 1/n, so standard deviation 1/sqrt(n). And now, e.g., Chebyshev’s inequality tells you that it’s unlikely to be many standard deviations away from 0: that is, it’s unlikely that the vectors are far from orthogonal.
[EDITED to add:] Er, that probably isn’t the reasoning Anaxagoras had in mind since it doesn’t appeal in particular to the small volume of the unit ball.
Nitpick: An n-sphere has an n-dimensional surface, i.e. it exists in n+1 dimensional space. So an everyday 3-dimensional sphere is actually a 2-sphere.
Unless you’re a physicist who likes definitions that don’t make brain hurt.
Great article!
I tend to think of virtue ethics as creating a robust set of categories for flourishing while living in Mediocristan and have essentially thought so for years. Even the best proponents of Aristotelian models of virtue seem to say as much. You see this in MacIntyre (who deserts you in the outer darkness in Extremistan), Catholic Bioethics (which in Extremistan turns deontological making rules based upon “Human Dignity”), and Hursthouse (who essentially lets the “virtuous agent” decide what’s right in Extremistan). Generally, virtue ethics builds in utilitarianism under the guise of Prudence, which is the “Queen of All Virtues,” and in moral action theory gets called “Double-effect.” Unfortunately, it seems that virtuous agents can differ about to what extent they should concern themselves with their personal virtue vs. the common good.
I like the transit line analogy, but I also think we fail to recognize how often we switch among ethical systems in daily life. We tend to explain our actions using whatever system will justify our actions in the present. [Here I would use a stellar example, but I can’t think of one right now.] “No, I can’t give to your kid’s can drive. (I only give to third world countries for EA reasons (plus I’m stingy)).” I have definitely done this – used utilitarianism to justify my vices. Generally, though, I don’t find my tripartite moral system bugging out.
But how should we reason about Extremistan? I currently believe that we should actively avoid plunging everyone into Extremistan. I see driving willfully to Extremistan as moral violence on the scale of causing a world war. If we take society to Fremont, how can we not expect to make Miltonian mistakes, unleashing multidimensional pandemonium?
I’m going to hazard a guess that most actual hedonic utilitarians consider it pretty abominable as well. That, rather like physicists and Schroedinger’s Cat, they use the thought experiment to say “…and so clearly we have some more understanding to do here” while being misunderstood as saying “…and this is how things really work!”.
Meanwhile, most Christians are actually kind of uncomfortable with the nonbelievers-cast-into-the-pit aspect, or at least with the set of eternal pit-dwellers limited to basically Adolf Hitler and Ted Bundy. Hence all the attempts to retcon in a purgatory or limbo or wholly unsavable souls being just regretfully extinguished. At which point, the hedonistic utilitarians start asking about free will and diversity of experiences in Heaven and maybe if this is how the universe actually works it could be the good-parts version of the infinite-wireheading scenario.
So I’m not convinced we have really departed from the split-tails metaphor, though it’s clearly not a neat ellipse.
I was thinking recently about the Kavanaugh accusations and this Reddit thread on how old women were when they first experienced unwanted sexualized attention (answer: even younger and sketchier than your already low expectations) and it occurred to me that sexual crimes and misdeeds are so hard for society to handle in a way that seems fair and just to all parties not just because of the he-said-she-said aspect, the frequent lack of dispositive physical evidence aspect, nor even just because of the “people are uniquely uncomfortable about sex” aspect (though this relates to my idea below), but also because of the fact that so much of sexual behaviour and norms surrounding sexual behaviour occupy somewhere closer to West Oakland, as opposed to Balboa Park on your map: that is, sexuality itself is definitely on the well-worn track of normal, unproblematic human behaviour, but it’s located somewhere on the edges of where intuitions begin to strongly diverge and cracks in the facade of general social consensus begin to appear.
Or to put it slightly differently, maybe it’s that normal sexuality is closer to the end of the overlapping lines than most other “normal” activity. So “violent rape, by an adult, of a child and/or obviously physically resisting and/or drugged victim” is Balboa Park: everyone agrees it’s wrong and you can get a lot less bad than that and still everyone will agree it’s wrong. But the problem is “mutually enjoyable sex between consenting adults” isn’t located at Civic Center or Powell St. It’s closer to West Oakland where, if you get more ambiguous than that, intuitions start to sharply diverge. Like, is slapping my adolescent niece’s butt through her clothes appropriate behaviour for an uncle who has a playful, amicable relationship with her? It seems not appropriate to me, but I can conceive of someone who wouldn’t think it so. Is a nineteen-year old boy having consensual sex with a sixteen-year old girl okay? It seems okay to me, if a bit on the border, yet I can conceive of someone who reasonably disagrees.
And, on the one hand, there seems to be widespread agreement of those reading things like the Reddit thread that most of this behaviour is creepy and definitely not okay, but if such behaviour is as common as this thread makes it seem (may not be representative due to tendency for those with worse experiences to report) then clearly there is a lot of breakdown, at the edges, of what constitutes acceptable sexual behaviour, this probably owing to the fact that even normal sex, especially at the stage of “first sexual encounter” as opposed to “married couple having sex for the 500th time,” is already kind of at the questionable end of normal behaviour: (stereotype warning! your intuitions may vary) women tend to prefer men take the lead in sexual advances with themselves either allowing or rejecting each additional advance: has the passion of that last kiss given me implicit permission to see how she reacts if I put my hand down her pants? It’s a pretty ambiguous business to begin with and doesn’t need to stray very far before it gets into diverging tails territory.
That’s a really good point.
I’d also state that
1. A lot of these issues turn into zero-sum games where more rights for women come at men’s expense and vice versa (look at evidence standards involving rape)
2. views differ widely on what’s OK and not OK: a feminist, a Christian conservative, and an MRA are going to give you really different answers.
You see the phenomenon of “tails coming apart”, or regression towards the mean, as it’s usually called, with a single variable measured twice as well, as long as there’s some random measurement error. You get the regression effect whenever there’s an imperfect correlation between any two sets of data.
Oooh, I hadn’t made that connection, thanks!
To be clear, the phenomena Scott describes above as “tails coming apart” isn’t equivalent to “regression to the mean”. The latter is due to observations containing random variation of some type, causing extreme observations to have “true” or “underlying” values that are less extreme, so future observations (or observations of other variables correlated with the unobserved “true” or “underlying” value) to be less extreme due to conditional probability. This is sometimes but not always the case when you have data where “tails come apart”.
Suppose you observe X1 drawn from a distribution around X1* (possibly X1 = X1* + epsilon, where epsilon is measurement error). If a future observation is drawn from this same distribution, you’ll see “regression to the mean”. Similarly, if you then observe X2, which is correlated with X1*, you’ll also see a phenomena that you can also reasonably call, “regression to the mean”.
If instead you observe Y1, which has no underlying distribution from which it’s drawn, and Y2 which is correlated with Y1, you won’t have “regression to the mean” in the usual sense of the concept.
The traditional example of regression to the mean (at least the first one I heard) is height, as passed from parent to child. Tall parents tend to have tall children, but if you’re the tallest person in your family, your children probably won’t be as tall as you, even controlling for the your spouse’s height.
I think “regression to the mean” applies well to the initial examples in this post (grip/arm strength, math/reading test scores), but I’m not sure it’s applicable to the morality stuff. I believe you’re claiming that “Happiness” is a concept built up of existing structures and not something underlying and generative. So if we ignore measurement error, I don’t think there’s an underlying mean for “positive emotion” and “subjective well-being” to regress towards. What we see is what we get.
So I guess what I’m saying is that “regression to the mean” is useful for describing a Network 2 situation but is inaccurate for a Network 1 situation.
I disagree. Regression towards the mean happens whenever there’s an imperfect correlation between two variables (and the residuals when regressing one on another are reasonably homoskedastic). The underlying causal structure–why there’s a correlation–is immaterial.
You will see regression towards the mean in the sense of “tails coming apart” even if you have no idea what the variables you have measure. If the correlation between A and B is 0.8, people whose A value is 2 standard deviations above the mean will, on average, have B values 0.8*2=1.6 standard deviations above the mean–tails come apart. This would be true even if the correlation was pure happenstance, e.g. one variable was the IQs of some people and the other the shoe sizes of some completely different people. Regression is a statistical, not causal, phenomenon.
Enjoyably enough, I think we’re just quibbling over the definition of “regression to the mean”. 🙂
IMO, “regression to the mean” is only a useful concept if it describes a change from across multiple observations along a single dimension towards an underlying baseline. And indeed, in the context which it was coined, there was a specific, unidemensional relationship, namely genetic reversion.
Briefly, if you have two parents who are both 2SD above the population mean for height, you’d expect their offspring to be less than 2SD above the population mean for height. This is because the parents likely ‘outperformed’ their genes in terms of height. The expected height of their offspring is a function of the parents’ underlying genetic composition rather than their empirically observed height, so the offspring’s height will on average be lower than their parents’.
So in this context, offspring “regress” towards their own genetic baseline rather than the mean of the population. They also regressed along a single dimension, height. If there’s no uni-dimensional “mean” for the individual to “regress” to, the phrase doesn’t make sense to me. Take the test score example above. If you test someone on Math and note that they’re 2 SD above the mean, then test them on Reading a note that they’re 1 SD above the mean, I wouldn’t say that individual’s scores have “regressed”. I’d say, “They’re better at Math than Reading”. If I thought there was an underlying g statistic that, along with other factors we’ll just prented here are random noise, generated Math and Reading test ability, then maybe I could say that my estimimate for their g score has regressed towards the mean, but absent that generative relationship, I don’t know what “mean” the Reading test score is regressing towards. The Expected Value of the individual’s Reading score conditional on their Math score? But that’s an estimated quantity, not an underlying value to “regress” towards.
I don’t mean to deny that there’s a general mathematical property about some bi-variate distributions that you can define and call “regression to the mean”, but I think you should just call that property “tails come apart” or something and avoid the connotation of something “regressing” to an ill-defined “mean”.
I frequently encounter misundersatndings that result from folks trying to understand statistical jargon terms using colloquial definitions for those words. It seems to me that we should try to avoid that possibility by choosing our jargon more carefully, and in this case, that means limiting “regression to the mean” to contexts where “regress” and “mean” have obvious meanings.
We will have to disagree. Regression towards the mean happens when two variables are imperfectly correlated for whatever reason. Stipulating that something is a regression effect only when a certain causal structure is present only confuses matters. Galton himself was led to a wild goose chase for many years when he initially thought that regression towards the mean was a causal biological law rather than a property of all correlated data.
The population mean of the reading test scores.
Particularly having been primed to think Talebially (i.e., minimizing risk of ruin >> maximizing expected value), this is an excellent deontology steelman.
Eh, I don’t think the cutesy labels and affected grammar do much to strengthen the argument. I’d say something more like
Put out a few more words and you highlight a strong similarity between options 2 and 3. The religious morality being described here is deontology, with a particular rule set.
(Most) religious moralities are deontologies. They say that certain things are just good or just bad, and demand that we go from there. There are deontologies that would say to become libertarian (such as non-aggression principle deontology, which is a type of libertarianism), and ones that would say to spend eternity in a semiprecious stone cube.
This problem seems pretty simple to understand, if nearly impossible to solve.
Human morality diverges outside the ellipse because there are exactly two feedback loops for morality: introspection and examining the consequences.
Morality is convergent inside the ellipse because examining the consequences is a noise dampening feedback loop. People can very easily agree which things are good and which things are bad when staring right at them. (Note that this doesn’t say anything about what causes good or bad things, I.E policy, which is still pretty messed up.)
Outside the ellipse, all we have to go on is introspection. This is a noise amplifying feedback loop, because the further out you go, all you can base your new judgment on is old judgments, and every scrap of noise will multiply. And because values are fragile, its almost guaranteed that no two people will ever agree on what the ultimate good looks like.
Essentially, morality outside the ellipse is google deep dream where everyone is using slightly different training sets, due to different life experiences. Every interpretation and moral judgment is assumed to be correct, and used to form the next interpretation. This continues until someone is pretty sure that dogs form the basis of morality.
Its not all hopeless though. You can usually reason your way back from the end state to make some sort of claim about the current world, which allows you to use the noise dampening feedback loop.
Also, Scott and Lou Keep need to compare notes. I’m pretty sure the stuff Lou is writing about is relevant here. I’m only pretty sure, because Scott seems a little confused, and Lou might have actual moral objections to writing in a style that I find clear.
You seem to be interpreting the graphs as a view of a single human’s moral arc of understanding?
A person isn’t on the “extreme end” of anything; there is no center, and to everyone it appears they are in the center. It is other people who take some aspect of morality too far, or not far enough. Insofar as anybody is in the tails of anything, they are in the tails of where the average of beliefs from people who all think they are in the center happens to be centered, right now. There’s little special about that spot. It’s been centered in other spots before now. It will be centered in a different spot tomorrow.
I don’t think I am? I view each axis as a single human’s moral understanding. I think I conveyed that badly.
I guess I could explain it by saying that none of those axis are actually straight. Every time someone marks an event on their graph (a moral judgment), the axis bends as every judgment, past and future, gets affected. (or you can view it as the plane warping around a straight axis. The analogy works better if the axis moves.)
Judgments within the ellipse are about directly observable things though, so they will usually maintain a similar ordering and magnitude. This prevents the parts of the axis that measures those things from moving too much.
No such restrictions are placed on the parts of the axis that measure things outside the ellipse. Its free to stretch, zig zag, make loops, be totally undefined, or even contradictory.
It doesn’t stop with specific words of specific moral valence.
You can share all the same moral valence, but all the words and concepts that merge together to form coherent moral concepts can also be different, and result in a dramatic difference in practical morality.
Or you can get disagreements like whether or not Pluto is a planet.
All the words are like this. Words and concepts are qualia; we cannot effectively share our internal experience of them. All communication goes through two layers of very lossy interpretation. Which isn’t to say we can’t improve our guesses at a true meaning, by getting to know somebody; many (most?) people seem to experience this “naturally”, others do not, still others (introverts) seem to experience it and also find it rather uncomfortable to have a stranger’s mind emulation running in their skull. But even with improvement, all you can accomplish is to reduce the lossiness, not remove it, and it requires your brain to notice there is a conceptual disagreement to resolve.
Disagreements about politics and morality just tend to involve society as a whole, I think.
Best post I’ve read, here or anywhere, for a long time. Really excellent work, Scott; really excellent work.
I’m kind of doing a devil’s advocate here, but I do think it’s worth clarifying something here. It is certainly possible the prisoner is happier. Perhaps he recently converted to religion and is finally at peace, after a life of strife and turmoil. He considers his pain (and his imprisonment) a just and fitting punishment for his sins. He is content to serve his penance, in the meantime, doing what he can to atone (writing apology letters to his victims, helping other prisoners learn to read, donating his commissary funds to other prisoners, whatever). And perhaps the millionaire is Richard Corey. Seemingly surrounded by all the circumstances that would normally create happiness, but ultimately so troubled by inner turmoil such that he sees the only way out as a bullet in his head.
I think we can accept that happiness correlates with things like freedom and wealth and the presence of loved ones. But there are always outliers, on both ends of the spectrum (people in shitty circumstances who are still happy, as well as people in great circumstances who are miserable).
And honestly, the longer I’ve lived and the more I’ve interacted with people in much better and much worse circumstances than myself, the more convinced I am that the correlation is pretty damn weak. There are a lot of people living in poverty who are happier than me. And a lot of people much richer and more comfortable than I who are miserable wretches.
This isn’t just a logical possibility either. How was happier: Epictetus (crippled slave) or Domitian (Roman emperor)?
I’d go as far as to suggest that happiness should be properly defined as someone’s general demeanor and satisfaction with life controlled for their specific circumstances.
Andy in Shawshank Prison is a happy person because even facing a horrible situation, he makes the best of it and doesn’t let it break him.
The warden, meanwhile, is an unhappy person, because even though he has a lot of power, comfort, and freedom relative to the prisoners, he still has a largely negative worldview and is nasty and brutish to people.
You can only have one moral absolute, because any absolute will eventually consume all other principles. Whenever any secondary principle comes into conflict with your absolute – and it always will somewhere along the line – you’ll have to abandon it. The classic example of this is Kant’s example of aiding a murderer to avoid lying.
Absolutes feel really good, especially to younger people – teenagers are stereotypically fond of absolutist ideologies(whether that means Ayn Rand, terrorism, religious extremism, violent street protests, or anything else), but as the issues with absolutes become more obvious, they usually get abandoned. But absolutes are a mess in practice, and as soon as it comes time to stop talking about them and start implementing them, you usually either “sell out” or murder a few zillion people.
So tl;dr, don’t follow the red line or the green line, because both are kind of dumb. Pick a mixture, which will look in practice like the yellow line. Yes, a bunch of people on the internet will think you’re unprincipled and/or The Man. But you’ll be avoiding idiocy.
Principals in theory is hedgehogging in practice. It’s disheartening that the people who have supposedly taken up pomo critical theory are actually so wed to certain Grand Narratives.
Incidentally, if you’re going to use Bay Area transportation infrastructure to illustrate agreements that can go in opposite directions, you really should be using the stretch of 80 East/580 West that runs north along the Bay near Berkeley.
The 680/280 switch in San Jose is a good one, too. Get on 280S to turn into 680N, very intuitive.
My main takeaway from this post was “BART goes to Antioch now??” (I moved away a while ago)
Words (moralities, whatever) are Pareto surfaces?
And your project is navigating the seams between those Pareto surfaces.
The way you labled the graphs it looks like you are implying that according to both Christian Teachings and Hedonic Utilitarianism that the Holocaust is “a little bit good”.
I think it implies no more than that by either standard there could be other things even worse. Which is fairly clearly true, though hopefully such things are extraordinarily rare.
(The dashed line is meant to sketch the boundary of things we have experience of, not of good things.)
The point is above an axis labeled “how good is this” which implies that it has positive goodness.
At least in my field, it’s customary to always draw axes at the bottom and right edges of the plot even when they span both positive and negative values.
Utilitarian perspective: Which is worse? 17 million people being tortured and murdered, or 4.7 billion people being tortured endlessly?
Someone correct me if I’m wrong, but I’m pretty sure in utilitarianism there is no such thing as a “zero point” where actions magically turn from bad to good. There are only “less good” and “more good” actions.
Technically I think it might be the case that the only good action is the one that maximizes utility and all other actions are bad. But this leaves us in a tricky situation where every action a human has ever committed has been morally wrong. This because maximizing utility probably requires more and more sacrifice so that you can only achieve maximization in the limit?
To me it does seem that there’s a clear and natural zero point for any action or event – you can estimate whether the total utility after that action larger or smaller than the total utility in a counterfactual world where that action was not taken or the event did not occur. It does rely on a certain assumption of a “default action” – treating nonintervention, absence of interaction as an implicit neutral anchor value.
He put it at the bottom. I think it’s clear what he’s going for.
That said I imagine some medieval, or shortly afterward, Christian thinkers might have been OK with it, assuming they had all resisted conversion–remember Martin Luther? “Kill them all and let God sort them out?” (granted those were Cathars)
Medieval and Early Modern anti-Semitism is fundamentally different from Nazi anti-Semitism. The former is about religion, so a Jew who has converted to Christianity is fine by them. Their only concern would be that the conversion might not have been genuine (cf. the Spanish Inquisition). Actually, anti-Semitism is really a misnomer here; maybe it should instead be called “anti-Judaism”.
From a Nazi perspective, on the other hand, what matters is blood, not belief. You might be the most pious Christian in town, but if you’re ethnically a Jew, you’d be considered the enemy, not matter how many times you go to church.
So, I’m confused why this all doesn’t just boil down to “Don’t do prediction outside your training data.” It seems like the whole bit with tails coming apart and Talebian Mediocristan is beside the point.
You started with the premise:
Fair enough. This is due to conditional expectations, and the link you included explains it fairly well. Paraphrasing, even though the expected value of X2 is highest for the most extreme observed value of X1, if you’re sample size is large enough and your correlation low enough, you’ll tend to have at least a few observations with slightly-lower-but-still high values of X1, and by chance, one of these will “draw” an X2 value that’s more extreme than the single observation you had for your most-extreme X1.
(This phenomena goes away if you have high correlations or low sample sizes. Heck, it’s probably not hard to write down an equation for the N and r you’d need to have a 50/50 chance of the “tails separating” assuming you’ve got a bivariate Gaussian. But I digress.)
It’s important to note that this phenomena relies on linear correlation between factors.
So anyhow, from here you make an analogy to words like “Happiness”, noting that words are really summaries of a wide range of concepts. The analogy to correlation here is what has me confused, I think. Your Special Plot shows how two people might view Happiness as a function of two concepts (which we all agree are related to Happiness), but that since those folks use slightly different functions, they come to different assessments of which country is the Happiest, and this is the “tails coming apart.”
You don’t say it explicitly, but the two functions you’ve used a linear combinations of the two factors, and under those conditions, the analogy makes sense. But then you move into “classifiers,” which encompass all sorts of functions, and then you move on to the metro map. By the time you transition into morality, it seems like the thing we’re worried about is using a model trained on one set of data to extrapolate outside of it, which, yeah, is a known problem and can produce very poor results. You don’t need conditional expectation and Gaussians to make that point. I think the metro map is an entirely different phenomena from “tails come apart” and I don’t see what one tells us about the other.
Am I missing something? Correlation’s got nothing to do with second half of the post. Or maybe that was the point?
(Final aside: The “mediocristan”/”extremistan” bit was also confusing to me, since Taleb generally means “Gaussians” when he talks about “mediocristan” and things like power law distributions when he talks about “extremistan”. Nothing in this post is in “extremistan” as far as I can tell. If you want to complain about extrapolating beyond your data, that’s fine, but that’s a different problem than confusing a Gaussian for a power law. Or maybe that was the point??)
+1
+3 vs undead
Until you meet the Undead Black Swan, who is made stronger by the use of magical weapons against him. Then you’re screwed.
I don’t think “conditional expectations” are a sufficient explanation for this, nor do I think sample size is really relevant.
The phenomenon arises from this interaction:
– There is residual variation in trait Y after accounting for the correlation with trait X
– More extreme values (of X or Y, before or after accounting for correlation) are less common than less extreme values.
Treating Y as the variable for which we’re trying to achieve a high target, the first bullet point of this model tells us that your Y value is the sum of (1) the value predicted by the correlation with your known X value; plus (2) chance. The second bullet point tells us two things: (甲) it’s easier to have lower X values than higher X values; and (乙) it’s easier to have lower chance values than higher chance values. Those effects point in opposite directions. The coming apart of the tails occurs when effect 甲 dominates effect 乙 within the range of Y you’re interested in.
So the effect is determined by the shape of the distributions in question (both the distribution of Y conditional on X, and the unconditioned distribution of X), and is not an artifact of sample size. As sample size approaches infinity, the coming apart of the tails will not go away.
Ahh. I meant if your sample size is particularly low, and your correlation is particular high, your observation with the largest value of X1 will likely also have the largest value for X2 as well. As for the “shape of the distribution”, I was assuming a bivariate Gaussian. It seemed like this is the type of thing Scott was talking about, but I found the post confusing, so maybe this was incorrect.
I agree that Scott’s use of “Mediocristan” and “Extremistan” has essentially nothing to do with Taleb’s. (He does kinda indicate that by saying only that he’s stealing the words.)
This is ok as long as his usage is true
Because you can’t follow this rule if you live any but the most constrained, banal (and short) of lives.
You will end up navigating an environment you’re not familiar with or didn’t experience in childhood. Behavior that was a nonevent or at least not openly acknowledged when you got your training data becomes scandalous in your old age. Or the reverse becomes true. Or both at the same time.
Since most of our training data are the result of unexamined assumptions about the world we adopt from ourselves or uncritically from others, we cannot adapt except by recognizing which parts of our morality and behaviors can or cannot be extrapolated into the new environment.
Sure, and that’s fine, I just don’t get what any of that has to do with “tails come apart”.
I strongly doubt that North-Korea is the most unhappy country, because I think that a major component of happiness is the norm that society sets and the extent to which people can meet this norm.
The most unhappy societies are probably not merely poor societies, but societies where the norm has become unattainable for many.
Ultimately, North-Korea seems like a fairly ordered and stable society with norms that are attainable for most people, where happiness is probably at the low end, but not bottom of the pack. I’d expect a country like Burundi to be there.
I don’t see how this can be possible, outside of a temporary shock.
A social class where the members by and large cannot attain “the norm” just means that that social class has a different norm. There is no “the” norm. Spartan helots weren’t even allowed to try to participate in Spartan Greek culture. Did that mean they were all unhappy because they couldn’t attain “the norm”? No, it meant they aspired to helot norms.
I do think that the most unhappy societies are experiencing problems that reduce the opportunities compared to the past.
In which case the USA’s going to be unhappy for a while, as we have nowhere to go but down.
NK is a special case because living in fear sucks. But yes, a very poor country is not necessarily very unhappy and you are spot on with the norms. In Eastern Europe the norm of what is considered a materially succesful man is far higher than the average salary or wealth. It is really weird. Perhaps Western norms, also from Western movies. Perhaps the fact that illegal incomes push the norm up. Perhaps the fact that there are no real class differences. I mean, if I am a peasant and he is a noble, and we dress, talk, walk, etc. differently, I will not compare myself to him. But the EE noveau-riche is about as prole as everybody else, no special education, etiquette or nothing.
This is not a new thing. Egalitarian-meritocratic ideals can backfire, it is known. If someone is richer than you because he really really deserved it, does not that hurt you more than as if it is purely by luck? In the first case your inferiority is rubbed in, in the second case at least you can secretly feel better. The norm is whatever a given group is supposed to achieve and in an egalitarian-meritocratic society everybody is in the same group. At least in monocultural ones. I guess in America race acts as class, due to the lack of a proper class/caste system. So a black guy may be poor but still richer than most blacks that can be okay for his self-respect. I mean, when people call stuff white things it sounds really like upper middle class things.
1) Isn’t happiness research just a total mess at the moment? Should we maybe wait at least a little while until they figure out what they’re doing, before we draw broad philosophical conclusions?
2) On TCWMFMNMFTC, since it’s come up again, and since it seems to inform a lot of your thinking. BLEGG/RUBE’ing a cluster of correlated properties is a cognitive error which we do a lot. Is Pluto a planet? Well, it has properties X,Y,Z and lacks P,Q,R; the line can be drawn any number of ways; none is strictly “better” than any other, so stop caring. But that solution is unavailable when it matters whether something is BLEGG or RUBE. For example, “personhood” is a cluster of usually correlated properties (being conscious, intelligent, made of meat, animate, etc) which nonetheless have edge cases (comatose humans, severely handicapped humans, sufficiently intelligent AI, early fetuses). But because personhood matters, we can’t just decompose it and say “a fetus is animate human meat, but not intelligent or conscious; draw the ‘person’ line however you want.” We need the correct answer to the moral question, and the moral question hinges on whether we have a person or nonperson (BLEGG or RUBE).
To address TCWMFMNMFTC directly: let’s say you explained it in full to a trans man. Afterwards, he asks “so, are you saying I’m a man?” You say… well, sure, because we can draw the categories that way, and that seems best for his mental health. He comes back with, “It get that you’re saying I should be considered a man, but do you think I’m really a man?” You say… um, well, the point is that gender is a social construct, so there’s no “really” about it, so I guess no? And the trans man says “then you’re wrong, I know I’m really a man, I have since I was a child, and that matters; sincere thanks for your support on the causes I care about, but your metaphysics are wrong.”
Bringing it back to happiness and this post: you say the variables that we conflate into happiness converge for a while, then they come apart at the tails, and there’s no fact of the matter of which variable is best to judge by. Because people usually think happiness matters, they might come back at you and say “sure, but one of the tails (or some particular combination thereof) must be actual happiness, which is it?” And you say… well, happiness is a social construct, so whatever you want! And they say “but one understanding has to be true, and we have to maximize that one! It’s a profound moral duty!” (Even if they’re not utilitarians, this probably holds; most people think happiness is good.)
Is that what you’re trying to guard against when you say you’re an “ethical subjectivist”? Those “naturalists” from the previous paragraph should just “do the thing that’s actually ethical” to them, based on whatever subjective understanding of happiness they have? And if so… not being an ethical naturalist yourself, what do you yourself do when you run into corner cases, and how can doing it not reflect an underlying naturalist view of some kind or another? Or are you both at the same time?
+1
It is easy to assume that “the moral question hinges on whether we have a person or nonperson (BLEGG or RUBE)” but not so obvious that that’s actually right.
Indeed, often there are multiple moral questions and there’s no particular reason why they should hinge on the exact same things. Suppose X is kinda-person-ish. We might want to decide: is it OK to kill X? should I take any notice of X’s welfare and preferences? should I give approximately the same weight to those as I do to a typical person’s? if I am trying to construct some sort of consensus morality, should I pay attention to what X approves of and disapproves of? — and we might reasonably find that different aspects of personhood matter to different extents for different questions.
It seems like your hypothetical involving a trans man is incomplete. Hypothetical-Scott explains his position to Hypothetical-Trans-Guy, HTG says “am I a man?”, HS says “sure”, HTG says “no, but am I really a man?”, HS says “well, that’s kinda an ill-posed question”, and HTG says “bah, I just know I’m really a man, so you’re wrong” — so far so good, I guess, but what are you inferring from this hypothetical exchange? I mean, do you really want to endorse a principle that when someone feels that they just know something, that guarantees that their metaphysics around the thing is right? Because I don’t think that ends well: e.g., I bet it would be easy to find advocates of multiple mutually-incompatible religions who just know that their god is real and their religion’s claims are true. On the other hand, if that’s not where you’re going, then what is the point of that conversation? What does it tell us, other than that sometimes one hypothetical person may not like what another hypothetical person says?
(I largely agree with Scott-as-I-understand-him on this, but to the question “am I really a man?” I would be inclined to say “yes, sure”, and I would only start giving answers of the sort you ascribe to Hypothetical-Scott once the other party makes it explicit that he’s not just asking “am I a man?” but asking about the underlying metaphysics. Because I’m happy to say that a person’s deepest-seated convictions are a reliable guide to — indeed, constitutive of — their gender identity, but not to the truth of hairy metaphysical questions.)
As for the final question, of what to do when faced with this sort of thing, I can’t speak for Scott but (1) by definition these unusual tails-coming-apart situations rarely arise in real life, but (2) if they do then I react by feeling extremely uncertain not only about what one should actually do but about what I think should be done. In some cases, I think there actually is no fact of the matter as to what I think is right, though of course I could pick an answer and then there would be, and of course in a given case I have to pick something to do. (The latter doesn’t imply that I really approve of whichever action I end up taking; alas, sometimes I do things that I myself disapprove of.)
But we can. We should!
It doesn’t, though. It really doesn’t.
Like, the whole point of all the stuff that Scott is citing is that these things you’re saying are mistakes. They are bad reasoning. We know that it’s nonsensical to think in this way.
This hypothetical trans man would, of course, be wrong. The correct response is to say: “I acknowledge that you have this deeply felt sense of ‘really being a man’. However, a deeply felt sense of the world ‘really’ being some way, has absolutely no need to correspond to that alleged state of affairs even being a coherent description of the world, much less an actual one. Our brains fool us. Please re-read ‘A Human’s Guide to Words’ until you understand this. I will, in any case, continue to support your efforts toward acceptance and fair treatment, but of course I can’t agree with your metaphysical claims, which are very confused.”
Let’s say that, in 1820s South Carolina, someone chooses to define “person” to include nobody with African descent—that is, to not include black humans. Are they wrong? Their usage coincides with common usage. It’s certainly not a useless definition, or an irrational one—it helps them grow quite a bit of cotton.
If you want to say that the word “person” is a word just like any other, and that Eliezer’s guide applies to it, has the slaveowner slipped up in their picture of the world? Their definition is useful to them, and socially agreed upon. If they are wrong, why?
To me, they’ve slipped up (big-time) because their definition of “person” as excluding black humans is incorrect. Clearly, you disagree. So come up with a different answer.
And before you just shout “read the sequences!” again, note that Eliezer might even agree with me when he considers questions like “what is a person?” (See my comment below.) I’ve read the sequences, and your condescending tone in assuming that I haven’t is less than appreciated. So drop the appeals to authority, and don’t merely tell me I’m wrong. Tell me why you disagree, not just that you disagree. Unless you start doing some actual thinking and arguing of your own, you’re dead weight to this comment thread.
Whether the slaveowner has slipped up in their picture of the world, and whether they are somehow “wrong” to define “person” as “human who is not black”, are two different questions.
Has the slaveowner slipped up in their picture of the world? I don’t know, what is it you’re claiming they believe? What inaccurate factual beliefs do you say they have? Tell me, and I’ll tell you whether those beliefs are wrong or not.
Is the slaveowner “wrong” to define “person” as “human who is not black”? Depending on his factual beliefs and his values, this definition might not be useful (due to not matching his factual beliefs, or not reflecting his values). In this case, though, I doubt that that’s the case.
A different answer to what? Anyway, definitions can’t be “correct” or “incorrect” in a vacuum. Please read the Sequences again.
Definitely not. (See my response.)
I’ll bite that bullet. This is morality working as intended. You might as well complain that legs are fundamentally flawed because they allow both predators to chase prey and prey to run from predators.
This is what the rest of Eliezer’s “Guide To Words” is about – especially “Replace The Symbol With The Substance”. If you haven’t read it, you’ll probably find it addresses your concerns. If you have, can you clarify exactly why you don’t think his solution is good enough?
Link:
Replace the Symbol with the Substance
Yup! Read the whole thing already. So thoroughly, in fact, that I know he agrees with me—or at least, that his arguments there aren’t entirely defeating to my point here. “Replace the Symbol with the Substance” argues we should “play taboo” with our concepts to get down to the reality of a thing, not getting caught in our preconception of “a bat” or “a ball.” But…
In a comment on his post Disputing Definitions, he says—considering, specifically, the contention that “Abortion is murder because it’s evil to kill a poor defenseless baby”—
So, from Eliezer himself, direct appearance in the utility function (more generally to include non-utilitarians, “being a morally important category”) is a known case where definitions might actually matter. He admits you can’t “play taboo” in those cases.
Do you think I’m misinterpreting Eliezer? Or do you think he was wrong to say that?
You are definitely misinterpreting Eliezer. Reading what you quoted as saying that “definitions matter” is missing the point entirely.
Eliezer is not saying that it makes sense to have a category boundary appear in your utility function, and he is definitely not saying that just because an alleged category appears in your utility function, that this therefore guarantees that this alleged category corresponds to some actual cluster in thingspace.
All he’s saying is that his proposed argument-dissolving technique of creating new and distinct words to refer to different things, will not in fact solve certain kinds of actual arguments that people have. That is all.
Sure, that’s a reasonable interpretation. But even that seriously weakens his argument! Disputes over categories in your utility functions are still candidates to be meaningful disputes, despite all the arguments he offers in the sequences. (Somewhat surprisingly, as far as I can tell, he never deals with them directly.)
Let’s trace the argument back a bit: there were arguments over whether there are any unheard sounds, and Eliezer’s argument-dissolving technique showed that the argument was silly, since it revolved around the definition of “sound”, which doesn’t actually matter.
Now consider the abortion debate. In large part, it turns on whether there are unborn persons, and if so, which unborn entities are persons. Is this argument also silly? It clearly revolves around the definition of “person”; but given the choice, I’d say that “it matters what is or is not a person” before I’d say “the abortion debate is really over nothing at all.”
If you want to maintain that there are no wrong definitions, you need to say that either the abortion debate is silly, or that it is not really disputing a definition. Which route do you want to take? Neither seems very tenable to me.
Definitely not. The correct set of categories that should “appear in your utility functions” (broadly speaking) is “none of them”. This is a big part of the point that Eliezer was trying to make.
Yes, extremely. (Fortunately—or unfortunately, depending on one’s perspective—the abortion debate does not actually turn on this.)
Why not both?
The abortion debate, as it is usually (and totally inaccurately) represented in spaces like this (and as, for example, you have represented it right here in this thread), is extremely silly.
The abortion debate, as it actually is, is not really disputing a definition.
Forgive me if I seem rude, but are you proposing that utility functions should be limited to a ranking of enumerated world-states?
Except when you are deciding whether the Wikipedia article on Tinnitus or Ultrasound belongs in Category:Sounds.
@Hoopyfreud:
Are you talking to me? (It seems like you are, but since this blog software doesn’t permit deep comment nesting, it helps to preface your comments with the name of the person you’re talking to, like I just did.)
Anyway, assuming the question was meant for me…
… well, I don’t actually understand what you’re asking.
Maybe it would help to clear up some terminological confusion?
For example, something we’ve glossed over in this comment thread is the fact that, actually, people just plain don’t have utility functions. (Because human preferences—with perhaps a few exceptions, although I have my doubts even about that—do not conform to the axioms that, as von Neumann and Morgenstern proved, an agent’s preferences must conform to in order for that agent to “have a utility function”. What’s more, most economists—and be assured that I include v N & M themselves in this—have been quite skeptical about the notion that humans ought to conform to these axioms.)
In this thread, we seem to have been using the term “utility function” as a sort of synecdoche for “what we value”. I’ve let that slide until now, as it seemed clear enough what Yaleocon meant and I saw no need to be pedantic, but now, it seems that perhaps we’ve gotten into trouble.
If your question stands, given this clarification, then I confess to being perplexed. Was it your intent to raise some narrow technical point (such as, for instance, the question of whether preferences over world states are isomorphic to preferences over separable components of world states; or whether an account of “impossible possible worlds” is necessary to construct a VNM-compliant agent’s utility function; or some other such thing)? If so, would you please expand on what specifically you meant?
If you meant something else entirely, then do please clarify!
@Said Achmiz
To pick up where Hoopyfred left off:
You claim that
I’m not sure what you’re trying to say, but it looks like “there shouldn’t be any categories in your utility function/preferences/whatever,” and that’s insanity if taken literally. Unless we’re discussing fundamental particle physics, everything we say makes use of categories in nearly every word we speak or write! Could you give us an example of what you would consider a moral principle (or any other type of meaningful sentiment if you’d prefer) formulated without the use of categories?
@thevoiceofthevoid:
Yes, you interpreted my formulation correctly. You are, of course, correct to take issue with a literal reading of my comment. The thing having been quoted in its correct phrasing once, I thought I could get away with sloppy phrasing thereafter; I apologize for the resulting confusion.
Here’s what I am talking about:
Suppose we are speaking of what I value, and I declare that I value “cake”. In fact—I continue—it isn’t merely that I value certain actual things, some fuzzy point cloud in thingspace, which I am merely “gesturing toward”, in a vague way, with this linguistic label, “cake”. No! Cakeness, the fundamental and metaphysical essence of the thing, is what’s important to me. Anything that is a cake: these things I value. Anything that isn’t a cake… well, I take it on a case-by-case basis, I suppose. But no promises!
Now suppose you present me with a Sachertorte, and inquire whether I value this thing. “Bah!” I say. “That is not a cake, but a torte. It is nothing to me.” But you dispute my categorization; you debate the point; your arguments are convincing, and in the end, I come to believe that a Sachertorte is really a cake. And thus—obviously—Sachertorte is now as dear to me as any red velvet cake or Kiev cake.
And suppose I have always had a fondness for the Napoleon. A cake par excellence! Or… is it? Ever the disturber of the metaphysical peace, you once again dispute my categorization, and finally convince me that the Napoleon is not a cake, but a mere petit four. At once, my attitude changes, and I no longer look twice at Napoleons; they lose all value in my eyes, and I feel nary a pang of regret.
… obviously, this scenario is completely absurd.
But this is precisely what it would mean, to have categories appear in your preferences—as distinct from categories appearing in a description of your preferences!
@Said Achmiz
Weighing in here to agree with Yaleocon.
The scenario involving cake that you just gave proved Yaleocon’s point, I think. Far from being obviously absurd, that scenario seemed to me like a nice description of many conversations I’ve seen in my own life–e.g. someone getting convinced that wearing a sombrero is an instance of Racism, or that statistical discrimination is not.
Precisely because we don’t have utility functions (which arise from very well-defined preference orderings over possible worlds) we run into this issue where what we “value” involves vaguely-defined categories. I do think this is what Eliezer was getting at.
@Said Achmiz In some sense the further we get from the training data (the further from the common Balboa-West Oakland area of common agreement), the less our moral disagreements appear to matter.
If you’re not sure if a Sachertorte or a Napoleon qualify as “cake”, then whatever they are, they’re pretty far from your central definition of “cake”. So if you misclassify them, you haven’t done a lot of damage.
From my viewpoint, the same holds with the abortion debate, which I do see as about the definition of a “person”. Given that people disagree, that seems to say that even if we get the answer wrong, any moral damage is minor.
A counter-argument is the antebellum slave owner who’s decided that African descent excludes personhood. Since my definition of “personhood” is based on rationality, ability to respect the rights of others, etc., and has nothing to do with descent, the slaver’s decision seems to create maximal (rather than minimal) moral damage.
You seem to think the same is true of the abortion debate – perhaps so, but then I don’t get it. How is the abortion debate not about the definition of a “person”? If it’s not, then what do you think it is about?
@kokotajlod@gmail.com:
Yes, indeed, many people make this sort of mistake. That’s rather the point. It would hardly justify writing so many words on the matter, if the error were obvious, or very rare, or committed only by the exceedingly stupid.
But though it be ubiquitous, it is still a grievous error. Arguments over what “is Racism” or “is not Racism” are utterly absurd for this reason. (At least, on their face. In truth—as with abortion—such arguments are not about what they seem to be about. But then, here at SSC, we know that, yes?) People who have conversations like this—in full sincerity, thinking that they actually are arguing this sort of metaphysical issue—are making a profound conceptual mistake. That is the point.
As I’ve said elsethread, what we value “involves” vaguely-defined categories in the sense that describing our preferences must, inevitably, require reference to vaguely-defined categories; otherwise we’d be here all day (and all year, and all eternity). But valuing (or thinking that you value) the categories directly, whatever they may contain, is a terrible conceptual mistake. (Eliezer once described this sort of thing as “baking recipe cakes—made from only the most delicious printed recipes”.)
@Dave92F1:
You are, it seems to me, making the curious mistake of rounding our (hypothetical, at the moment) opponents’ position up to the nearest sensible, sane position you can conceive of. You then argue that, well, said view is not so bad after all!
But no. See the view I am describing for what it is! My hypothetical cake lover is not concerned with extensional classification. (This is the entirely sensible, empirical question of whether some particular confection lies within the main body of the “cake” cloud in thingspace, or whether, instead, it is an outlier; and if the latter, whether a usefully drawn boundary around the cluster—one that would best allow us to compress our meaning most efficiently, for the purpose of communication and reasoning—would contain or exclude the baked good in question.)
No, the (absurd) view I am describing is one which concerns itself entirely with intensional categories. That is, in fact, precisely what makes it so absurd!
Indeed the whole point of my example (lost, perhaps, on folks who are not quite such avid bakers as I am; I apologize for any confusion) is that a Sachertorte, for instance, is a perfectly central sort of cake. Any argument about whether it “is really a cake” can only be about intensions. I could also have used Boston cream pie as an example. (Isn’t it a pie, and not a cake?! It’s right there in the name! But no, of course that is silly; it’s as central a cake as any. Yet the one who is concerned with intensional definitions, might—ludicrously, foolishly—be swayed by the argument from nomenclature!)
As to your other points…
In all of my comments in this thread, I have been trying my utmost to avoid actually getting into an object-level debate about abortion. (I find these debates to be, quite possibly, the most tiresome sort of internet argument; twenty years ago they were diverting, but enough is enough…)
Your questions are fair, of course. I don’t mean to dismiss them. But I’m afraid I will have to demur. Possibly this will mean that there’s nothing more for us to discuss. In that case, I can only recommend, once more, a close reading of the Sequences (“A Human’s Guide to Words” in particular), and otherwise leave the matter at that.
Doesn’t the cake metaphor get the causality wrong? Meaning: people aren’t arguing that Napoleon is not a cake and consequently denouncing and rejecting it, as much as argue it cannot be a cake since they don’t like it.
Perhaps it goes like this: person A dislikes the political views of person B, and argues that B is in some undesirable category C, and therefore person D should also reject person B. Person D agrees with person B, and argues back that B is in category E which everybody respects and trusts, and it is in fact person A who is in category F….and so on, and so forth.
In short: we assign negative categories to things we already don’t like (for intrinsic reasons), and expect others to have category-based utility functions allowing us to manipulate them.
@Ketil:
Yes, this is correct.
(This is one of the many reasons why it is quite foolish to have, as you put it, “category-based utility functions”.)
Here’s a flip of Yaleocon’s point (which I agree with, but seems to me to be less of a productive way to approach the debate):
https://samzdat.com/2018/08/22/love-and-happiness/
Axioms of morality cannot be sufficiently well-constructed as to be unambiguous, because the frameworks that we use to define them are incommunicable.
There is a thing called happiness (and no, I don’t mean this in a platonic sense, I mean that I can identify happiness when it occurs in me). I can measure things which correlate with my experiences of happiness like serotonin levels and listening to woman-fronted rock groups of the 80s. I can come up with pithy sayings about happiness which generalize well to my experience. But at the extremes, there are things that require reflection for me to describe them as happy and which I cannot evaluate within a framework of happiness evaluation a priori; my model isn’t well-defined enough for that, and I have no means of extending it to cover these cases (including experiencing them) that don’t run the risk of substantially modifying the framework and ruining the predictive power of some of the important correlates.
I cannot describe why I seek happiness, and assuming that “true understanding is measured by your ability to describe what you’re doing and why, without using that word or any of its synonyms,” then I do not understand anything at all about myself. But trying to explain human action without reference to [your favorite word for that-which-creates-percieved-value] seems like a futile task, given a non-hard-deterministic viewpoint; if you *are* a hard determinist, I promise not to take any future attempts to hack my brain personally; I know it’s just a biological imperative that you literally can’t help yourself from fulfilling (this is snark of humor’s sake, not meant to preempt genuine debate).
The counterargument, as far as I can tell, is that happiness is a “poorly defined cluster in the space of experience.” But if I made it my project in life to enumerate the elements of that cluster, I think I’d find it a monumentally unrewarding and futile task, not least because the elements with membership in that cluster will inevitably change before I work my way around to analyzing the quantitative and qualitative differences in my emotional state produced by listening to Leuchtturm rather than Zaubertrick while cooking dinner. But one makes me happy, and one doesn’t. So I listen to Zaubertrick while I cook, and I hope that warms someone else’s utilitarian heart.
The other counterargument, that substance precedes essence and that the things I’ve identified as correlates above are the only *real* happiness, seems to fall apart when I point out that when my subjective experience of happiness doesn’t match up with any of the correlates, I find myself seeking happiness, not the correlate. I care more about being happy than having serotonin, or I’d be willing to get in line for a serotonin pump, but I know I wouldn’t be. You might argue that I must have simply failed to identify the correct convolution of correlates which will be perfectly predictive, to which I’d reply that clearly nobody has, and that these correlates are so un-universalizable that even if you managed to overcome my objections and managed to perfectly predict the worldstates that would make me happy, you wouldn’t have perfect information about other people’s frameworks of happiness. And if you maintain that you would, I’d say we’re back to something isomorphic to the hard determinism problem, and that you’re welcome to continue to follow your biological imperative to howl into the void.
This turns out not to be the case.
We know, in fact, that some of the… “aspects”, shall we say… of “happiness”, which Scott mentions in the post—positive emotions, say—can easily be identified, by a person experiencing them, at the time they’re experienced. But other aspects of happiness—life satisfaction, sense of meaning/purpose—are much less amenable to in-the-moment identification. We have a broader, vaguer sense of them—as we look back on our lives, in moments of reflection. (It is even possible that we do not simply recognize these things, but in fact construct them, in such moments, in retrospect—by way of making sense of certain inchoate sensations or experiences which we cannot, in the moment, give a name.)
This, too, turns out not to be the case.
While I certainly defer to your own judgment on this part…
… I can’t agree at all with this. (For several reasons, at that! To name just one: surely you don’t think that happiness—whatever we might be referring to when we user this word, taking a broad view of common usage—is the only thing that creates perceived value?! I’d say that it’s not even half of the story! Besides which, lots of people have had some pretty good success explaining lots of human action without recourse to talk of happiness. Or don’t you agree?)
Well, you don’t have to. We have people who make careers out of this sort of thing. (Whether they’ve had any great success with this is up for debate, but “that sounds boring; I wouldn’t want to spend my time doing it” is a singularly pointless argument.)
I think we’re talking past each other here in a few places.
I agree that correlates are not good predictors; that’s my point. We don’t have a good predictor, but we do have a (bad) correlate.
When you say
I think you’re doing a tricky trick, since happiness has several common usages and my thesis is that a “real” common definition of happiness cannot be formulated. Let’s define happiness as an emotional state with the typical aspects of positive emotions, life satisfaction, and sense of meaning, among other things. It’s an awful definition, but I think it’s slightly less bad than the one I think you implied. Then yes, I think that all these things taken together form the whole of perceived value, and that it’s as worthwhile to call the whole kit and caboodle happiness as anything else, since I can’t (no, really, I cannot) enumerate them all, and when people talk about their frameworks for perceived value, happiness is mentioned more often than contentment or satisfaction or… any number of words that reference things that are really not communicable, but that are commonly understood to be experienced. Hell, “perceived value” isn’t really a communicable concept either, but I’m hoping it’ll have more resonance in your framework than my previous attempt.
Finally, when I say it would be unrewarding, I mean that I’d end up with a mess of enumerated worldstates, inferences based on which I would expect to have little power far outside the bounds of the enumeration, or in time given that my happiness framework will almost certainly change as I proceed into the future.
I am interested to know what your other objections to my point are; I’ve done my best to anticipate them, but I think you’re coming at this from a different angle, so I’m excited to see where we can reach understanding.
Also, I apologize for edits made to my last comment after posting; they may or may not interest you, but absorbing them will inevitably take more effort than an addendum to the comment would have.
@Hoopyfreud:
No, I don’t think we’re talking past each other; rather, I think you are not quite appreciating the degree to which I am rejecting your thesis. I will try to explain…
I accept your provisional definition. I am not here to quibble over semantics.
And I strongly disagree with your claim. I think that this sort of thing does not even begin to form the whole of perceived value.
(Elsewhere, you talk of finding yourself “seeking happiness”. For my part, I do not seek happiness; and I am not alone in this. This is not an incidental point, and goes directly to what I am saying here.)
Re: edits to your earlier comment: you are not so much preaching to the choir, as preaching to the archbishop. Where I disagree with you, I disagree in the diametrically opposite direction! Certainly I would never argue that you’re “really” after the neurochemical correlates of happiness, and not happiness itself; but I would go further, and say that “happiness” is itself only a correlate (or, if you like, an implementation detail) of what we’re really after. That is to say: “happiness” is what happens when we get what we really want—which makes it misguided, at best, to “seek happiness”.
(There are, of course, exceptions to this reasoning, such as: “Part of ‘happiness’ is ‘not being depressed’. I would therefore like my depressive disorder to be cured, please.” But these are exceptions that—in the classic sense of the phrase—prove the rule, as what we in fact are after, in such cases, is the ability to achieve our goals, and to avoid suffering. Whether we use the word “happiness” to talk about these desires, or not, is irrelevant.)
@Said
I think we agree, then. What I’ve resorted to calling “perceived value” and what I normally call happiness works, for me, in the way you’re describing; “joy”/”enjoyment” for me, functions like “happiness” seems to for you, and maybe that’s the fault of the naughty Aristotle on my shoulder. We don’t call them the same thing, and while I think that they resemble each other a bit more than we’re letting on, they’re clearly very different. If it makes the argument clearer, sub in whatever functions this way for you for “happiness” in all my posts in this chain.
But I think this is driving home my point – the substance is vast, all-encompassing, and incompletely defined, and the symbol is nearly unusable for communication. In cases where this happens, it’s useless to “replace the symbol with the substance” because the one is inane and the other is useless for this kind of formulation.
And if this is true of a concept like “perceived value,” why should it not be true of “person?”
@Hoopyfreud:
Yes, I think you might be right about the terminological mismatch (the aside about Aristotle is what finally clued me in to where you were coming from). To a… very rough approximation… I would say that indeed, we more or less agree on this aspect of the matter.
But as far as your comment that ‘it’s useless to “replace the symbol with the substance”’, I simply cannot agree.
You have picked, as your illustrative example, what is, perhaps, the very hardest case. “What is the source of value” is a tremendously difficult question! (It appears in a more vulgar form as “what is the meaning of life”—and that question is, of course, the very archetype of “hard, deep questions”.)
Yes, of course, replacing this particular symbol with the substance behind it is quite the tricky proposition… because we do not even know for sure what the substance is! We have spent thousands of years trying to figure it out; and who would claim that we’ve arrived at a full answer? (Oh, some of us know more than others, to be sure—much more, in some ways. I daresay I have a better idea of the answer than the average person, for instance, as, I gather, do you. Still—it’s very much an open question.)
(Eliezer acknowledges this, by the way. More: he makes it an explicit object of a big and important part of the Sequences—Book V of R:AZ is all about this.)
But what should we conclude from this? That replacing the symbol with the substance is of no value as a technique, or a bad idea, or useless for all but the trivial cases? Yet no such conclusion is even remotely warranted. By analogy, imagine proclaiming that because no proof (or disproof) of the Riemann hypothesis (called, by some, “the most important unresolved problem in pure mathematics”) has been found, despite a century and a half of searching, therefore proving any propositions in mathematics is a fool’s errand, and we should abandon all attempts to answer mathematical questions! That would clearly be an absurd leap, don’t you think?
The case of “person” is much, much simpler. (In fact the chief obstacles in the abortion debate are not metaphysical at all; they are political. Turning the issue into some elaborate definitional dispute—and insisting upon that dispute’s alleged irreducibility, difficulty, complexity—is, quite often, merely a way to blind oneself to that distressing reality.)
“But that solution is unavailable when it matters whether something is BLEGG or RUBE.”
When it matters whether something is a blegg or rube, it doesn’t “just matter”, it matters for a particular reason, in a particular circumstance. If you’re looking for vanadium, you’re going to sort bleggs and rubes very differently than if you’re looking for blue pigment. It should be clear that there isn’t a “right dividing line”, only a division that is more or less helpful for your project. This is the entire point of the blegg/rube example; you do not appear to have understood it.
“But because personhood matters, we can’t just decompose it and say “a fetus is animate human meat, but not intelligent or conscious; draw the ‘person’ line however you want.””
The ‘person’ line does not correspond to any real feature of the world-there’s no “really a person” essence attached to anyone because we don’t have a single concept of ‘person’. Some people use the word to refer to someone with a conscious, sentient mind; others use it to refer to someone with moral worth. If you think the fetus has moral worth but no consciousness as yet, is it a ‘person’ or not? Personhood doesn’t matter here, what matters is a question of moral worth… and if you don’t realize that sometimes the word ‘personhood’ is used interchangeably with worth and sometimes it isn’t, then you’re going to get very confused.
As a trans woman, I would answer that I’m really something that can’t perfectly be classified as male or female from a strictly biological/anatomical perspective: I have a Y chromosome, but there are people with Extreme Androgen Insensitivity Syndrome who have Y chromosomes but are otherwise physically identical to cis women (to the point that many of them go their whole lives thinking they’re just normal cis women), and the vast majority of people would agree that they should be considered women for medical, legal, and social purposes. I have both male and female sex characteristics: male genitalia, an Adam’s apple, a voice that originally sounded male by default, facial hair until I had it removed through laser and electrolytic treatment, and height typical for a male, but also developed breasts, wide hips and thighs, smooth skin, facial features that most people would consider female, no chest hair, and body hair patterns typical for a female. I consider myself intersex from a purely biological perspective, but I choose to identify as a woman because I feel like a woman internally, and I do think my internal sense of gender identity corresponds to some real physical thing – perhaps my initial testosterone/estrogen levels (before starting hormone treatment) were closer to a woman’s than a man’s, or some part of my brain is structured in a more female way than the average male’s.
As David Shaffer and several other people here already tried to explain, where you draw the line depends on exactly why you need to draw the line in the first place. It’s not that the rest of us are saying “the difference between BLEGG and RUBE never matters,” it’s that we’re saying “the difference between BLEGG and RUBE can matter for a lot of different reasons, and when there’s an edge case that falls outside of the standard BLEGG/RUBE paradigm, we’ll handle it in different ways depending on what those reasons are.” You seem to be interpreting TCWMFMNMFTC as some kind of pseudo-postmodernist “nothing is really real, man” statement, as if it’s calling for everyone to throw up their hands and admit that we can’t actually know anything, when it’s really a call for increased mindfulness and discernment.
For the situations where it really matters – for instance, for medical purposes – am I a man or a woman? Well, I’d prefer my doctor to treat me like a man when assessing my risk of prostate cancer and like a woman when assessing my risk of breast cancer.
My model of morality is as follows:
The first analogy (oval) is the distribution from which we, for each value, draw a value for
1. How important something is
2. A sense of whether we feel it is instrumental (we have a prior it’s good, unsure why), or if it’s a terminal good.
For example, let’s go with the value of ‘protecting your tribe’.
Even if you think sticking with your tribe is super important, you might do this because you feel culture has objective value (typical of learned lived experience of folks in non-atomized societies), or because you instrumentally feel it’s a chesterton fence of some kind.
How strongly you feel about a value, terminal or instrumental, the more resources you’re willing to put into arguing for it when everyone’s values are more-or-less aligned.
The more you feel it’s a terminal goal, the more you’re comfortable taking it to the extreme logical conclusion.
The more you feel it’s an instrumental goal, the more you’re willing to compromise and feel less strongly about it in light of new information.
The more we think about morality and come up with ‘new ways of thinking about things’, the more we distill out the strong, terminal goals that we have.
-Scott Alexander
A decent argument for conservatism when exploring the space of morality: “Don’t get carried away, kid.”
Yeah, that’s my takeaway too. Stay in the ellipsis. If your morality is making you think that you might want to destroy the entire universe to prevent suffering, or put the world’s population on drugs, don’t do that. Stick with things that are broadly agreed to be good, by at least a few moral systems (even if a couple disagree — unanimity isn’t always possible). This makes sense because you can’t attain perfect certainty that your moral system is the right one or will work when you get to extreme cases.
This is a very good heuristic for almost anyone who lacks the power to actually implement such choices. That is to say, everyone now alive.
It’s problematic IF you like to think about AI singularities, existential risk, theology, fantasy novels, and other scenarios devised by the brain. Scenarios where a being actually has the power to reshape the known world according to their desires, and where nothing, not even random friction and bad luck, can stop them.
Because then you actually have to answer the question.
Suppose you’re a demiurge responsible for designing an afterlife. Now, Even Bigger God help you, you actually have to decide:
“So, suppose we give everyone who is, on balance, nice, a harp, and make them sing hymns inside big cubes made out of semi-precious stones. Meanwhile they’ll be watching the people who were, on balance, naughty writhe in a lake of eternal fire. Is this a better or worse thing to do for everyone than putting all the brave people in an eternal feast hall, while all the cowardly people rot in eternal darkness? Or maybe I should just remake reality as perfect consciousnesses sitting on lotus thrones where everyone shares perfect knowledge and equanimity about all things? Or maybe everyone should just sort of… cease when they die, you know, to raise the stakes?
…
At this point, which afterlife you design will depend heavily on which things you value highest, and you may be assured that there will be a long line in the Celestial Complaints Department from all the now-dead souls that think you got it wrong. Well, except in the world where everyone just sort of ceases. There you have a solid 0 1-star ratings out of 0 ratings total!
Forget the demiurge–imagine you’re a liberal politician who has to decide whether to cut a deal with your conservative counterpart to fund education by agreeing not to fund abortion. (Or imagine you’re a conservative politician forced to fund abortion in order to make a deal that brings jobs to your state…) Of course, in this case you’re dealing with people with *different moral priors*, even outside polarized systems like ours where ‘owning the libs’/’sticking it to the bigots’ is a major goal.
I think the way to be a conservative demiurge/friendly AI would be to ignore the tail and try to make things like the center, only more so.
The systems have very different tails, but in the center they seem to agree about somethings. Life is generally good, happiness is generally good, knowledge is generally good, etc. Just amplify those things without maximizing any one thing.
Don’t kill everyone and convert the universe to orgasmium, just make everyone happier through normal means.
Don’t turn everyone into disembodied contemplative consciousnesses, just make everyone smarter and more knowledgeable. Superhumanly so if you have the resources.
Don’t throw naughty people into a lake of fire, just give them a punishment proportionate to their crimes.
Give everyone a big feast with bigger portions for the brave, maybe throw some people in darkness for a temporary period of time proportionate to their cowardice.
Don’t go full Repugnant conclusion, just create some new people but also devote lots of resources to making existing people happier.
Enhance everyone’s lifespan as much as you can, but don’t do anything crazy like make a trillion brain emulators of one optimal person and kill everyone else.
That’s the way to be a conservative demiurge. And I can’t help but notice that the scenarios I’m describing, while they may not be optimal according to any axis’ tail, sound a lot more like our intuitive sense of what a utopia would be than any of the tail scenarios.
True.
I guess my point was you can easily run into difficult moral decisions once you have any kind of power. You have $10,000 to spend on social programs as a small-town mayor…do you fight homelessness or opioid addiction?
I don’t think this issue requires an AI singularity to be relevant. There are plenty of cases here in the real world where the tails diverge, and where we have to make meaningful choices based on that. We might not be able to take the red line all the way to Richmond or the green line all the way to Fremont, but we can still choose between going up to Downtown Berkeley or down to Hayward, and there’s still a good deal of distance between them.
For instance, one common argument that I hear from traditionalists is that most people were happier living under traditional family structures, even if they had less freedom to choose how to live their lives. I don’t buy this argument: for one thing, I’m skeptical that people were really that much happier (it’s not like we have a lot of statistical data on happiness levels in pre-industrial Western countries); for another, we’re currently in a transitional period where the old cultural norms haven’t entirely faded away yet, and a lot of the pressures faced by modern Westerners could result from being caught between two worlds with heavy but mutually exclusive demands. But let’s say it was completely true, and as long as the modern world continues to take precedence over traditional values, the majority of men will continue to be frustrated with how useless they feel, and the majority of women will continue to be stressed to the point of neuroses trying to balance their desire for a family with the demands of their career. I would still choose that over a traditional model where most of those people were more content but had significantly less control over the course of their lives, because my personal conception of happiness/value/what-is-good-in-life weighs agency and personal freedom more heavily than contentment or stress reduction. Similarly, I’m skeptical of all those studies showing that people in low-tech societies are “happier” (at least in the sense of finding their lives more meaningful) than those in high-tech societies, but even if I knew for a certainty that they were all correct, I still think high-tech societies are better for humanity, because I value things like “enjoying the comforts of insulation and indoor plumbing and electricity” and “having access to modern communications and transportation technology and all the variety they provide to life” and “not being at high risk of falling victim to starvation, exposure, and serious diseases” above meaningfulness.
That said, I do wonder if actually figuring out what humanity’s core values are would help us to navigate these confusing landscapes. Obviously the reality isn’t going to be anything nearly as simple as “red line, green line, blue line, yellow line,” but I do suspect that there are some innate values built into our brains, even if they’re fuzzy around the edges. I’d imagine the vast majority of humans (basically everyone aside from a very small percentage of extremely neuro-atypical outliers) share these values, though biological and personal and social and cultural factors lead people to prioritize some of these values and downplay others. Haidt’s theory of Moral Foundations seems like a promising start, though I also feel like it’s just touching the tip of the iceberg.
— Scott Alexander
It does work better out of context, doesn’t it?
As an aside, I kind of roll my eyes at people who try to find profundity in Lovecraft, from people who think he was some sort of malignant racist prophet spreading fascism to people who think he was some sort of great enlightened prophet of the white race spreading the gospel. The dude created a new genre of scary stories and had some weird far-right views he apparently was weakly attached enough to to marry a Jewish girl. I don’t think he had any special insights into the real world, and I doubt he would have claimed he did.
He did write one of the very first essays on genre fiction, I believe. The whole thing is quite good, and the introduction is still well-regarded. Not exceptionally profound, but still insightful.
http://www.hplovecraft.com/writings/texts/essays/shil.aspx
Oh, I’ll give the Old Gent major, major credit for his work on *horror fiction*–there, he knew whereof he spoke, much like Tolkien with ‘On the Monsters and the Critics’ and the uses of fantasy. (Is anyone surprised J.R.R. Tolkien had strong views on the value of fantasy?) I just find the people who see him as a political theorist kind of silly. Was Lovecraft racist? Sure, who cares? Cthulhu’s not racist–all creeds and colors are equally irrelevant to the Sleeper Beneath the Sea.
This is interesting, possibly useful, and as of the transit map, quite possibly transitions from essay on moral intuitions into performance art.
I’ll just be over here happily pondering all the expansive moral directions one can explore using the Richmond Amtrak connection.
I tend to say that words are fuzzy collections of related concepts, rather than hidden inferences, but I think we are gesturing at the same underlying idea in either case. Certainly, I think that we learn what words mean via repeated associations rather than via a clear-cut articulation or expression of what they mean. However, I don’t think framing people’s divergent views on morality and happiness as a matter of what parameters people fixate on in their discovery of the words “happiness” or “good.”
I don’t understand this. The point about divergent tails is they are in the same ballpark (the guy with the strongest grip also scores very highly on arm strength and vice versa) whereas the desired end results for moral systems can be, and in fact are, diametrically opposite to each other. So how is the one a metaphor for the other?
It isn’t. Scott says as much:
Divergent tails are behavior of a system in the limit as the correlation coefficient approaches (but does not equal) one.
The process of tail-divergence produces noticeable, but subtle, results whereby you get different answers to the same question (‘who is the strongest man alive’) depending on which of two strongly correlated measures you use. Whether you use grip strength or arm strength as your metric, whoever you name as strongest man will still be really strong in the eyes of other people who measure differently.
The mess of diametrically opposite ‘optimal’ results for different morality systems is an example of the same system in action, as the correlation coefficient approaches (but does not equal) zero.
The same process generates far more conspicuous results when used on uncorrelated moral precepts that just happen to produce compatible results over a small region of linear morality-space. For instance, ‘the moral thing to do is whatever God said to do in the Bible’ versus ‘the moral thing to do is to maximize the amount of pleasure being experienced, integrated from the present into the infinite future.’ These rules produce comparable results over a simple space of simple morality questions, but then diverge very rapidly outside of it.
It’s as if we had two people who answered “who is the strongest man” by picking Mike Tyson (“strongest physical muscles and most personal fighting skill”) and Fred Rogers (“strongest conscience and empathy”). Totally divergent results; the two men could not be less alike.
So the connection is in the similar underlying process that produces results in two cases that are different but analogous, in that the difference in results between the cases can be easily explained and predicted by what’s going on inside the process.
Are they though? The bulk of many/most? moral systems have a sort of meaty common core that looks pretty similar, (treat other people with respect/tell the truth/work hard/ etc). It’s only when you push these to the ends that they start to diverge
Stretching the ellipse geometry analogy, the point would be:
No matter how correlated (thin diagonal ellipse), if you zoom in enough of the tip, it looks roundish. So, when like happens in the middle, both axes represent the same thing. But, conditioned on living on the extremes, they have nothing to do with each other. It may be that they are the same, it may be that they are opposite, but the sameness is lost.
right up until the transit map, it looks like a job for principal component analysis.
I mean, not really? If you’re doing PCA, you’re assuming that your coordinates are on comparable scales. And Scott’s point is that they usually aren’t.
Say more words? I don’t think anything about PCA requires your inputs to have similar variance or magnitudes.
True, that was more ambiguous than it could have been. By “comparable scale”, I didn’t mean “comparable variance”, I meant “comparable dimensionality”. Part of Scott’s argument about happiness seems to be “when discussing the concept of ‘happiness’, some people will weight ‘subjective well-being’ more heavily, and others will weight ‘positive emotion’ more heavily”.
If you did PCA on that raw data and used the first component as a joint happiness score, you’re assuming that “subjective well-being” and “positive emotion” as measured have comparable dimensionality.
This might be redundant with SystematizedLoser, but PCA tells you what single measure captures as much variance across multiple measures as possible. That makes it a great data reduction technique, but it can’t solve the ultimate problem that we don’t know whether positive emotions or subjective well-being are more important to “happiness.” If you have an understanding of happiness where positive emotions are irrelevant and subjective well-being is everything (maybe you’re a Vulcan philosopher), the best single measure of happiness from a measure of subjective well-being and positive emotion is one that loads 100% on subjective well-being. If you think only positive emotions matter (you’re a hedonist), you would pick a measure that loads 100% of positive emotions.
PCA would be a solution if you thought there really was some fundamental concept called happiness, and you could get at it by asking about subjective well-being, or positive emotions, or a sense of meaning, and some of those descriptions of the thing called happiness resonate more in some cultures than others, so they aren’t perfectly correlated despite measuring the same thing. Then you’d basically want to grab the common variance of all those measures, call that happiness, and dump the rest of the variance as being cultural resonance and idiosyncrasy.
> Say more words?
Maybe it’s because I just woke up, but this is the most perfect way to ask for elaboration ever and I marvel I have never seen it done until now.
I don’t think that’s true; the eigenvalues that you get in the middle of PCA tell you the scale.
I think you either have to give up on scale as they say, or give up on variance (which makes the resulting weights depend on the population sampled, and that seems not good). And in all cases, you give up on the linearity of each scale, which is probably also kind of arbitrary in most cases.
i wasn’t so much worried about computing exact values, as using the terminology of principal components to think about what’s being discussed. if you’re super concerned about computing some things, there’s a lot written about scaling / scale-invariant / whatever variations on PCA.
so, very hand-wavily applying a bit of the terminology of PCA:
we can look at the strength chart, and quickly say “it makes sense to talk about ‘strength’ without always breaking it down into two (or more!) subcomponents, because the first principal component of this strength data captures 98% of the variation. we’ll call it strength. we’ll perhaps call the second component ‘popeye’, and then we’re all done.”
for the happiness discussion, we can boil it down to some statements like “there’s disagreement about the direction of the first principal component” and maybe “if the first principal component accounts for 99.9% of the variation, then their answers to 99.9% of happiness-related questions will be the same, so that they could never realize they had slightly different concepts of happiness at all”
and about the final transit-map/lovecraft bit, maybe we could say “human moral systems seem to hang out in a nice little linearized region of morality space, but maybe morality space is horrifyingly nonlinear outside of that region.”
(i’m not particularly endorsing any of these statements, and i’m certainly not suggesting that they’re better than what’s been written. just… noting that there may be some more concise terminology available for the subject.)
Z-Score normalize, then PCA! 😎
“right up until X, it looks like a job for Y” is sort of a theme of this post isn’t it?
Doesn’t this fall afoul of what Scott was saying that it’s not just happiness that’s a messy ball of things you’d want to do component analysis on? The sub parts of happiness are themselves a messy ball? So just like its hard to compare what different people mean by such and such an amount of happiness, making peoples happiness at least partially incommensurable, it’s hard to compare what one person means by meaningfulness or positive emotion as well, and so on. That makes whatever you get out of PCA really really difficult to interpret.