
I.
The big news in psychiatry this month is Cipriani et al’s Comparative efficacy and acceptability of 21 antidepressant drugs for the acute treatment of adults with major depressive disorder: a systematic review and network meta-analysis. It purports to be the last word in the “do antidepressants work?” question, and a first (or at least early) word in the under-asked “which antidepressants are best?” question.
This study is very big, very sophisticated, and must have taken a very impressive amount of work. It meta-analyzes virtually every RCT of antidepressants ever done – 522 in all – then throws every statistical trick in the book at them to try to glob together into a coherent account of how antidepressants work. It includes Andrea Cipriani, one of the most famous research psychiatrists in the world – and John Ioannidis, one of the most famous statisticians. It’s been covered in news sources around the world: my favorite headline is Newsweek’s unsubtle Antidepressants Do Work And Many More People Should Take Them, but honorable mention to Reuters’ Study Seeks To End Antidepressant Debate: The Drugs Do Work.
Based on the whole “we’ve definitely proven antidepressants work” vibe in coverage, you would think that they’d directly contradicted Irving Kirsch’s claim that antidepressants aren’t very effective. I’ve mentioned my disagreements with Kirsch before, but it would be nice to have a definitive refutation of his work. This study isn’t really it. Both Kirsch and Cipriani agree that antidepressants have statistical significance – they’re not literally doing nothing. The main debate was whether they were good enough to be worth it. Kirsch argues they aren’t, using a statistic called “effect size”. Cipriani uses a different statistic called “odds ratio” that is hard to immediately compare.
[EDIT: Commenters point out that once you convert Cipriani’s odds ratios to effect sizes, the two studies are pretty much the same – in fact, Cipriani’s estimates are (slightly) lower. That is, “the study proving antidepressants work” presents a worse picture of antidepressants than “the study proving antidepressants don’t work”. If I had realized this earlier, this would have been the lede for this article. This makes all the media coverage of this study completely insane and means we’re doing science based entirely on how people choose to sum up their results. Strongly recommend this Neuroskeptic article on the topic. This is very important and makes the rest of this article somewhat trivial in comparison.]
Kirsch made a big deal of trying to get all the evidence, not just the for-public-consumption pharma-approved data. Cipriani also made such an effort, but I’m not sure how comparable the two are. Kirsch focused on FDA trials of six drugs. Cipriani took every trial ever published – FDA, academia, industry, whatever- of twenty-one drugs. Kirsch focused on using the Freedom Of Information Act to obtain non-public data from various failed trials. Cipriani says he looked pretty hard for unpublished data, but he might not have gone so far as to harass government agencies. Did he manage to find as many covered-up studies as Kirsch did? Unclear.
How confident should we be in the conclusion? These are very good researchers and their methodology is unimpeachable. But a lot of the 522 studies they cite are, well, kind of crap. The researchers acknowledge this and have constructed some kind of incredibly sophisticated model that inputs the chance of bias in each study and weights everything and simulates all sorts of assumptions to make sure they don’t change the conclusions too much. But we are basically being given a giant edifice of suspected-crap fed through super-powered statistical machinery meant to be able to certify whether or not it’s safe.
Of particular concern, 78% of the studies they cite are sponsored by pharmaceutical industries. The researchers run this through their super-powered statistical machinery and determine that this made no difference – in fact, if you look in the supplement, the size of the effect was literally zero:
In our analyses, funding by industry was not associated with substantial differences in terms of response or dropout rates. However, non-industry funded trials were few and many trials did not report or disclose any funding.
This is surprising, since other papers (which the researchers dutifully cite) find that pharma-sponsored trials are about five times more likely to get positive results than non-sponsored ones (though see this comment). Cipriani’s excuse is that there weren’t enough non-industry trials to really get a good feel for the differences, and that a lot of the trials marked “non-industry” were probably secretly by industry anyway (more on this later). Fair enough, but if we can’t believe their “sponsorship makes zero difference to outcome” result, then the whole thing starts seeming kind of questionable.
I don’t want to come on too strong here. Science is never supposed to have to wait for some impossible perfectly-unbiased investigator. It’s supposed to accept that everyone will have an agenda, but strive through methodological rigor, transparency, and open debate to transcend those agendas and create studies everyone can believe. On the other hand, we’re really not very good at that yet, and nobody ever went broke overestimating the deceptiveness of pharmaceutical companies.
And there was one other kind of bias that did show up, hard. When a drug was new and exciting, it tended to do better in studies. When it was old and boring, it tended to do worse. You could argue this is a placebo effect on the patients, but I’m betting it’s a sign that people were able to bias the studies to fit their expected results (excited high-tech thing is better) in ways we’re otherwise not catching.
All of this will go double as we start looking at the next part, the ranking of different antidepressants.
II.
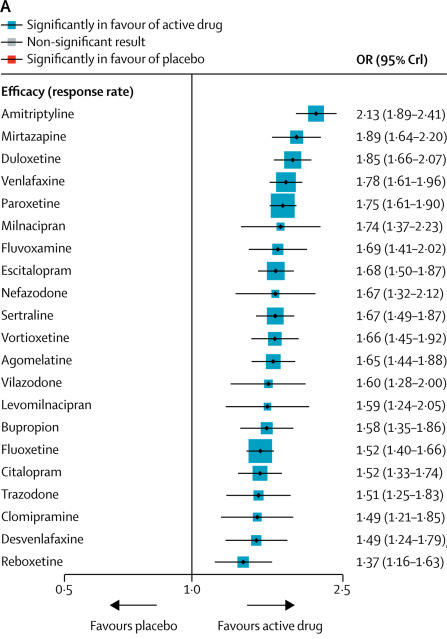
All antidepressants, from best to worst! (though note the wide error bars)
If this were for real, it would be an amazing resource. Psychiatrists have longed to know if any antidepressant is truly better than any other. Now that we know this, should we just start everyone on amitriptyline (or mirtazapine if we’re worried about tricyclic side effects) and throw out the others?
(as a first line, of course. In reality, we try the best one first, but keep going down the list until we find one that works for you and your unique genetic makeup.)
This matches some parts of the psychiatric conventional wisdom and overturns other parts. How much should we trust this versus all of the rest of the lore and heuristics and smaller studies that have accreted over the years?
Some relevant points:
1. The study finds that all the SSRIs cluster together as basically the same, as they should. The drugs that stand out as especially good or especially bad are generally unique ones with weird pharmacology that ought to be especially different. Amitriptyline is a tricyclic, and very different from clomipramine which is the only other tricyclic tested. Mirtazapine does weird things to presynaptic norepinephrine. Duloxetine and venlafaxine are SNRIs. This passes the most obvious sanity check.
2. Amitriptyline, the most effective antidepressant in this study, is widely agreed to be very good. See eg Amitriptyline: Still The Leading Antidepressant After 40 Years Of Randomized Controlled Trials. Amitriptyline does have many side effects that limit its use despite its impressive performance. I secretly still believe MAOIs, like phenelzine and tranylcypromine, to be even better than amitriptyline, but this study doesn’t include them so we can’t be sure.
3. Reboxetine, the least effective antidepressant in this study, is widely known to suck. It is not available in the United States becaues the FDA wouldn’t even approve it here.
4. On the other hand, agomelatine, another antidepressant widely known to suck, gains solid mid-tier status here, being about as good as anything else. The study even lists it as one of seven antidepressants that seems to do especially well (though it’s unclear what they mean and it’s obviously a different measure than this graph). But agomelatine was rejected by the FDA for not being good enough, scathingly rejected by the European regulators (although their decision was later reversed on appeal), and soundly mocked by various independent organizations and journals (1, 2). It doesn’t look like Cipriani has access to any better data than anyone else, so how come his results are so much more positive?
5. Venlafaxine and desvenlafaxine are basically the same drug, minus a bunch of BS from the pharma companies trying to convince that desvenlafaxine is a super-new-advanced version that you should spend twenty times as much money on. But venlafaxine is the fourth most efficacious drug in the analysis; desvenlafaxine is the second least efficacious drug. Why should this be? I have similar complaints about citalopram and escitalopram. Should we privilege common sense over empiricism and say Cipriani has done something wrong? Or should we privilege empiricism over common sense and conclude that the super-trivial differences between these chemicals have some outsized metabolic significance that makes a big clinical difference? Or should we just notice that the 95% confidence intervals of almost everything in the study (including these two) overlap, so really Cipriani isn’t claiming to know anything about anything and it’s not surprising if the data are wrong?
6. I’m sad to see clomipramine doing so badly here, since I generally find it helpful and have even evangelized it to my friends. I accept that it has serious side effects, but I expected it to do at least a little better in terms of efficacy.
Hoping to rescue its reputation, I started looking through some of the clomipramine studies cited. First was Andersen 1986, which compared clomipramine to Celexa and found some nice things about Celexa. This study doesn’t say a pharmaceutical company was involved in any way. But I notice the study was done in Denmark. And I also notice that Celexa is made by Lundbeck Pharmaceuticals, a Danish company. Am I accusing an entire European country of being in a conspiracy to promote Celexa? Would that be crazy?
The second clomipramine study listed is De Wilde 1982, which compared clomipramine to Luvox and found some nice things about Luvox. This study also doesn’t say a pharmaceutical company was involved in any way. But I notice the study was done in Belgium. And I also notice that Luvox is made by Solvay Pharmaceuticals, a Belgian company. Again, I’m sure Belgium is a lovely country full of many people who are not pharma shills, but this is starting to get a little suspicious.
To Cipriani’s credit, his team did notice these sorts of things and mark these trials as having “unclear” sponsorship levels, which got fed into the analysis. But I’m actually a little concerned about the exact way he did this. If a pharma company sponsored a trial, he called the pharma company’s drug’s results biased, and the comparison drugs unbiased. That is, suppose that Lundbeck sponsors a study, comparing their new drug Celexa to old drug clomipramine. We assume that they’re trying to make it look like Celexa is better. In this study, Cipriani would mark the Celexa patients as biased, but the clomipramine patients as unbiased.
But surely if Lundbeck wants to make Celexa look good, they can either finagle the Celexa numbers upward, finagle the clomipramine numbers downward, or both. If you flag Celexa as high risk of being finagled upwards, but don’t flag clomipramine as at risk of being finagled downwards, I worry you’re likely to understate clomipramine’s case.
I make a big deal of this because about a dozen of the twenty clomipramine studies included in the analysis were very obviously pharma companies using clomipramine as the comparison for their own drug that they wanted to make look good; I suspect some of the non-obvious ones were too. If all of these are marked as “no risk of bias against clomipramine”, we’re going to have clomipramine come out looking pretty bad.
Clomipramine is old and canonical, so most of the times it gets studied are because some pharma company wants to prove their drug is at least as good as this well-known older drug. There are lots of things like this, where certain drugs tend to inspire a certain type of study. Cipriani says they adjusted for this. I hope they were able to do a good job, because this is a big deal and really hard to factor out entirely.
This is my excuse for why I’m not rushing to prescribe drugs in the exact order Cipriani found. It’s a good study and will definitely influence my decisions. But it’s got enough issues that I feel justified in taking my priors into account too.
III.
Speaking of which, here’s another set of antidepressant rankings:
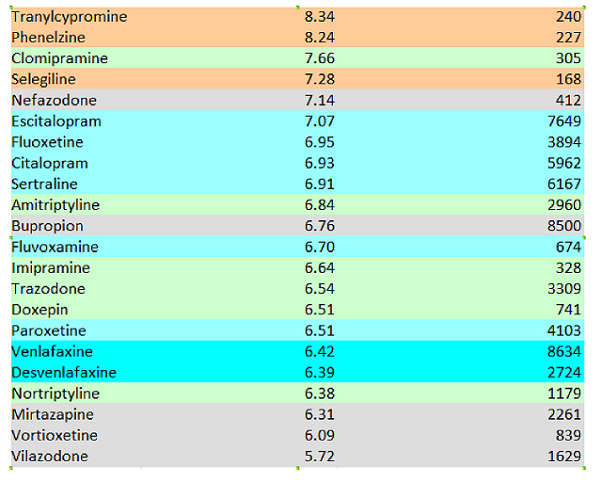
This is from Alexander et al 2017, which started life as this blog post but which with help from some friends I managed to get published by a journal. We looked at some different antidepressants than Cipriani did, but there are enough of the same ones that we can compare results.
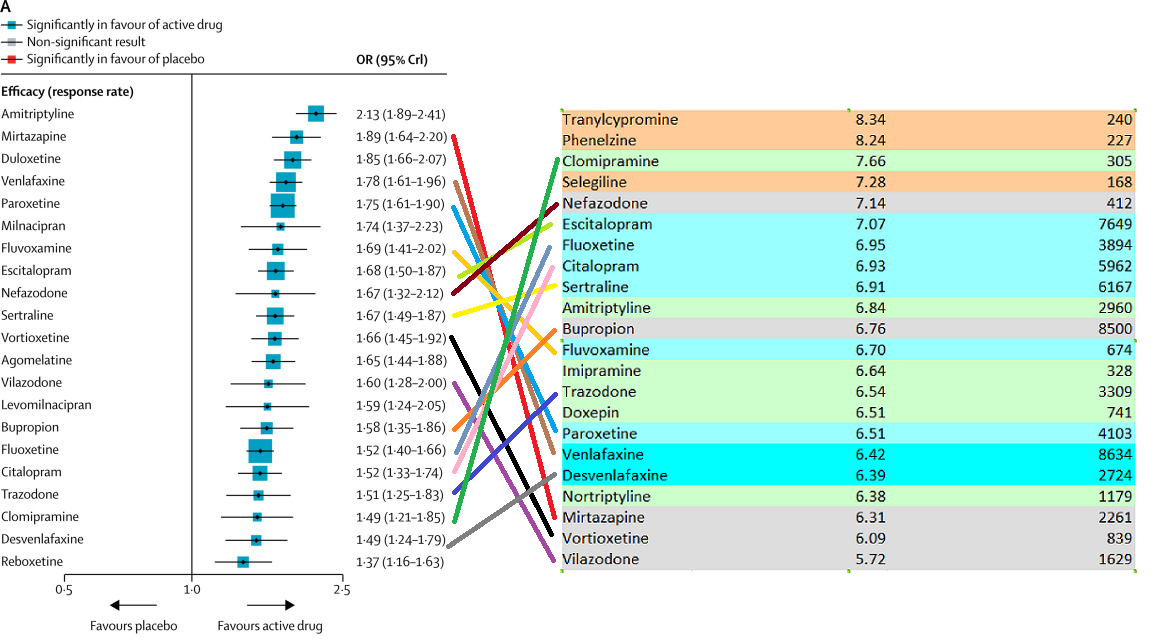
Everything is totally different. I haven’t checked formally, but the correlation between those two lists looks like about zero. We find mirtazapine and venlafaxine to be unusually bad, and amitriptyline to be only somewhere around the middle.
I don’t claim anywhere near the sophistication or brilliance or level of work that Cipriani et al put in. But my list – I will argue – makes sense. Drugs with near-identical chemical structure – like venlafaxine and desvenlafaxine, or citalopram and escitalopram – are ranked similarly. Drugs with similar mechanisms of action are in the same place. We match pieces of psychiatric conventional wisdom like “Paroxetine is the worst SSRI”.
Part of the disagreement may be related to all the antidepressants being very close together on both lists. On Cipriani’s, the difference between the 25th vs. 75th percentile is OR 1.75 vs. OR 1.52. On mine, it’s a rating of 7.14 vs. 6.52. Aside from a few outliers, there’s not a lot of light between any of the antidepressants here, which makes it likely that different methodologies will come up with very different orders. And the few outliers that each of us did identify as truly distinct often didn’t make it into the other’s study – Cipriani doesn’t have MAOIs and I don’t have reboxetine. But this isn’t a good enough excuse. One of my top performers, clomipramine, is near the bottom for Cipriani. One of my bottom performers, mirtazapine, is near his top. I have to admit that these just don’t match.
And a big part of the disagreement has to be that we’re not doing the same things Cipriani did – we’re looking at a measure that combines efficacy and acceptability, whereas Cipriani looked at each separately. This could explain why my data penalizes some side-effect-heavy drugs like mirtazapine and amitriptyline. But again, this isn’t a good enough excuse. Why doesn’t my list penalize other side-effect-heavy meds like clomipramine?
In the end, these are two very different lists that can’t be easily reconciled. If you have any sense, trust a major international study before you trust me playing around with online drug ratings. But also be aware of the study’s flaws and why you might want to retain a bit of uncertainty.
















Was gonna suggest the acceptability thing til I saw you also did at the end. Idk how acceptability was assessed but I did have a thought: with other patients I have talked to, tricyclics would be a topic only broached by doctors after after trying everything else (NHS docs seem to go antipsychotics-for-depression before they go tricyclics?!) with a serious talk along the lines of ‘yeah this is gonna fuck you up but we’re out of options here’. Mirtazepine and venlafaxine get dropped in casually after a couple SSRIs failed with a kinda ‘here’s something a bit different’ sort of vibe. If this is true more generally, and if acceptability is patient-reported, I can see tricyclics getting less panned in that area simply because of different expectations and desperation levels on the part of the people taking them.
(Mirtazepine: 0/10, I want antidepressants to help me get out of bed. 10/10 as a sleep aid provided you never want to get up.
Venlafaxine: 6/10, 8 if you never have to come off it. Makes pringles Extra Delicious.)
Could the this due to causal confounders?
Doctors prescribe antidepressants according to psychiatric conventional wisdom. It could be the case that some patients are easy to treat and respond well to pretty much any antidepressant, so if you give them one from the top of the conventional wisdom list they are happy and go online and give it a positive rating, some patients on the other hand to treat and respond poorly to any antidepressant, thus their doctor goes down the list until they find something that kinda works or they just run out of options, and the patient, still unsatisfied, goes online to give the a poor rating to whatever drug they ended up with.
The randomized controlled trials reviewed by Cipriani et al. should not have this issue, although of course they can be biased by conflicts of interests or other issues.
Maybe the conventional wisdom is self-reinforcing, but in the earlier blog post people (maybe including Scott, I forget) argued the opposite, that people rate last ditch drugs highly because they come into them with low expectations. Actually, they argued that patients do that, but I don’t see any reason to expect doctors to make this error less than the opposite error you suggest. (We should expect patients to make both errors more than doctors because they have fewer observations.)
A few people have said it already, but I don’t think it’s been said enough: ERROR BARS. Most of this post is chasing ghosts, because those error bars say there is no significant ranking of the drugs. The order is just random noise. In aggregate, they clearly have nonzero effect, but the differences between them are probably all insignificant.
I have a question about anti depressants that I’ve been wondering for a long time: What exactly do these efficacy ratings _mean_? Compare two rough outlines of how to interpret these kinds of numbers:
a) drugs near the top of these kinds of rankings are more effective/more likely to be effective for a given individual compared to drugs near the bottom of these rankings. So, say I am depressed. Going off of the study you’re looking at, I might have a reasonable expectation that clomipramine may help a _little bit_, while duloxetine is likely to help me _quite a bit_
b) since peoples’ biologies are different, most drugs on the list are likely to have close to no effect on one’s depression, but finding The Right Drug will cause a dramatic improvement. The relative efficacy rankings are not very accurate as a measure of _how effective_ a given drug will be for someone, but more a measure of _how likely_ a given drug is the miracle cure drug for a given person.
I have a strong hunch that (b) is a more accurate reflection of reality than (a) is. However, I’m not a doctor, not a biologist, not a statistician; I’m just someone who’s tried half a dozen crazy meds in my life and found most of them to be worse-than-useless.
I think that, if this reading is correct, it explains a lot of what I consider to be otherwise paradoxical data.
I hope this is clear enough to make sense
I, too, would find the answer to this interesting.
More (a) than (b). There is a continuous range of effects.
At the end of the day, if it’s this hard to prove something, then I don’t think we can say we have definitive answer.
This is probably covered in “SSRIs: More Than You Wanted to Know” so sorry if I’ve forgotten, but if Kirsch finds an effect for anti-depressants on the same level as this study (moderate, but there), why is Kirsch so against them? Even if he really does think they only work on depression as elaborate active placebos, isn’t that nonetheless helpful in many cases?
Does he think side-effects are too dangerous/unknown, or does he think there are more effective ways of fighting depression?
Kirsch thinks that antidepressants are moderately effective for severe depression and not effective for mild to moderate depression. Consistent with this study. You can probably get his book at the library if you want the less-simplified version.
>Even if he really does think they only work on depression as elaborate active placebos, isn’t that nonetheless helpful in many cases?
Antidepressants come with side effects and costs that a sugar pill doesn’t have. So if they don’t work, we shouldn’t take them.
Maybe the study considers the compared drugs unbiased in pharma sponsored studies, cause everyone will compare to the same set of drugs, so if your study finds something really wrong with, say, Clomipramine, it will look weird and be an important result by itself. Particularly if there are a bunch of other studies, maybe pharma sponsored, maybe not, that do not find that same effect with Clomipramine.
It would attract attention to the study in the wrong way, aka that Clomipramine is not working as expected, and that’s not the study’s purpose.
The main debate was whether they were good enough to be worth it. Kirsch argues they aren’t, using a statistic called “effect size”. Cipriani uses a different statistic called “odds ratio” that is hard to immediately compare.
I was tentatively imagining a way of reconciling “yes they do work by this metric”/”no they don’t work by this metric” would be that, comparing a depressed person on anti-depressants to a depressed person not on them they do work (e.g. “I don’t want to throw myself off a bridge anymore”) but that they don’t magically make you ‘normal’ (“I don’t want to throw myself off a bridge but I’m still depressed, though it’s a bit better than it used to be”).
Medicine! Science! Who knows how they work or even if they work! May just as well make a novena to St Dymphna and hope for the best while your doctor Googles “most prescribed antidepressant” before writing a prescription 🙂
You are over-interpreting those rankings. Look at the error bars! Imagine posterior samples of those odds ratios — how stable are those rankings going to be? Not stable at all. Ranks are generally very hard to infer — you basically need the posterior credible intervals to not overlap.
For that matter, consider the overlap in the intervals between venlafaxine (1.8 +/- 0.2) and desvenlafaxine (1.5 +/- 0.3). On this assessment venlafaxine is probably better than desvenlafaxine but even that is far from certain. Same goes for escitolapram (1.7 +/- 0.2) versus citolapram (1.5 +/- 0.2).
I don’t know if Cipriani et al. did any shrinkage of those odds ratio estimates but if they didn’t, the best assessment of these rankings is probably just “everything has an odds ratio of 5 to 3; maybe bump that up a bit for amitriptyline and down a bit for reboxetine”.
interesting enough i had just read an interview with a researcher at the Zurich University of Applied Sciences who argues strongly that the data is so flawed that the meta study is at best worthless:
https://www.heise.de/tp/features/Largely-ineffective-and-potentially-harmful-3977892.html
Very interesting. Pretty nasty if stopping withdrawal gets counted as an anti-depressant effect.
Reads like an anti-psychiatry loon like Breggin.
The main result of your old blog post was that older antidepressants are better than newer ones. What does this study say on older vs. newer drugs?
No clear result, especially since they excluded most old antidepressants. And they are kinder to vilazodone and vortioxetine than I was. But their top-rated antidepressant, amitriptyline, was approved in 1961, and I think is the oldest one they looked at.
Wouldn’t older antidepressants that had little benefit have been selected out, Darwin-style, by doctors no longer prescribing them, so any old drugs still in production would have to have some demonstrable effect, while newer but relatively ineffective ones would still be on the market because doctors haven’t yet given up on them?
Is a simple ranking of antidepressants really the best way to go about this? I’d love to see more of these studies account for different etiologies or genetic variances, such as the COMT val158met polymorphism or the MTHFR C677T polymorphism.
https://www.mthfrdoctors.com/depression-genetic-mutations-mthfr-comt/
It’s actually easy to convert an odds ratio to a Cohen’s d and vice versa. The reported odds ratio of 1.66 corresponds to d = ln 1.66*sqrt(3)/π ≈ .28.
Kirsch et al. (2008) reported an effect size of d = .32, so the results are similar.
Wait, really?
…wait a second…
REALLY? The “now we have proven antidepressants work” study got a lower estimate of antidepressant efficacy than the “now we have proven antidepressants don’t work” study, and nobody thinks this is a relevant thing to report? REALLY?!
Can someone else who knows more about stats look over the two papers and confirm Mazirian is right and I’m not missing anything?
Neuroskeptic agrees, but I think you don’t even have to do the conversion, just dig through the 200 page supplement.
https://twitter.com/Neuro_Skeptic/status/967462728204980224
In fact, Cipriani et al. report the Cohen’s d effect size (they call it SMD) as well in their results section:
Scott (or anyone else who knows about this sort of thing), I ran across this rereading the SSRI Much More … post:
How does that affect a comparison between the Kirsch and Cipriani results? Do the new results go from “about the same as Kirsch” to “worse than Kirsch”?
Did you see the paper that reckoned they found out something about how ketamine worked? Did that sound persuasive?
Can somebody share the link to “Alexander et al. 2017”?
I found it without a lot of work but based on Scott’s comment above I assumed he didn’t want people posting it here… (that comment also does a lot towards helping one find it 😛 )
Google “[Scott’s real name] 2017 antidepressants” and you will find it.
The obvious way to reconcile this with the claim of same effect size is the pharma does power analyses and doctors don’t. Which is obvious from the incentives.
My doctor (generalist/endocrine specialist, not psychiatrist) told me that the effectiveness of specific antidepressants correlates with specific genetic factors, and that these are clear enough that genetic tests can predict which set of antidepressants are more likely to be effective for a given patient. (But not clear enough to be 100% right.)
Unfortunately I didn’t ask her for research citations, and now I see you commenting as if it’s self evident that the same priority order (most likely to work ahead of less likely) should apply to all patients.
What’s going on here?
Also, I notice that the meta-study that’s been reported all over the place recently was specifically about reactions to (acute?) major depression – not long term/chronic/somewhat less major. I get the impression a lot of drugs are prescribed for the latter case. Maybe more than for the former. (But I am not a doctor, psychotherapist, statistician, or other relevant professional.) Is it even reasonable to expect the same ranking of effectiveness – or even the same amount of effectiveness – in the long term case?
See https://slatestarcodex.com/2017/03/06/antidepressant-pharmacogenomics-much-more-than-you-wanted-to-know/
This…isn’t how odds ratios work, right? Suppose you start with a prior odds of 1:1 someone gets better in a given time period; using the antidepressant ups this to 1.66:1. In probabilities, you’ve upped their odds of recovery from 50% to 62.5%, which is an increase of 25%.
It’s late, but I worked through the algebra and get that going from a:b to 5a:3b increases the probability of the event by 2b / (5a + 3b); this agrees with the 25% number from above when a = b = 1.
Notably, the “how much more likely you are to get better” number depends on how likely you were to get better, which makes sense: you can apply an odds ratio of 1.66 at any probability level, but it’ll be a lot less useful if you started off 99% likely to get better on your own.
I think that communicating what the hell these odds ratios mean is a difficult problem and it’s not obvious how to talk about the math I just wrote to a lay audience in a single sentence.
Can someone please link to Alexander et al (2017) ? All the other posts from this site on antidepressants are thwarting my Google-fu
Avoiding it because it uses my real name. Just read the blog post; it says the same thing.
Just give depressed people a hit of DMT.
I’m getting a correlation of r=-0.14 between Cipriani’s odds ratio and Alexander’s rating, and r=-0.21 if we use rankings for both. So the correlation is close to zero, and in the wrong direction.
I wonder if the different populations surveyed could partially explain some of the difference between the ratings-based method and the random study method. It seems clear that part of the reason it’s so hard to get a statistical handle on antidepressants is that different people react very differently, and it seems plausible that there could be some general trends. Maybe there’s some correlation between “people willing to write reviews about a drug online” and having better outcomes with some types of drugs. On the other hand maybe “people willing to sign up for randomized depression trials” correlates better with other drugs. I have no idea how you would actually determine if this is true though.
According to ‘people writing reviews online’ Black Panther is the greatest movie of all time and Paddington 2 is pretty close. Paddington 2 isn’t even the best Paddington movie.
When taking into account the error bars, isn’t there no statistical difference between the vast majority of the drugs?
That’s what it looks like to me as well.
That’s not exactly how error bars work.
As a first approximation, eyeballing the confidence bounds and looking for overlap will give you an idea of whether there is a “significant difference”, but if you actually want to make that claim, you need to do a formal test for the comparison you want to make. There are cases when you’ll have an overlap and the difference will be statistically significant. This will occur less often if the confidence interval displayed is based on a similar inferential process as was used to perform the test. (For example, many test statistics are asymptotically normal, so people will build confidence intervals based on a critical value from a Z-distribution and the estimated standard error of the statistic. But this isn’t the only way to do it.)
Having said all that, your intuition here is basically correct: Outside of Amytriptyline, the rest looks about the same. I’d certainly expect patient-to-patient variability in responsiveness to swamp these aggregated numbers. If I were prescribing something and had even a moderate prior, seeing this paper would not likely change much for me. If anything, it reinforces how difficult it is to rank-order these things at the population level. The only reason I spent so much time “correcting” you above is that you mentioned a “statistical difference”, which implies something more official or technical than the more practical, “These all look about the same”. 🙂
Exactly so
Did this study address the Irving Kirsch objection re: active versus passive placebos?
I don’t think so, but that was always questionable. See eg https://slatestarcodex.com/2018/01/31/powerless-placebos/ and Part 7 of https://slatestarcodex.com/2014/07/07/ssris-much-more-than-you-wanted-to-know/